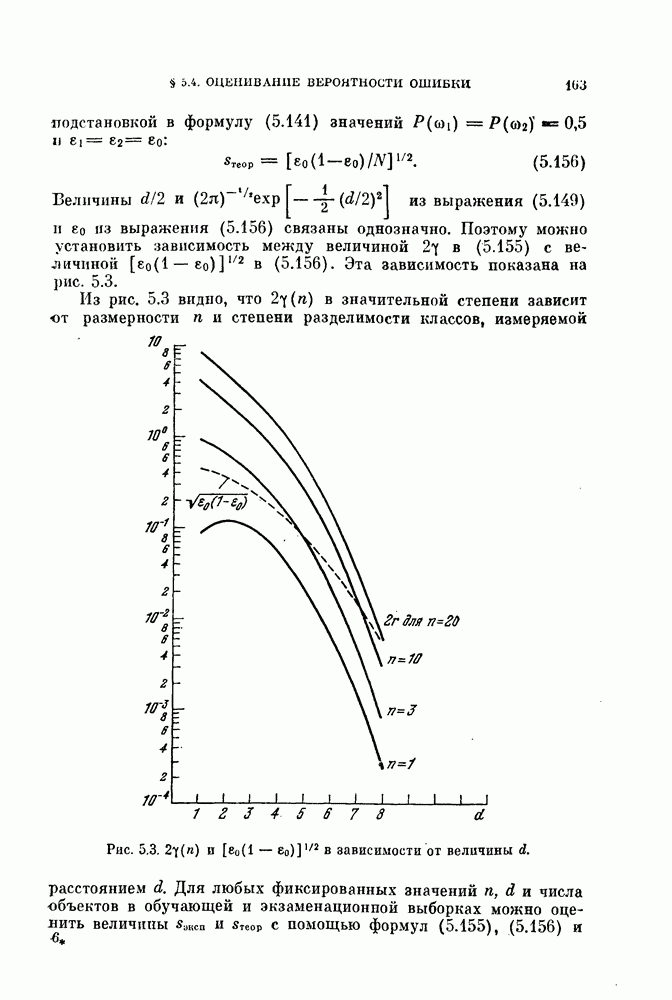
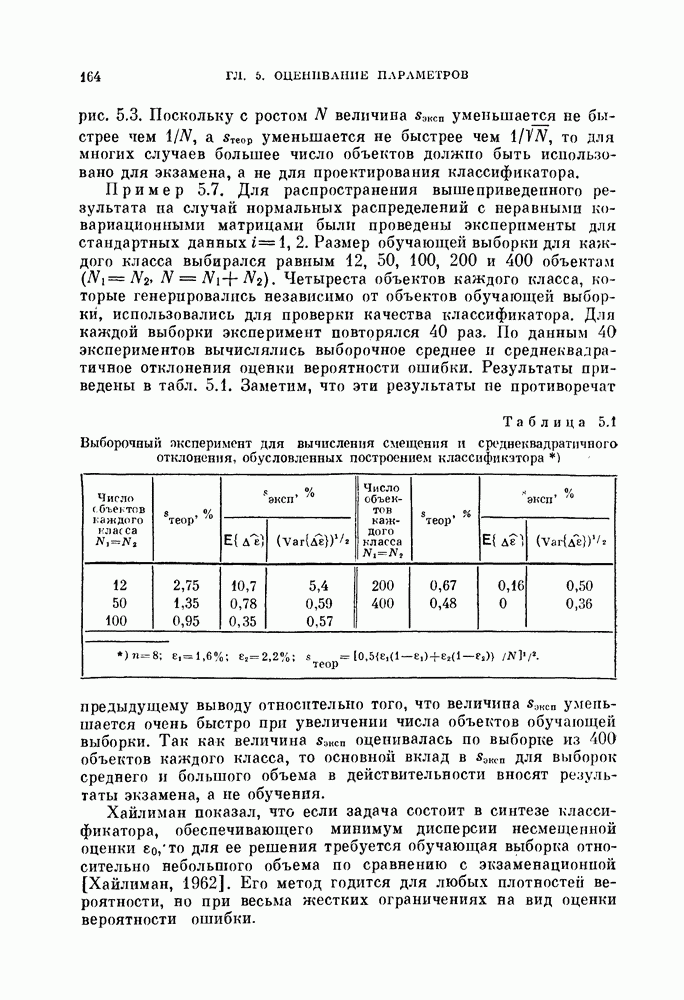
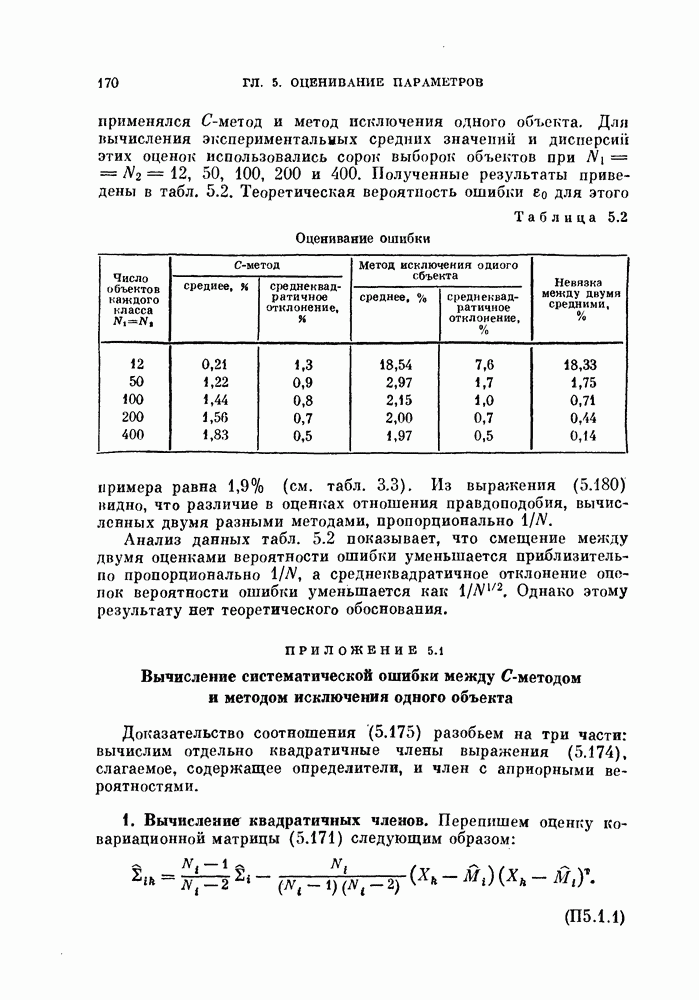
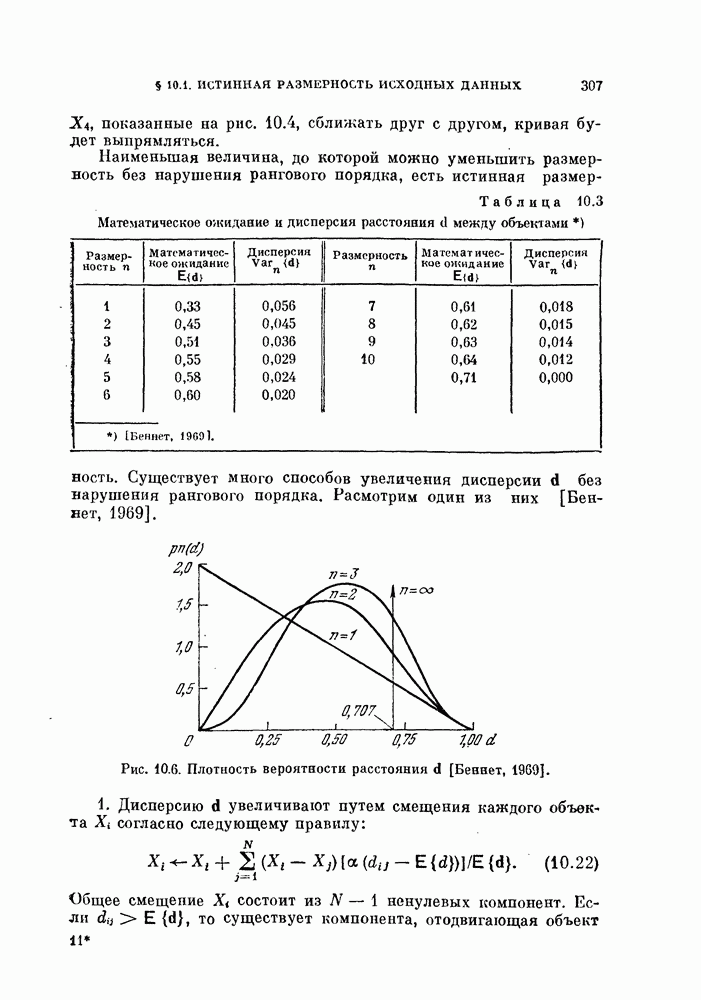
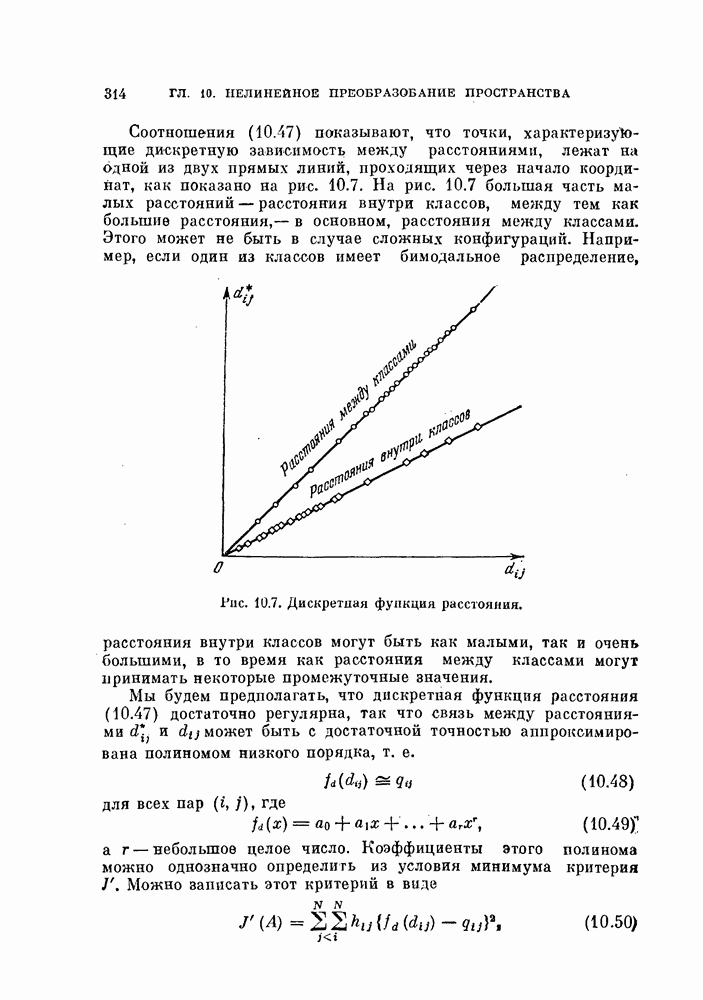
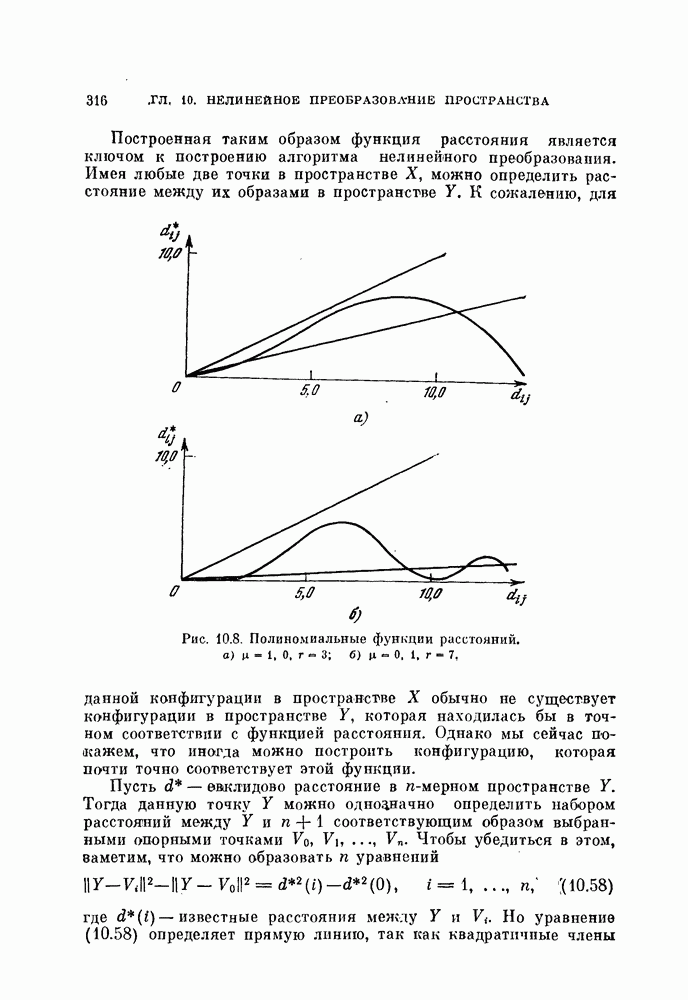
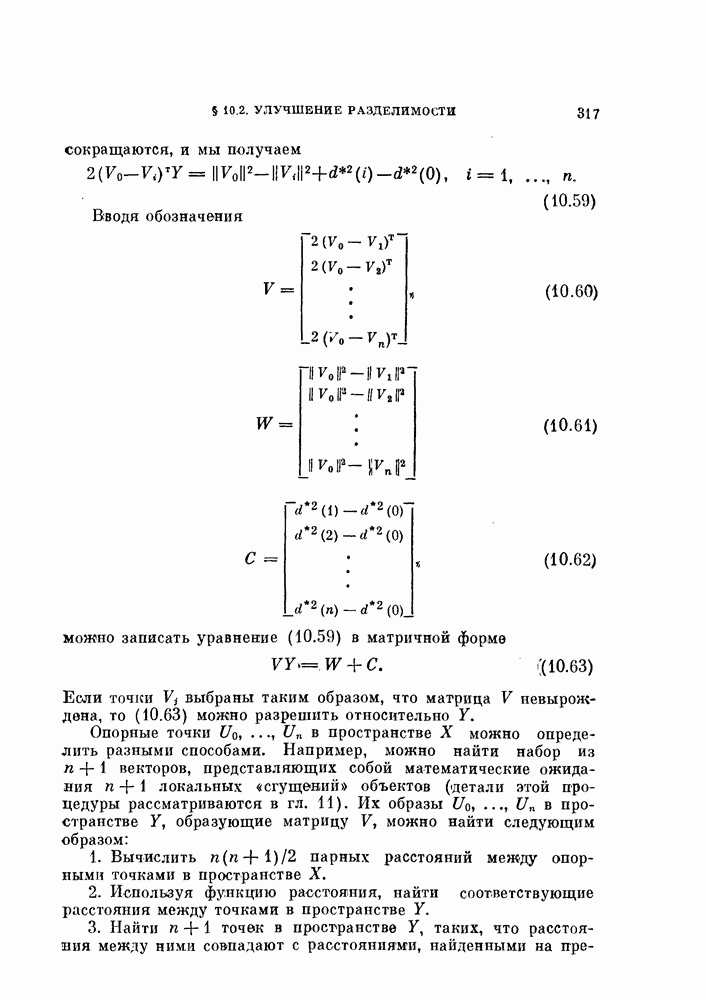
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
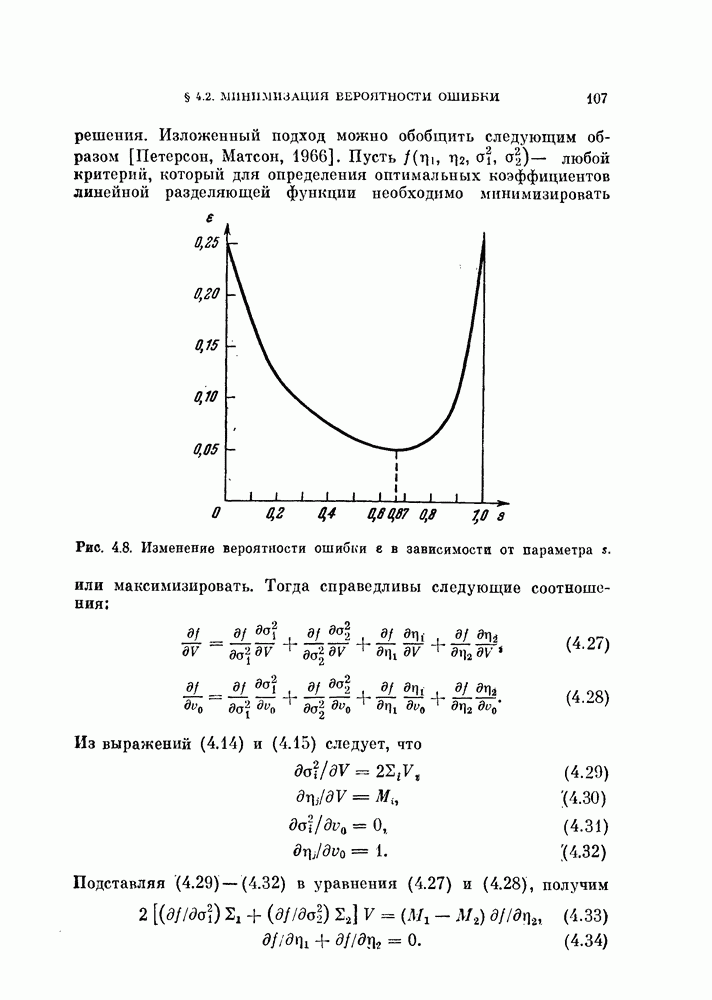
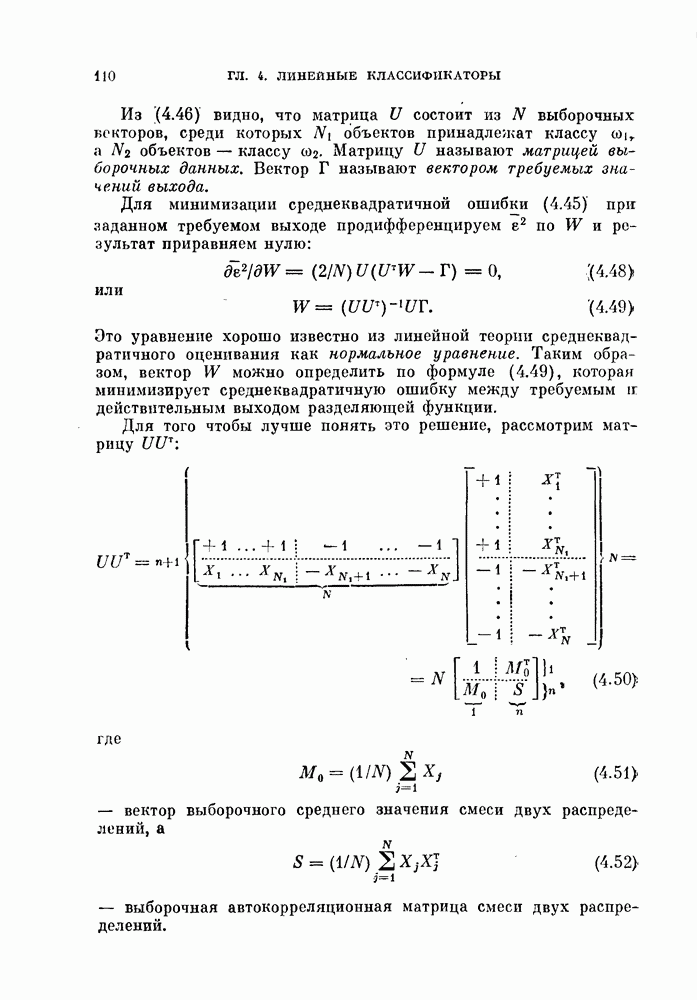
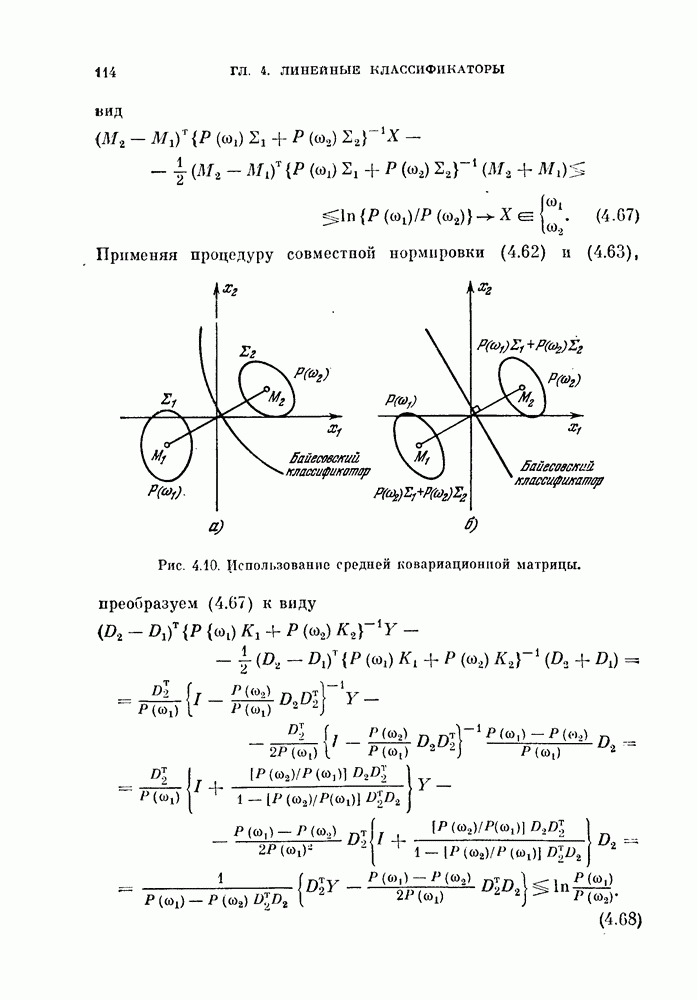
ZADANIA.TO
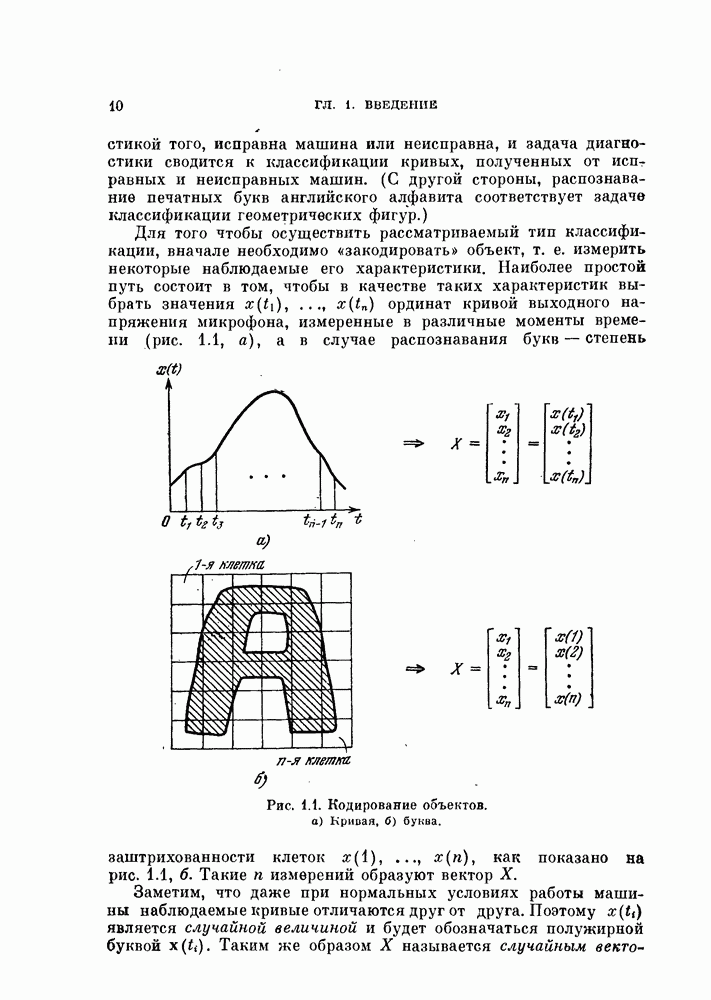
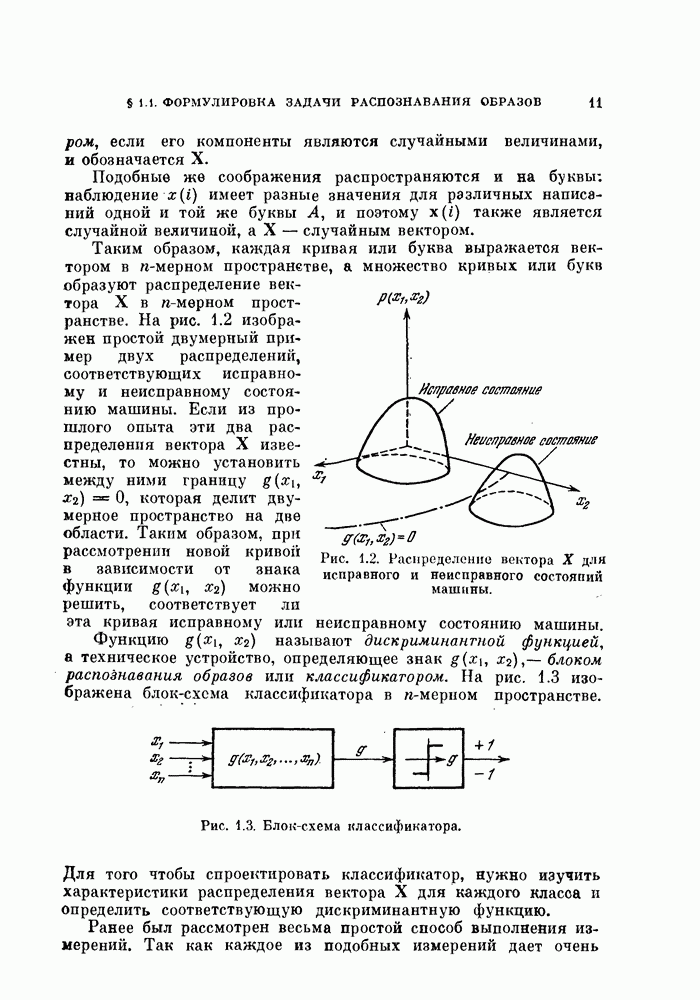
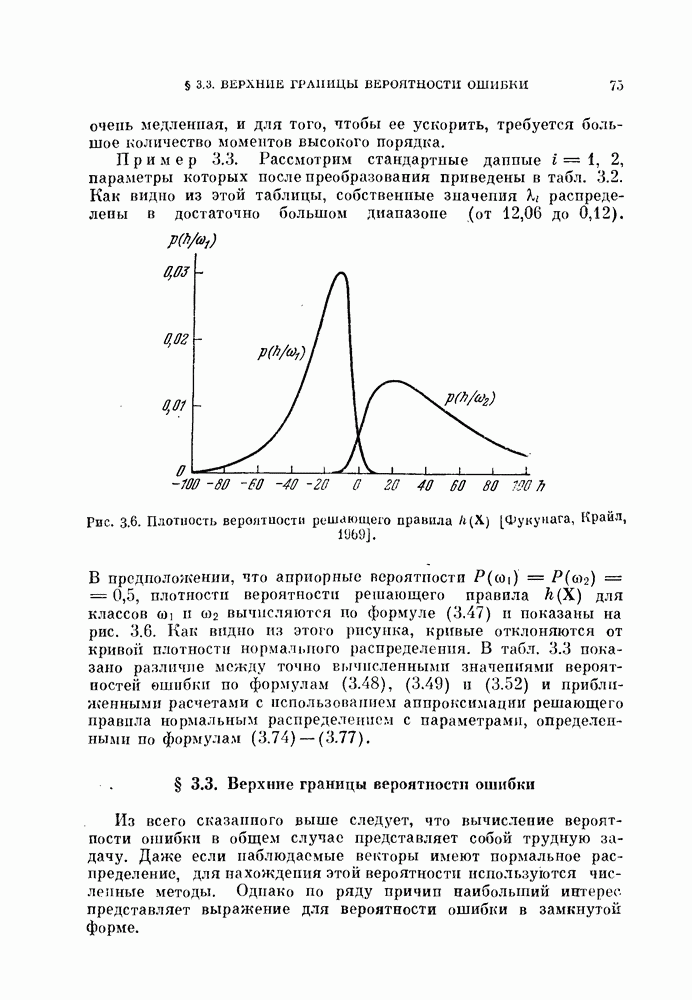
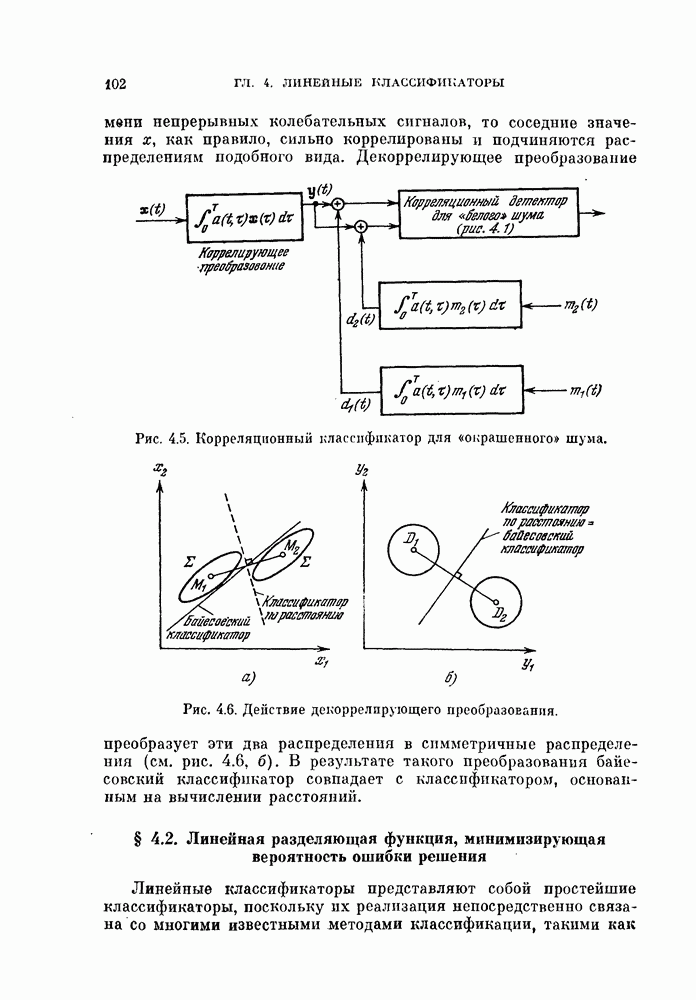
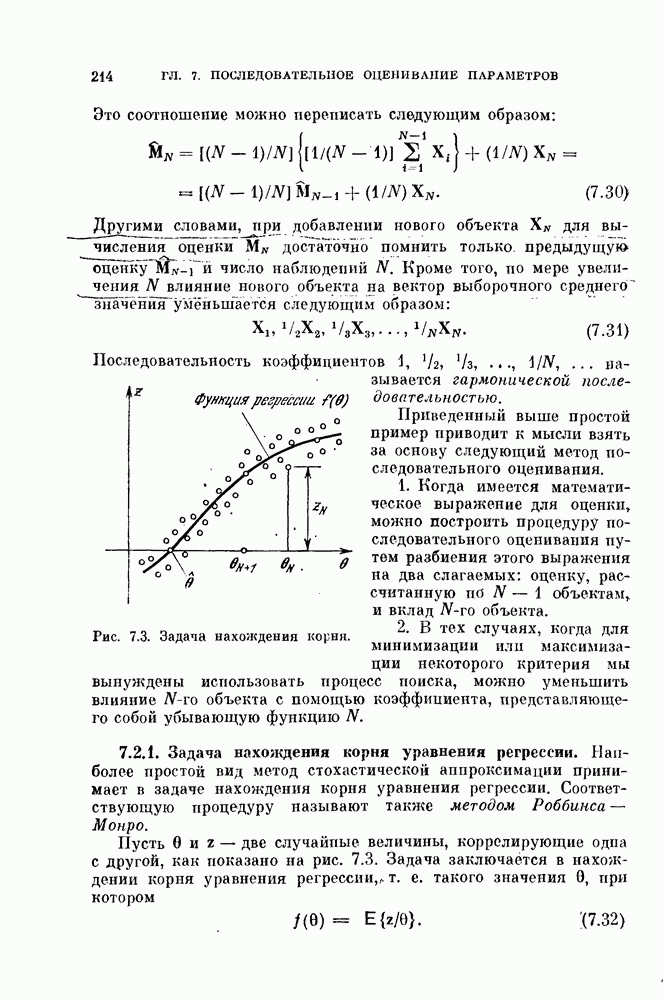
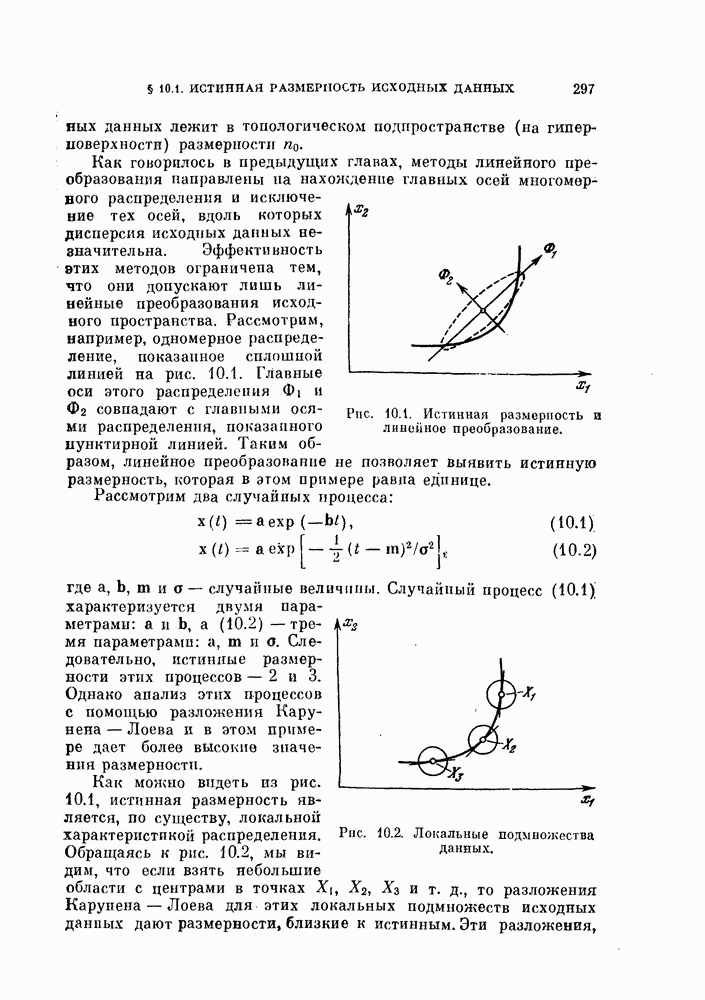
§ 8.1. Дискретное разложение Карунена — ЛоеваРассмотрим вначале выбор признаков в случае одного распределения. При наличии только одного распределения нельзя говорить о разделимости классов, т. е. о задаче распознавания образов. Вместо этого мы рассмотрим, насколько точно можно описать объекты, генерированные в соответствии с распределеним с помощью набора признаков. Если с помощью небольшого числа признаков удается точно описать объекты, то можно сказать, что такие признаки эффективны. Хотя эта задача непосредственно не связана с распознаванием образов, знание характеристик отдельных распределений помогает отделить одно распределение от других. Кроме того, выбор признаков для случая одного распределения находит широкое применение в других областях, таких, как представление сигналов и сжатие данных в системах связи. Еще одно ограничение связано с тем, что ищутся только такие признаки, которые можно получить линейным преобразованием исходных переменных. Как видно из рис. 8.1, новый признак у весьма эффективен для представления данных объектов, но этот признак является нелинейной функцией относительно
Рис. 8.1. Нелинейное преобразование. 8.1.1. Критерий минимума среднеквадратичной ошибки.Пусть X — n-мерный случайный вектор. Тогда X можно точно представить разложением
где
а
Матрица Ф является детерминированной и состоит из
Следовательно, линейные комбинации столбцов матрицы Ф образуют
Если условие ортонормированности выполнено, то компоненты вектора
Следовательно, Предположим, что мы определили только
Без ограничения общности можно считать, что вычисляются только первые
Заметим, что как X, так и признаков:
Каждому набору базисных векторов и значений констант соответствует некоторое значение
Другими словами, мы должны заменить те
Теперь среднеквадратичную ошибку можно записать следующим образом:
где
т. е. оптимальные базисные векторы — это собственные векторы ковариационной матрицы
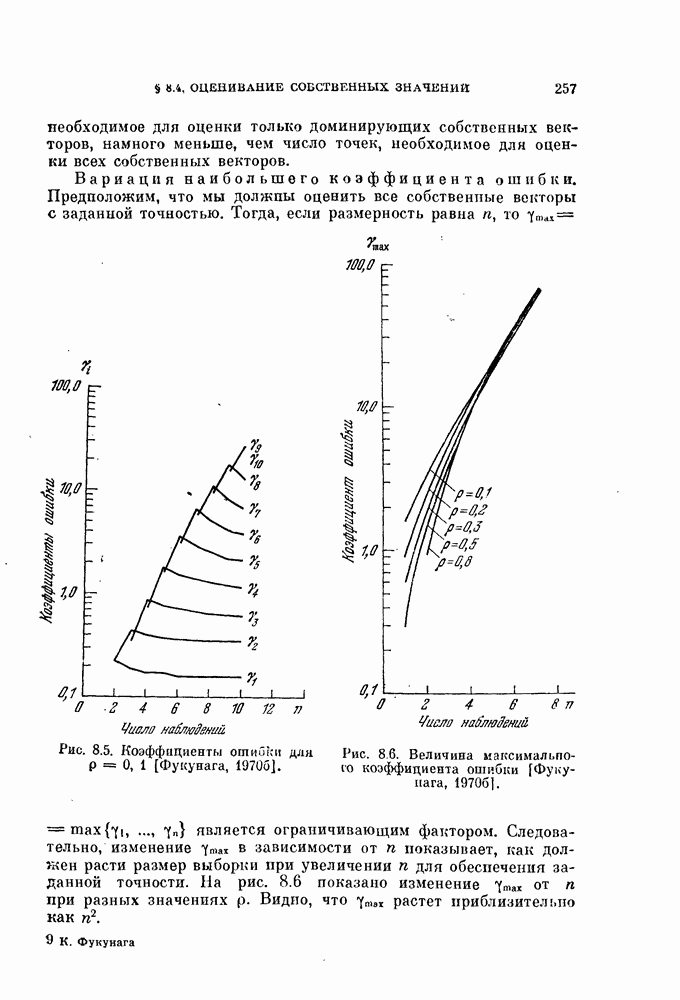
Разложение случайного вектора по собственным векторам ковариационной матрицы представляет собой дискретный вариант разложения Карунена — Лоева. В задачах распознавания образов коэффициенты 1. Эффекгвность каждого признака, т. е. его полезность с точки зрения представления X, определяется соответствующим собственным значением. Если некоторый признак, например, у» исключается из разложения, то среднеквадратичная ошибка увеличивается на
то признаки должны быть упорядочепы по важности таким же образом. 2. Рассматриваемые признаки взаимно иекоррелировапы, т. е. ковариационная матрица случайного вектора
В частном случае, когда случайный вектор X распределен нормально, признаки 3. Собственные векторы ковариационной матрицы дают наименьшее значение среднеквадратичной ошибки Доказательство свойства 3. Предположим, что мы разложили случайный вектор X по столбцам другой ортогональной матрицы
диагональный элемент которой имеет вид
Разобьем матрицу Н на подматрицы следующим образом:
Тогда среднеквадратичная ошибка в случае, если измеряются только
(в соответствии с равенством (8.12), которое было получена только из условия ортогональности Ф. Наша цель состоит Пусть
Так как матрицы
Разобьем матрицу (8.21) аналогично (8.19):
Из этого следует, что
Тогда суть нашего доказательства состоит в том, чтобы показать:
Из ортогональности матрицы
Продолжим доказательство:
Первое неравенство следует из того, что
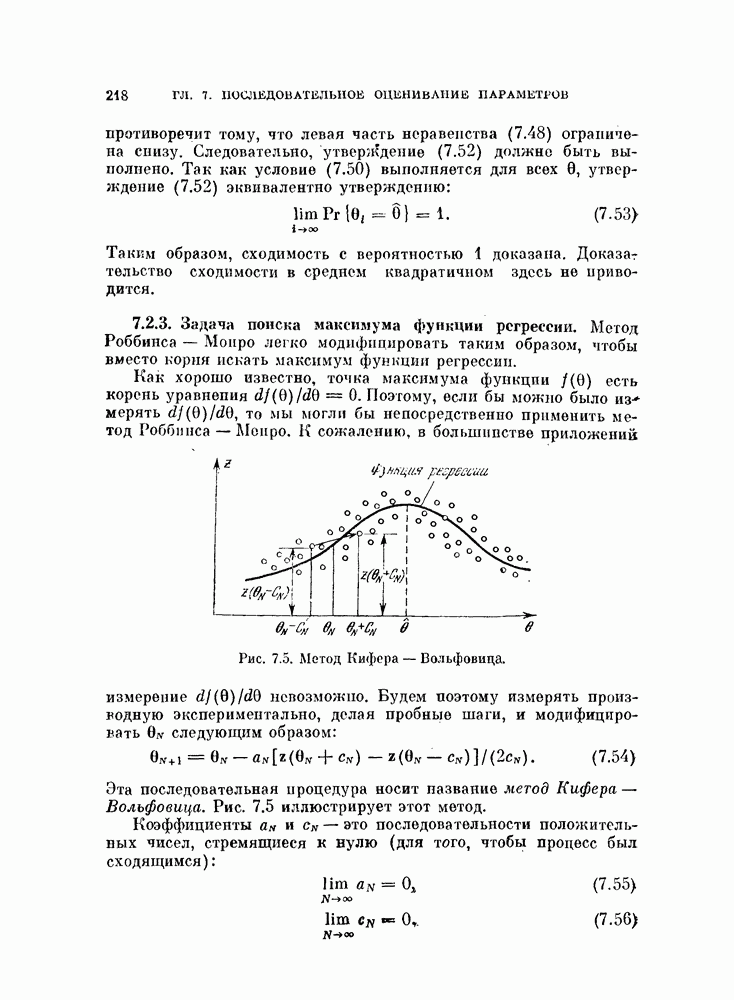
Рис. 8.2. Примеры разложения Карунена — Лоева. Доказательство окончено. Чтобы лучше почувствовать особенности разложения Карунена — Лоева, рассмотрим два простых примера. Пример 8.1. Рассмотрим два мпожества дапных, показанные на рис. 8.2, а и б. В обоих случаях векторы математического ожидания равны нулю. Во-первых, вычислим выборочную ковариационную матрицу
Во вторых, найдем собственные значения и собственные векторы матрицы 2
Таким образом, в обоих случаях базисные векторы повернуты на угол 45°, как показано на рис. 8.2. Наконец, рассмотрим влияние исключения одного из Рис. 8.2, а показывает, что все четыре объекта можно без ошибки выразить через первый базисный вектор
т. е. равна собственному значению
|
 |
Оглавление
|

























































































































































































































































































































 линейно независимых векторов-столбцов, т. е.
линейно независимых векторов-столбцов, т. е.

 -мерное пространство, содержащее X. Столбцы матрицы Ф называются базисными векторами. Далее можно предположить, что эти столбцы ортоиормированы, т. е.
-мерное пространство, содержащее X. Столбцы матрицы Ф называются базисными векторами. Далее можно предположить, что эти столбцы ортоиормированы, т. е.

 определяются следующим образом:
определяются следующим образом:

 представляет собой ортогональное преобразование случайного вектора X и тоже является случайным вектором. Каждая компонента
представляет собой ортогональное преобразование случайного вектора X и тоже является случайным вектором. Каждая компонента  является признаком, который вносит вклад в представление наблюдаемого вектора X.
является признаком, который вносит вклад в представление наблюдаемого вектора X.
 компонент вектора
компонент вектора  и все еще хотим если не точно представить, то по крайней мере оценить X. Это можно сделать, заменив заранее выбранными константами те компоненты
и все еще хотим если не точно представить, то по крайней мере оценить X. Это можно сделать, заменив заранее выбранными константами те компоненты  которые мы не вычисляем, и получить следующую оценку:
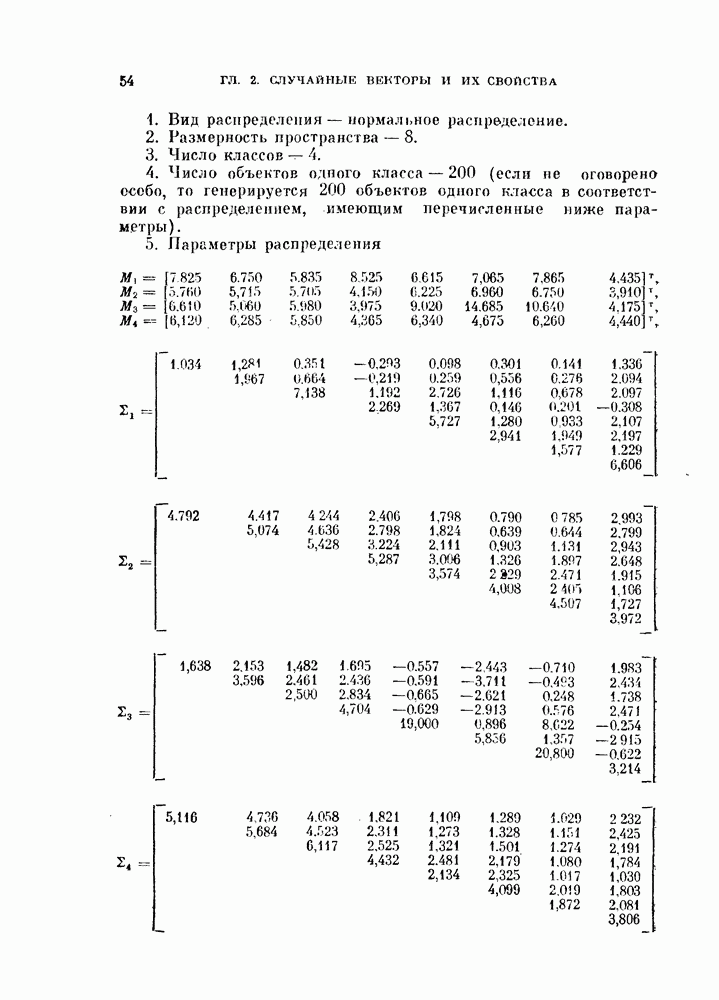
которые мы не вычисляем, и получить следующую оценку:

 компонент вектора у. Если используются не все признаки, то вектор X представляется с ошибкой, которая определяется выражением
компонент вектора у. Если используются не все признаки, то вектор X представляется с ошибкой, которая определяется выражением

 являются случайными векторами. Используем среднюю величину квадрата
являются случайными векторами. Используем среднюю величину квадрата  в качестве критерия для измерейия эффективности подмножества, состоящего из
в качестве критерия для измерейия эффективности подмножества, состоящего из 

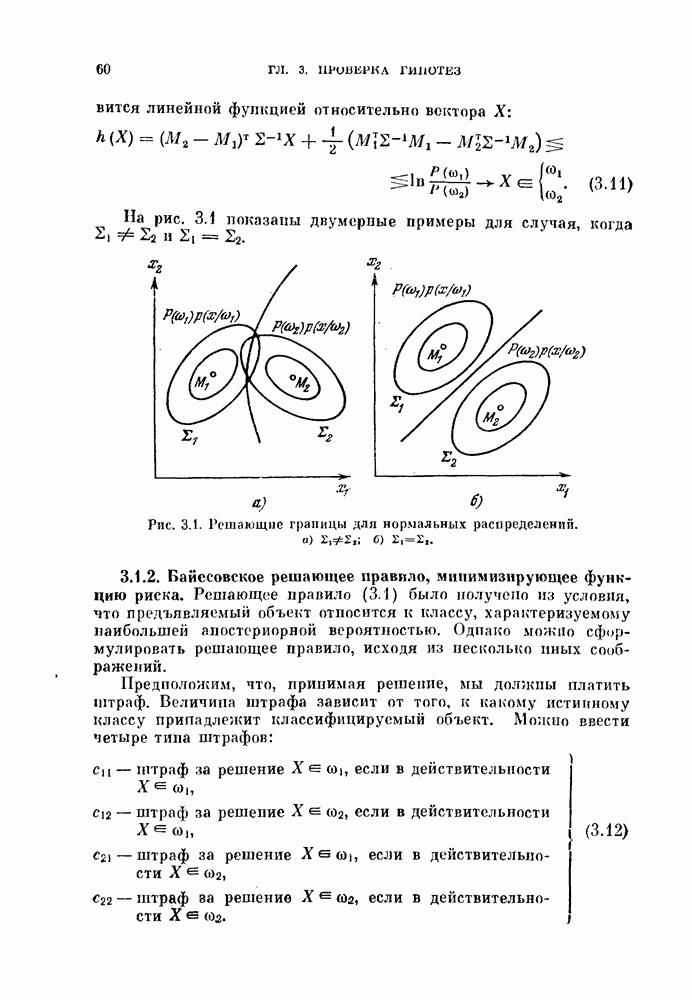
 Выберем их таким образом, чтобы минимизировать
Выберем их таким образом, чтобы минимизировать  Оптимальный выбор констант
Оптимальный выбор констант  производится следующим образом:
производится следующим образом:

 которые не измеряются, их математическими ожиданиями. Это легко показать, минимизируя
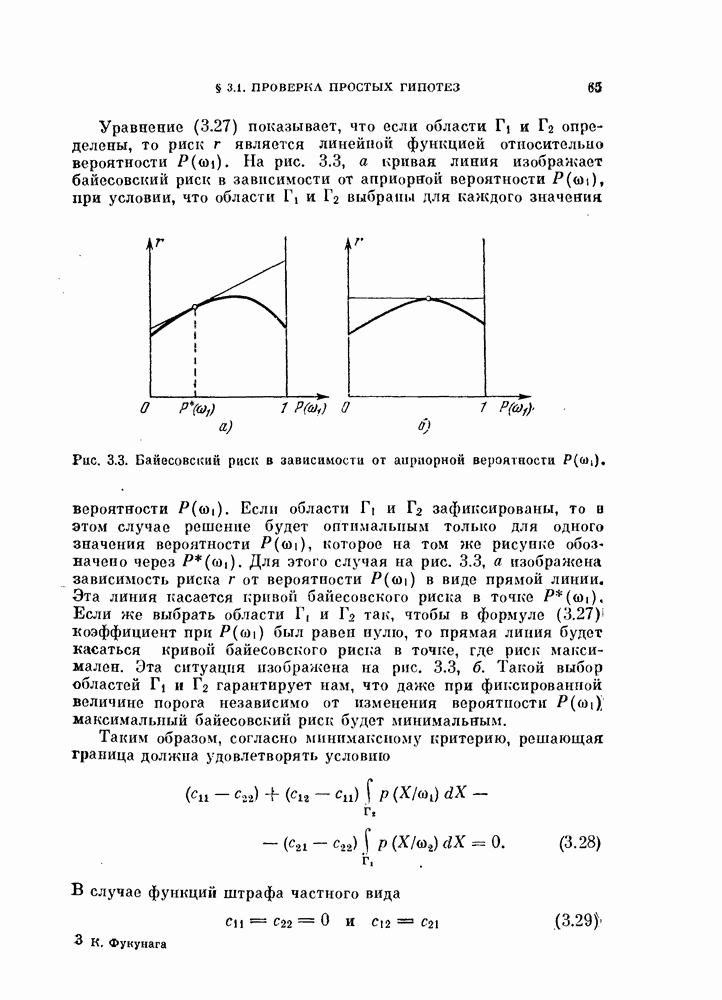
которые не измеряются, их математическими ожиданиями. Это легко показать, минимизируя  по
по 


 — ковариационная матрица случайного вектора X. Ниже будет показано, что оптимальный выбор матрицы Ф удовлетворяет условию
— ковариационная матрица случайного вектора X. Ниже будет показано, что оптимальный выбор матрицы Ф удовлетворяет условию

 Таким образом, минимальная среднеквадратичная ошибка равна
Таким образом, минимальная среднеквадратичная ошибка равна

 этого разложения рассматриваются как признаки, представляющий наблюдаемый вектор X. Эти признаки обладают некоторыми замечательными свойствами, которые мы здесь перечислим.
этого разложения рассматриваются как признаки, представляющий наблюдаемый вектор X. Эти признаки обладают некоторыми замечательными свойствами, которые мы здесь перечислим.
 Поэтому, если мы хотим уменьшить число признаков, признак с наименьшим собственным значением следует исключить в первую очередь и т. д. Если собственные значения перенумерованы в порядке убывания.
Поэтому, если мы хотим уменьшить число признаков, признак с наименьшим собственным значением следует исключить в первую очередь и т. д. Если собственные значения перенумерованы в порядке убывания.

 диагональна:
диагональна:

 взаимно независимы.
взаимно независимы.
 среди всех ортонормированных базисных векторов. Неортогональные» линейные преобразования в зтой главе не рассматриваются: в случае одного распределения нас интересуют лишь те преобразования, которые сохраняют структуру распределения.
среди всех ортонормированных базисных векторов. Неортогональные» линейные преобразования в зтой главе не рассматриваются: в случае одного распределения нас интересуют лишь те преобразования, которые сохраняют структуру распределения.
 Рассмотрим матрицу
Рассмотрим матрицу



 компопент вектора
компопент вектора  имеет вид
имеет вид

 том, чтобы показать, что среднеквадратичная ошибка
том, чтобы показать, что среднеквадратичная ошибка  ограничена снизу значением
ограничена снизу значением  выражения (8.14).
выражения (8.14).
 — матрицы, составленные соответственно из собственных векторов и собственных значений ковариационной матрицы
— матрицы, составленные соответственно из собственных векторов и собственных значений ковариационной матрицы  Тогда можно записать
Тогда можно записать

 ортогональны, матрица
ортогональны, матрица  также ортогональна, так как
также ортогональна, так как




 имеем следующие тождества:
имеем следующие тождества:


 наименьшее собственное значение матрицы
наименьшее собственное значение матрицы  , a
, a  - наибольшее собственное значение матрицы
- наибольшее собственное значение матрицы  Мы воспользовались здесь матричным тождеством
Мы воспользовались здесь матричным тождеством  и тождествами (8.26) — (8.28). Подробное обоснование неравенства (8.29) оставлено в качестве упражнения. Когда
и тождествами (8.26) — (8.28). Подробное обоснование неравенства (8.29) оставлено в качестве упражнения. Когда  имеем
имеем  так что неравенство превращается в равенство.
так что неравенство превращается в равенство.

 Для данных
Для данных  соответственно имеем:
соответственно имеем:


 базисных векторов. Для данных а) собственное значенне
базисных векторов. Для данных а) собственное значенне  Поэтому, даже в том случае если исключить вектор
Поэтому, даже в том случае если исключить вектор  из раз ложения Карунена — Лоева, среднеквадратичная ошибка будет равна нулю.
из раз ложения Карунена — Лоева, среднеквадратичная ошибка будет равна нулю.
 . С другой стороны, для данных б) собственное значение
. С другой стороны, для данных б) собственное значение  Поэтому мы ожидаем, что при исключении из разложения вектора
Поэтому мы ожидаем, что при исключении из разложения вектора  среднеквадратичная ошибка будет равна 1. Из рис.
среднеквадратичная ошибка будет равна 1. Из рис.  видног что объекты
видног что объекты  можно выразить через вектор
можно выразить через вектор  без ошибки, но объекты
без ошибки, но объекты  и
и  выражаются с ошибкой, равной
выражаются с ошибкой, равной  Поэтому сред неквадратичная ошибка равна
Поэтому сред неквадратичная ошибка равна

