Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
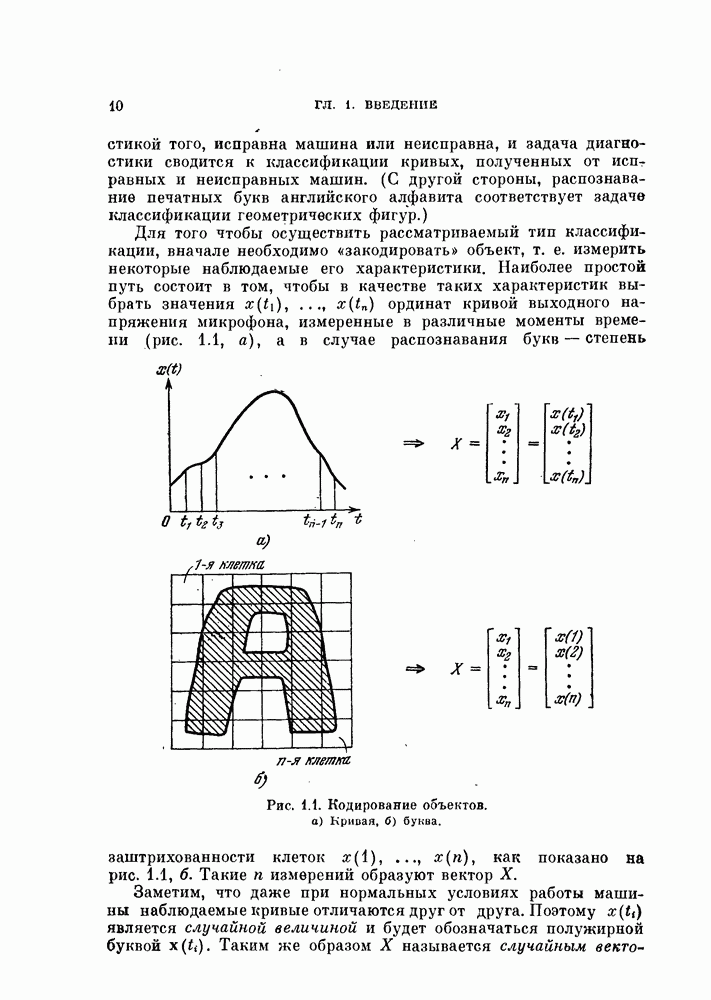
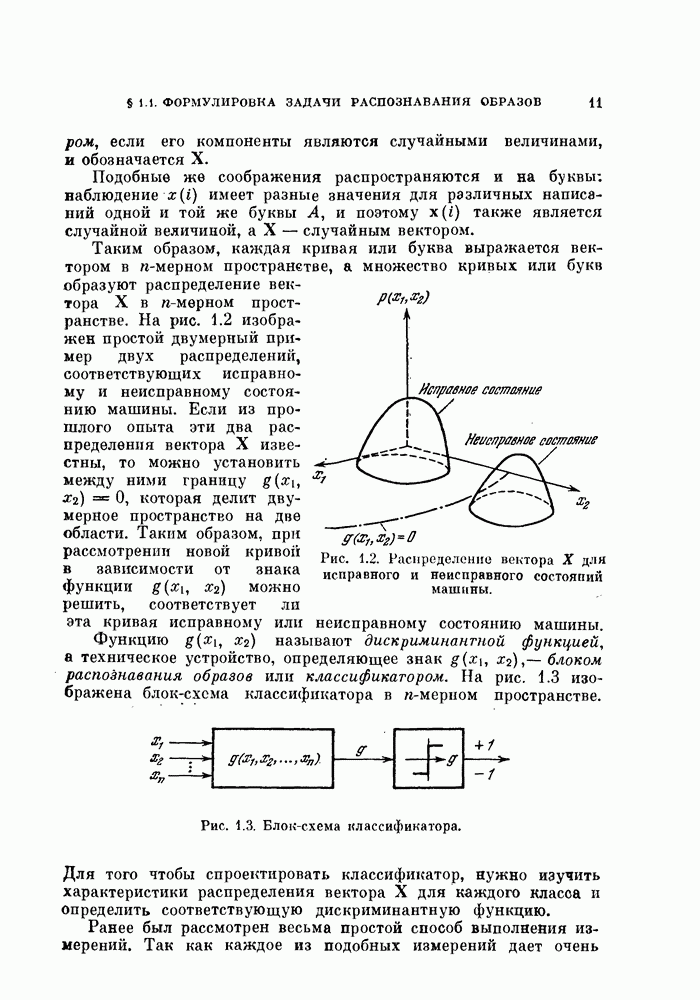
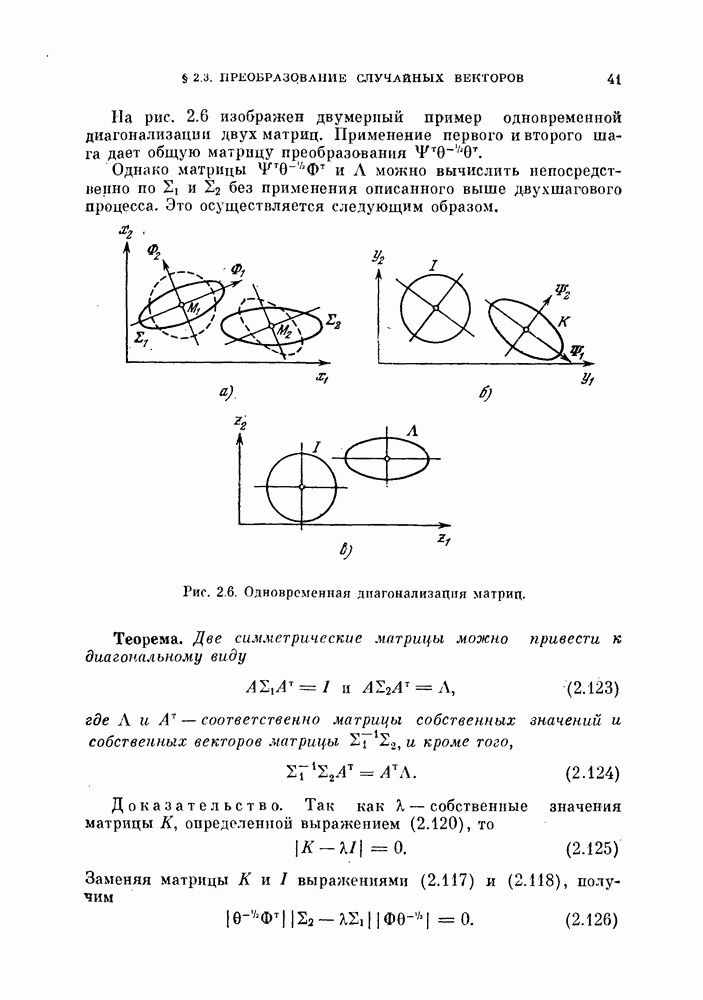
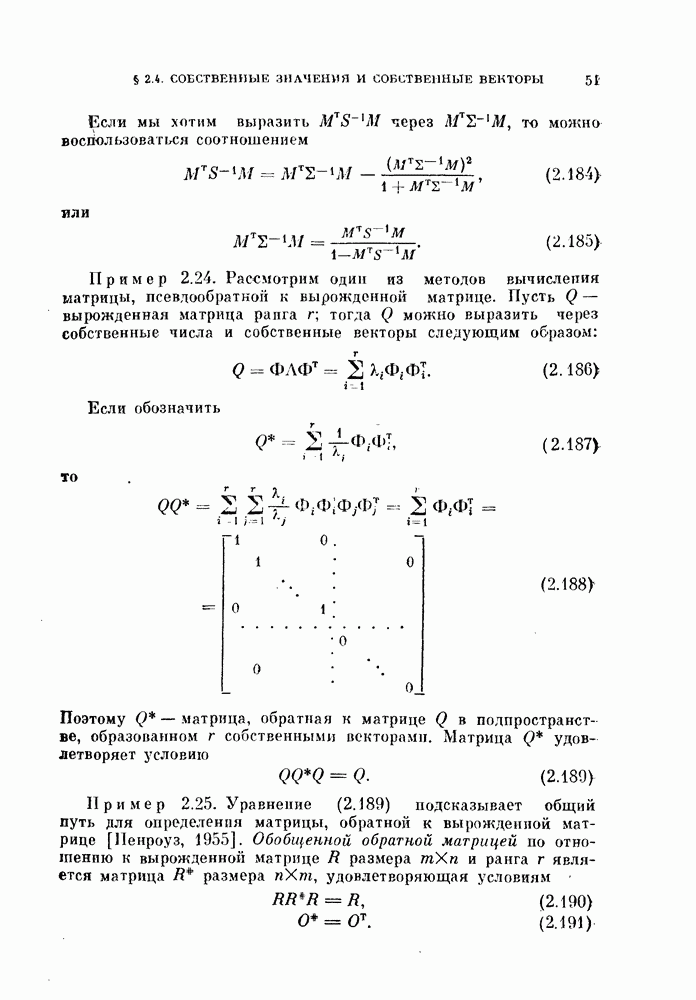
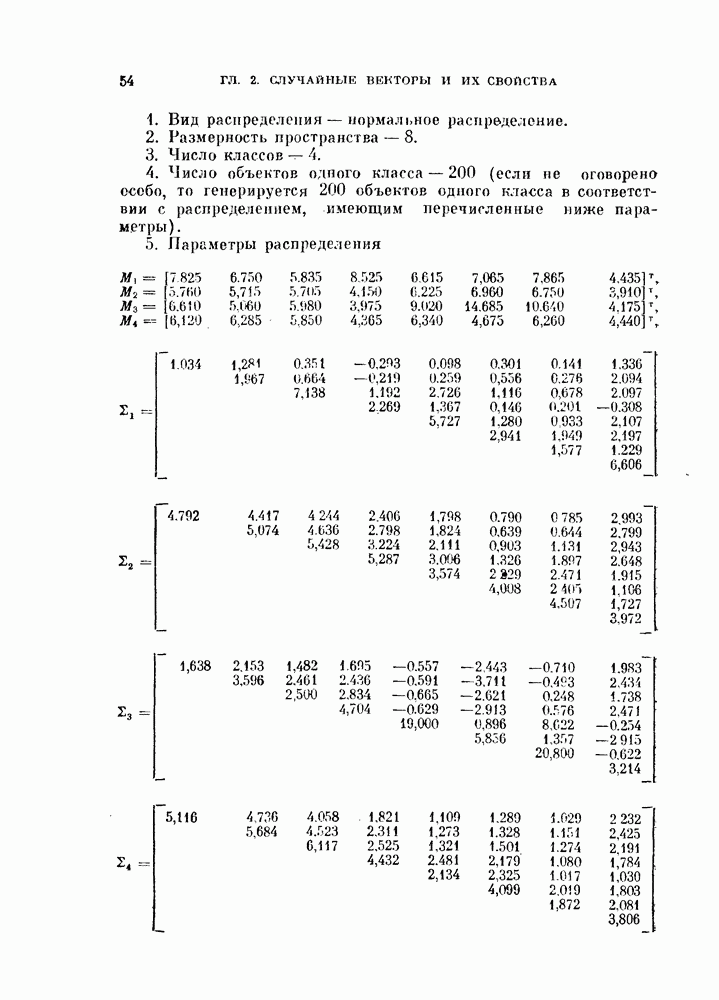
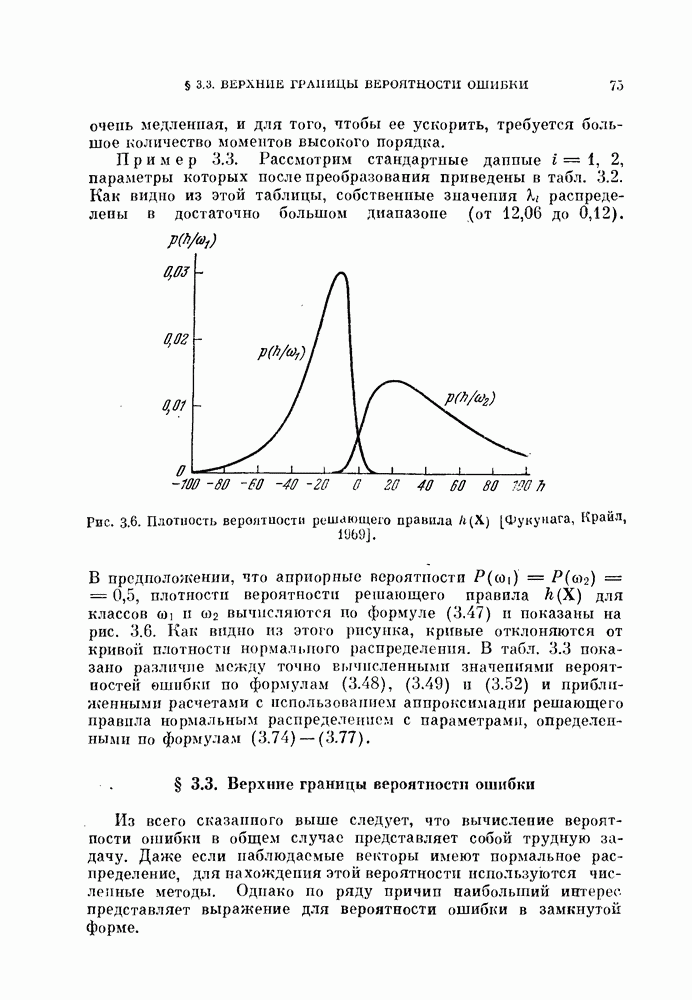
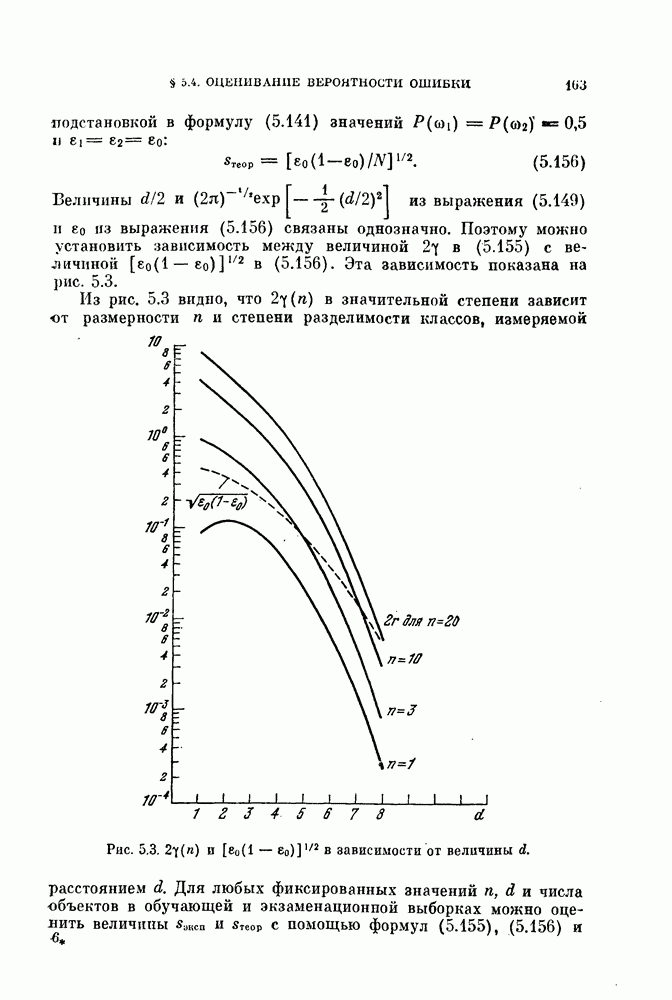
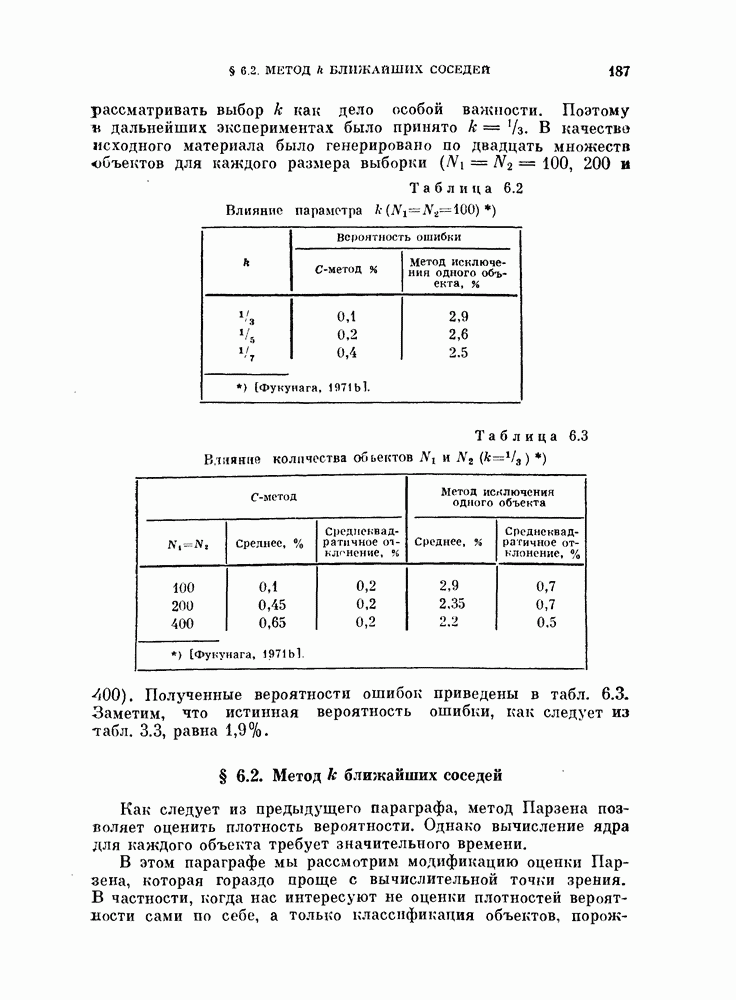
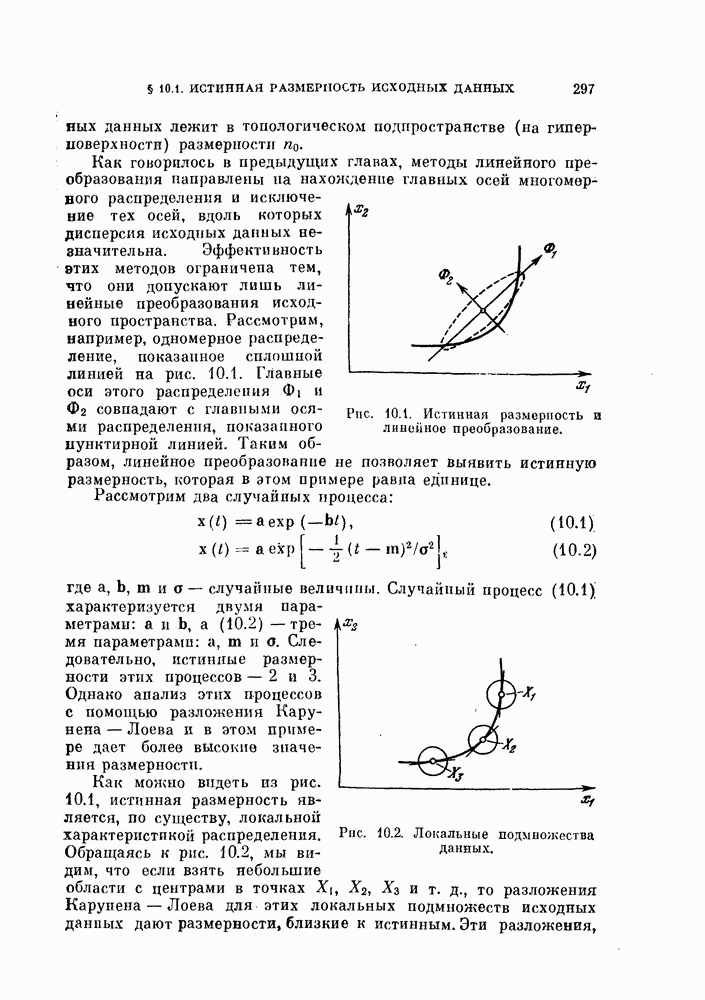
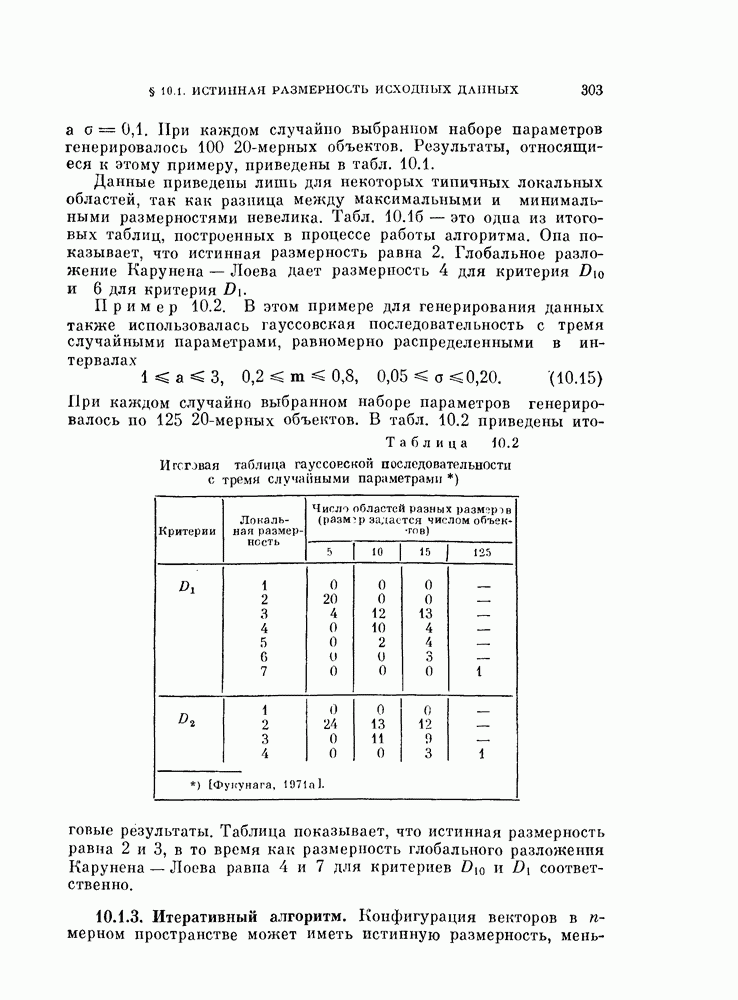
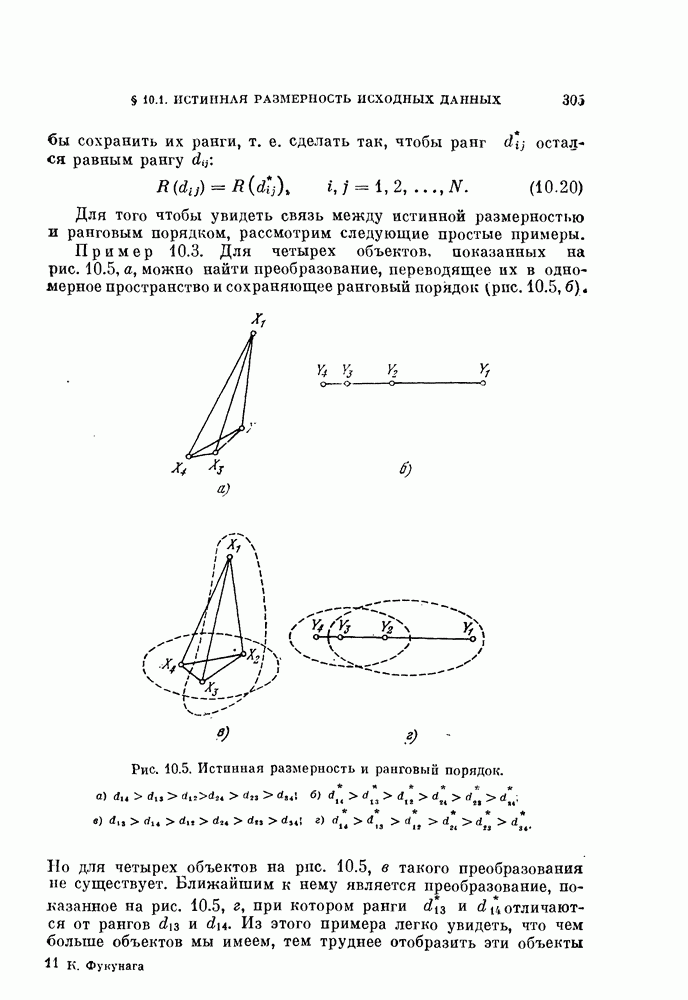
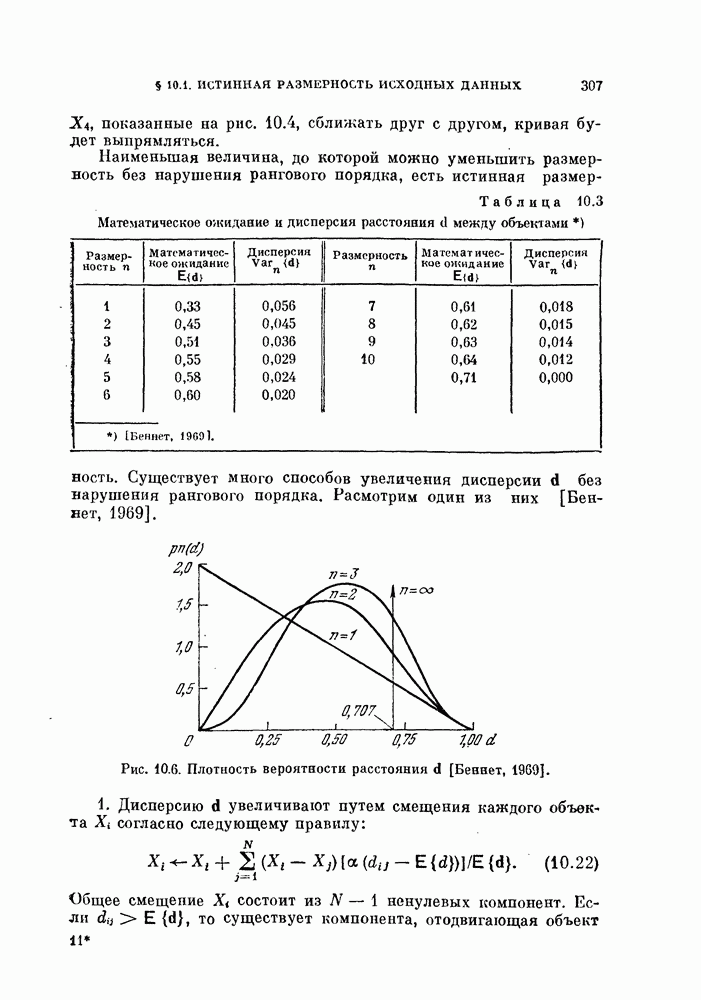
Глава 10. НЕЛИНЕЙНОЕ ПРЕОБРАЗОВАНИЕ ИСХОДНОГО ПРОСТРАНСТВАДо сих пор при обсуждении вопроса о нахождении оптимальных признаков данного множества исходных данных рассматривались только линейные преобразования исходного пространства. К сожалению, линейное преобразование, как правило, не позволяет выделить минимальное число эффективных признаков. Несмотря на это, математические вопросы нелинейных отображений остаются неисследованными вследствие их сложности, и на практике эффективные признаки находят, в основном, за счет интуиции исследователя. Трудности решения нелнпейных задач являются общими для всех технических дисциплин. Однако в задачах распознавания образов из-за большого числа переменных эти трудности особенно велики. В этой главе будут рассмотрены некоторые методы нелинейного преобразования исходного пространства, связанные с нахождением истинной размерности множества исходных данных, улучшением разделимости классов и двумерным отображением исходных данных без потери разделимости. § 10.1. Истинная размерность исходных данных10.1.1. Локальные свойства распределения.Всякий раз, когда мы имеем дело с большими множествами многомерных дапных, задача их обработки упрощается, если удается обнаружить или павязать этим данным некоторую структуру. Поэтому можно предположить, что исходные данные подчиняются закону, который характеризуется определенным числом основных параметров. Минимальное число параметров данных лежит в топологическом подпространстве (на гиперповерхности) размерности Как говорилось в предыдущих главах, методы линейного преобразования направлены на нахождение главных осей многомерного распределения и исключение тех осей, вдоль которых дисперсия исходных данных незначительна. Эффективность этих методов ограничена тем, что они допускают лишь линейные преобразования исходного пространства. Рассмотрим, например, одномерное распределение, показанное сплошной линией на рис. 10.1. Главные оси этого распределения Рассмотрим два случайных процесса:
где
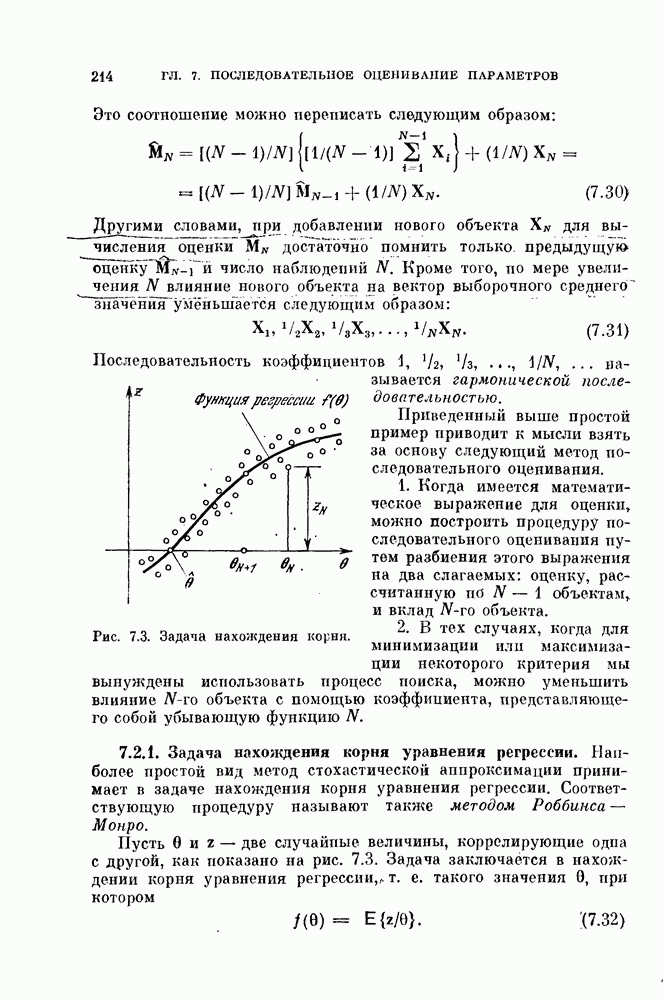
Рис. 10.1. Истинная размерность и линейное преобразование.
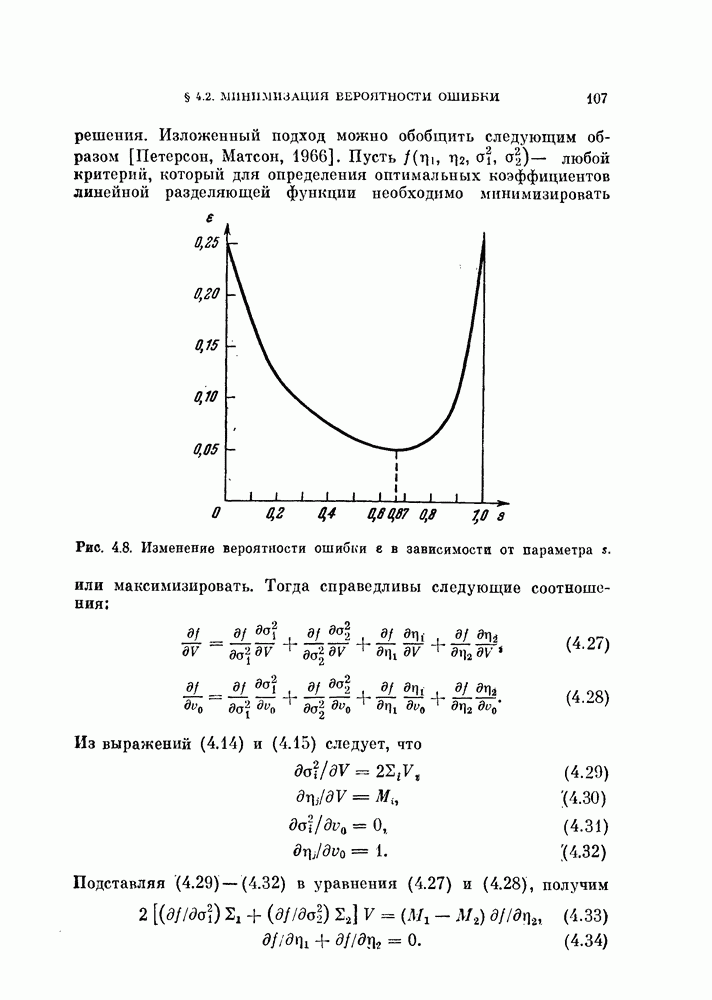
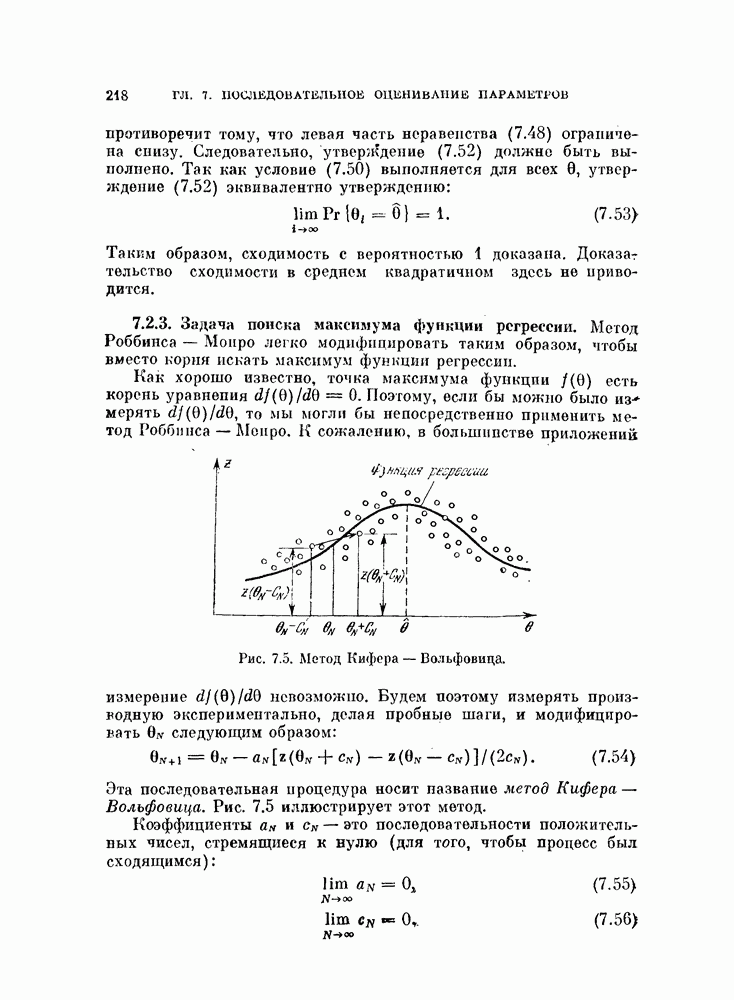
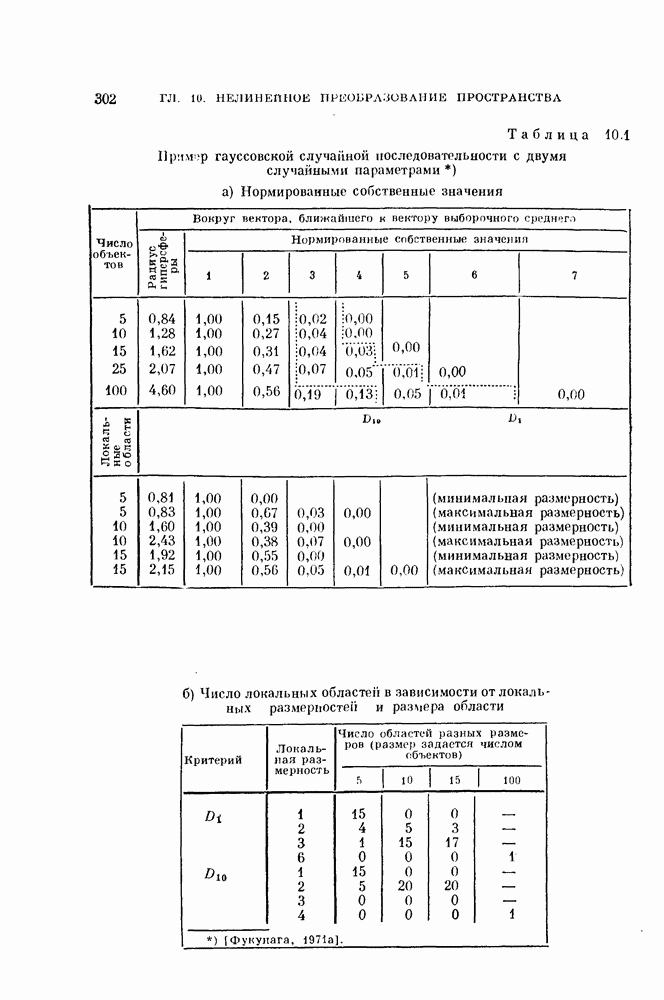
Рис. 10.2. Локальные подмножества данных. Случайный процесс Однако анализ этих процессов с помощью разложения Карунена — Лоева и в этом примере дает более высокие значения размерности. Как можно видеть из рис. 10.1, истинная размерность является, по существу, локальной характеристикой распределения. Обращаясь к рис. 10.2, мы видим, что если взять небольшие области с центрами в точках кроме того, дают базисные векторы для локальных распределений. Этот метод аналогичен методу локальной линеаризации нелинейных функций. Универсальное средство исследования локальных свойств — разложение в ряд Тейлора является общим средством. Для того чтобы применить это разложение, введем истинные случайные величины
где по — истинная размерность. Тогда наблюдаемый случайный вектор X, размерпость которого
В случае случайного процесса эта зависимость записывается в виде
Например, для
где
и
Таким образом, 1. Так как разложение (10.6) является приближенным, фактическая ковариационная матрица наблюдаемых данных 2. К сожалению, базисные векторы
где
Так как 3. Вообще говоря, нет гарантии, что в ряде Тейлора (10.6) доминируют члены первого порядка. Если минимальный размер локальной области ограничен по каким-либо техническим соображениям, доминирующими могут оказаться некоторые члены более высокого порядка или, другими словами, некоторые члены более низкого порядка могут быть малозначимыми. Поэтому упомянутая выше процедура эквивалентна подсчету числа значимых членов в ряде Тейлора, которое, как мы надеемся, близко к 4. На всех реальных ситуациях исходные данные искажены шумом. Поучительно рассмотреть влияние аддитивного белого шума. Так как белый шум имеет нулевое среднее значение, некоррелирован с сигналом
Буквой
Следовательно, если свободные от шума исходные данные имеют по доминирующих собственных значений и являются доминирующими, означает, что эта разность значительна, и может быть использовано для выбора
|
 |
Оглавление
|






















































































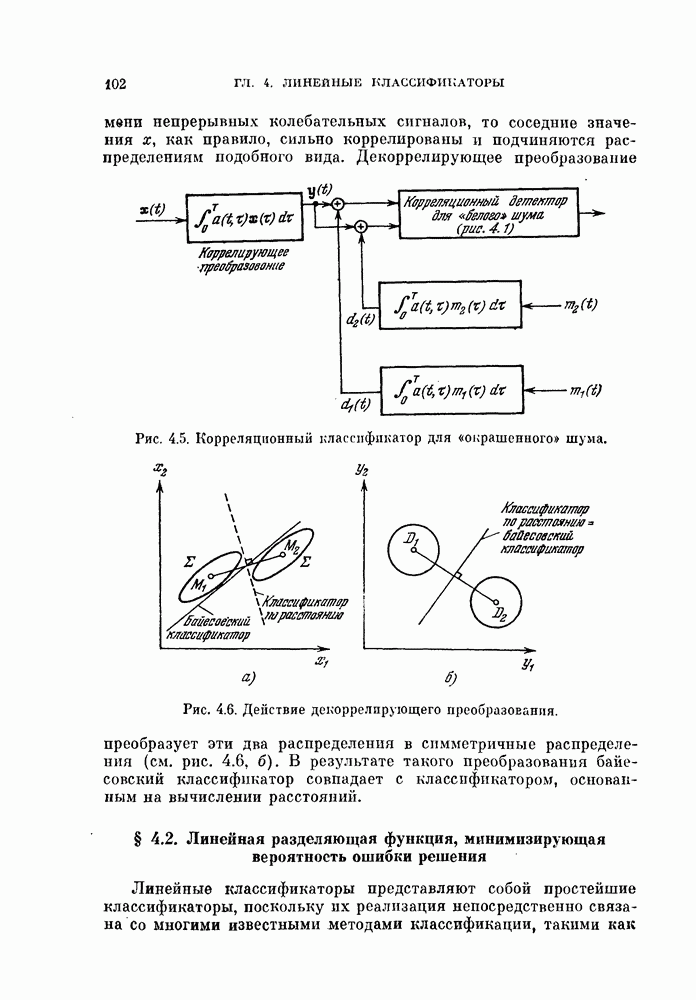































































































































































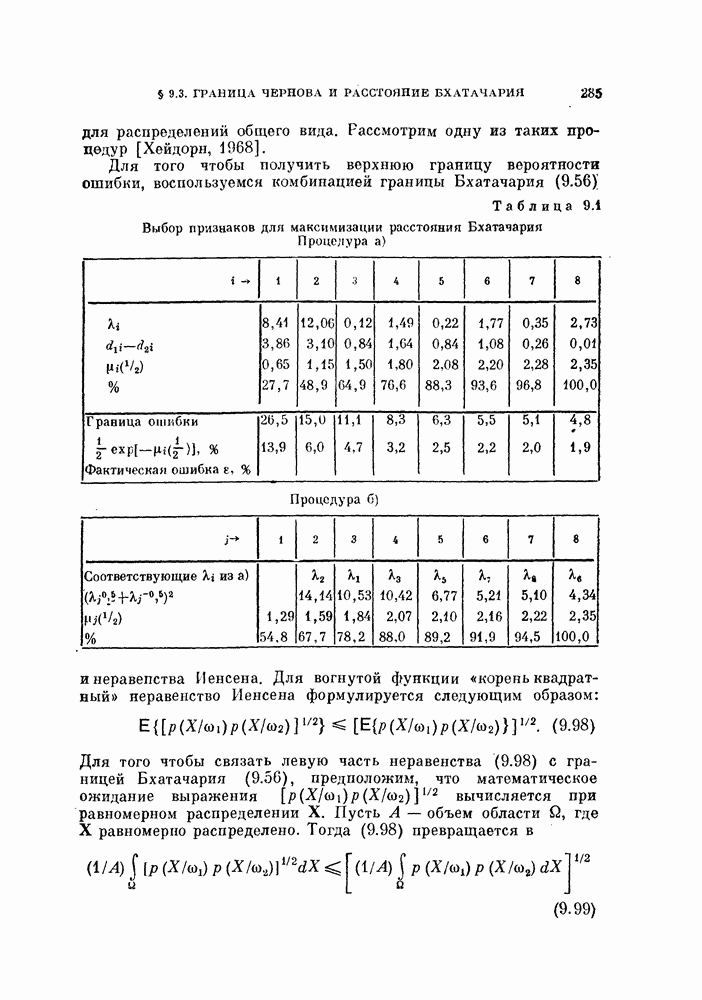






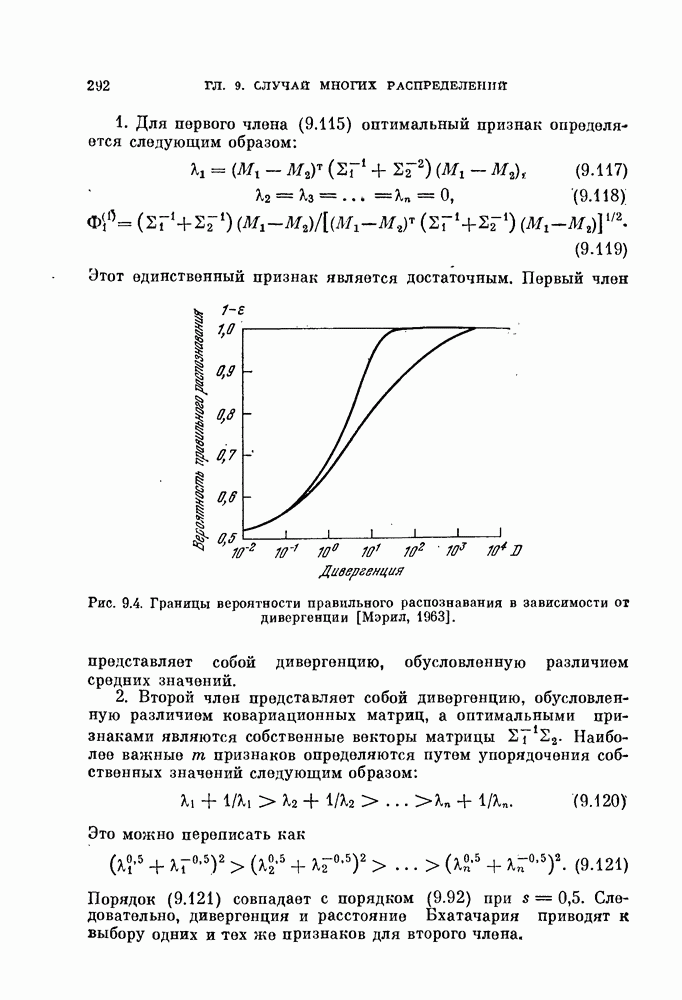
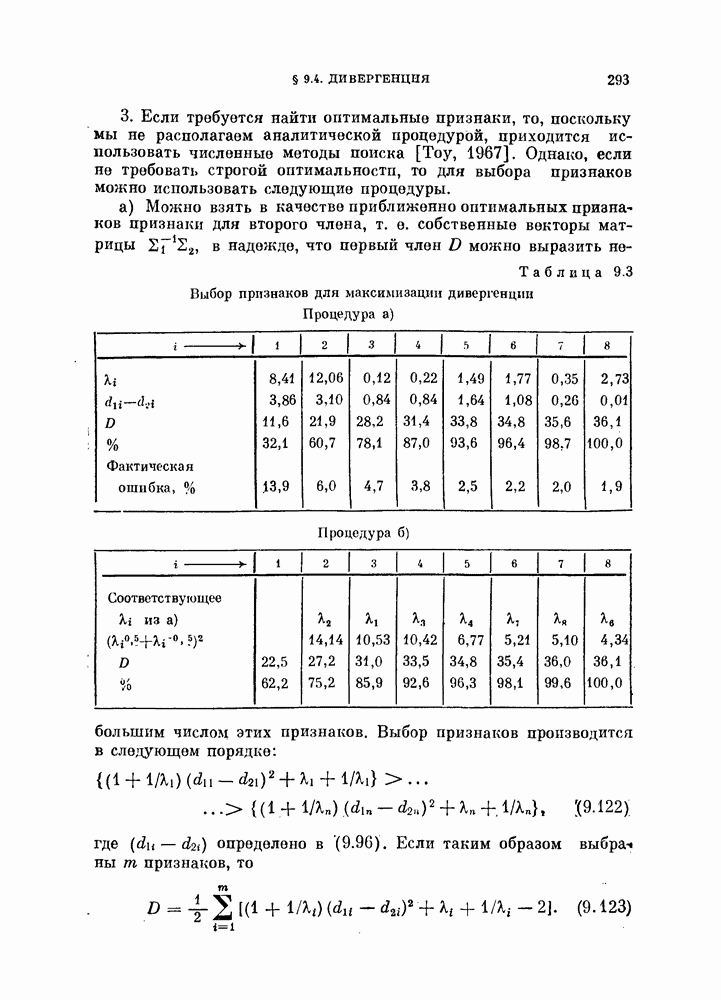





















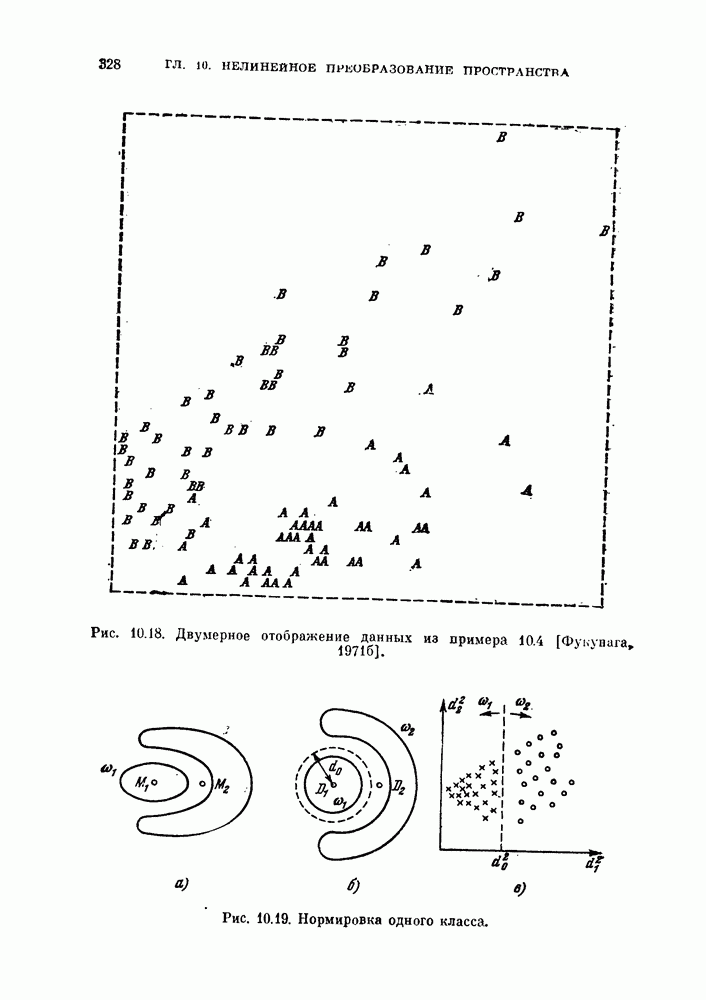




























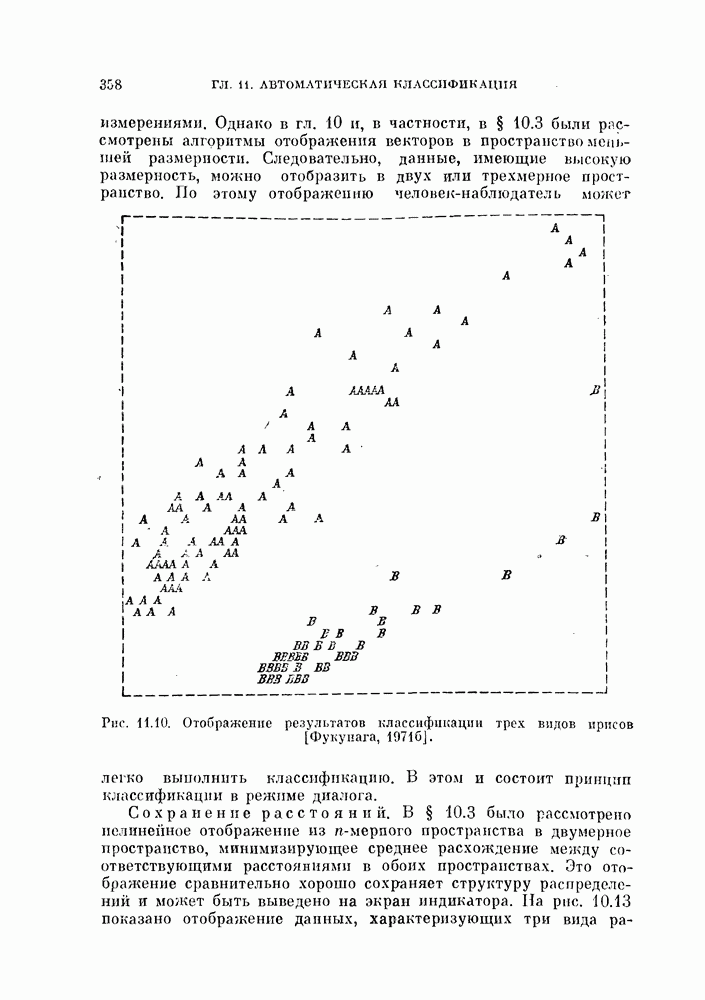
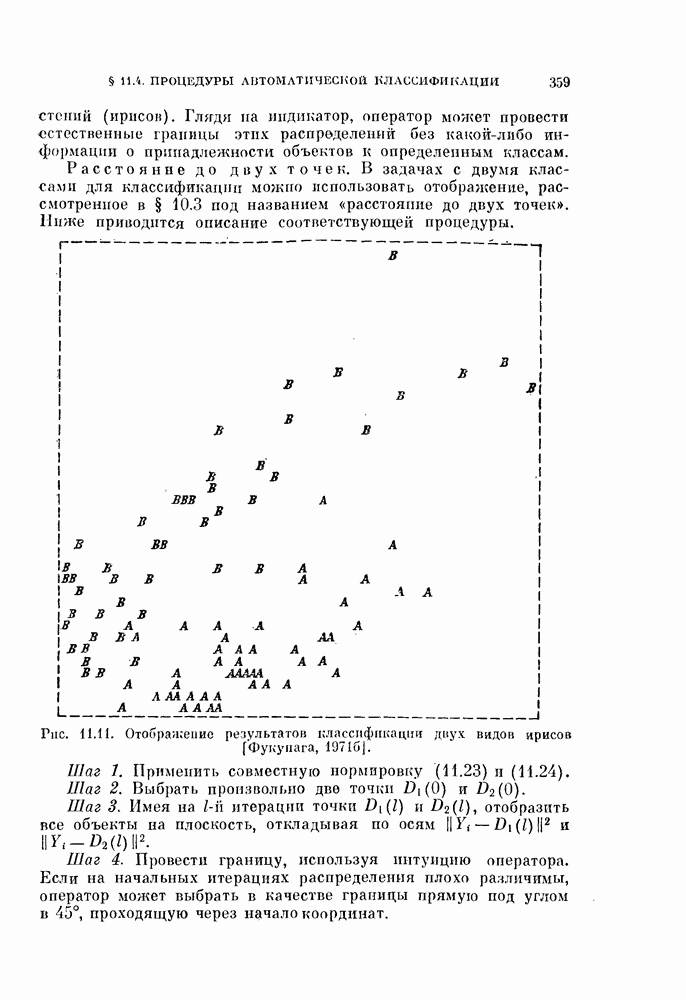








 , которые необходимо принять в расчет для объяснения наблюдаемых свойств исходных данных, называют истинной размерностью множества исходных данных или, что то же самое, истинной размерностью процесса, порождающего исходные данные. Геометрическая интерпретация этого определения заключается в том, что все множество исходных
, которые необходимо принять в расчет для объяснения наблюдаемых свойств исходных данных, называют истинной размерностью множества исходных данных или, что то же самое, истинной размерностью процесса, порождающего исходные данные. Геометрическая интерпретация этого определения заключается в том, что все множество исходных

 совпадают с главными осями распределения, показанного нунктирнох! линией. Таким образом, линейное преобразование не позволяет выявить истинную размерность, которая в этом примере равна единице.
совпадают с главными осями распределения, показанного нунктирнох! линией. Таким образом, линейное преобразование не позволяет выявить истинную размерность, которая в этом примере равна единице.

 - случайные величины.
- случайные величины.


 характеризуется двумя параметрами: а и b, а
характеризуется двумя параметрами: а и b, а  — тремя параметрами:
— тремя параметрами:  . Следовательно, истинные размерности этих процессов — 2 и 3.
. Следовательно, истинные размерности этих процессов — 2 и 3.
 то разложения Карунена — Лоева для этих локальных подмножеств исходных данных дают размерности, близкие к истинным. Эти разложения,
то разложения Карунена — Лоева для этих локальных подмножеств исходных данных дают размерности, близкие к истинным. Эти разложения,

 больше истинной размерности
больше истинной размерности  является нелинейной функцией
является нелинейной функцией 


 . В пределах малой окрестности
. В пределах малой окрестности  вектор X можно представить усеченным рядом Тейлора:
вектор X можно представить усеченным рядом Тейлора:



 можно аппроксимировать линейным разложением по содержащим
можно аппроксимировать линейным разложением по содержащим  членов. То обстоятельство, что
членов. То обстоятельство, что  выражается через
выражается через  или меньшее число линейно независимых векторов, приводит к выводу, что ковариационная матрица
или меньшее число линейно независимых векторов, приводит к выводу, что ковариационная матрица  имеет ранг (или число ненулевых собственных значений) равный или меньший, чем
имеет ранг (или число ненулевых собственных значений) равный или меньший, чем  . В этом месте необходимо сделать следующие замечания.
. В этом месте необходимо сделать следующие замечания.
 имеет ранг
имеет ранг  , а не
, а не  . Но
. Но  или меньшее число собственных значений доминируют в области, где справедливо (10.6).
или меньшее число собственных значений доминируют в области, где справедливо (10.6).
 не являются взаимно ортогональными, а
не являются взаимно ортогональными, а  — некоррелированными. Это означает, что если базисные векторы ищутся по наблюдаемым данным
— некоррелированными. Это означает, что если базисные векторы ищутся по наблюдаемым данным  с помощью разложения Корунена — Лоева, то при этом будет получено другое разложение
с помощью разложения Корунена — Лоева, то при этом будет получено другое разложение


 и
и  — собственные векторы и собственные значения ковариационной матрицы
— собственные векторы и собственные значения ковариационной матрицы  то
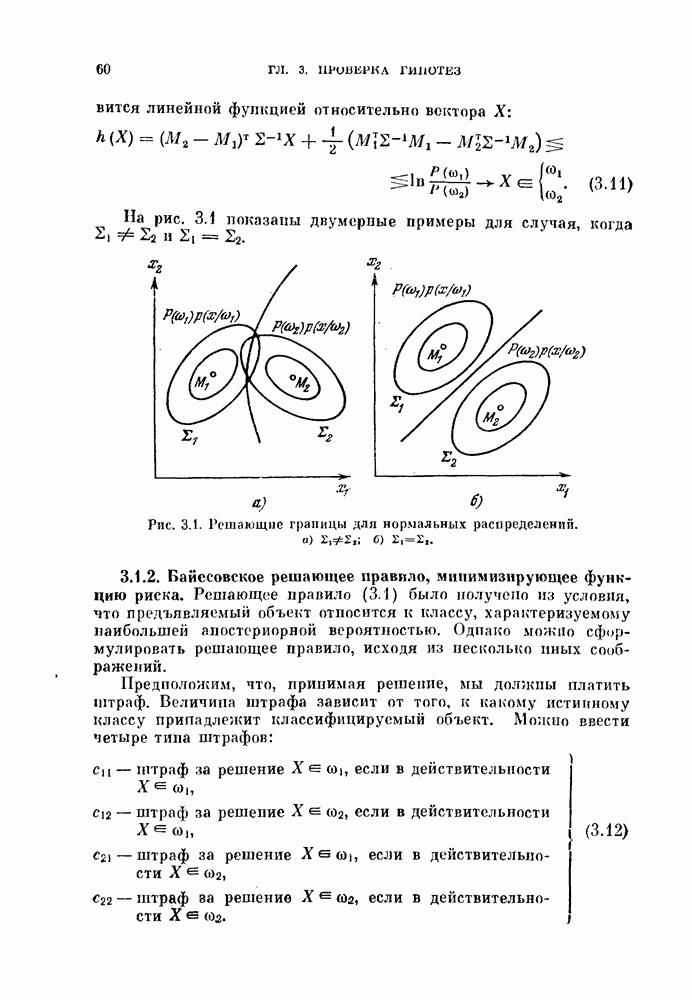
то  взаимно ортонормированы,
взаимно ортонормированы,  — нехшррелированы. Выражения (10.6) и
— нехшррелированы. Выражения (10.6) и  являются линейными выражениями относительно
являются линейными выражениями относительно  базисных векторов с
базисных векторов с  случайными коэффициентами. Поэтому
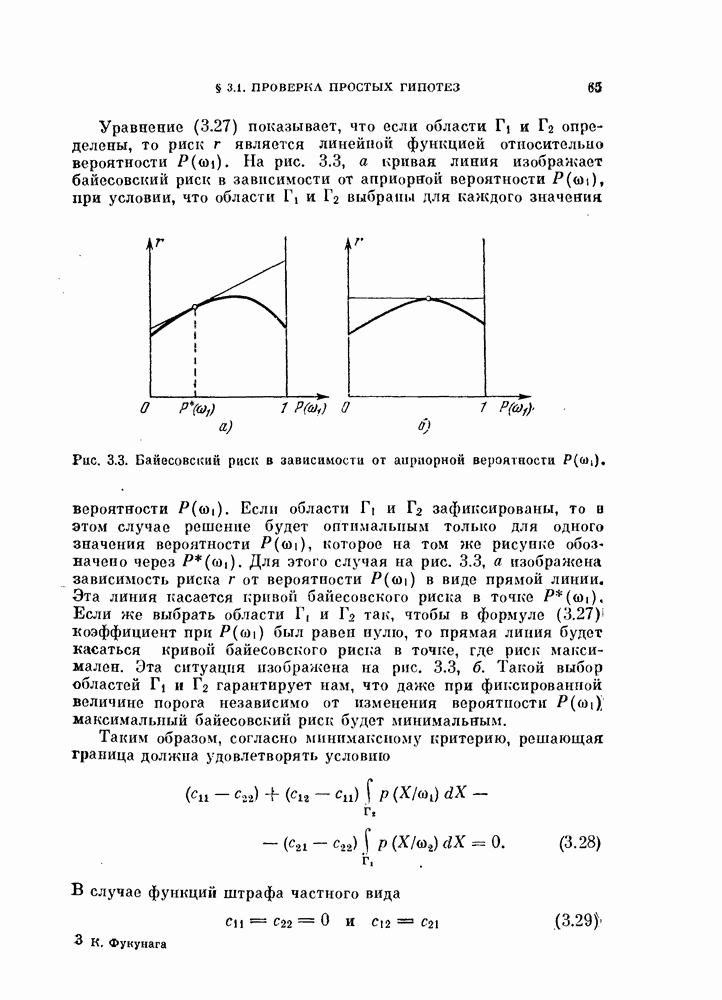
случайными коэффициентами. Поэтому  должны быть связаны с
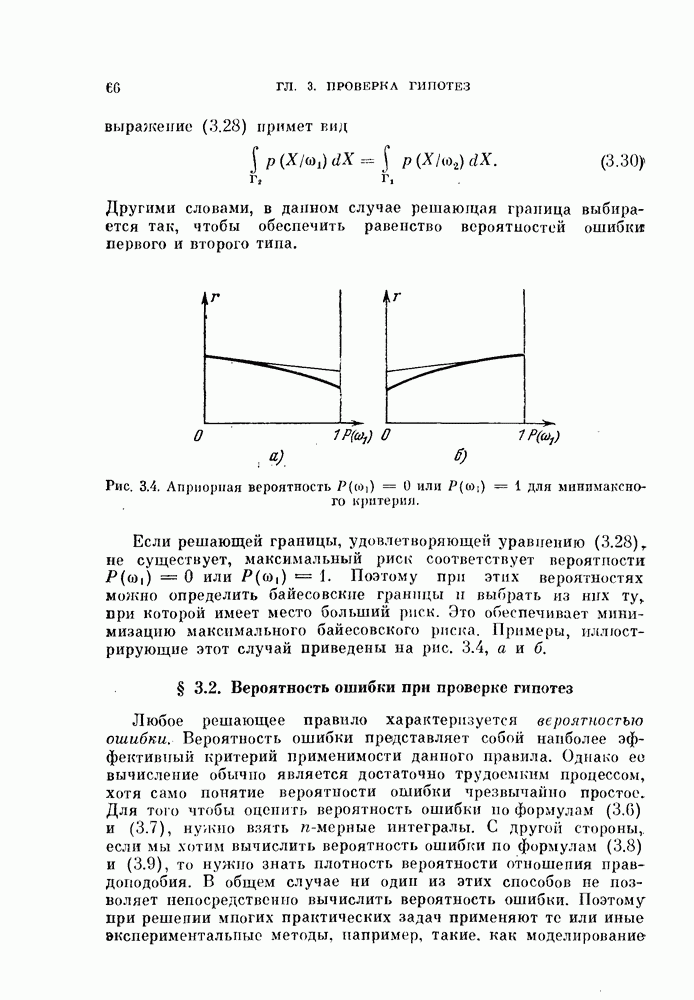
должны быть связаны с  линейным преобразованием, хотя матрица преобразования неизвестна. Если бы можно было найти эту матрицу, то мы могли бы вычислить по
линейным преобразованием, хотя матрица преобразования неизвестна. Если бы можно было найти эту матрицу, то мы могли бы вычислить по  Так как — это частные производные от
Так как — это частные производные от  вычисленные значения
вычисленные значения  можно использовать для оценки вида функции
можно использовать для оценки вида функции 
 Эта надежда, однако, подтверждается экспериментально, на примерах.
Эта надежда, однако, подтверждается экспериментально, на примерах.
 и имеет единичную ковариационную матрицу
и имеет единичную ковариационную матрицу  то ковариационная матрица
то ковариационная матрица  плюс шум равна
плюс шум равна

 обозначен вектор шума со спектральной плотностью 4, а
обозначен вектор шума со спектральной плотностью 4, а  определено в (10.10). Собственные векторы матрицы
определено в (10.10). Собственные векторы матрицы  идентичны собственным векторам матрицы
идентичны собственным векторам матрицы  Собственные значения матрицы
Собственные значения матрицы  равны
равны

 несущественных, то зашумленные данные будут иметь такое же распределение собственных значений, каждое из которых лишь увеличивается на некоторую хшнстанту у. Это означает, что разность между собственными значениями с номерами
несущественных, то зашумленные данные будут иметь такое же распределение собственных значений, каждое из которых лишь увеличивается на некоторую хшнстанту у. Это означает, что разность между собственными значениями с номерами  не изменяется. Обнаружение факта, что
не изменяется. Обнаружение факта, что  собственных векторов
собственных векторов
 собственных значений
собственных значений  при наличии шума.
при наличии шума.