Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
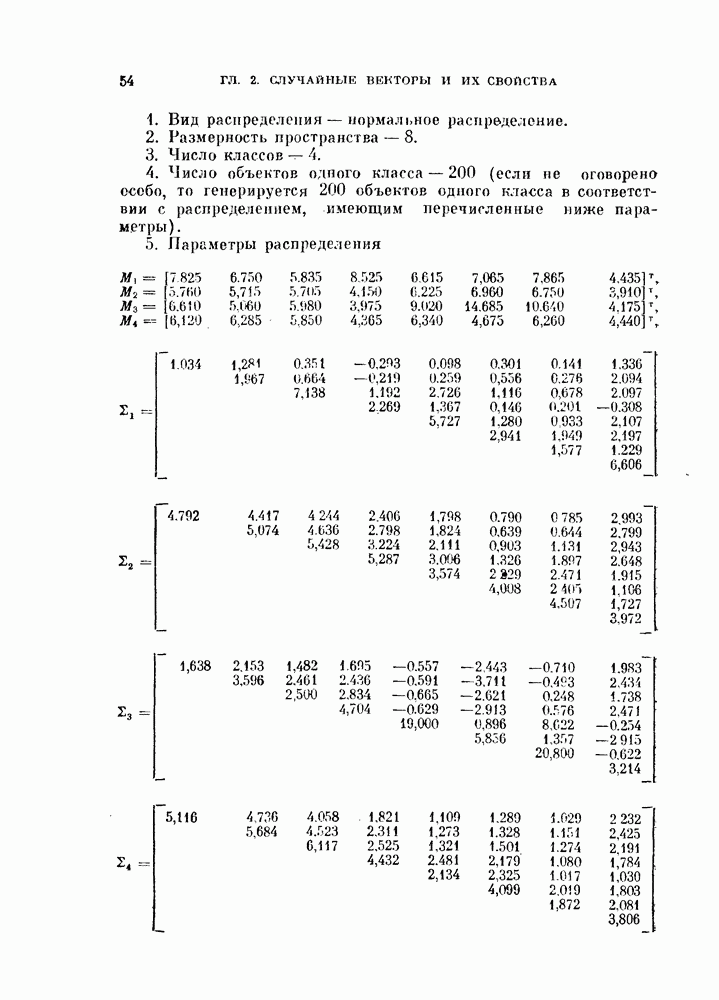
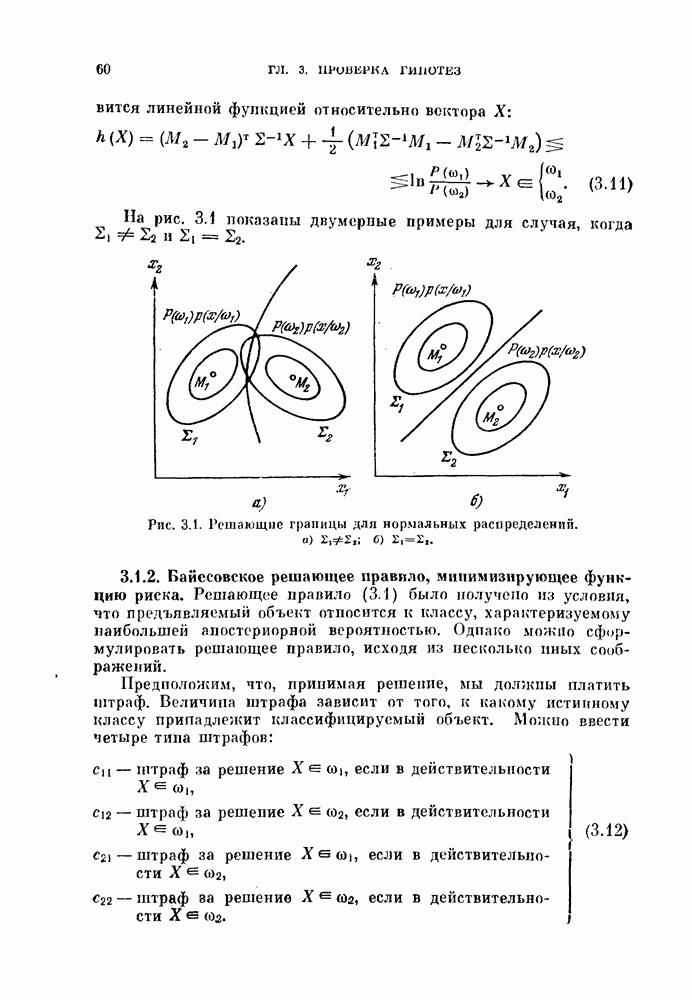
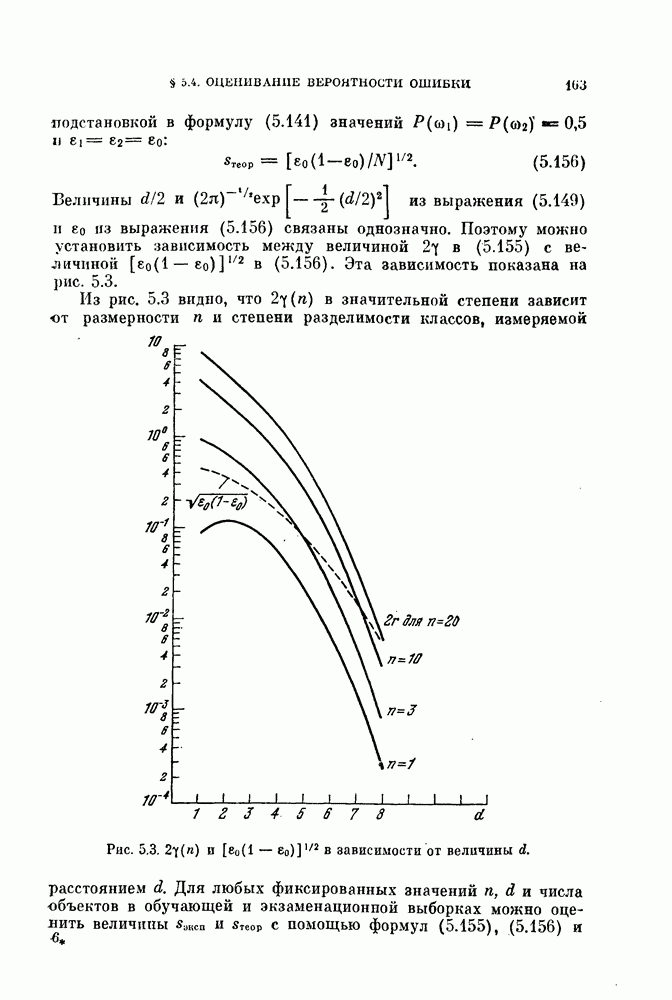
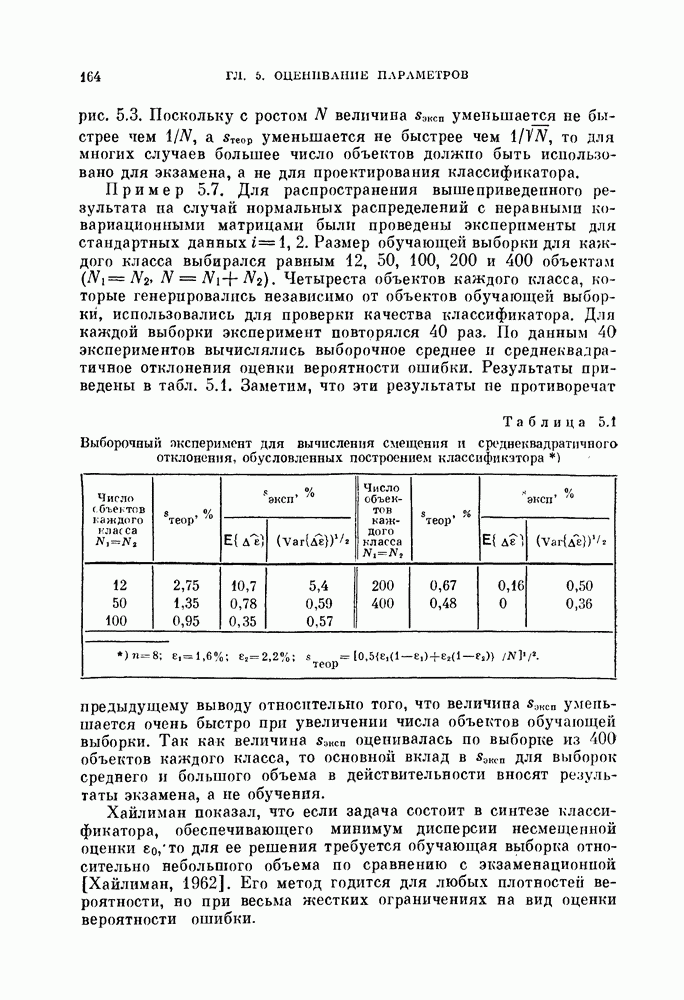
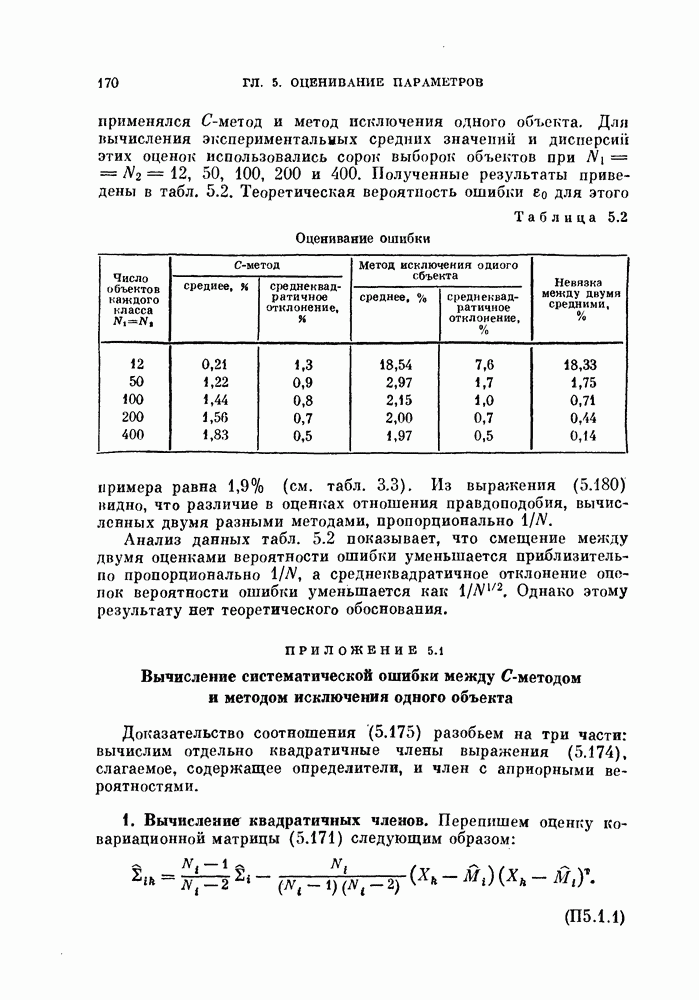
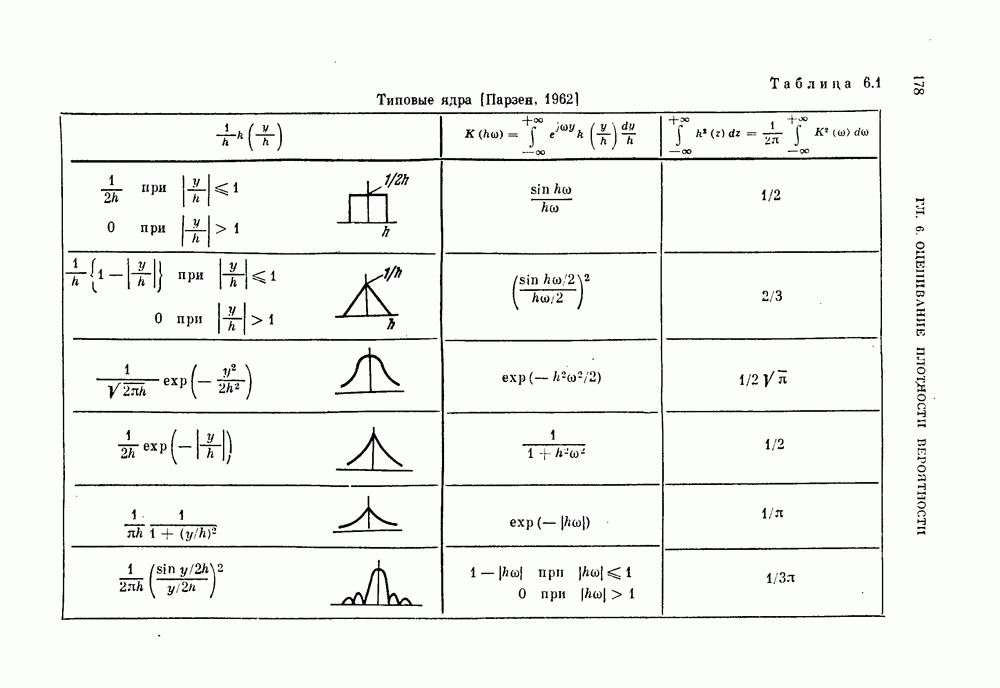
Глава 4. ЛИНЕЙНЫЕ КЛАССИФИКАТОРЫКак было показано в предыдущей главе, байесовский критерий отношения правдоподобия является оптимальным в том смысле, что он минимизирует риск или вероятность ошибки. Однако для получения отношения правдоподобия необходимо располагать для каждого класса условными плотностями вероятности. В большинстве приложений оценка этих плотностей осуществляется по конечному числу выборочных векторов наблюдений. Процедуры оценивания плотностей вероятности известны, но они являются очень сложными, либо требуют для получения точных результатов большого числа векторов наблюдений. Однако даже при наличии плотностей вероятности метод, основанный на критерии отношения правдоподобия, на практике может оказаться трудно реализуемым, так как он может потребовать для классификации больших объемов памяти и машинного времени. В связи с этим часто мы вынуждены рассматривать более простые методы разработки классификаторов. В частности, можно задать математический вид классификатора с точностью до параметров, подлежащих определению. Наиболее простым и общим видом является линейный или кусочно-линейный классификатор, изучению которого посвящена эта глава. Вначале рассматривается частный случай байесовского линейного классификатора. Далее будут приведены другие методы разработки «хороших» линейных классификаторов. Читателю, однако, следует помнить, что байесовский классификатор во всех случаях является наилучшим. Никакой линейный классификатор не превосходит по качеству работы классификатор, полученный по критерию отношения правдоподобия. § 4.1. Байесовский линейный классификаторДля двух нормально распределенных случайных величии байесовское решающее правило можно представить в виде квадратичной функции относительно вектора наблюдений X следующим образом:
Если обе ковариационные матрицы одинаковы, т. е.
Сначала рассмотрим частный случай, при котором 4.1.1. Наблюдения — белый шум.Если ковариационная мат рица равна единичной, то можно считать, что вектор X представ ляет собой наблюдение, искаженное белым шумом. Компоненты вектора X при этом некоррелированы и имеют единичную дисперсию, а байесовское решающее правило принимает вид
4.1.2. Корреляционный классификатор.Произведение
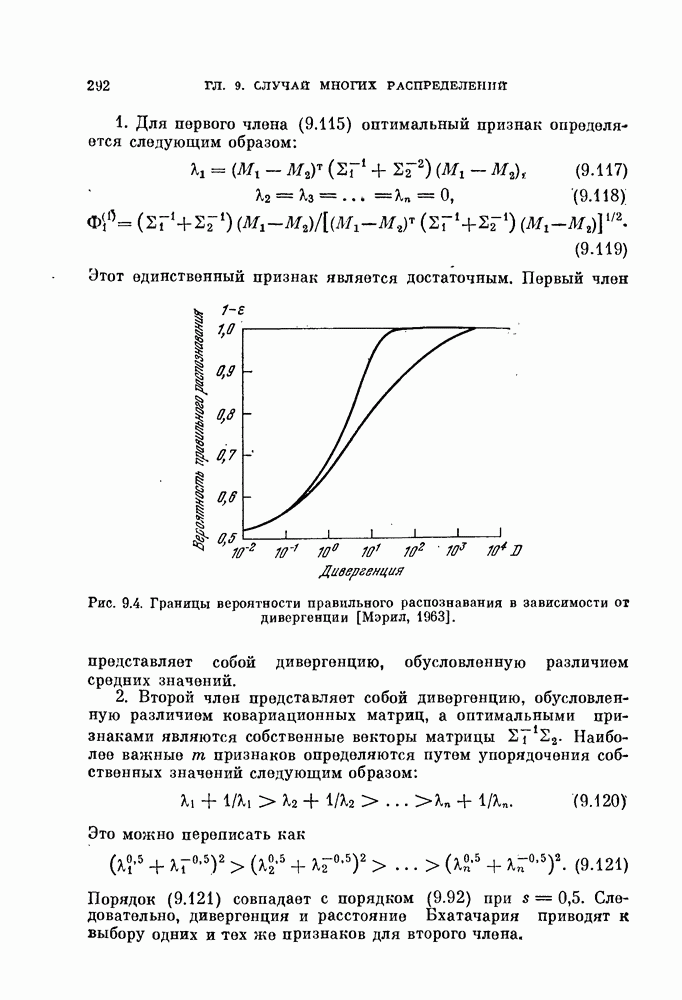
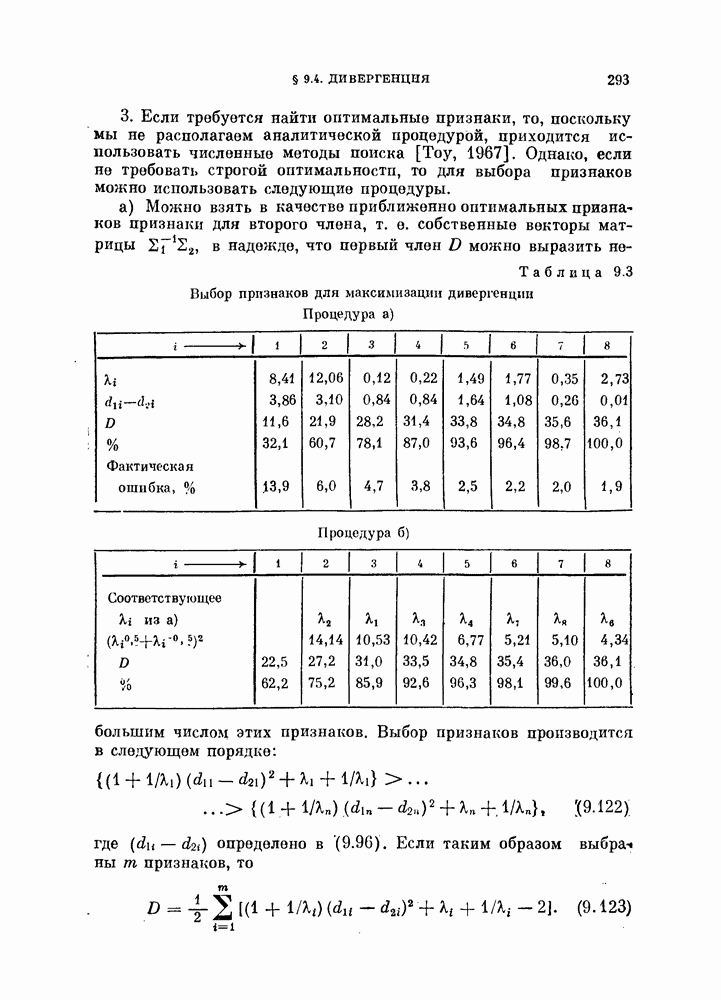
В случае непрерывного времени коэффициент корреляции выражается через интеграл, т. е.
Легко видеть, что для принятия решения рассматриваемый; классификатор сравнивает разность коэффициентов корреляции векторов X и
Рис. 4.1. Блок-схема корреляционного классификатора. 4.1.3. Согласующийся фильтр.Коэффициент корреляции между векторами
Рис. 4.2. Функции Предположим, что мы формируем функции
Функции
Таким образом, на выходе линейного фильтра с импульсной переходной функцией Такой фильтр называют согласующимся фильтром. Классификатор, который основан на согласующемся фильтре и реализует ту же самую функцию, что и корреляционный классификатор, показан на рис. 4.3.
Рис. 4.3. Блок-схема согласующегося фильтра. 4.1.4. Классификатор, основанный на вычислении расстоянияУмножив выражение (4.3) на 2, а затем прибавив и вычтя
или
Полученному решающему правилу можно дать следующую геометрическую интерпретацию: сравниваются расстояния между вектором X и векторами 4.1.5. Наблюдения — не белый шум.В общем случае, когда ковариационная матрица не равна единичной, т. е. шум в белый:
Заметим, что пока ковариационная матрица 2 является положительно определенной, матрица А существует и невырождена. Таким образом, декоррелирующее преобразование обратимо, и наблюдения вектора
а ковариационная матрица
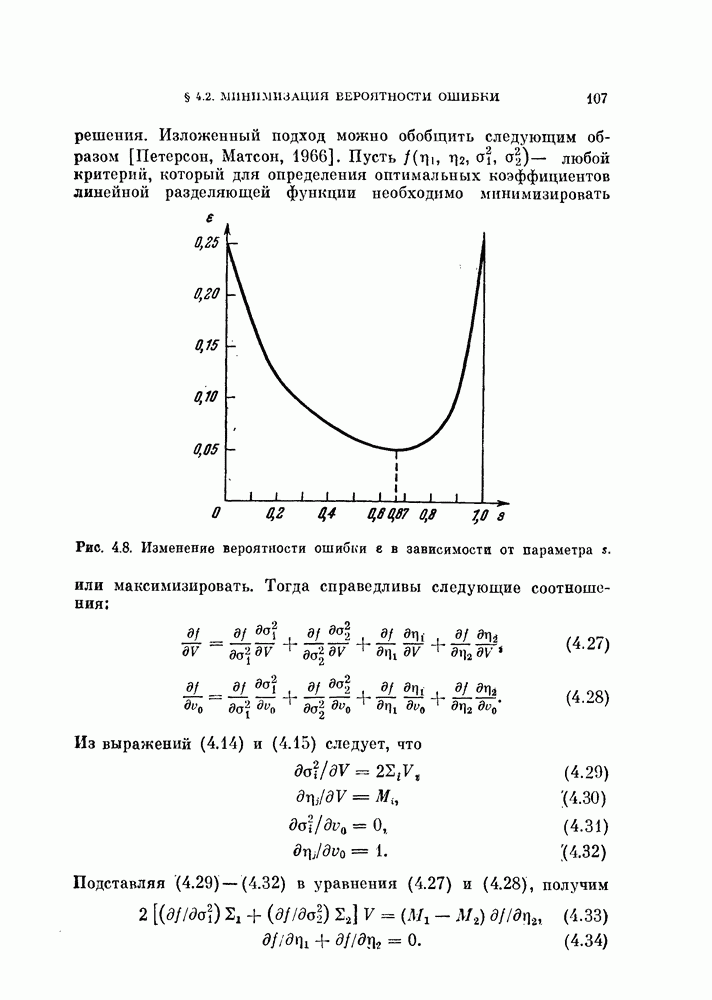
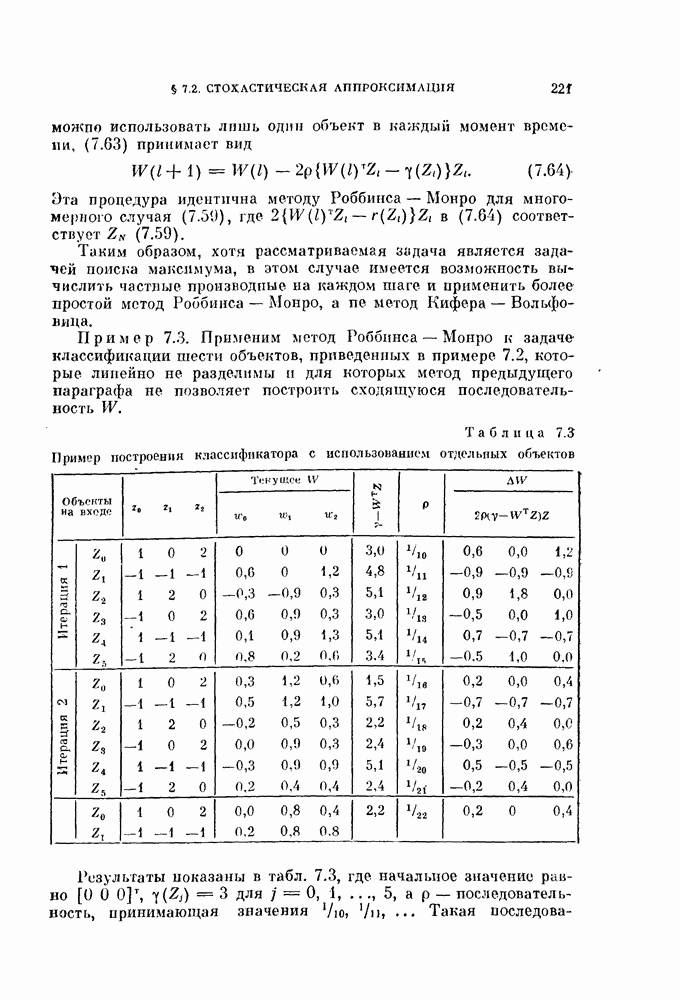
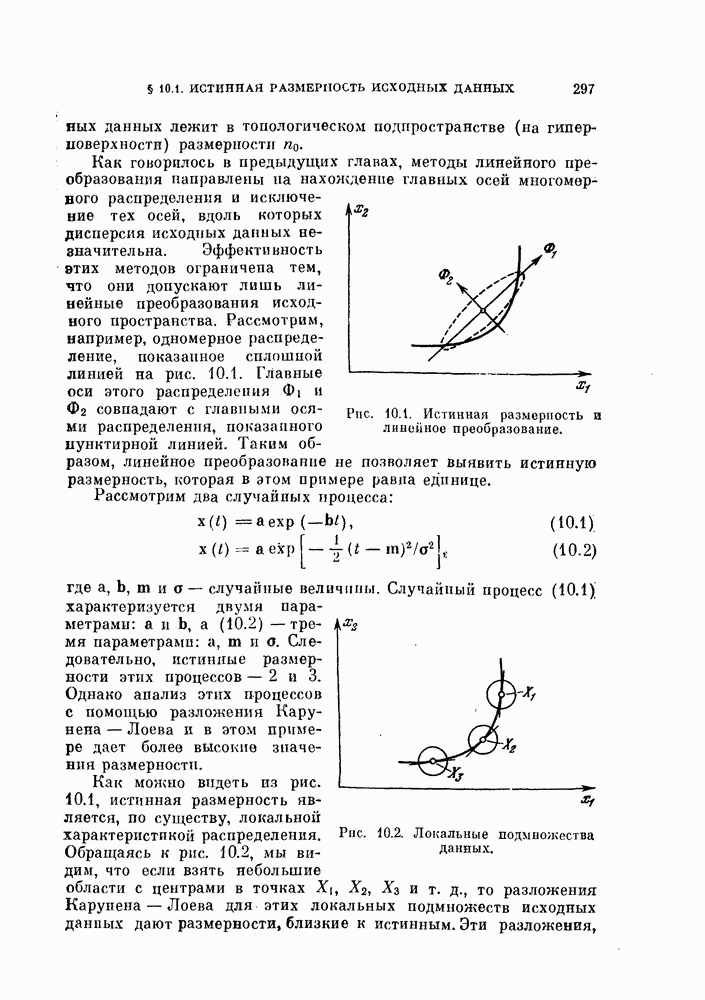
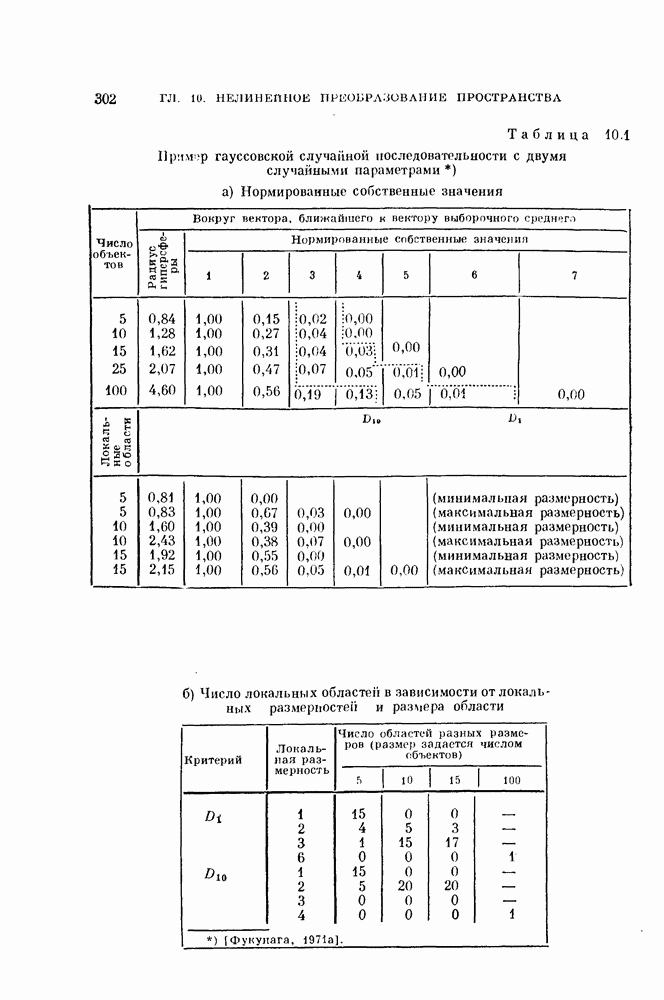
Рис. 4.4. Классификатор, основанный на вычислении евклидова расстояния. Ядро Пример 4.1. На рис. 4.6 изображен двумерный пример, для которого декоррелирующее преобразование является эффективным. Хотя два распределения на рис. 4.6, а хорошо разделимы байесовским классификатором решающее правило, основанное на вычислении расстояний, или простой корреляционный классификатор дают плохие результаты. На рис. 4.6, а изображены вытянутые распределения, соответствующие случаю сильной коррелированности величин времени непрерывных колебательных сигналов, то соседние значения
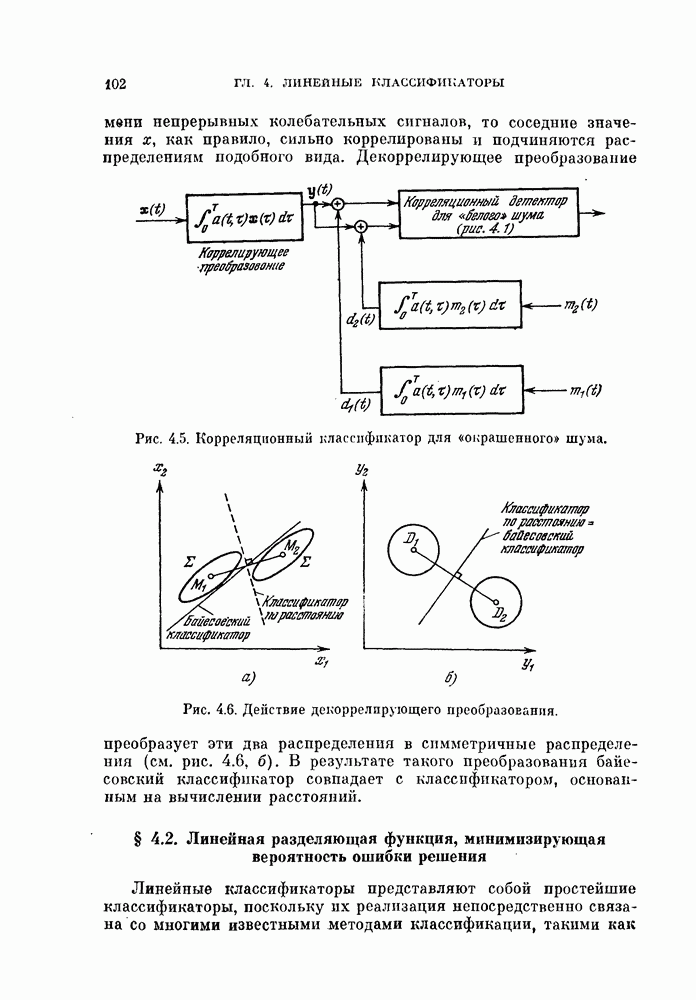
Рис. 4.5. Корреляционный классификатор для «окрашенного» шума.
Рис. 4.6. Действие декоррелпрующего преобразования. Декоррелирующее преобразование преобразует эти два распределения в симметричные распределения (см. рис. 4.6, б). В результате такого преобразования байесовский классификатор совпадает с классификатором, основанным на вычислении расстояний.
|
 |
Оглавление
|






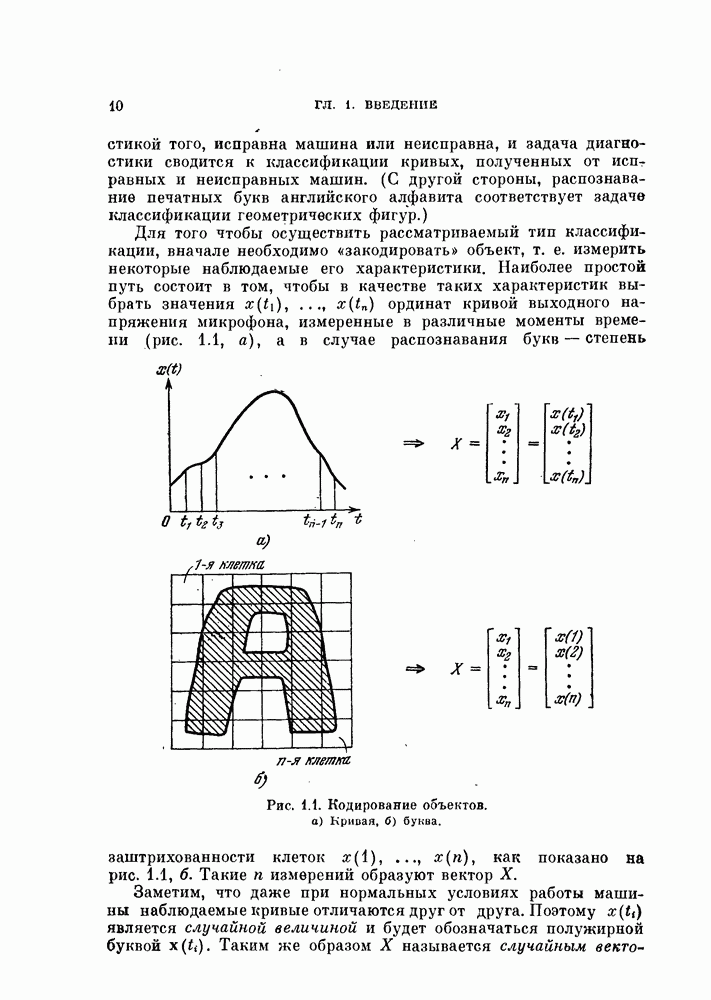
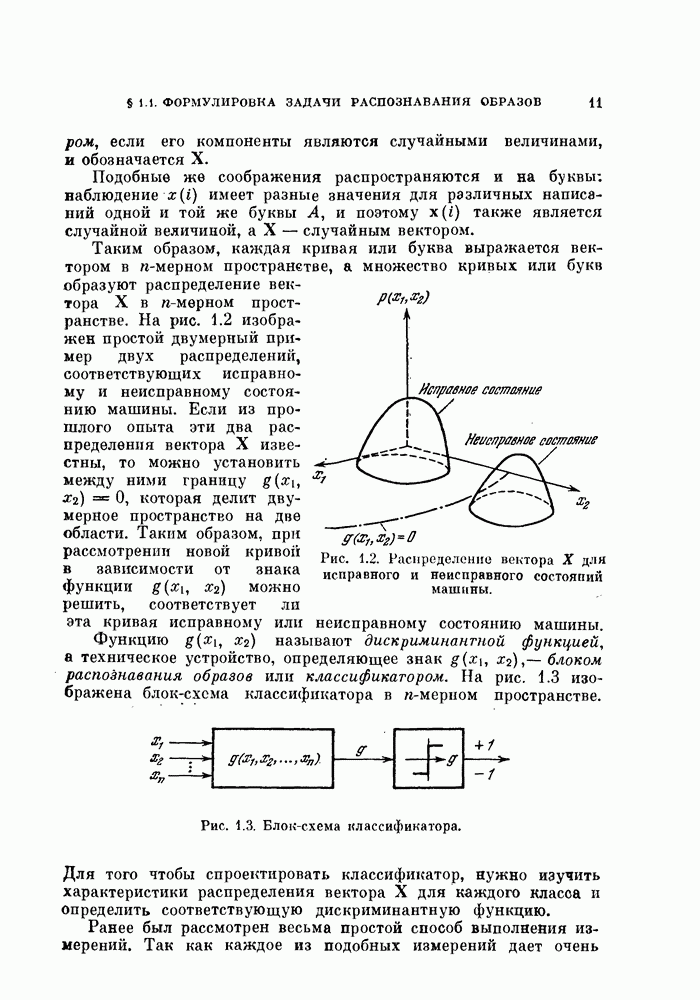





























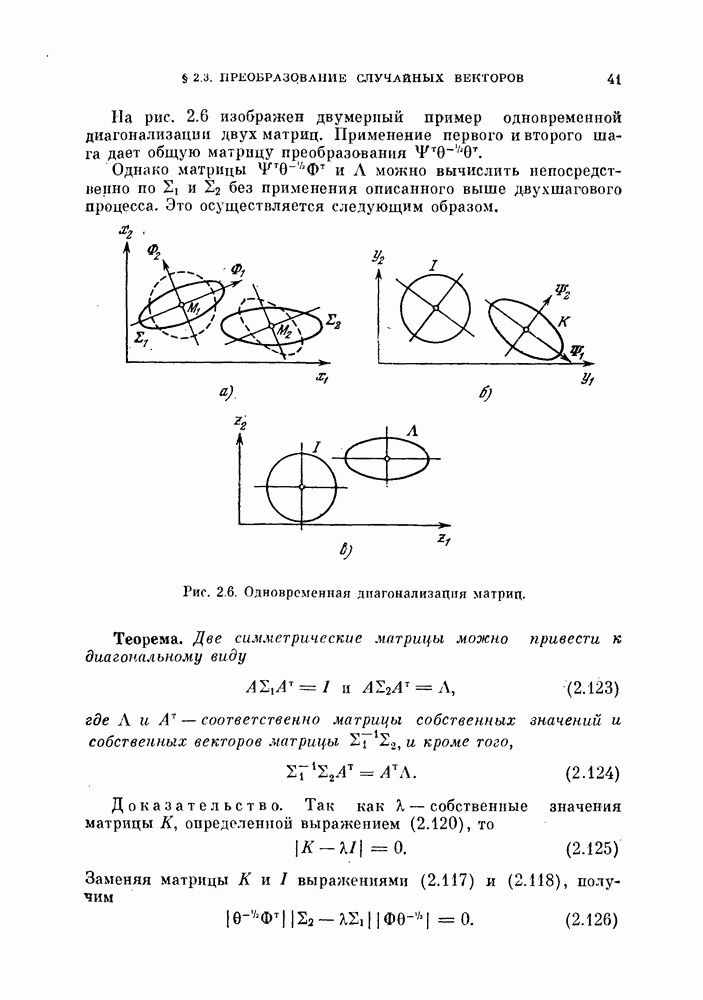









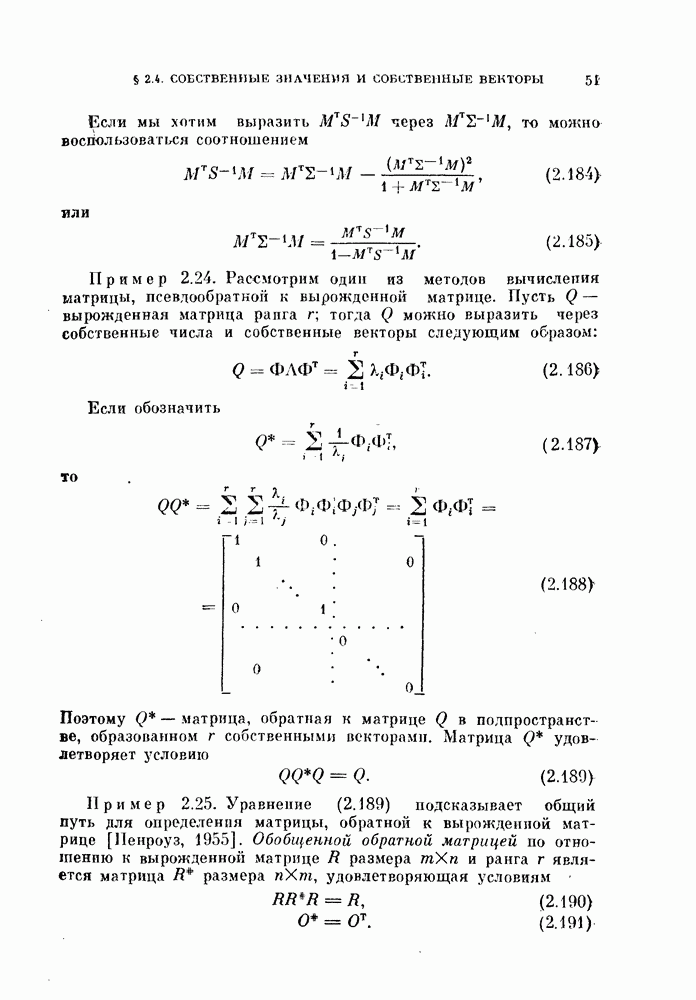














































































































































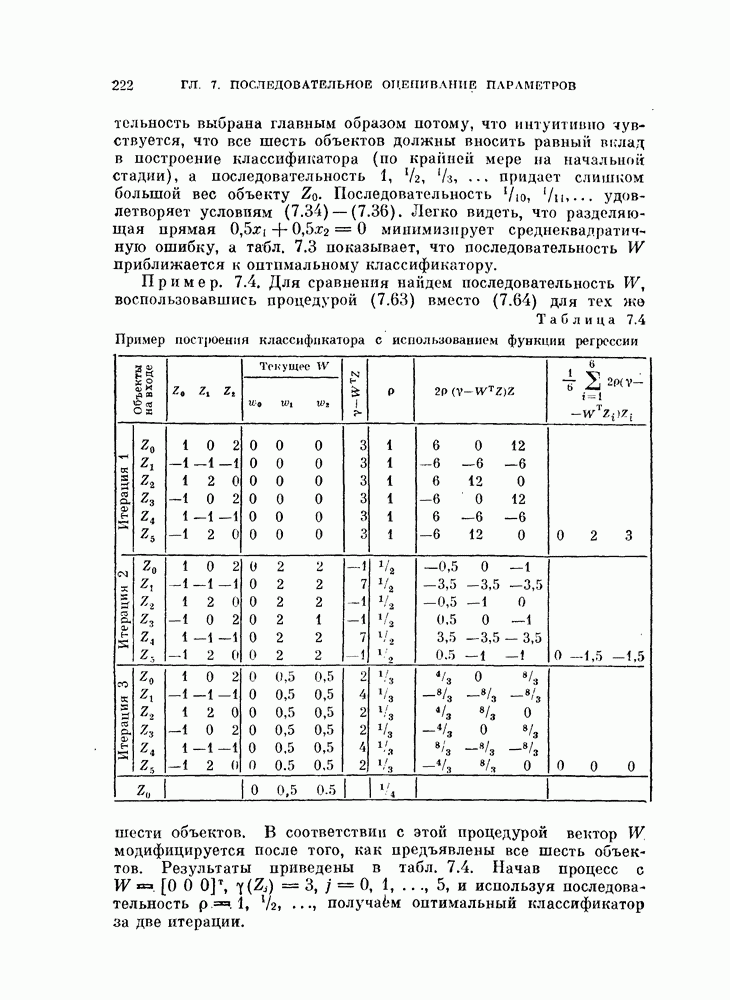


































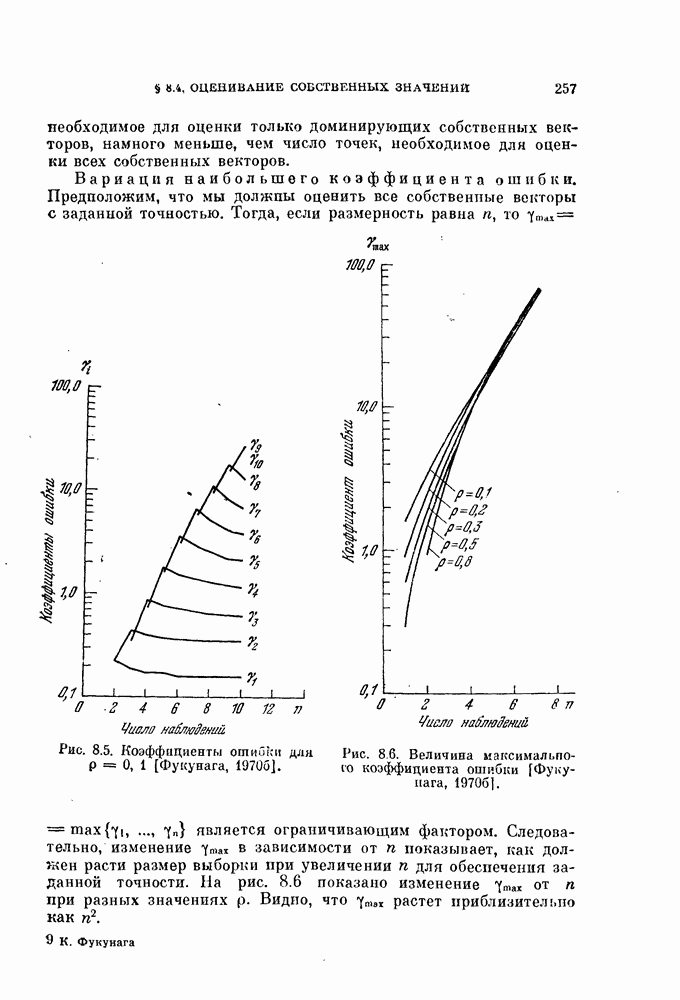




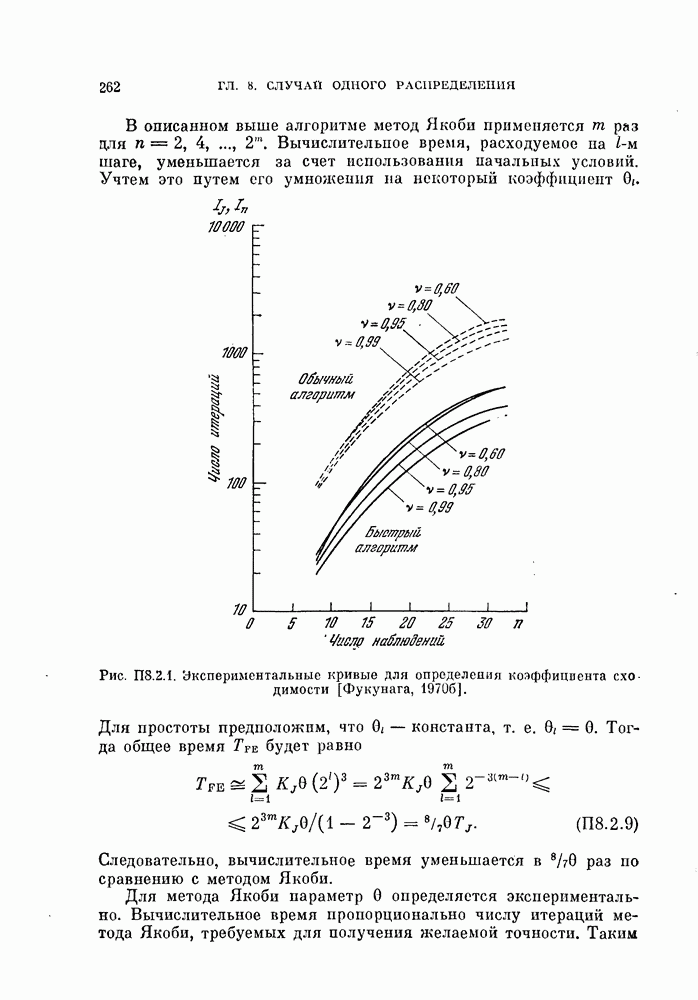





















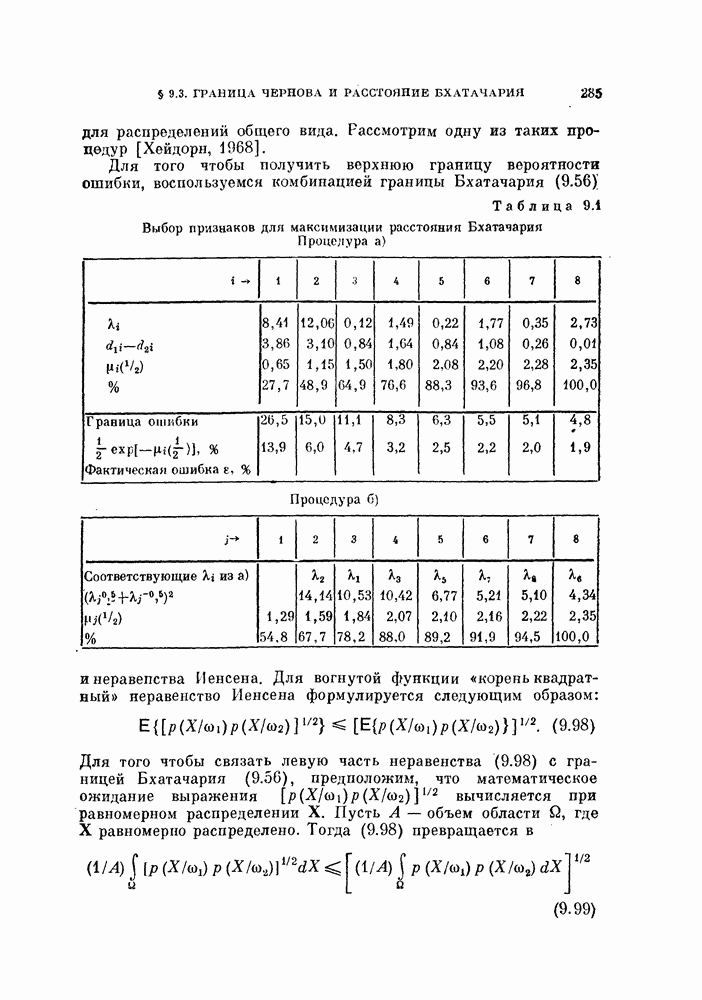
































































 выражение (4.1) приобретает вид линейной функции относительно X:
выражение (4.1) приобретает вид линейной функции относительно X:

 а затем покажем, что выражение (4.2) представляет собой модификацию этого случая.
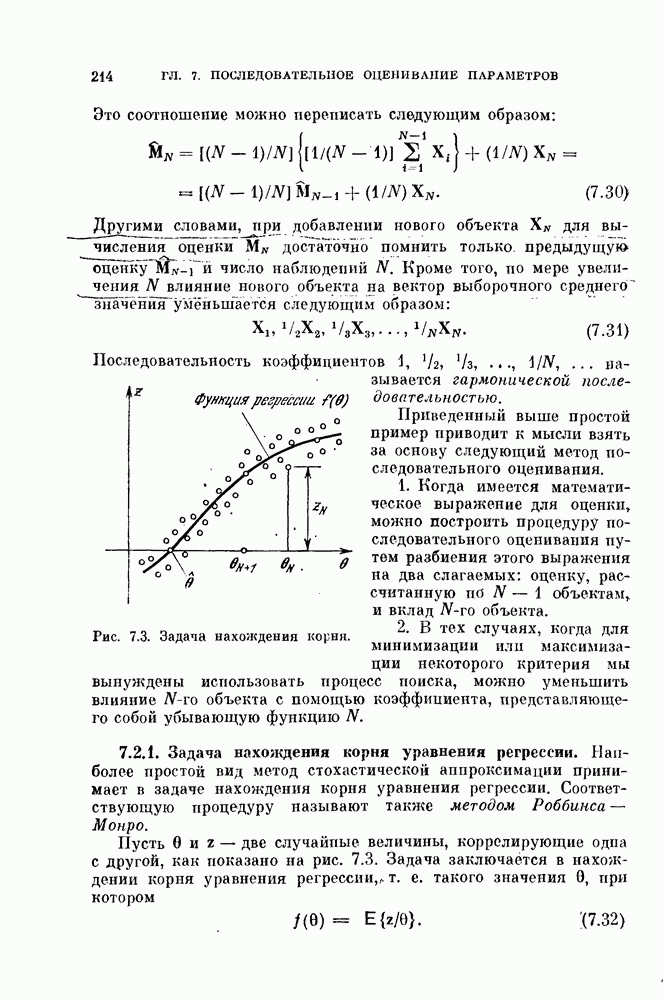
а затем покажем, что выражение (4.2) представляет собой модификацию этого случая.

 называют коэффициентом корреляции между векторами
называют коэффициентом корреляции между векторами  и X. Если вектор X состоит из выборочных значений, полученных дискретизацией по времени замерами непрерывного случайного процесса, то можно записать коэффициент корреляции следующим образом:
и X. Если вектор X состоит из выборочных значений, полученных дискретизацией по времени замерами непрерывного случайного процесса, то можно записать коэффициент корреляции следующим образом:


 и векторов X и
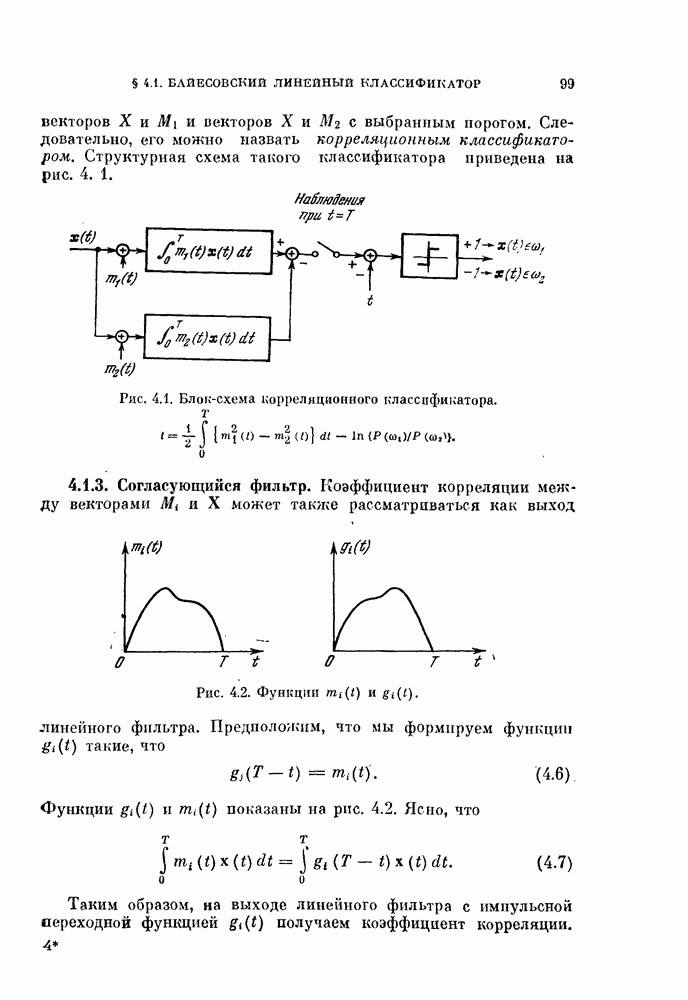
и векторов X и  с выбранным порогом. Следовательно, его можно назвать корреляционным классификатором. Структурная схема такого классификатора приведена на рис. 4. 1.
с выбранным порогом. Следовательно, его можно назвать корреляционным классификатором. Структурная схема такого классификатора приведена на рис. 4. 1.


 и X может также рассматриваться как выход линейного фильтра.
и X может также рассматриваться как выход линейного фильтра.


 такие, что
такие, что

 показаны на рис. 4.2. Ясно, что
показаны на рис. 4.2. Ясно, что

 получаем коэффициент корреляции.
получаем коэффициент корреляции.

 из левой части (4.3), получим решающее правило
из левой части (4.3), получим решающее правило


 с порогом. Если априорные вероятности одинаковы,
с порогом. Если априорные вероятности одинаковы,  то решающая граница перпендикулярна к отрезку прямой, соединяющей векторы
то решающая граница перпендикулярна к отрезку прямой, соединяющей векторы  проходит через его середину, как показано на рис. 4.4.
проходит через его середину, как показано на рис. 4.4.
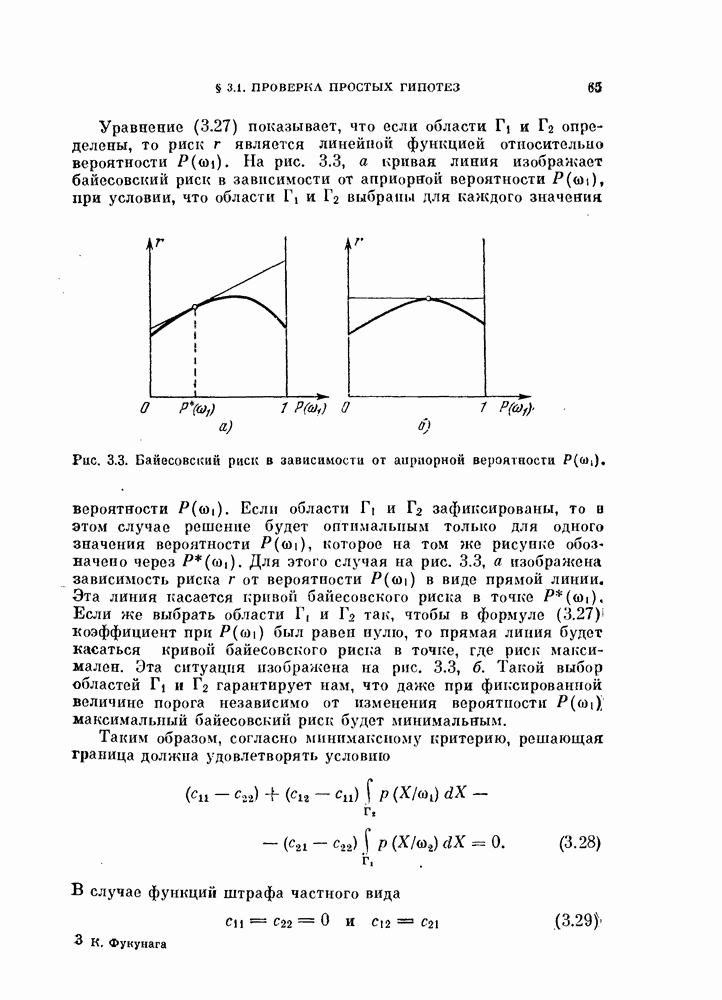
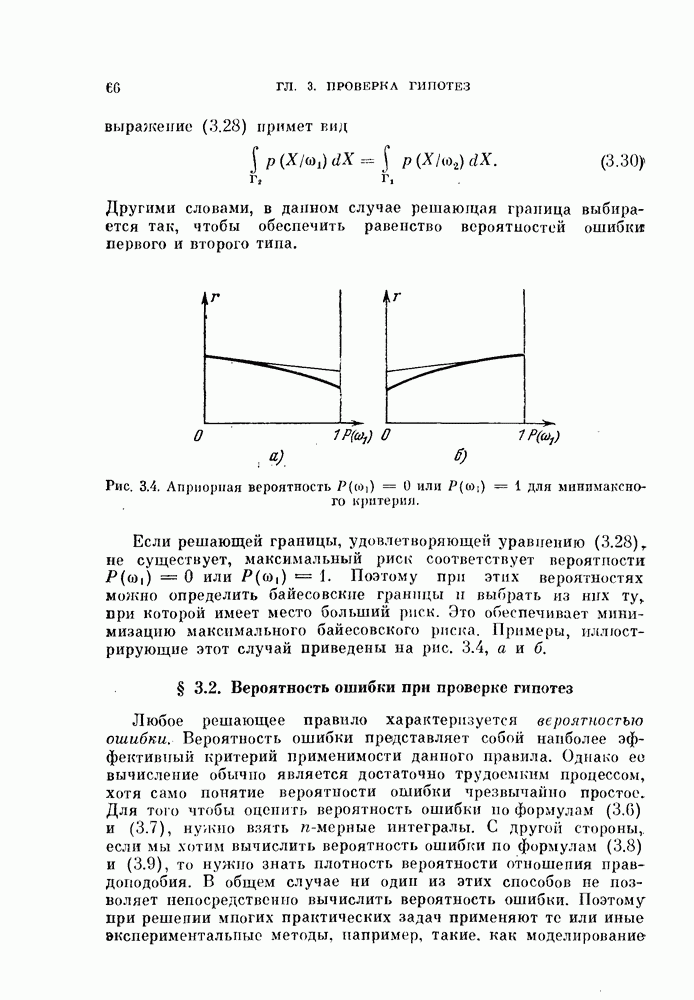
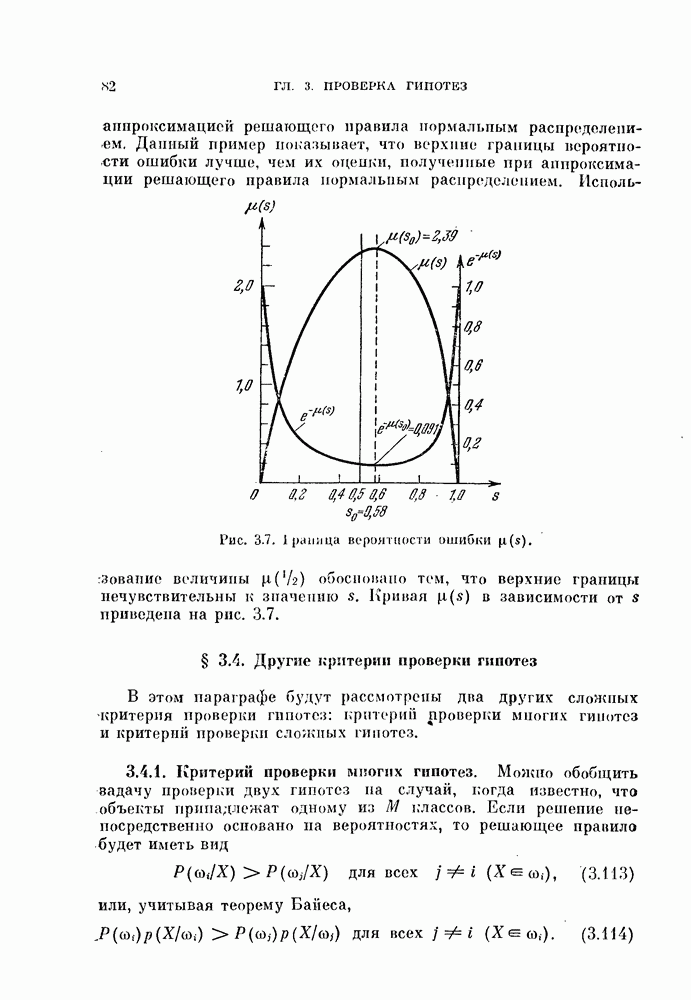
 наблюдаемый шум является коррелированным, и его часто называют «окрашенным». В этом случае байесовский классификатор так легко не интерпретируется. Однако по-прежнему целесообразно в качестве решающего правила рассматривать корреляционный классификатор или классификатор, основанный на вычислении расстояния. Для этого введем декоррелирующее преобразование
наблюдаемый шум является коррелированным, и его часто называют «окрашенным». В этом случае байесовский классификатор так легко не интерпретируется. Однако по-прежнему целесообразно в качестве решающего правила рассматривать корреляционный классификатор или классификатор, основанный на вычислении расстояния. Для этого введем декоррелирующее преобразование  которое переводит коррелированный («окрашенный)))
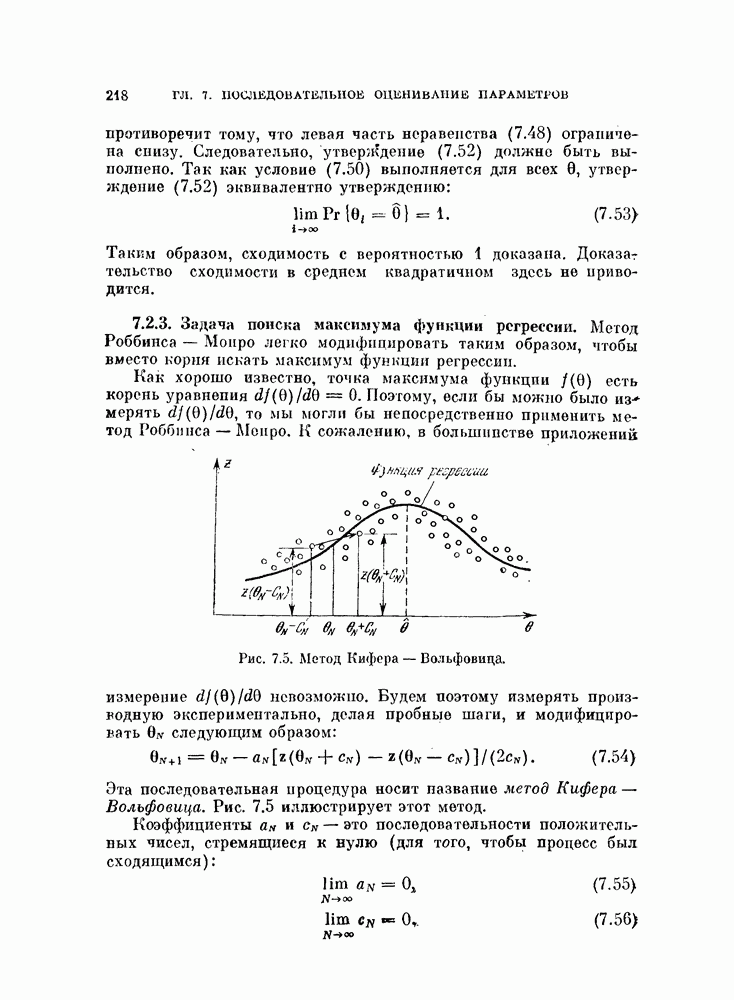
которое переводит коррелированный («окрашенный)))

 можно классифицировать такж эффективно, как и наблюдения вектора X. Вектор математического ожидания
можно классифицировать такж эффективно, как и наблюдения вектора X. Вектор математического ожидания  для класса
для класса  равен
равен

 для обоих классов равна единичной матрице I. Следовательно, все рассуждения предыдущего раздела данного параграфа применимы и для вектора
для обоих классов равна единичной матрице I. Следовательно, все рассуждения предыдущего раздела данного параграфа применимы и для вектора  если заменить вектор
если заменить вектор  . В случае непрерывного времени декоррелирующее преобразование имеет интегральный вид
. В случае непрерывного времени декоррелирующее преобразование имеет интегральный вид


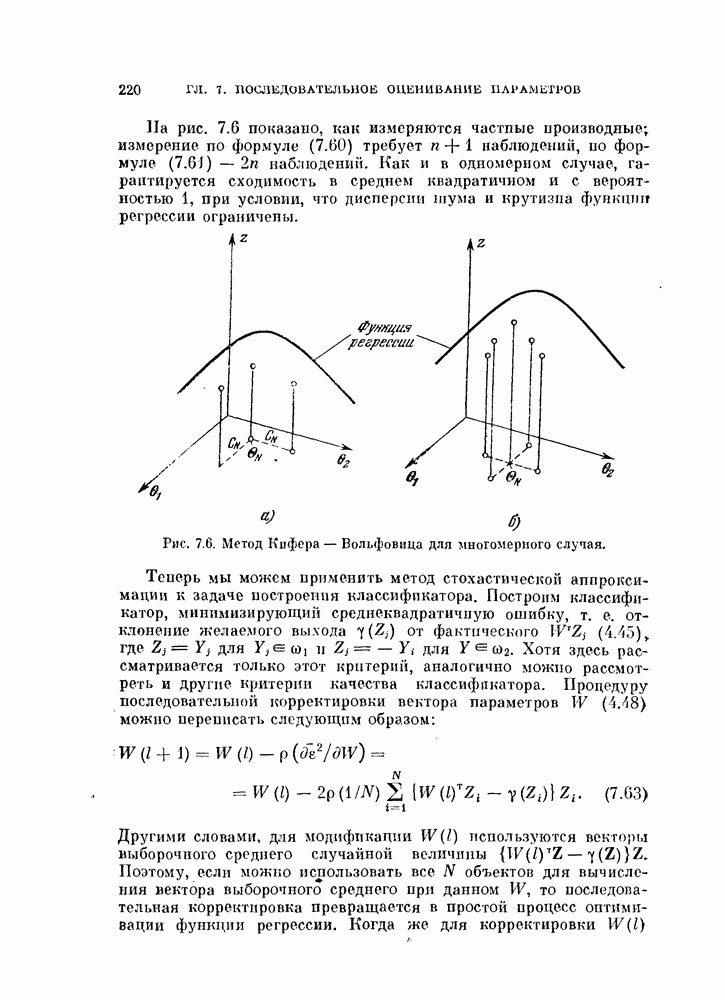
 можно рассматривать как импульсную переходную функцию декоррелирующего фильтра. Возможная структурная схема байесовского классификатора показана на рис. 4.5. Из схемы видно, что это корреляционный классификатор (см. рис. 4.1), модифицированный за счет добавления декоррелирующего фильтра.
можно рассматривать как импульсную переходную функцию декоррелирующего фильтра. Возможная структурная схема байесовского классификатора показана на рис. 4.5. Из схемы видно, что это корреляционный классификатор (см. рис. 4.1), модифицированный за счет добавления декоррелирующего фильтра.
 между собой. В частности, если
между собой. В частности, если  — выборочные значения, полученные дискретизацией по
— выборочные значения, полученные дискретизацией по
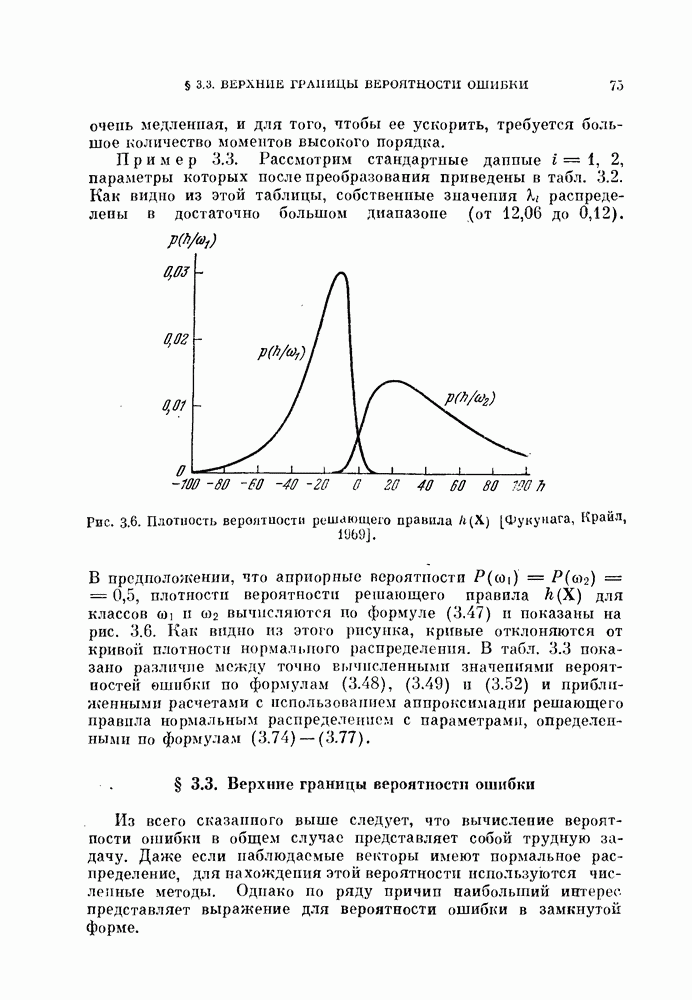
 как правило, сильно коррелированы и подчиняются распределениям подобного вида.
как правило, сильно коррелированы и подчиняются распределениям подобного вида.

