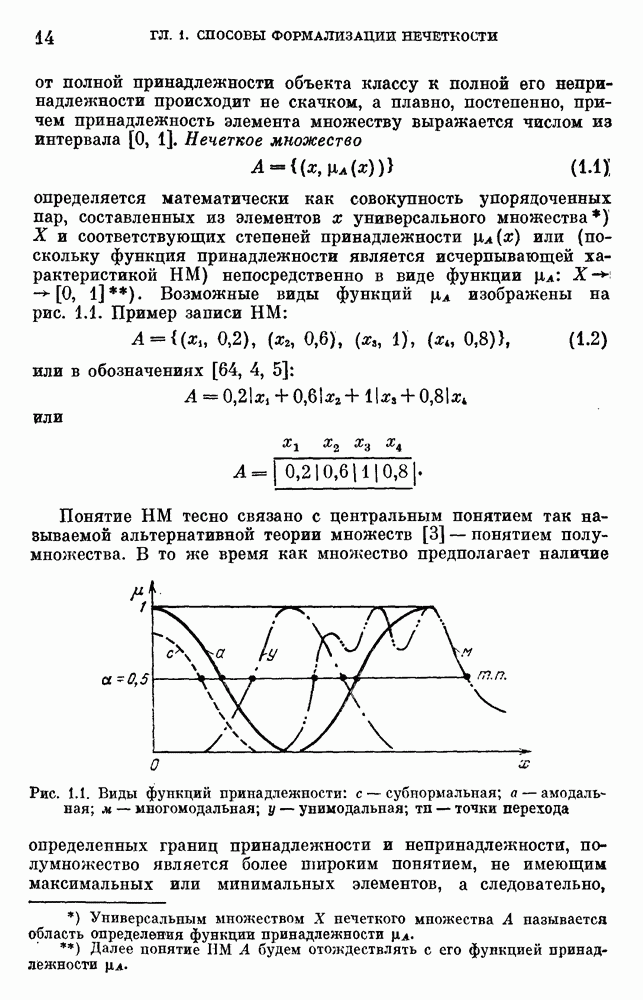
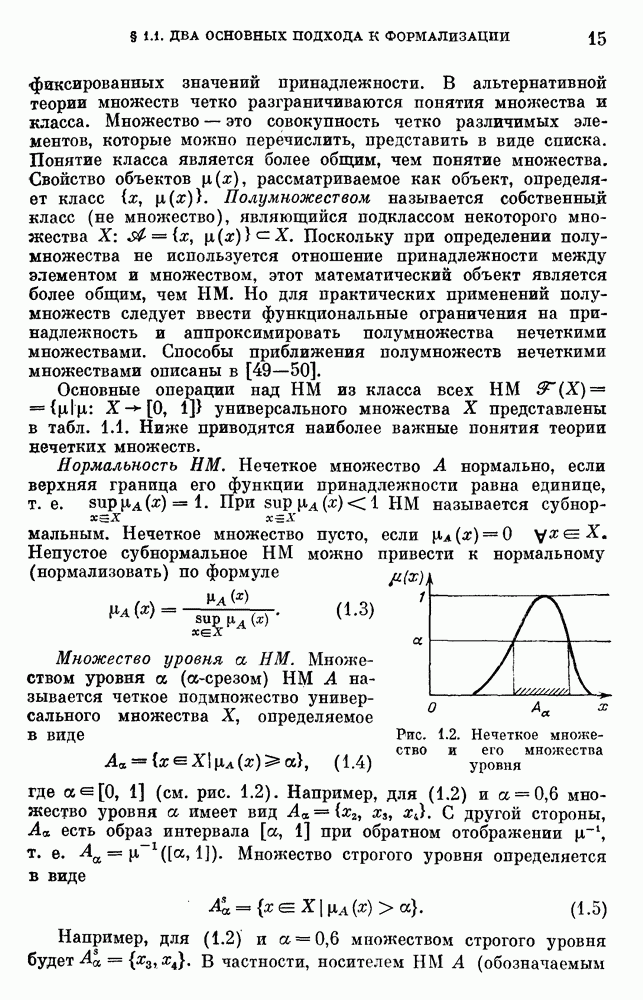
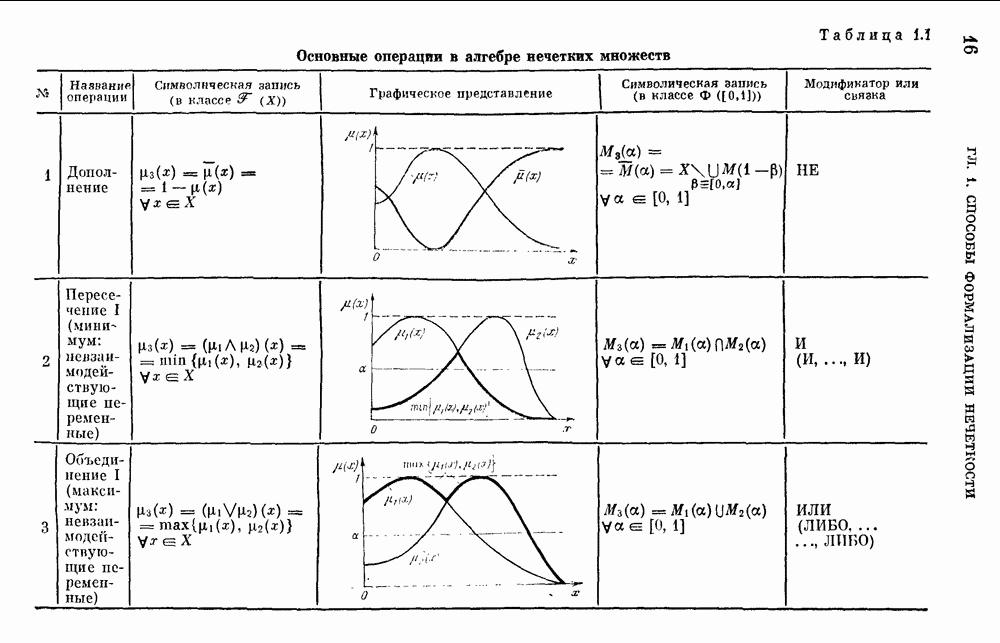
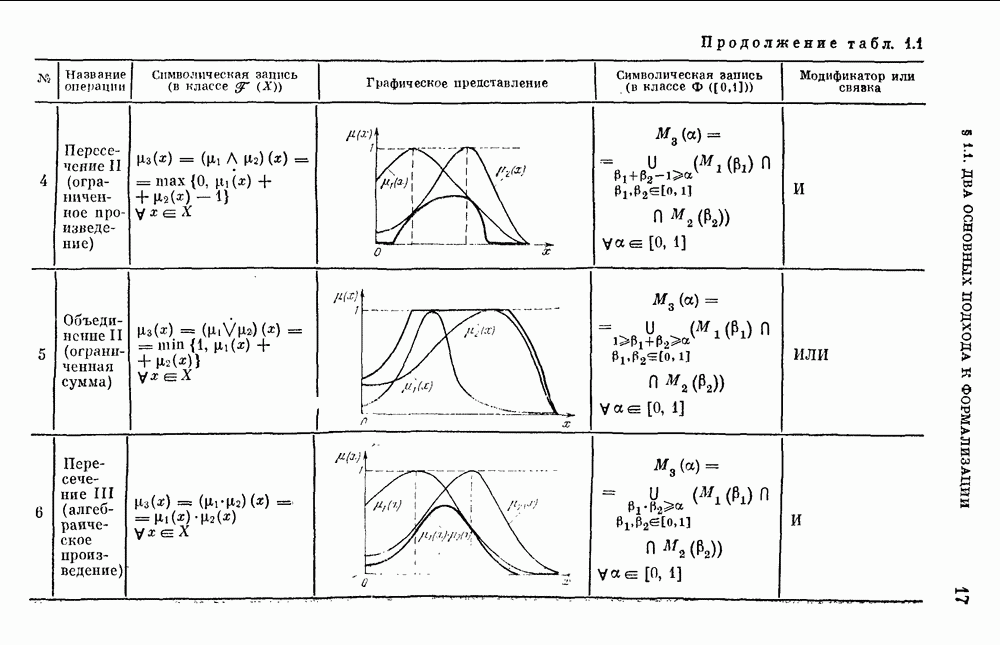
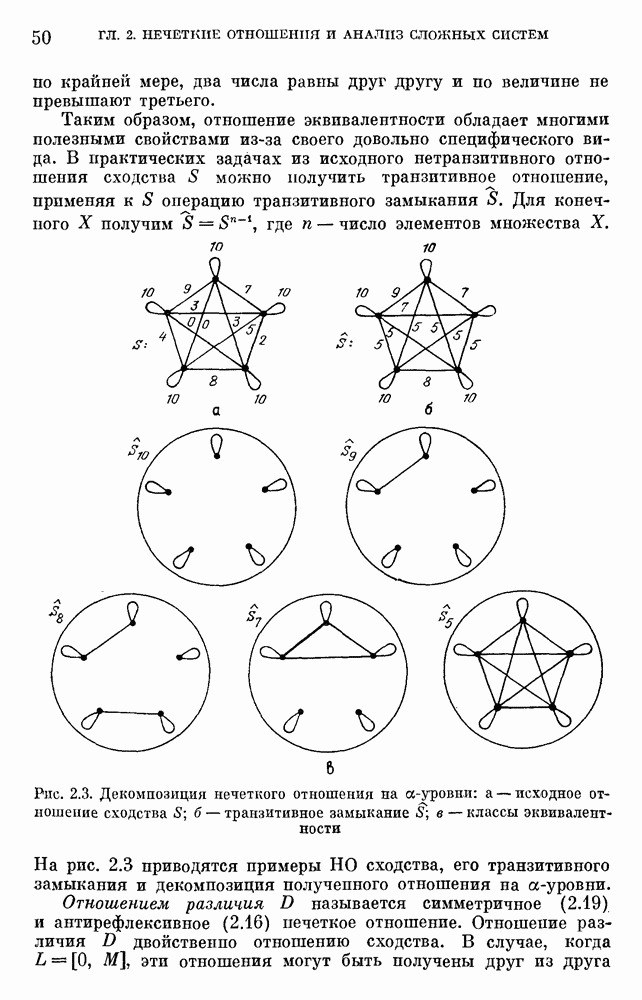
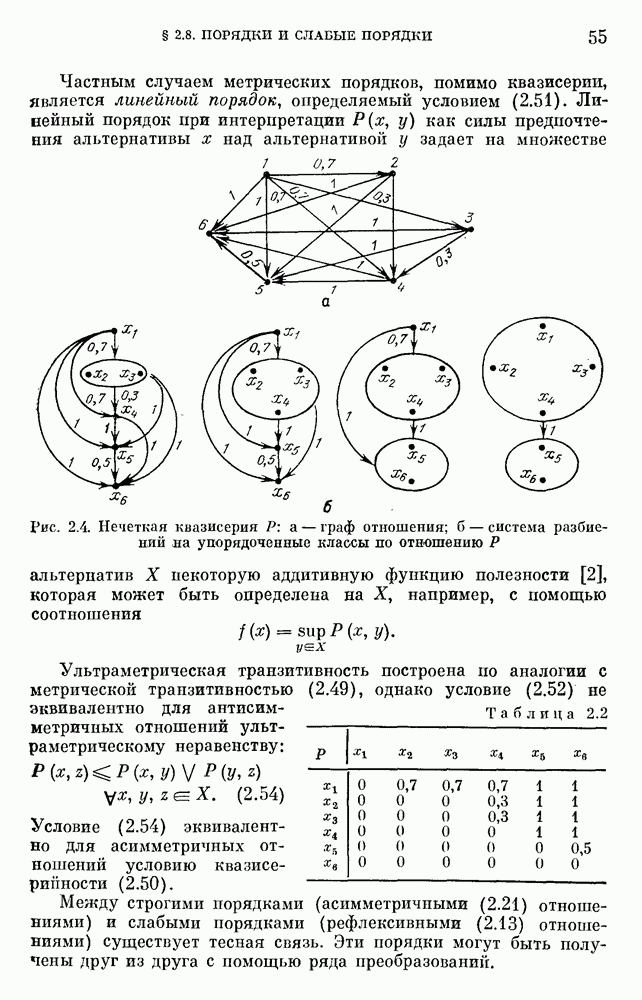
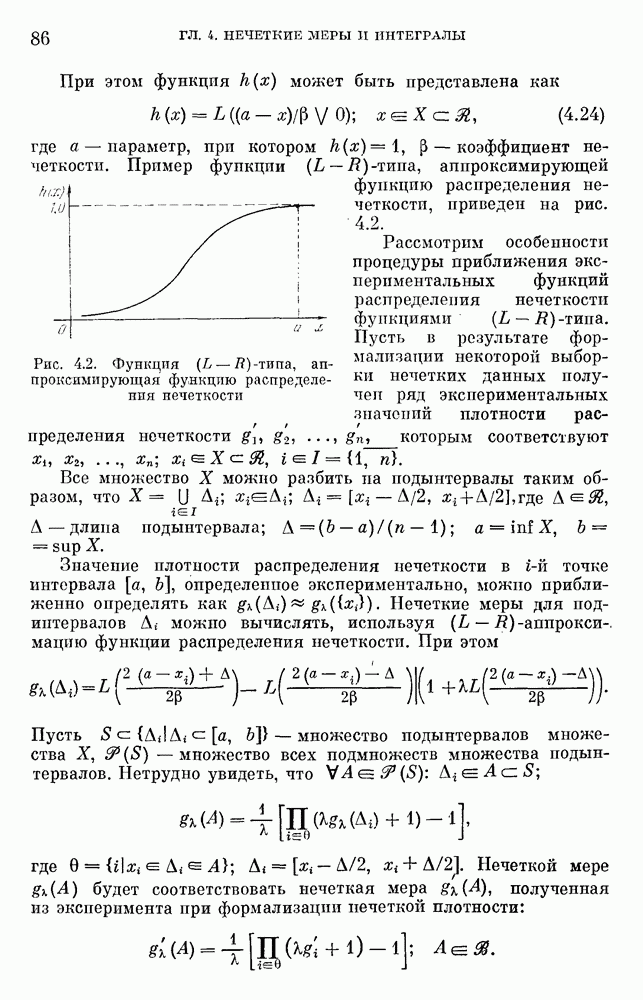
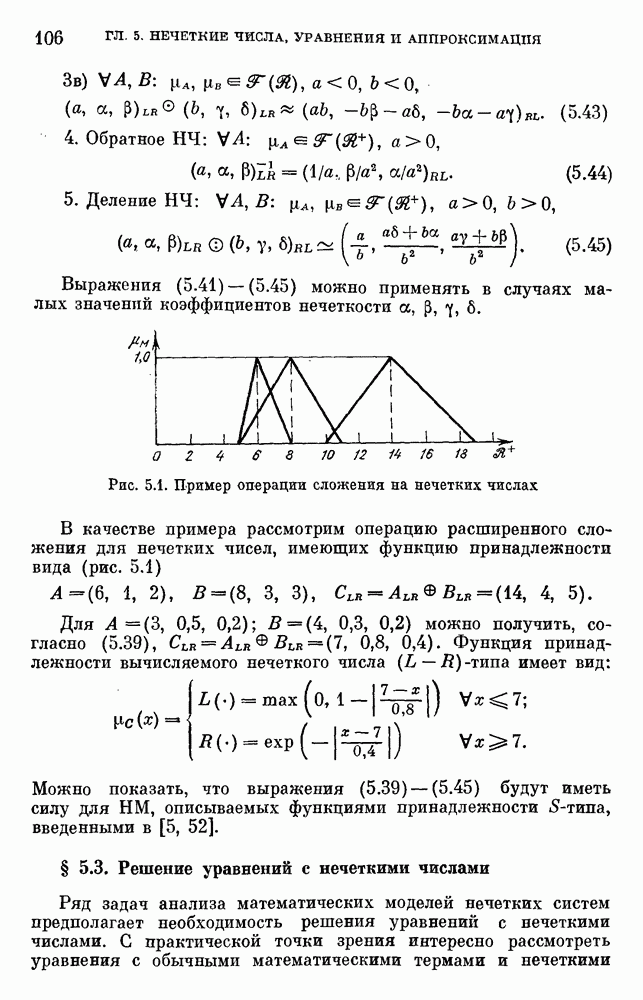
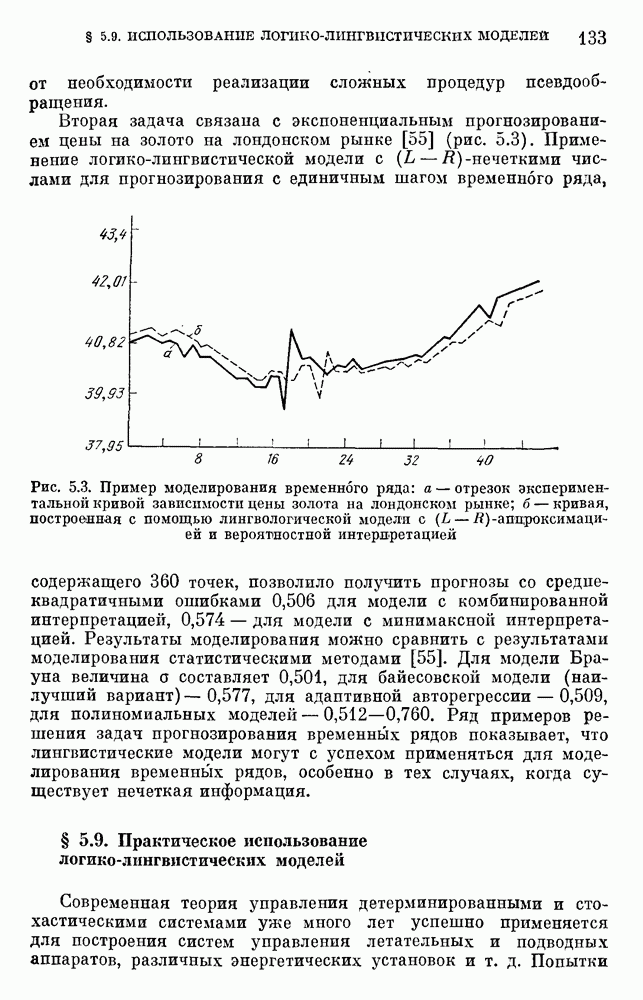
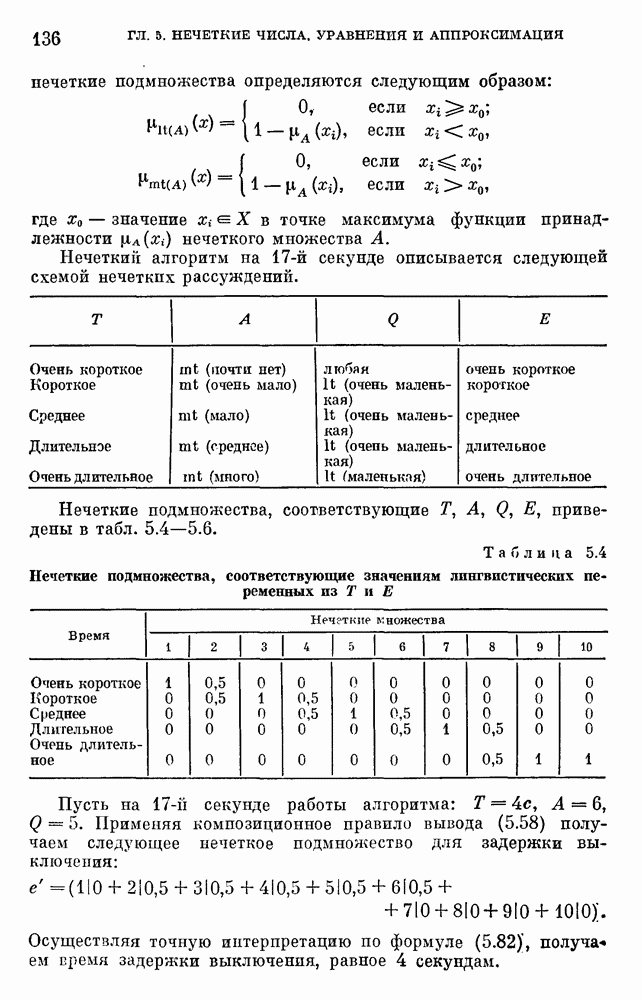
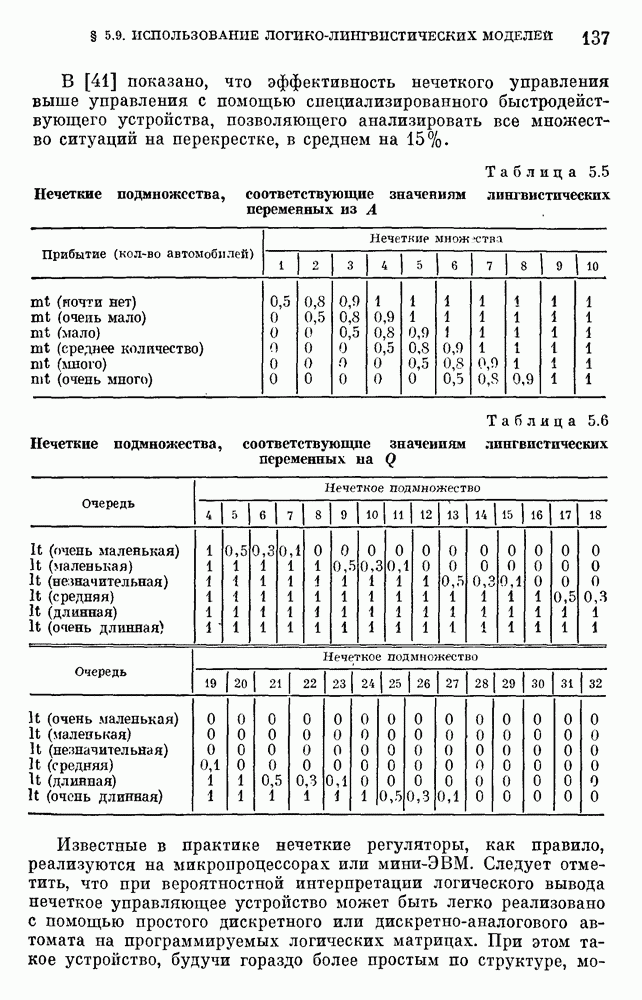
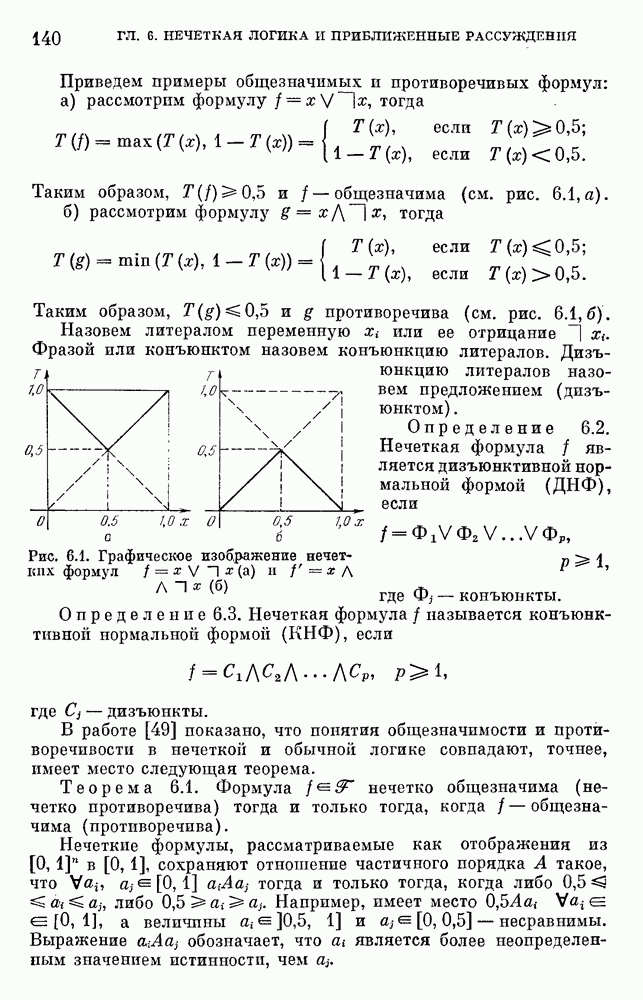
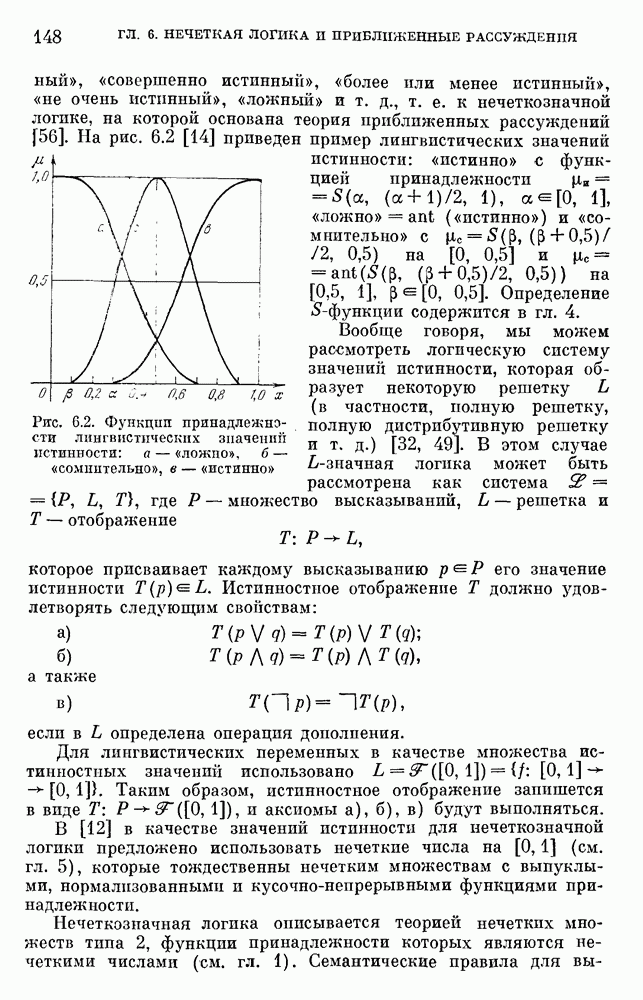
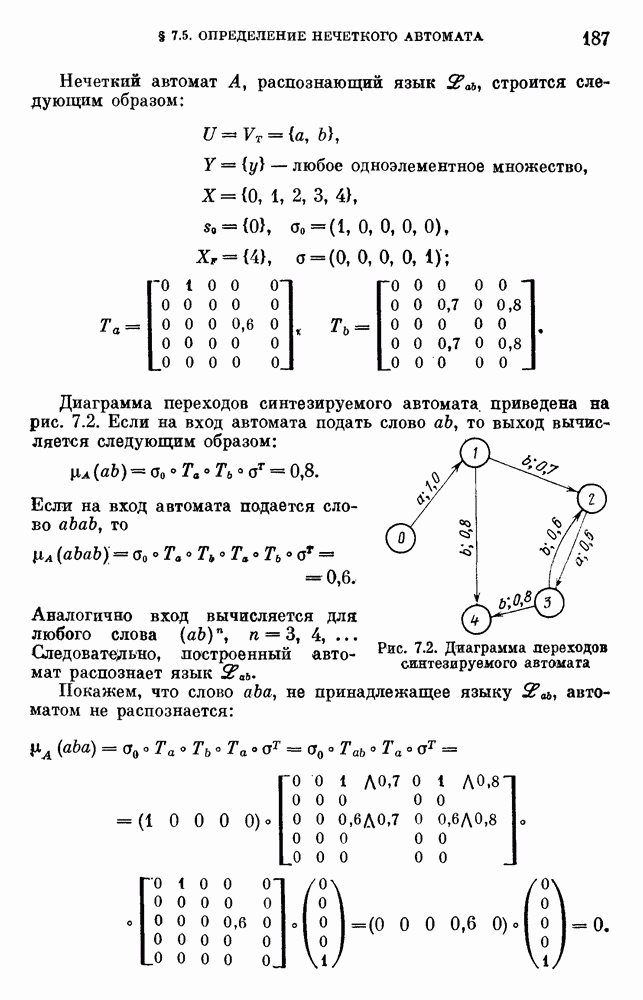
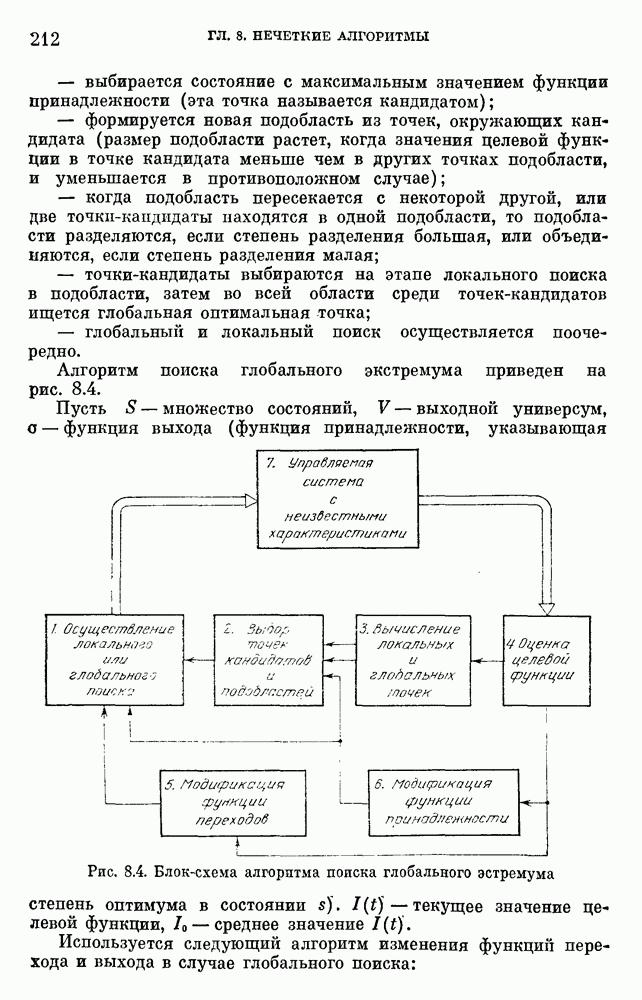
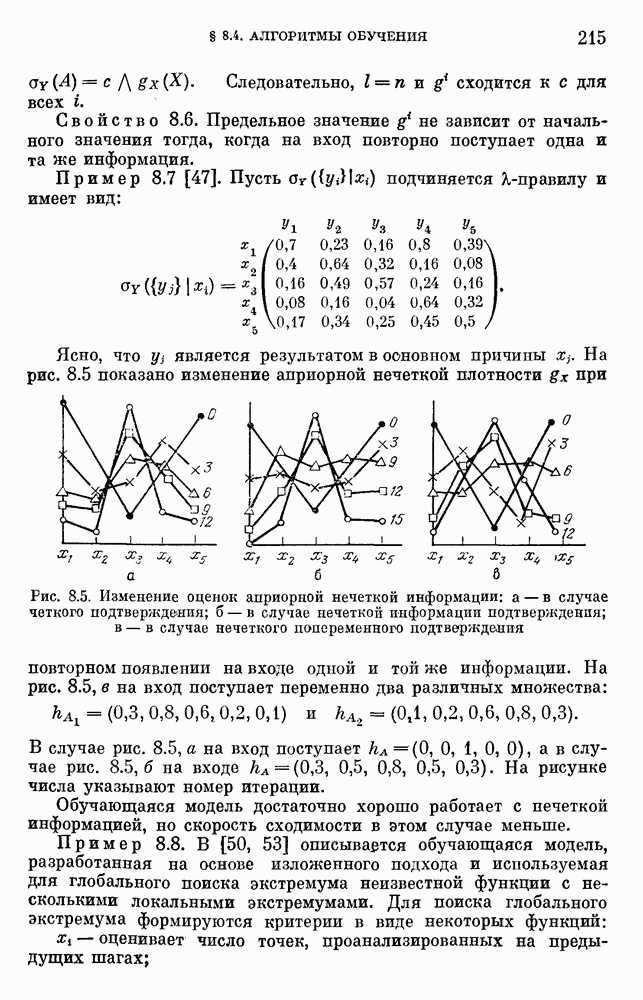
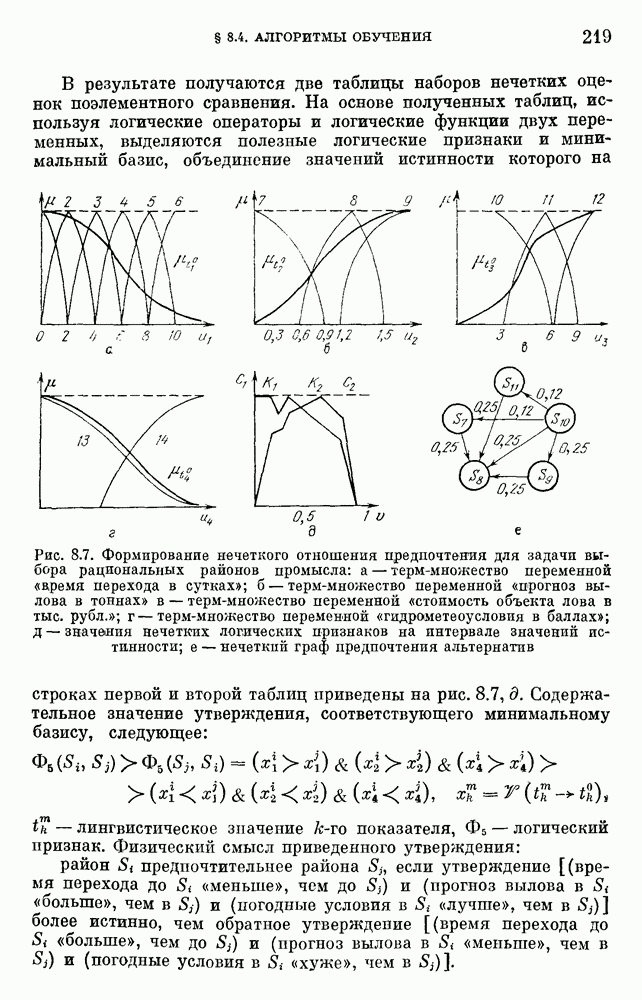
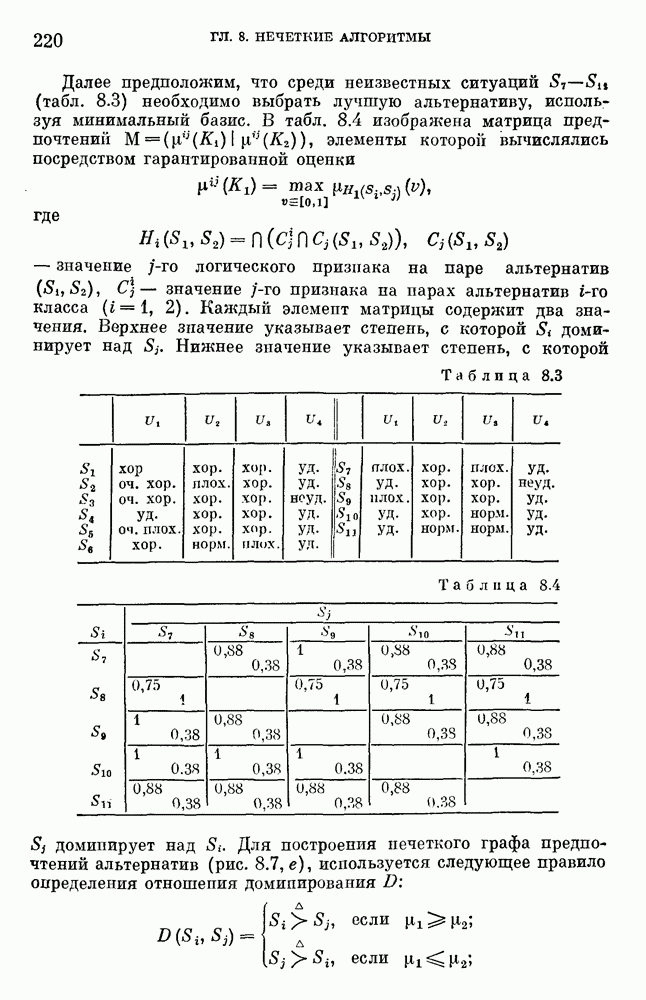
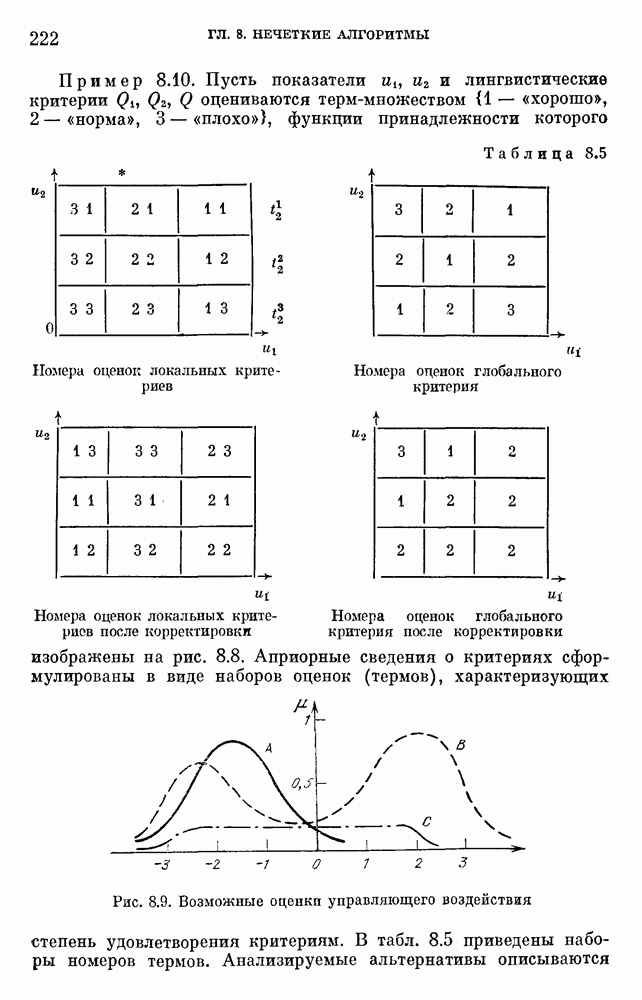
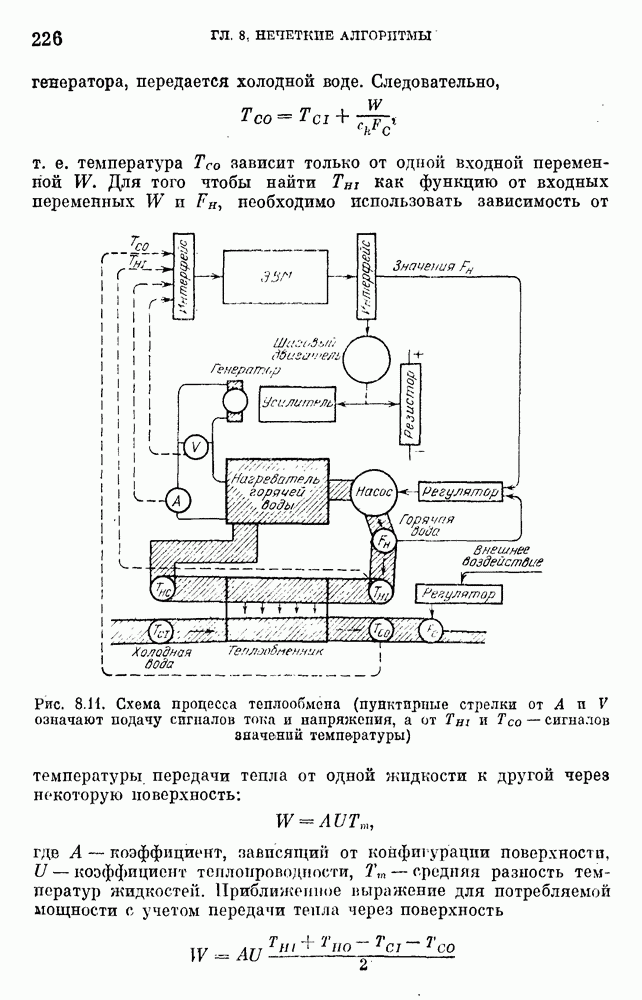
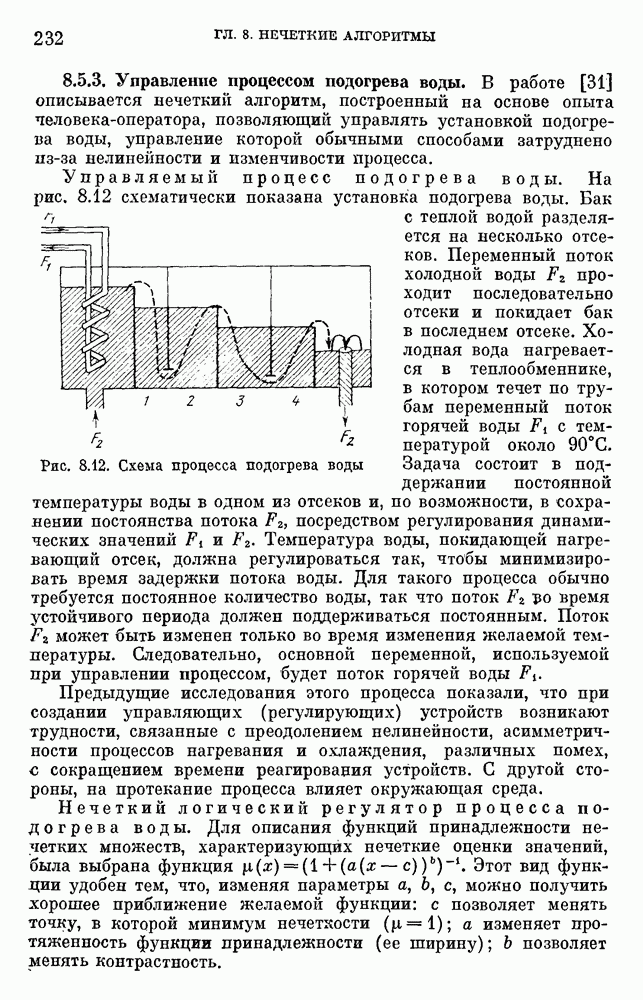
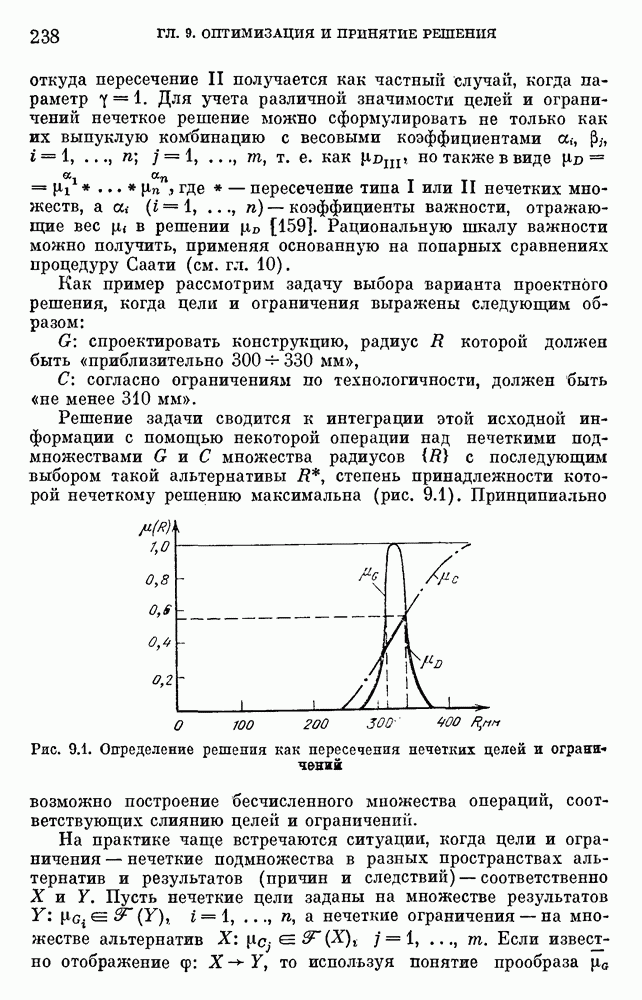
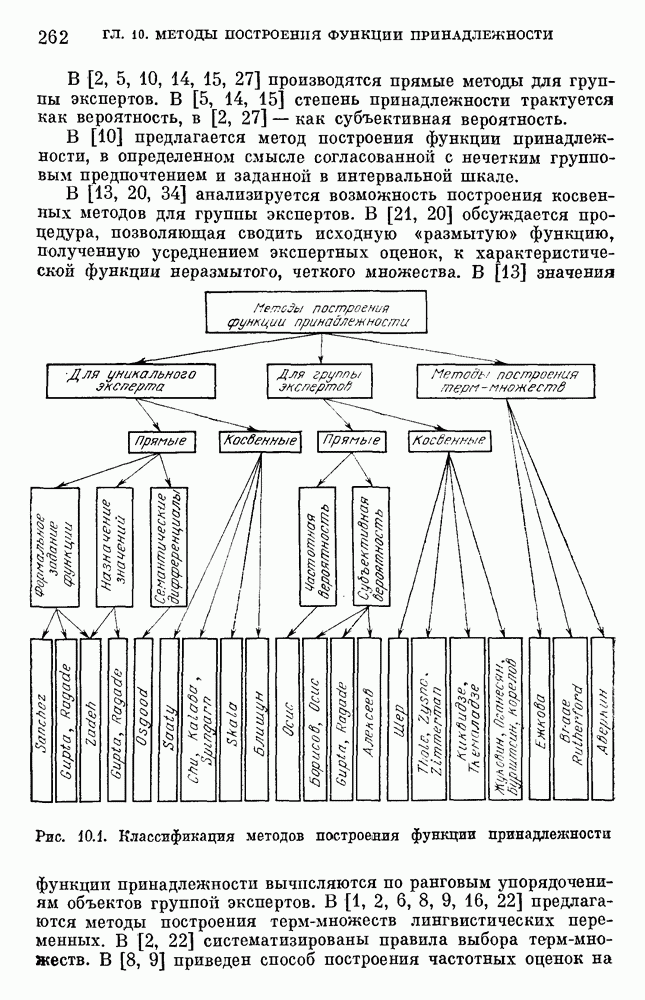
6.4.3. Применение приближенных рассуждений в прикладных задачах.
Одной из основных областей применения теории приближенных рассуждений и композиционных правил вывода являются нечеткие лингвистические регуляторы (см. гл. 8), [25—27], [34— 38, 55]. В частности, в [38] проведено сравнение четырех типов импликации, используемых при управлении работой парового котла с помощью лингвистических правил, а именно

Импликация 1 удобна тем, что сохраняет ширину значений функций принадлежности правил и позволяет выделить каждое правило и процесс его изменения даже из информации в табличной форме. Среди недостатков этого метода вывода можно отметить коммутативность, отсутствие разницы между выражениями типа  и невозможность использовать связку ИЛИ вместо И для интерпретации связки ИНАЧЕ для получения протокола применения правил:
и невозможность использовать связку ИЛИ вместо И для интерпретации связки ИНАЧЕ для получения протокола применения правил:
Правило 1. ИНАЧЕ Правило 2. ИНАЧЕ ...
Другие типы импликаций лишены этого недостатка за счет того, что каждому правилу нельзя сопоставить его область влияния. Например, арифметические связки в операции 3 приводят к получению новых значений функций принадлежности и требуют некоторой аппроксимации.
Импликация 4 лишена всех указанных недостатков и является наиболее «человеческой» по природе, так как если антецедент А дает следствие В, то антецедент А, близкий к А, дает следствие В, близкое к В. Это свойство особенно важно для систем с участием «человеческого фактора», где все ситуации не могут быть заданы с помощью набора правил.
Примеры реальных правил с использованием этих импликаций приведены в гл. 8.
В качестве других приложений следует упомянуть использование композиционного modus ponens в качестве семантического правила вывода на всех уровнях архитектуры баз данных: на экстенсиональном, интенсиональном и на уровне баз знаний [16]. Для случая экспертных консультационных систем особенно важно, чтобы модель базы знаний обладала возможностью оперировать при принятии решений с нечетко заданной обстановкой. Особенно важным для экспертных систем, основанных на теории возможности [59], является введение распределения возможности в интенсиональные базы данных, чтобы выводить нечеткие семантические категории как внешние представления базы данных, и в базы знаний, чтобы вычислять функции, связанные с метаправилами.
Для дедуктивных консультационных систем, использующих приближенные рассуждения и взаимодействующих с реляционными базами данных, введение распределения возможности является наиболее привлекательным в связи с необходимостью расширения семантической ограниченности реляционной модели данных и создания гибкой и универсальной структуры управления, включающей в себя эвристические стратегии поиска ответа на вопросы. Одной из многообещающих попыток в этом направлении является использование распределения возможностей для описания значений атрибутов в реляционных базах данных [52].