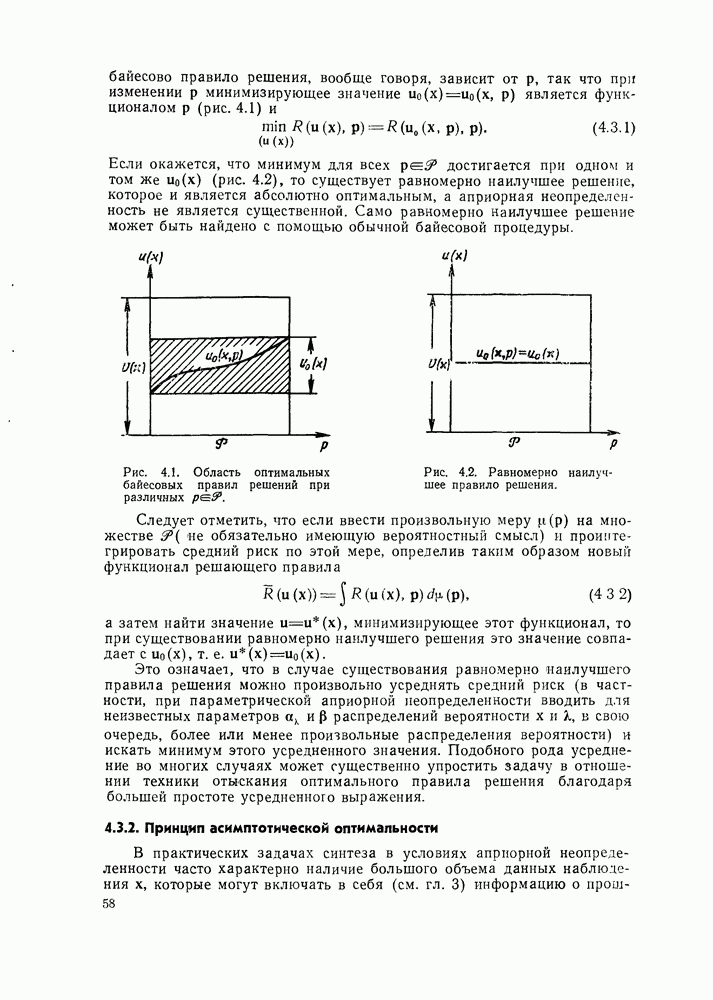
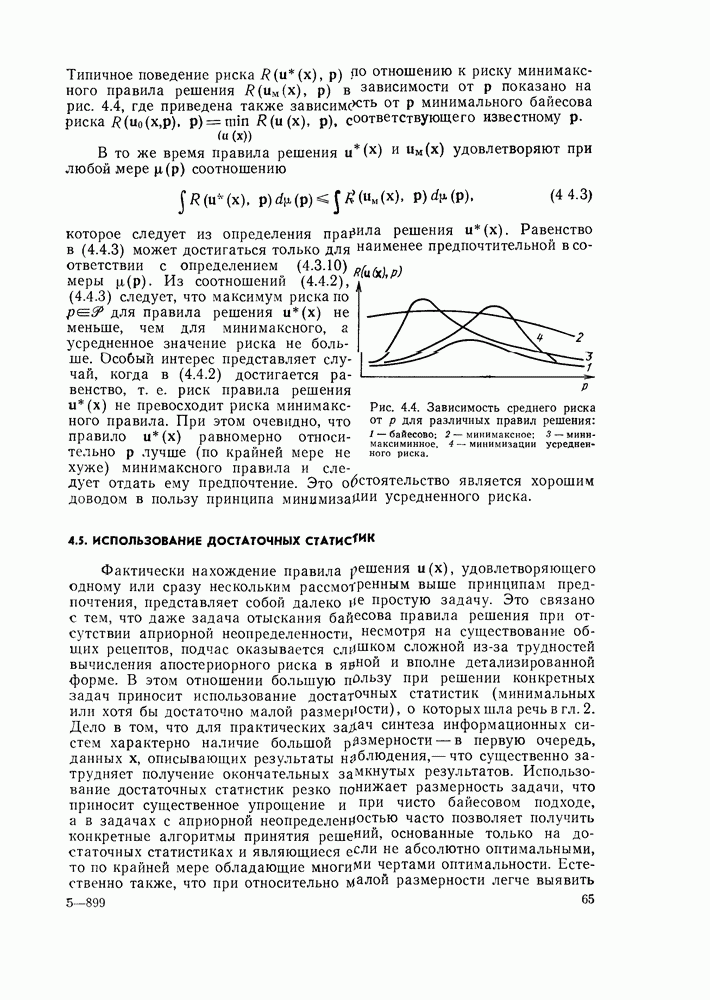
2.6. ДОСТАТОЧНЫЕ СТАТИСТИКИ
Рассмотренные в § 2.4 примеры позволяют уяснить еще одно важнейшее понятие, связанное с фактам существования полных классов решающих правил, — понятие достаточной статистики. Для этих примеров
характерно то, что оптимальное правило решения  оказывается зависящим не от всей совокупности наблюдаемых данных х непосредственно, которые могут иметь очень большую или даже неограниченную размерность, а от сравнительно небольшой совокупности величин, являющихся функцией (функционалом) наблюдаемых данных х.
оказывается зависящим не от всей совокупности наблюдаемых данных х непосредственно, которые могут иметь очень большую или даже неограниченную размерность, а от сравнительно небольшой совокупности величин, являющихся функцией (функционалом) наблюдаемых данных х.
Наиболее наглядно это видно для случая двухальтернативного решения, в котором реализация оптимального решения требует использования вместо всей совокупности входных данных х единственной скалярной величины — отношения правдоподобия  которое является функцией х и в сжатом виде отображает всю необходимую для принятия решения информацию, содержащуюся в совокупности данных наблюдения х. Аналогично при многоальтернативном решении можно ввести
которое является функцией х и в сжатом виде отображает всю необходимую для принятия решения информацию, содержащуюся в совокупности данных наблюдения х. Аналогично при многоальтернативном решении можно ввести  функций х, например функции
функций х, например функции

которые содержатвсю имеющуюся в х информацию, необходимую для принятия решения, поскольку оптимальное решение при любом х может быть выражено только через эти функции.
Подобным же свойством, очевидно, обладает функция  на которой достигается максимум апостериорной плотности вероятности, для задачи оценки параметров к, в примере б. Эта функция имеет ту же размерность, что и вектор к, и с учетом отмеченных в § 2.4 ограничений настолько хорошо концентрирует содержащуюся в
на которой достигается максимум апостериорной плотности вероятности, для задачи оценки параметров к, в примере б. Эта функция имеет ту же размерность, что и вектор к, и с учетом отмеченных в § 2.4 ограничений настолько хорошо концентрирует содержащуюся в  информацию, что непосредственно является решением — оптимальной оценкой вектора параметров k.
информацию, что непосредственно является решением — оптимальной оценкой вектора параметров k.
Из приведенных в § 2.4 результатов, определяющих оптимальные правила решений, ясно, что можно было бы вообще не знать значение  а знать только значения некоторых функций от
а знать только значения некоторых функций от  соответственно. Это означает, что существуют такие преобразования
соответственно. Это означает, что существуют такие преобразования  которые содержат всю необходимую для принятия решения информацию, получаемую при наблюдении, и обладающие тем свойством, что оптимальное правило решения
которые содержат всю необходимую для принятия решения информацию, получаемую при наблюдении, и обладающие тем свойством, что оптимальное правило решения  зависящее только от
зависящее только от  имеет те же качества — дает тот же уровень риска, что и оптимальное решение.
имеет те же качества — дает тот же уровень риска, что и оптимальное решение.
Такие преобразования называются достаточными статистиками и играют важнейшую роль при нахождении как байесовых, так и небайесовых оптимальных правил принятия решения, т. е. при синтезе оптимальных информационных систем. Конечно, среди достаточных статистик могут быть и тривиальные, например взаимооднозначные преобразования  которые, очевидно, обладают требуемым свойством, но не имеют никакой ценности. Достаточная статистика тем более интересна, чем большее сжатие входных данных
которые, очевидно, обладают требуемым свойством, но не имеют никакой ценности. Достаточная статистика тем более интересна, чем большее сжатие входных данных  она обеспечивает, т. е. чем меньше ее размерность. Достаточное преобразование минимальной размерности называется минимальной достаточной статистикой для данной задачи или данного класса задач.
она обеспечивает, т. е. чем меньше ее размерность. Достаточное преобразование минимальной размерности называется минимальной достаточной статистикой для данной задачи или данного класса задач.
Для каждой конкретной задачи (вполне определенные функции потерь и априорное распределение) минимальной достаточной статистикой является, очевидно, сама решающая функция  или любое взаимооднозначное преобразование функции
или любое взаимооднозначное преобразование функции  Значимость такой достаточной статистики относительно невелика, поскольку она ограничена строгими рамками этой конкретной задачи. Поэтому наибольшую ценность представляют достаточные статистики, минимальные для целого
Значимость такой достаточной статистики относительно невелика, поскольку она ограничена строгими рамками этой конкретной задачи. Поэтому наибольшую ценность представляют достаточные статистики, минимальные для целого
класса задач и позволяющие воспользоваться ими для решения всех задач этого класса. Так, в приведенных ранее примерах преобразование  является минимальной достаточной статистикой для всей совокупности двухальтернативных решений, преобразование
является минимальной достаточной статистикой для всей совокупности двухальтернативных решений, преобразование  где
где  - определяемая (2.6.1) минимальная достаточная статистика для всей совокупности многоальтернативных задач; положение максимума апостериорной плотности вероятности
- определяемая (2.6.1) минимальная достаточная статистика для всей совокупности многоальтернативных задач; положение максимума апостериорной плотности вероятности  минимальная достаточная статистика для всех задач оценки с симметричной относительно разности
минимальная достаточная статистика для всех задач оценки с симметричной относительно разности  апостериорной плотностью вероятности и относительно разности
апостериорной плотностью вероятности и относительно разности  функцией потерь.
функцией потерь.
Найти минимальную достаточную статистику — это означает практически решить задачу синтеза оптимальной информационной системы; найти достаточную статистику малой размерности — значит максимально приблизиться к ее решению или получить основу для решения целого класса задач; даже отыскание достаточных статистик не очень малой размерности — существенный успех в решении задачи синтеза, поскольку позволяет перейти к более сжатому, но вполне содержательному описанию входной информации. Стоит подчеркнуть, что достаточные статистики, сформированные без использования сведений, содержащихся в априорном распределении и функции потерь, определяют структуру оптимального решения и оптимальный способ обработки входной информации как для байесовых, так и для любых небайесовых правил. В этом заключается их огромная ценность и важность способов их нахождения для задач синтеза оптимальных информационных систем в условиях априорной неопределенности.
Наиболее универсальный способ отыскания достаточных статистик малой размерности заключается в анализе функции правдоподобия  Допустим, что можно ввести некоторое взаимооднозначное преобразование
Допустим, что можно ввести некоторое взаимооднозначное преобразование  где размерность
где размерность  меньше размерности х, а функция
меньше размерности х, а функция  дополняет преобразование
дополняет преобразование  до взаимооднозначного. В силу взаимной однозначности х и
до взаимооднозначного. В силу взаимной однозначности х и  можно использовать для описания полной совокупности данных наблюдения не
можно использовать для описания полной совокупности данных наблюдения не  При этом решение и будет функцией
При этом решение и будет функцией  и вместо функции правдоподобия
и вместо функции правдоподобия  нужно рассматривать
нужно рассматривать

Если  выбраны так, что распределение вероятности
выбраны так, что распределение вероятности  не зависит от к, т. е.
не зависит от к, т. е.  то преобразование
то преобразование  является достаточной статистикой, а преобразование
является достаточной статистикой, а преобразование  описывает ту часть сведений, содержащихся в совокупности входных данных х, которая не несет никакой информации о к и, следовательно, о последствиях от принятия того или иного решения и, естественно, не участвует при его формировании.
описывает ту часть сведений, содержащихся в совокупности входных данных х, которая не несет никакой информации о к и, следовательно, о последствиях от принятия того или иного решения и, естественно, не участвует при его формировании.
Если преобразование  удовлетворяя приведенным выше условиям, имеет наименьшую возможную размерность, то оно является минимальной достаточной статистикой для всего класса задач, связанных с принятием любых решений, последствия которых зависят от к, какие бы ни вводились функции потерь и априорные распределения вероятности. Дальнейшее сжатие достаточной статистики возможно только при дополнительных ограничениях функции потерь и априорных распределений или при конкретном их задании.
удовлетворяя приведенным выше условиям, имеет наименьшую возможную размерность, то оно является минимальной достаточной статистикой для всего класса задач, связанных с принятием любых решений, последствия которых зависят от к, какие бы ни вводились функции потерь и априорные распределения вероятности. Дальнейшее сжатие достаточной статистики возможно только при дополнительных ограничениях функции потерь и априорных распределений или при конкретном их задании.
Приведем простой пример. Пусть  последовательность независимых нормальных величин с одинаковой дисперсией
последовательность независимых нормальных величин с одинаковой дисперсией  и математическим ожиданием которое может принимать одно из
и математическим ожиданием которое может принимать одно из  значений
значений  что соответствует Дискретно изменяющемуся параметру
что соответствует Дискретно изменяющемуся параметру 
Введем линейное преобразование вектора х с неособой квадратной матрицей F

где  представлена в виде двух блоков:
представлена в виде двух блоков:

причем матрица А имеет порядок  и элементы
и элементы

а матрица В имеет порядок  Обозначим через
Обозначим через  -мерный вектор
-мерный вектор  а через
а через  -мерный вектор, дополняющий преобразование
-мерный вектор, дополняющий преобразование

до взаимнооднозначного, и найдем совместное распределение вероятности  при условии, что имеет место
при условии, что имеет место  гипотеза
гипотеза  Это распределение является нормальным с математическим ожиданием
Это распределение является нормальным с математическим ожиданием

где

и корреляционной матрицей

Используя явный вид выражений Для матрицы

и математического ожидания  плотность распределения вероятности вектора
плотность распределения вероятности вектора  можно представить в виде
можно представить в виде









































































































































































































































































































































































































































 соответствующая подматрица матрицы, обратной
соответствующая подматрица матрицы, обратной  матрица порядка
матрица порядка  вектор математических ожиданий величин
вектор математических ожиданий величин

 (значения дискретно изменяющегося параметра Я). Из этого представления для плотности вероятности следует, что вектор
(значения дискретно изменяющегося параметра Я). Из этого представления для плотности вероятности следует, что вектор  является достаточной статистикой и любая из задач различения сигналов
является достаточной статистикой и любая из задач различения сигналов  каких угодно предположениях об априорных вероятностях их появления и функциях потерь может быть решена с использованием только совокупности величин
каких угодно предположениях об априорных вероятностях их появления и функциях потерь может быть решена с использованием только совокупности величин  а не первоначальной совокупности
а не первоначальной совокупности 
