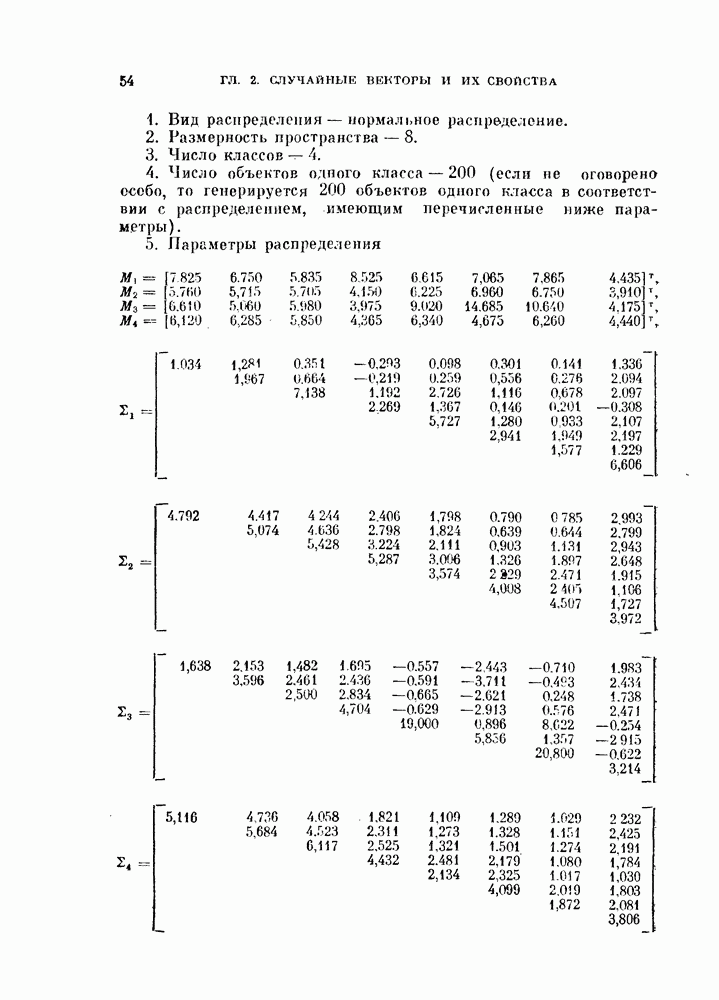
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
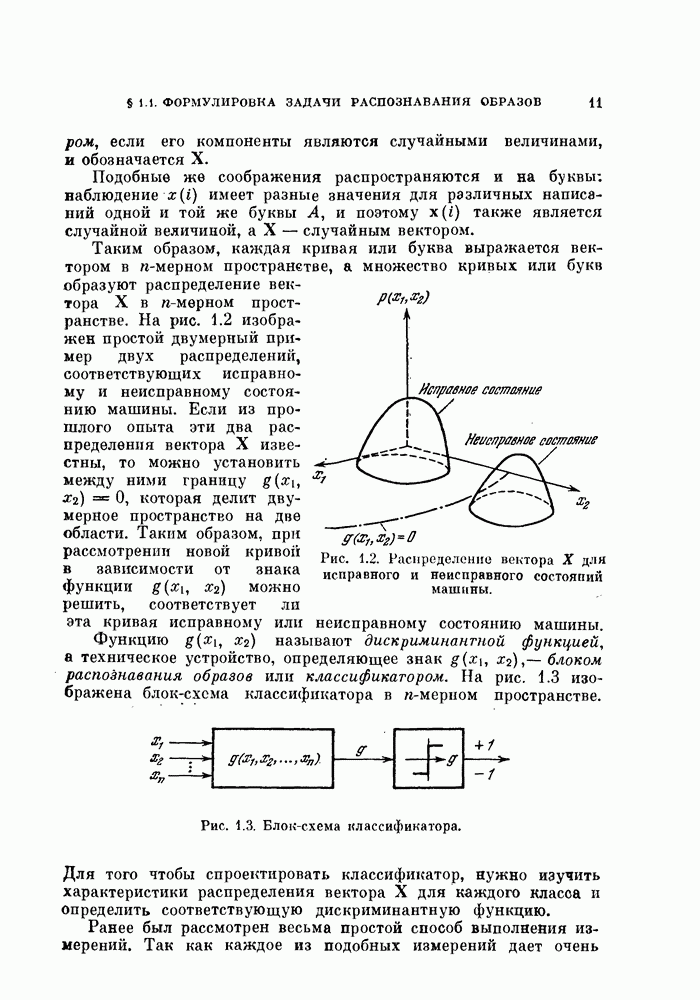
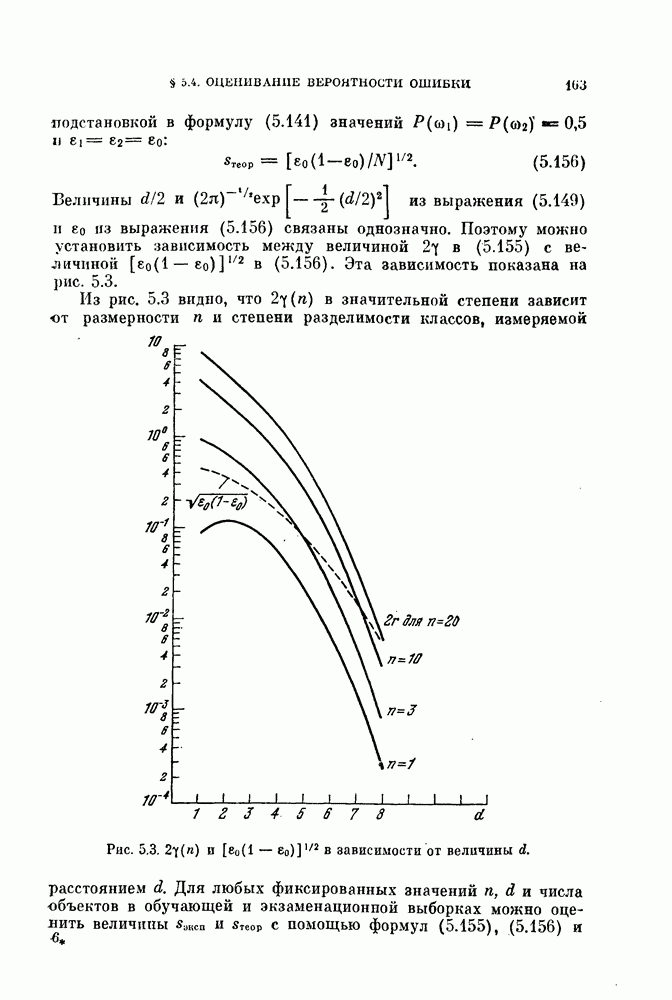
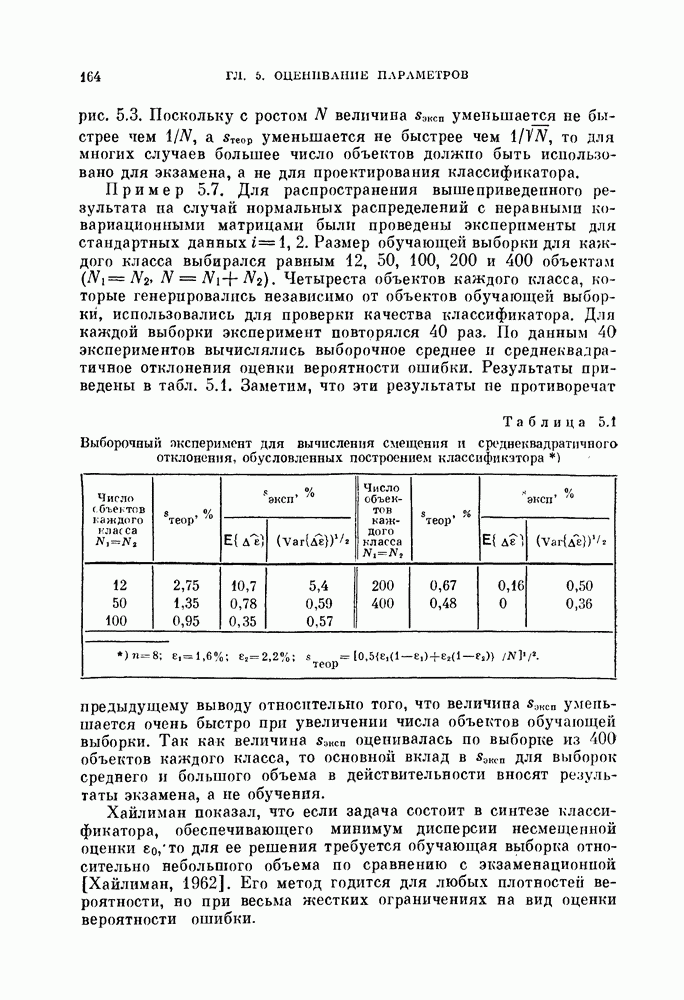
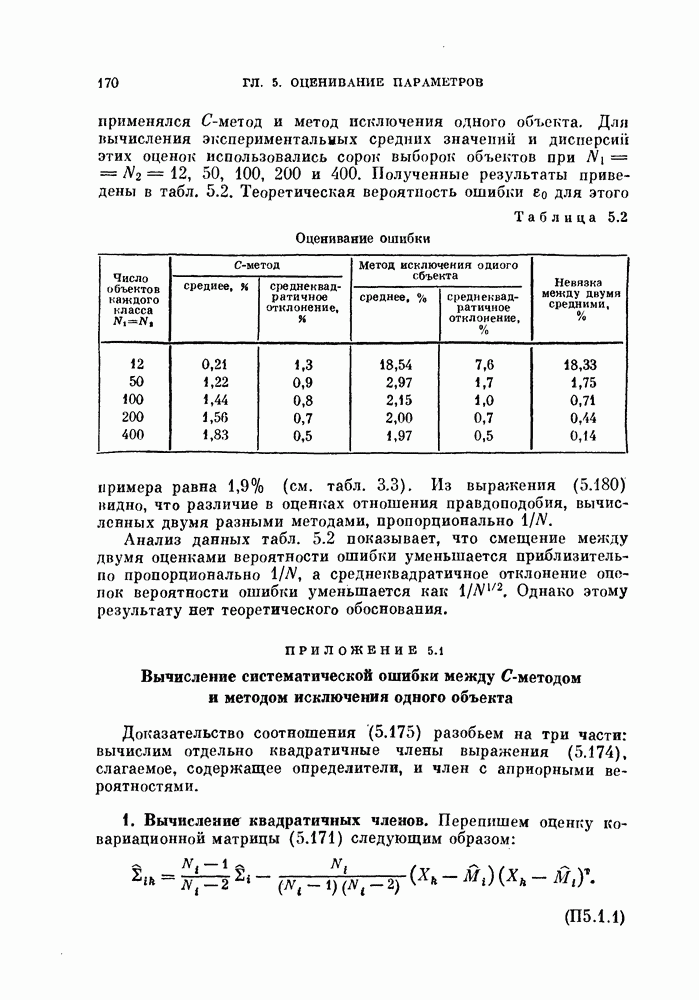
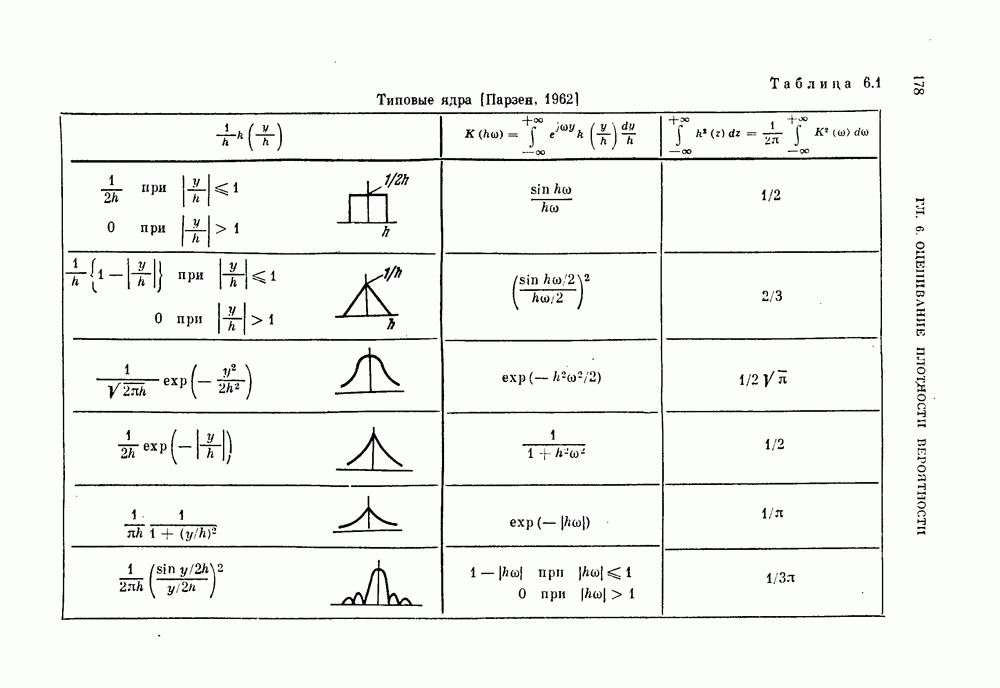
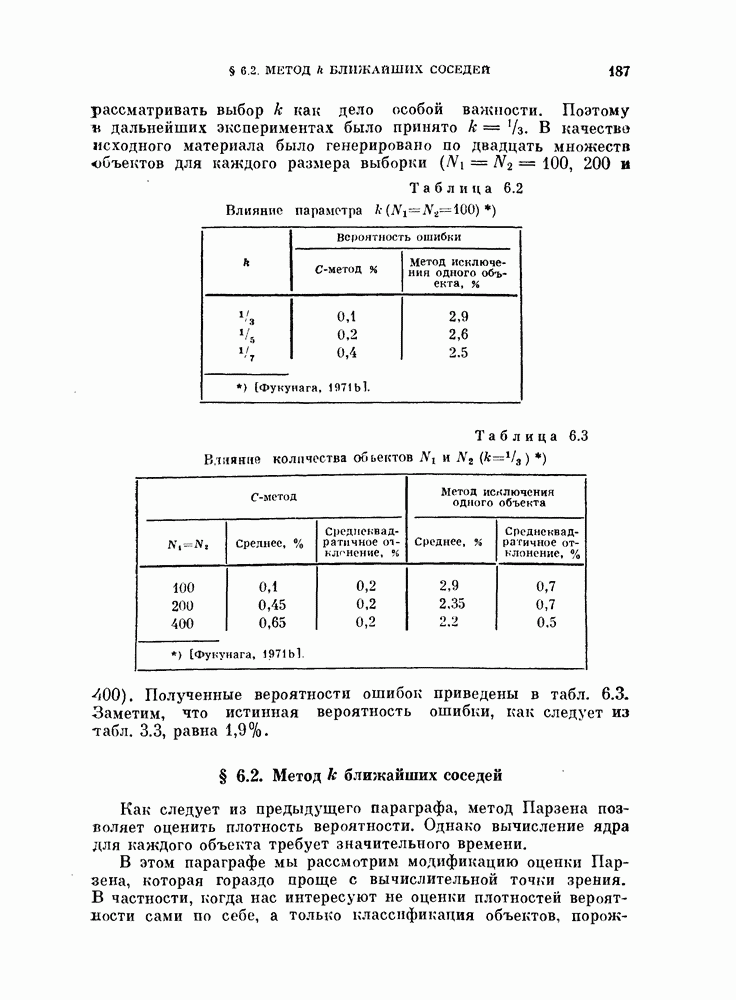
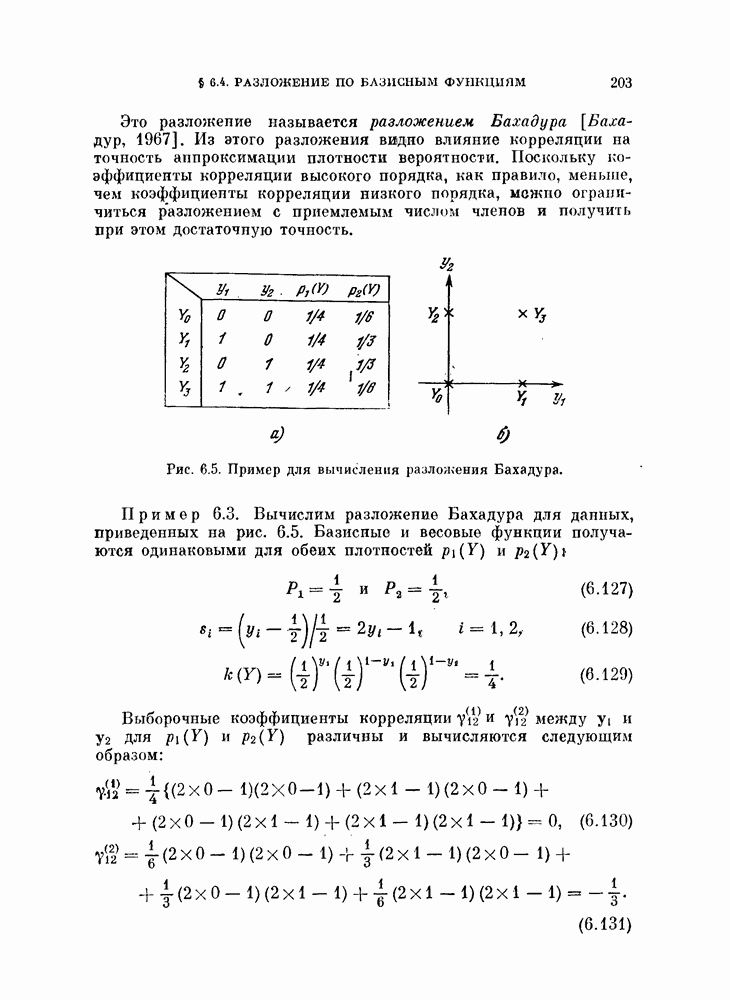
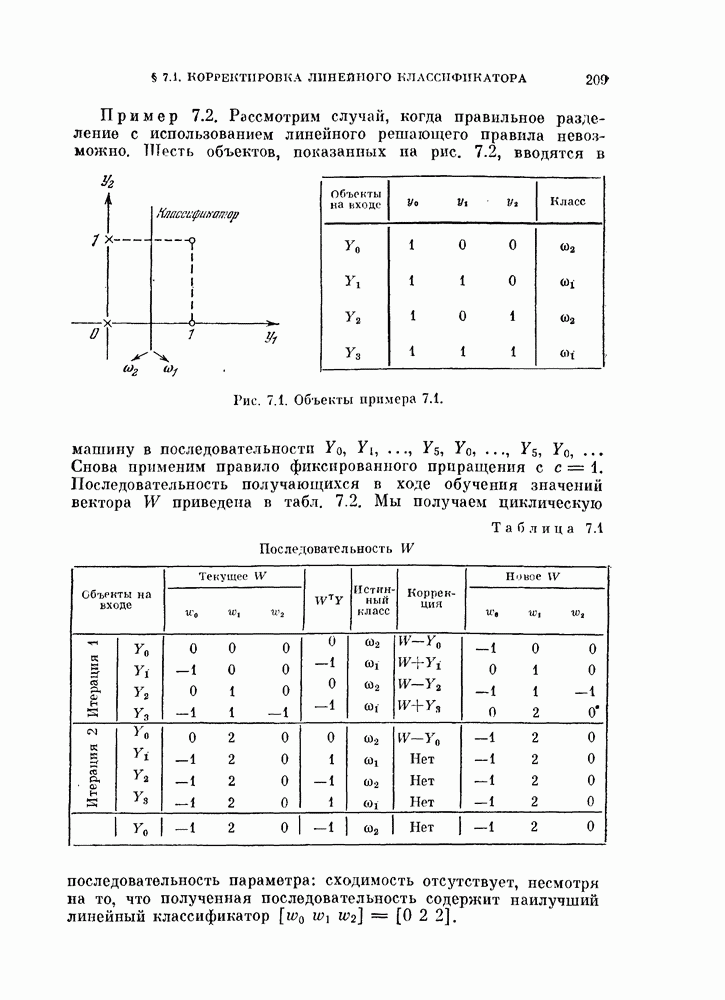
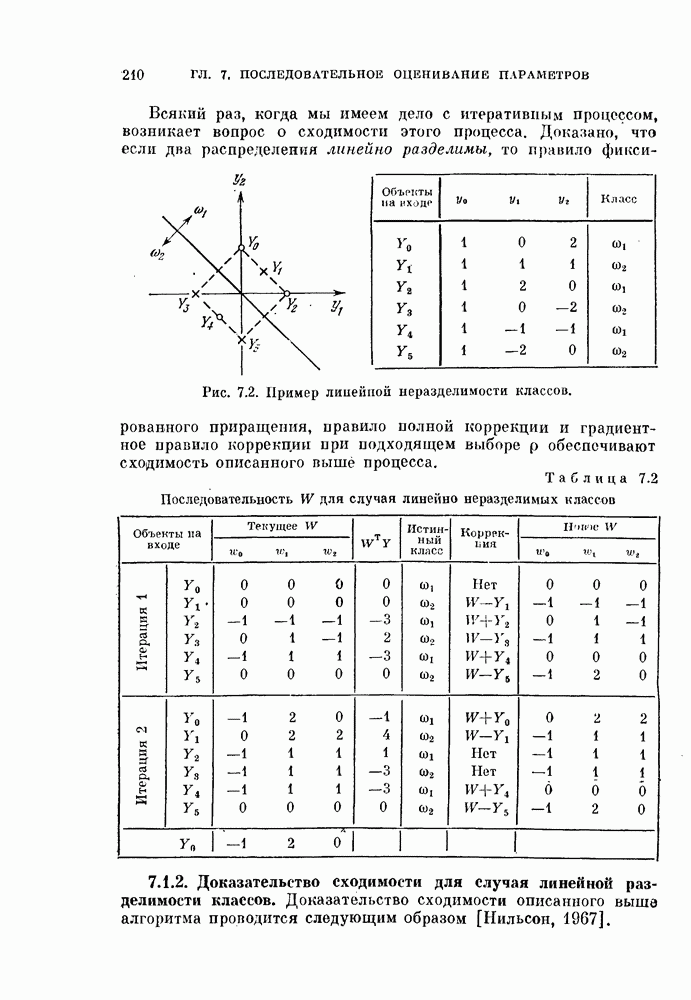
§ 5.4. Оценивание вероятности ошибки
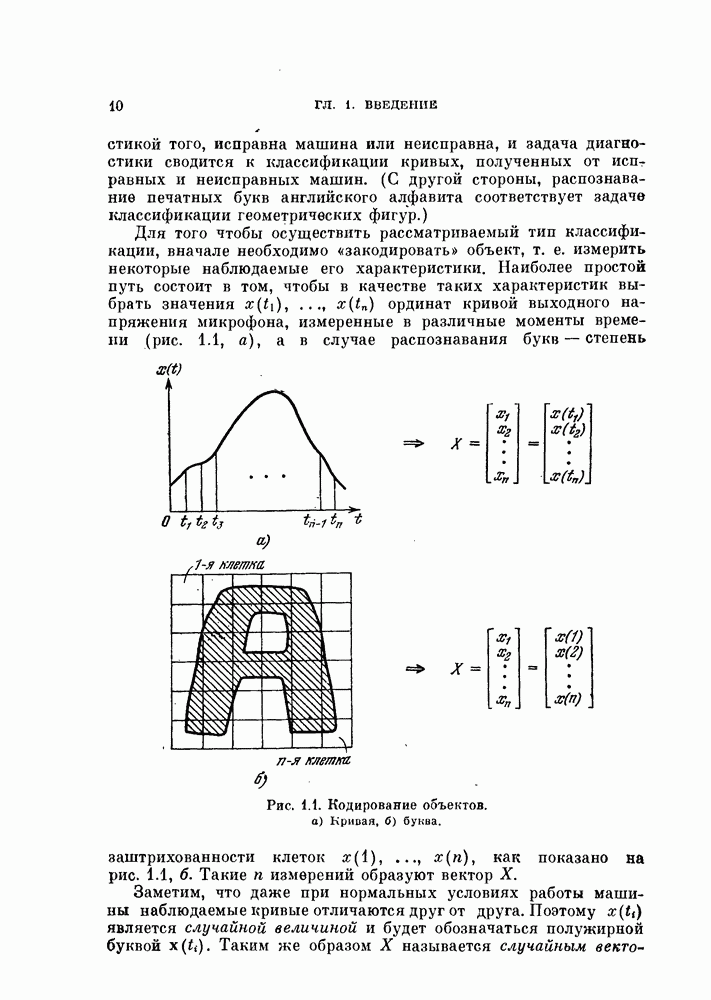
Вероятность ошибки является основным показателем качества распознавания образов, и поэтому ее оценивание представляет собой очень важную задачу. Как было показано в предыдущих главах, вероятность ошибки является сложной функцией, содержащей  -кратный интеграл от плотности вероятности при наличии сложной границы. Поэтому нет надежды получить общие методы ее вычисления из теоретических результатов. Необходимо обратиться к экспериментальным методам.
-кратный интеграл от плотности вероятности при наличии сложной границы. Поэтому нет надежды получить общие методы ее вычисления из теоретических результатов. Необходимо обратиться к экспериментальным методам.
При оценке вероятности ошибки рассматривают две задачи. Первая задача заключается в оценивании вероятности ошибки по имеющейся выборке в предположении, что задан классификатор. Эта задача является простой и будет рассмотрена в начале этого параграфа.
Вторая задача заключается в оценке вероятности ошибки при заданных распределениях. Для этой задачи вероятность ошибки зависит как от используемого классификатора, так и от вида распределений. Поэтому сначала зададимся типом классификатора, например, выберем байесовский классификатор, минимизирующий вероятность ошибки. Далее задача будет состоять в том, каким образом использовать имеющуюся выборку для синтеза классификатора и вычисления вероятности ошибки классификации. Поскольку в нашем распоряжении имеется конечное число объектов, нельзя построить оптимальный классификатор. Поэтому параметры такого классификатора представляют собой случайные величины. Используя этот классификатор, попытаемся оценить вероятность ошибки. Вторая задача также будет рассмотрена в этом параграфе.
5.4.1. Оценка вероятности ошибки для заданного классификатора.
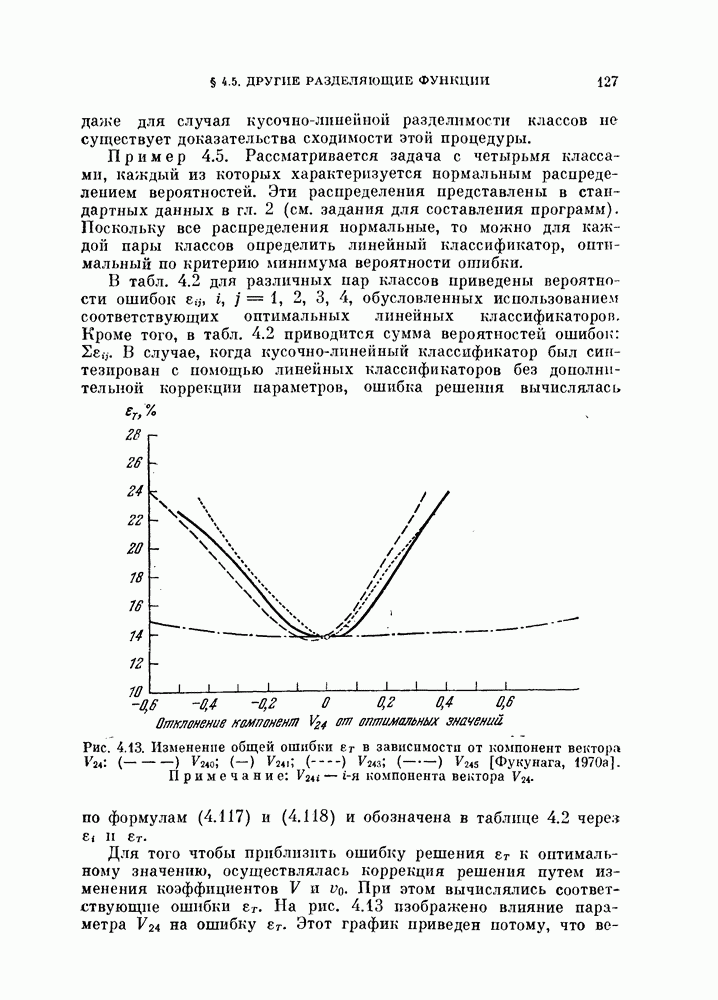
Предположим, что заданы распределения обоих классов и классификатор. Задача заключается в оценивании вероятности ошибки по  объектам, полученным в соответствии с этими распределениями [Хайлиман, 1962].
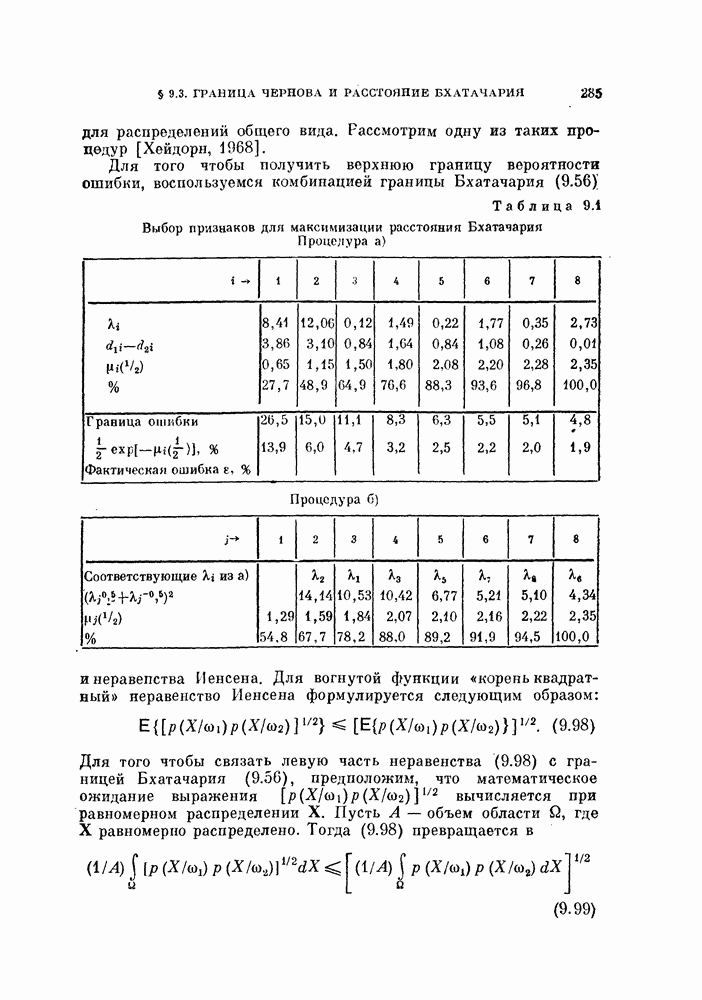
объектам, полученным в соответствии с этими распределениями [Хайлиман, 1962].
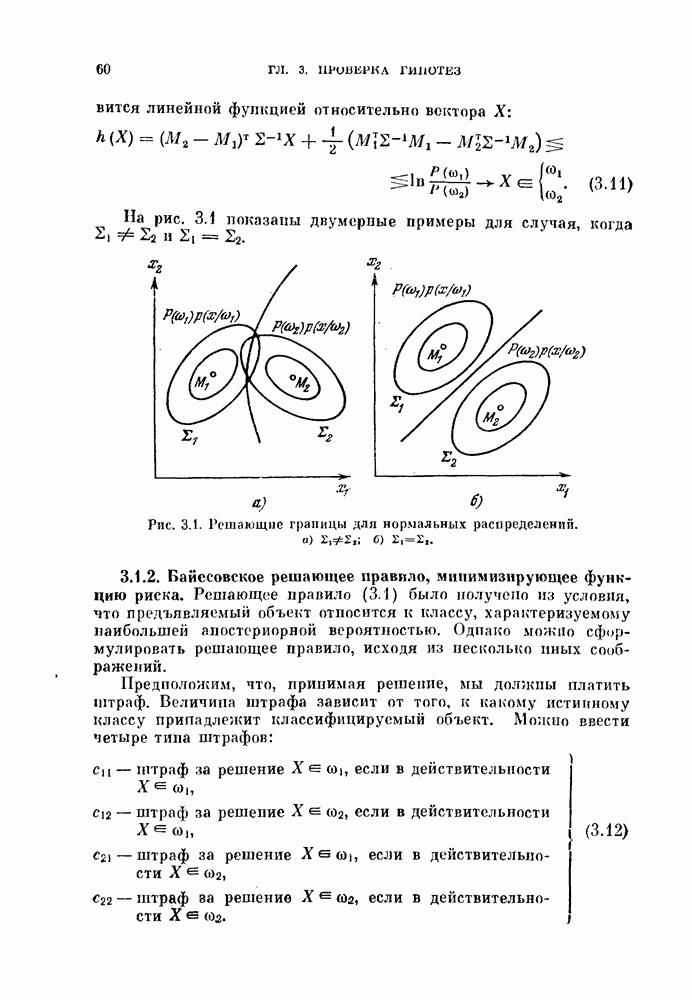
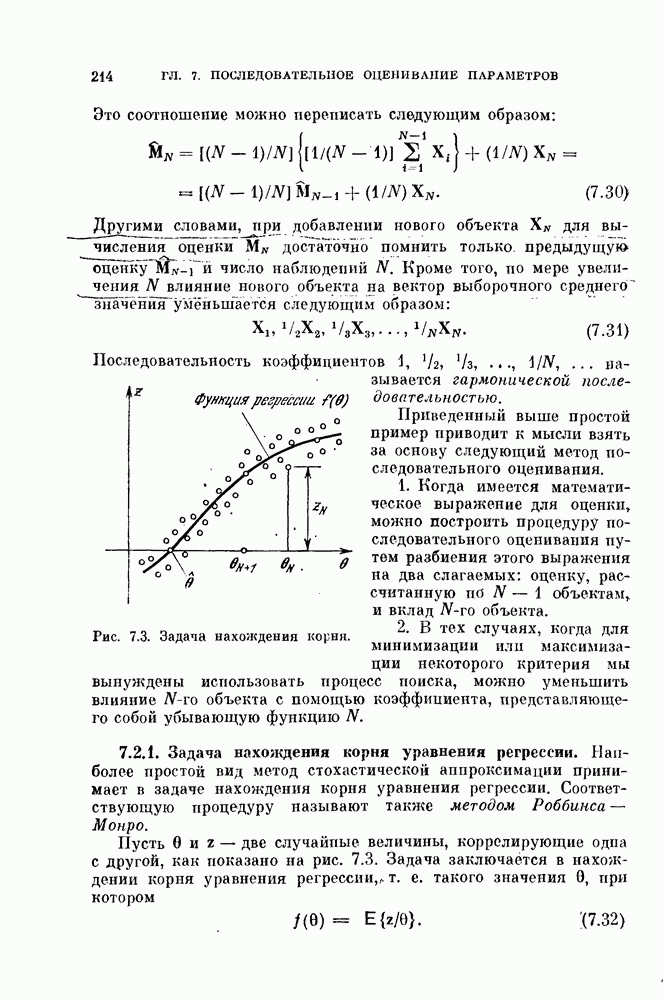
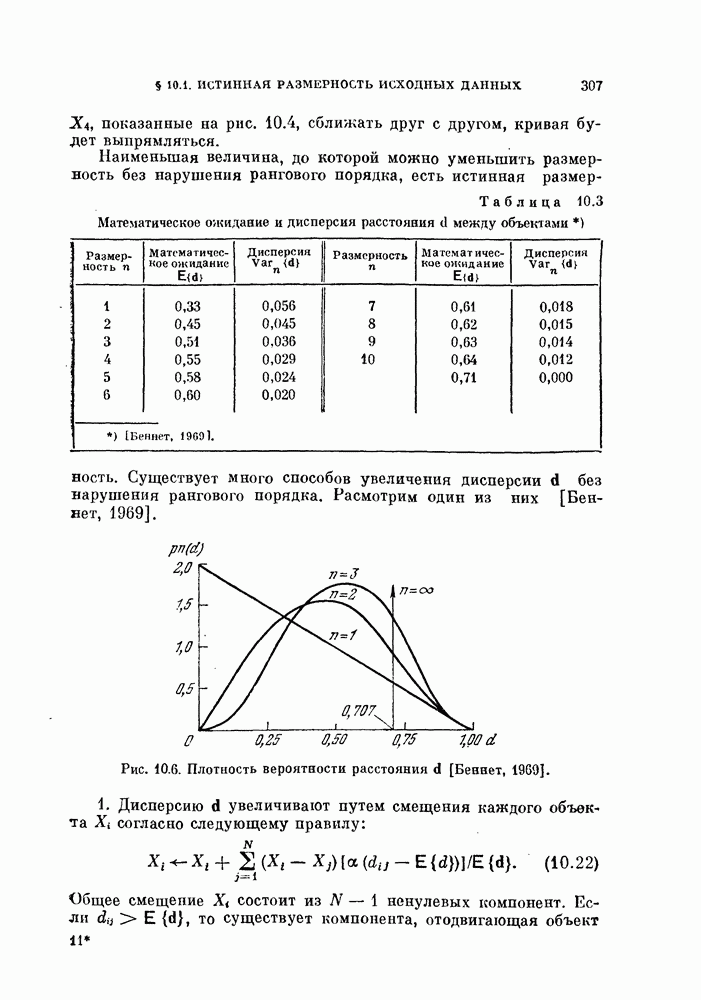
1. Неизвестны априорные вероятности — случайная выборка? Когда неизвестны априорные вероятности  то
то
можно случайно извлечь  объектов и проверить, дает ли данный классификатор правильные решения для этих объектов. Такие объекты называют случайной выборкой.
объектов и проверить, дает ли данный классификатор правильные решения для этих объектов. Такие объекты называют случайной выборкой.
Пусть  — число объектов, неправильно классифицированных в результате этого эксперимента. Величина
— число объектов, неправильно классифицированных в результате этого эксперимента. Величина  является дискретной случайной величиной. Обозначим истинную вероятность ошибки через 8. Вследствие дискретности
является дискретной случайной величиной. Обозначим истинную вероятность ошибки через 8. Вследствие дискретности  вместо условной плотности вероятности
вместо условной плотности вероятности  при фиксированном
при фиксированном  рассмотрим вероятность
рассмотрим вероятность  которая задается биномиальным распределением:
которая задается биномиальным распределением:

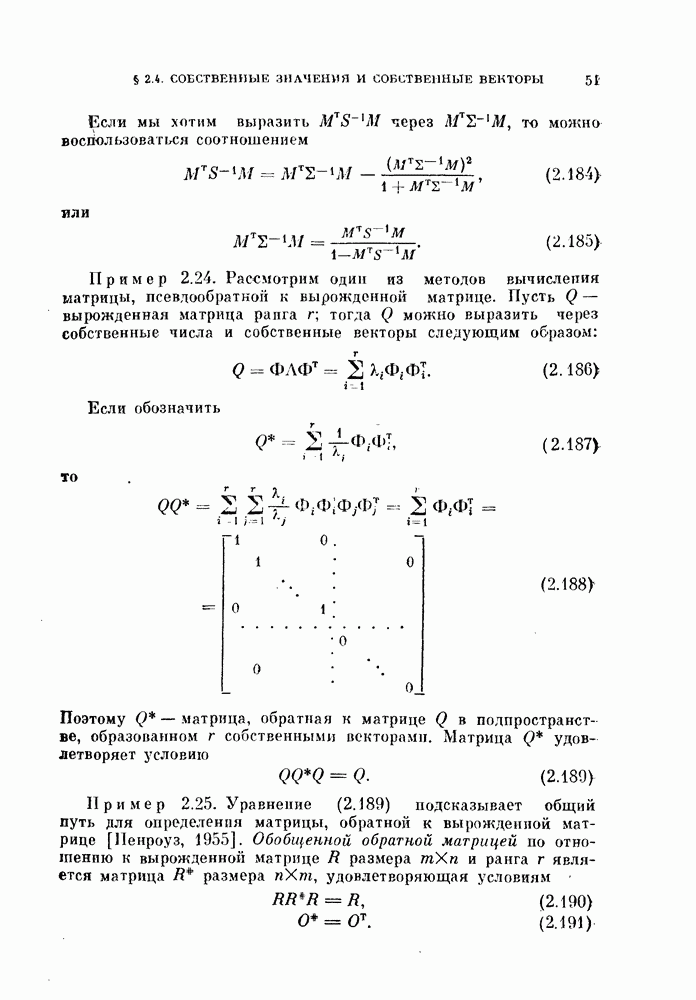
Оценка максимального правдоподобия  величины 8 есть решение следующего уравнения правдоподобия:
величины 8 есть решение следующего уравнения правдоподобия:

Следовательно,

Другими словами, оценка максимального правдоподобия равна отношению числа неправильно классифицированных объектов к общему числу объектов.
Свойства биномиального распределения хорошо известны. Характеристическая функция, математическое ожидание и дисперсия определяются следующим образом:

Поэтому

Таким образом, оценка  является несмещенной.
является несмещенной.
Поскольку плотность вероятности оценки  известна, можно вычислить доверительные интервалы по формуле
известна, можно вычислить доверительные интервалы по формуле

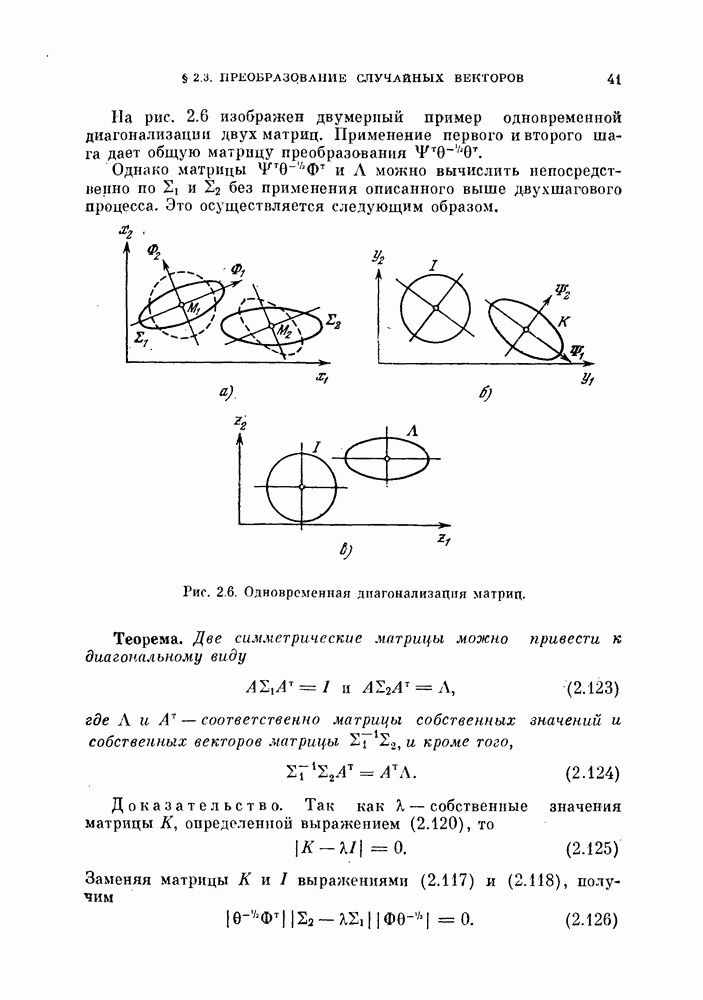
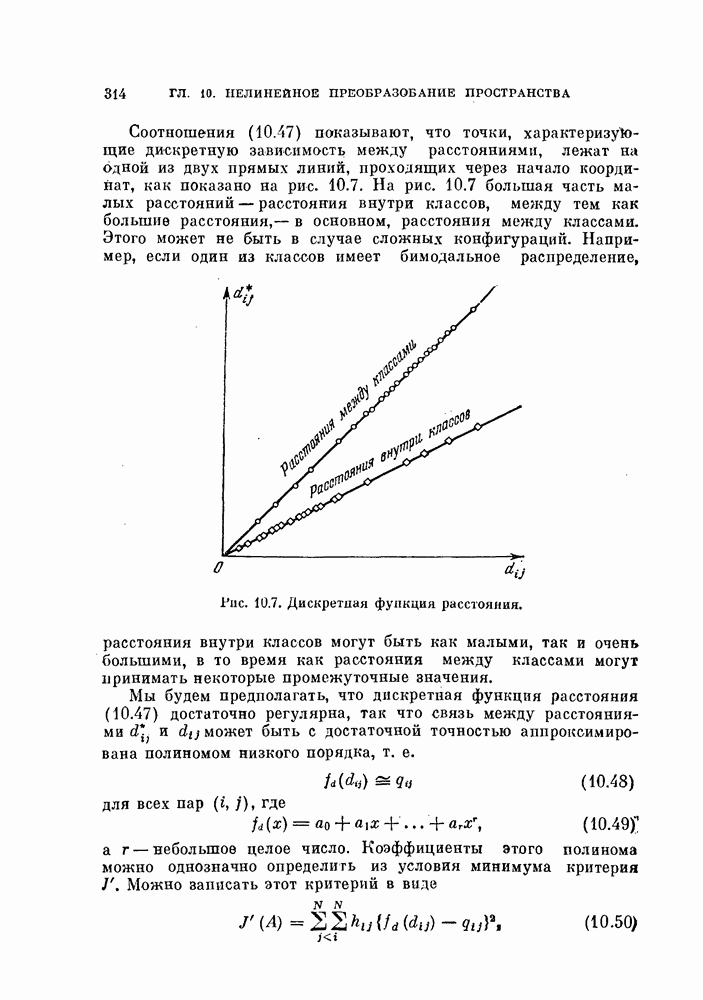
К сожалению, не найден явный вид для суммы слагаемых в выражении (5.127). Но соотношения между величинами 
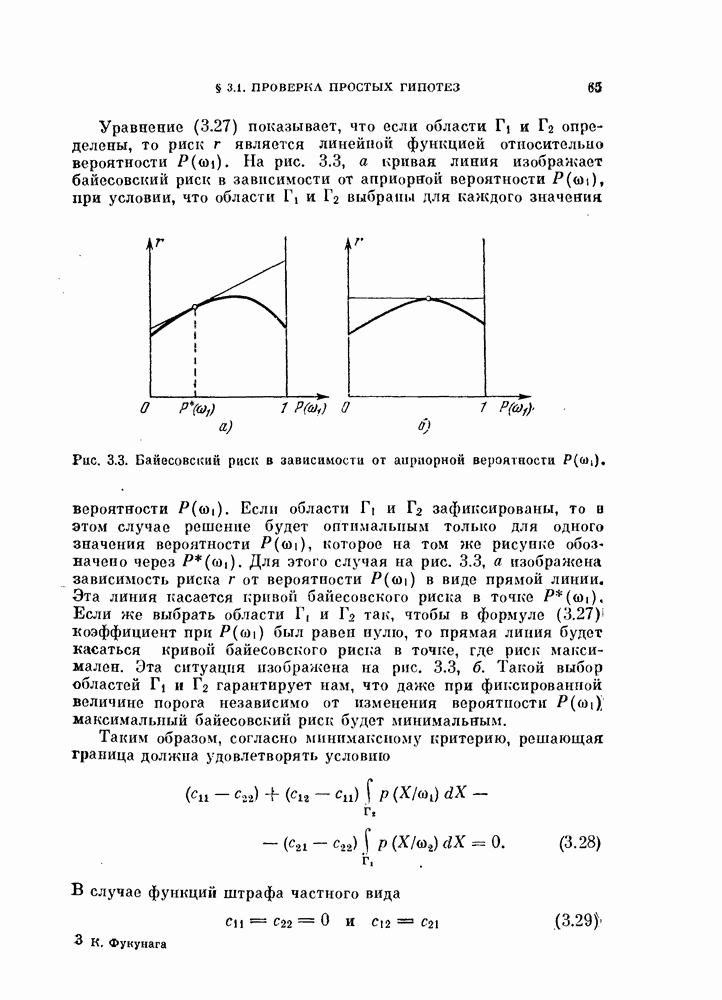
вероятности  будет равна
будет равна

где  — истинная вероятность ошибки для класса
— истинная вероятность ошибки для класса  . Рассуждения, аналогичные тем, с помощью которых были выписаны формулы (5.119) -(5.126), приводят к следующей оценке максимального правдоподобия
. Рассуждения, аналогичные тем, с помощью которых были выписаны формулы (5.119) -(5.126), приводят к следующей оценке максимального правдоподобия  величины
величины 

Математическое ожидание и дисперсия оценки соответственно

и

Таким образом, оценка (5.129) также несмещенная.
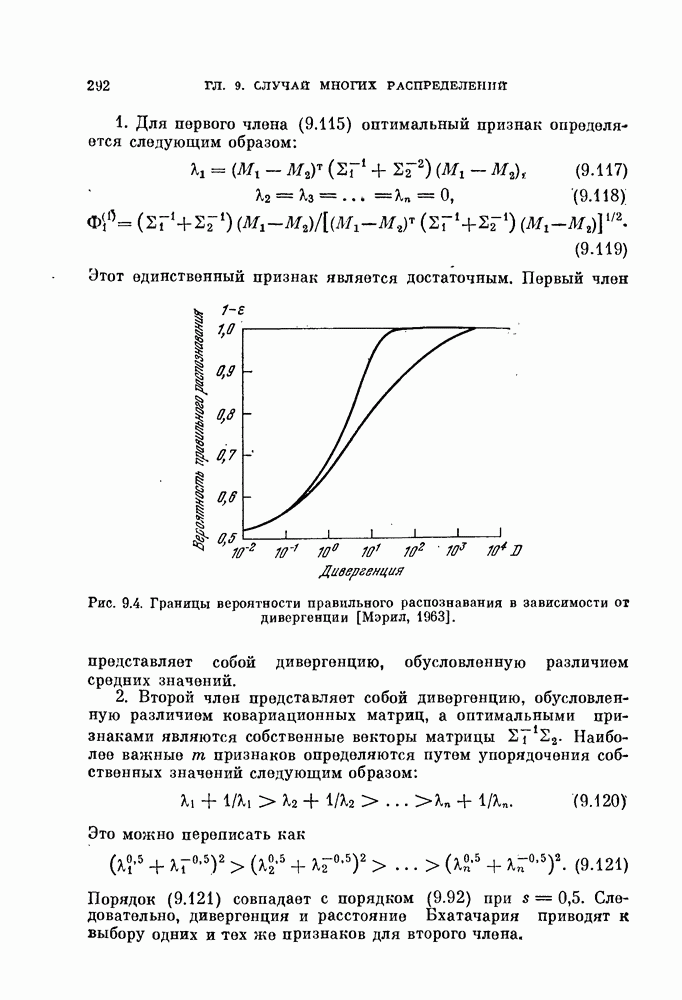
Можно показать, что дисперсия (5,131) меньше, чем дисперсия (5.126):

Это — естественный результат, так как в случае селективной выборки используется априорная информация.
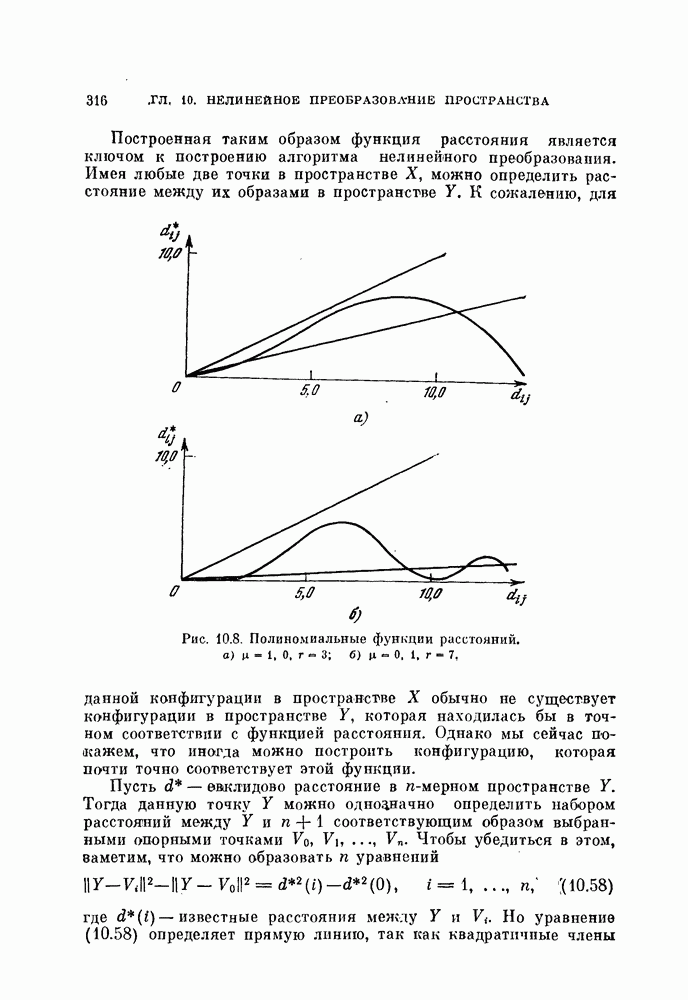
Вычисление доверительного интервала для этого случая является значительно более трудной задачей, чем при случайной выборке, так как плотность вероятности искомой оценки более сложная. На самом деле доверительный интервал зависит от величин  и
и  , взятых в отдельности, а не просто от е. Однако» так как плотность вероятности оценки
, взятых в отдельности, а не просто от е. Однако» так как плотность вероятности оценки  в данном случае известна, то доверительный интервал можно найти численными методами.
в данном случае известна, то доверительный интервал можно найти численными методами.
Изложенное выше можно легко распространить на случай многих классов. Для этого необходимо изменить с 2 на М верхние пределы у знаков произведения и суммы в формулах (5.128, (5.129) и (5.131) (М — число классов).























































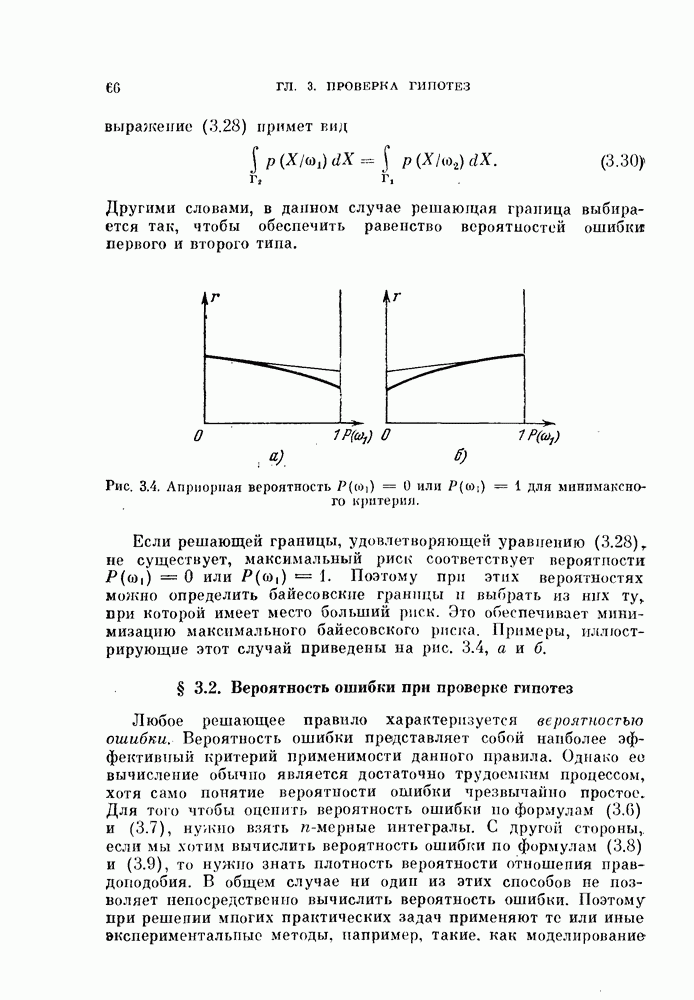








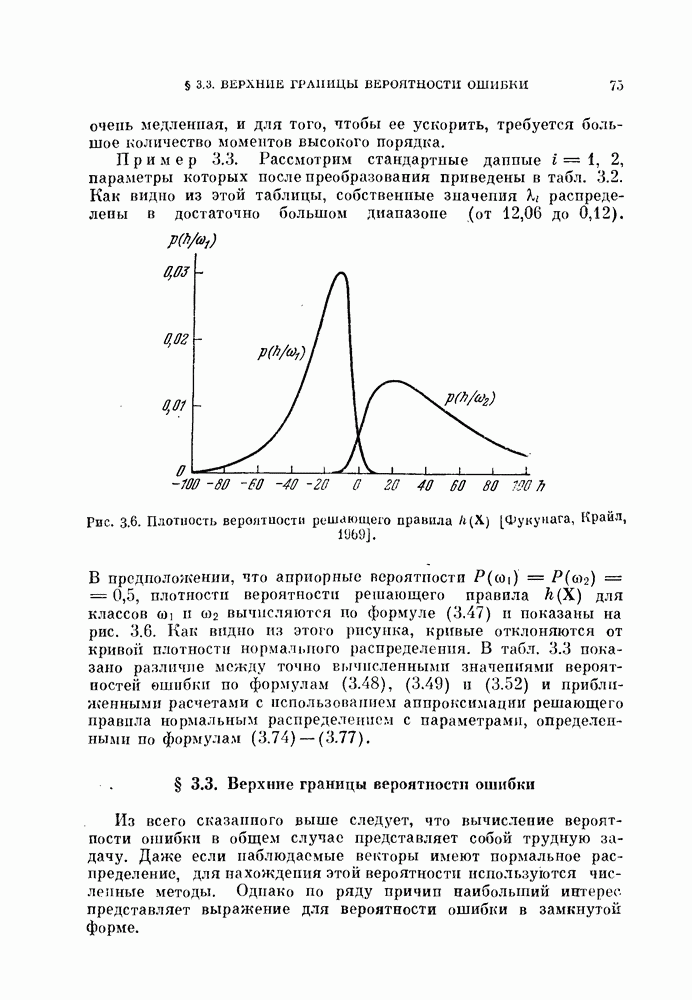























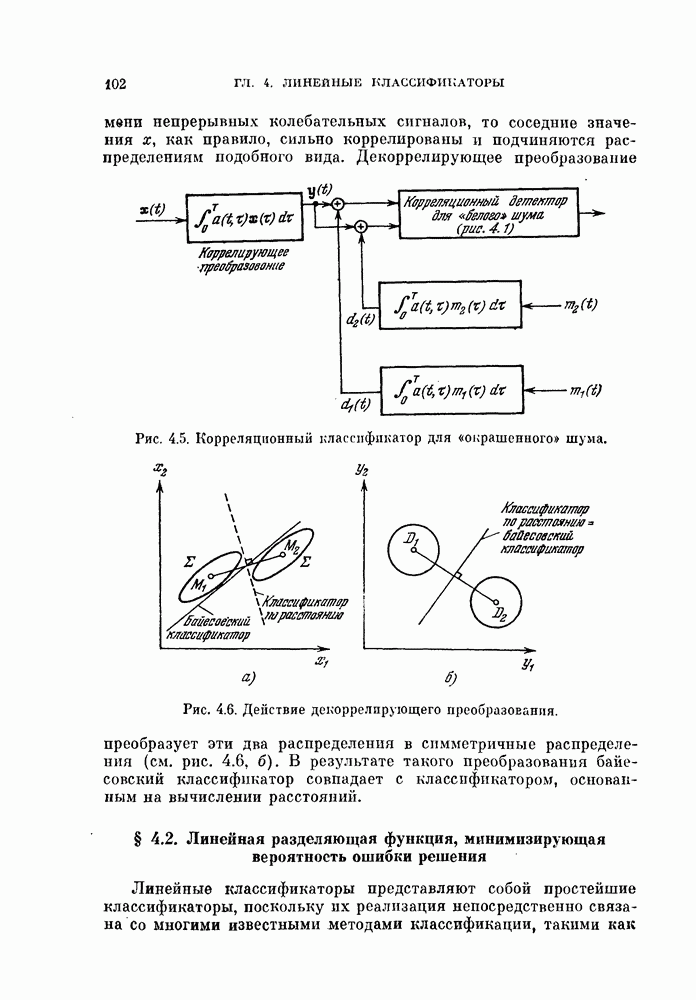




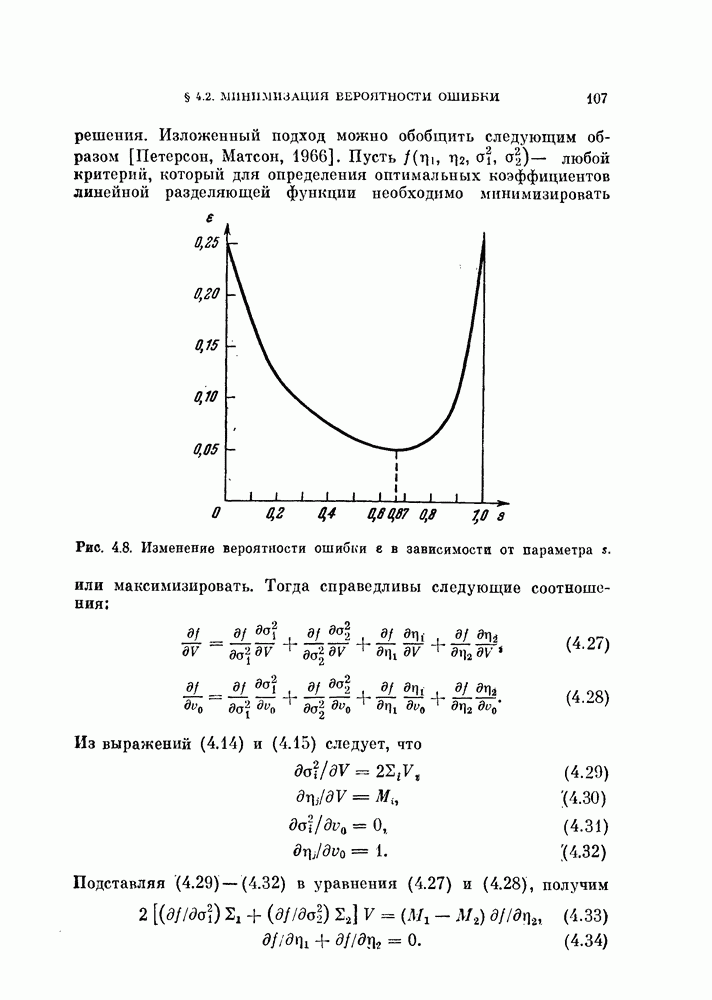


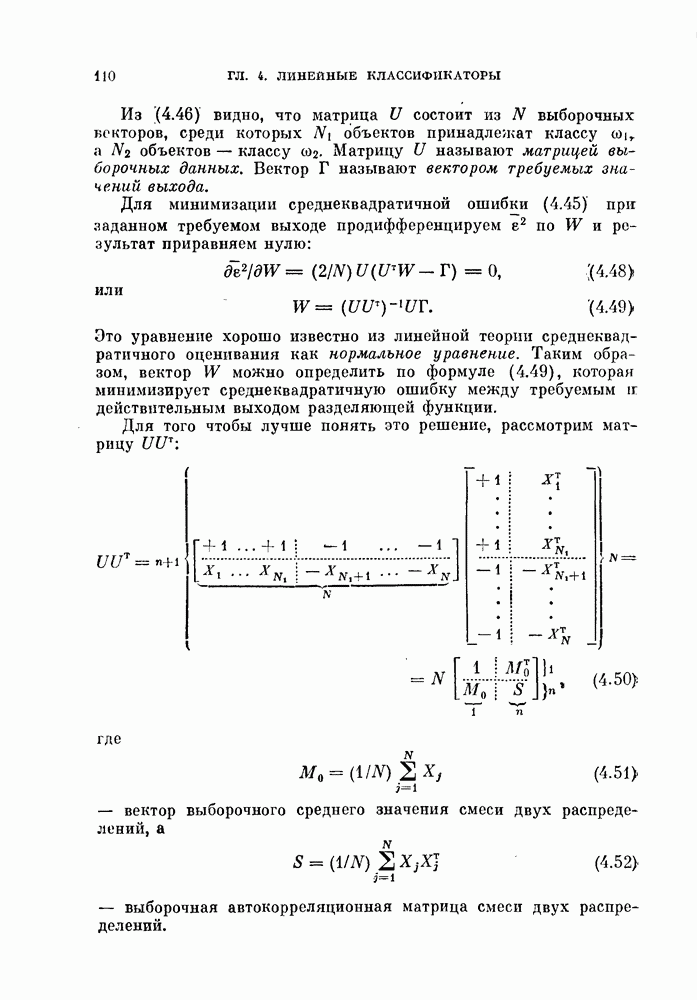



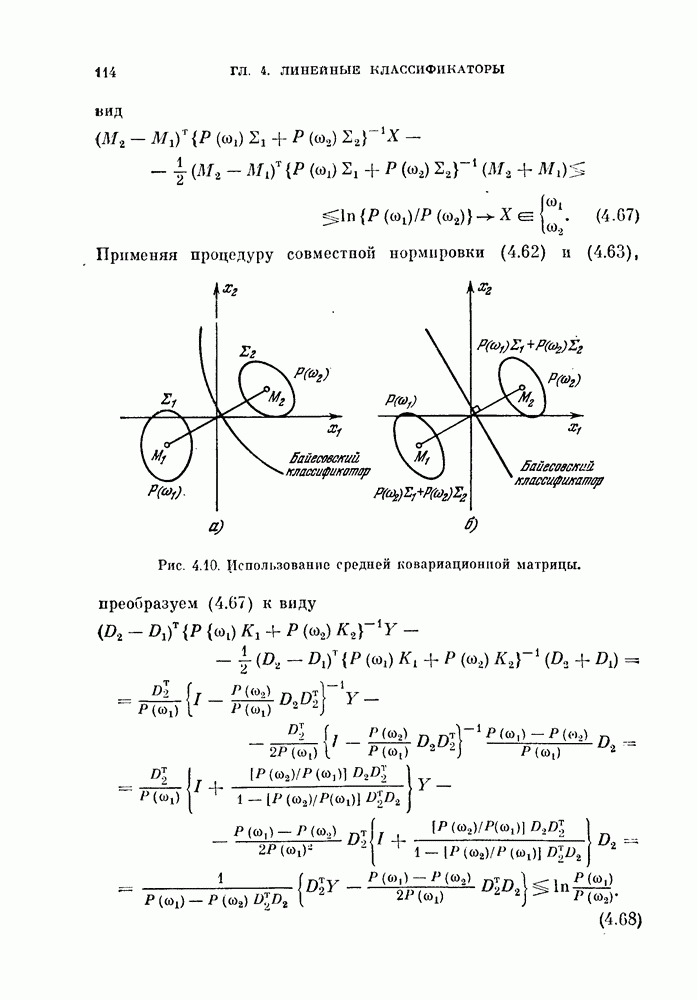






































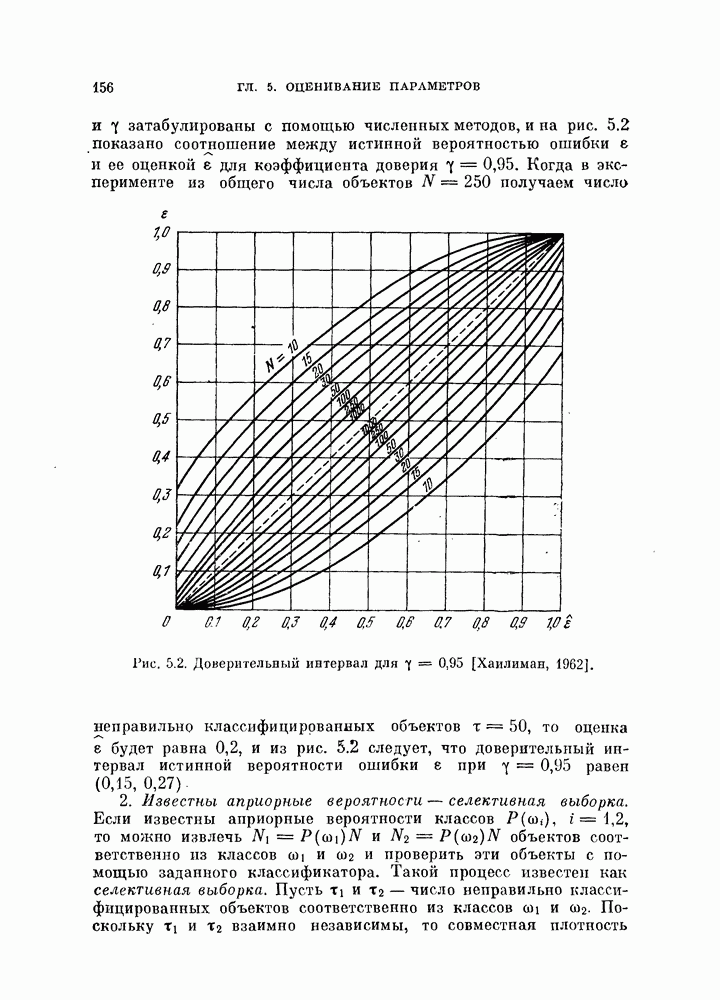





















































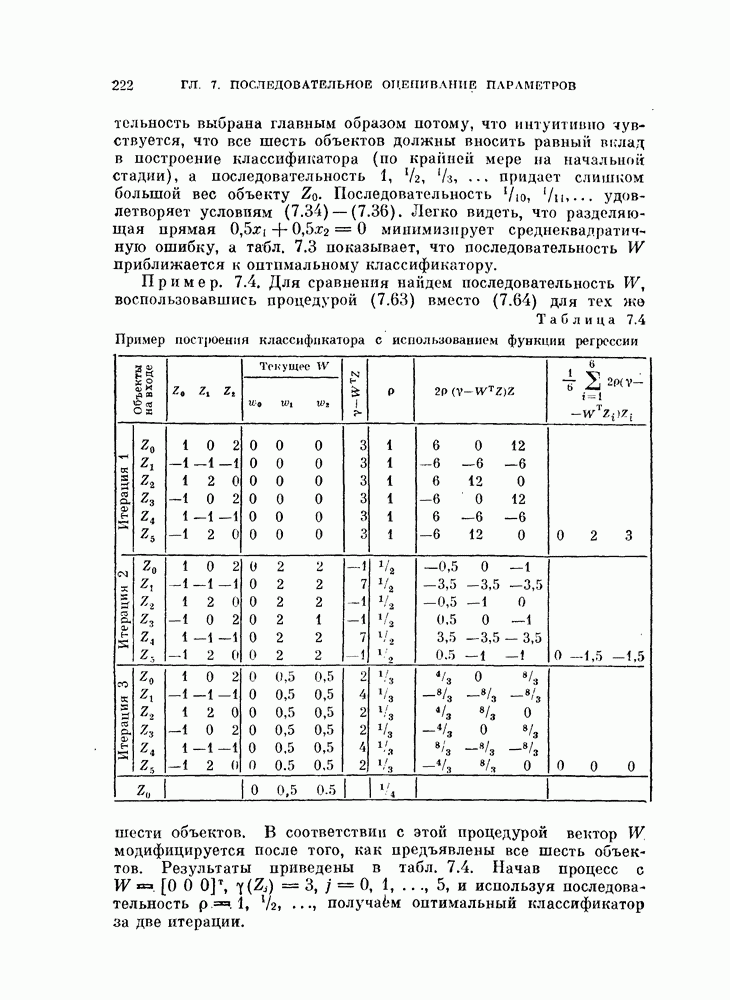


































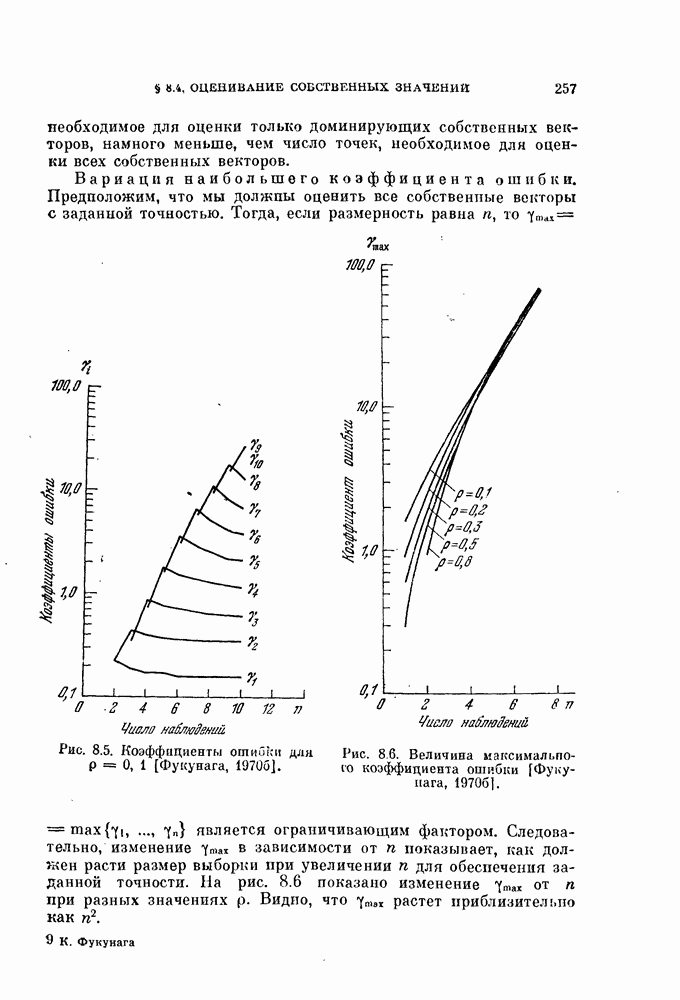




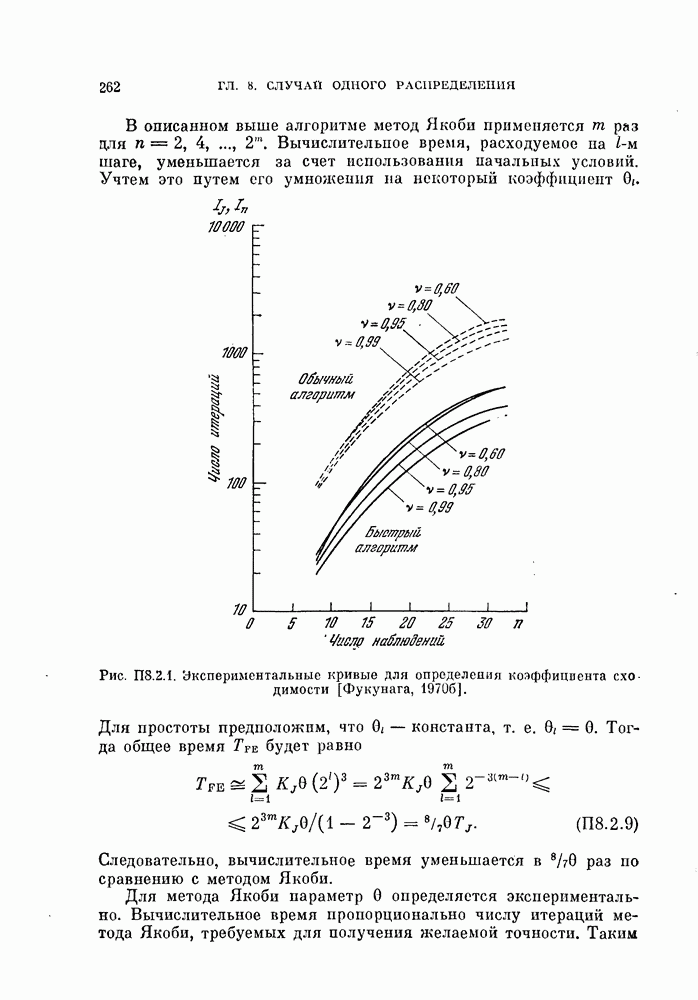



























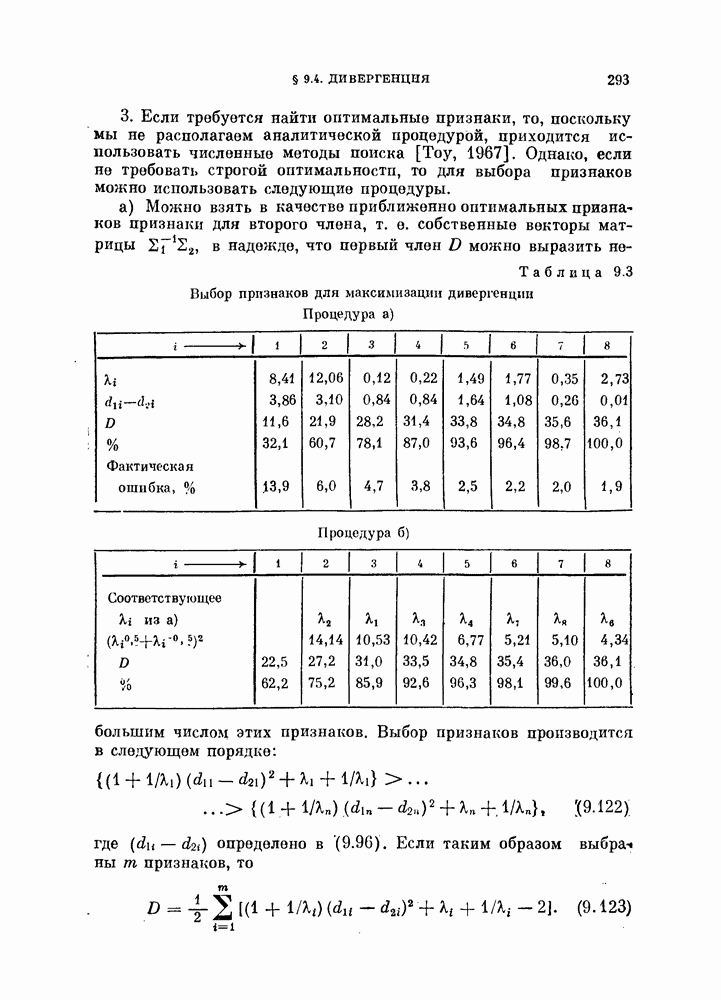















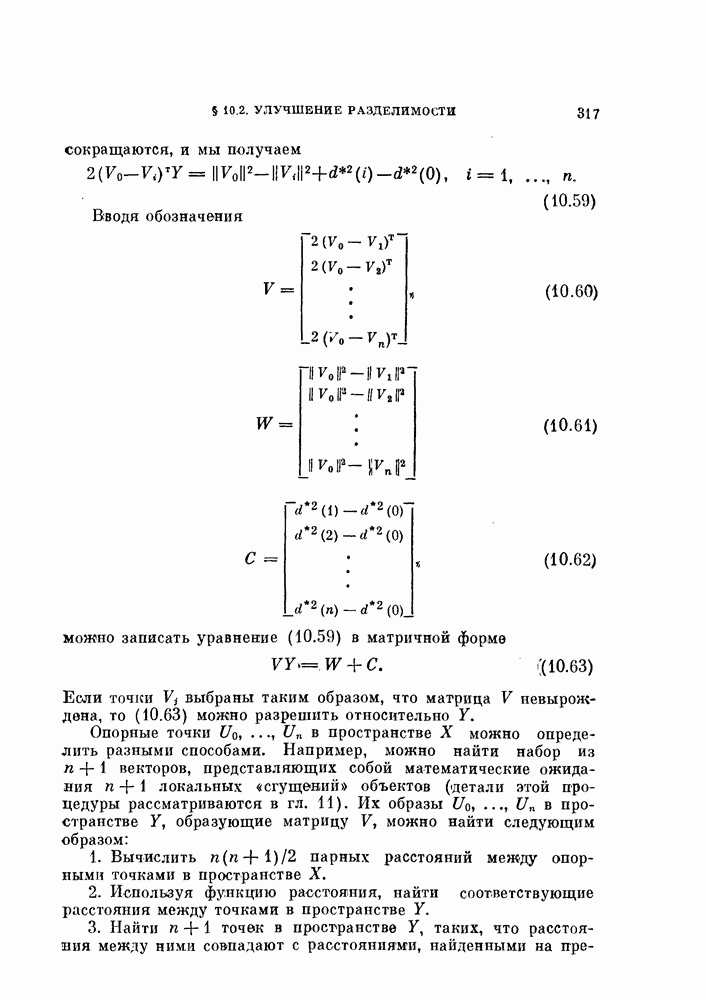










































 и ее оценкой
и ее оценкой  для коэффициента доверия
для коэффициента доверия  .
.

 [Хаилиман, 1962].
[Хаилиман, 1962].
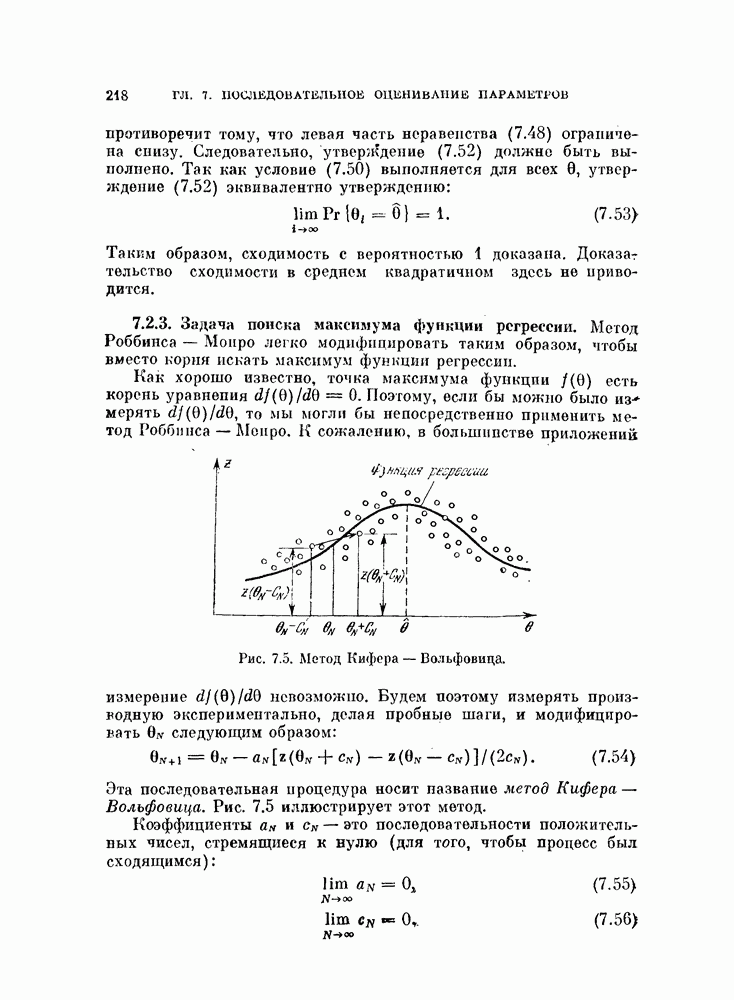
 получаем число неправильно классифицированных объектов
получаем число неправильно классифицированных объектов  то оценка
то оценка  будет равна 0,2, и из рис. 5.2 следует, что доверительный интервал истинной вероятности ошибки
будет равна 0,2, и из рис. 5.2 следует, что доверительный интервал истинной вероятности ошибки  при
при  равен (0,15, 0,27).
равен (0,15, 0,27).
 то можно извлечь
то можно извлечь  объектов соответственно из классов
объектов соответственно из классов  и проверить эти объекты с помощью заданного классификатора. Такой процесс известен как селективная выборка. Пусть
и проверить эти объекты с помощью заданного классификатора. Такой процесс известен как селективная выборка. Пусть  — число неправильно классифицированных объектов соответственно из классов он и
— число неправильно классифицированных объектов соответственно из классов он и  Поскольку
Поскольку  взаимно независимы, то совместная плотность
взаимно независимы, то совместная плотность
