§ 11.2. Параметрические критерии качества классификации
Очень часто критерии качества классификации задают в виде функций от параметров, возникающих в других задачах математической статистики. Вначале мы дадим некоторое обоснование этих критериев, а затем изучим их свойства. Будет показано, что при использовании одного из этих критериев алгоритм предыдущего параграфа принимает особенно простой вид. Мы рассмотрим также идею инвариантного преобразования и некоторые результаты, которые можно из нее получить.
11.2.1. Матрицы рассеяния и разделимость классов в задаче автоматической классификации.
Задачу автоматической классификации можно рассматривать как задачу поиска такой группировки объектов, при которой максимизируется разделимость классои. Тогда все критерии, рассмотренные в гл. 9, можно использовать в качестве критериев качества классификации.
В этом параграфе мы ограничимся рассмотрением только функций матриц рассеяния. Такое ограничение обусловлено следующими причинами: 1) критерии этого типа, непосредственно обобщаются на случай многих классов; 2) они имеют более простой вид, чем расстояние Бхатачария или дивергенция. Простота в данном случае необходима, так как в задачах автоматической классификации возникают дополнительные сложности, связанные с отнесением объектов к заранее не известным классам.
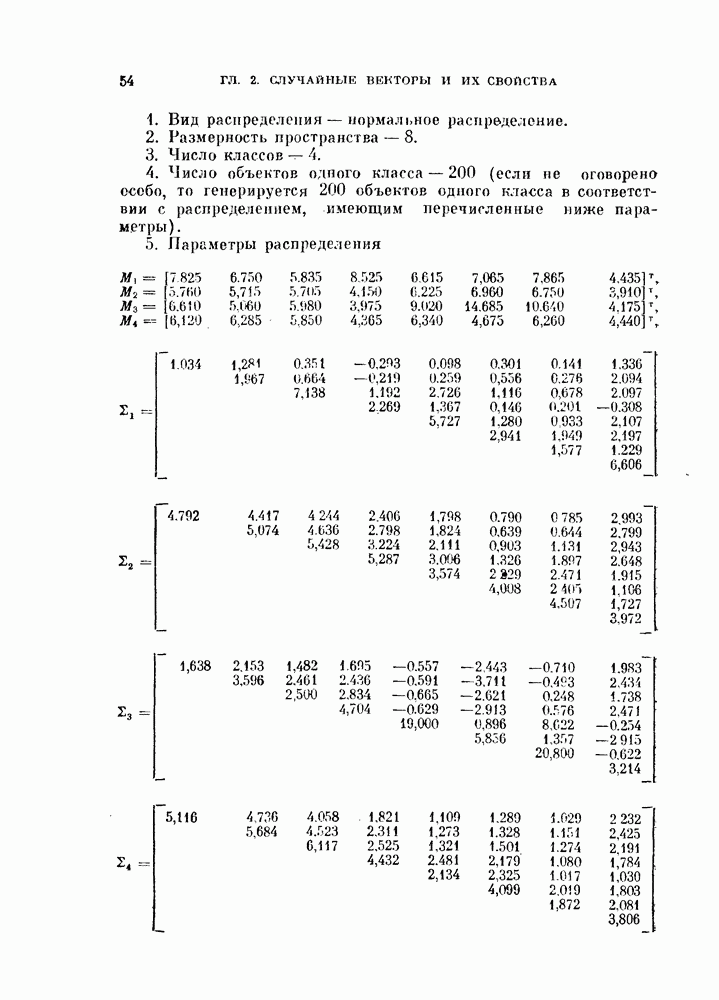
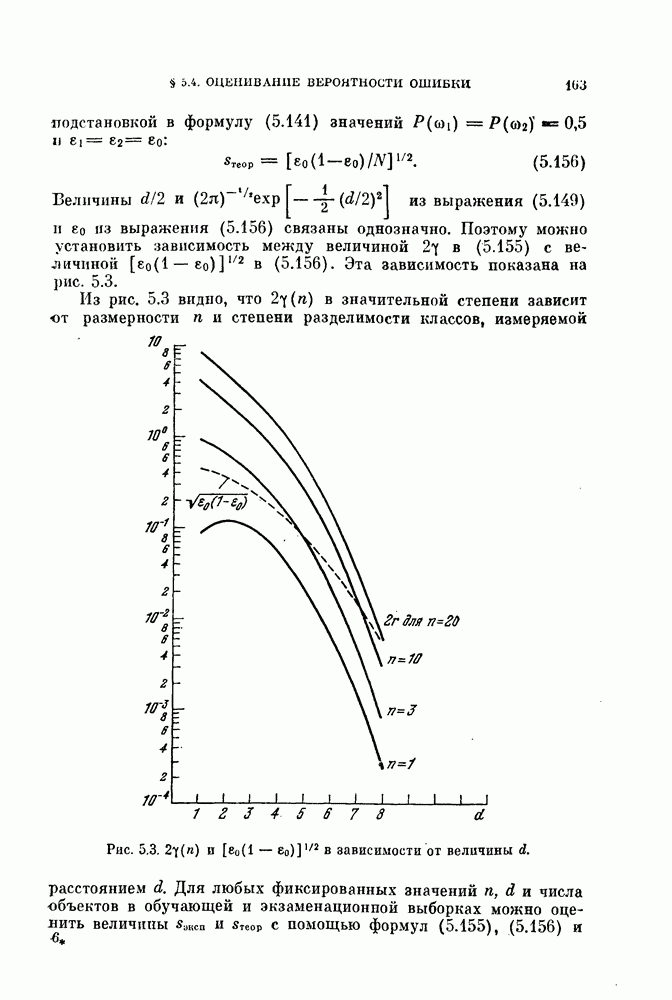
Выберем в качестве матриц рассеяния матрицы  и определенные выражениями (9.7), (9.8) и (9.12). Обобщение на случай многих классов производится следующим образом:
и определенные выражениями (9.7), (9.8) и (9.12). Обобщение на случай многих классов производится следующим образом:


Здесь  — соответственно матрицы рассеяния внутри классов, между классами и совместная матрица рассеяния.
— соответственно матрицы рассеяния внутри классов, между классами и совместная матрица рассеяния.
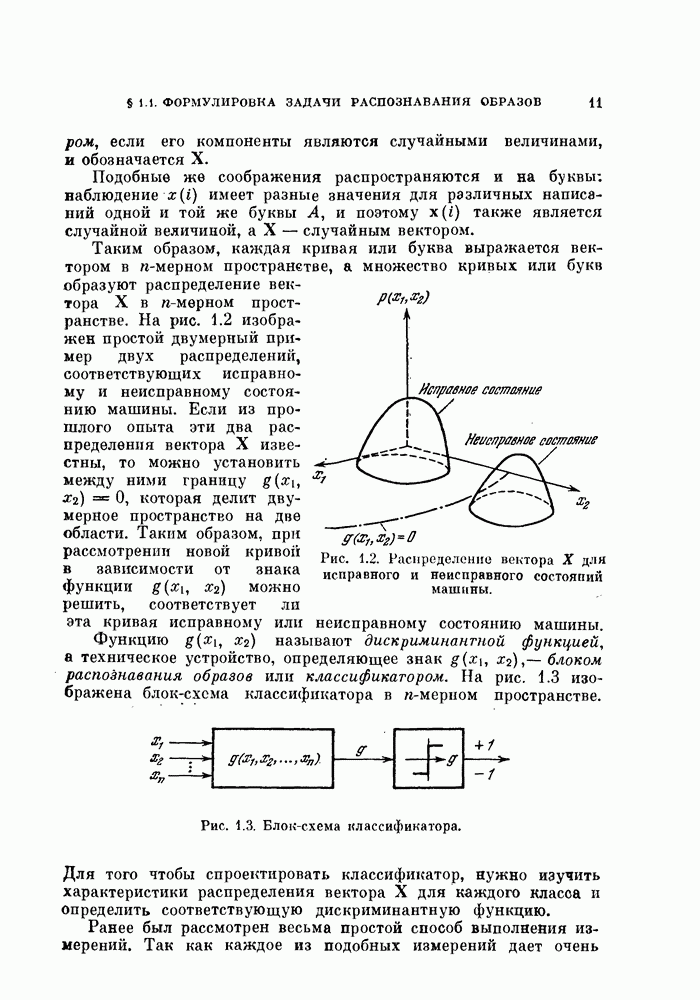
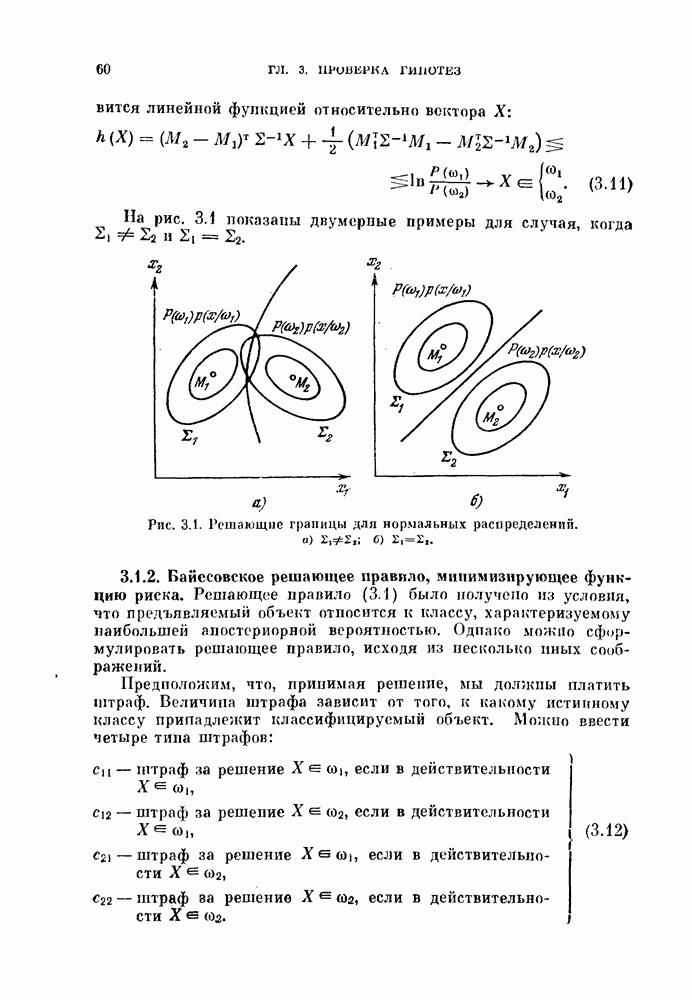
Когда качество классификации оценивается разделимостью построенных классов, то процедура автоматической классификации должна обладать свойством инвариантности по отношению к линейному преобразованию системы координат, т. е. давать одну и ту же классификацию данного множества объектов независимо от системы координат, в которой производится измерение.
Как было указано в гл. 9, критерии (9.13) и (9.14) не зависят от системы координат. Выбирая  в соответствии с (9.13) и (9.14), имеем следующие критерии качества классификации:
в соответствии с (9.13) и (9.14), имеем следующие критерии качества классификации:

Более простые выражения получаются, если использовать совместную нормировку (4.53):

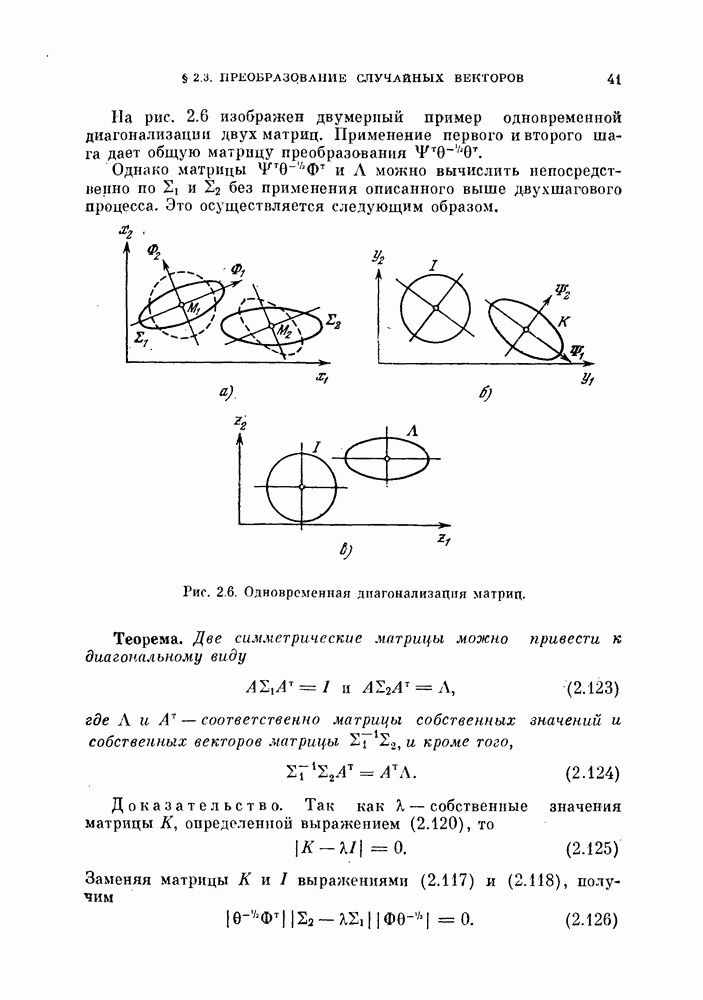
где А — невырожденное линейное преобразование. Соответственно преобразуются переменные, матрицы рассеяиия и векторы математических ожиданий. В преобразованной системе координат они имеют вид

и удовлетворяют условиям

Следует отметить, что результат совместной нормировки не зависит от распределения объектов по классам. Критерии (11.15)-(11.17) можно переписать в виде функций от матриц  и собственных значений
и собственных значений  матрицы
матрицы  (которые
(которые
совпадают с собственными значениями матрицы 

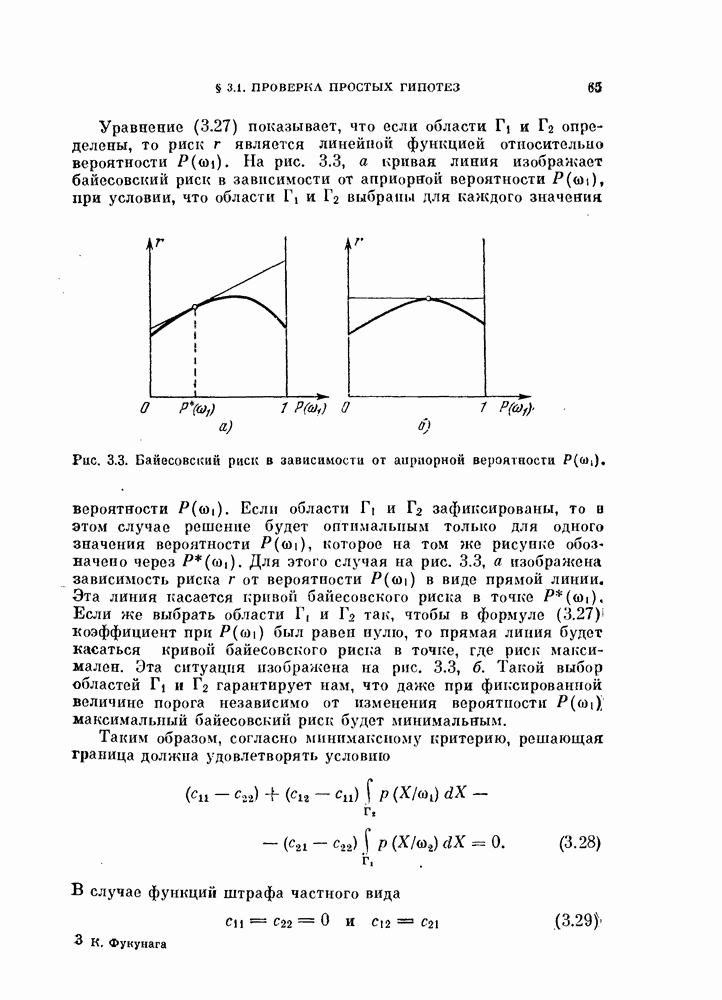
Приведенные выше критерии приводят к более или менее одинаковым классификациям, а в случае двух классов все они сводятся к одному критерию. Для двух классов ранг матрицы  равен 1, потому что
равен 1, потому что

где вторая строчка получается из (11.24). Поэтому

Таким образом,

Все эти выражения оптимизируются при максимизации Следовательно, в задаче с двумя классами эти три критерия дают в точности один и тот же результат.
Хотя все три критерия можно оптимизировать описанным в предыдущем параграфе алгоритмом, использование критерия  позволяет построить особенно простой алгоритм автоматической классификации. Предположим, что на I-й итерации число векторов, отнесенных к каждому классу, достаточно велико, так что при переброске одного вектора из класса в класс средние векторы изменяются незначительно. Тогда формула для приращения
позволяет построить особенно простой алгоритм автоматической классификации. Предположим, что на I-й итерации число векторов, отнесенных к каждому классу, достаточно велико, так что при переброске одного вектора из класса в класс средние векторы изменяются незначительно. Тогда формула для приращения  (см. параграф 11.1) принимает особенно простой вид:
(см. параграф 11.1) принимает особенно простой вид:

Так как второй член (11.34) не зависит от  решающее правило на
решающее правило на  итерации имеет вид
итерации имеет вид

а алгоритм может быть описан следующим образом.






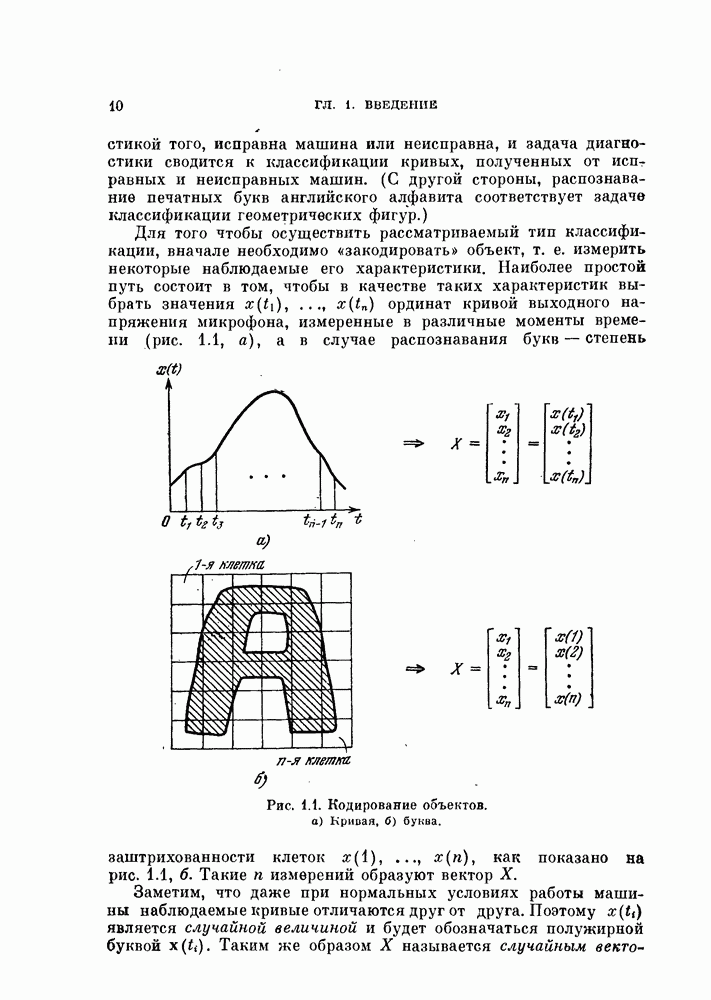
















































































































































































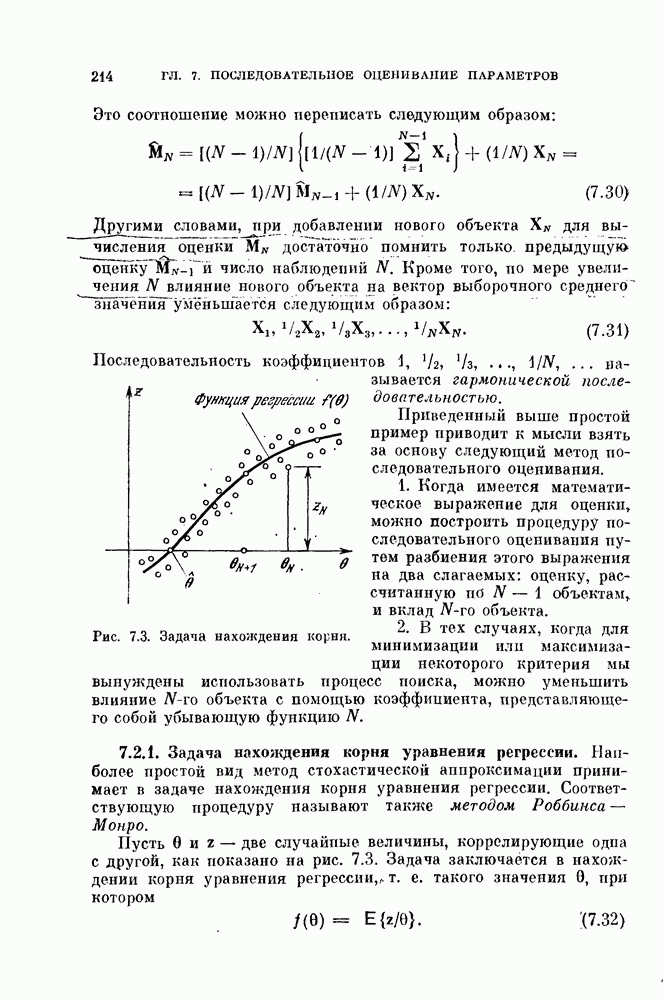



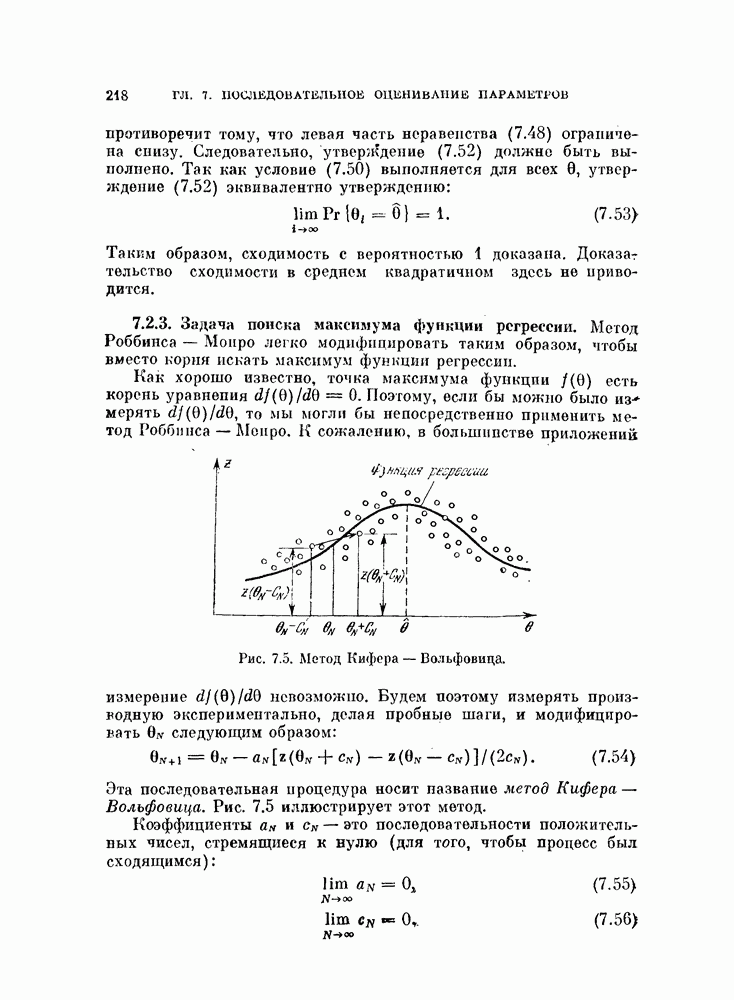

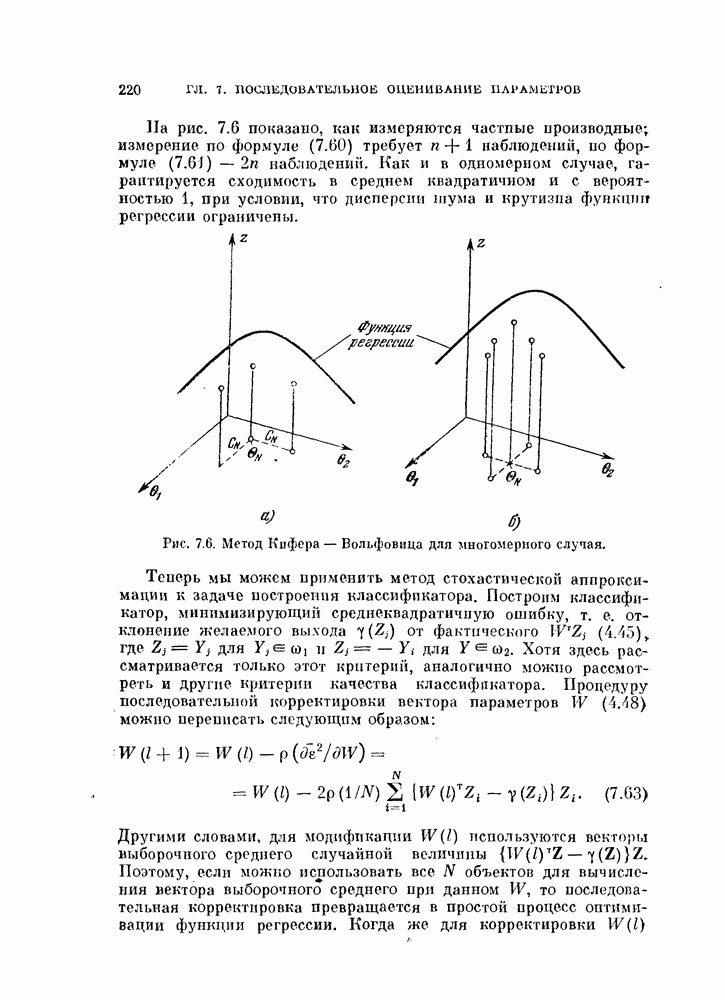
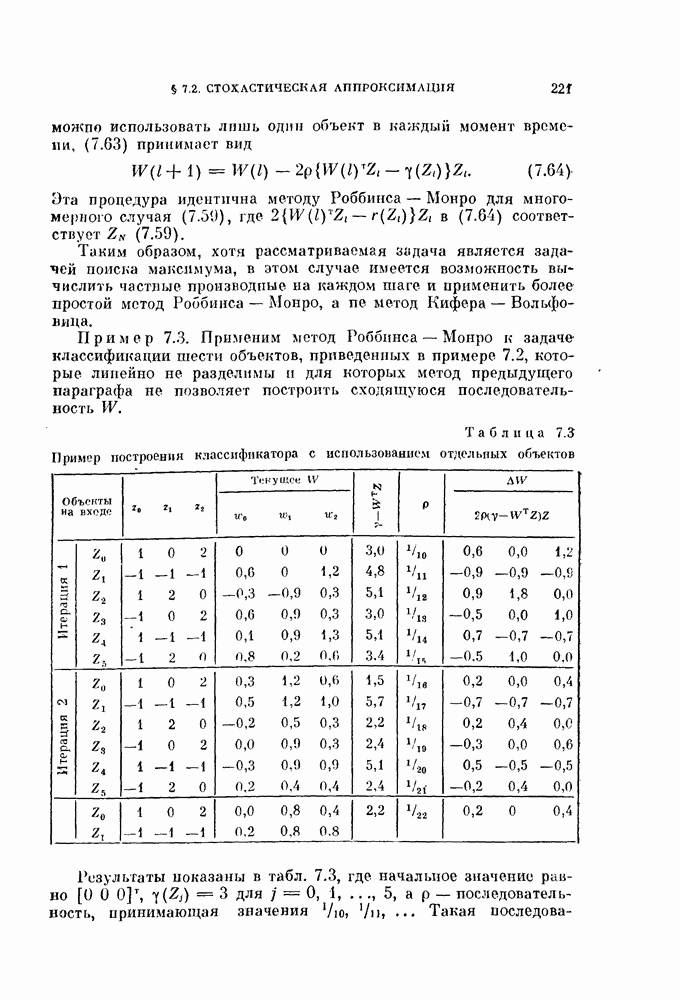


























































































































 и вычислить
и вычислить 
 переклассифицировать каждый объект
переклассифицировать каждый объект  отнеся его к классу с ближайшим
отнеся его к классу с ближайшим 
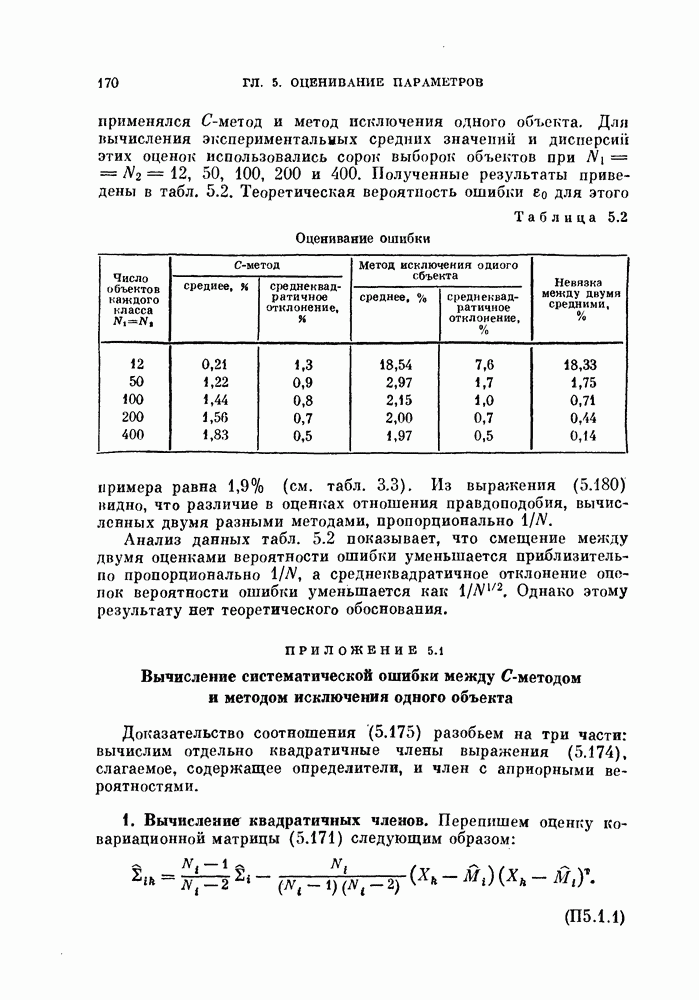
 изменяется, вычислить новые выборочные средние
изменяется, вычислить новые выборочные средние  для нового задания класса и вернуться к шагу 2; в противном случае — закончить вычисления.
для нового задания класса и вернуться к шагу 2; в противном случае — закончить вычисления.
 хотя эта последняя работает в исходной системе
хотя эта последняя работает в исходной системе  ординат. Свойства сходимости этой процедуры при
ординат. Свойства сходимости этой процедуры при  больших
больших  исследовались в [Маккуин, 1967].
исследовались в [Маккуин, 1967].
