Пред.
След.
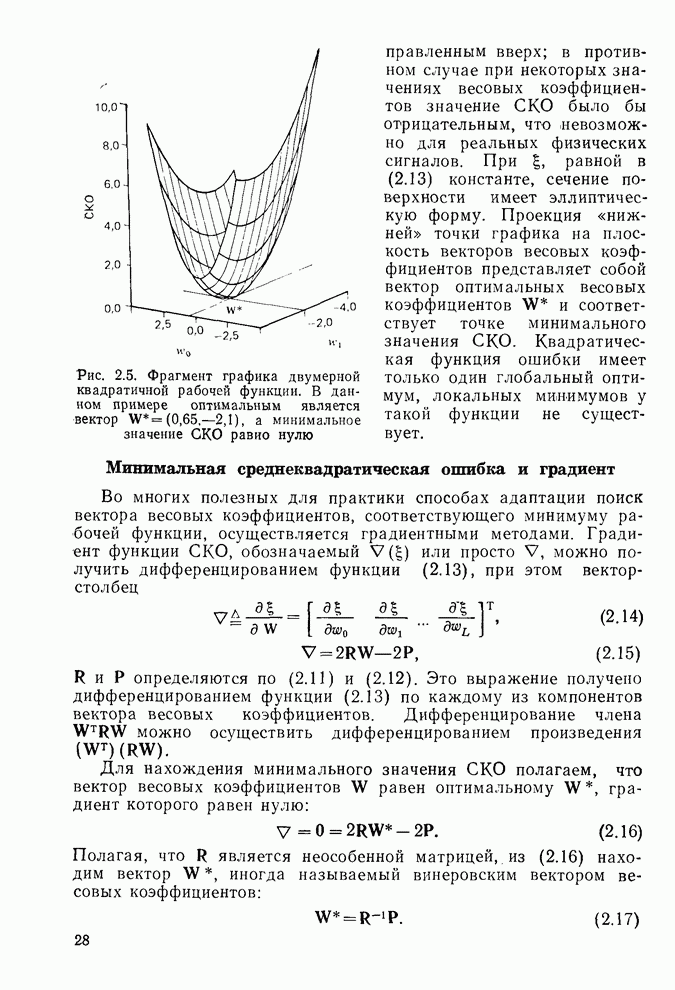
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
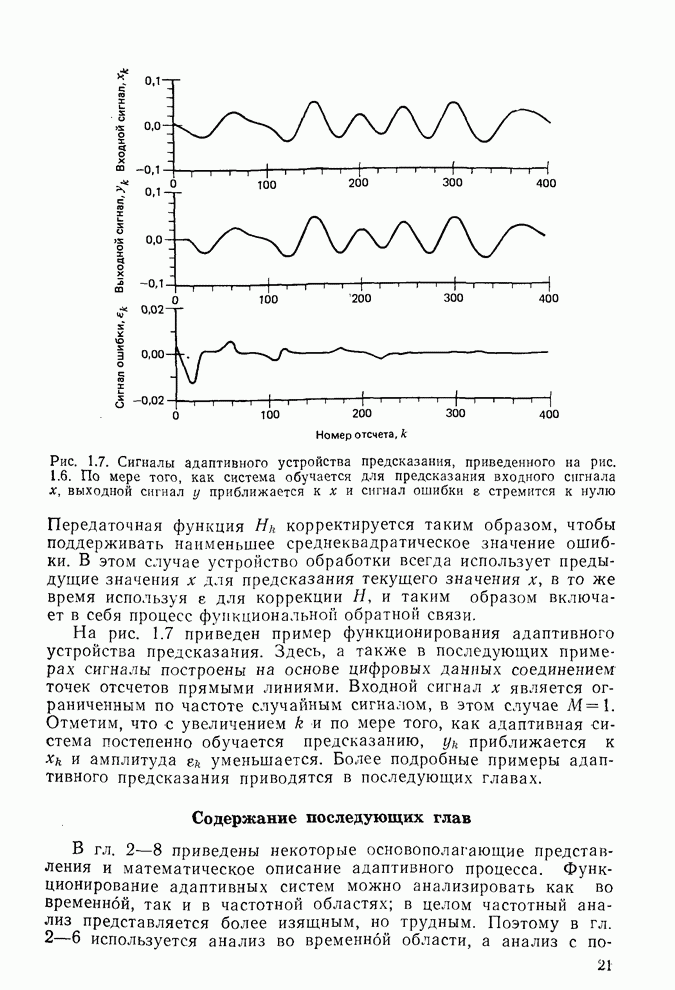
Адаптивная решетка предсказания сигналаНа рис. 8.17 одношаговое устройство предсказания представлено в виде решетчатой структуры, в которой коэффициенты Для адаптации решетки на рис. 8.17 следует изменить все коэффициенты к так, чтобы минимизировать СКО предсказания Однако наилучшим способом [28, 29] является минимизация СКО каждой ячейки На рис. 8.17 и в (8.94)
Положим теперь, что сигналы в решетке являются стационарными Прежде всего рассмотрим функции
Для левой части решетки
Можно показать, что при подстановке (8.98) в (8.96) и (8.97)
Если кг корректируется в каждой ячейке для минимизации ошибки предсказания
или
Звездочка здесь использована для обозначения оптимального значения Для этой решетки из (8.99) получаем СКО
Отсюда снова можно найти выражение для
которое, в свою очередь, следует из (8.95). В обоих случаях
Теперь необходимо найти значение
Таким образом, показано, что Отметим, что глобальный минимум в рассмотренном примере достигается только тогда, когда Ко и Из (8.100) можно вывести алгоритм наименьших квадратов адаптивной решетки для предсказания сигнала. Для этого найдем оценку градиента СКО
Окончательное выражение получается дифференцированием
Значения сигналов вычисляются здесь в соответствии с (8.94). Следует предположить, что не зависящий от времени параметр Прежде чем рассматривать применение алгоритма (8.106), остановимся кратко на анализе области значений параметра для каждой ячейки решетки. Полагая, что оценка градиента является точной, подставляем производную от (8.99) в (8.106):
Введем теперь весовой коэффициент
Подставляя это выражение, а также (8.100) в (8.107), имеем
Поскольку
Для применяемых на практике адаптивных решеток можно вычислить На рис. 8.18-8.21 показан пример функционирования устройства предсказания сигнала. Схема устройства представлена на рис. 8.18, где, как и в предыдущих примерах, предсказываемый сигнал является суммой синусоидального колебания и шума. Устройство осуществляет предсказание сигнала Автокорреляционная матрица сигнала
Рис. 8.18. Схема устройства предсказания на один шаг, используемого в качестве примера
Рис. 8.19. Проекция сечений функции и траектория сходимости весовых коэффициентов по алгоритму наименьших квадратов для приведенной на рис. 8.18 адаптивной решетки предсказания при
Рис. 8.20. Проекции сечений рабочей функции и траектория сходимости весовых коэффициентов по алгоритму наименьших квадратов, аналогичные приведенным на рис. 8.19, при замене адаптивной решетки на адаптивный трансверсальный фильтр для
Рис. 8.21. Обучающие кривые адаптивного трансверсального устройства предсказания и адаптивной решетки. Приведенные кривые почти одинаковы В данном примере рассмотрим решетку с двумя ячейками и весовыми коэффициентами
Очевидно, что эта рабочая функция — квадратичная по каждому весовому коэффициенту, но в отличие от адаптивного трансверсального фильтра проекции сечений графика рабочей функции для фиксированных значений не являются эллиптическими. На рис. 8.19 построены проекции сечений рабочей функции (8.112) и показана характерная траектория адаптации. Отметим, что, как обсуждалось ранее,
Эти значения
Кривая на рис. 8.19 достигает окрестности оптимальных значений весовых коэффициентов менее чем за 200 итераций. Для сравнения с примером на рис. 8.19 на рис. 8.20 представлен тот же адаптивный процесс, но здесь вместо адаптивной решетки применен адаптивный трансверсальный фильтр. В этом примере проекции сечений рабочей функции эллиптические. Около точки На рис. 8.21 представлены обучающие кривые для обоих видов устройств предсказания. Среднеквадратическая ошибка оценивается здесь усреднением каждого Поскольку Аналогично тому, как это сделано выше для адаптивного линейного сумматора, можно вывести алгоритм последовательной регрессии (т. е. алгоритм, приближенный к методу Ньютона) для адаптивной решетки. Из (8.99) имеем СКО на выходе
Найдем производную (8.115) по к, и назовем ее градиентом:
Далее найдем решение уравнения (8.116) для
В результате имеем формулу одношагового алгоритма Ньютона, аналогичную равенству (4.30) в гл. 4, поэтому, как и в (8.1), умножим второе слагаемое на
Для адаптивного линейного сумматора необходима оценка матрицы R, поэтому в данном алгоритме требуется оценка
Многократно подставляя (8.119), получаем следующую рекурсивную формулу:
При нулевых начальных условиях и выбранном в соответствии с (8.44) а полный алгоритм последовательной регрессии для решетки
Как и для алгоритма наименьших квадратов (8.106), полагаем, что значения сигналов вычисляются в соответствии с (8.94). В действительности, как видно из (8.106) и (8.121), для решетки алгоритмы наименьших квадратов и последовательной регрессии, по существу, являются одинаковыми, за исключением того, что в (8.121) оценка Итак, в данном подразделе рассмотрено использование адаптивной решетки в качестве устройства предсказания. Одним из основных ее приложений являются устройства сжатия речевого сигнала, в которых осуществляется предсказание речевого сигнала с помощью адаптивной решетки, длина которой достаточна для формирования выходного сигнала, близкого к белому шуму [35].
Рис. 8.22. Проекции сечений рабочей функции и траектория сходимости весовых коэффициентов по алгоритму последовательной регрессии для адаптивной решетки предсказания, приведенной на рис. 8.18, при Значения коэффициентов решетки записываются с относительно низкой скоростью. Затем для восстановления речевого сигнала по этим коэффициентам строится решетка с передаточной функцией без нулей и изменяющейся во времени структурой (рис. 8.13), управление которой осуществляется формируемыми для нее шумовыми последовательностями. Восстановленный речевой сигнал снимается с выхода решетки без нулей. Основное преимущество применения здесь решетки состоит в том, что она всегда является устойчивой, т. е. нули устройства предсказания и полюсы восстанавливающего устройства находятся внутри круга единичного радиуса при условии, что
|
 |
Оглавление
|

































































































































































































































































































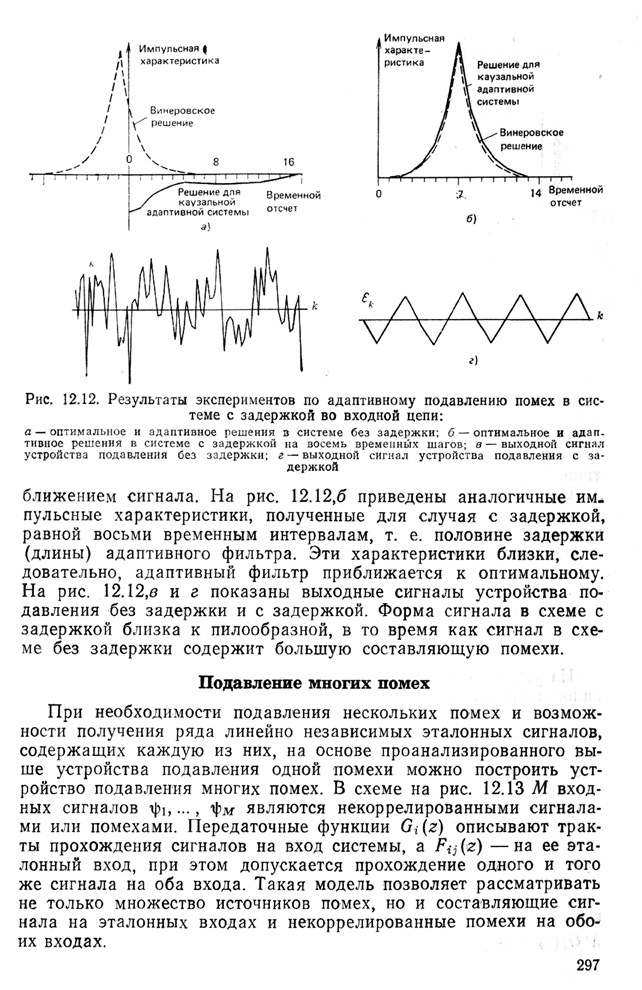











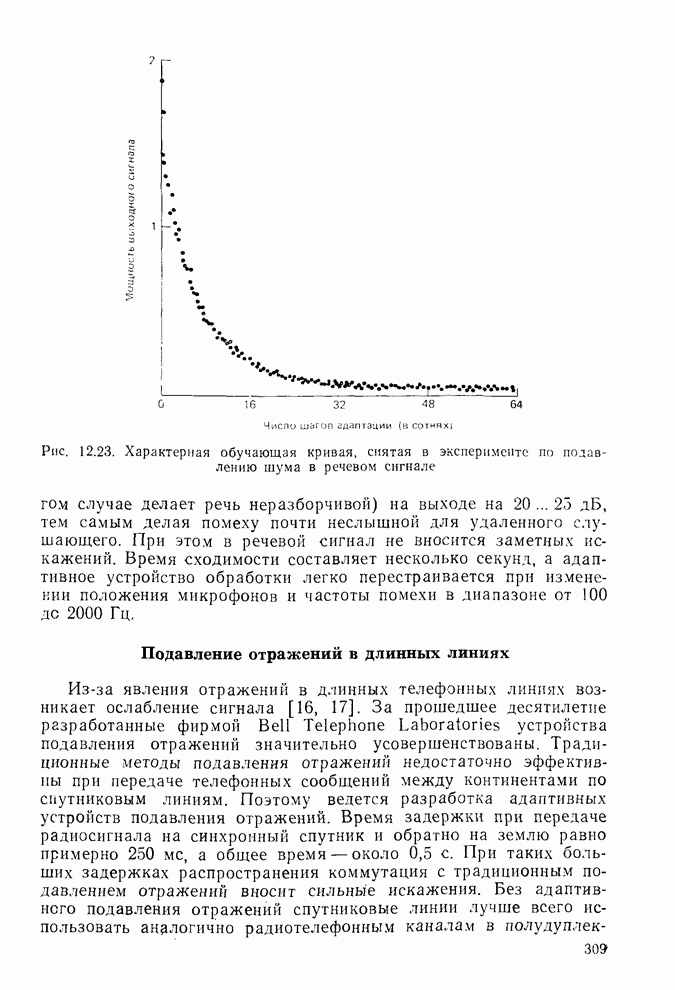








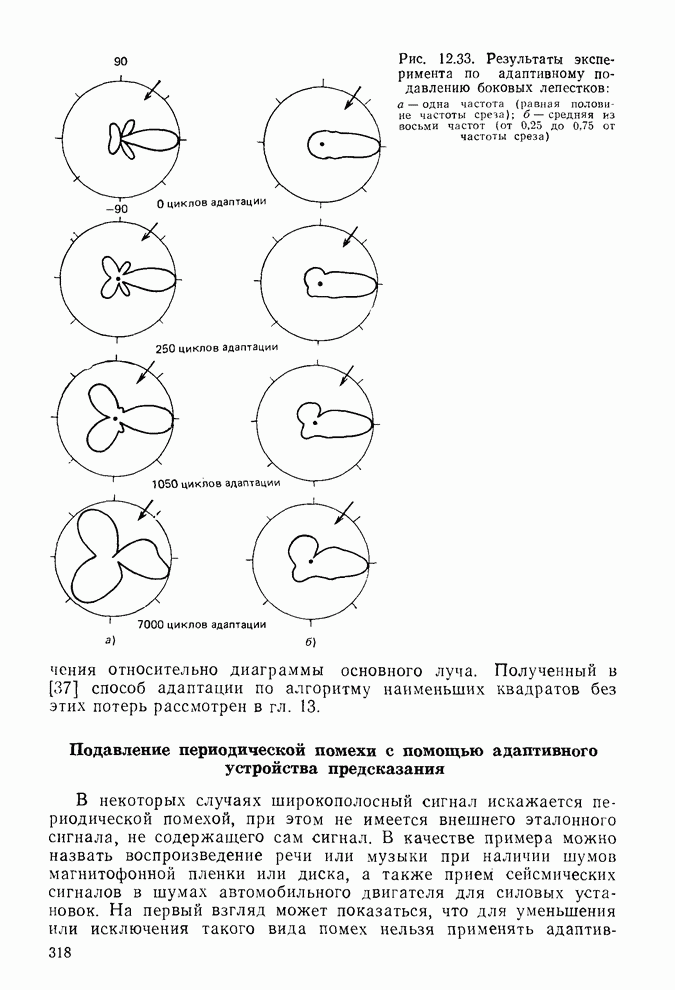



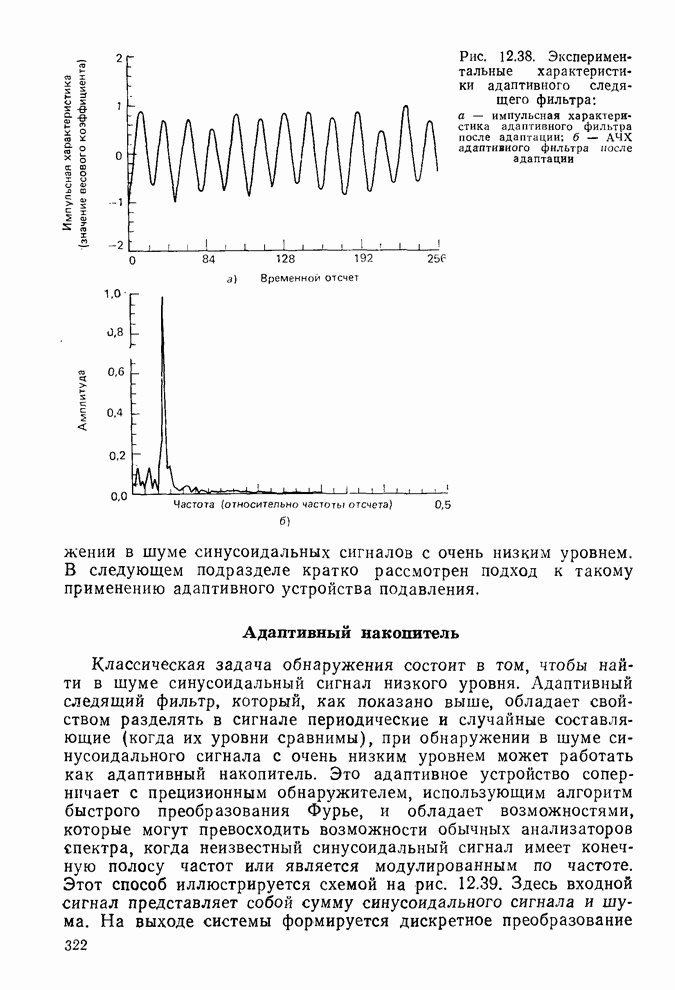


















































































































 должны быть изменяющимися во времени или адаптивными. Другие решетчатые структуры, приведенные на рис. 8.11 и 8.13, также могут быть (и в действительности являются) адаптивными [26], но адаптивные решетки в основном используют для предсказания сигнала, особенно при обработке речевых сигналов.
должны быть изменяющимися во времени или адаптивными. Другие решетчатые структуры, приведенные на рис. 8.11 и 8.13, также могут быть (и в действительности являются) адаптивными [26], но адаптивные решетки в основном используют для предсказания сигнала, особенно при обработке речевых сигналов.

 вместо коррекции каждого к, при этом из (8.94)
вместо коррекции каждого к, при этом из (8.94) 
 — ошибки предсказания и измерения. Для обозначения различных среднеквадратических значений этих ошибок запишем аналогично тому, как это сделано в гл. 7, корреляционные функции
— ошибки предсказания и измерения. Для обозначения различных среднеквадратических значений этих ошибок запишем аналогично тому, как это сделано в гл. 7, корреляционные функции

 . Определяя среднеквадратическое значение (8.94), имеем
. Определяя среднеквадратическое значение (8.94), имеем


 , тогда
, тогда  и т. д., откуда
и т. д., откуда

 то из (8.99)
то из (8.99)

 (8.100)
(8.100)
 Для доказательства того, что к является оптимальным в том смысле, что достигается минимум не только
Для доказательства того, что к является оптимальным в том смысле, что достигается минимум не только  но и СКО предсказания
но и СКО предсказания  необходимо, использовав рекурсивную формулу (8.76), найти для каждой ячейки оптимум
необходимо, использовав рекурсивную формулу (8.76), найти для каждой ячейки оптимум  . В [30, 31] получены алгоритмы вычисления оптимальных весовых коэффициентов фильтра. Не повторяя приведенного в этих работах вывода, рассмотрим решетку с двумя ячейками и коэффициентами
. В [30, 31] получены алгоритмы вычисления оптимальных весовых коэффициентов фильтра. Не повторяя приведенного в этих работах вывода, рассмотрим решетку с двумя ячейками и коэффициентами 
 (8.101)
(8.101)
 на основе (8.99) и
на основе (8.99) и  исходя из общего соотношения
исходя из общего соотношения
 (8.102)
(8.102)
 не являются функциями от
не являются функциями от  поэтому в соответствии с (8.100) можно минимизировать
поэтому в соответствии с (8.100) можно минимизировать  по
по  . При
. При  имеем
имеем
 (8.103)
(8.103)
 минимизирующее (8.103). Если находить
минимизирующее (8.103). Если находить  в соответствии с (8.100), то минимизируется
в соответствии с (8.100), то минимизируется  в (8.103), и его производная по
в (8.103), и его производная по  должна быть равна нулю. Таким образом, для минимизируемого по
должна быть равна нулю. Таким образом, для минимизируемого по  производная последнего члена в (8.103) также должна быть равна нулю. (Поскольку максимальное значение не ограничено, решение должно привести к минимуму.) Следовательно, из (8.102)
производная последнего члена в (8.103) также должна быть равна нулю. (Поскольку максимальное значение не ограничено, решение должно привести к минимуму.) Следовательно, из (8.102)
 (8.104)
(8.104)
 в (8.100) является оптимальным весовым коэффициентом, минимизирующим
в (8.100) является оптимальным весовым коэффициентом, минимизирующим  а также
а также  . Такой же результат можно получить, если оптимизировать адаптивный линейный сумматор, а затем преобразовать коэффициенты по табл. 8.2, как это делается в упражнениях 24—26.
. Такой же результат можно получить, если оптимизировать адаптивный линейный сумматор, а затем преобразовать коэффициенты по табл. 8.2, как это делается в упражнениях 24—26.
 принимают свои оптимальные значения. Поэтому можно считать, что процесс сходимости в адаптивной решетке проходит примерно от одной ячейки к другой, при этом осуществляется поиск
принимают свои оптимальные значения. Поэтому можно считать, что процесс сходимости в адаптивной решетке проходит примерно от одной ячейки к другой, при этом осуществляется поиск  минимизирующего
минимизирующего  сначала для
сначала для  затем для
затем для  и т. д. В адаптивном линейном сумматоре такого процесса сходимости не происходит.
и т. д. В адаптивном линейном сумматоре такого процесса сходимости не происходит.
 , используя, как и ранее, градиент самой квадратической ошибки:
, используя, как и ранее, градиент самой квадратической ошибки:
 (8.105)
(8.105)
 в (8.94). Далее, как и в (6.3), подставляем оценку градиента в выражение (4.36) для алгоритма наискорейшего спуска и получаем алгоритм наименьших квадратов для решетки:
в (8.94). Далее, как и в (6.3), подставляем оценку градиента в выражение (4.36) для алгоритма наискорейшего спуска и получаем алгоритм наименьших квадратов для решетки:

 различен для каждой ячейки согласно [28], где, по существу, приводится тот же алгоритм.
различен для каждой ячейки согласно [28], где, по существу, приводится тот же алгоритм.
 (8.107)
(8.107)
 который получен преобразованием коэффициента
который получен преобразованием коэффициента  по аналогии с преобразованием вектора V в вектор W (3.29):
по аналогии с преобразованием вектора V в вектор W (3.29):
 (8-108)
(8-108)
 (8.109)
(8.109)
 должны сходиться к нулю, можно заключить, что необходимым условием сходимости является
должны сходиться к нулю, можно заключить, что необходимым условием сходимости является
 (8.110)
(8.110)
 усреднив
усреднив  повеем предшествующим значениям, и тем самым проверить выполнение условия (8.110) для
повеем предшествующим значениям, и тем самым проверить выполнение условия (8.110) для  Как и для адаптивного линейного сумматора, эти параметры сходимости определяют как значения ошибки.
Как и для адаптивного линейного сумматора, эти параметры сходимости определяют как значения ошибки.
 вперед на один временной отсчет. Таким образом, производится выделение из
вперед на один временной отсчет. Таким образом, производится выделение из  синусоидального колебания и подавление непредсказуемой составляющей белого шума
синусоидального колебания и подавление непредсказуемой составляющей белого шума  . Полагаем, что мощность выходного сигнала
. Полагаем, что мощность выходного сигнала  равна мощности шума
равна мощности шума  .
.
 определенная ранее выражениями (2.20) и (6.13),
определенная ранее выражениями (2.20) и (6.13),
 (8.111)
(8.111)


 . Траектория содержит 200 итераций
. Траектория содержит 200 итераций

 и нулевых начальных значений весовых коэффициентов. Траектория содержит 300 итераций
и нулевых начальных значений весовых коэффициентов. Траектория содержит 300 итераций

 . Из (8.98), (8.99) и (8.102) можно получить следующее выражение для рабочей функции:
. Из (8.98), (8.99) и (8.102) можно получить следующее выражение для рабочей функции:
 (8.112)
(8.112)
 является независимым, т. е. для любого значения
является независимым, т. е. для любого значения  коэффициент
коэффициент  можно независимо характеризовать для поиска его оптимального значения. Эта процедура рассматривается ниже, при этом приняты следующие параметры:
можно независимо характеризовать для поиска его оптимального значения. Эта процедура рассматривается ниже, при этом приняты следующие параметры:
 (8.113)
(8.113)
 удовлетворяют неравенству (8.110), когда
удовлетворяют неравенству (8.110), когда  (или
(или  ). Так же, как и для адаптивного линейного сумматора, в данном случае обычно выбирают значение параметра
). Так же, как и для адаптивного линейного сумматора, в данном случае обычно выбирают значение параметра  , равное 0,1 от верхней границы неравенства (8.110). Отметим, что кривая на рис. 8.19 приблизительно совпадает с кривой для метода паискорейшего спуска. В соответствии с (8.99), (8.100) и (8.102) оптимальные значения весовых коэффициентов составляют:
, равное 0,1 от верхней границы неравенства (8.110). Отметим, что кривая на рис. 8.19 приблизительно совпадает с кривой для метода паискорейшего спуска. В соответствии с (8.99), (8.100) и (8.102) оптимальные значения весовых коэффициентов составляют:

 график рабочей функции достаточно плоский, однако для достижения окрестности точки
график рабочей функции достаточно плоский, однако для достижения окрестности точки  при
при  необходимо около 300 итераций. Решетчатая структура для предсказания сигнала обладает тем преимуществом, что каждая ячейка имеет свой, отличный от других, параметр сходимости, выбираемый из условия (8.11), и в общем случае это позволяет осуществлять процесс адаптации быстрее, чем для обычного метода наименьших квадратов [34]. (В примерах на рис. 8.19 и 8.20 использована одна и та же случайная последовательность.)
необходимо около 300 итераций. Решетчатая структура для предсказания сигнала обладает тем преимуществом, что каждая ячейка имеет свой, отличный от других, параметр сходимости, выбираемый из условия (8.11), и в общем случае это позволяет осуществлять процесс адаптации быстрее, чем для обычного метода наименьших квадратов [34]. (В примерах на рис. 8.19 и 8.20 использована одна и та же случайная последовательность.)
 по десяти ближайшим значениям. Для полученных таким образом параметров
по десяти ближайшим значениям. Для полученных таким образом параметров  и одной и той же случайной последовательности обе обучающие кривые почти одинаковы. Отметим, что установившееся значение g примерно равно 0,05.
и одной и той же случайной последовательности обе обучающие кривые почти одинаковы. Отметим, что установившееся значение g примерно равно 0,05.
 и осуществляется предсказание синусоидального колебания,
и осуществляется предсказание синусоидального колебания,  а относительное среднее значение СКО М в этом случае должно быть равно примерно 4.
а относительное среднее значение СКО М в этом случае должно быть равно примерно 4.
 ячейки решетки:
ячейки решетки:
 (8.115)
(8.115)

 , подставим его в (8.100):
, подставим его в (8.100):

 . Если теперь заменить в (8.105) градиент на его оценку, то получим формулу алгоритма последовательной регрессии, сравнимую с выведенной выше:
. Если теперь заменить в (8.105) градиент на его оценку, то получим формулу алгоритма последовательной регрессии, сравнимую с выведенной выше:
 (0)
(0)
 . Для нестационарных условий процесса адаптации вводятся, как и в (8.21), коэффициенты при
. Для нестационарных условий процесса адаптации вводятся, как и в (8.21), коэффициенты при  отсюда оценка
отсюда оценка
 (8.119)
(8.119)
 (8.120)
(8.120)

 осуществляется на каждом шаге. На рис. 8.22 показана кривая для алгоритма последовательной регрессии в рассматриваемом примере. Отметим, что здесь кривая несколько ближе к оптимальной, чем на рис. 8.19.
осуществляется на каждом шаге. На рис. 8.22 показана кривая для алгоритма последовательной регрессии в рассматриваемом примере. Отметим, что здесь кривая несколько ближе к оптимальной, чем на рис. 8.19.

 Траектория содержит 200 итераций
Траектория содержит 200 итераций
 для
для 