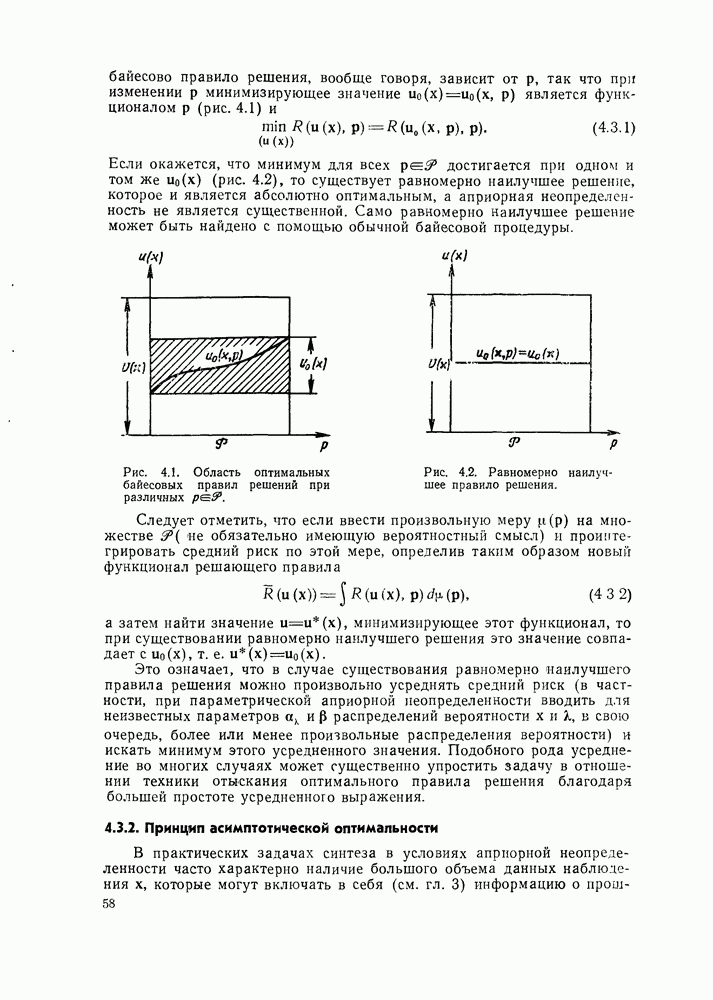
Последнее равенство в этой цепочке справедливо в силу того, что

благодаря отсутствию корреляции между полезным сигналом и помехой.
Из выражения (9.6.3) следует, что для получения оценки среднего риска  достаточно располагать только набором эмпирических значений х, с помощью которых оценка
достаточно располагать только набором эмпирических значений х, с помощью которых оценка  находится как эмпирическое среднее функции
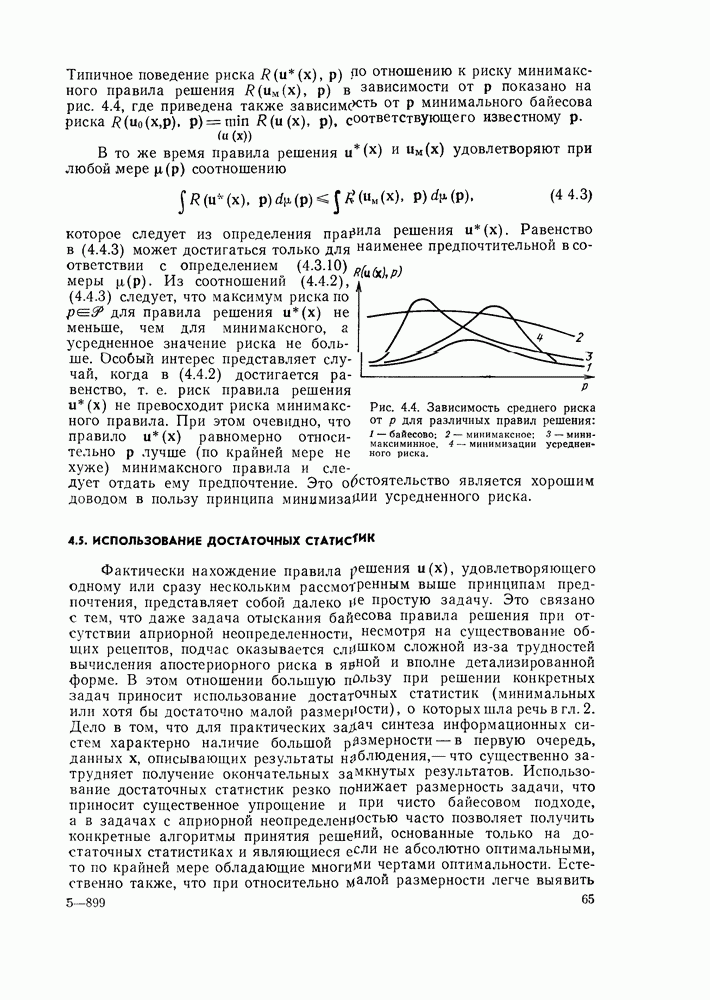
находится как эмпирическое среднее функции

Как и в предыдущем примере, для получения этого среднего достаточно располагать эмпирической оценкой корреляционной матрицы  определяемой так же, как в § 9.5, и с помощью которой наилучшее значение
определяемой так же, как в § 9.5, и с помощью которой наилучшее значение  вычисляется по уравнению
вычисляется по уравнению

прямым методом либо с помощью рекуррентного соотношения, аналогичного (9.5.3),

где  — та же самая матрица, что в (9.5.3), (9.5.4). Аналогично (9.5.5) можно перейти от
— та же самая матрица, что в (9.5.3), (9.5.4). Аналогично (9.5.5) можно перейти от  к матрице
к матрице  соответствующей процедуре стохастической аппроксимации Робинса — Монро, и, как и в предыдущем примере, рекуррентная процедура не имеет преимуществ перед конечным методом решения (9.6.5) в вычислительном отношении.
соответствующей процедуре стохастической аппроксимации Робинса — Монро, и, как и в предыдущем примере, рекуррентная процедура не имеет преимуществ перед конечным методом решения (9.6.5) в вычислительном отношении.
Замечание. В рассмотренных выше примерах матрица с, осуществляющая преобразование данных наблюдения х в оценку вектора к для линейного правила решения  при выборе ее наилучшего значения предполагалась совершенно произвольной. Это обеспечивало сходимость найденного в условиях априорной неопределенности правила решения к наилучшему линейному правилу, полученному для случая известных статистических характеристик
при выборе ее наилучшего значения предполагалась совершенно произвольной. Это обеспечивало сходимость найденного в условиях априорной неопределенности правила решения к наилучшему линейному правилу, полученному для случая известных статистических характеристик  Однако, в свою очередь, полная свобода в выборе с требует нахождения эмпирических оценок всех элементов матрицы
Однако, в свою очередь, полная свобода в выборе с требует нахождения эмпирических оценок всех элементов матрицы  что при большой размерности
что при большой размерности  вектора х приводит к довольно громоздким вычислениям, а при переходе к непрерывному времени, когда х представляет собой отрезок случайного процесса
вектора х приводит к довольно громоздким вычислениям, а при переходе к непрерывному времени, когда х представляет собой отрезок случайного процесса  на некотором интервале времени (бесконечномерный вектор), делает задачу вообще неразрешимой, если не ввести каких-то дополнительных ограничений. При этом можно, конечно, наложить какие-либо ограничения на корреляционную матрицу
на некотором интервале времени (бесконечномерный вектор), делает задачу вообще неразрешимой, если не ввести каких-то дополнительных ограничений. При этом можно, конечно, наложить какие-либо ограничения на корреляционную матрицу  так чтобы упростить задачу ее оценки, например задать ее параметрически с точностью до некоторого числа неизвестных параметров. Однако при таких ограничениях целесообразнее использовать более сильные параметрические методы адаптивного байесова подхода. Если же оставаться в рамках непараметрического описания априорной неопределенности и параметрического задания правила решения, которые мы
так чтобы упростить задачу ее оценки, например задать ее параметрически с точностью до некоторого числа неизвестных параметров. Однако при таких ограничениях целесообразнее использовать более сильные параметрические методы адаптивного байесова подхода. Если же оставаться в рамках непараметрического описания априорной неопределенности и параметрического задания правила решения, которые мы
рассматриваем в настоящей главе, то следует подчинить дополнительным ограничениям множество допустимых матриц с, так чтобы задача имела разумную вычислительную сложность и при очень больших или даже бесконечных значениях 
Довольно стандартным приемом, который часто используется даже при известных корреляционных матрицах  является замена произвольного линейного преобразования
является замена произвольного линейного преобразования  линейной комбинацией некоторых стандартных преобразований вида
линейной комбинацией некоторых стандартных преобразований вида

где матрица  имеет порядок
имеет порядок  меньше или много меньше
меньше или много меньше  и сохраняет постоянное значение при увеличении
и сохраняет постоянное значение при увеличении  или
или  в случае перехода к непрерывному времени), а матрица
в случае перехода к непрерывному времени), а матрица  имеет порядок
имеет порядок  и предполагается заданной для любых
и предполагается заданной для любых  Задание правила решения в виде (9.6.7) уменьшает число неизвестных параметров этого правила, подлежащих оценке с помощью эмпирических данных, с
Задание правила решения в виде (9.6.7) уменьшает число неизвестных параметров этого правила, подлежащих оценке с помощью эмпирических данных, с  до
до  Физически (9.6.7) означает реализацию алгоритма фильтрации с помощью
Физически (9.6.7) означает реализацию алгоритма фильтрации с помощью  фильтров заданной структуры (совокупность
фильтров заданной структуры (совокупность  этих фильтров описывается матрицей
этих фильтров описывается матрицей  выходные величины которых
выходные величины которых

образующие вектор размерности 

для получения оценки параметра  суммируются с коэффициентами
суммируются с коэффициентами  При переходе к непрерывному времени, когда данные наблюдения х представляют собой отрезок случайного процесса
При переходе к непрерывному времени, когда данные наблюдения х представляют собой отрезок случайного процесса  на интервале времени
на интервале времени 

 вектор-столбец функций времени
вектор-столбец функций времени  возможно зависящих также от
возможно зависящих также от  или
или  В частности, если фильтры, реализующие преобразование
В частности, если фильтры, реализующие преобразование  стационарны, то
стационарны, то  и представляет собой импульсную реакцию
и представляет собой импульсную реакцию  фильтра.
фильтра.
Задача нахождения наилучшего значения с в правиле решения (9.6.7) ничем не отличается от рассмотренной выше. Поскольку (9.6.7) и правило решения (9.3.1) тождественны с точностью до замены х в (9.3.1) на  в (9.6.7), то во всех полученных ранее результатах нужно всюду заменить х на
в (9.6.7), то во всех полученных ранее результатах нужно всюду заменить х на  и тогда эти результаты определяют наилучшее значение с для правила решения (9.6.7). Само преобразование
и тогда эти результаты определяют наилучшее значение с для правила решения (9.6.7). Само преобразование  является средством понижения размерности исходных данных наблюдения.
является средством понижения размерности исходных данных наблюдения.
Безусловно также, что правило решения (9.6.7) даже при самом лучшем выборе с может быть существенно хуже наилучшего линейного правила типа (9.3.1) и тем более оптимального правила решения. Поэтому переходить к упрощениям, подобным (9.6.7), следует с очень большой осторожностью.








































































































































































































































































































































































































































 что и дало возможность найти зависимость
что и дало возможность найти зависимость  имея только эмпирические данные для х, получить оценку оптимального значения
имея только эмпирические данные для х, получить оценку оптимального значения  линейного правила решения.
линейного правила решения.
 с помехой
с помехой  которая имеет известную корреляционную матрицу
которая имеет известную корреляционную матрицу

 т. е.
т. е.

 подлежащий оценке по данным наблюдения
подлежащий оценке по данным наблюдения  связан с полезным сигналом
связан с полезным сигналом  закодированным в данных наблюдения, линейным соотношением
закодированным в данных наблюдения, линейным соотношением

 матрица порядка
матрица порядка  Различным способам ее задания соответствуют весьма разнообразные задачи линейной фильтрации. Так, задаче оценки последнего (или текущего) значения
Различным способам ее задания соответствуют весьма разнообразные задачи линейной фильтрации. Так, задаче оценки последнего (или текущего) значения  (обычная задача фильтрации) соответствует
(обычная задача фильтрации) соответствует  при
при  задаче оценки сигнала
задаче оценки сигнала  в целом —
в целом —  задаче совместной оценки значений сигнала
задаче совместной оценки значений сигнала  например, двух первых его производных в конце интервала наблюдения (в момент
например, двух первых его производных в конце интервала наблюдения (в момент 

 интервал времени, разделяющий последовательностные значения
интервал времени, разделяющий последовательностные значения  и матрица
и матрица

 линейное правило решения
линейное правило решения  для среднего риска этого правила с учетом (9.6.1) получаем
для среднего риска этого правила с учетом (9.6.1) получаем

