Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
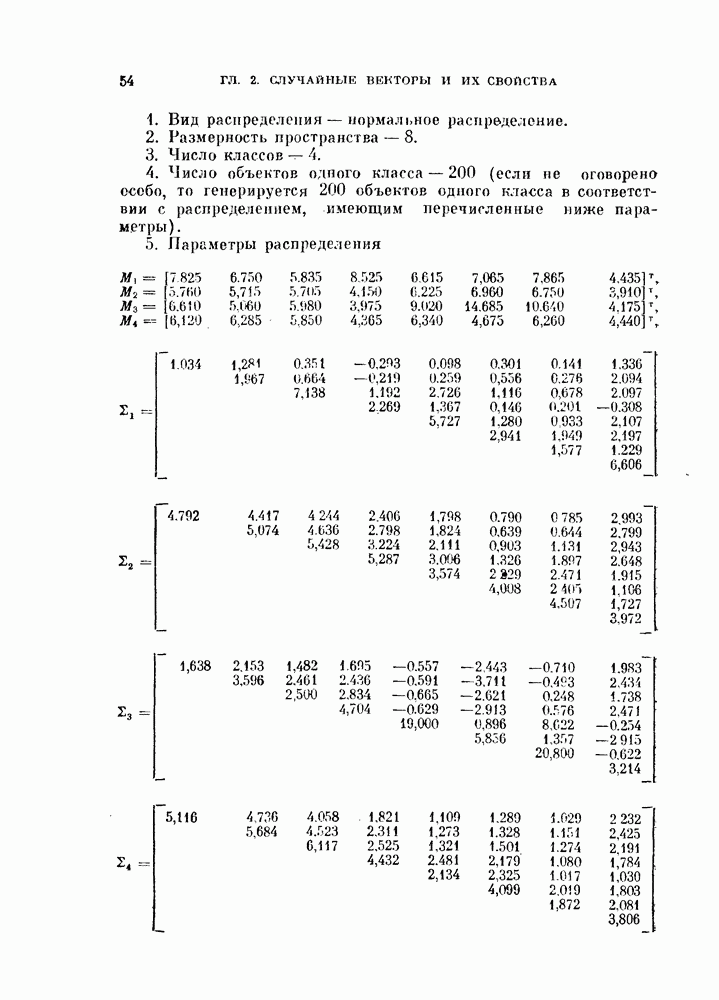
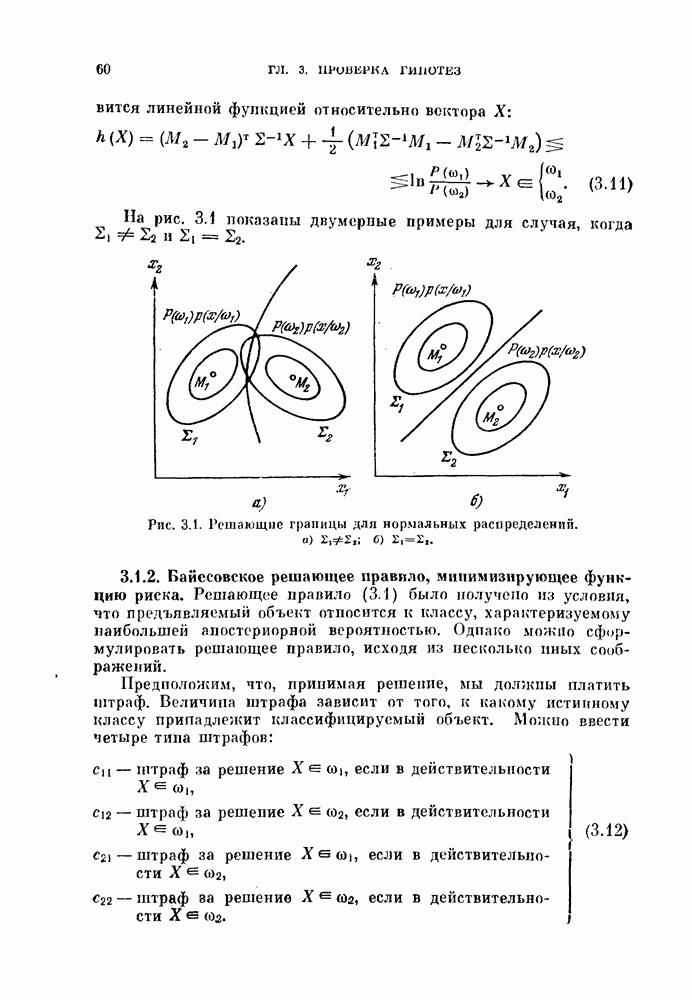
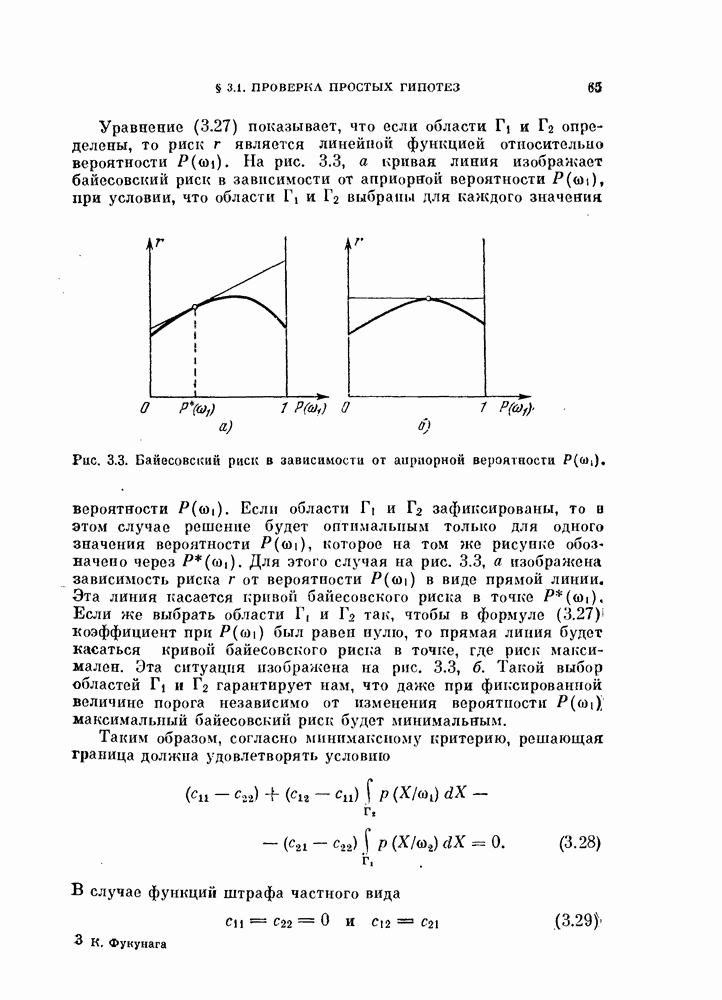
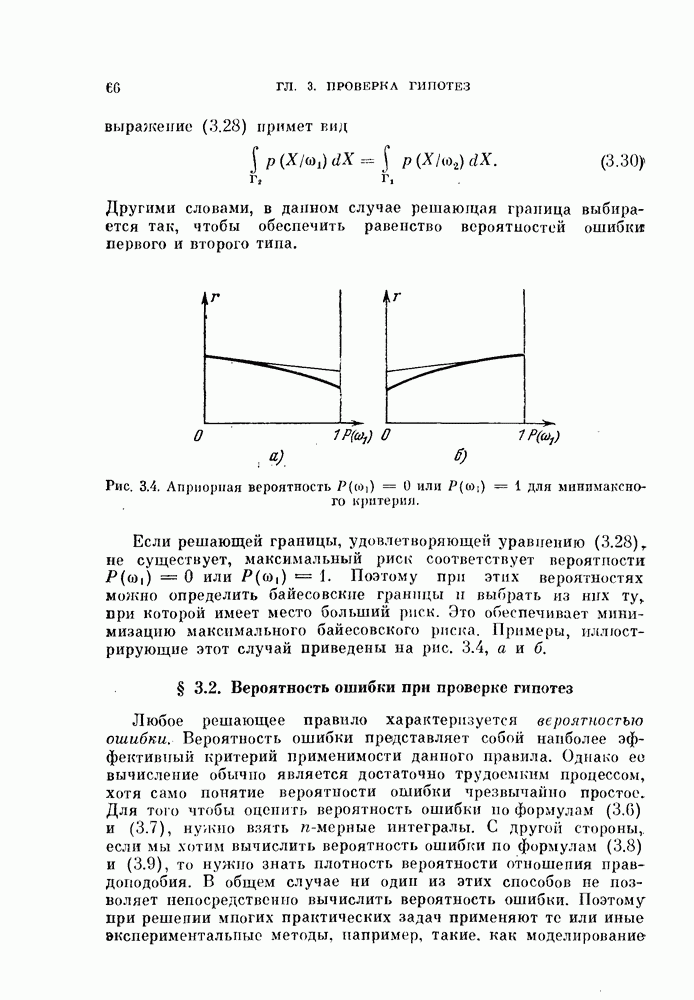
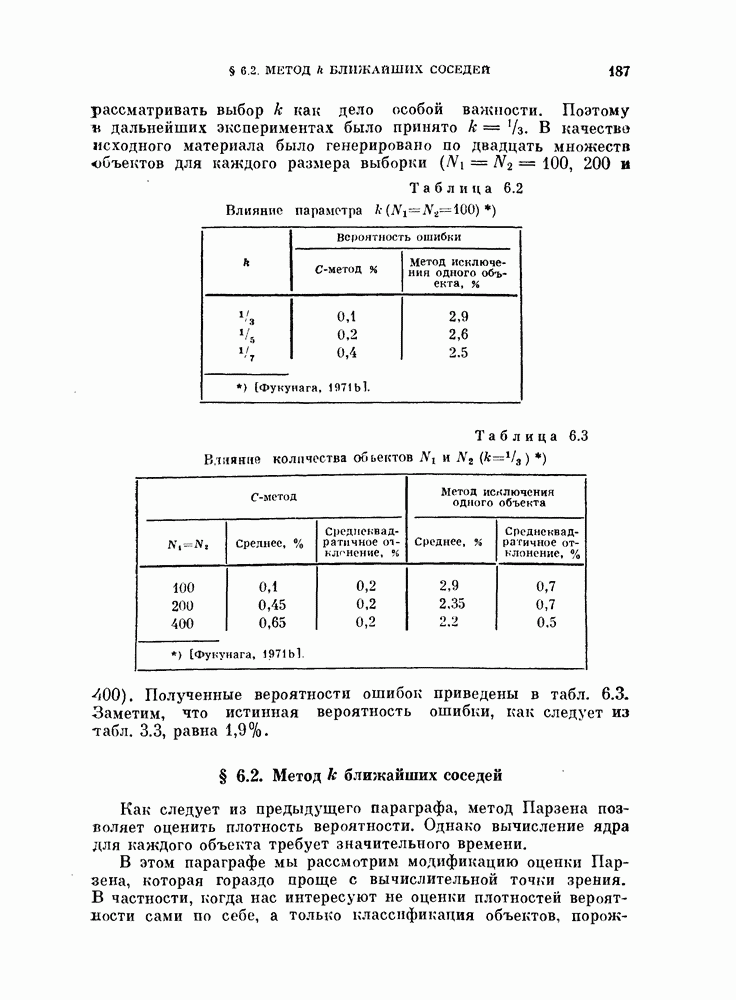
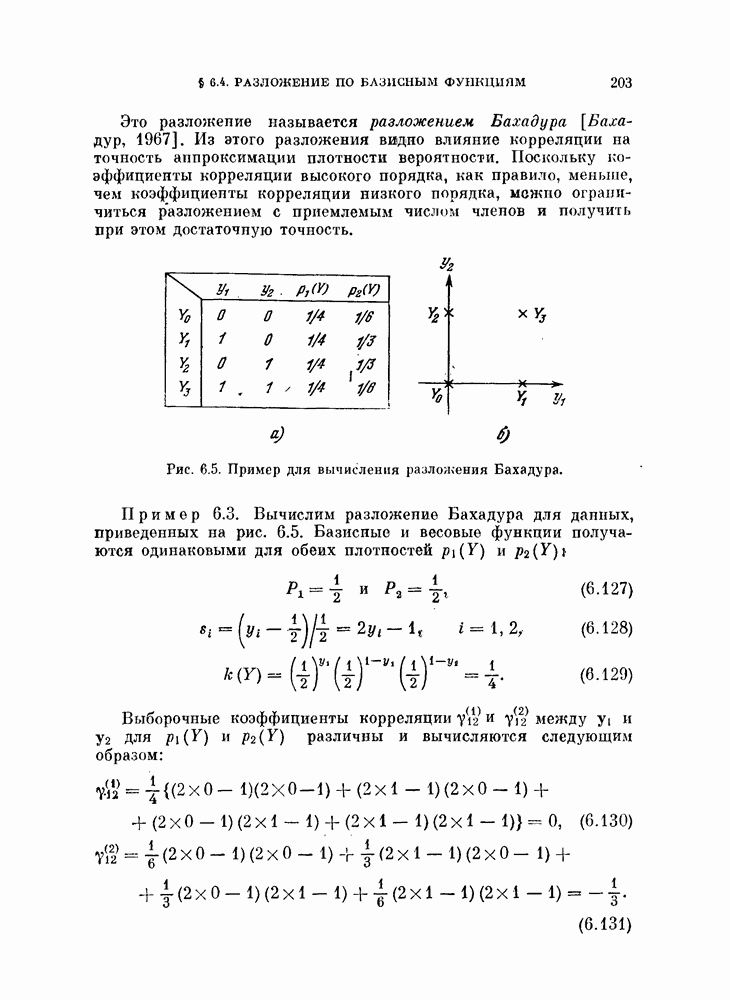
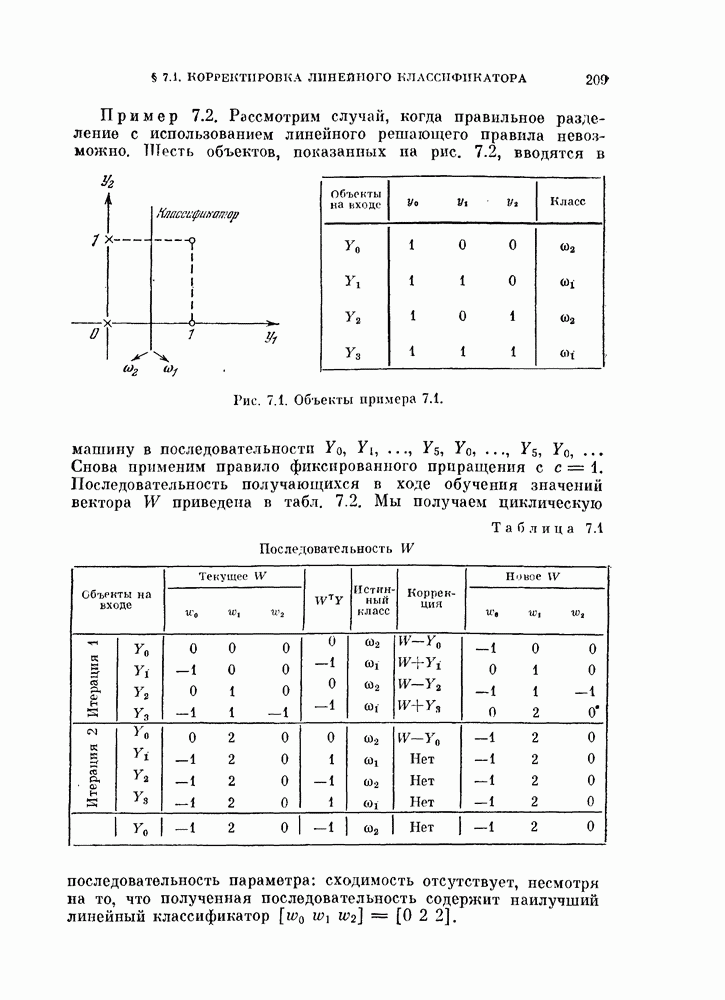
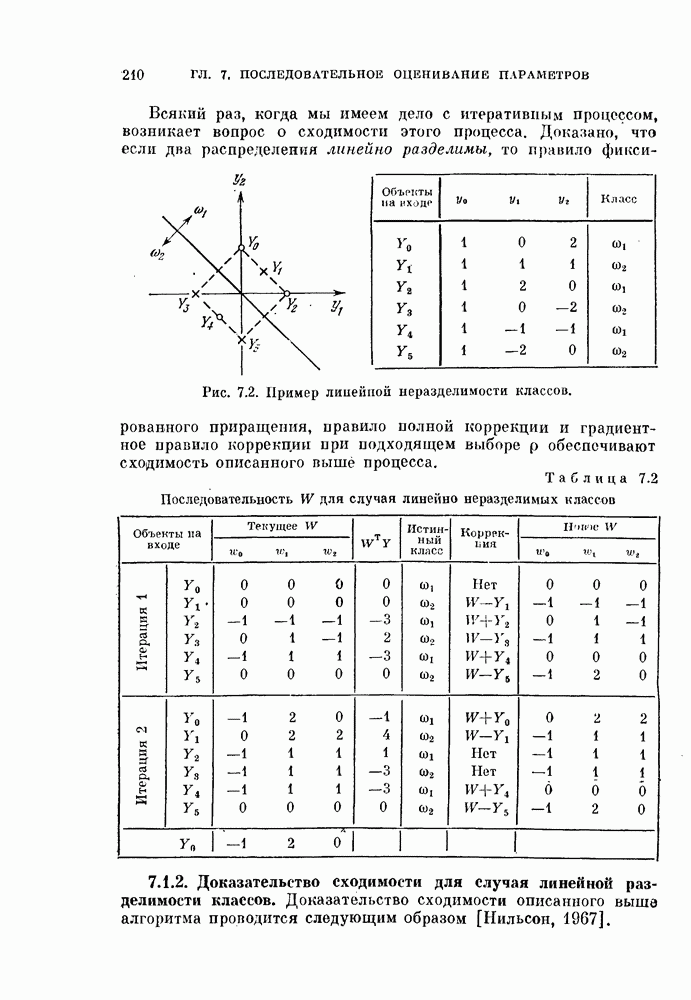
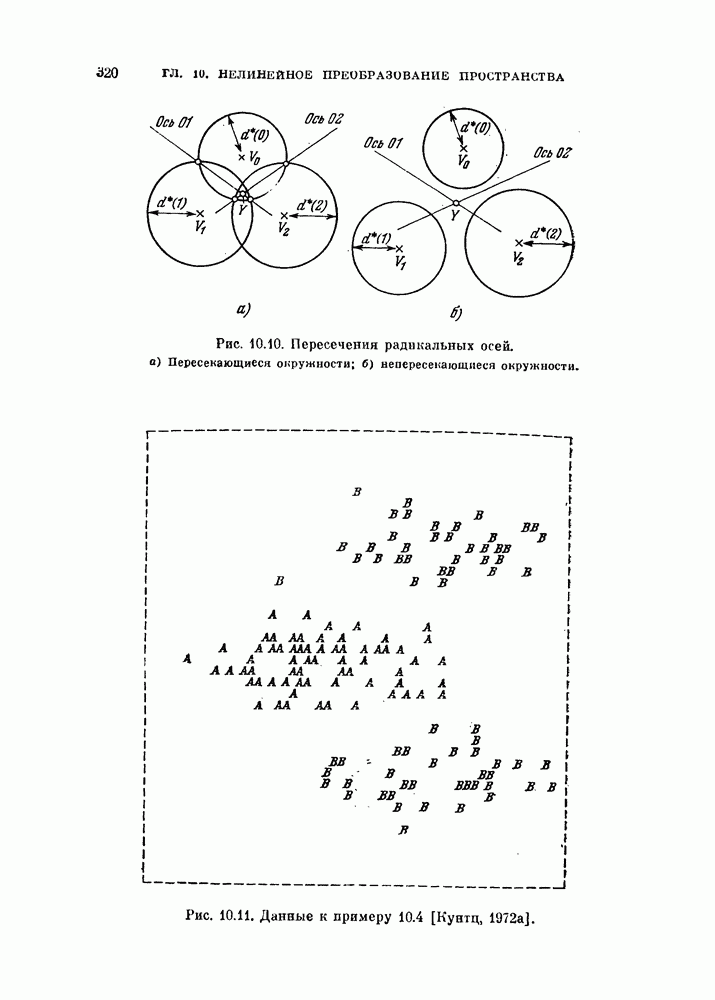
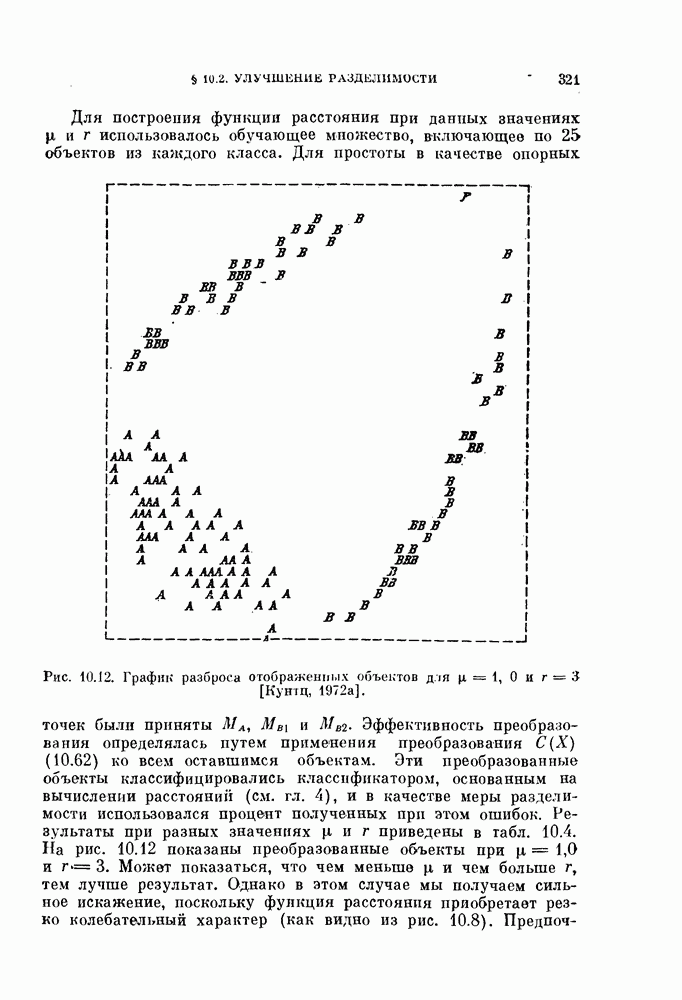
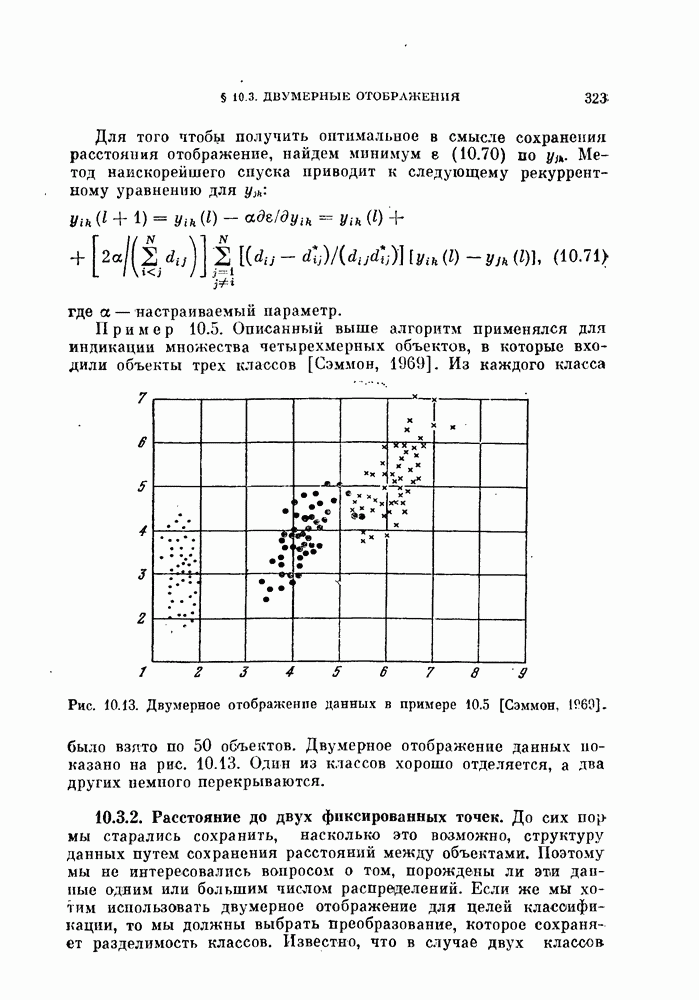
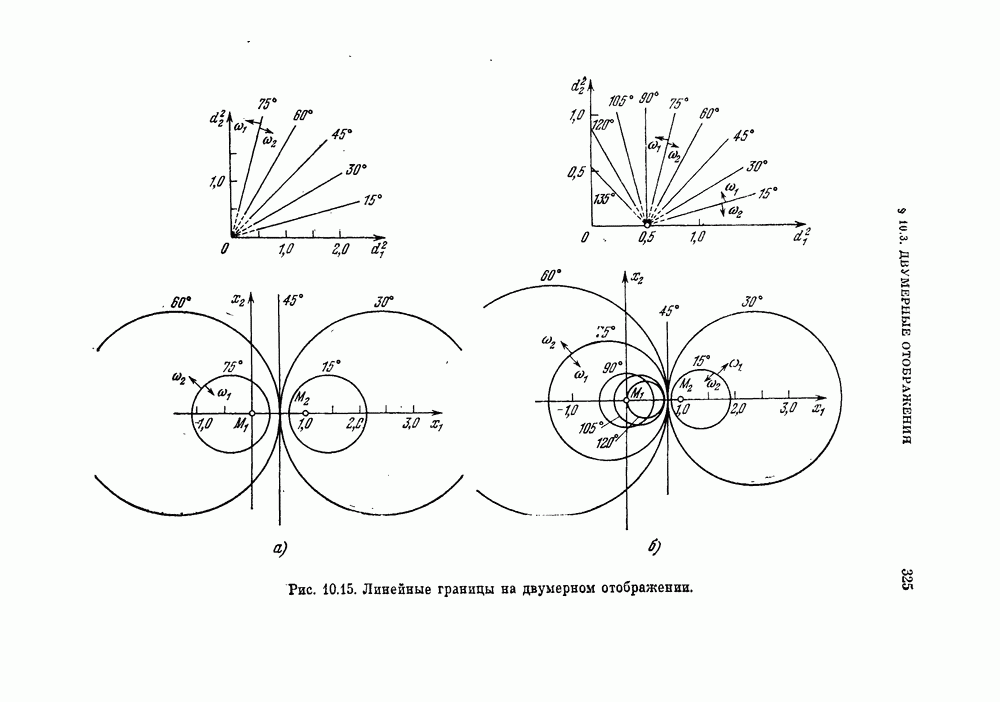
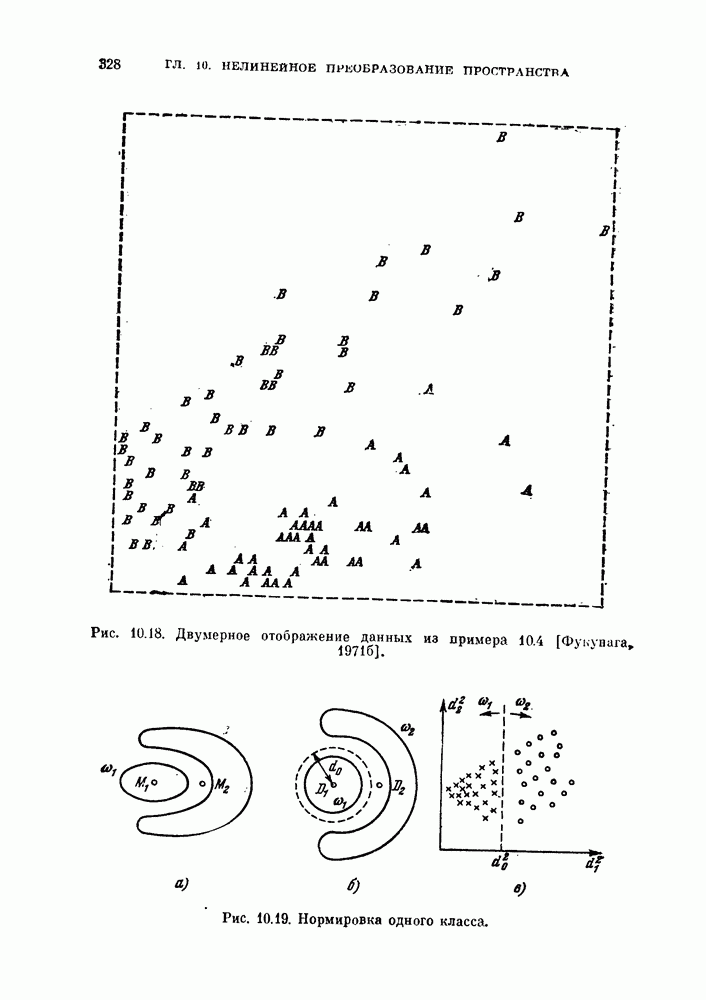
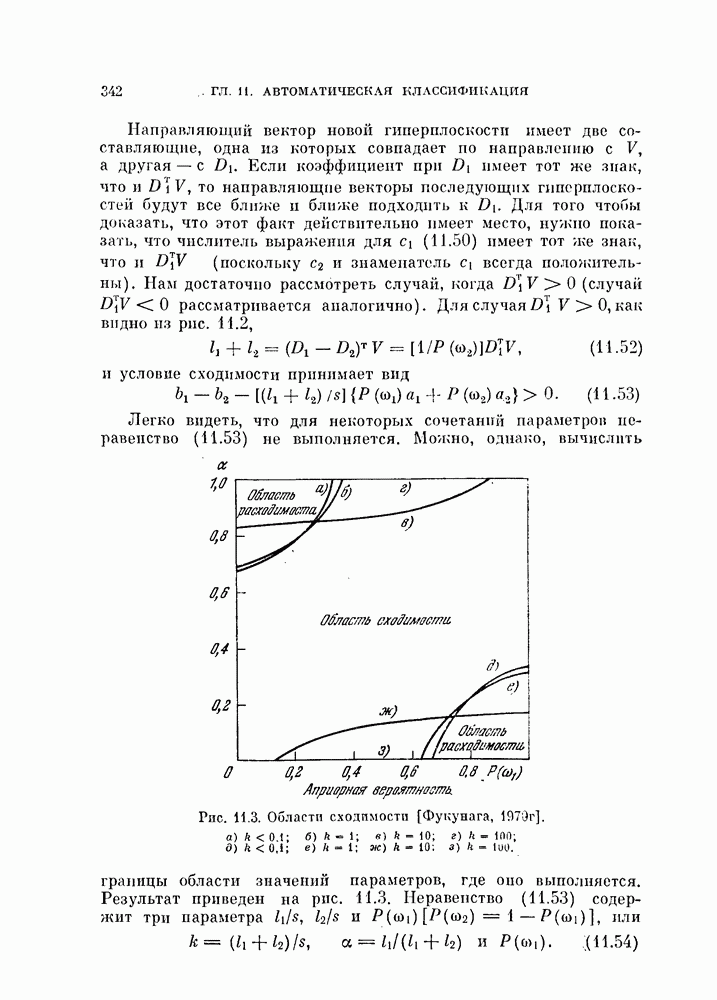
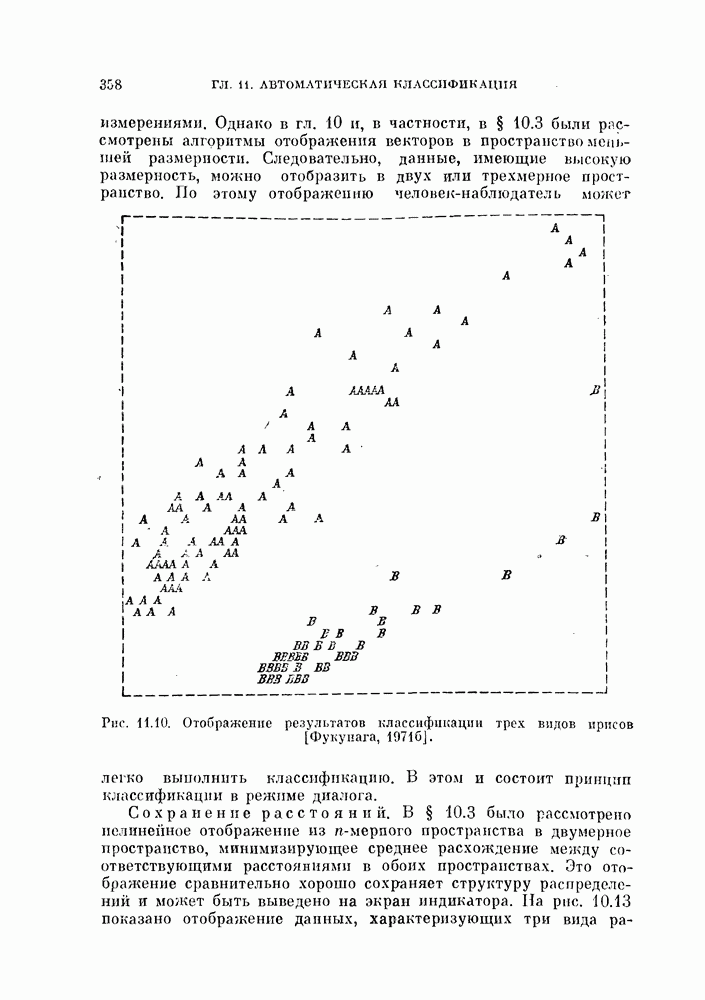
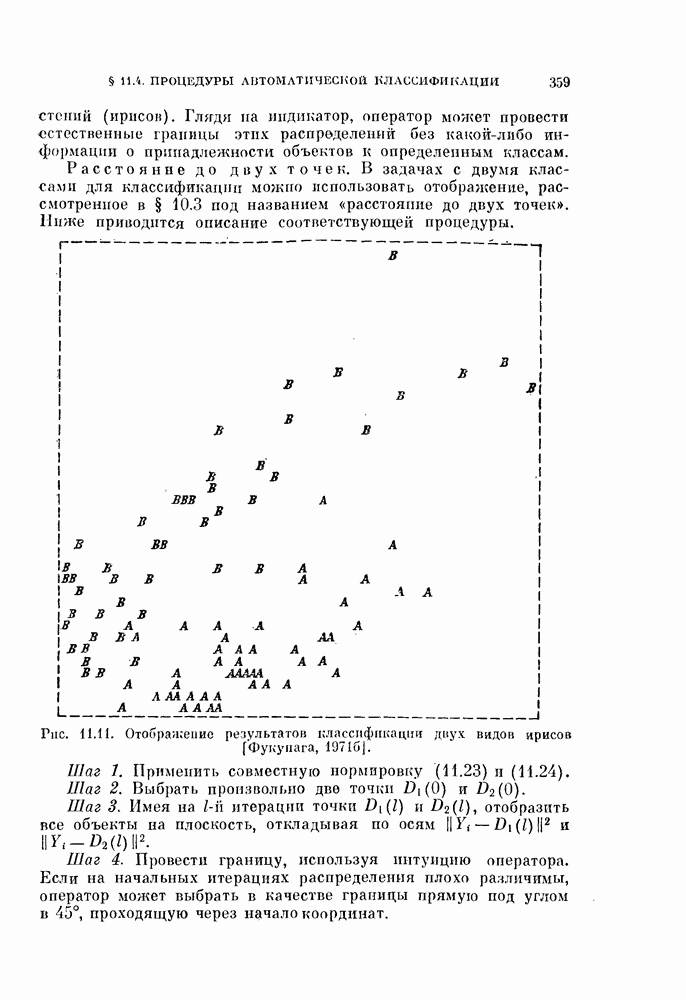
§ 1.2. Обзор содержания книги по главамКнига разделена на десять глав (главы 2—11). В главе 2 рассматриваются свойства случайных векторов и методы линейной алгебры. Знание этого материала необходимо для понимания книги. Предполагается, однако, что читатель знаком со свойствами случайных величин и случайных векторов, поэтому в главе 2 дается лишь краткий обзор этих вопросов. Кроме того, так как во всей книге широко используются векторы и матрицы, в главе 2 дается обзор некоторых разделов линейной алгебры; особый упор сделан на подход с точки зрения собственных значений и собственных векторов. Главы 3—7 посвящены задаче построения классификатора. В главе 3 отыскивается теоретически наилучший способ построения классификатора в предположении, что распределения случайных векторов, подлежащих классификации, известны. В этом -случае задача превращается в обычную задачу статистической проверки гипотез. Доказывается, что байесовский классификатор является оптимальным, в смысле минимизации вероятности ошибки классификации или минимизации риска, если возможным решениям приписываются определенные стоимости. Рассматриваются также критерий Неймана — Пирсона и минимаксный критерий. Вероятность ошибки является ключевым параметром в распознавании образов. Это есть мера разделимости классов при данных распределениях, если предполагается использовать байесовский классификатор. Кроме того, вероятность ошибки характеризует качество классификатора по сравнению с байесовским классификатором для данных распределений. Вследствие важности этого параметра в главе 3 рассматривается задача его вычисления для данных распределений. Рассматривается также более простая задача нахождения верхней границы вероятностл ошибки. В различных постановках задач распознавания образов входная информация представляет собой некоторую последовательность объектов из одного и того же класса. Хорошо известно, что класс можно описать с большей уверенностью, если мы наблюдаем последовательность объектов, а не один объект. Поэтому глава 3 включает также последовательную проверку гипотез. В главе 4 исследуется линейный классификатор. Хотя байесовский классификатор является оптимальным, на практике его часто трудно реализовать из-за его сложности, особенно когда размерность пространства высока. Поэтому мы часто вынуждены рассматривать более простой классификатор. Линейный или кусочно-линейный классификаторы являются самыми простыми и наиболее часто употребляемыми. В главе 4 рассматриваются различные процедуры построения линейных классификаторов. Сюда относятся процедуры построения байесовского классификатора для некоторых типов распределений, оптимального линейного классификатора в смысле минимума вероятности ошибки или в смысле минимума среднеквадратичной ошибки и т. д. Рассматривается также случай, когда входные данные являются бинарными. В главе 5 рассматривается задача оценивания параметров В предыдущих главах предполагалось, что подлежащие классификации распределения известны. Однако на практике мы имеем лишь конечное число объектов и должны по ним оценить распределения. Если функциональный вид распределения известен плотность вероятности можно оценить, заменяя неизвестные параметры их оценками. Например, нормальное распределение можно оценить с помощью оценок вектора средних значений и ковариационной матрицы. Этот метод оценивания плотностей вероятности называют параметрическим. Оцениваемые параметры могут быть случайными величинами или неизвестными константами; оба эти случая рассматриваются; в главе 5. Поскольку оценки параметров зависят от множества объектов, по которым они вычисляются, и могут меняться от одного множества объектов к другому, было бы желательно установить для оценки некоторый доверительный интервал. Задача этого типа носит название интервальное оценивание и также рассматривается в главе 5. Как упоминалось выше, в теории распознавания образов вероятность ошибки является важным параметром, и нам часто приходится оценивать этот параметр по имеющимся объектам. Однако оценивание ошибки несколько отличается от обычнога оценивания параметров, главным образом потому, что при оценивании ошибки мы должны использовать имеющиеся объекты как для построения классификатора, так и для его проверки. Параметрический вариант задачи оценивания ошибки рассматривается в глэве 5. В главе 6 рассматривается оценивание плотности вероятности без предположения о том, что она имеет какой-либо определенный вид. Этот подход называют непараметрическим. Вначале: вводится оценка Парзена плотности вероятности, идея которой заключается в построении вокруг каждого объекта симметричных функций — ядер и их последующем суммировании. После изучения математических свойств этой оценки рассматриваются различные ее варианты с разными типами ядер. Одним из важных методов непараметрической классификации является решающее правило k - ближайших соседей, по которому неизвестный объект классифицируется в зависимости от того, к каким классам принадлежат к ближайших к нему и уже расклассифицированных объектов. Кроме того, в главе 6 рассматривается наиболее простой метод оценивания плотности вероятности — метод гистограмм, при котором оценка получается подсчетом числа объектов, попавших в заранее заданную область. Все методы, описанные в главе 6, не зависят от вида распределений. Однако за это преимущество приходится расплачиваться усложнением вычислении, поскольку эти методы основаны на использовании самих наблюдаемых объектов, вместо небольшого числа параметров, В главе 7 рассматривается последовательное оценивание параметров. В главе 5 оценки параметров определялись, исходя из информации о всех наблюдаемых объектах. Однако на практике иногда более удобной оказывается процедура, ориентированная на последовательное поступление объектов. В этом случае из эвристических соображений выбирается некоторая начальная приближенная оценка. Затем каждый вновь поступивший объект используется для уточнения оценки. Задача заключается в том, чтобы выяснить, сходится ли оценка в каком-либо смысле к истинным значениям параметров и как быстро она сходится. Вначале рассматривается последовательное оценивание параметров линейной дискриминантной функции. В этом случае сходимость может быть доказана при условии, что два распределения линейно разделимы. Для того чтобы доказать сходимость в случае перекрывающихся распределений, вводится в рассмотрение стохастическая аппроксимация. Метод стохастической аппроксимации представляет собой итеративную процедуру нахождения корней или экстремальных точек функции регрессии при наличии случайных помех. Оценка параметра является случайной величиной, имеющей свое распределение. Плотность вероятности оценки можно последовательно уточнять, используя теорему Байеса. Метод решения задачи, получивший название последовательного байесовского оценивания, кратко излагается в главе 7. Главы 8—10 посвящены выбору признаков. В главе 8 рассматривается выбор признаков при наличии одного распределения. В случае одного распределения задача классификации не возникает, а имеется лишь задача представления. Предполагается, что признаки, представительные для каждого отдельного распределения, должны привести к признакам, хорошим с точки зрения классификации этих распределений. Выбор признаков для одного распределения — это такое отображение исходного n-мерного пространства в Идея метода заключается в том, чтобы выбрать некоторый критерий, а затем — линейное преобразование, которое оптимизирует этот критерий. Если в качестве критерия берется среднеквадратичная ошибка, то наилучшим преобразованием является разложение Карунена — Лоева, использующее в качестве признаков собственные векторы ковариационной матрицы. Критерии разброса и энтропии также приводят к признакам, связанным с вычислением собственных векторов. Поскольку собственные значения и собственные векторы играют важную роль в выборе признаков, в главе 8 рассматриваются методы их оценивания. Задача состоит в том, чтобы определить влияние числа наблюдений и величины интервала между соседними наблюдениями (если рассматривается непрерывный случайный процесс) на точпость оценки. Кроме того, рассматривается задача оценивания доминирующих собственных значений и собственных векторов, поскольку число доминирующих собственных значений обычно значительно меньше, чем размерность распределения. В главе 9 рассматривается выбор признаков при наличии двух распределений. Если имеется два распределения, подлежащие классификации, то целью выбора признаков является выбор с помощью подходящего преобразования небольшого числа важных признаков, так, чтобы сохранить, насколько это возможно, разделимость классов. Поскольку свойство разделимости классов должно сохраняться при любом взаимно однозначно! преобразовании, можно рассматривать все виды преобразований, включая нелинейные. Однако в главе 9 изучаются только линейные преобразования. Лучшим критерием разделимости классов является вероятность ошибки. Однако, поскольку в большинстве случаев для вероятности ошибки не удается получить явного математического выражения, то изыскиваются альтернативные критерии, более удобные с вычислительной точки зрения. Много критериев можно образовать, комбинируя разными способами меры разброса точек внутри классов и между классами. Эти критерии просты и легко могут быть обобщены на случай миогих классов. Более сложными критериями разделимости классов являются расстояние Бхатачария и дивергенция, но эти критерии более тесно связаны с вероятностью ошибки. В главе 9 изучаются различные свойства указанных критериев разделимости классов. Кроме того, решается задача нахождения оптимального линейного преобразования исходного пространства в пространство меньшей размерности, т. е. такого преобразования, которое приводит к минимальному уменьшению критерия. В главе 10 рассматриваются три задачи нелинейного преобразования исходного пространства. Первая задача — это задача определения истинной размерности данного распределения. Истинная размерность определяется числом доминирующих случайных параметров, характеризующих распределение, и не может быть выявлена линейными преобразованиями, если наблюдаемые измерения являются нелинейными функциями этих параметров. Истинная размерность указывает наименьшее числа признаков, необходимых для представления распределения. Вторая задача — найти для целей классификации такое нелинейное преобразование, чтобы дискриминантная функция в новом пространстве была простой (например, линейной) и имела низкую размерность. Третья задача — это задача индикации. Индикация многомерных объектов на экране электронно-лучевой трубки, отображающая исходное 10 рассматриваются нелинейные преобразования, предназначенные как для представления информации, так и для классификации. В главе 11 рассматривается автоматическая классификацият или классификация без учителя. Например, распределение кривых, характеризующих работу неисправной машины, может иметь несколько мод. Разделение отдельных мод без внешнего контроля помогает как обнаруживать «дефектные» кривые, так и понять природу дефектов. Автоматическая классификация включает выбор критериев и поисковых алгоритмов их оптимизации. Рассматриваются различные параметрические и непараметрические критерии. Эти критерии характеризуют разделимость классов, плотность точек внутри классов и т. д. Они очень субъективны, но если критерий выбран, определены и характеристики получающихся классов. Рассматриваются также поисковые алгоритмы, позволяющие таким образом распределить объекты по классам, чтобы выбранный критерий принял экстремальное значение. Чтобы помочь читателю лучше понять излагаемый материал, в конце каждой главы приводятся задачи. Кроме того, даются задания на составление программ. Опыт показывает, что эти задания повышают интерес у студентов. Однако они больше ориентированы на тех исследователей в области распознавания образов, которые хотели бы разработать систему базовых программ и использовать ее в качестве инструмента для своих исследований. Необходимость существенных модификаций этих программ определяется специфическими особенностями имеющихся в распоряжении данных.
|
 |
Оглавление
|






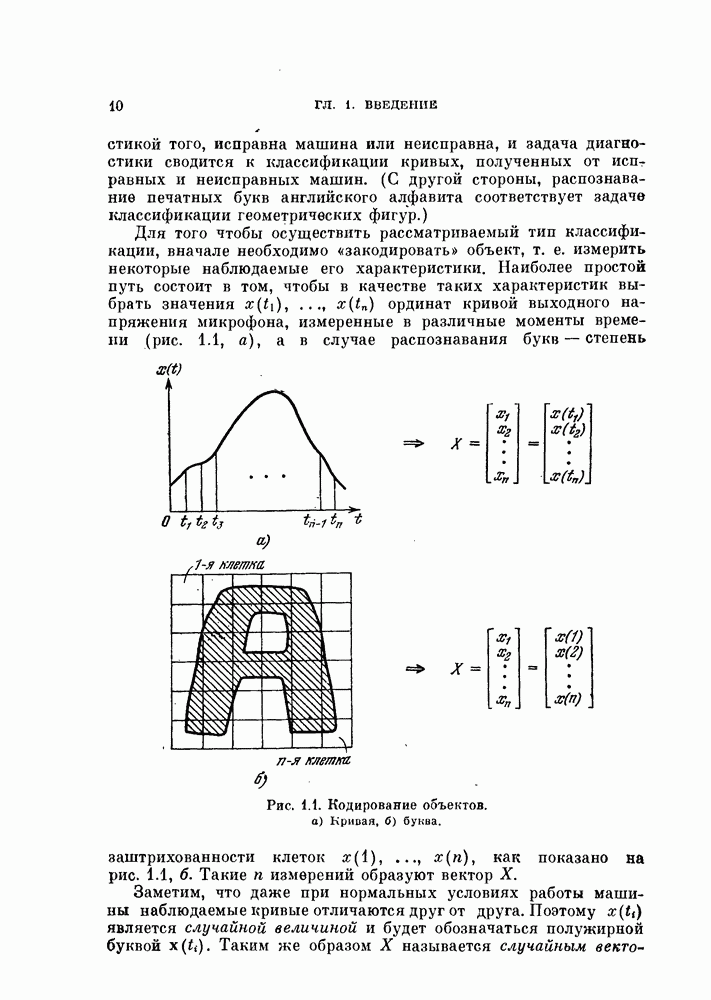
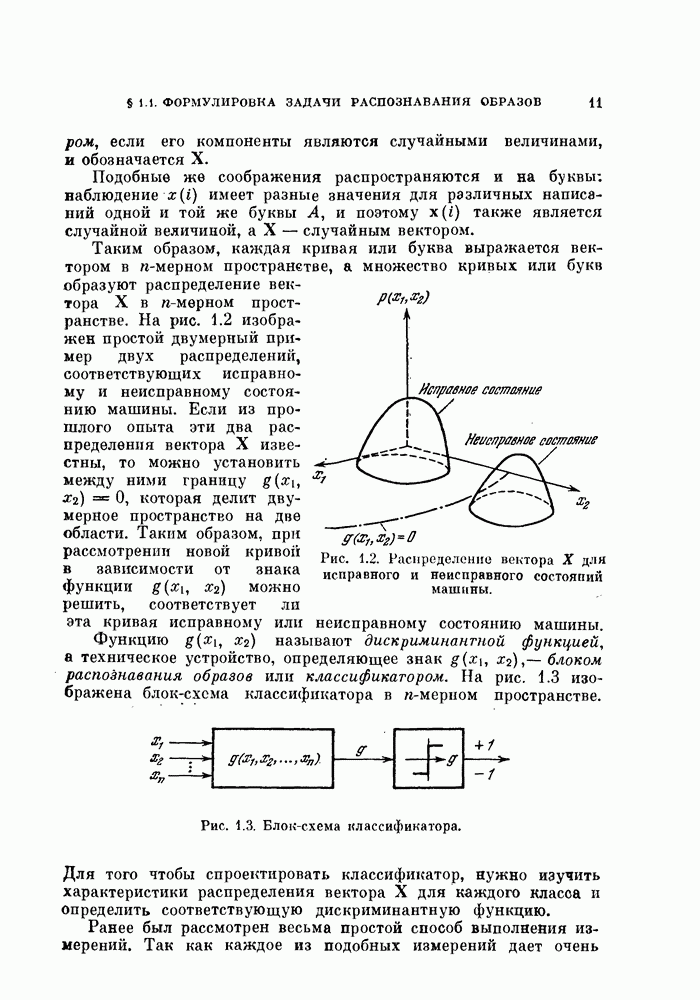





























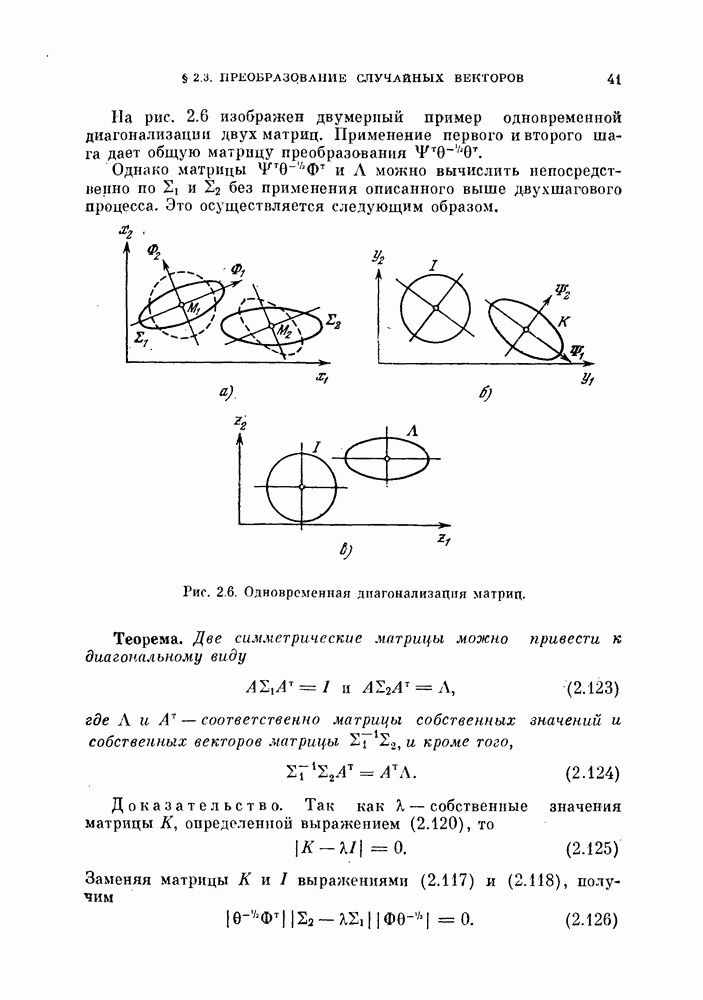









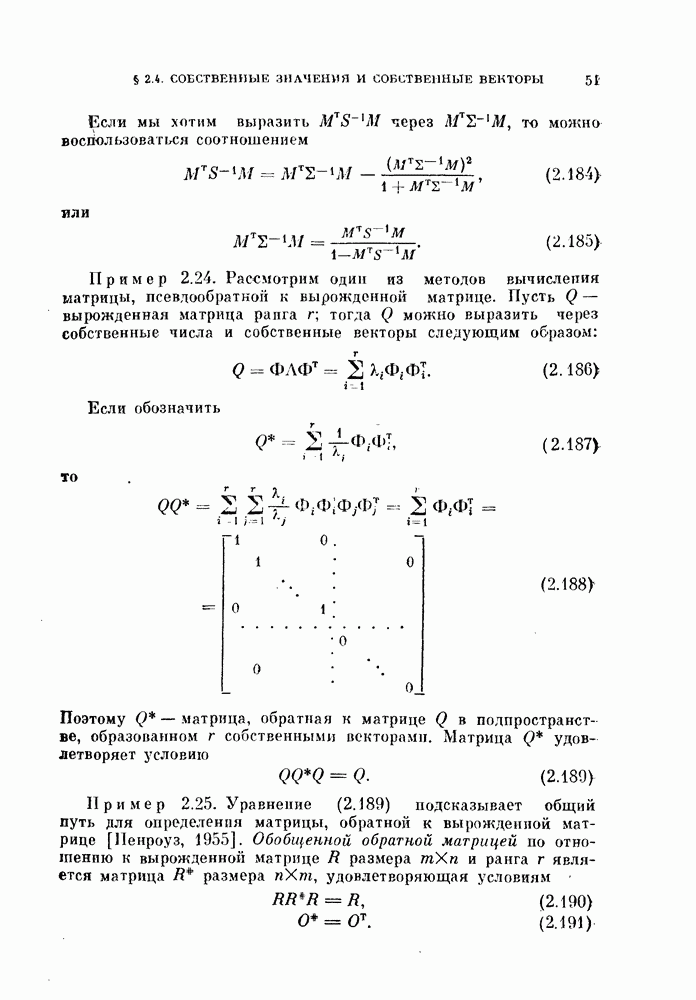










































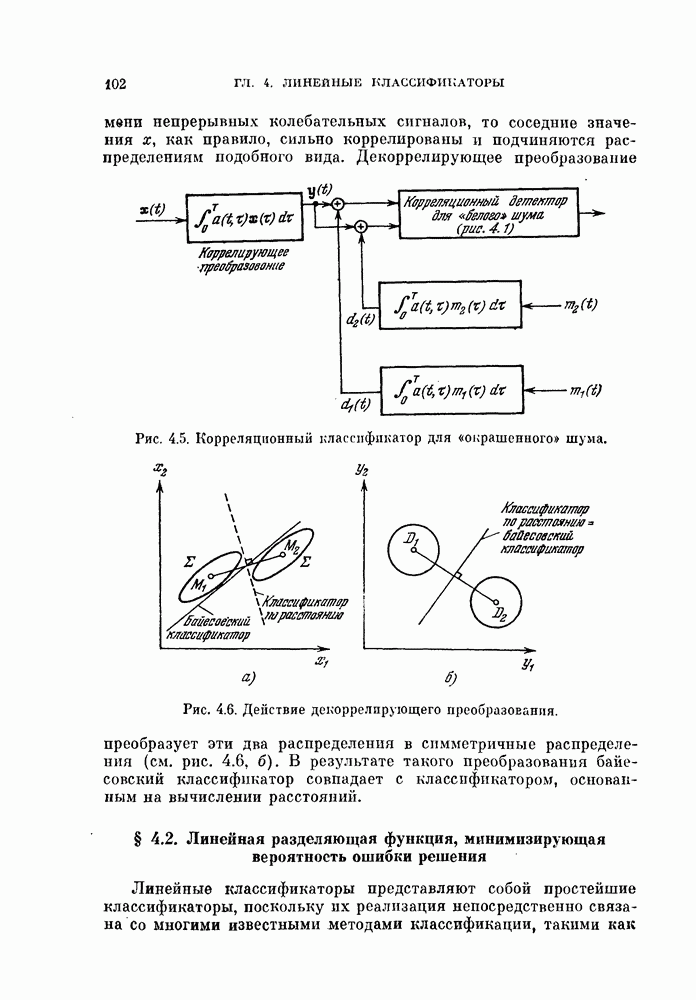




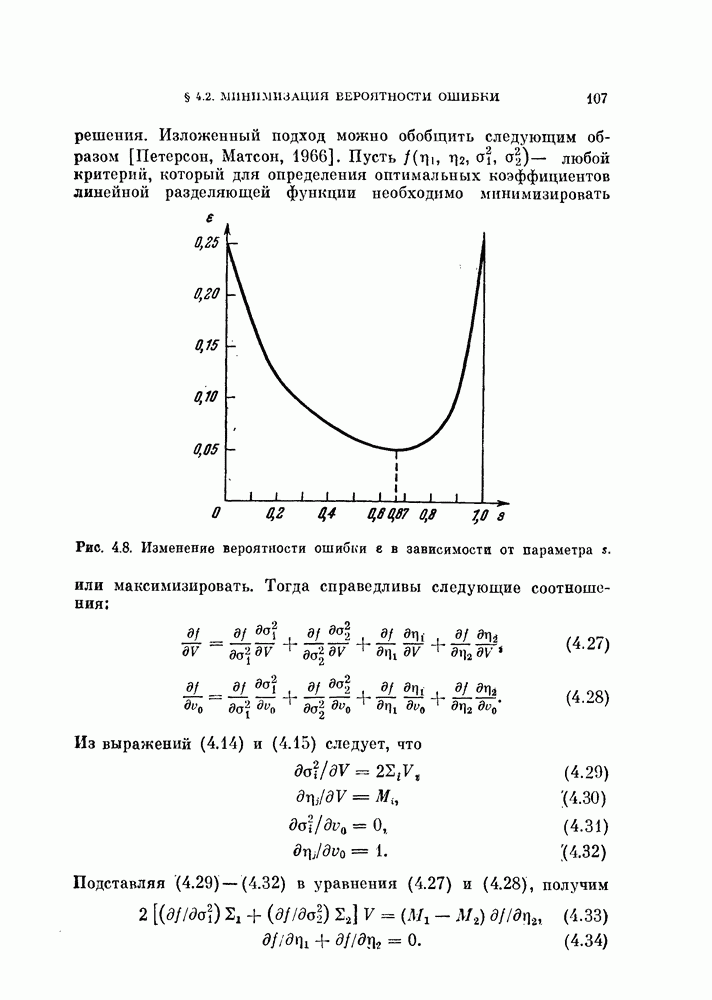


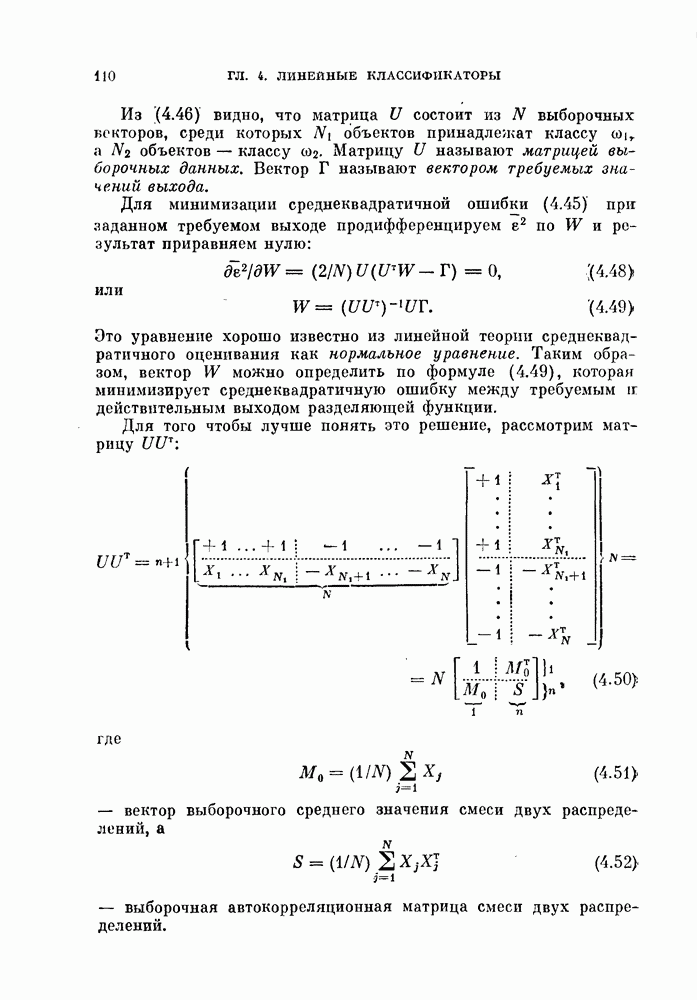



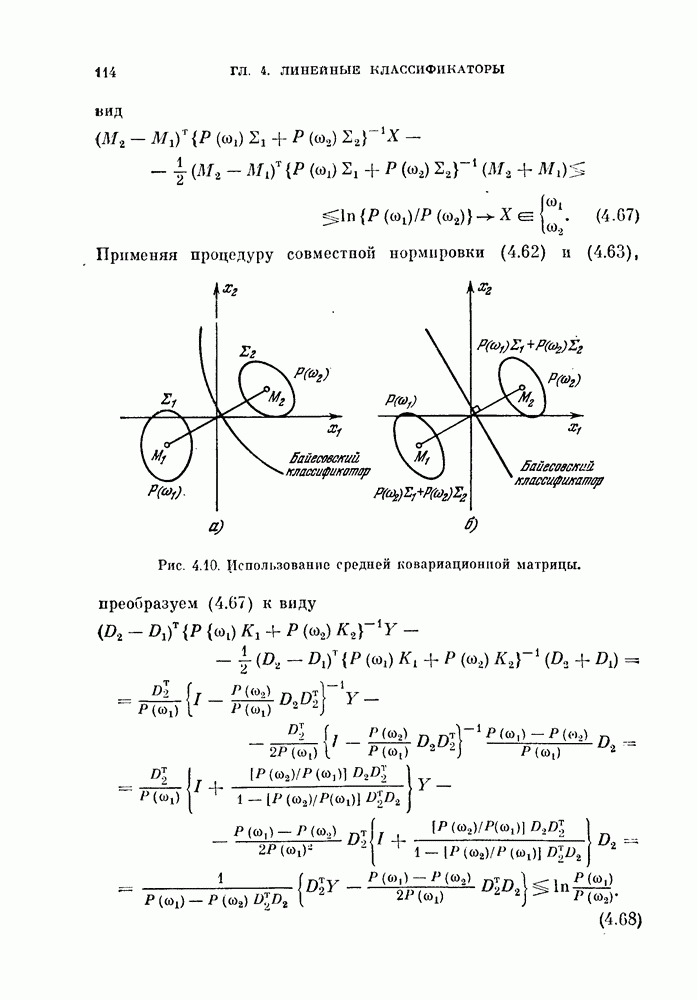












































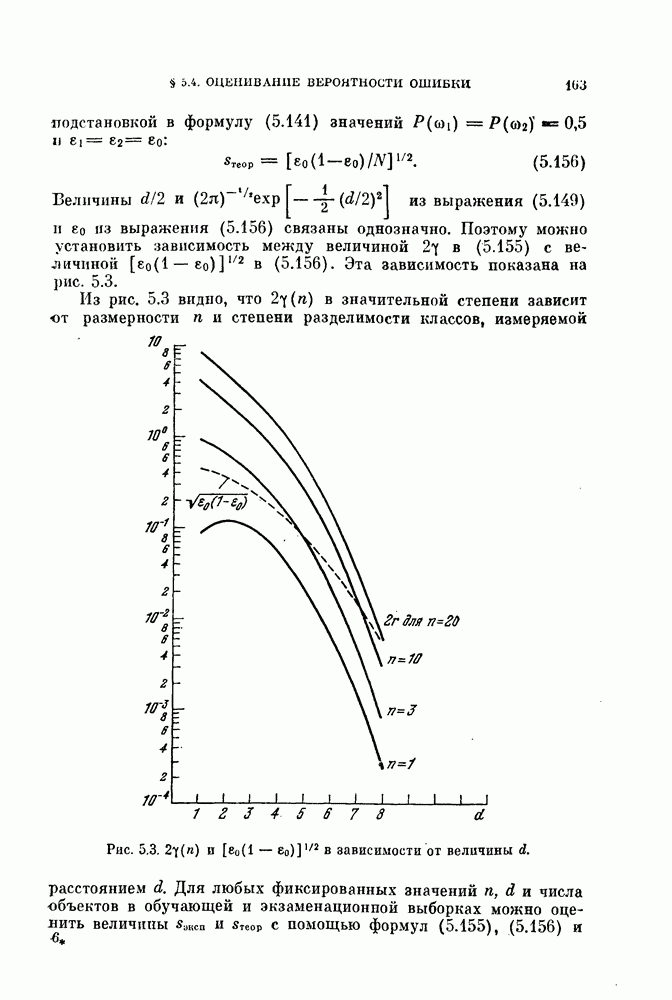
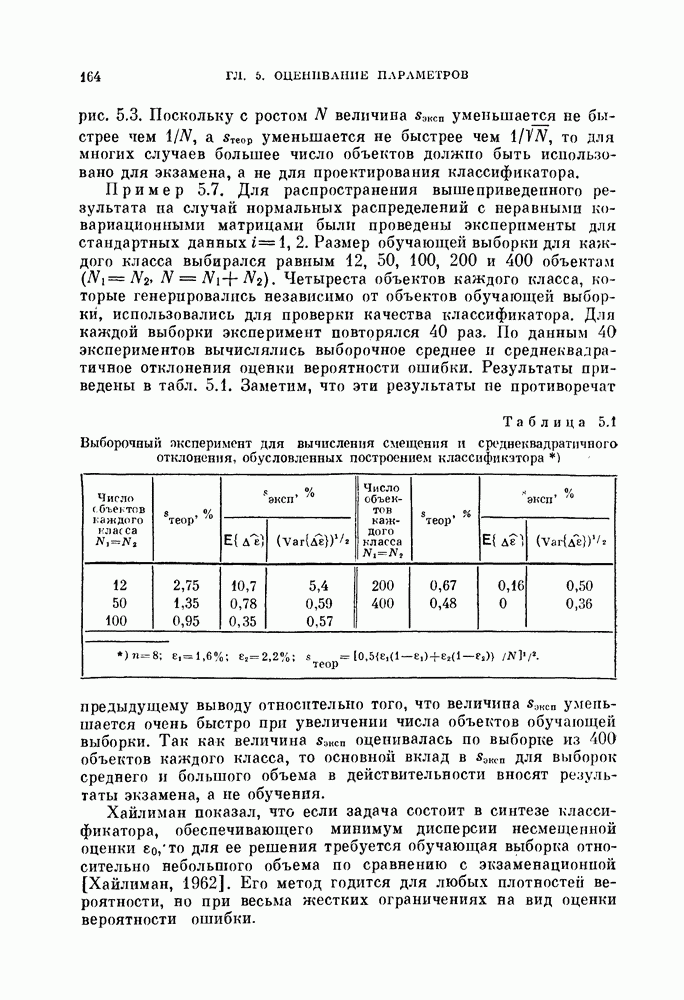





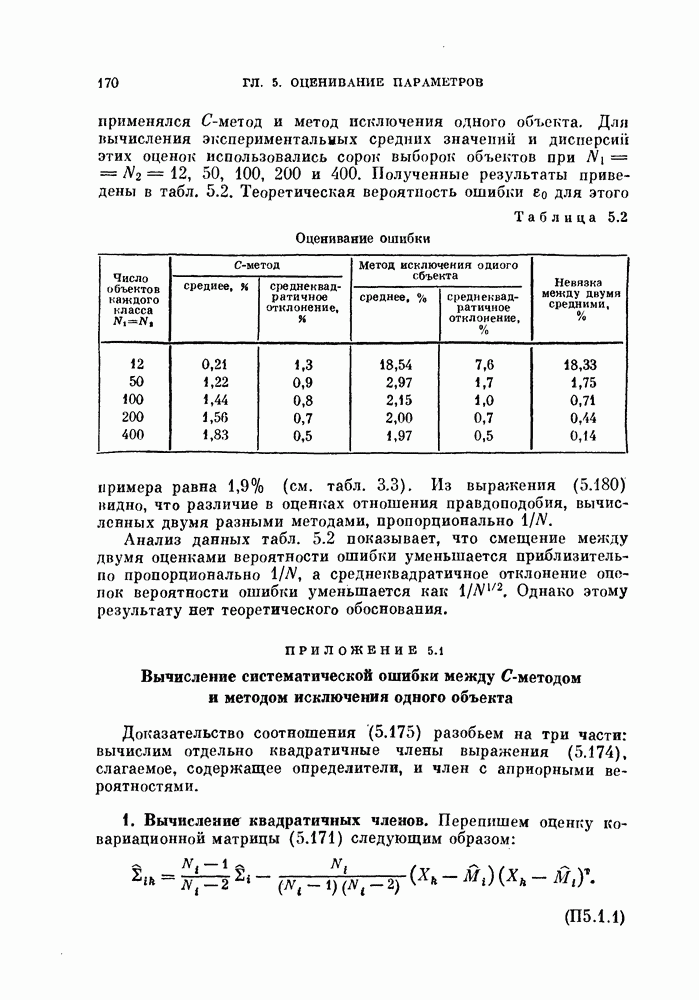







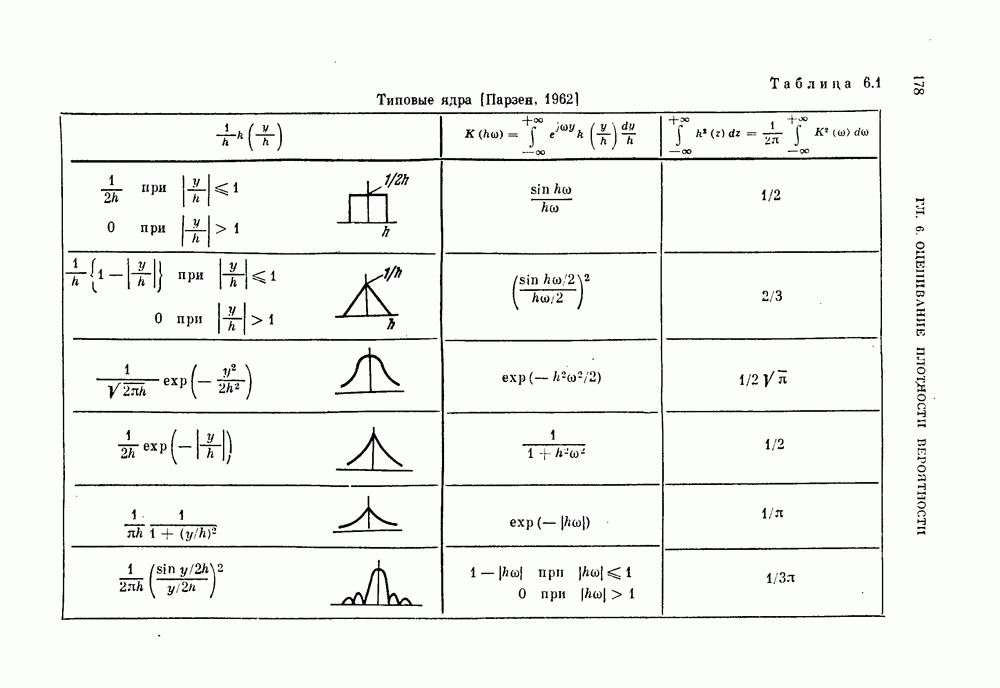






































































































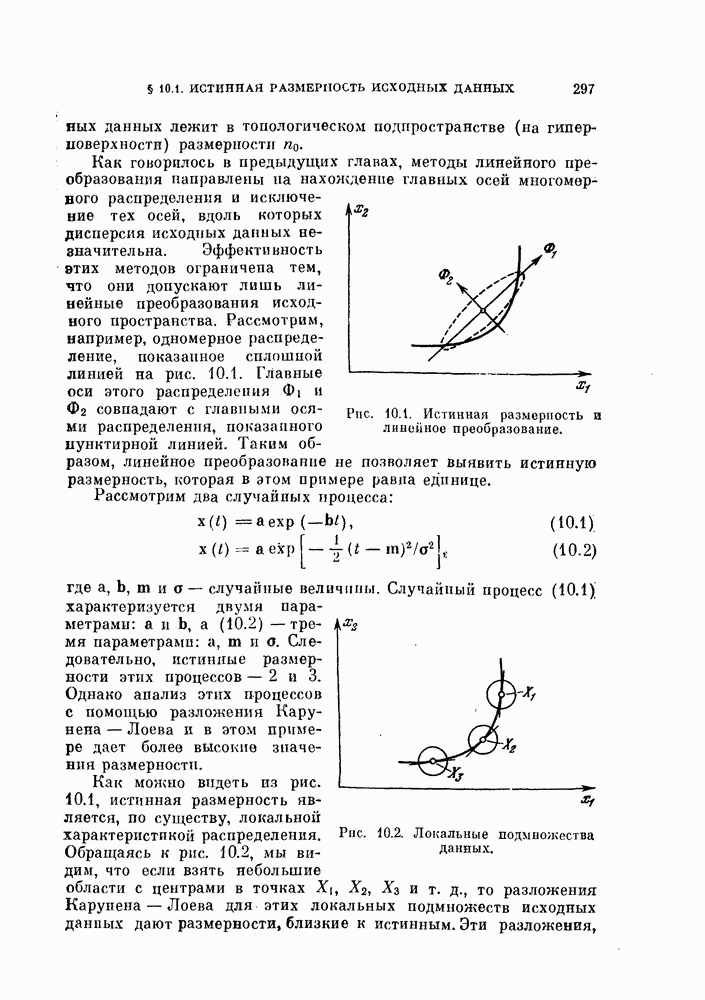




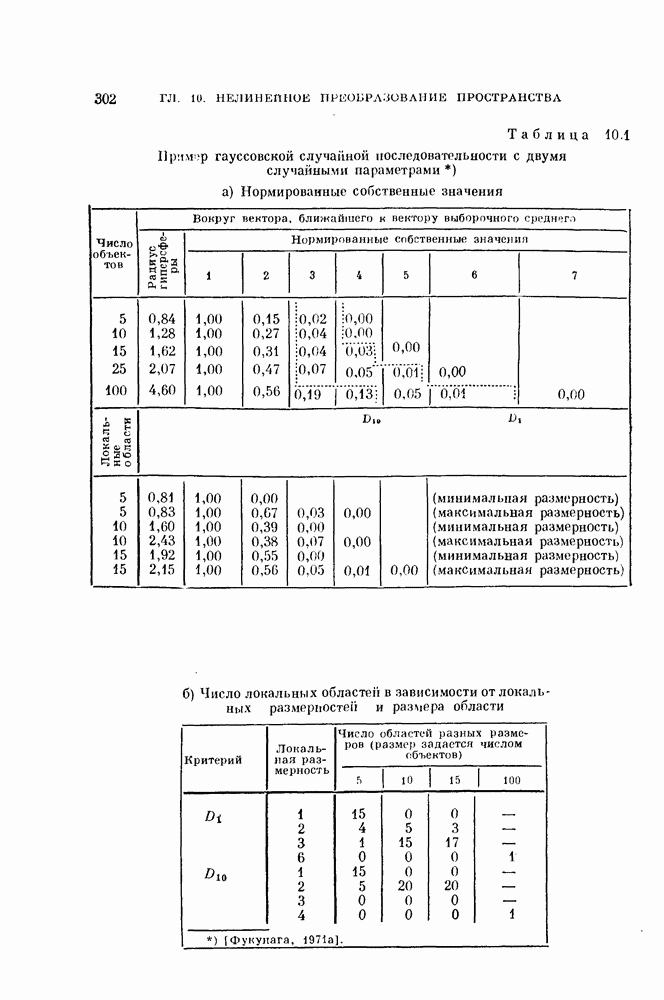
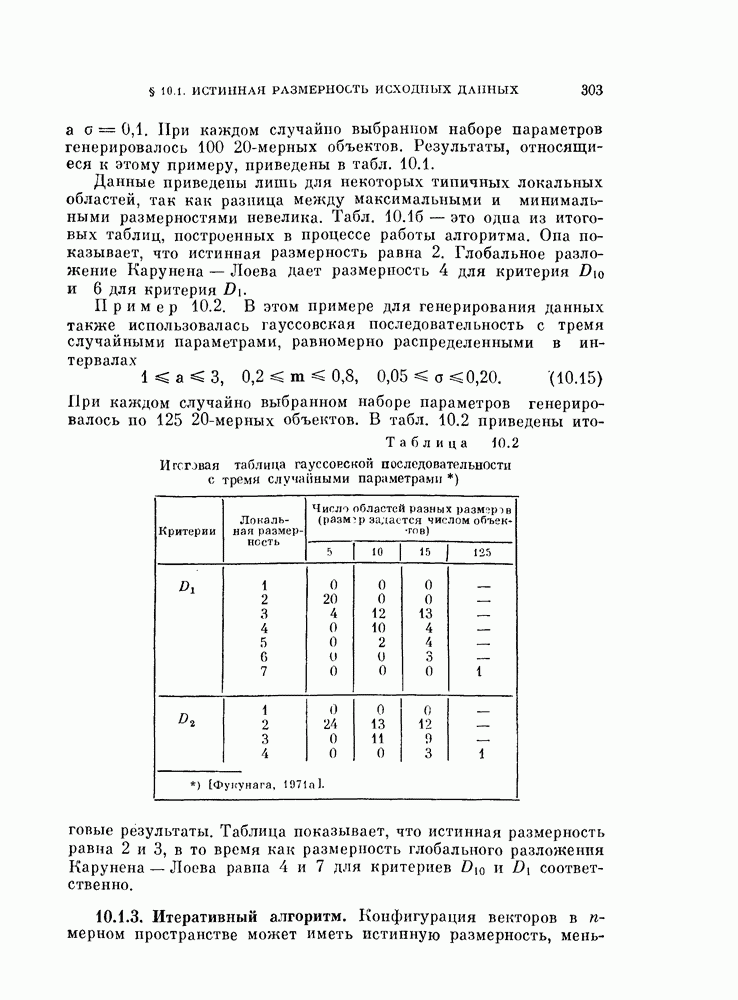

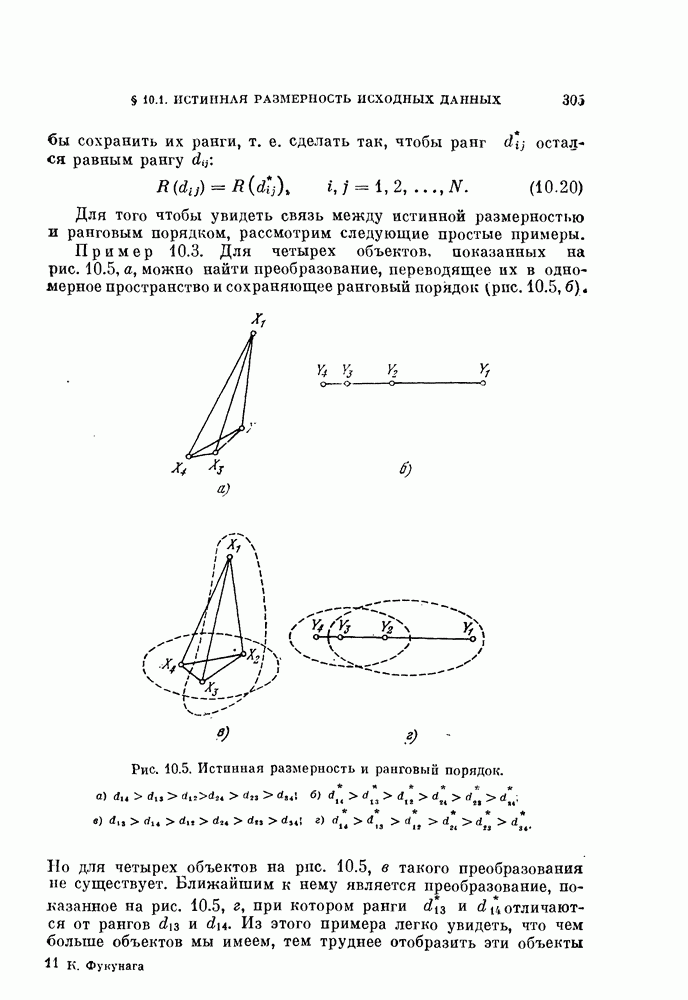


















































 -мерное пространство
-мерное пространство  которое не искажает данного распределения. Так как задача классификации в явном виде не рассматривается, то нет возможности определить, какие свойства данного распределения должны быть сохранены. Поэтому мы ограничиваемся использованием в качестве отображений лишь ортогональных линейных преобразований, в целом сохраняющих структуру распределения.
которое не искажает данного распределения. Так как задача классификации в явном виде не рассматривается, то нет возможности определить, какие свойства данного распределения должны быть сохранены. Поэтому мы ограничиваемся использованием в качестве отображений лишь ортогональных линейных преобразований, в целом сохраняющих структуру распределения.
 -мерное пространство в двумерное, — это мощное средство, помогающее понять свойства распределений. В главе
-мерное пространство в двумерное, — это мощное средство, помогающее понять свойства распределений. В главе