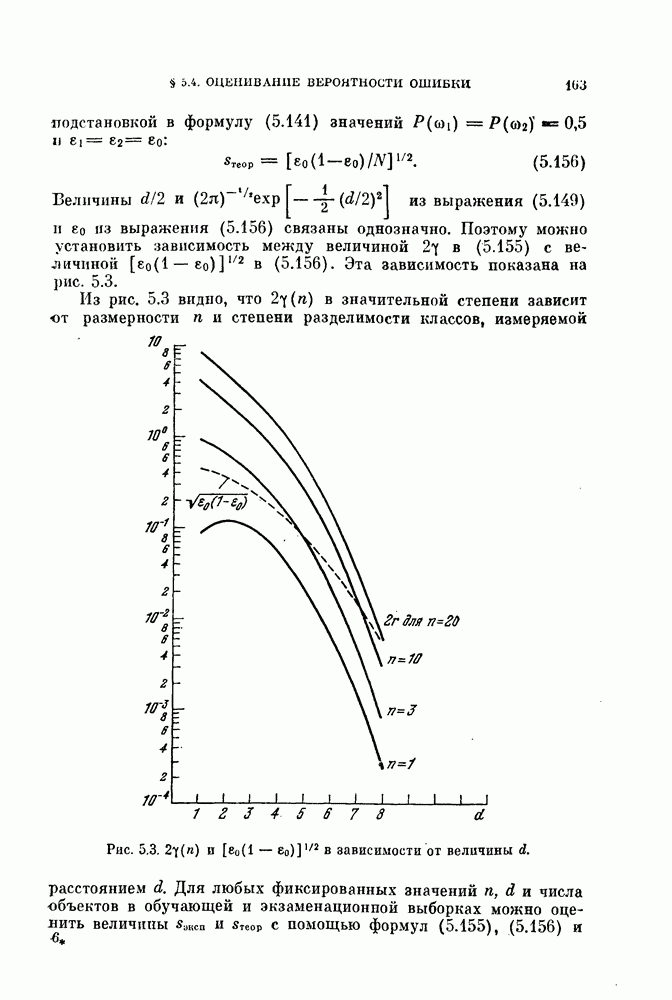
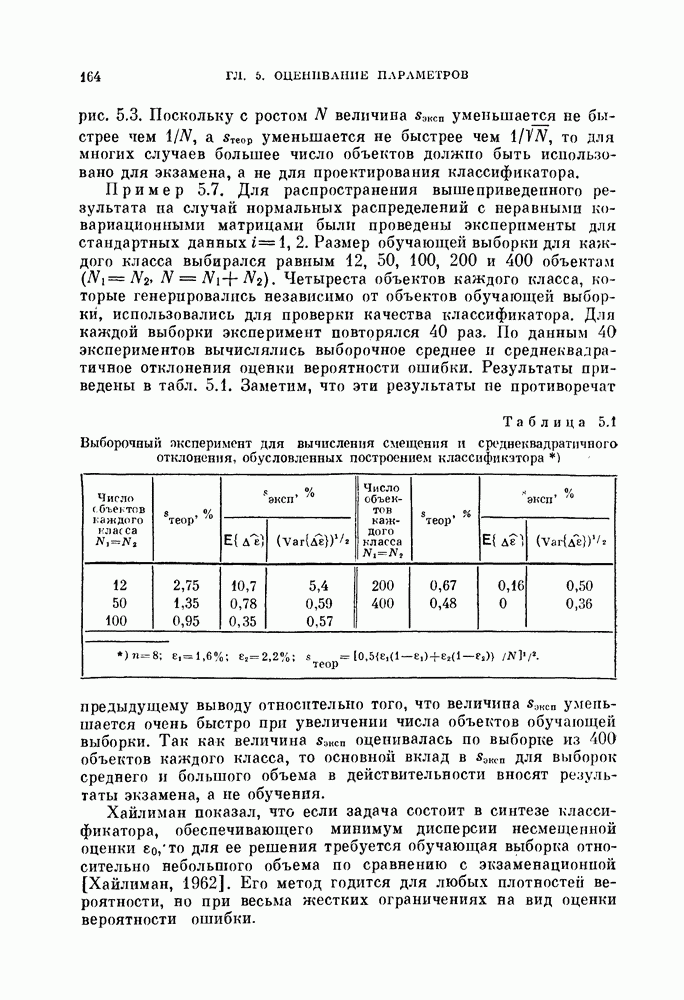
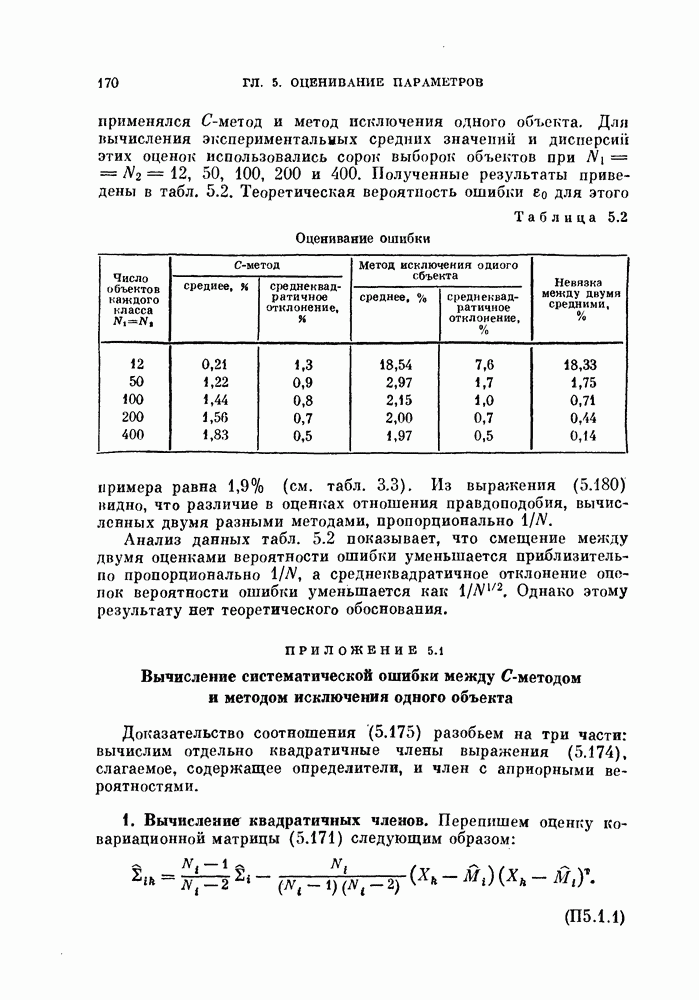
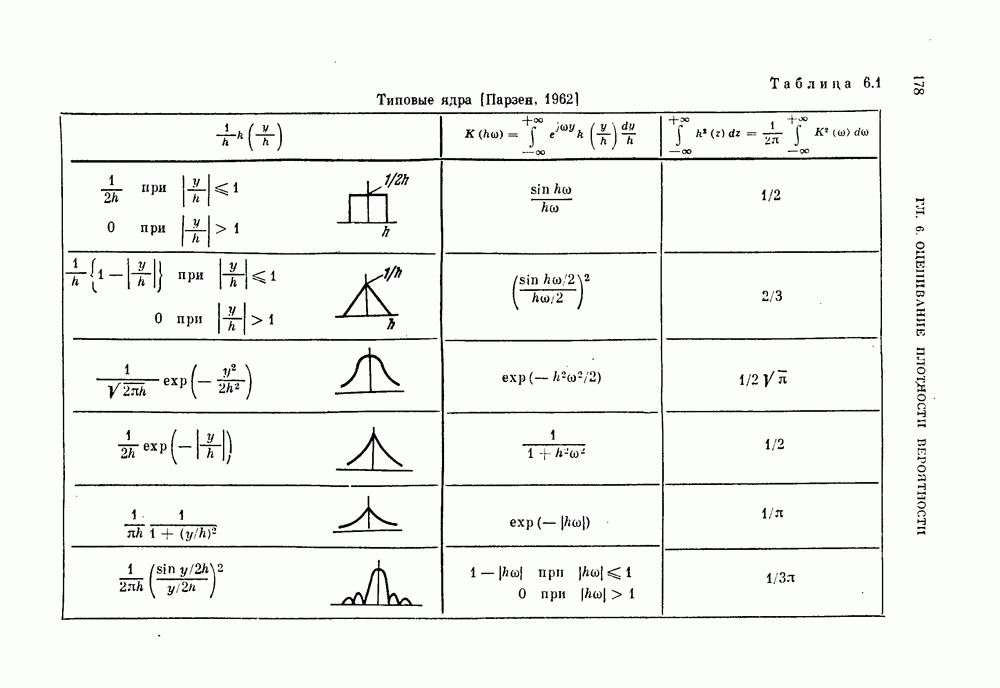
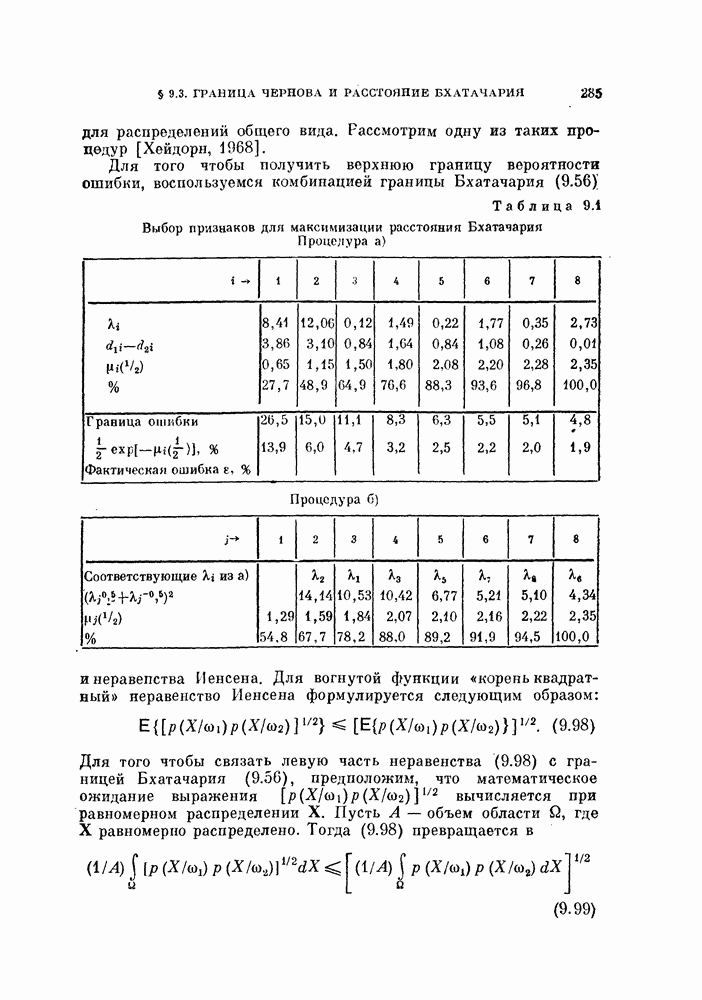
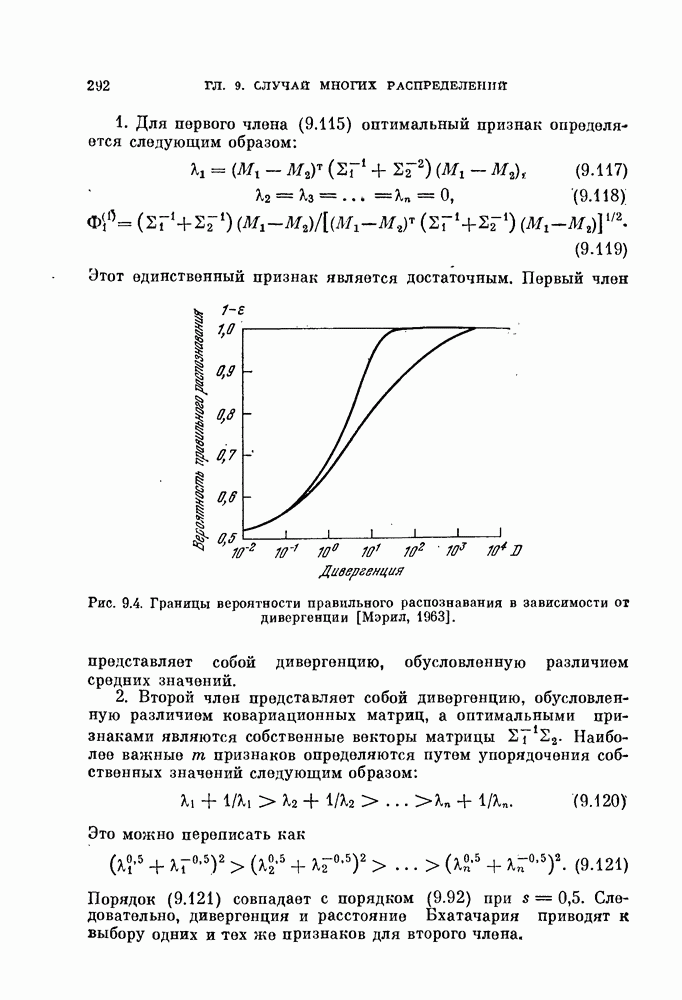
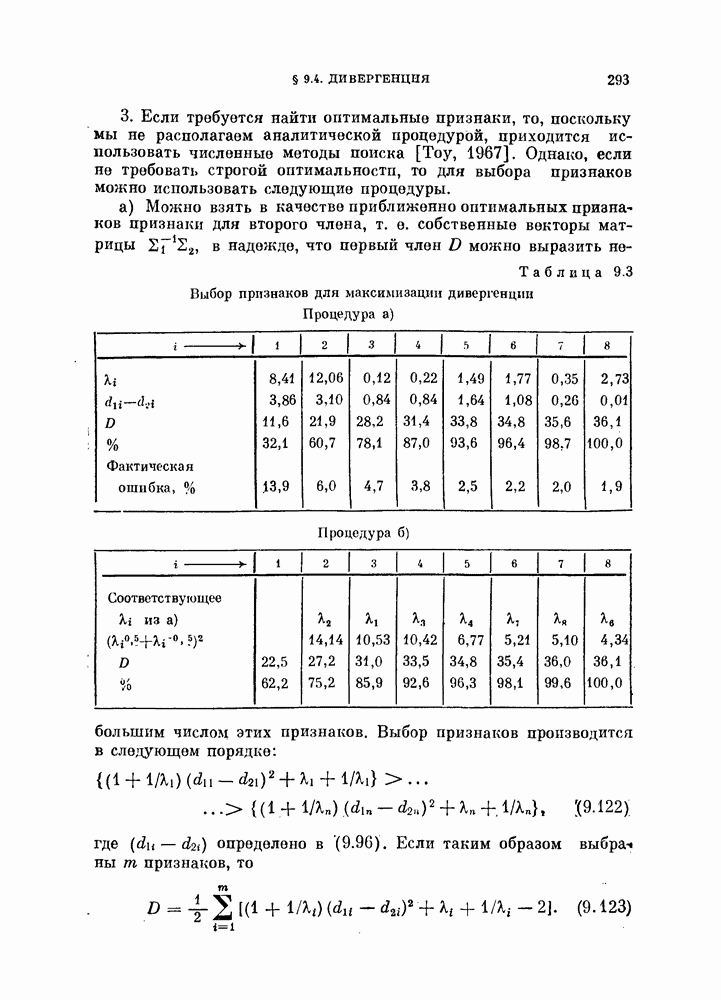
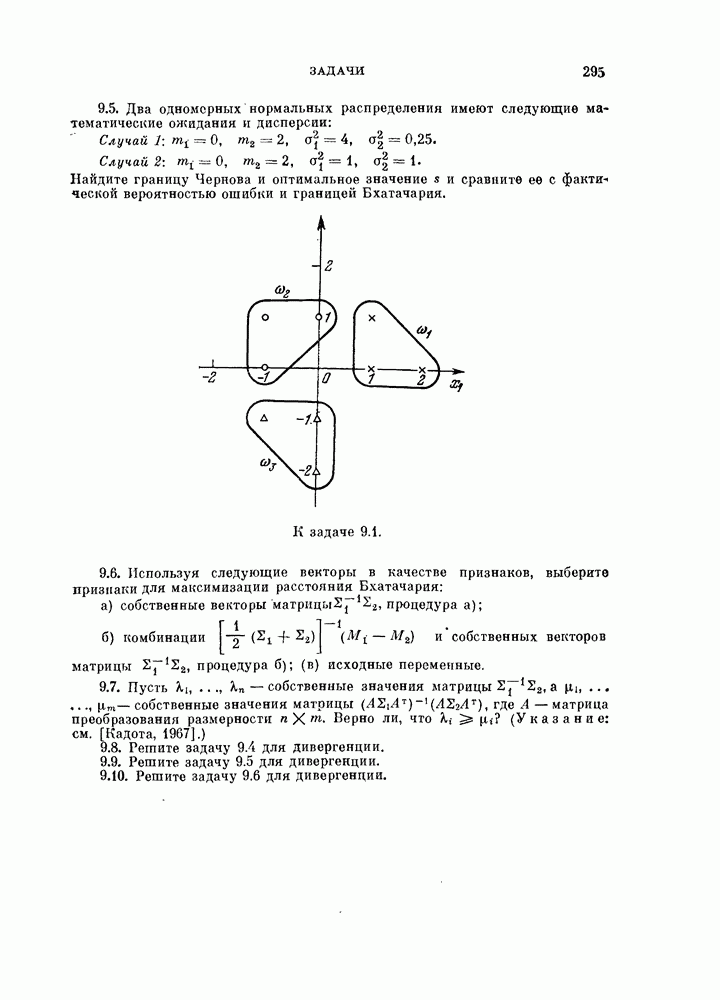
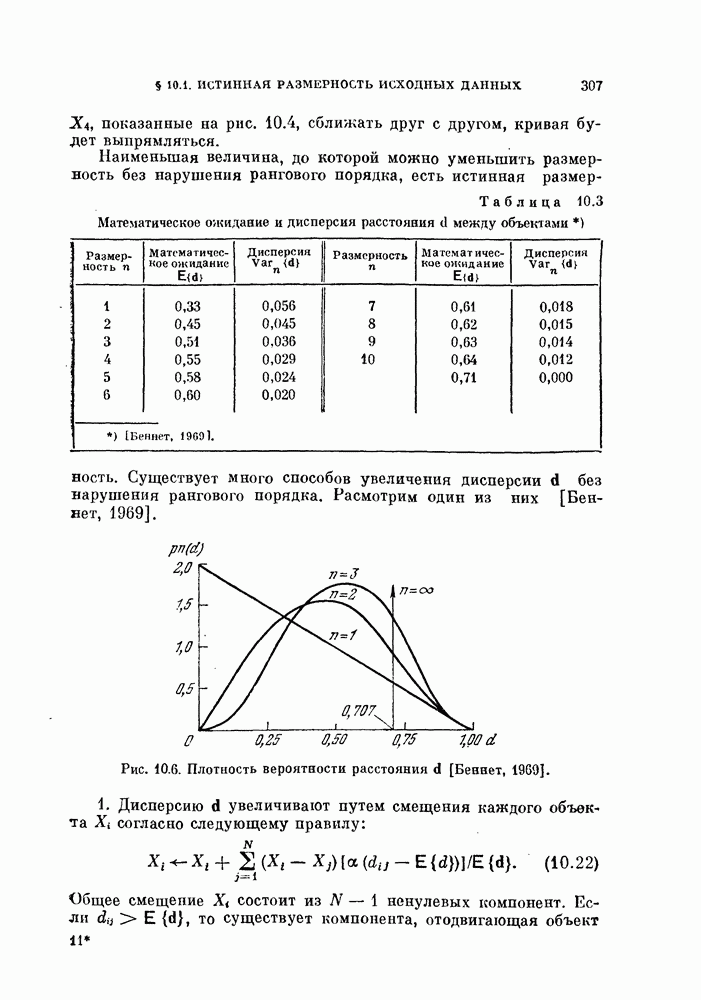
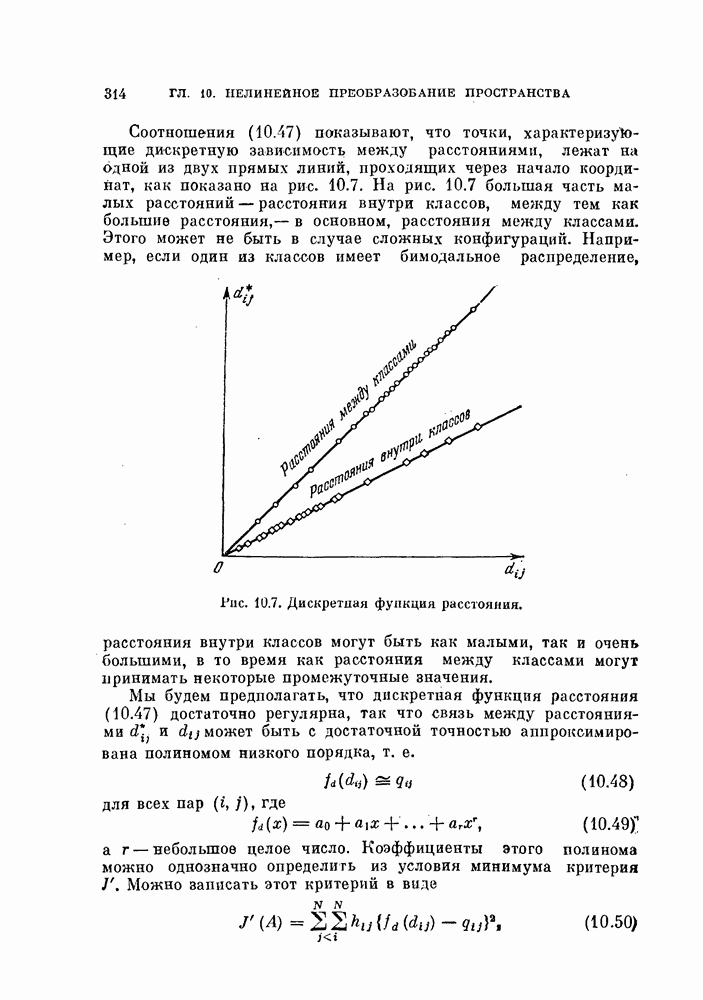
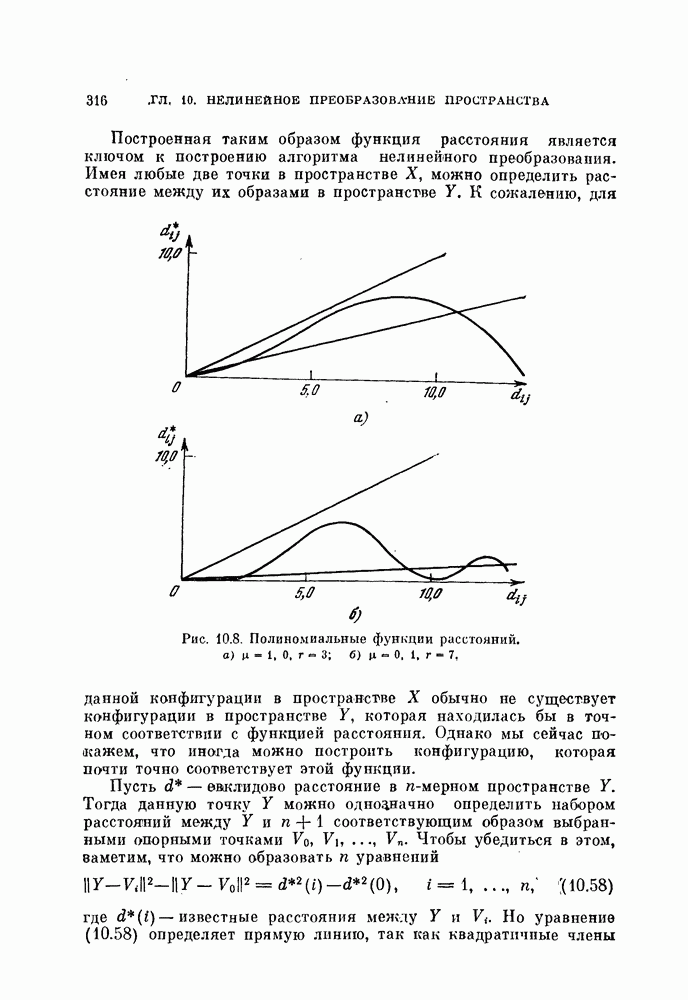
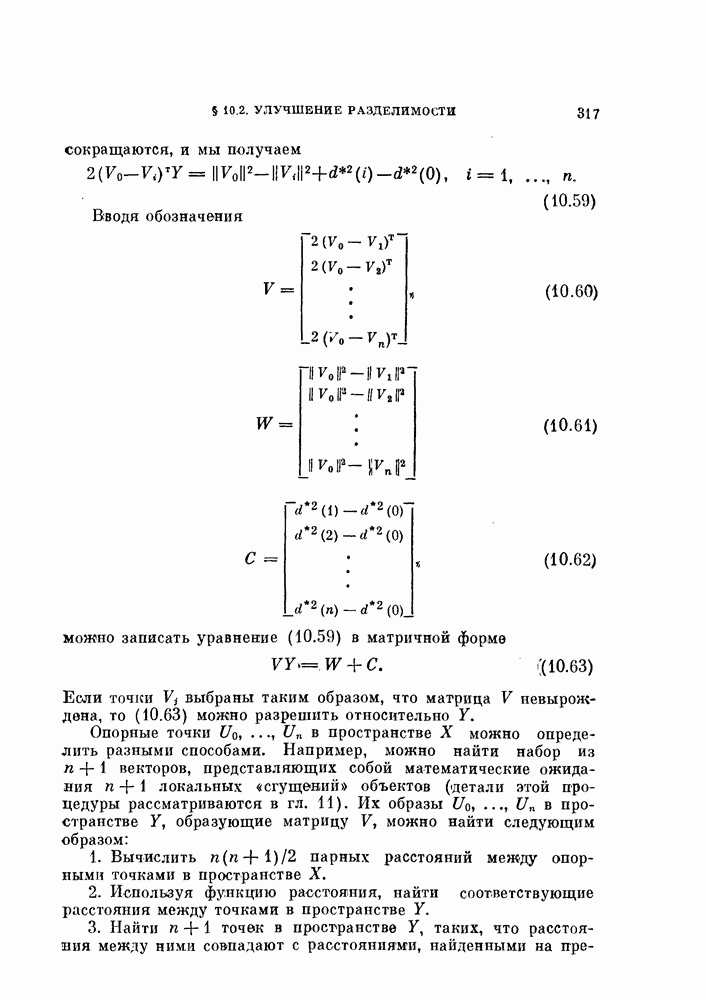
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
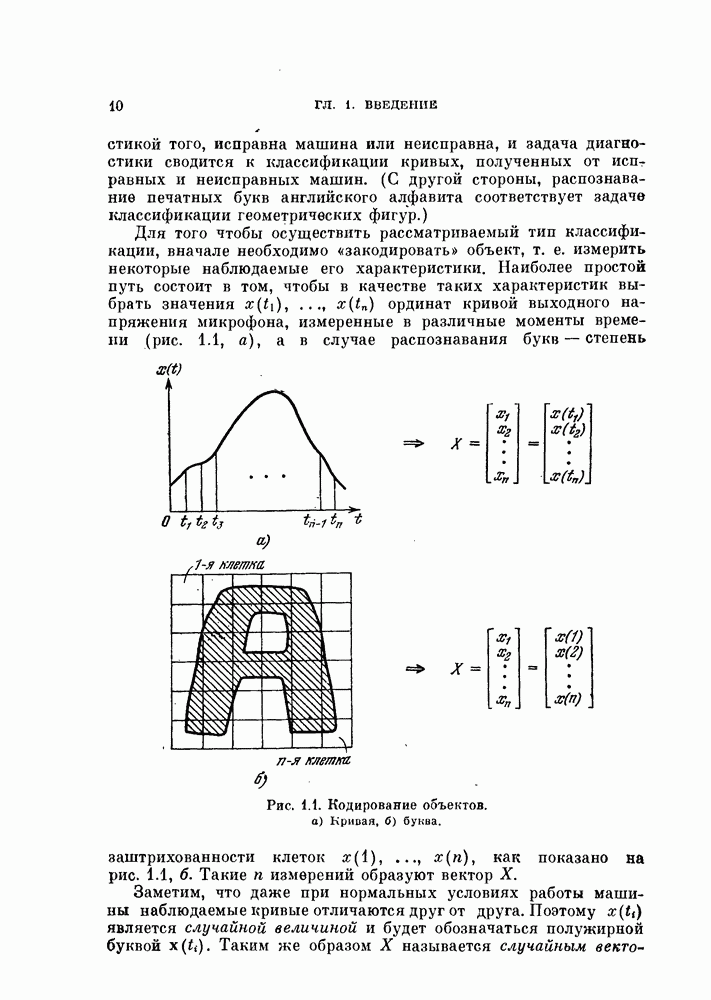
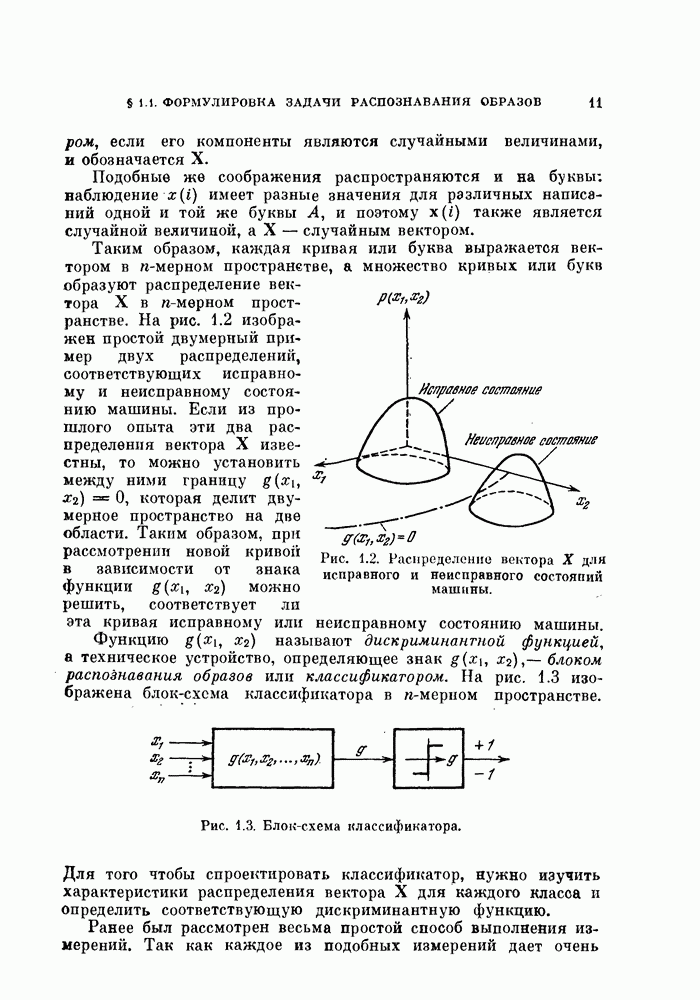
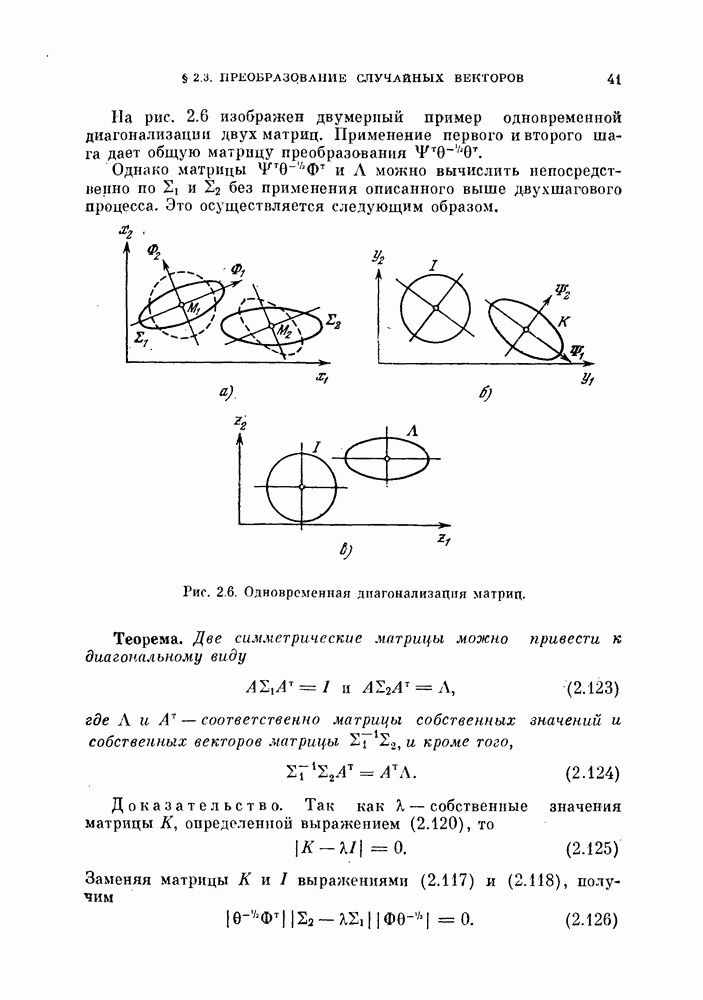
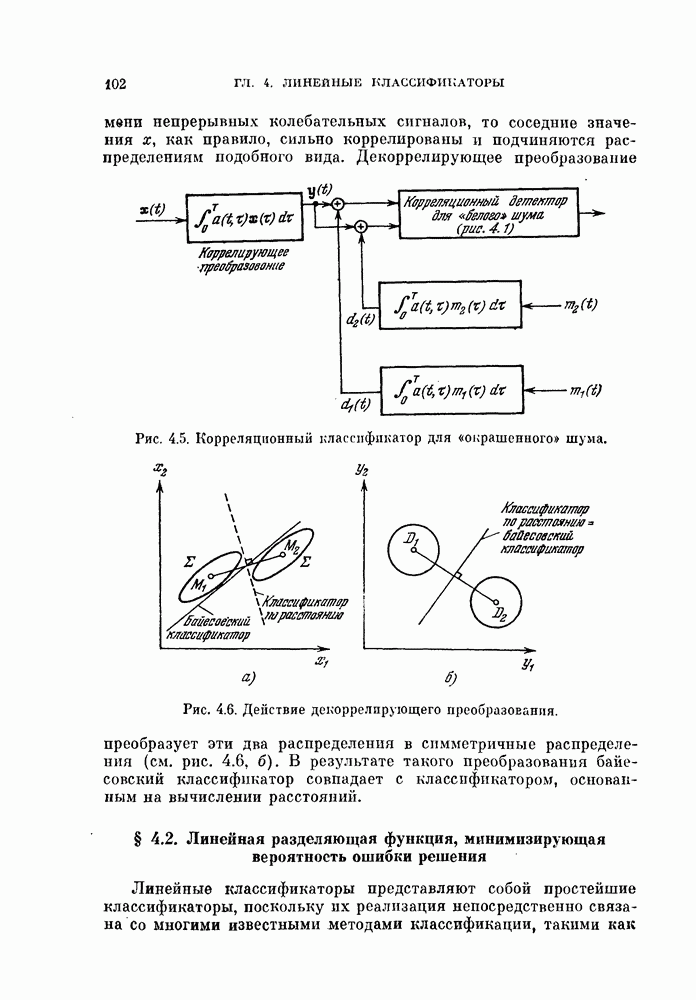
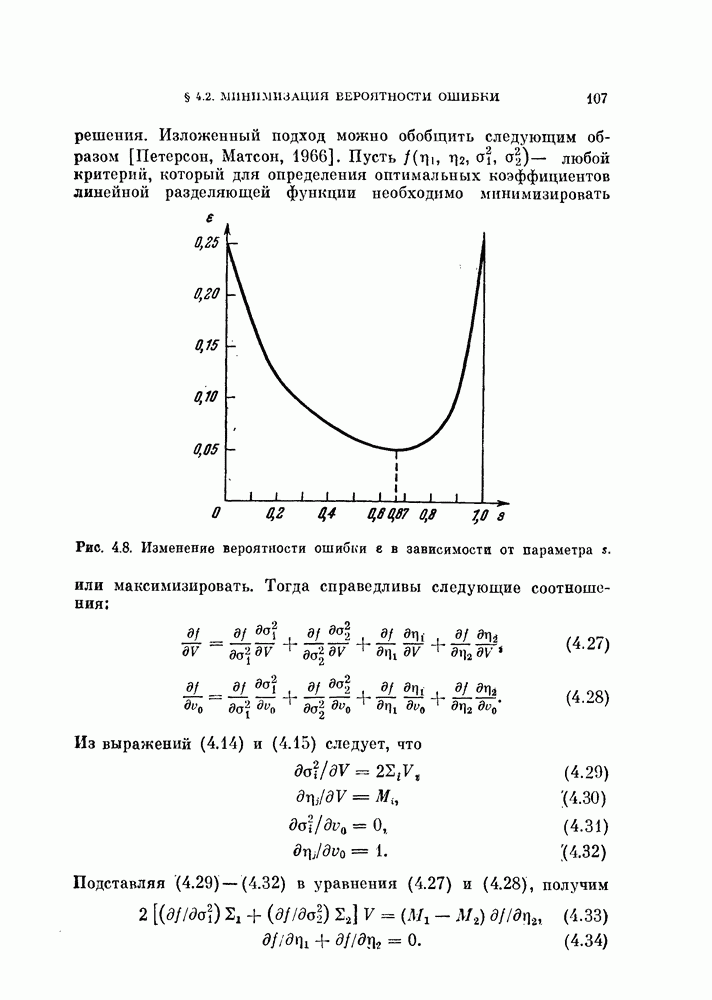
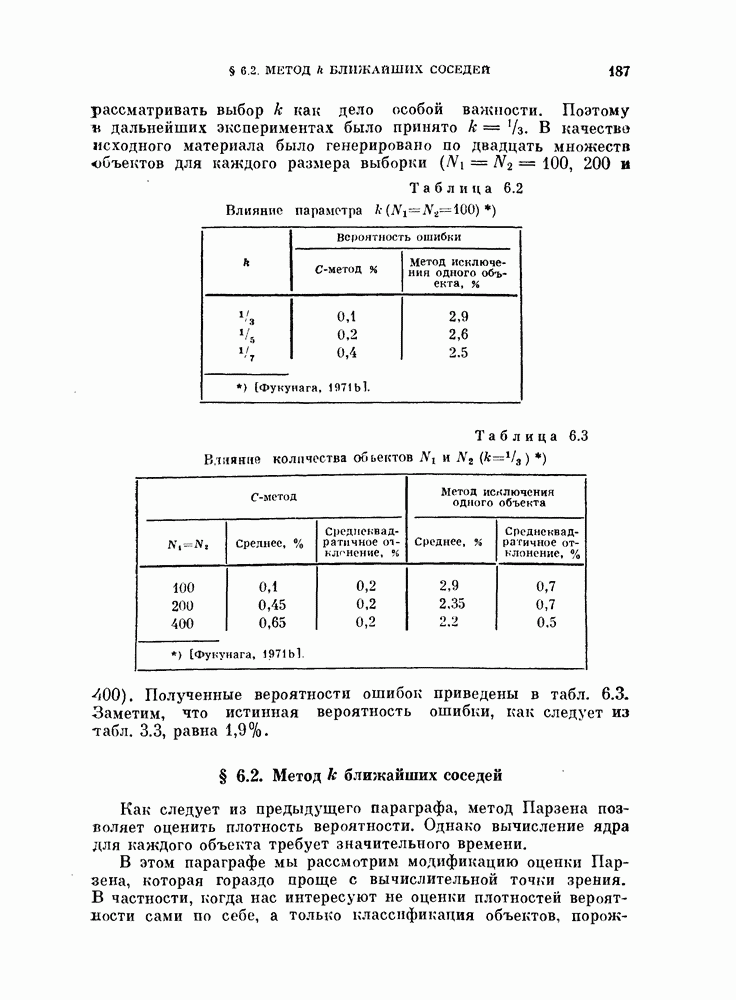
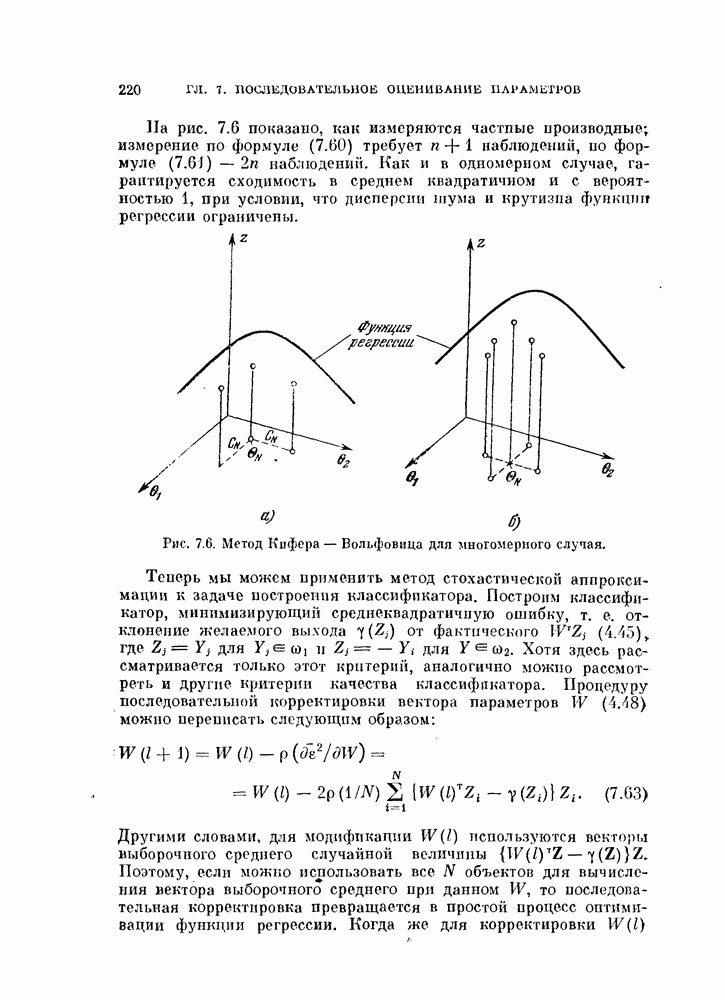
4.5.2. Кусочно-линейные разделяющие функции.Линейные разделяющие функции находят широкое применение в задачах. распознавания образов для случая двух классов, хотя при этом неизбежна некоторая потеря качества распознавания. Однако при трех или большем числе классов качество распознавания с использованием линейной разделяющей функции часто оказывается неприемлемым. Это может произойти и при двух классах, если каждый класс состоит из нескольких групп объектов. Если в этих случаях воспользоваться совокупностью линейных разделяющих функций, т. е. кусочно-линейной разделяющей функцией, то появляются дополнительные возможности улучшения качества распознавания. На рис. 4.11 изображен пример задачи распознавания при наличии четырех классов.
Рис. 4.11. Четыре распределения: а) байесовский классификатор; б) кусочно-линейный классификатор. В задачах со многими классами критерии проверки многих гипотез дают наилучшее в байесовском смысле решающее правило, обеспечивающее минимум риска пли вероятности ошибки В соответствии с критерием проверки гипотез плотность вероятности каждого класса или ее логарифм следует сравнить с плотностями вероятности других классов, как следует из (3.114). На рис. 4.11, а изображены полученные таким образом границы. Если оценивание плотностей вероятности является слишком сложной задачей или границы, определяемые в соответствии с критерием проверки гипотез, достаточно «вычурные», то можно заменить эти сложные границы множеством простых линейных границ. Такая замена, конечно, приводит к некоторому ухудшению качества распознавания. Однако использование линейных границ особенно эффективно для задач распознавания многих классов, т. е. в тех случаях, когда сложность границ быстро возрастает с увеличением числа классов, и является желательным некоторое упрощение процедуры синтеза классификатора. Например, на рис. 4.11, б показана замена байесовских границ (рис. 4.11, а) кусочно-линейными границами. Множество линейных функций, соответствующее кусочно-линейной разделяющей функции, определяется следующим образом:
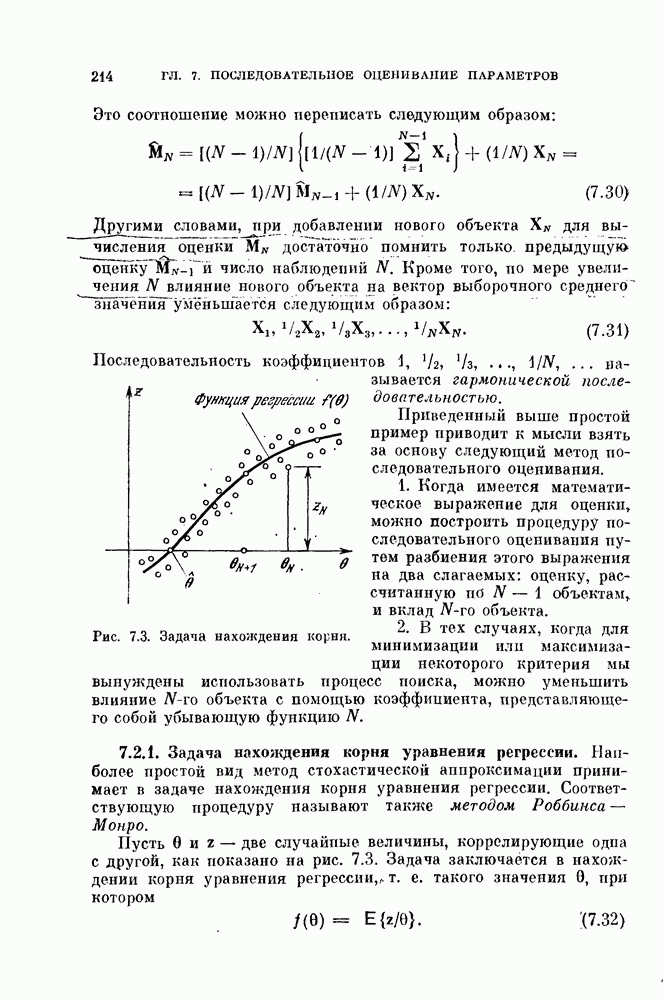
где М — число классов. Знаки
Предположим, что для каждого класса соответствующая область является выпуклой, как изображено на рис. 4.11,б. Тогда область класса
(функция
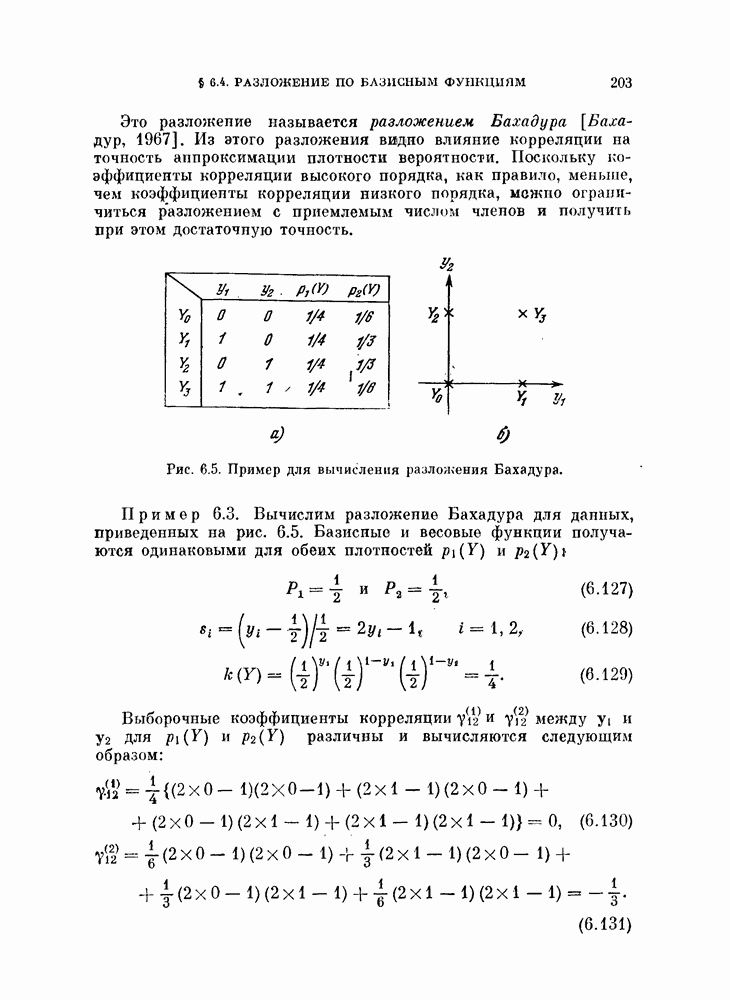
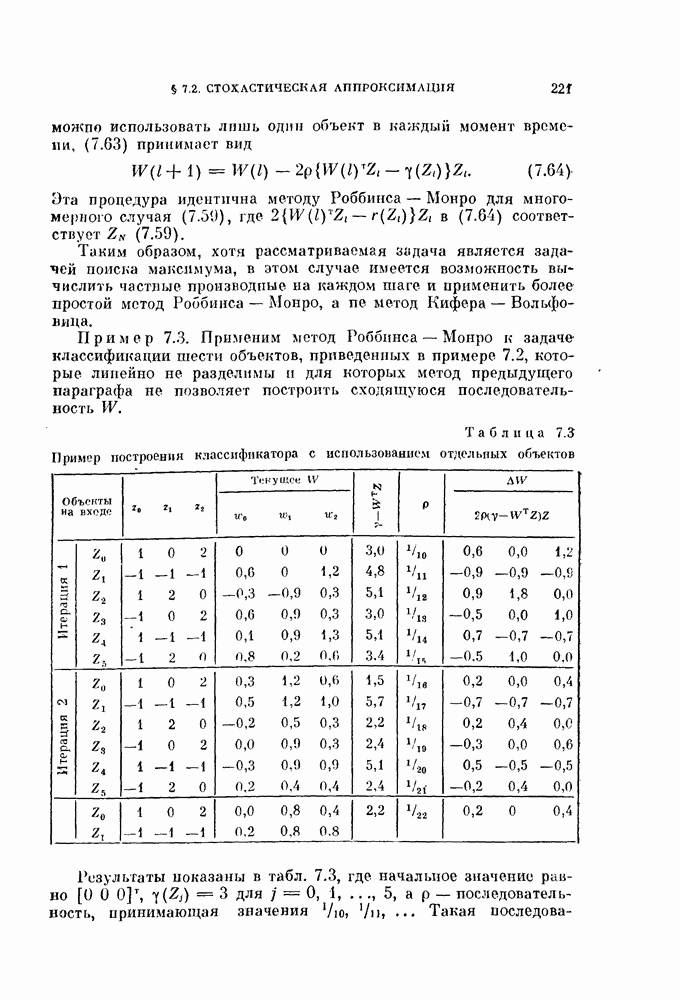
Рис. 4.12. Реализация кусочио-лниейиого классификатора. Наличие заштрихованной области на рис. 4.11, б показывает, что М областей определяемые условиями (4.116), не обязательно покрывают принадлежиости к определенному классу; эту область называют областью отказов. Решающее правило (4.116) состоит из Соответствующая блок-схема изображена на рис. 4.12. Поскольку каждая из параллельных цепей состоит из двух последовательно соединенных элементов, то такой кусочно-линейный классификатор иногда называют двуслойной машиной. Если предположение о выпуклости областей не выполняется, то необходимо определить взаимные пересечения Вероятность ошибки решения для каждого класса 8 можно выразить через
(функция
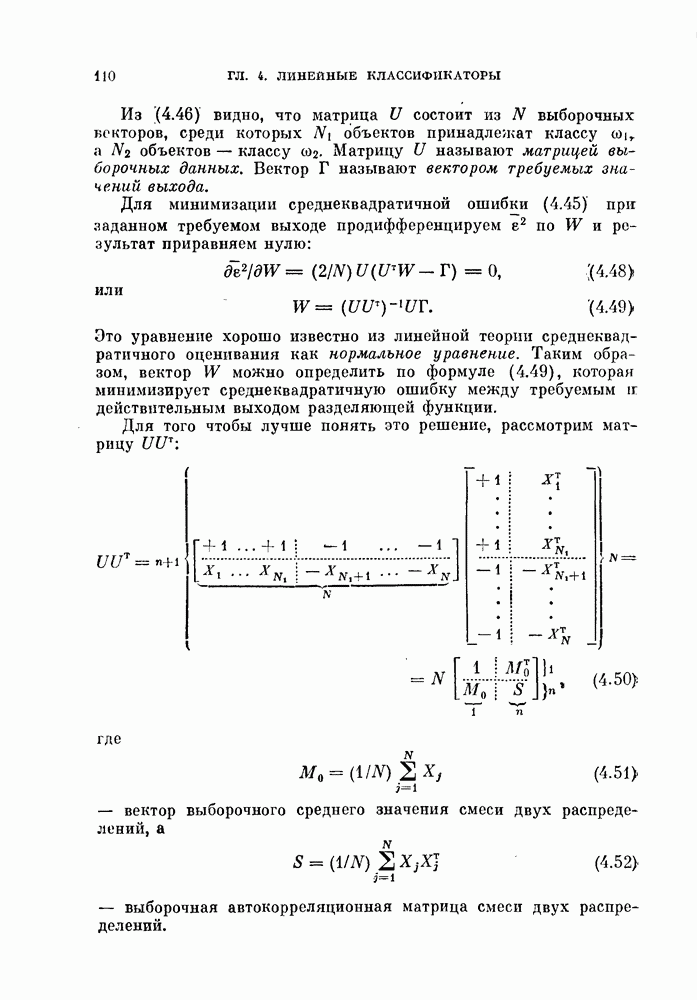
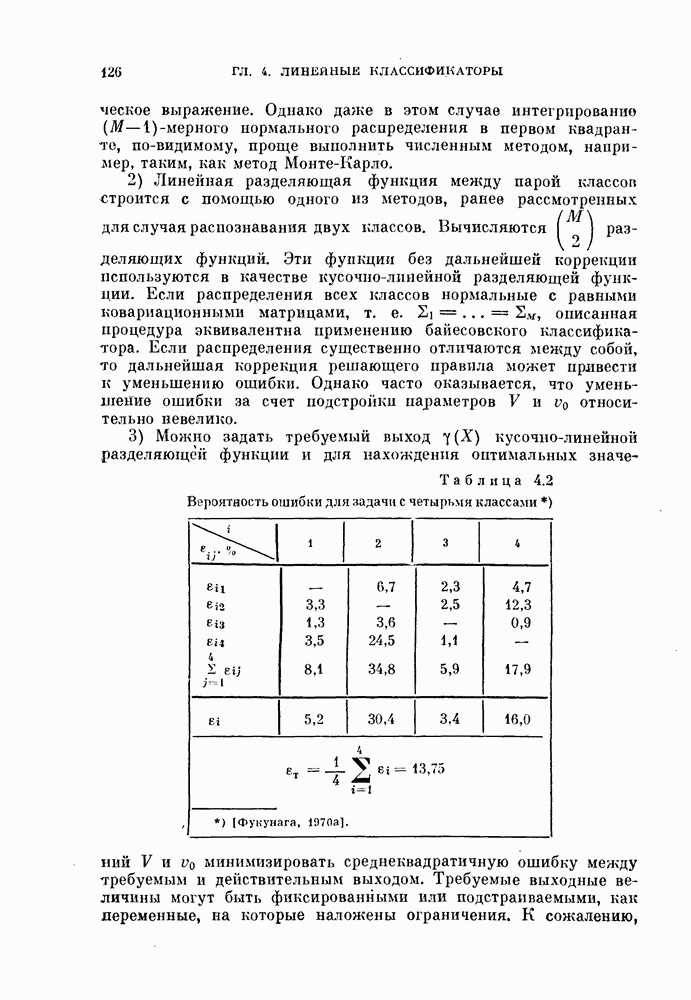
Задача теперь состоит в том, чтобы определить значения Кратко отметим три приближенных метода решения задачи. 1) Можно подстраивать коэффициенты Поскольку для в трудно получить явное математическое выражение, то 8 следует оценивать численными методами всякий раз, когда корректируются параметры V и математическое выражение. Однако даже в этом случае интегрированно 2) Линейная разделяющая функция между парой классов строится с помощью одного из методов, ранее рассмотренных для случая распознавания двух классов. Вычисляются 3) Можно задать требуемый выход Таблица 4.2 Вероятность ошибки для задачи с четырьмя классами
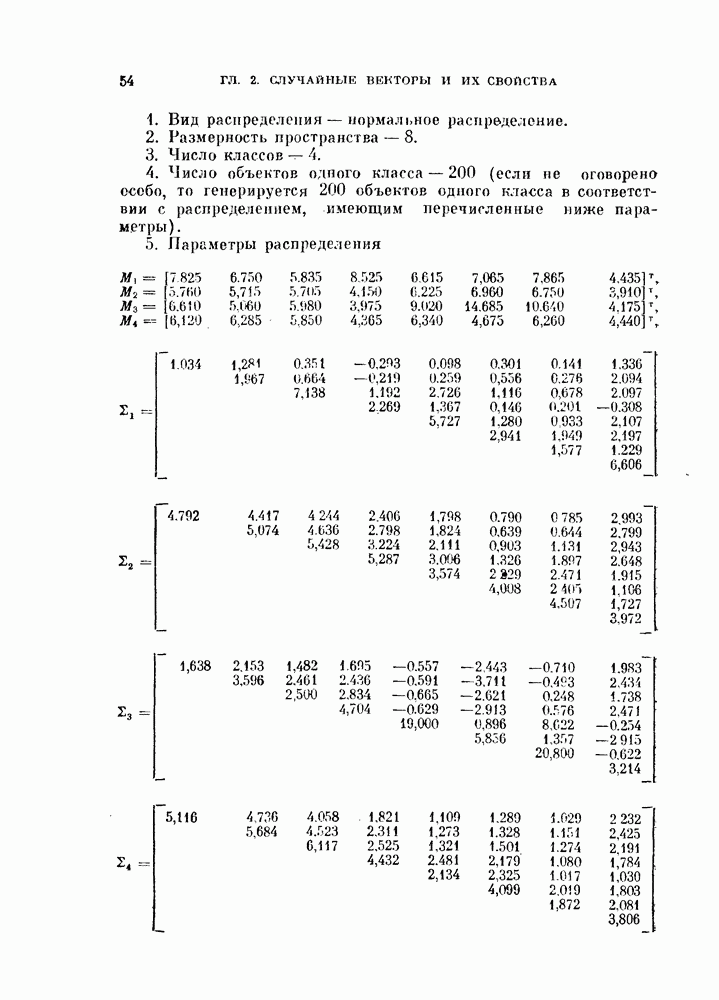
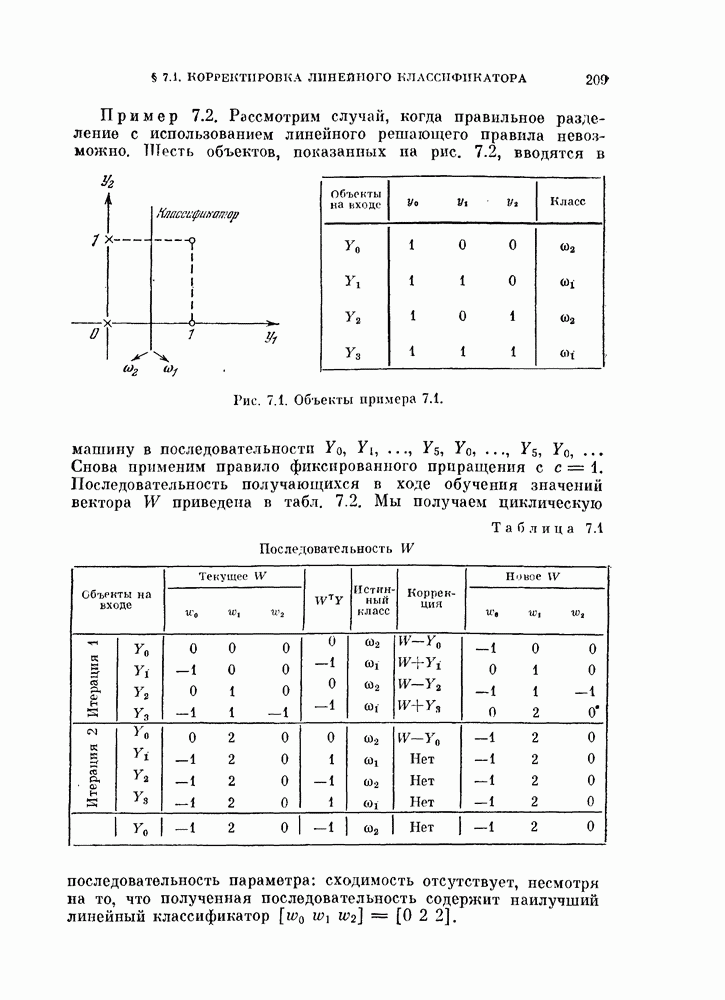
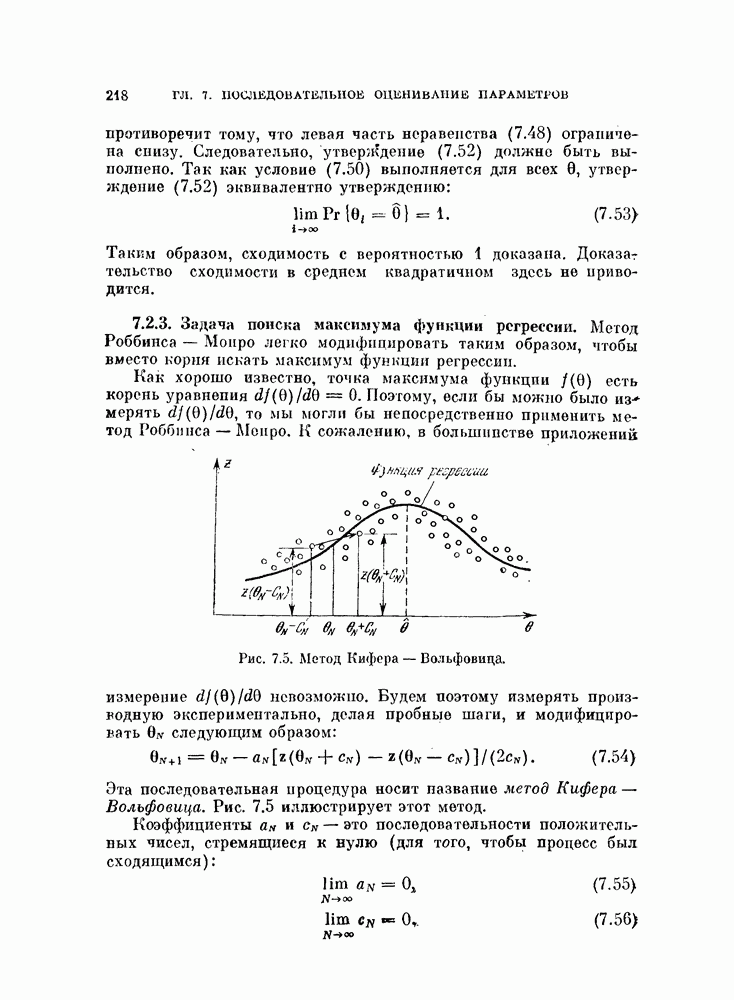
Требуемые выходные величины могут быть фиксированными или подстраиваемыми, как переменные, на которые наложены ограничения. К сожалению, даже для случая кусочно-линейной разделимости классов не существует доказательства сходимости этой процедуры. Пример 4.5. Рассматривается задача с четырьмя классами, каждый из которых характеризуется нормальным распределением вероятностей. Эти распределения представлены в стандартных данных в гл. 2 (см. задания для составления программ). Поскольку все распределения нормальные, то можно для каждой пары классов определить линейный классификатор, оптимальный по критерию минимума вероятности ошибки. В табл. 4.2 для различных пар классов приведены вероятности ошибок
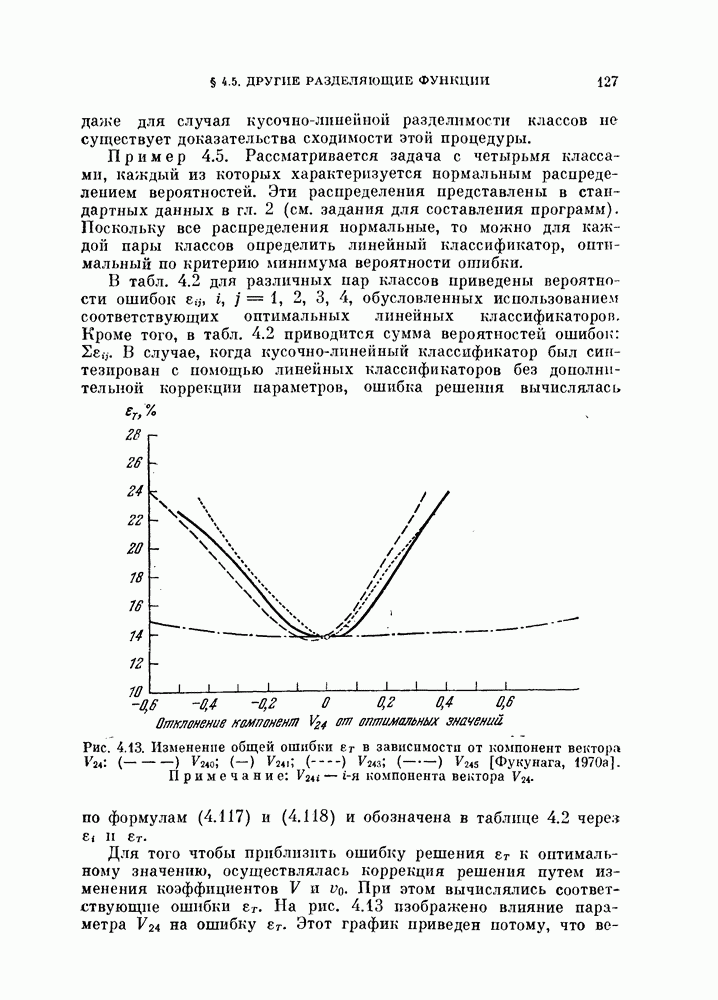
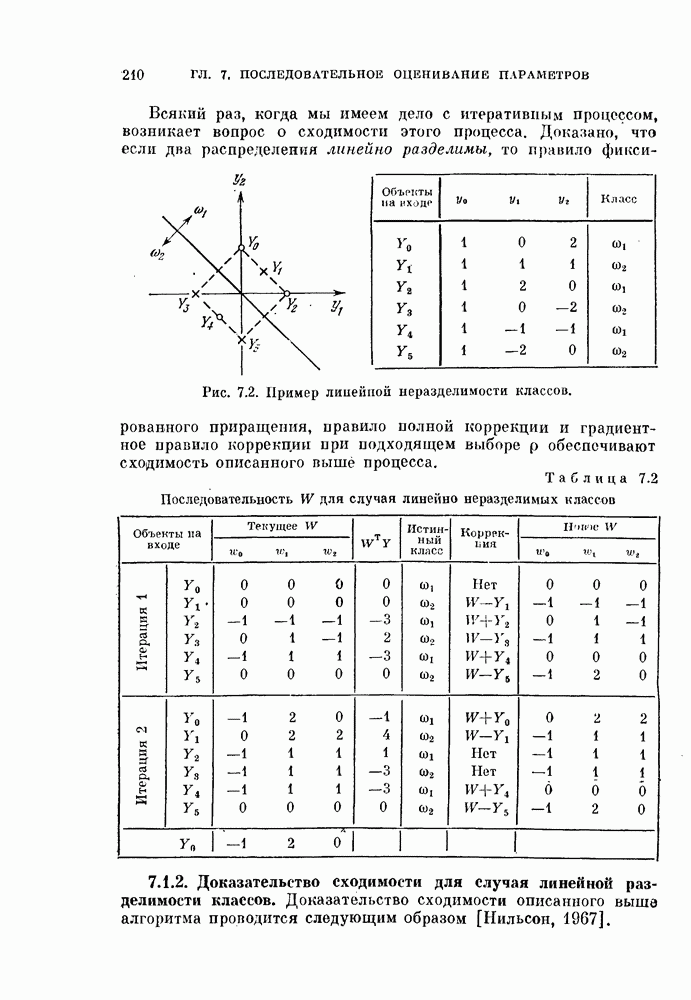
Рис. 4.13. Изменение общей ошибки Для того чтобы приблизить ошибку решения вероятности
|
 |
Оглавление
|






















































































































































































































































































































 выбираются так, чтобы распределение класса
выбираются так, чтобы распределение класса  находилось в области положительных значений линейной функции
находилось в области положительных значений линейной функции  а распределение класса
а распределение класса  — в области отрицательных значений. Из этого требования следует, что
— в области отрицательных значений. Из этого требования следует, что

 может быть просто определена следующим образом:
может быть просто определена следующим образом:

 исключена из рассмотрения).
исключена из рассмотрения).

 пространство. Если объект попадает в эту область, то кусочнолинейный классификатор не может принять решение о его
пространство. Если объект попадает в эту область, то кусочнолинейный классификатор не может принять решение о его
 линейных разделяющих функций и логического элемента
линейных разделяющих функций и логического элемента  с
с  входами, которые принимают значения
входами, которые принимают значения 
 гиперплоскостей и строить решающее правило в соответствии с этими пересечениями. Одиако при этом классификатор становится весьма сложным для решения практических задач. Поэтому в данной книге рассмотрение будет ограничено только выпуклыми областями.
гиперплоскостей и строить решающее правило в соответствии с этими пересечениями. Одиако при этом классификатор становится весьма сложным для решения практических задач. Поэтому в данной книге рассмотрение будет ограничено только выпуклыми областями.
 -мерную функцию распределения вероятности:
-мерную функцию распределения вероятности:

 — исключена из рассмотрения). Тогда общая ошибка решения
— исключена из рассмотрения). Тогда общая ошибка решения

 для данного множества М распределений, при наличии информации о структуре кусочно-линейного классификатора. Вследствие сложности этой задачи ее решение не является таким наглядным, как для линейного классификатора.
для данного множества М распределений, при наличии информации о структуре кусочно-линейного классификатора. Вследствие сложности этой задачи ее решение не является таким наглядным, как для линейного классификатора.
 так, чтобы минимизировать вероятность ошибки решения
так, чтобы минимизировать вероятность ошибки решения  определяемую формулой (4.118).
определяемую формулой (4.118).
 Если Случайные величины X для всех классов распределены по нормальному закону, то возможно некоторое упрощение решения, так как а этом случае разделяющие функции
Если Случайные величины X для всех классов распределены по нормальному закону, то возможно некоторое упрощение решения, так как а этом случае разделяющие функции  также распределены нормально, а для
также распределены нормально, а для  существует явное
существует явное
 -мерного нормального распределения в первом квадранте, по-видимому, проще выполнить численным методом, например, таким, как метод Монте-Карло.
-мерного нормального распределения в первом квадранте, по-видимому, проще выполнить численным методом, например, таким, как метод Монте-Карло.
 разделяющих функций. Эти функции без дальнейшей коррекции используются в качестве кусочно-линейной разделяющей функции. Если распределения всех классов нормальные с равными ковариационными матрицами, т. е.
разделяющих функций. Эти функции без дальнейшей коррекции используются в качестве кусочно-линейной разделяющей функции. Если распределения всех классов нормальные с равными ковариационными матрицами, т. е.  описанная процедура эквивалентна применению байесовского классификатора. Если распределения существенно отличаются между собой, то дальнейшая коррекция решающего правила может прдвести к уменьшению ошибки. Однако часто оказывается, что уменьшение ошибки за счет подстройки параметров
описанная процедура эквивалентна применению байесовского классификатора. Если распределения существенно отличаются между собой, то дальнейшая коррекция решающего правила может прдвести к уменьшению ошибки. Однако часто оказывается, что уменьшение ошибки за счет подстройки параметров  относительно невелико.
относительно невелико.
 кусочно-линейной разделяющей функции и для нахождения оптимальных значений
кусочно-линейной разделяющей функции и для нахождения оптимальных значений  минимизировать среднеквадратичную ошибку между требуемым и действительным выходом.
минимизировать среднеквадратичную ошибку между требуемым и действительным выходом.

 обусловленных использованием соответствующих оптимальных линейных классификаторов. Кроме того, в табл. 4.2 приводится сумма вероятностен ошибок:
обусловленных использованием соответствующих оптимальных линейных классификаторов. Кроме того, в табл. 4.2 приводится сумма вероятностен ошибок:  . В случае, когда кусочно-линейный классификатор был синтезирован с помощью линейных классификаторов без дополнительной коррекции параметров, ошибка решения вычислялась по формулам (4.117) и (4.118) и обозначена в таблице 4.2 через
. В случае, когда кусочно-линейный классификатор был синтезирован с помощью линейных классификаторов без дополнительной коррекции параметров, ошибка решения вычислялась по формулам (4.117) и (4.118) и обозначена в таблице 4.2 через  .
.

 в зависимости от компонент вектора
в зависимости от компонент вектора  [Фукунага, 1970а]. Примечание:
[Фукунага, 1970а]. Примечание:  компонента вектора
компонента вектора 
 к оптимальному значению, осуществлялась коррекция решения путем изменения коэффициентов
к оптимальному значению, осуществлялась коррекция решения путем изменения коэффициентов  При этом вычислялись соответствующие ошибки
При этом вычислялись соответствующие ошибки  . На рис. 4.13 изображено влияние параметра
. На рис. 4.13 изображено влияние параметра  на ошибку
на ошибку  . Этот график приведен потому, что
. Этот график приведен потому, что
 являются преобладающими слагаемыми в
являются преобладающими слагаемыми в  Как видно из рис. 4.13, оптимальное значение
Как видно из рис. 4.13, оптимальное значение  смещено относительно значения
смещено относительно значения  , соответствующего линейному классификатору для классов
, соответствующего линейному классификатору для классов  Однако при этом изменение ошибки
Однако при этом изменение ошибки  находится в пределах 0,3%. Влияние же других компонент вектора V намного меньше. Этот результат оправдывает для данного частного примера применение совокупности оптимальных классификаторов без дополнительной коррекции параметров.
находится в пределах 0,3%. Влияние же других компонент вектора V намного меньше. Этот результат оправдывает для данного частного примера применение совокупности оптимальных классификаторов без дополнительной коррекции параметров.