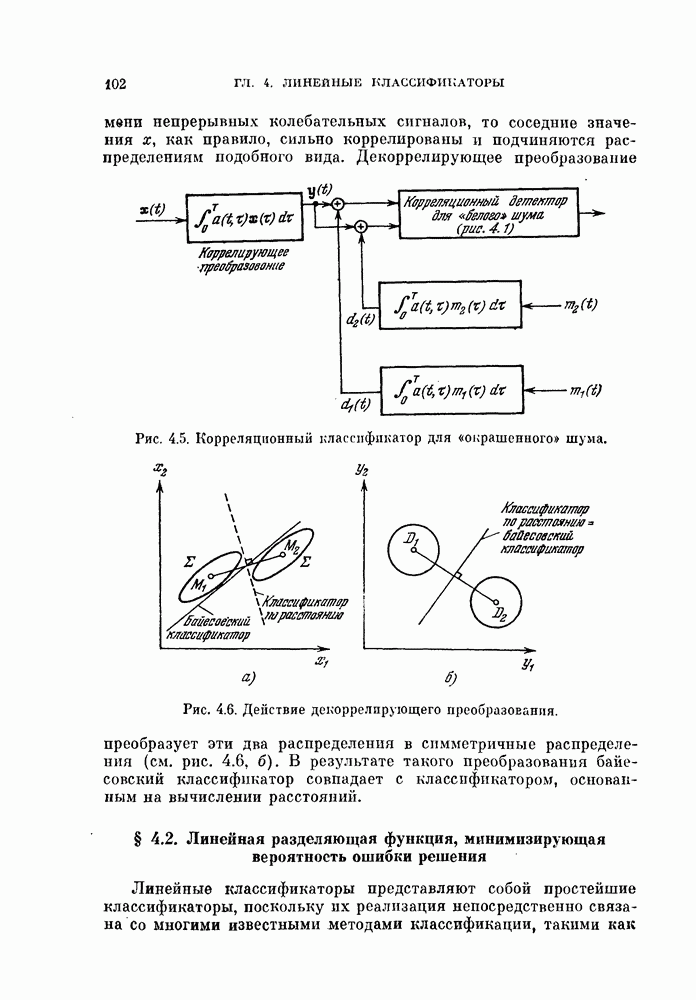
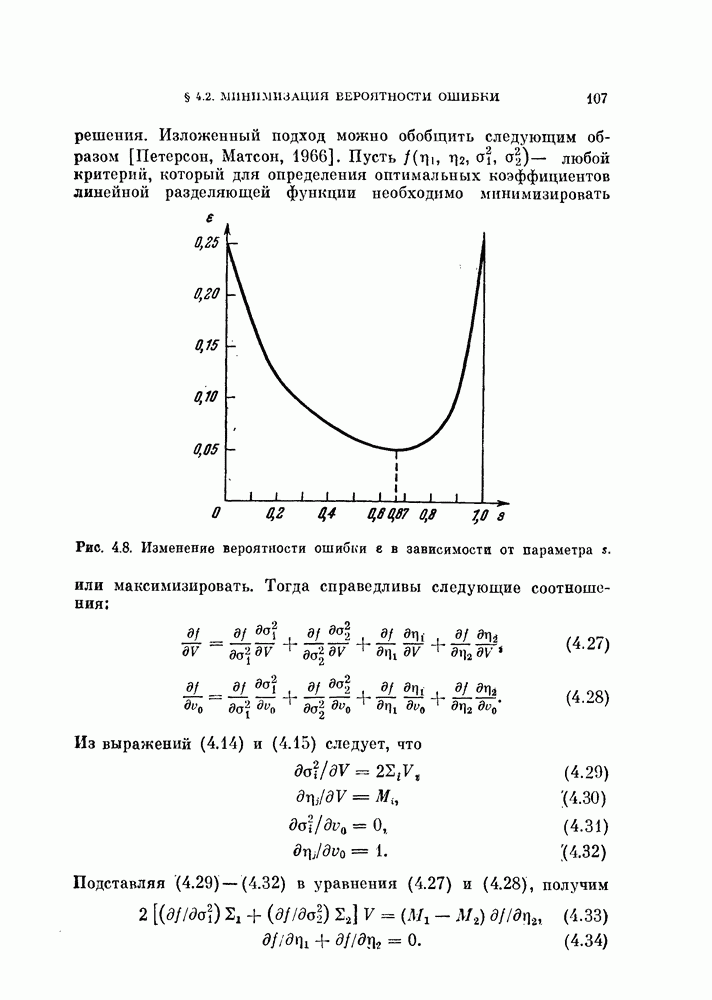
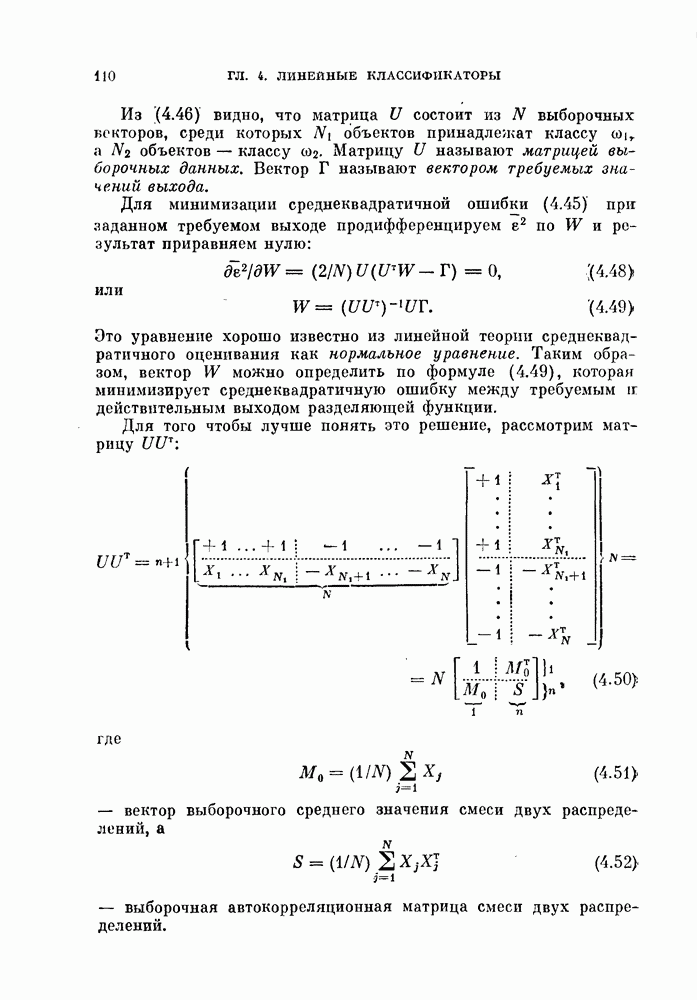
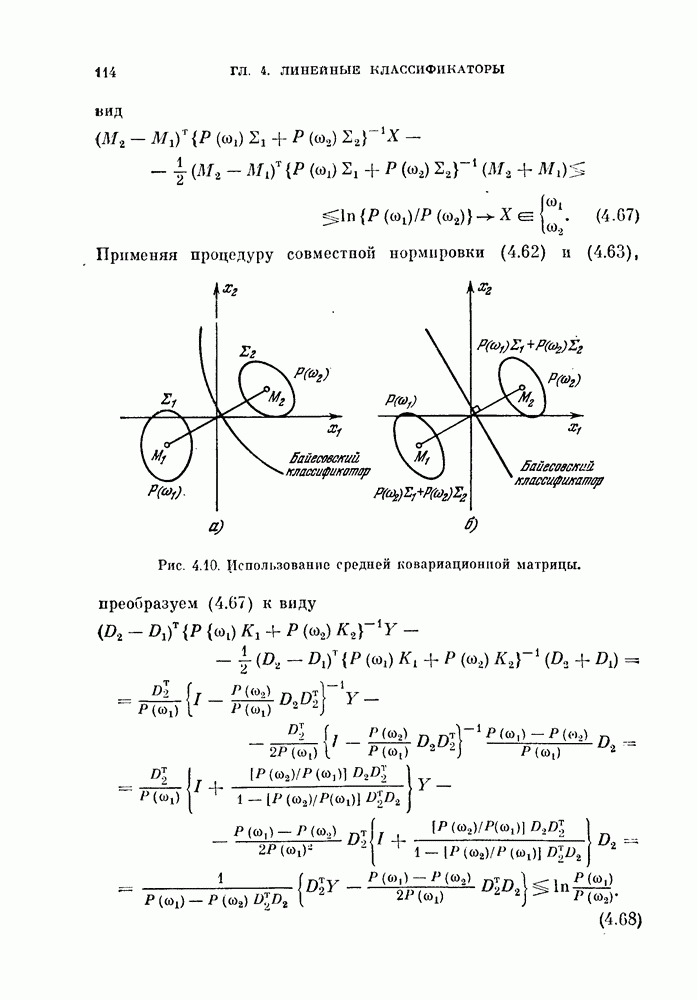
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
ОТ РЕДАКТОРА ПЕРЕВОДАСтатистические методы распознавания образов, которым посвящена настоящая книга, привлекают все большее внимание специалистов в области теории и практики распознавания образов и автоматической классификации. Однако в настоящее время сложилась парадоксальная ситуация: при обилии журнальных публикаций и специальных монографий отсутствует литература, ориентированная на широкий круг читателей, впервые знакомящихся с предметом. Более того, даже специалисты, знакомые с «классической» математической статистикой, испытывают определенные трудности при изучении статистических методов распознавания образов в силу значительной специфики задач классификации. Так, например, в большинстве задач распознавания образов отсутствует информация о виде законов распределения значений характеристик исследуемых объектов, обучающие выборки имеют малые размеры. В этих случаях приходится использовать специальные непараметрические методы. Предлагаемая книга в определенной степени восполняет создавшийся пробел. Разумеется, она не является всеобъемлющей. Так, например, в книге очень бегло и неполно изложены методы классификации параметров (факторного анализа и экстремальной группировки), адаптивные методы классификации и выбора информативных переменных. В книге почти не отражено бурно развивающееся направление в распознавании образов — методы классификации для малых выборок и в условиях пропущенных наблюдений. Определенный отпечаток на структуру и содержание книги наложило то обстоятельство, что она была написана на основе курса лекций автора для студентов и аспирантов ряда университетов США и Японии. Книга построена по принципу «от простого к сложному» — первые главы содержат элементарные сведения по математической статистике, затем излагаются «классические» статистические методы распознавания образов и в заключительных главах приведены последние результаты в этой области. К достоинствам книги следует отнести стиль изложения — она написана простым языком; в ней, в отличие от большинства монографий, не опускаются «очевидные» промежуточные выкладки и результаты, что значительно облегчает понимание основных идей и особенностей используемого математического аппарата при проведении доказательств. Усвоению материала способствуют хорошо подобранные задачи. Следует подчеркнуть, что многие из них достаточно близки к реальным задачам распознавания, возникающим на практике. Современные методы решения задач распознавания образов и автоматической классификации, как правило, могут быть реализованы лишь с использованием ЭВМ. Для того чтобы обратить внимание читателя на особенности реализации тех или иных алгоритмов на ЭВМ, в книге даны задания на составление программ по каждому разделу и тестовые материалы для их проверки. Все это позволяет использовать книгу как учебное пособие при подготовке специалистов в области технической кибернетики. В процессе перевода и редактирования были выявлены и устранены ошибки, опечатки и неточности оригинала, причем специальных оговорок и ссылок в тексте не делается. А. А. Дорофеюк ПРЕДИСЛОВИЕ АВТОРАЭта книга представляет собой введение в статистическую теорию распознавания образов. Эта теория охватывает широкий круг задач, и в ней трудно выделить единую «сквозную» точку зрения или универсальный метод. Распознавание образов применяют как для решения технических задач, таких как чтение букв и анализ кривых, так и для моделирования функций мозга в биологии и психологии. Однако теория статистических решений и теория оценивания, являющиеся предметом этой книги, могут рассматриваться как основные направления исследований в распознавании образов. Статистические решения и теория оценивания изучаются в разных разделах математической статистики, статистической теории связи, теории управления и т. д. Очевидно, однако, что для каждой области применения характерны свои цели и своя точка зрения. Для того чтобы работающим в области распознавания образов не было необходимости искать то, что им нужно, по разным книгам, в настоящей книге излагаются основы этих статистических теорий с точки зрения распознавания образов. Материал этой книги излагался в лекциях для студентов старших курсов университета Пердью, а также на специальном летнем курсе фирмы ИБМ в Рочестере (Миннесота). Автор в связи с этим надеется, что эта книга будет служить как в качестве пособия для вводных курсов по распознаванию образов, так и в качестве справочника для работающих в данной области. Одна из трудностей теории распознавания образов заключается в том, что мы имеем дело с большим числом коррелированных случайных величин. Это вынуждает нас использовать аппарат линейной алгебры. В связи с этим в главе 2 рассмотрен ряд вопросов линейной алгебры, а также свойств случайных величин и векторов. На протяжении всей книги основной упор делается на описание задач и методов их решения в терминах собственных значений и собственных векторов. В главах 3—7 рассматривается задача построения классификатора. Помимо обычного материала по проверке гипотез (глава 3) и оцениванию параметров (глава 5), в этих главах особое внимание обращается на оценивание вероятности ошибки. Вероятность ошибки — это основной параметр в теории распознавания образов. Глава 4 посвящена линейным и кусочно-линей-ным классификаторам, так как зачастую только эти классификаторы могут быть практически реализованы. Одна из трудностей в теории распознавания образов состоит в том, что в большинстве приложений не выполняется предположение о наличии нормального (гауссовского) распределения. Вследствие этого на практике становится неизбежным применение непараметрических методов (глава 6). В главе 7 рассматриваются последовательные методы, при которых классификатор модифицируется (подстраивается) всякий раз, когда предъявляется очередной объект. В главах 8—10 рассматривается задача выбора признаков, которая понимается как преобразование (отображение) исходного пространства в пространство признаков меньшей размерности без потери интересующей нас информации. Линейные преобразования применяются для выбора множества признаков, минимизирующих ошибку представления объектов, порождаемых одним распределением (глава 8), или максимизирующих разделимость классов при наличии нескольких распределений (глава 9). В главе 10 рассматривается возможность использования для этих же целей нелинейных преобразований. Глава 11 посвящена автоматической классификации, или классификации без учителя. В этом случае объекты классифицируются при минимальной априорной информации об их распределении. Автор хотел бы выразить благодарность доктору Хэнкоку и его коллегам по университету Пердыо за их поддержку. Кроме того, автор пользуется случаем выразить признательность Национальному научному фонду за поддержку исследований по распознаванию образов. Значительная часть материала этой книги была предоставлена автору его бывшими и нынешними сотрудниками Д. Л. Кеселом, доктором Л. Д. Кунтцем, доктором Т. Ф. Крайлом и доктором Д. Р. Олсеном. Особую благодарность автор выражает доктору Кунтцу как за его глубокий и детальный критический разбор всей рукописи, так и за существенный вклад, который он внес в содержание книги. Кроме того, автор хотел бы поблагодарить свою жену Рейко за печатание рукописи. Автор признателен Институту инженеров по электротехнике и электронике, Институту математической статистики и Американской телефонной и телеграфной корпорации за разрешепие пользоваться материалами, опубликованными в их журналах.
|
 |
Оглавление
|