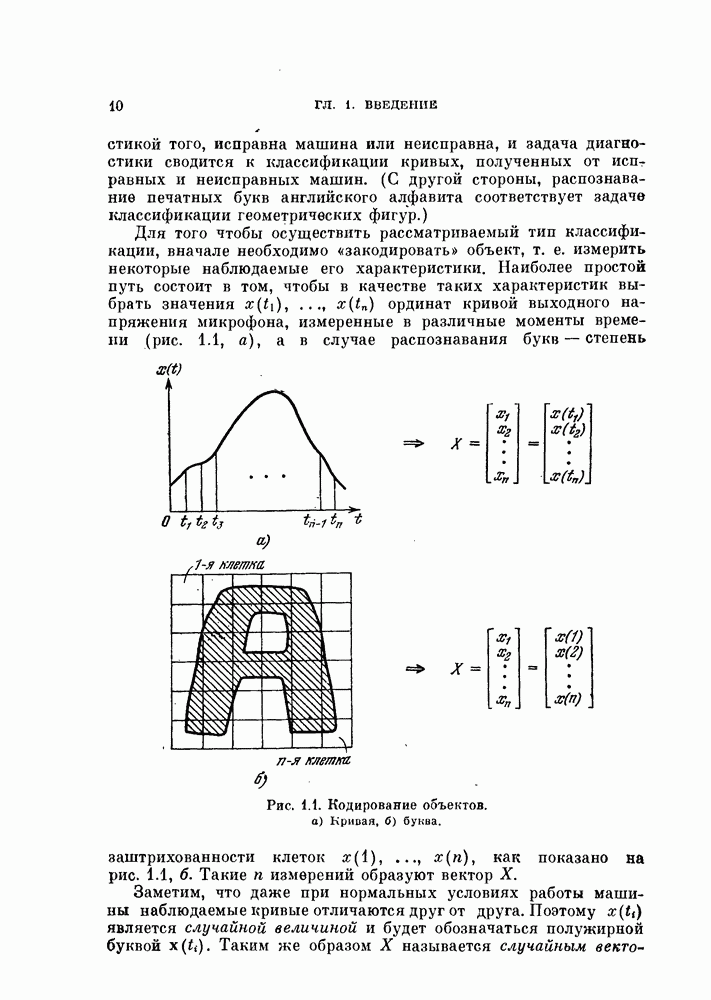
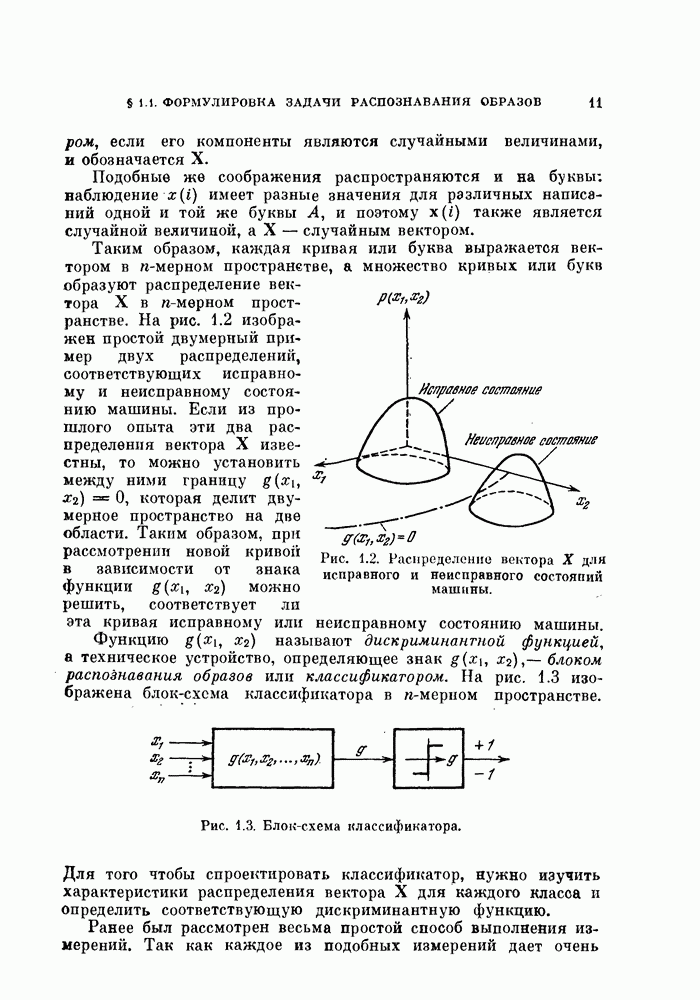
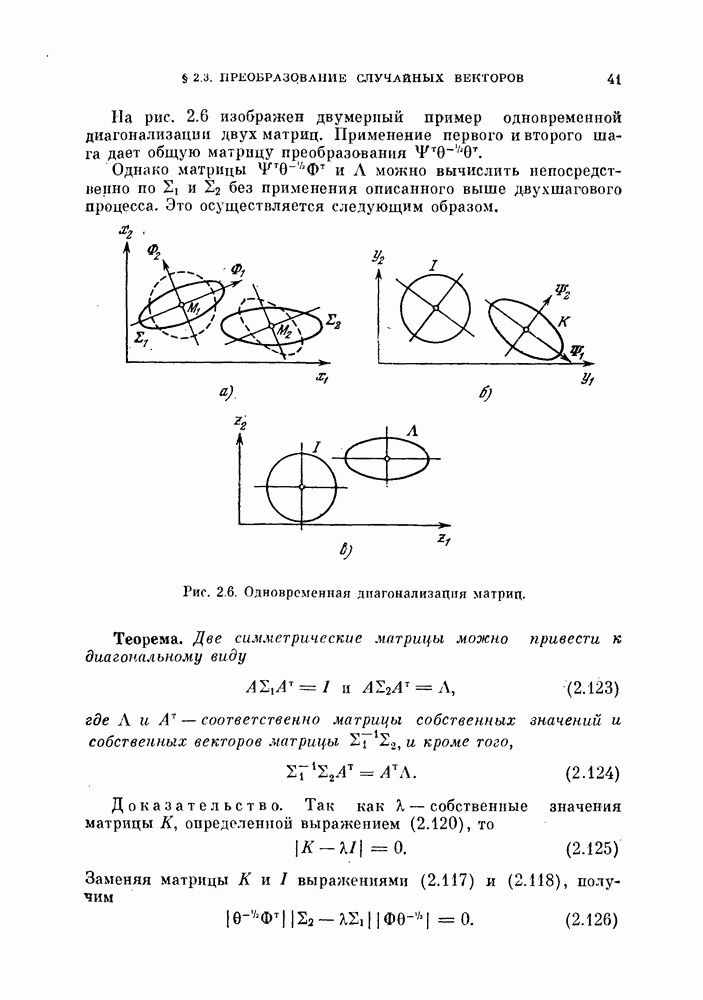
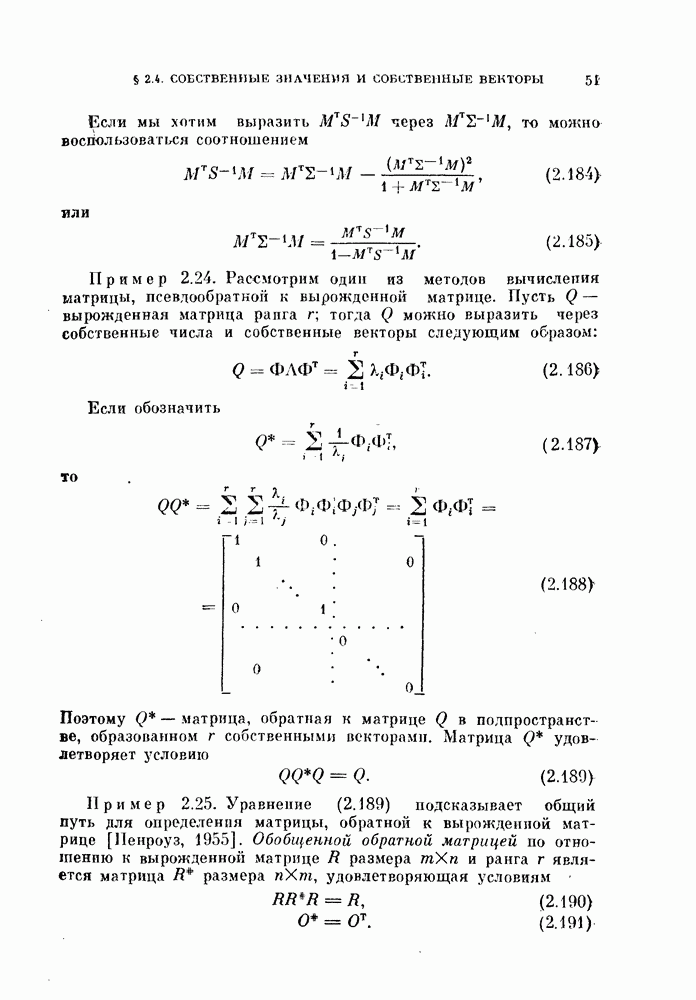
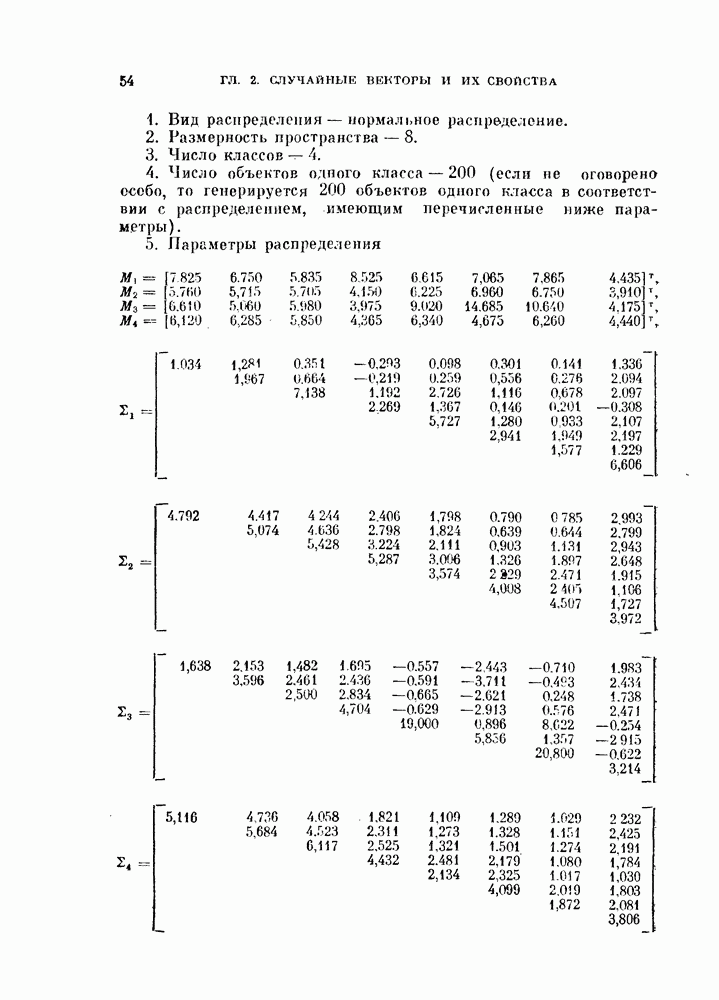
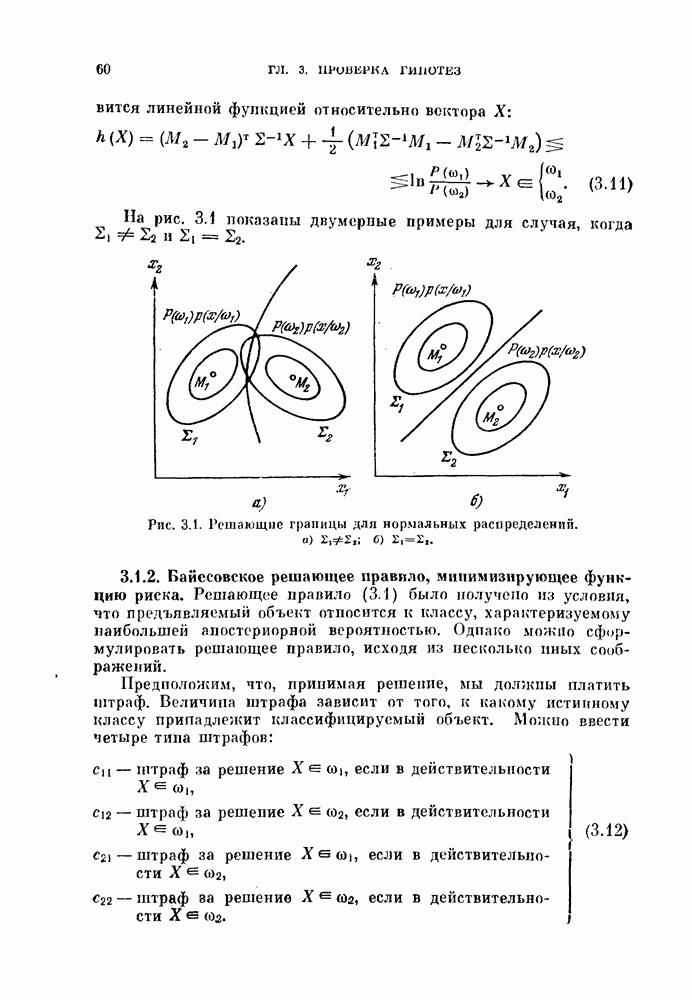
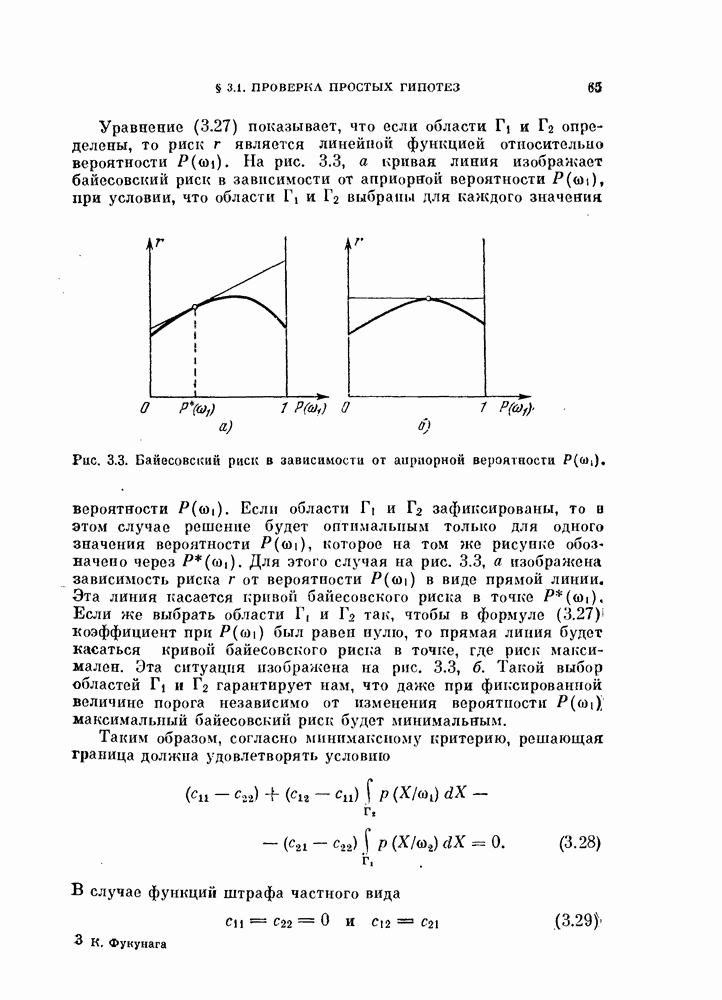
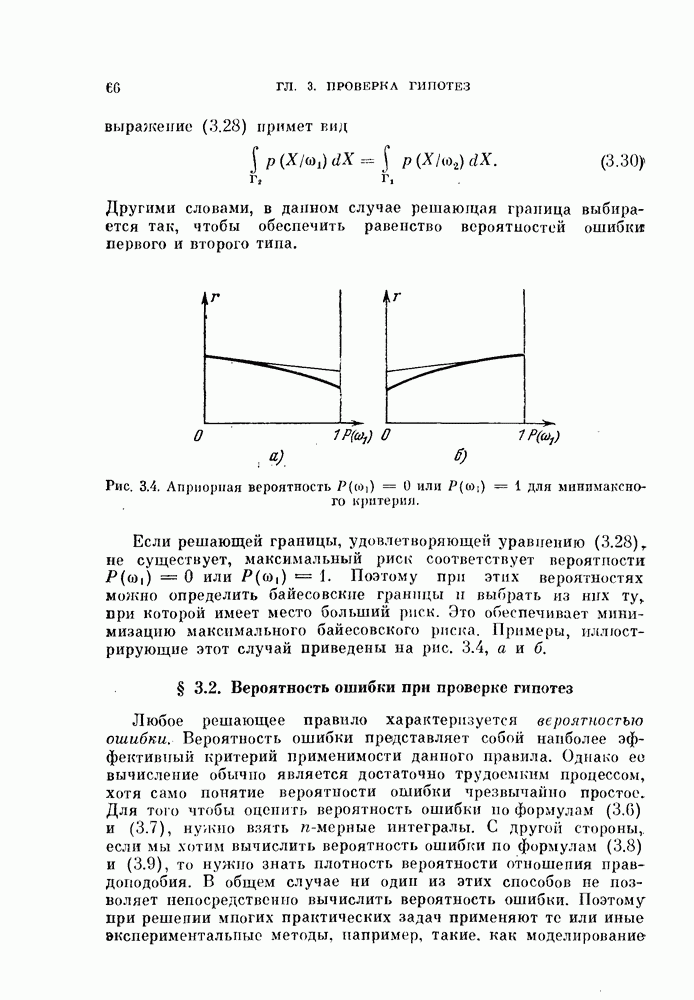
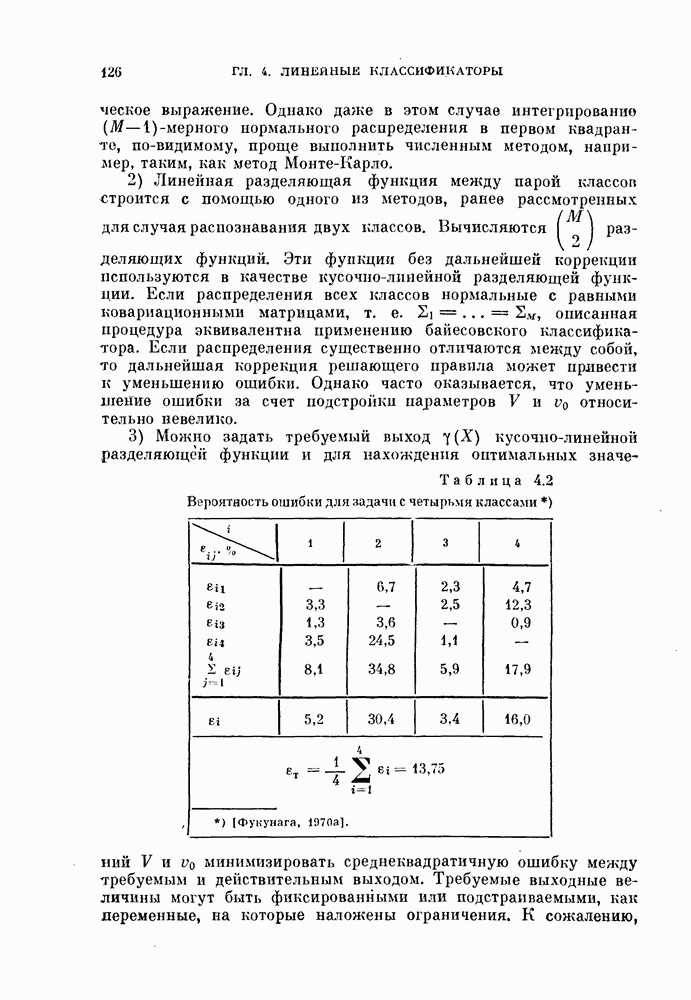
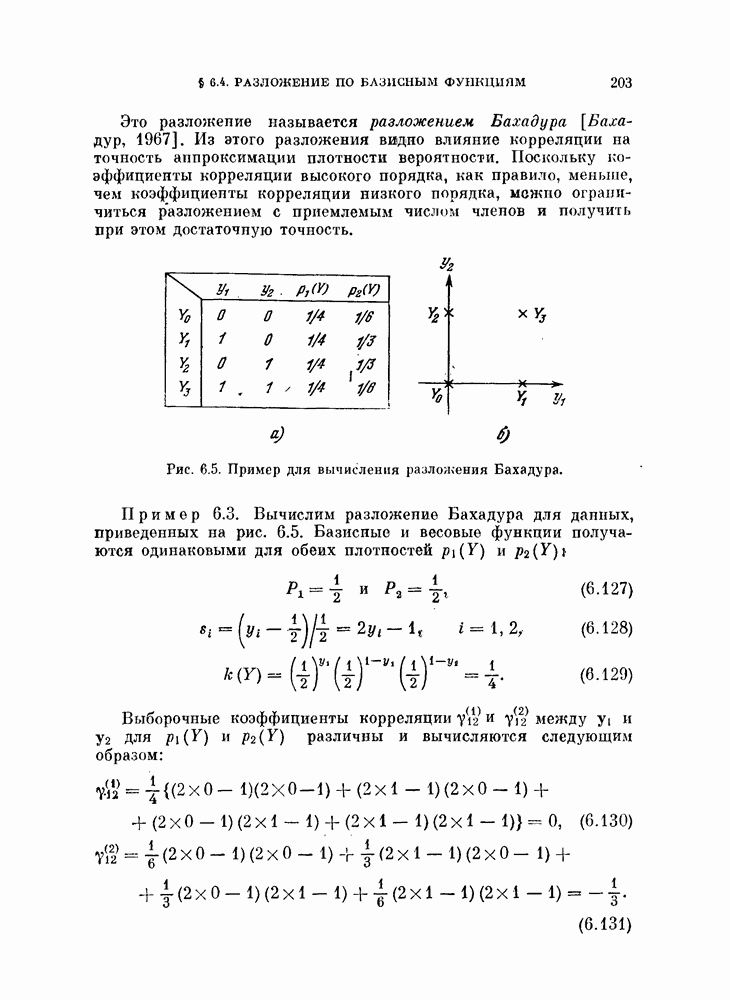
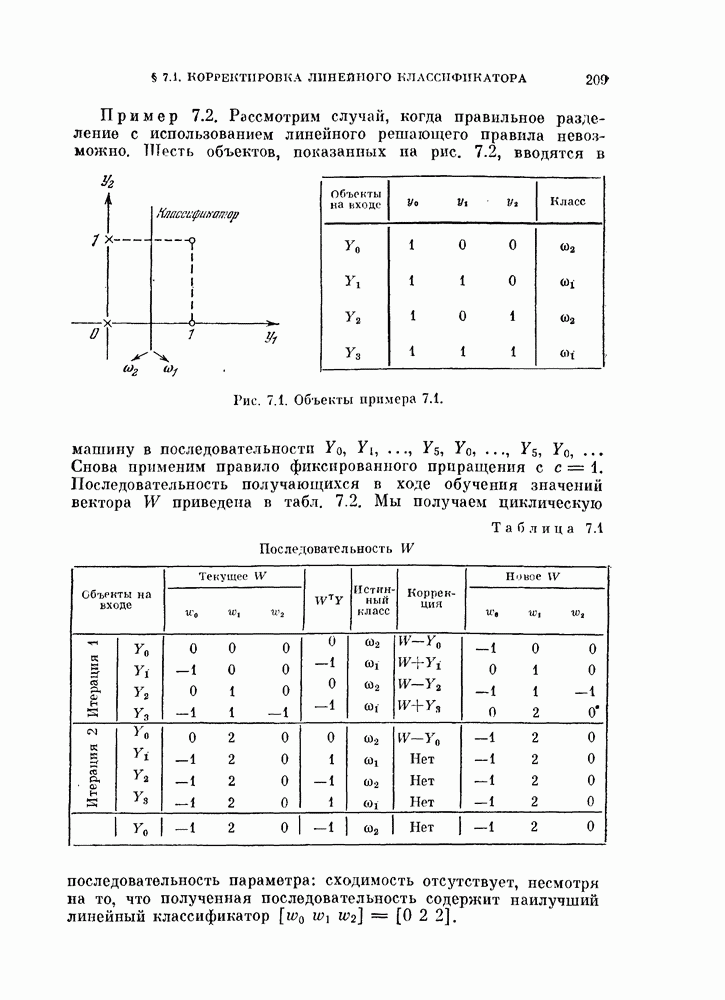
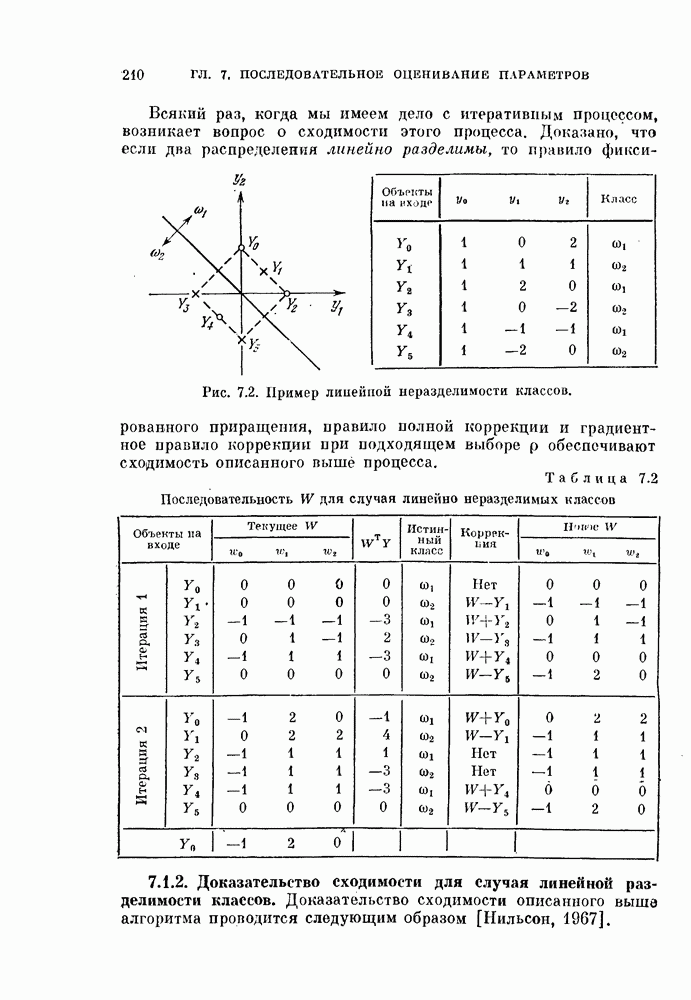
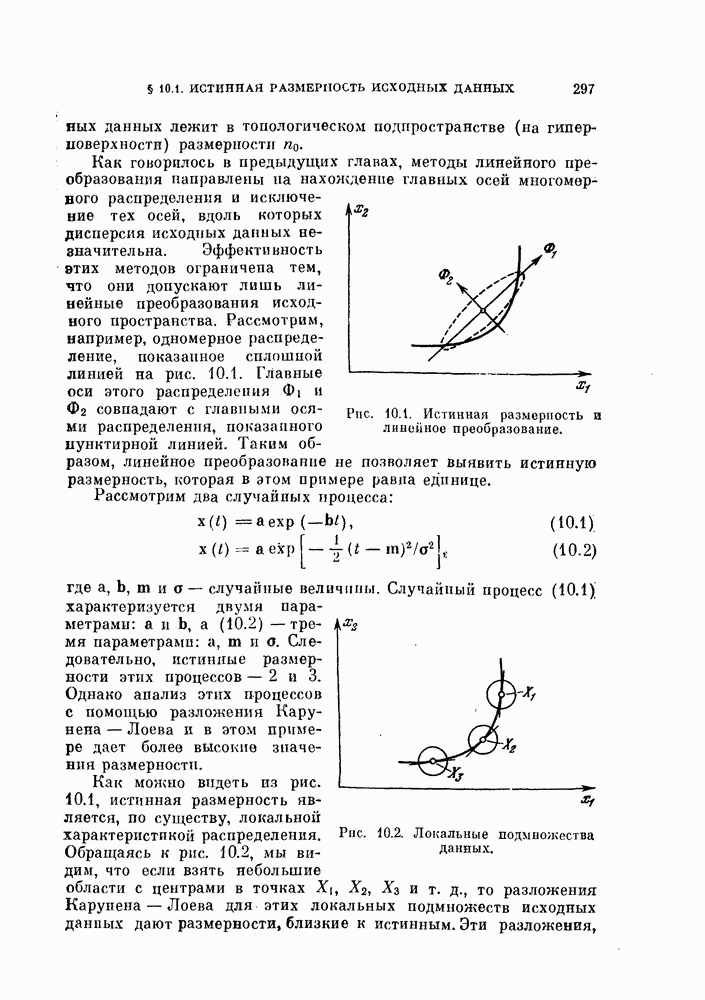
11.3.2. Непараметрический алгоритм автоматической классификации.
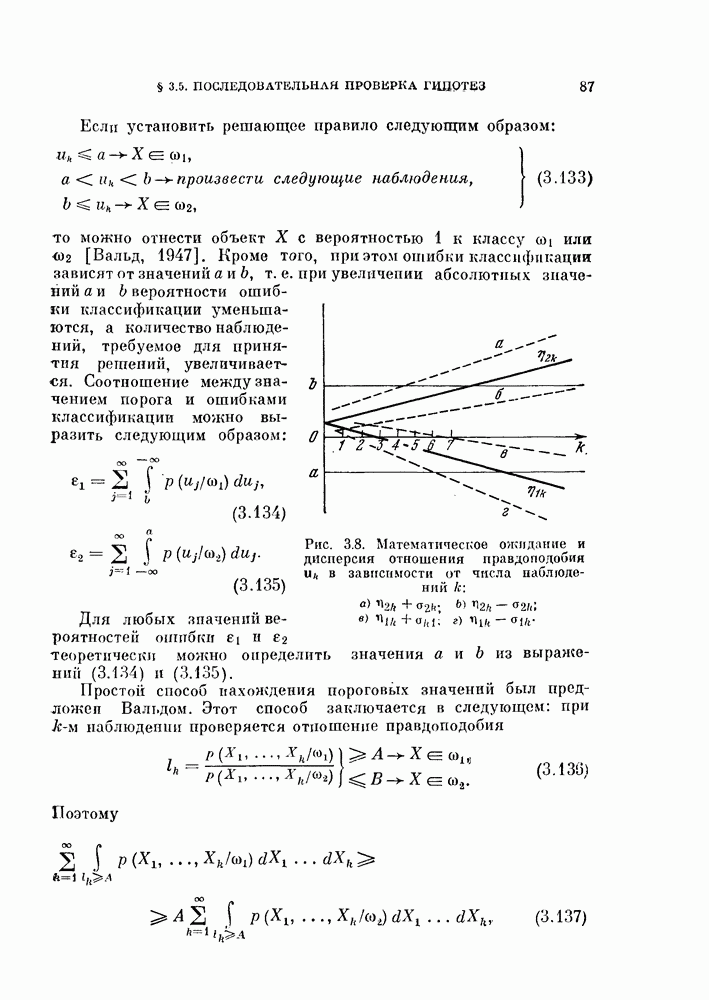
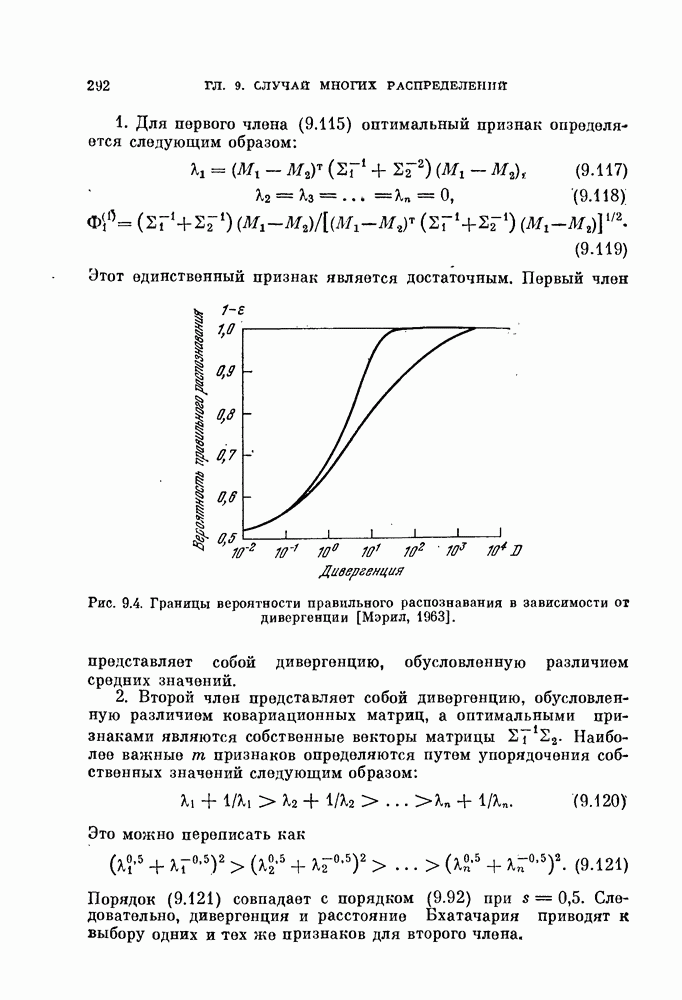
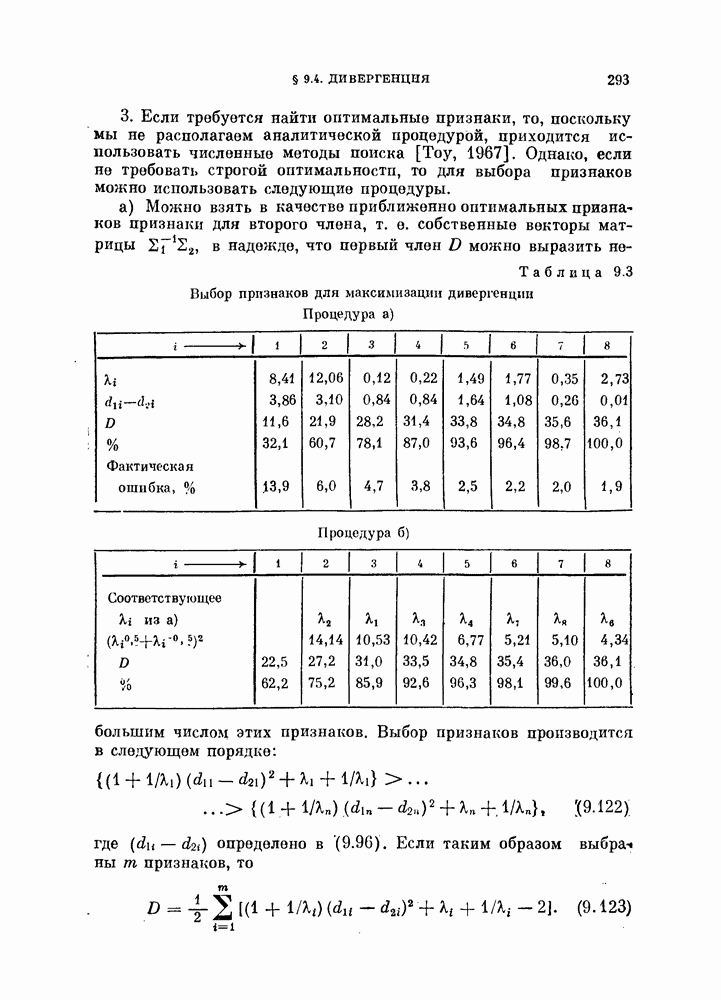
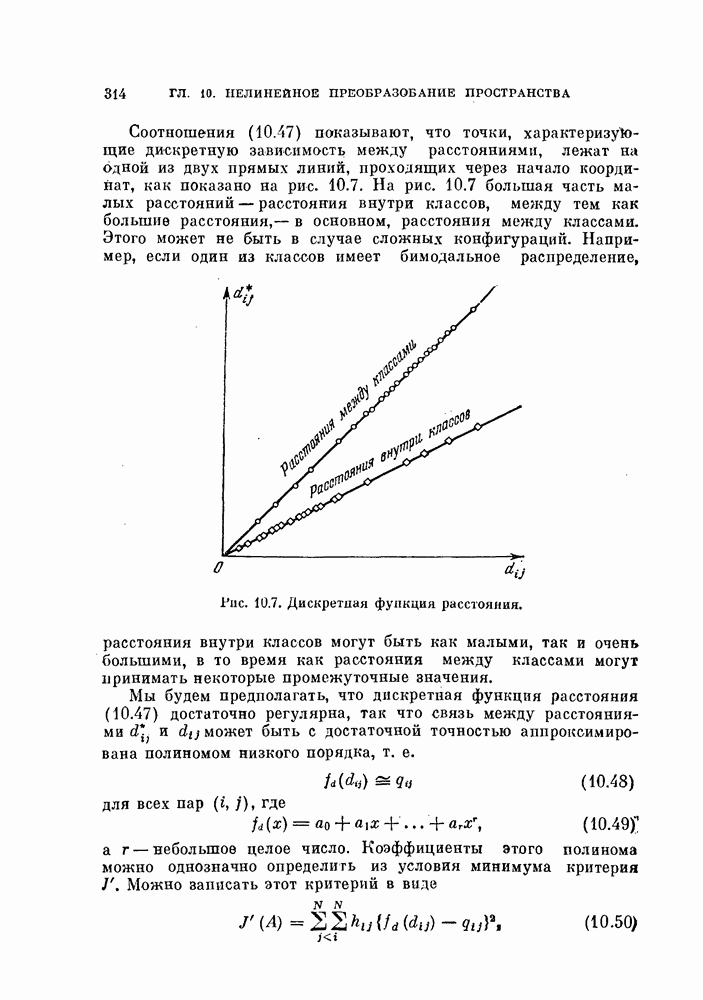
Возвращаясь к общему случаю, мы можем описать алгоритм в терминах приращений  при изменении
при изменении  т. е.
т. е.

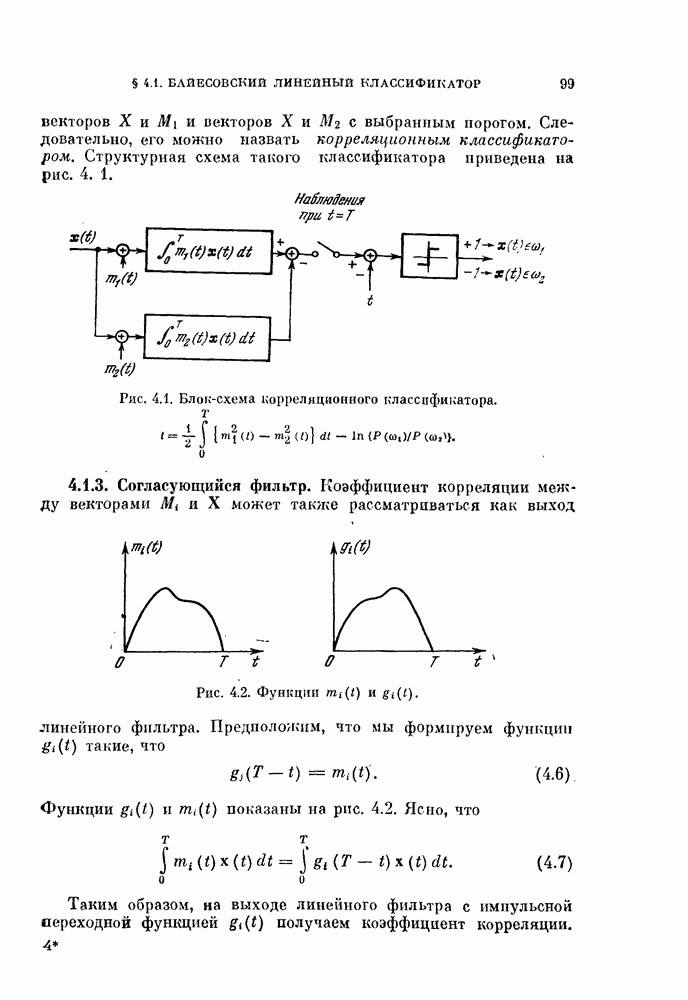
Если используются критерии  , приращение имеет более простои вид:
, приращение имеет более простои вид:

Как  так и
так и  содержит два члена, один из которых не зависит от у. Таким образом, можно записать их, как решающие
содержит два члена, один из которых не зависит от у. Таким образом, можно записать их, как решающие
функции на  итерации. Приращению
итерации. Приращению  соответствует решающая функция
соответствует решающая функция  определяемая выражением
определяемая выражением

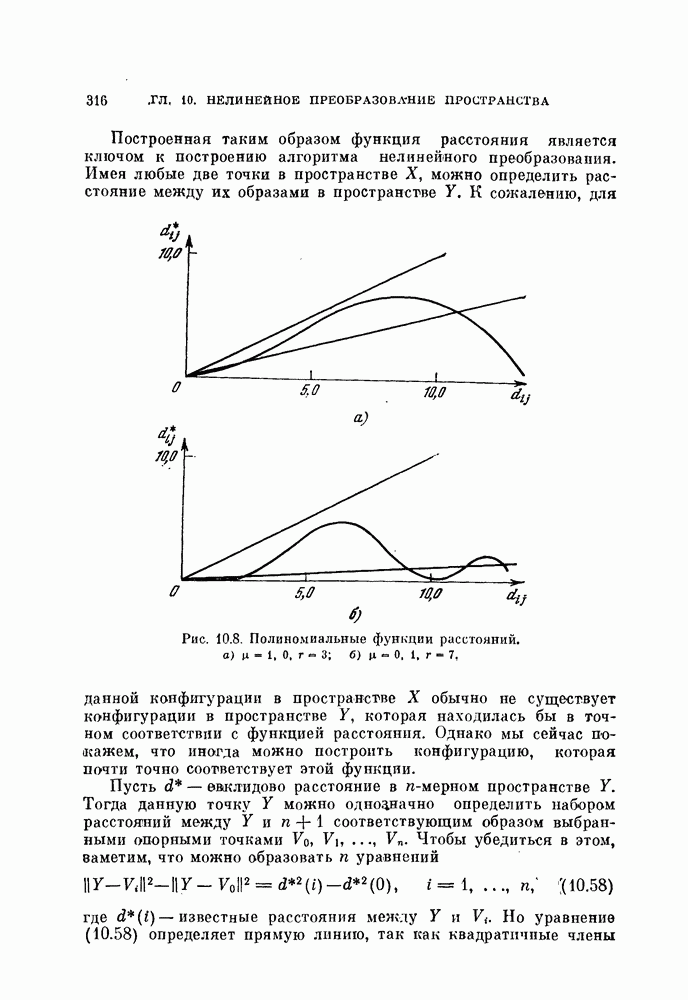
 представляет собой число векторов, отнесенных в
представляет собой число векторов, отнесенных в  класс на I-й итерации и отстоящих от
класс на I-й итерации и отстоящих от  на расстояние, меньшее
на расстояние, меньшее  Правило классификации на
Правило классификации на  итерации имеет вид
итерации имеет вид

т. e. перебрасывается в тот класс, который в настоящий момент имеет наибольшее число члеиов, отстоящих от  меньше, чем на
меньше, чем на  Назовем эту реализацию основного алгоритма правилом фиксированной окрестности.
Назовем эту реализацию основного алгоритма правилом фиксированной окрестности.
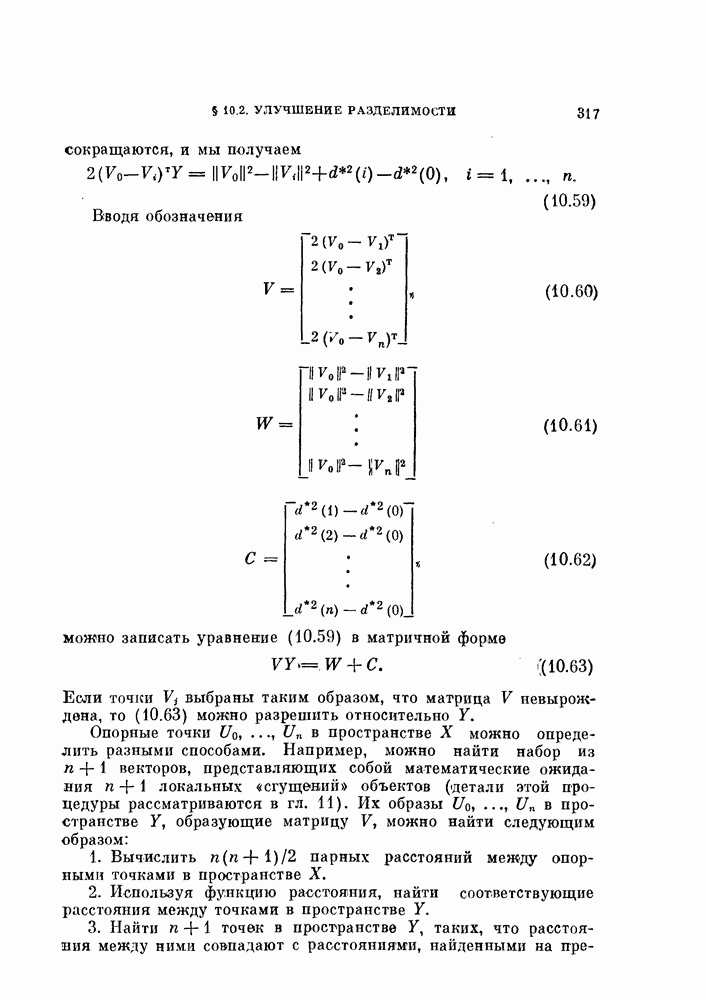
Как критерий  так и связанный с ним алгоритм имеют весьма естественную физическую интерпретацию. Ненулевой вклад в
так и связанный с ним алгоритм имеют весьма естественную физическую интерпретацию. Ненулевой вклад в  дают векторы, близкие к границам, разделяющим классы. Таким образом,
дают векторы, близкие к границам, разделяющим классы. Таким образом,  меньше, когда эти границы проходят через области, в которых векторы расположены с малой плотностью. Рассмотрим границу, разделяющую классы и
меньше, когда эти границы проходят через области, в которых векторы расположены с малой плотностью. Рассмотрим границу, разделяющую классы и  на
на  итерации. Предположим, что плотность является более высокой с той стороны границы, где расположен класс
итерации. Предположим, что плотность является более высокой с той стороны границы, где расположен класс 
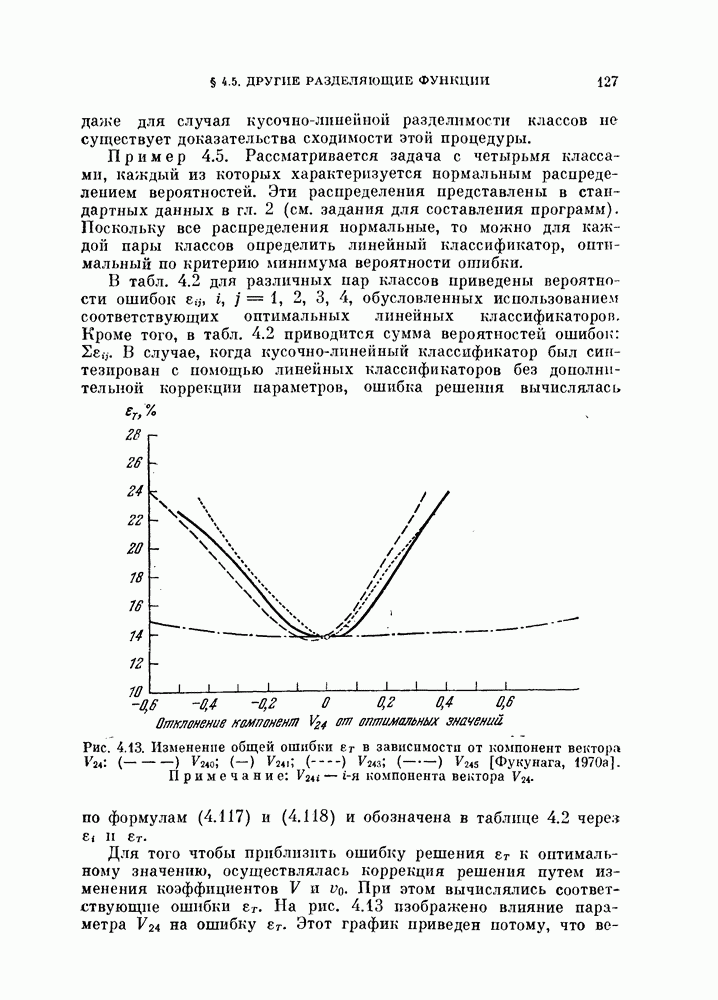
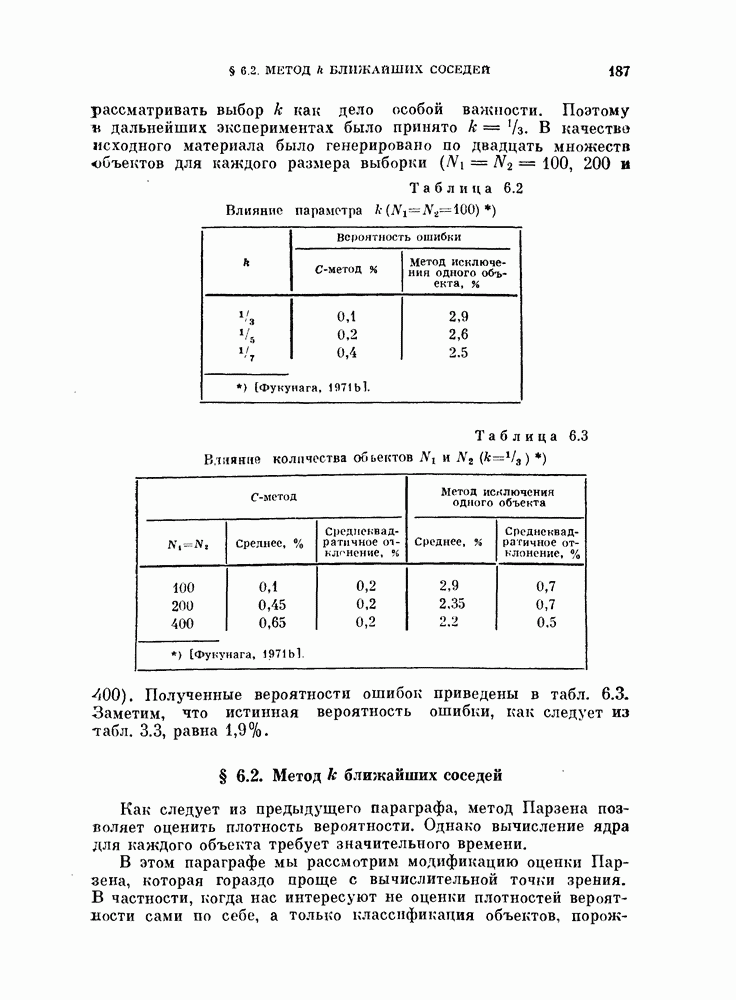
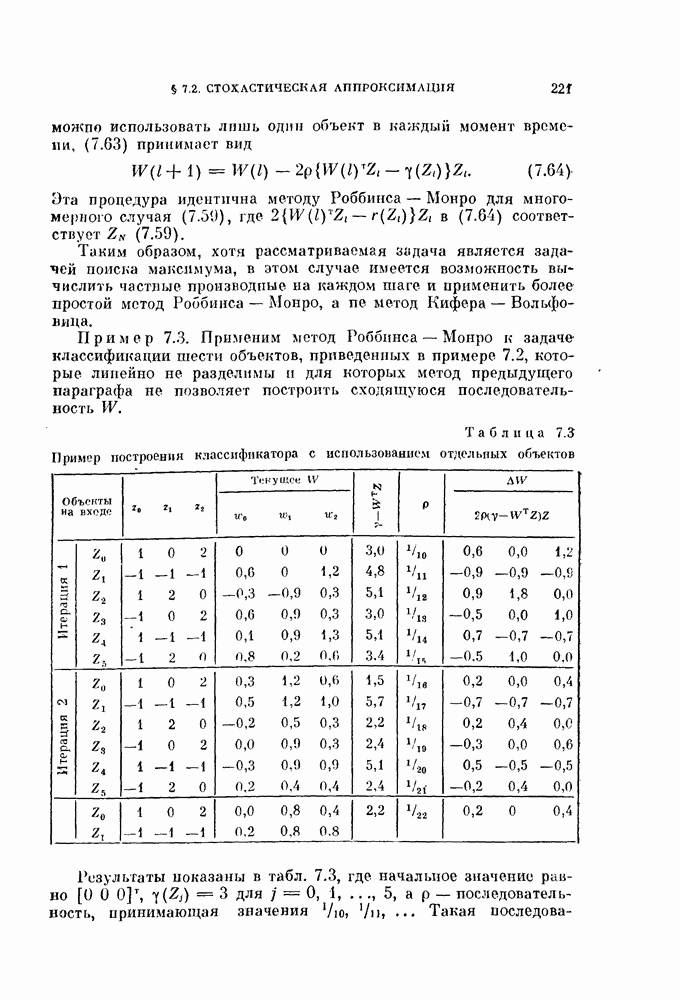
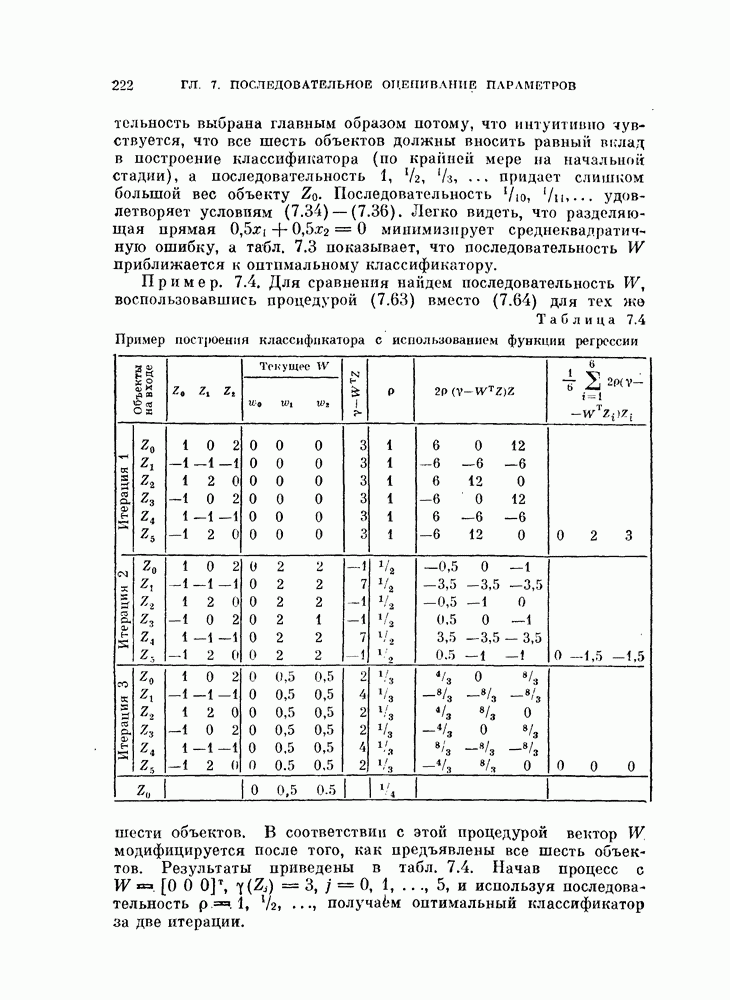
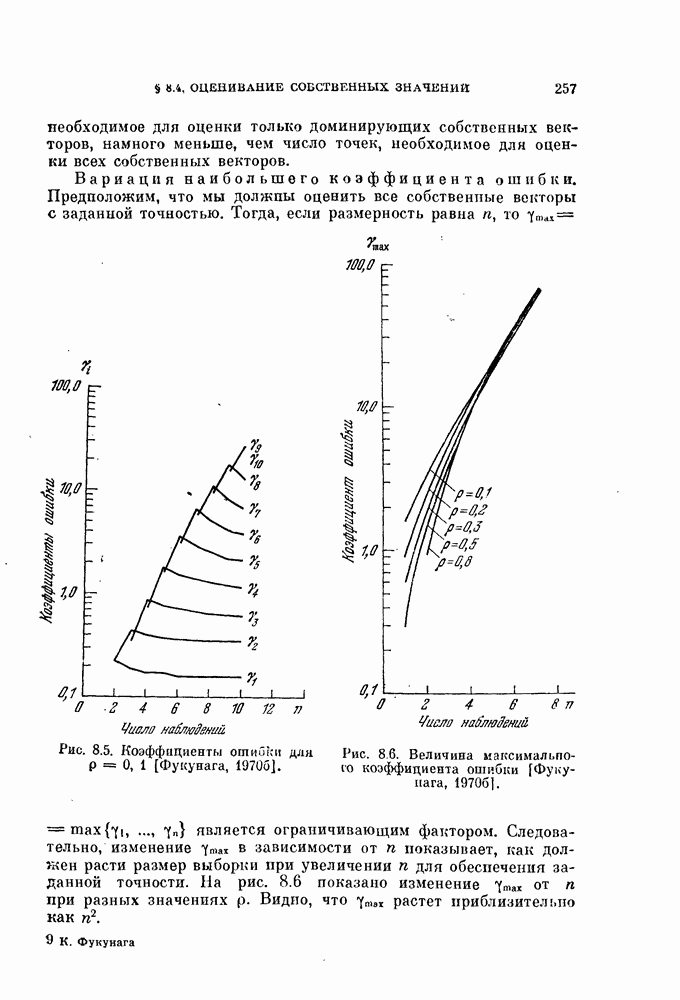
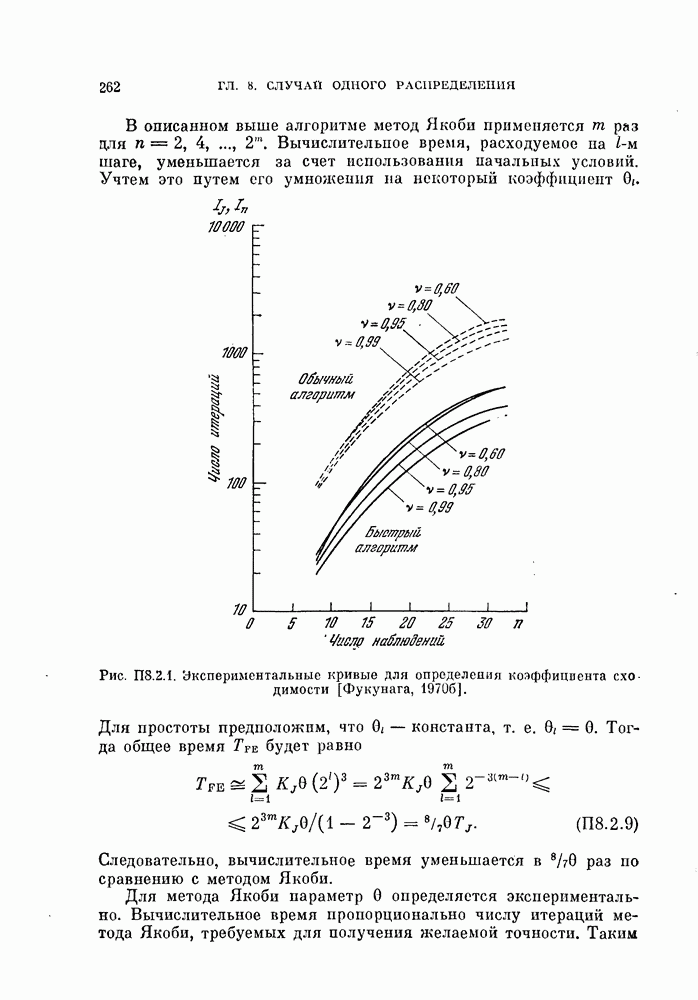
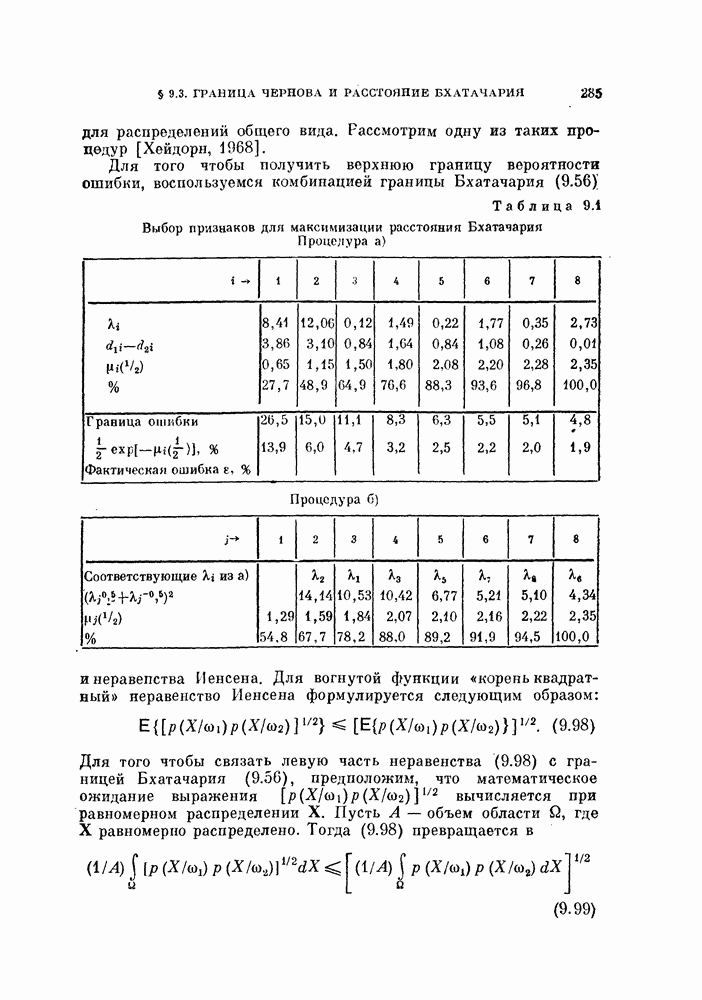
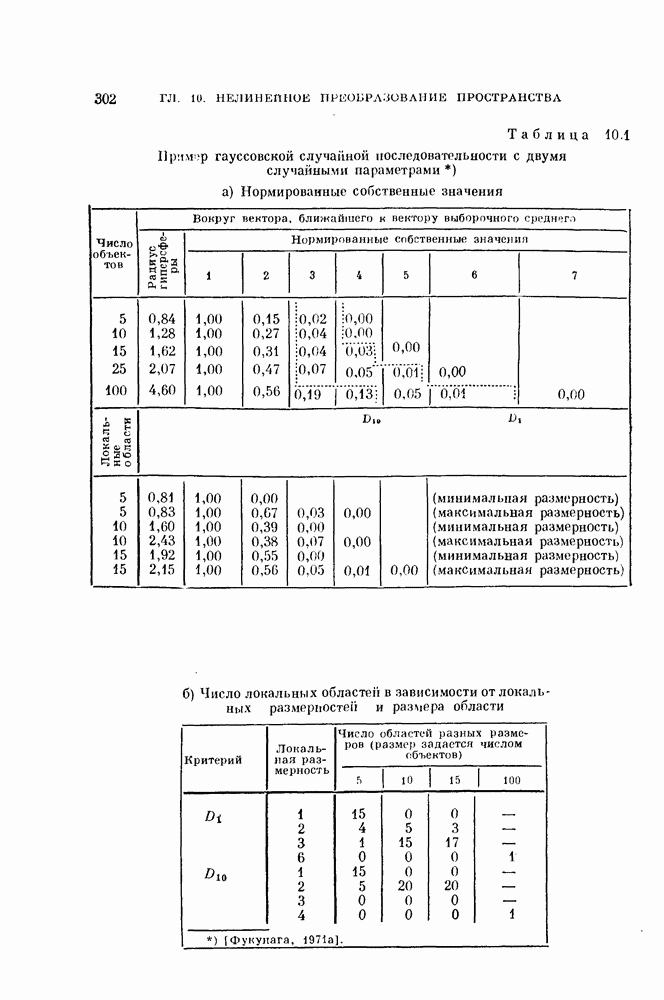
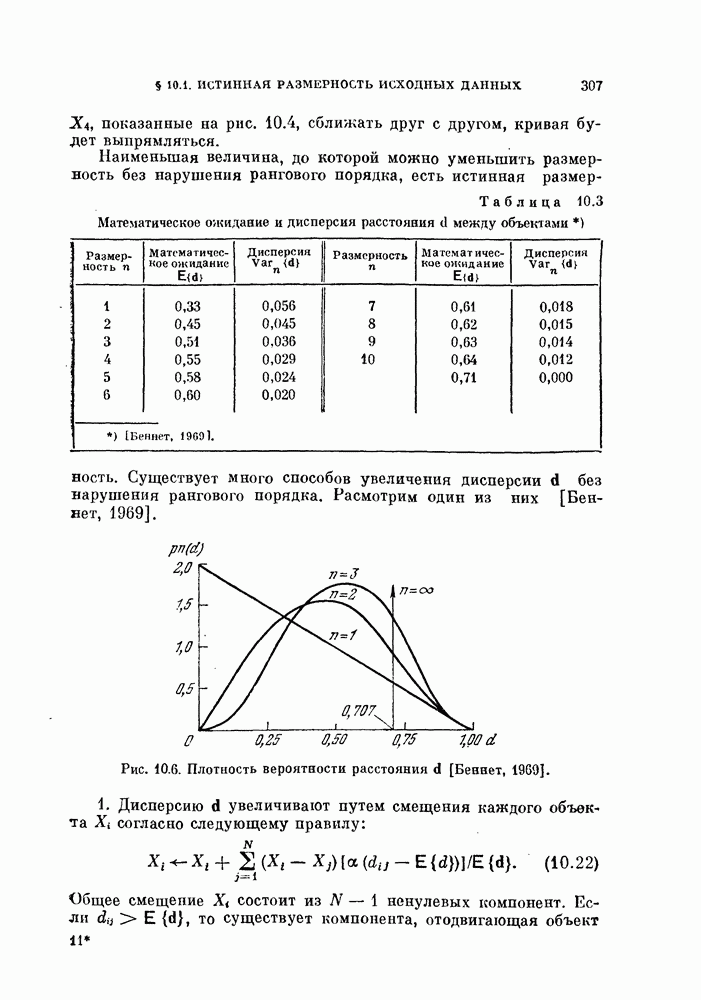
Таблица 11.3
Данные, характеризующие эффективность процедуры, основанной на правиле фиксированной окрестности

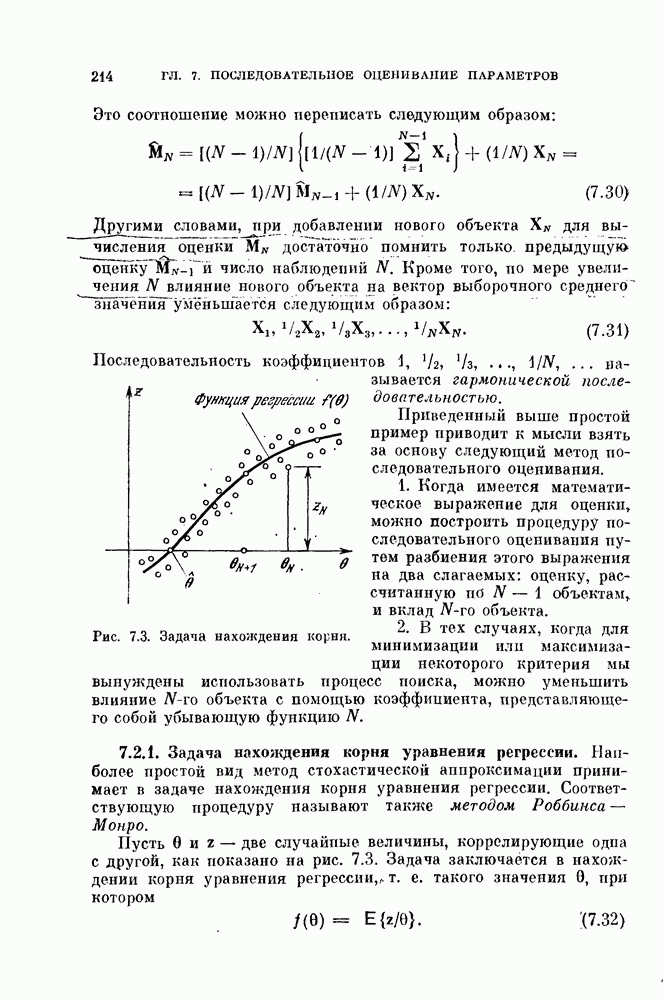
Тогда векторы, лежащие вблизи границы, будут переброшены в класс а граница переместится в направления меньшей плотности. Таким образом, процедура, основанная на правиле фиксированной окрестности, представляет собой метод поиска «долин». Это разумный способ классификации векторов в условиях отсутствия априорной информации.
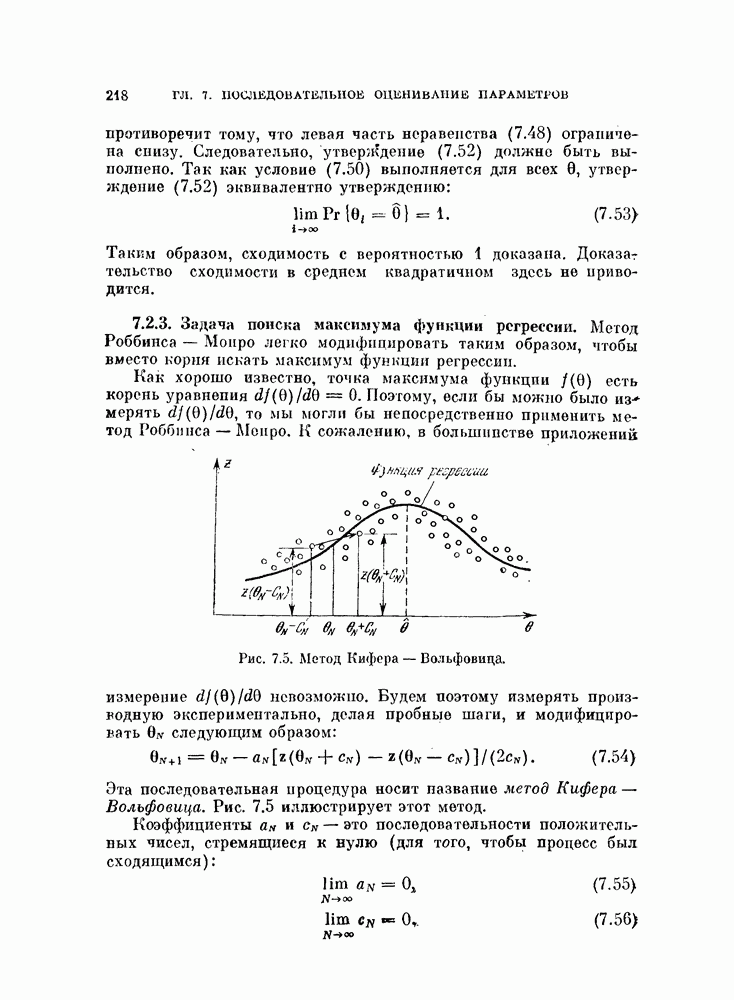
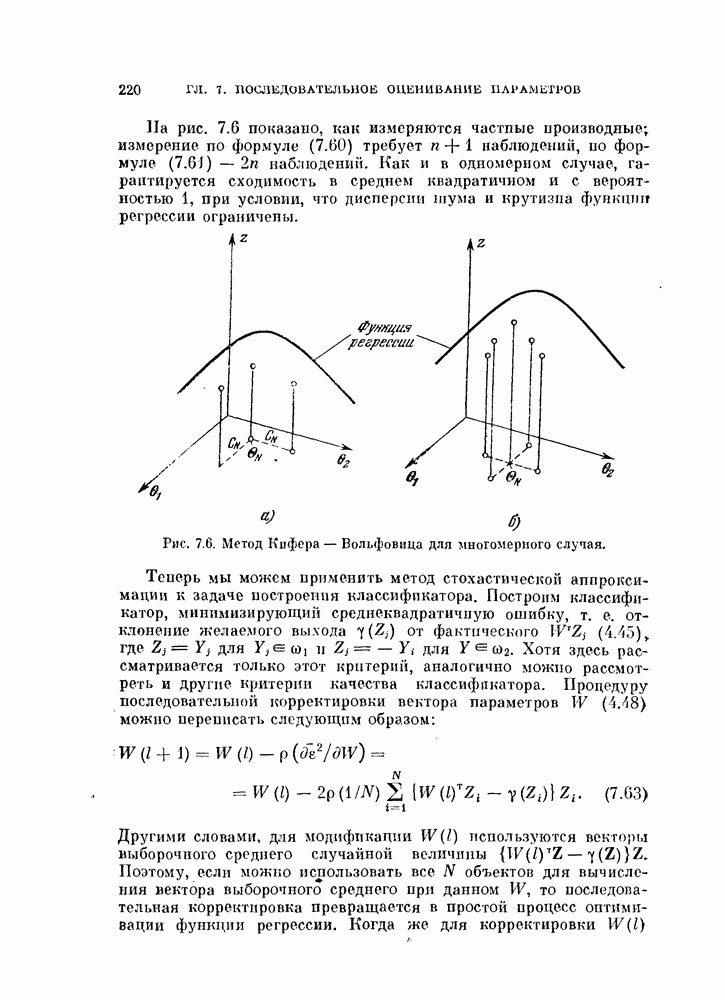
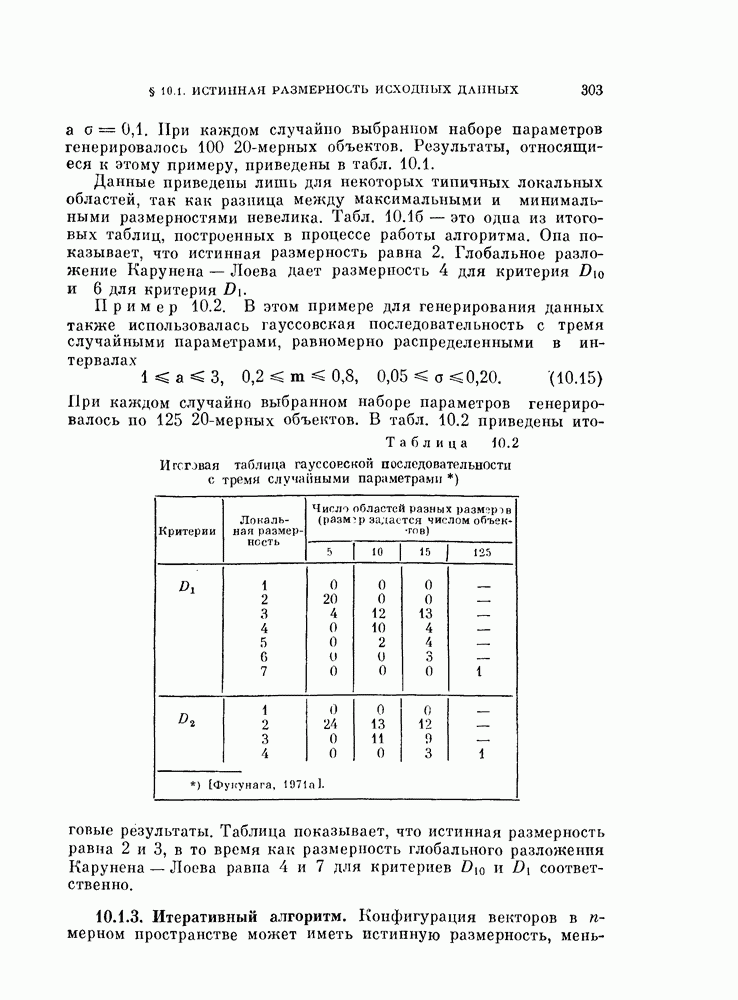
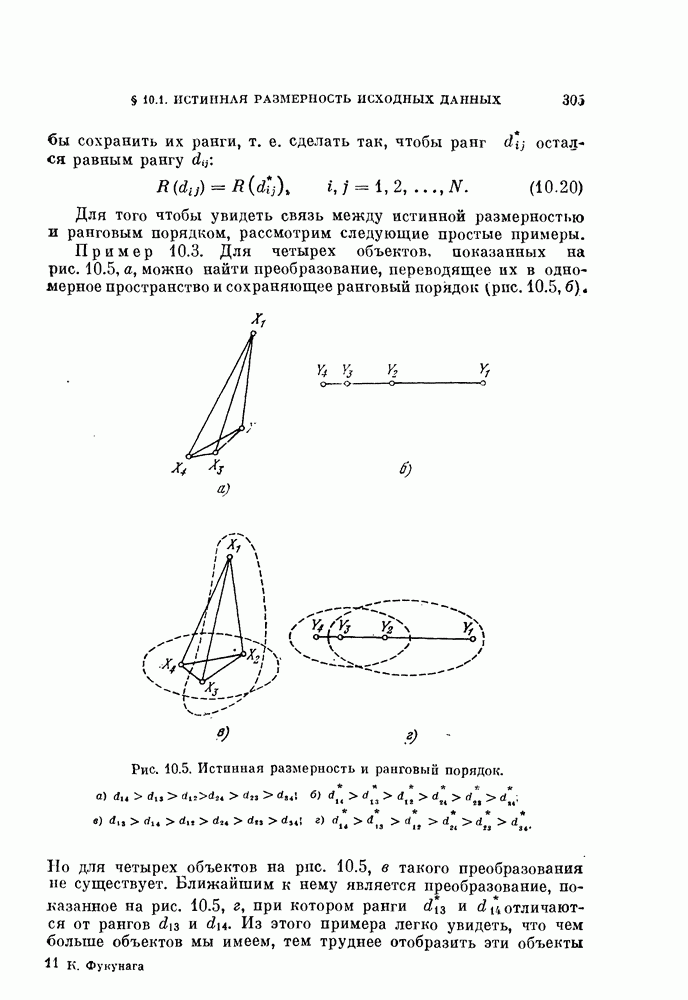
Описанная выше процедура легко программируется. На рис. 11.5 и 11.6 и в табл. 11.3 приведены результаты двух машинных экспериментов. В таблице для каждого эксперимента приводится число объектов  предполагаемое число классов
предполагаемое число классов  размер окрестности число
размер окрестности число  разных пар точек, находящихся
разных пар точек, находящихся

(кликните для просмотра скана)
друг от друга на расстоянии, меньшем  число потребовавшихся итераций
число потребовавшихся итераций  а также начальные и конечные штрафы
а также начальные и конечные штрафы  и
и  . В экспериментах, использовались следующие данные.
. В экспериментах, использовались следующие данные.
Пример 11.2. Два класса, данные двумерные, по 75 объектов в каждом классе:

где  — независимые, одинаково распределенные нормальные случайные величины с нулевыми средними и единичными дисперсиями;
— независимые, одинаково распределенные нормальные случайные величины с нулевыми средними и единичными дисперсиями;  для каждого класса фиксированы:
для каждого класса фиксированы:  для
для  класса;
класса;  для
для  класса; 0 — нормально распределенная случайная величина со средним
класса; 0 — нормально распределенная случайная величина со средним  и среднеквадратичным отклонением
и среднеквадратичным отклонением  где
где  для
для  класса,
класса,  для
для  класса, для обоих классов
класса, для обоих классов 
Пример 11.3. Три класса, данные двумерные, по 50 объектов в каждом классе: 1-й и 2-й классы — такие же, как и в примере 11.2, со значениями параметров  для
для  класса;
класса;  для
для  класса.
класса.
3-й класс генерируется в соответствии с двумерным нормальным распределением со средним вектором М и ковариационной матрицей 2

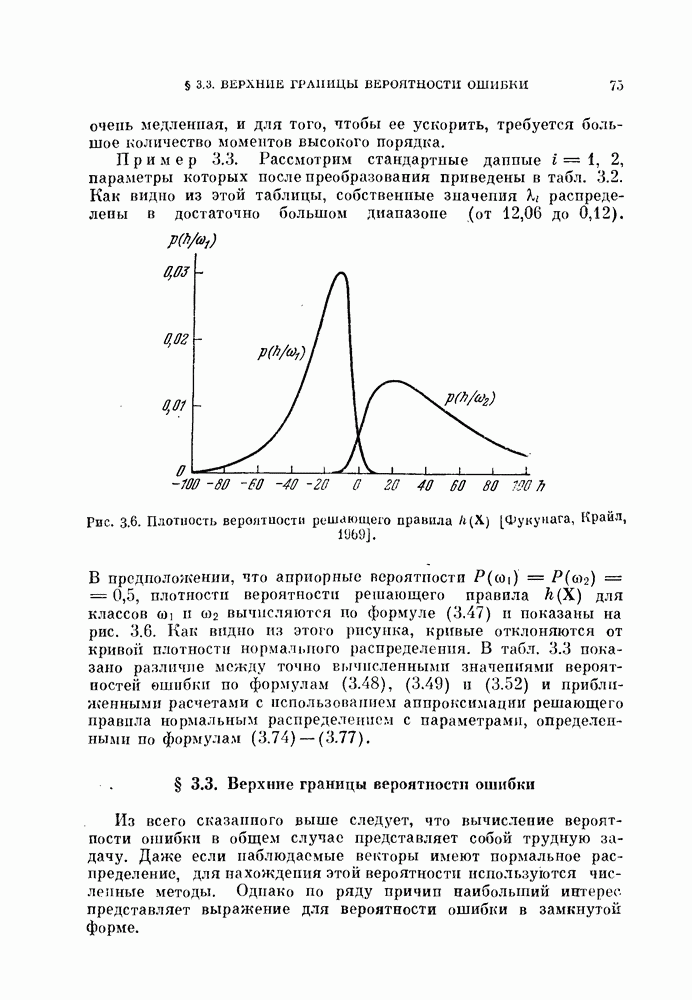
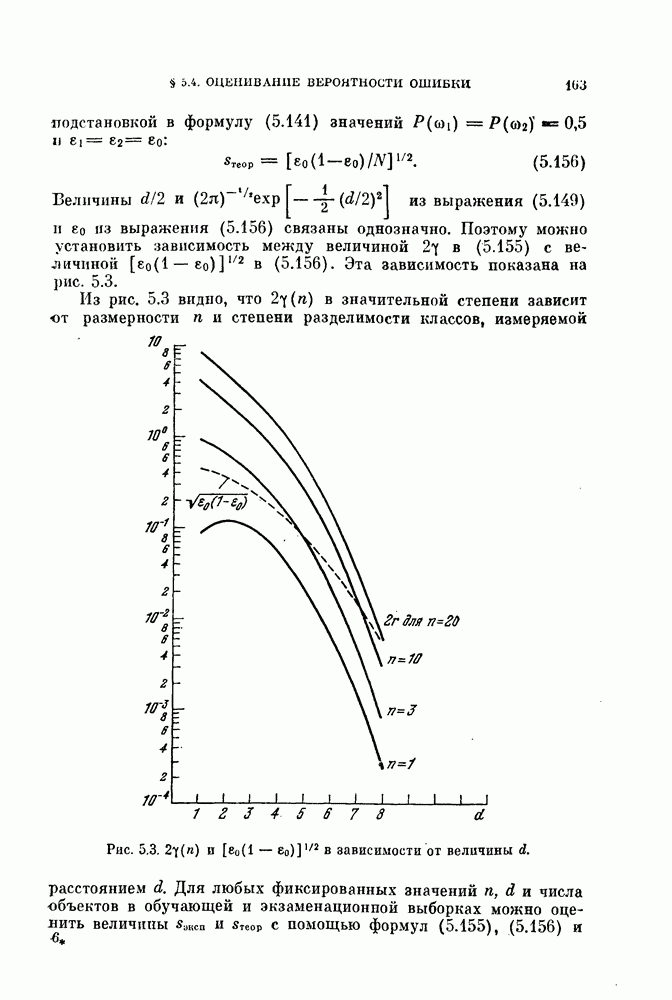
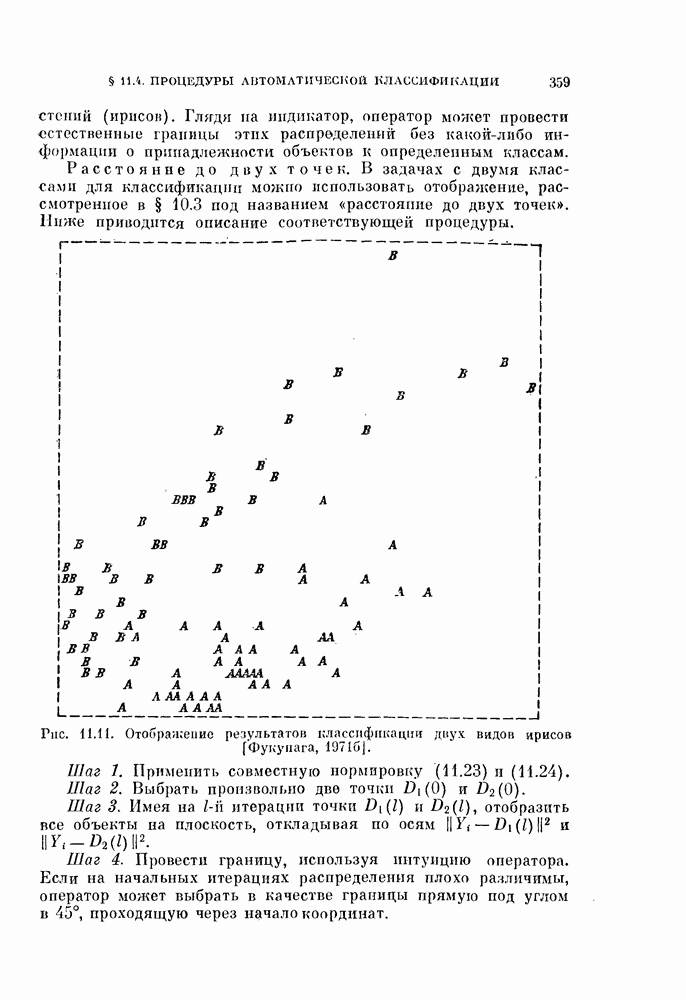
Совместная нормировка применялась ко всем данным. Рис. 11.5 и 11.6 показывают, что классификация получается приемлемой.
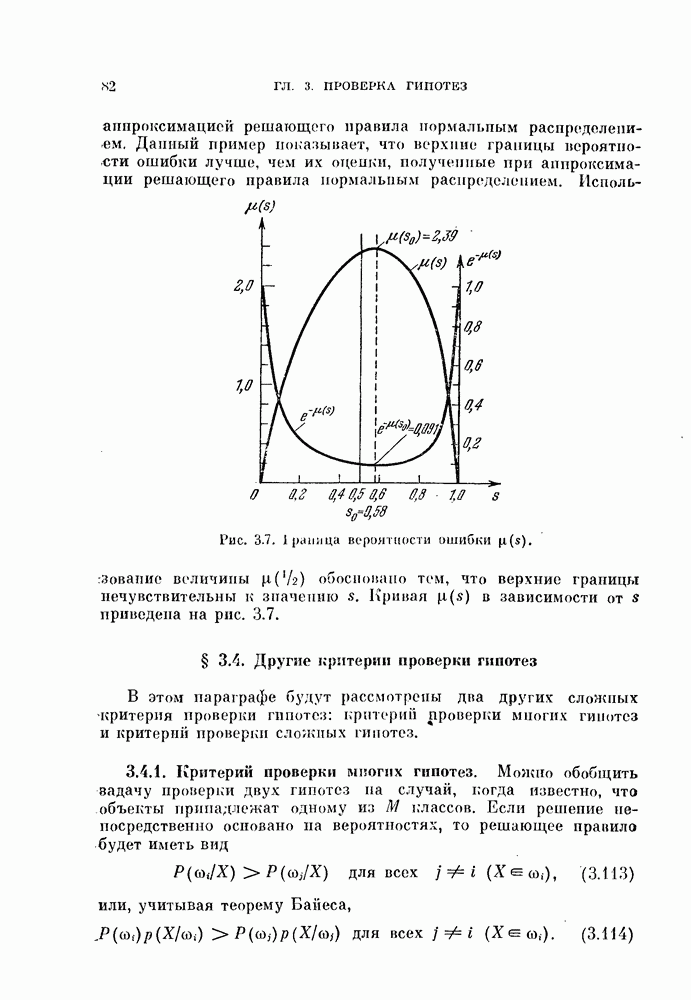
Процедура довольно чувствительна к величине свободного параметра  Если
Если  слишком велико, появляется тенденция к объединению всех векторов в один класс. С другой стороны, если
слишком велико, появляется тенденция к объединению всех векторов в один класс. С другой стороны, если  слишком мало, то из-за наличня «пробелов» в распределениях образуется много устойчивых границ.
слишком мало, то из-за наличня «пробелов» в распределениях образуется много устойчивых границ.
Для данного  обозначим через
обозначим через  число пар точек, находящихся друг от друга на расстоянии, меньшем
число пар точек, находящихся друг от друга на расстоянии, меньшем  Тогда можно указать следующее эмпирическое правило выбора
Тогда можно указать следующее эмпирическое правило выбора  выбирать
выбирать  таким, чтобы
таким, чтобы  Это правило гарантирует, что объем памяти, требуемой для реализации описанной процедуры, будет находиться в разумных пределах и лишь линейно расти с ростом
Это правило гарантирует, что объем памяти, требуемой для реализации описанной процедуры, будет находиться в разумных пределах и лишь линейно расти с ростом