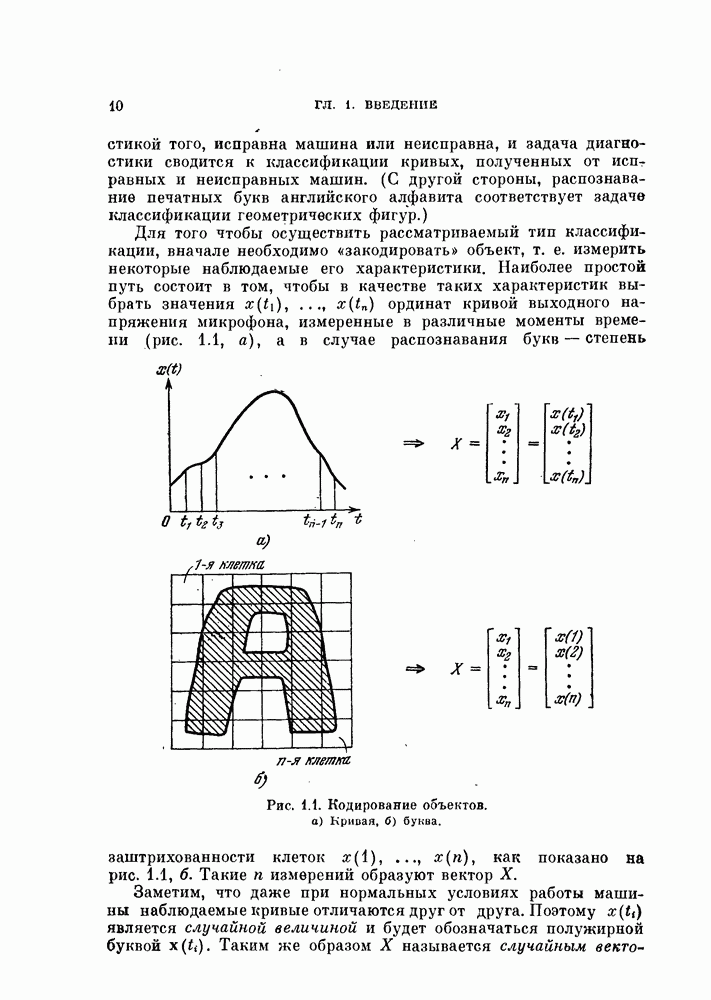
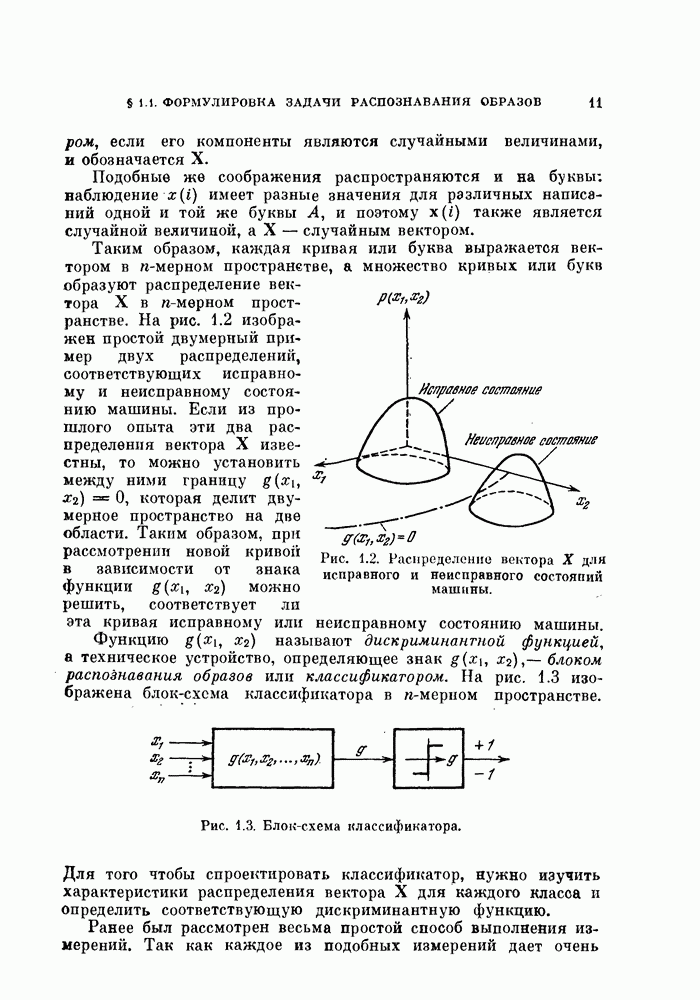
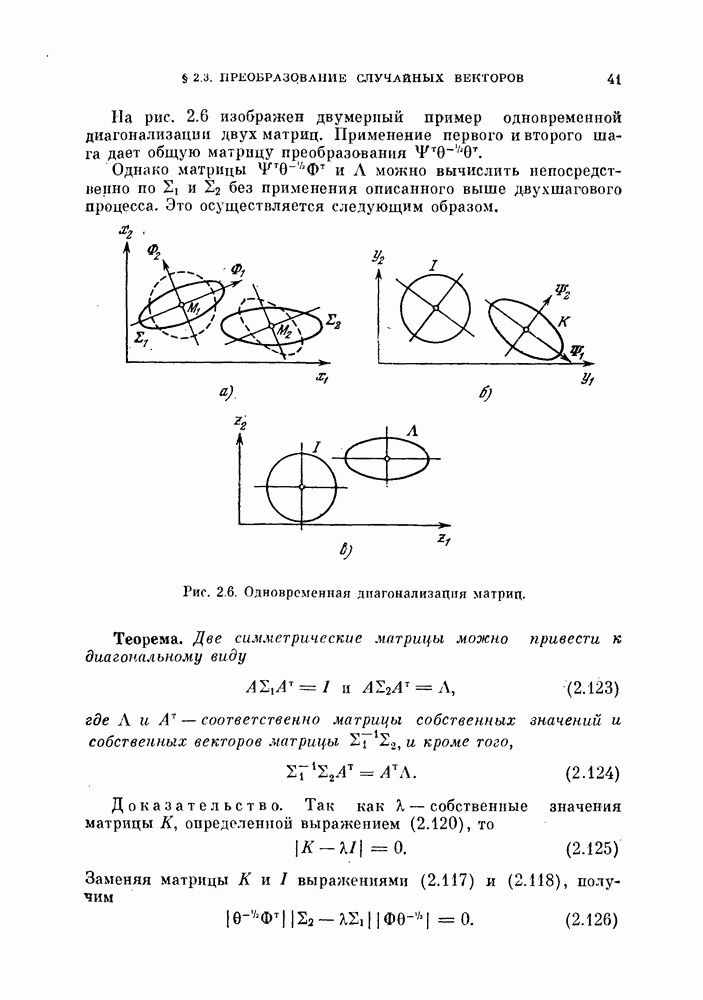
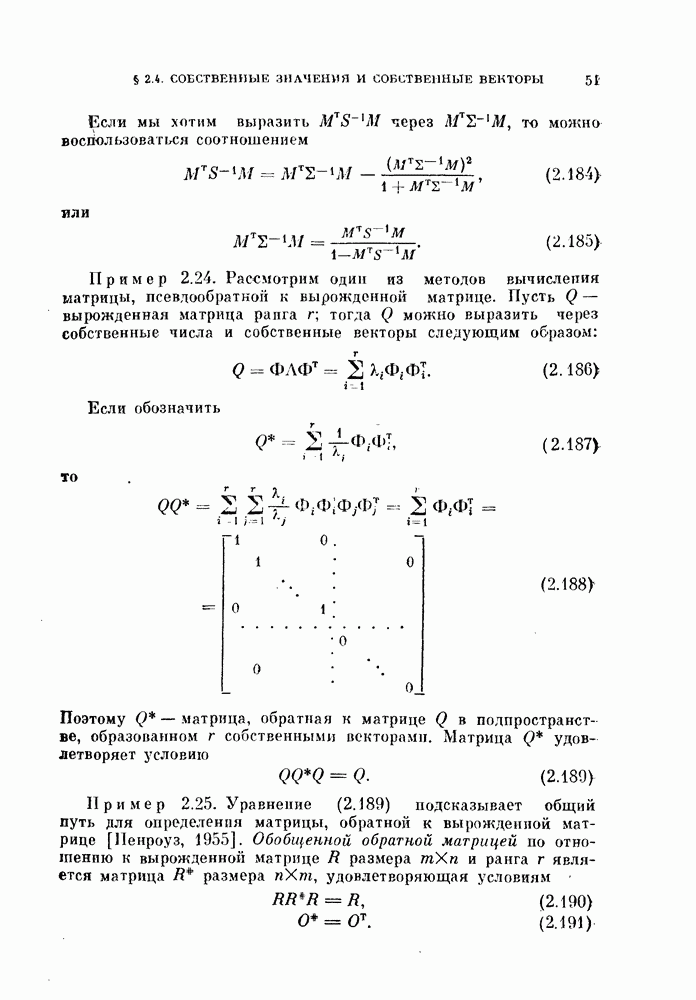
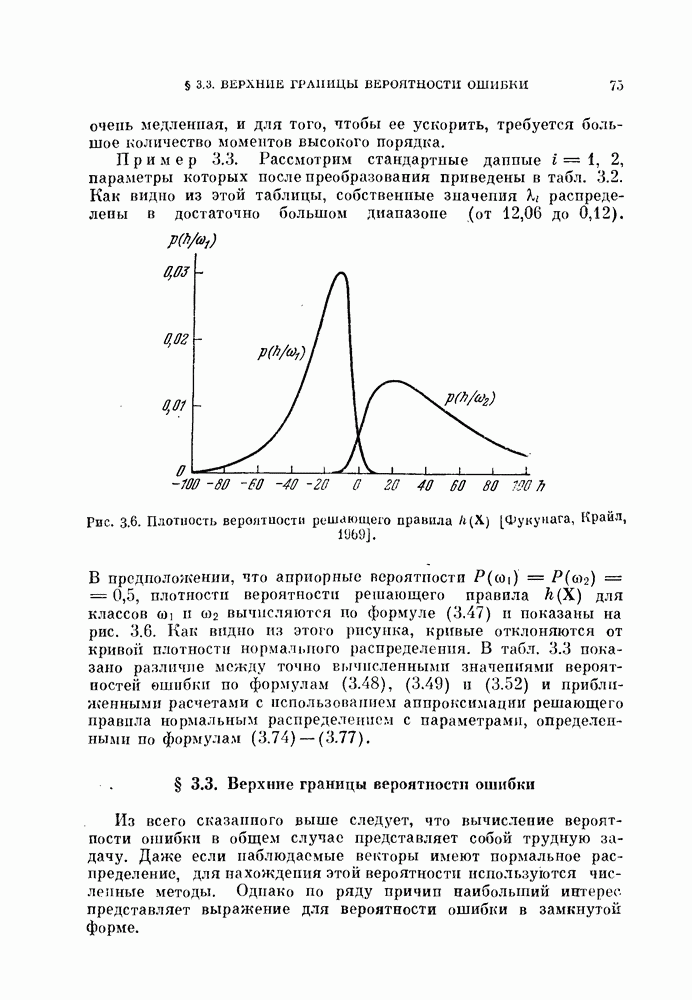
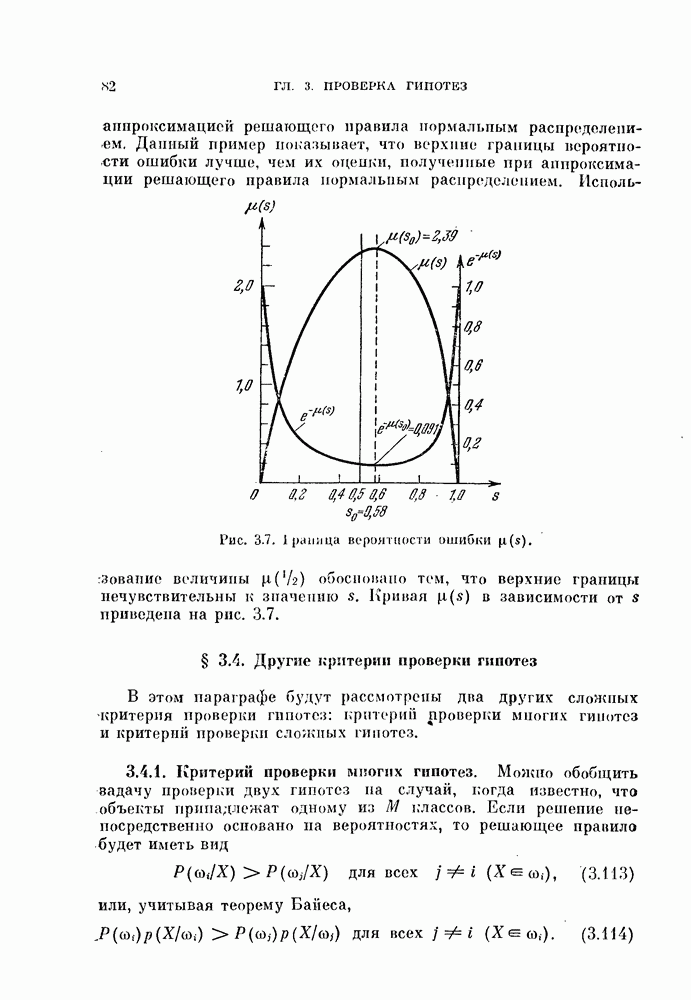
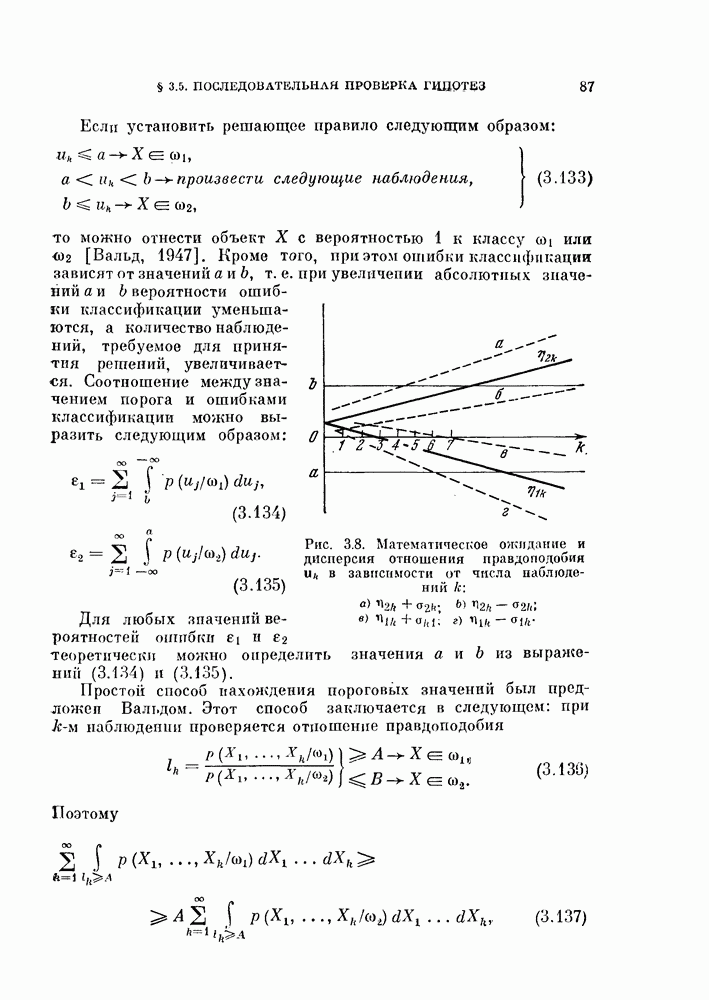
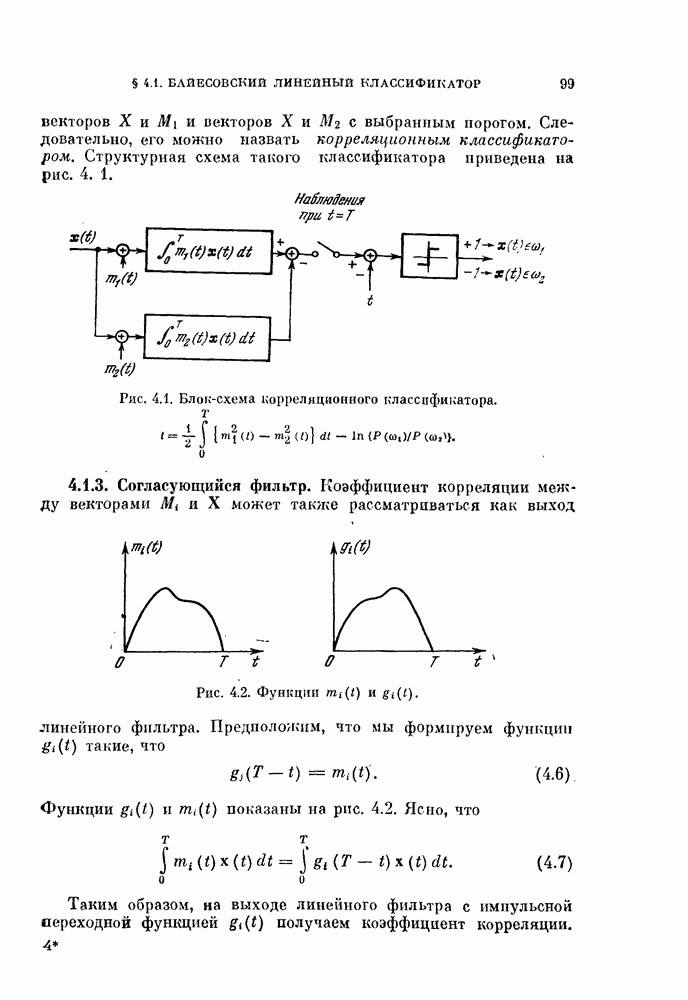
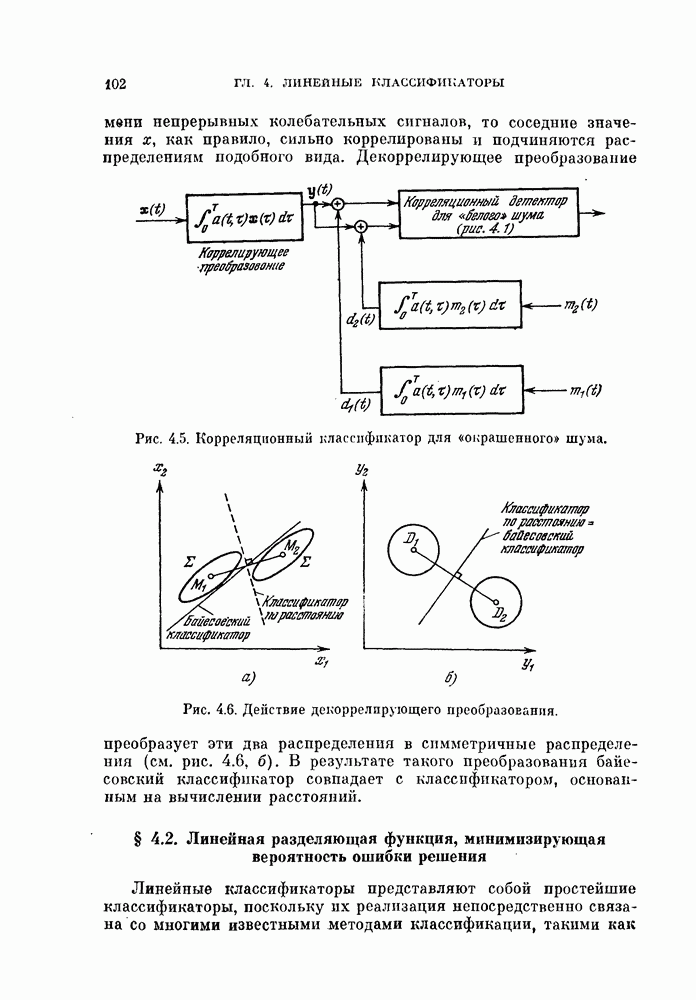
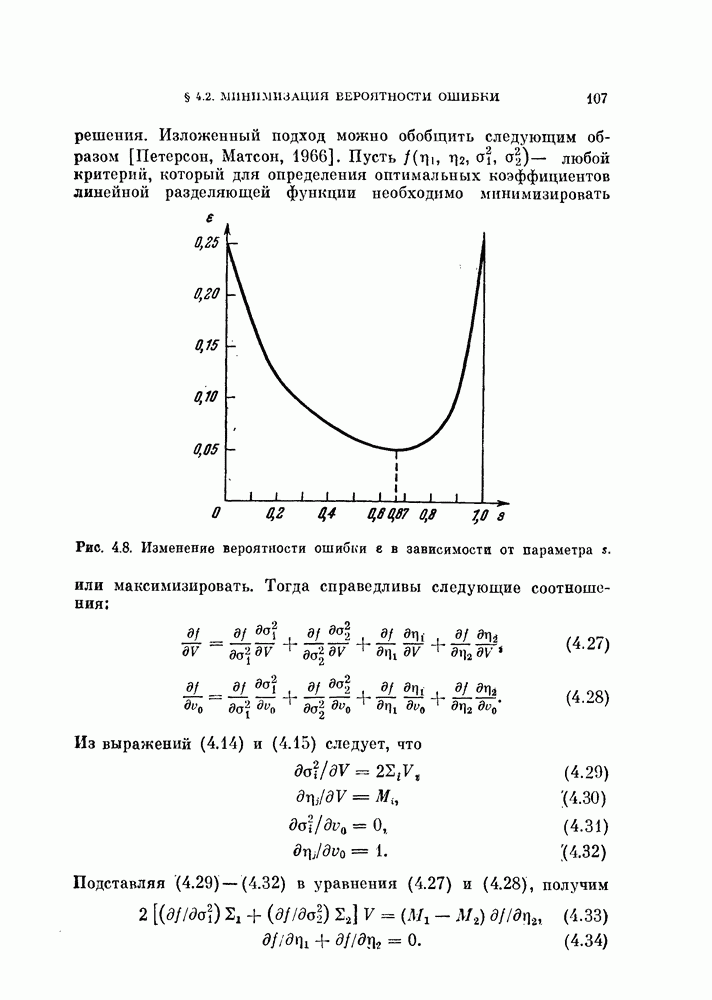
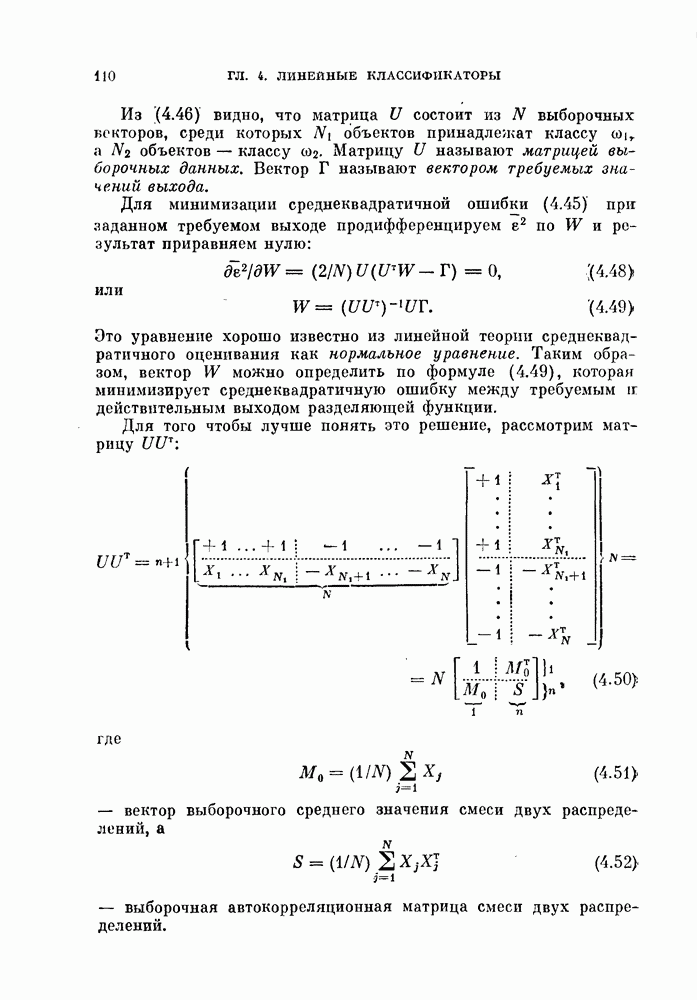
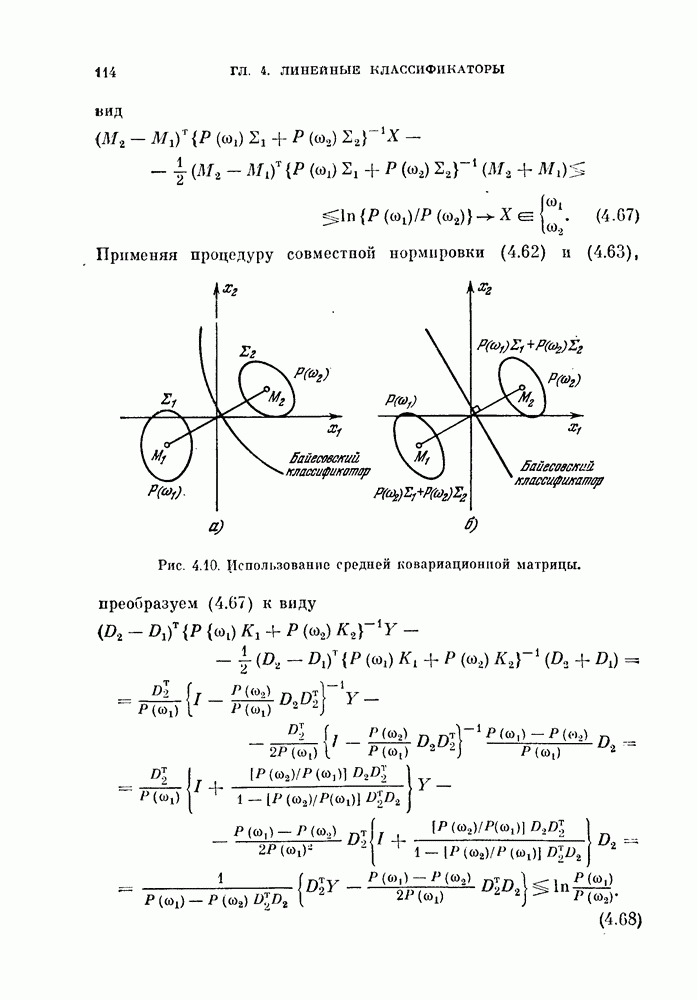
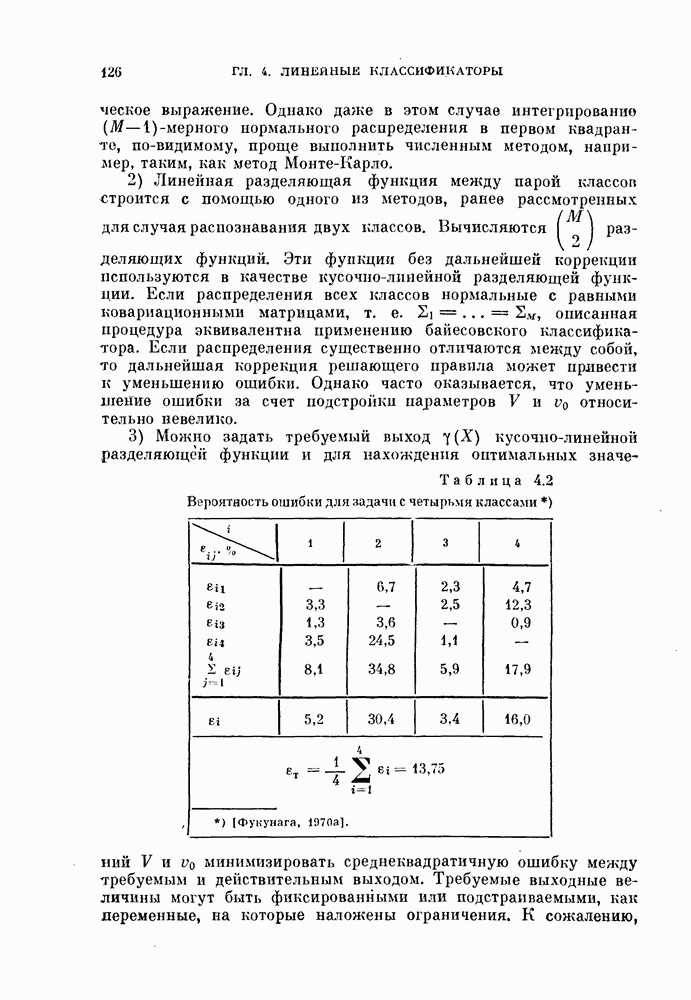
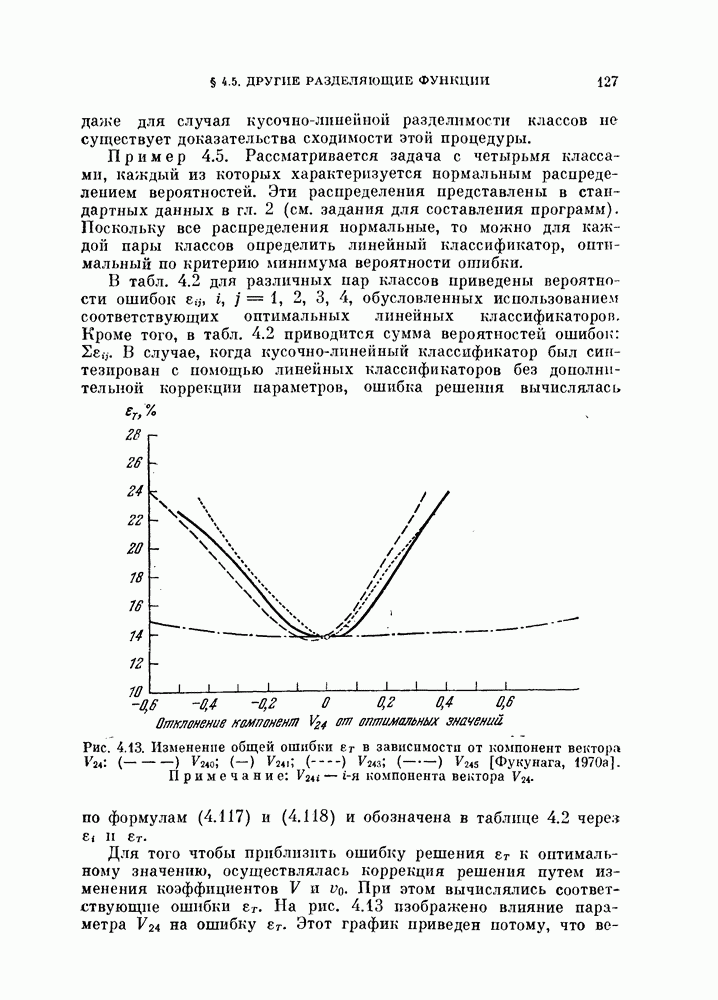
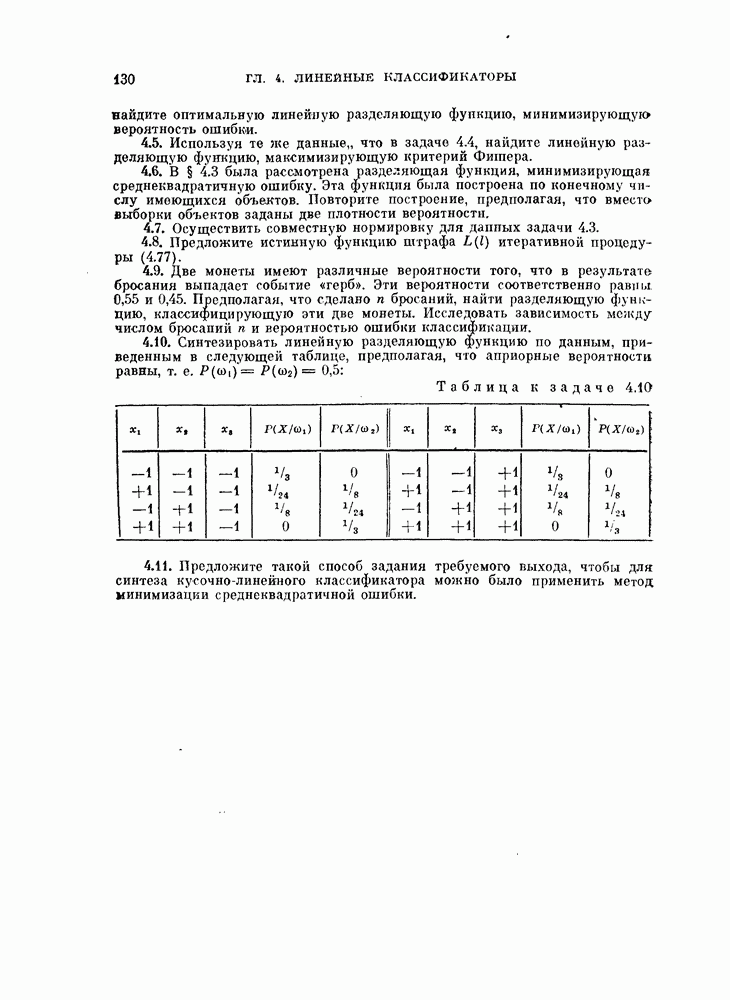
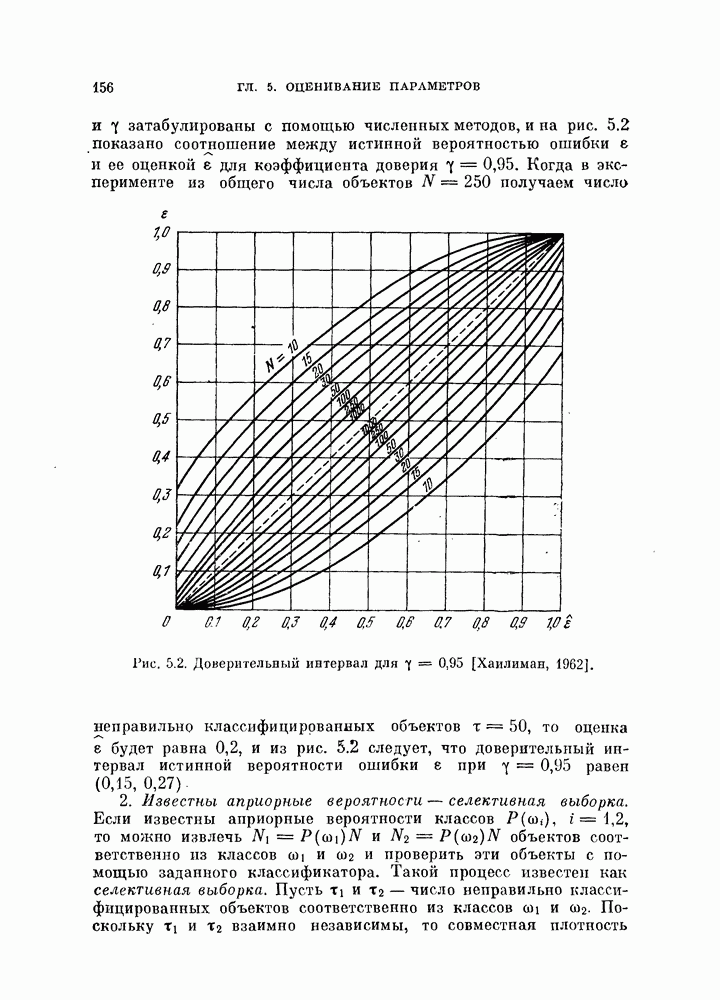
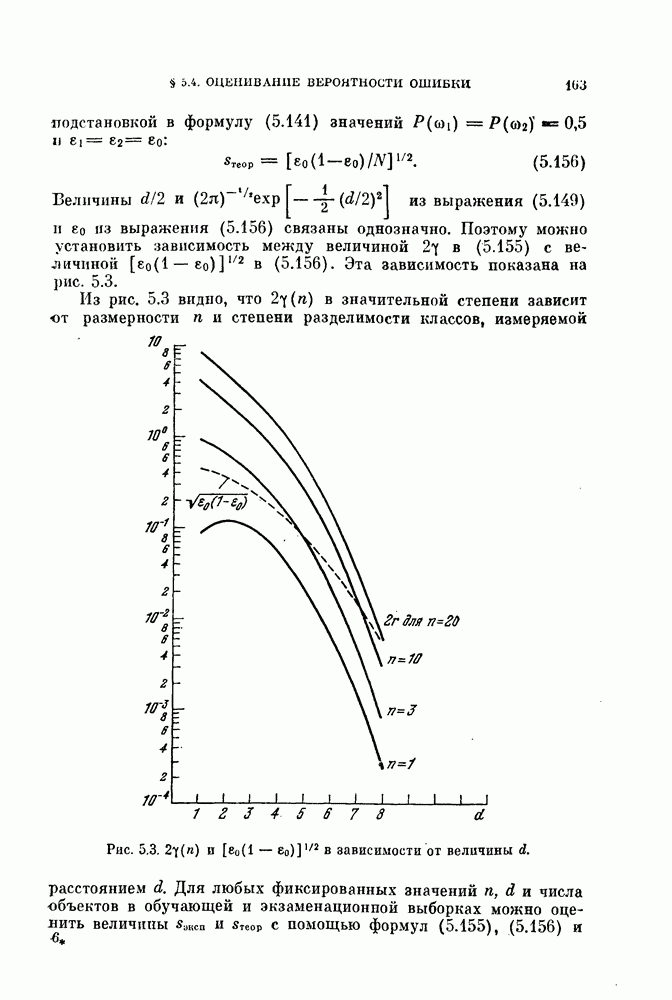
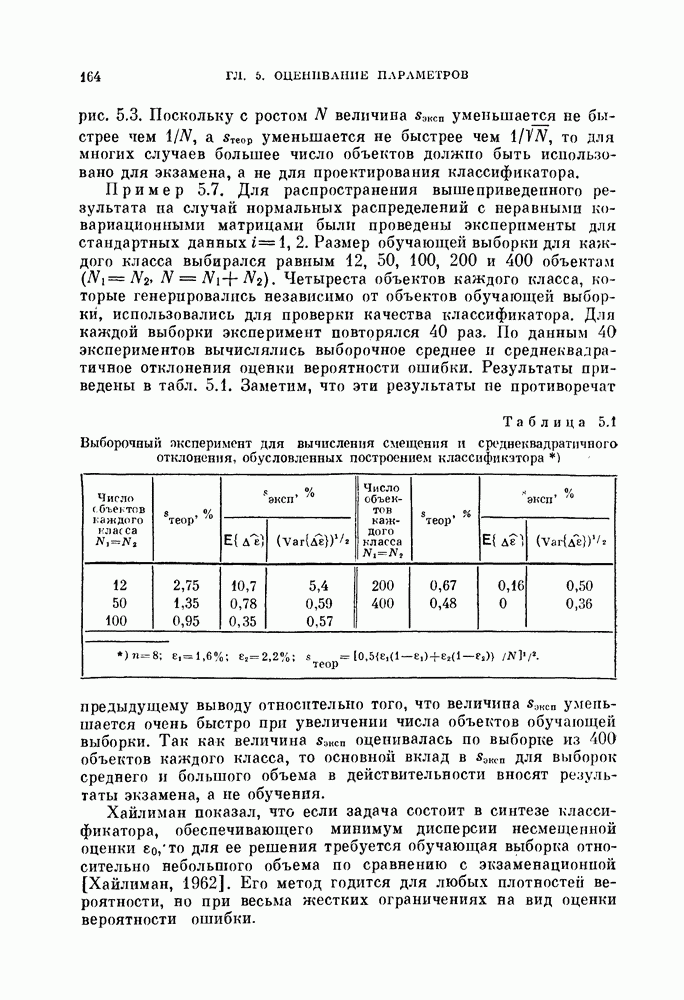
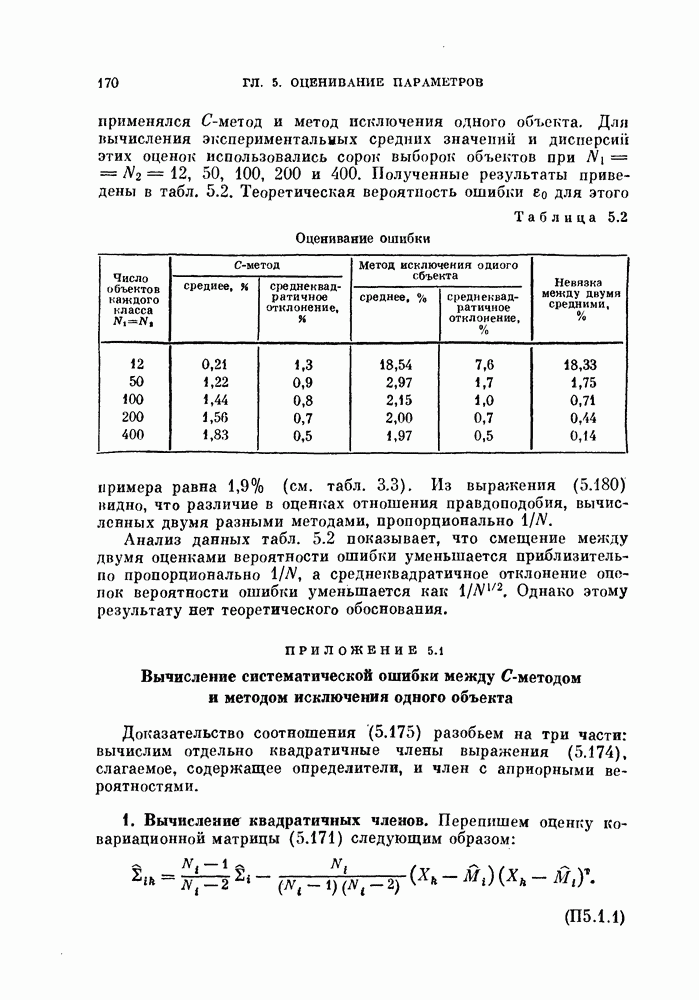
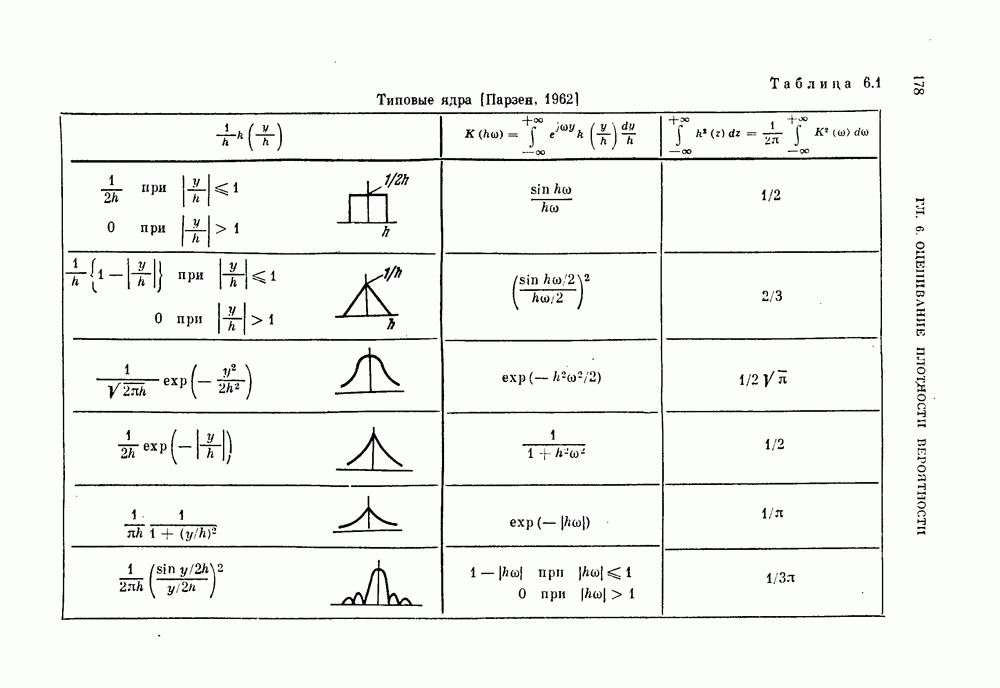
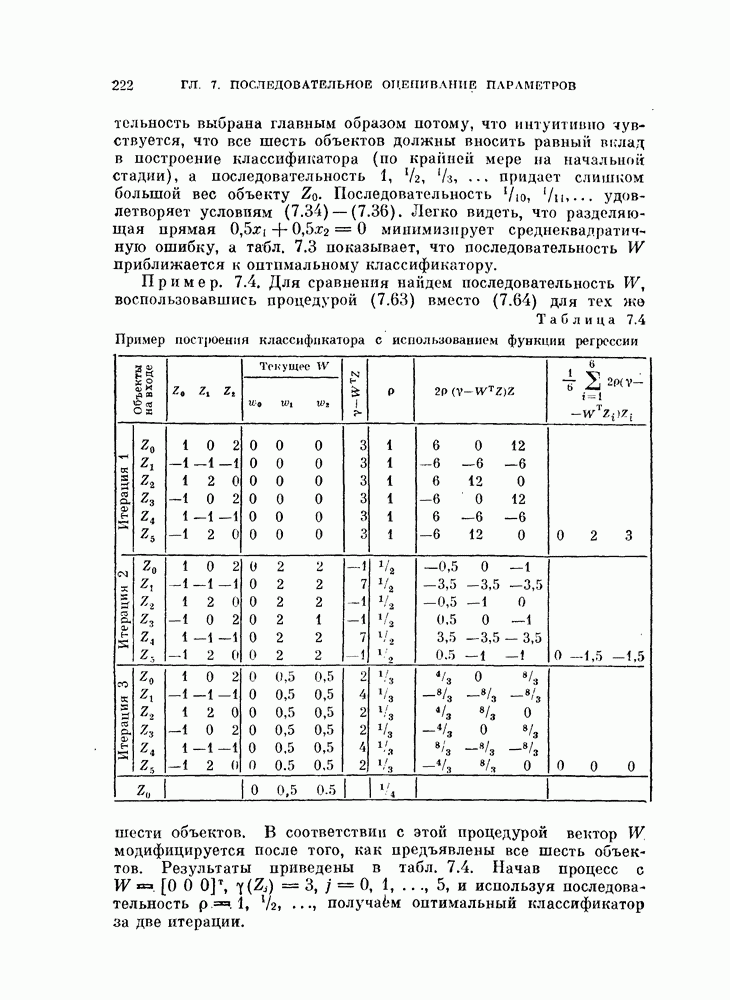
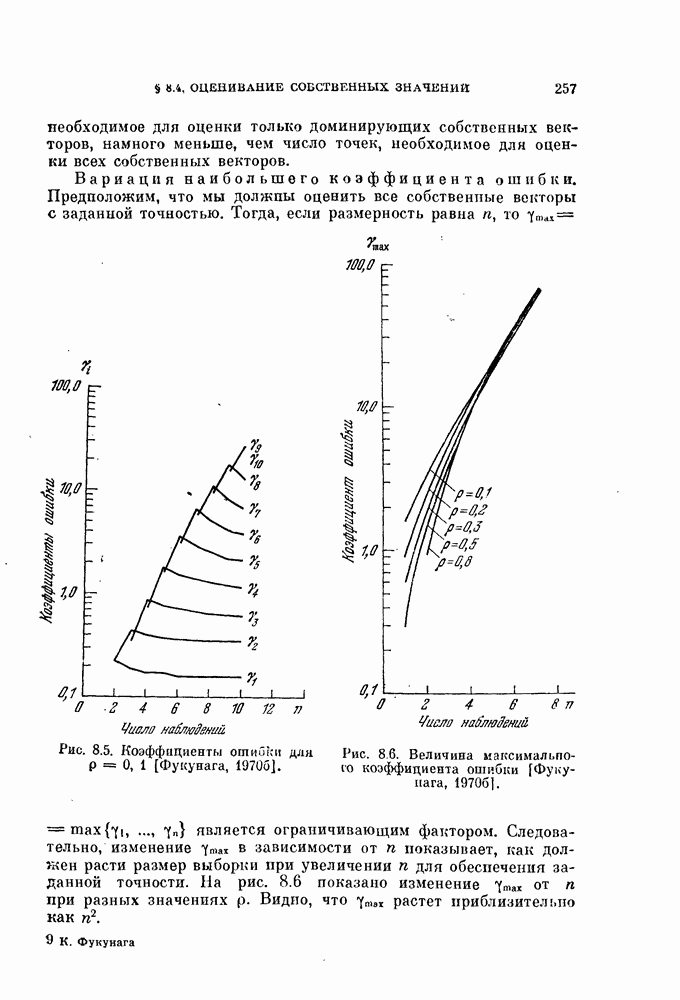
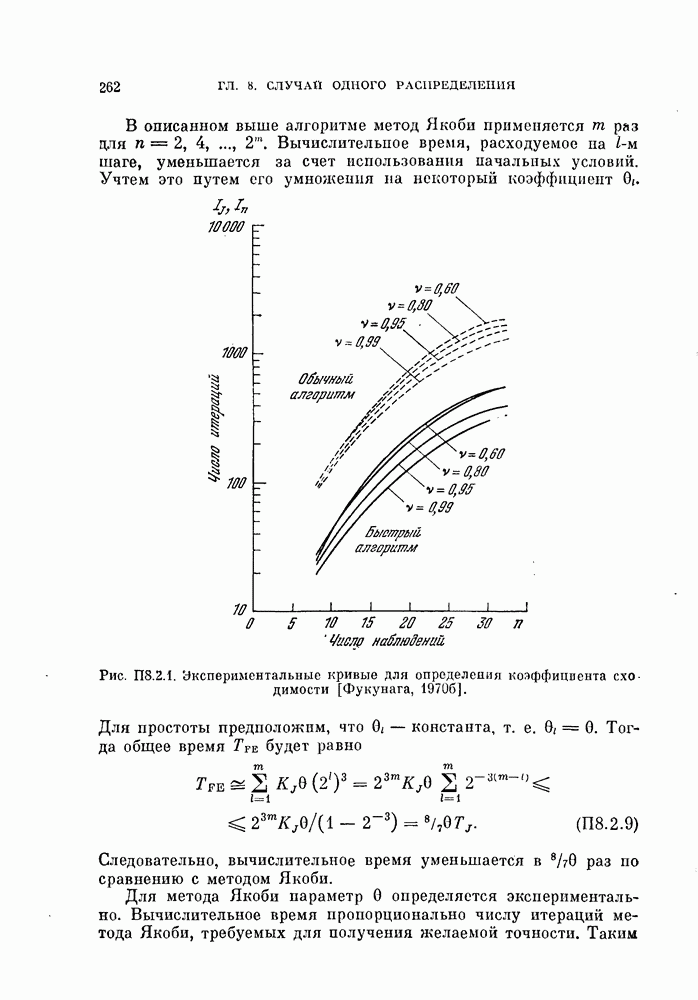
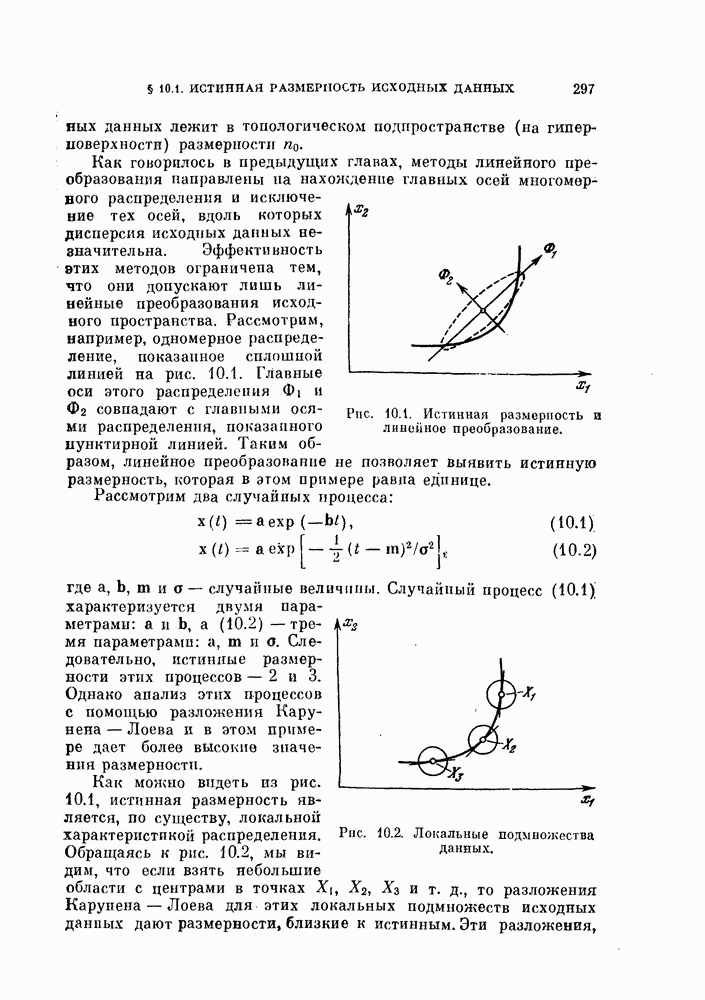
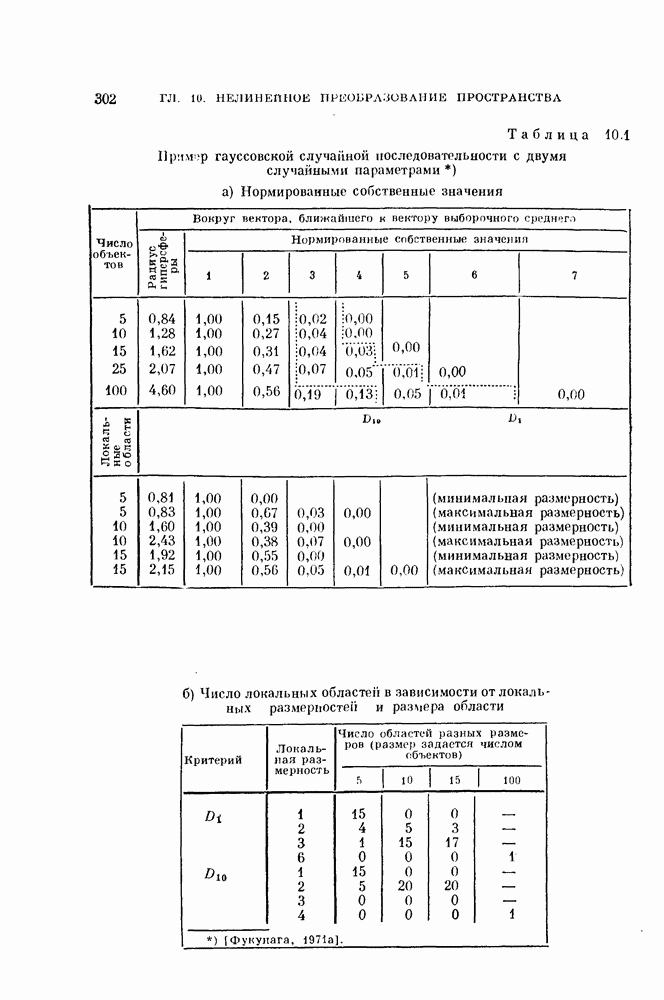
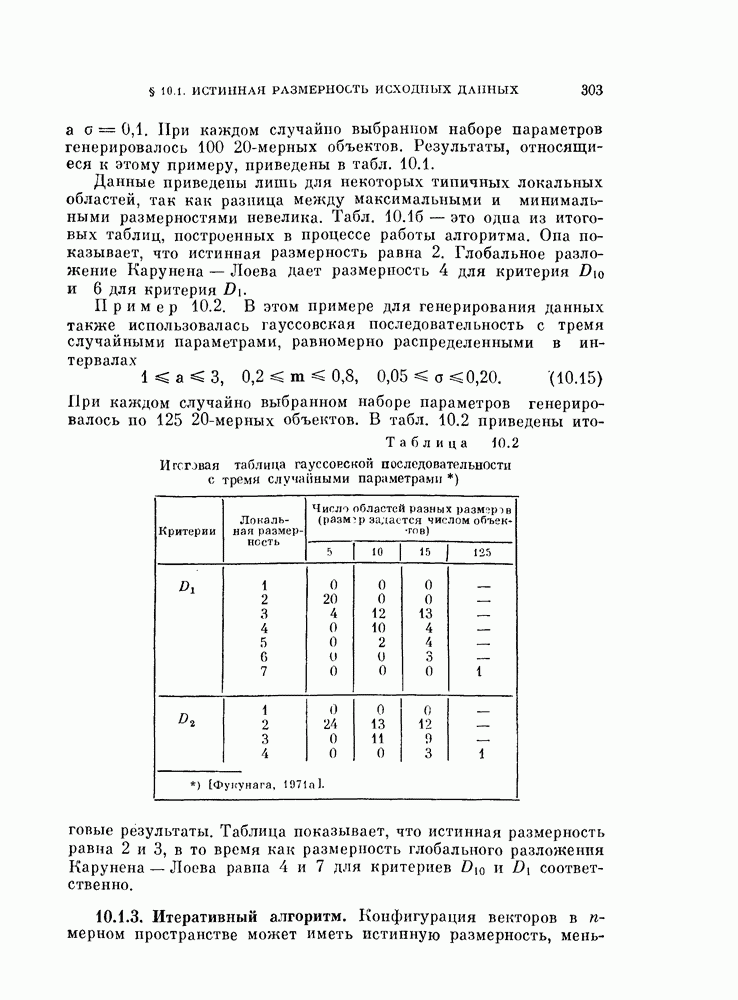
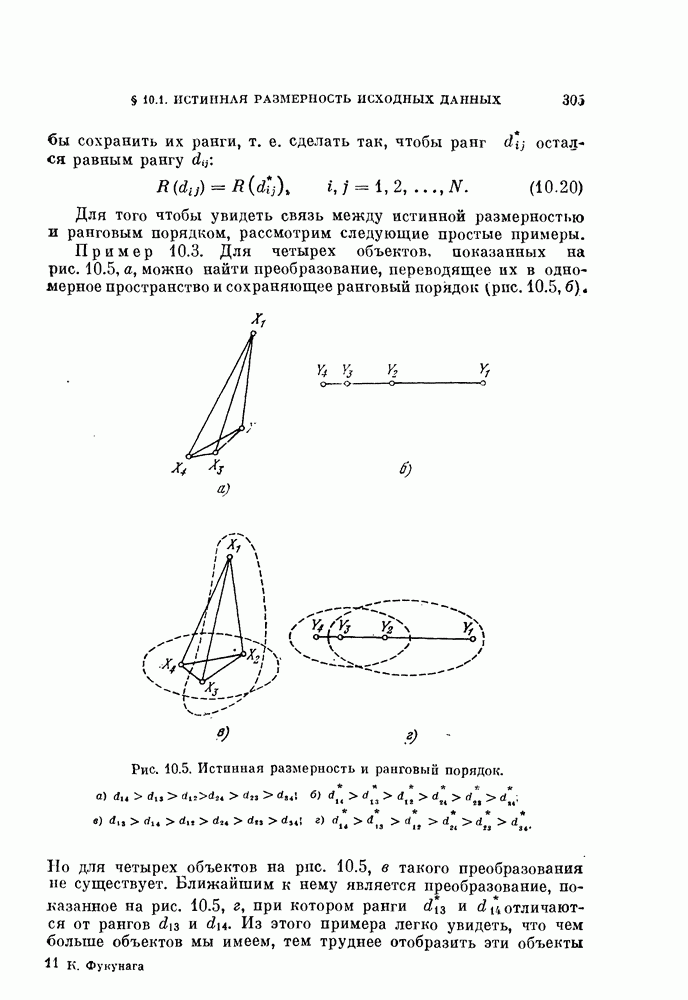
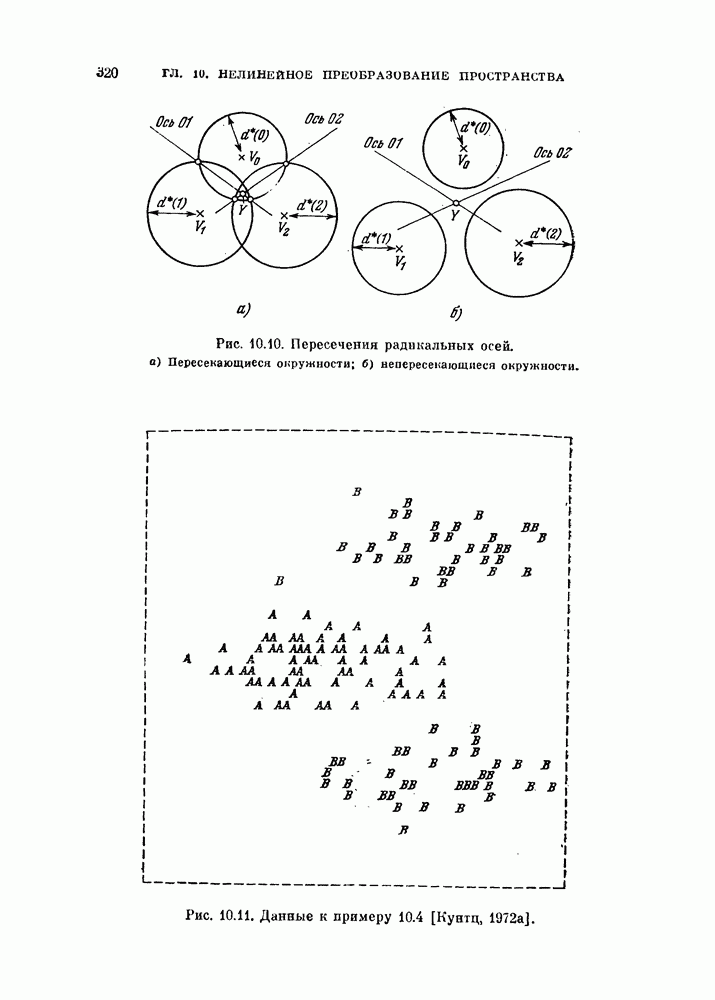
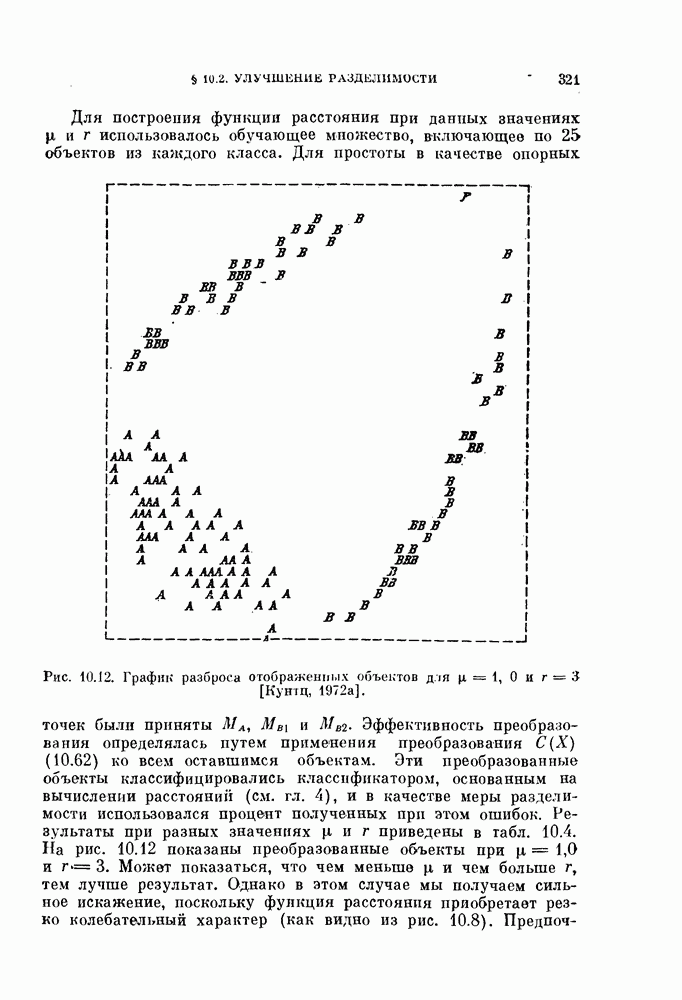
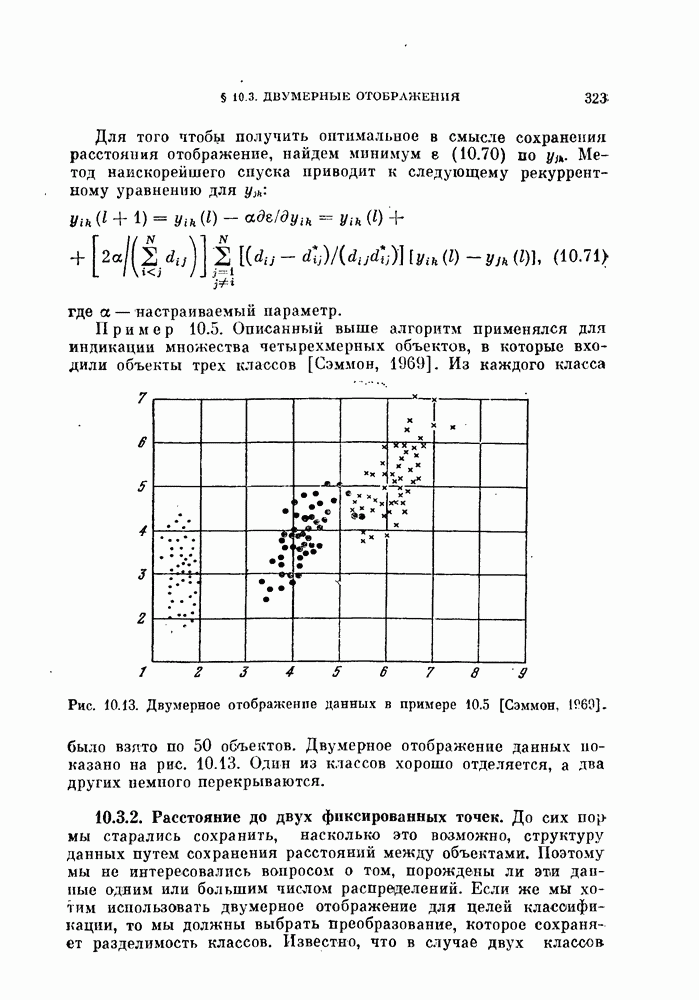
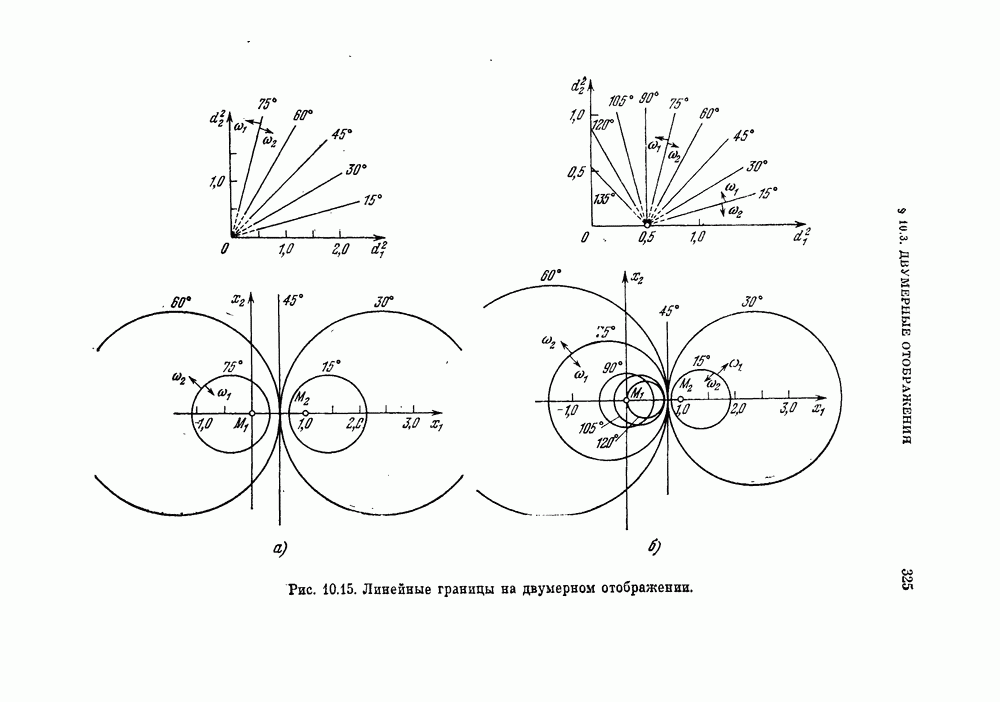
Глава 7. ПОСЛЕДОВАТЕЛЬНОЕ ОЦЕНИВАНИЕ ПАРАМЕТРОВ
В рассмотренных до сих пор методах оценивания параметров оценивание производилось по всем наблюденным данным за один просчет. Иногда более практичной оказывается процедура, основанная на последовательных вычислениях. В этом случае параметры в первом приближении определяются путем «угадывания». Затем каждый вектор наблюдения используется для: улучшения оценки. Предполагается, что по мере увеличения числа наблюдений оценка будет сходиться в каком-либо смысла к истинным значениям параметров.
Основное преимущество последовательного метода заключается в том, что он позволяет использовать бесконечное число наблюдений, располагая лишь конечным объемом памяти.
§ 7.1. Последовательная корректировка линейного классификатора
Если каждая из условных плотностей вероятности, соответствующих разделяемым классам, принадлежит известному параметрическому семейству, то классификатор строится довольно просто: оцениваются неизвестные параметры, после чего находится байесовское решающее правило. Однако довольно часто даже вид условных плотностех! вероятности неизвестен. Эти плотности можно аппроксимировать методами, описанными: в гл. 6.
Однако существует и другой путь решения задачи, позволяющей избежать вычисления плотности вероятности. Допустим, что можно априори предположить, что решающее правило принадлежит некоторому параметрическому семейству решающих правил. Тогда задача сводится к задаче оценивания параметров этого решающего правила. При таком подходе к решению задачи мы жертвуем, быть может, более глубоким пониманием ее сущности, однако, эта жертва часто оказывается более чем оправданной с вычислительной точки зрения.
Пусть в задаче классификации на два класса решено использовать линейный классификатор вида

Тогда задача сводится к оцениванию параметров  Линейный классификатор выбран здесь из-за его простоты, однако, как уже говорилось в гл. 4, решающее правило (7.1) включает широкий класс нелинейных разделяющих функций. Это имеет место, когда X рассматривается как вектор в функциональном пространстве, а не в пространстве исходных переменных.
Линейный классификатор выбран здесь из-за его простоты, однако, как уже говорилось в гл. 4, решающее правило (7.1) включает широкий класс нелинейных разделяющих функций. Это имеет место, когда X рассматривается как вектор в функциональном пространстве, а не в пространстве исходных переменных.
В гл. 4 рассматривалась процедура нахождения параметров У и  по данному множеству наблюдений при условии, что наблюдения имеются в нашем распоряжении одновременно. В алгоритмах, рассматриваемых в этой главе, мы не запоминаем одновременно все наблюдаемые векторы. Вместо этого в памяти хранится только текущая оценка параметра, которая обновляется всякий раз, когда на вход системы поступает очередной вектор наблюдений. Система этого типа, первоначально предложенная в качестве упрощенной модели обучения и принятия решений в первых исследованиях по распознаванию образов, получила название персептрон. Модель этого типа должна иметь алгоритм, который модифицирует параметры с учетом вновь поступившего вектора наблюдений и текущего значения этих параметров.
по данному множеству наблюдений при условии, что наблюдения имеются в нашем распоряжении одновременно. В алгоритмах, рассматриваемых в этой главе, мы не запоминаем одновременно все наблюдаемые векторы. Вместо этого в памяти хранится только текущая оценка параметра, которая обновляется всякий раз, когда на вход системы поступает очередной вектор наблюдений. Система этого типа, первоначально предложенная в качестве упрощенной модели обучения и принятия решений в первых исследованиях по распознаванию образов, получила название персептрон. Модель этого типа должна иметь алгоритм, который модифицирует параметры с учетом вновь поступившего вектора наблюдений и текущего значения этих параметров.