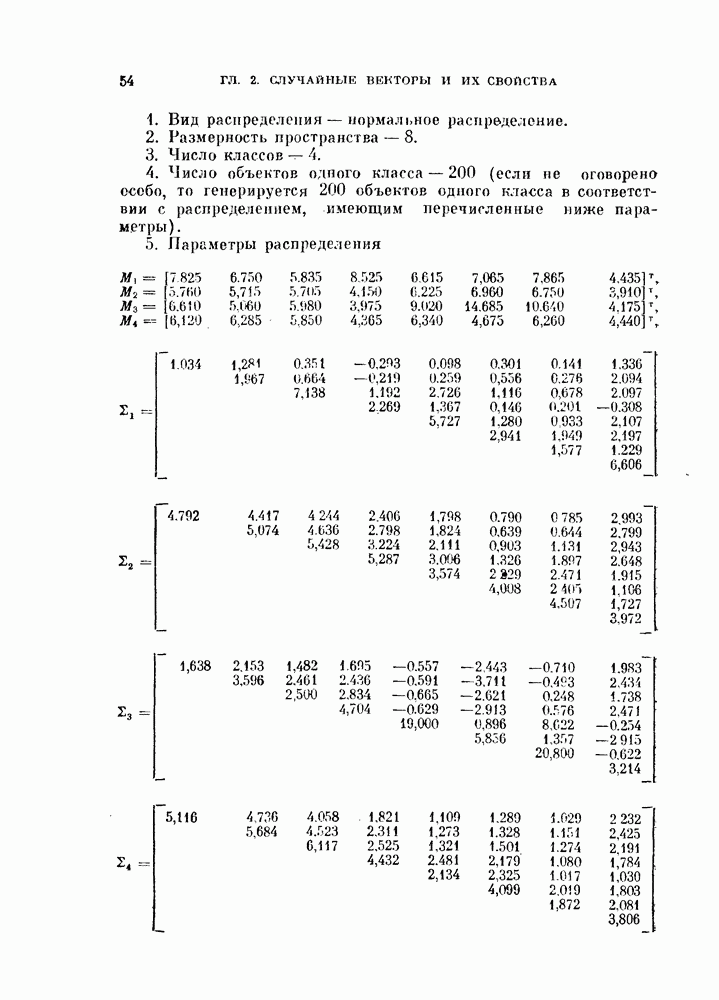
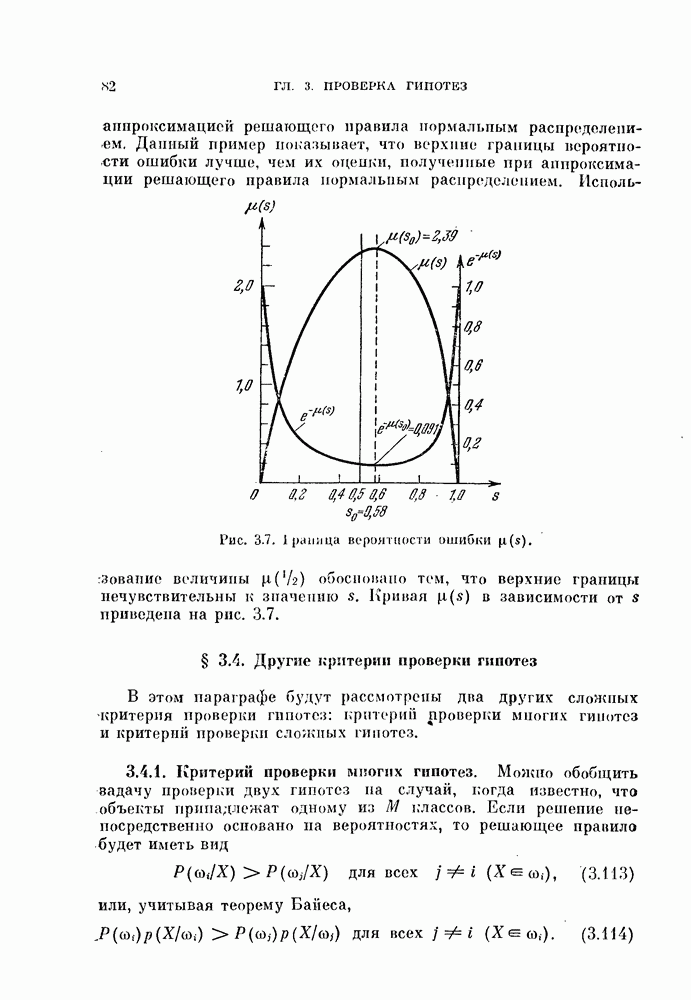
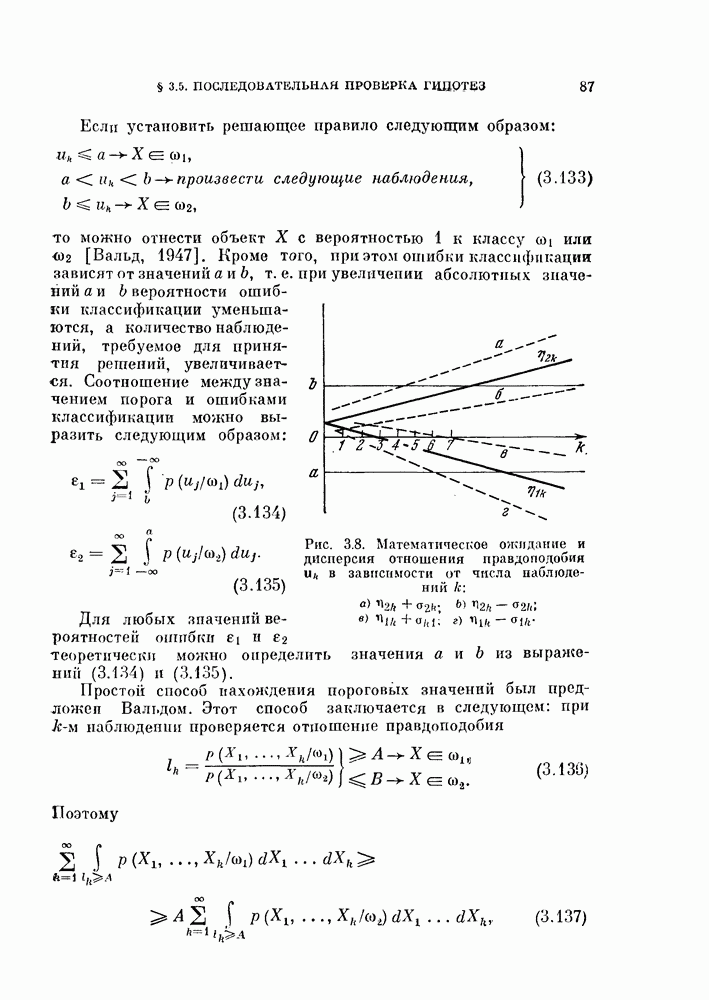
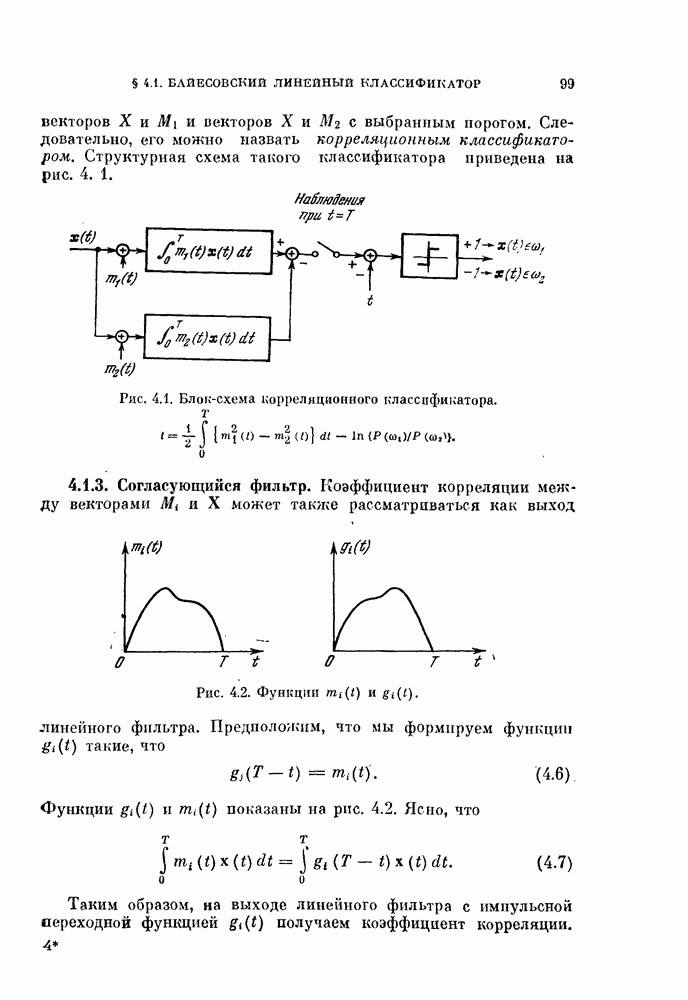
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
где

Абсолютное значение и фазовый угол характеристической функции (3.55) имеют следующий вид:

Характеристическая функция

где

Соотношение (3.61) совпадает с (3.55), если  заменить на
заменить на  Поэтому с точностью до этих параметров абсолютные значения
Поэтому с точностью до этих параметров абсолютные значения  и фазовые углы
и фазовые углы  характеристических функций
характеристических функций  совпадают.
совпадают.
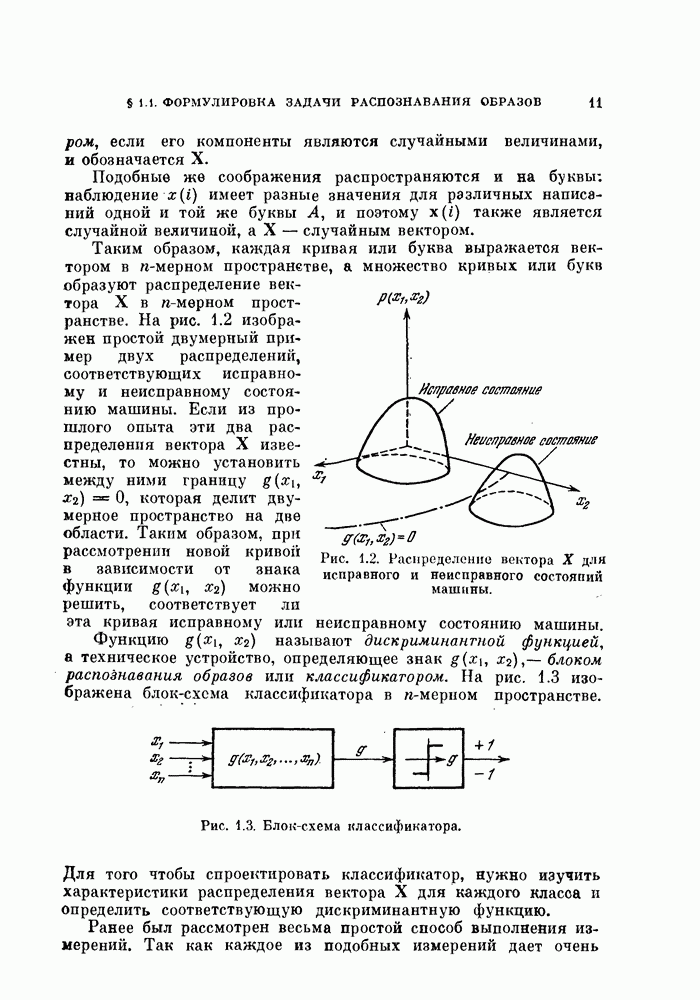
Таким образом, если распределения являются нормальными, то вероятности ошибки можно вычислить следующим образом [Фукунага, Крайл, 1969].
1) Для одновременной диагонализации ковариационных матриц классов  применить линейное преобразование.
применить линейное преобразование.
2) Для классов  по формулам (3.55) и (3.61) вычислить характеристические функции решающего правила
по формулам (3.55) и (3.61) вычислить характеристические функции решающего правила 
3) Вычислить вероятности ошибки по формулам (3.48), (3.49) и (3.52). (Эта процедура заключается в одномерном численном интегрировании для получения вероятностей ошибки каждого класса.)
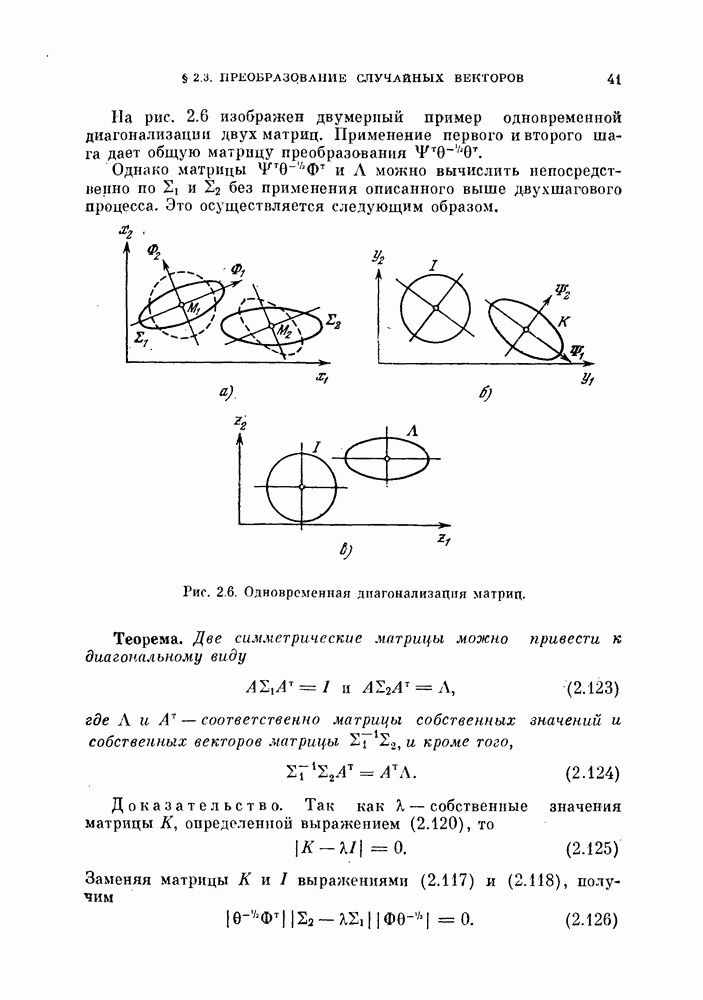
Эти же величины можно выразить через собственные значения  и
и 

Подставляя эти выражепия в формулы (3.35) и (3.36), можно грубо оценить вероятности ошибки. Поэтому моменты более 
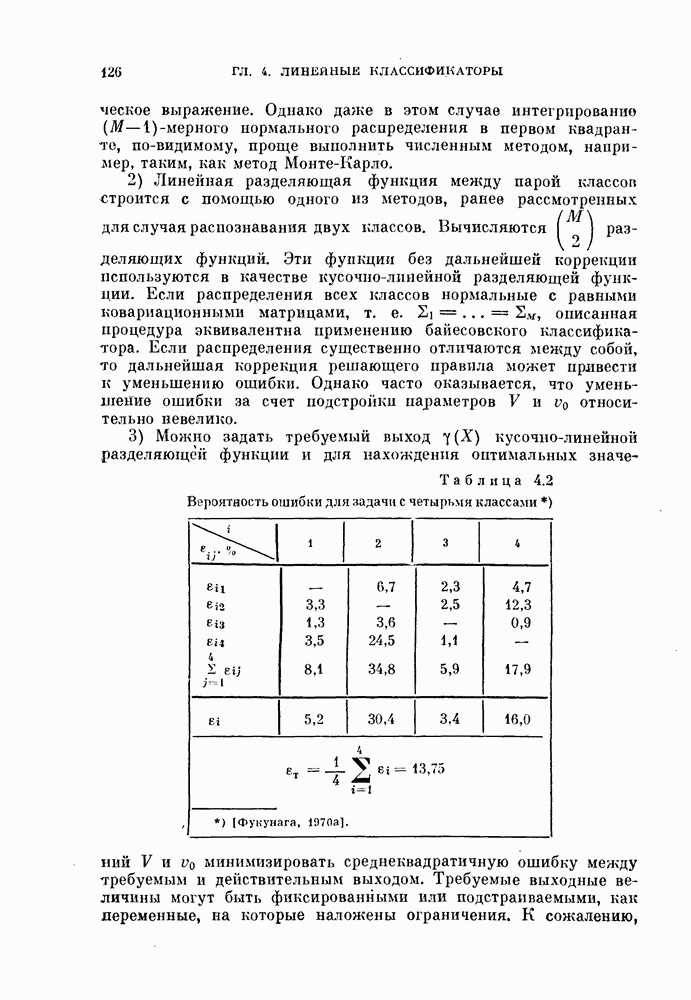
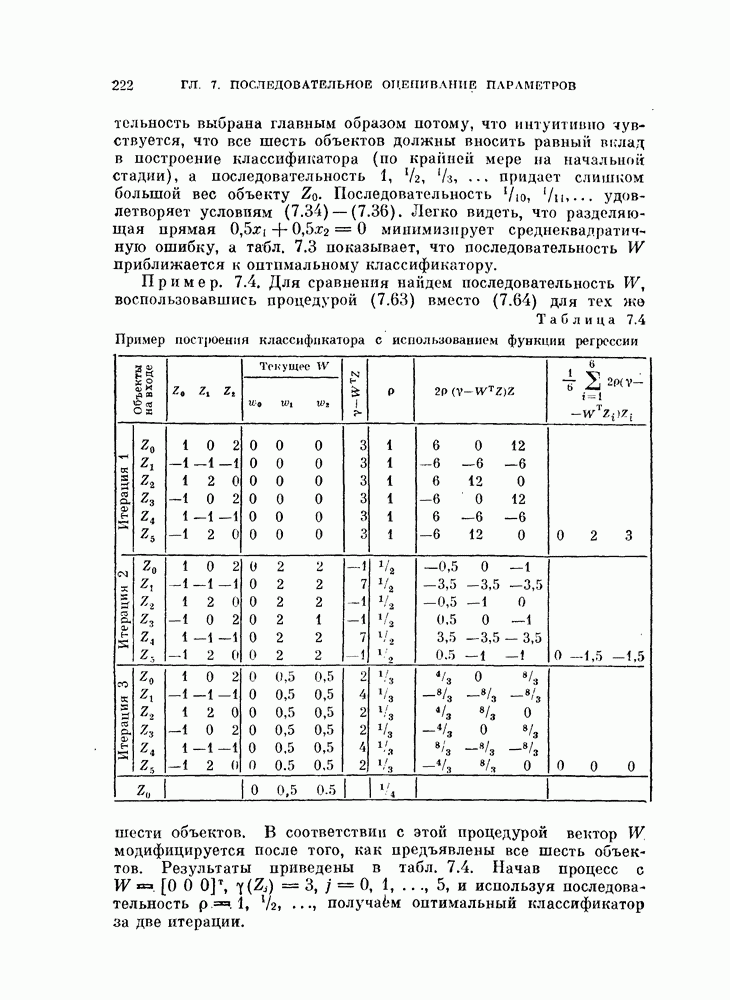
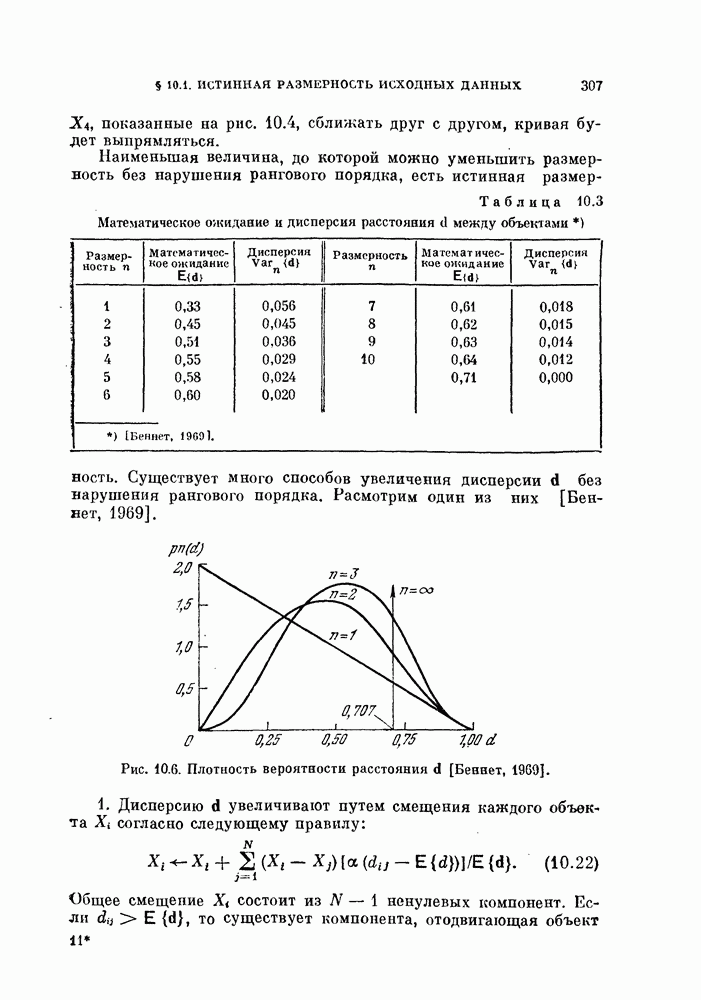
Таблица 3.2. Стандартные данные  после одновременной диагоиализащш ковариационных матриц
после одновременной диагоиализащш ковариационных матриц

сокого порядка также можно определить по характеристической функции.
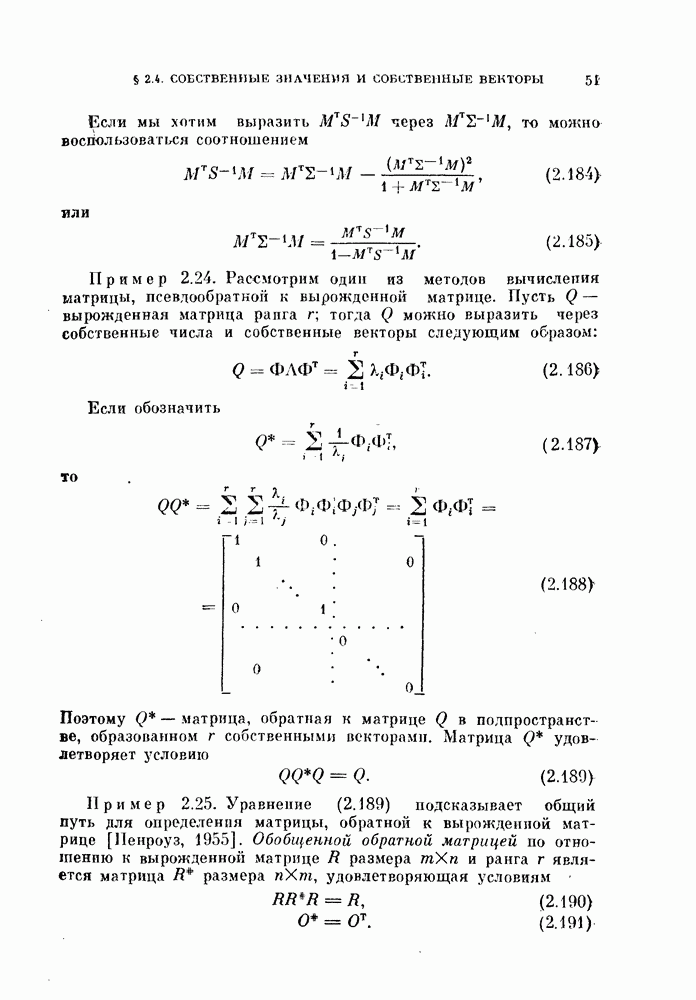
Теоретически возможно улучшить аппроксимацию с помощью полиномиальных рядов Эрмита, коэффициенты которых являются функциями моментов случайных величии [Фишер, 1923; Папулис, 1965].
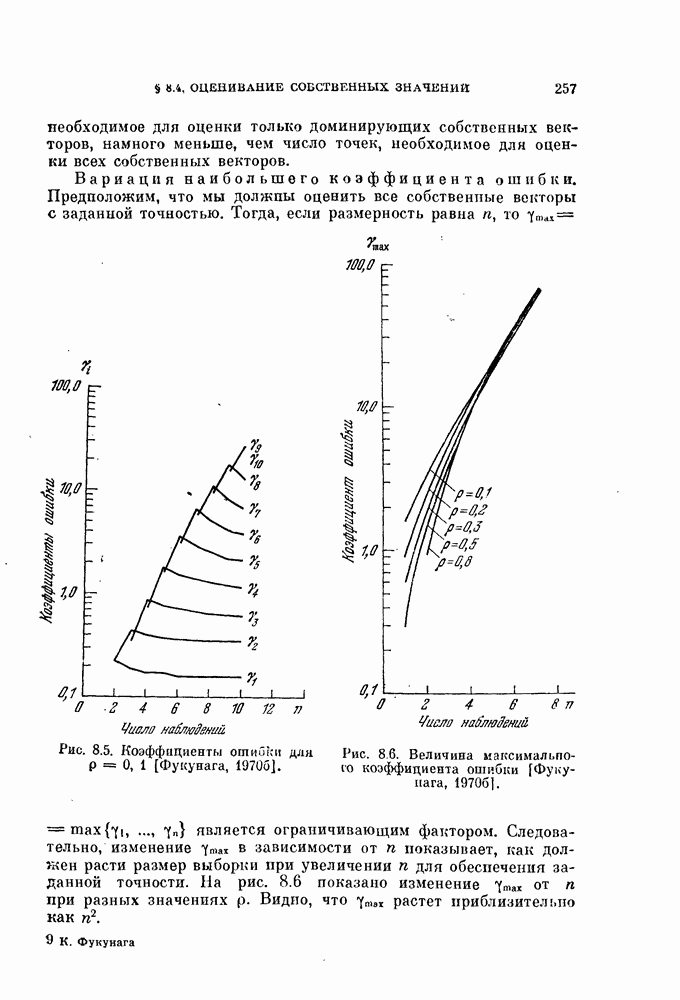
Таблица 3.3. Сравнение вероятностей ошибки [Фукунага, Крайл, 1969]

Однако эксперименты показывают, что если не все собственные значепия  близки к 1, то сходимость этих рядов
близки к 1, то сходимость этих рядов
очень медленная, и для того, чтобы ее ускорить, требуется большое количество моментов высокого порядка.
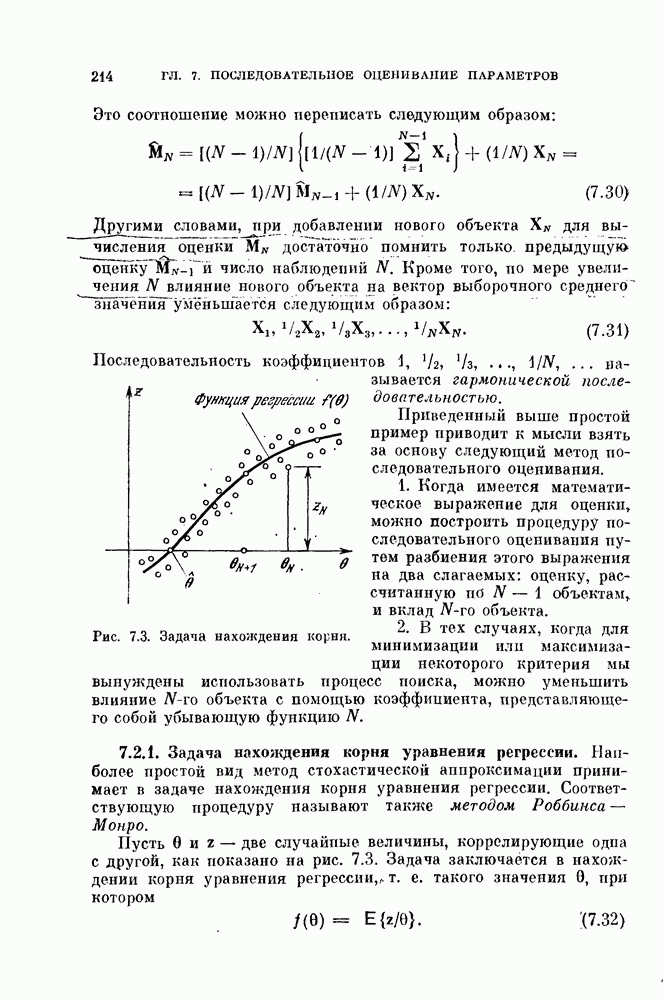
Пример 3.3. Рассмотрим стандартные даппые  параметры которых после преобразования приведены в табл. 3.2. Как видно из этой таблицы, собственные значепия
параметры которых после преобразования приведены в табл. 3.2. Как видно из этой таблицы, собственные значепия  распределены в достаточно большом диапазоне (от 12,06 до 0,12).
распределены в достаточно большом диапазоне (от 12,06 до 0,12).

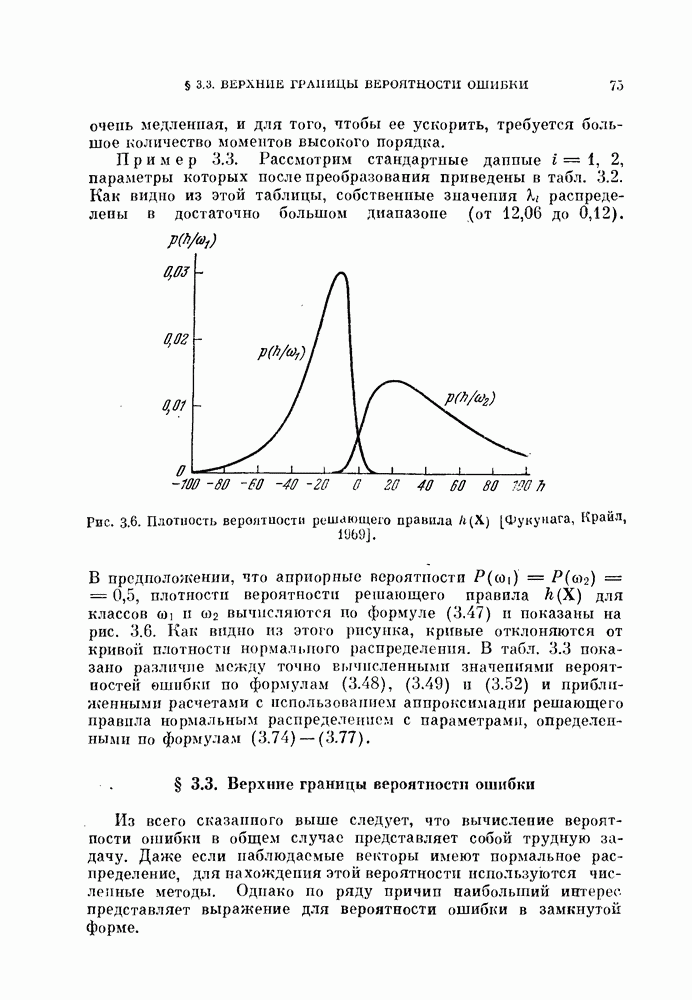
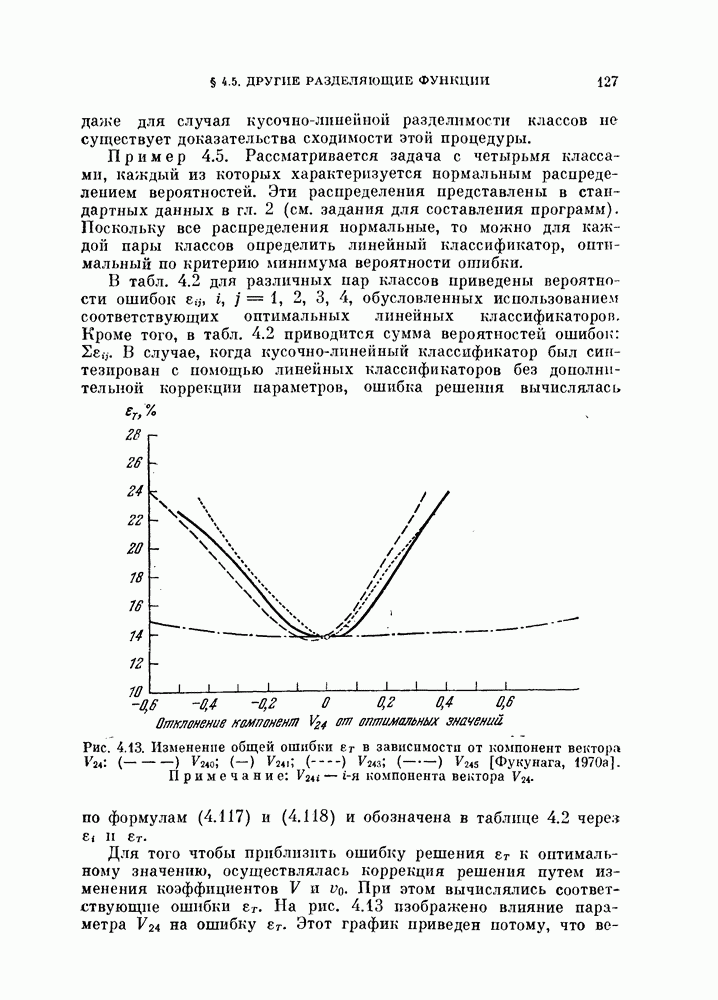
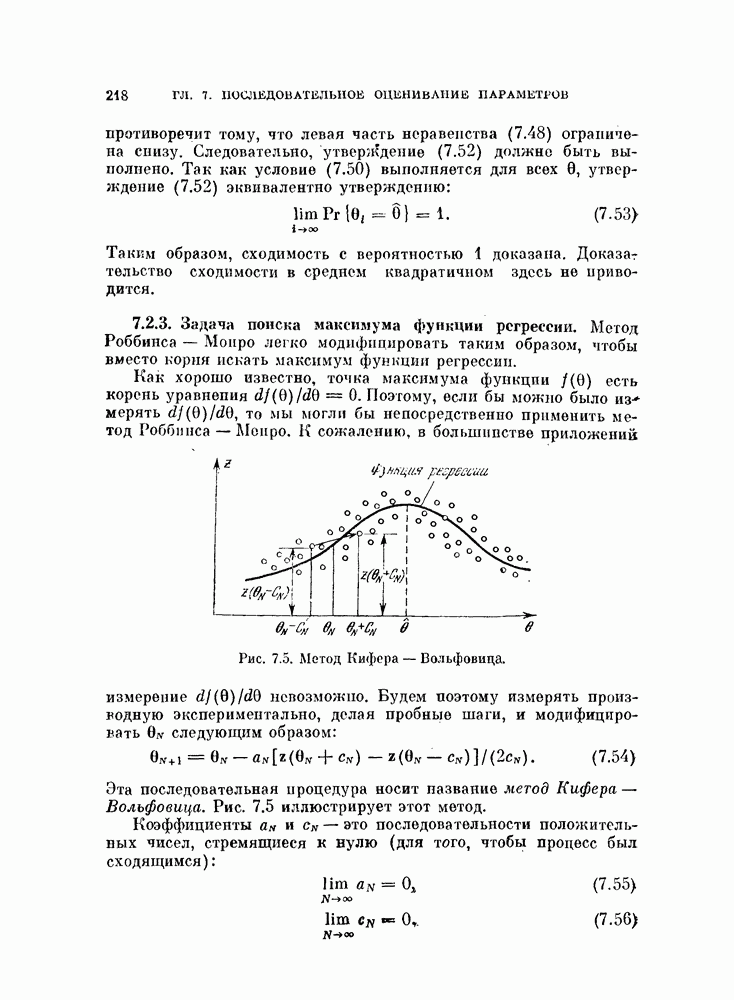
Рис. 3 6. Плотность вероятности решающего правила  [Фукунага, Крайл, 1969].
[Фукунага, Крайл, 1969].
В предположении, что априорные вероятности  плотности вероятности решающего правила
плотности вероятности решающего правила  для классов
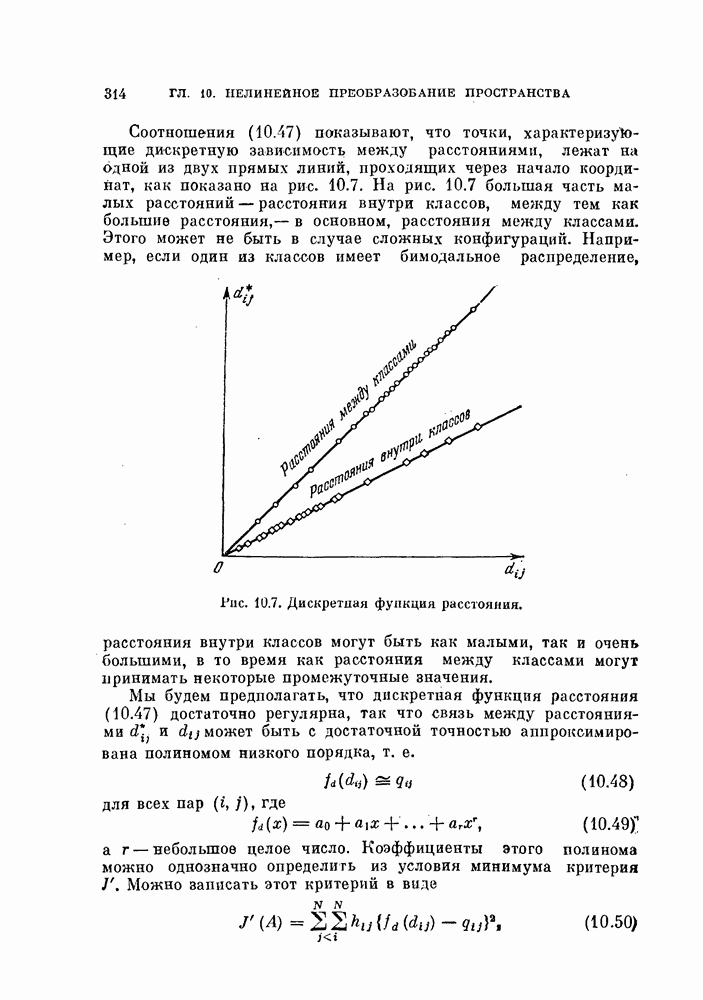
для классов  вычисляются по формуле (3.47) и показаны на рис. 3.6. Как видно из этого рисунка, кривые отклоняются от кривой плотности нормального распределения. В табл. 3.3 показано различие между точно вычисленными значениями вероятностей ошибки по формулам (3.48), (3.49) и (3.52) и приближенными расчетами с использованием аппроксимации решающего правила нормальным распределением с параметрами, определенными по формулам (3.74) — (3.77).
вычисляются по формуле (3.47) и показаны на рис. 3.6. Как видно из этого рисунка, кривые отклоняются от кривой плотности нормального распределения. В табл. 3.3 показано различие между точно вычисленными значениями вероятностей ошибки по формулам (3.48), (3.49) и (3.52) и приближенными расчетами с использованием аппроксимации решающего правила нормальным распределением с параметрами, определенными по формулам (3.74) — (3.77).






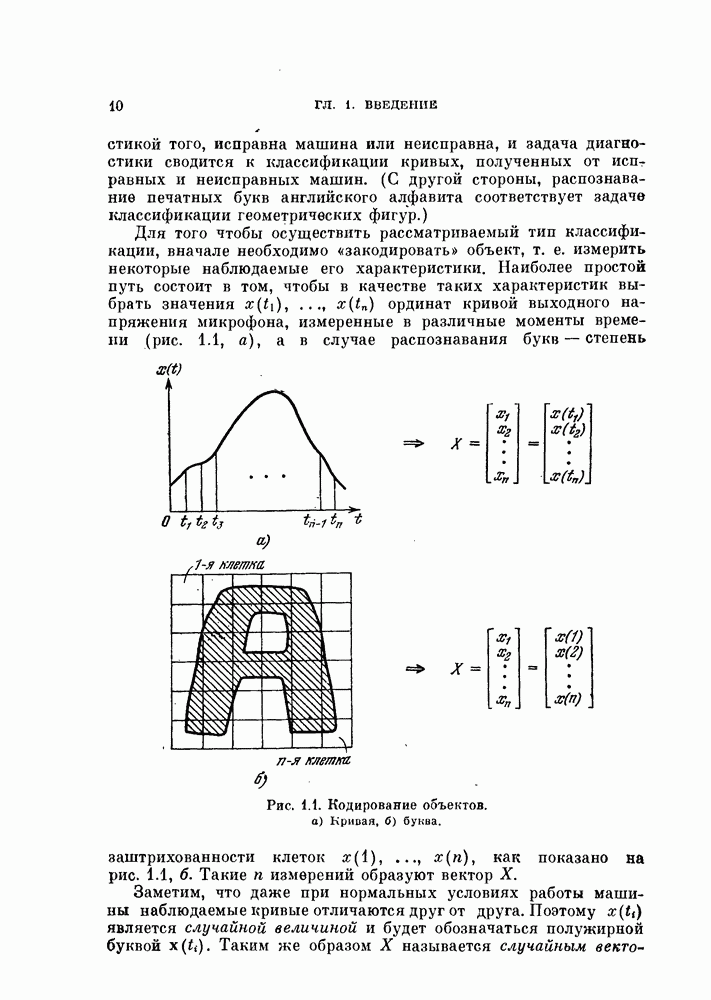





































































































































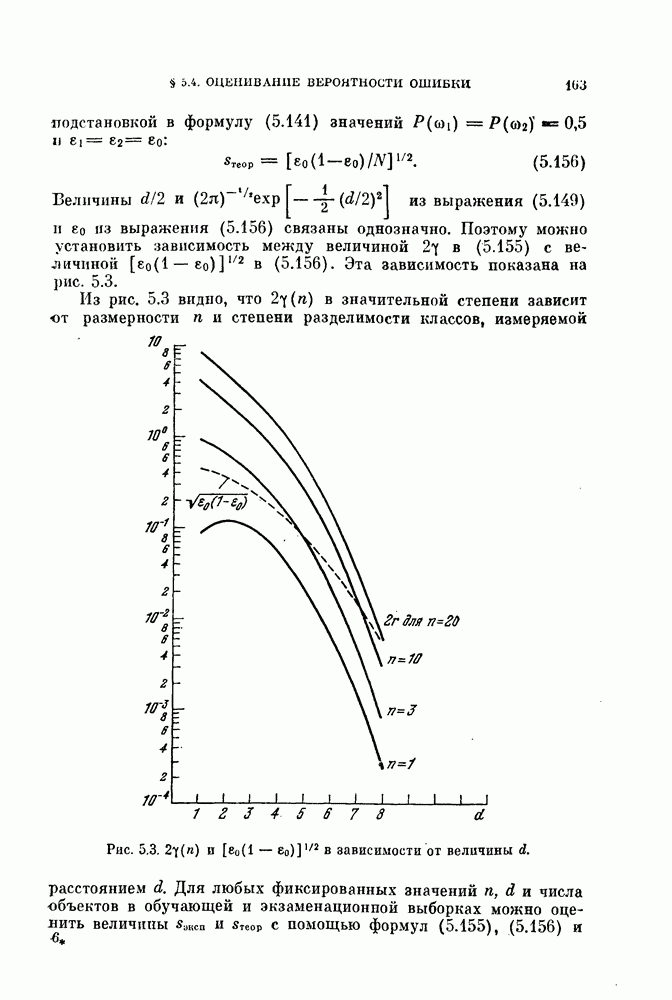









































































































































































 — соответственно векторы математического ожидания и ковариационные матрицы классов
— соответственно векторы математического ожидания и ковариационные матрицы классов  и
и  для нового случайного вектора
для нового случайного вектора  полученного в результате данного преобразования. Решающее правило (3.10) в преобразованной системе координат примет вид
полученного в результате данного преобразования. Решающее правило (3.10) в преобразованной системе координат примет вид

 компонента вектора математического ожидания
компонента вектора математического ожидания  Следовательно, решающее правило
Следовательно, решающее правило  и характеристическая функция
и характеристическая функция  будут равны
будут равны

 то матрица
то матрица  близка к единичной матрице
близка к единичной матрице  а параметры и
а параметры и  близки к 0. В этом случае характеристические функции примут вид
близки к 0. В этом случае характеристические функции примут вид

 представляют собой характеристические функции нормальных распределений, математические ожидания и дисперсии которых соответственно равны
представляют собой характеристические функции нормальных распределений, математические ожидания и дисперсии которых соответственно равны

 и
и  достаточно различаются между собой, то все же можно получить грубую аппроксимацию вероятности ошибки, предполагая, что решающее правило
достаточно различаются между собой, то все же можно получить грубую аппроксимацию вероятности ошибки, предполагая, что решающее правило  имеет нормальное распределение. Так как характеристические функции известны, то можно вычислить математическое ожидание и дисперсию этого распределения:
имеет нормальное распределение. Так как характеристические функции известны, то можно вычислить математическое ожидание и дисперсию этого распределения:

