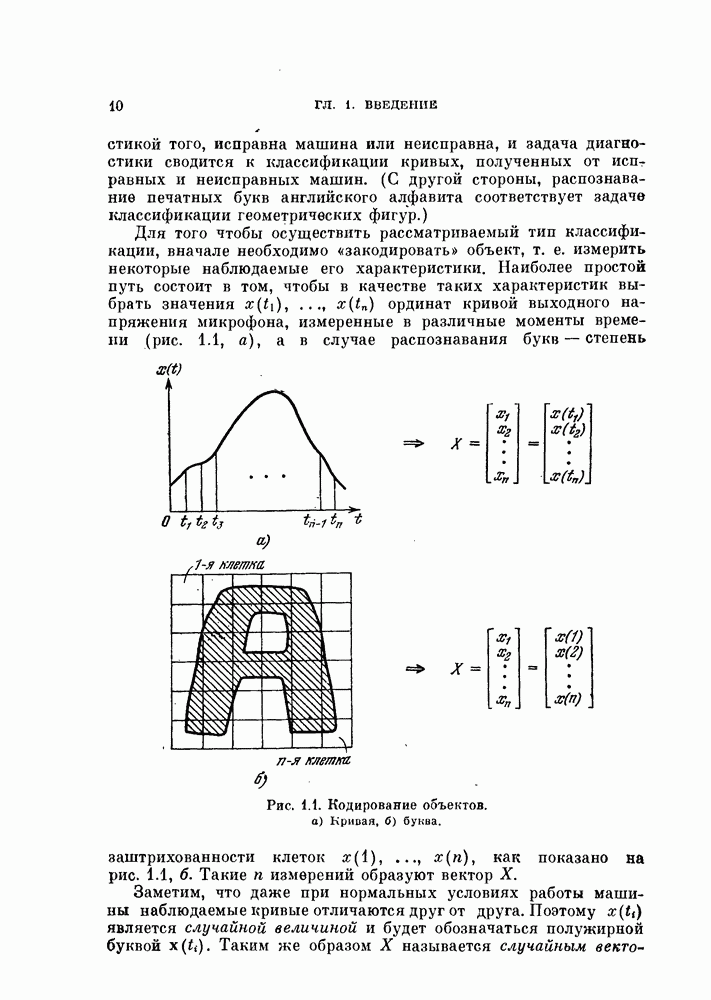
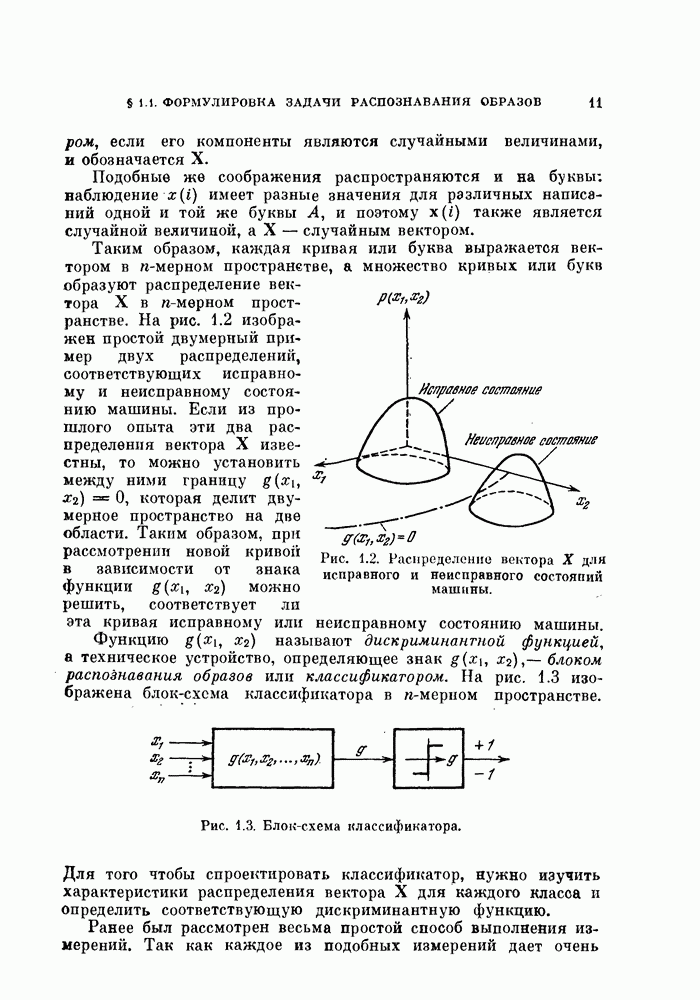
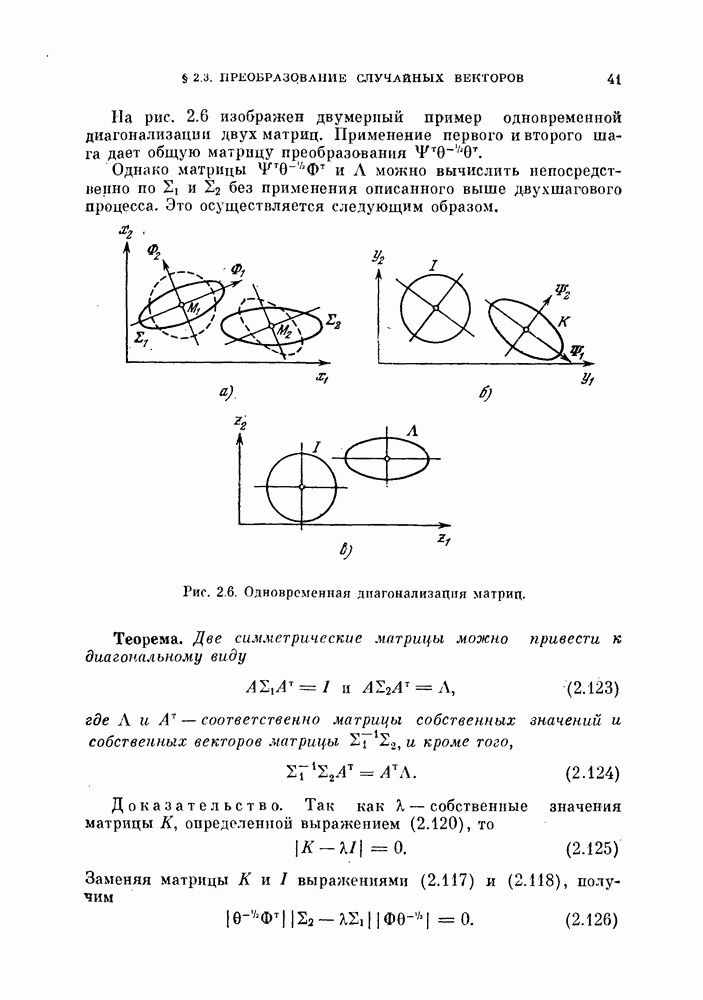
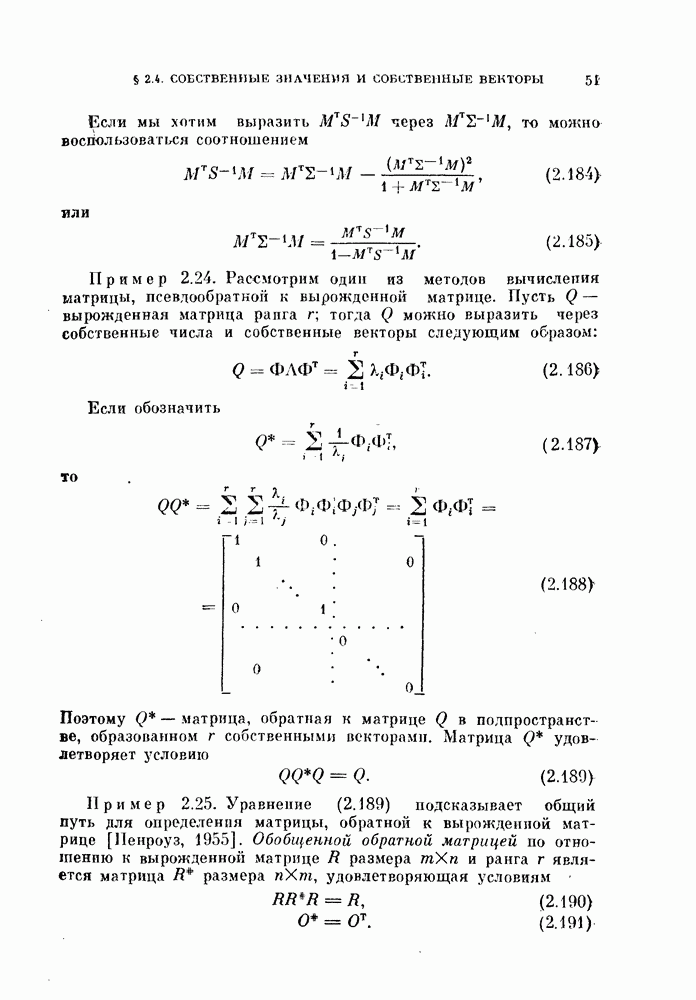
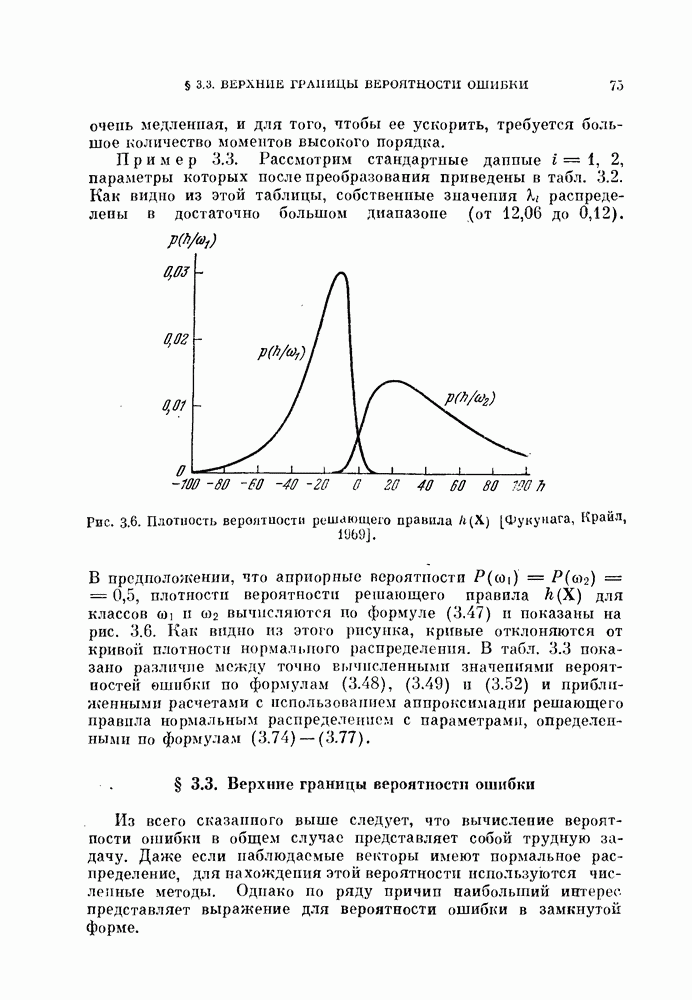
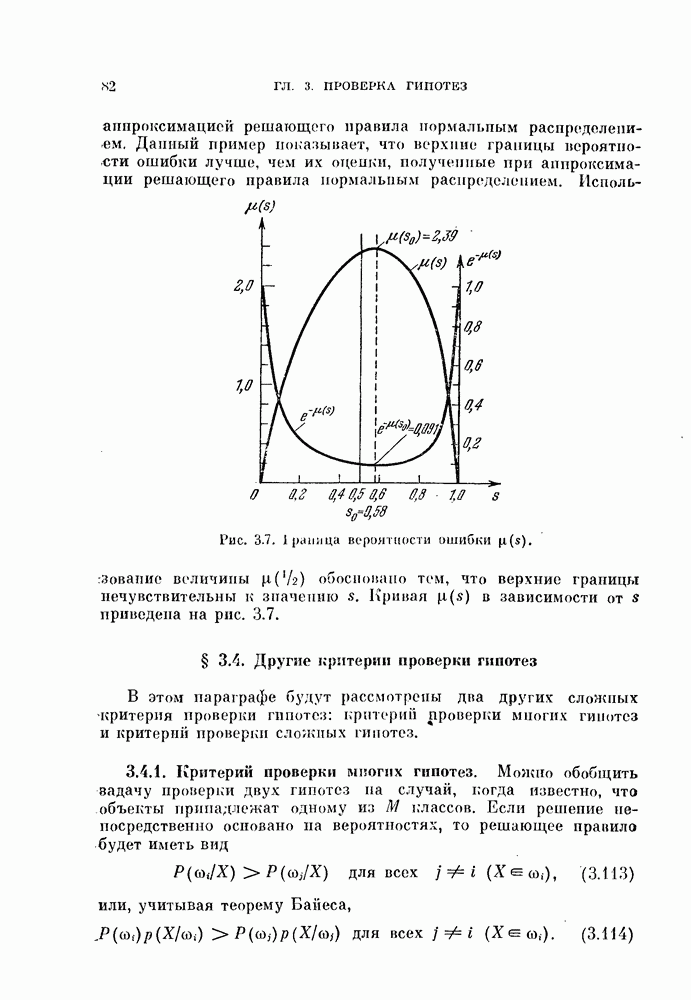
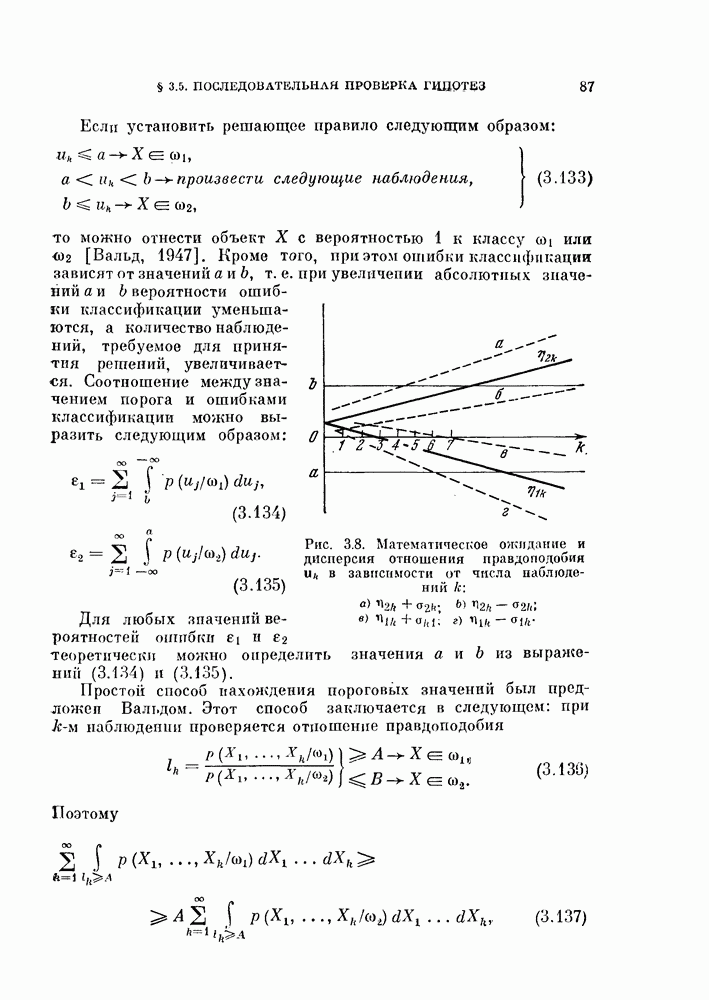
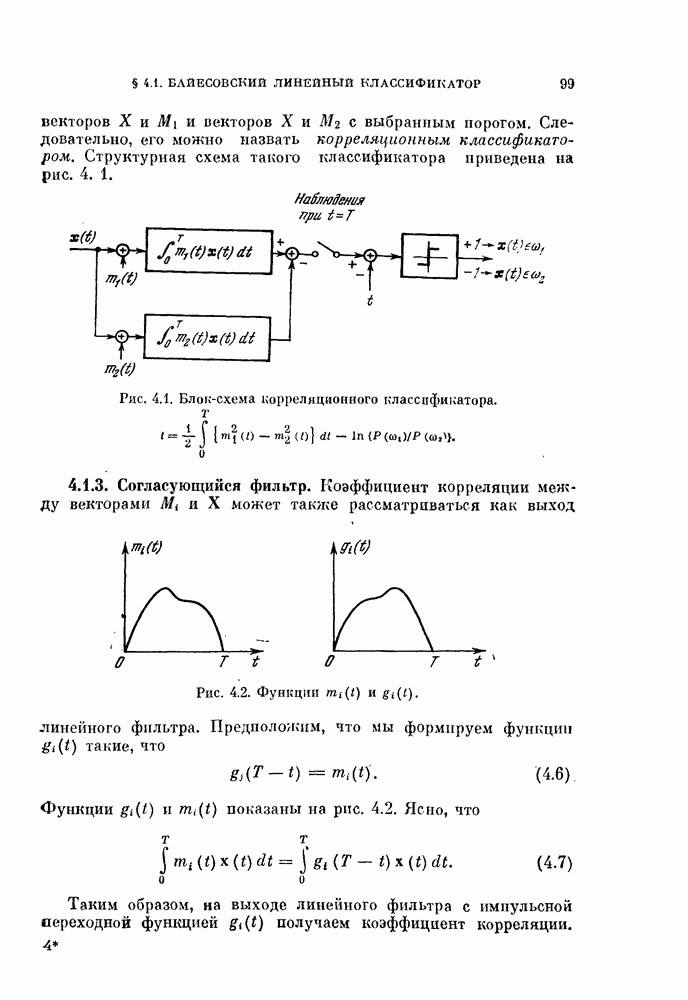
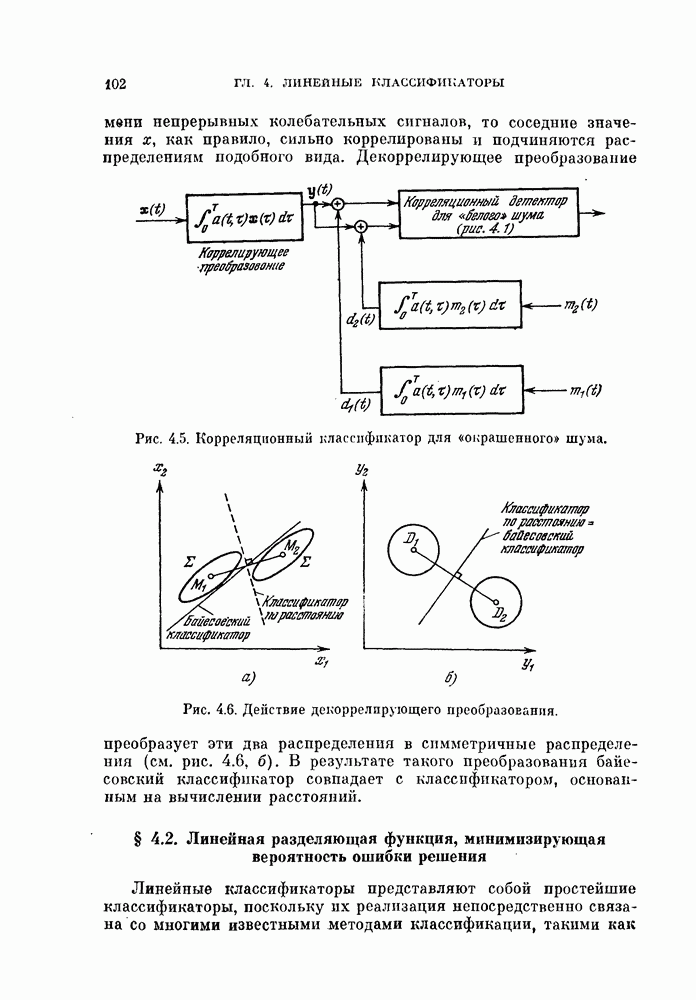
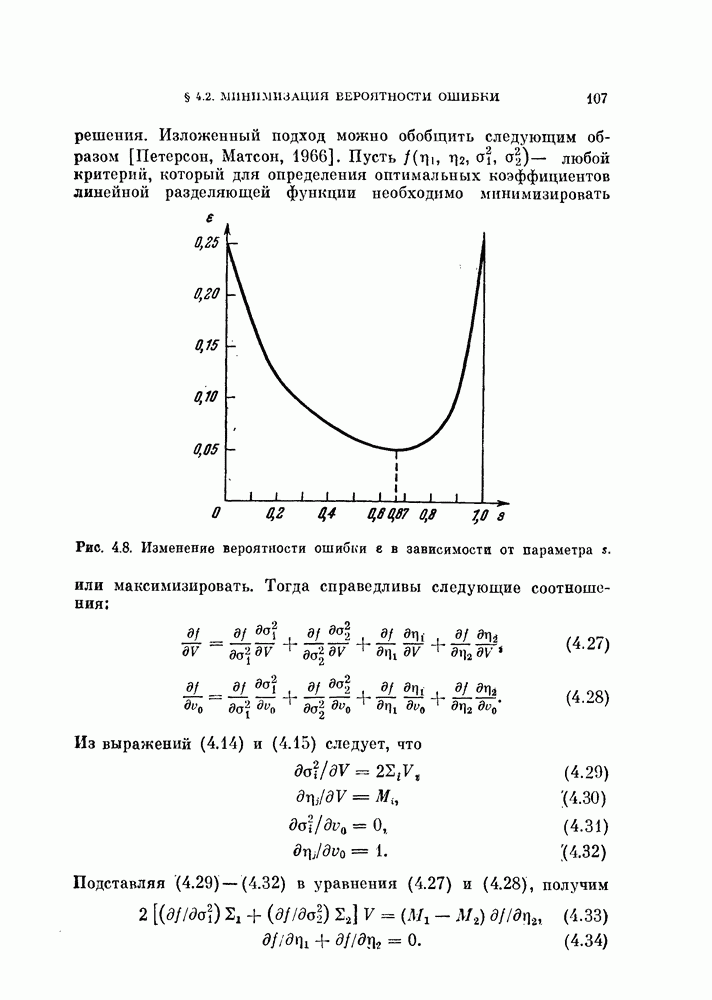
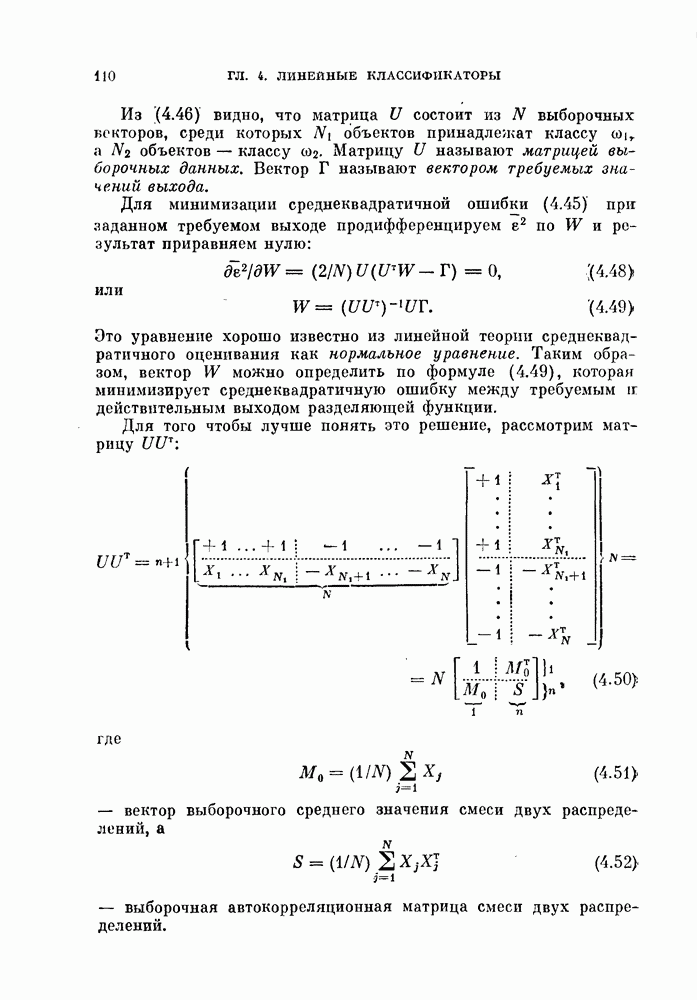
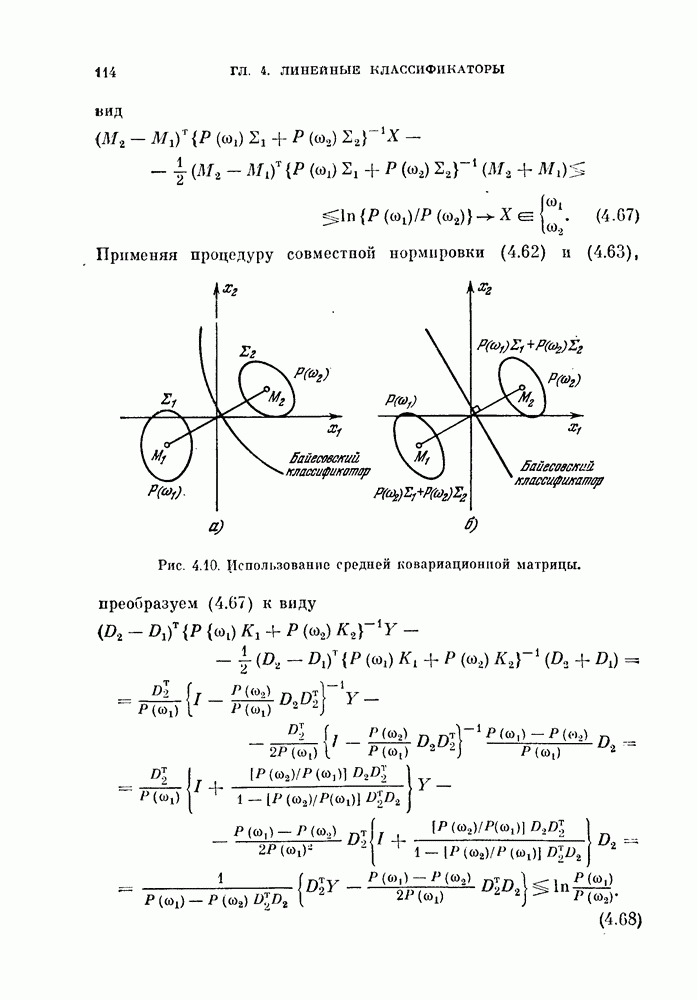
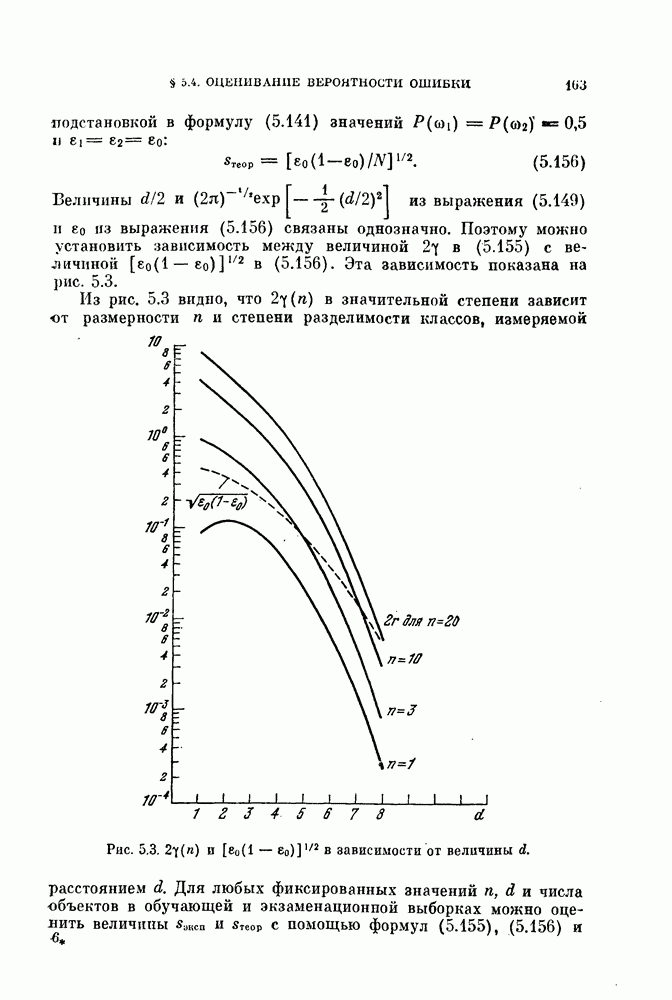
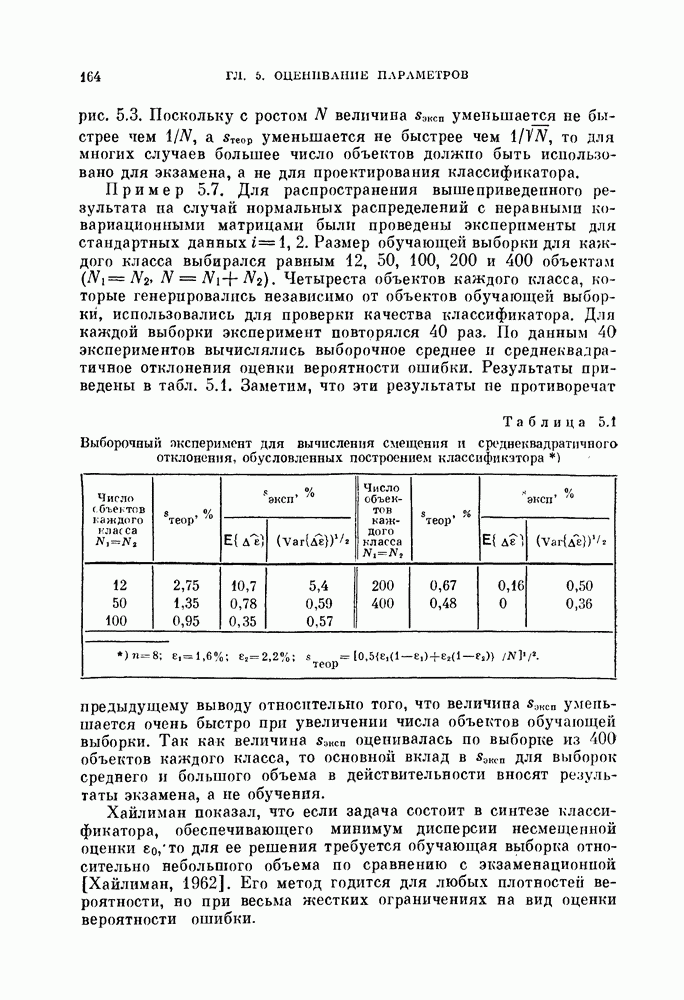
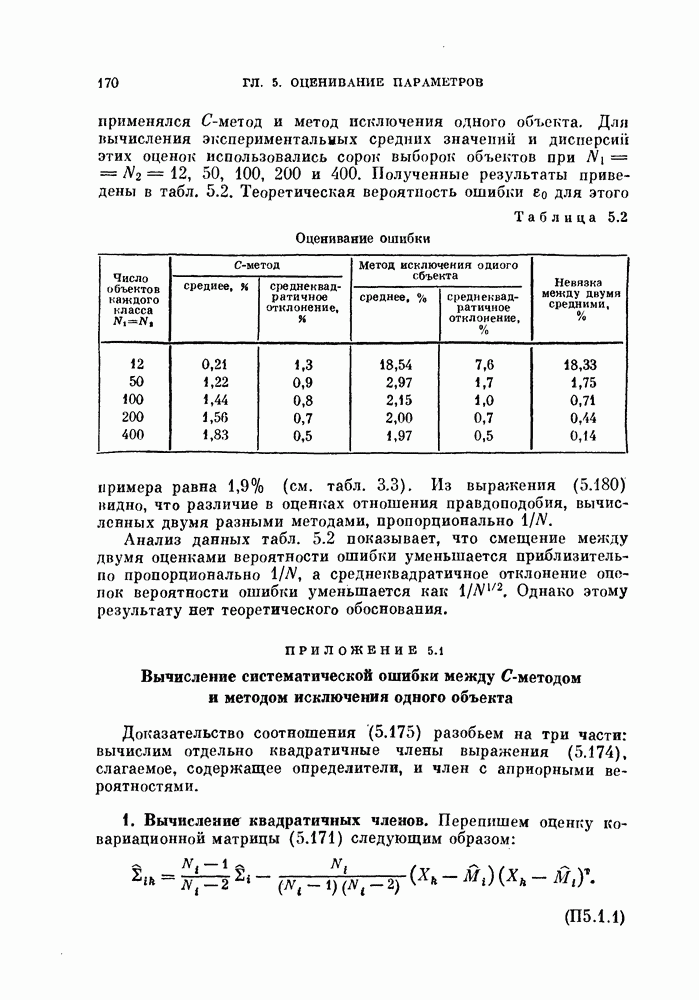
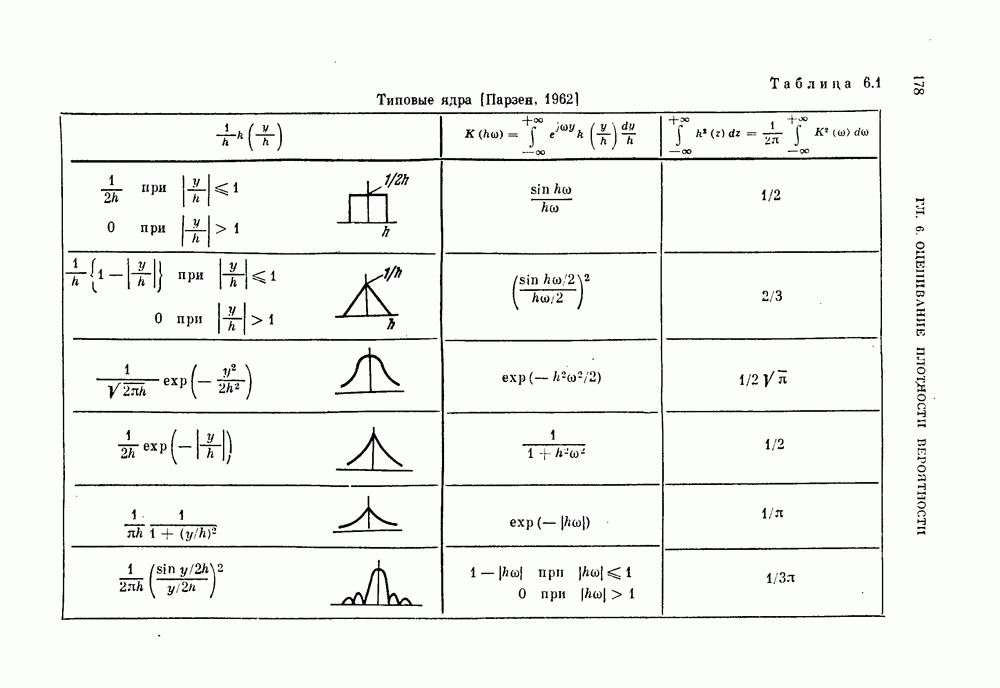
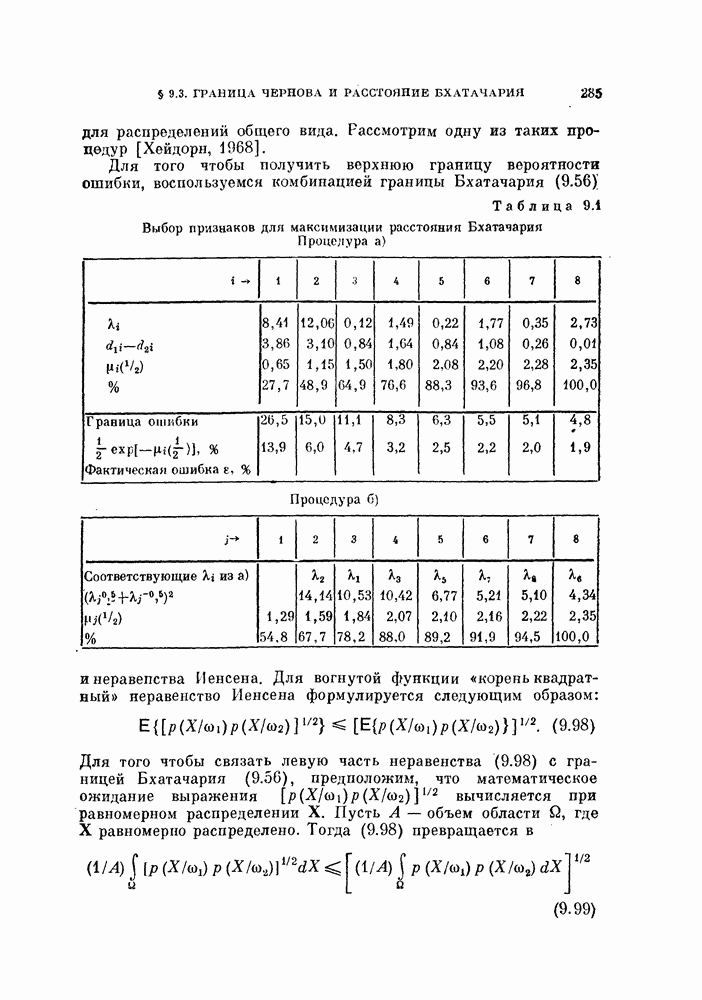
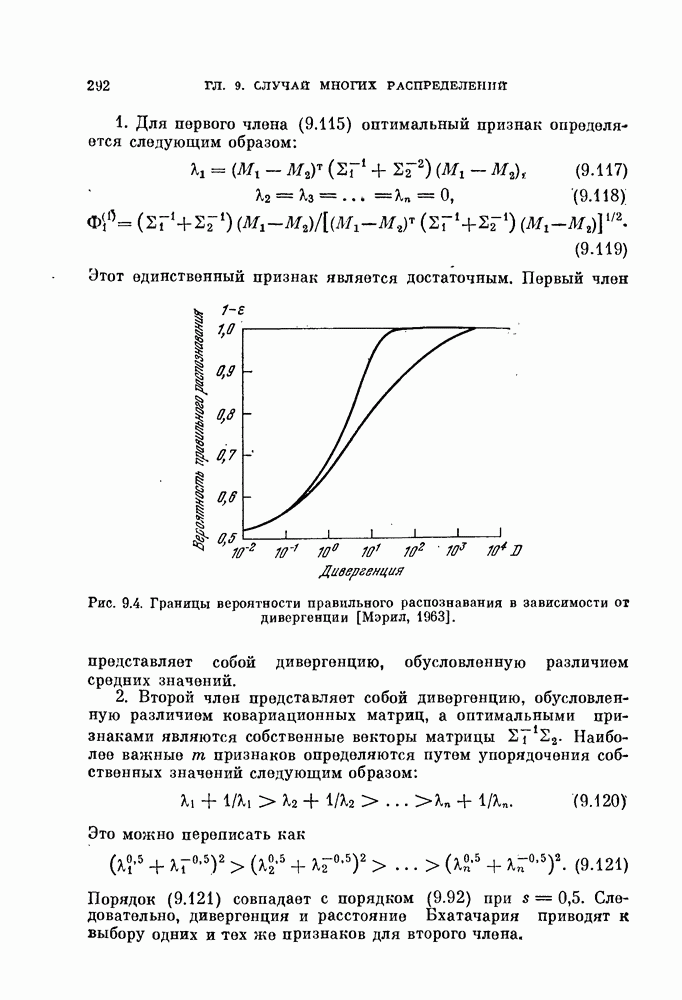
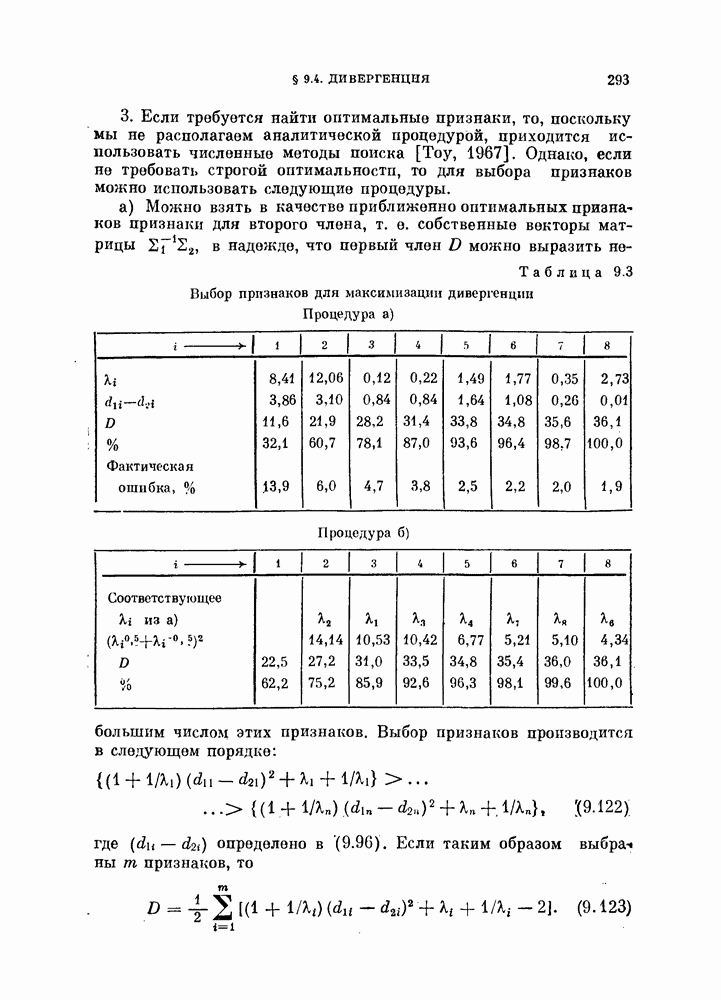
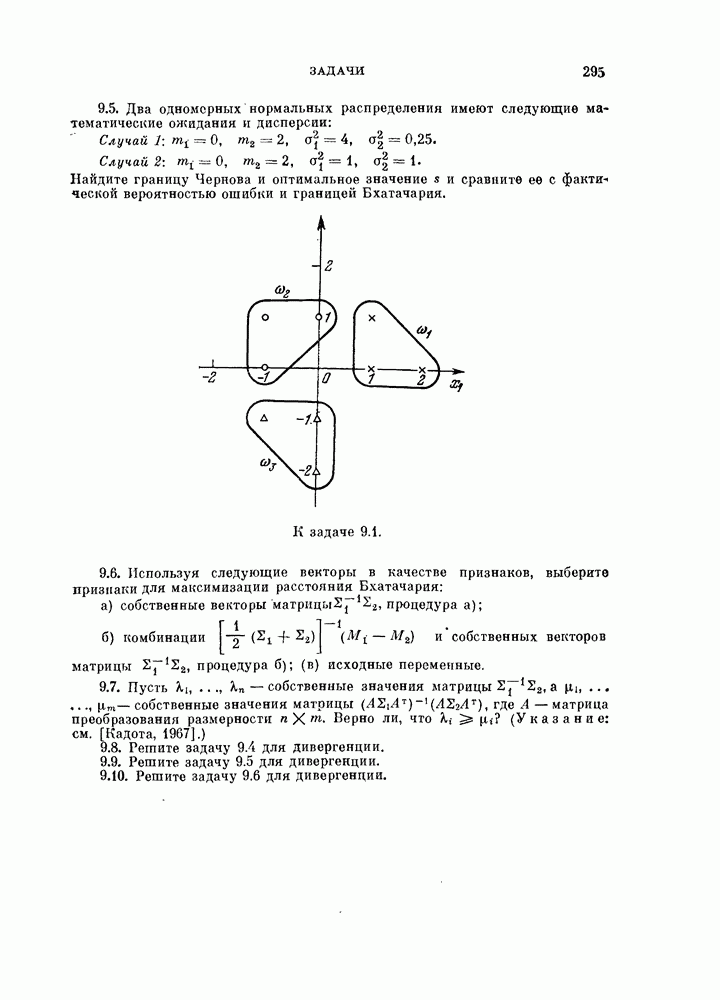
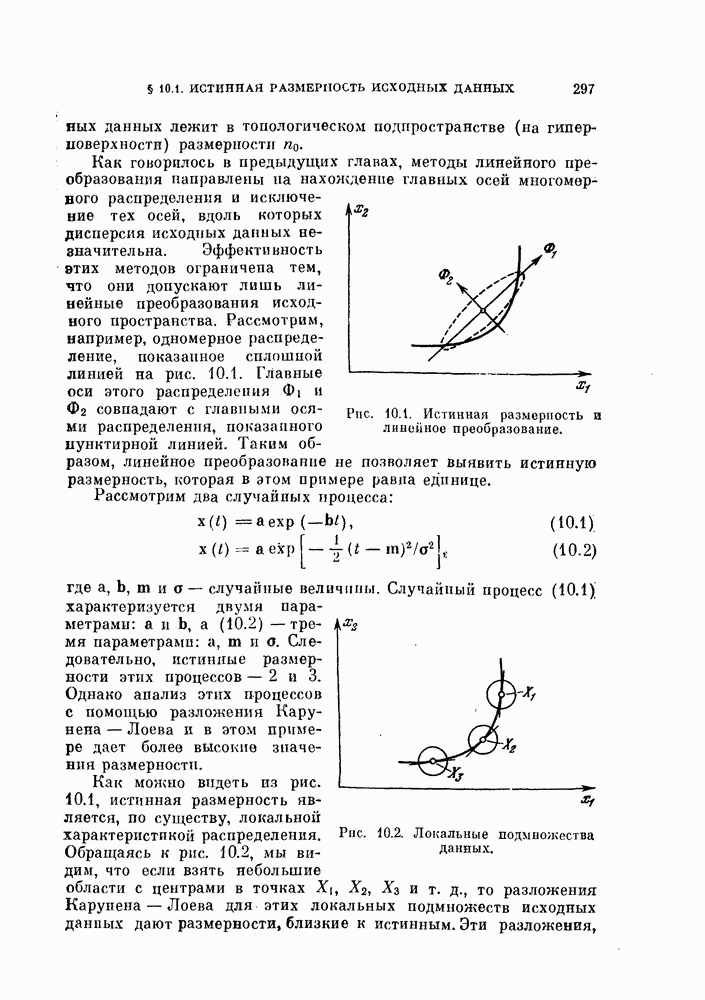
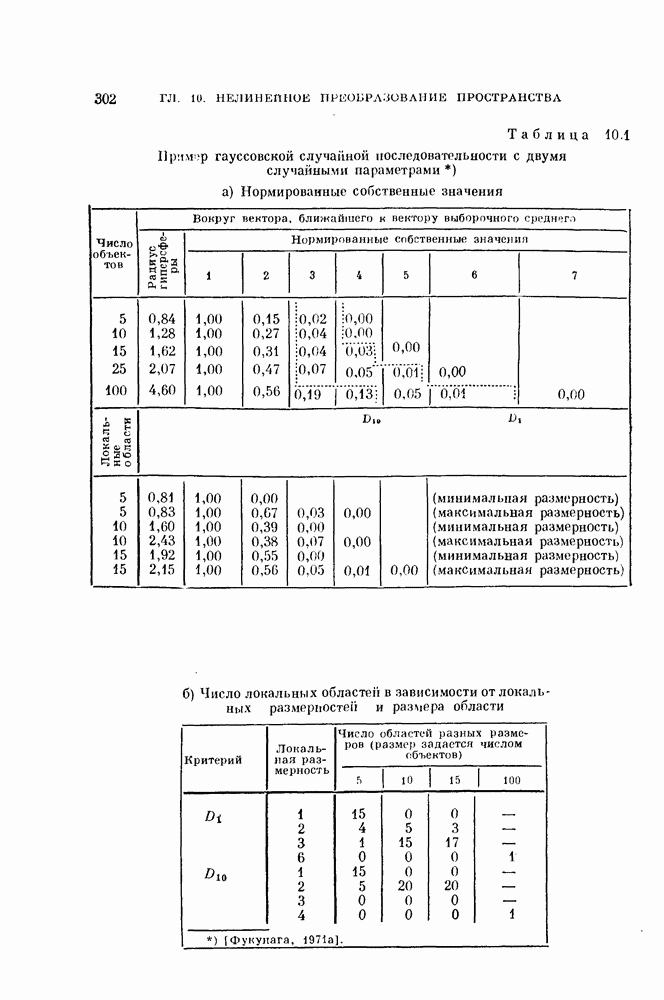
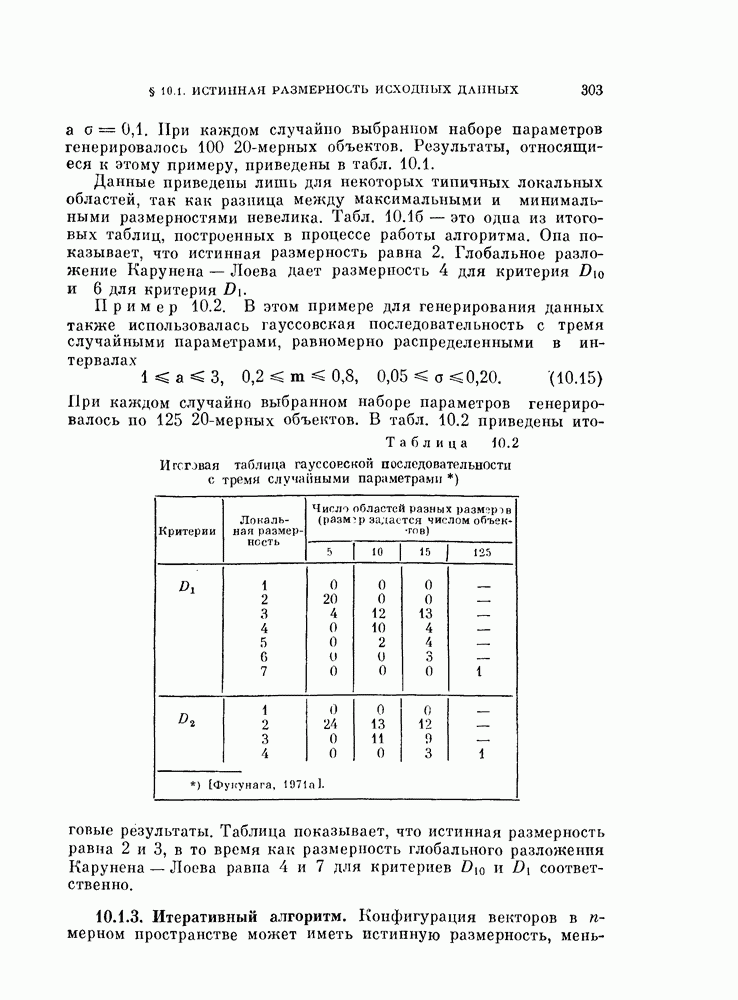
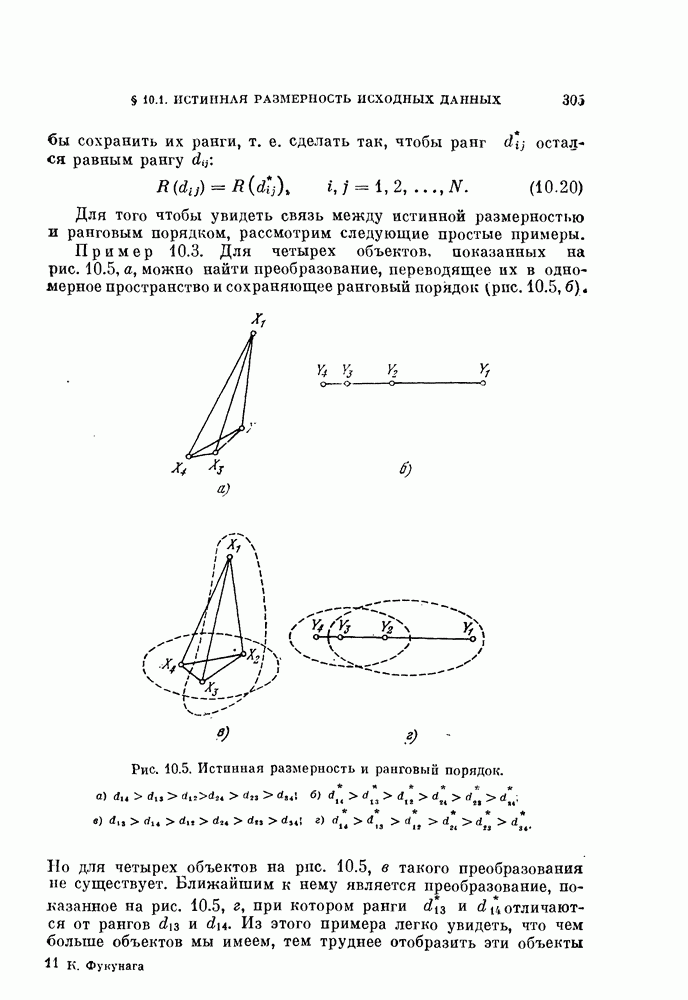
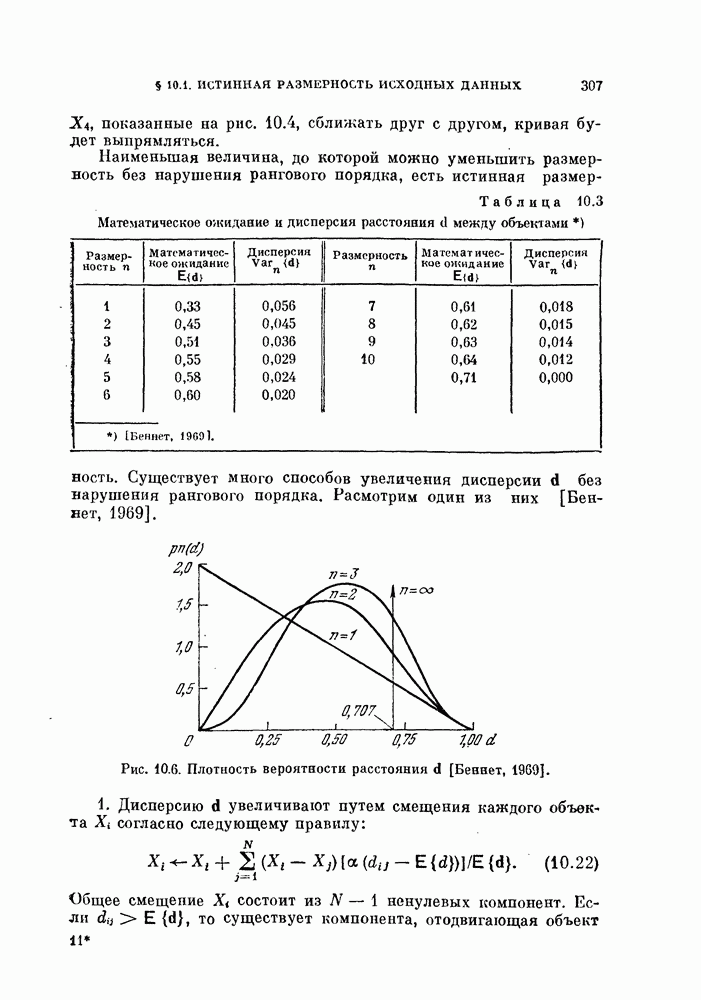
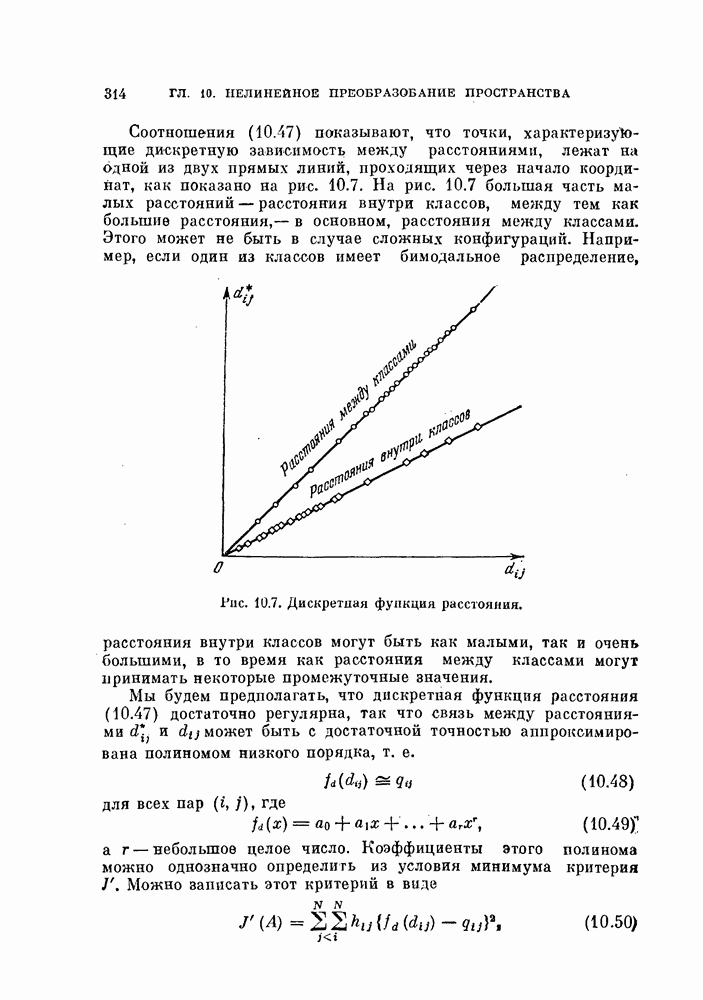
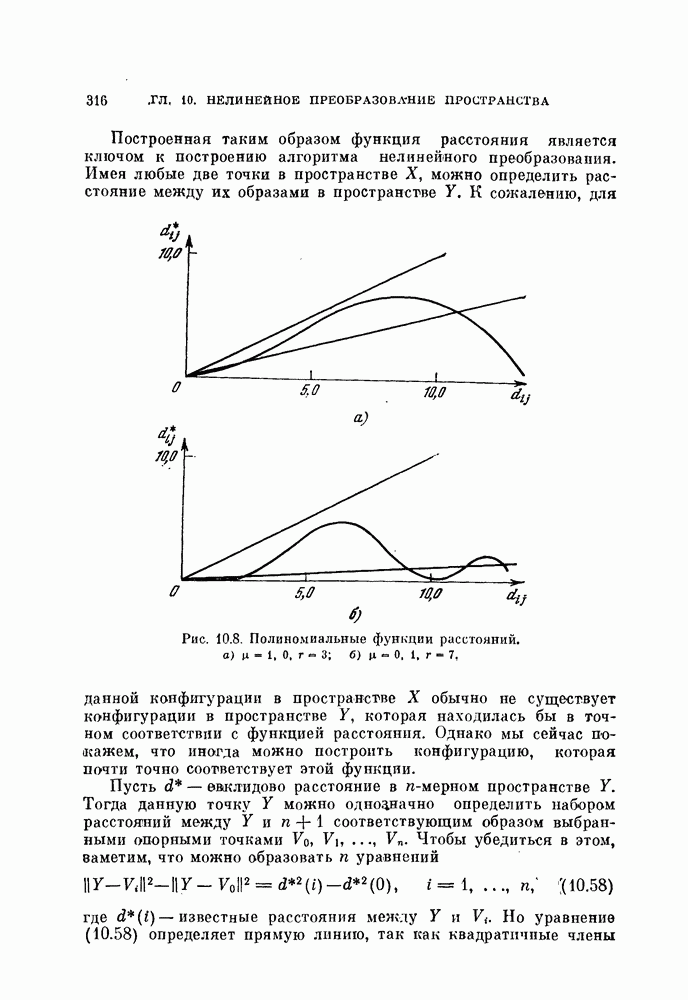
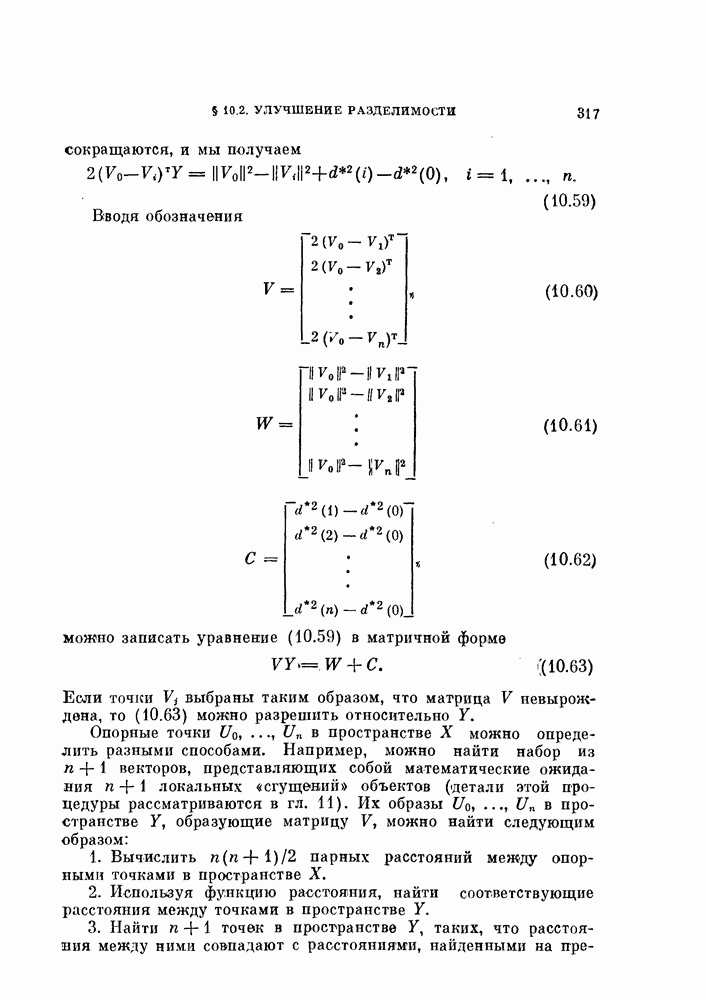
§ 11.4. Другие процедуры автоматической классификации
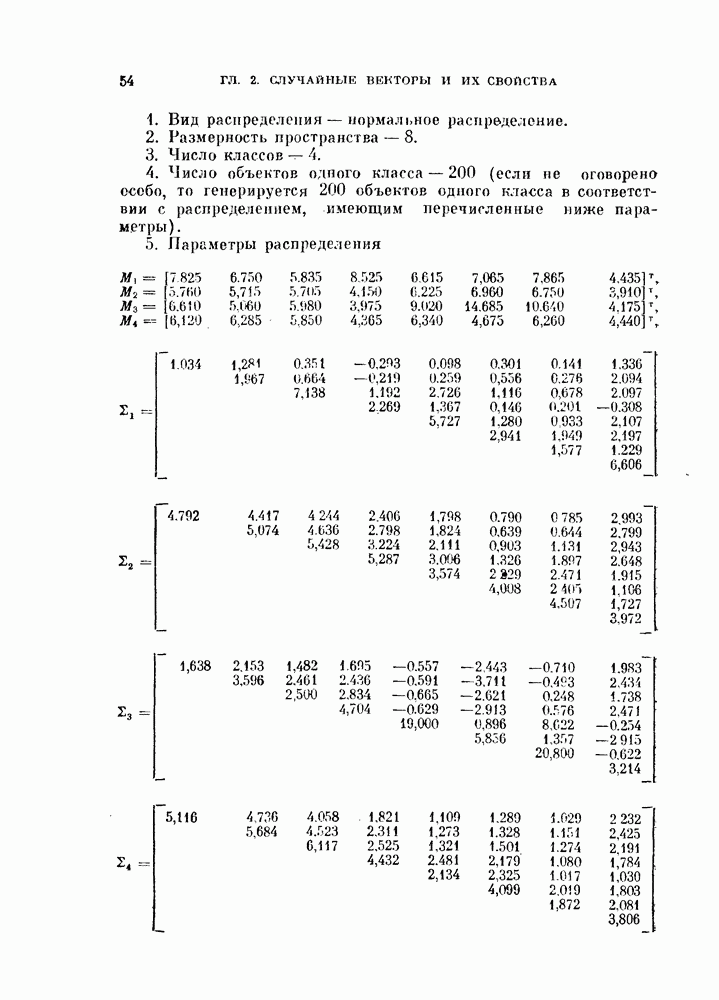
Мы закончим эту главу кратким обзором других постановок задачи автоматической классификации. Рассмотрение при этом будет носить значительно более поверхностный характер, чем в предыдущих параграфах. Читатель, желающий углубить свои знания в этой области, имеет возможность обратиться к цитированной в этой главе литературе.
Сначала мы рассмотрим теоретико-информационный подход к автоматической классификации, а затем — теорию иерархической классификации.
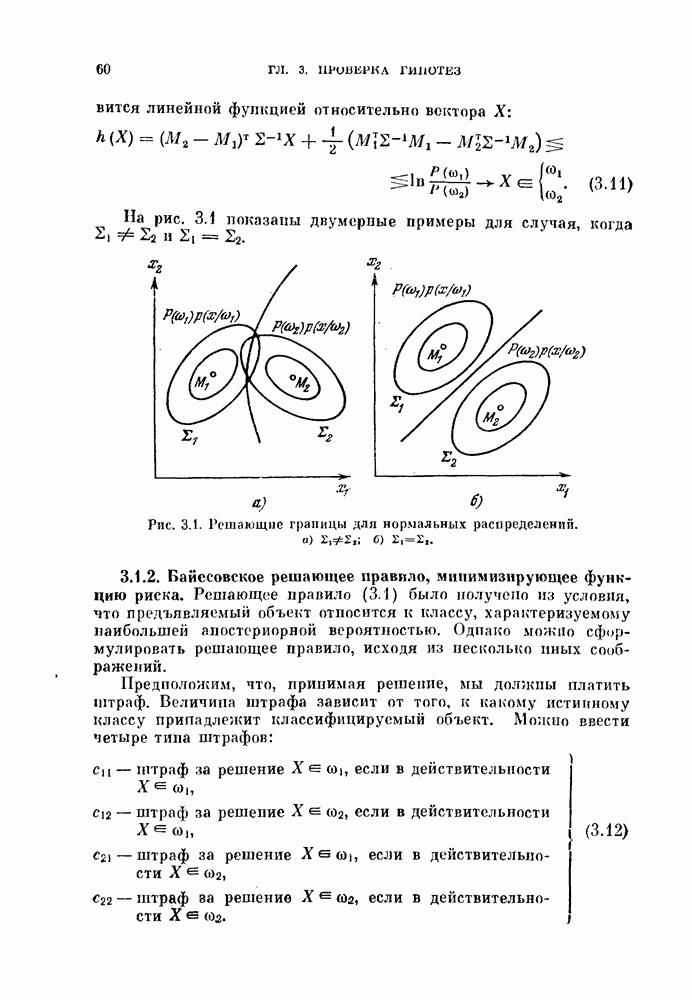
11.4.1. Статистическая связанность.
Все упоминавшиеся до сих пор критерии основывались на попарном сходстве объектов. В [Ватавабе, 1969] была предложена несколько иная постановка задачи автоматической классификации, при которой учитывается наличие статистической связи между переменными. Вместо того, чтобы классифицировать независимо наблюдаемые объекты  (как это обычно делается), вычисляются статистические связи между переменными
(как это обычно делается), вычисляются статистические связи между переменными  и полученные результаты используются для классификации этих переменных, т. е. разделения их на разные группы. Классификация основана на степени статистической зависимости внутри подмножеств
и полученные результаты используются для классификации этих переменных, т. е. разделения их на разные группы. Классификация основана на степени статистической зависимости внутри подмножеств  При этом естественно воспользоваться хорошо известной функцией энтропии.
При этом естественно воспользоваться хорошо известной функцией энтропии.
Рассмотрим все подмножества переменных х, вида

Индекс подмножества к принимает столько значений, сколько можно образовать подмножеств,  число переменных в
число переменных в  подмножестве. Предположим, что х, — дискретные случайные величины. Тогда энтропия
подмножестве. Предположим, что х, — дискретные случайные величины. Тогда энтропия  определяется как
определяется как

где  — плотность вероятности дискретных случайных величин:
— плотность вероятности дискретных случайных величин:

Энтропия максимальна, когда переменные  статистически независимы. Кроме того, можно показать, что
статистически независимы. Кроме того, можно показать, что

для любого подмножества 
Статистическая связанность  определяется следующим образом:
определяется следующим образом:

Таким образом,  это неотрицательная величина, возрастающая по мере того, как элементы
это неотрицательная величина, возрастающая по мере того, как элементы  становятся все более и более зависимыми. Статистическая связанность подмножества статистически независимых случайных величии равна нулю.
становятся все более и более зависимыми. Статистическая связанность подмножества статистически независимых случайных величии равна нулю.
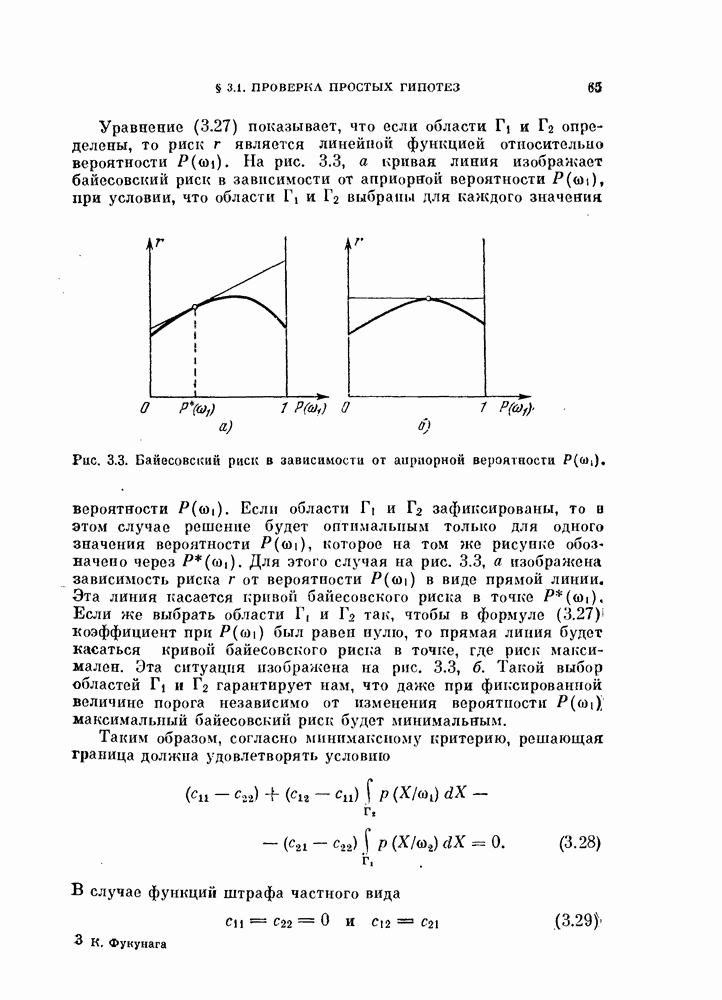
Разделим множество  , состоящее из всех
, состоящее из всех  переменных
переменных  на два пепересекаюхцихся подмножества
на два пепересекаюхцихся подмножества  и Тогда
и Тогда
суммарная статистическая связанность обоих подмножеств не превышает статистической связанности исходного множества  так как согласно известным свойствам энтропии
так как согласно известным свойствам энтропии

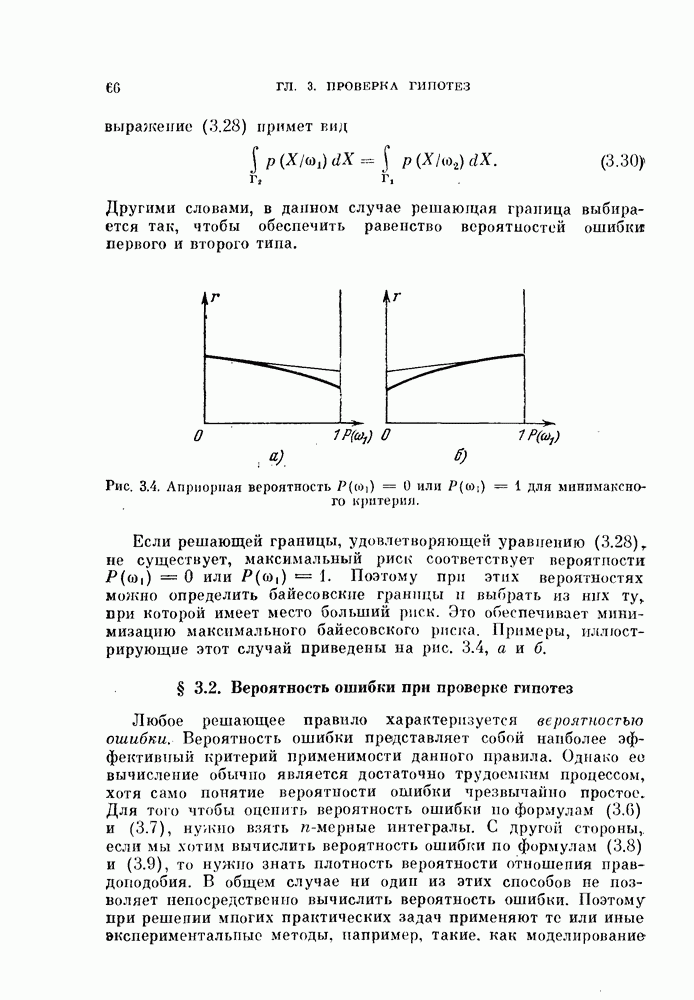
Нам хотелось бы разделить случайные величины на М подмножеств  с минимальной потерей статистической связанности. Таким образом, критерий, подлежащий минимизации, имеет вид
с минимальной потерей статистической связанности. Таким образом, критерий, подлежащий минимизации, имеет вид

Этот критерий полностью определен, когда известны совместные вероятности  На практике, однако, мы имеем только множество из
На практике, однако, мы имеем только множество из  наблюдений переменных
наблюдений переменных  Следовательно, для того чтобы реализовать этот критерий, мы должны использовать наблюдения для оценки
Следовательно, для того чтобы реализовать этот критерий, мы должны использовать наблюдения для оценки  методом относительных частот.
методом относительных частот.
Нелишне напомнить здесь, что постановка задачи автоматической классификации, основанная на идее статистической связанности, отличается от той, которая рассматривалась ранее. Однако эта процедура единственная в своем роде и позволяет решать задачи, для которых другие известные методы непригодны.