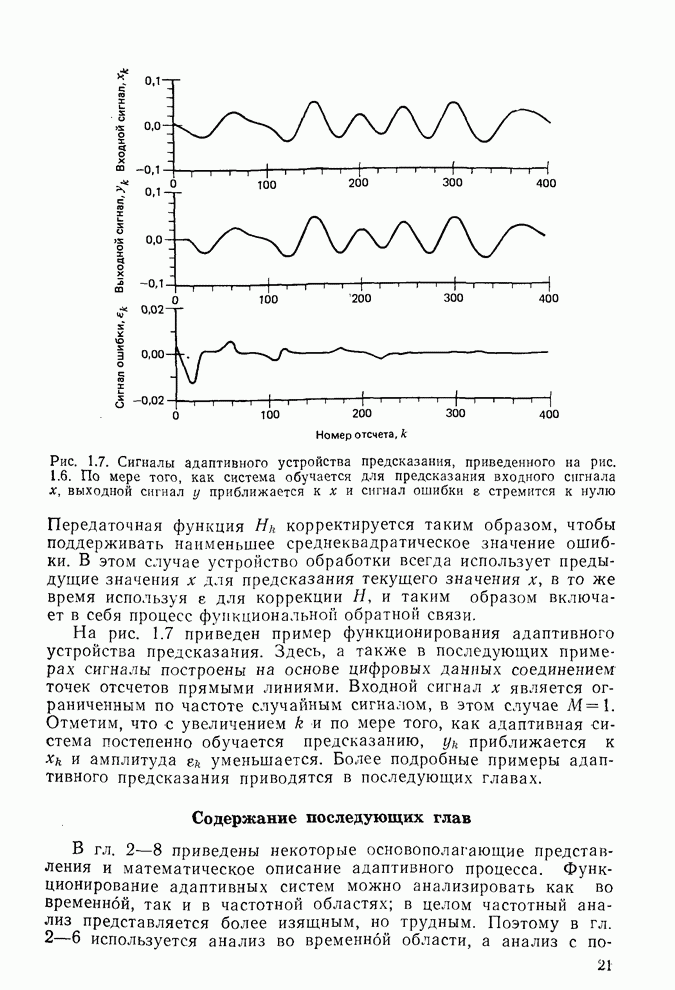
Пред.
След.
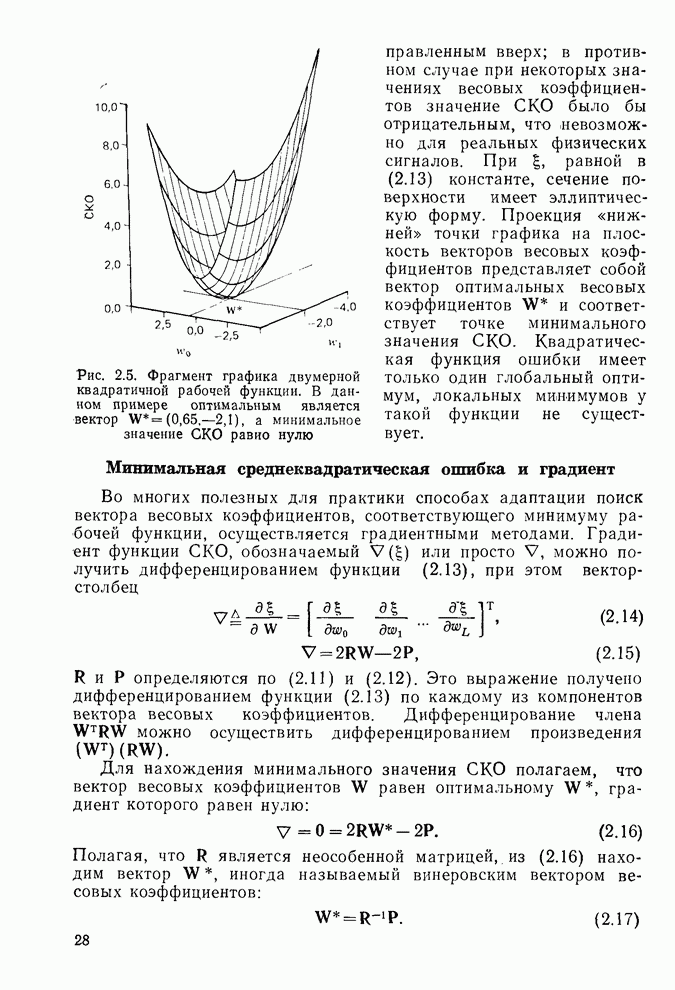
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
Глава 8. ДРУГИЕ АДАПТИВНЫЕ АЛГОРИТМЫ И СТРУКТУРЫВо введении к гл. 6 отмечалось, что метод наименьших квадратов, несмотря на свою простоту и эффективность, находит ограниченное применение, поскольку его можно использовать в основном для нерекурсивных линейных фильтров. Кроме того, было показано, что этот метод является одним из видов алгоритма наискорейшего спуска, в котором спуск к точке минимума СКО не обязательно осуществляется по самой прямой траектории. В данной главе рассматриваются различные виды алгоритмов, более сложных, чем метод наименьших квадратов, но обладающих явными преимуществами. Сначала вводится алгоритм последовательной регрессии, который является приближением метода Ньютона. При использовании этого алгоритма поиск оптимальных весовых коэффициентов обычно осуществляется по более прямой траектории, чем в методе наискорейшего спуска. Далее применение алгоритма наименьших квадратов распространяется на рекурсивные адаптивные фильтры, т. е. адаптивные фильтры, имеющие полюсы. Эти фильтры, как следует из примера на рис. 7.8, могут иметь неквадратичную рабочую функцию с локальными минимумами и областями неустойчивости, поэтому при использовании для адаптивных рекурсивных фильтров таких градиентных методов, как метод наименьших квадратов, необходимо принимать специальные меры. Помимо поиска минимума СКО по направлению градиента (в методе наискорейшего спуска) и при прямом движении в точку минимума (в методе Ньютона), существует возможность случайного поиска. Поэтому вводится алгоритм случайного поиска, который имеет свои преимущества в случаях, когда рабочая функция не является унимодальной, и в ряде других случаев. Кроме этих алгоритмов в данной главе рассматривается решетчатая структура, представляющая собой основную альтернативу обычной структуре адаптивного линейного сумматора. Ниже показано, что решетчатая структура имеет определенные преимущества по сравнению с обычной. Идеальный алгоритмПрежде чем ввести алгоритм последовательной регрессии, представляющей собой приближение метода Ньютона, рассмотрим адаптивный алгоритм, который является идеальным в том смысле, что характеристики его функционирования не достижимы в практических случаях, но к их реализации можно стремиться. Поэтому идеальный алгоритм является эталоном для сравнения с ним других алгоритмов. Для вывода формулы идеального алгоритма запишем заданный соотношением (4.32) алгоритм Ньютона
Отсюда следует, что при идеальных условиях сходимость к оптимальному вектору весовых коэффициентов осуществляется за один шаг, т. е. при начальном векторе Если нарушено первое из этих условий и Далее, если исключить второе условие и предположить, что вместо градиентного вектора используется его оценка V, то
Теперь алгоритм является идеальным только по третьему условию, т. е. остается только предположение о том, что точно известна матрица
где
Рис. 8.1. Иллюстрация метода Ньютона для двух весовых коэффициентов при Подставляя (8.3) и (8.2), имеем
Теперь это соотношение аналогично соотношению (6.3) для метода наименьших квадратов, за исключением того, что во втором слагаемом есть сомножитель
Этот алгоритм назовем идеальным. Отметим, что единицами измерения величин
Алгоритм (8.5) является идеальным, если предположить, что точно известна матрица
Рис. 8.2. Сравнение метода наименьших квадратов и метода, описываемого выражением (8.5). Рабочая функция задана выражением (6.14) при Выше показано, что при адаптации эта матрица обычно не известна, т. е. X, как правило, нестационарный сигнал, и полагают, что R медленно меняется во времени по неизвестному закону. Помимо этого, алгоритм является идеальным из-за того, что при отсутствии шума траектория изменения весовых коэффициентов для квадратичной рабочей функции является прямой, соединяющей точки В этом смысле даже в условиях шума идеальный алгоритм в общем случае эффективнее метода наименьших квадратов, что видно из рис. 8.2. Кривые на рис. 8.2 также построены для рабочей функции (6.14) при
Элементы
Итак, на рис. 8.2 построены траектории первых 100 итераций для алгоритмов (6.3) и (8.5). Траектория для метода наименьших квадратов почти совпадает с траекторией для метода наискорейшего спуска и в итоге достигает оптимальной точки В обоих случаях траектории на каждой итерации имеют шумовые составляющие из-за шумовой составляющей в оценке градиента, но, как видно, идеальный алгоритм более эффективен.
|
 |
Оглавление
|










































































































































































































































































































































































































































 имеем
имеем  . Идеальными являются следующие условия:
. Идеальными являются следующие условия:  на каждой итерации точно известен вектор градиента V; 3) точно известна (и не изменяется) обратная корреляционная матрица сигнала
на каждой итерации точно известен вектор градиента V; 3) точно известна (и не изменяется) обратная корреляционная матрица сигнала  .
.
 находится в интервале от 0 до 1/2, то необходимо большее число шагов, но поиск по-прежнему осуществляется по прямому пути к вектору W, как показано на рис. 8.1, который аналогичен рис. 4.6, за исключением того, что
находится в интервале от 0 до 1/2, то необходимо большее число шагов, но поиск по-прежнему осуществляется по прямому пути к вектору W, как показано на рис. 8.1, который аналогичен рис. 4.6, за исключением того, что  находится в пределах от 0,05 до 0,5, и поэтому для нахождения оптимального вектора требуется более одного шага. (Сравните с рис. 4.9, где представлена обучающая кривая.) Конкретная рабочая функция, используемая для примера на рис. 8.1, аналогична функции на рис. 6.3 и задана соотношением (6.14) при
находится в пределах от 0,05 до 0,5, и поэтому для нахождения оптимального вектора требуется более одного шага. (Сравните с рис. 4.9, где представлена обучающая кривая.) Конкретная рабочая функция, используемая для примера на рис. 8.1, аналогична функции на рис. 6.3 и задана соотношением (6.14) при  .
.

 . Не исключая третьего условия, можно теперь привести (8.2) к виду, соответствующему алгоритму наименьшего квадрата, если в качестве оценки
. Не исключая третьего условия, можно теперь привести (8.2) к виду, соответствующему алгоритму наименьшего квадрата, если в качестве оценки  взять
взять  как это сделано в гл. 6. По аналогии с (6.2) эта оценка градиента
как это сделано в гл. 6. По аналогии с (6.2) эта оценка градиента

 — вектор входного сигнала на
— вектор входного сигнала на  итерации.
итерации.

 . Рабочая функция задана выражением (6.14) при
. Рабочая функция задана выражением (6.14) при  Траектория от
Траектория от  до W является прямой
до W является прямой

 . Отметим, что если R — диагональная матрица с одинаковыми собственными значениями, то
. Отметим, что если R — диагональная матрица с одинаковыми собственными значениями, то  Таким образом, параметр
Таким образом, параметр  имеет ту же, что и в гл. 6, область значений, если
имеет ту же, что и в гл. 6, область значений, если  является масштабным множителем в (8.4):
является масштабным множителем в (8.4):

 являются единицы измерения мощности, единицами измерения
являются единицы измерения мощности, единицами измерения  — единицы, обратные единицам измерения мощности, a W является безразмерным, поэтому
— единицы, обратные единицам измерения мощности, a W является безразмерным, поэтому  (8.5) также является безразмерным. Отметим также, что из-за масштабного множителя
(8.5) также является безразмерным. Отметим также, что из-за масштабного множителя  изменяется область значений параметра
изменяется область значений параметра  и из (6.8) и первого условия имеем теперь
и из (6.8) и первого условия имеем теперь

 .
.

 . Каждая траектория представлена 100 итерациями
. Каждая траектория представлена 100 итерациями
 и т. д. с точкой W, как показано на рис. 8.1.
и т. д. с точкой W, как показано на рис. 8.1.
 , а начальный вектор
, а начальный вектор  равен (6, —9). Обратная матрица
равен (6, —9). Обратная матрица  по предположению известная в идеальном алгоритме, находится обращением двумерной матрицы
по предположению известная в идеальном алгоритме, находится обращением двумерной матрицы 

 находятся из (6.13) при
находятся из (6.13) при  . Для вычисления по формуле (8.5) нужно знать также значение
. Для вычисления по формуле (8.5) нужно знать также значение  Из (3.2)
Из (3.2)

 время как траектория для идеального алгоритма приближается к прямой и достигает оптимума уже за 100 итераций.
время как траектория для идеального алгоритма приближается к прямой и достигает оптимума уже за 100 итераций.