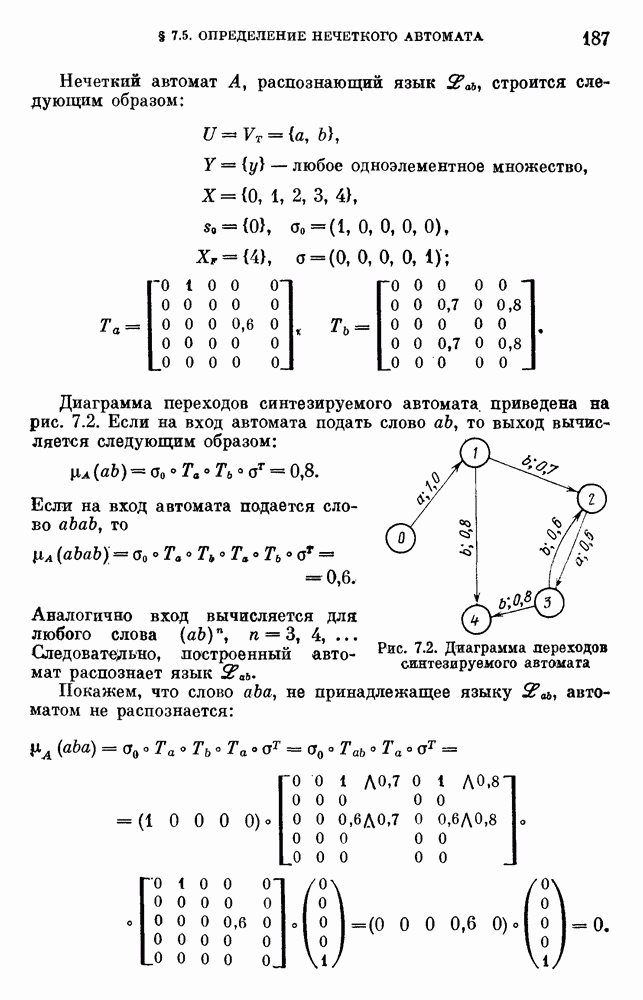
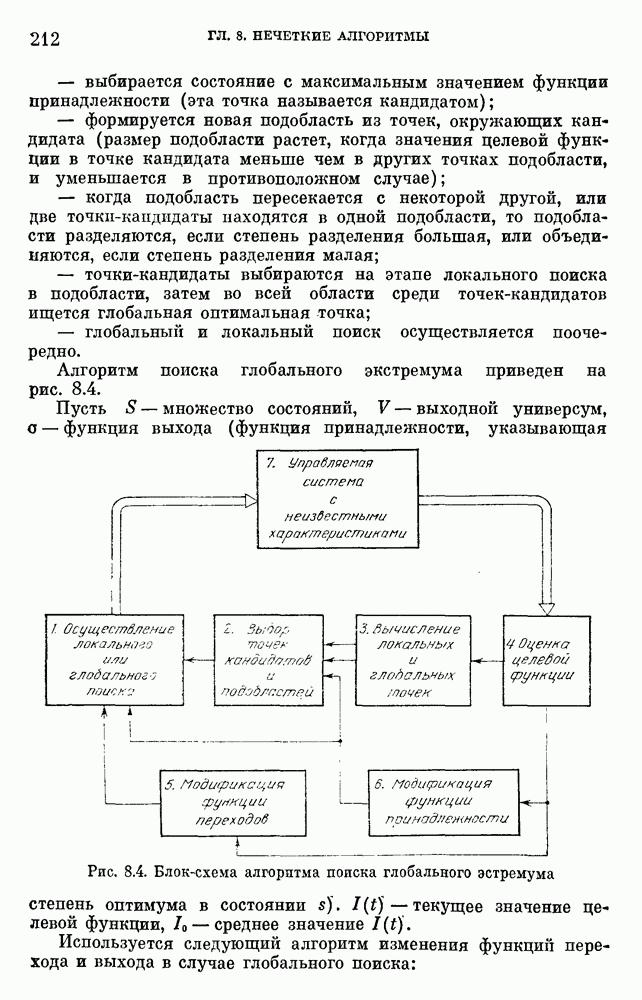
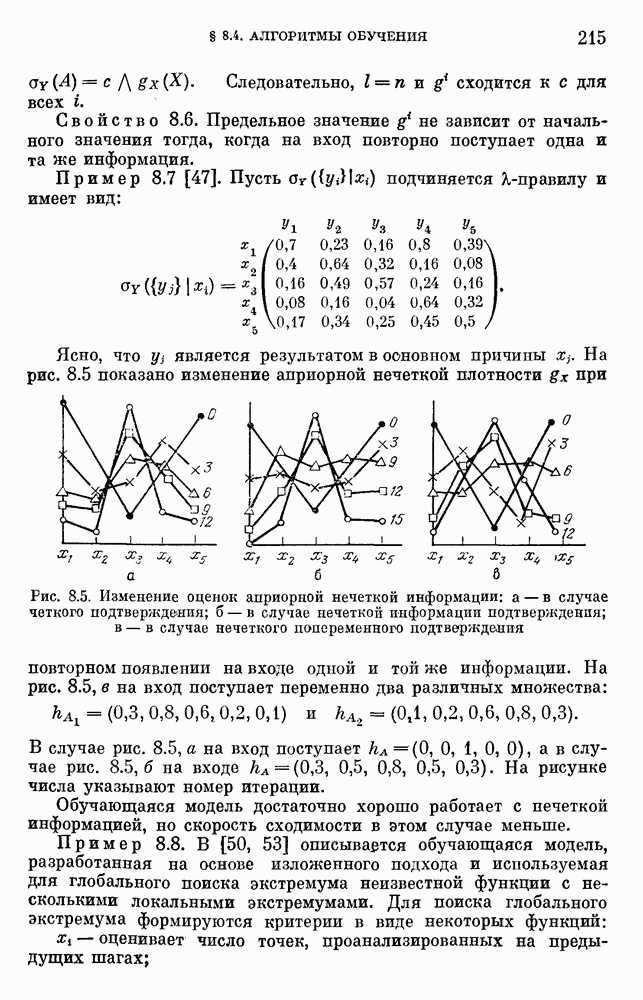
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
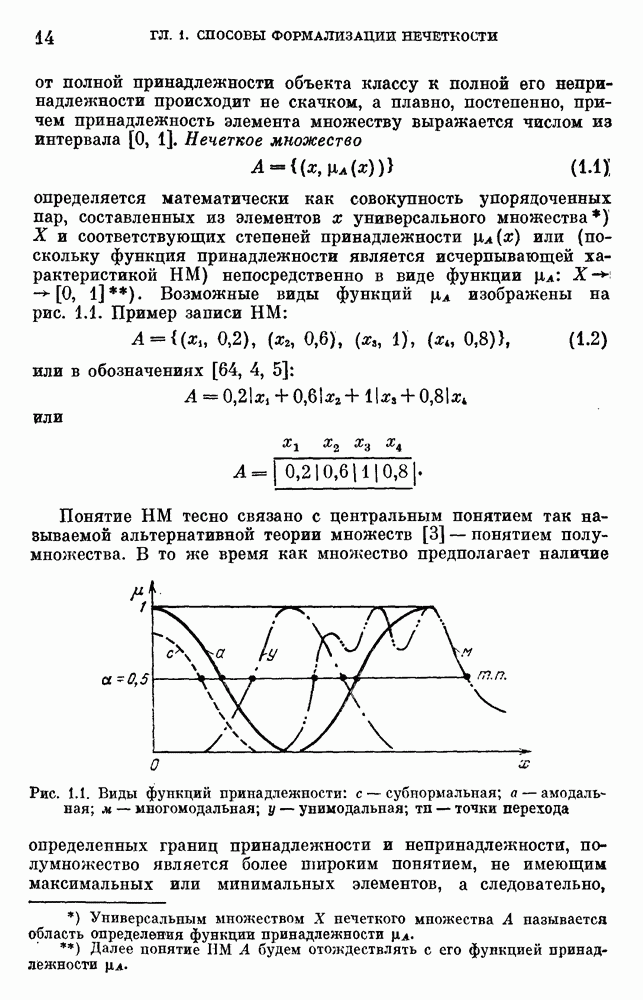
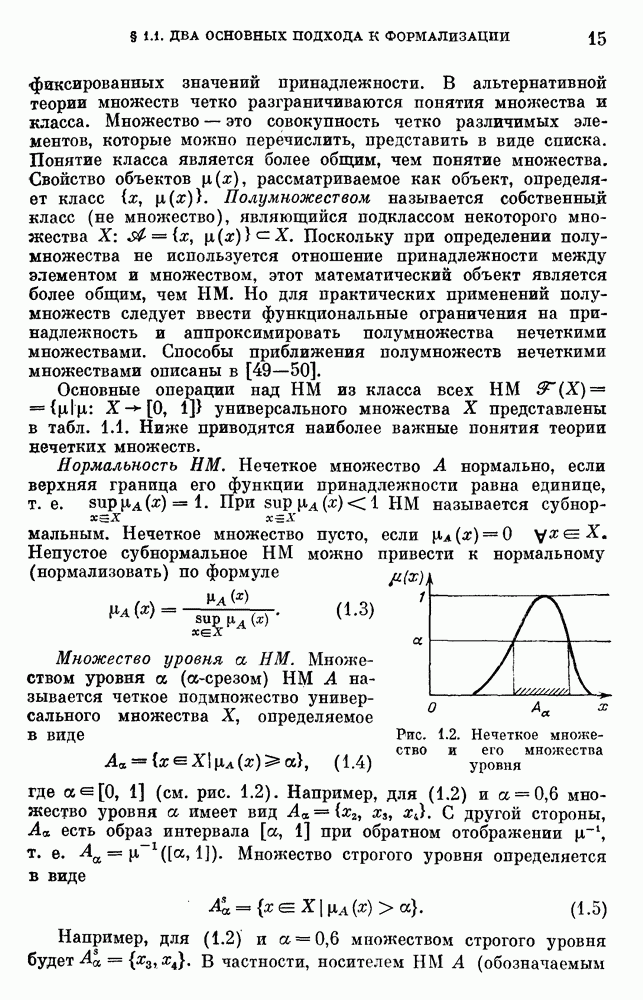
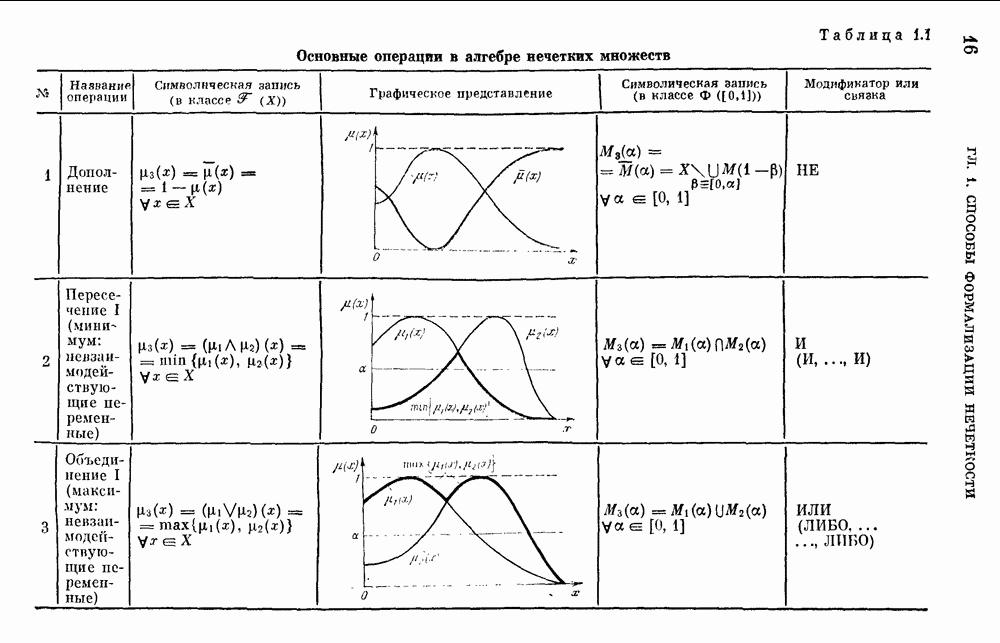
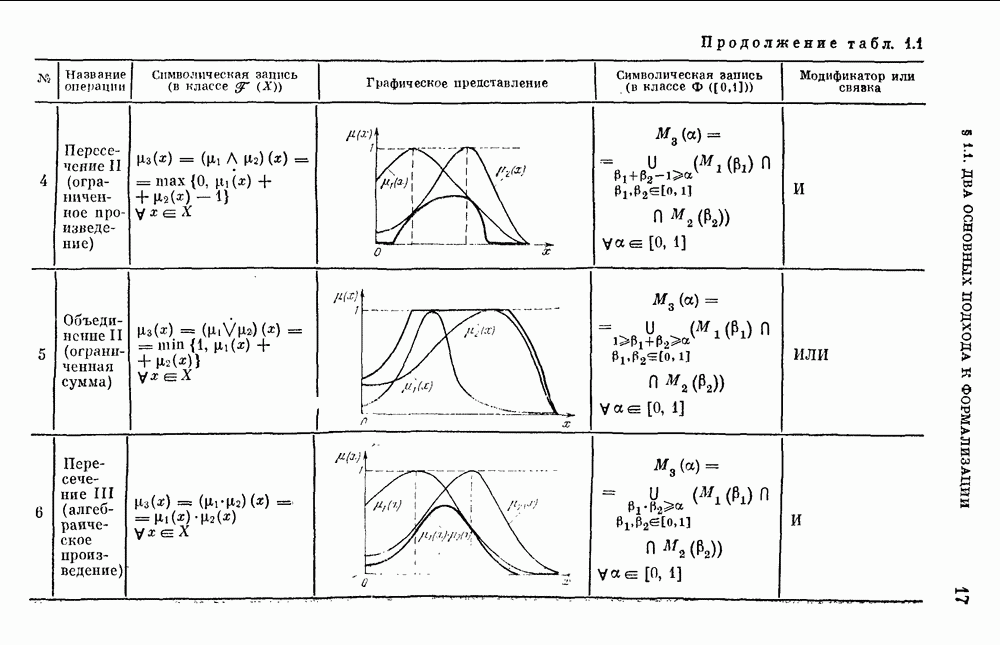
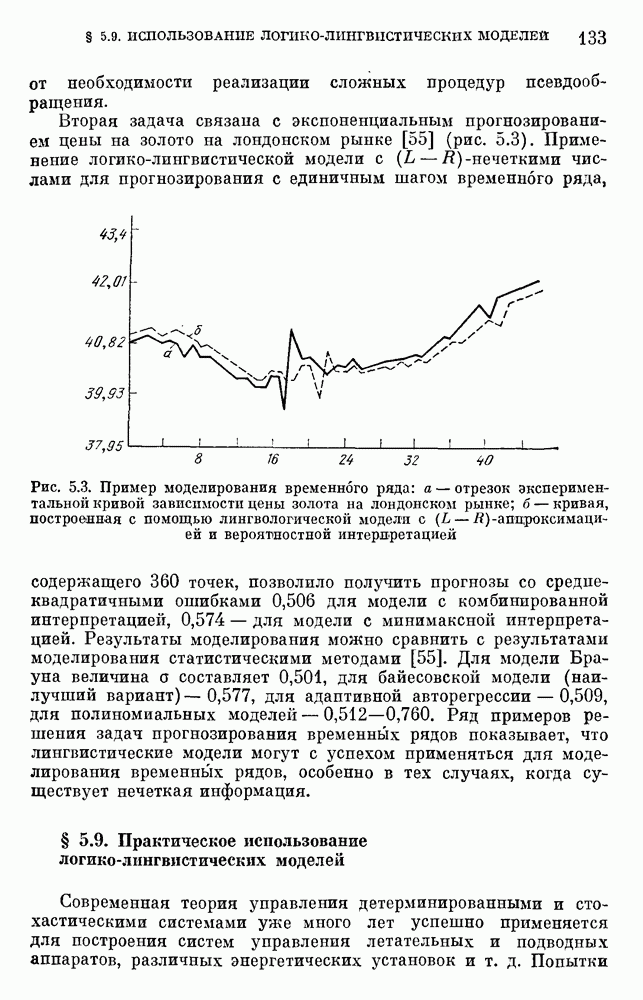
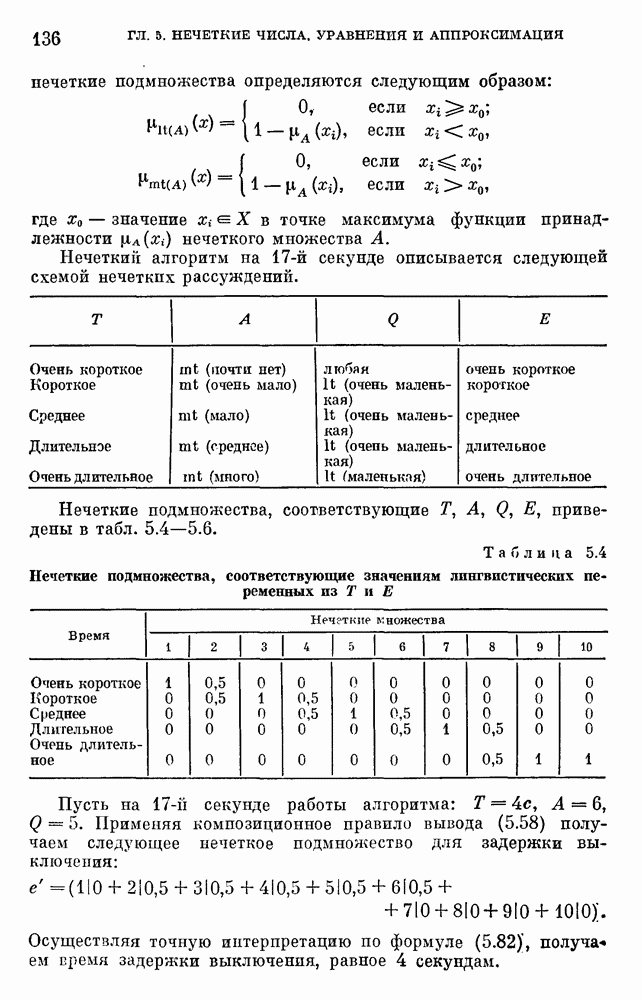
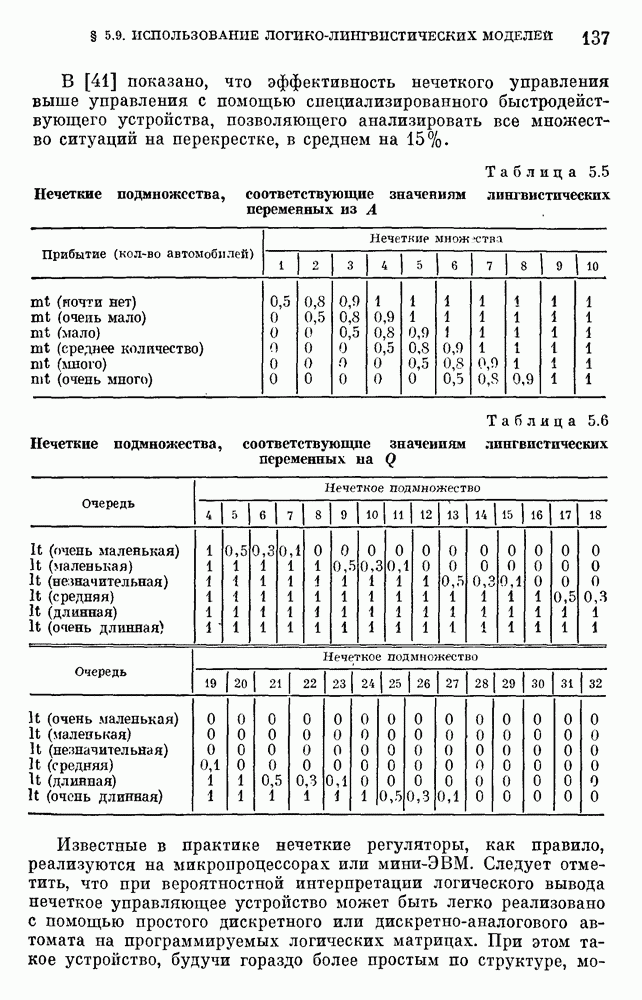
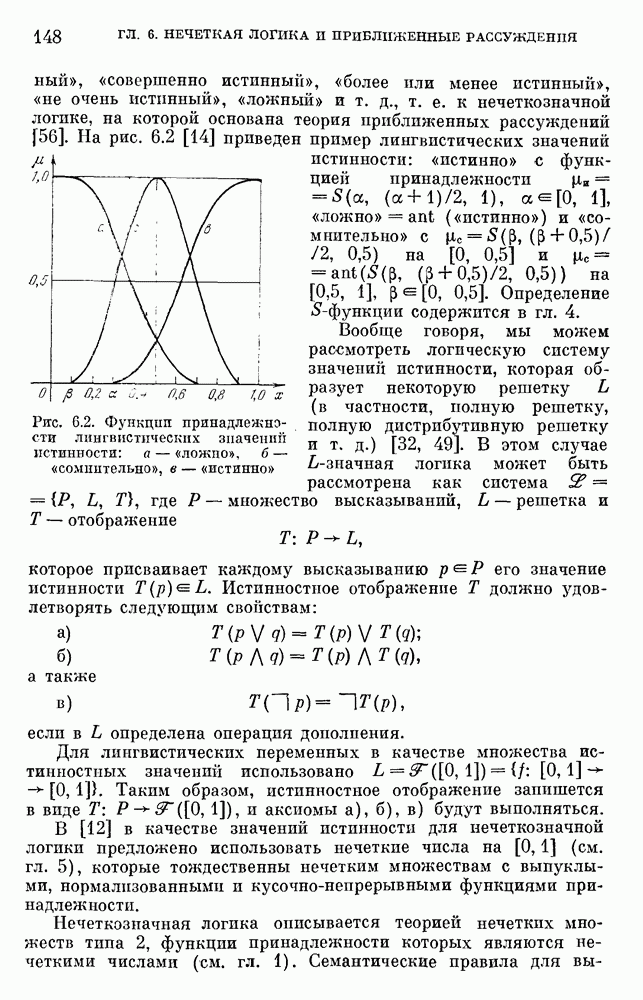
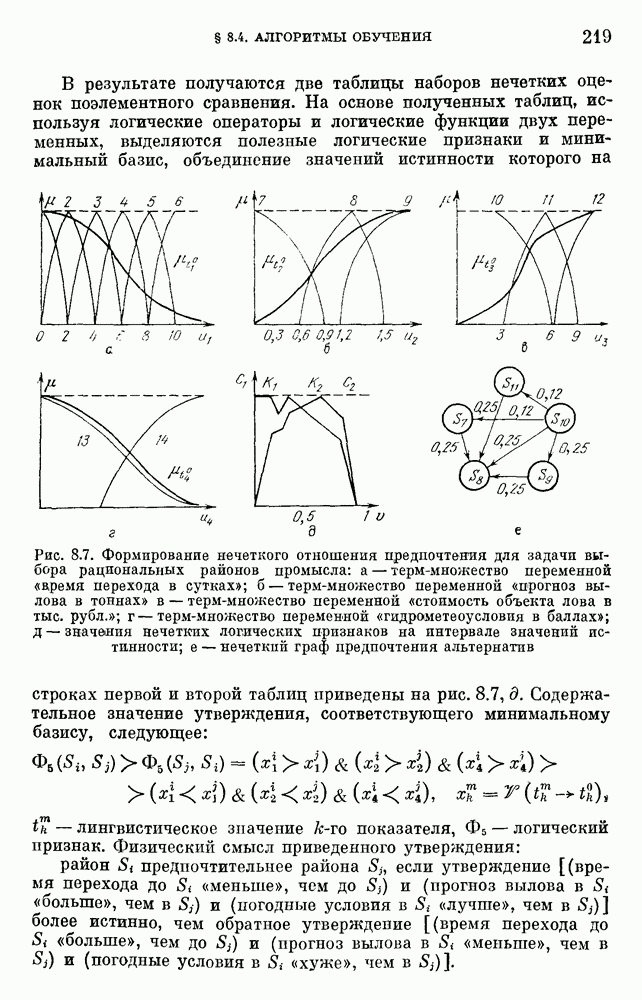
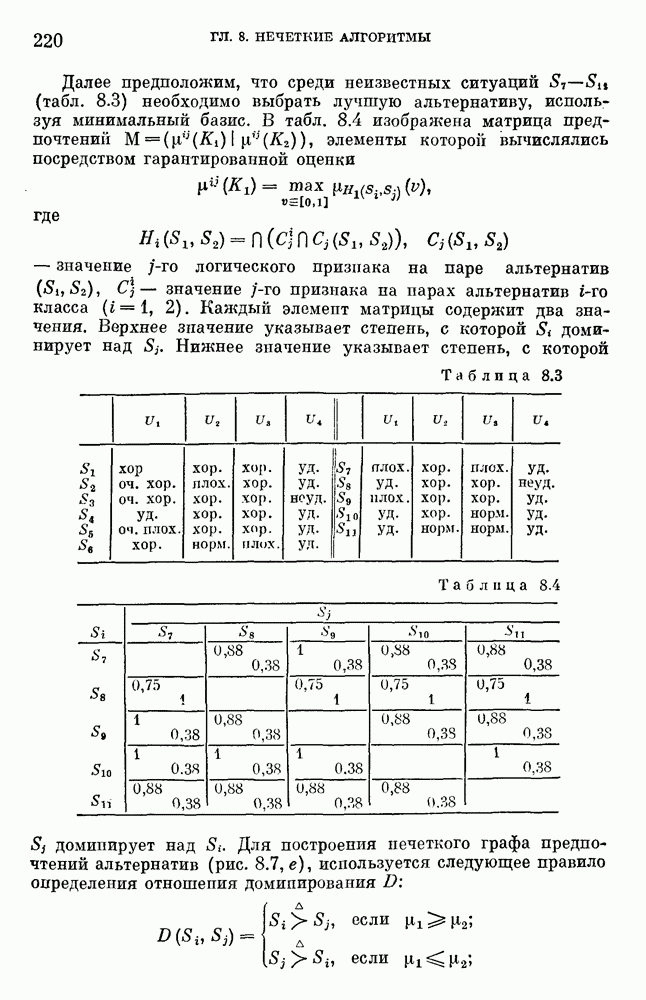
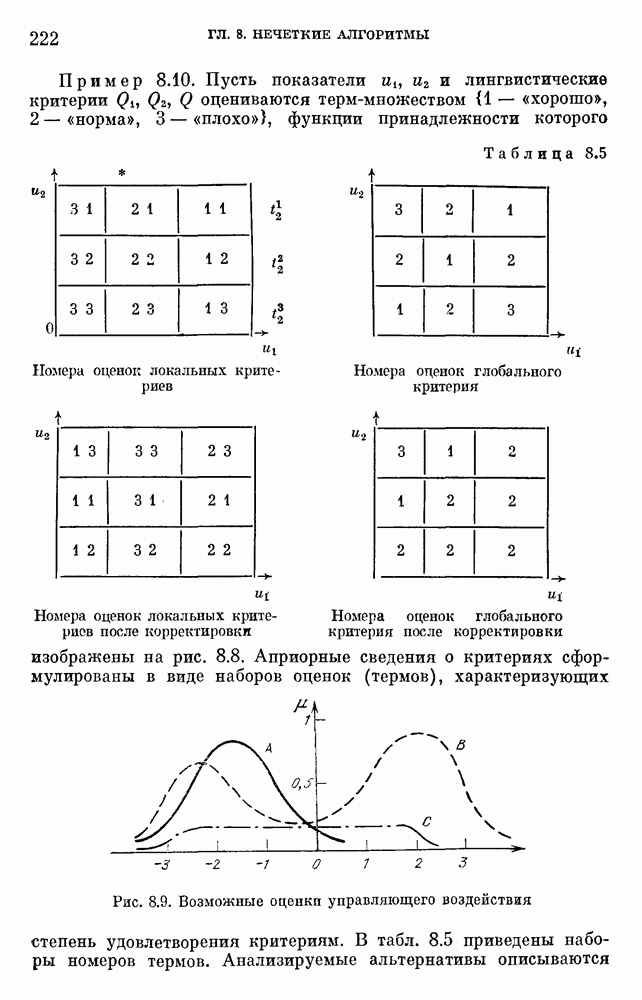
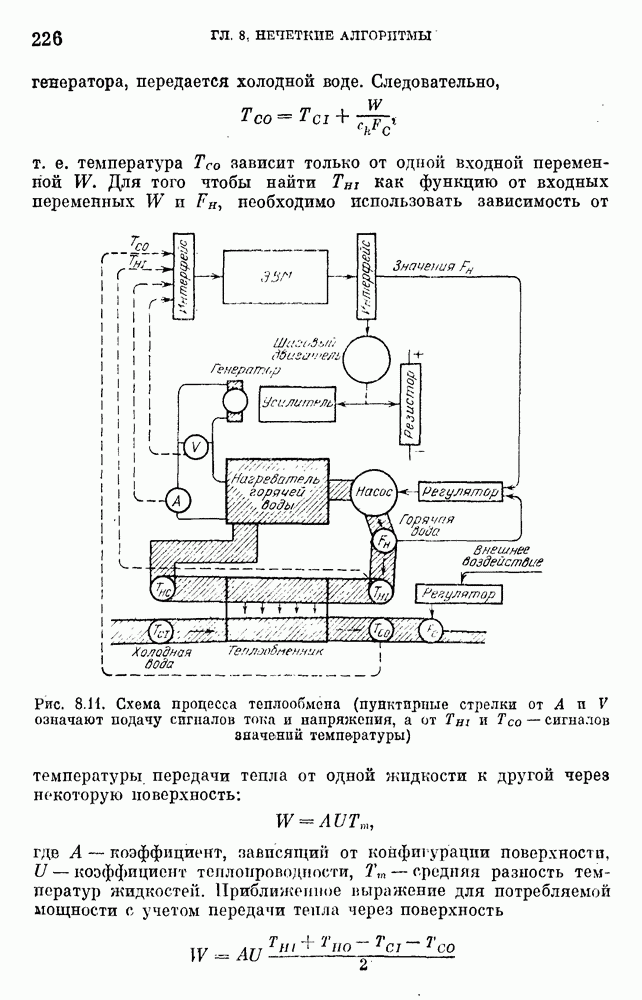
§ 10.6. Методы построения терм-множествВ [22] утверждается, что для практических задач достаточно наличия нечеткого языка с фиксированным, конечным словарем. Это ограничение не сишком сильное с точки зрения практического использования. Лингвистическая переменная описывается некоторым
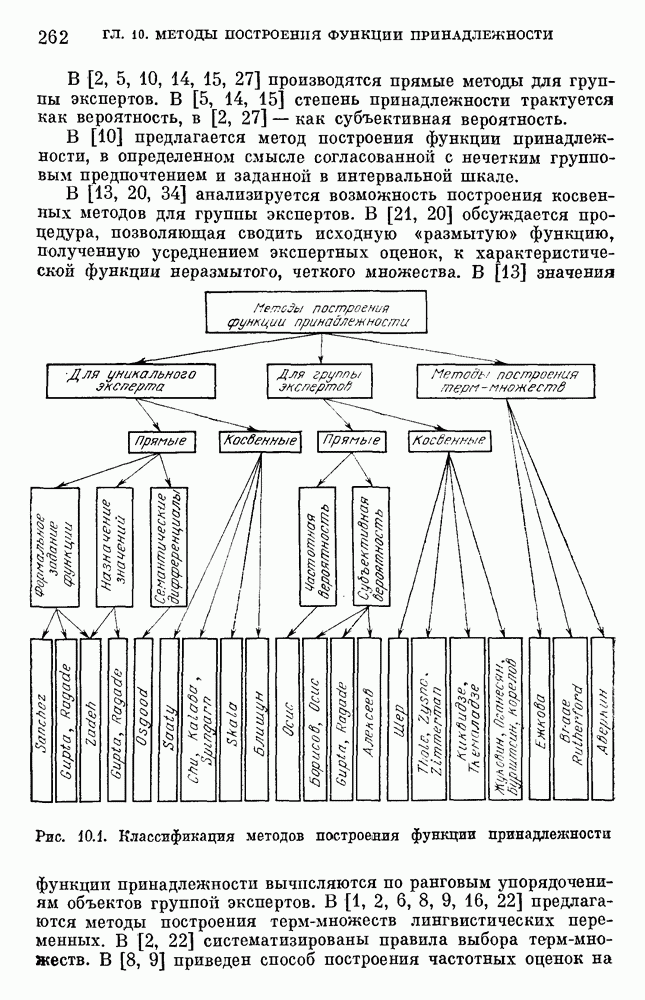
Рис. 10.2. Правило выбора функции принадлежности при наличии шума вероятностного характера Для определения нечетких множеств из Т, описывающих некоторый элемент и из Правила для выбора терм-множества сводятся в табл. 10.2. Таблица 10.2 (см. скан) В [2] перенумеровываются все термы
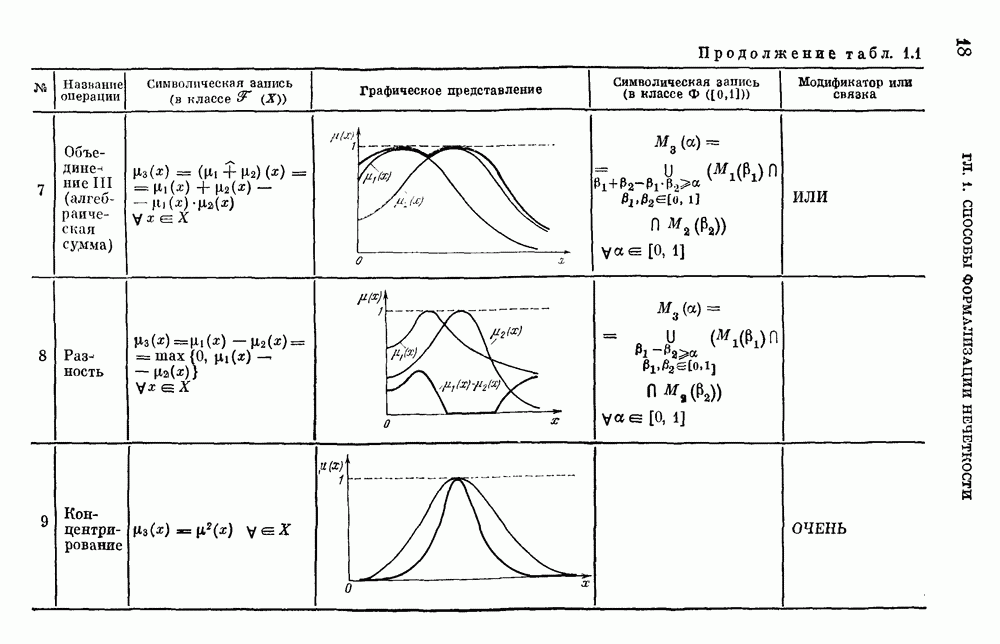
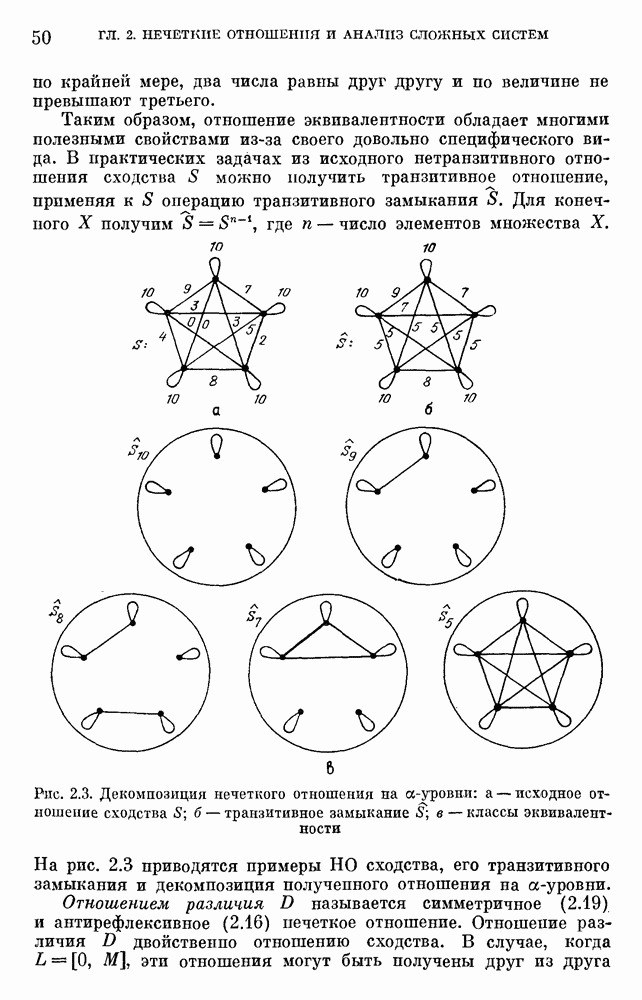
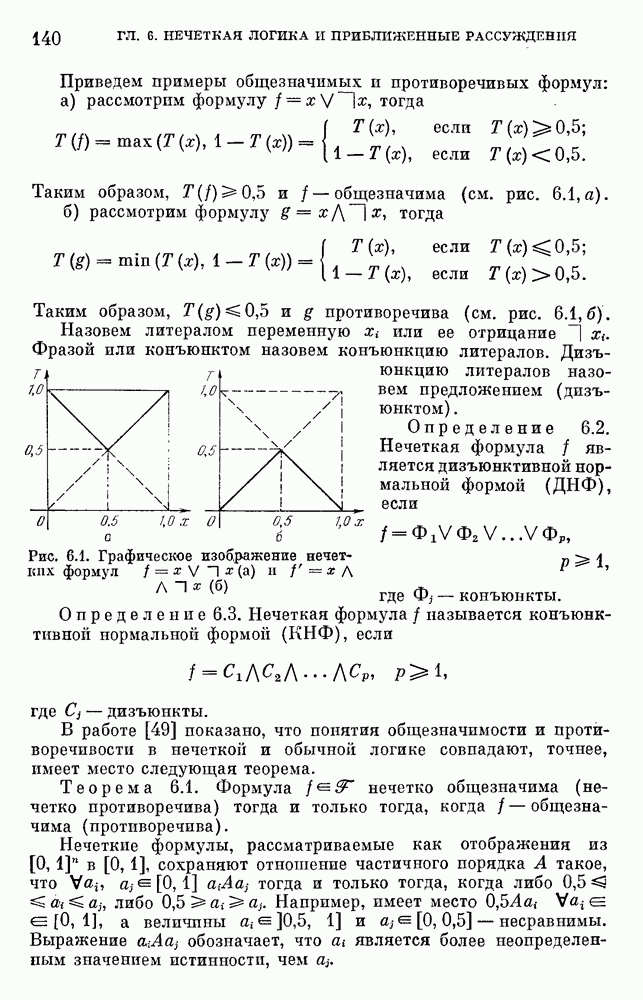
3) для любого 4) для любого В [8] приведен способ построения частотных оценок Предложенная методика оправдывается следующим: выбор обозначения категорий не влияет сколь-нибудь значительно на результаты эксперимента; число категорий (делений шкалы) не влияет кардинально на результаты эксперимента, в котором производится шкалирование субъективных ощущений; шкала из к категорий является шкалой равнокажущихся интервалов, поскольку предполагается, что ее деления отстоят на психологическом континууме на равные интервалы. Естественным шагом при построении функций принадлежности элементов терм-множества лингвистической переменной является построение одновременно всех функций принадлежности этого терм-множества, сгруппированных в так называемое отношение моделирования строки и столбцы, постараться сделать строки и столбцы унимодальными. Если это удается, то исходное терм-множество может быть использовано для построения нечеткой шкалы измерений, точками отсчета которой являются сами элементы терм-множества. Перевод в эту шкалу будет осуществляться с помощью минимаксного умножения строки, задающей исходную лингвистическую переменную в шкале метров, на отношение моделирования. Отношение сходства между элементами терм-множества
|
 |
Оглавление
|



































































































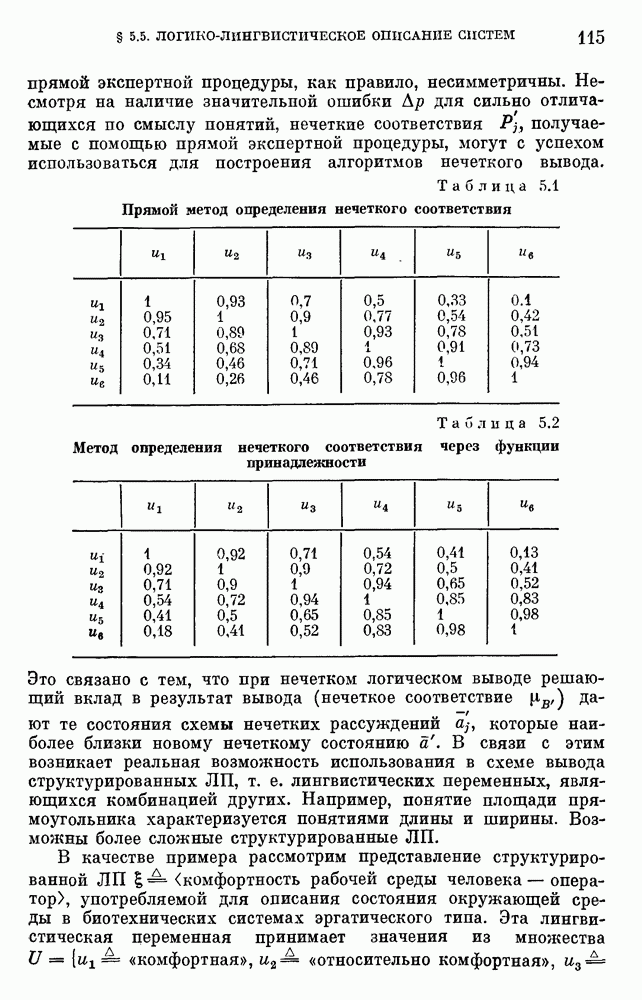

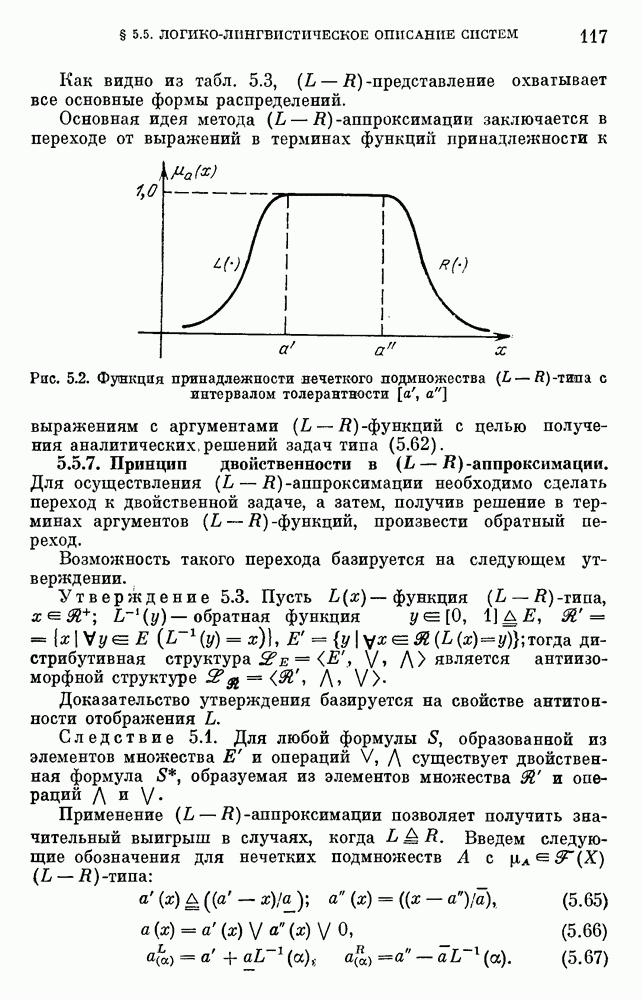
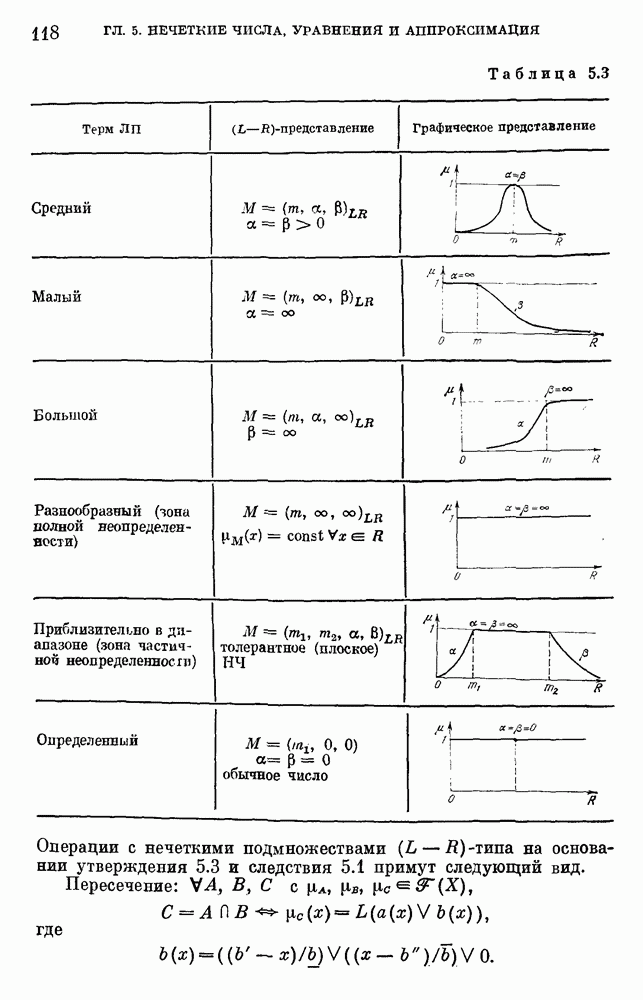





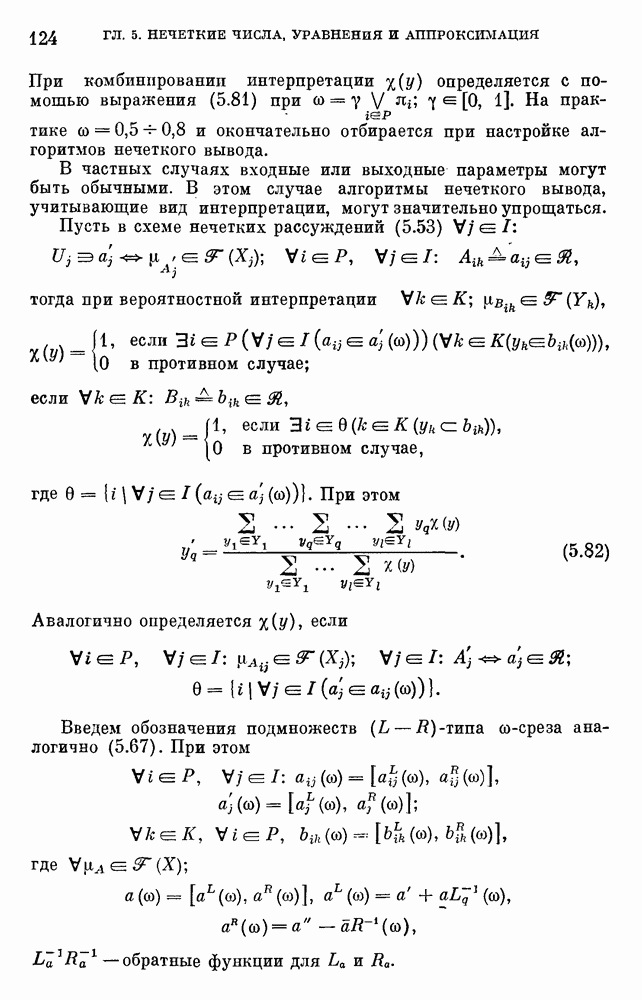































































































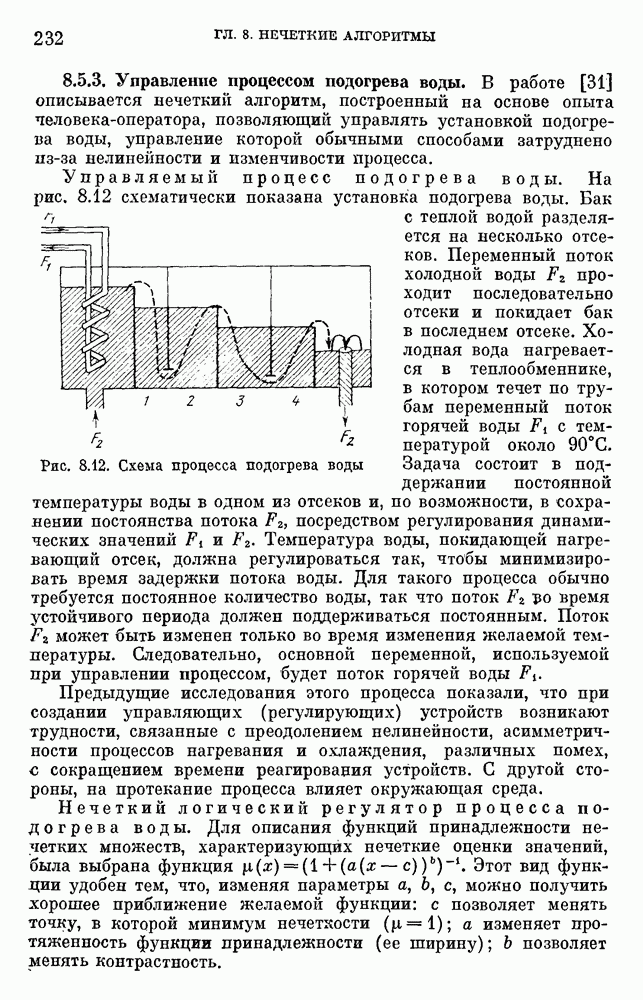





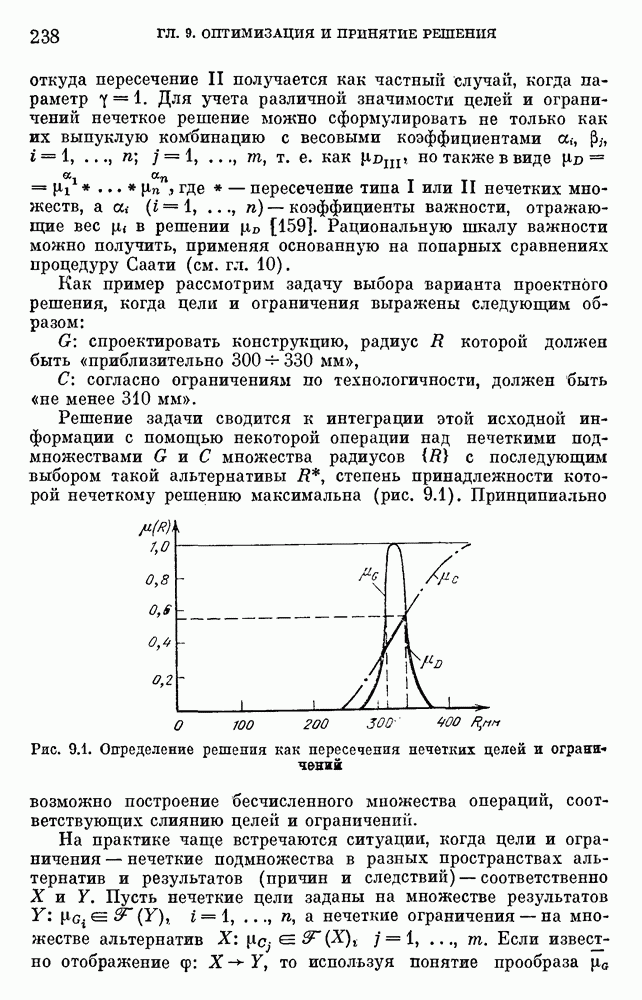



































































 используемая при формализации задач принятия решений, на практике, как правило, имеет базовое терм-множество
используемая при формализации задач принятия решений, на практике, как правило, имеет базовое терм-множество  состоящее из 2—10 термов. Каждый терм описывается нечетким подмножеством множества значений
состоящее из 2—10 термов. Каждый терм описывается нечетким подмножеством множества значений  некоторой базовой переменной и и рассматривается как лингвистическое значение
некоторой базовой переменной и и рассматривается как лингвистическое значение  Предполагается, что объединение всех элементов терм-множества покрывает полностью
Предполагается, что объединение всех элементов терм-множества покрывает полностью  Это гарантирует то, что любой элемент
Это гарантирует то, что любой элемент 
 На практике для представления нечетких отношений в матричном виде определяют нечеткое отображение терм-множества в дискретный (целочисленный) универсум
На практике для представления нечетких отношений в матричном виде определяют нечеткое отображение терм-множества в дискретный (целочисленный) универсум  Отображение
Отображение  определяется множителем [19, 22]
определяется множителем [19, 22]  — число элементов в
— число элементов в 

 вычисляется индекс
вычисляется индекс  где
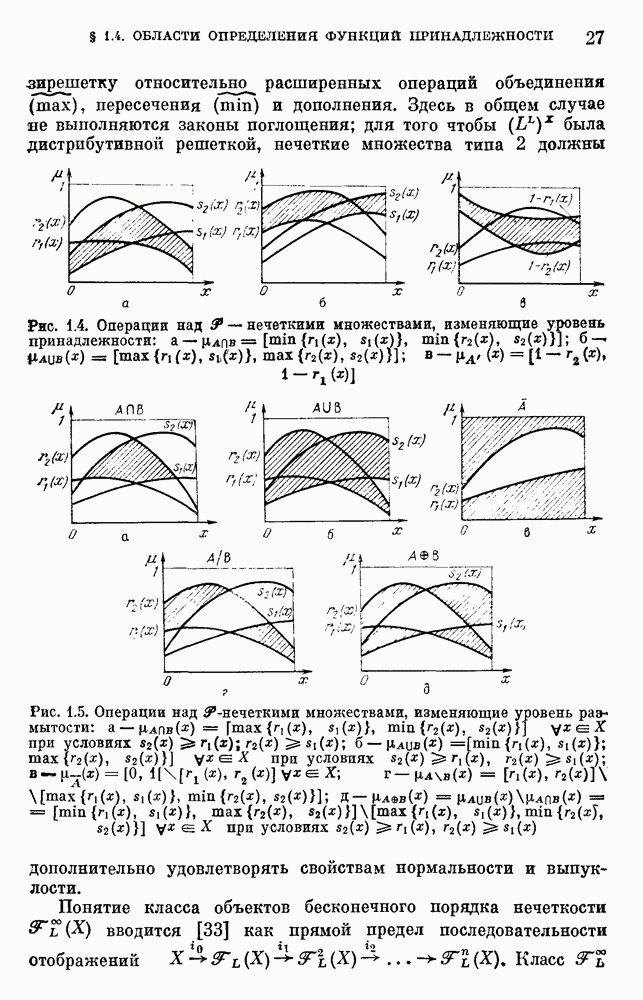
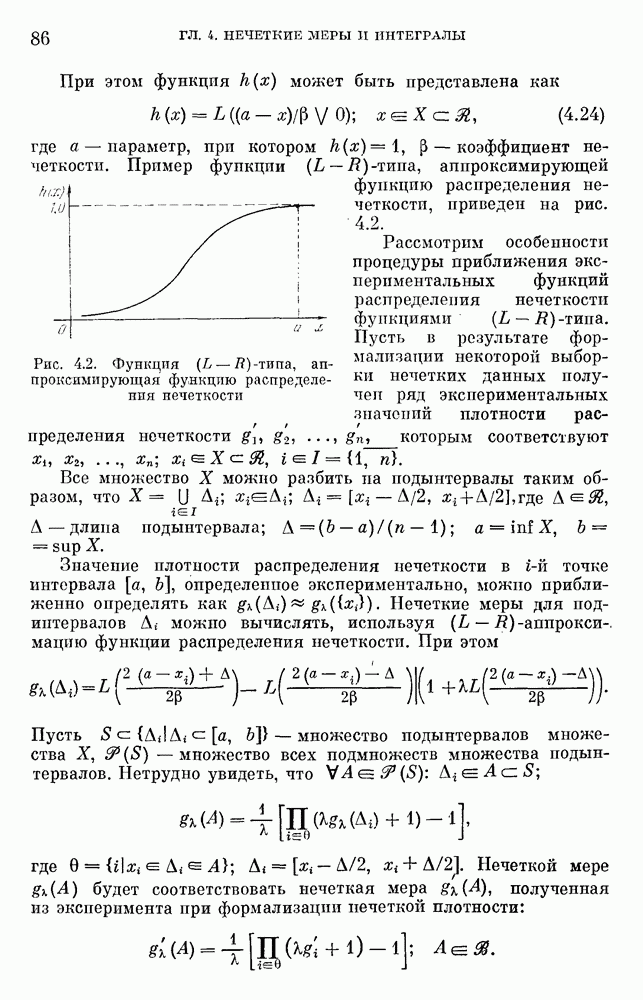
где  . В практических задачах значения на входе, например, для нечеткого управляющего устройства часто сильно зашумлены (шум в общем случае характеризуется функцией распределения вероятности), поэтому функции принадлежности должны выбираться достаточно широкими, чтобы шум не давал ощутимого эффекта (рис. 10.2).
. В практических задачах значения на входе, например, для нечеткого управляющего устройства часто сильно зашумлены (шум в общем случае характеризуется функцией распределения вероятности), поэтому функции принадлежности должны выбираться достаточно широкими, чтобы шум не давал ощутимого эффекта (рис. 10.2).
 на множестве действительных чисел и
на множестве действительных чисел и  так что терм, имеющий левее расположенный носитель, имеет меньший номер, вводятся более строгие условия:
так что терм, имеющий левее расположенный носитель, имеет меньший номер, вводятся более строгие условия:

 существует
существует 
 и
и 
 «часто», «иногда», который основан на предположении о том, что слово
«часто», «иногда», который основан на предположении о том, что слово  употребляется человеком не для обозначения зарегистрированной частоты появления факта, а для обозначения относительного числа событий в прошлой деятельности человека, когда рассматривалась такая же частота. Каждому
употребляется человеком не для обозначения зарегистрированной частоты появления факта, а для обозначения относительного числа событий в прошлой деятельности человека, когда рассматривалась такая же частота. Каждому  ставится в соответствие нечеткое подмножество интервала
ставится в соответствие нечеткое подмножество интервала  Функции принадлежности получаются на основании психологического эксперимента следующим образом [18]: группе испытуемых предъявляется набор стимулов (оценок частоты) и шкала из к категорий, упорядоченных по степени интенсивности частоты от наименьшей (1) до наибольшей
Функции принадлежности получаются на основании психологического эксперимента следующим образом [18]: группе испытуемых предъявляется набор стимулов (оценок частоты) и шкала из к категорий, упорядоченных по степени интенсивности частоты от наименьшей (1) до наибольшей  испытуемым предлагается разбить стимулы на к классов согласно интенсивности частоты, независимо оценивая каждый стимул и помещая в любую категорию любое число стимулов. Каждому числу
испытуемым предлагается разбить стимулы на к классов согласно интенсивности частоты, независимо оценивая каждый стимул и помещая в любую категорию любое число стимулов. Каждому числу  из
из  ставятся в соответствие степени употребления группой испытуемых слова
ставятся в соответствие степени употребления группой испытуемых слова  для обозначения категорий. Значения функции принадлежности определяются в результате нормирования:
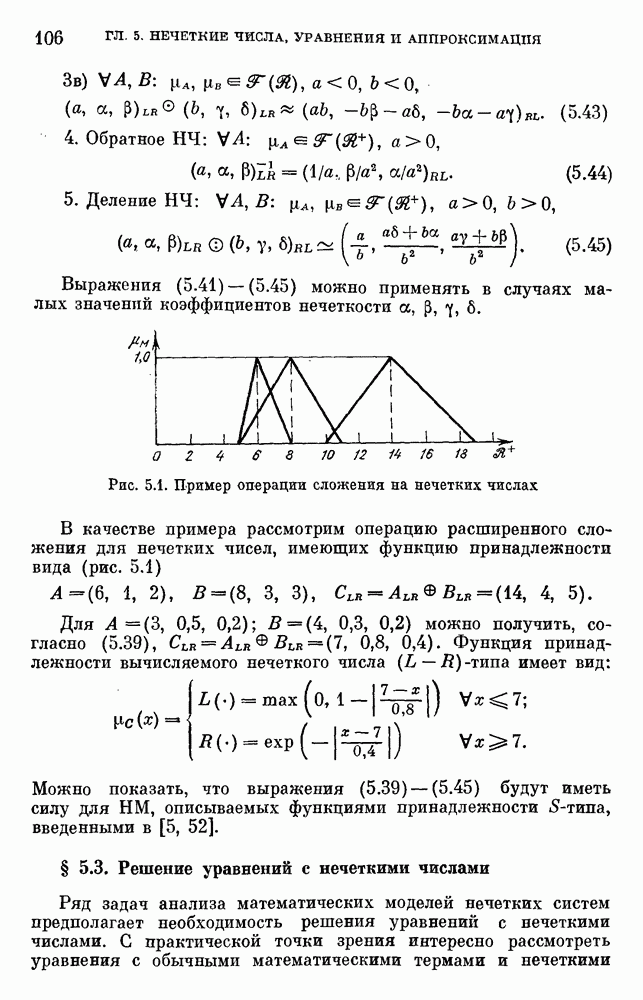
для обозначения категорий. Значения функции принадлежности определяются в результате нормирования:  .
.
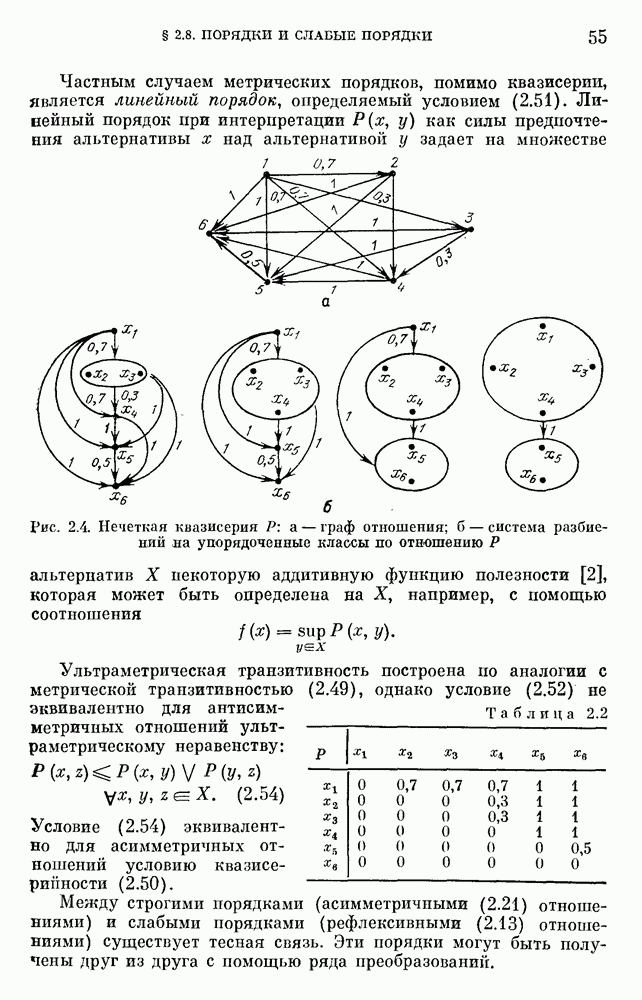
 . Процесс построения состоит в заполнении таблицы, где, например, для лингвистической переменной «расстояние» столбцы индексированы расстояниями в метрах, а строки — элементами терм-множества «очень близко», «близко»,
. Процесс построения состоит в заполнении таблицы, где, например, для лингвистической переменной «расстояние» столбцы индексированы расстояниями в метрах, а строки — элементами терм-множества «очень близко», «близко»,  «далеко», «очень далеко». На пересечении соответствующей строки и столбца стоит степень сходства для испытуемого данных понятий между собой в данной семантической ситуации, например, насколько сходны понятия «близко» и 5 метров в ситуации перебегания улицы перед быстро идущим транспортом. Расстояние берется от пешехода до машины и в данном случае является синонимом опасности. Вообще говоря, каждую клеточку таблицы можно заполнять отдельно, а потом, переставляя
«далеко», «очень далеко». На пересечении соответствующей строки и столбца стоит степень сходства для испытуемого данных понятий между собой в данной семантической ситуации, например, насколько сходны понятия «близко» и 5 метров в ситуации перебегания улицы перед быстро идущим транспортом. Расстояние берется от пешехода до машины и в данном случае является синонимом опасности. Вообще говоря, каждую клеточку таблицы можно заполнять отдельно, а потом, переставляя
 полученное с помощью умножения матрицы
полученное с помощью умножения матрицы  на транспонированную, задает набор функций принадлежности элементов лингвистической шкалы в самой шкале, а отношение
на транспонированную, задает набор функций принадлежности элементов лингвистической шкалы в самой шкале, а отношение  задает набор функций принадлежности расстояний в метрах в метрической шкале.
задает набор функций принадлежности расстояний в метрах в метрической шкале.