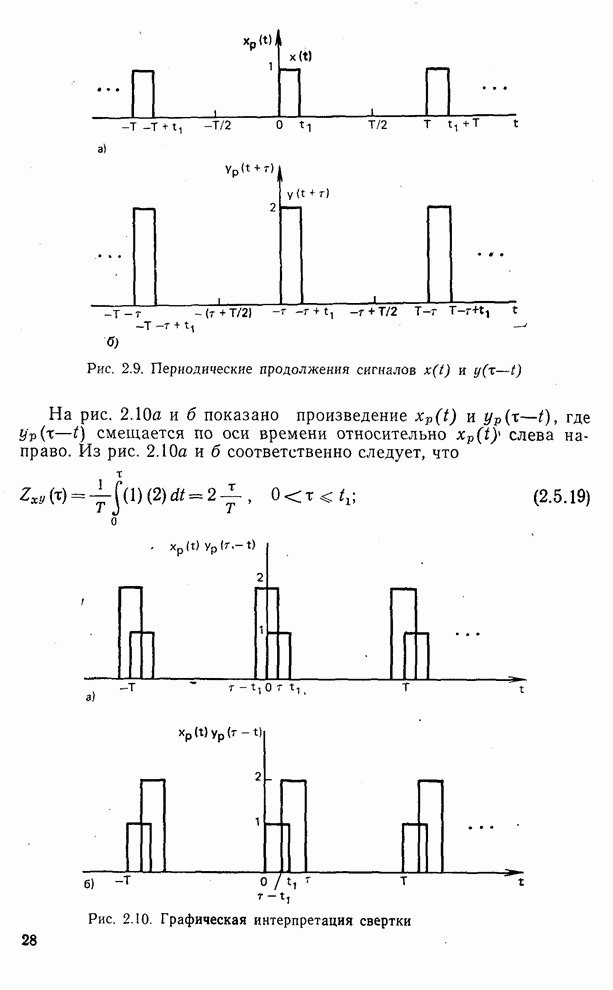
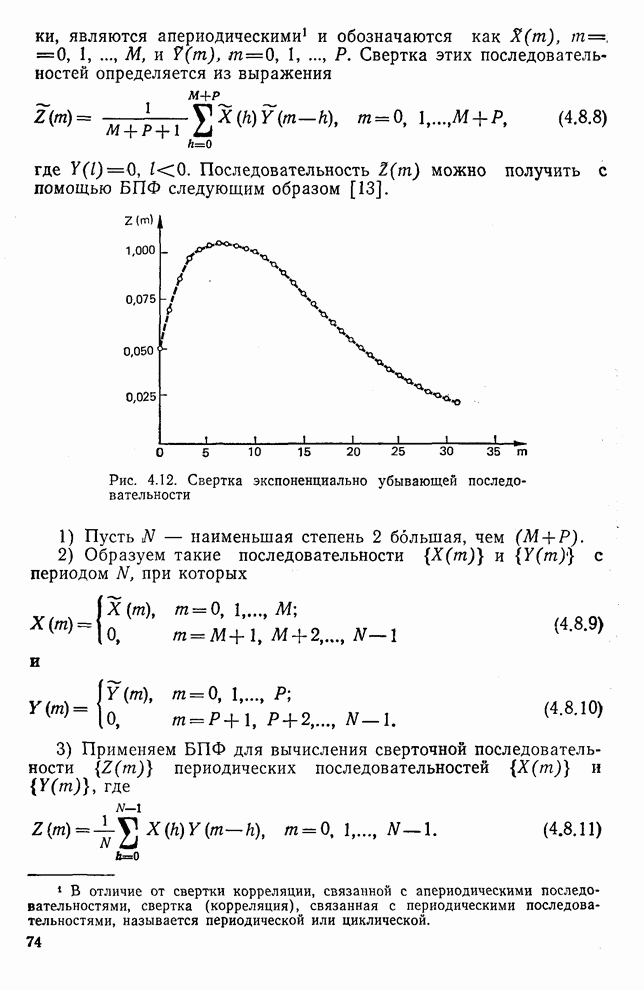
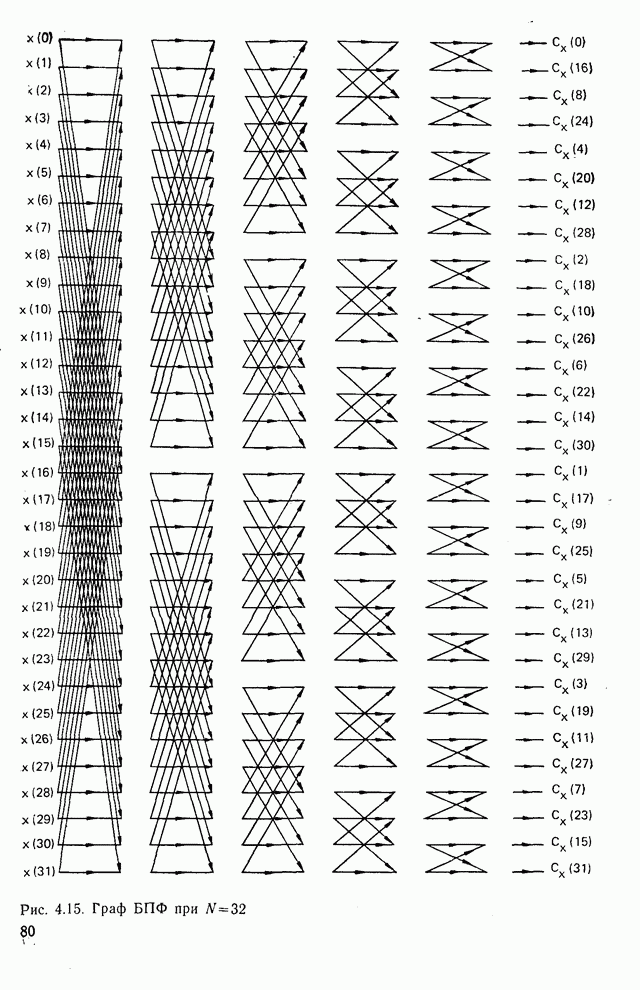
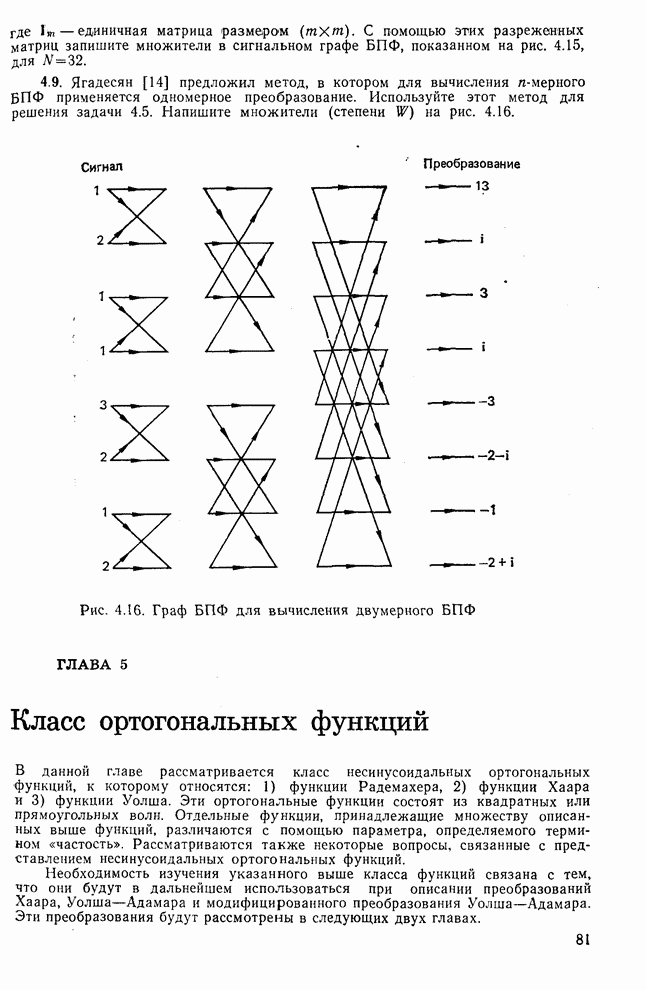
Пред.
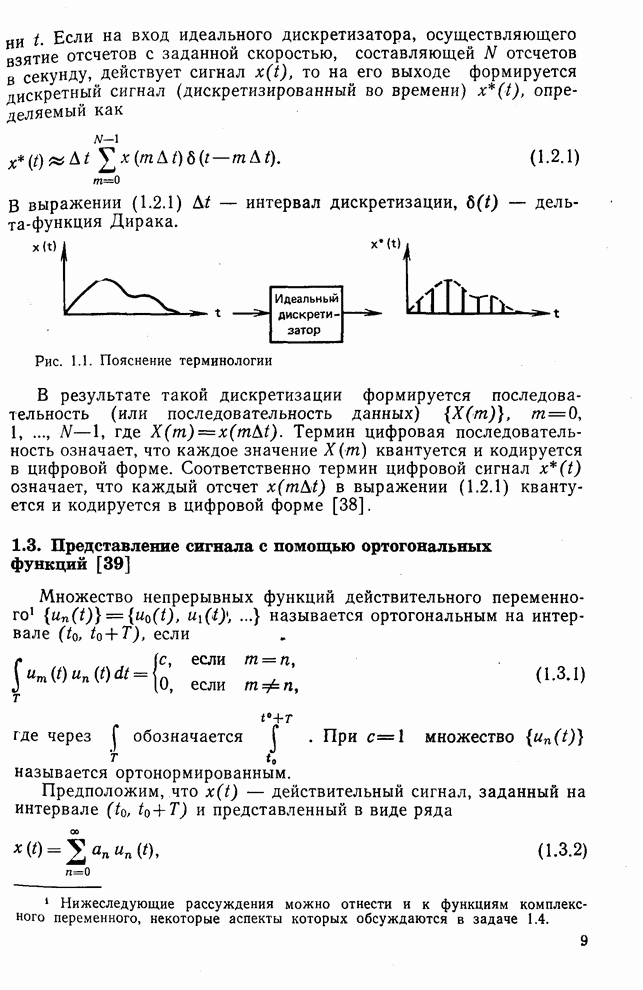
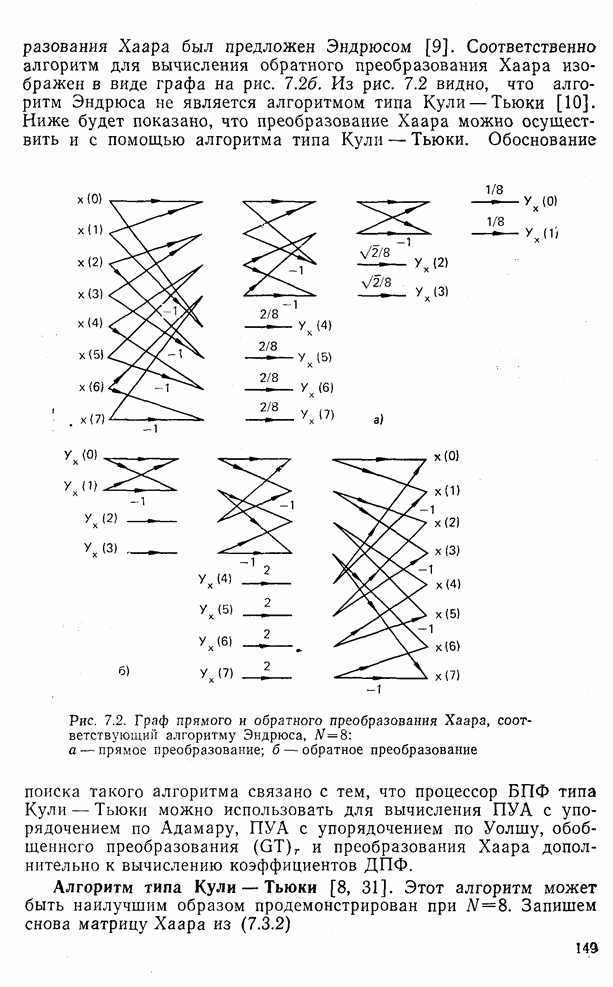
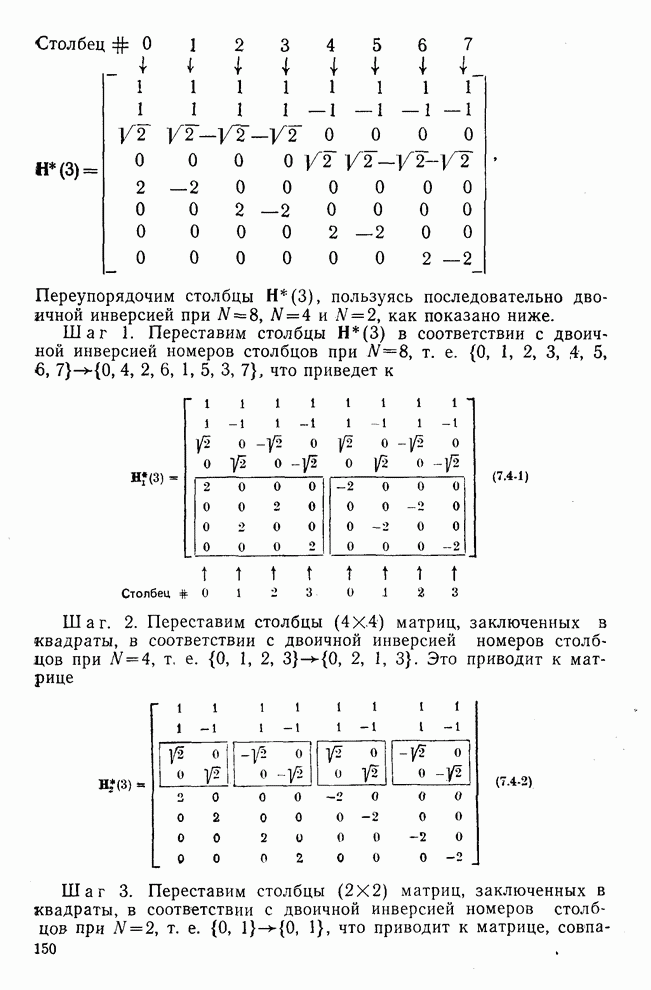
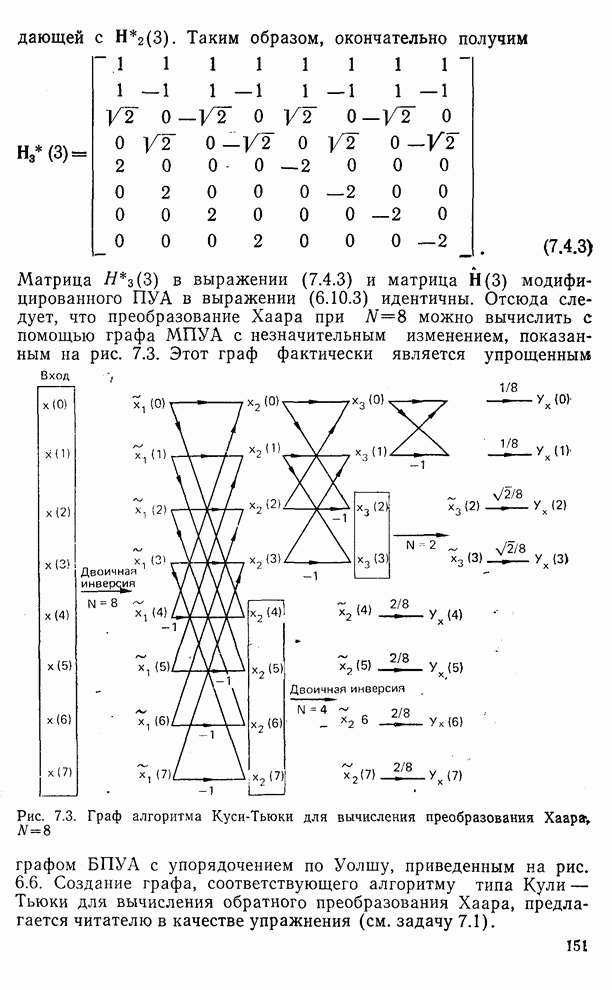
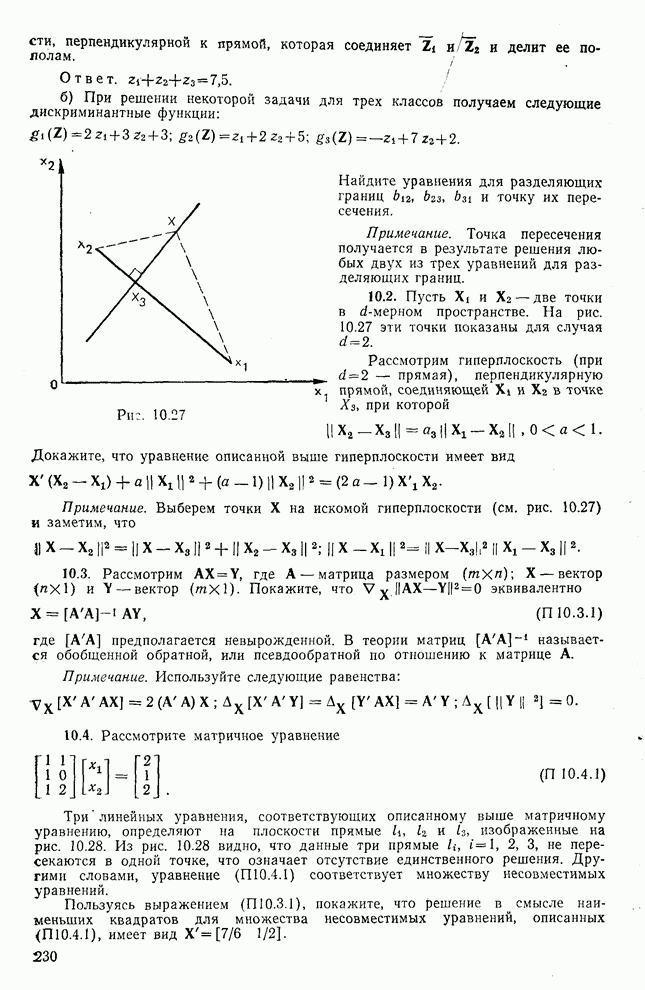
След.
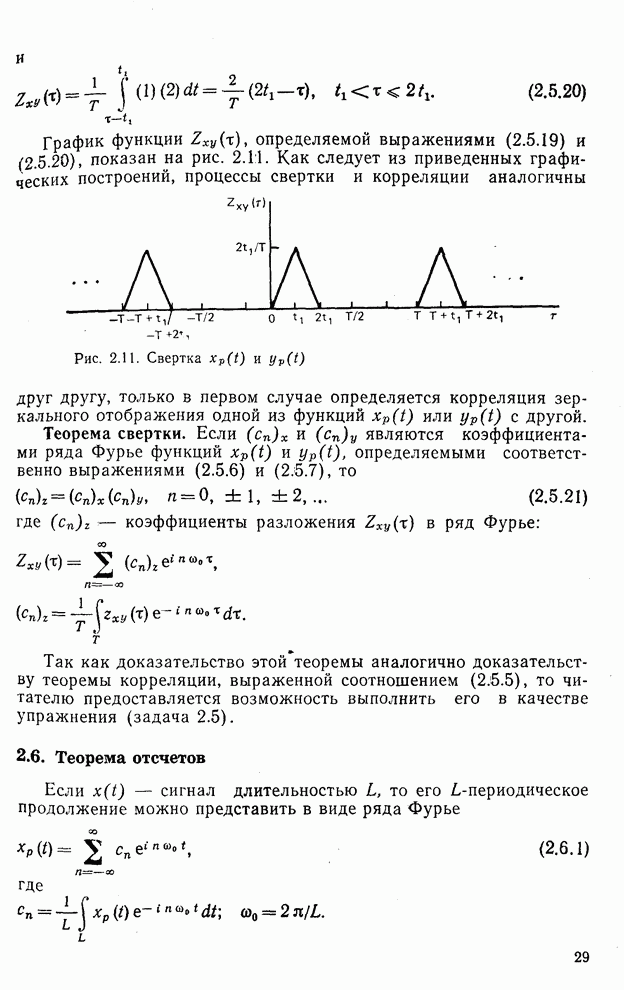
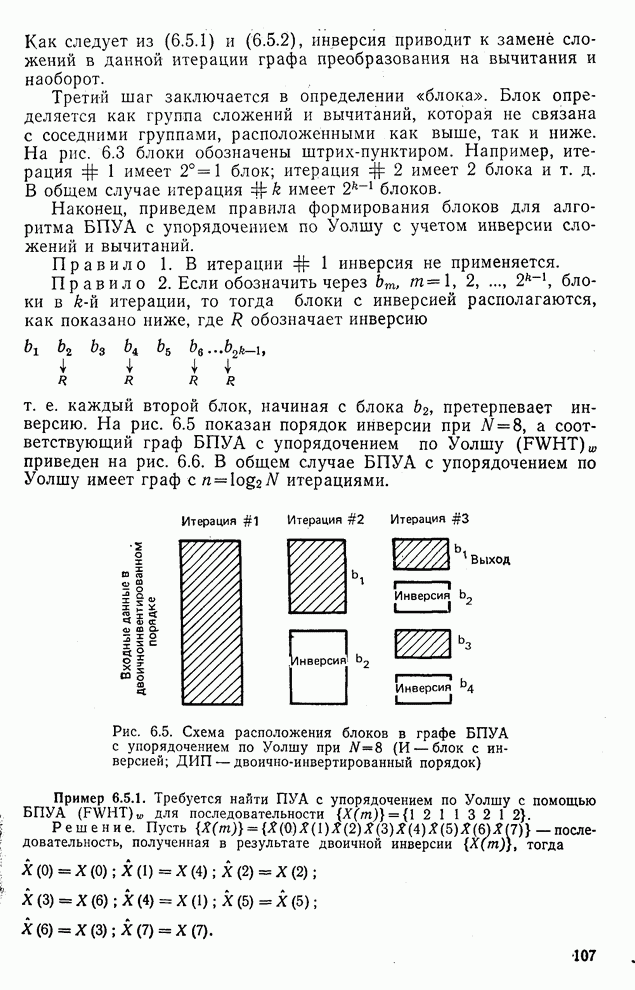
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
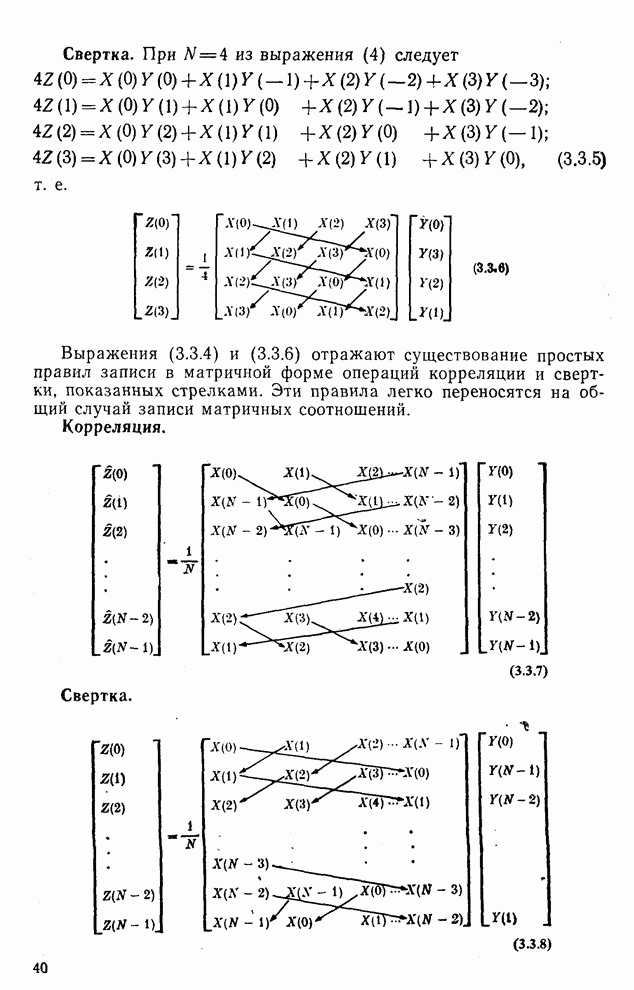
ZADANIA.TO
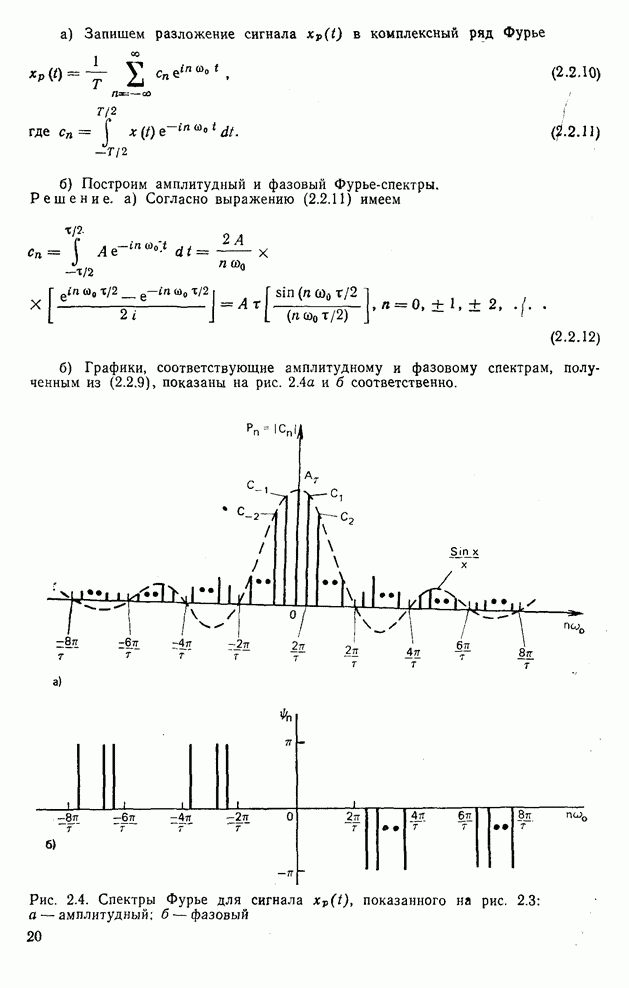
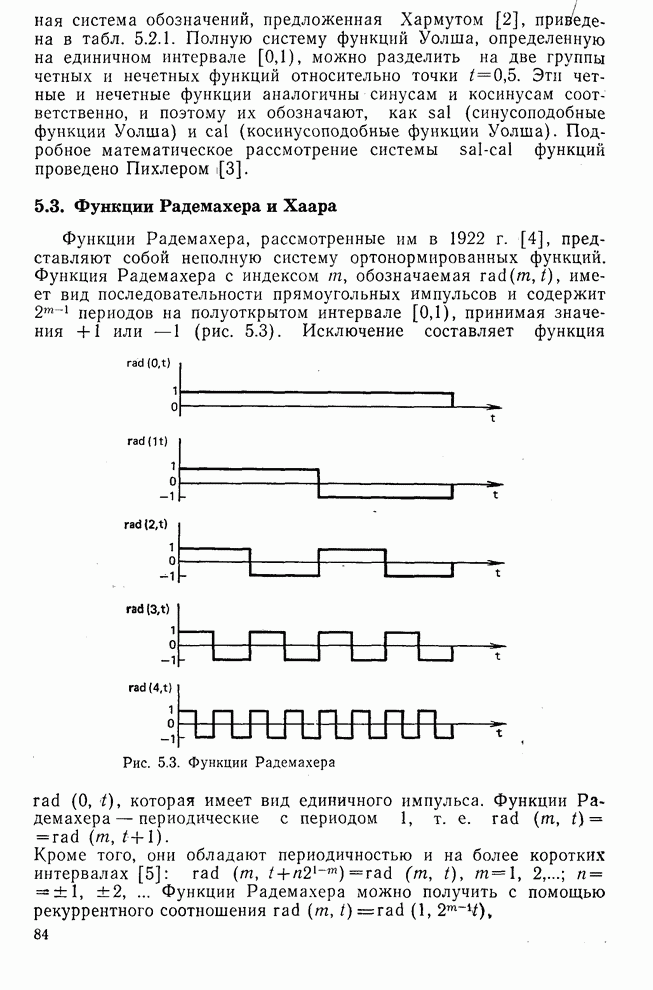
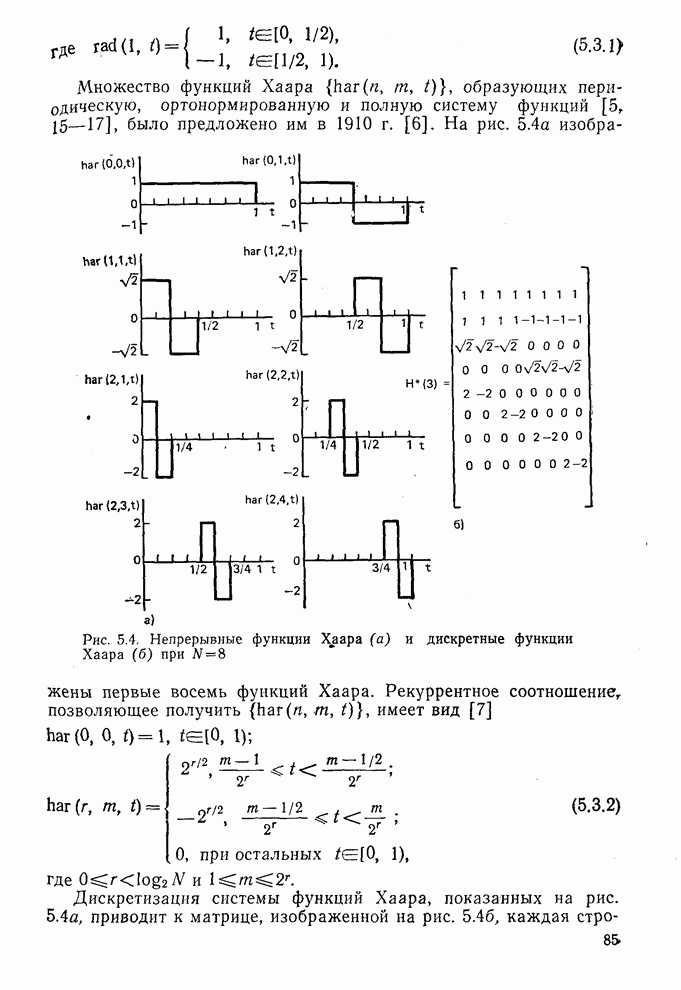
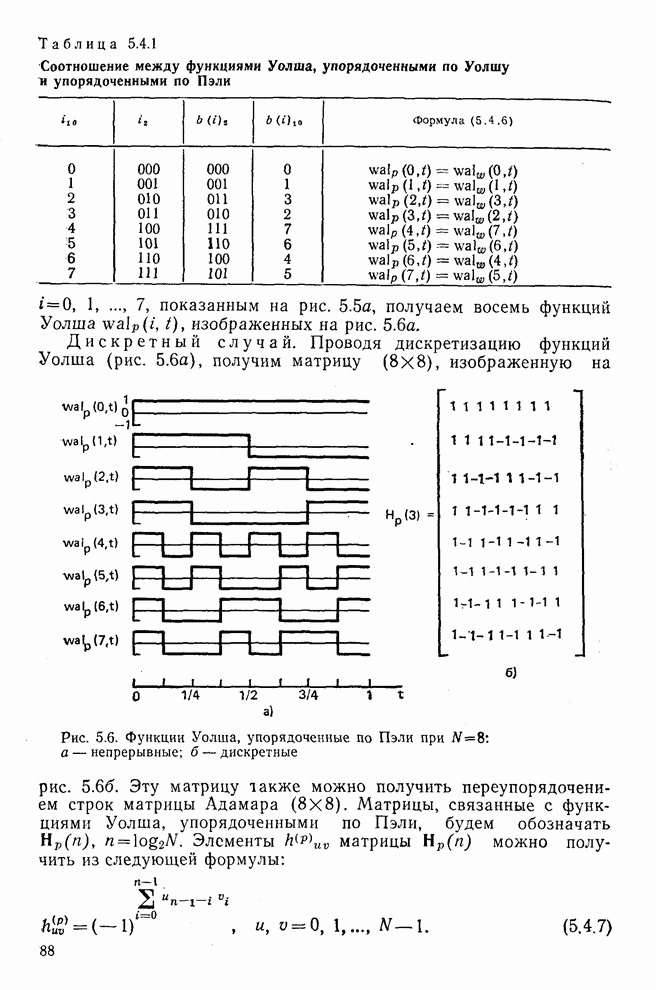
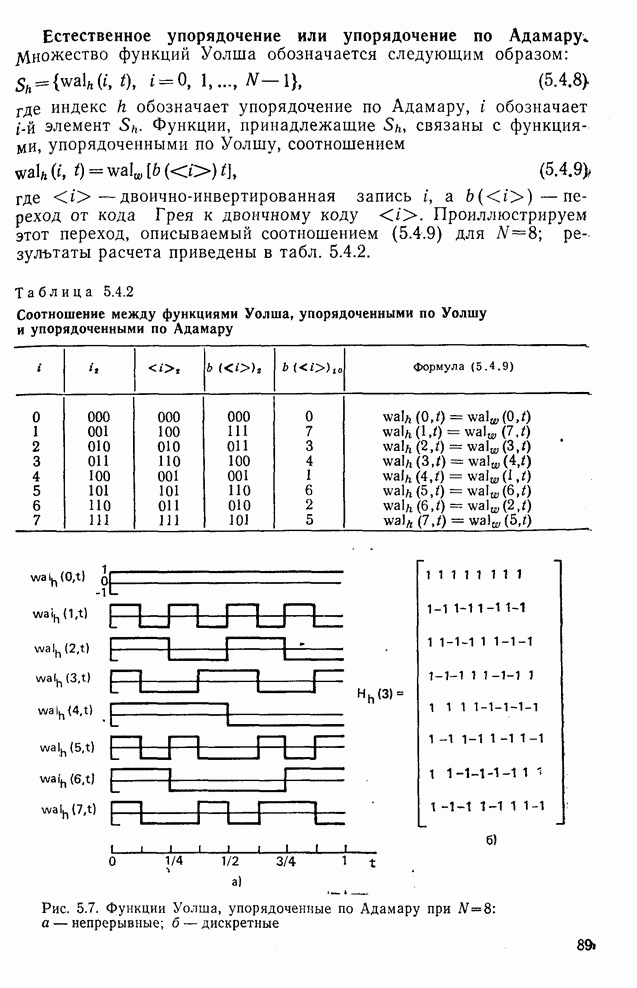
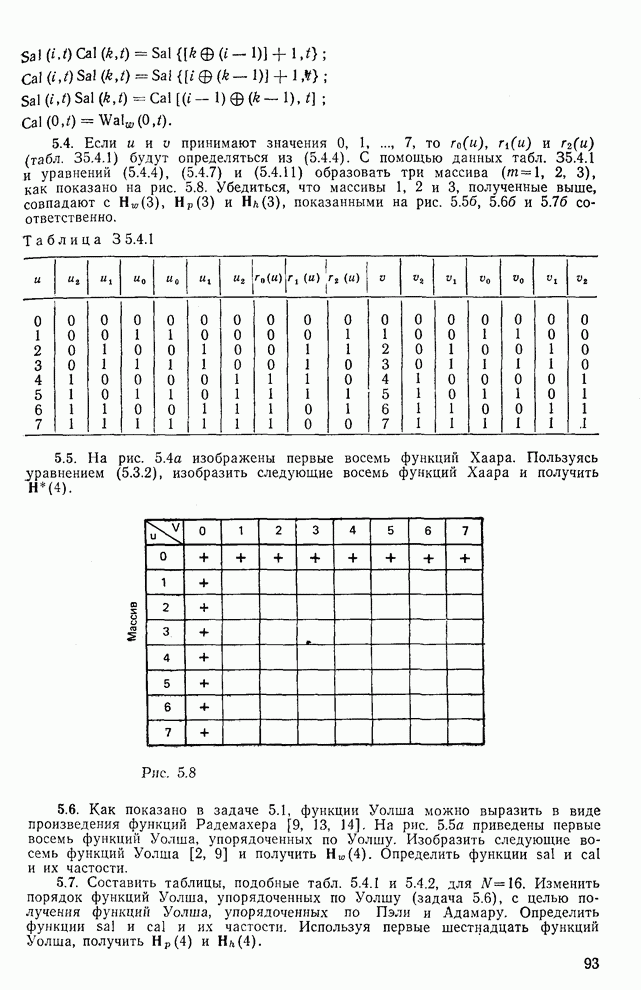
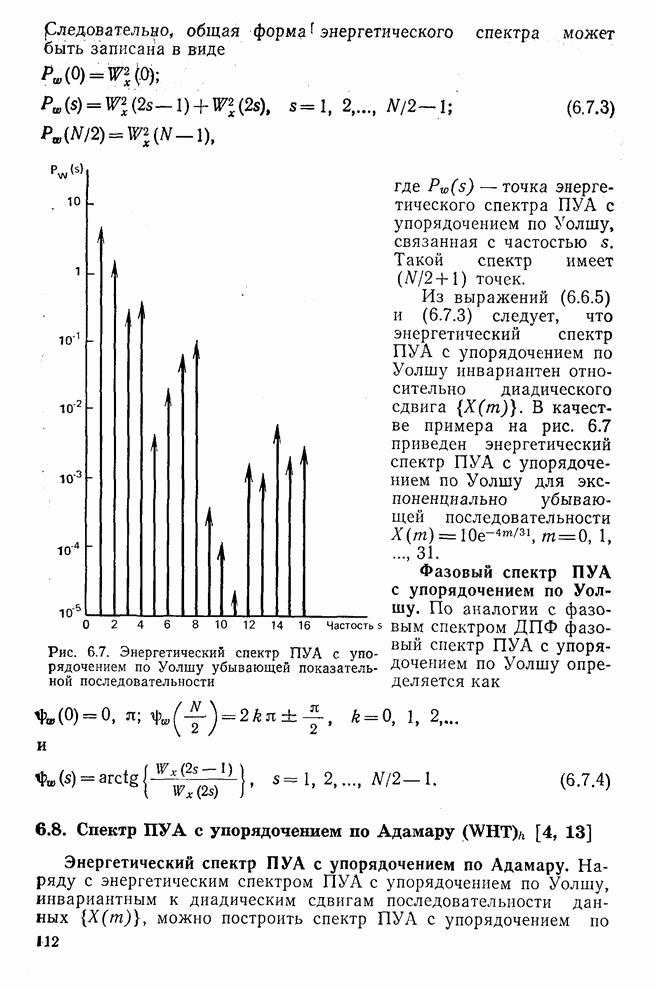
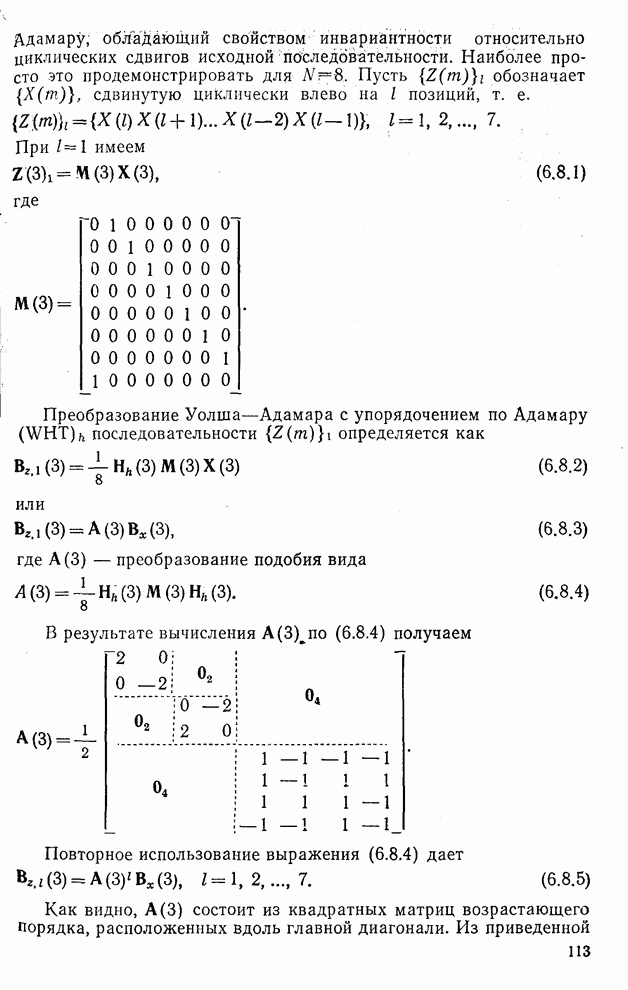
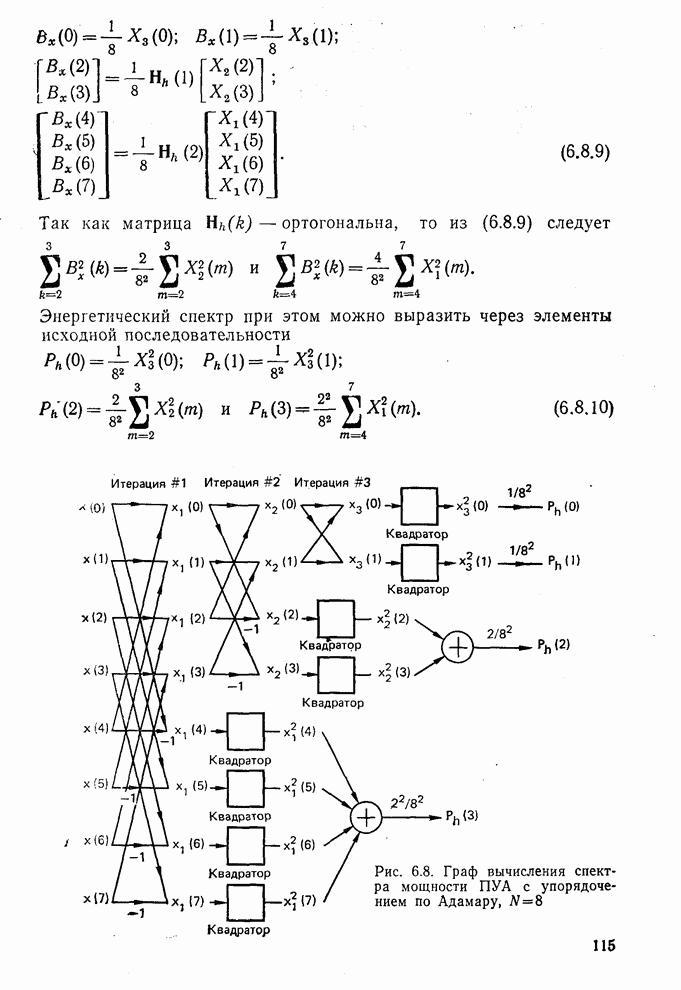
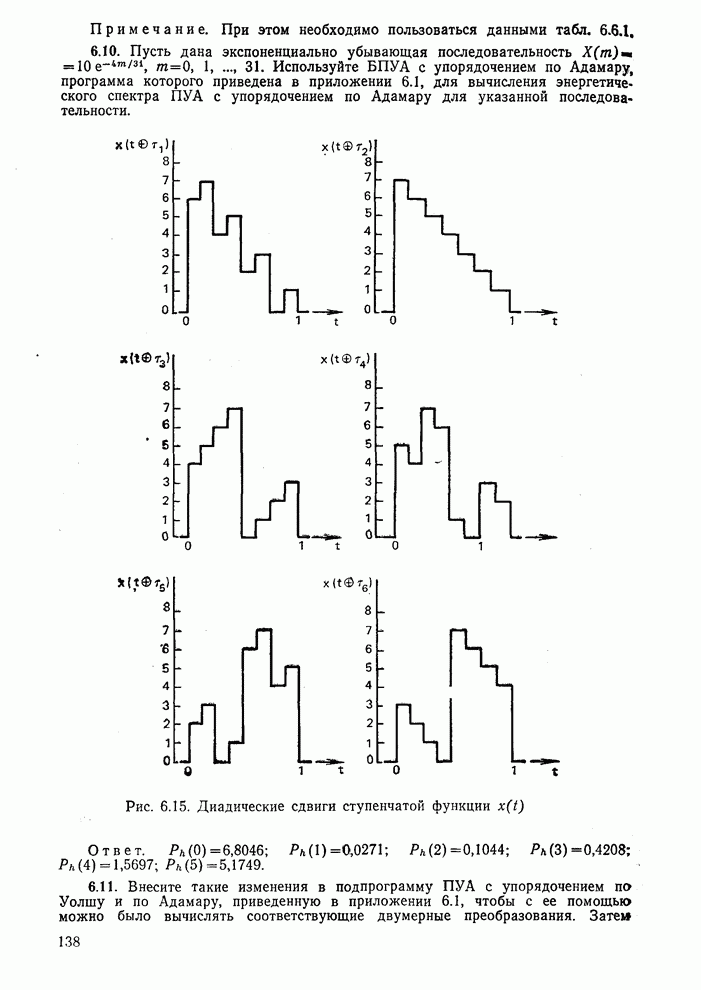
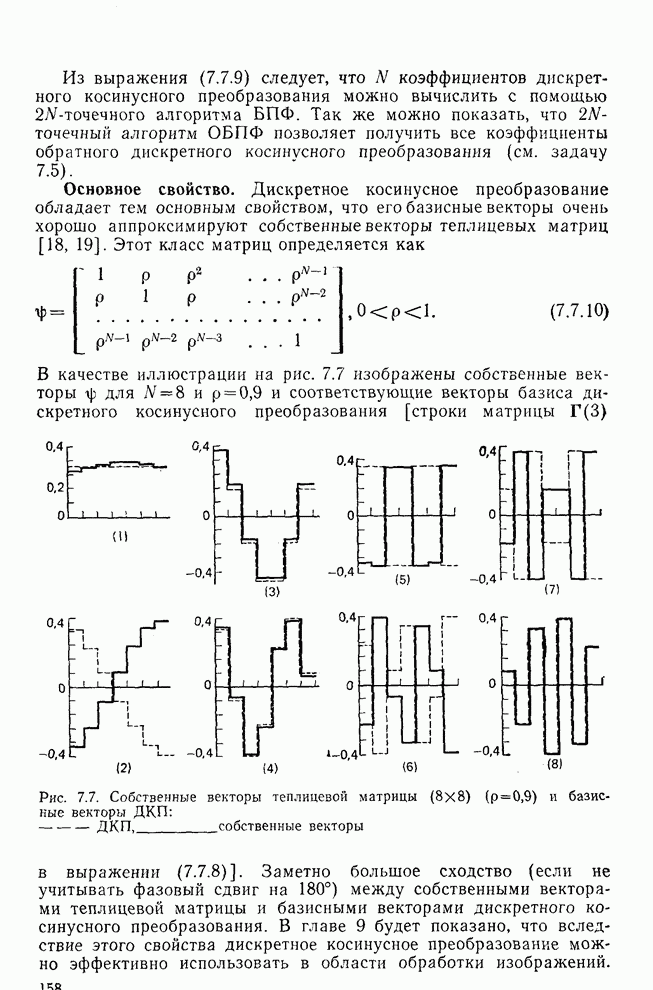
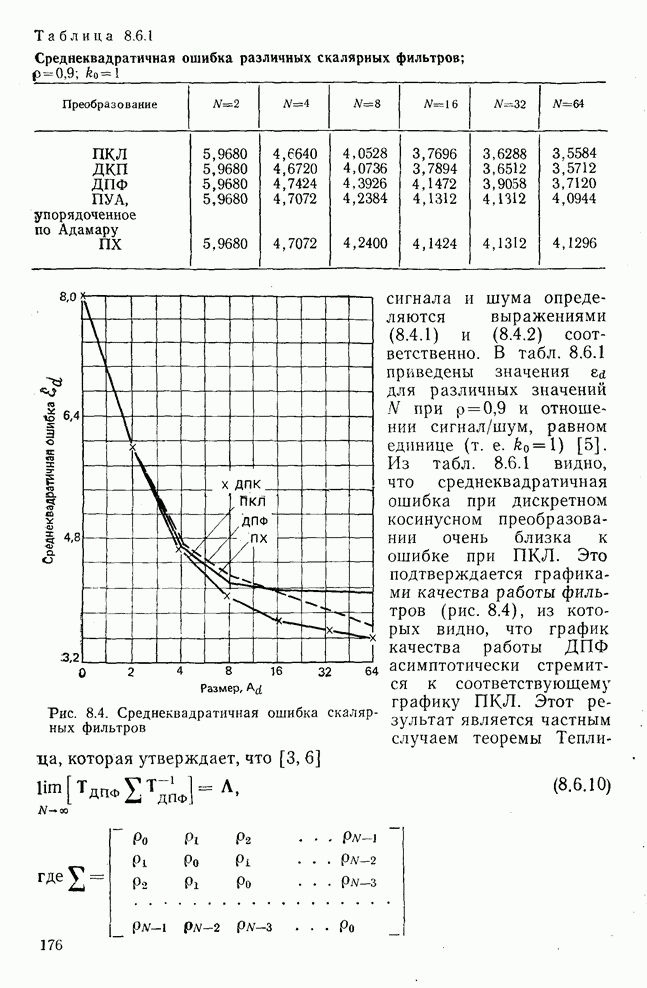
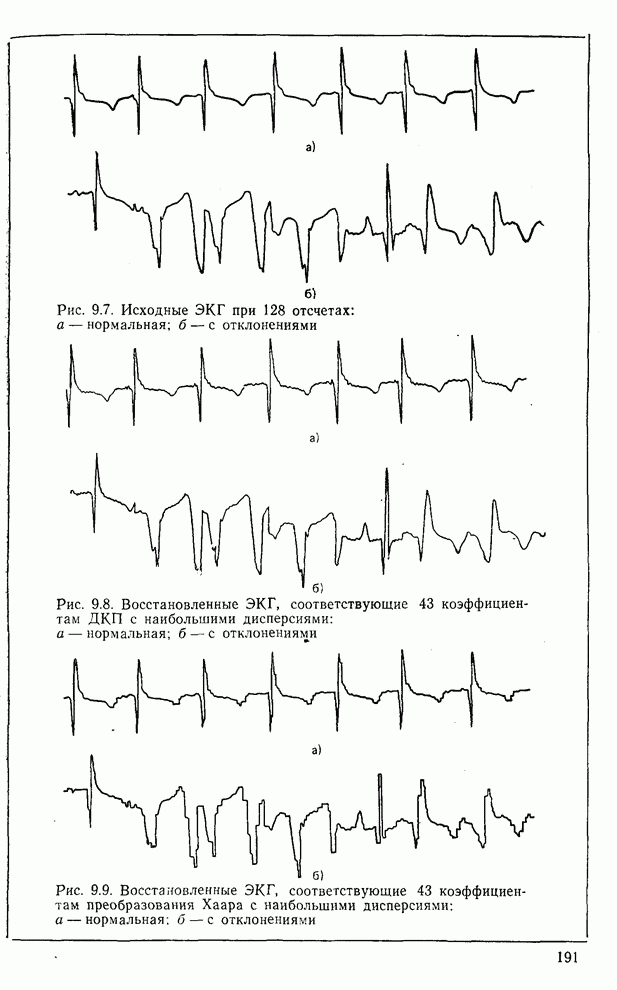
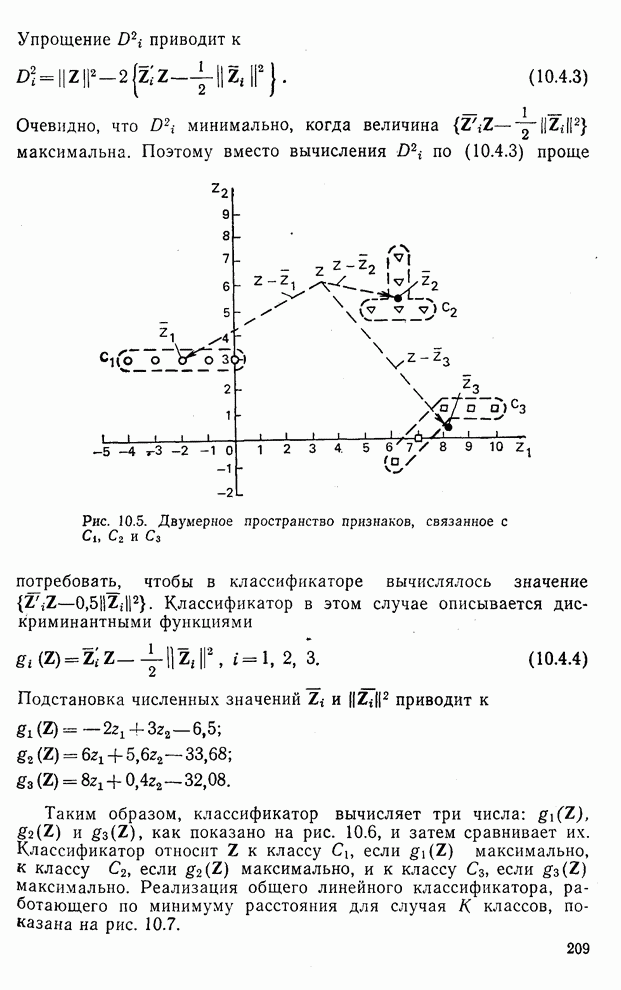
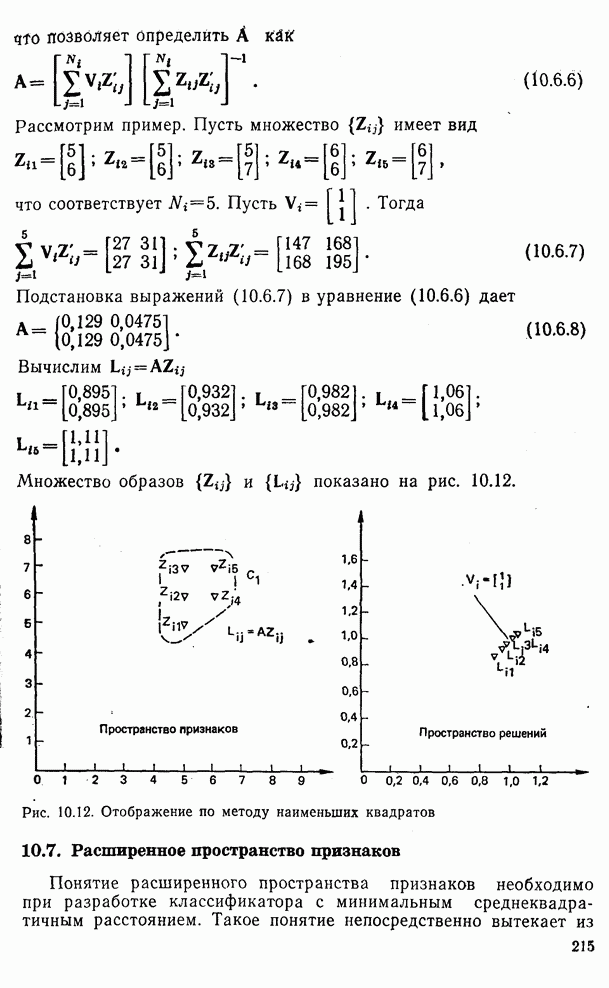
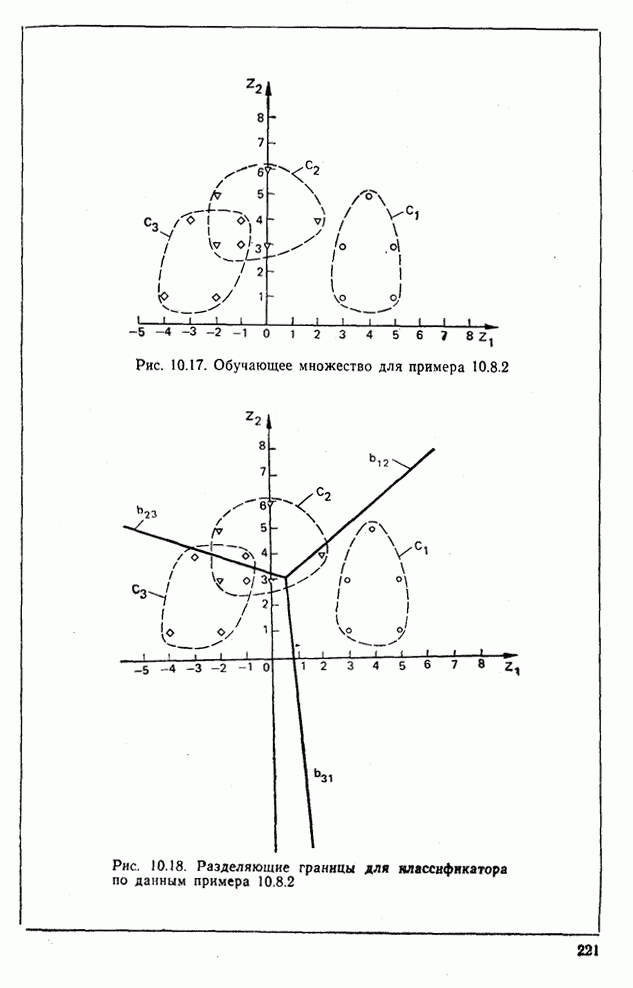
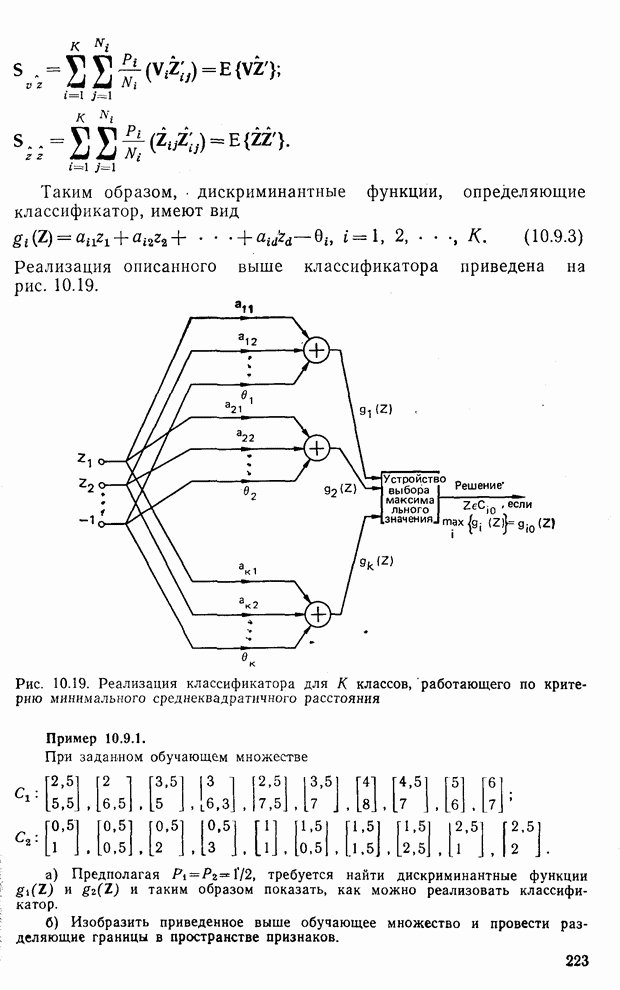
10.5. Эксперимент по классификации изображенийИнтересный эксперимент, проведенный Эндрюсом [7, 8], заключался в распознавании цифр, принадлежащих к десяти классам Пример распечатки, полученной с АЦПУ, приведен на рис. 10.8. Эта информация представлена в виде вектора, имеющего 192 отсчета. Для облегчения вычислений каждый из этих векторов дополнялся нулями до вектора размером 256 (см. рис. 10.1):
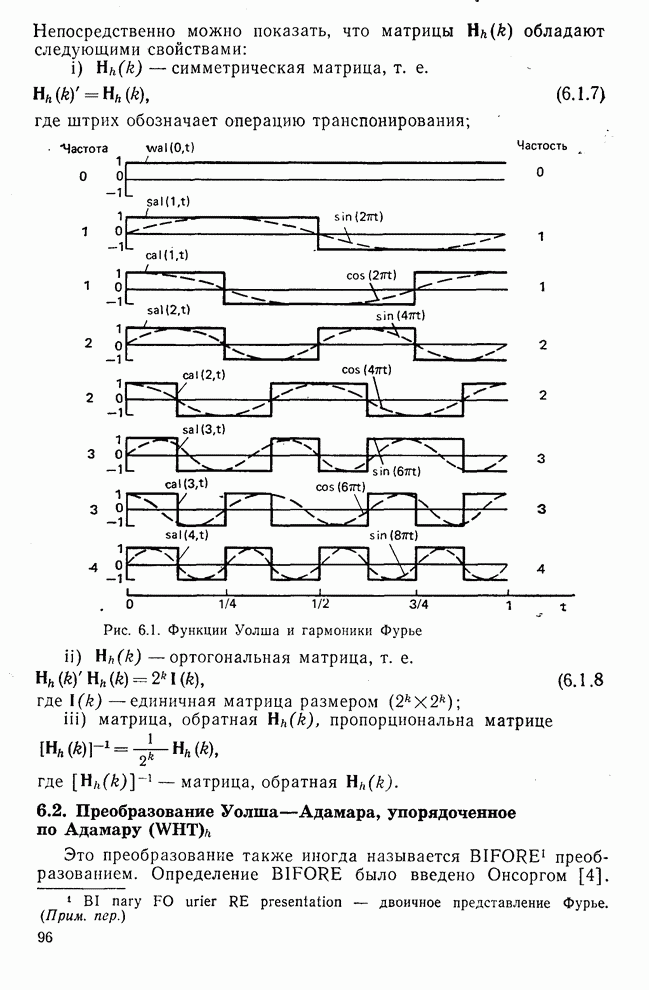
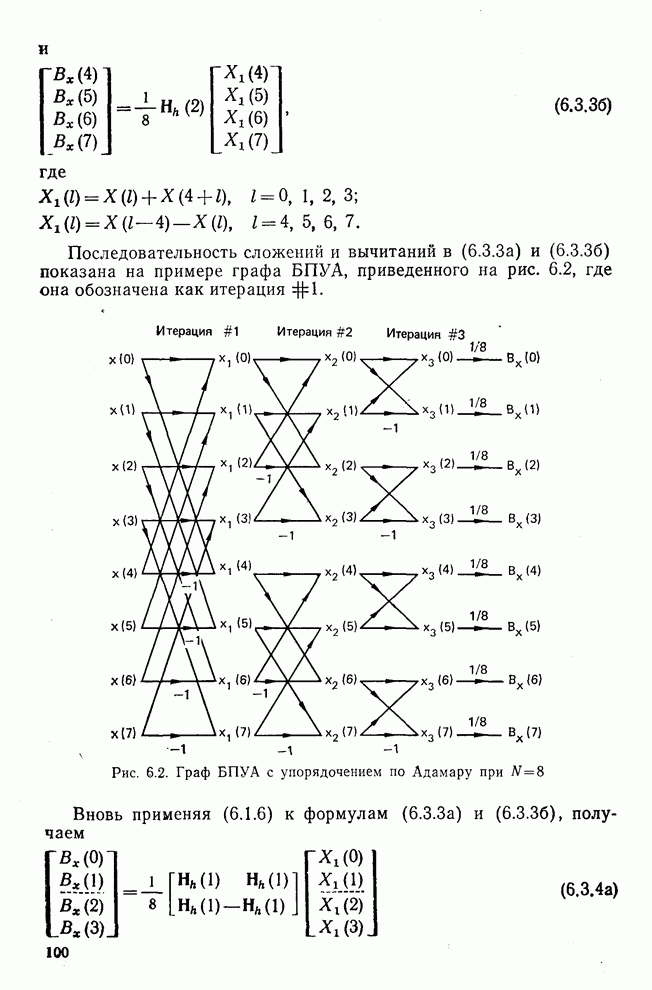
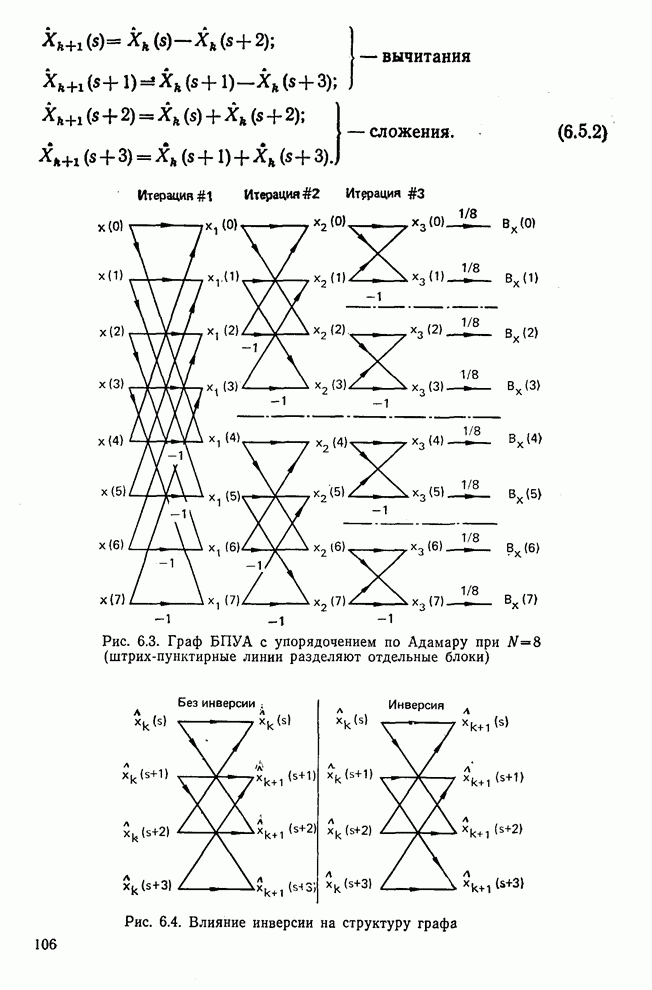
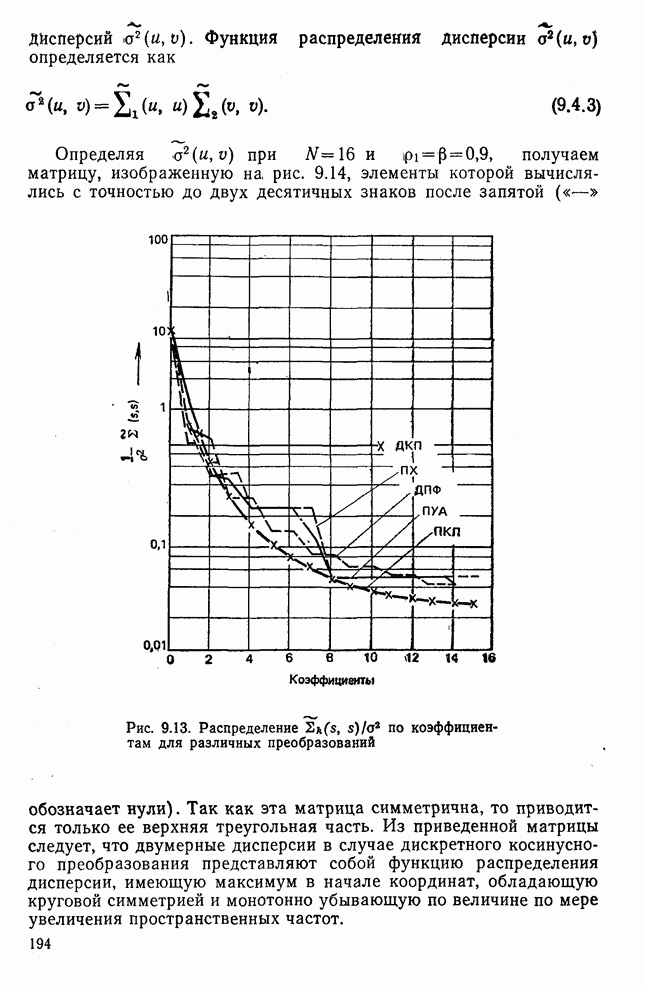
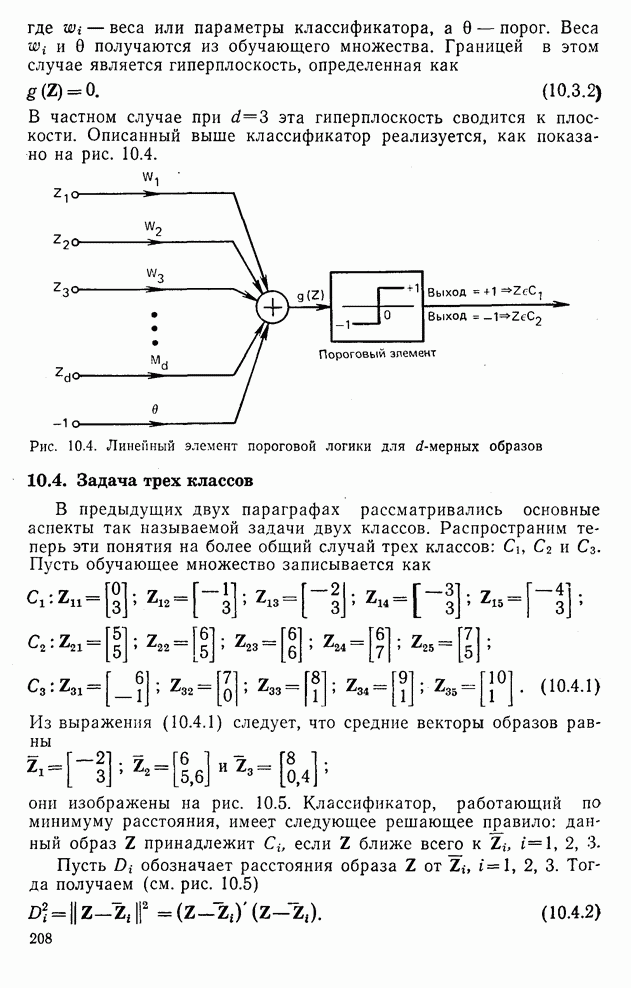
Процедура выбора признаков. Общая ковариационная матрица вычисляется как [см. выражение (9.2.1)]
где
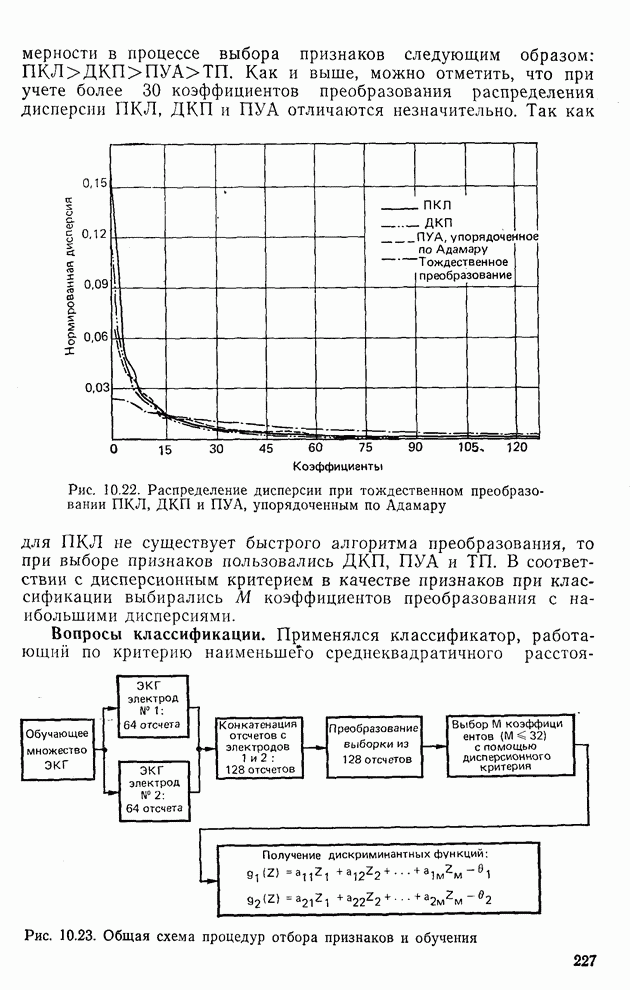
Рис. 10.8. Четырехуровневое представление цифры 4 [8] Соображения по классификации. Для распознавания применялся классификатор на 10 классов, работающий по критерию минимума расстояния, дискриминантные функции такого классификатора записываются в виде
где
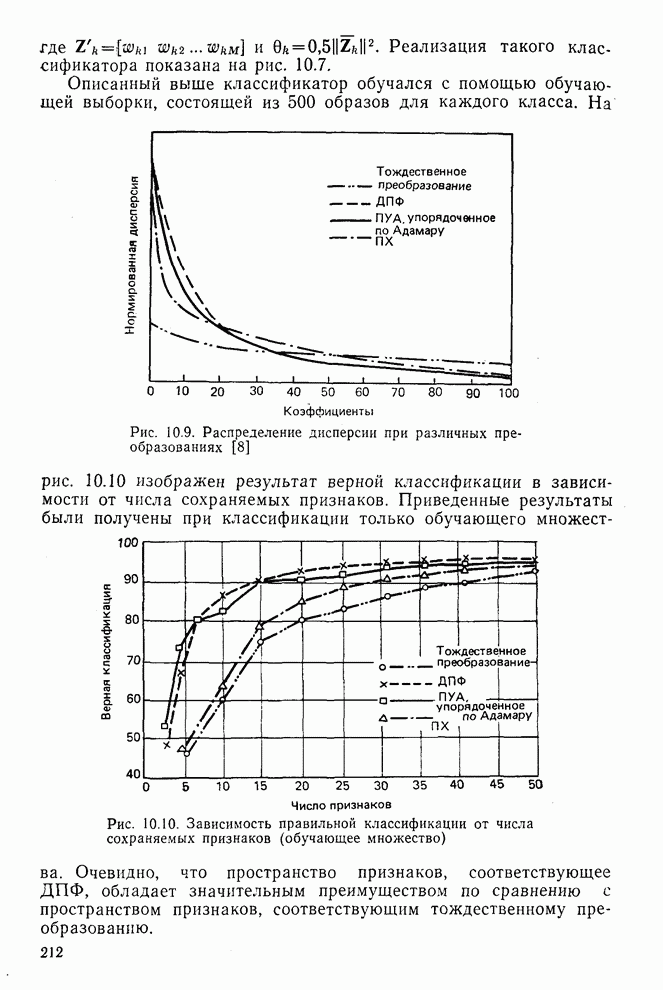
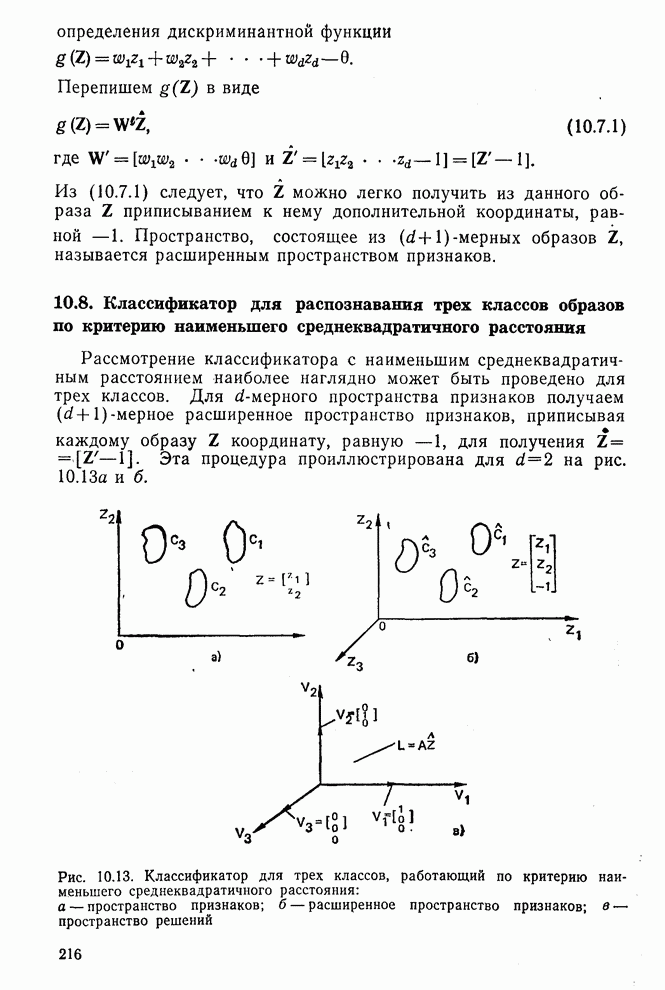
где Описанный выше классификатор обучался с помощью обучающей выборки, состоящей из 500 образов для каждого класса. На рис. 10.10 изображен результат верной классификации в зависимости от числа сохраняемых признаков. Приведенные результаты были получены при классификации только обучающего множества.
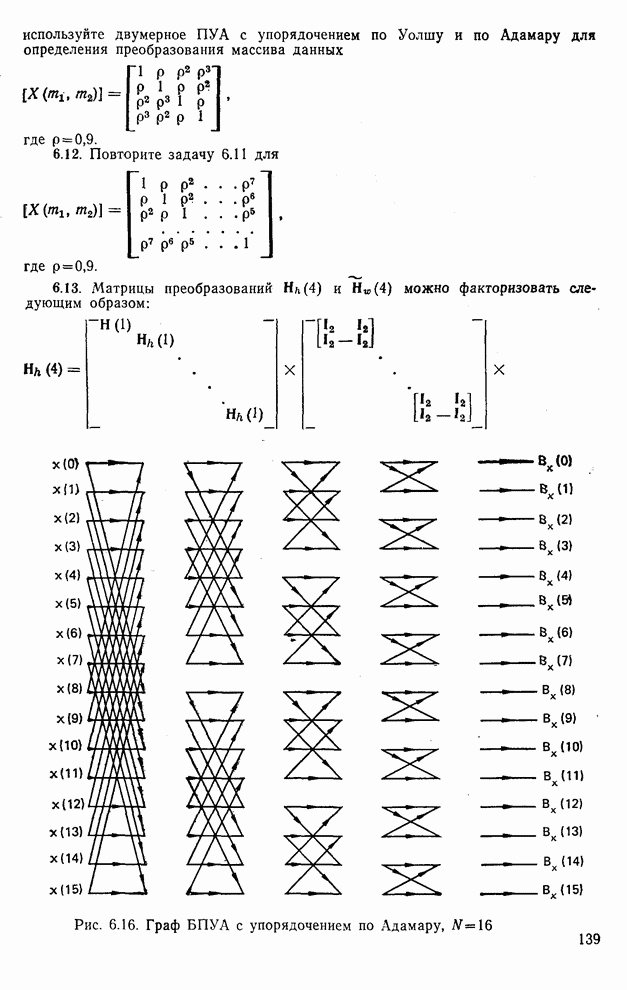
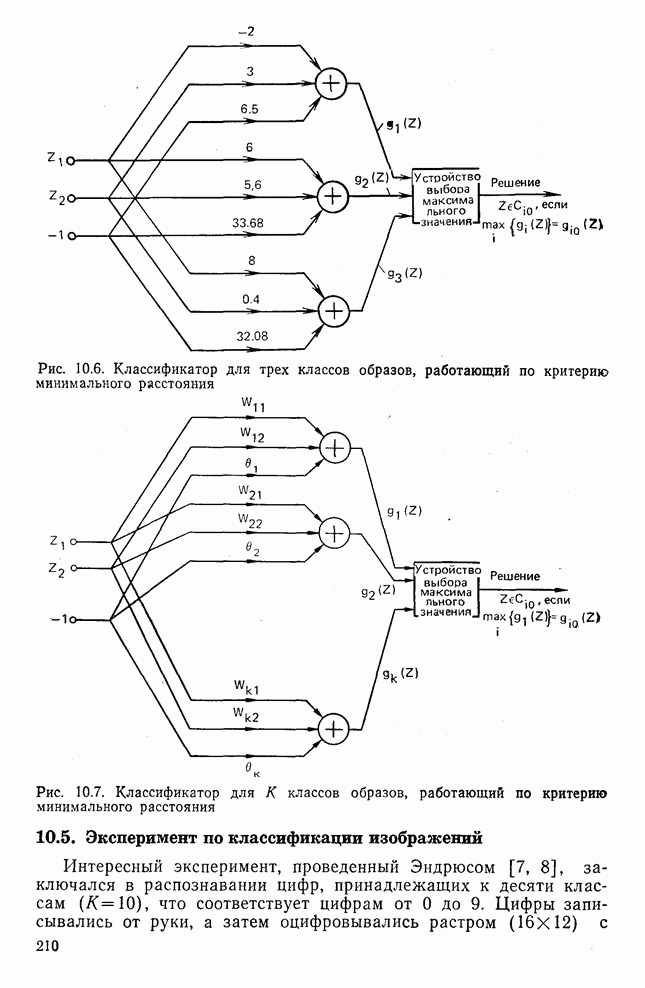
Рис. 10.9. Распределение дисперсии при различных преобразованиях [8]
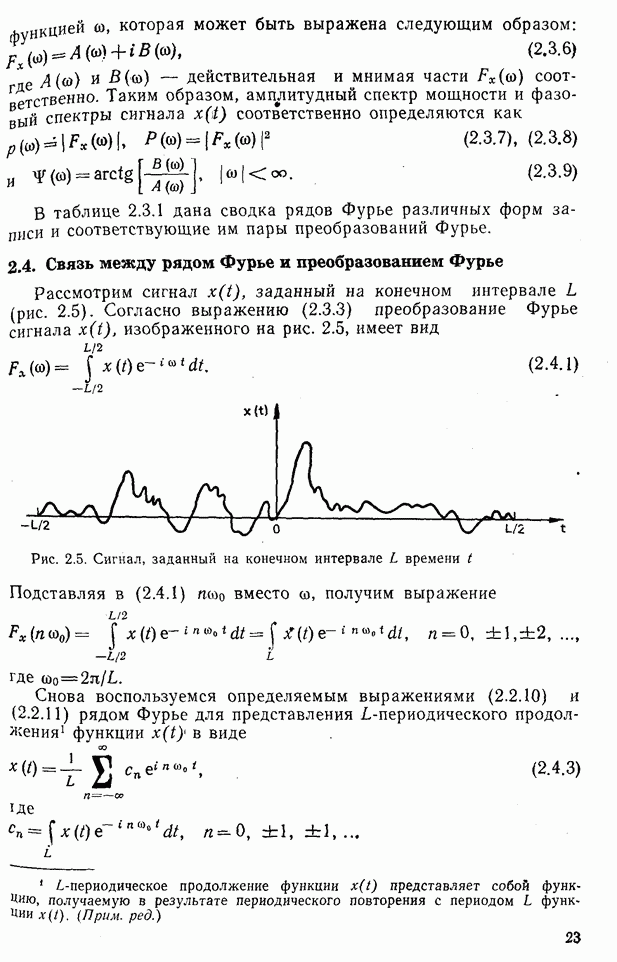
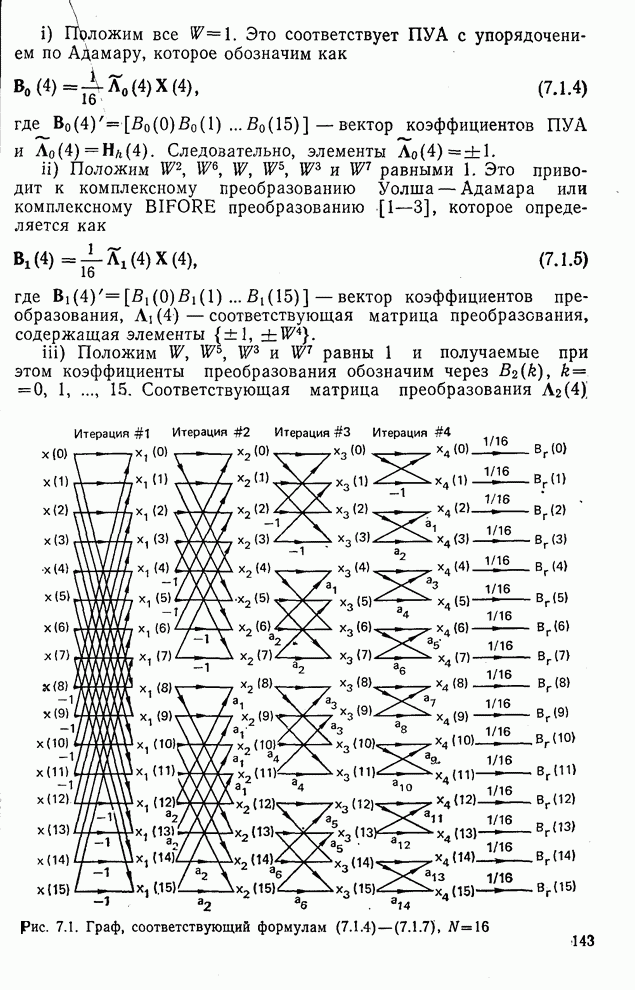
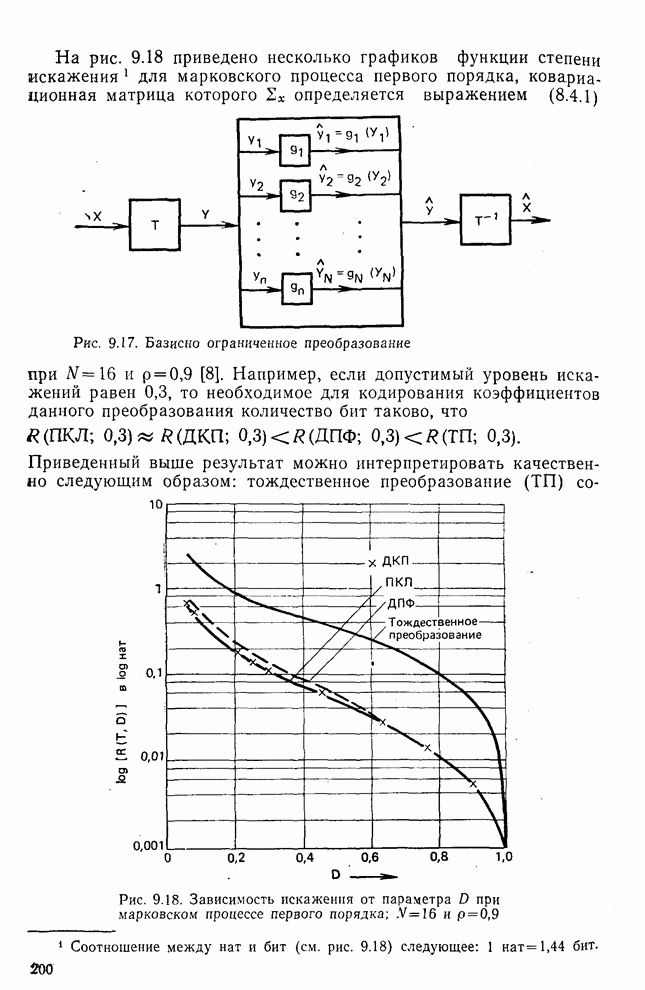
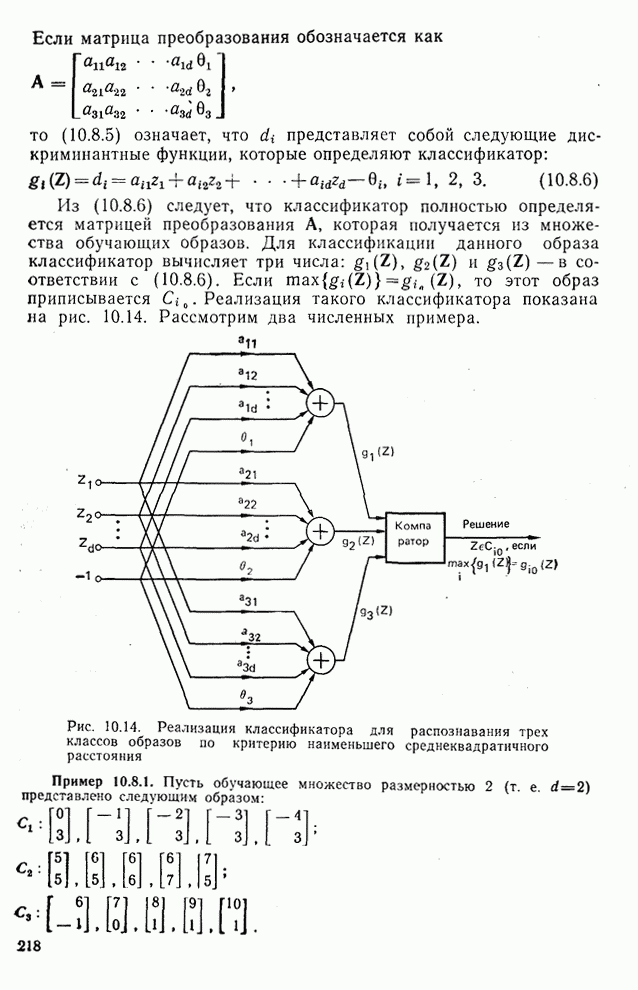
Рис. 10.10. Зависимость правильной классификации от числа сохраняемых признаков (обучающее множество) Очевидно, что пространство признаков, соответствующее ДПФ, обладает значительным преимуществом по сравнению с пространством признаков, соответствующим тождественному преобразованию. Описанный выше эксперимент был повторен для состоящего из 500 образов испытательного множества, заменившего обучающее множество, по которому определялись
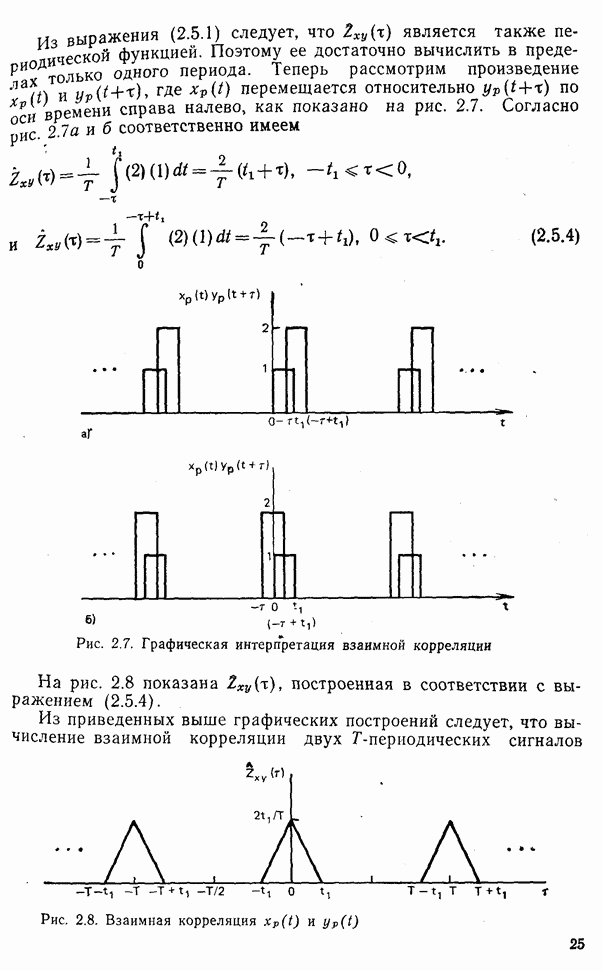
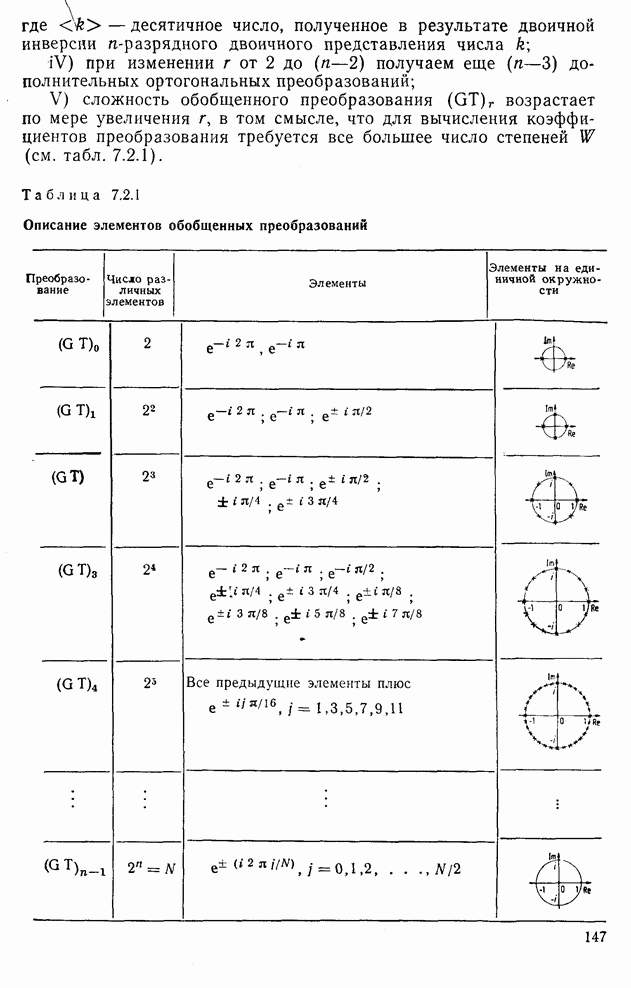
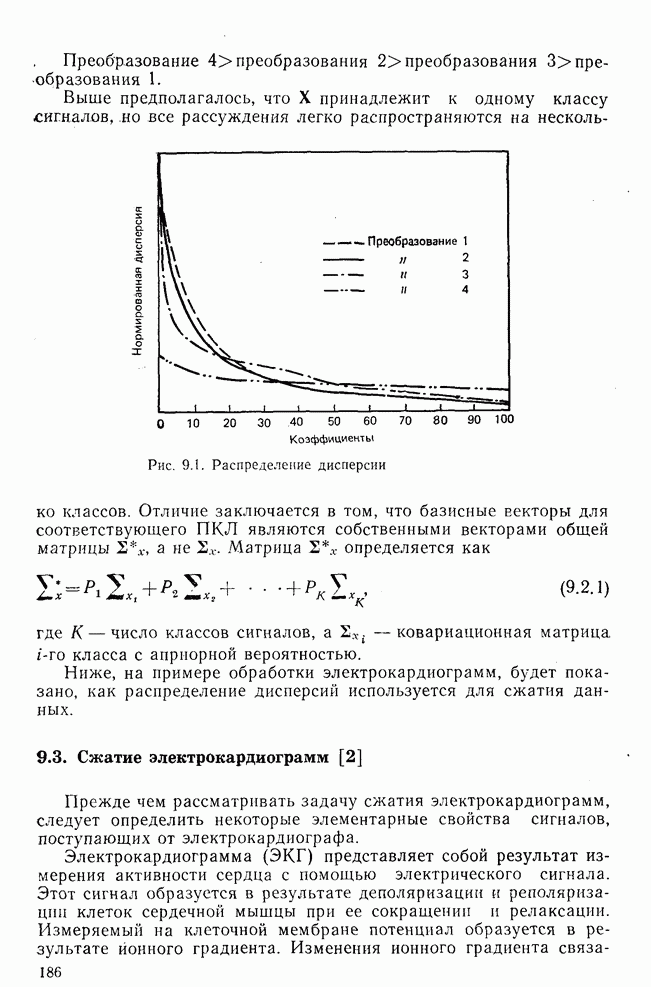
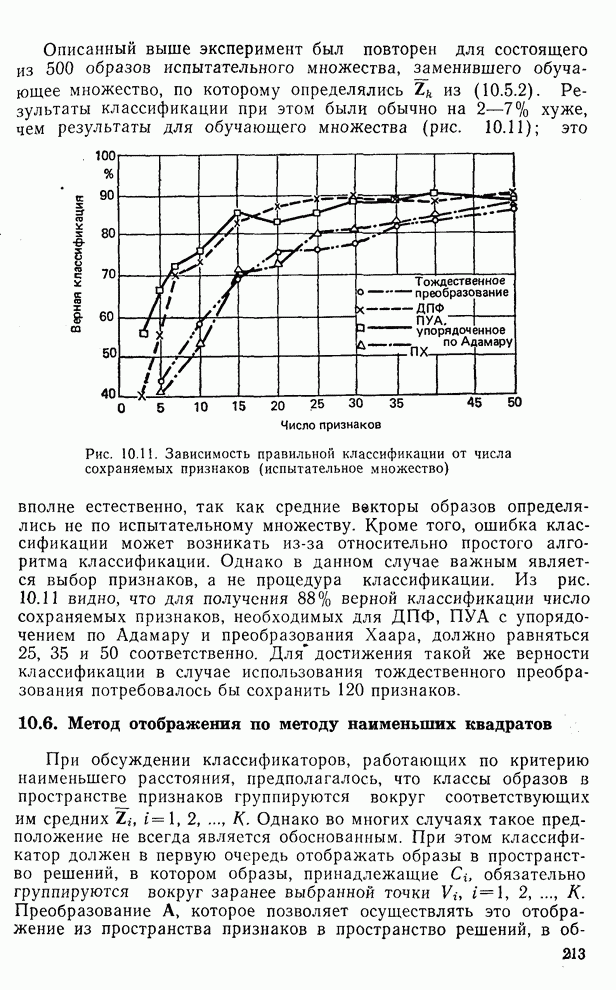
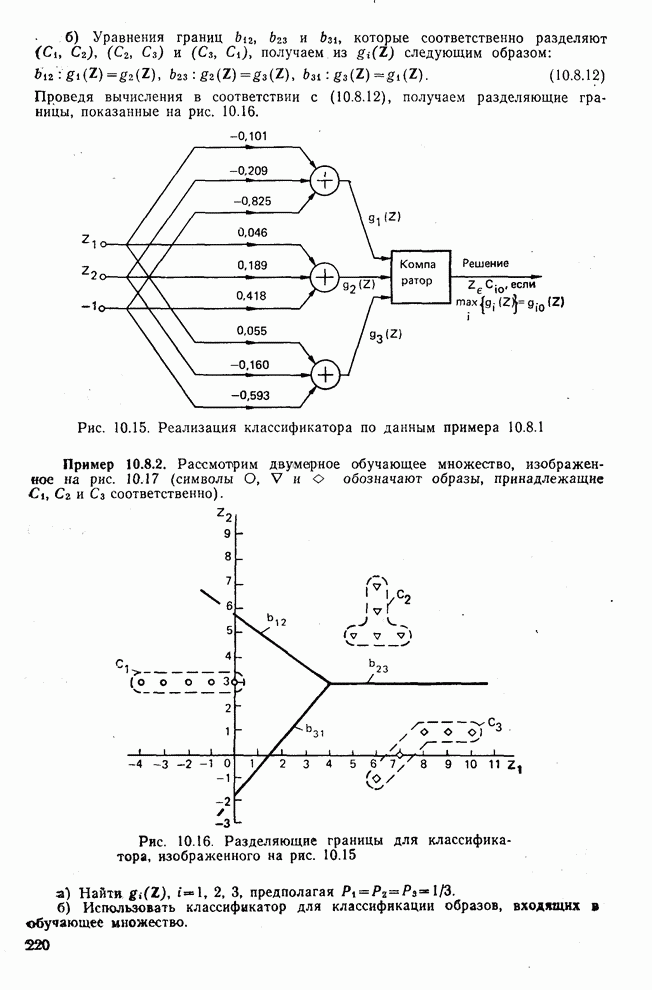
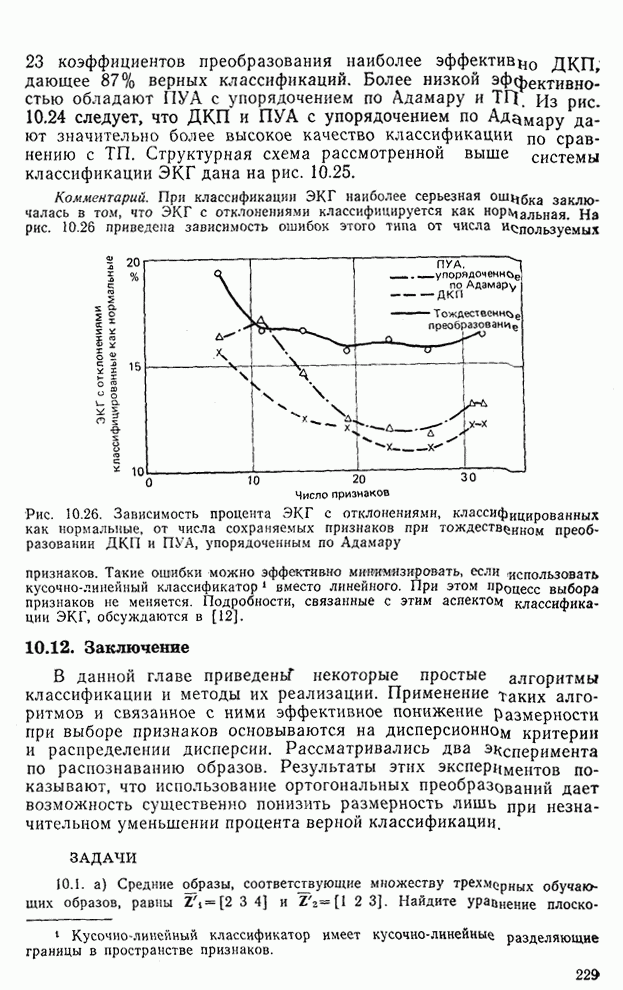
Рис. 10.11. Зависимость правильной классификации от числа сохраняемых признаков (испытательное множество) Однако в данном случае важным является выбор признаков, а не процедура классификации. Из рис. 10.11 видно, что для получения 88% верной классификации число сохраняемых признаков, необходимых для ДПФ, ПУА с упорядочением по Адамару и преобразования Хаара, должно равняться 25, 35 и 50 соответственно. Для достижения такой же верности классификации в случае использования тождественного преобразования потребовалось бы сохранить 120 признаков.
|
 |
Оглавление
|
















































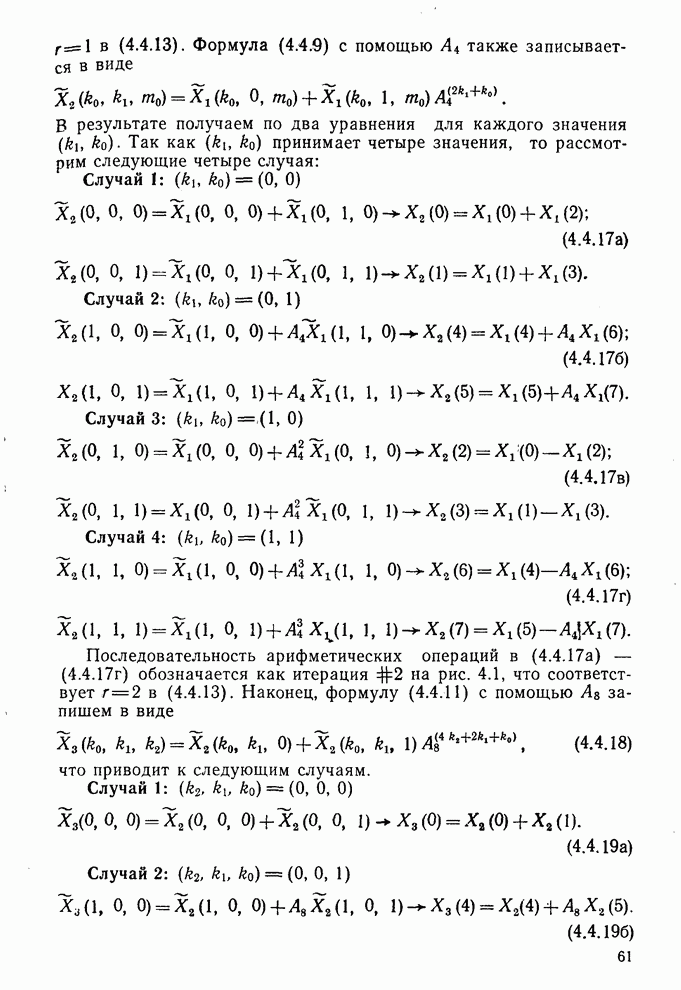






























































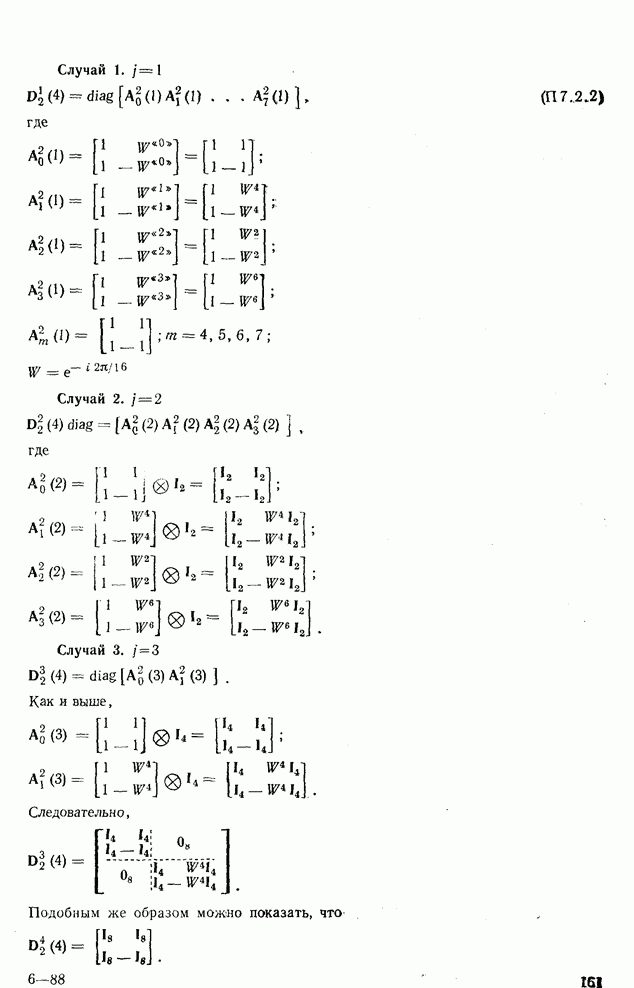













































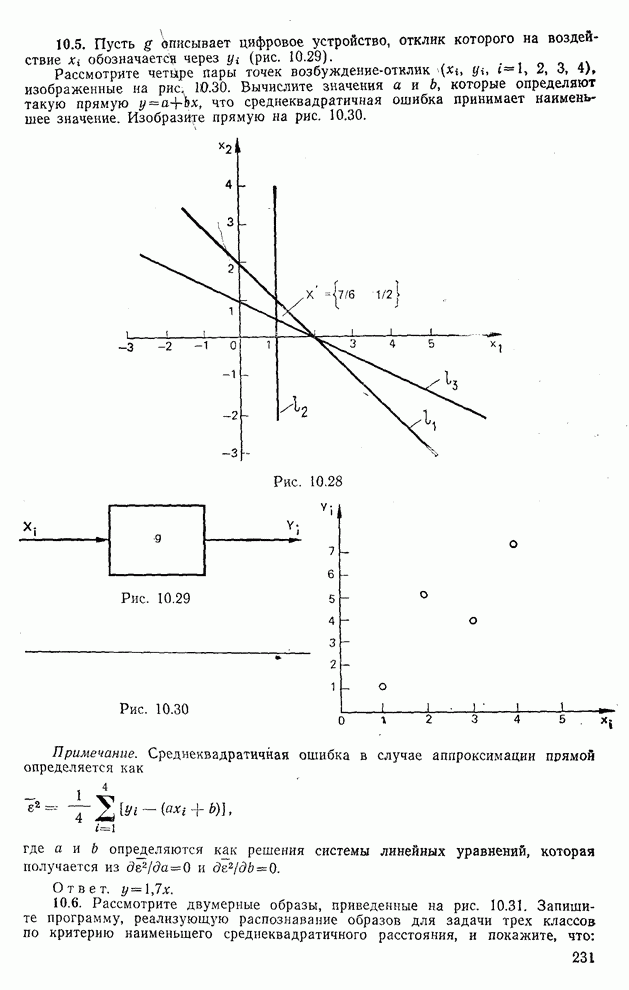











 , что соответствует цифрам от 0 до 9. Цифры записывались от руки, а затем оцифровывались растром
, что соответствует цифрам от 0 до 9. Цифры записывались от руки, а затем оцифровывались растром  с восемью уровнями серого.
с восемью уровнями серого.


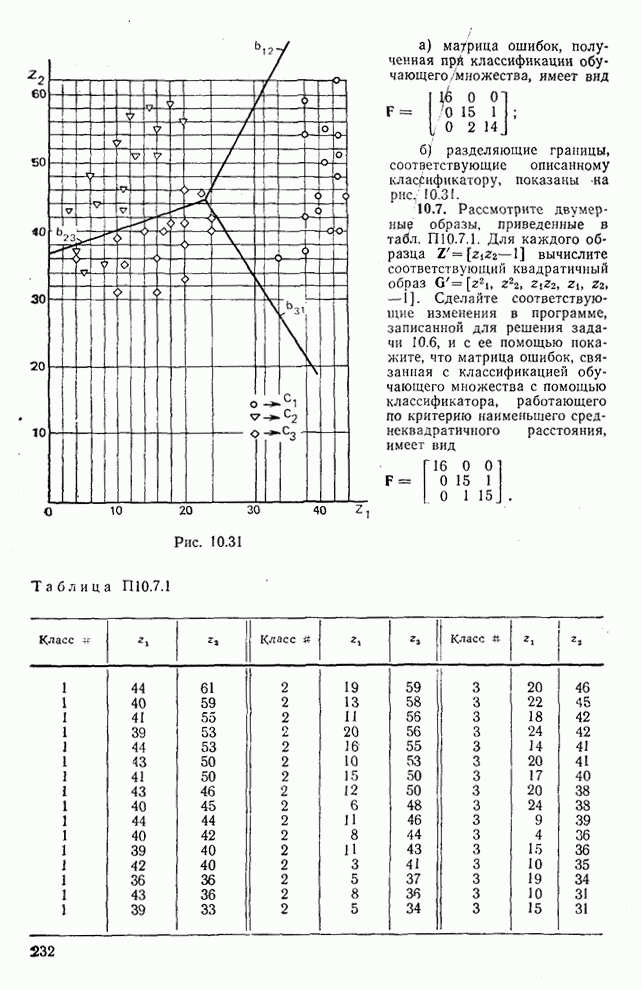
 — ковариационная матрица k-гo класса;
— ковариационная матрица k-гo класса;  — априорная вероятность класса
— априорная вероятность класса  , которая предполагалась равной
, которая предполагалась равной  . Распределение дисперсии, вычисленной с использованием
. Распределение дисперсии, вычисленной с использованием  , показано на рис. 10.9 (на графике изображены только 100 первых составляющих). Если через
, показано на рис. 10.9 (на графике изображены только 100 первых составляющих). Если через  обозначить вектор коэффициентов преобразования
обозначить вектор коэффициентов преобразования  , то очевидно, что энергия для тождественного преобразования (соответствующая площади, ограниченной каждой кривой) распределяется по значительно большему числу коэффициентов преобразования, чем при других преобразованиях. В соответствии с дисперсионным критерием в качестве признаков выбираются М коэффициентов с наибольшими дисперсиями. Такая процедура позволяет получить множество образов, каждый из которых обозначается как
, то очевидно, что энергия для тождественного преобразования (соответствующая площади, ограниченной каждой кривой) распределяется по значительно большему числу коэффициентов преобразования, чем при других преобразованиях. В соответствии с дисперсионным критерием в качестве признаков выбираются М коэффициентов с наибольшими дисперсиями. Такая процедура позволяет получить множество образов, каждый из которых обозначается как  .
.

 (10.5.2)
(10.5.2)
 средний вектор образа для k-гo класса. Так как
средний вектор образа для k-гo класса. Так как  , то
, то  дискриминантная функция принимает вид
дискриминантная функция принимает вид

 и
и  . Реализация такого классификатора показана на рис. 10.7.
. Реализация такого классификатора показана на рис. 10.7.


 из (10.5.2). Результаты классификации при этом были обычно на 2-7% хуже, чем результаты для обучающего множества (рис. 10.11); это вполне естественно, так как средние векторы образов определялись не по испытательному множеству. Кроме того, ошибка классификации может возникать из-за относительно простого алгоритма классификации.
из (10.5.2). Результаты классификации при этом были обычно на 2-7% хуже, чем результаты для обучающего множества (рис. 10.11); это вполне естественно, так как средние векторы образов определялись не по испытательному множеству. Кроме того, ошибка классификации может возникать из-за относительно простого алгоритма классификации.
