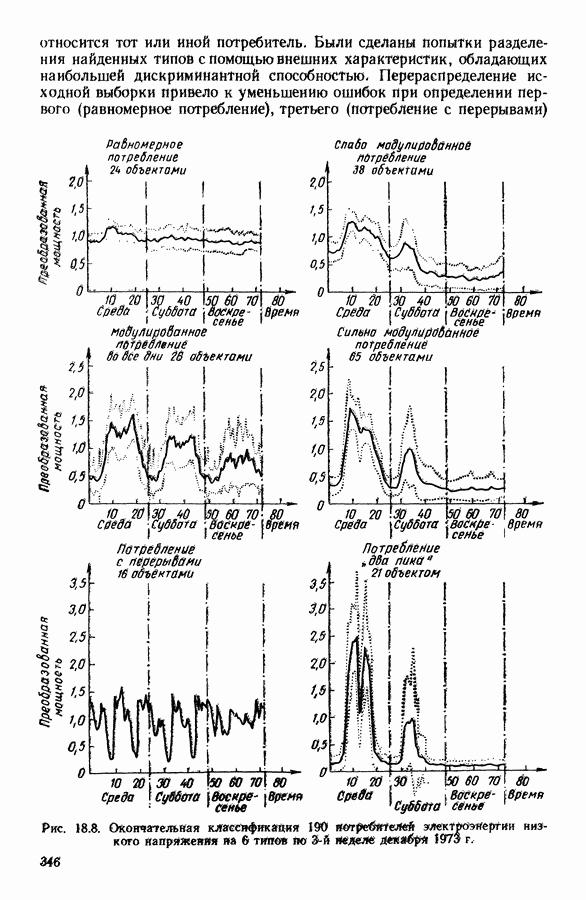
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
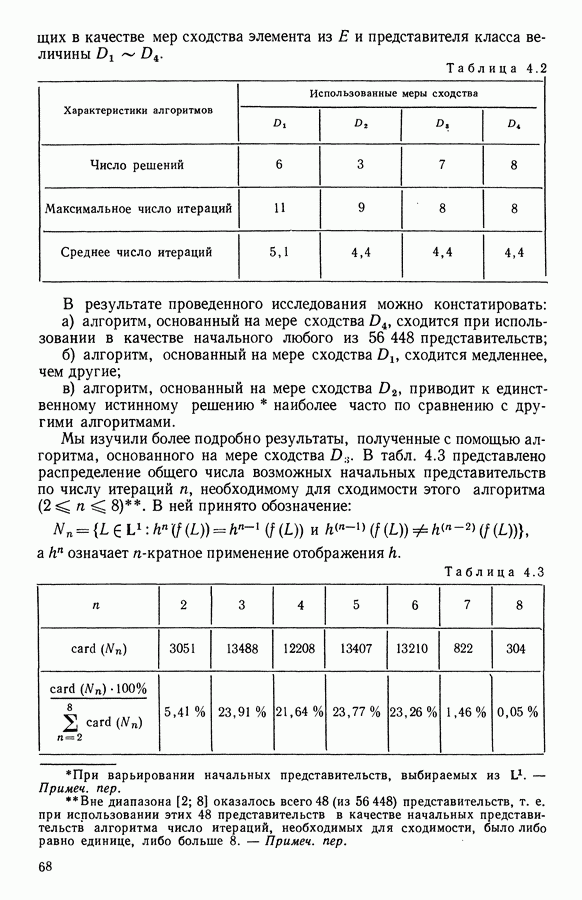
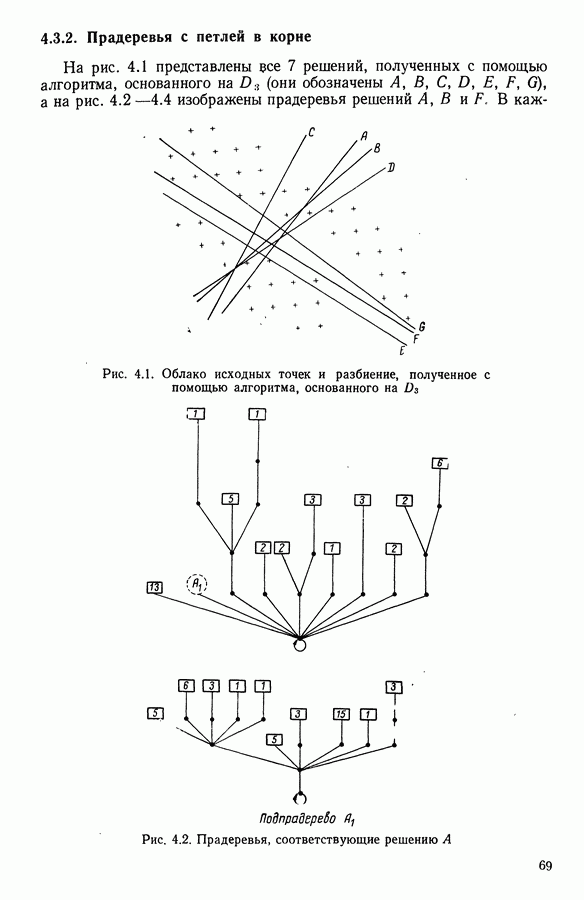
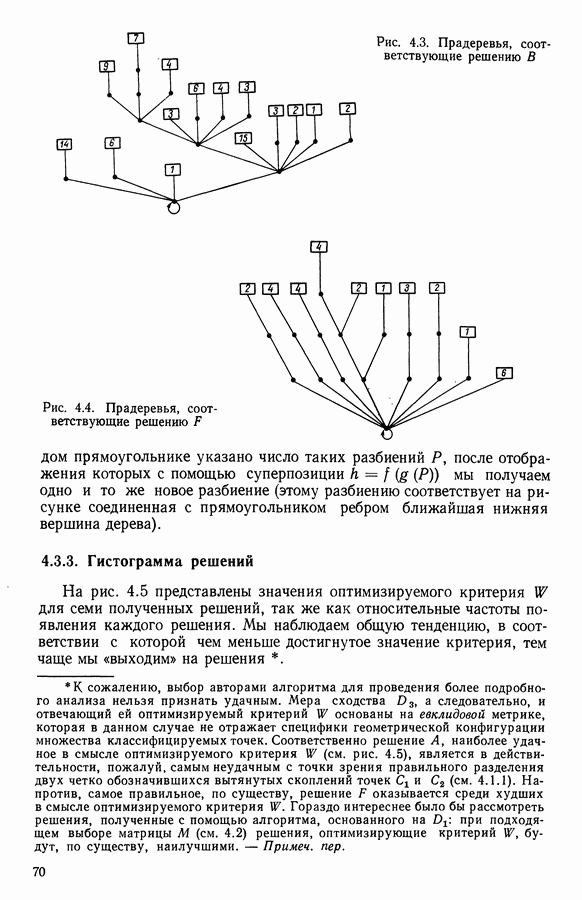
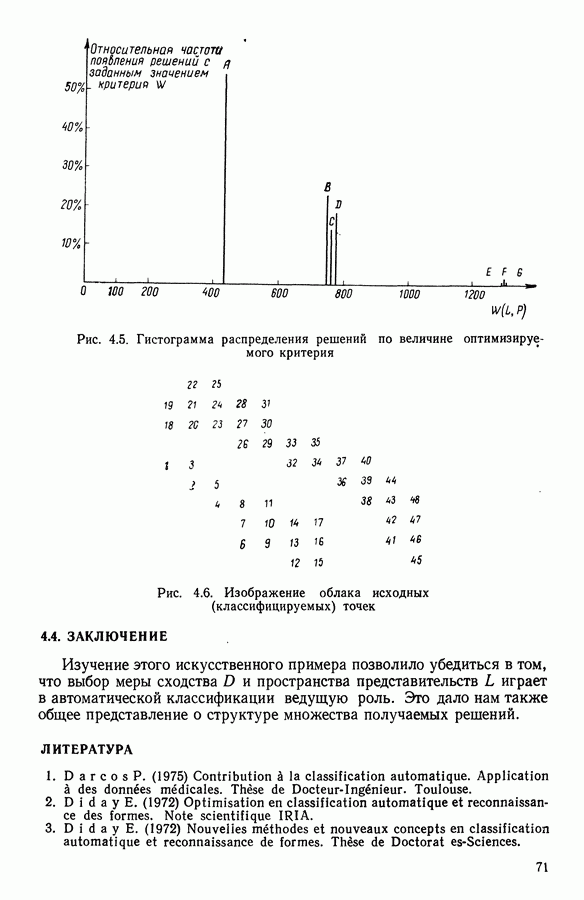
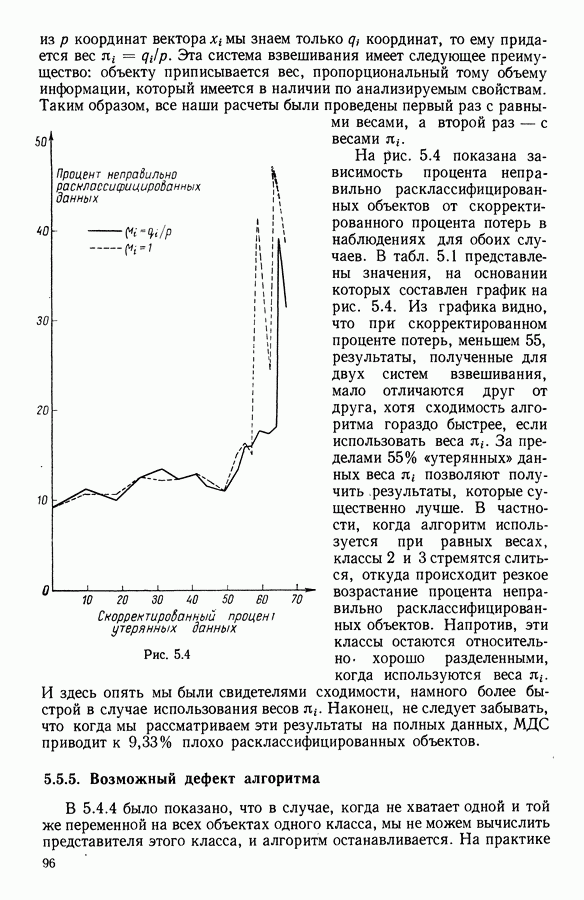
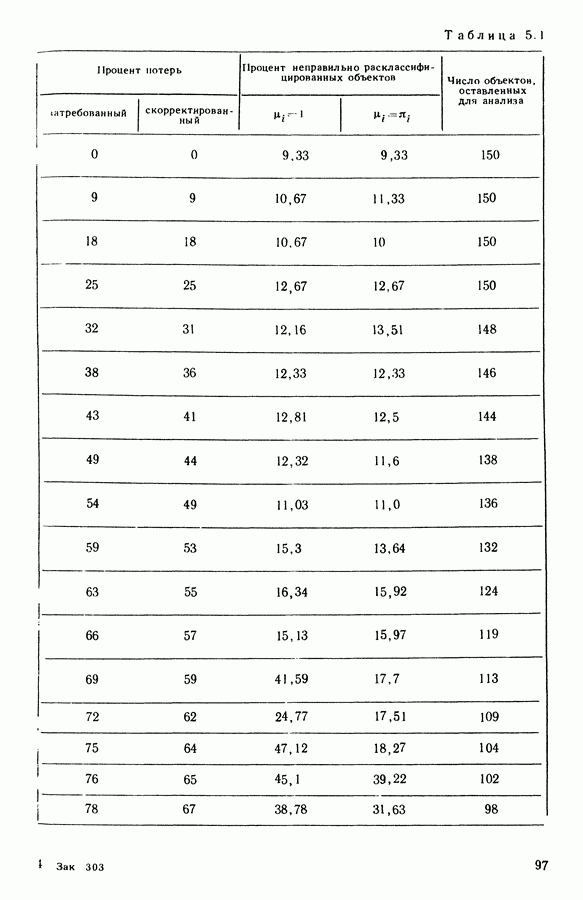
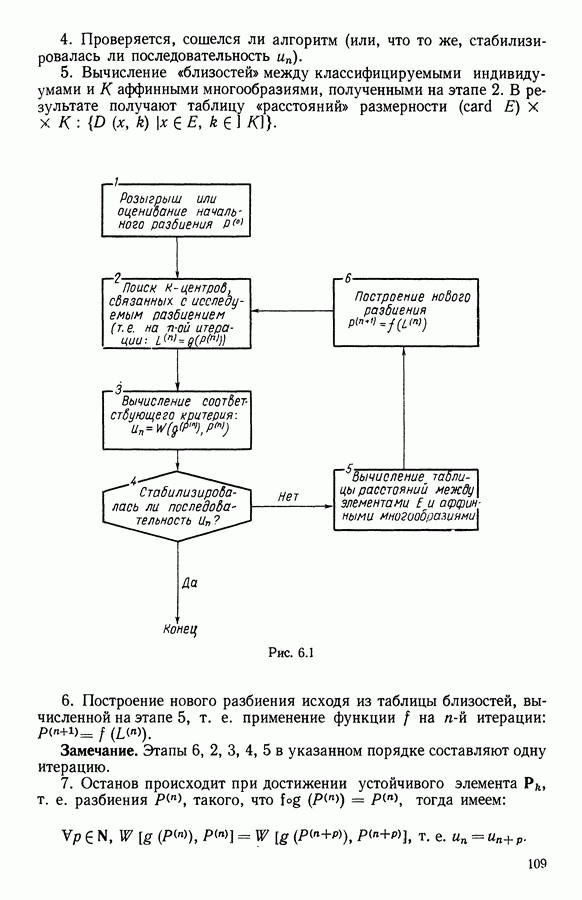
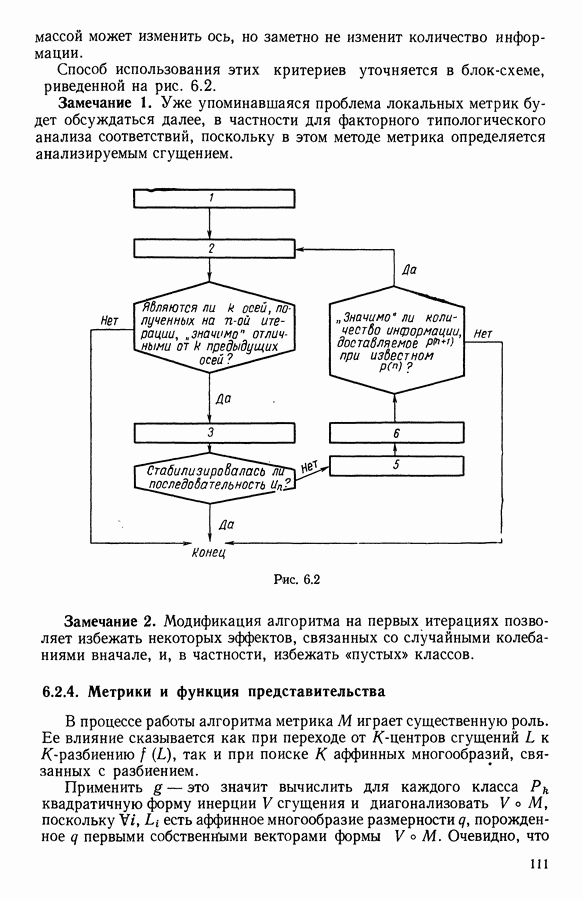
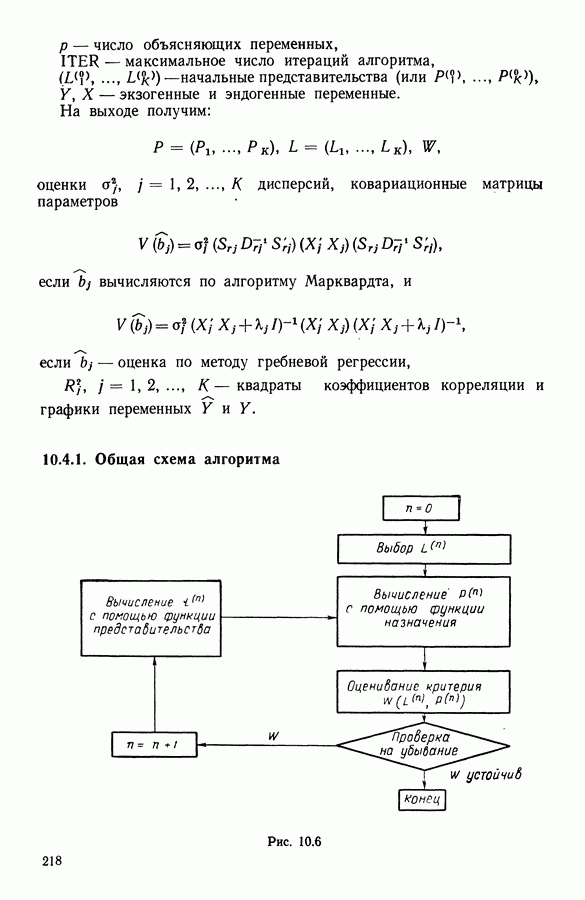
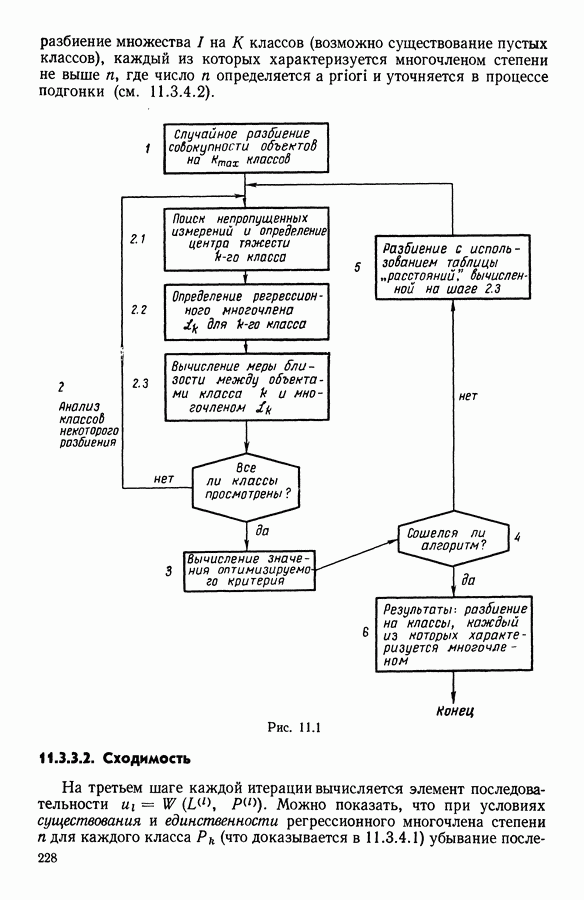
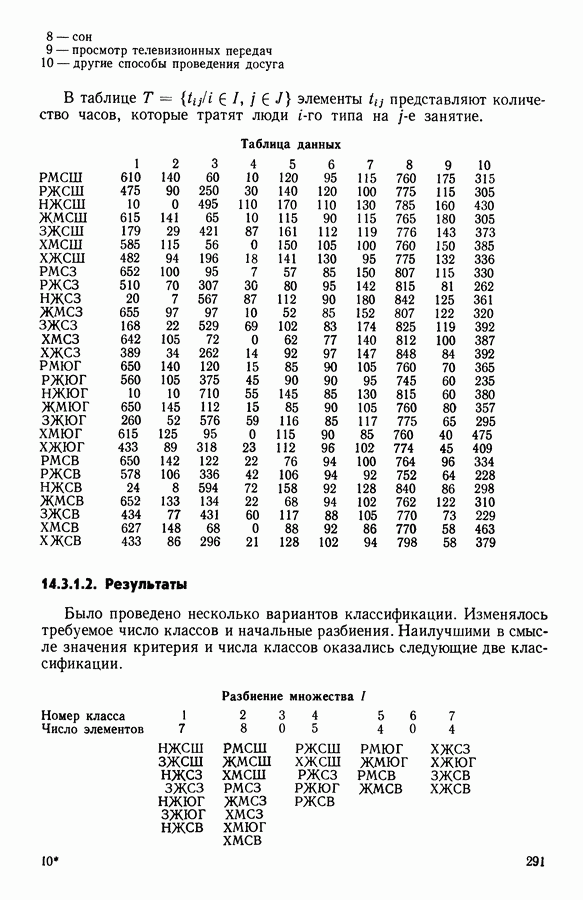
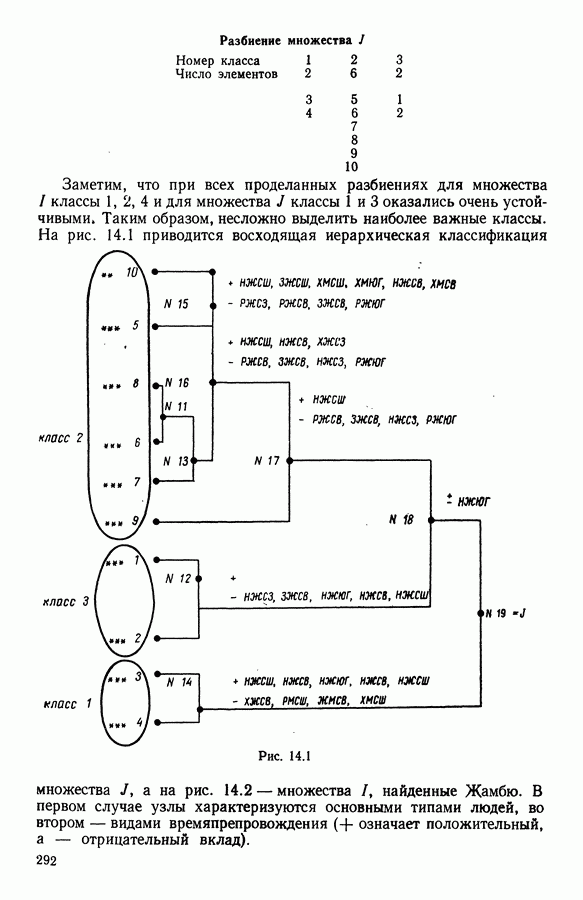
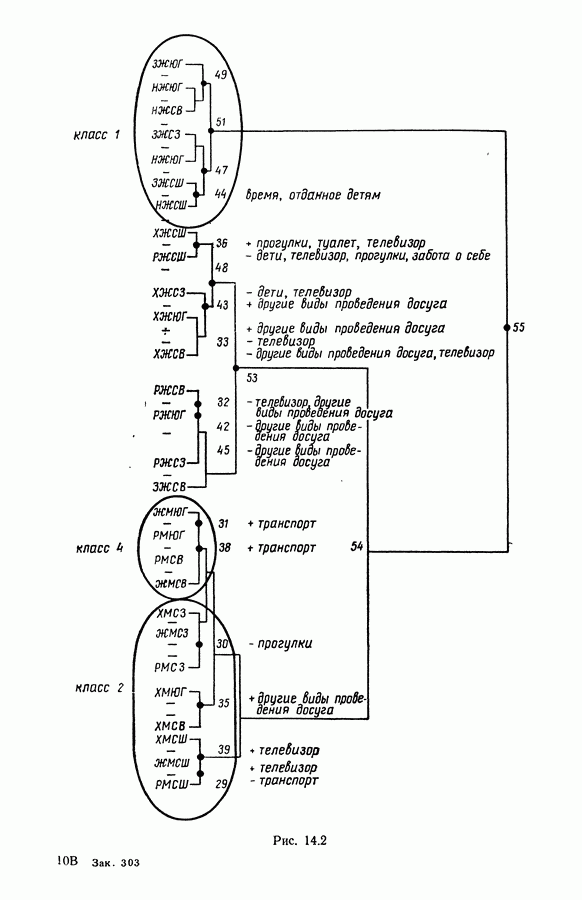
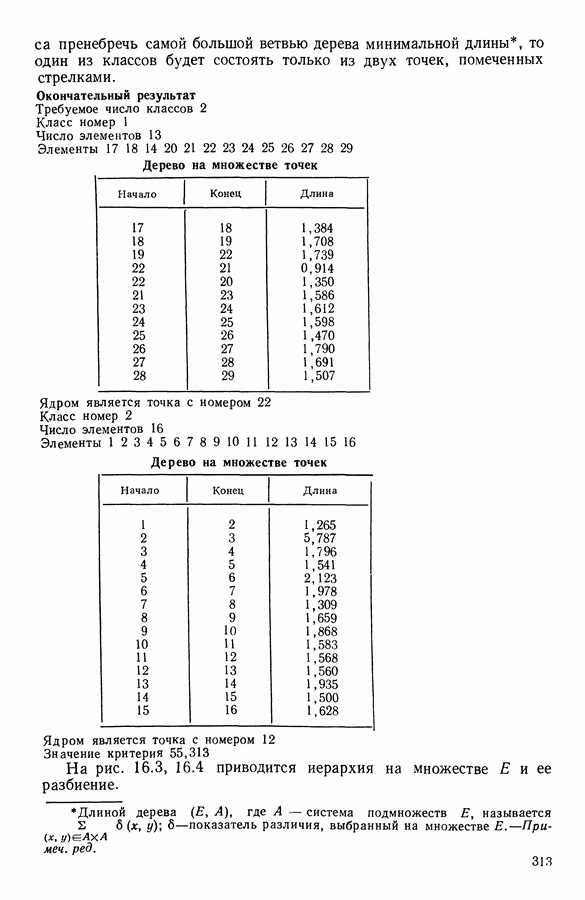
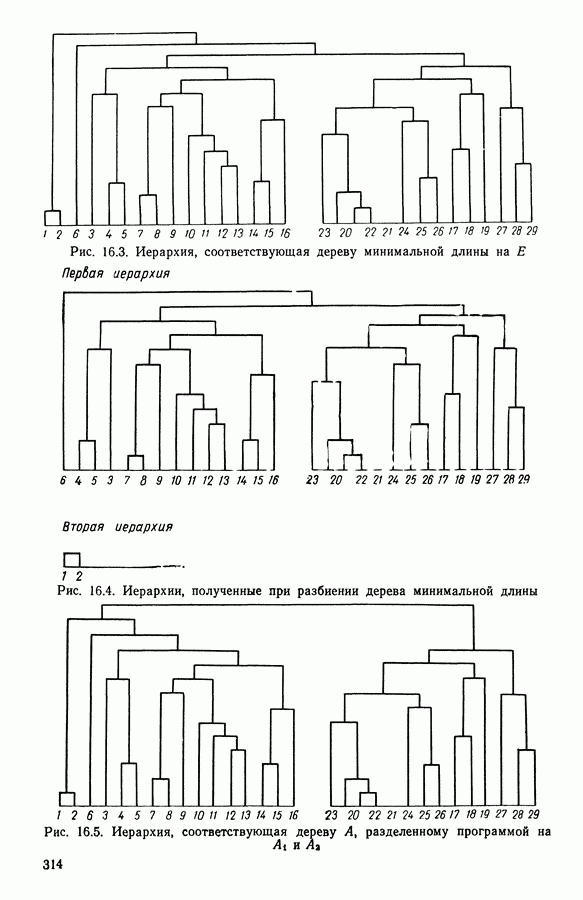
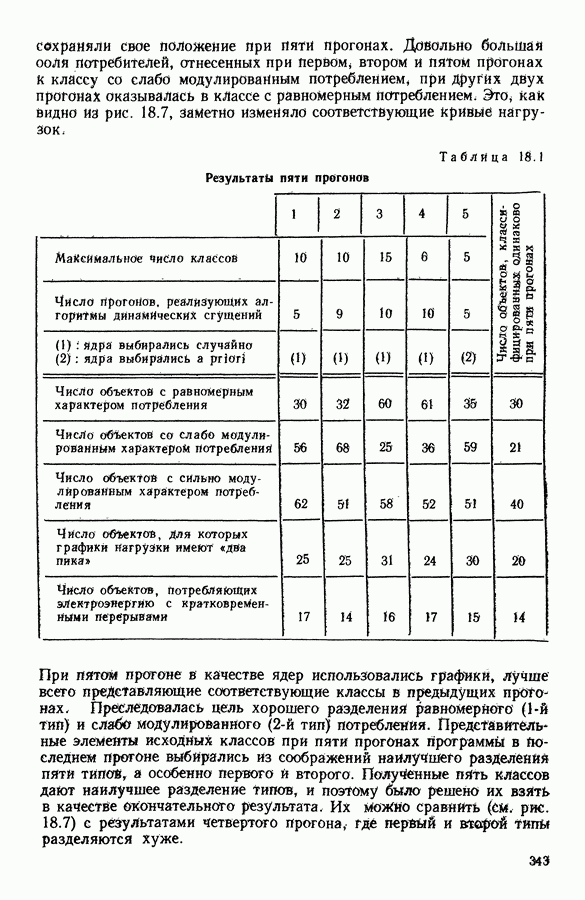
15.3. МЕТОД С ОГРАНИЧЕНИЯМИ НА РАЗБИЕНИЯ15.3.1. ВведениеЗадача состоит в определении элементов пространства представительств, позволяющих получить разбиение, близкое к заданному. Она похожа на задачу дискриминантного анализа, однако не требует оценки или определения a priori функции плотности для каждого класса. Более того, можно найти простое решающее правило, зависящее только от множества классифицируемых объектов 15.3.2. Описание метода и алгоритмаАлгоритм может быть разделен на две части: в первой определяется наилучший представитель для каждого класса, а во второй проверяется, не притягивает ли этот представитель элементы, принадлежащие другим классам. Пусть
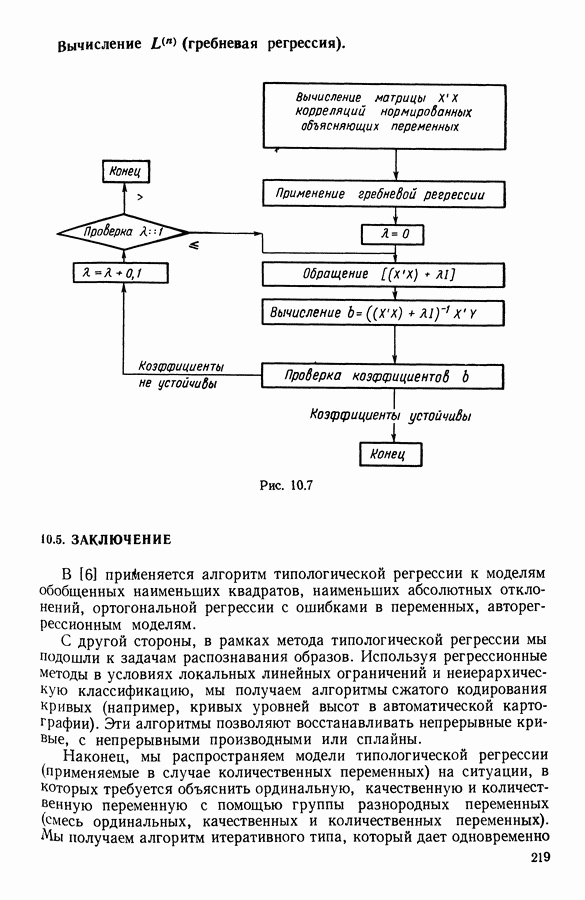
где Используемый алгоритм заключается в следующем. 1. Начальный шаг. Определяются для каждого из заданных классов 2. Назначение. По представителям С строится разбиение
3. Представительство. Пусть Если
принимает максимальное значение. 4. Критерий остановки. Производится проверка: если множество представителей изменилось, то осуществляется переход к шагу (2), иначе работа алгоритма прекращается. Замечание. Существуют и другие способы начала работы алгоритма, кроме описанного на шаге 1. В качестве представителя класса С можно, например, взять элемент, наиболее удаленный от всех других классов, т. е.
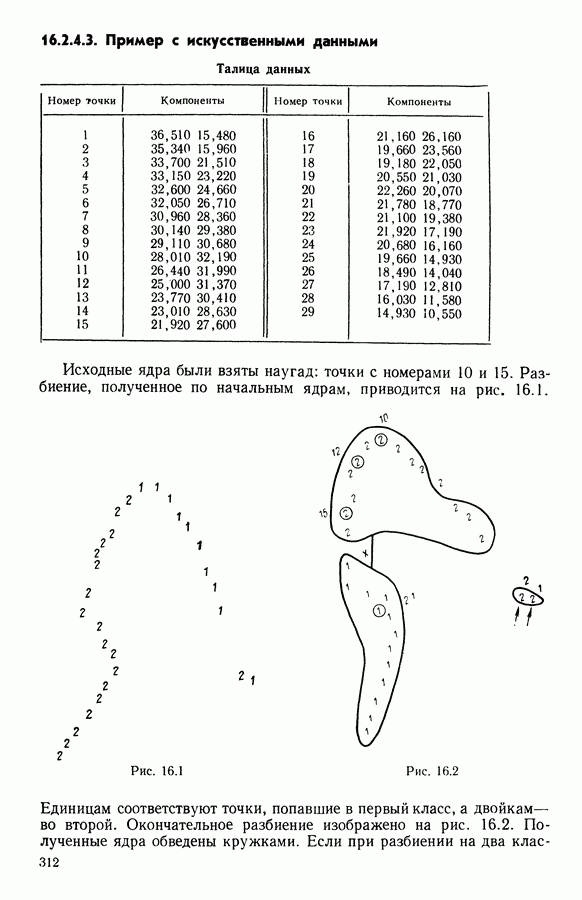
для каждого набора Этот метод можно применять к различным расстояниям для того, чтобы определить расстояние и набор соответствующих представителей, порождающих разбиение, наиболее близкое к заданному. 15.3.3. Применение классификации с ограничениями на разбиенияПусть дано 26 букв латинского алфавита и 10 цифр. Каждому символу соответствует несколько характеристик (написаний). Цель анализа состоит в том, чтобы для каждого символа определить написание, представляющее его наилучшим образом и достаточно сильно отличающееся от написаний других букв. Определенный таким образом набор написаний позволяет лучше распознавать новые написания. Множество таких характеристик было найдено (см. [13]). Анализ может быть разделен на две части. В первой части производится описание, цель которого определить существенные черты, позволяющие различать семейства написаний. При этом каждому написанию ставится в соответствие описательный вектор. Поскольку на следующем этапе будут применяться методы многомерного анализа, необходимо, чтобы описывающие переменные (координаты описательного вектора) были однотипными. Для получения количественных описывающих переменных можно воспользоваться методами оцифровки. Затем с помощью факторного анализа соответствий можно будет изучить связи между множеством выбранных количественных переменных и множеством написаний. Такой подход позволяет геометрически визуализировать соотношения между написаниями и переменными в метрике Вторая часть анализа заключается в классификации и дискриминации. Ищется простое правило, решающее вопрос о соответствии написания одному из символов. Здесь можно использовать классические методы, например линейный дискриминантный анализ или метод ближайшего соседа. Ни один из этих методов не позволяет отобрать новый набор характеристик. Однако дискриминантный анализ дает возможность оценить силу дискриминации данного набора характеристик. Например, выбрав дискриминантную функцию
где При таком определении решающего правила имеются два пути улучшения дискриминантной способности: модификация дискриминантной функции множество ошибочно классифицированных его написаний, а также множество написаний других символов, попавших в класс
а показателем отклонения от элементов из
Задача сводится к определению
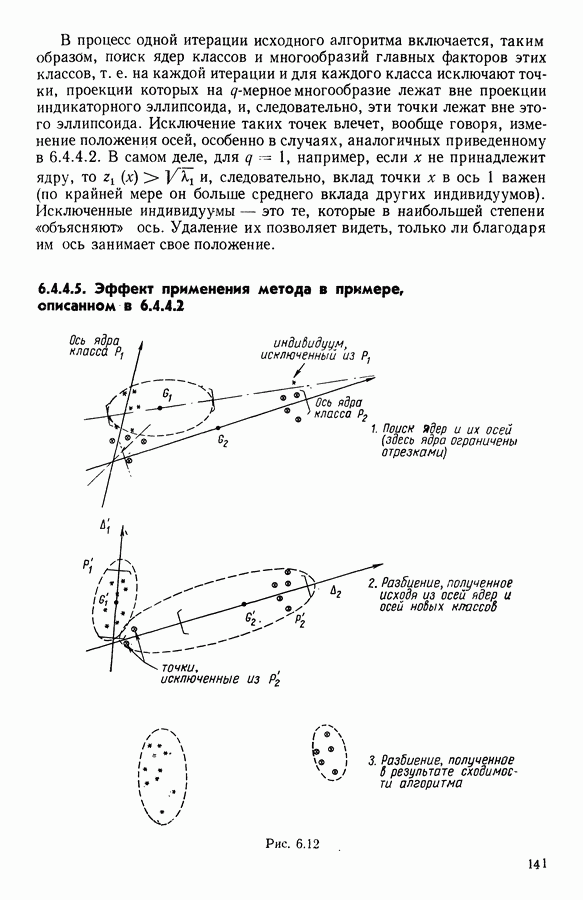
Рис. 15.1 Описанный выше метод был применен для анализа 121 вида написаний, получаемых на устройстве точечной печати, например буква А может быть представлена четырьмя написаниями (рис. 15.1).
Рис. 15.2 Для буквы
|
 |
Оглавление
|













































































































































































































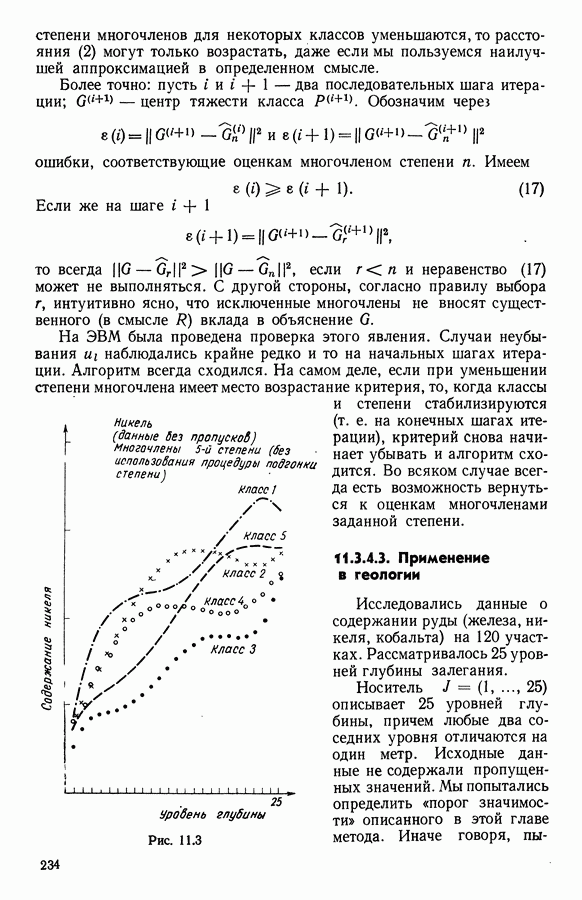


















































































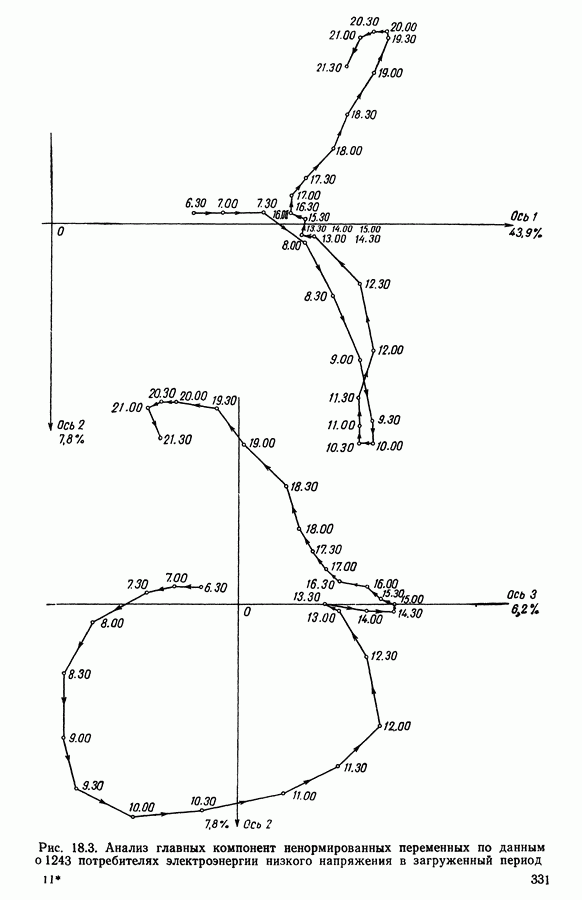









 и расстояния на
и расстояния на  Для этого необходимо определить две операции: агломерацию и раздвигание.
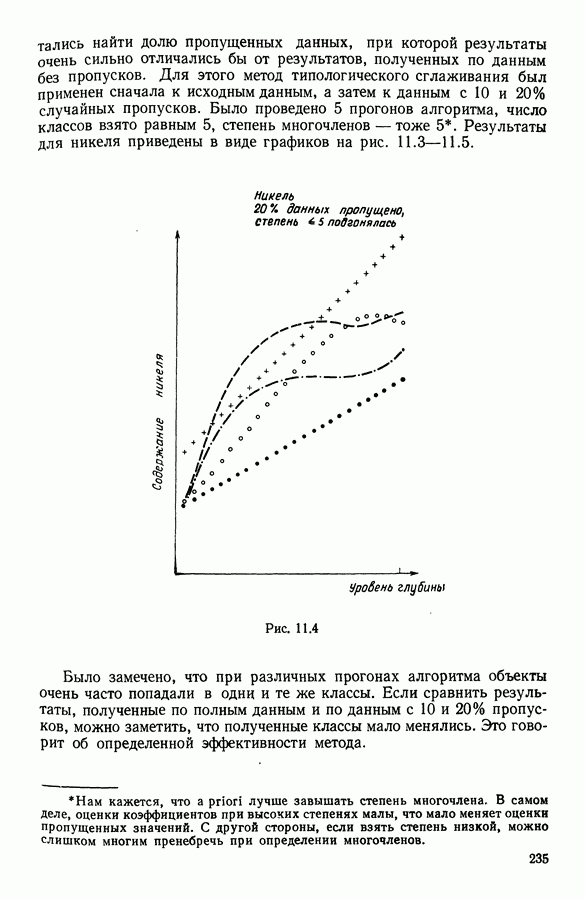
Для этого необходимо определить две операции: агломерацию и раздвигание.
 множество, подлежащее классификации;
множество, подлежащее классификации;  разбиение
разбиение  на
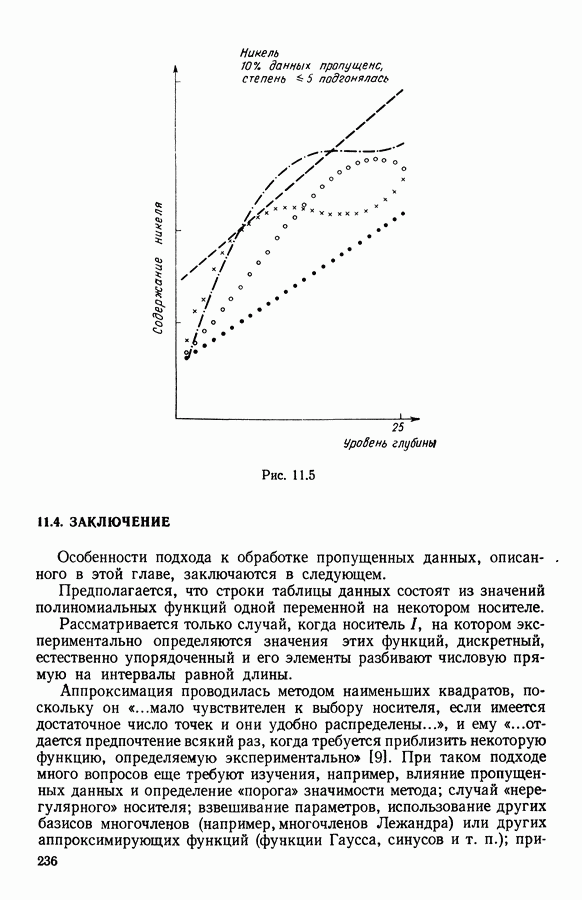
на  классов, заданное a priori; d - расстояние на
классов, заданное a priori; d - расстояние на  Пространством представительств будет само множество
Пространством представительств будет само множество  а меру адекватности элементов
а меру адекватности элементов  и
и  определим следующим образом:
определим следующим образом:


 лучшие представители, т. е. такие элементы
лучшие представители, т. е. такие элементы  для которых сумма
для которых сумма  минимальна.
минимальна.

 класс
класс  полностью восстанавливается по представителю
полностью восстанавливается по представителю  В этом случае не требуется менять представителя этого класса. Если же
В этом случае не требуется менять представителя этого класса. Если же  т. е. некоторые элементы
т. е. некоторые элементы  не вошли в
не вошли в  то следует определить нового представителя, при котором на следующей итерации была бы сделана попытка собрать неправильно классифицированные элементы (элементы
то следует определить нового представителя, при котором на следующей итерации была бы сделана попытка собрать неправильно классифицированные элементы (элементы  , где
, где  Ищется элемент
Ищется элемент  такой, чтобы величина
такой, чтобы величина  принимала минимальное значение. Этот этап алгоритма в данном случае представляет собой этап «агломерации».
принимала минимальное значение. Этот этап алгоритма в данном случае представляет собой этап «агломерации».
 то следует рассмотреть три множества:
то следует рассмотреть три множества:  множество элементов из
множество элементов из  удачно классифицированных на этом шаге;
удачно классифицированных на этом шаге;  — множество элементов из
— множество элементов из  ошибочно классифицированных;
ошибочно классифицированных;  множество элементов других классов, попавших в этот класс. Задача состоит в определении элемента из
множество элементов других классов, попавших в этот класс. Задача состоит в определении элемента из  который позволил бы на следующей итерации разбросать по другим классам элементы из
который позволил бы на следующей итерации разбросать по другим классам элементы из  и собрать в
и собрать в  элементы из
элементы из  Таким образом, в данном случае добавляется этап «раздвигания», цель которого найти элемент
Таким образом, в данном случае добавляется этап «раздвигания», цель которого найти элемент  такой, что величина
такой, что величина

 такой, что сумма
такой, что сумма  принимает максимальное значение. Или же можно методом динамического программирования выявить наиболее удаленные друг от друга элементы
принимает максимальное значение. Или же можно методом динамического программирования выявить наиболее удаленные друг от друга элементы  и взять их в качестве представителей, т. е. такие элементы, что
и взять их в качестве представителей, т. е. такие элементы, что

 где
где 
 Вопросы метрики
Вопросы метрики  и ее адекватности этой задачи рассмотрены в работе [11].
и ее адекватности этой задачи рассмотрены в работе [11].
 и набор написаний
и набор написаний  и 10 цифр, можно построить разбиение
и 10 цифр, можно построить разбиение  по следующему правилу:
по следующему правилу:

 множество написаний,
множество написаний,  класс, соответствующий
класс, соответствующий  символу. 36 таких классов составляют разбиение
символу. 36 таких классов составляют разбиение  Дискриминантная способность набора
Дискриминантная способность набора  определяется как число (или процент) ошибочно классифицированных элементов разбиения
определяется как число (или процент) ошибочно классифицированных элементов разбиения 
 или изменение набора характеристик [9]. Была проведено изучение различных дискриминантных функций. Если можно менять весовые коэффициенты, то для заданного набора написаний можно оптимизировать
или изменение набора характеристик [9]. Была проведено изучение различных дискриминантных функций. Если можно менять весовые коэффициенты, то для заданного набора написаний можно оптимизировать  как функцию от обучающей выборки. Определение оптимального набора написаний осуществляется с помощью итерационной процедуры с ограничениями на разбиения. Эта процедура состоит из двух шагов. На первом шаге по имеющемуся набору написаний и выбранному решающему правилу строится разбиение (4). Второй шаг заключается в выборе нового набора написаний из полученного разбиения. Для каждого символа
как функцию от обучающей выборки. Определение оптимального набора написаний осуществляется с помощью итерационной процедуры с ограничениями на разбиения. Эта процедура состоит из двух шагов. На первом шаге по имеющемуся набору написаний и выбранному решающему правилу строится разбиение (4). Второй шаг заключается в выборе нового набора написаний из полученного разбиения. Для каждого символа  существует
существует
 Пусть
Пусть  составлено из написаний 1-го символа. Это множество является объединением подмножеств
составлено из написаний 1-го символа. Это множество является объединением подмножеств  Для каждого символа
Для каждого символа  требуется найти представителя, который попытался бы на первом шаге следующей итерации собрать соответствующие ошибочно классифицированные элементы из
требуется найти представителя, который попытался бы на первом шаге следующей итерации собрать соответствующие ошибочно классифицированные элементы из  и в то же время который был бы достаточно далек от элементов из
и в то же время который был бы достаточно далек от элементов из  Пусть, например, для
Пусть, например, для  показателем агрегирования элементов из
показателем агрегирования элементов из  будет
будет

 будет
будет

 минимизирующего
минимизирующего  и максимизирующего
и максимизирующего  Как правило, оптимальные решения для этих двух функций достигаются на двух различных элементах. Приходится искать компромисс. Этот компромисс выражается в задании весовых коэффициентов для функций
Как правило, оптимальные решения для этих двух функций достигаются на двух различных элементах. Приходится искать компромисс. Этот компромисс выражается в задании весовых коэффициентов для функций  и выборе в качестве оптимизируемого критерия взвешенной суммы этих функций.
и выборе в качестве оптимизируемого критерия взвешенной суммы этих функций.


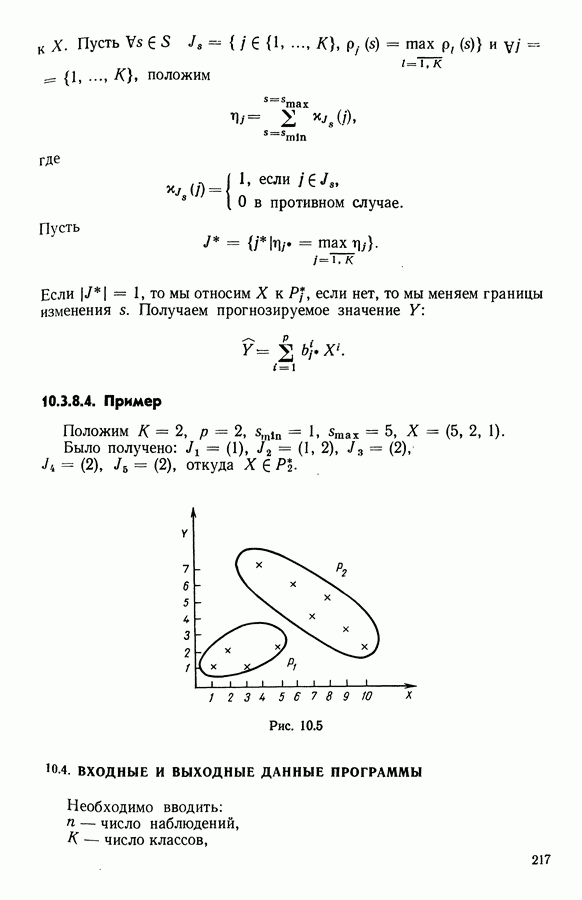
 возможны 9 представлений (рис. 15.2). После того как были выполнены все шаги алгоритма, 105 написаний из 121 были правильно классифицированы.
возможны 9 представлений (рис. 15.2). После того как были выполнены все шаги алгоритма, 105 написаний из 121 были правильно классифицированы.