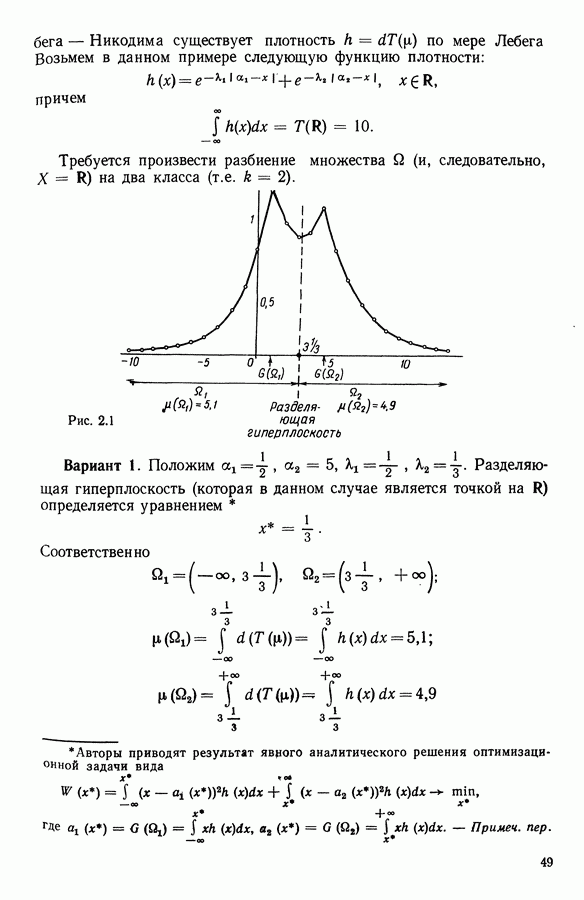
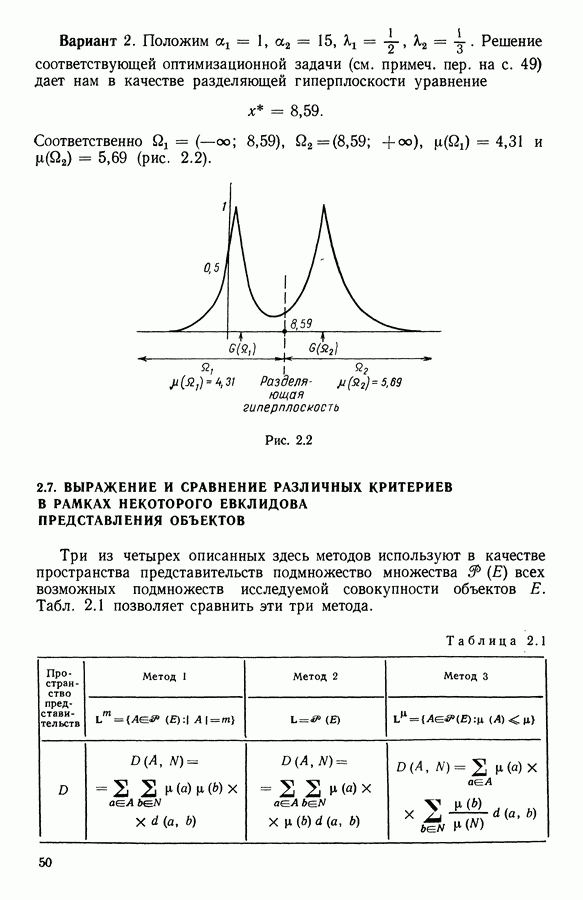
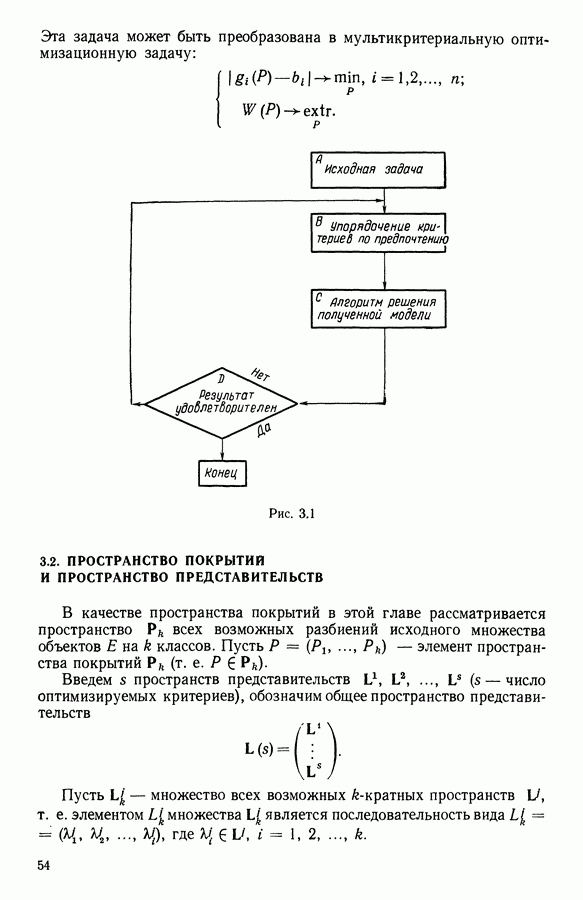
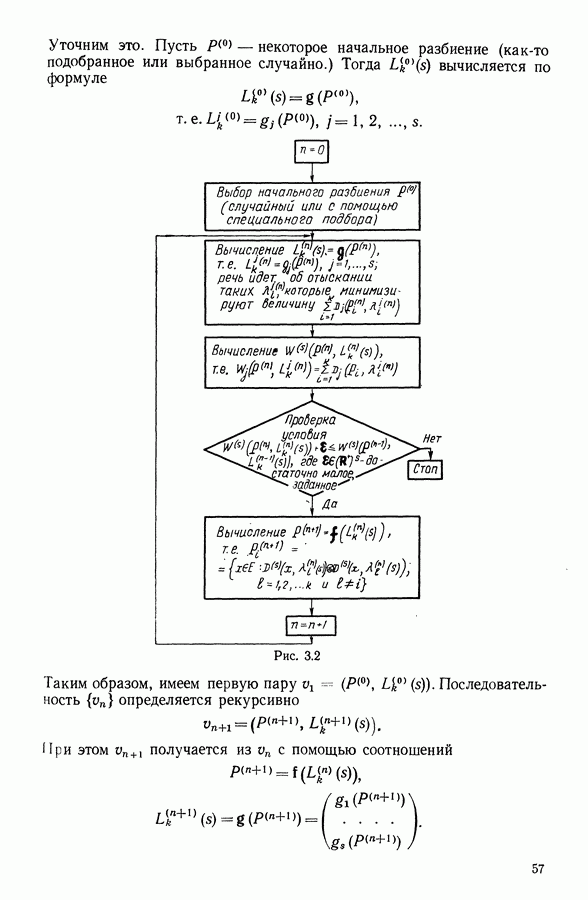
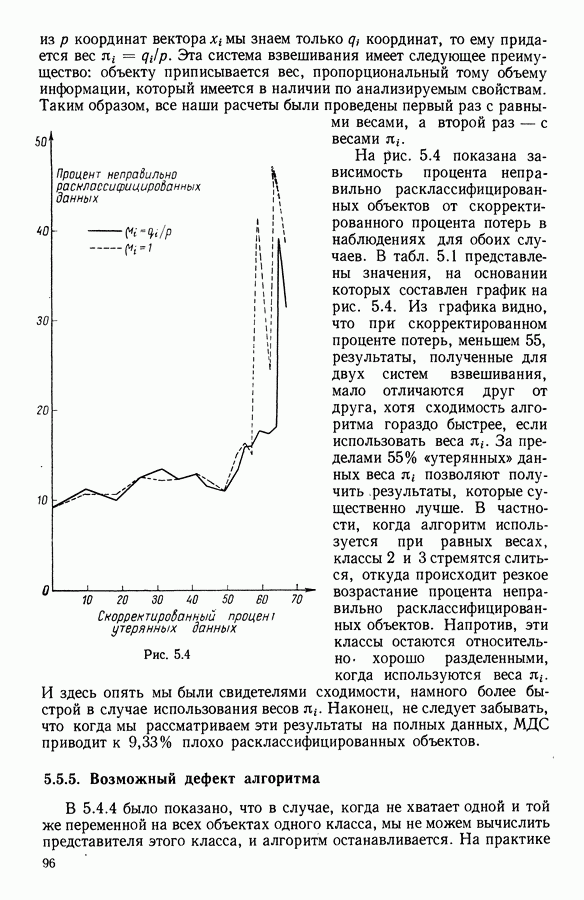
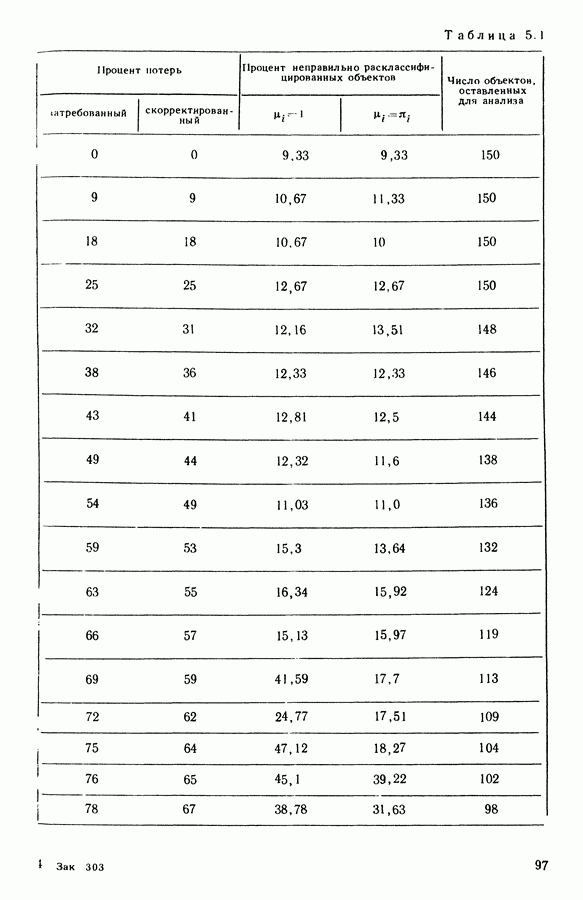
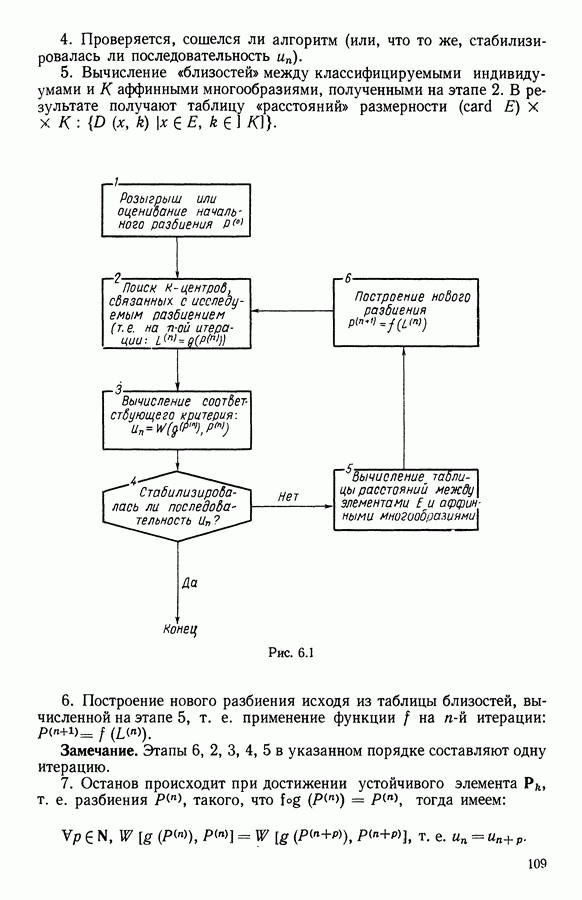
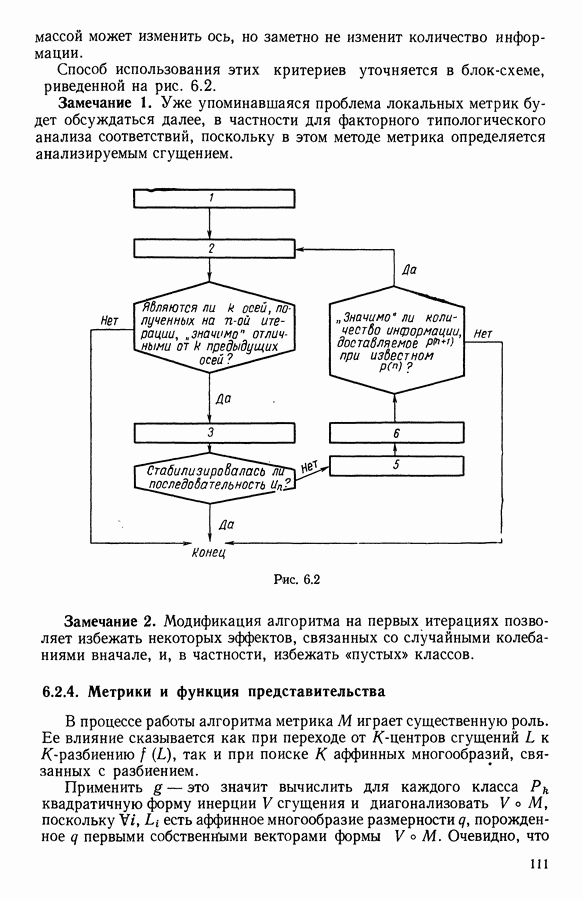
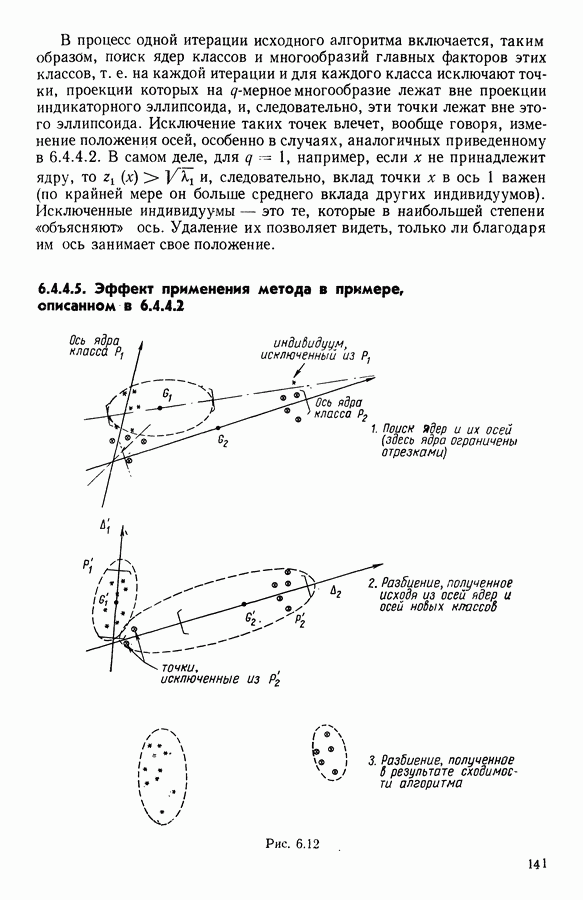
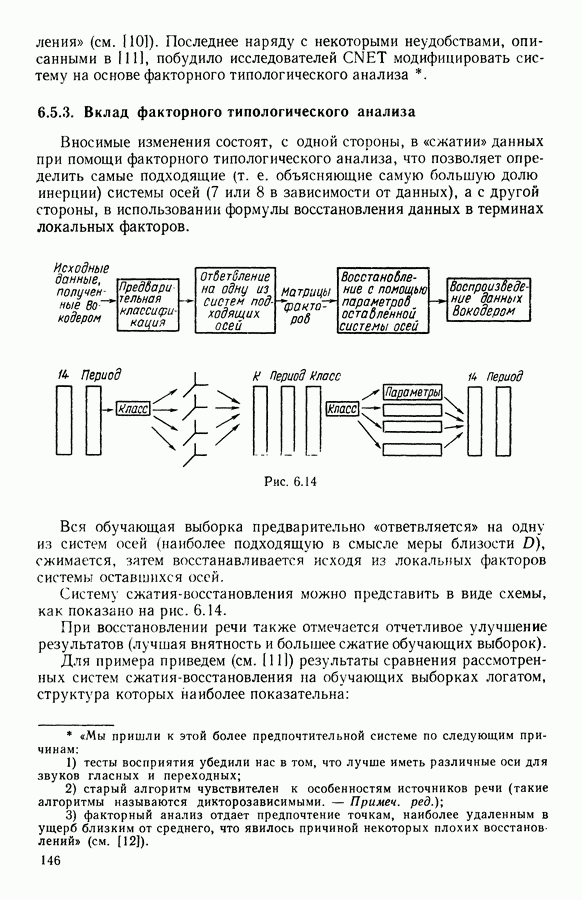
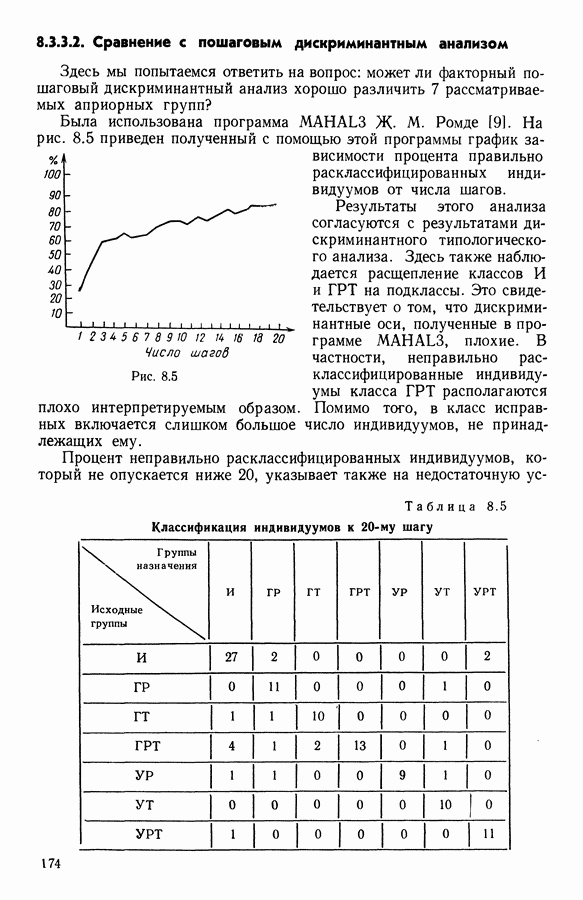
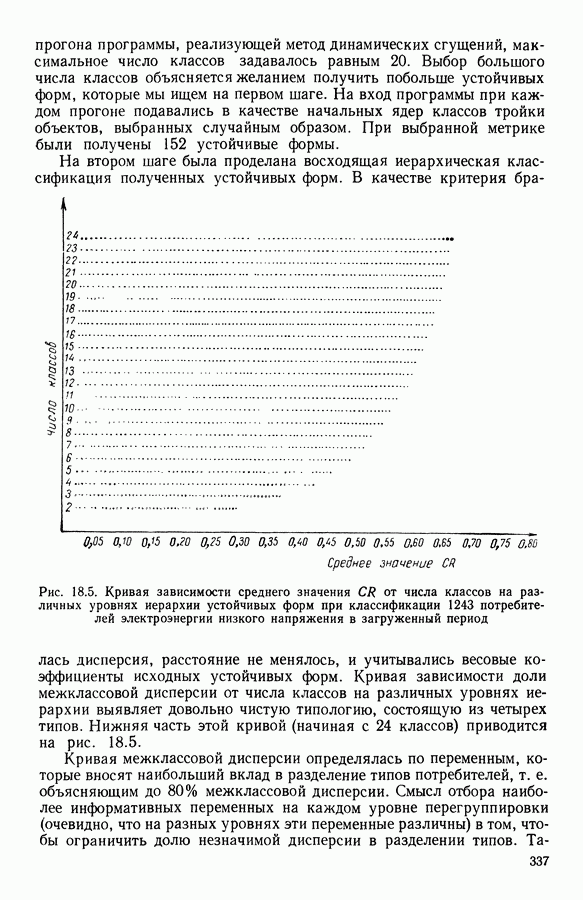
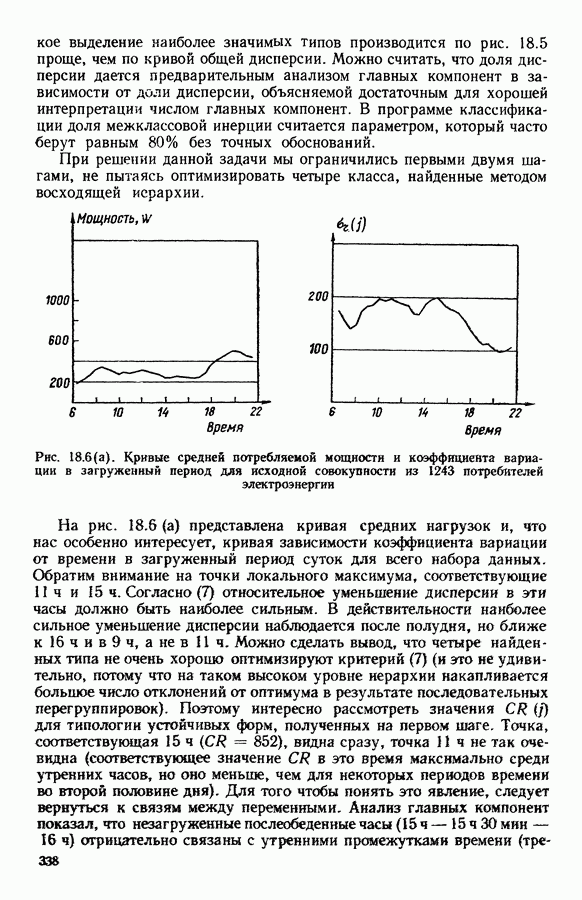
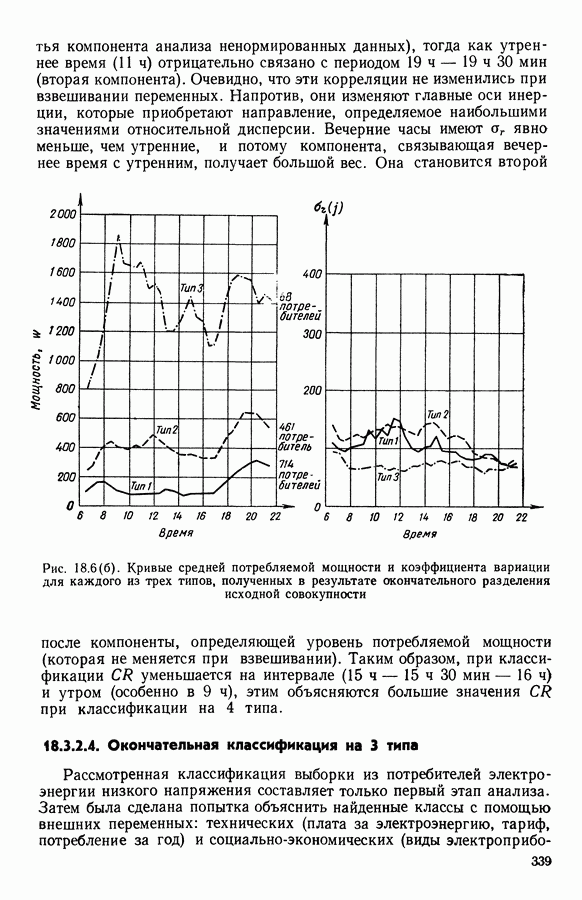
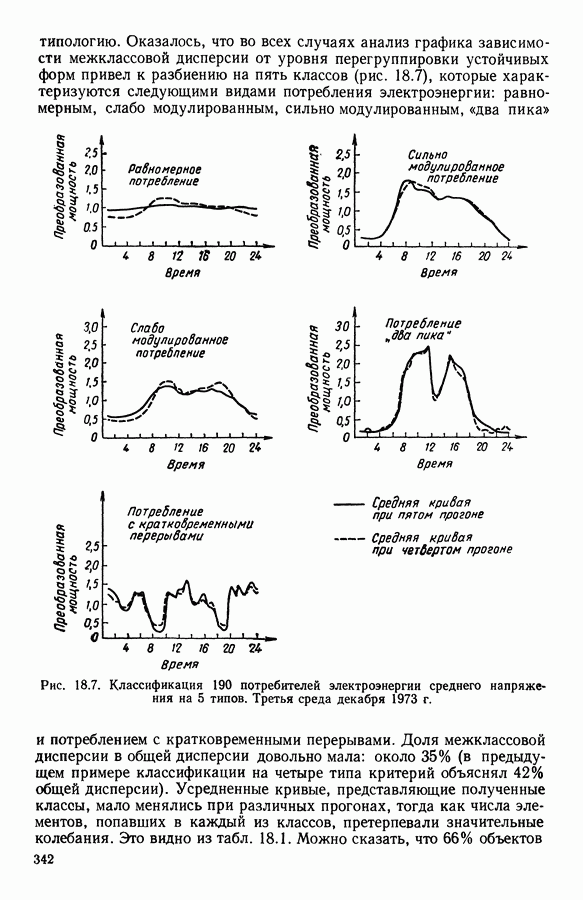
9.1.3. Типологическое агрегирование данных о предпочтениях
Несколько описанных выше моделей показывают разнообразие алгоритмических проблем, с которыми приходится сталкиваться, когда нужно агрегировать индивидуальные данные о предпочтениях.
Для получения все более и более сложных синтезов индивидуальных предпочтений, позволяющих, с одной стороны, лучше передать все нюансы мнений, для выражения которых применяются турниры, порядки, предпорядки, квазипорядки, вложенные квазипорядки и т. п., а с другой стороны, использовать эвристические методы решения задачи  мы предлагаем заменить глобальное описание предпочтений более простым локальным. Это оправдано тем, что аналогичным образом определяют основные тенденции судейства, и тем, что при таком описании можно ограничиться наиболее однородными группами индивидуальных предпочтений, добиваясь большей простоты структуры локальных синтезов и упрощения этапов алгоритма по агрегированию.
мы предлагаем заменить глобальное описание предпочтений более простым локальным. Это оправдано тем, что аналогичным образом определяют основные тенденции судейства, и тем, что при таком описании можно ограничиться наиболее однородными группами индивидуальных предпочтений, добиваясь большей простоты структуры локальных синтезов и упрощения этапов алгоритма по агрегированию.
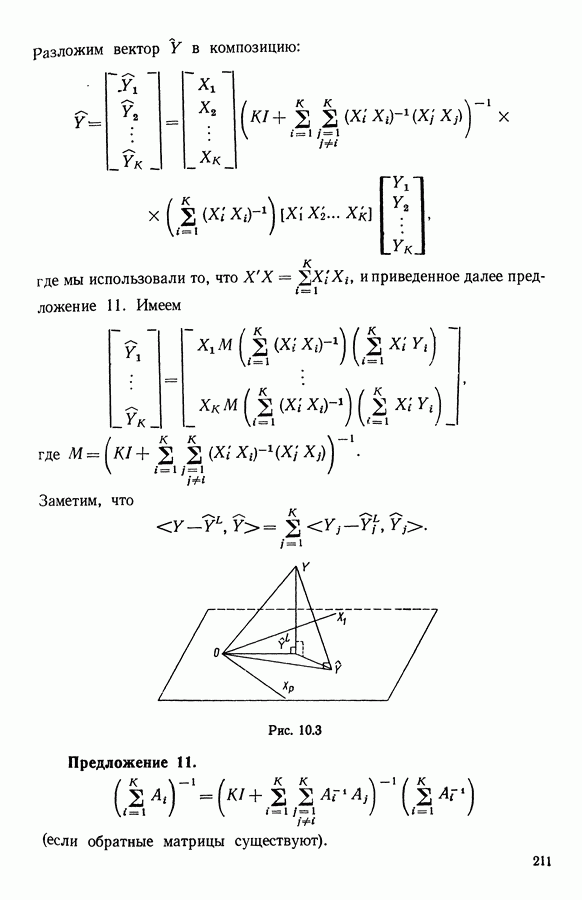
Как и в 9.1.2, агрегировать предпочтение судей, принадлежащих к подмножеству  значит решить задачу
значит решить задачу

где на этот раз

Как и выше, мы предполагаем, что

Обозначая теперь через  минимальное значение
минимальное значение  полученное при решении задачи
полученное при решении задачи  запишем задачу типологического агрегирования в виде
запишем задачу типологического агрегирования в виде

где  разбиение
разбиение 
Очевидно, что выигрыш в простоте при ограничении наиболее простыми синтезами (порядки, предпорядки и т. п.) не бесплатен, так как теперь возникает проблема поиска разбиения множества  а комбинаторные трудности задач классификации хорошо известны.
а комбинаторные трудности задач классификации хорошо известны.
Два подхода к задаче  были предложены Е. Жакет-Лагрезом. В [14] был рассмотрен случай двух классов с использованием алгоритма типа динамических сгущений и медианных порядков. В [16] развивается иерархический подход, который обосновывается устойчивостью множества предпочтений по отношению к операциям усреднения. Систематическое исследование метода динамических сгущений содержится в работах [18], [19] и [7]. Развитие этого метода рассматривается в 9.2.
были предложены Е. Жакет-Лагрезом. В [14] был рассмотрен случай двух классов с использованием алгоритма типа динамических сгущений и медианных порядков. В [16] развивается иерархический подход, который обосновывается устойчивостью множества предпочтений по отношению к операциям усреднения. Систематическое исследование метода динамических сгущений содержится в работах [18], [19] и [7]. Развитие этого метода рассматривается в 9.2.