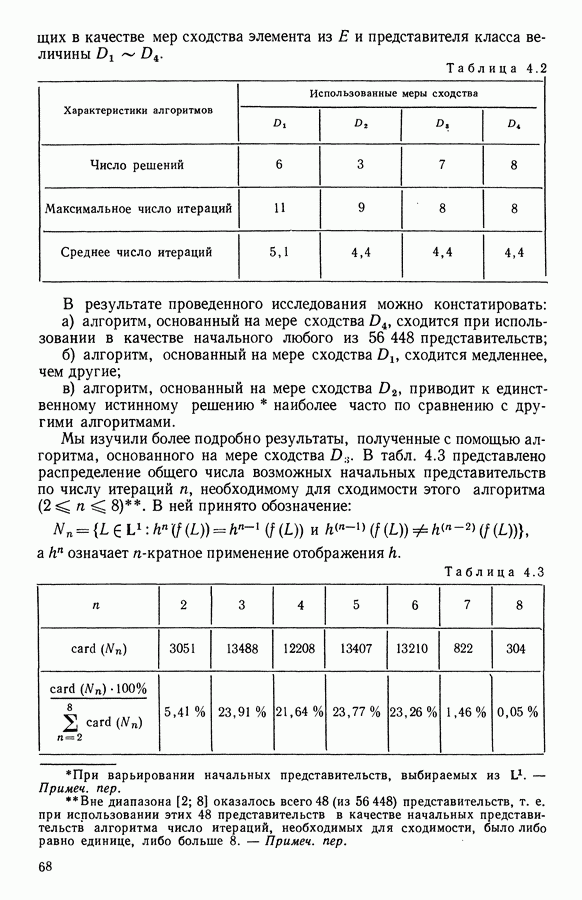
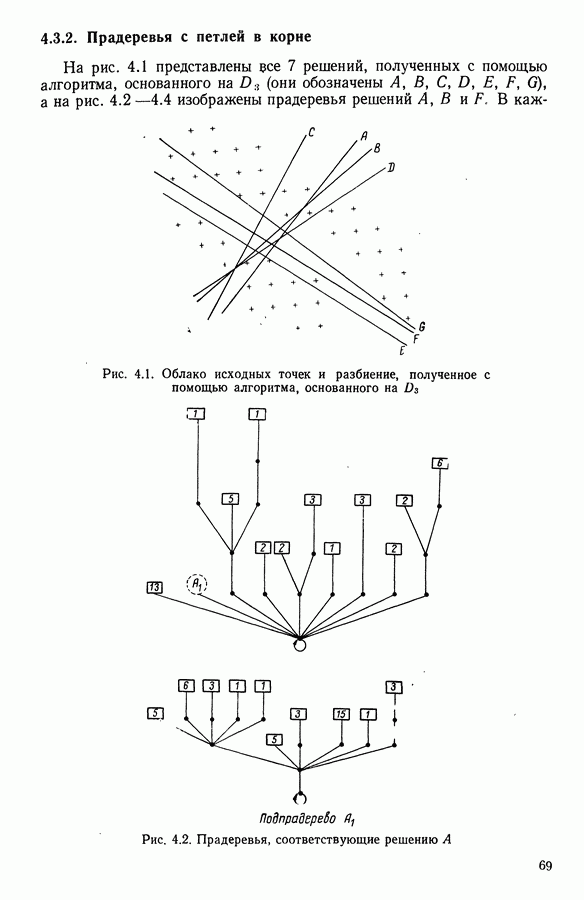
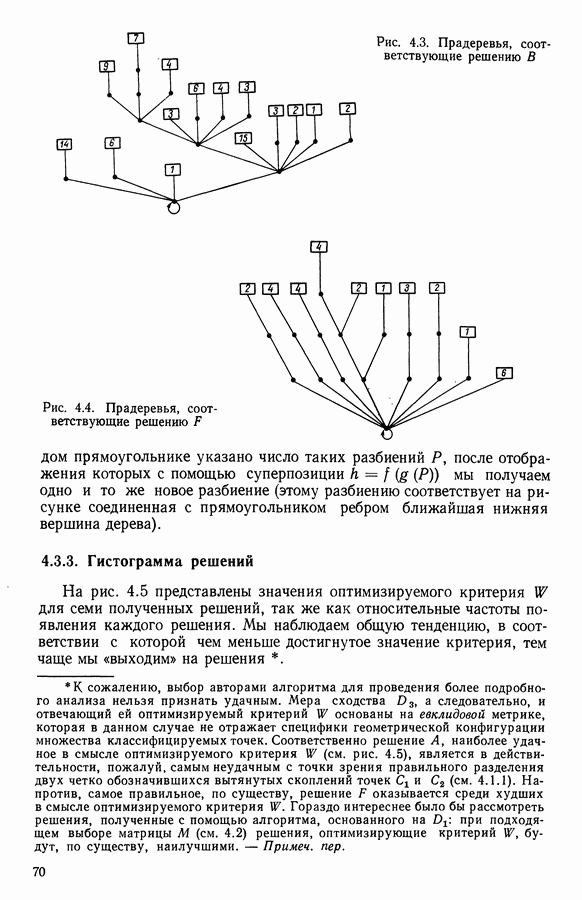
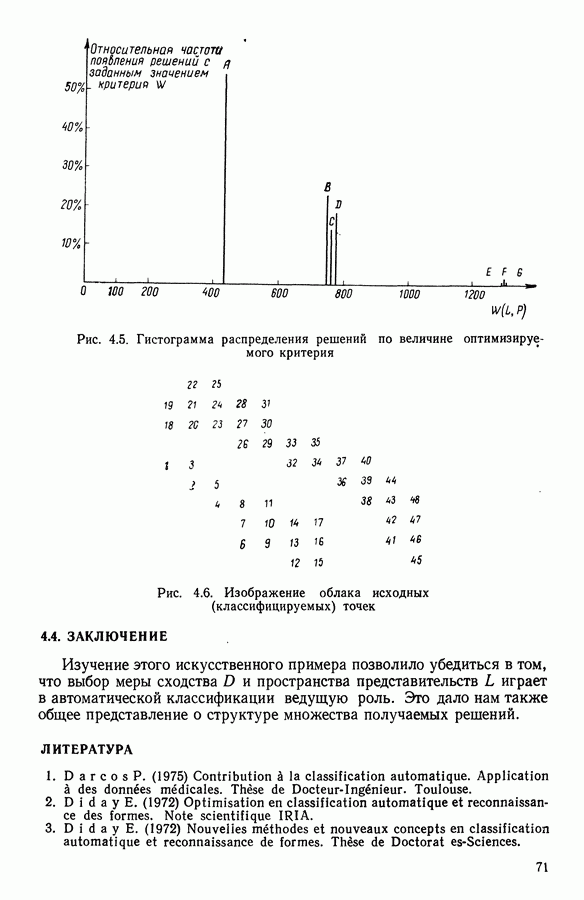
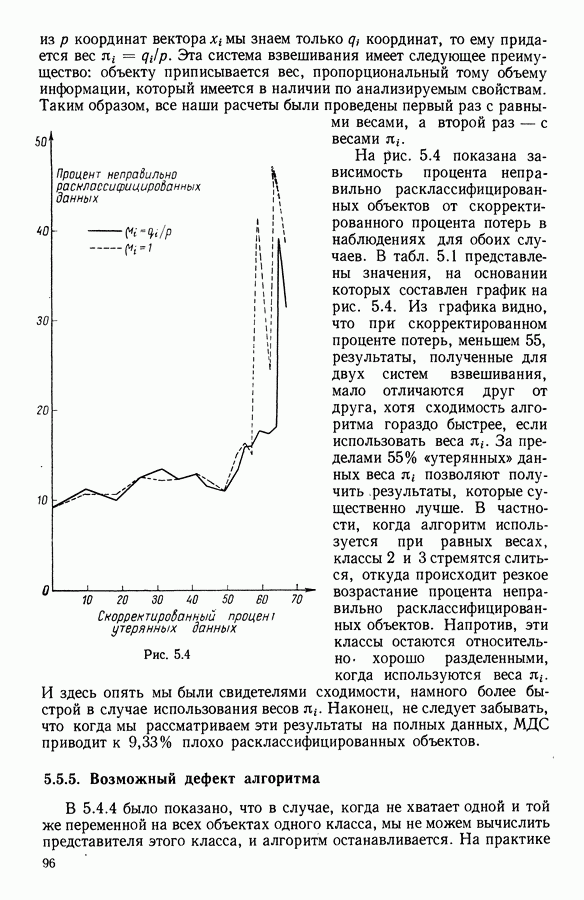
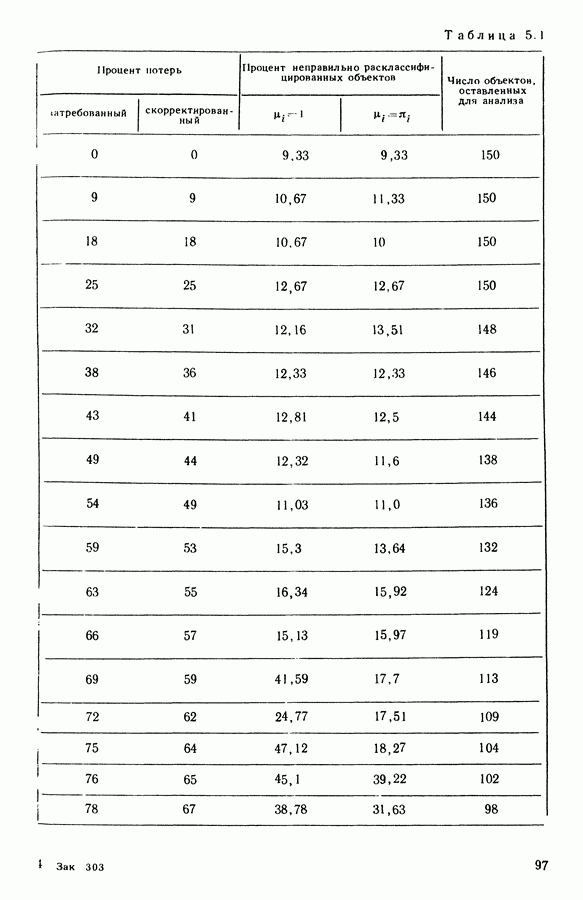
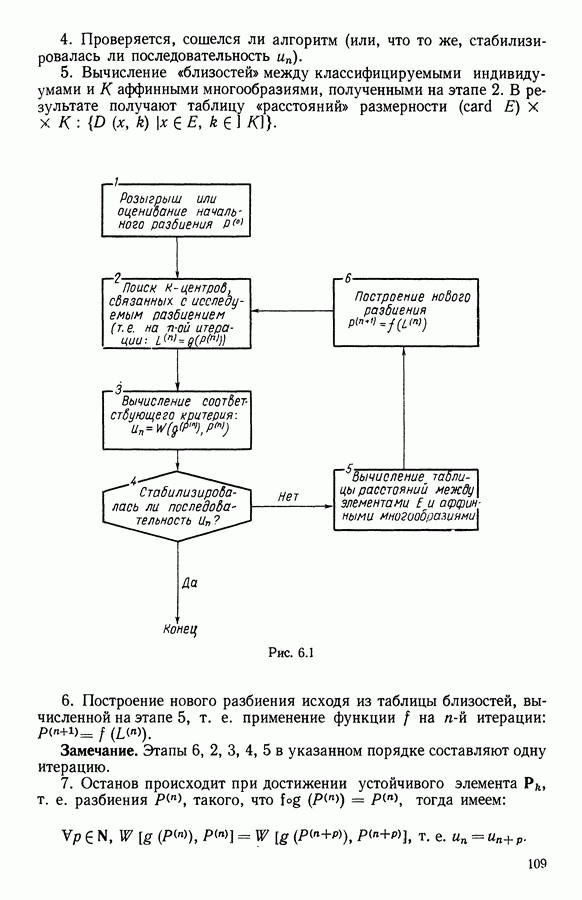
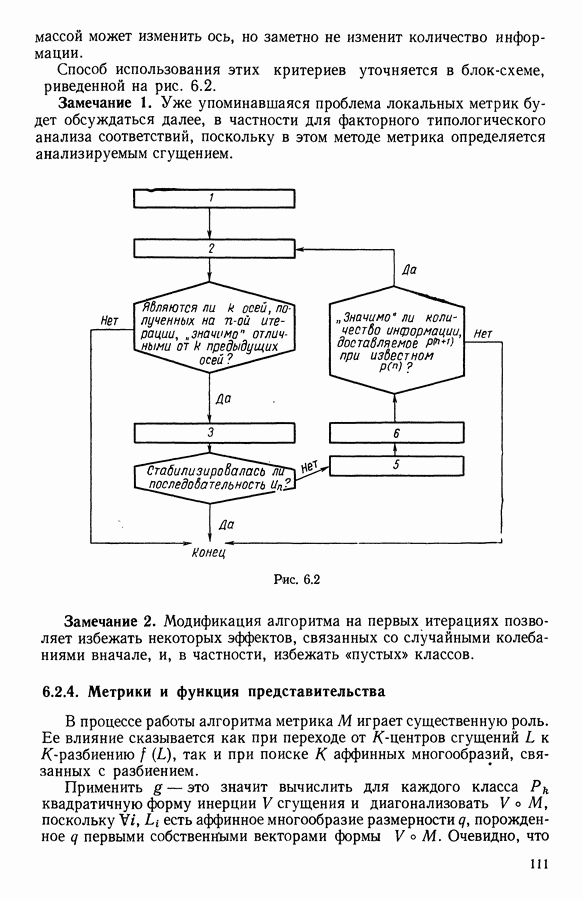
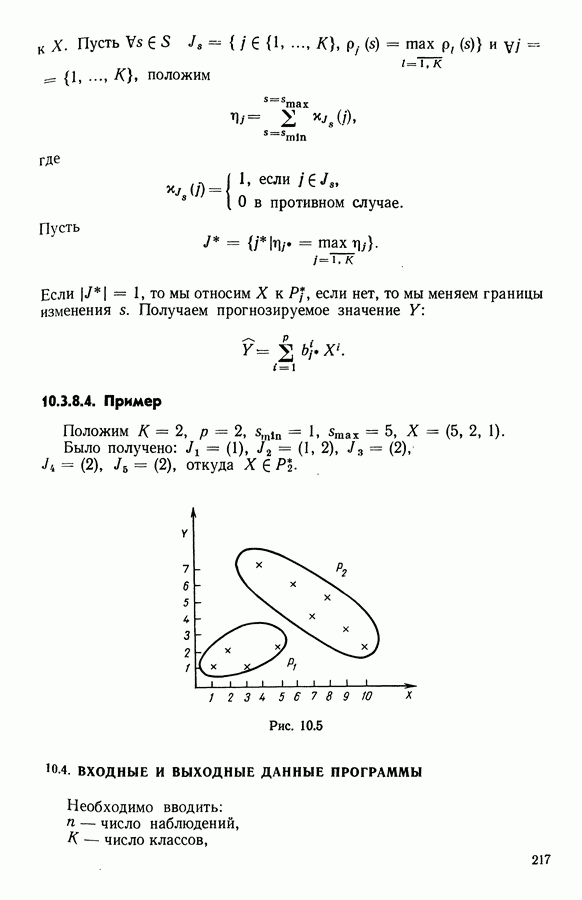
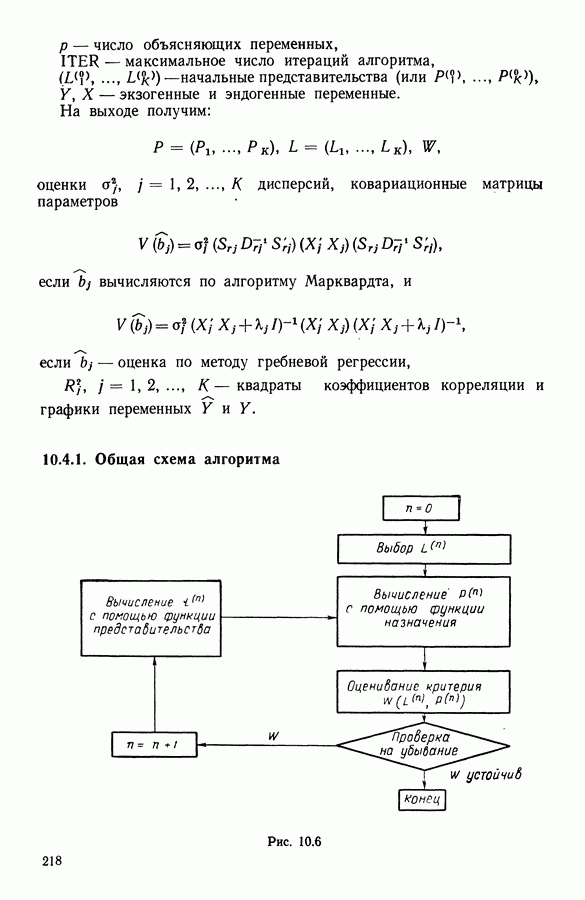
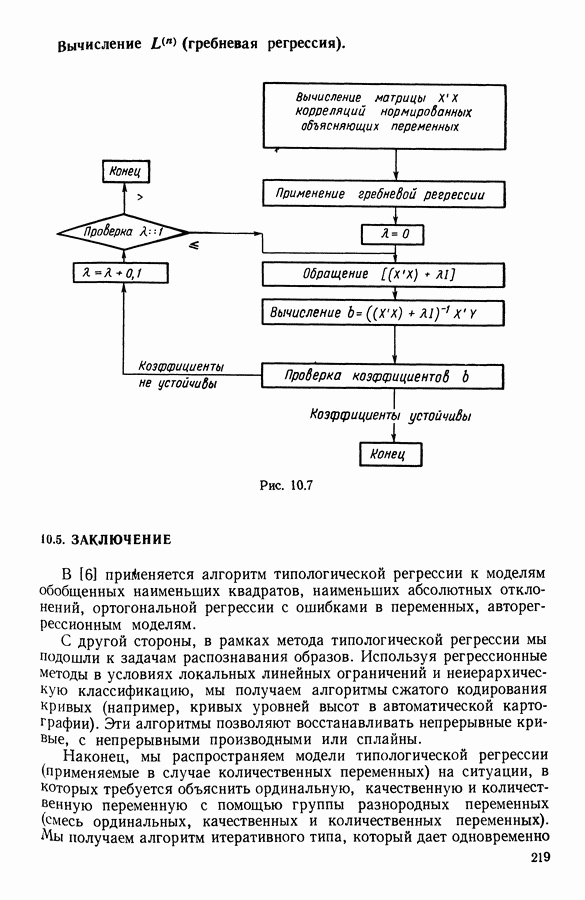
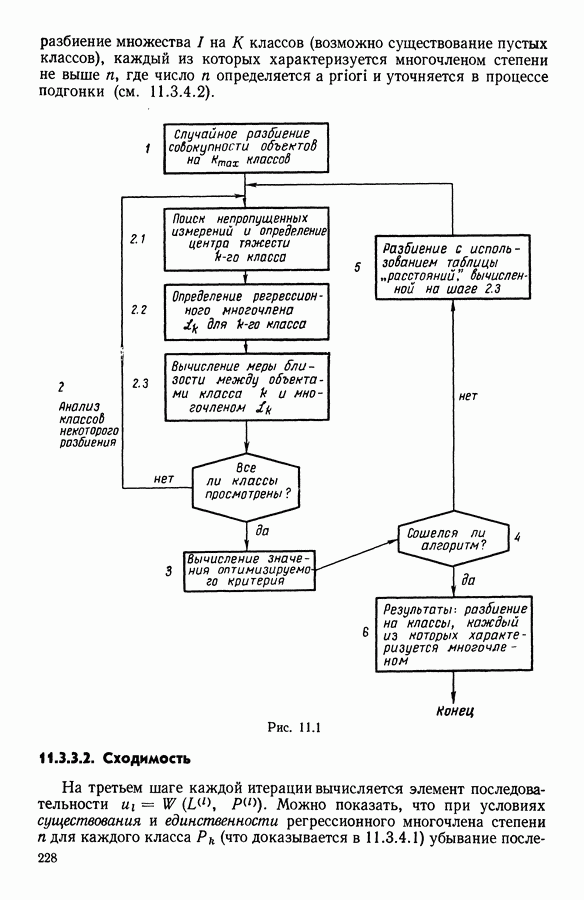
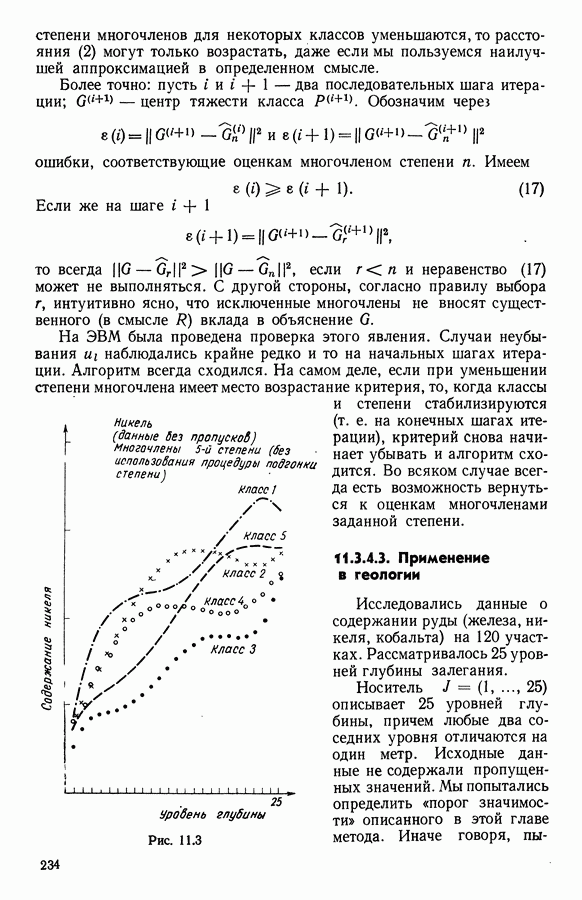
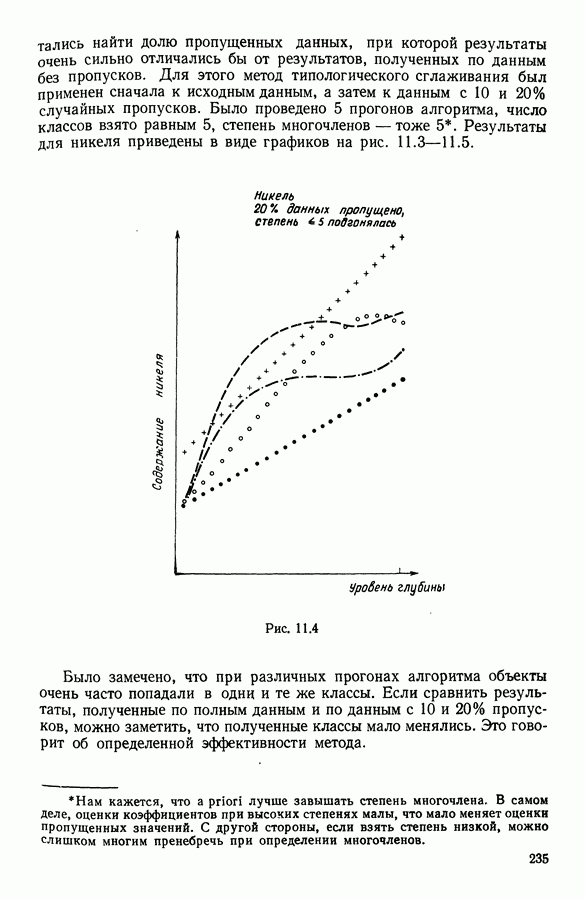
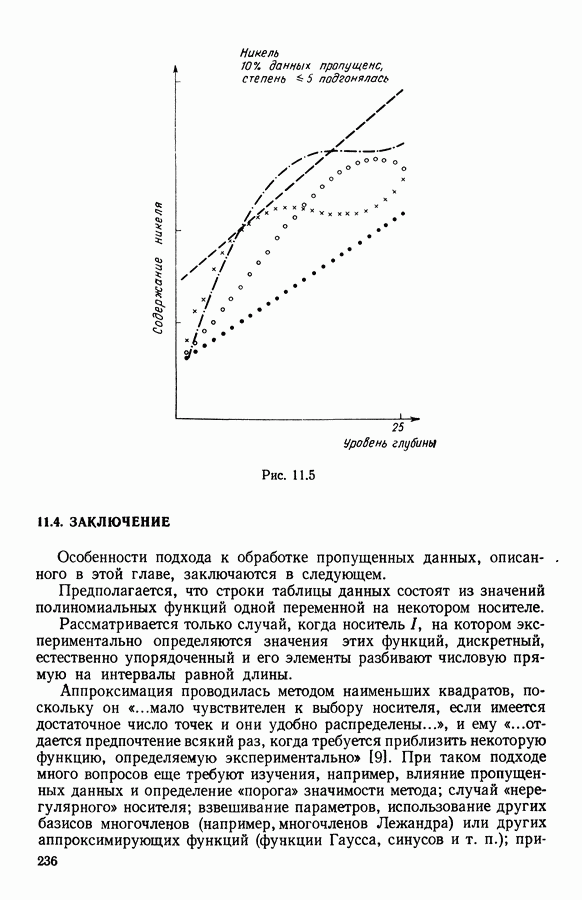
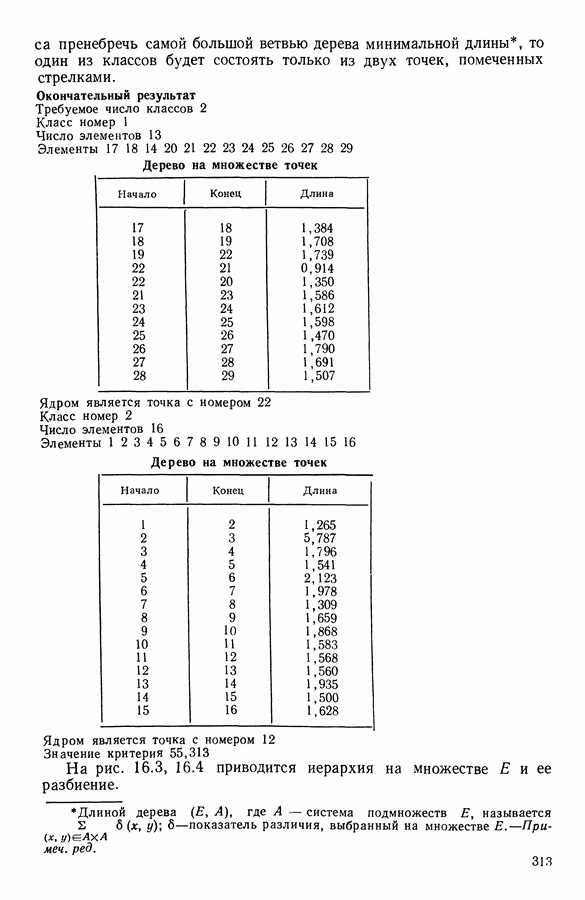
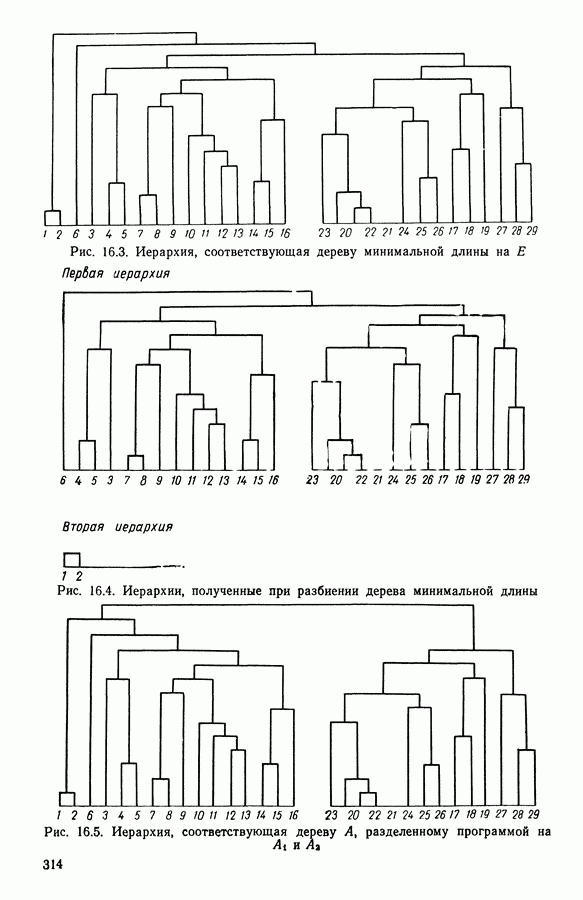
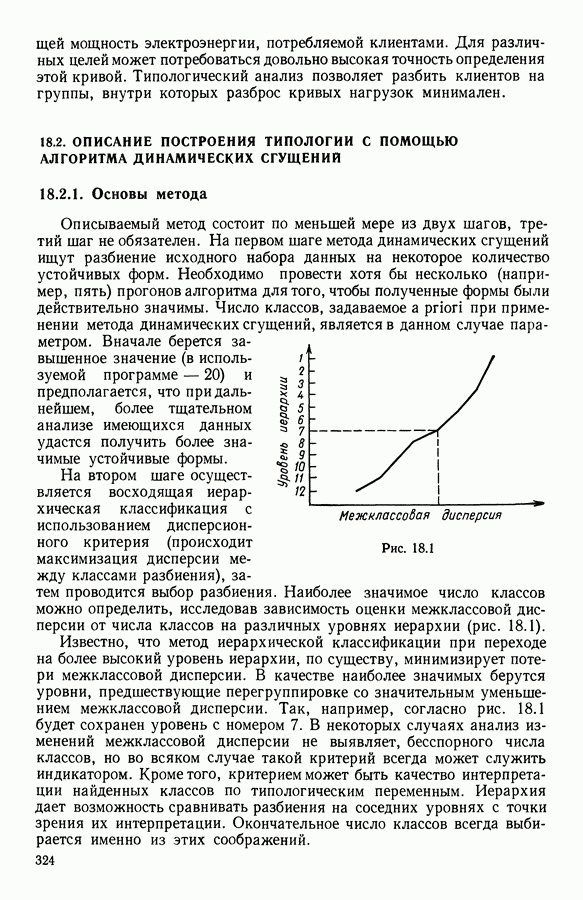
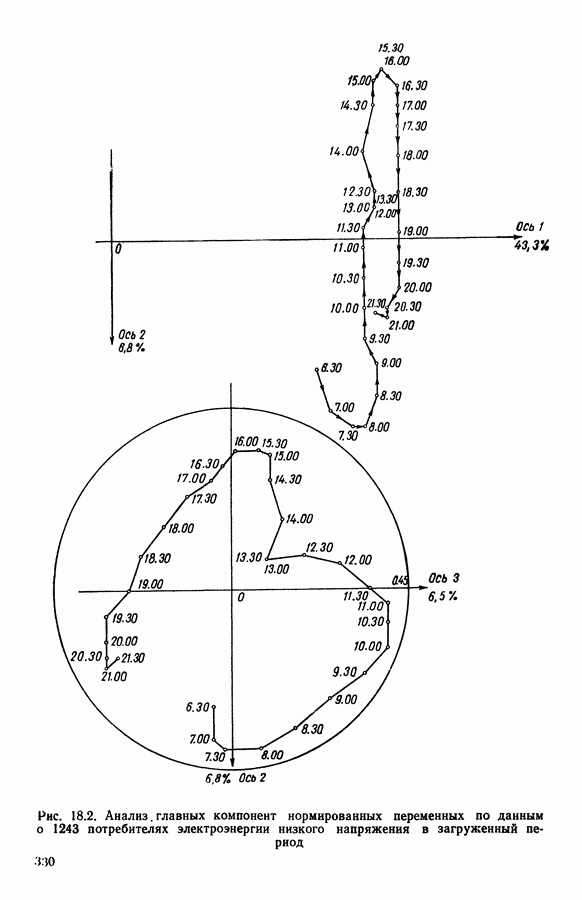
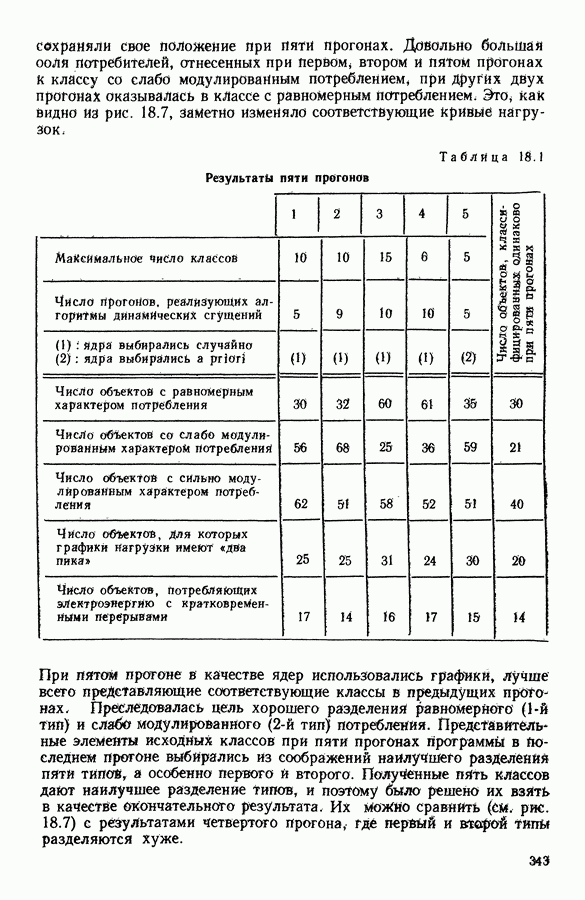
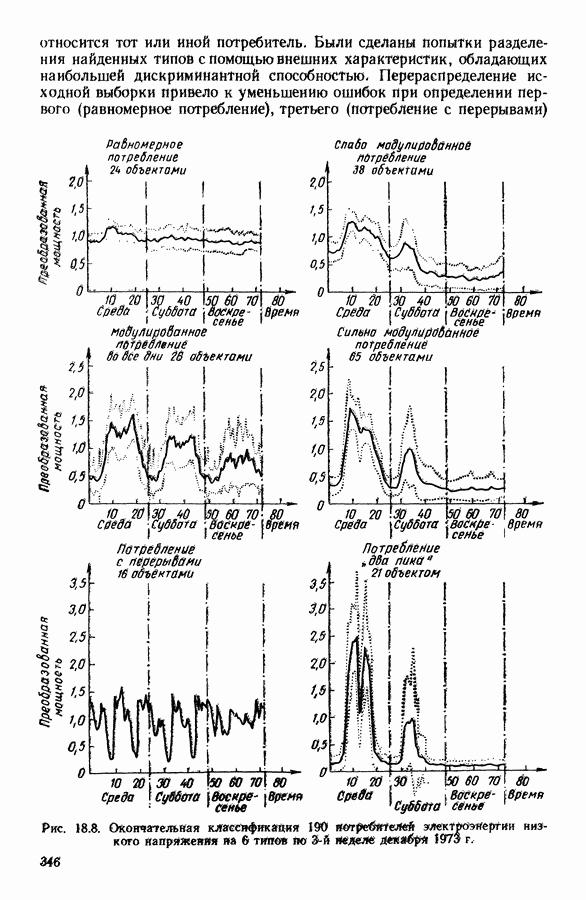
Глава 5. АВТОМАТИЧЕСКАЯ КЛАССИФИКАЦИЯ НЕПОЛНЫХ ДАННЫХ
5.1. ВВЕДЕНИЕ
5.1.1. Задача
Метод анализа данных предполагает выполнение гипотезы о том, что каждый из изучаемых объектов описывается по всей совокупности анализируемых свойств переменных.
На практике часто случается, что некоторые из переменных на тех или иных объектах не были (или не могут быть) зарегистрированы: индивид может отказаться отвечать на некоторые вопросы, может не оказаться необходимой для измерений экспериментальной базы, отдельные данные могут быть «стерты» или потеряны и т. д.
В таких ситуациях при обработке данных используются различные паллиативы, не имеющие под собой теоретической базы. Чаще всего объекты, на которых отдельные переменные не наблюдаются, не принимаются в расчет вовсе. Эта процедура имеет два главных недостатка: сокращение (порой существенное) объема рассматриваемой выборки и возможность появления определенного смещения в наших статистических выводах (когда оставшаяся часть выборки уже не является случайной).
Другой часто применяемый метод состоит в замене любого недостающего значения переменной средней величиной имеющихся наблюдений по рассматриваемой переменной. Это также приводит к смещению выводов.
Конечно, подобные данные по своей природе являются неполными и нельзя надеяться на появление возможности анализировать их так же точно и строго, как полные данные. Тем не менее следует стремиться сделать как можно меньше ошибок при обработке неполных данных, на что и направлены усилия различных авторов, о которых мы здесь будем говорить.
5.1.2. Предшествующие работы
В многочисленных статьях, посвященных этой теме, представлены в основном два подхода. Первый из них характеризуется тем, что авторы стремятся восстановить недостающие данные, не заботясь о том, какого рода обработке эти данные подвергнутся в дальнейшем. Методы, используемые для этой цели, различны. Для восстановления недостающего на объекте наблюдения некоторые из авторов [3], [8], [10]
используют регрессию переменной, по которой недостает наблюдения по одной или нескольким переменным полностью «обеспеченным» наблюдениями. Другие [5], [10] применяют для восстановления данных прогностическую модель, построенную на базе анализа главных компонент. Наконец, третьи [13] используют формулу восстановления данных, основанную на факторном анализе соответствий.
При втором подходе авторы ставят задачу по-иному: зная, какую именно задачу нужно решить в результате анализа данных (например, провести анализ главных компонент или построить регрессию), они стараются произвести наилучшую оценку параметров анализируемых моделей по тем неполным данным, которыми располагают [1], [2], [4], [5], [9], [11], [12].
Метод, представленный в этой главе, следует логике второго порядка.
5.1.3. Предлагаемый подход
Как и в других методах анализа данных, в методе динамических сгущений предполагается наличие полных исходных данных. В этой главе будет показано, как МДС может «работать» при неполных количественных данных.
Итак, пусть  множество классифицируемых объектов и
множество классифицируемых объектов и  совокупность переменных, описывающих «состояние» каждого из объектов
совокупность переменных, описывающих «состояние» каждого из объектов  Наша цель — разделить множество
Наша цель — разделить множество  на
на  непересекающихся классов (наилучшим, в смысле критерия
непересекающихся классов (наилучшим, в смысле критерия  образом), зная при этом, что по некоторым переменным отдельные объекты не были статистически обследованы.
образом), зная при этом, что по некоторым переменным отдельные объекты не были статистически обследованы.
Можно предложить несколько подходов к решению сформулированной задачи.
Прежде всего такой, который состоит в восстановлении тем или иным способом недостающих данных и в применении к укомплектованным таким образом данным метода динамических сгущений.
Можно использовать также подход, при котором в ходе реализации МДС происходит включение фазы восстановления недостающих данных между фазой «переназначения» объектов по классам и фазой изменения представительства классов. Значение по недостающей переменной может быть восстановлено на объекте, например, с помощью ее аппроксимации соответствующей координатой центра тяжести класса, к которому относится этот объект.
Наконец, можно применить подход, который не предусматривает восстановления недостающих данных, а автоматическая классификация производится непосредственно на базе имеющихся в наличии наблюдений. Именно такой подход описывается в настоящей главе.
Чтобы точнее определить основные характеристики этого подхода, введем некоторые понятия и обозначения.