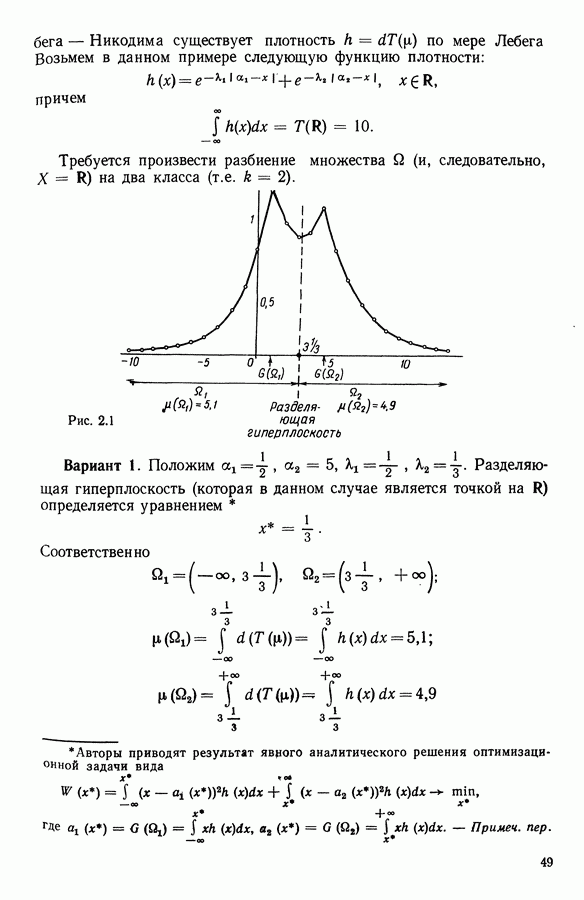
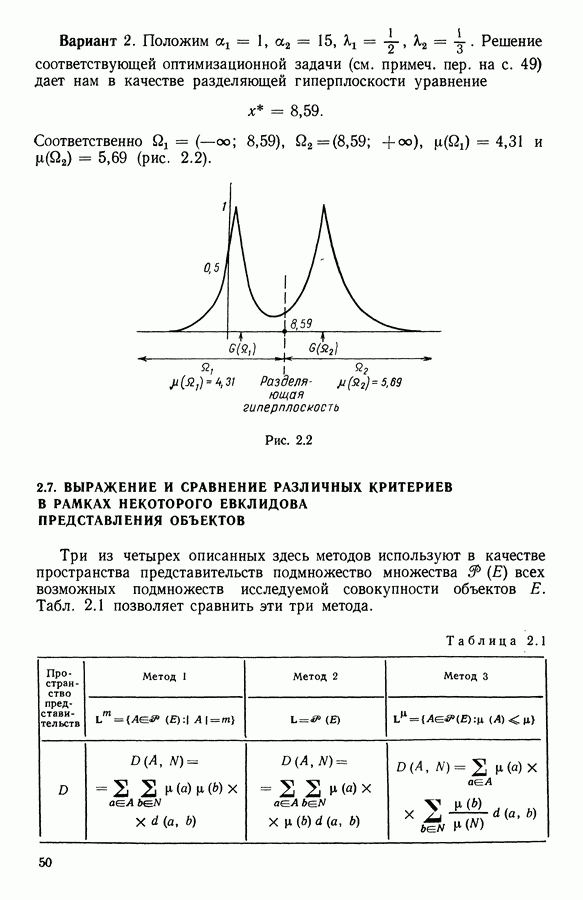
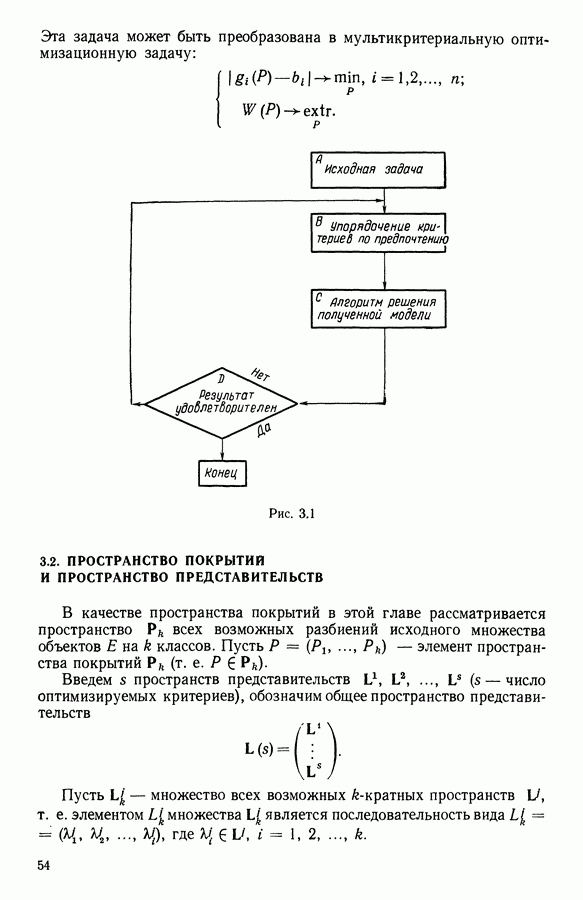
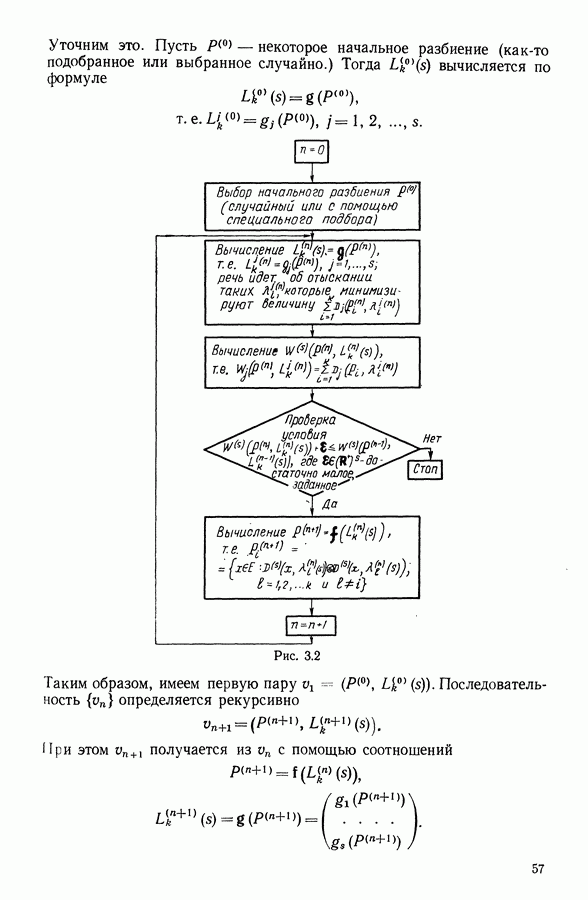
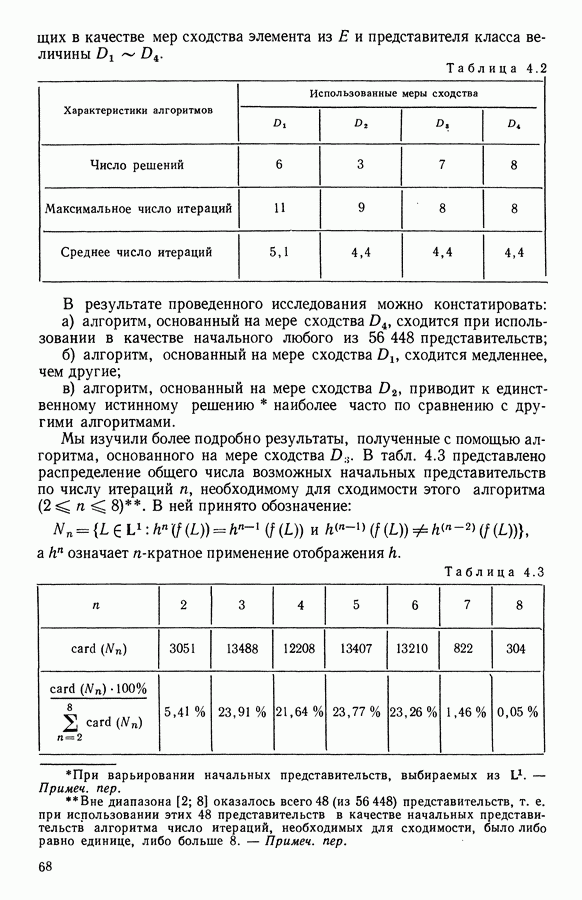
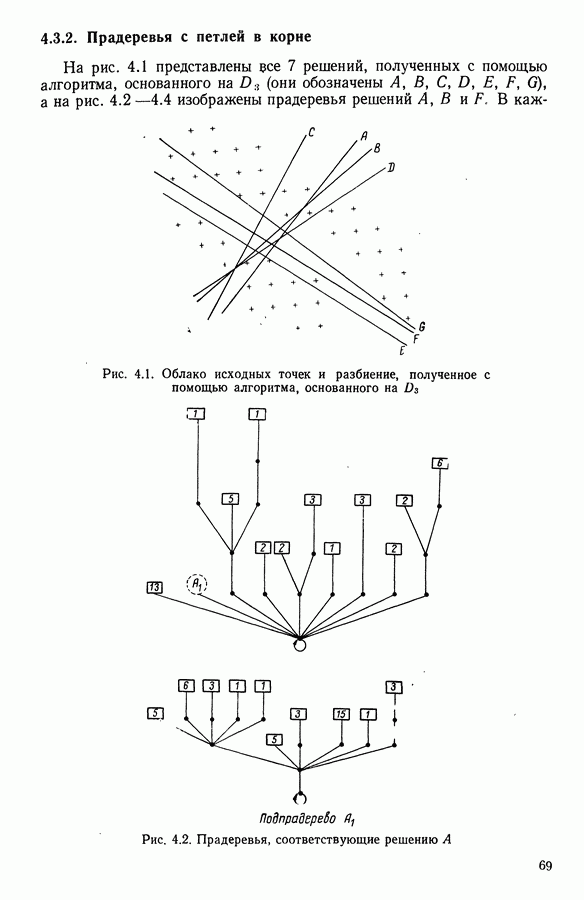
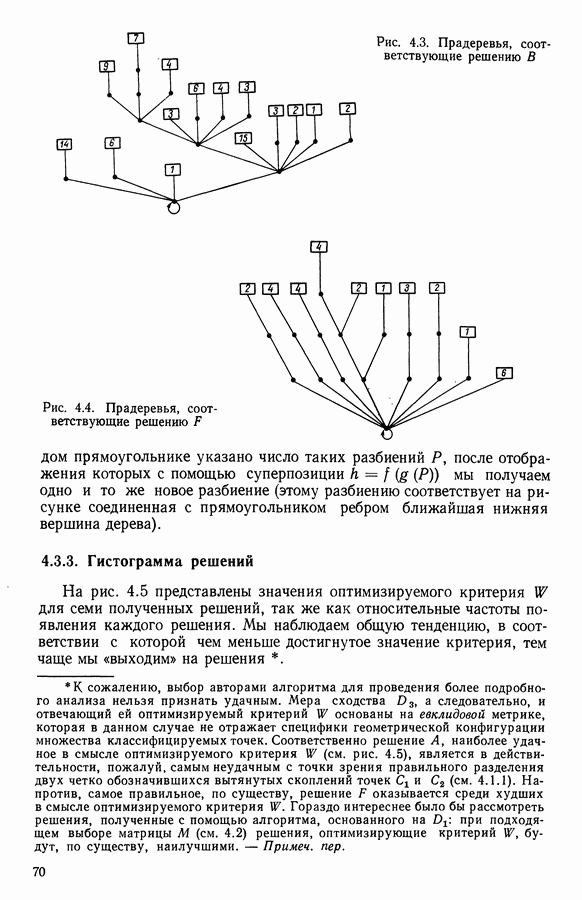
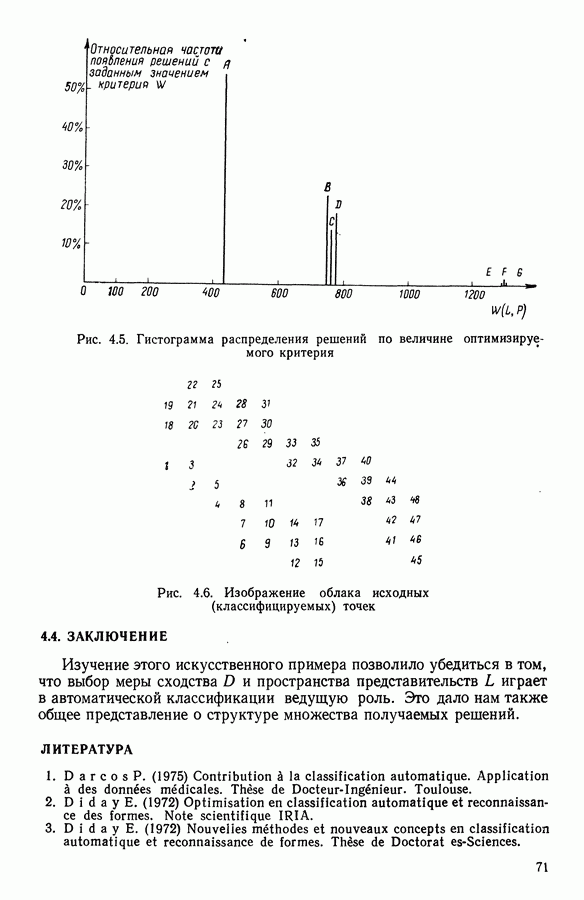
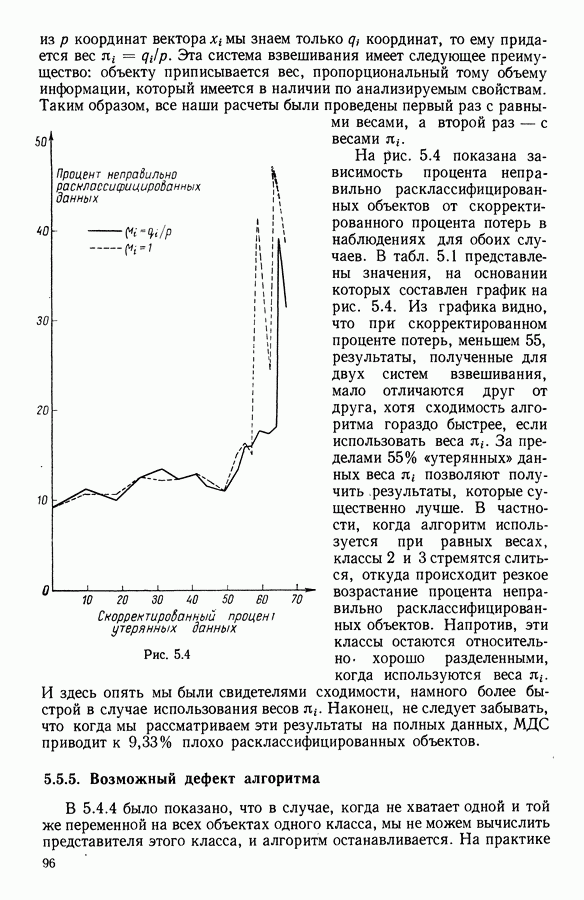
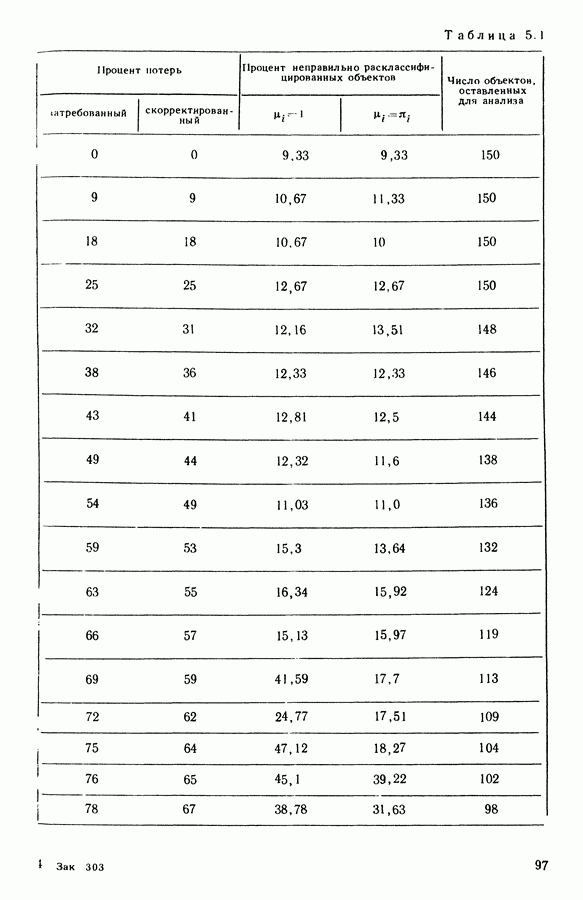
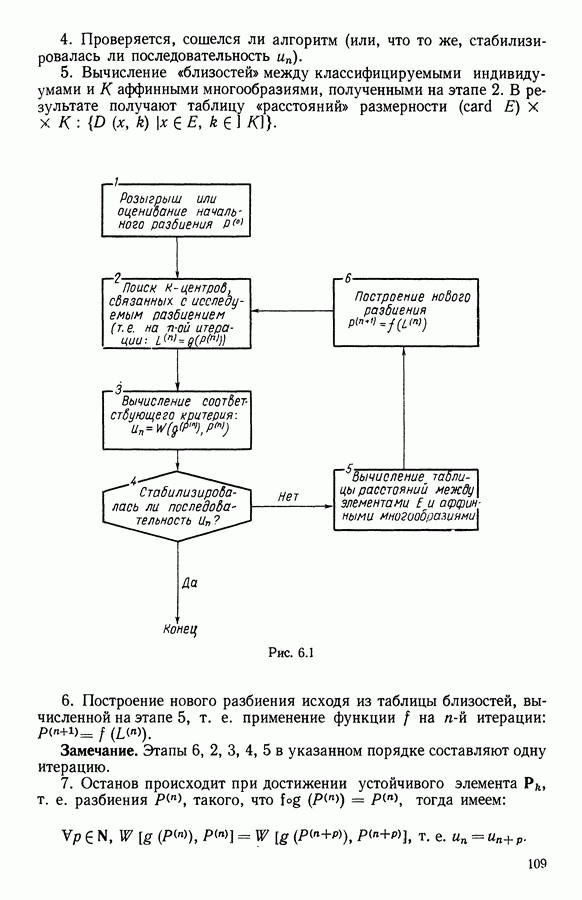
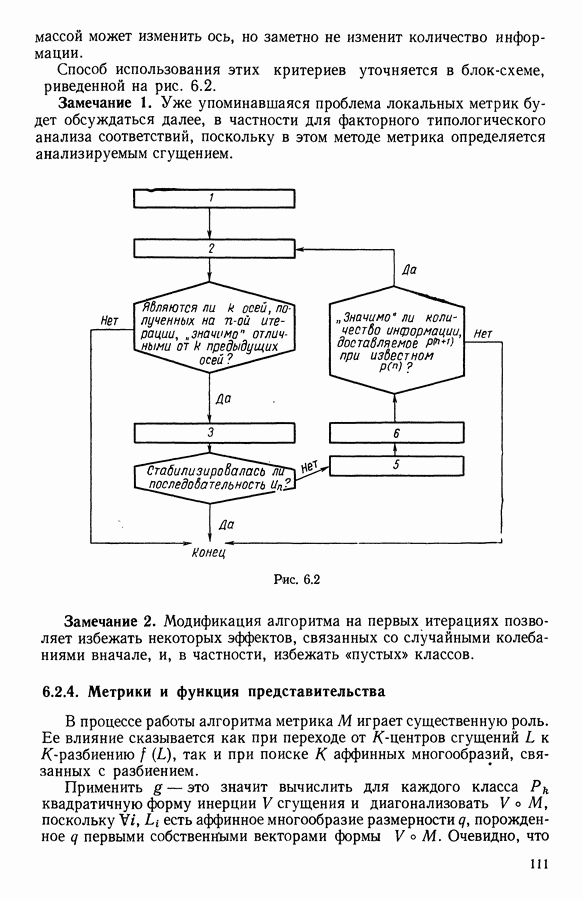
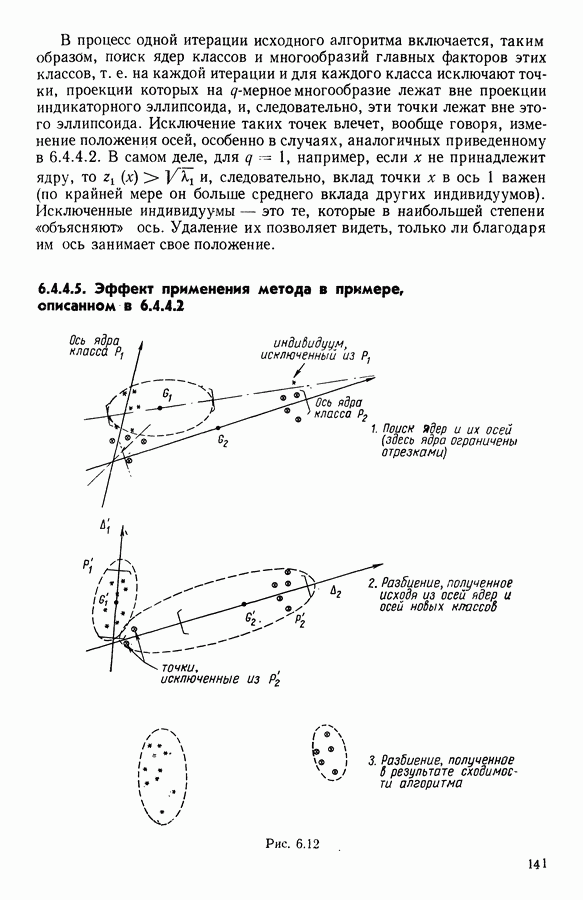
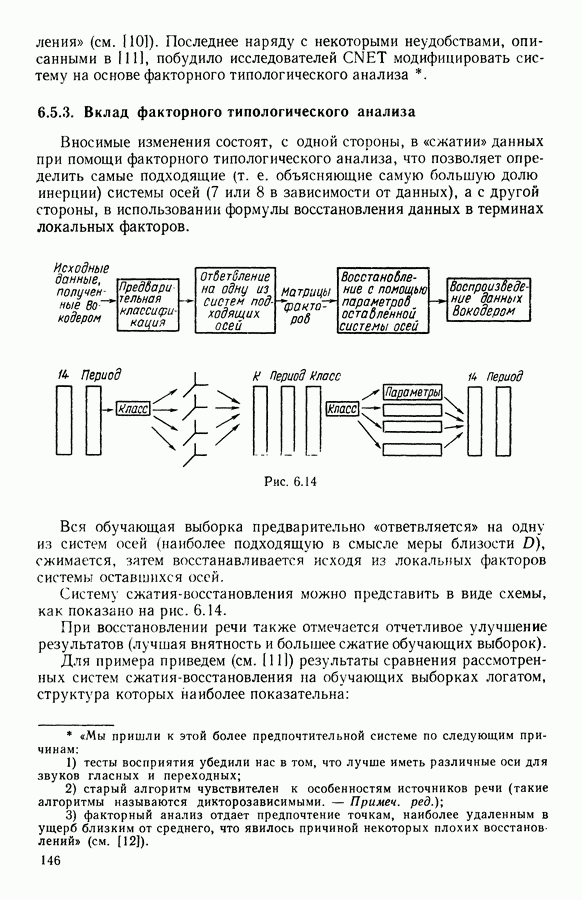
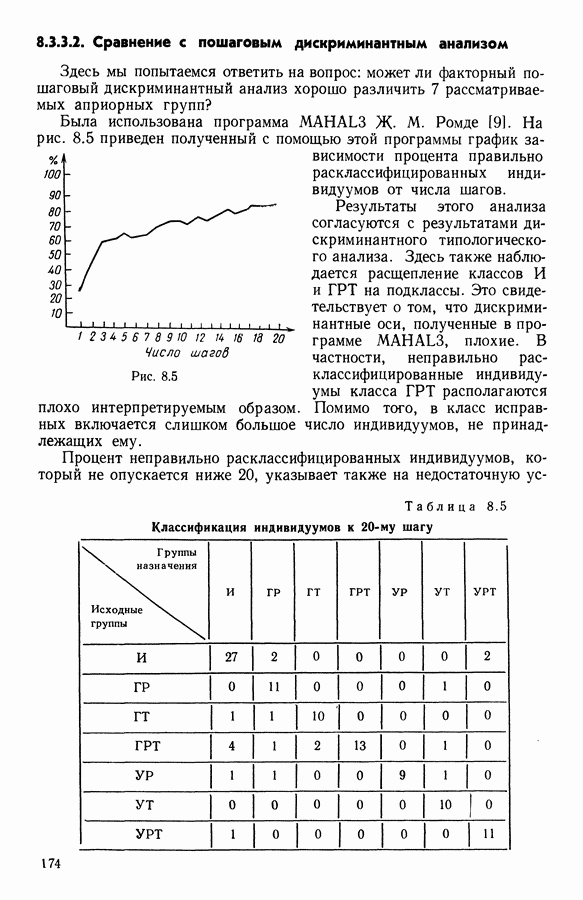
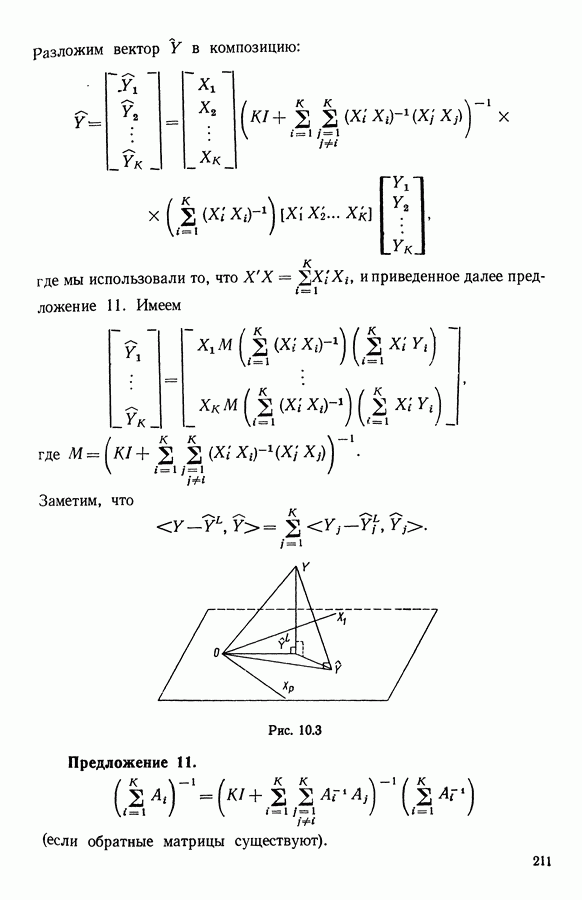
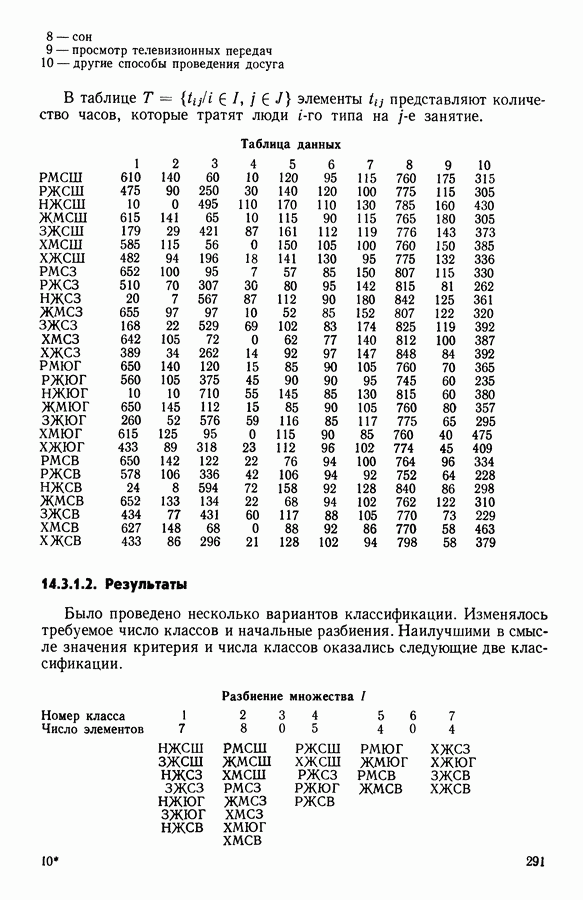
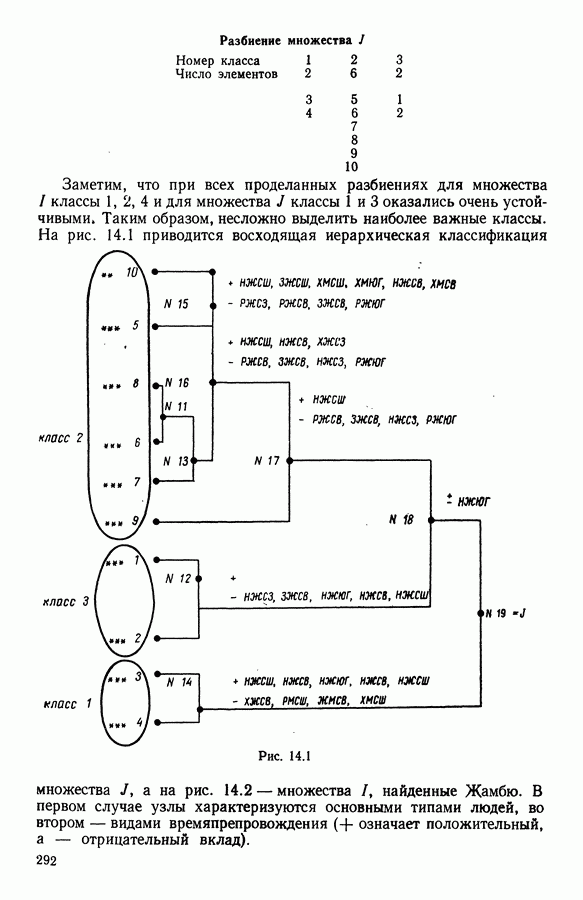
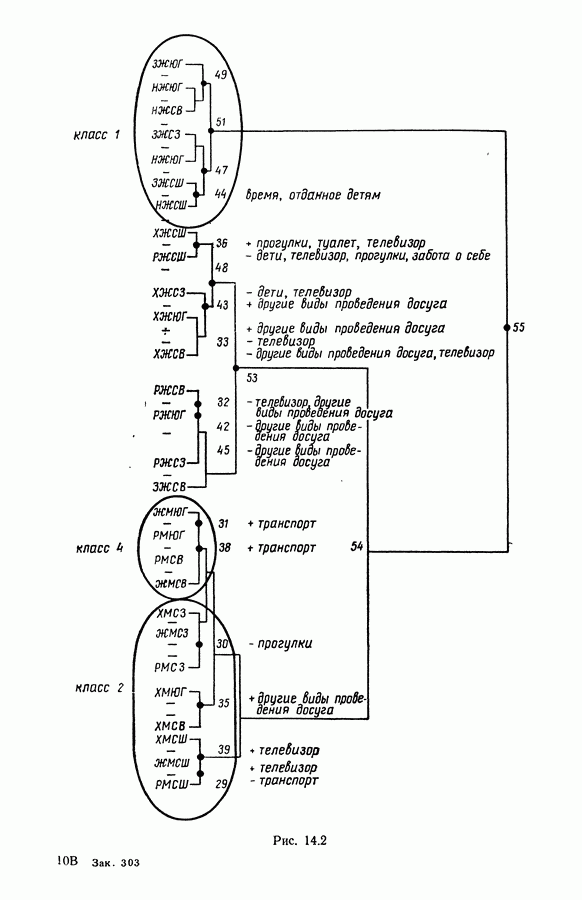
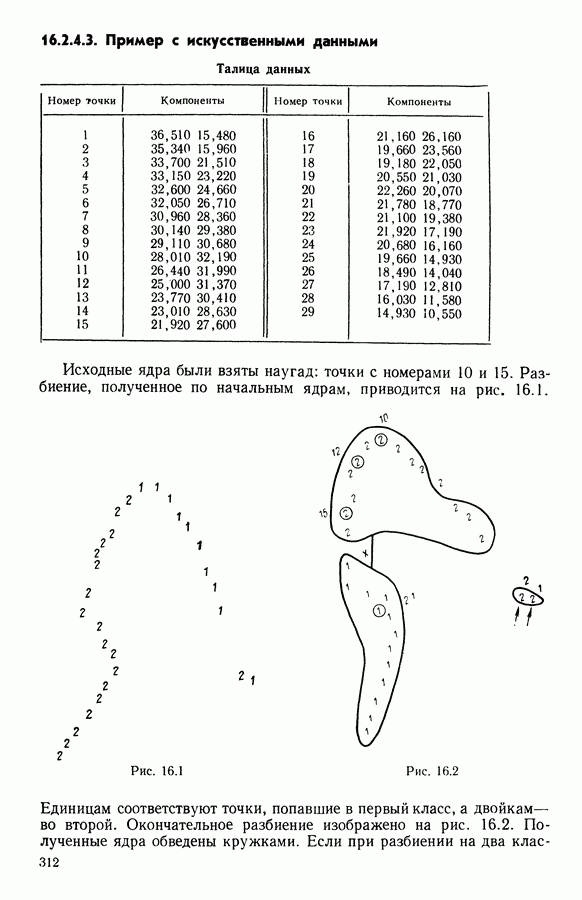
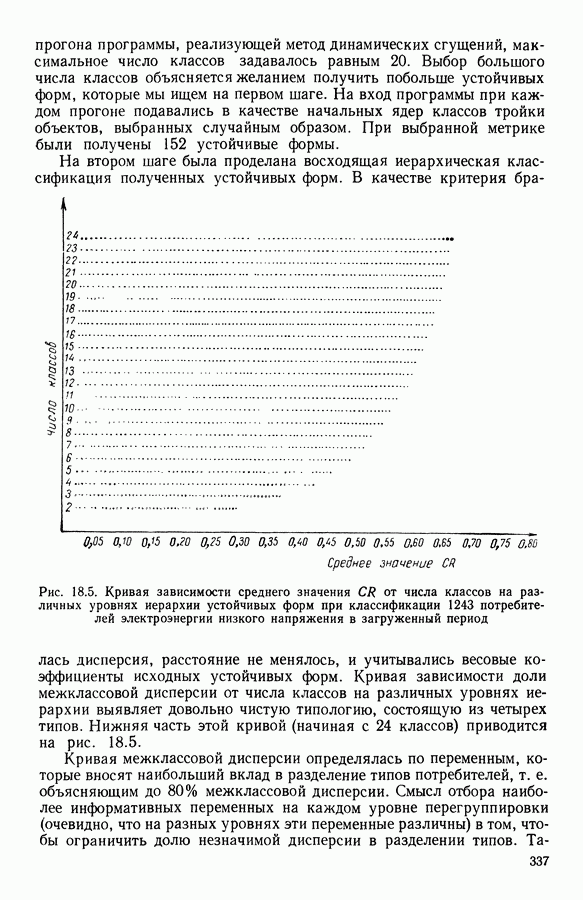
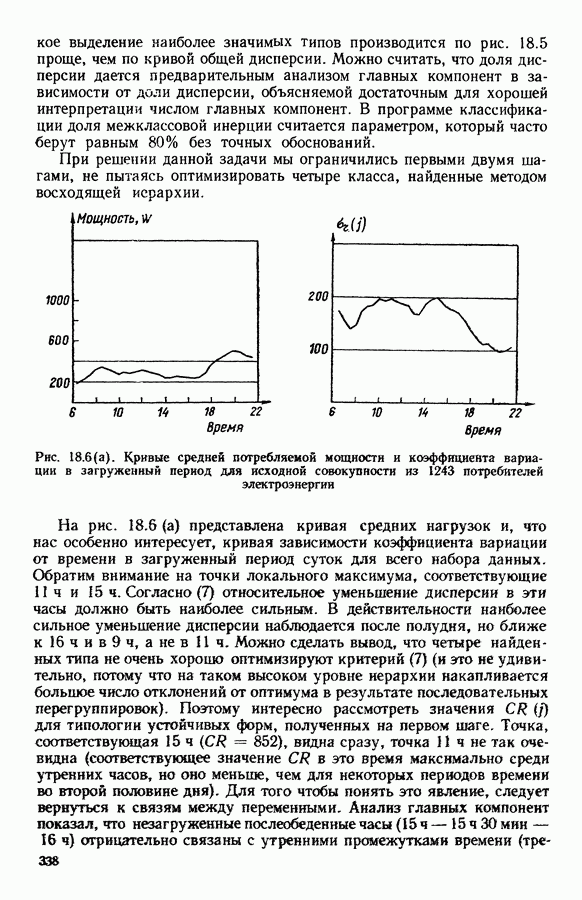
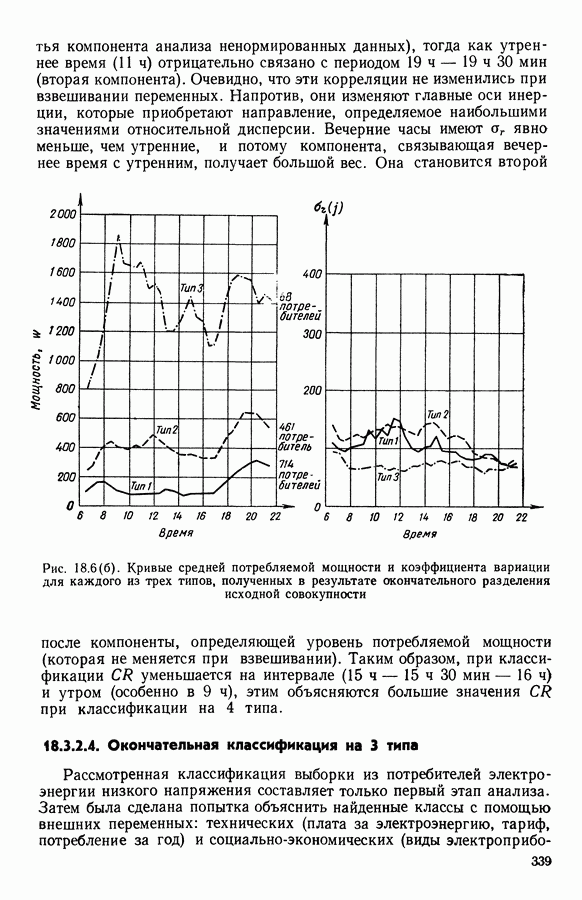
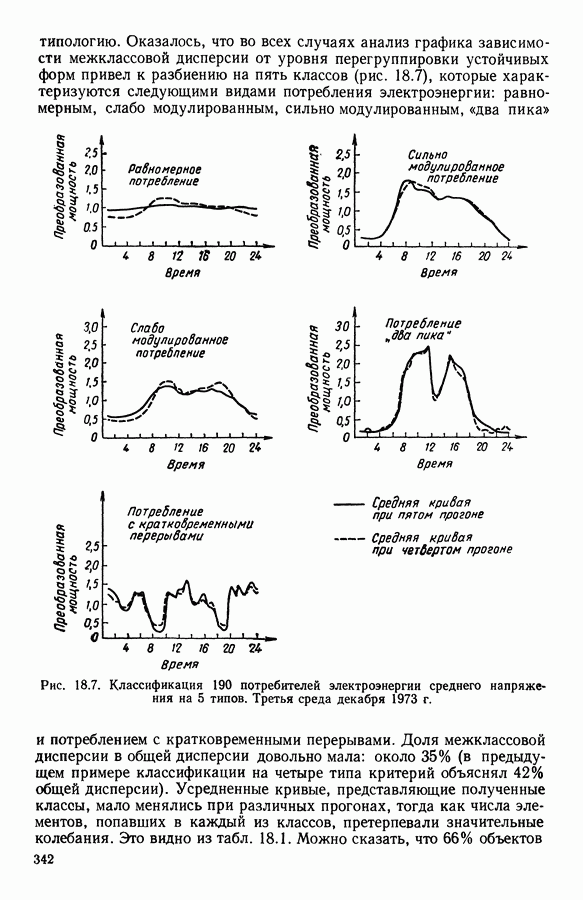
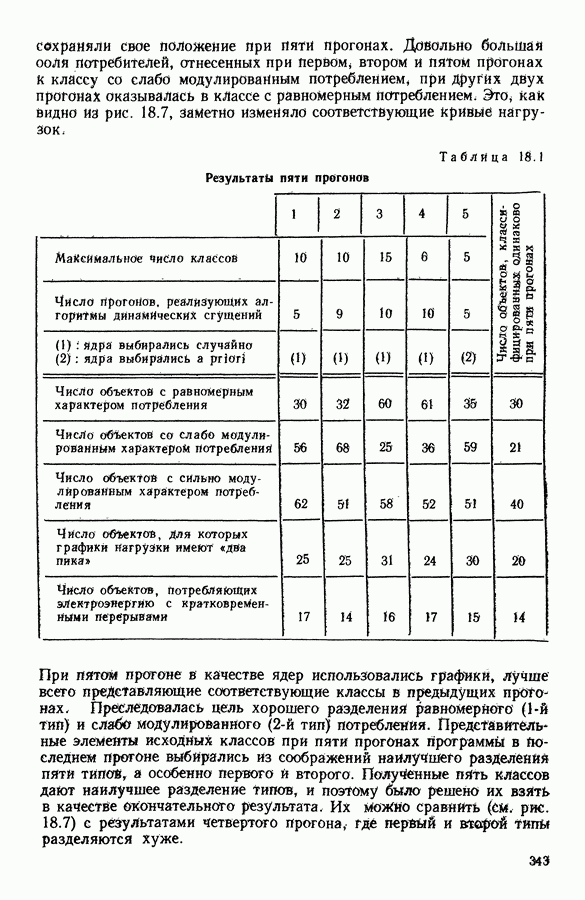
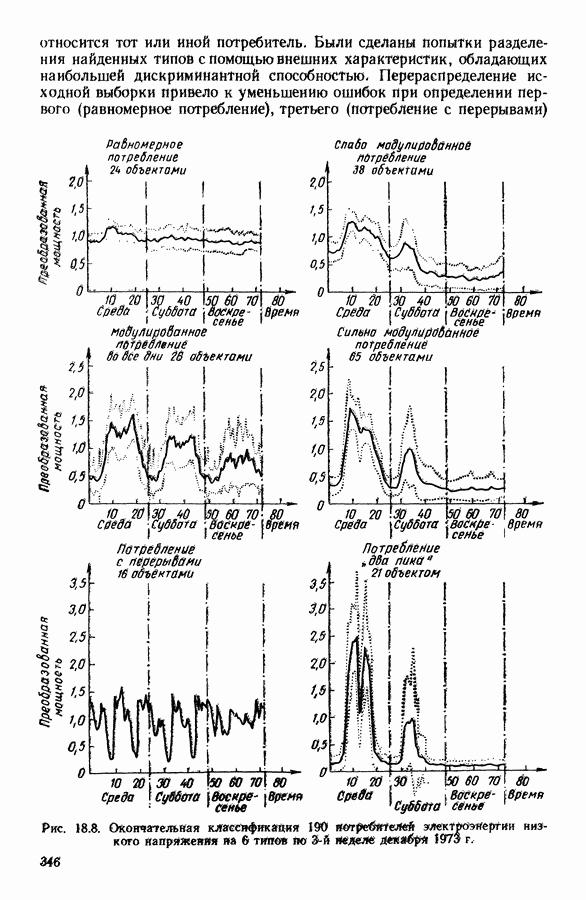
Глава 11. ТИПОЛОГИЧЕСКОЕ СГЛАЖИВАНИЕ
11.1. ВВЕДЕНИЕ
Метод, которому посвящена эта глава, появился в связи с некоторыми проблемами, часто возникающими при анализе данных. Во-первых, это обработка данных, описывающих эволюцию явления в виде графика, иначе говоря, данных, к которым удобно применить полиномиальную модель. И во-вторых, это проблема обработки таблиц данных с пропусками. Дело в том, что часто не все наблюдения могут быть проведены в одинаковых условиях. Речь идет о таких измерениях, как, например, содержание минерала на различной глубине (в геологии), увеличение веса животного (в животноводстве), изменение в численности популяций (в агробиологии).
Наша задача состоит в определении групп, каждая из которых состоит из объектов, или наблюдений, изменяющихся по одному и тому же закону и принадлежащих некоторой исходной, возможно неполной, совокупности. Иначе говоря, в многомерной выборке требуется выделить подмножества, каждое из которых может быть описано полиномиальной функцией. Метод типологических сглаживаний состоит в автоматической классификации данных, содержащих пропущенные значения. Обычно при неполных данных классификации предшествует оценка пропущенных значений. Особенностью описываемого метода является то, что в нем одновременно выполняются классификация и аппроксимация. На наш взгляд, это позволяет избежать многих неудобств.
Прежде всего процедура, в процессе которой выполняется столько аппроксимаций, сколько существует объектов, может оказаться чересчур дорогостоящей. С другой стороны, при оценке пропущенного значения было бы желательно принимать во внимание все похожие объекты, и, таким образом, заменять классическую интерполяцию статистической интерполяцией (группы объектов), поскольку характерные и отличительные черты групп нас интересуют больше, чем особенности отдельных объектов.
Из практических соображений будем считать, что строки таблицы Данных являются известными определяемыми экспериментально значениями на некотором носителе функций одной переменной. Ограничимся случаем, когда носитель j дискретный, естественно упорядоченный и его элементы разбивают числовую прямую на интервалы равной длины. Поскольку, как правило, вид наиболее подходящих Функций неизвестен, нам кажется уместным для характеризации классов искать многочлены небольшой степени. Будет показано, что такие
условия можно наложить и на неполные данные, допуская при этом некоторую ошибку.
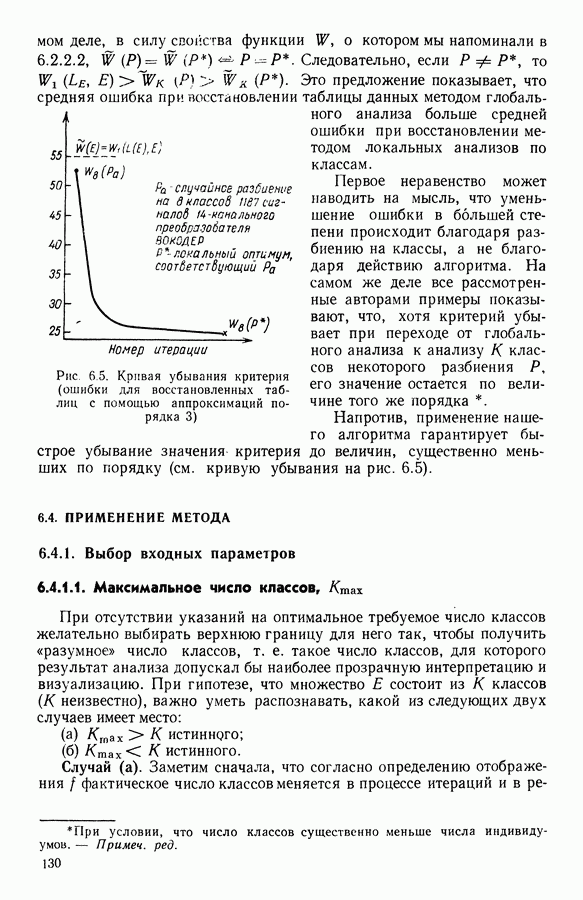
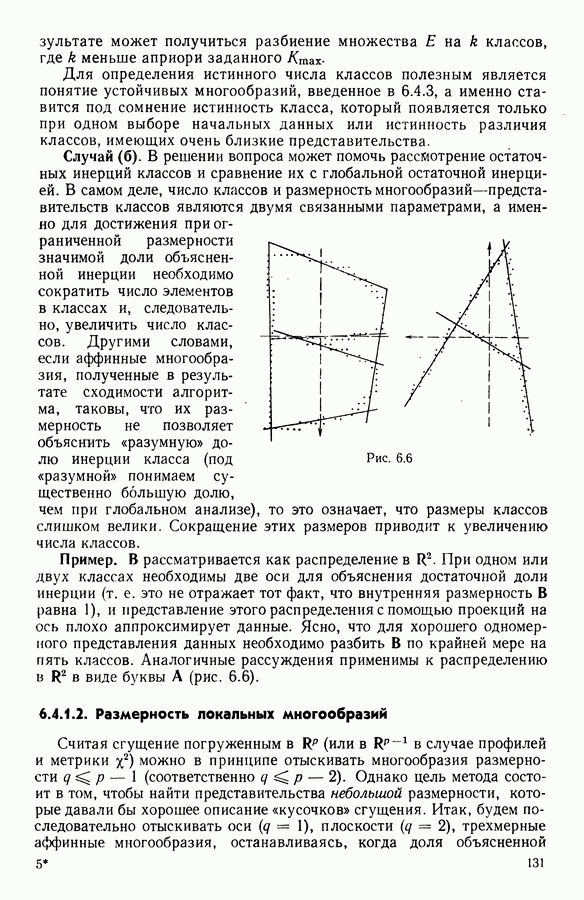
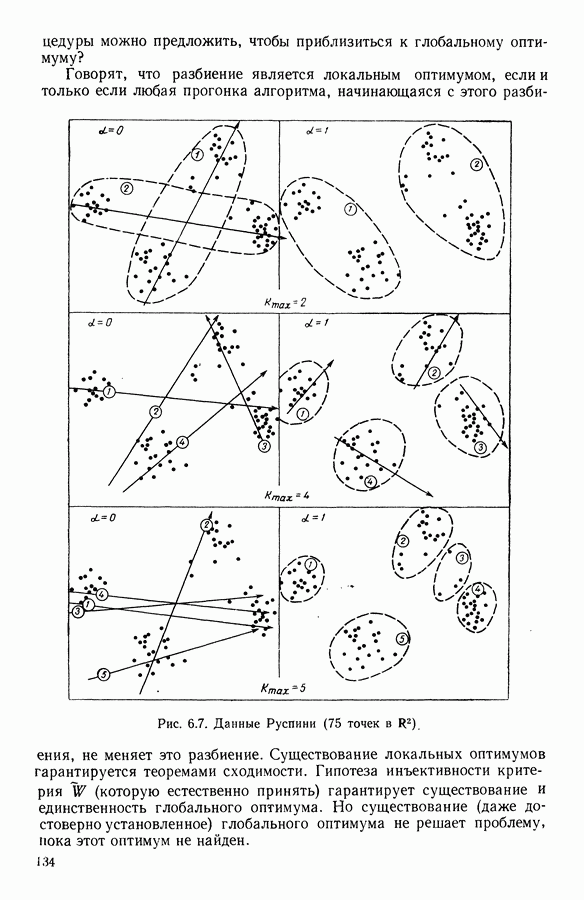
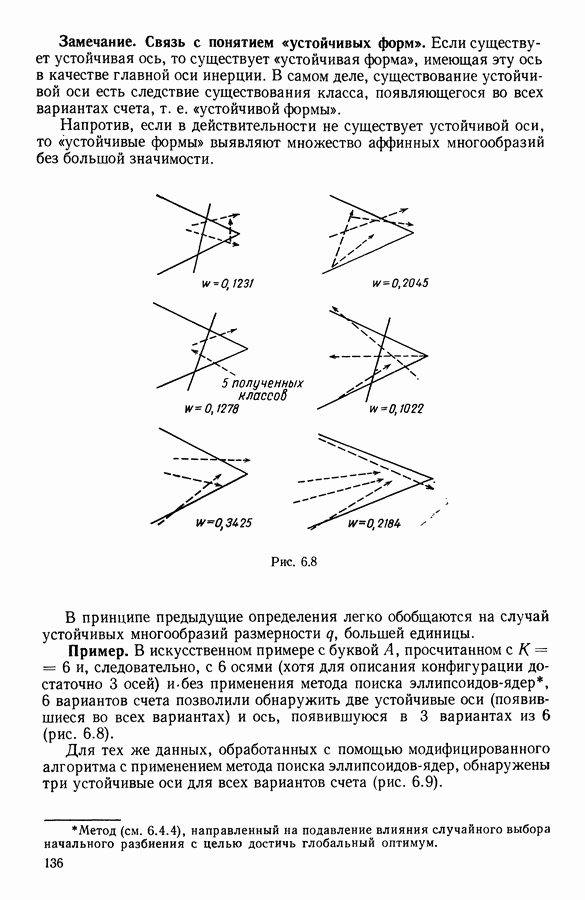
Алгоритм, который приводится далее, определяет разбиение совокупности на классы, каждый из которых характеризуется многочленом. Степень многочлена определяется в процессе подгонки. Вклад класса в значение критерия говорит о его дисперсии относительно характеризующей кривой и позволяет оценить качество характеризации.