Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
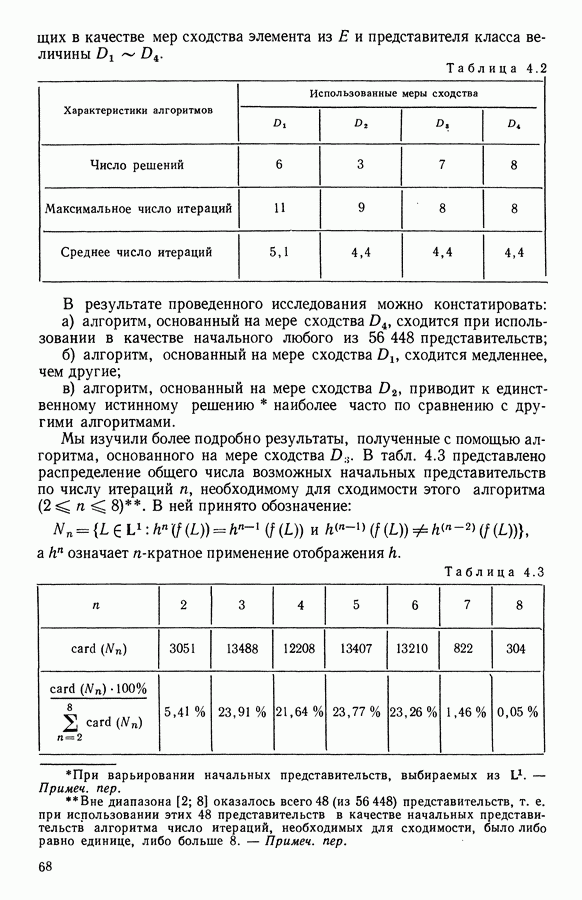
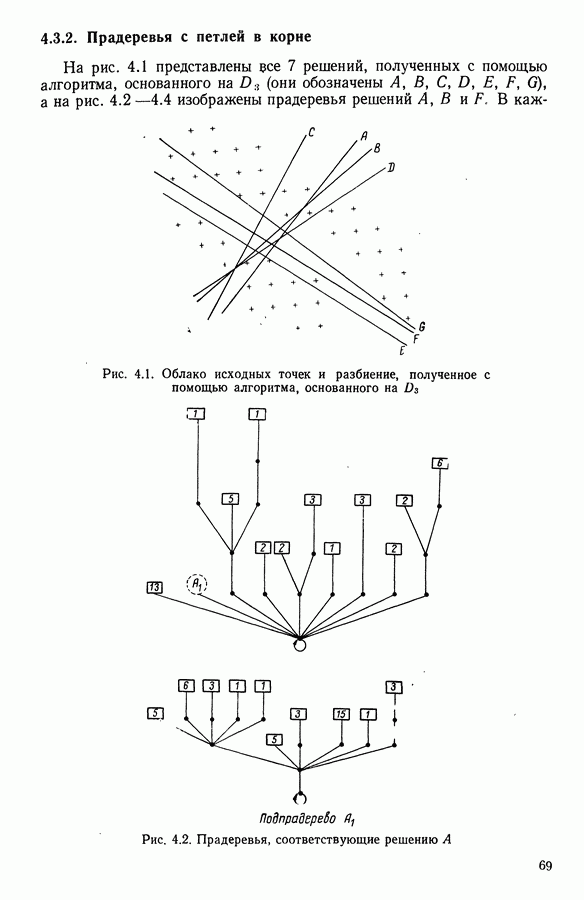
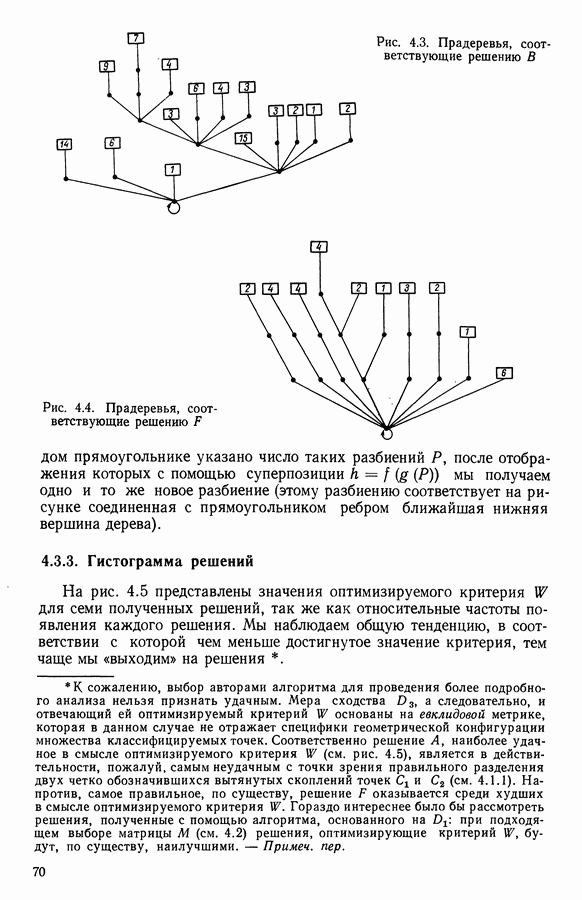
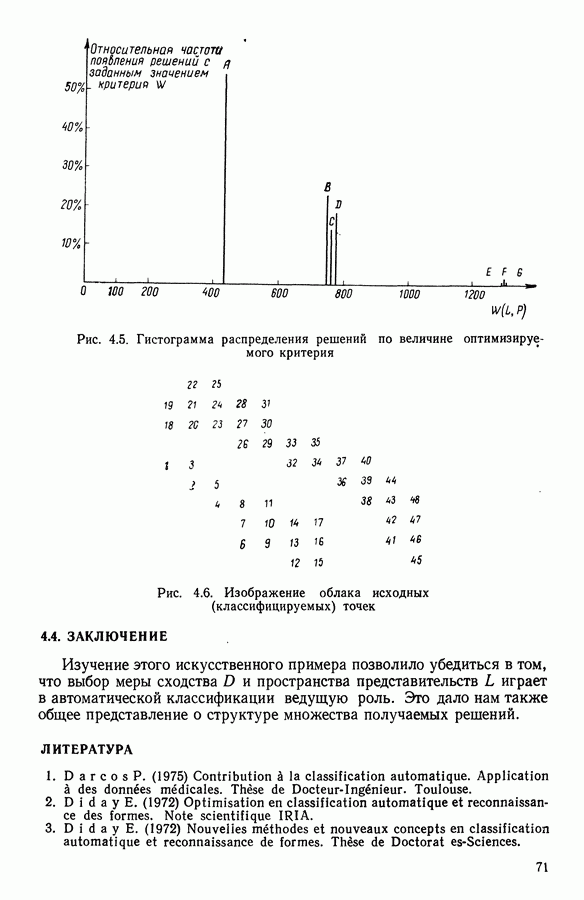
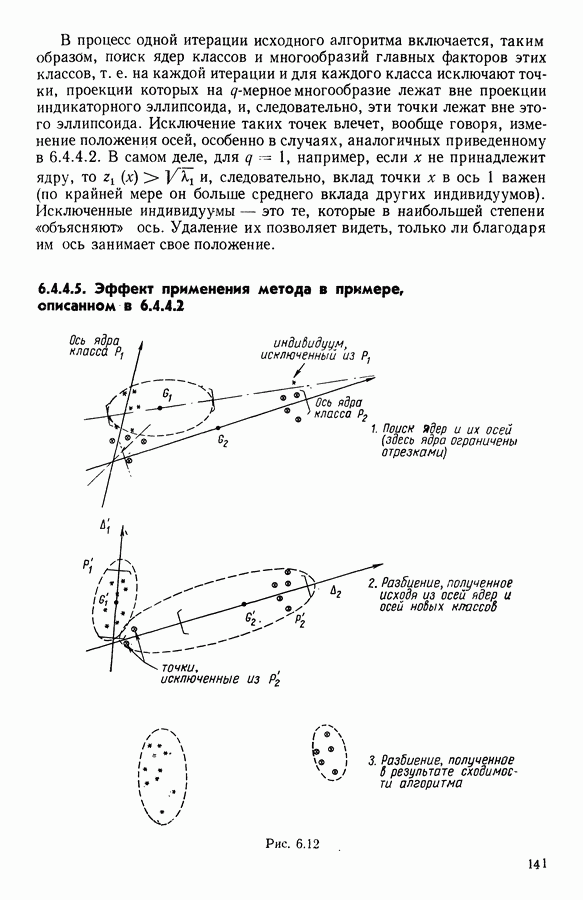
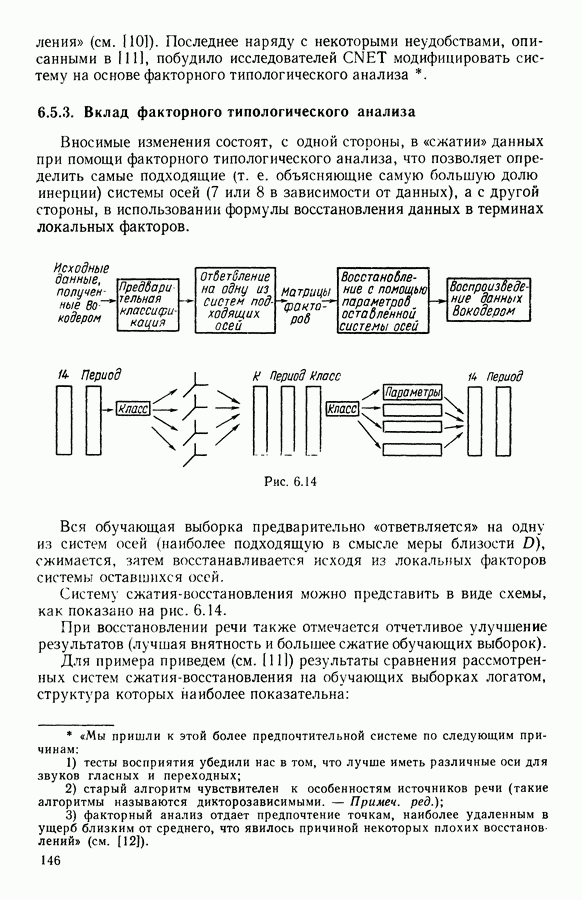
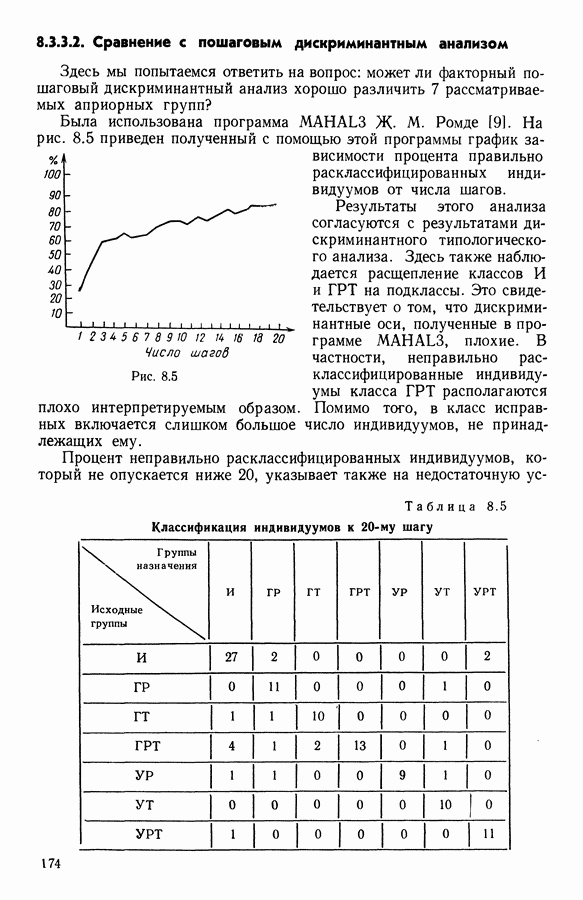
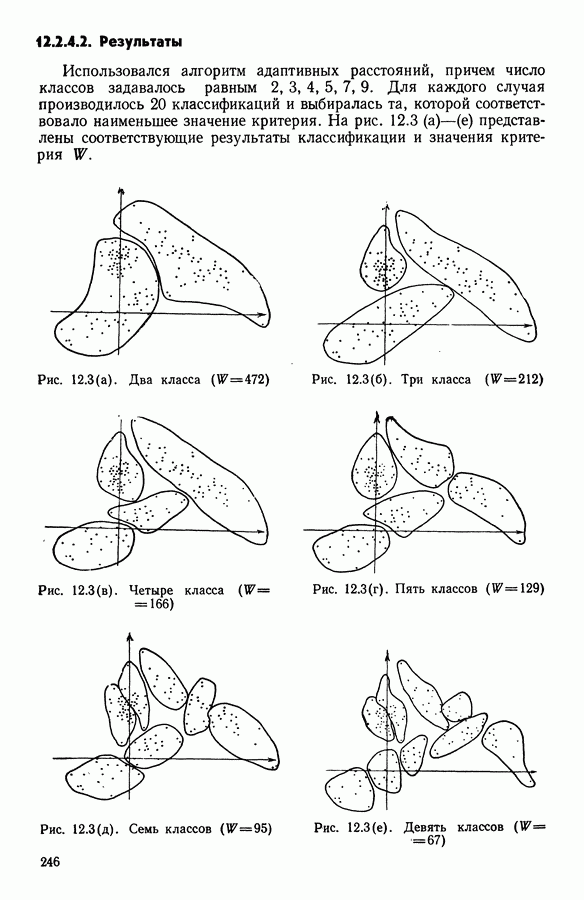
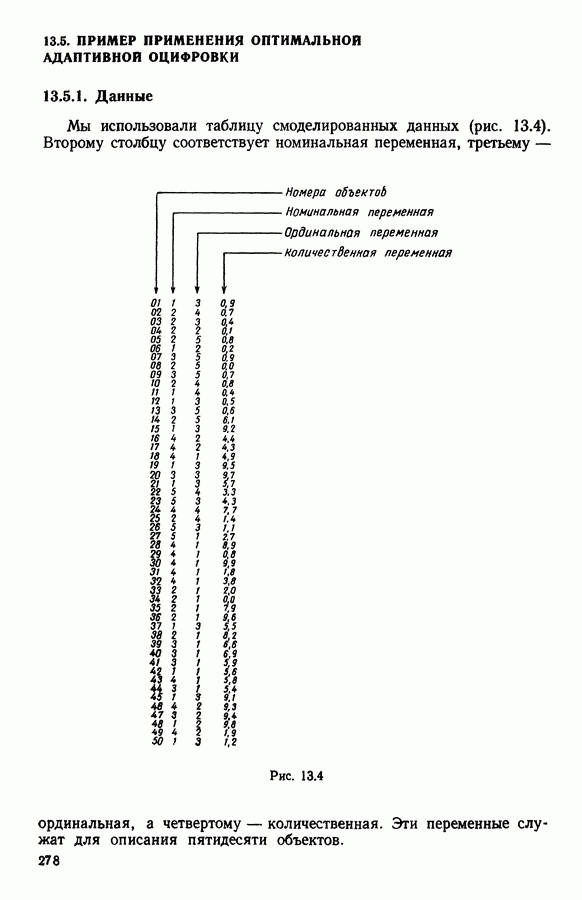
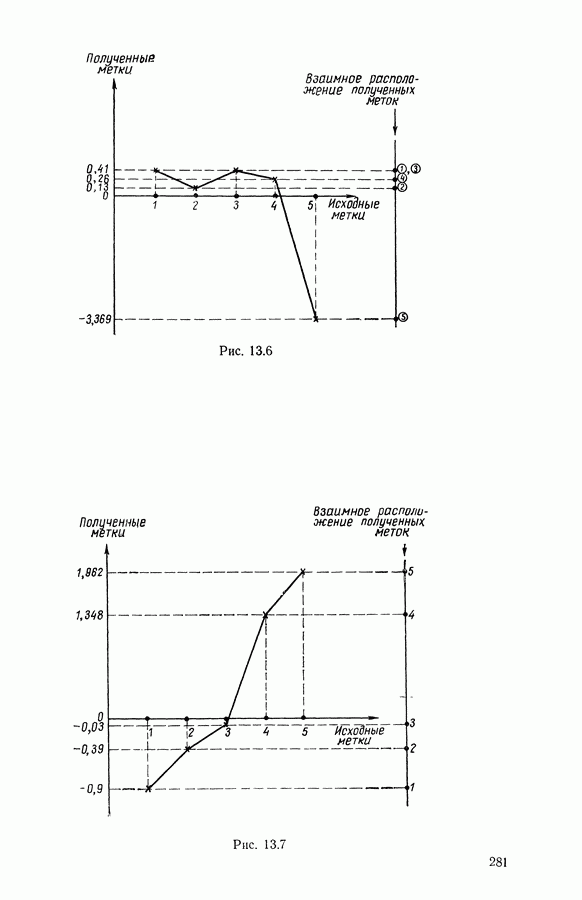
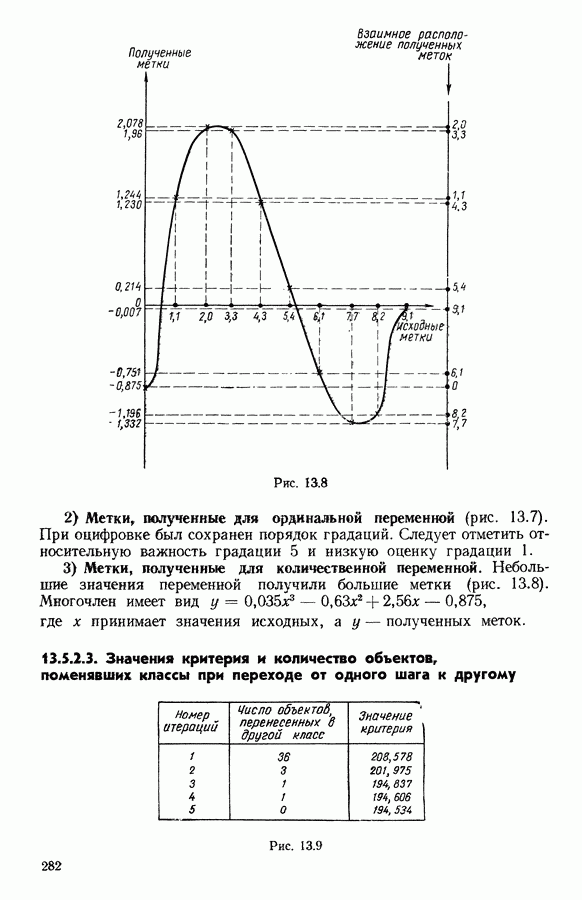
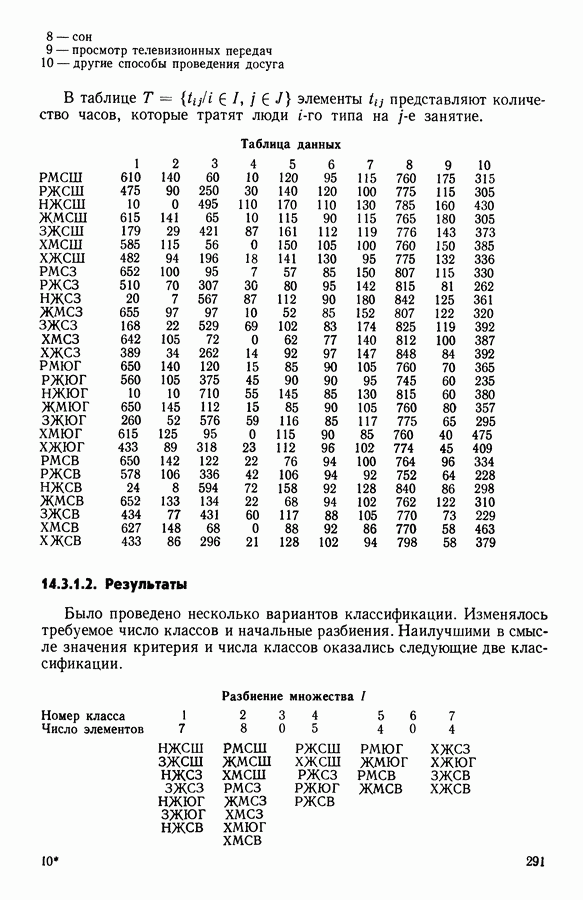
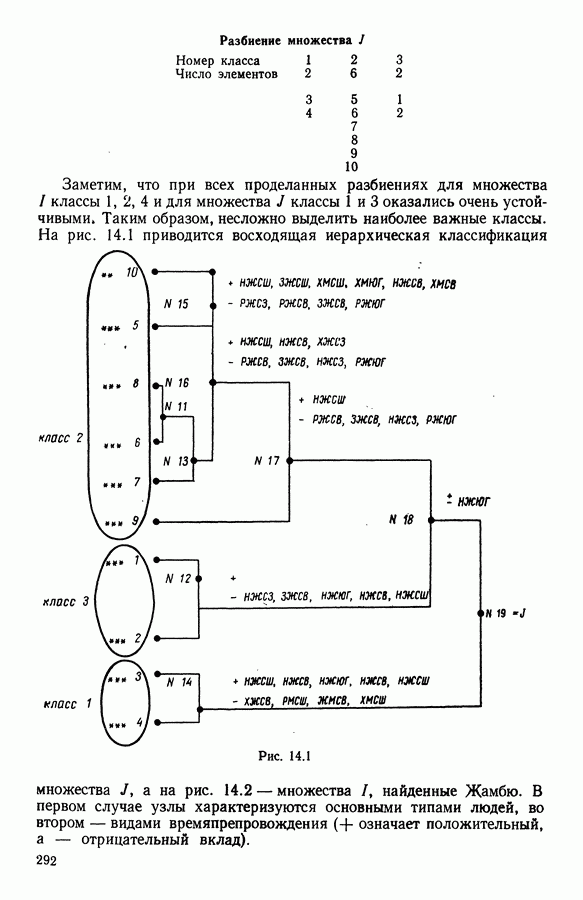
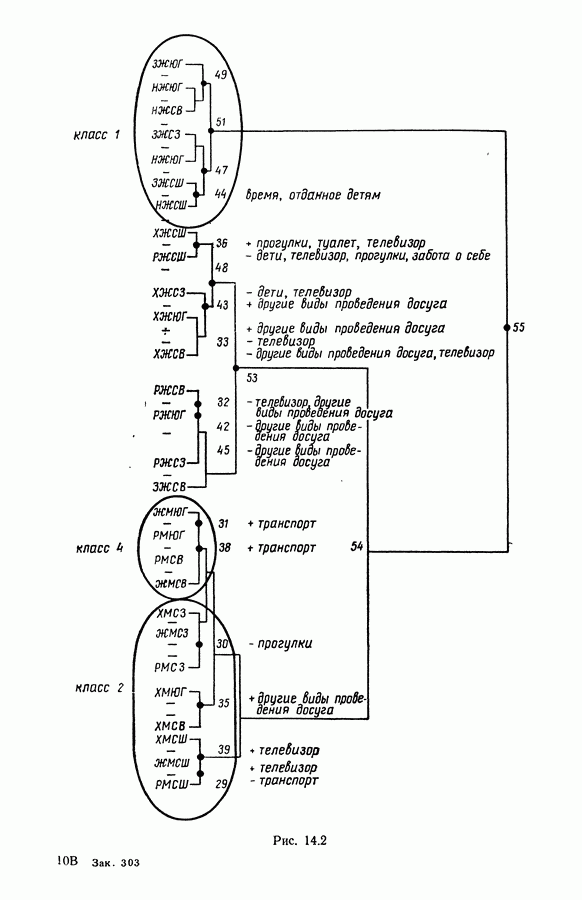
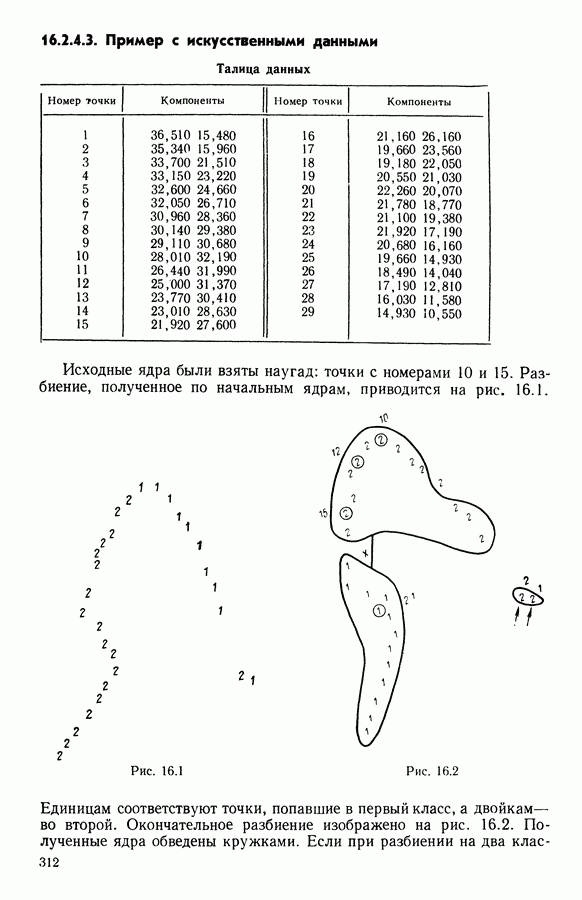
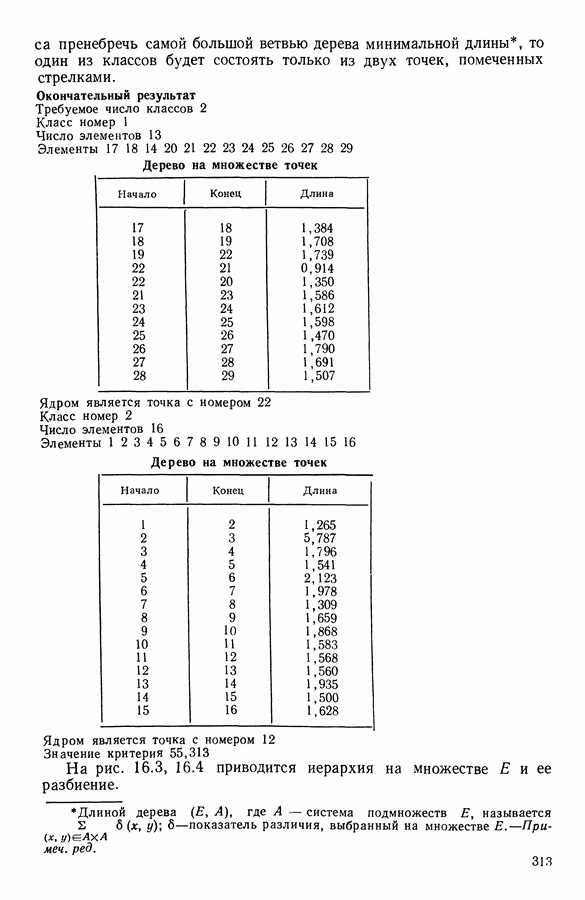
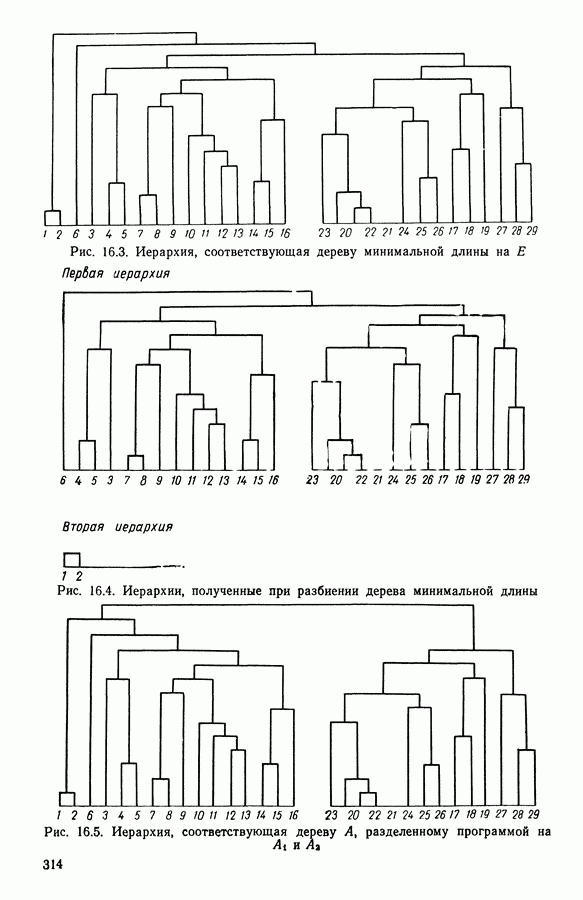
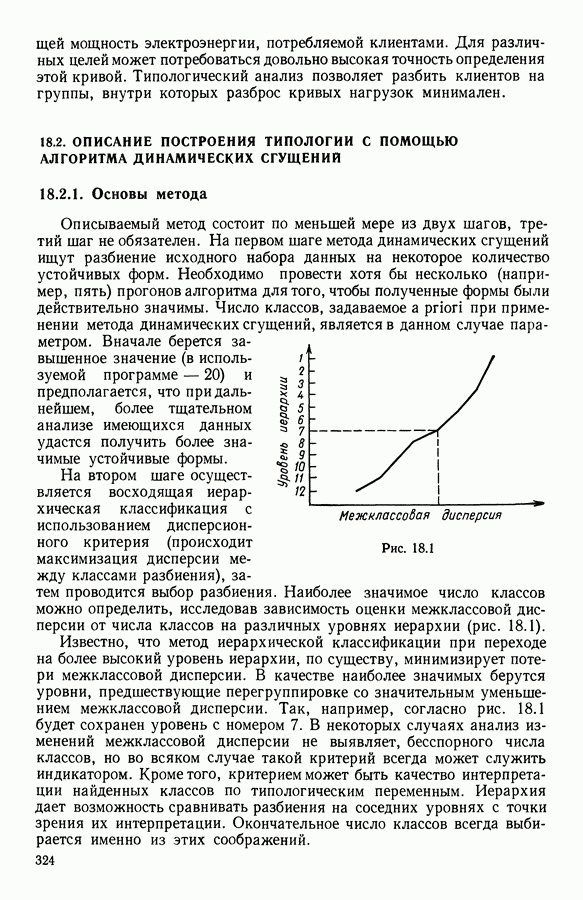
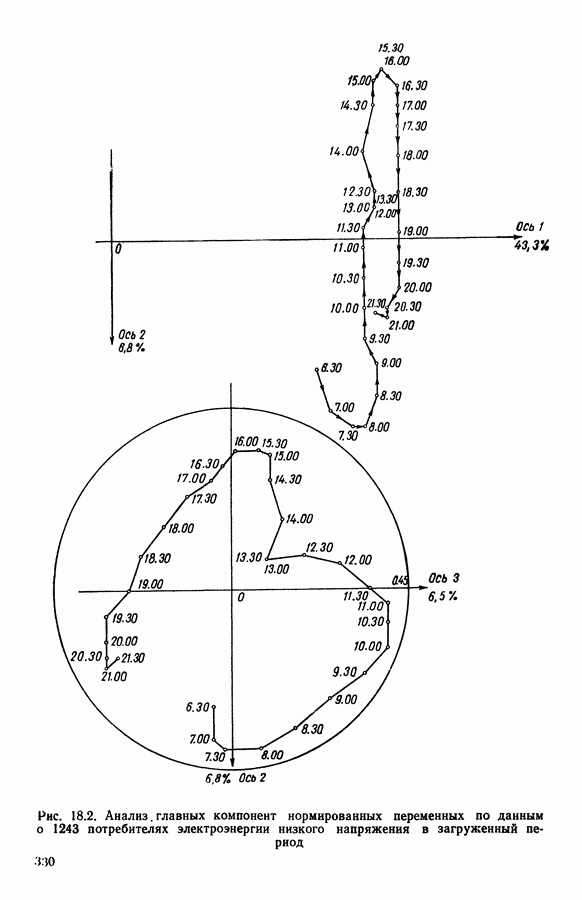
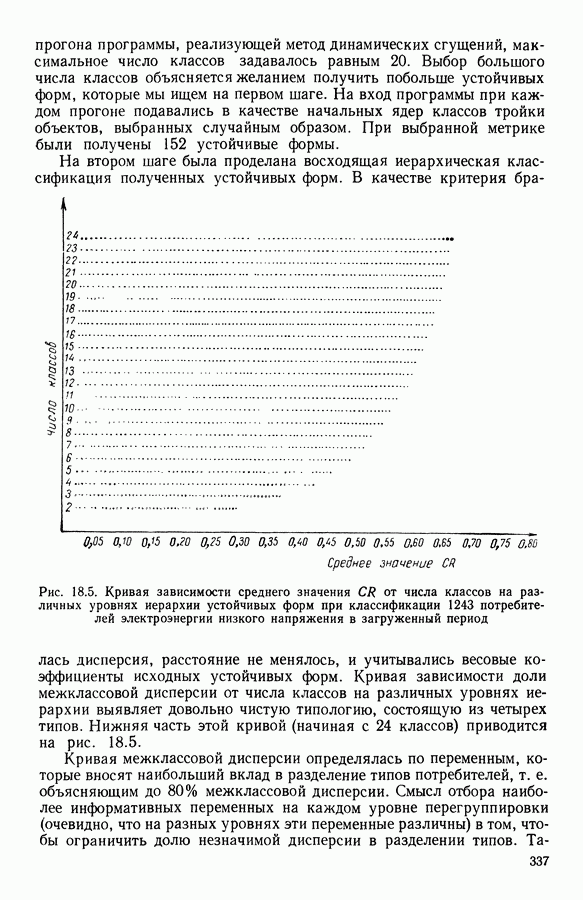
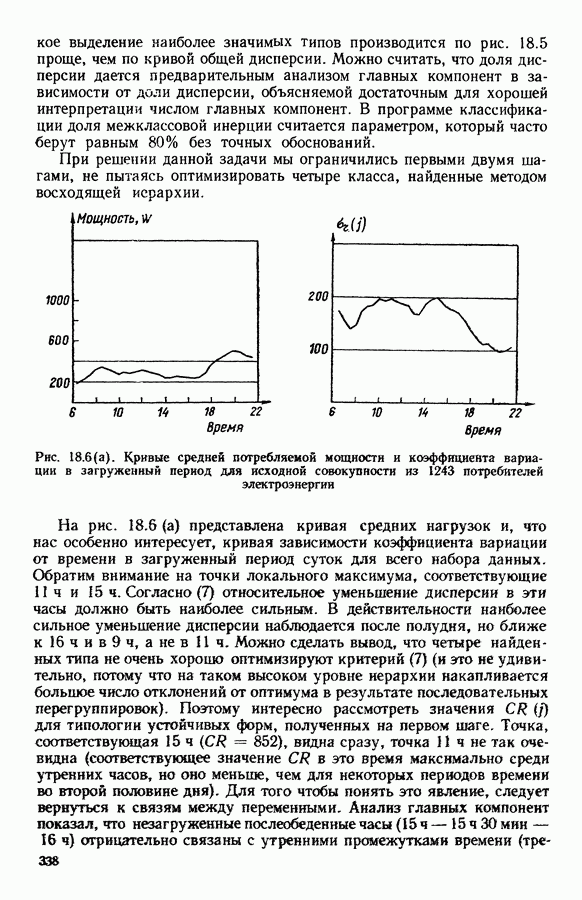
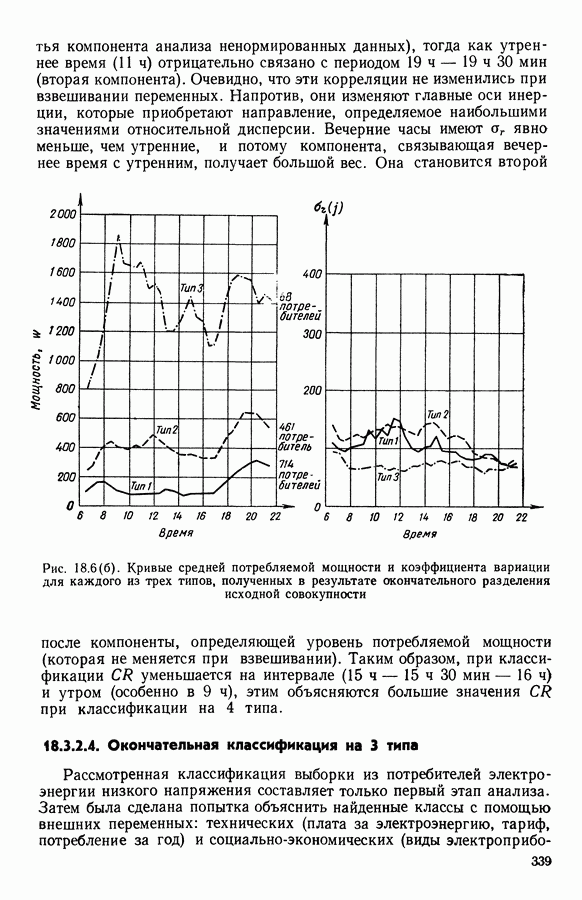
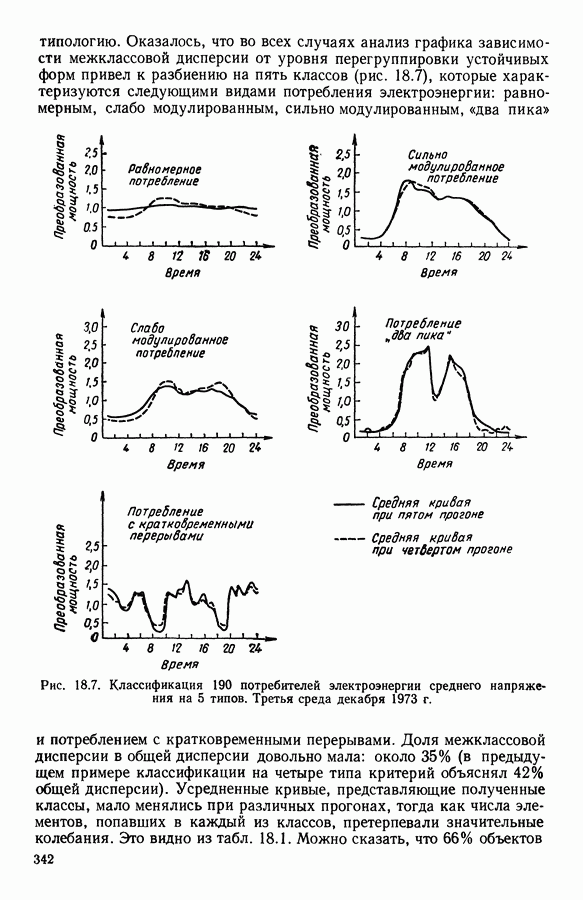
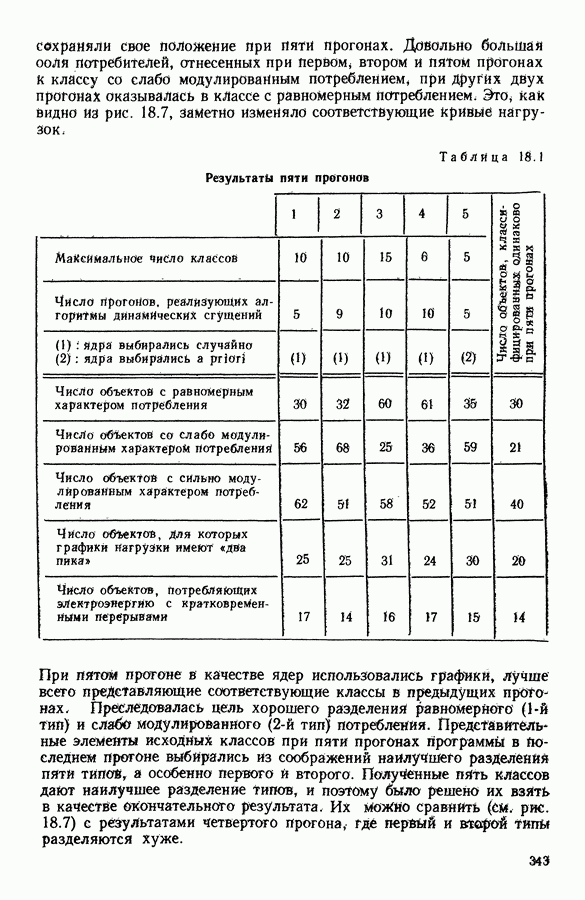
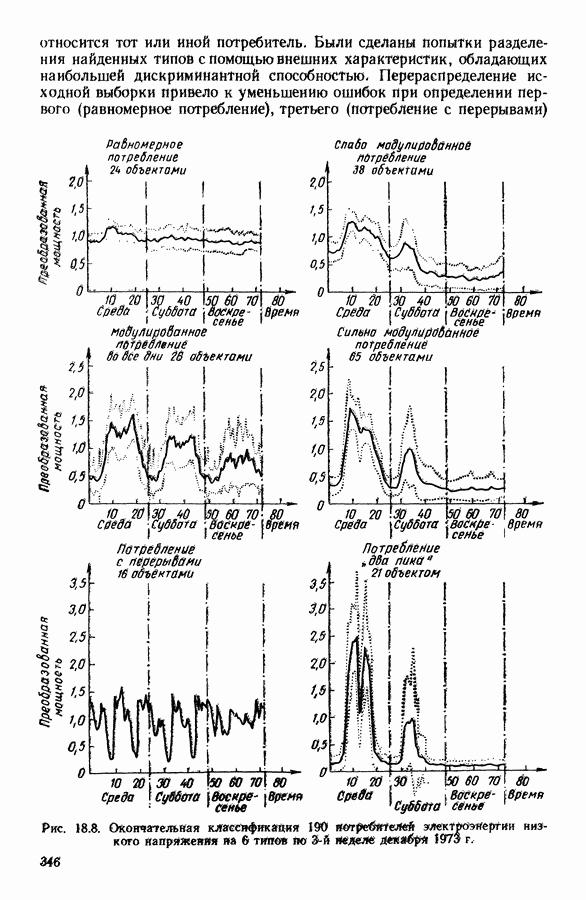
5.5. РЕЗУЛЬТАТЫМы подвергли анализу данные Р. Фишера, которые приведены в [15] 5.5.1. Описание исходных данныхИсходные данные образованы в результате измерения параметров на трех разновидностях цветов. Первой разновидности (ирис selosa) соответствуют объекты с номерами Измеренные на цветах параметры: длина и ширина чашелистиков, длина и ширина лепестков. Эти данные интересно подвергнуть обработке с помощью МДС, поскольку априорно известна идеальная классификация на три класса, что позволяет оценить качество классификации, которую мы получим с помощью этого метода, путем ее сравнения с идеальной. Для этого достаточно вычислить процент неправильно расклассифицированных объектов. 5.5.2. Реализованное моделированиеВначале мы применили к этим данным вариант центра тяжести МДС. Оказалось, что класс 1 прекрасно отделяется от классов 2 и 3, разделение которых между собой не столь отчетливо в силу того, что ирис virginica имеет некоторую тенденцию «назначаться» в один класс с ирисом versicolor. Затем мы изъяли из полной выборки исходных данных некоторое число наблюдений, случайно извлекая их из шестисот Все представленные здесь результаты имеют своей отправной точкой одно и то же начальное (случайное) разбиение случайно извлеченных чисел, так что общее число недостающих данных составило 240 чисел (40% общего числа). Подчеркнем, что среди этих 240 «стертых» наблюдений первые 120 наблюдений как раз те самые, которых недоставало в первом варианте расчетов. При такой схеме возникает возможность сравнить полученные результаты, а именно результаты, достигнутые с помощью МДС в первом варианте (при 120 «стертых» наблюдениях), с результатами, достигнутыми во втором варианте (240 «стертых» наблюдений). 5.5.3. Процент «утерянных» данныхРечь идет об «утере» данных. В действительности мы не можем знать заранее процента «утерянных» данных. Но мы можем «проигрывать» различные варианты с помощью моделирования. Предположим, например, что программа изымает 72% имеющихся наблюдений. В таком случае будет недоставать 5.5.4. Взвешивание классифицируемых данных и процент неправильно расклассифицированных объектовСравним результаты, используя две системы взвешивания исходных данных: в первой — все объекты имеют один и тот же вес, во второй — принята следующая система приписывания весов. Пусть из
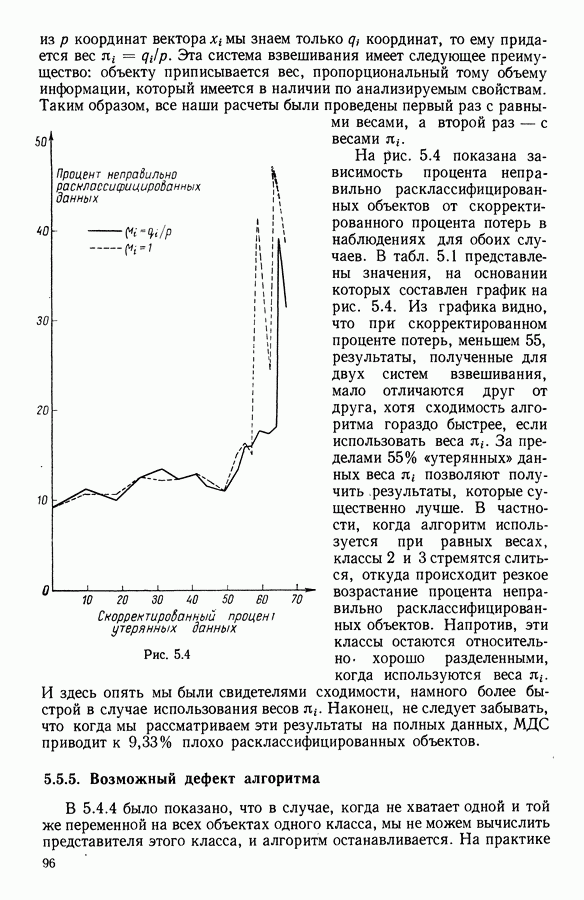
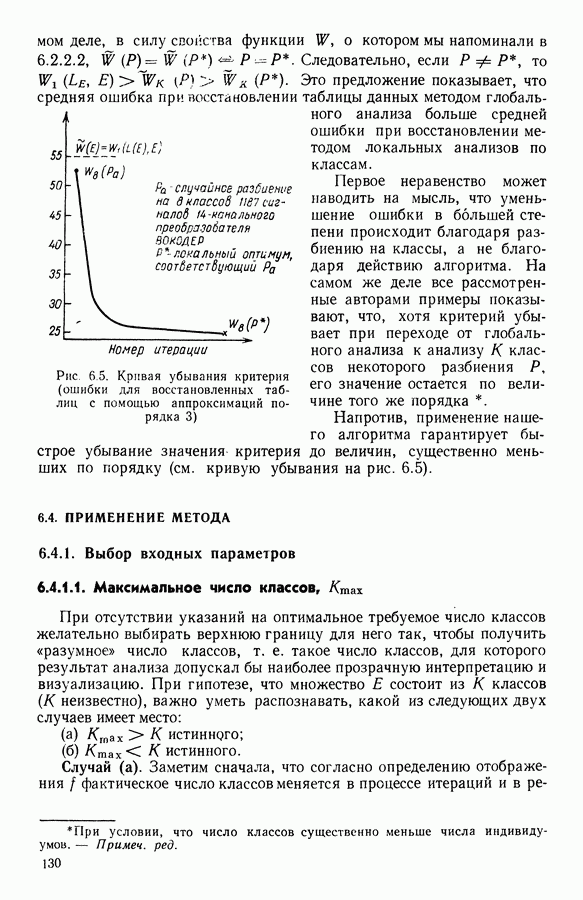
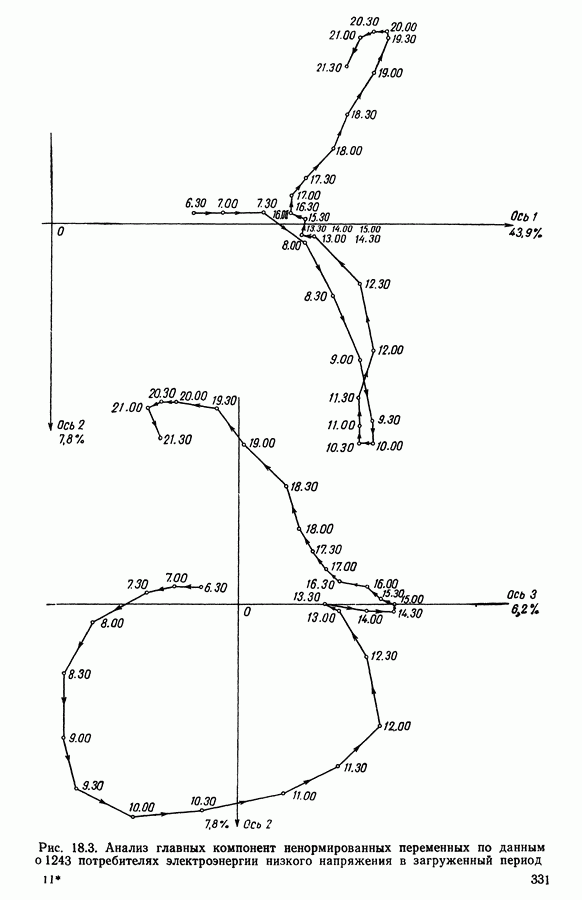
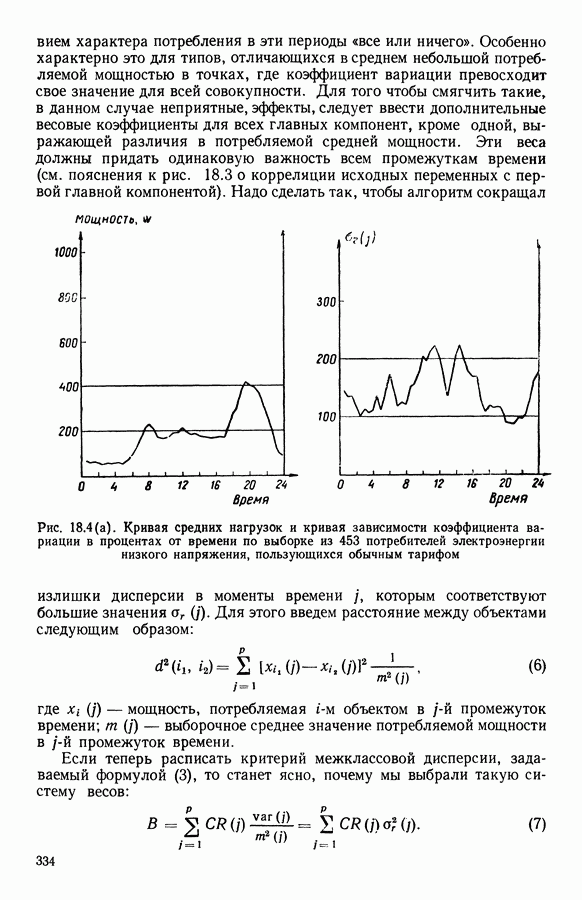
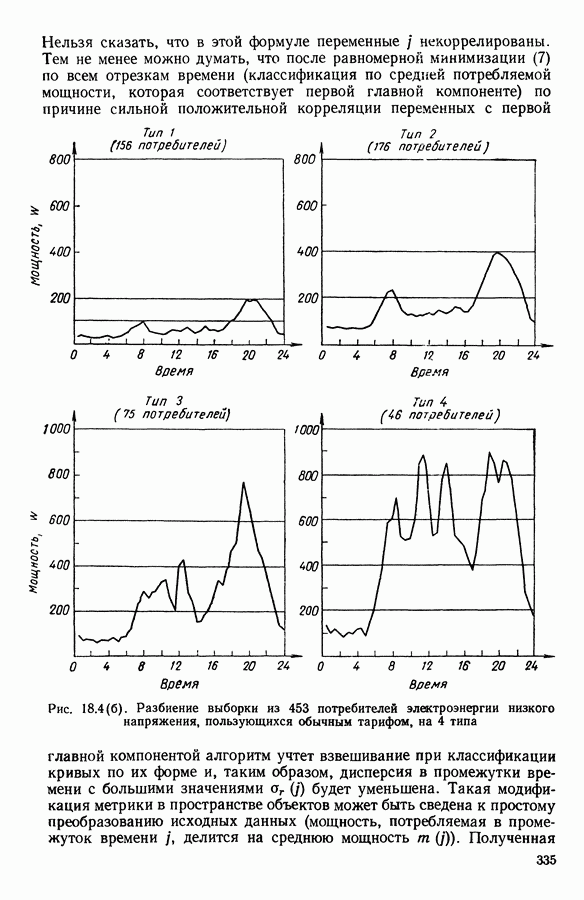
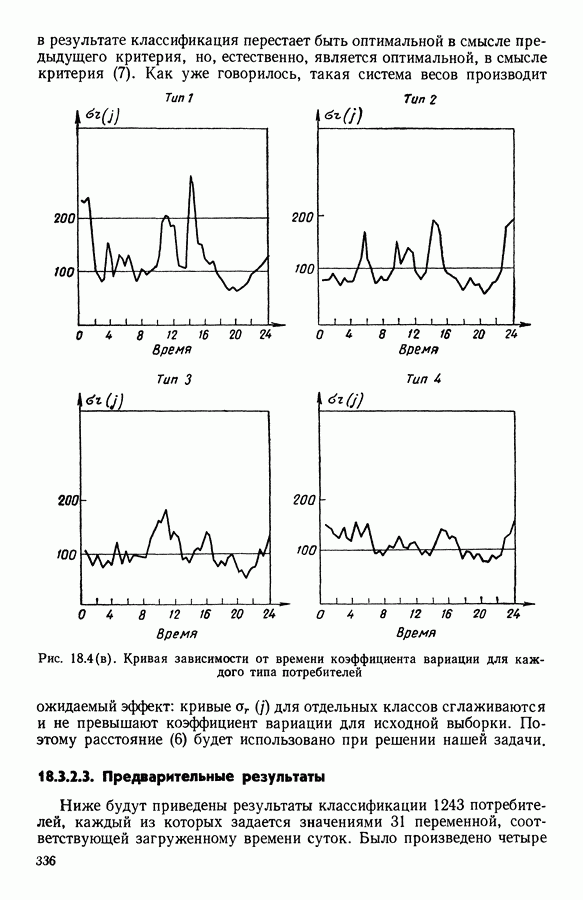
Рис. 5.4 На рис. 5.4 показана зависимость процента неправильно расклассифицированных объектов от скорректированного процента потерь в наблюдениях для обоих случаев. В табл. 5.1 представлены значения, на основании которых составлен график на рис. 5.4. Из графика видно, что при скорректированном проценте потерь, меньшем 55, результаты, полученные для двух систем взвешивания, мало отличаются друг от друга, хотя сходимость алгоритма гораздо быстрее, если использовать веса 5.5.5. Возможный дефект алгоритмаВ 5.4.4 было показано, что в случае, когда не хватает одной и той же переменной на всех объектах одного класса, мы не можем вычислить представителя этого класса, и алгоритм останавливается. На практике (см. скан) Таблица 5.2 (см. скан) для тех вариантов счета, которые здесь были представлены, это происходит только тогда, когда затребованный процент потерь в исходных данных достигает 80. При этом скорректированный процент потерь составляет 67, а количество анализируемых объектов уменьшается до 88.
|
 |
Оглавление
|













































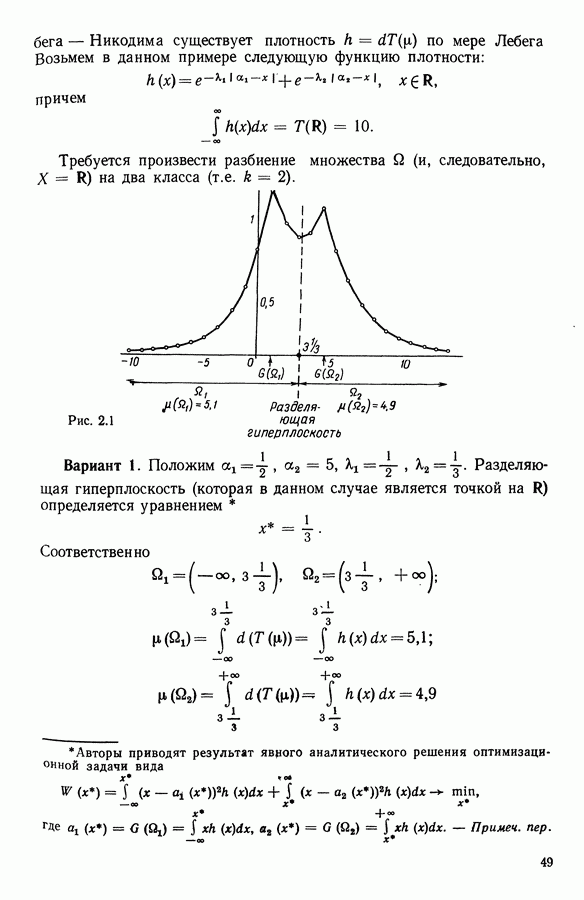
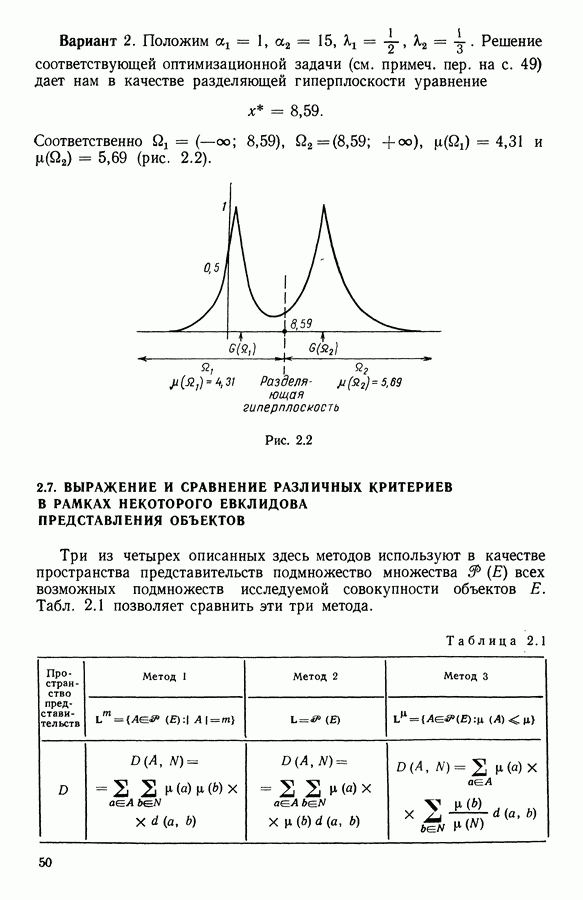















































































































































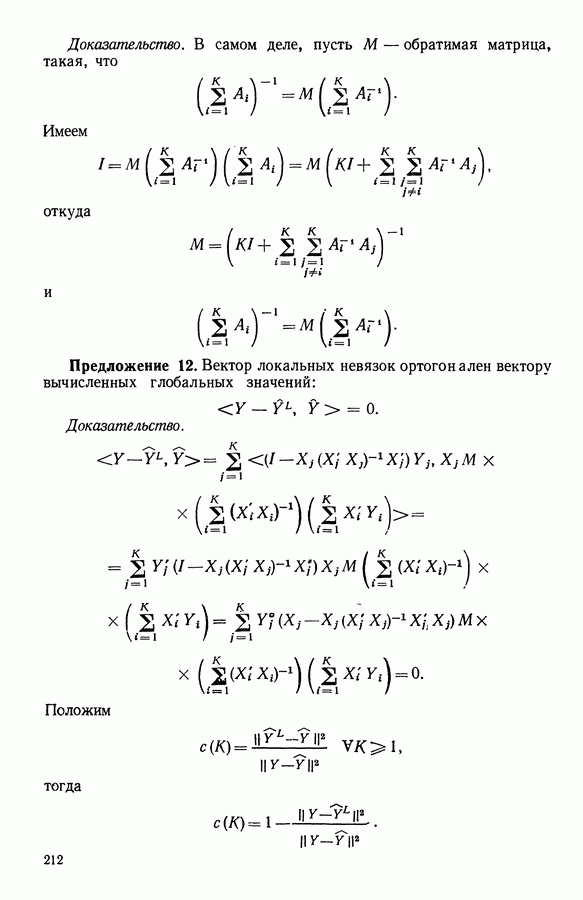












































































































 Второй (ирис versicolor) соответствуют объекты с номерами
Второй (ирис versicolor) соответствуют объекты с номерами  Третьей (ирис virginica) соответствуют объекты с номерами
Третьей (ирис virginica) соответствуют объекты с номерами 
 имеющихся чисел. К оставшимся неполным данным был применен алгоритм, который мы только что описали.
имеющихся чисел. К оставшимся неполным данным был применен алгоритм, который мы только что описали.
 Что касается случайной выборки изъятых («утерянных») наблюдений, то она реализована в двух вариантах. В первом варианте случайным образом было изъято 120 наблюдений (20% общего числа). Во втором варианте к этим 120 «утерянным» наблюдениям было добавлено еще 120 так же
Что касается случайной выборки изъятых («утерянных») наблюдений, то она реализована в двух вариантах. В первом варианте случайным образом было изъято 120 наблюдений (20% общего числа). Во втором варианте к этим 120 «утерянным» наблюдениям было добавлено еще 120 так же
 наблюдений, и тогда возможна ситуация, при которой все 4 координаты, соответствующие одному и тому же объекту, окажутся среди этих «стертых» наблюдений. Так что нам следует изъять подобные объекты перед «запуском» алгоритма. В результате такой операции был полностью изъят, например, 41 объект, так что классификации подверглись бы только
наблюдений, и тогда возможна ситуация, при которой все 4 координаты, соответствующие одному и тому же объекту, окажутся среди этих «стертых» наблюдений. Так что нам следует изъять подобные объекты перед «запуском» алгоритма. В результате такой операции был полностью изъят, например, 41 объект, так что классификации подверглись бы только  оставшихся объектов. Таким образом, среди 432 стертых наблюдений
оставшихся объектов. Таким образом, среди 432 стертых наблюдений  относятся к объектам, которые мы не классифицируем. В действительности количество «стертых» данных (на оставшихся 109 объектах) равно
относятся к объектам, которые мы не классифицируем. В действительности количество «стертых» данных (на оставшихся 109 объектах) равно  Если эти объекты были бы полностью статистически обследованными, то мы имели бы
Если эти объекты были бы полностью статистически обследованными, то мы имели бы  наблюдений. Так что доля «утерянных» данных (по объектам, сохраненным для дальнейшего анализа) равна
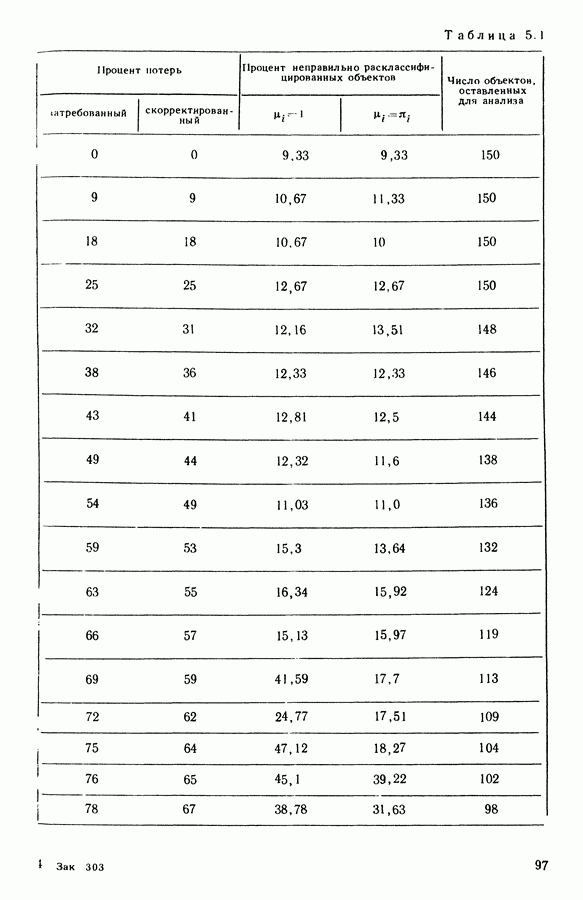
наблюдений. Так что доля «утерянных» данных (по объектам, сохраненным для дальнейшего анализа) равна  Эта величина определяет скорректированный процент потерь, в то время как тот же показатель, подсчитанный до изъятия необследованных объектов (72% в нашем примере), назовем затребованным процентом потерь. Заметим, что уменьшение количества объектов, подвергаемых дальнейшему анализу, побуждает нас использовать в качестве характеристики метода процент неправильно расклассифицированных объектов, а не их количество, что обеспечивает возможность сопоставимости результатов. В частности, этот процент определяется отношением количества неправильно расклассифицированных объектов к количеству анализируемых объектов. В табл. 5.1 представлены взаимосвязанные изменения затребованного и скорректированного процента потерь в наблюдениях, процента неправильно расклассифицированных объектов и числа объектов, оставленных для дальнейшего анализа после изъятия необследованных.
Эта величина определяет скорректированный процент потерь, в то время как тот же показатель, подсчитанный до изъятия необследованных объектов (72% в нашем примере), назовем затребованным процентом потерь. Заметим, что уменьшение количества объектов, подвергаемых дальнейшему анализу, побуждает нас использовать в качестве характеристики метода процент неправильно расклассифицированных объектов, а не их количество, что обеспечивает возможность сопоставимости результатов. В частности, этот процент определяется отношением количества неправильно расклассифицированных объектов к количеству анализируемых объектов. В табл. 5.1 представлены взаимосвязанные изменения затребованного и скорректированного процента потерь в наблюдениях, процента неправильно расклассифицированных объектов и числа объектов, оставленных для дальнейшего анализа после изъятия необследованных.
 Если
Если
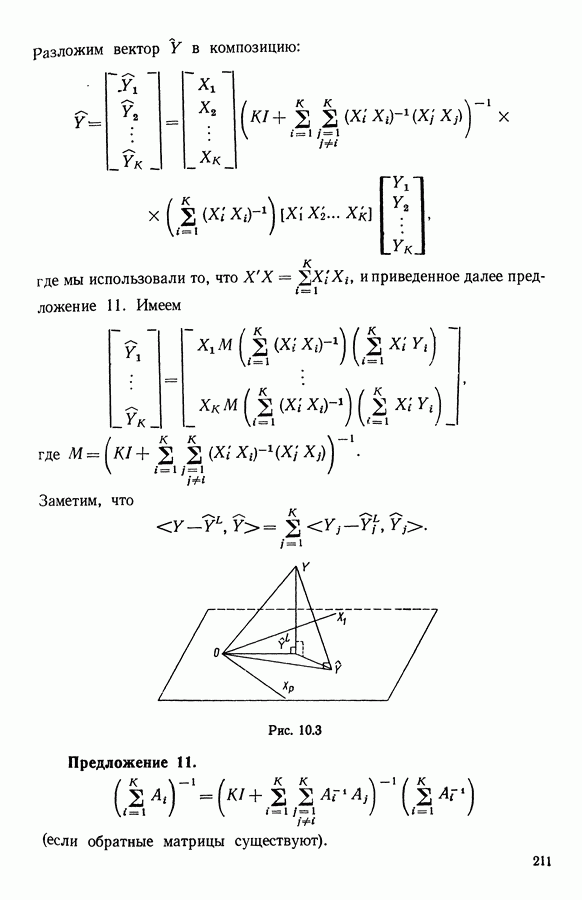
 координат вектора
координат вектора  мы знаем только
мы знаем только  координат, то ему придается вес
координат, то ему придается вес  Эта система взвешивания имеет следующее преимущество: объекту приписывается вес, пропорциональный тому объему информации, который имеется в наличии по анализируемым свойствам. Таким образом, все наши расчеты были проведены первый раз с равными весами, а второй раз — с весами
Эта система взвешивания имеет следующее преимущество: объекту приписывается вес, пропорциональный тому объему информации, который имеется в наличии по анализируемым свойствам. Таким образом, все наши расчеты были проведены первый раз с равными весами, а второй раз — с весами  .
.

 За пределами 55% «утерянных» данных веса
За пределами 55% «утерянных» данных веса  позволяют получить результаты, которые существенно лучше. В частности, когда алгоритм используется при равных весах, классы 2 и 3 стремятся слиться, откуда происходит резкое возрастание процента неправильно расклассифицированных объектов. Напротив, эти классы остаются относительно хорошо разделенными, когда используются веса
позволяют получить результаты, которые существенно лучше. В частности, когда алгоритм используется при равных весах, классы 2 и 3 стремятся слиться, откуда происходит резкое возрастание процента неправильно расклассифицированных объектов. Напротив, эти классы остаются относительно хорошо разделенными, когда используются веса  И здесь опять мы были свидетелями сходимости, намного более быстрой в случае использования весов
И здесь опять мы были свидетелями сходимости, намного более быстрой в случае использования весов  Наконец, не следует забывать, что когда мы рассматриваем эти результаты на полных данных, МДС приводит к 9,33% плохо расклассифицированных объектов.
Наконец, не следует забывать, что когда мы рассматриваем эти результаты на полных данных, МДС приводит к 9,33% плохо расклассифицированных объектов.