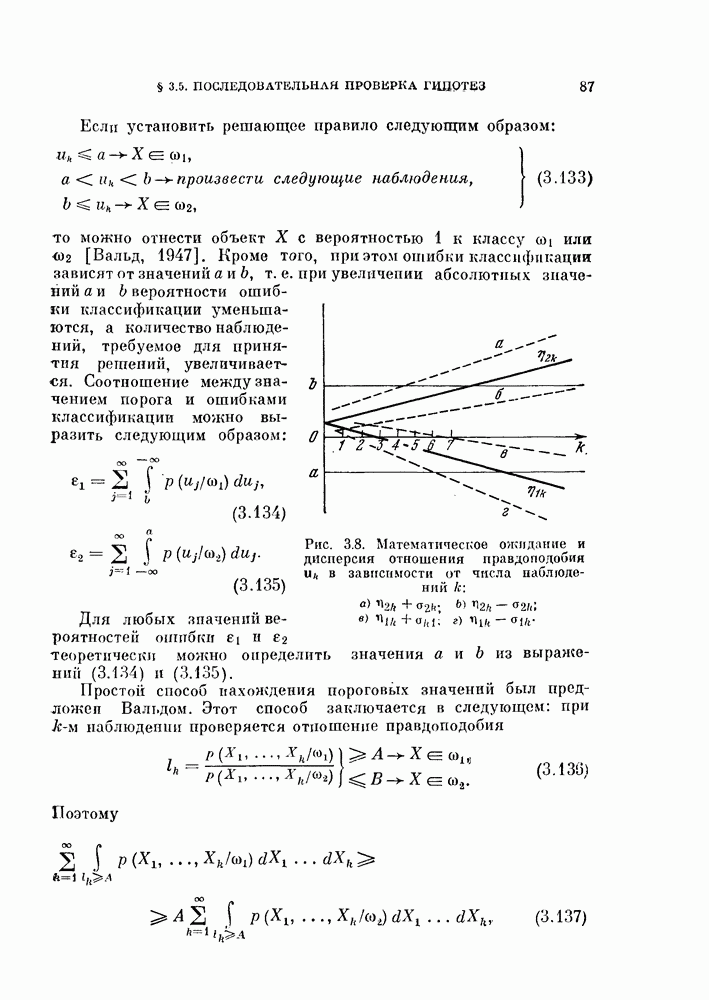
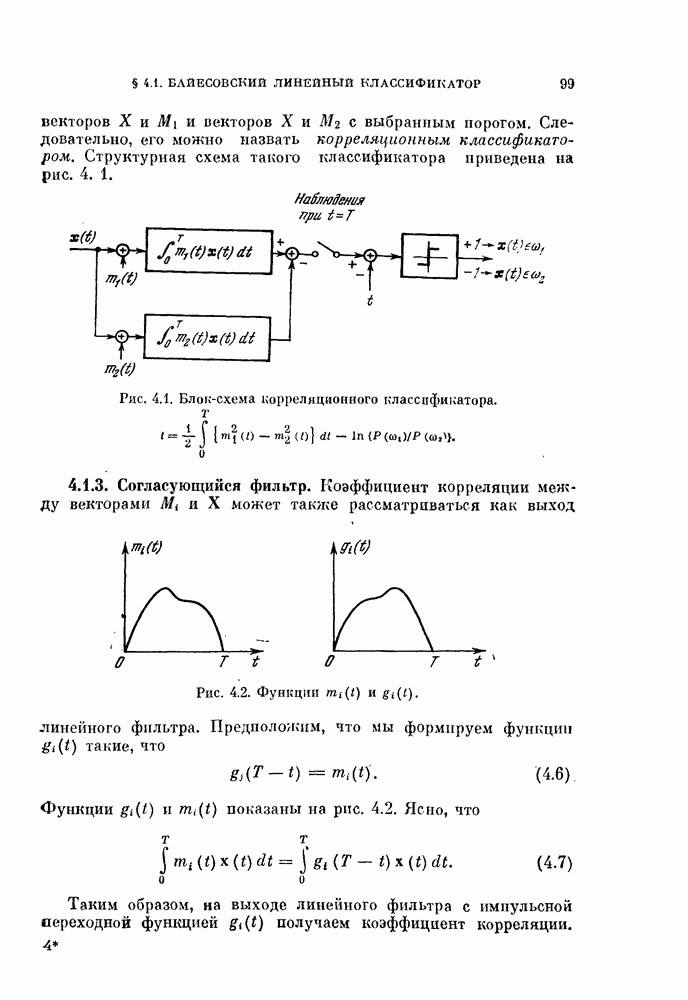
предельной теоремы, то распределение величины  может быть близко к нормальному.
может быть близко к нормальному.
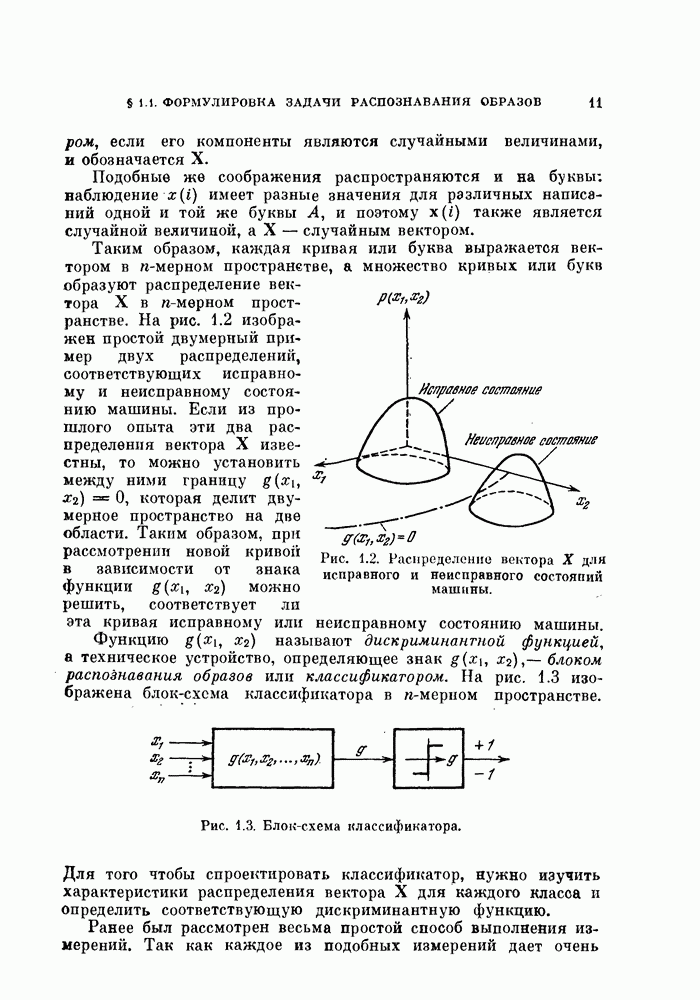
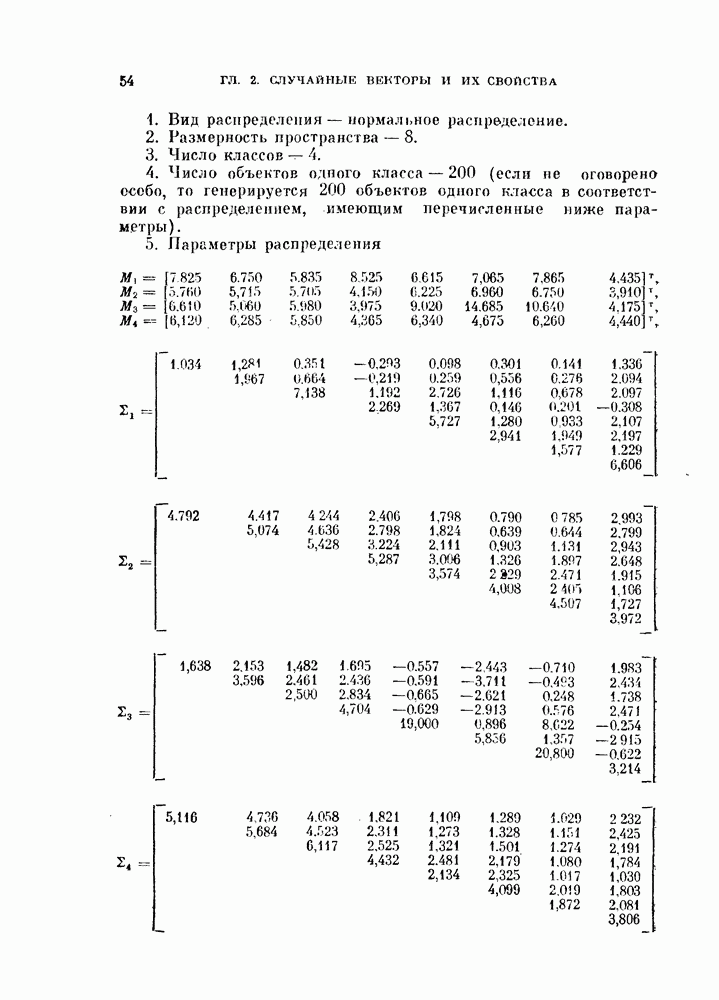
Математические ожидания и дисперсии величины  в классах
в классах  равны
равны

Поэтому вероятность ошибки можно записать следующим образом:

Если требуется минимизировать риск  то вместо вероятностей
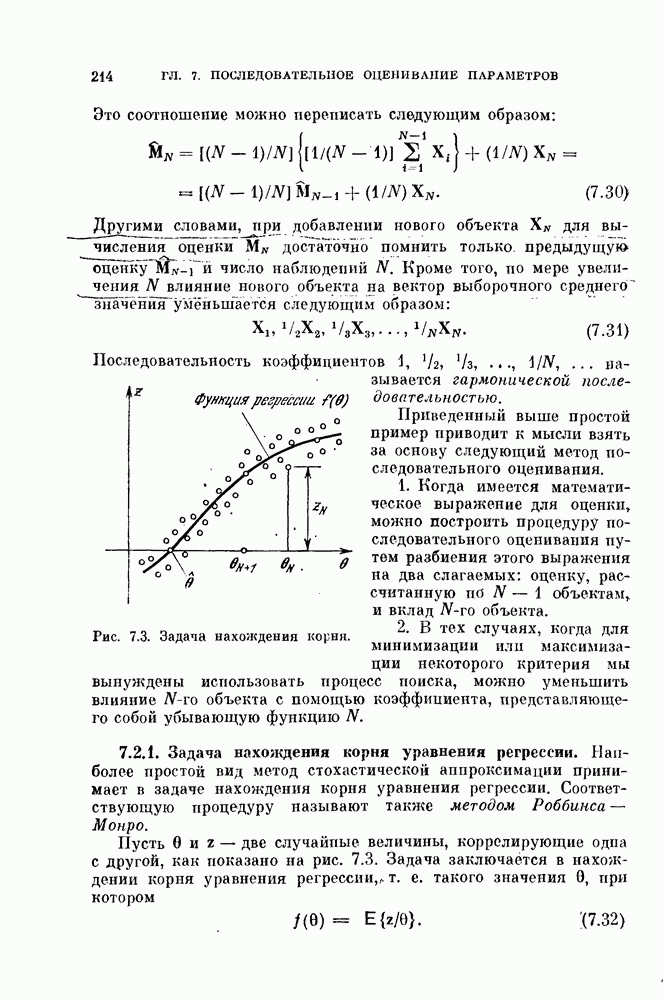
то вместо вероятностей  в формуле (4.16) должны быть использованы величины
в формуле (4.16) должны быть использованы величины  При такой замене предполагается, что штрафы
При такой замене предполагается, что штрафы 
Дифференцируя выражение (4.16) по параметрам  приравнивая производные нулю, получим
приравнивая производные нулю, получим
(см. скан)
где

Апализ уравнений (4.18) показывает, что величины  должны быть одинаковыми при
должны быть одинаковыми при  т. е.
т. е.

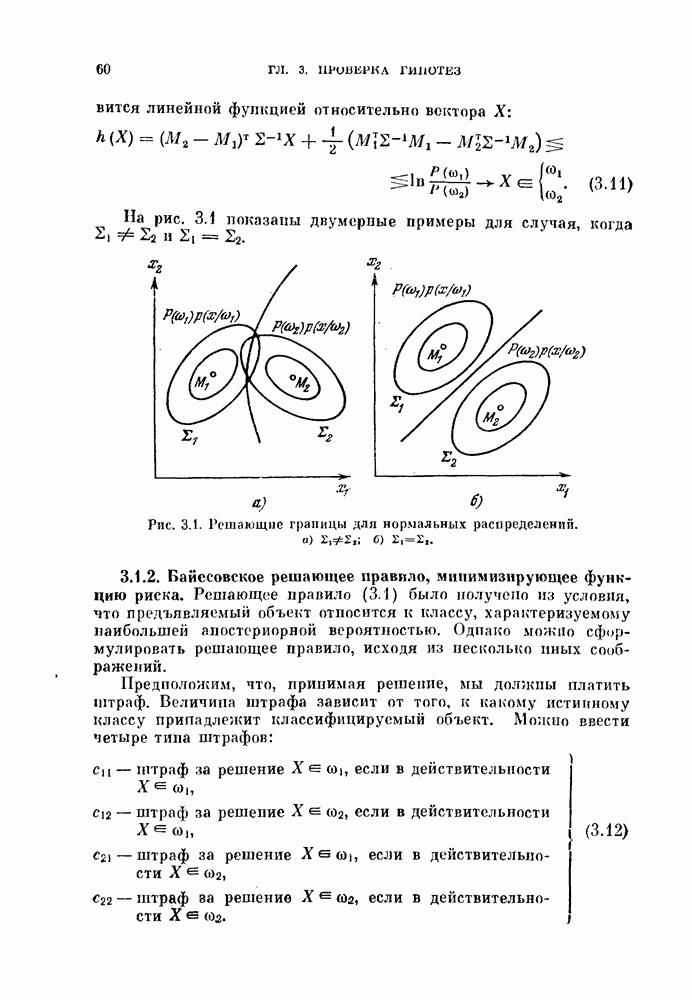
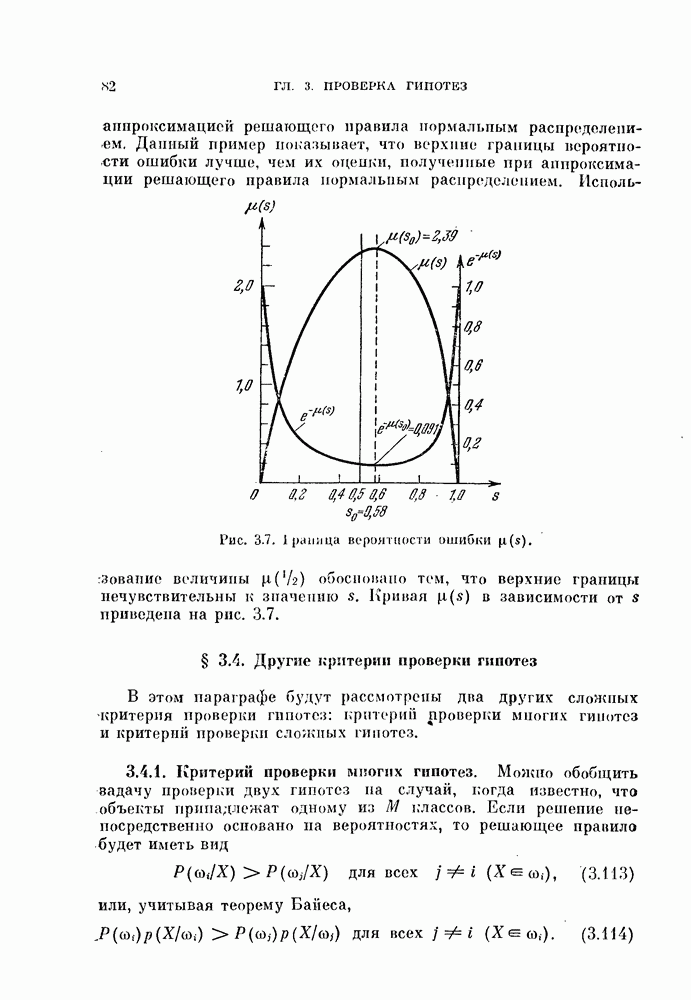
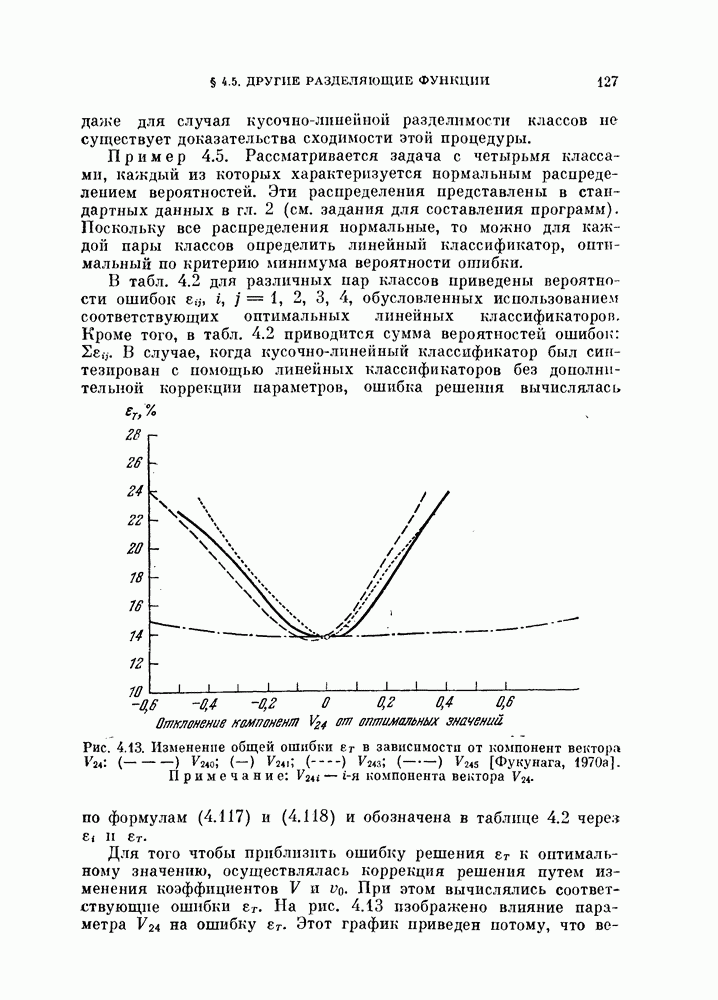
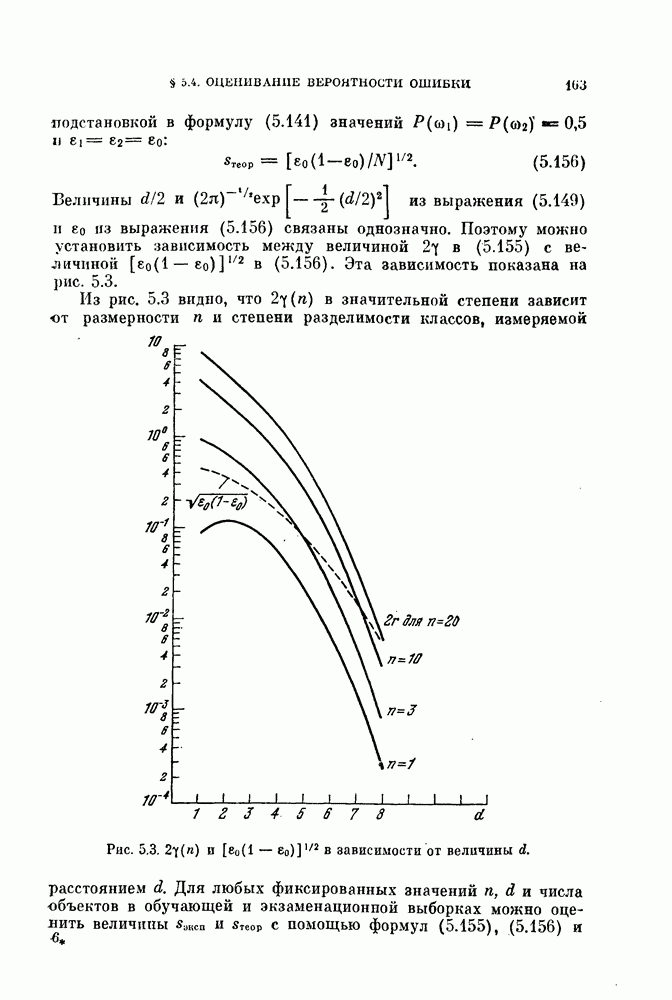
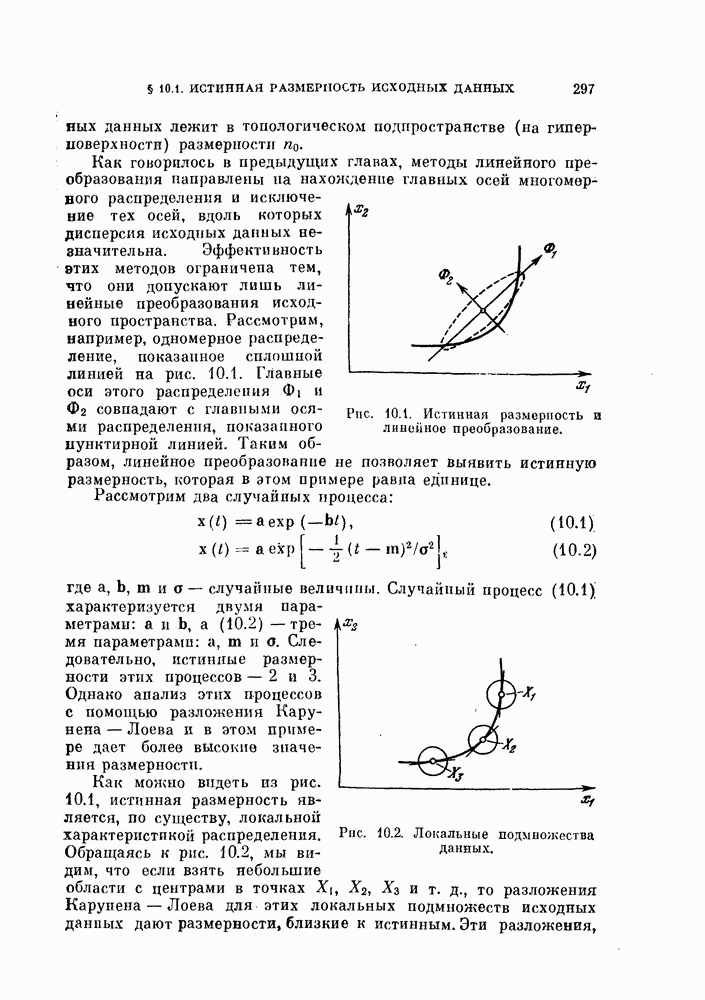
Это показано на рис. 4.7.
Кроме условия (4.20), должно выполняться соотношение (4.17), т. е.

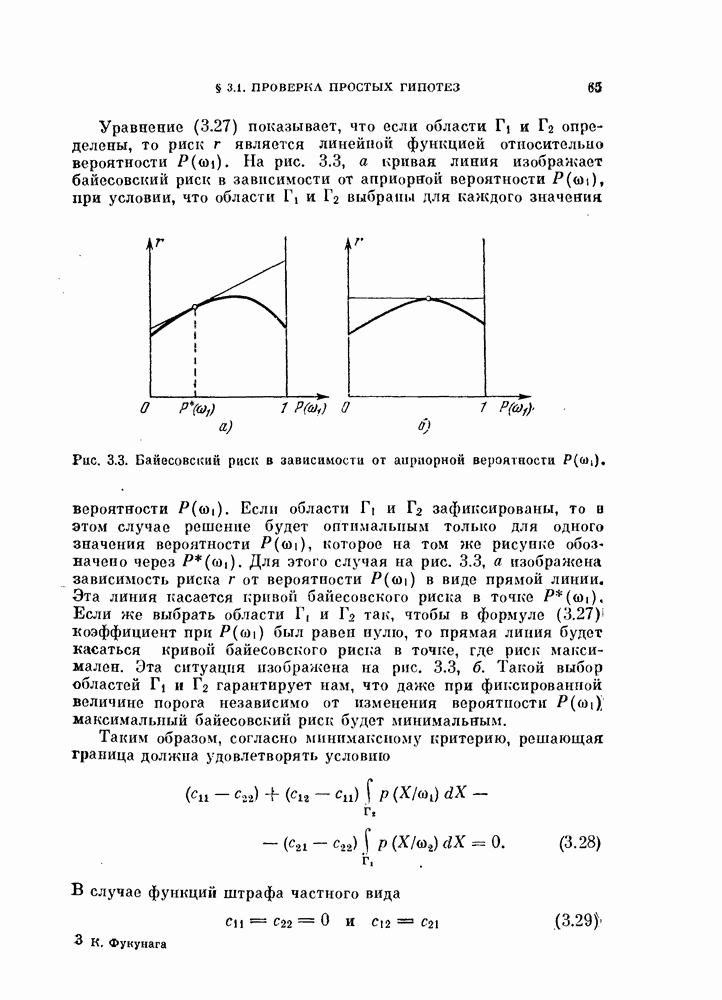
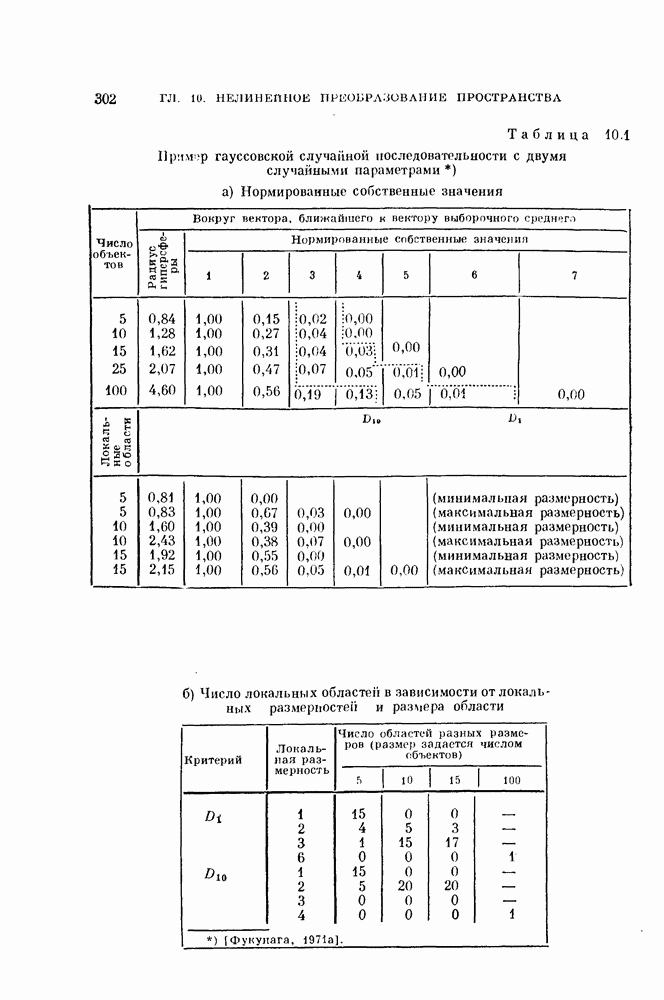
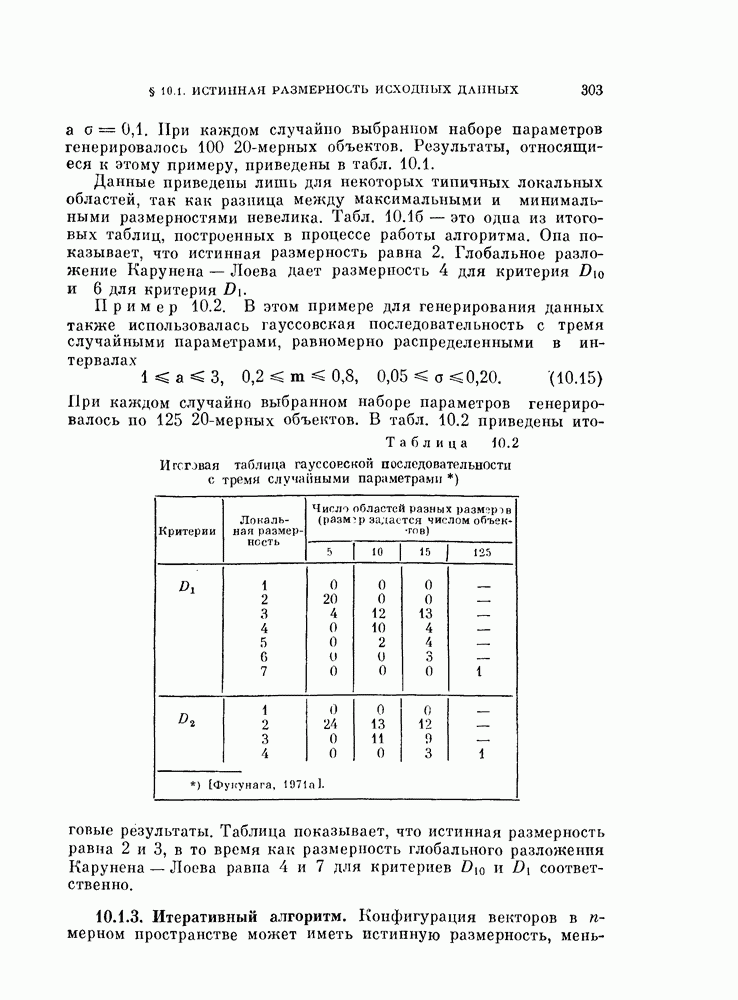
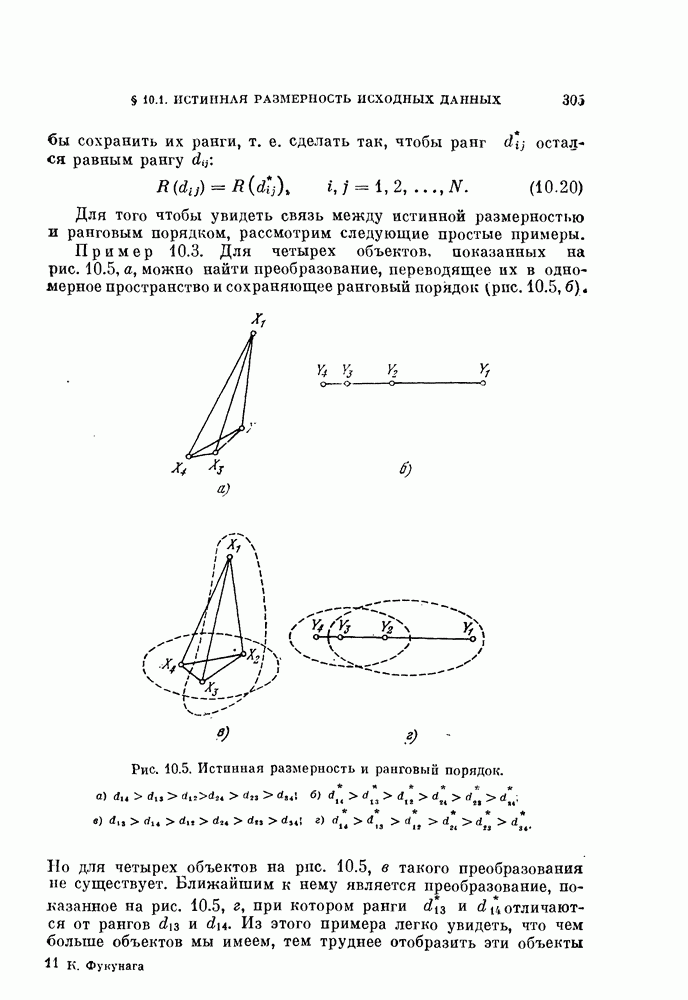
Таким образом, если возможно отыскать значения параметров V удовлетворяющие уравнениям (4.20) и (4.21), то эти значения минимизируют вероятность ошибки (4.16) [Андерсон, Бахадур, 1962].

Рис. 4.7. Распределение решающего правила 
К сожалению, поскольку параметры и  являются функциями величин
являются функциями величин  точное решение уравнений (4.20), (4.21) получить не удалось. Поэтому для нахождения решения следует использовать итеративную процедуру.
точное решение уравнений (4.20), (4.21) получить не удалось. Поэтому для нахождения решения следует использовать итеративную процедуру.
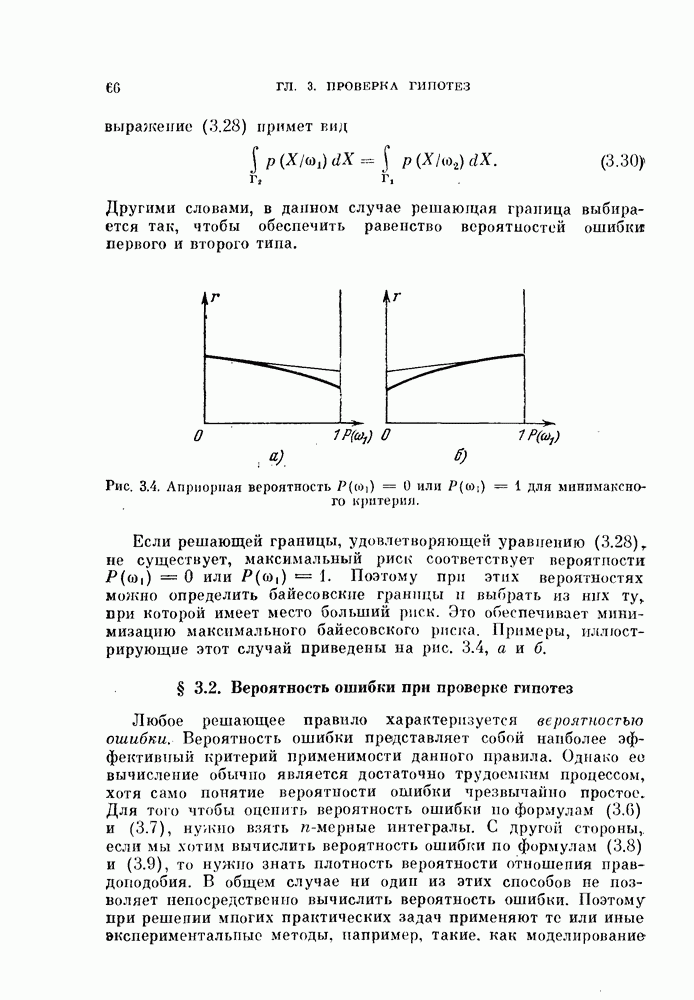
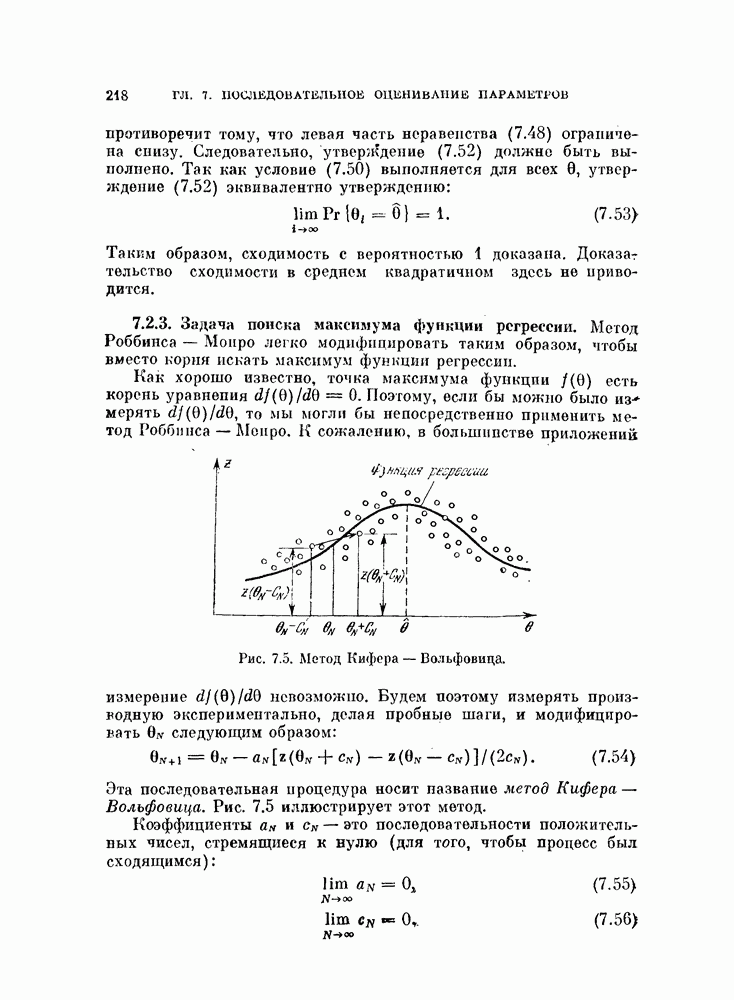
Простой итеративный процесс был предложен в работе [Петерсон, Матсон, 1966]. Вместо решения уравнений (4.20) и (4.21) минимум вероятности ошибки  ищется при условии (4.21) следующим образом:
ищется при условии (4.21) следующим образом:

где

Так как из формулы (4.24) следует, что  и
и  то
то  можно вычислить по формуле
можно вычислить по формуле

Из (4.25) видно, что если вектор V умножить на а, то значение  также увеличится в а раз. Напомним, что решение, получаемое из условия
также увеличится в а раз. Напомним, что решение, получаемое из условия  эквивалентно решению
эквивалентно решению  Кроме того, вероятность ошибки (4.16) инвариантна относительно изменения масштаба, так как
Кроме того, вероятность ошибки (4.16) инвариантна относительно изменения масштаба, так как

Поэтому, пренебрегая масштабным коэффициентам а в формуле (4.22), можно вычертить график вероятности ошибки  как функции одного параметра
как функции одного параметра  следующим образом:
следующим образом:
1) для данного  при
при  вычислить V по формуле (4.22);
вычислить V по формуле (4.22);
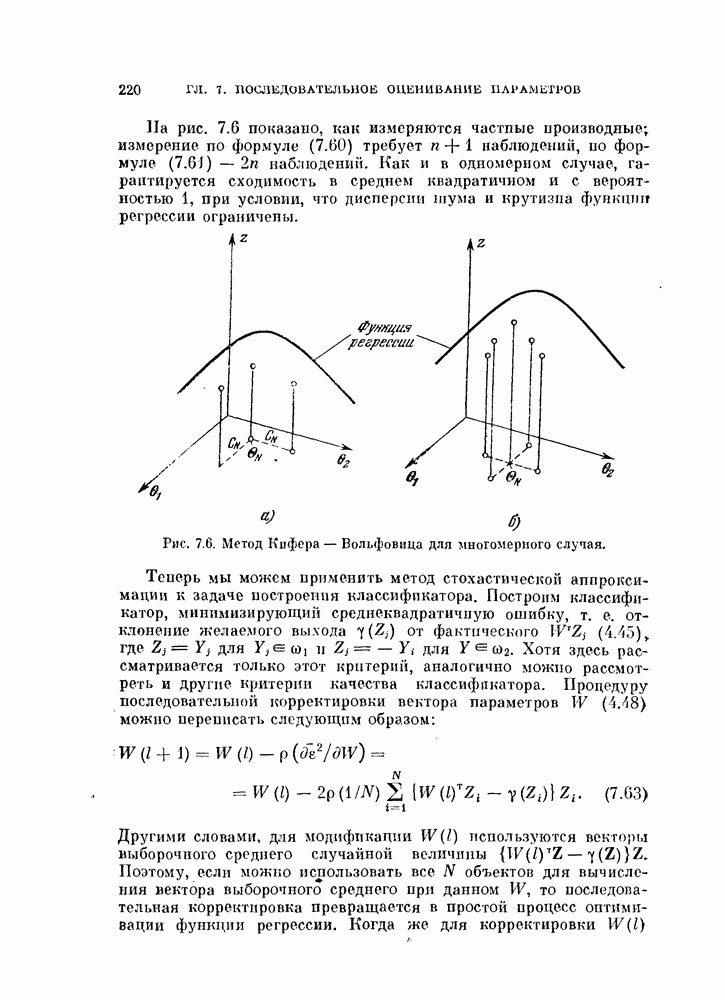
2) используя полученное значение У, вычислить по уравнениям (4.15) и (4.25) величины 
3) вычислить вероятность ошибки  по формуле (4.16);
по формуле (4.16);
4) изменять значения  от 0 до 1.
от 0 до 1.
Значение  минимизирующее вероятность ошибки
минимизирующее вероятность ошибки  можно определить из графика функции
можно определить из графика функции 
Преимущество этой процедуры заключается в том, что для настройки имеется только один параметр  Это делает процедуру намного проще, чем решение уравнений (4.20) и (4.21) относительно
Это делает процедуру намного проще, чем решение уравнений (4.20) и (4.21) относительно  переменной. Кроме того, чтобы сэкономить вычислительное время, предлагается вначале процедуры одновременно привести к диагональному виду ковариационные матрицы
переменной. Кроме того, чтобы сэкономить вычислительное время, предлагается вначале процедуры одновременно привести к диагональному виду ковариационные матрицы  и и далее работать в преобразованной системе координат. В этом случае вычисление дисперсий
и и далее работать в преобразованной системе координат. В этом случае вычисление дисперсий  и обращение матрицы в (4.22) выполняются очень просто.
и обращение матрицы в (4.22) выполняются очень просто.
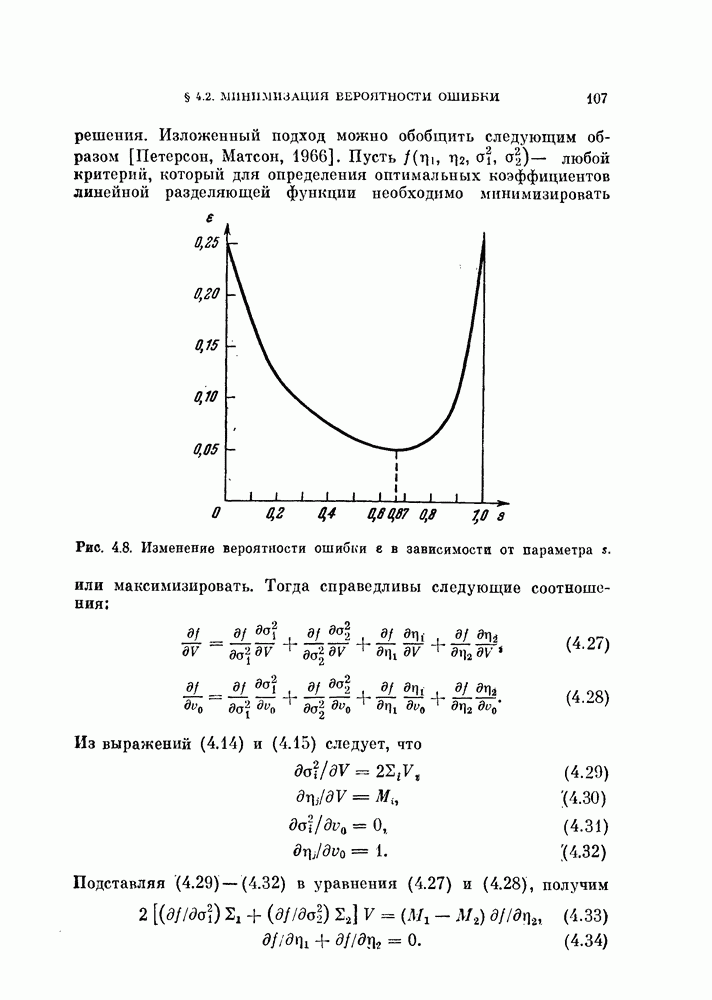
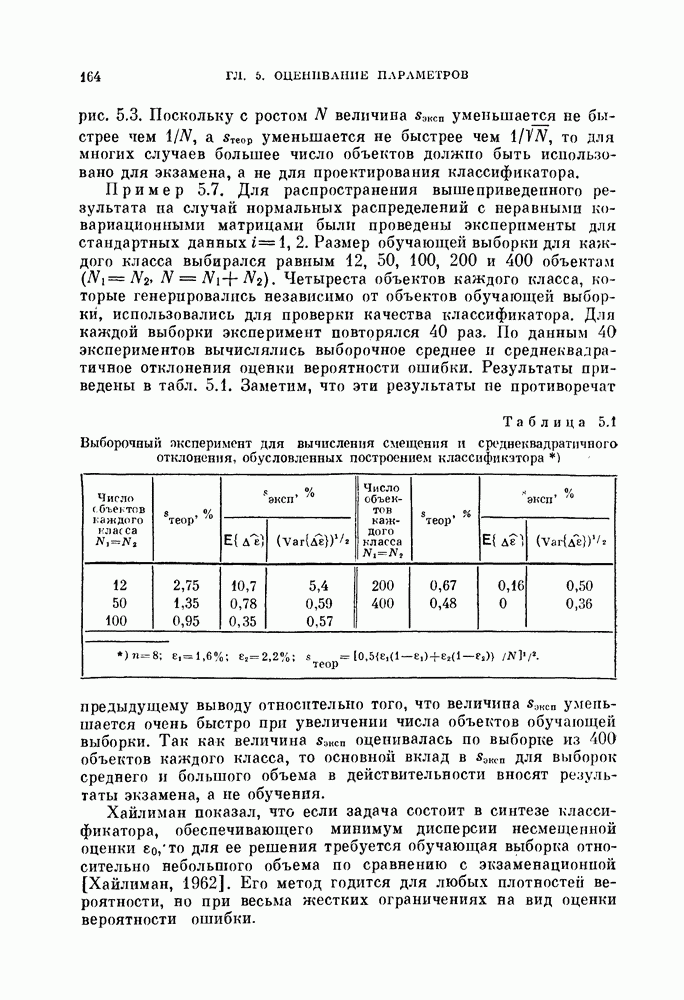
Пример 4.2. Используются данные примера 3.3. График вероятности ошибки  в зависимости от параметра
в зависимости от параметра  приведен на рис. 4.8, из которого видно, что вероятность ошибки
приведен на рис. 4.8, из которого видно, что вероятность ошибки  не очень чувствительна к 5 вблизи оптимальной точки. Наилучшая линейная разделяющая функция дает минимальную ошибку в 5%, в то время как байесовский классификатор с квадратичной функцией дает
не очень чувствительна к 5 вблизи оптимальной точки. Наилучшая линейная разделяющая функция дает минимальную ошибку в 5%, в то время как байесовский классификатор с квадратичной функцией дает  как следует из примера 3.3.
как следует из примера 3.3.






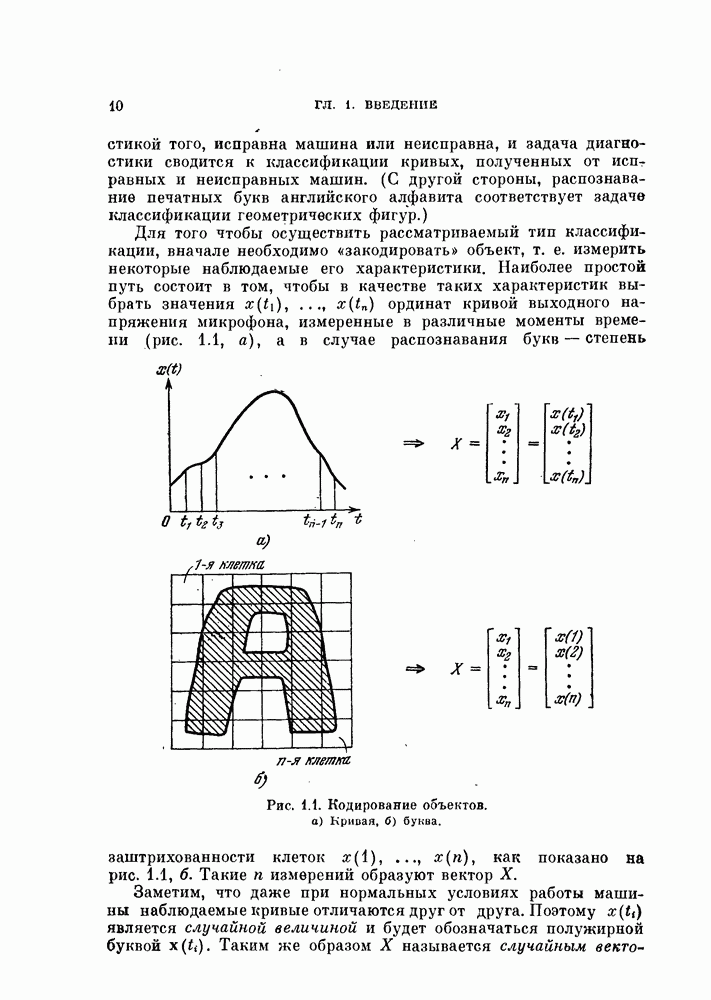

























































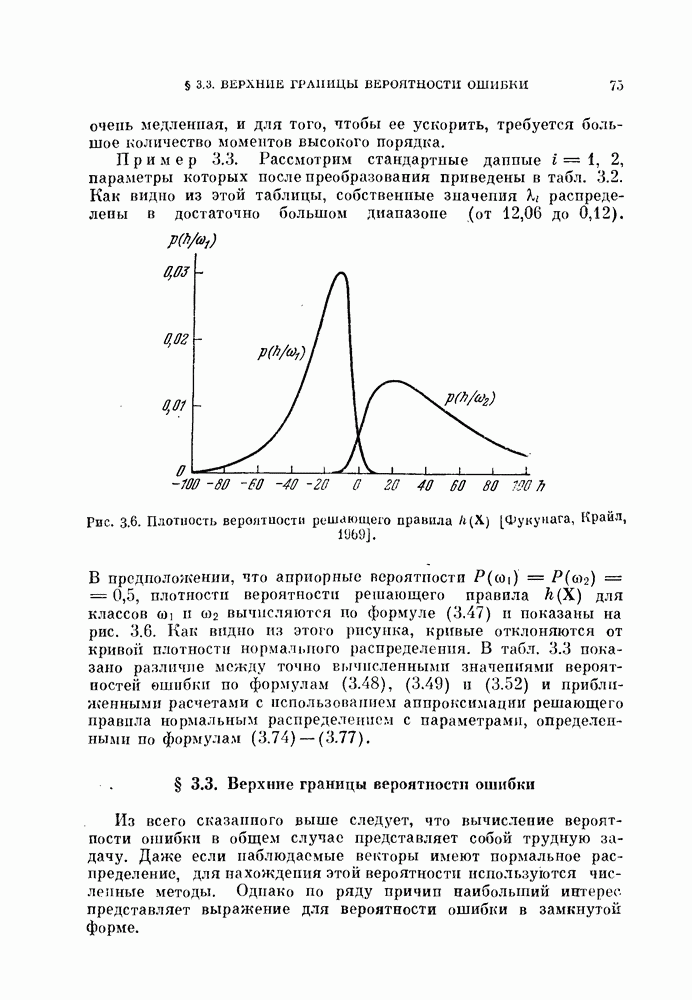























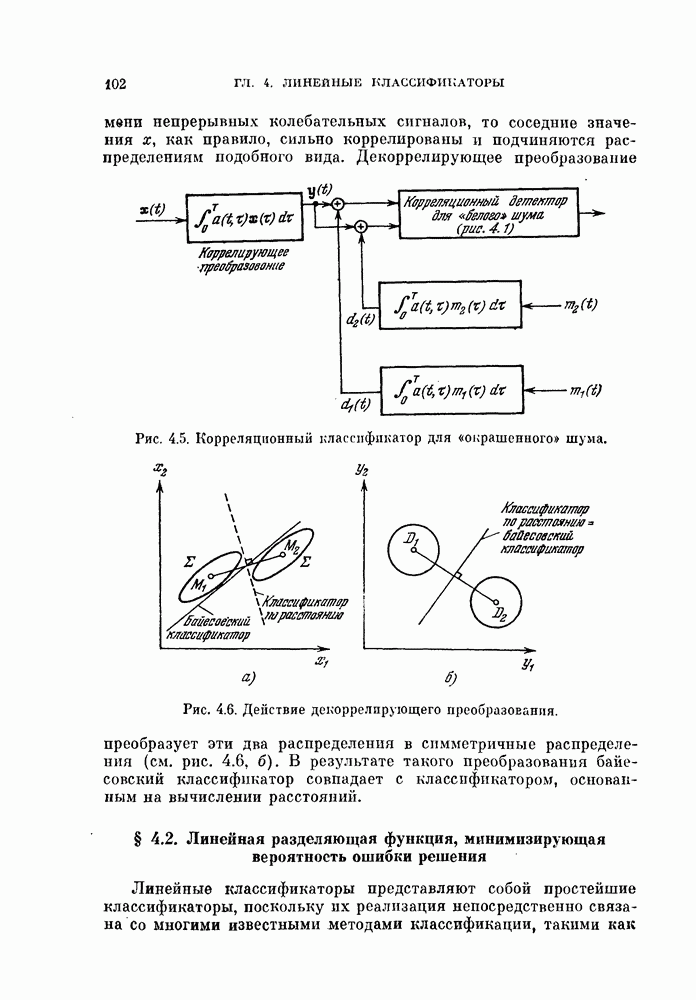






























































































































































































































 распределена по нормальному или близкому к нему закону, то для вычисления вероятности ошибки можно использовать математическое ожидание и дисперсию
распределена по нормальному или близкому к нему закону, то для вычисления вероятности ошибки можно использовать математическое ожидание и дисперсию  для классов со и
для классов со и  а затем выбрать параметры V и
а затем выбрать параметры V и  так, чтобы минимизировать ошибку решения. Вспоминая, что
так, чтобы минимизировать ошибку решения. Вспоминая, что  является суммой, состоящей из
является суммой, состоящей из  слагаемых
слагаемых  приходим к выводу:
приходим к выводу:
 также имеет нормальное распределение:
также имеет нормальное распределение:
 выполнены условия центральной
выполнены условия центральной
