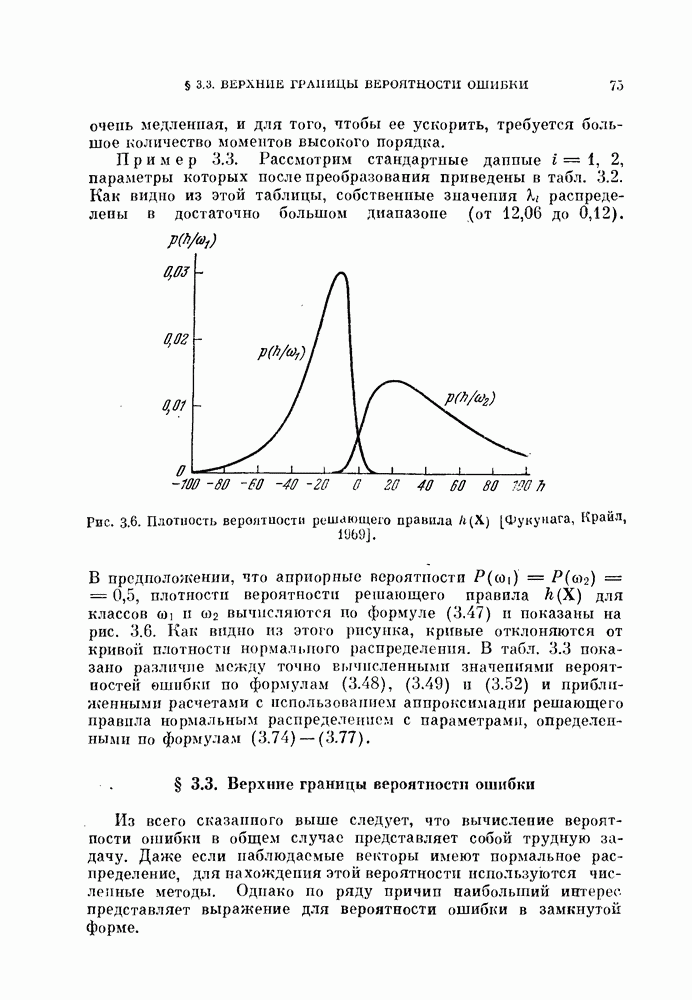
5.4.2. Оценка вероятности ошибки, когда классификатор заранее не задан.
Когда даны  объектов в случае отсутствия классификатора, то можно использовать эти объекты как для проектирования классификатора, так и для проверки его качества. Очевидно, оцениваемая вероятность ошибки зависит от данных распределений и используемого классификатора.
объектов в случае отсутствия классификатора, то можно использовать эти объекты как для проектирования классификатора, так и для проверки его качества. Очевидно, оцениваемая вероятность ошибки зависит от данных распределений и используемого классификатора.
Для упрощения задачи предположим в этом параграфе, что всегда используется байесовский классификатор, минимизирующий вероятность ошибки. Тогда минимальную вероятность ошибки байесовского классификатора, которую необходимо оценить, можно рассматривать как фиксированный параметр при заданных распределениях. Кроме того, эта вероятность является минимальной для данных распределений.  Как правило, вероятность ошибки
Как правило, вероятность ошибки  является функцией двух аргументов [Хиле, 1966]:
является функцией двух аргументов [Хиле, 1966]:

где  — множество параметров распределений, используемых для синтеза байесовского классификатора, а
— множество параметров распределений, используемых для синтеза байесовского классификатора, а  — множество параметров распределений, используемых для проверки его качества.
— множество параметров распределений, используемых для проверки его качества.
Оптимальная классификация объектов, характеризуемых распределением с параметром  осуществляется байесовским классификатором, который построен для распределения с параметром
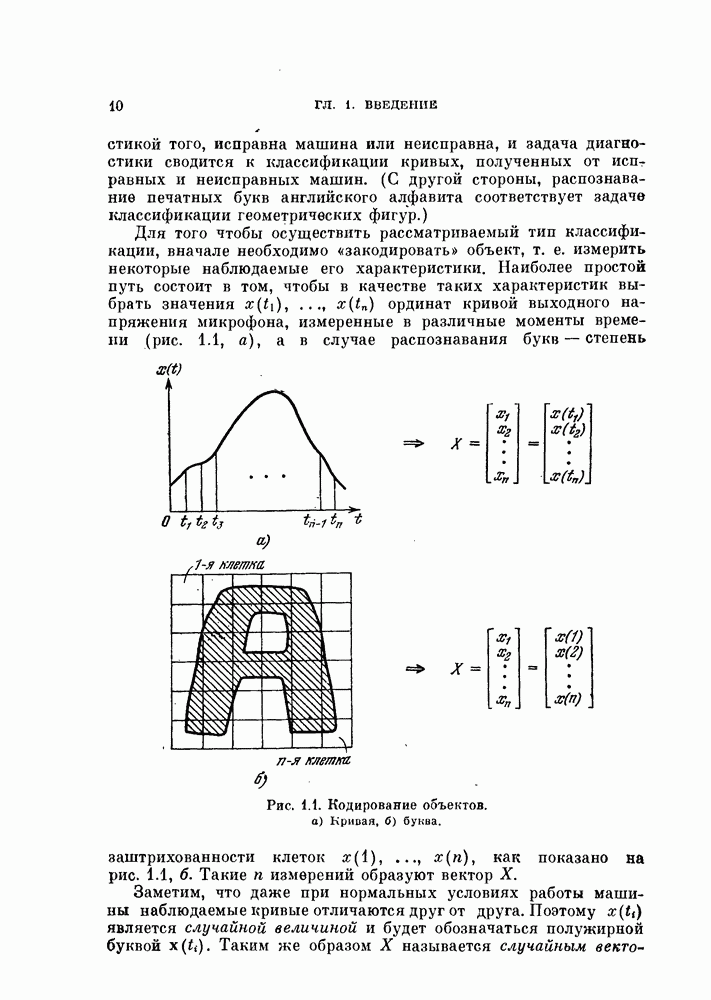
осуществляется байесовским классификатором, который построен для распределения с параметром  Поэтому
Поэтому

Пусть для данной задачи  — вектор истинных параметров,
— вектор истинных параметров,  его оценка. Таким образом, оценка
его оценка. Таким образом, оценка  является случайным вектором и
является случайным вектором и  Для любого конкретного значения оценки
Для любого конкретного значения оценки  на основании (5.134) справедливы неравенства
на основании (5.134) справедливы неравенства

Выполнив над обеими частями этих неравенств операцию математического ожидания, получим

и

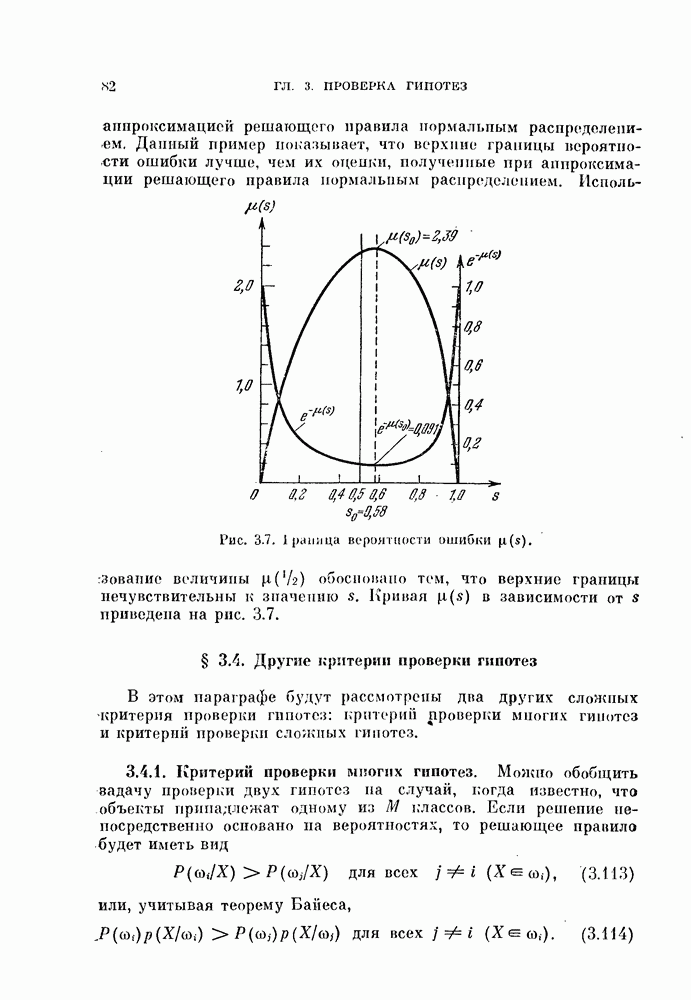
Если

то для вероятности ошибки байесовского классификатора  имеет место двустороннее ограничение
имеет место двустороннее ограничение

Левое неравенство (5.140) основано на предположении (5.139) и не доказано для произвольных истинных плотностей вероятности. Однако это неравенство можно проверить многими экспериментальными способами. Из выражения (3.7) видно, что равенство (5.139) выполняется тогда, когда оценка проверяемой плотности вероятности, основанная на  наблюдениях, является несмещенной и классификатор заранее фиксирован. Следует отметить, что нижняя граница менее важна, чем верхняя.
наблюдениях, является несмещенной и классификатор заранее фиксирован. Следует отметить, что нижняя граница менее важна, чем верхняя.
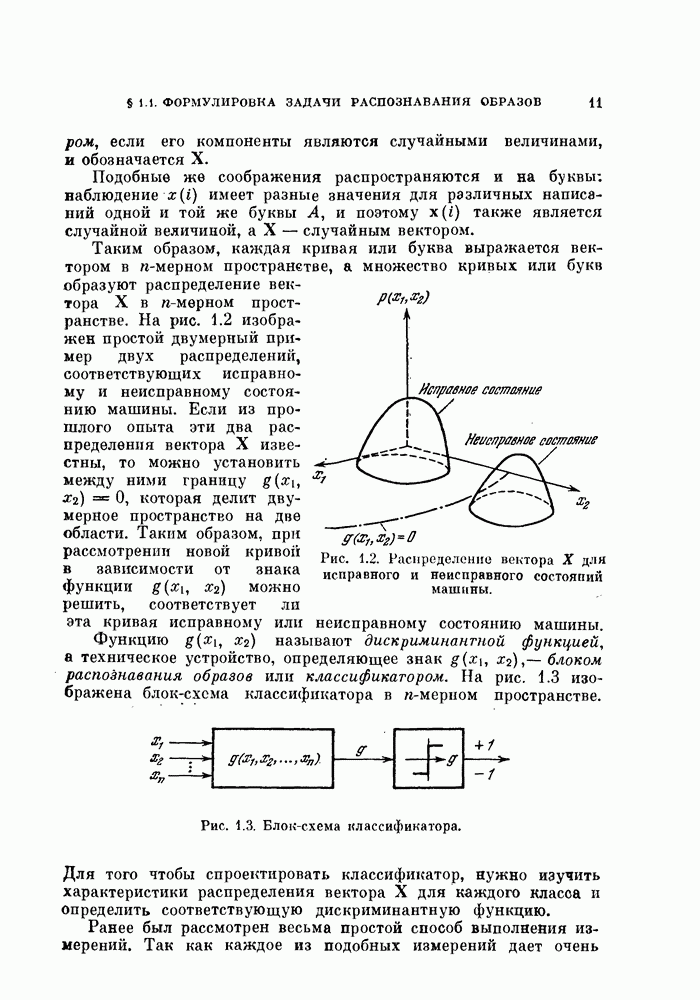
Обе границы вероятности ошибки  можно интерпретировать следующим образом:
можно интерпретировать следующим образом:
1.  : одни и те же
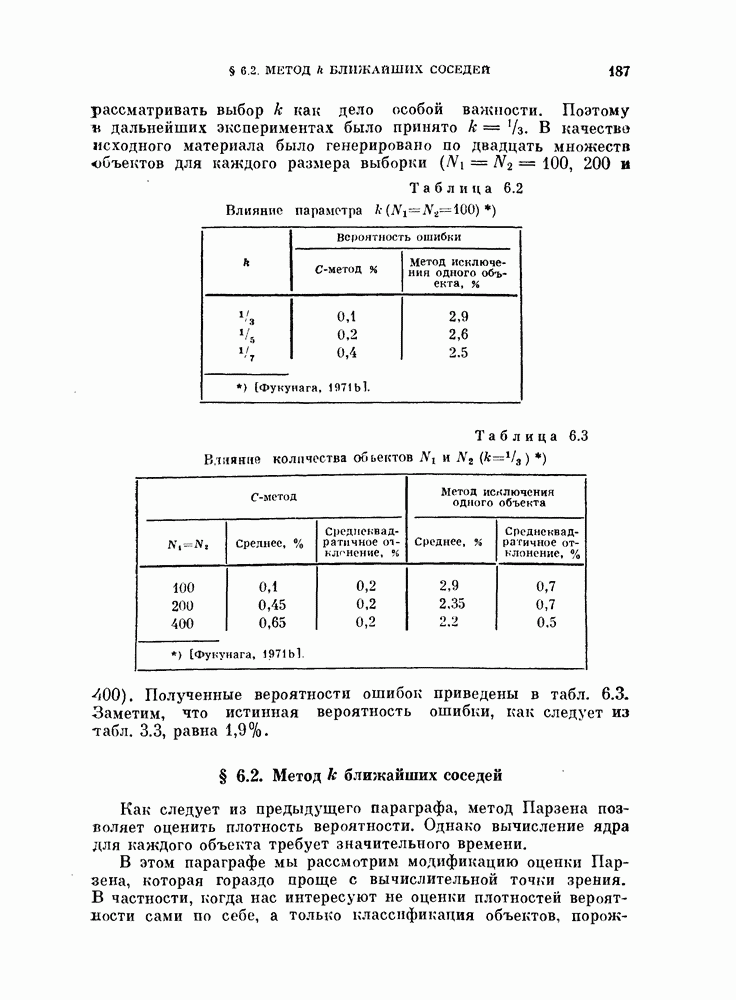
: одни и те же  объектов используются и для синтеза байесовского классификатора, и для последующей классификации. Этот случай назовем С-методом. Из (5.140) следует, что С-метод дает, вообще говоря, заниженную оценку вероятности ошибки.
объектов используются и для синтеза байесовского классификатора, и для последующей классификации. Этот случай назовем С-методом. Из (5.140) следует, что С-метод дает, вообще говоря, заниженную оценку вероятности ошибки.
2.  : для синтеза байесовского классификатора используется
: для синтеза байесовского классификатора используется  объектов, а классифицируются объекты из истинных распределений. Эту процедуру называют
объектов, а классифицируются объекты из истинных распределений. Эту процедуру называют  -методом. [
-методом. [ -метод также дает смещенную оценку вероятности ошибки во. Это смещение таково, что его математическое ожидание является верхней границей вероятности ошибки. Объекты из истинного распределения могут быть заменены объектами, которые не были использованы для синтеза классификатора и независимы от объектов, по которым классификатор был синтезирован. Когда число классифицируемых объектов увеличивается, их распределение стремится к истинному распределению.
-метод также дает смещенную оценку вероятности ошибки во. Это смещение таково, что его математическое ожидание является верхней границей вероятности ошибки. Объекты из истинного распределения могут быть заменены объектами, которые не были использованы для синтеза классификатора и независимы от объектов, по которым классификатор был синтезирован. Когда число классифицируемых объектов увеличивается, их распределение стремится к истинному распределению.
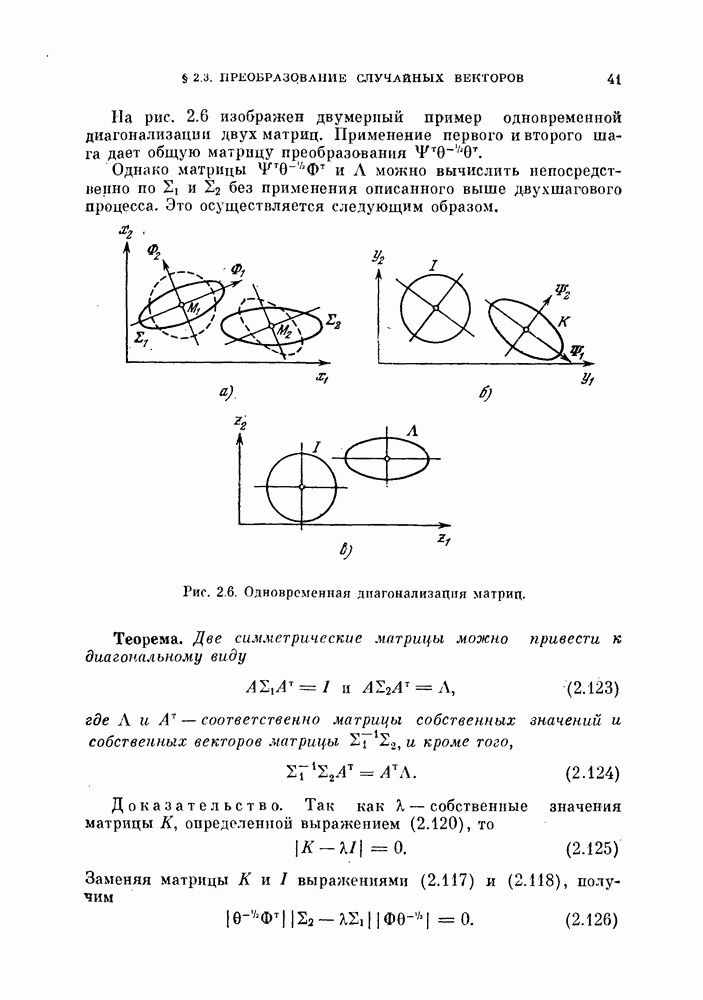
Для реализации  -метода имеется много возможностей. Здесь мы рассмотрим две типовые процедуры.
-метода имеется много возможностей. Здесь мы рассмотрим две типовые процедуры.
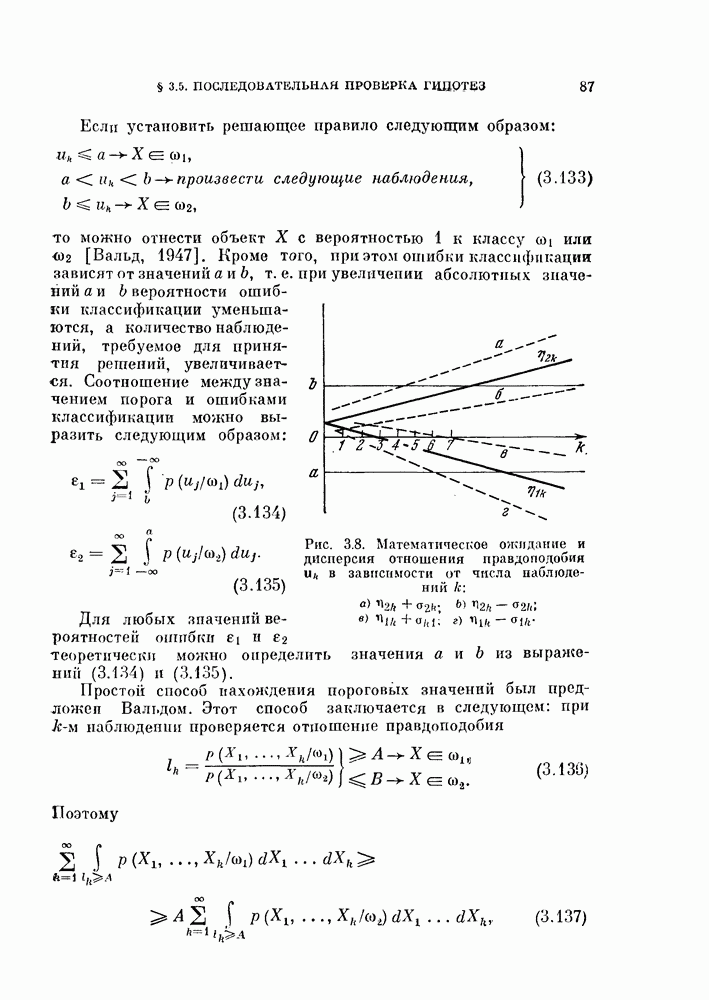
1. Метод разбиения выборкц. Вначале имеющиеся объекты разбивают на две группы и используют одну из них для синтеза классификатора, а другую — для проверки его качества. Этот метод называют методом разбиения выборки. Основной вопрос, характерный для этого метода, заключается в том, как разделить объекты. Для ответа на этот вопрос изучим в следующем разделе влияние числа «обучающих» и числа «экзаменационных» объектов на дисперсию оценки ошибки классификации.
2. Метод исключения одного объекта. Во втором методе попытаемся использовать имеющиеся объекты более эффективно, чем в методе разбиения выборки. Для оценки  необходимо, вообще говоря, извлечь много выборок объектов и синтезировать большое число классификаторов, проверить качество каждого классификатора с помощью неиспользованных объектов и определить среднее значение показателя качества.
необходимо, вообще говоря, извлечь много выборок объектов и синтезировать большое число классификаторов, проверить качество каждого классификатора с помощью неиспользованных объектов и определить среднее значение показателя качества.
Подобная процедура может быть выполнена путем использования только имеющихся  объектов следующим образом
объектов следующим образом












































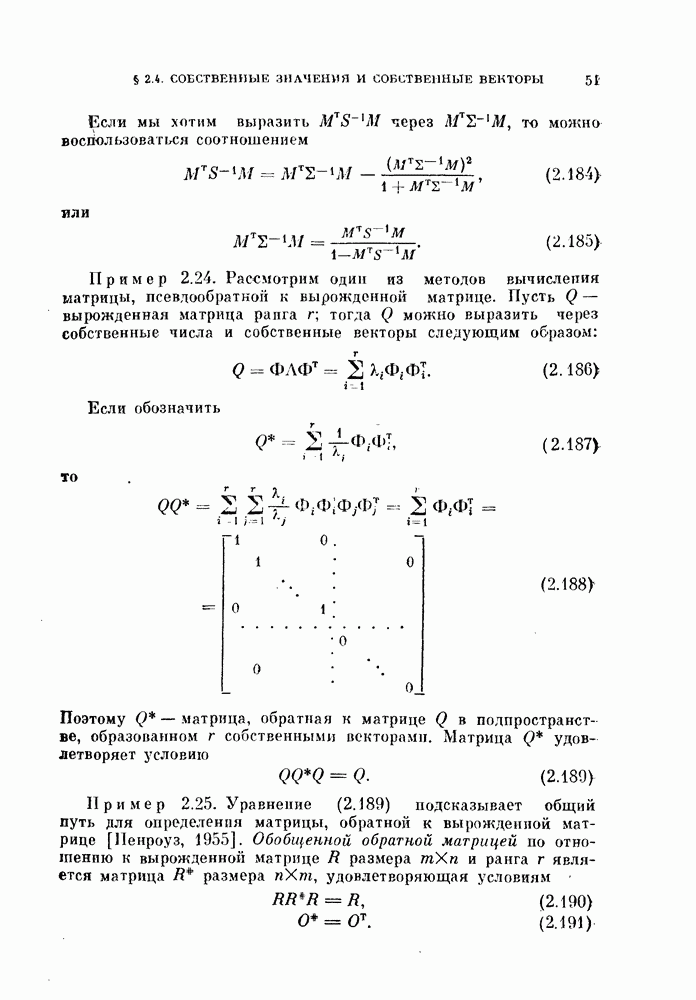








































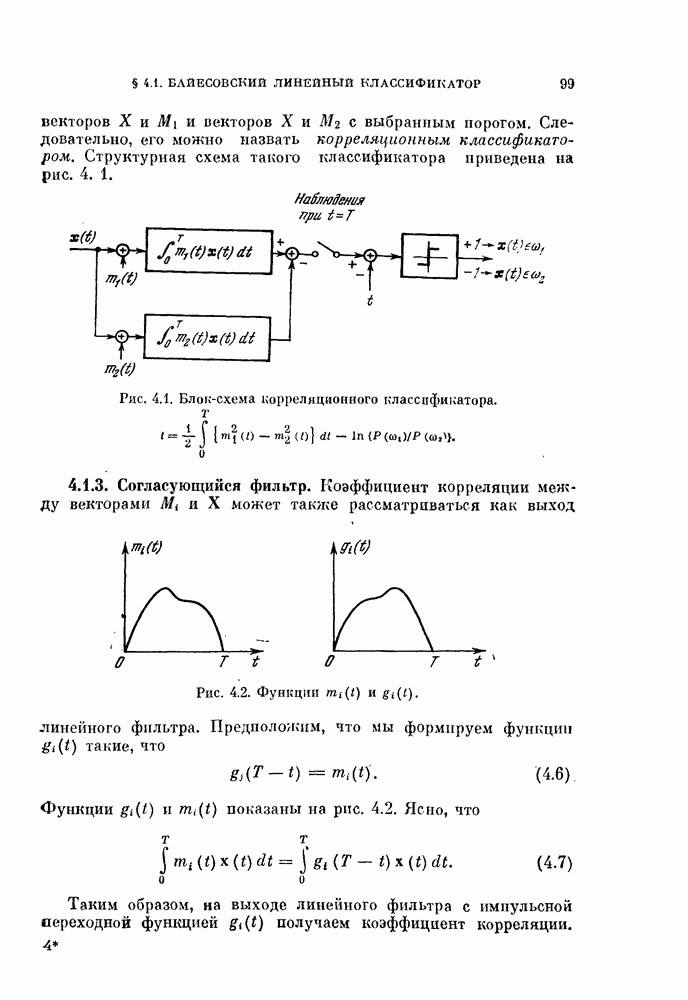


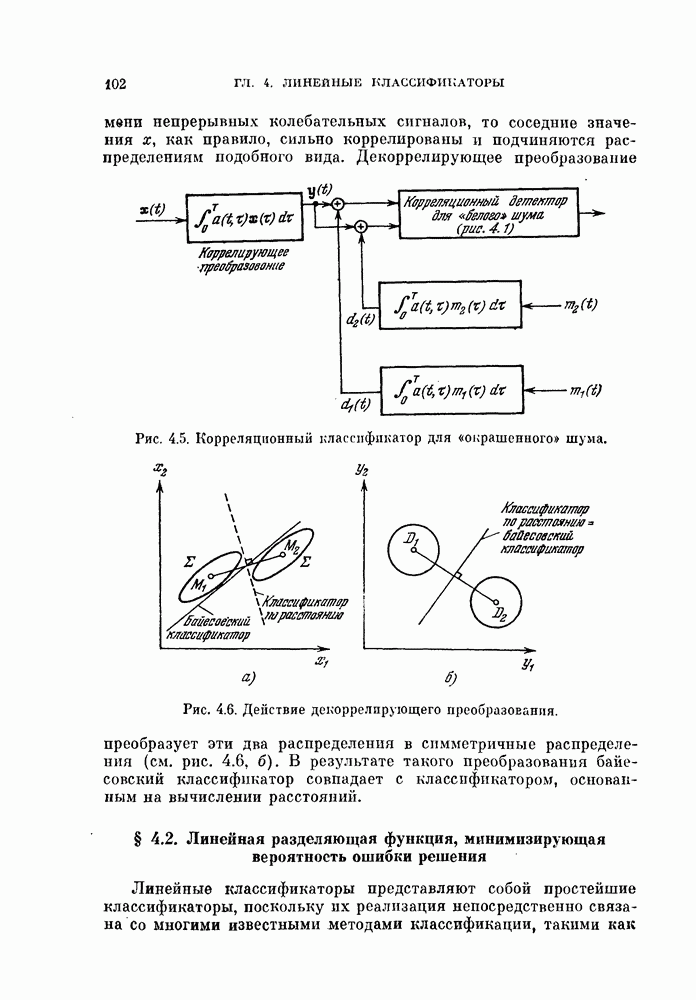




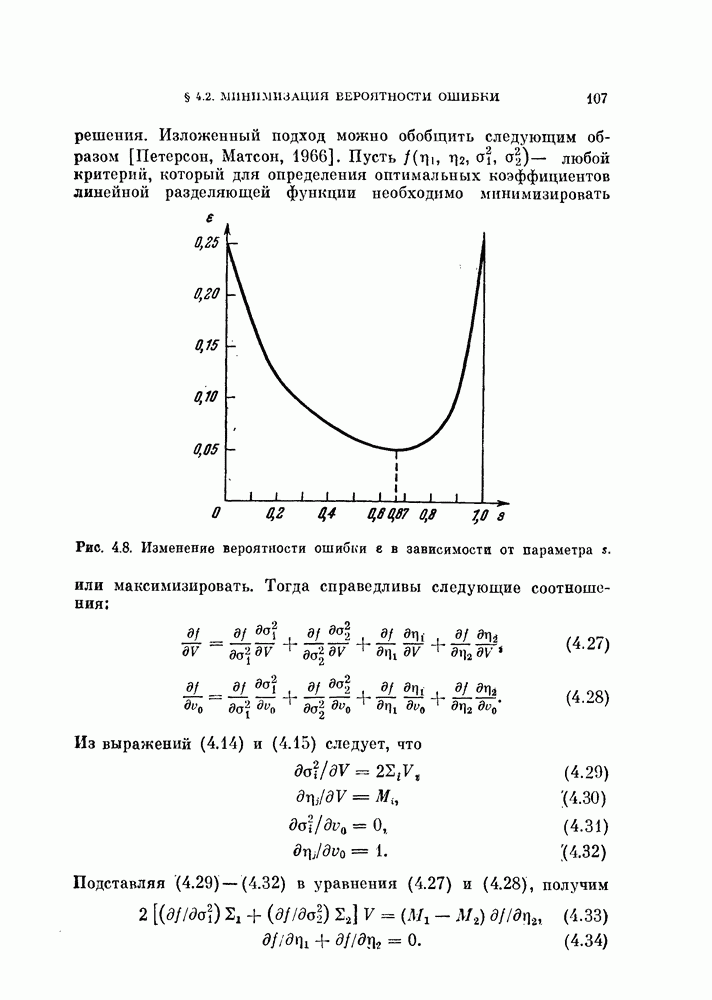


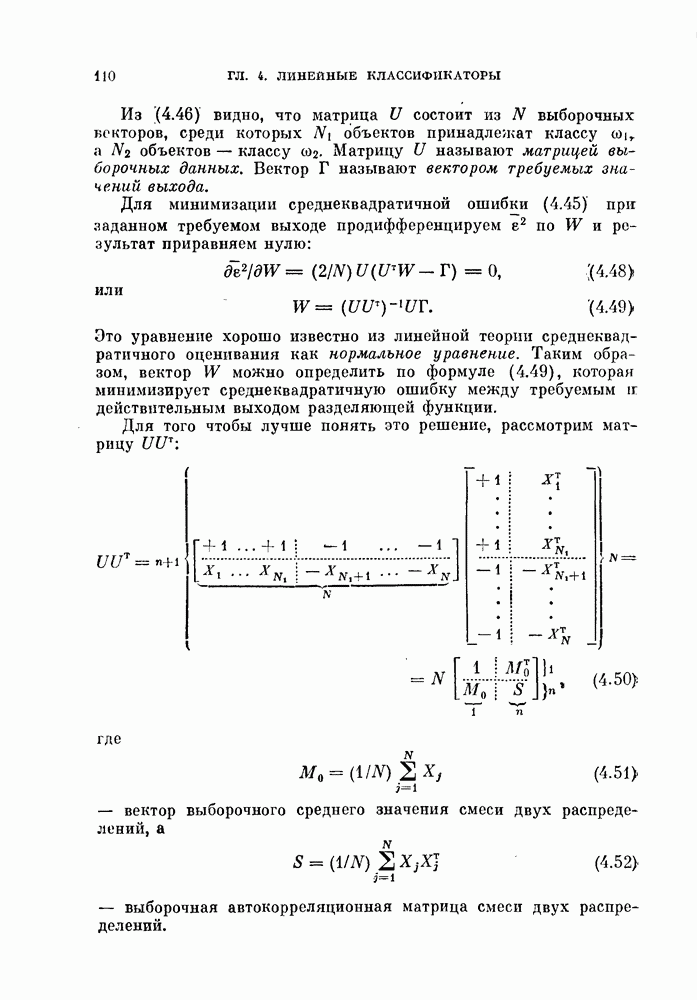



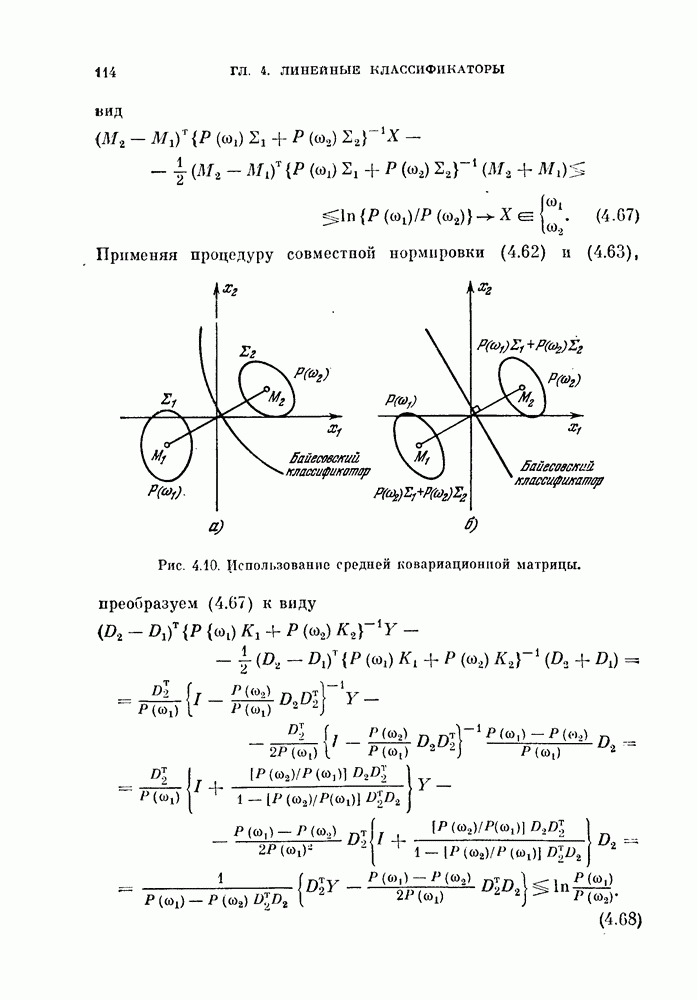











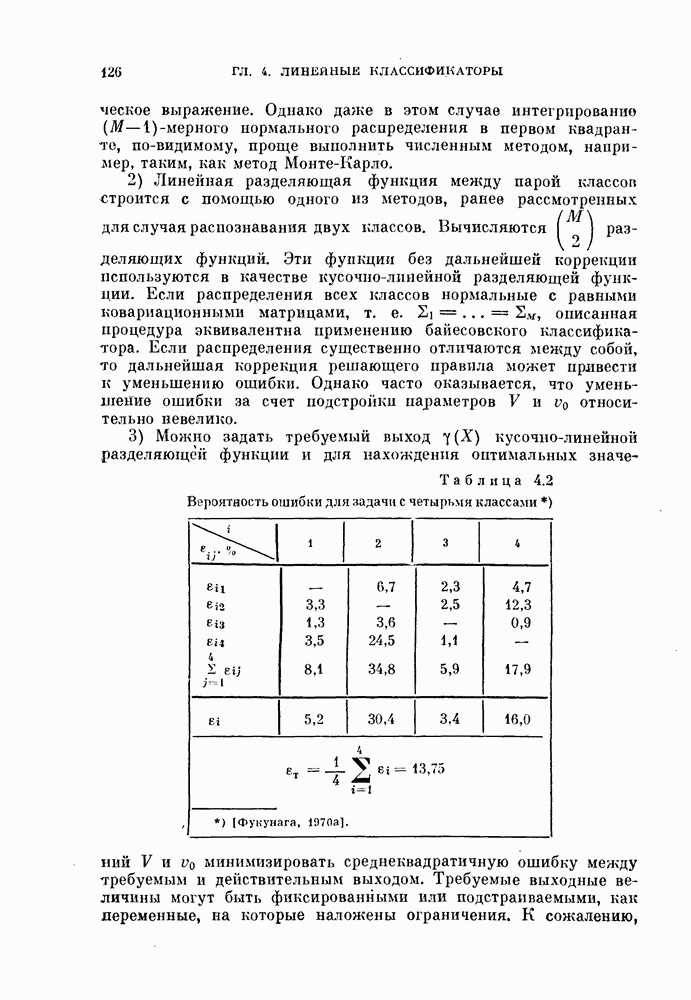
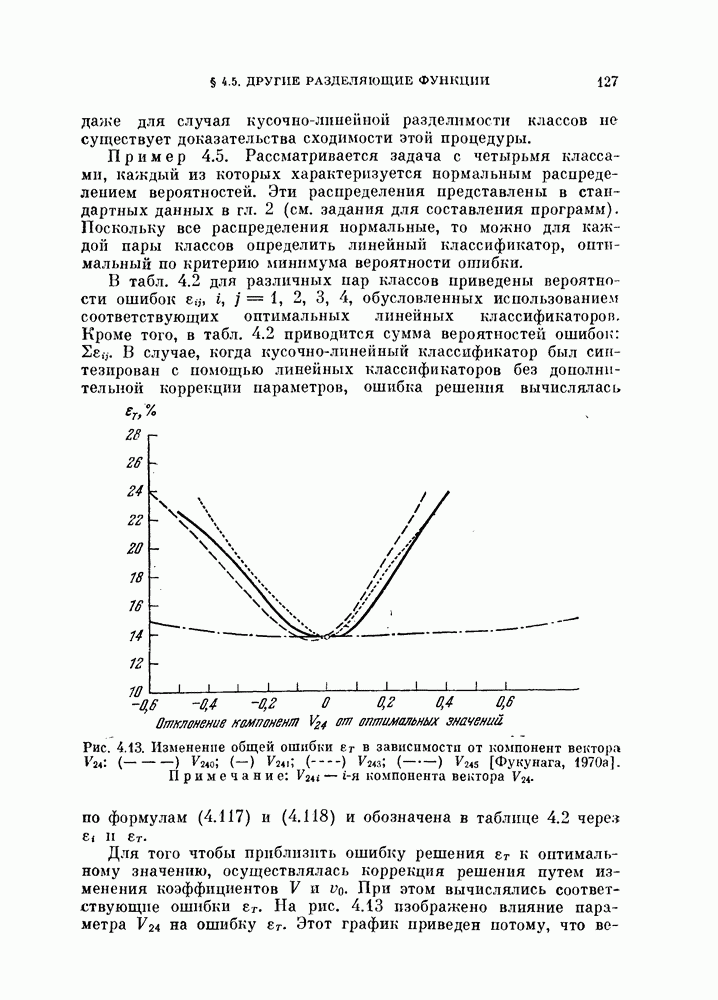


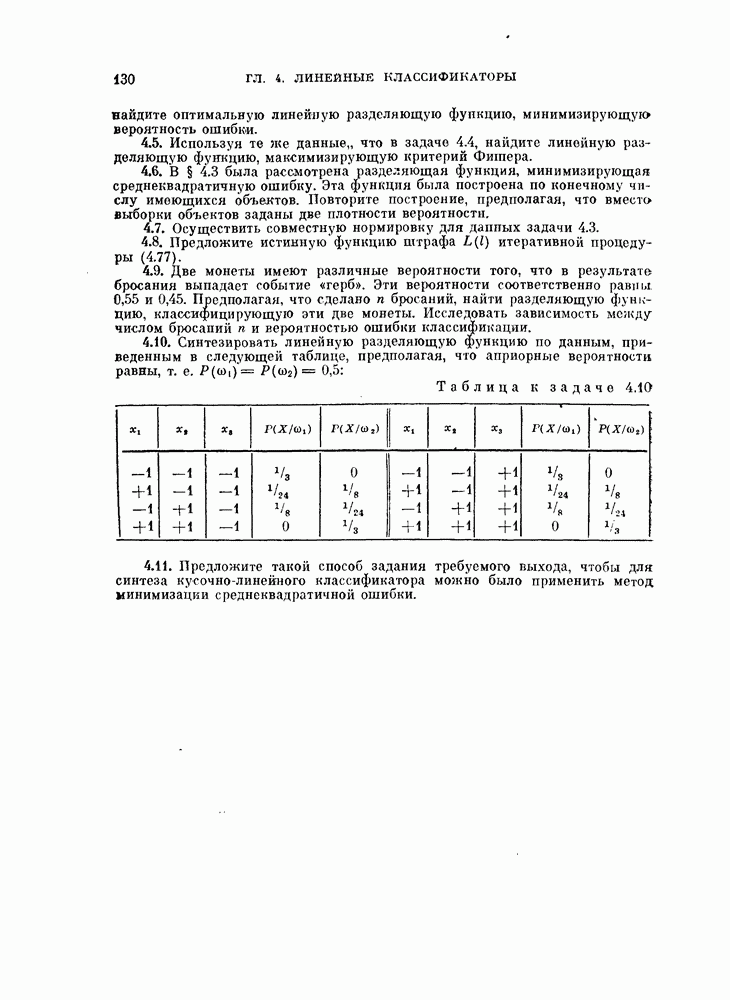

























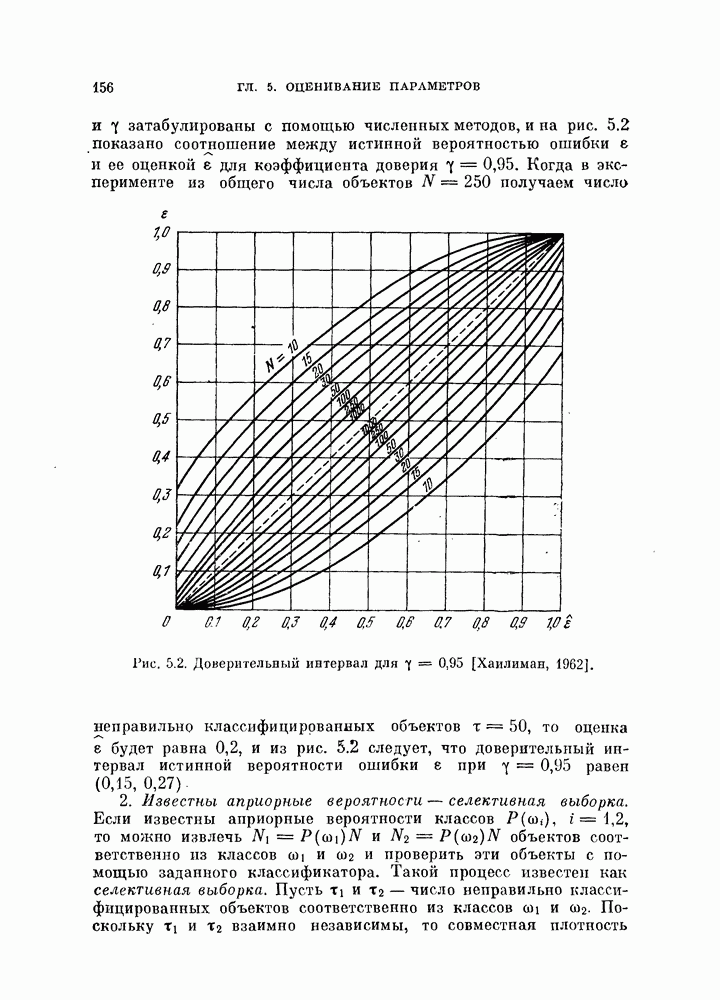






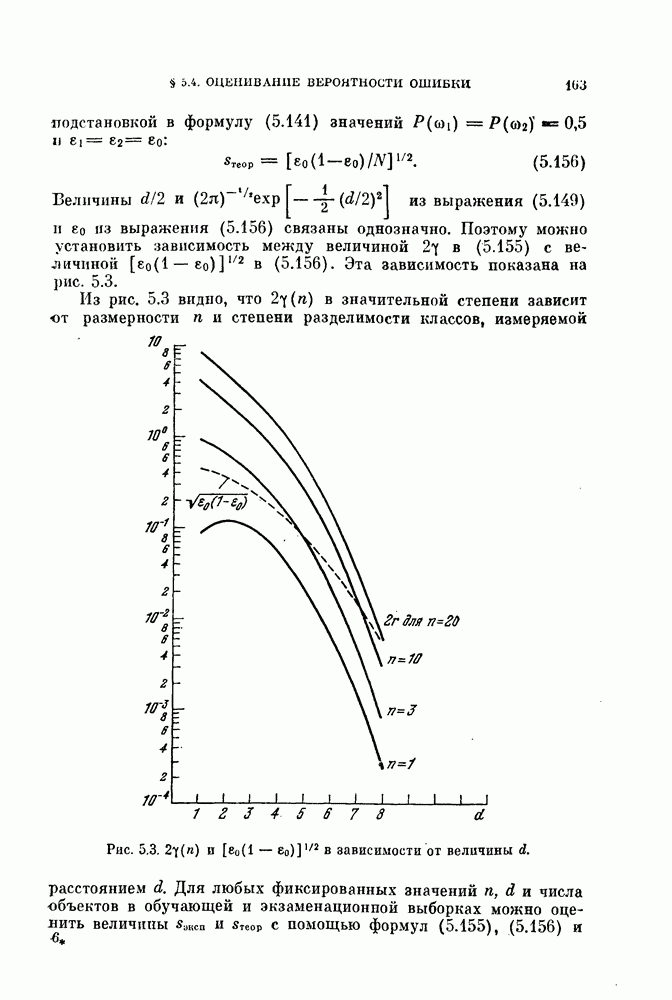
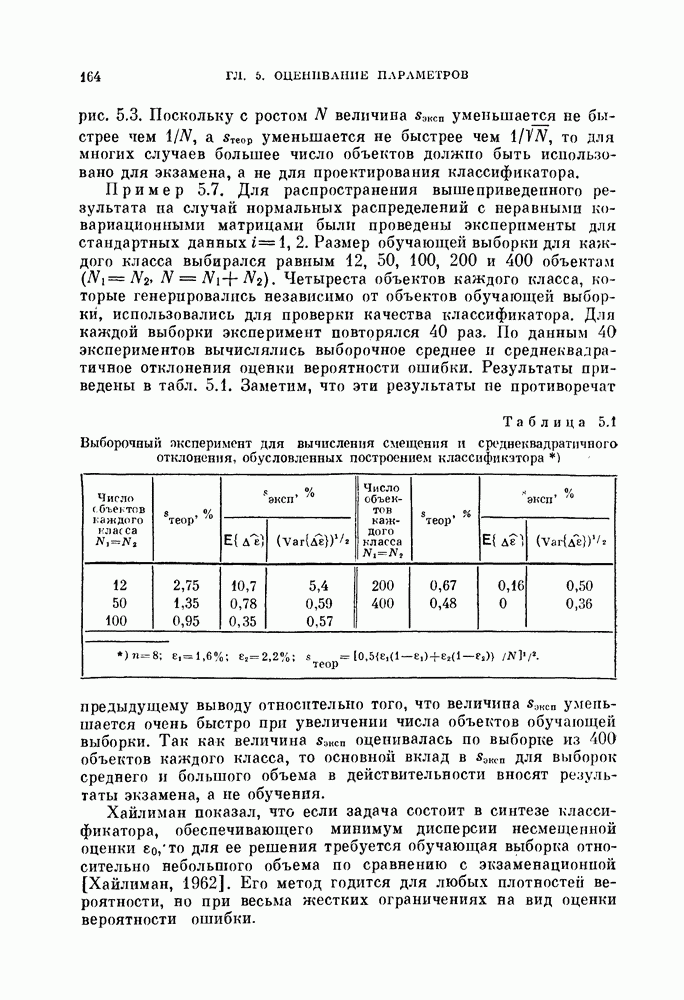











































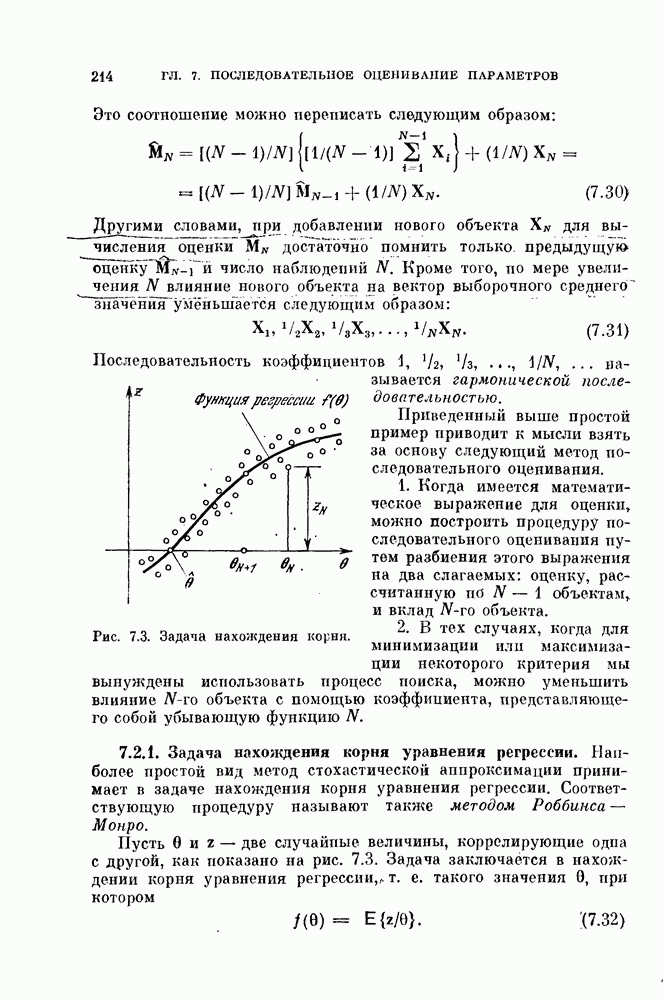



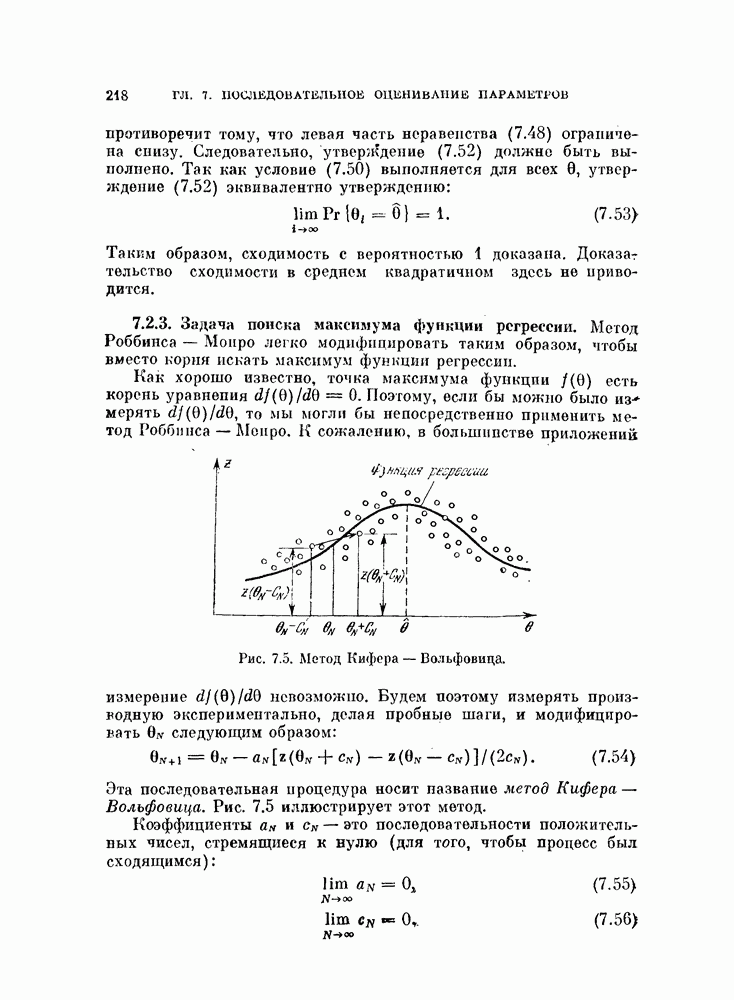

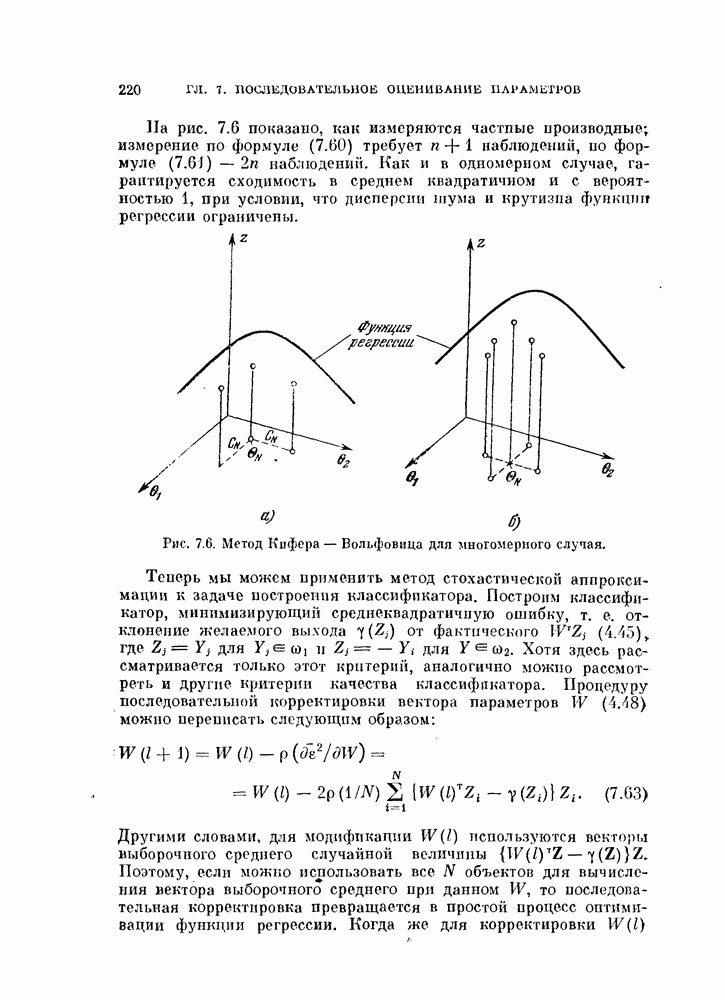
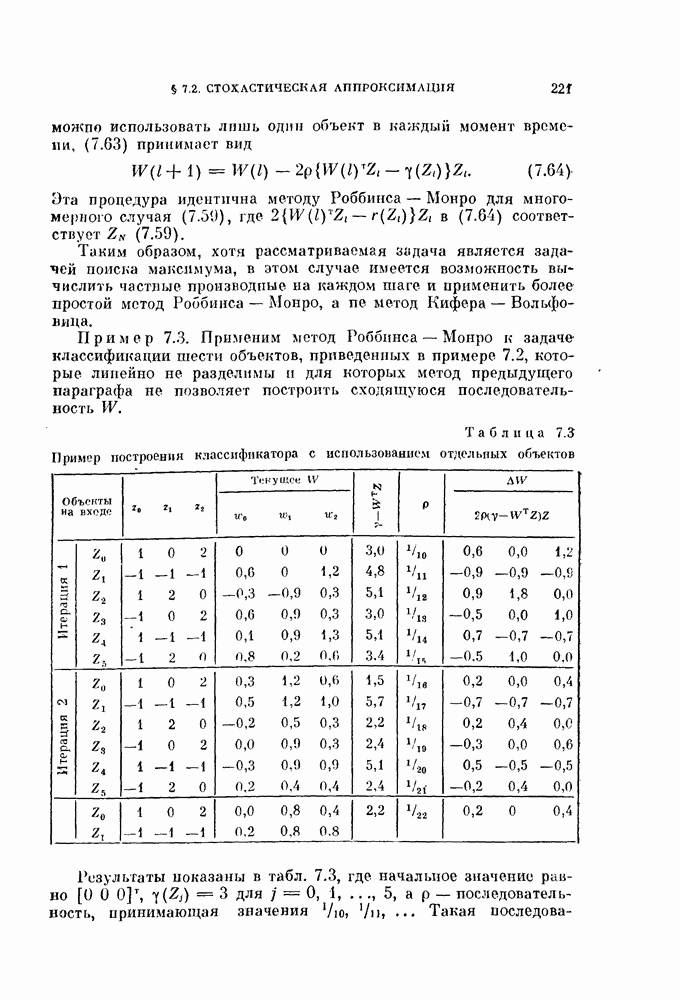


























































































































 объектам, и классифицируется неиспользованный объект. Затем эту процедуру повторяют
объектам, и классифицируется неиспользованный объект. Затем эту процедуру повторяют  раз и подсчитывают число неправильно классифицированных объектов. Эту процедуру называют методом исключения одного объекта. Этот метод позволяет эффективно использовать имеющиеся объекты и оценивать
раз и подсчитывают число неправильно классифицированных объектов. Эту процедуру называют методом исключения одного объекта. Этот метод позволяет эффективно использовать имеющиеся объекты и оценивать  Один из недостатков этого метода заключается в том, что приходится синтезировать
Один из недостатков этого метода заключается в том, что приходится синтезировать  классификаторов. Однако такая задача легко разрешима для случая нормальных распределений с помощью процедуры, которая будет рассмотрена в одном из следующих разделов.
классификаторов. Однако такая задача легко разрешима для случая нормальных распределений с помощью процедуры, которая будет рассмотрена в одном из следующих разделов.
