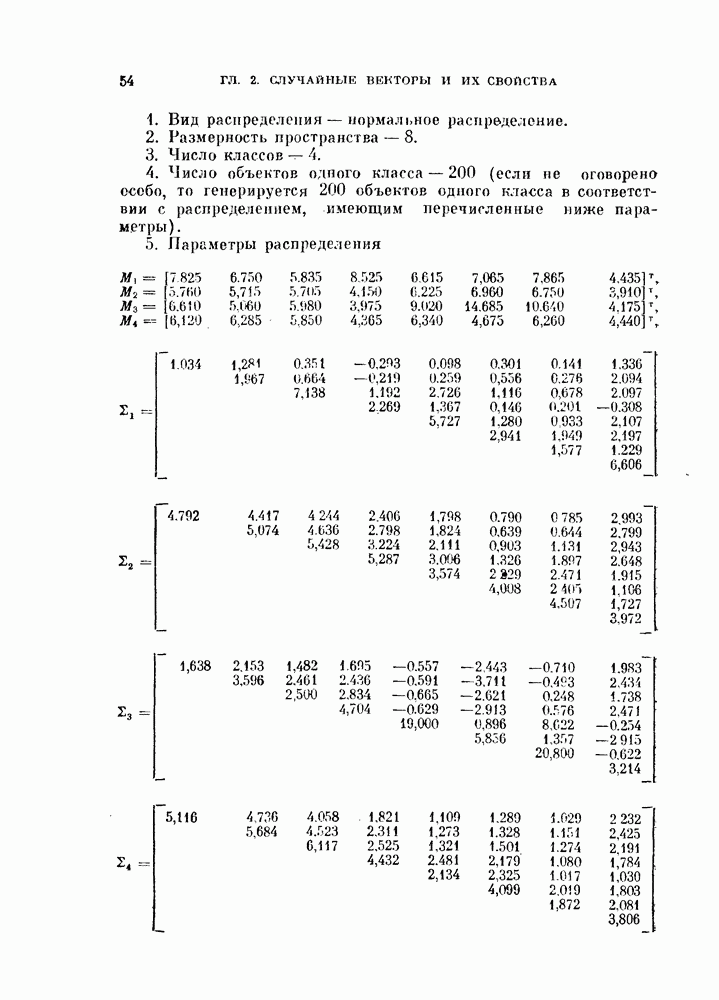
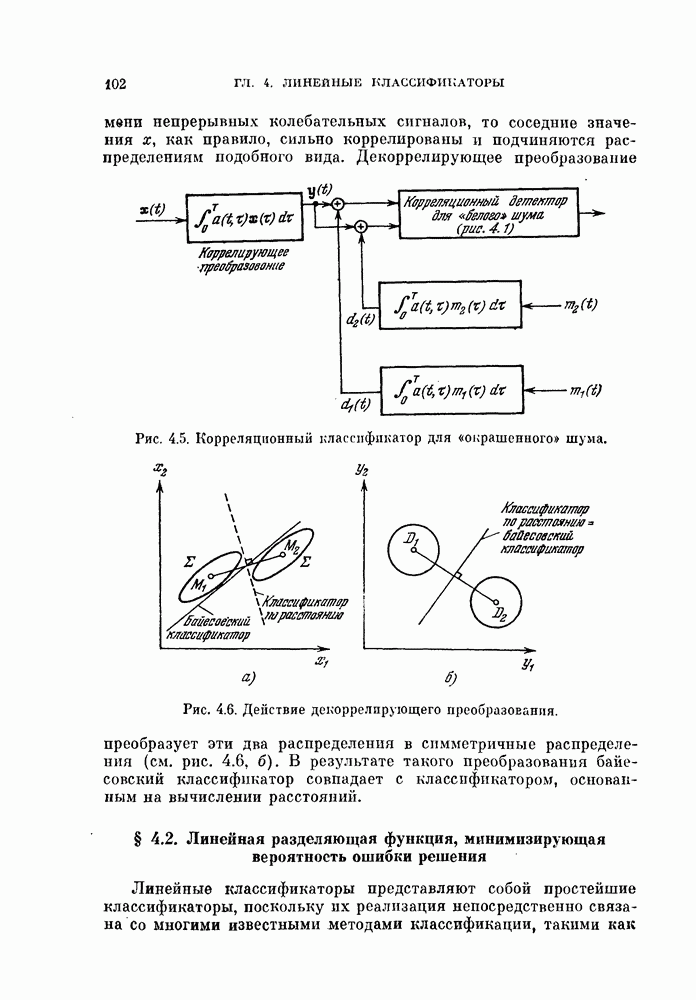
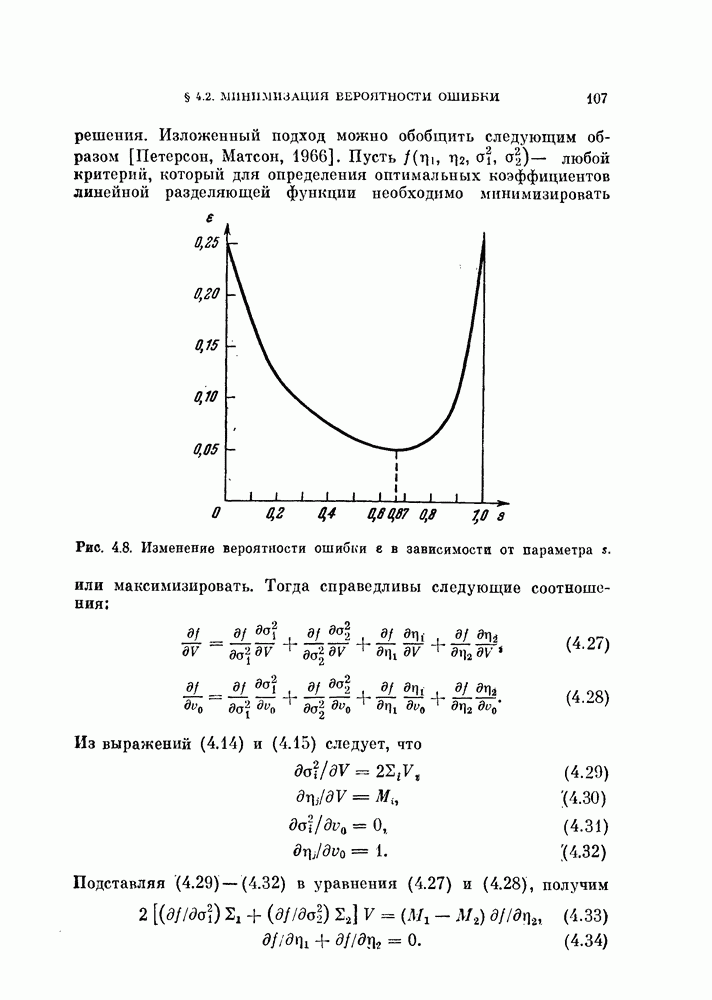
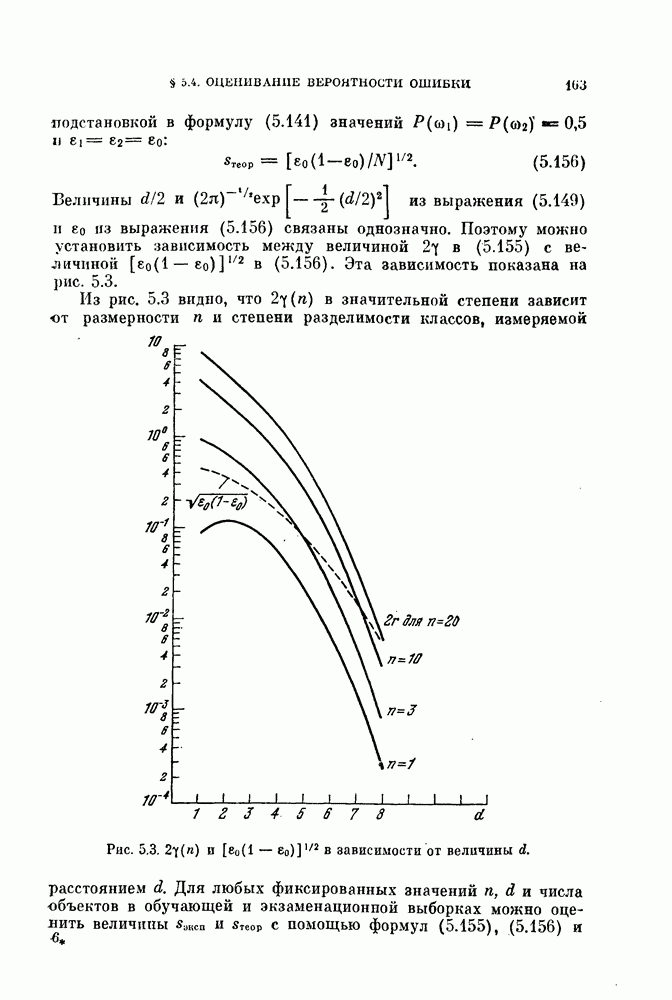
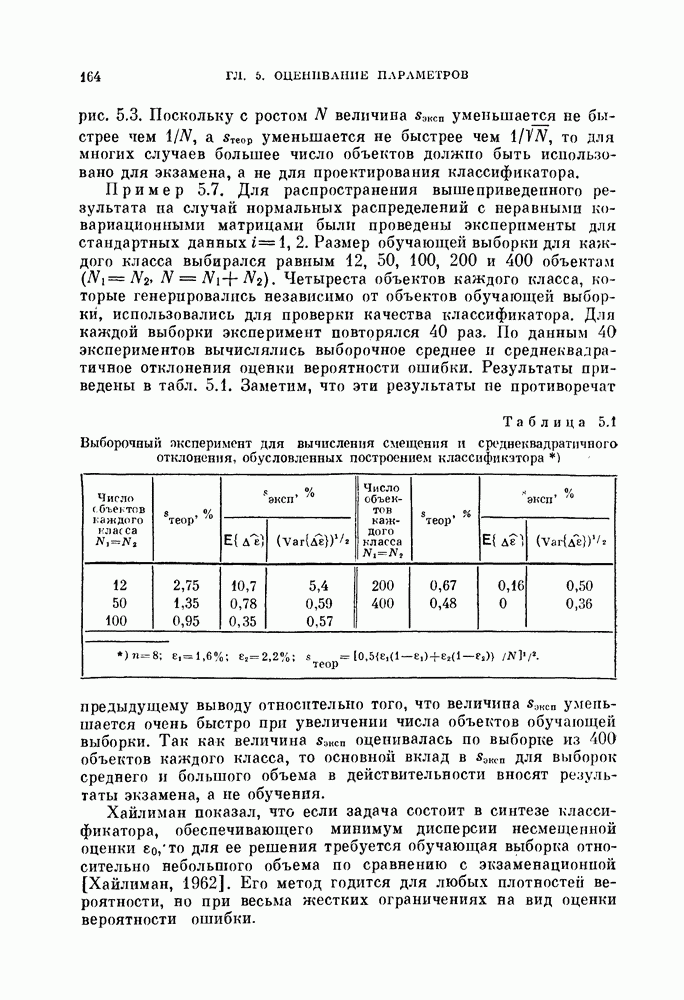
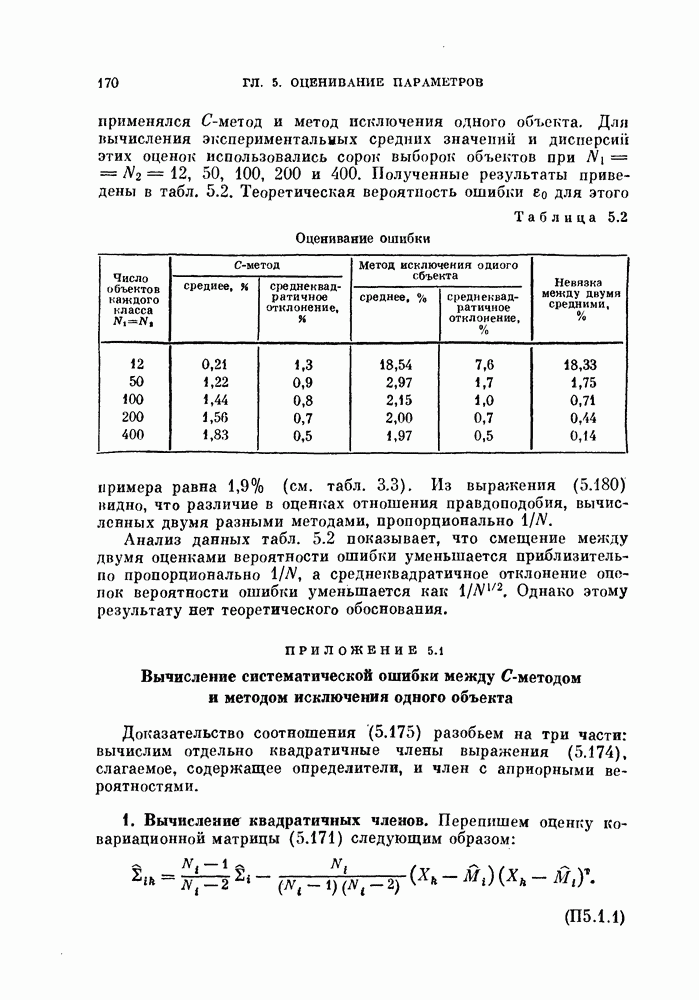
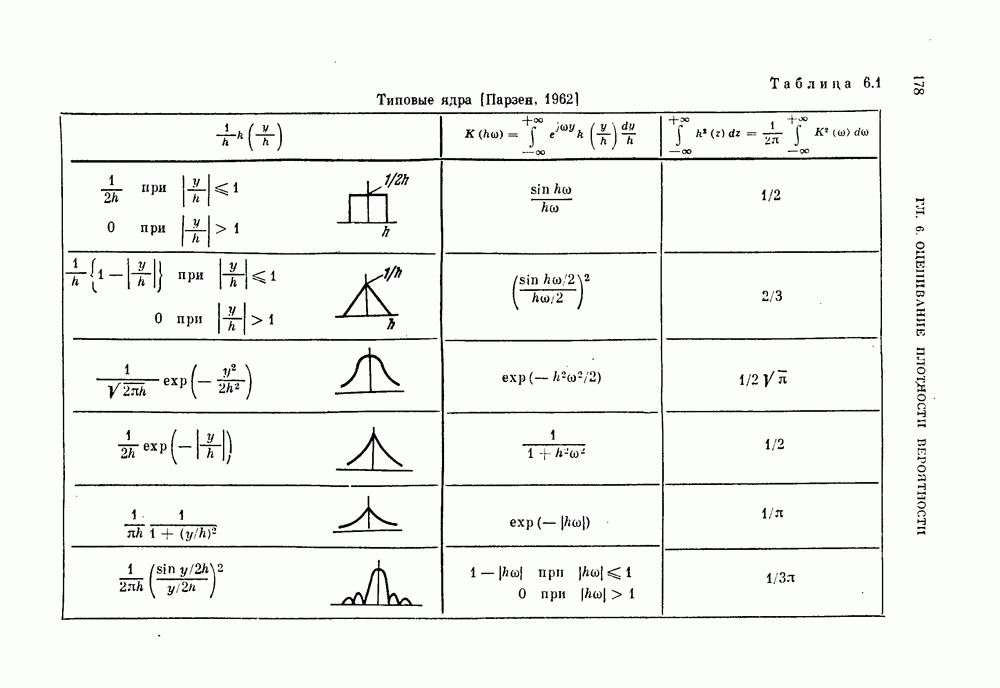
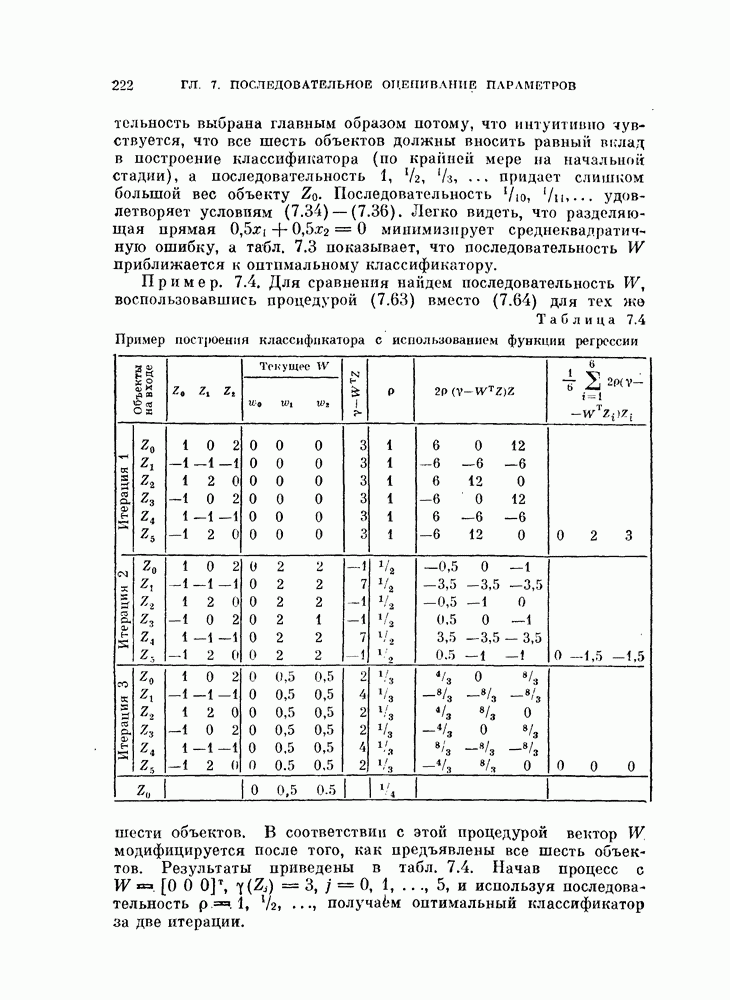
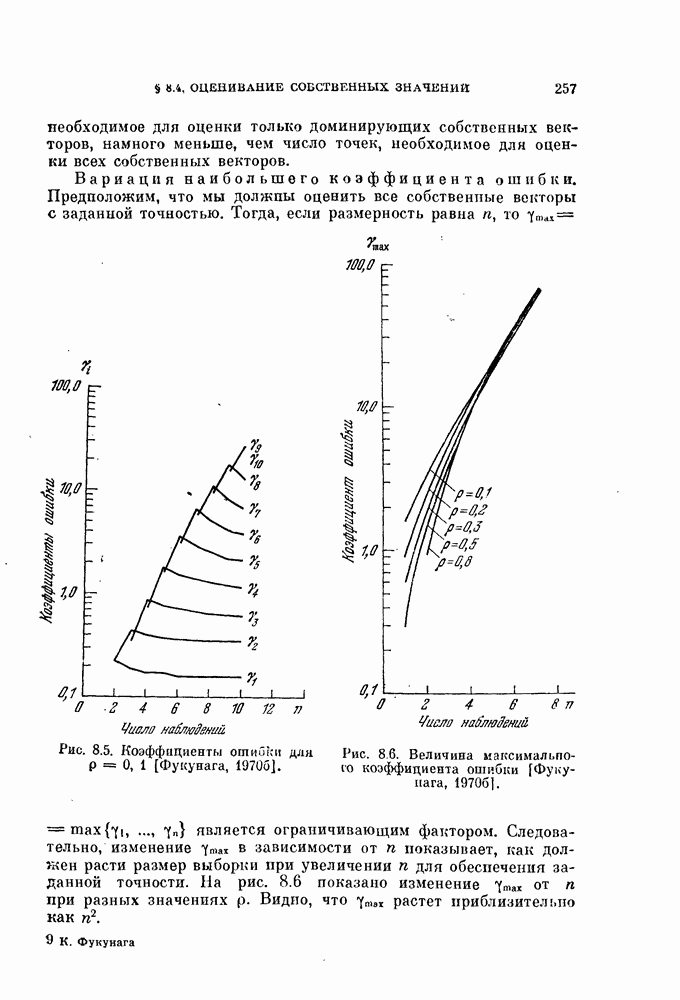
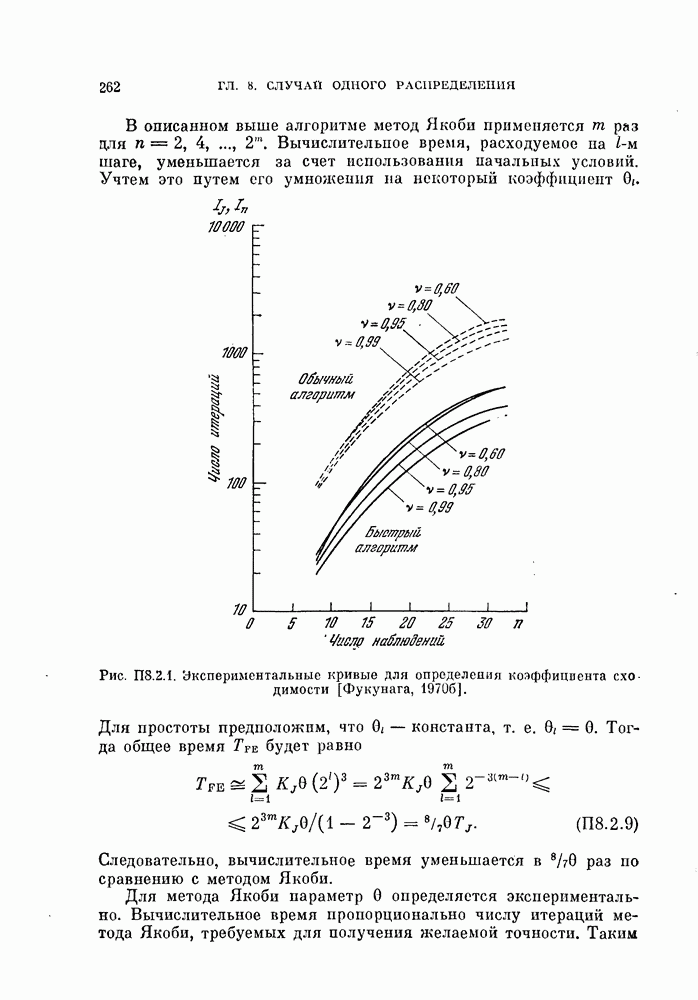
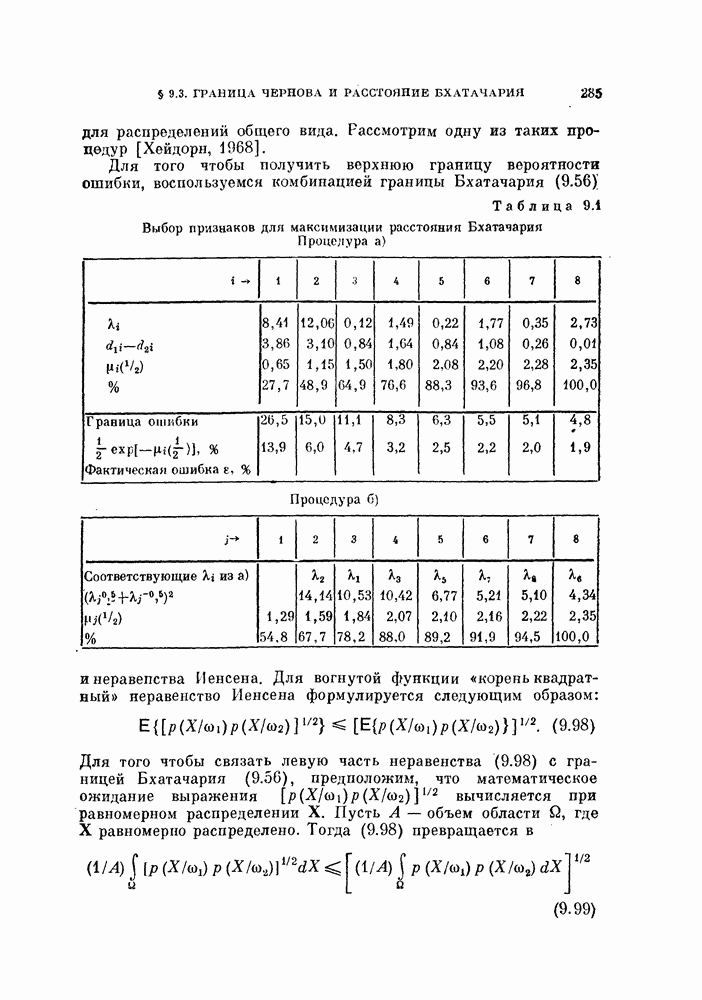
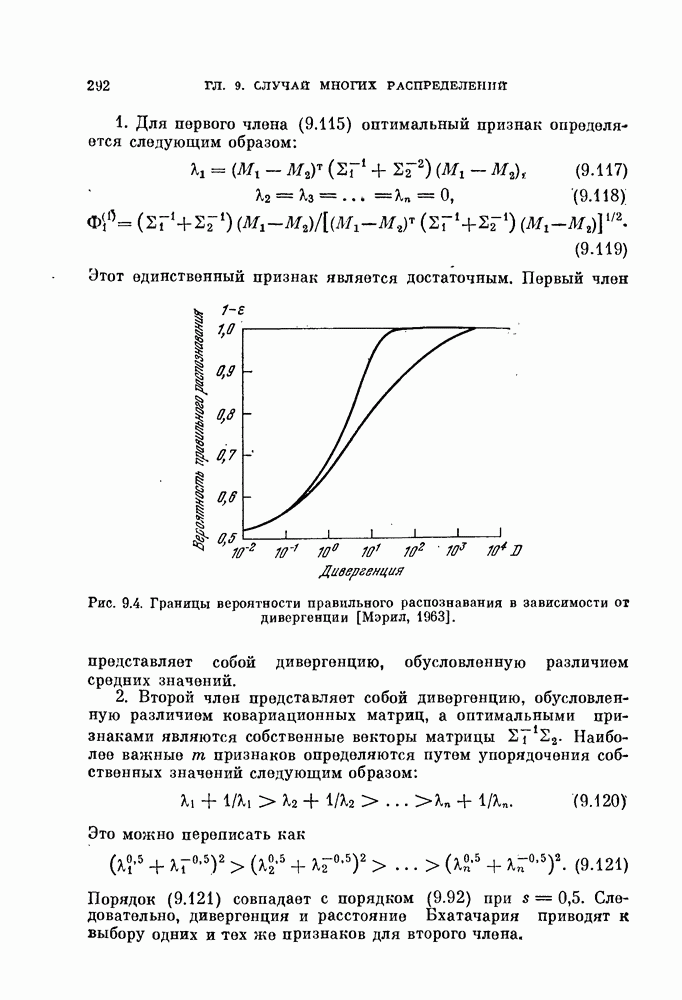
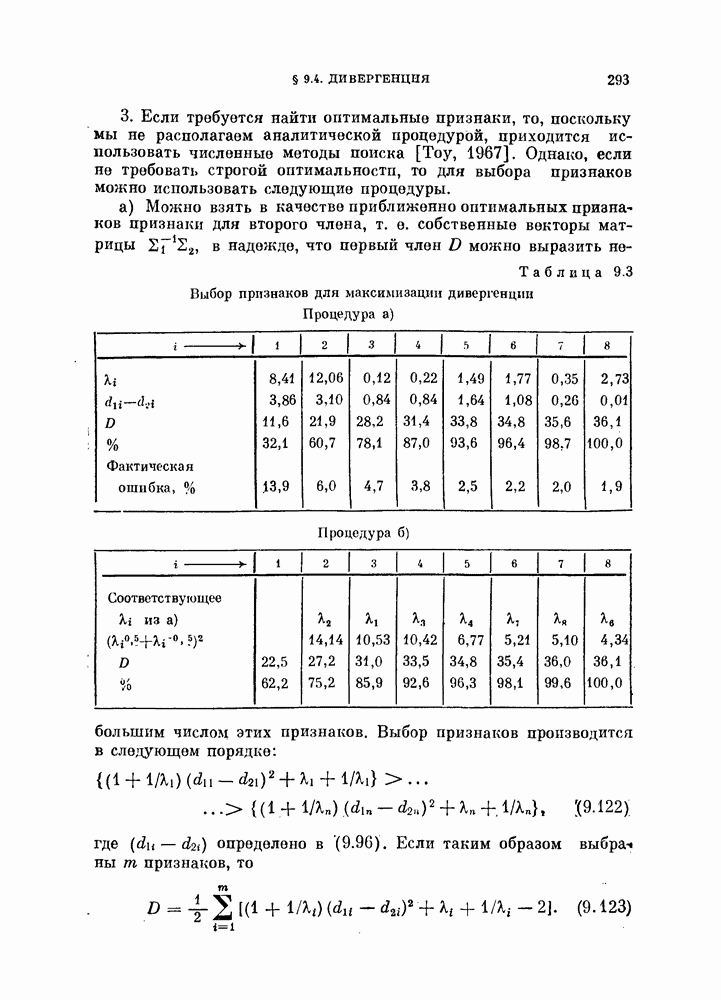
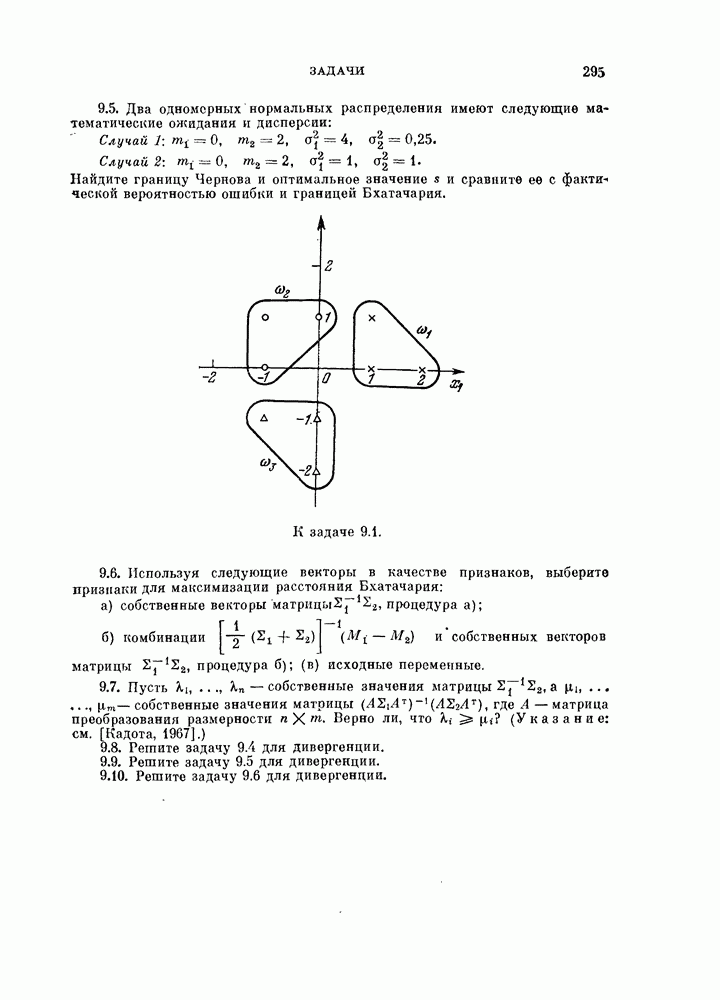
§ 4.3. Линейная разделяющая функция, минимизирующая среднеквадратичную ошибку решения
В предыдущем параграфе для определения оптимальной разделяющей функции, минимизирующей вероятность ошибки, предполагалось, что в классах  плотности вероятности значений линейной разделяющей функции являются нормальными или близкими к нормальным. Даже при выводе обобщенной формулы для различных критериев предполагалось, что критерии представляют собой функции математических ожиданий и дисперсий значений разделяющей функции. Если же применить метод, основанный на минимизации среднеквадратичной ошибки решения, то аналогичные результаты можно получить и без предположения о нормальности распределений. Вместо предположения о виде распределения вектора X будем предполагать, что имеется конечная выборка значений случайных величин X, состоящая из
плотности вероятности значений линейной разделяющей функции являются нормальными или близкими к нормальным. Даже при выводе обобщенной формулы для различных критериев предполагалось, что критерии представляют собой функции математических ожиданий и дисперсий значений разделяющей функции. Если же применить метод, основанный на минимизации среднеквадратичной ошибки решения, то аналогичные результаты можно получить и без предположения о нормальности распределений. Вместо предположения о виде распределения вектора X будем предполагать, что имеется конечная выборка значений случайных величин X, состоящая из  объектов.
объектов.
4.3.1. Линейные разделяющие функции.
Линейную разделяющую функцию можно представить в следующем виде, отличном от (4.13):

Далее, если ввести новую форму записи выборочных векторов

то разделяющая функция примет более простой вид

где  принимает значения
принимает значения  или —1.
или —1.
Таким образом, предлагаемая процедура построения разделяющей функции заключается в следующем:
1) получить из X новое множество векторов 
2) определить вектор  на условия, чтобы для всех известных векторов
на условия, чтобы для всех известных векторов  удовлетворялось неравенство (4.43).
удовлетворялось неравенство (4.43).
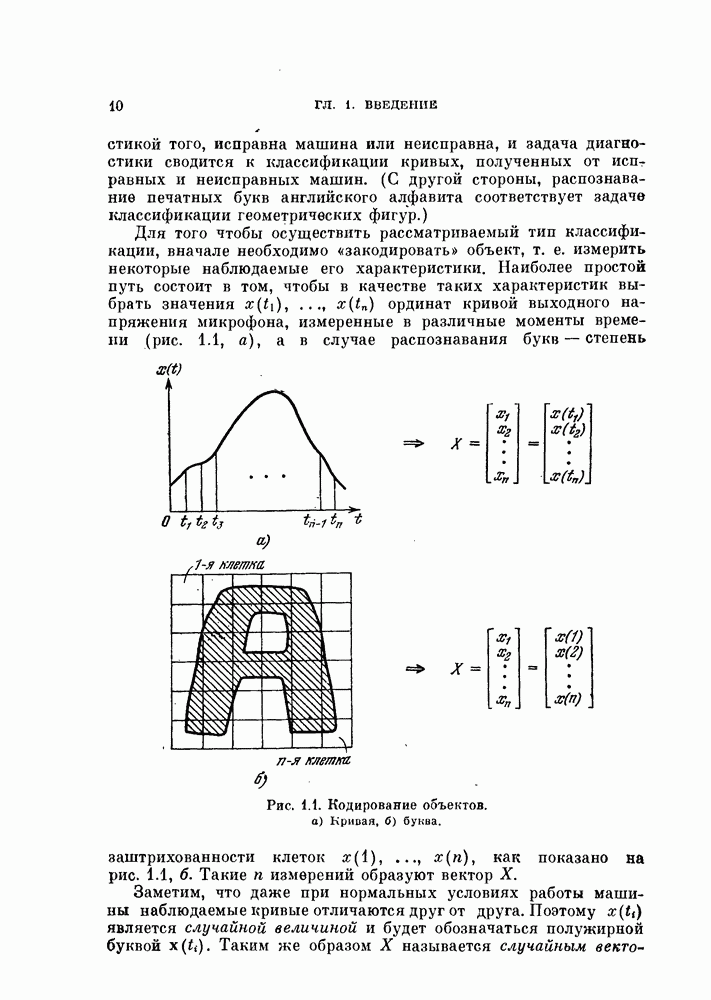
Предположим, что  — наилучшая разделяющая функция для двух классов. Тогда значения
— наилучшая разделяющая функция для двух классов. Тогда значения  можно рассматривать как требуемый выход разделяющей функции
можно рассматривать как требуемый выход разделяющей функции  Как правило, нам неизвестен точный вид
Как правило, нам неизвестен точный вид  но известна классификация объектов обучающей выборки. Поэтому можно постулировать обучающие значения
но известна классификация объектов обучающей выборки. Поэтому можно постулировать обучающие значения  которые, как следует из (4.43), должны быть положительными числами для каждого
которые, как следует из (4.43), должны быть положительными числами для каждого  Тогда среднеквадратичная ошибка между требуемым и действительным выходом разделяющей функции будет равна
Тогда среднеквадратичная ошибка между требуемым и действительным выходом разделяющей функции будет равна

Если вместо математического ожидания используется выборочное среднее значение, определенное по  объектам, то имеем
объектам, то имеем

где

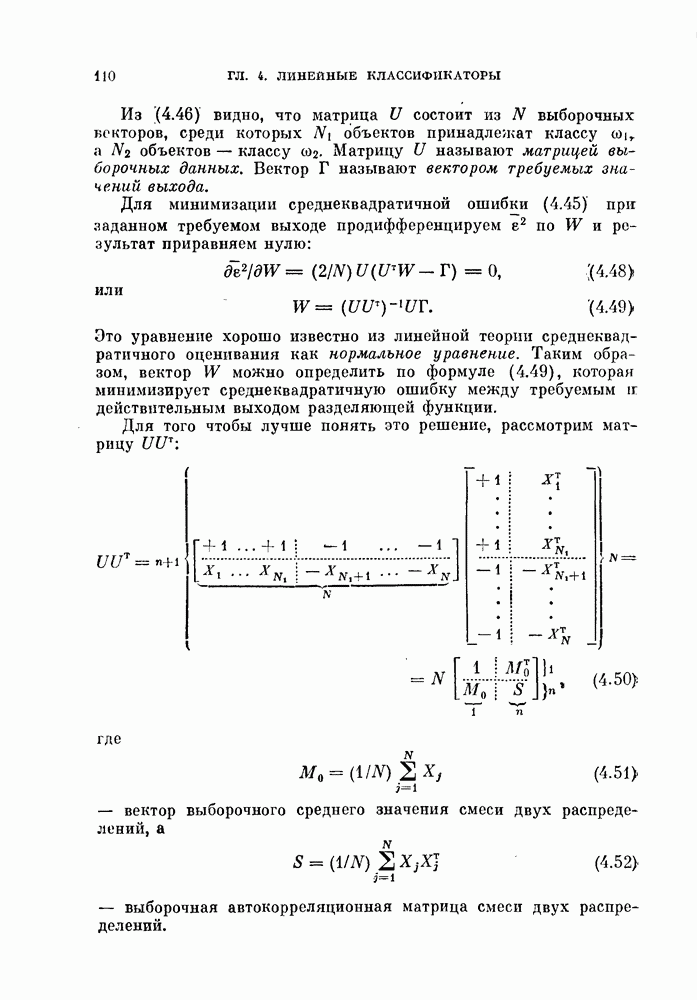
Из (4.46) видно, что матрица  состоит из
состоит из  выборочных векторов, среди которых
выборочных векторов, среди которых  объектов принадлежат классу
объектов принадлежат классу  а
а  объектов — классу
объектов — классу  Матрицу
Матрицу  называют матрицей выборочных данных. Вектор Г называют вектором требуемых значений выхода.
называют матрицей выборочных данных. Вектор Г называют вектором требуемых значений выхода.
Для минимизации среднеквадратичной ошибки (4.45) при заданном требуемом выходе продифференцируем  по
по  и результат приравняем нулю:
и результат приравняем нулю:

или

Это уравнение хорошо известно из линейной теории среднеквадратичного оценивания как нормальное уравнение. Таким образом, вектор  можно определить по формуле (4.49), которая минимизирует среднеквадратичную ошибку между требуемым
можно определить по формуле (4.49), которая минимизирует среднеквадратичную ошибку между требуемым  действительным выходом разделяющей функции.
действительным выходом разделяющей функции.
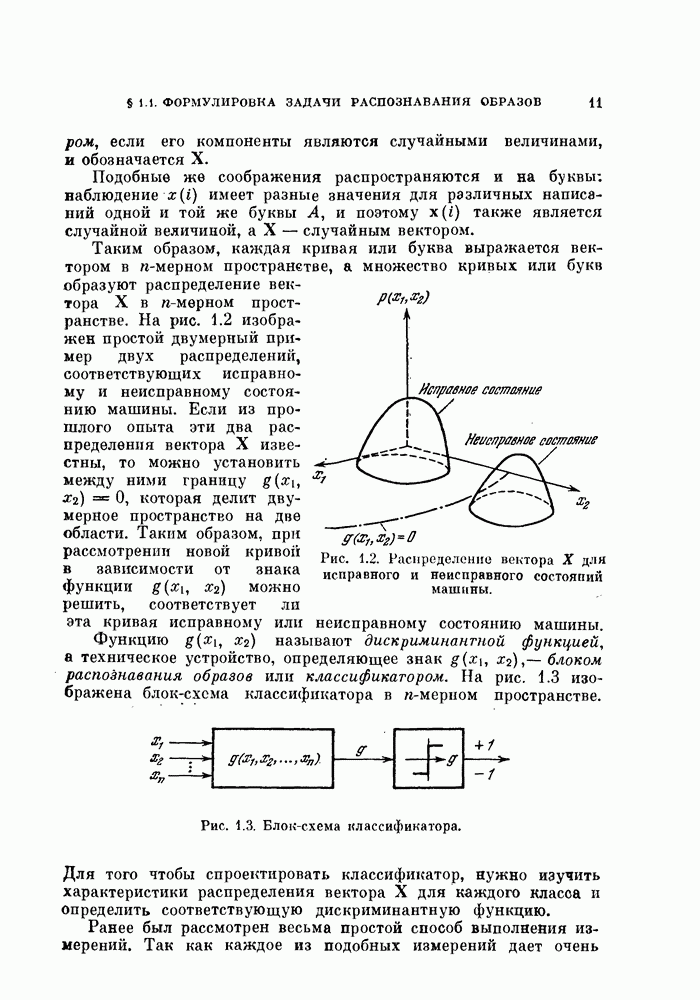
Для того чтобы лучше понять это решение, рассмотрим матрицу 

где

— вектор выборочного среднего значения смеси двух распределений, а

— выборочная автокорреляционная матрица смеси двух распределений.
Применим такое линейное преобразование системы координат, чтобы

где

Так как при этом матрица  преобразуется в матрицу
преобразуется в матрицу  то выражение (4.49) примет вид
то выражение (4.49) примет вид

где штрихом помечены векторы и переменные в преобразован ной системе координат. Таким образом,

или

Анализ уравнения (4.58) показывает, что коэффициенты  определяются корреляцией между требуемым выходом и
определяются корреляцией между требуемым выходом и  .
.
Более простой результат можно получить, если предположить, что

В этом случае

в предположении, что выборочные априорные вероятности и
выборочные средние значения равны истинным априорным вероятностям и векторам математического ожидания.
Из выражений (4.53) и (4.54) видно, что  в преобразованной системе координат связаны между собой следующим образом:
в преобразованной системе координат связаны между собой следующим образом:

Поэтому

Подставляя (4.64) в формулу (4.61), получим

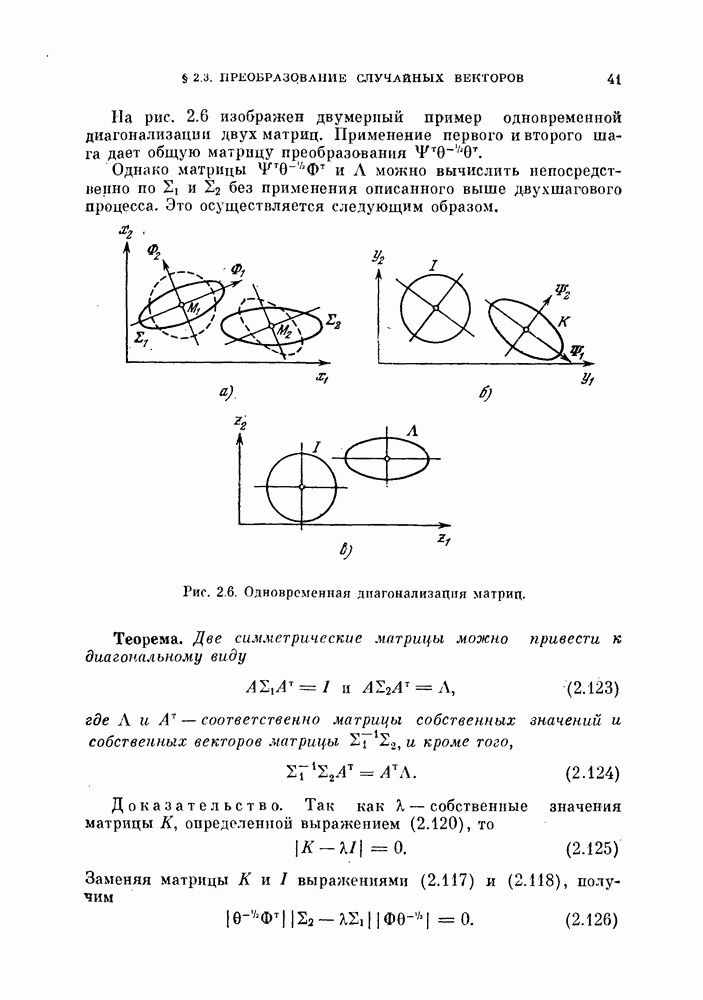
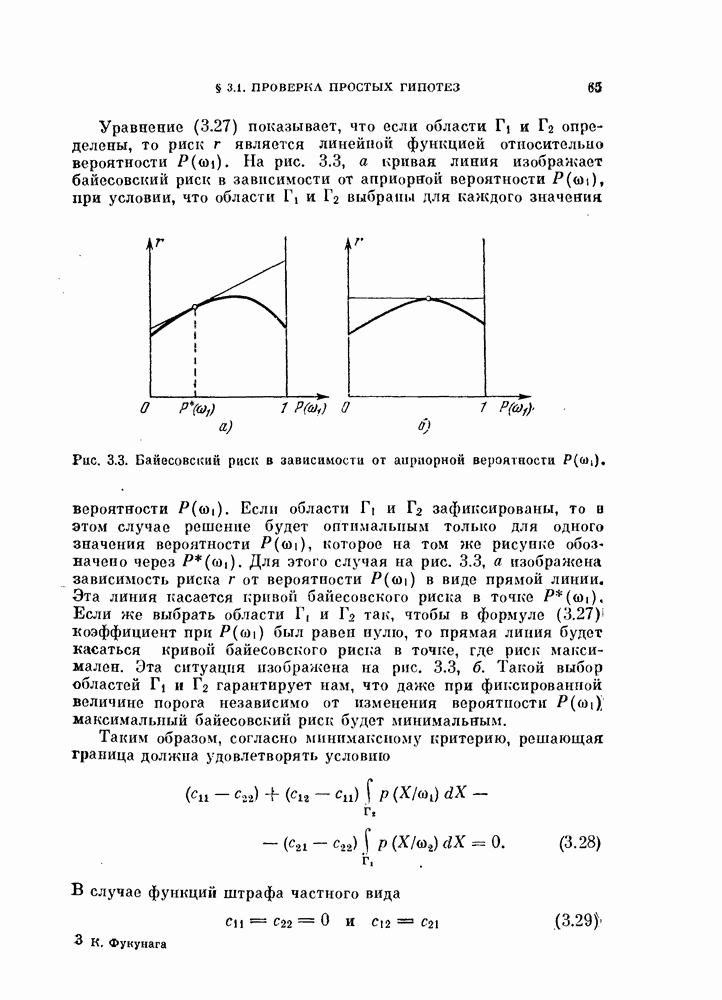
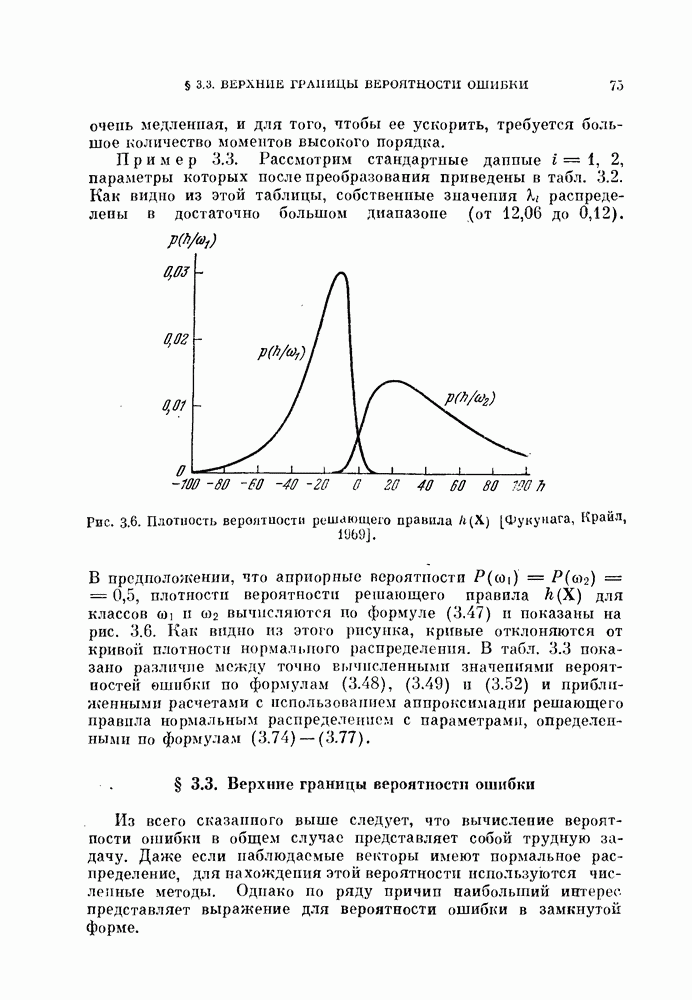
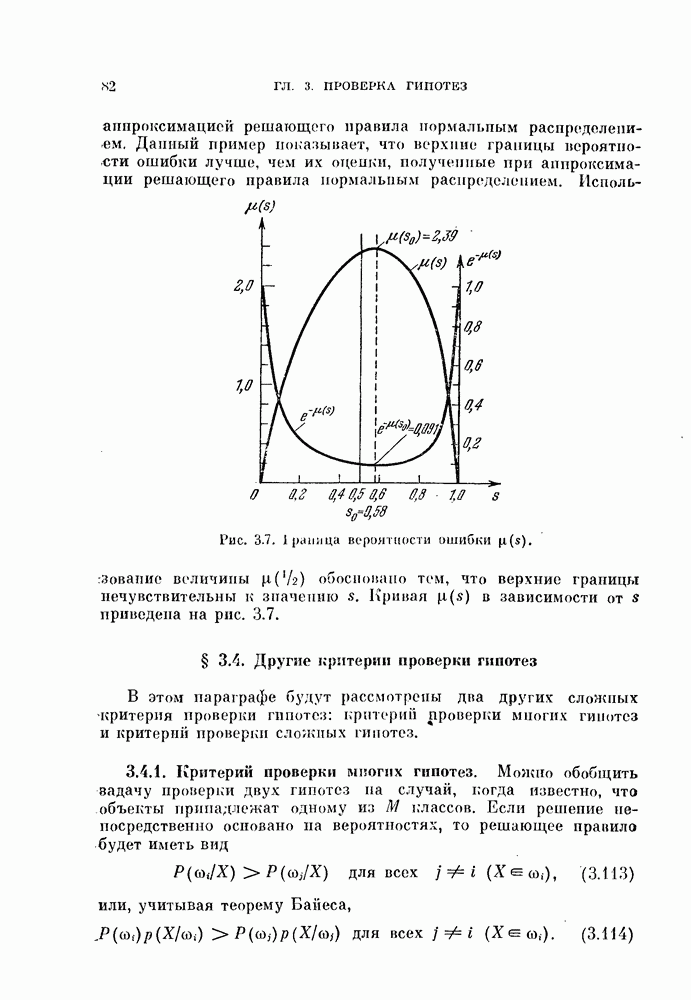
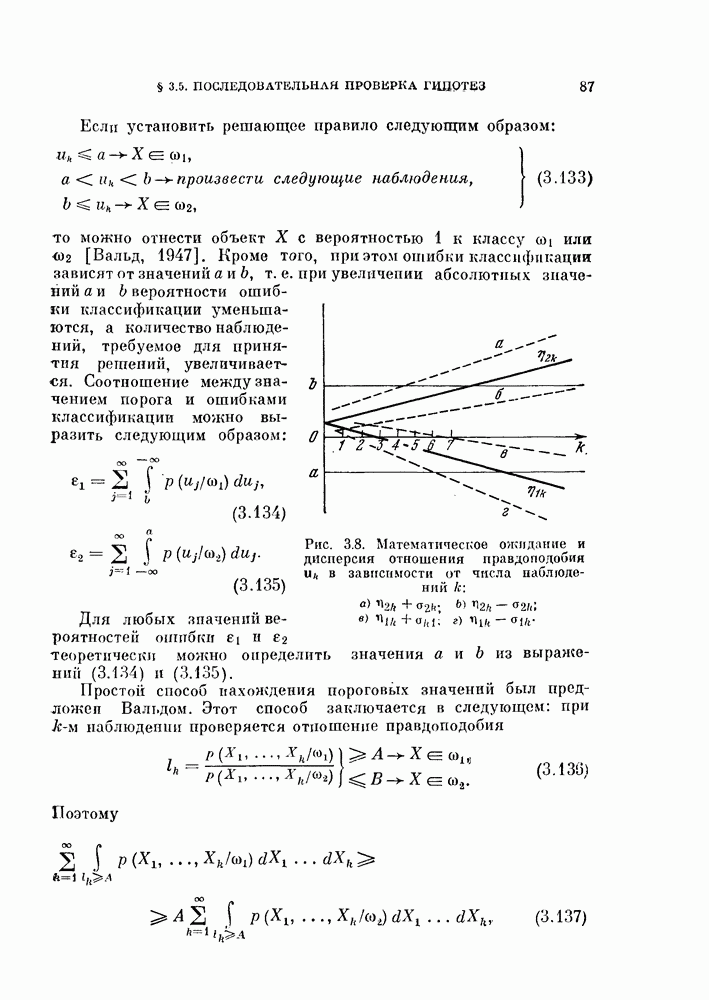
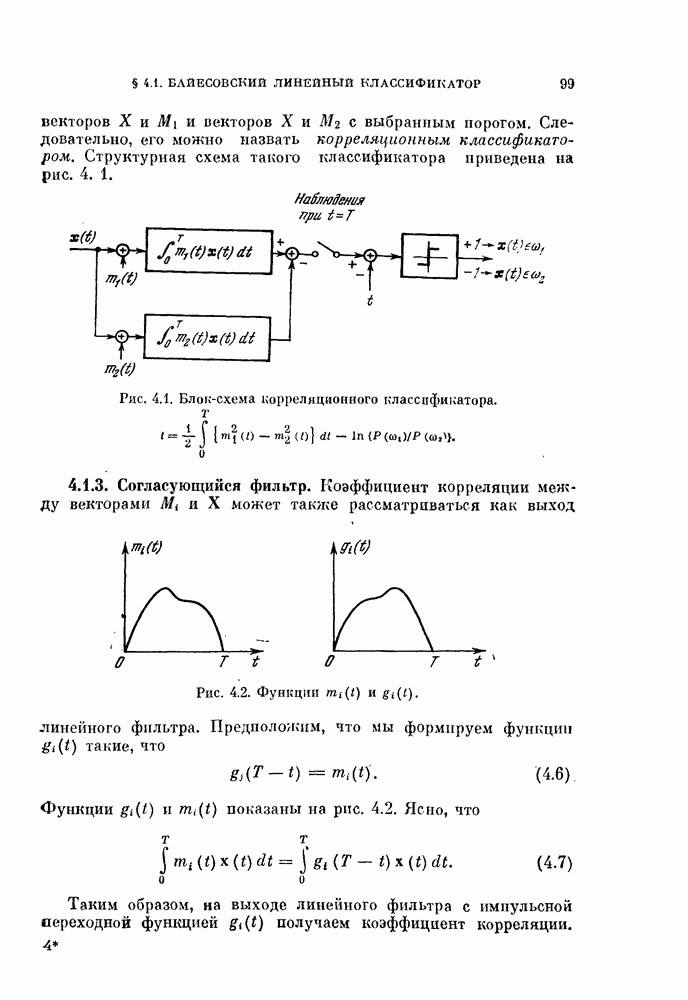
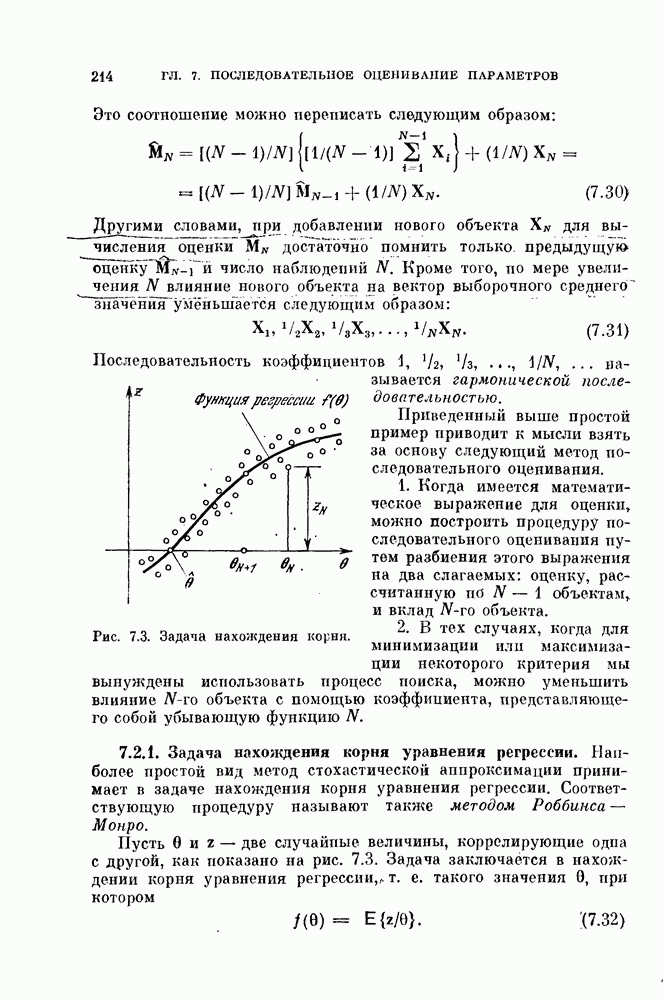
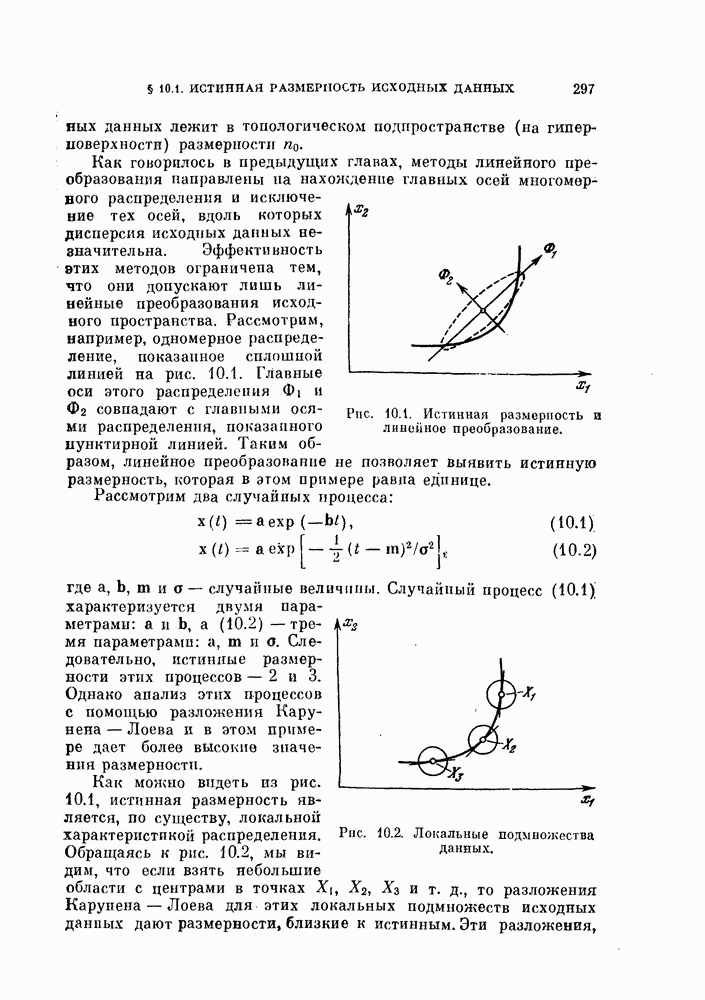
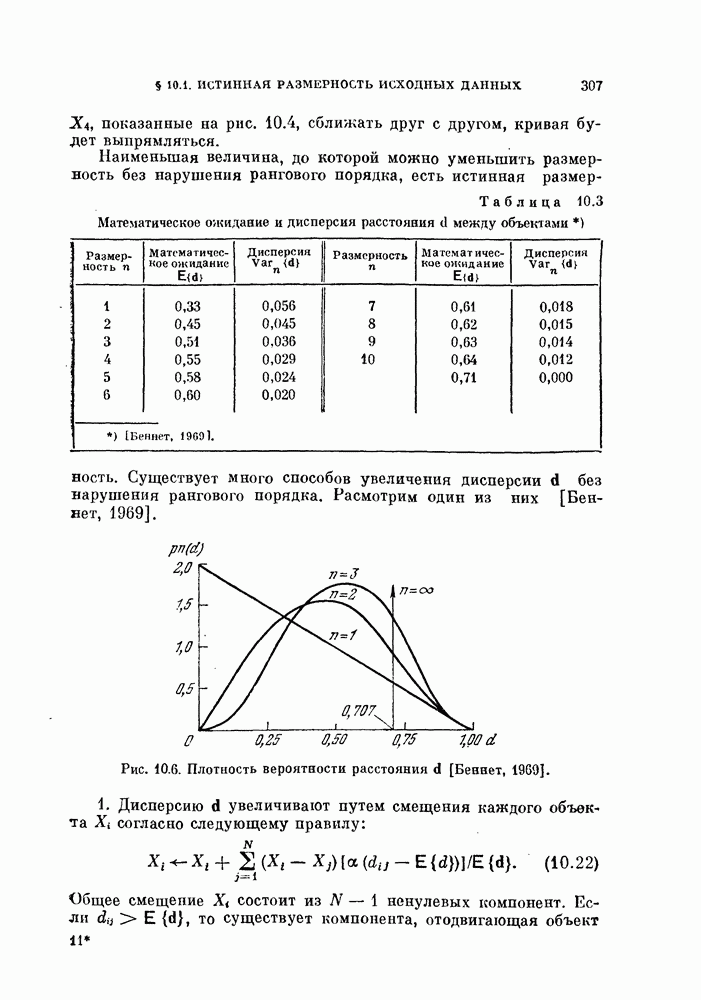
Таким образом, в преобразованной системе координат вектор V перпендикулярен к отрезку прямой, соединяющей  как изображено на рис. 4.9, а.
как изображено на рис. 4.9, а.

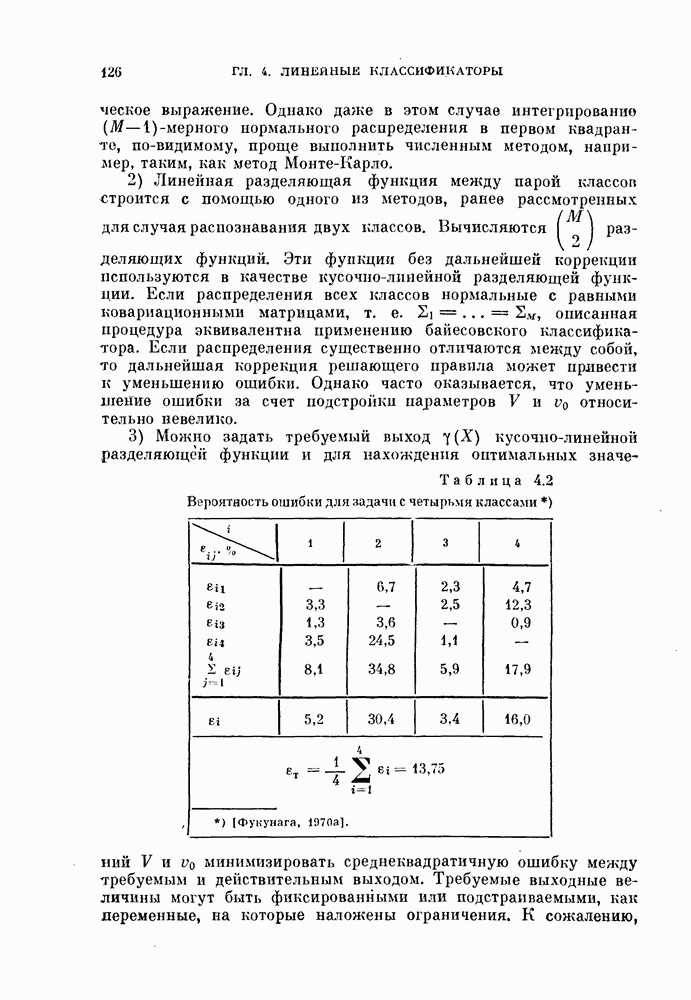
Рис. 4.9. Классификатор, минимизирующий среднеквадратичную ошибку. 
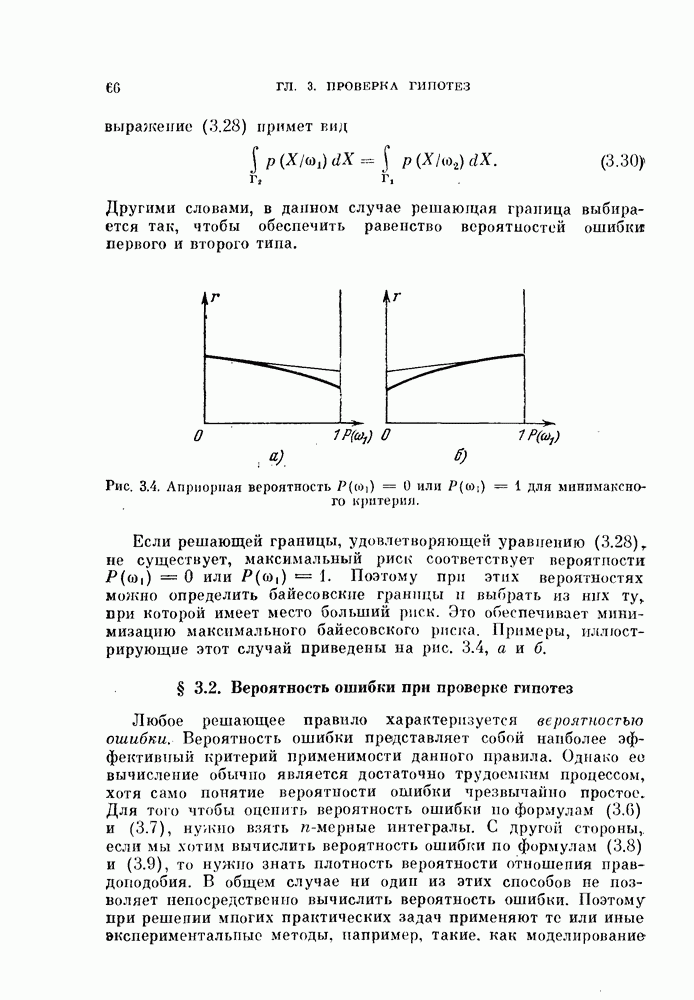
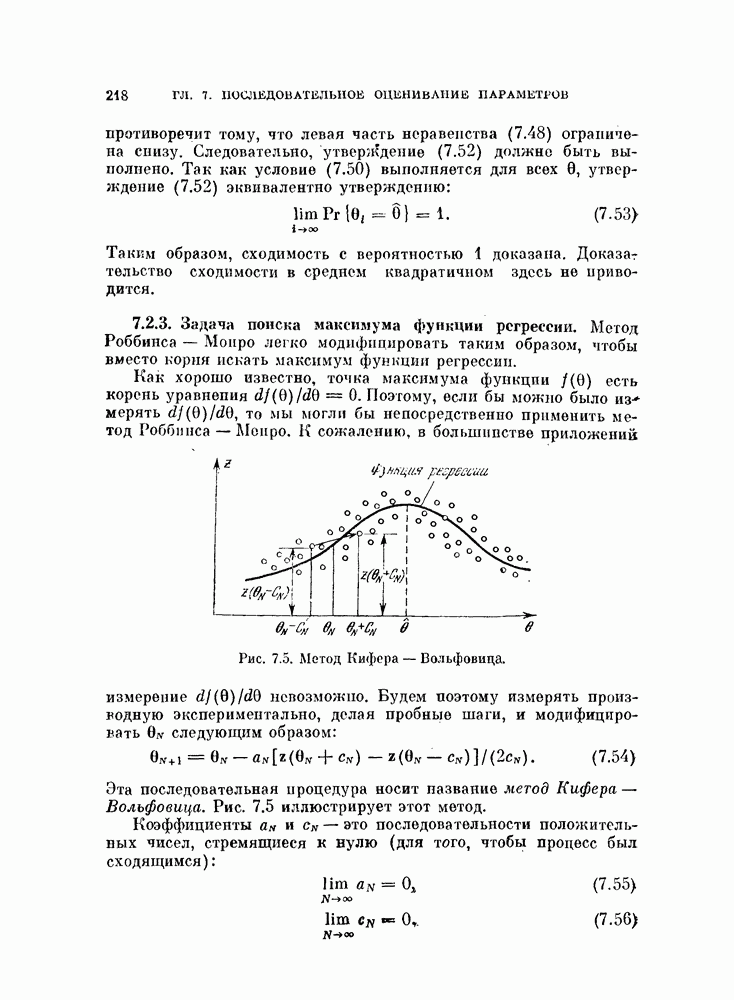
Если априорные вероятности классов равны, т. е.  то величина порога (4.60) будет равна нулю, как показано на рис. 4.9, б.
то величина порога (4.60) будет равна нулю, как показано на рис. 4.9, б.
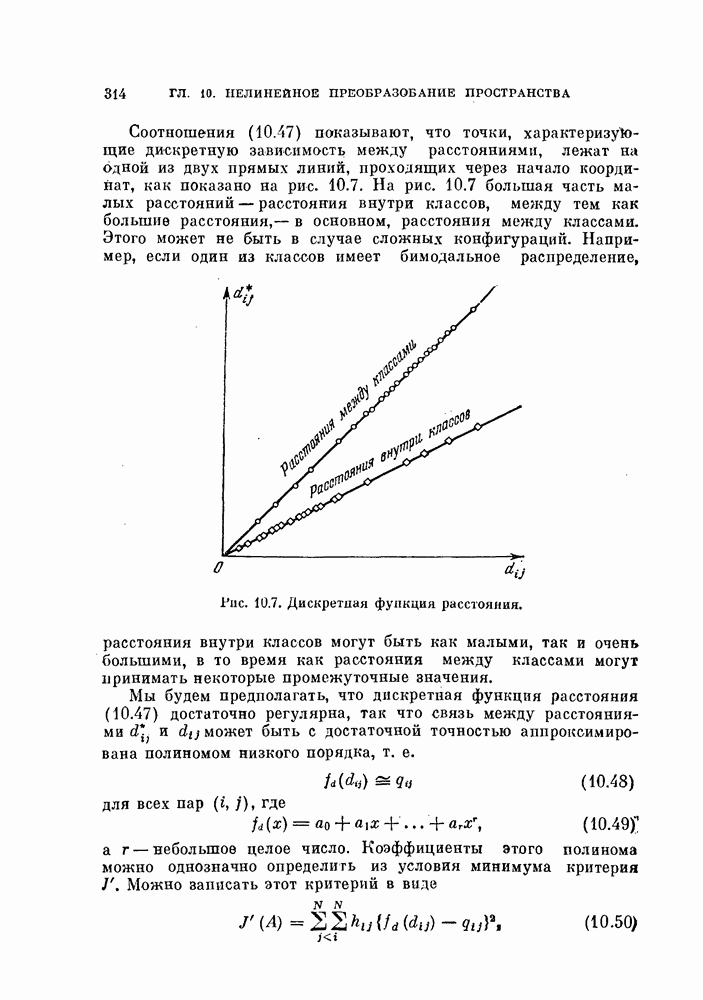
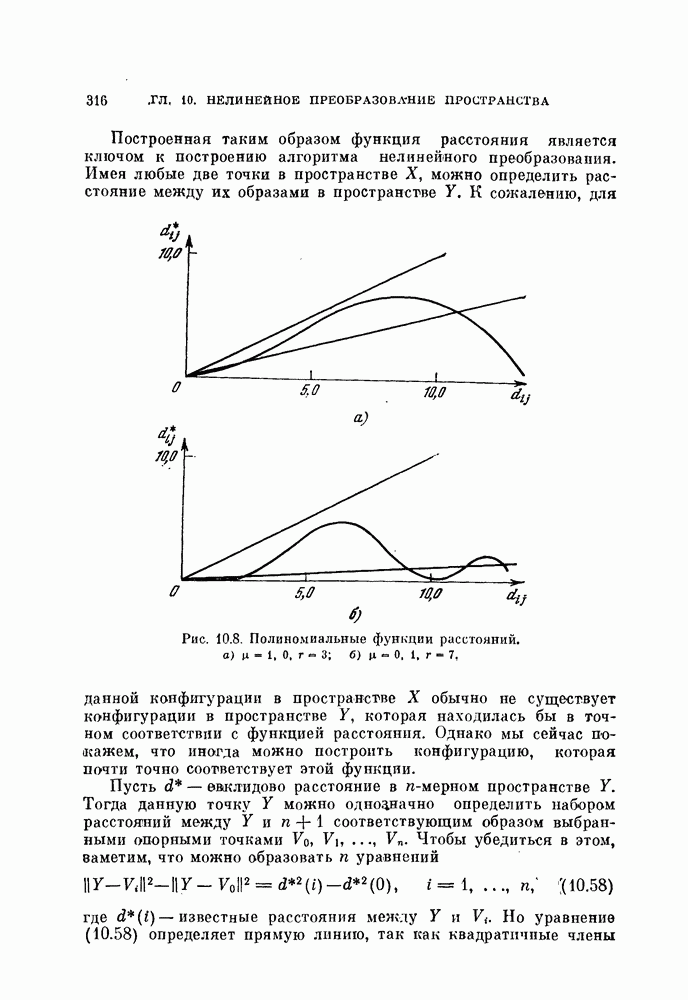
Преобразование (4.53) и (4.54) можно определить только по информации о смеси двух распределений, при этом не требуется информации о распределениях отдельных классов. Поэтому
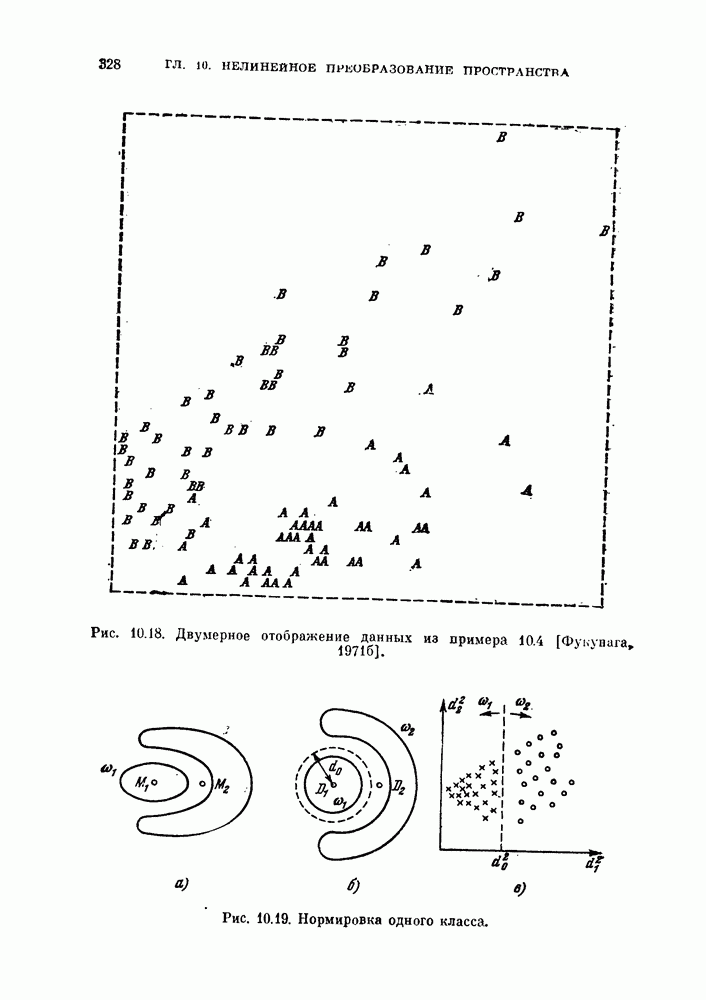
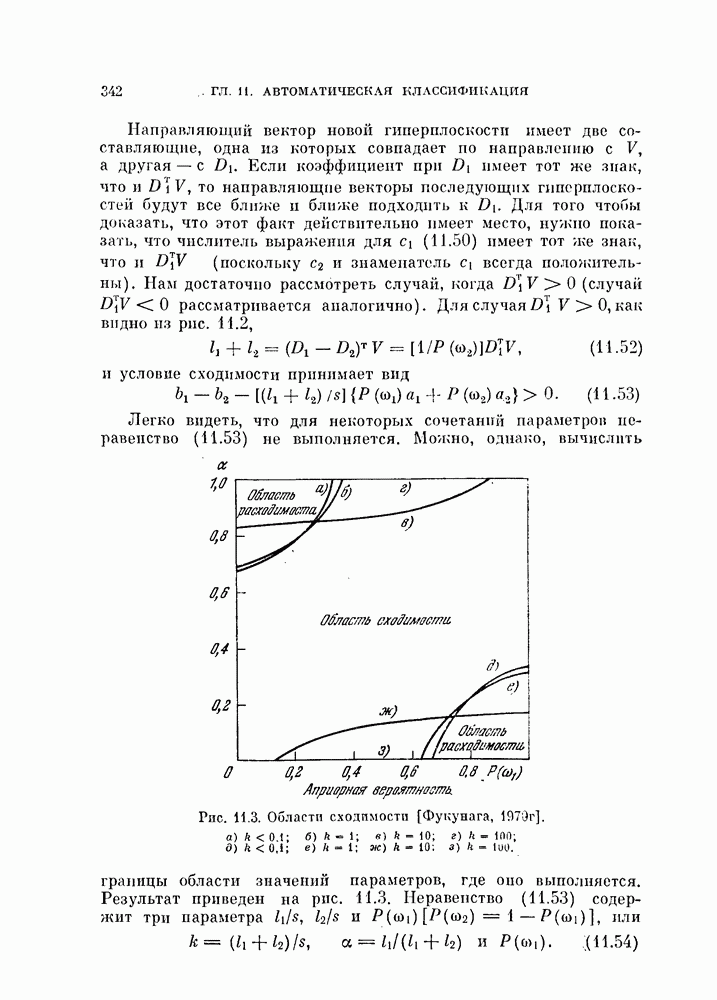
назовем это преобразование совместной нормировкой. Такое преобразование имеет важное значение, если необходимо разделить данные объекты на две группы в отсутствие информации о распределениях классов [Фукунага, Кунтц, 1970, в, г.]. Этот тип классификации называют классификацией без учителя, или автоматической классификацией. Она будет рассмотрена в последней главе. Данная классификация противопоставлена классификации с учителем, при которой для синтеза классификатора используется информация о распределениях каждого класса.
Таким образом, по этому разделу можно сделать следующие выводы.
1) В случае совместной нормировки линейная разделяющая функция, минимизирующая среднеквадратичную ошибку между требуемым и действительным выходом, определяется корреляцией между требуемым выходом и У. Это справедливо для любого распределения.
2) В частности, если все требуемые выходы равны  то классификатор превращается в гиперплоскость, перпендикулярную к отрезку прямой, соединяющей векторы
то классификатор превращается в гиперплоскость, перпендикулярную к отрезку прямой, соединяющей векторы  Это решение совпадает с тем, которое было получено в (4.3), где использовались корреляционный классификатор или классификатор, основанный на вычислении евклидова расстояния. Однако, так как выражения для значений порога в случае (4.3) и рис. 4.9, а различны, то выбор одного из них для каждого конкретного случая зависит от метода, используемого в конкретном приложении. Если априорные вероятности равны, т. е.
Это решение совпадает с тем, которое было получено в (4.3), где использовались корреляционный классификатор или классификатор, основанный на вычислении евклидова расстояния. Однако, так как выражения для значений порога в случае (4.3) и рис. 4.9, а различны, то выбор одного из них для каждого конкретного случая зависит от метода, используемого в конкретном приложении. Если априорные вероятности равны, т. е.  то значения порога также равны.
то значения порога также равны.