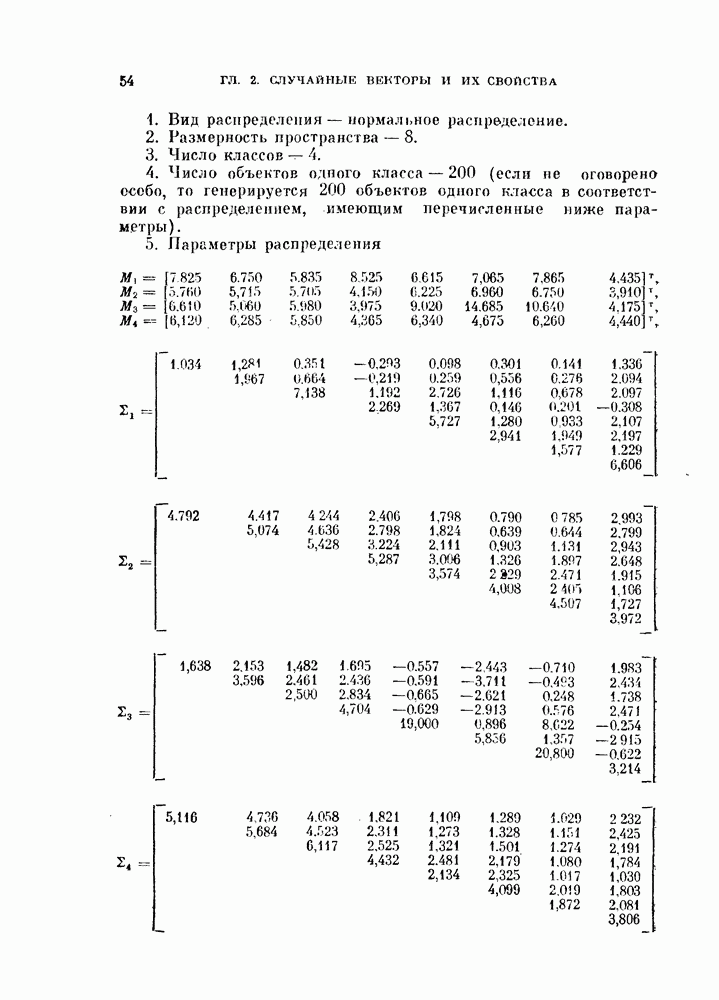
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
5.4.3. Метод разбиения выборки.Для того чтобы разбить имеющиеся объекты на обучающую и экзаменационную выборки Вначале предположим, что имеется бесконечное число объектов для синтеза классификатора и
где С другой стороны, если имеется
где Дисперсию оценки
где
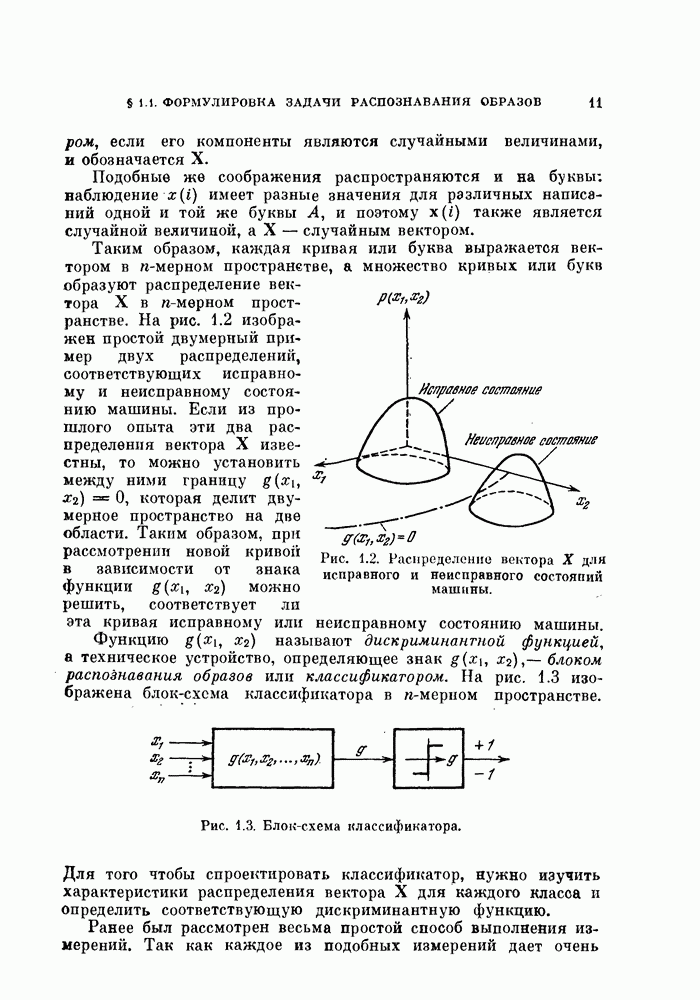
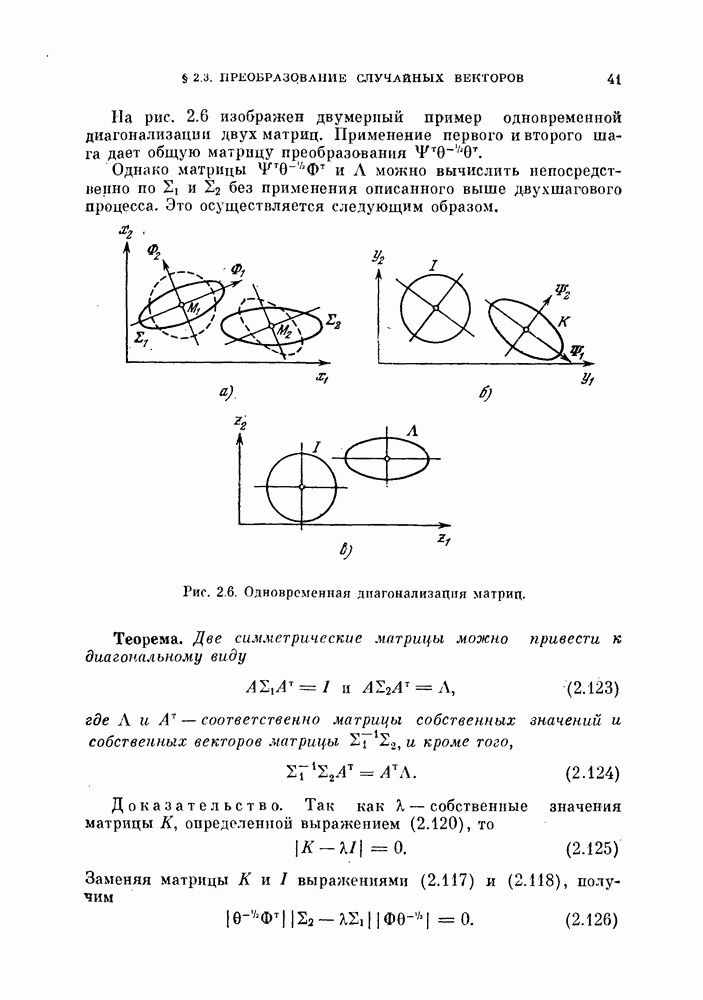
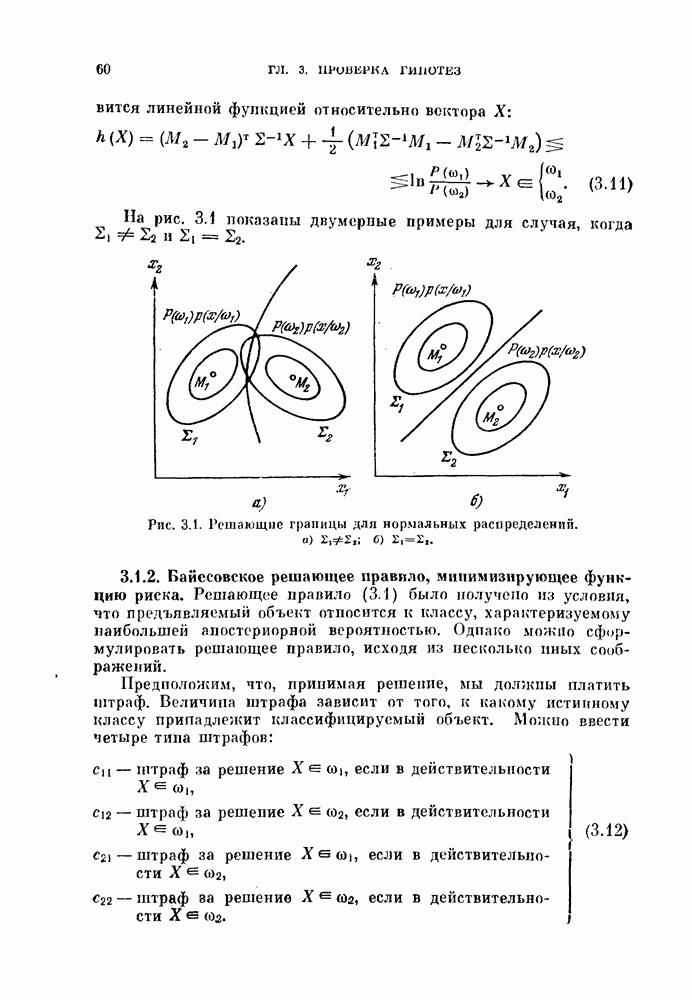
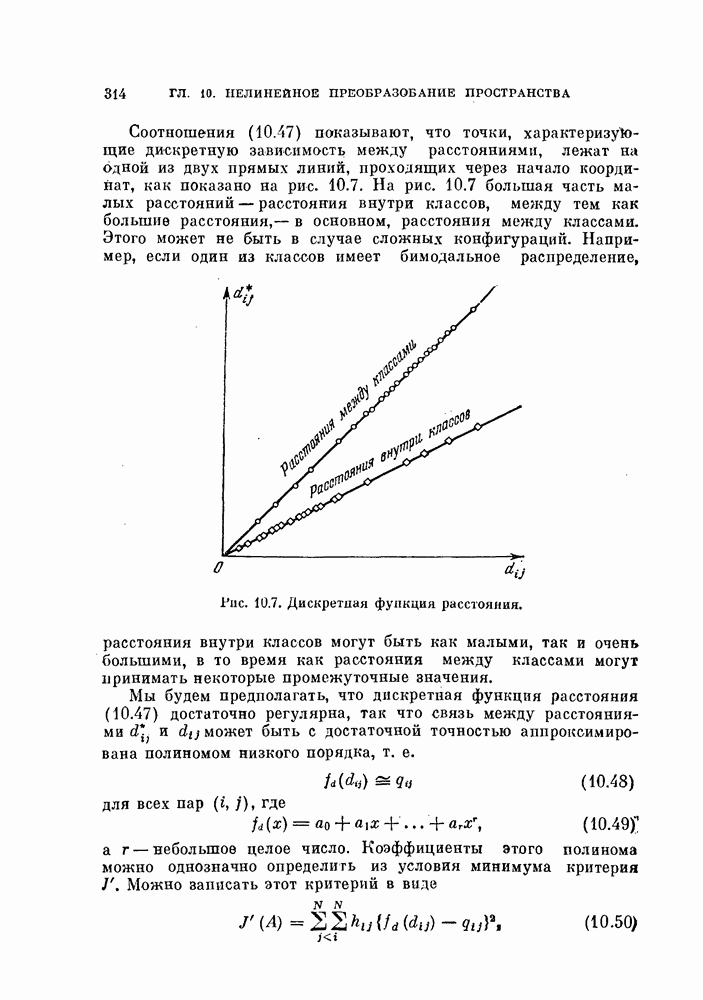
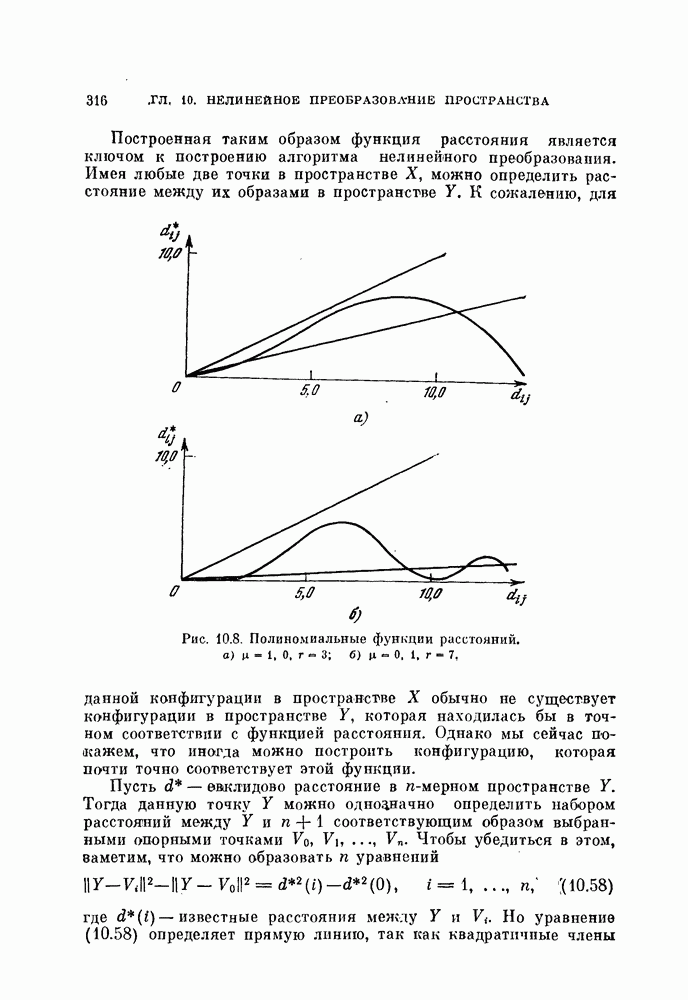
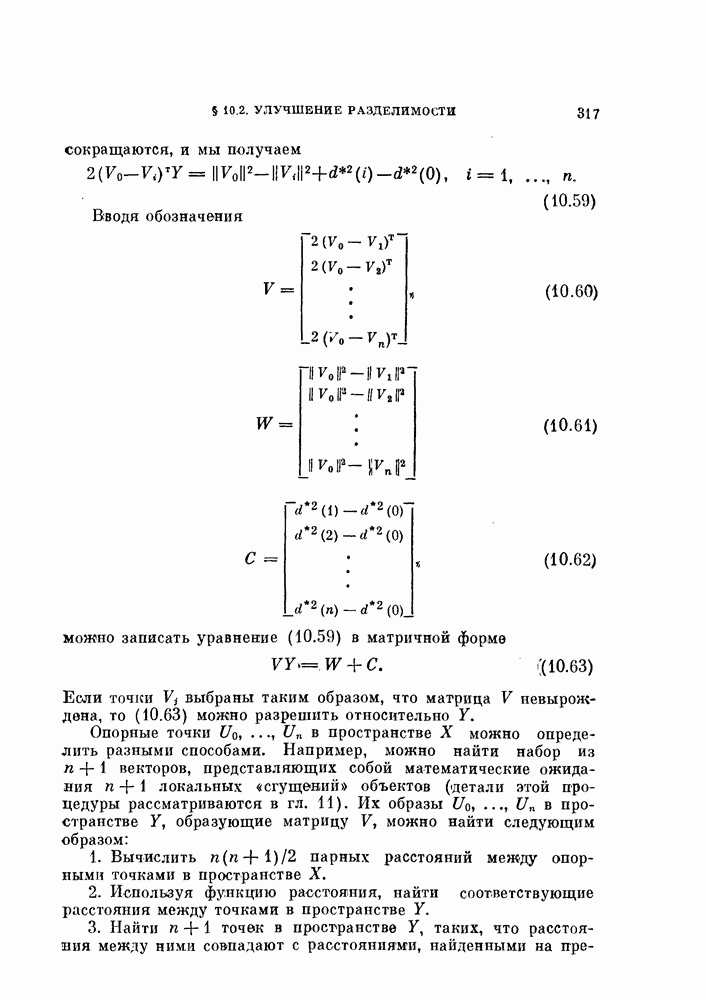
Это преобразование основано на том, что для нормальных распределений с равными ковариационными матрицами байесовский классификатор — линейный, а распределение отношения правдоподобия также является нормальным распределением. Подобные выражения встречались в формулах (3.35) — (3.38). Заметим, что даже если две истинные ковариационные матрицы равны, то оценки их различны. Однако для упрощения предположим, что обе эти оценки равиы и имеют вид
где Математическое ожидание оценки наипростейший случай, когда
где
Величина
Математическое ожидание и дисперсия плотности (5.151) равны:
Исключая с, получим верхнюю границу дисперсии
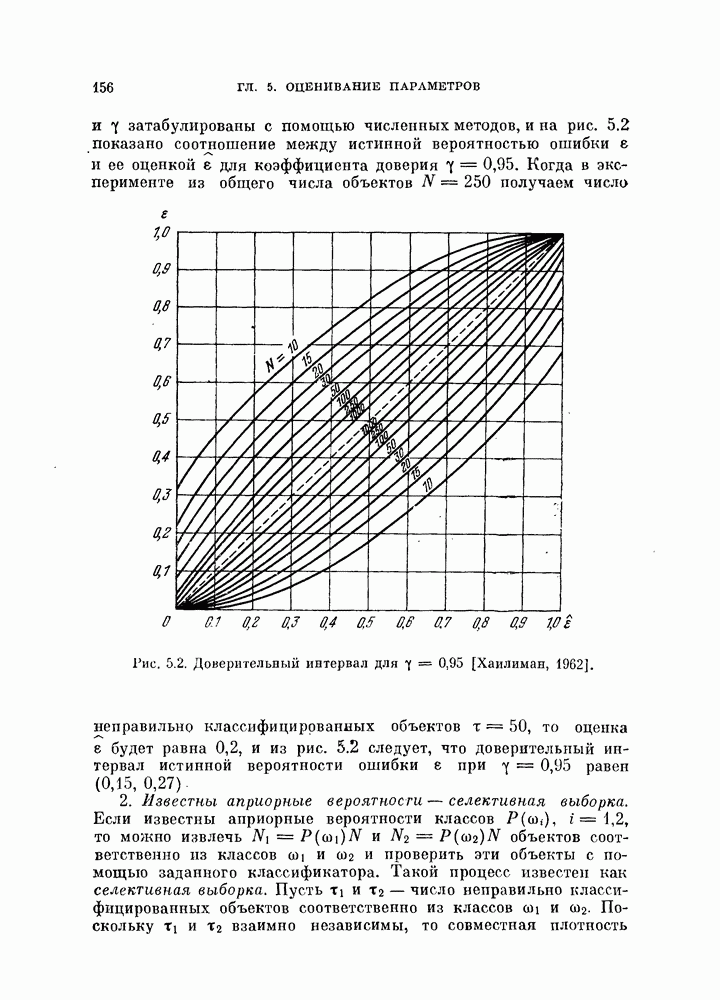
Таким образом, степень влияния числа обучающих объектов на оценку вероятности ошибки
Величину подстановкой в формулу (5.141) значений
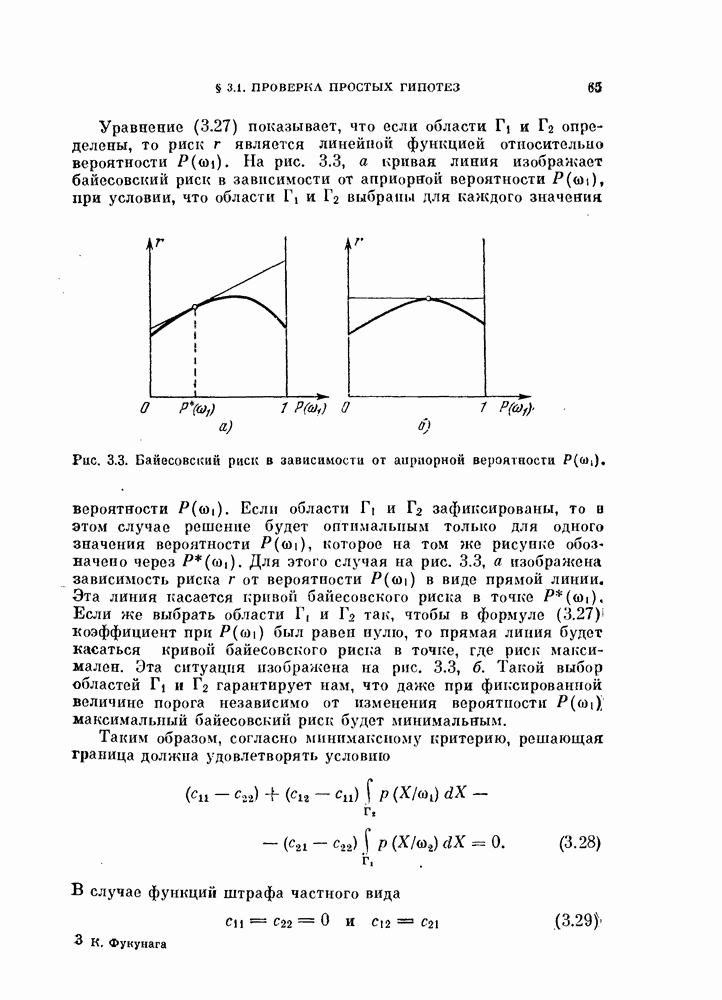
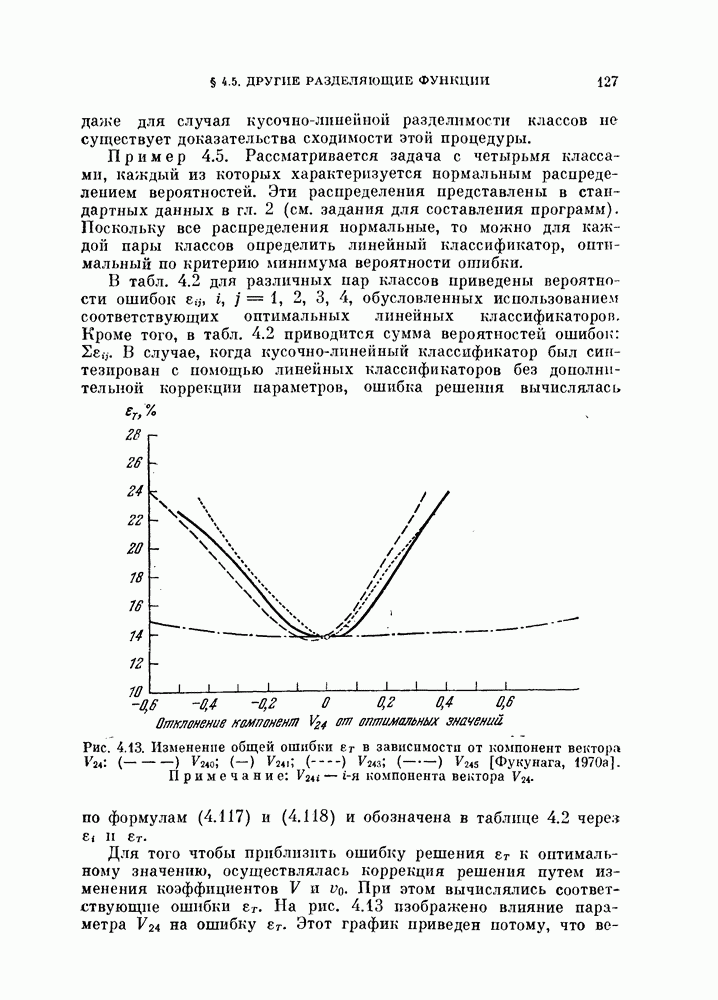
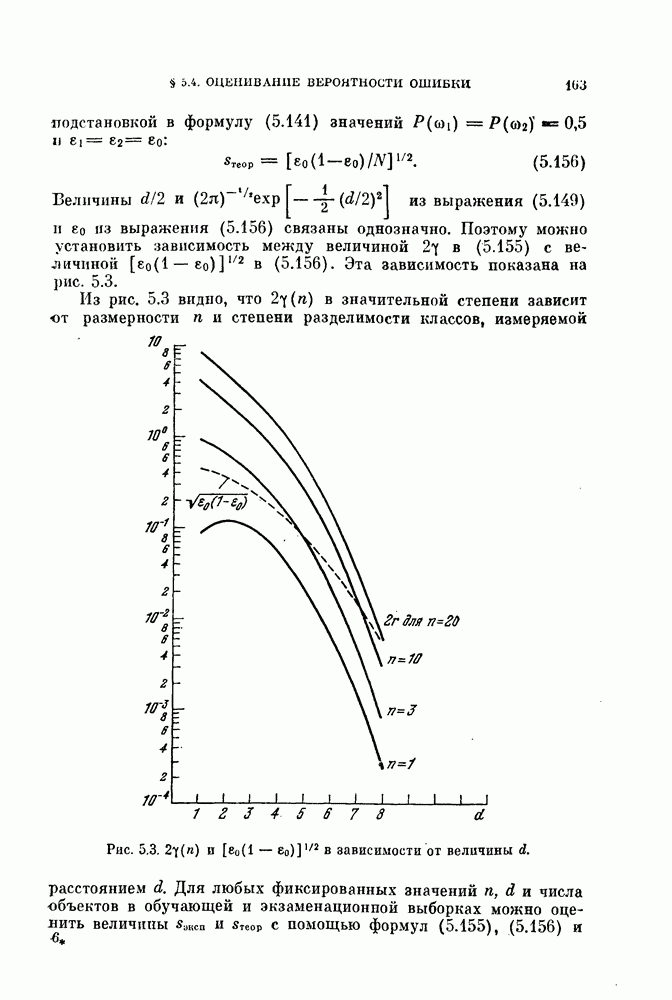
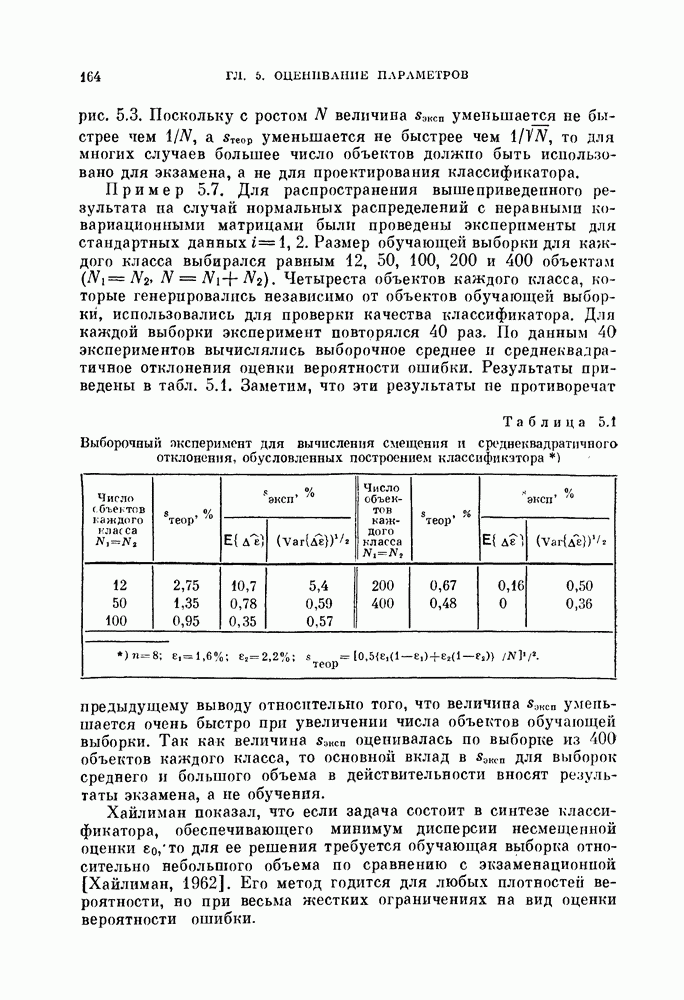
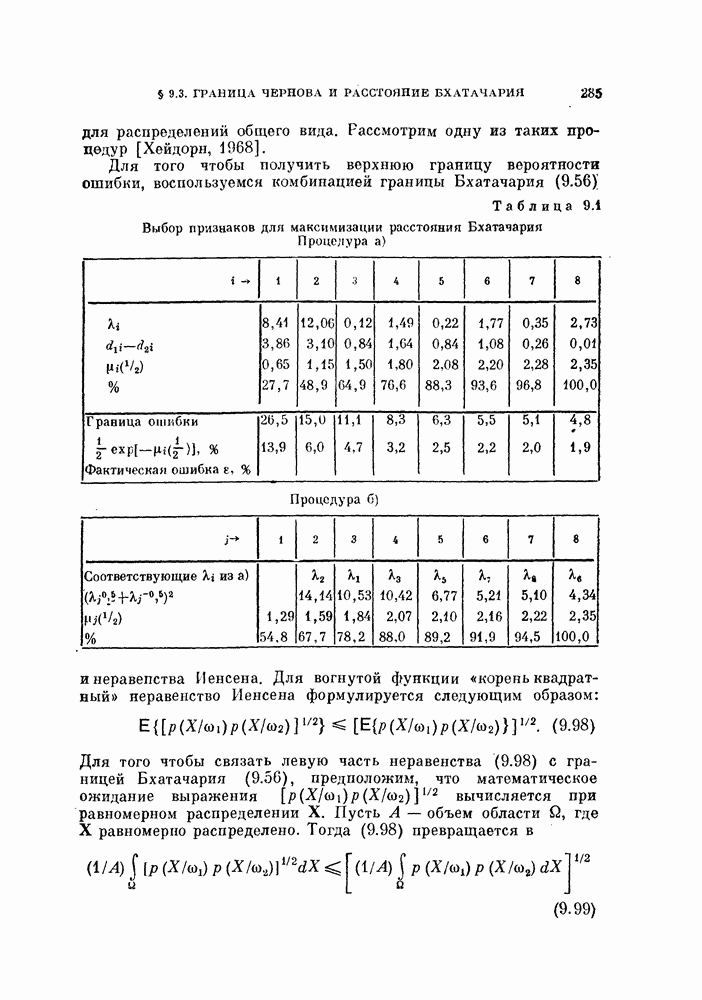
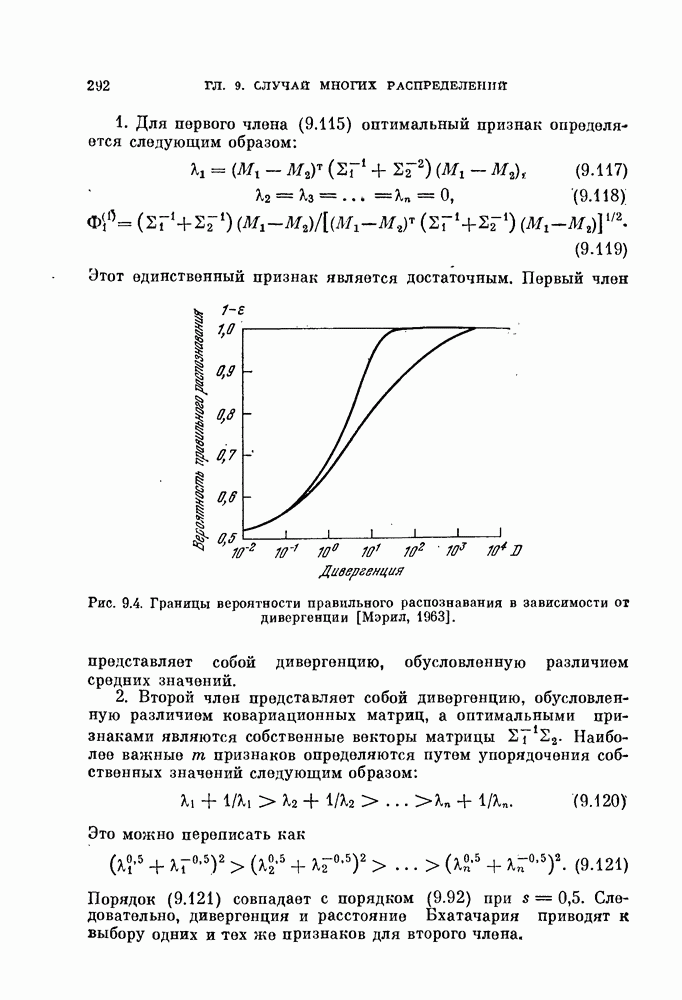
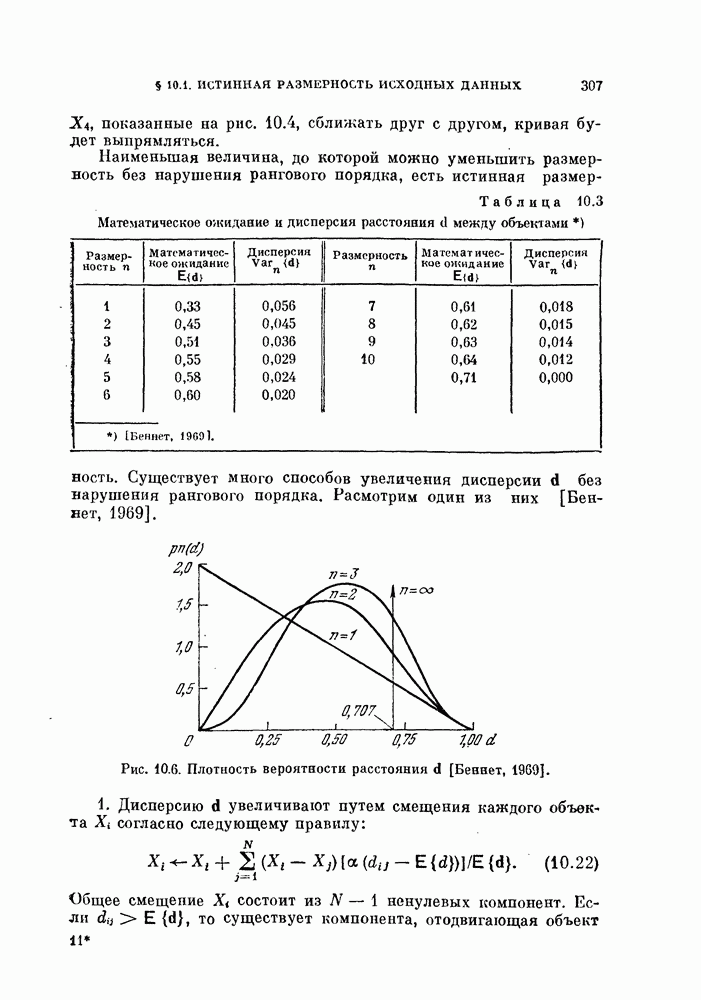
Величины Из рис. 5.3 видно, что Рис. 5.3. (см. скан) Для любых фиксированных значений рис. 5.3, Поскольку с ростом Пример 5.7. Для распространения вышеприведенного результата на случай нормальных распределений с неравными ковариационными матрицами были проведены эксперименты для стандартных данных Таблица 5.1. Выборочный эксперимент для вычисления смещения и среднеквадратичного отклонения, обусловленных построением классификатора
предыдущему выводу относительно того, что величина Хайлиман показал, что если задача состоит в синтезе классификатора, обеспечивающего минимум дисперсии несмещенной оценки Исключение задания класса для объектов экзаменационной выборки. Для того чтобы оценить вероятность ошибки как при обучении, так и на экзамене, требуются выборки объектов, в которых известно, какой объект к какому конкретному классу принадлежит. Однако в некоторых случаях получение такой информации связано с большими затратами. Рассмотрим метод оценки вероятности ошибки, не требующий информации о принадлежности объектов экзаменационной выборки к конкретному классу [Чоу, 1970]. Применение этого метода наиболее эффективно в случае, когда при оптимальном разбиении выборки на обучающую и экзаменационную, число объектов в экзаменационной выборке больше, чем в обучающей. Введем критическую область для задач классификации М классов:
где При таком решающем правиле вероятность ошибки
и
Предположим, что область отклонения увеличивается на
Интегрируя (5.161) в пределах области
где
Суммируя по всем дискретным значениям
Полагая
Уравнение (5.165) показывает, что вероятность ошибки
Рис. 5.4. Приращение областей отклонения. Воспользуемся выражением (5.165) для исключения задания класса объектов экзаменационной выборки. Для этого поступим следующим образом. 1. Для определения 2. Подсчитаем число неклассифицированных объектов экзаменационной выборки, которые попали в область 3. Тогда из выражения (5.165) следует, что оценка вероятности ошибки
В описанной процедуре использовалось то, что коэффициент отклонения является функцией от плотности вероятности смеси, а не от плотностей вероятности отдельных классов. Поэтому после того, как по классифицированным объектам найдены расширенные области отклонения, в дальнейшем для оценивания
|
 |
Оглавление
|































































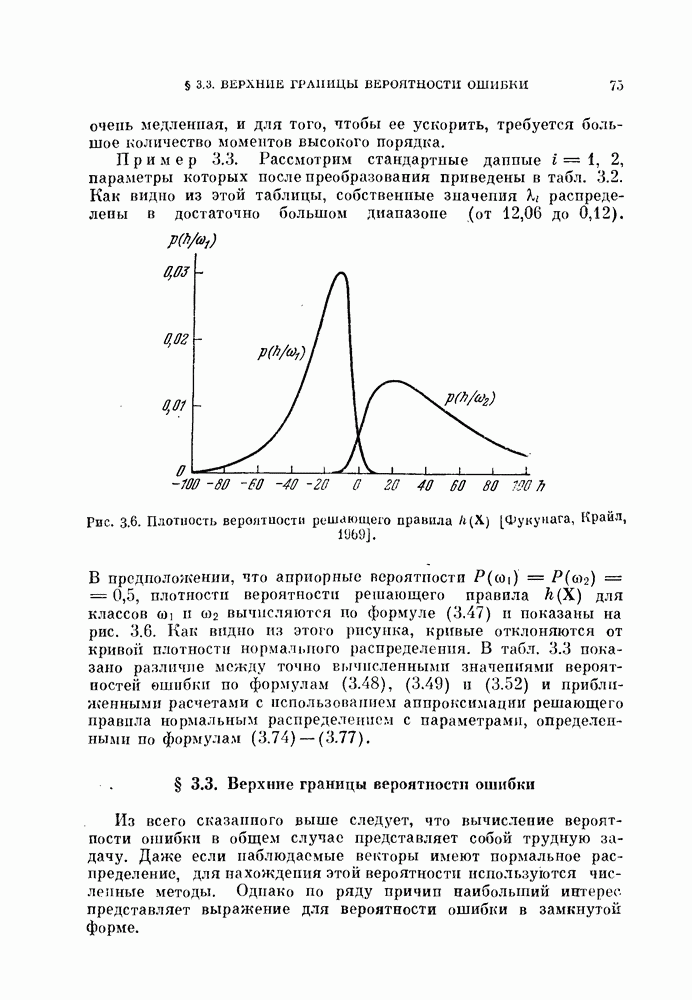






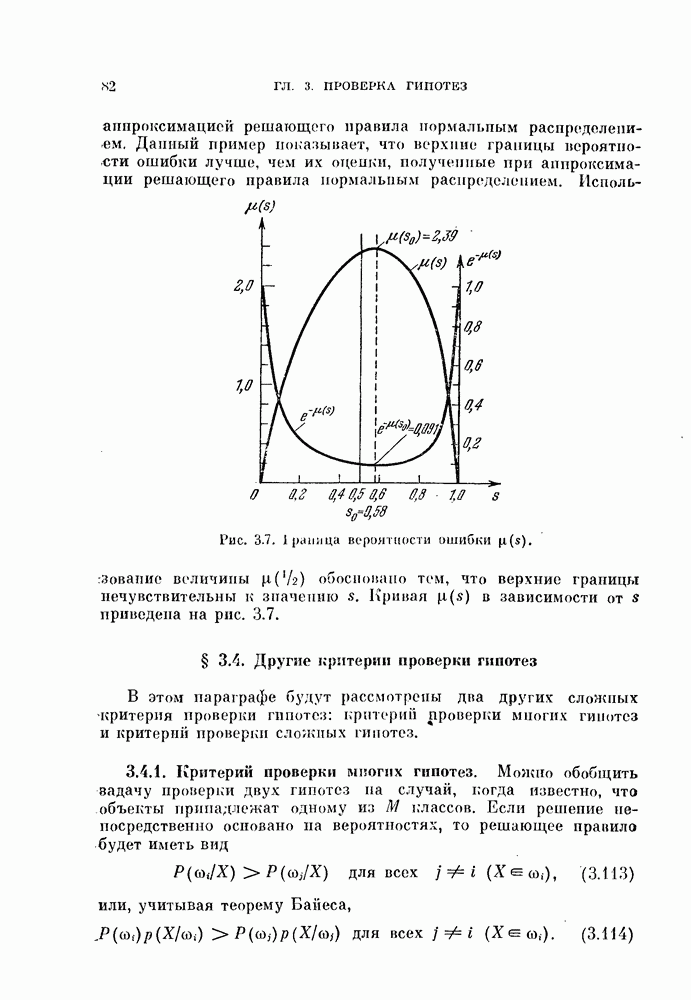




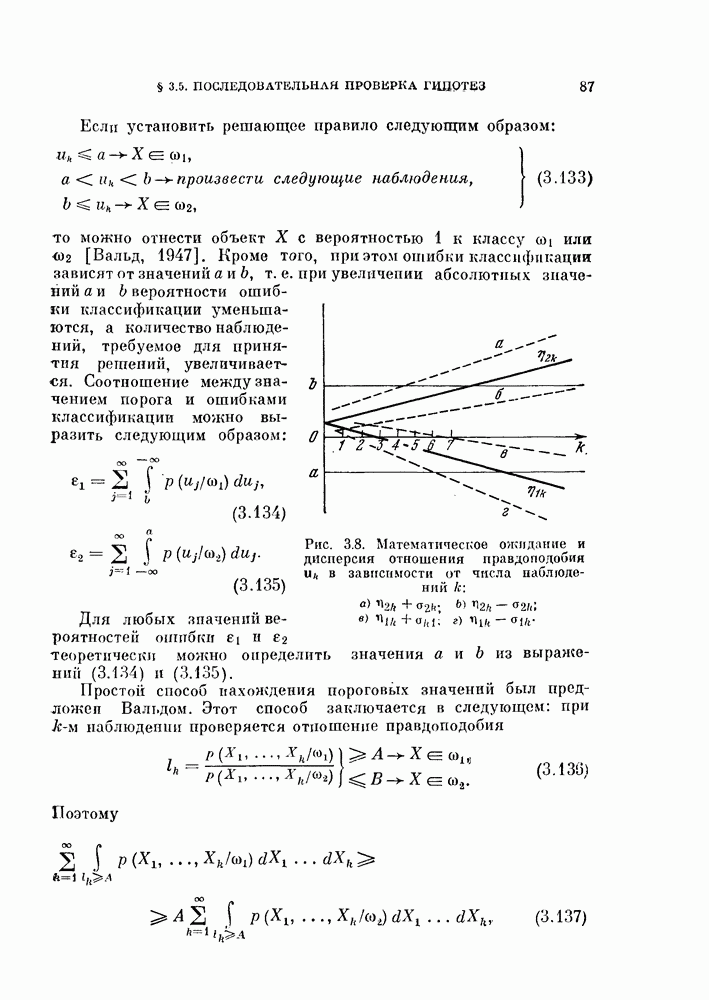











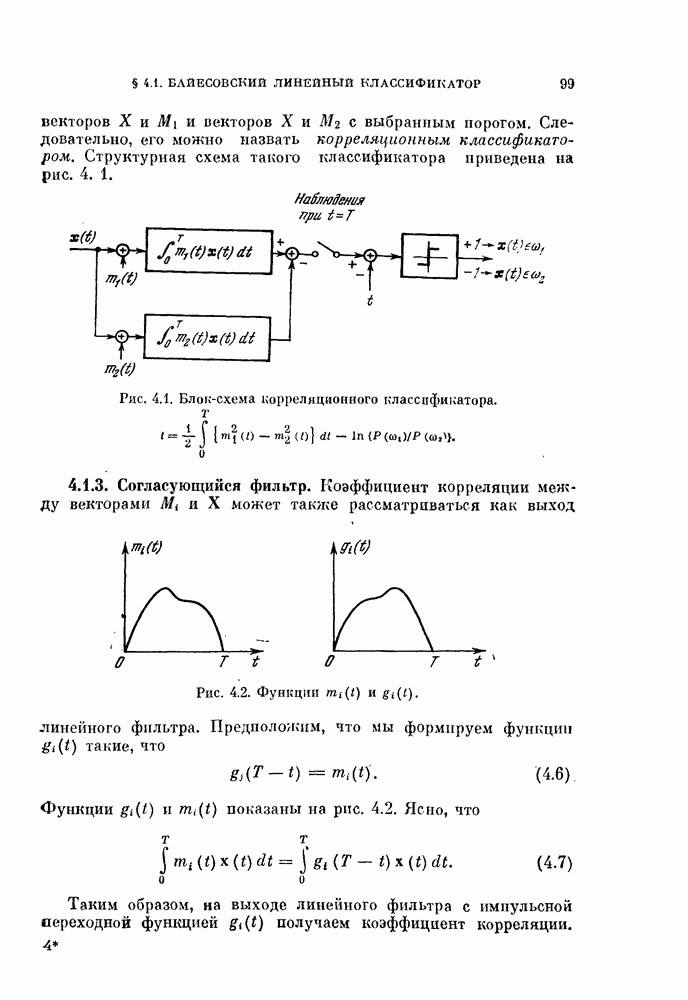


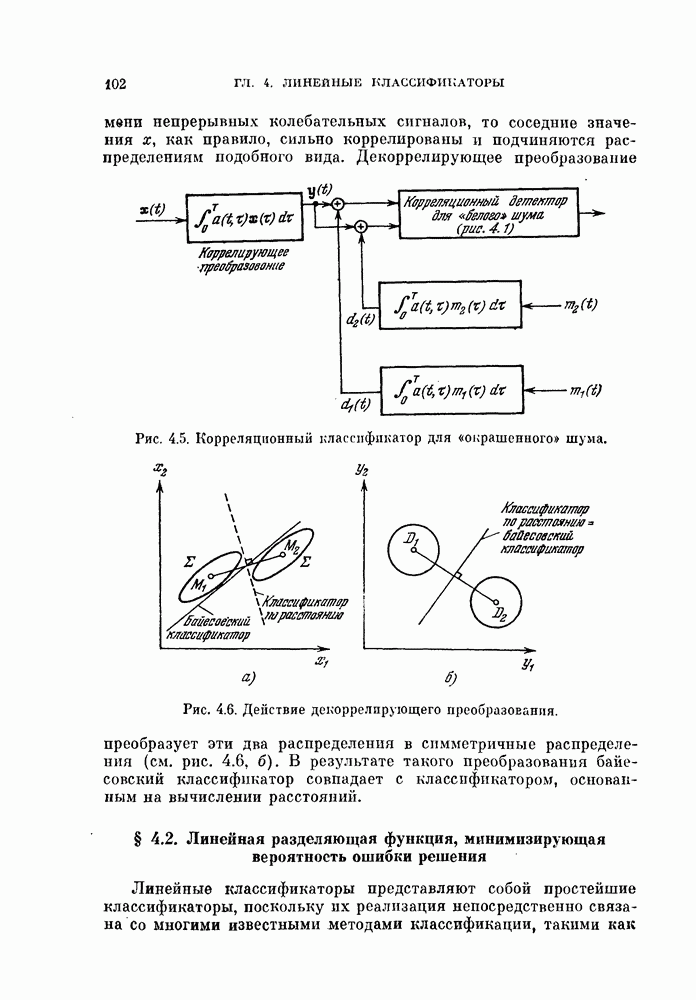




































































































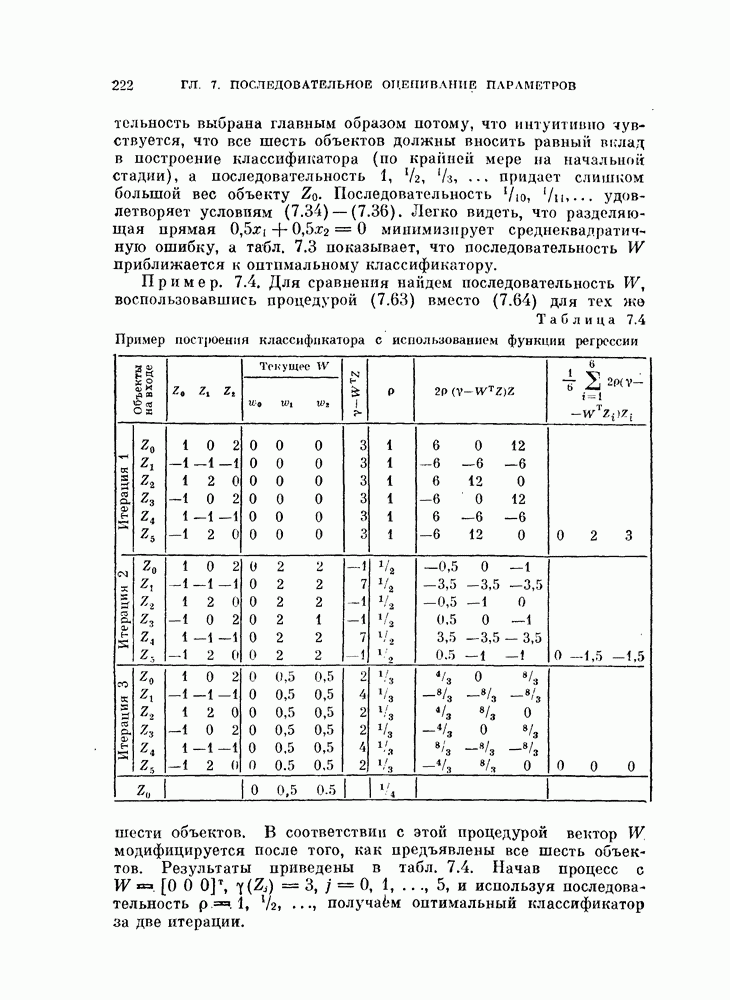


































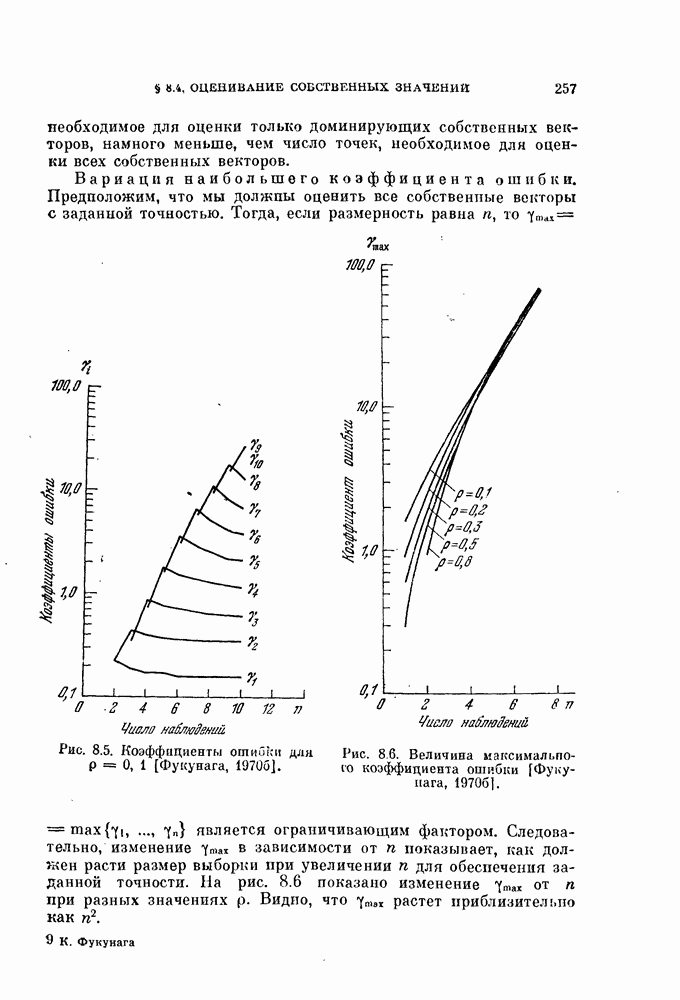




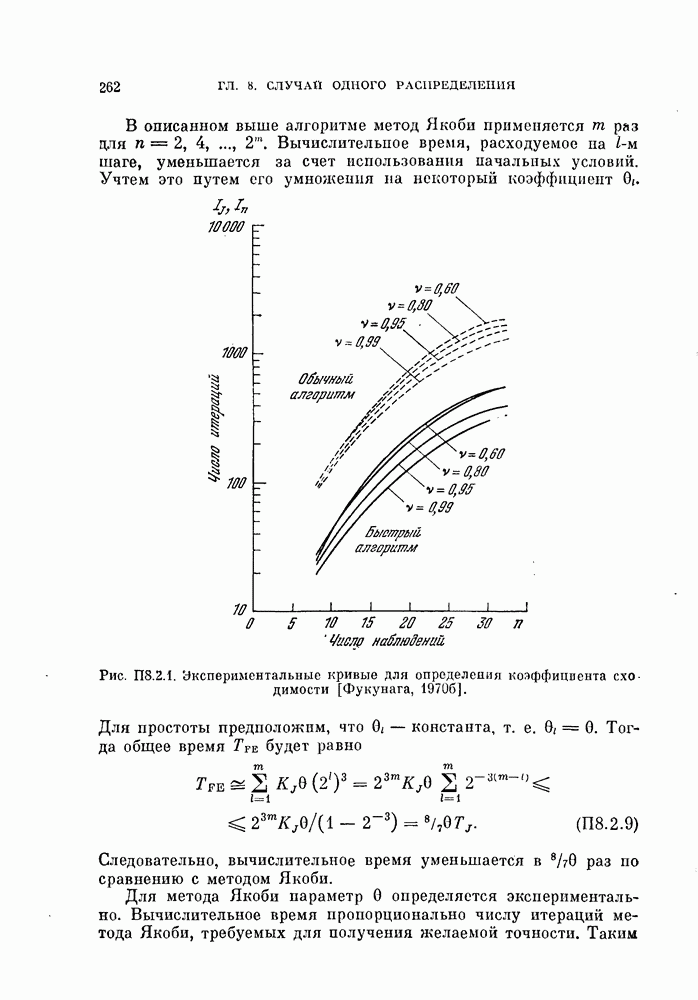




















































































 изучим, как это разбиение влияет на дисперсию оценки вероятности ошибки.
изучим, как это разбиение влияет на дисперсию оценки вероятности ошибки.
 объектов для проверки его качества. При бесконечном числе объектов синтезируемый классификатор является классификатором для истинных распределений, и его вклад в дисперсию равен нулю. Для фиксированного классификатора организуем селективную выборку. В этом случае распределение опенки вероятности ошибки подчиняется биномиальному закону с дисперсией
объектов для проверки его качества. При бесконечном числе объектов синтезируемый классификатор является классификатором для истинных распределений, и его вклад в дисперсию равен нулю. Для фиксированного классификатора организуем селективную выборку. В этом случае распределение опенки вероятности ошибки подчиняется биномиальному закону с дисперсией

 — истинная вероятность ошибки
— истинная вероятность ошибки  класса (см. выражение (5.131)).
класса (см. выражение (5.131)).
 объектов для синтеза классификатора и бесконечное число экзаменационных объектов, то оценка вероятности ошибки выражается следующим образом:
объектов для синтеза классификатора и бесконечное число экзаменационных объектов, то оценка вероятности ошибки выражается следующим образом:

 — область пространства признаков, соответствующая
— область пространства признаков, соответствующая  классу. В этом случае подынтегральные выражения постоянны, но граница этих областей изменяется в зависимости от выборки из
классу. В этом случае подынтегральные выражения постоянны, но граница этих областей изменяется в зависимости от выборки из  объектов.
объектов.
 для плотности вероятности генеральной совокупности вычислить сложно. Однако в случае нормальных распределений объектов в классах с равными ковариационными матрицами интегралы в (5.142) можно преобразовать к одномерным интегралам
для плотности вероятности генеральной совокупности вычислить сложно. Однако в случае нормальных распределений объектов в классах с равными ковариационными матрицами интегралы в (5.142) можно преобразовать к одномерным интегралам

 определяются условными математическими ожиданиями:
определяются условными математическими ожиданиями:


 число объектов класса
число объектов класса  используемых для синтеза классификатора.
используемых для синтеза классификатора.
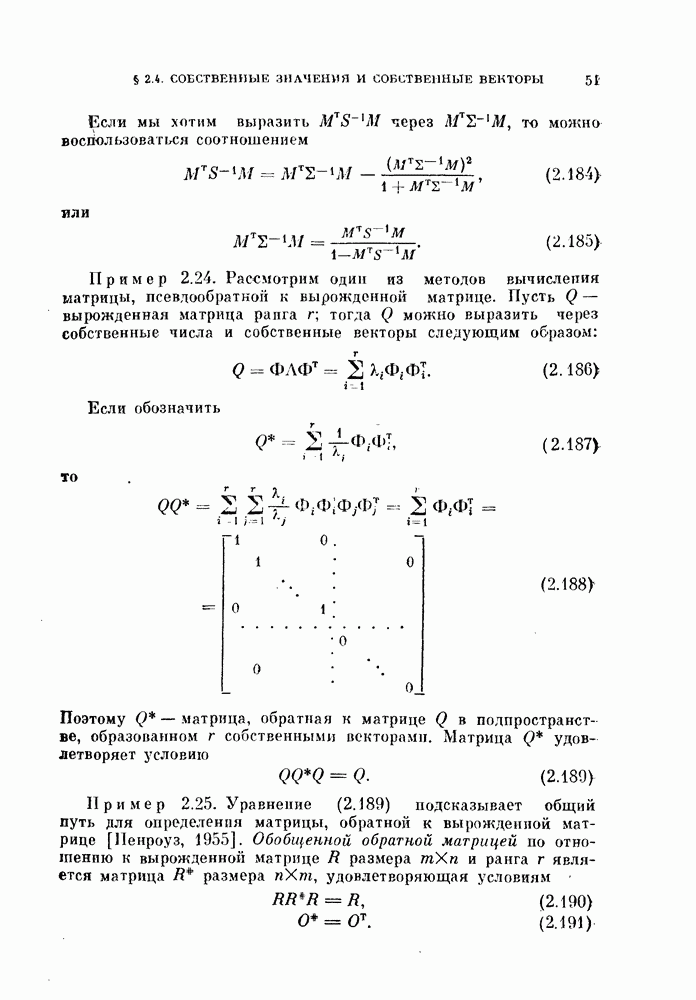
 было определено в работе [Окомото, 1963]. Так как выражение для этого математического ожидания достаточно громоздкое, то здесь приводится
было определено в работе [Окомото, 1963]. Так как выражение для этого математического ожидания достаточно громоздкое, то здесь приводится


 — расстояние между двумя векторами математических ожиданий, определяемое по формуле
— расстояние между двумя векторами математических ожиданий, определяемое по формуле

 является минимальной вероятностью ошибки байесовского классификатора. Так как
является минимальной вероятностью ошибки байесовского классификатора. Так как  — минимальное значение оценки
— минимальное значение оценки  то распределение для
то распределение для  является причинным. Поэтому можно определить оценку дисперсии величины
является причинным. Поэтому можно определить оценку дисперсии величины  , основанную на ее математическом ожидании. Предположим, что плотность вероятности Де является плотностью вероятности гамма-распределения, которое включает в себя широкий класс причин
, основанную на ее математическом ожидании. Предположим, что плотность вероятности Де является плотностью вероятности гамма-распределения, которое включает в себя широкий класс причин  распределений. Тогда
распределений. Тогда


 , т. е.
, т. е.

 в случае нормальных распределений с равными ковариационными матрицами и равными
в случае нормальных распределений с равными ковариационными матрицами и равными  риорными вероятностями равна
риорными вероятностями равна

 из (5.155) следует сравнить с величиной
из (5.155) следует сравнить с величиной  которая характеризует влияние числа объектов в экзаменациовной выборке на оценку вероятности ошибки. Значение
которая характеризует влияние числа объектов в экзаменациовной выборке на оценку вероятности ошибки. Значение  получается
получается


 из выражения (5.149) и
из выражения (5.149) и  из выражения (5.156) связаны однозначно. Поэтому можно установить зависимость между величиной
из выражения (5.156) связаны однозначно. Поэтому можно установить зависимость между величиной  в (5.155) с величиной
в (5.155) с величиной  в (5.156). Эта зависимость показана на рис. 5.3.
в (5.156). Эта зависимость показана на рис. 5.3.
 в значительной степени зависит
в значительной степени зависит  размерности
размерности  и степени разделимости классов, измеряемой расстоянием
и степени разделимости классов, измеряемой расстоянием 
 в зависимости от величины
в зависимости от величины 
 и числа объектов в обучающей и экзаменационной выборках можно оценить величины
и числа объектов в обучающей и экзаменационной выборках можно оценить величины  и
и  с помощью формул (5.155), (5.156) и
с помощью формул (5.155), (5.156) и
 величина
величина  уменьшается не быстрее чем
уменьшается не быстрее чем  уменьшается не быстрее чем
уменьшается не быстрее чем  то для многих случаев большее число объектов должно быть использовано для экзамена, а не для проектирования классификатора.
то для многих случаев большее число объектов должно быть использовано для экзамена, а не для проектирования классификатора.
 Размер обучающей выборки для каждого класса выбирался равным 12, 50, 100, 200 и 400 объектам
Размер обучающей выборки для каждого класса выбирался равным 12, 50, 100, 200 и 400 объектам  Четыреста объектов каждого класса, которые генерировались независимо от объектов обучающей выборки, использовались для проверки качества классификатора. Для каждой выборки эксперимент повторялся 40 раз. По данным 40 экспериментов вычислялись выборочное среднее и среднеквадратичное отклонения оценки вероятности ошибки. Результаты приведены в табл. 5.1. Заметим, что эти результаты не противоречат
Четыреста объектов каждого класса, которые генерировались независимо от объектов обучающей выборки, использовались для проверки качества классификатора. Для каждой выборки эксперимент повторялся 40 раз. По данным 40 экспериментов вычислялись выборочное среднее и среднеквадратичное отклонения оценки вероятности ошибки. Результаты приведены в табл. 5.1. Заметим, что эти результаты не противоречат

 уменьшается очень быстро при увеличении числа объектов обучающей выборки. Так как величина
уменьшается очень быстро при увеличении числа объектов обучающей выборки. Так как величина  оценивалась по выборке из 400 объектов каждого класса, то основной вклад в
оценивалась по выборке из 400 объектов каждого класса, то основной вклад в  для выборок среднего и большого объема в действительности вносят результаты экзамена, а не обучения.
для выборок среднего и большого объема в действительности вносят результаты экзамена, а не обучения.
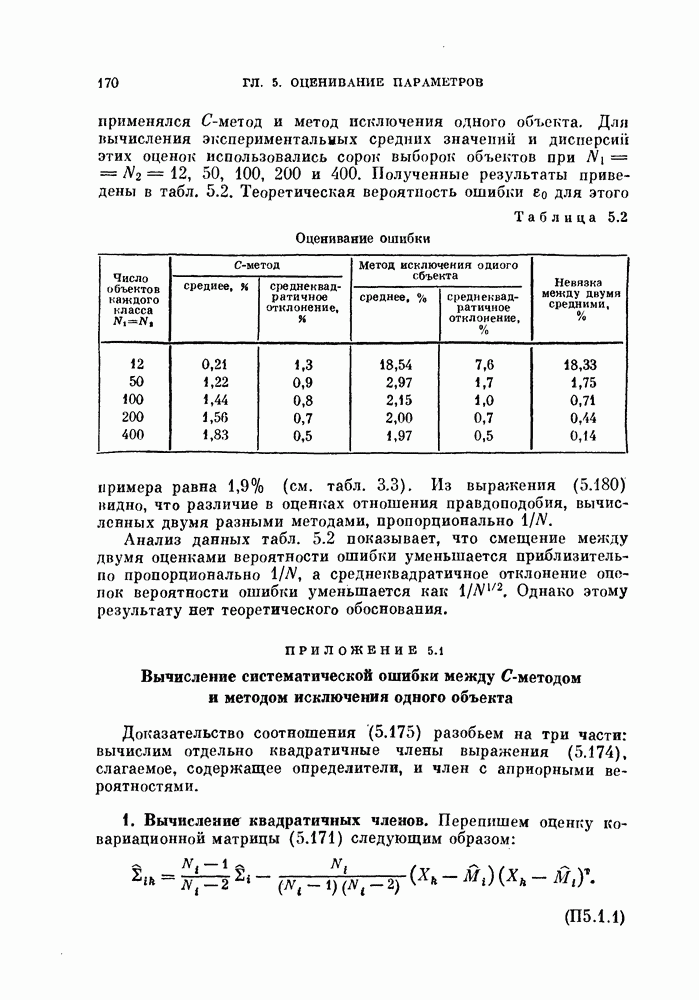
 для ее решения требуется обучающая выборка относительно небольшого объема по сравнению с экзаменационной [Хайлиман, 1962]. Его метод годится для любых плотностей вероятности, но при весьма жестких ограничениях на вид оценки вероятности ошибки.
для ее решения требуется обучающая выборка относительно небольшого объема по сравнению с экзаменационной [Хайлиман, 1962]. Его метод годится для любых плотностей вероятности, но при весьма жестких ограничениях на вид оценки вероятности ошибки.

 - плотность вероятности смеси,
- плотность вероятности смеси,  критический у ровень,
критический у ровень,  Условие (5.157) устанавливает, что если для данного объекта X значения
Условие (5.157) устанавливает, что если для данного объекта X значения  вычисленные для каждого класса М, не превышают величины
вычисленные для каждого класса М, не превышают величины  то объект X не классифицируют вообще; в противном случае объект X классифицируют и относят его к
то объект X не классифицируют вообще; в противном случае объект X классифицируют и относят его к  классу. Таким образом, вся область значений X делится на критическую область
классу. Таким образом, вся область значений X делится на критическую область  и допустимую область
и допустимую область  причем размеры обеих областей являются функциями критического уровня
причем размеры обеих областей являются функциями критического уровня 
 коэффициент отклонения
коэффициент отклонения  и коэффициент правильного распознавания
и коэффициент правильного распознавания  будут равны
будут равны


 за счет изменения значения
за счет изменения значения  на
на  Тогда те X, которые раньше распознавались правильно, теперь отклоняются:
Тогда те X, которые раньше распознавались правильно, теперь отклоняются:

 получим
получим

 — приращения
— приращения  вызванные изменением
вызванные изменением  формулы (5.160) следует, что неравенство (5.162) можно переписать следующим образом:
формулы (5.160) следует, что неравенство (5.162) можно переписать следующим образом:

 от 0 до
от 0 до  , получим
, получим

 получаем интеграл Стилтьеса
получаем интеграл Стилтьеса

 может быть вычислена после того, как известна зависимость между значениями
может быть вычислена после того, как известна зависимость между значениями  и
и  Из решающего правила (5.157) следует, что при
Из решающего правила (5.157) следует, что при  область отклонения отсутствует, так что байесовская ошибка
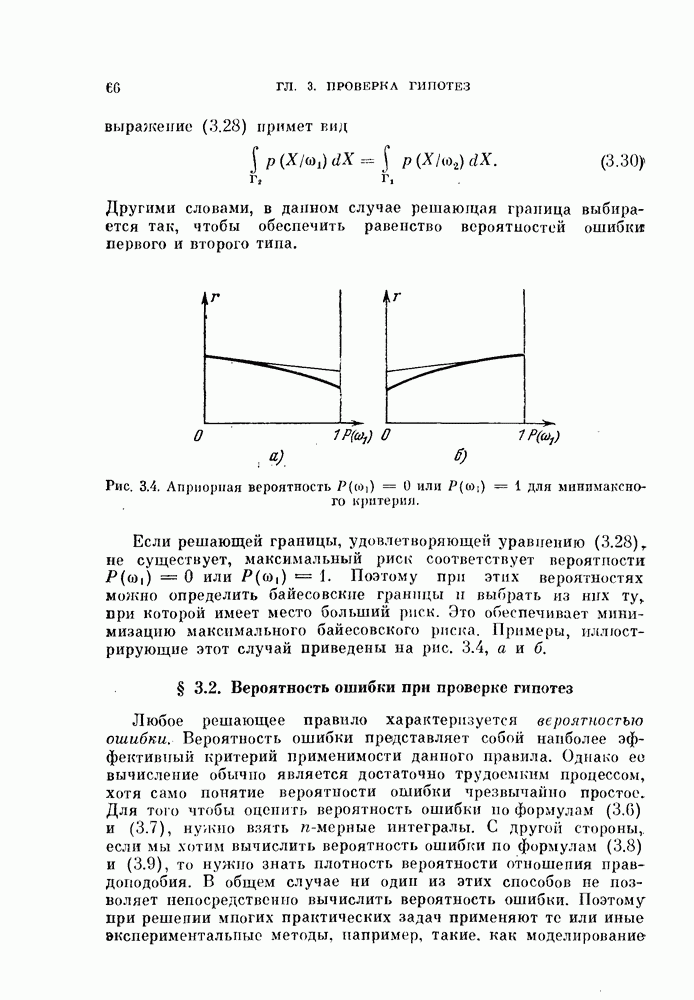
область отклонения отсутствует, так что байесовская ошибка  Кроме того, из формулы (5.165) можно установить взаимосвязь между вероятностью ошибки и коэффициентом отклонения, так как изменение вероятности ошибки можно вычислить как функцию от изменения коэффициента отклонения.
Кроме того, из формулы (5.165) можно установить взаимосвязь между вероятностью ошибки и коэффициентом отклонения, так как изменение вероятности ошибки можно вычислить как функцию от изменения коэффициента отклонения.


 при
при  где
где  — дискретный шаг переменной
— дискретный шаг переменной  будем использовать относительно дорогостоящие классифицируемые объекты. Это показано на рис. 5.4.
будем использовать относительно дорогостоящие классифицируемые объекты. Это показано на рис. 5.4.
 разделим это число на общее число объектов и обозначим полученное отношение через
разделим это число на общее число объектов и обозначим полученное отношение через 

 и вероятности ошибки
и вероятности ошибки  нет необходимости использовать классифицированные объекты.
нет необходимости использовать классифицированные объекты.