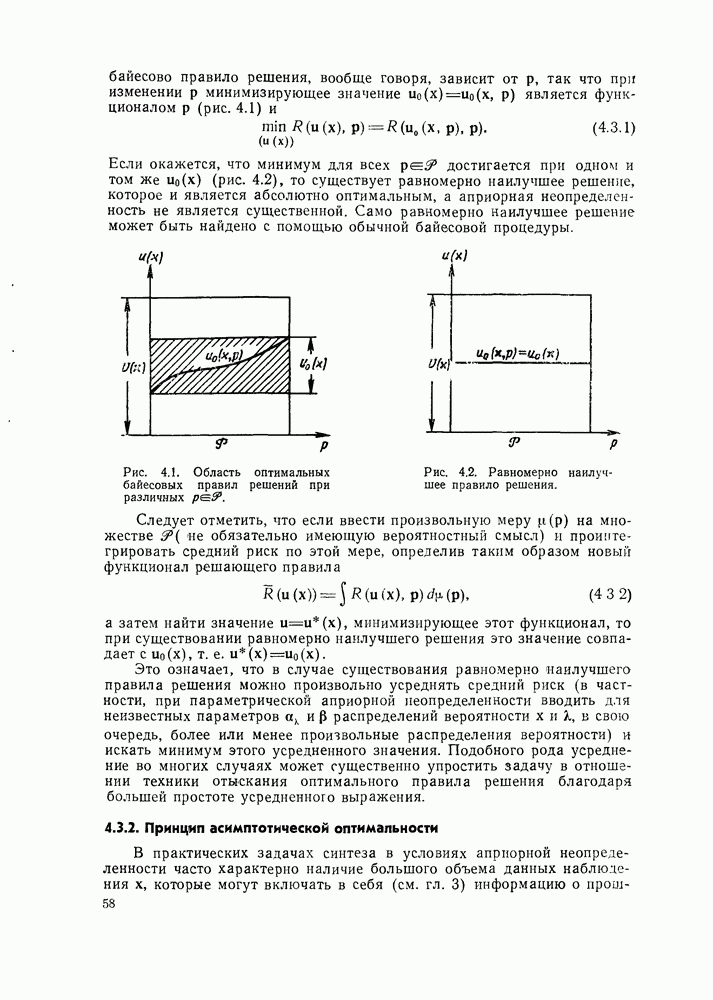
8.2. АДАПТИВНОЕ БАЙЕСОВО ПРАВИЛО РЕШЕНИЯ ПРИ ИЗВЕСТНОЙ ФУНКЦИИ ПОТЕРЬ
Часть ограничений примера 2 § 6.1 можно снять, если предположить наличие дополнительных априорных знаний аналитического характера и возможность расширения или изменения состава совокупности наблюдаемых данных х. Пусть в отличие от условий этого примера множество решений  не обязательно дискретно (оно может быть непрерывным или дискретно-непрерывным) и пусть по-прежнему о распределении вероятностей данных наблюдения
не обязательно дискретно (оно может быть непрерывным или дискретно-непрерывным) и пусть по-прежнему о распределении вероятностей данных наблюдения  ничего не известно. Для того чтобы найти адаптивное байесово правило решения (связь между принимаемым решением и значением
ничего не известно. Для того чтобы найти адаптивное байесово правило решения (связь между принимаемым решением и значением  для детализации которой допускается использование ранее наблюдавшихся значений
для детализации которой допускается использование ранее наблюдавшихся значений  и других величин, доступных наблюдателю), нужно по-прежнему предположить, что случайные величины
и других величин, доступных наблюдателю), нужно по-прежнему предположить, что случайные величины  и
и  принимают только дискретные значения
принимают только дискретные значения  (В дальнейшем индекс
(В дальнейшем индекс  у величины х, наблюдаемой на рабочем шаге, когда требуется принять решение, если не будет оговорено противоположное, будем опускать.)
у величины х, наблюдаемой на рабочем шаге, когда требуется принять решение, если не будет оговорено противоположное, будем опускать.)
Кроме того, нужно также предположить, что
1) известна функция потерь 
2) при  помимо значений мы наблюдаем и значения
помимо значений мы наблюдаем и значения  определяющие величину потерь в том случае, если бы на
определяющие величину потерь в том случае, если бы на  шаге принималось решение.
шаге принималось решение.
Знание решений  величин потерь
величин потерь  при
при  и даже само принятие решений при
и даже само принятие решений при  в этом случае, в отличие от примера 2 § 6.1, не требуется
в этом случае, в отличие от примера 2 § 6.1, не требуется
Таким образом, полная совокупность данных наблюдения составляет

и включает в себя  -кратное повторение
-кратное повторение  льтатов наблюдения
льтатов наблюдения  и результат наблюдения х на рабочем шаге, когда требуется принять решение. Нетрудно убедиться, что (8.2.1) дает минимально возможною совокупность данных, которая при отсутствии каких-либо дополнительных ограничений, кроме знания функции потерь
и результат наблюдения х на рабочем шаге, когда требуется принять решение. Нетрудно убедиться, что (8.2.1) дает минимально возможною совокупность данных, которая при отсутствии каких-либо дополнительных ограничений, кроме знания функции потерь  и предположения о дискретности
и предположения о дискретности  обеспечивает возможность построения состоятельной оценки функции апостериорного риска
обеспечивает возможность построения состоятельной оценки функции апостериорного риска  при любых значениях
при любых значениях  и х.
и х.
апостериорного риска для всех значений  и для любых значений
и для любых значений 

Все дальнейшее не отличается от обычного байесова подхода. Правило решения  определяется следующим образом: если
определяется следующим образом: если  то принимается решение и, для которого величина
то принимается решение и, для которого величина  достигает минимума, т. е.
достигает минимума, т. е.

где  определяется из уравнения
определяется из уравнения

и благодаря зависимости  от совокупности данных
от совокупности данных  также зависит от них.
также зависит от них.
Если функция потерь  дифференцируема по и (естественно, это может иметь место только в случае непрерывного множества решений
дифференцируема по и (естественно, это может иметь место только в случае непрерывного множества решений  то уравнение (8.2.7) можно заменить более простым условием равенства нулю градиента функции
то уравнение (8.2.7) можно заменить более простым условием равенства нулю градиента функции 

из которого определяется значение 
При решении уравнения (8.2.8) могут быть полностью использованы те же методы и идеи, которые мы рассмотрели в предыдущей главе при нахождении оценок максимального правдоподобия. Уравнение (8.2.8) при некоторых ограничениях на функцию потерь  допускает конечное решение или решается любым подходящим итерационным способом. Если, кроме того, функция потерь
допускает конечное решение или решается любым подходящим итерационным способом. Если, кроме того, функция потерь  дважды дифференцируема по и, то решение уравнения (8.2.8) находится с помощью удобной рекуррентной процедуры, определяющей непосредственно адаптивное байесово правило решения.
дважды дифференцируема по и, то решение уравнения (8.2.8) находится с помощью удобной рекуррентной процедуры, определяющей непосредственно адаптивное байесово правило решения.
Перепишем для этого уравнение (8.2.8) в следующем виде:

и пусть  значение, определяющее адаптивное байесово правило решения для серии наблюдений
значение, определяющее адаптивное байесово правило решения для серии наблюдений  объемом
объемом  на единицу меньшим, чем для
на единицу меньшим, чем для  т. е. решение уравнения
т. е. решение уравнения

Разложим функцию в правой части (8.2.9) в окрестности точки  Тогда с учетом (8.2.10)
Тогда с учетом (8.2.10)


где  симметричная квадратная матрица, равная
симметричная квадратная матрица, равная

 малая более высокого порядка, чем х. Пренебрегая в (8.2.11) малой поправкой, получаем следующее приближенное решение уравнения (8.2.9), определяющее
малая более высокого порядка, чем х. Пренебрегая в (8.2.11) малой поправкой, получаем следующее приближенное решение уравнения (8.2.9), определяющее 

Это выражение связывает значения  т. е. формально является рекуррентным соотношением, дающим возможность последовательно от шага к шагу уточнять структуру адаптивного байесова правила решения. Для того чтобы оно стало рекуррентным соотношением по существу, т. е. не требовало бы для нахождения
т. е. формально является рекуррентным соотношением, дающим возможность последовательно от шага к шагу уточнять структуру адаптивного байесова правила решения. Для того чтобы оно стало рекуррентным соотношением по существу, т. е. не требовало бы для нахождения  никаких иных данных, кроме
никаких иных данных, кроме  (предыдущего решения
(предыдущего решения  и вновь полученных данных наблюдения
и вновь полученных данных наблюдения  необходимо указать какую-то процедуру вычисления весовой матрицы
необходимо указать какую-то процедуру вычисления весовой матрицы  которая не требовала бы каждый раз обращения к ранее полученным данным наблюдения
которая не требовала бы каждый раз обращения к ранее полученным данным наблюдения 
Такая процедура существует строго без дополнительных приближений, если функция потерь  — квадратичная функция и, т. е.
— квадратичная функция и, т. е.

где  - вектор;
- вектор;  -положительно определенная квадратная матрица той же размерности, что
-положительно определенная квадратная матрица той же размерности, что  При этом
При этом

благодаря чему решение  и матрица
и матрица  определяются следующей системой рекуррентных соотношений:
определяются следующей системой рекуррентных соотношений:

правые части которых зависят действительно только от  причем сама матрица
причем сама матрица  также вычисляется рекуррентно.
также вычисляется рекуррентно.
Соотношения (8.2.16) определяют марковский процесс, сходящийся при  с вероятностью единица к значению иминимизирующему истинную величину апостериорного риска (8.2.2) при
с вероятностью единица к значению иминимизирующему истинную величину апостериорного риска (8.2.2) при  для
для
каждого  Более того, отклонение
Более того, отклонение  асимптотически нормально с дисперсией порядка
асимптотически нормально с дисперсией порядка  Таким образом, рекуррентные соотношения (8.2.16) определяют адаптивное байесово правило, сходящееся с вероятностью единица к оптимальному байесову правилу, причем среднеквадратичное отклонение решения от оптимального имеет порядок
Таким образом, рекуррентные соотношения (8.2.16) определяют адаптивное байесово правило, сходящееся с вероятностью единица к оптимальному байесову правилу, причем среднеквадратичное отклонение решения от оптимального имеет порядок 
Другой способ превращения формального соотношения (8.2.13) в рекуррентное заключается в выборе более или менее произвольной матрицы  или
или  уже не удовлетворяющей (8.2.12), но обеспечивающей сходимость процедуры (8.2.13) к истинному значению. Такой подход является стержневой идеей метода стохастической аппроксимации (процедуры Робинса — Монро), подробное рассмотрение сходимости которого приведено в [23]. При этом удобно выбрать
уже не удовлетворяющей (8.2.12), но обеспечивающей сходимость процедуры (8.2.13) к истинному значению. Такой подход является стержневой идеей метода стохастической аппроксимации (процедуры Робинса — Монро), подробное рассмотрение сходимости которого приведено в [23]. При этом удобно выбрать  в виде диагональной матрицы
в виде диагональной матрицы

где  число; I — единичная матрица. Если ряд
число; I — единичная матрица. Если ряд

расходится, а ряд

сходится; функция  которая определяет оптимальное байесово правило решения
которая определяет оптимальное байесово правило решения  согласно уравнению
согласно уравнению

удовлетворяет условию

при всех  — положительно определенная матрица и математическое ожидание
— положительно определенная матрица и математическое ожидание

где  константа, возможно зависящая от х, то процедура, определяемая рекуррентным соотношением (8.2.13) с матрицей
константа, возможно зависящая от х, то процедура, определяемая рекуррентным соотношением (8.2.13) с матрицей  сходится при
сходится при  с вероятностью единица к значению и для оптимального байесова правила решения [23]. Кроме того, при
с вероятностью единица к значению и для оптимального байесова правила решения [23]. Кроме того, при  и некоторых дополнительных условиях (см. [23]) отклонение
и некоторых дополнительных условиях (см. [23]) отклонение  -асимптотически нормально с дисперсией порядка
-асимптотически нормально с дисперсией порядка  (естественно, большей, а иногда существенно большей, чем при оптимальном выборе матрицы
(естественно, большей, а иногда существенно большей, чем при оптимальном выборе матрицы  в соответствии с (8.2.16)).
в соответствии с (8.2.16)).
Следующий способ аналогичен использованному в предыдущей главе при приближенном рекуррентном вычислении оценок максимального правдоподобия и сводится к приближенному рекуррентному вычислению весовых матриц  подобно тому, как это делается в (8.2.16) для
подобно тому, как это делается в (8.2.16) для
случая квадратичной функции потерь. При этом адаптивное байесово правило решения (значение  и весовая матрица
и весовая матрица  определяется из системы рекуррентных соотношений
определяется из системы рекуррентных соотношений

которые, как и предыдущие рекуррентные соотношения, нужно дополнить какими-либо начальными условиями. Допустимость перехода от (8.2.12) ко второму из рекуррентных соотношений (8.2.23) обосновывается так же, как в гл. 7 при нахождении аналогичной рекуррентной процедуры для оценок максимального правдоподобия.
Подобно (8.2.16) соотношения (8.2.23) определяют сходящийся марковский случайный процесс, для которого отклонение  асимптотически нормально с дисперсией порядка
асимптотически нормально с дисперсией порядка  меньшей, чем при использовании весовой матрицы (8.2.17), соответствующей процедуре стохастической аппроксимации Робинса — Монро.
меньшей, чем при использовании весовой матрицы (8.2.17), соответствующей процедуре стохастической аппроксимации Робинса — Монро.
Полученные выше результаты определяют структуру адаптивного байесова правила решения или непосредственно его вид для достаточно широкого круга непараметрических задач. Наиболее принципиальным ограничением является дискретность множества значений х. Это дает возможность сформировать при больших, но конечных значениях  достаточно близкую к истинному значению оценку апостериорного риска для каждого значения
достаточно близкую к истинному значению оценку апостериорного риска для каждого значения  и найти соответствующее правило решения, определенное для всех
и найти соответствующее правило решения, определенное для всех  При переходе к непрерывному множеству значений х необходимо формировать бесконечное множество таких оценок (вместо конечного числа
При переходе к непрерывному множеству значений х необходимо формировать бесконечное множество таких оценок (вместо конечного числа  что, естественно, невозможно сделать ни при каких конечных значениях
что, естественно, невозможно сделать ни при каких конечных значениях  если не принять каких-то дополнительных априорных предположений об особенностях распределения вероятностей х или сузить постановку задачи в части ограничения допустимого множества решений или, наконец, не ограничить каким-то образом класс возможных правил решения, например, задав правило решения
если не принять каких-то дополнительных априорных предположений об особенностях распределения вероятностей х или сузить постановку задачи в части ограничения допустимого множества решений или, наконец, не ограничить каким-то образом класс возможных правил решения, например, задав правило решения  с точностью до совокупности некоторых неизвестных параметров. Изложению последней возможности будет посвящена специальная глава, а сейчас рассмотрим примеры использования двух первых из перечисленных возможностей.
с точностью до совокупности некоторых неизвестных параметров. Изложению последней возможности будет посвящена специальная глава, а сейчас рассмотрим примеры использования двух первых из перечисленных возможностей.










































































































































































































































































































































































































































 число раз, когда в серии
число раз, когда в серии  наблюдалось значение
наблюдалось значение  а через
а через  множество тех значений
множество тех значений  для которых
для которых  подпоследовательность последовательности
подпоследовательность последовательности  то в результате эмпирического осреднения получим следующую оценку апостериорного риска для любых значений
то в результате эмпирического осреднения получим следующую оценку апостериорного риска для любых значений 

 и требует запоминания минимального объема данных от предыдущих шагов
и требует запоминания минимального объема данных от предыдущих шагов  Перепишем для этого выражение (8.2.3) в следующем виде:
Перепишем для этого выражение (8.2.3) в следующем виде:

 то же,
то же,  для серии
для серии  отличающейся от исходной сечи данных отсутствием последней пары
отличающейся от исходной сечи данных отсутствием последней пары  символ Кронекера
символ Кронекера  при
при  при
при  Первое слагаемое в (8.2.4), очевидно, есть
Первое слагаемое в (8.2.4), очевидно, есть  т. е. оценка апостериорного риска для любого значения
т. е. оценка апостериорного риска для любого значения  и дискретного значения
и дискретного значения  произведенная на совокупности данных
произведенная на совокупности данных

 повторения наблюдения пары
повторения наблюдения пары  Учитывая также очевидную связь между величинами
Учитывая также очевидную связь между величинами  получаем совокупность рекуррентных соотношений, определяющих оценки
получаем совокупность рекуррентных соотношений, определяющих оценки