Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
8.4.2. Обучение на основе условной нечеткой меры.В [47, 50] описывается модель обучения, использующая понятия нечеткой меры и нечеткого интеграла. Пусть
где Задача состоит в оценке (уточнении) причин по нечеткой информации. Пусть
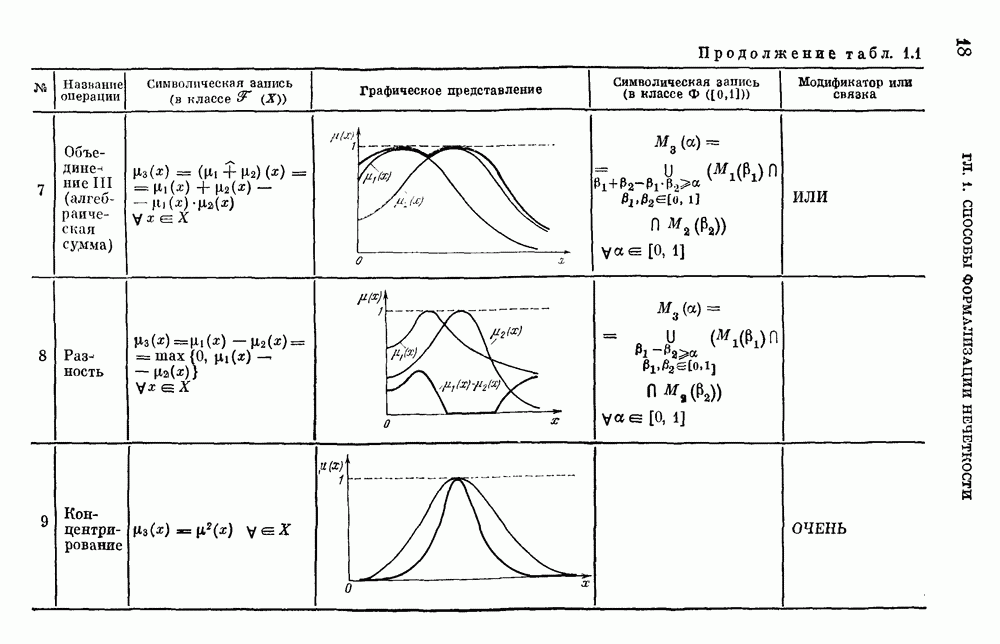
Предполагается следующая интерпретация вводимых мер: Пусть
откуда следует, что
где Метод обучения должен быть таким, чтобы при получении информации А нечеткая мера
где
Обучение может быть осуществлено увеличением тех значений
Параметр Свойство 8.4. Если повторно поступает одна и та же информация, то имеет место следующее: а) новое
б) при предположении Свойство 8.5. Если поступает одна и та же информация повторно:
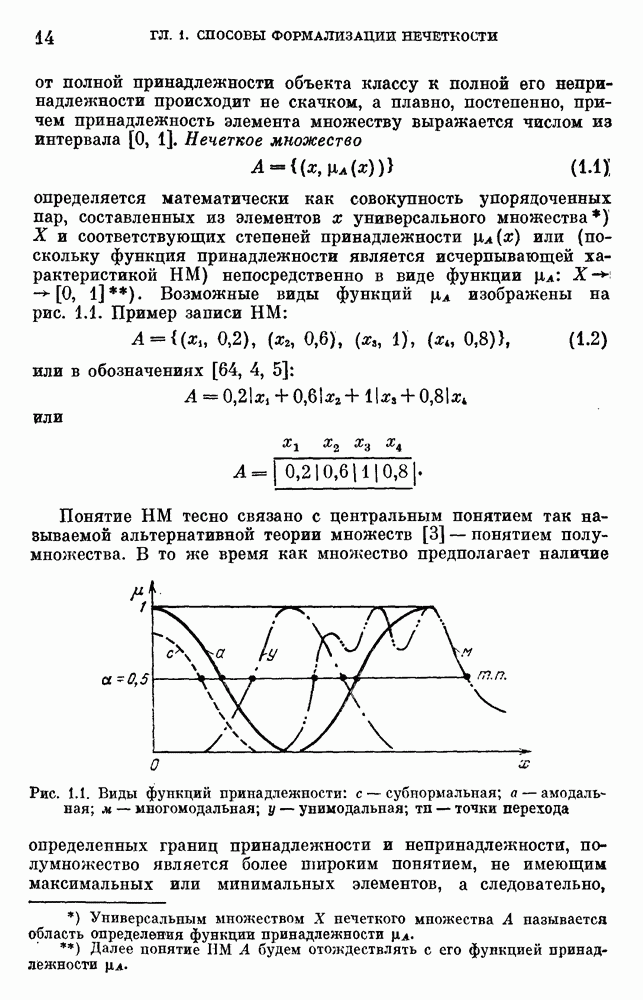
Свойство 8.6. Предельное значение Пример 8.7 [47]. Пусть
Ясно, что у, является результатом в основном причины
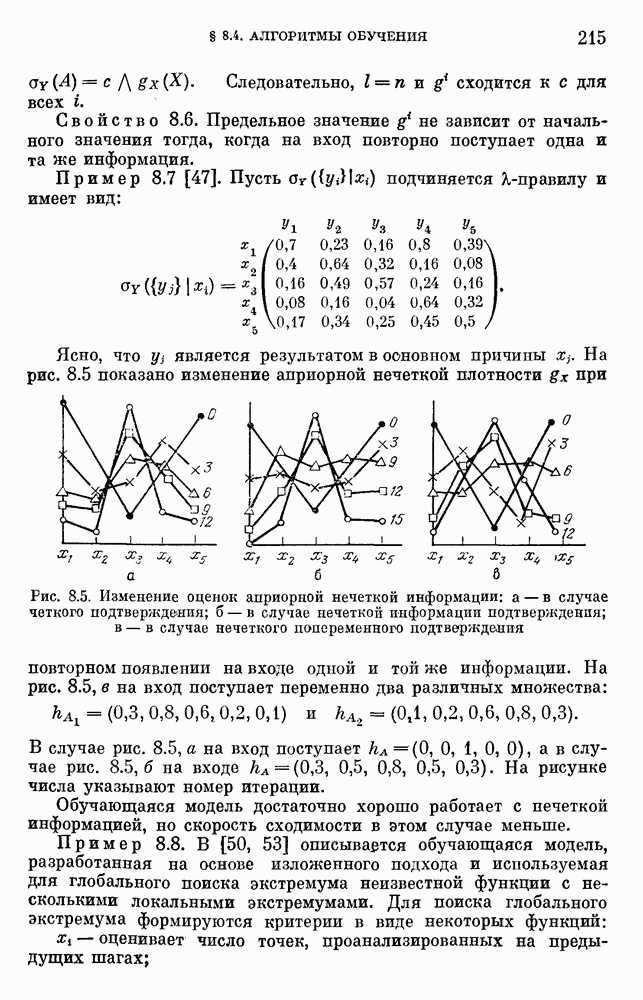
Рис. 8.5. Изменение оценок априорной нечеткой информации: а — в случае четкого подтверждения; б — в случае нечеткой информации подтверждения; в — в случае нечеткого попеременного подтверждения На рис. 8.5, в на вход поступает переменно два различных множества:
В случае рис. 8.5, а на вход поступает Обучающаяся модель достаточно хорошо работает с нечеткой информацией, но скорость сходимости в этом случае меньше. Пример 8.8. В [50, 53] описывается обучающаяся модель, разработанная на основе изложенного подхода и используемая для глобального поиска экстремума неизвестной функции с несколькими локальными экстремумами. Для поиска глобального экстремума формируются критерии в виде некоторых функций:
В описываемом случае
где В [47] приводится сравнительный анализ предлагаемой модели и вероятностной модели обучения [17]. Пусть
После получения нечеткой информации А обучение осуществляется по формуле Байеса, которая дает результирующую плотность вероятности
Если на вход модели поступает информация постоянной величины
|
 |
Оглавление
|










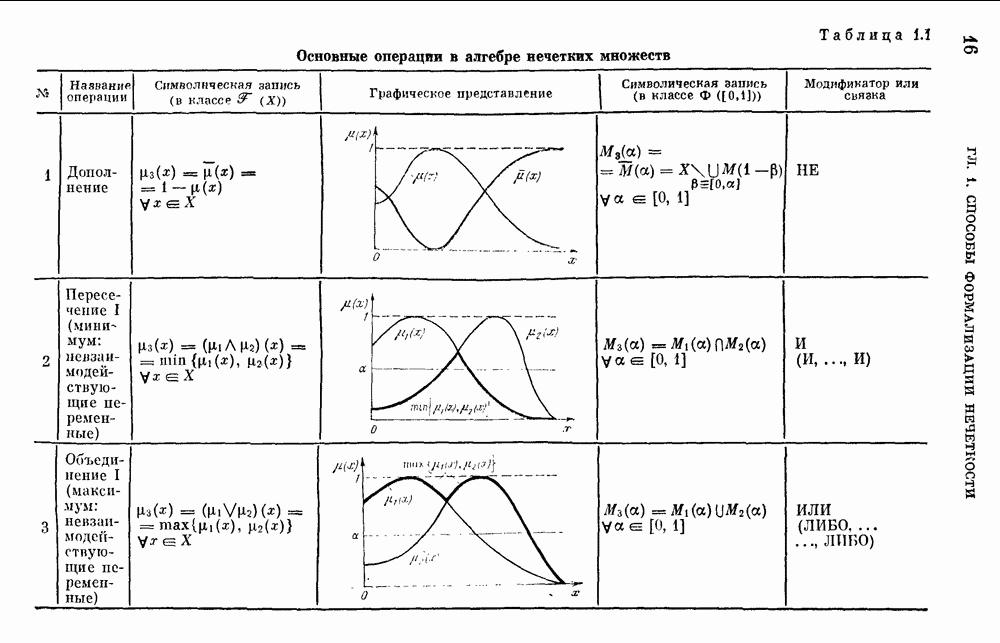
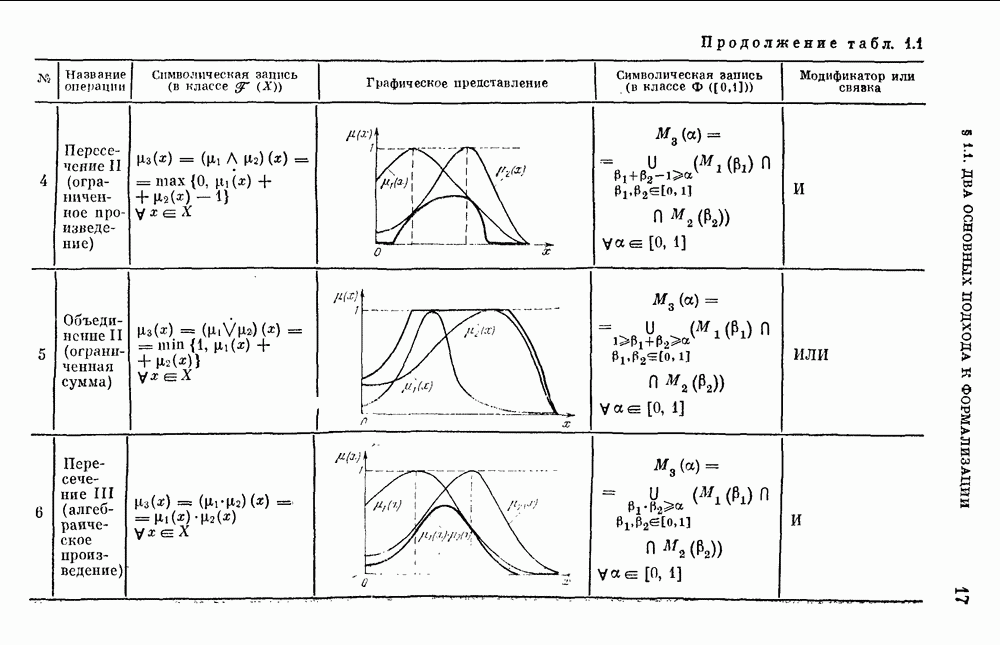




























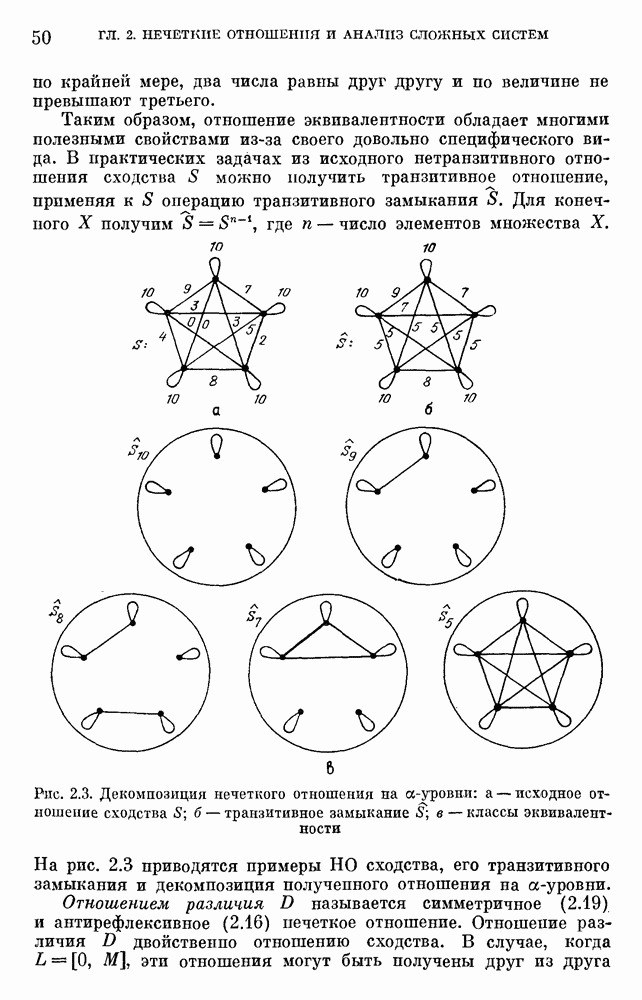




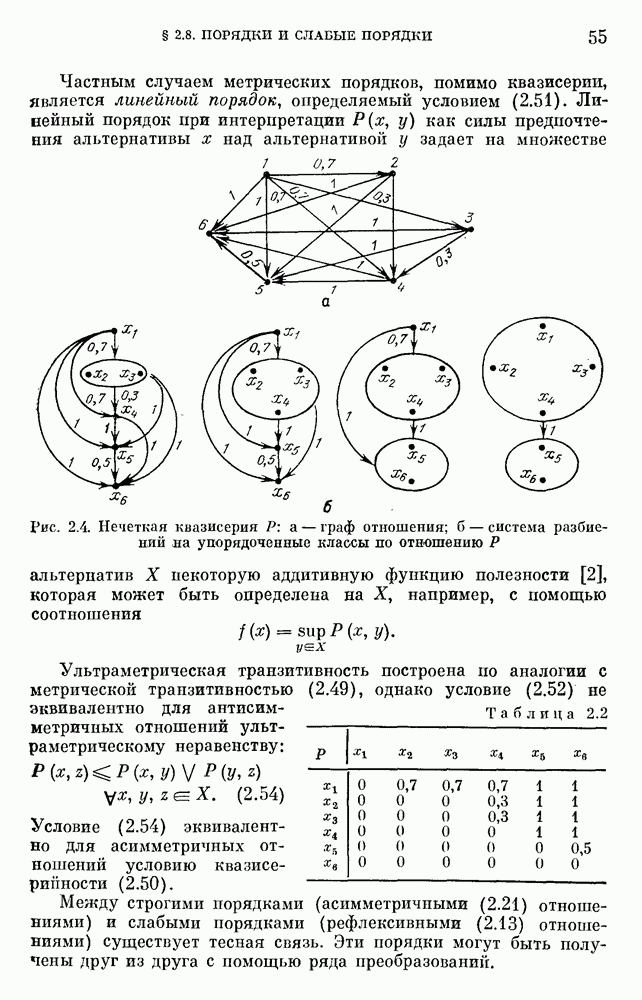






























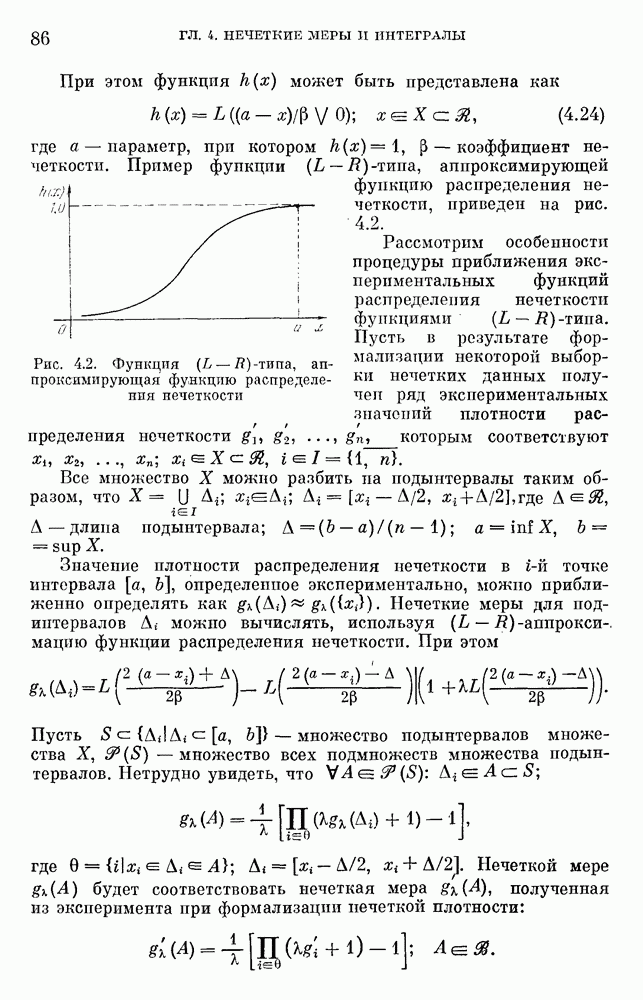



















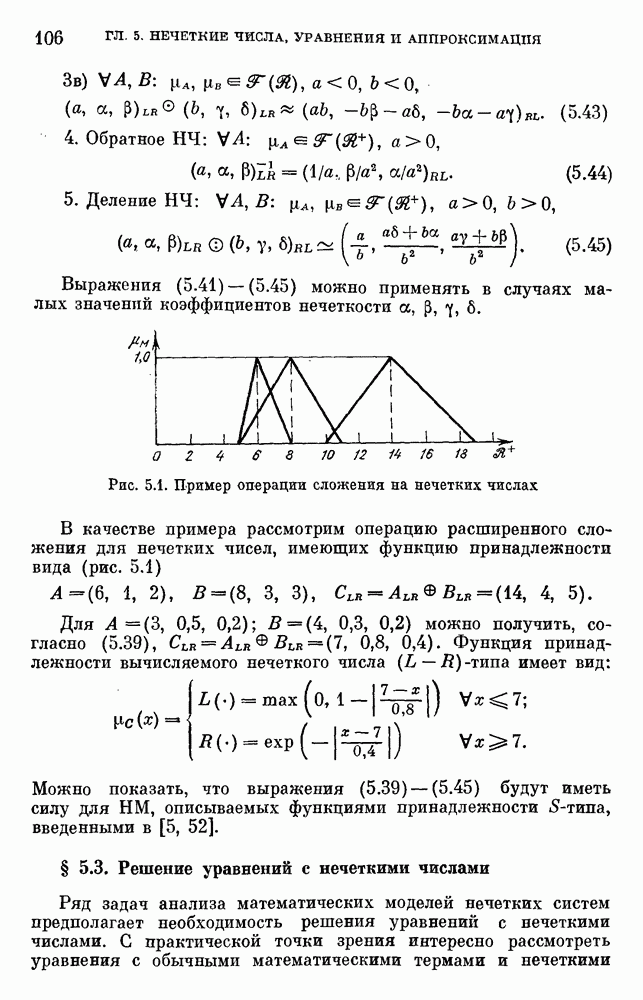




































































































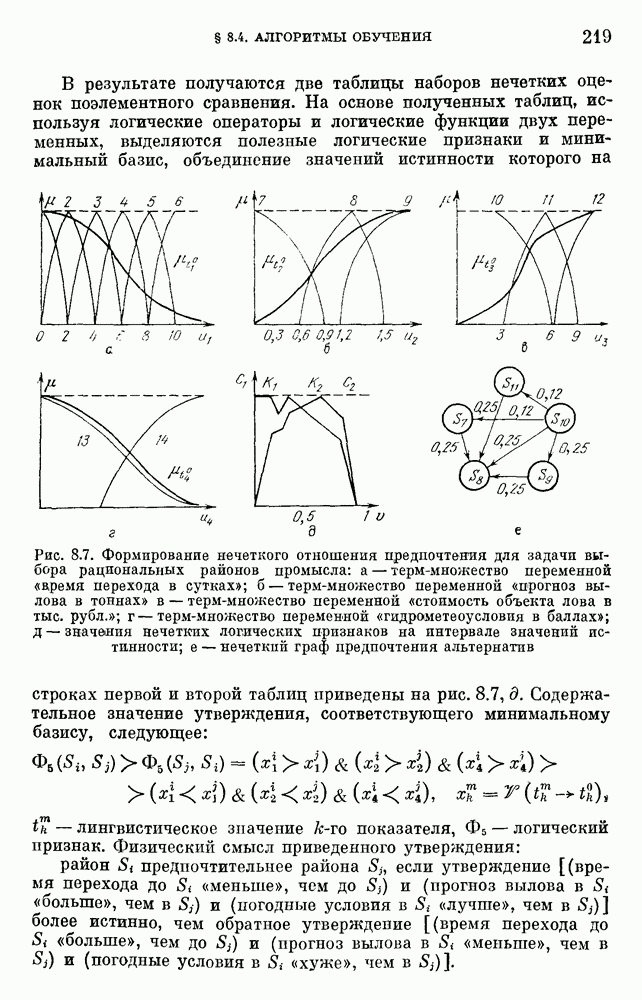
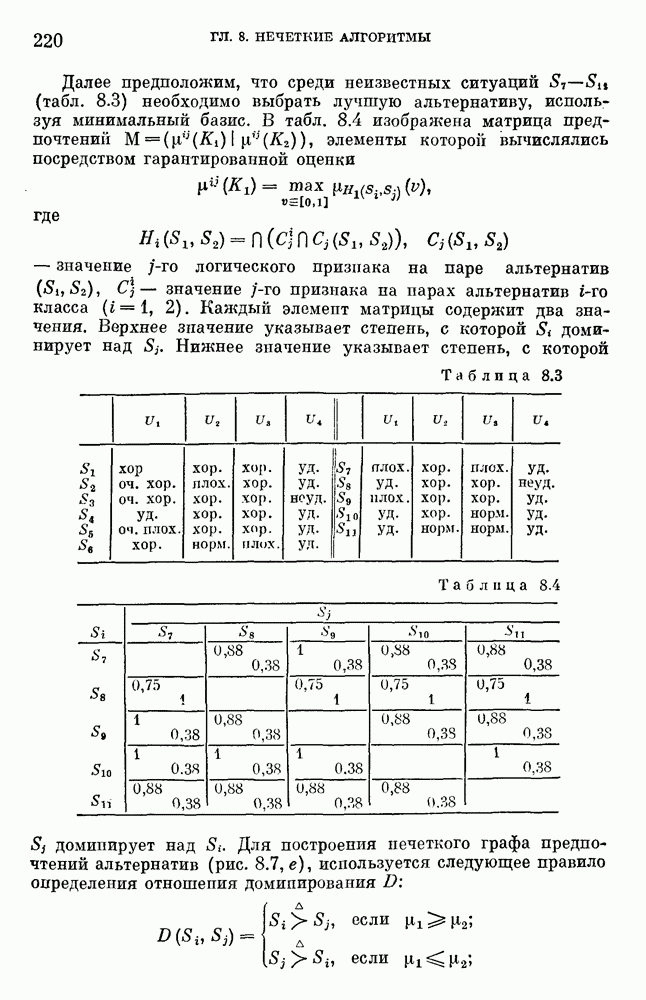




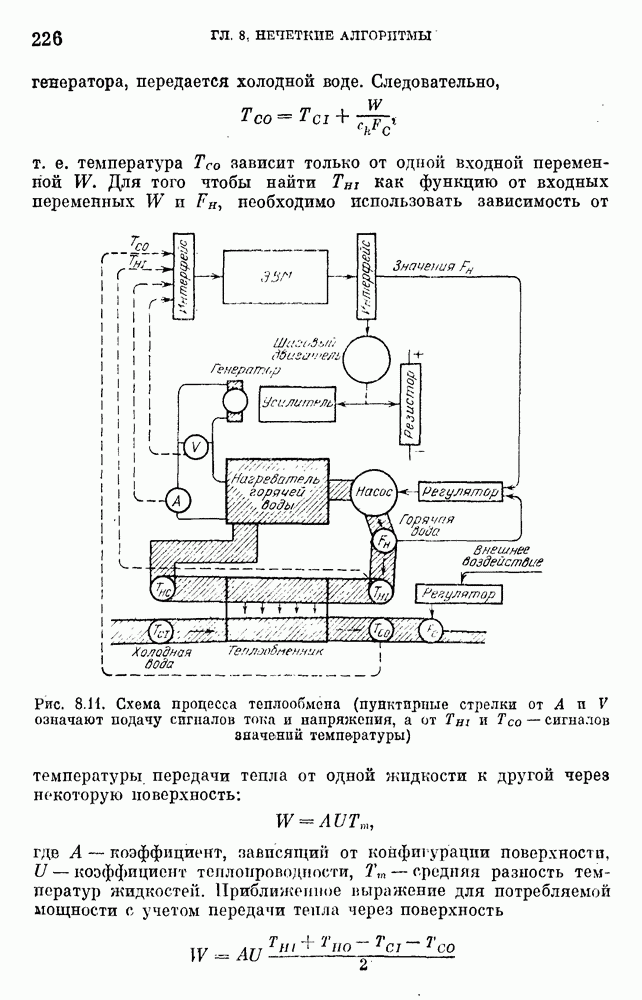













































































 — множество причин (входов) и
— множество причин (входов) и  — множество результатов. Если
— множество результатов. Если  — функция из X в интервал [0, 1],
— функция из X в интервал [0, 1],  — нечеткая мера на X, то
— нечеткая мера на X, то

 — нечеткая мера на
— нечеткая мера на  связана с
связана с  условной нечеткой мерой
условной нечеткой мерой 

 оценивает степень нечеткости утверждения «один из элементов X был причиной»,
оценивает степень нечеткости утверждения «один из элементов X был причиной»,  оценивает степепь нечеткости утверждения «один из элементов А является результатом благодаря причине
оценивает степепь нечеткости утверждения «один из элементов А является результатом благодаря причине  характеризует степень нечеткости утверждения:
характеризует степень нечеткости утверждения:  — действительный результат».
— действительный результат».
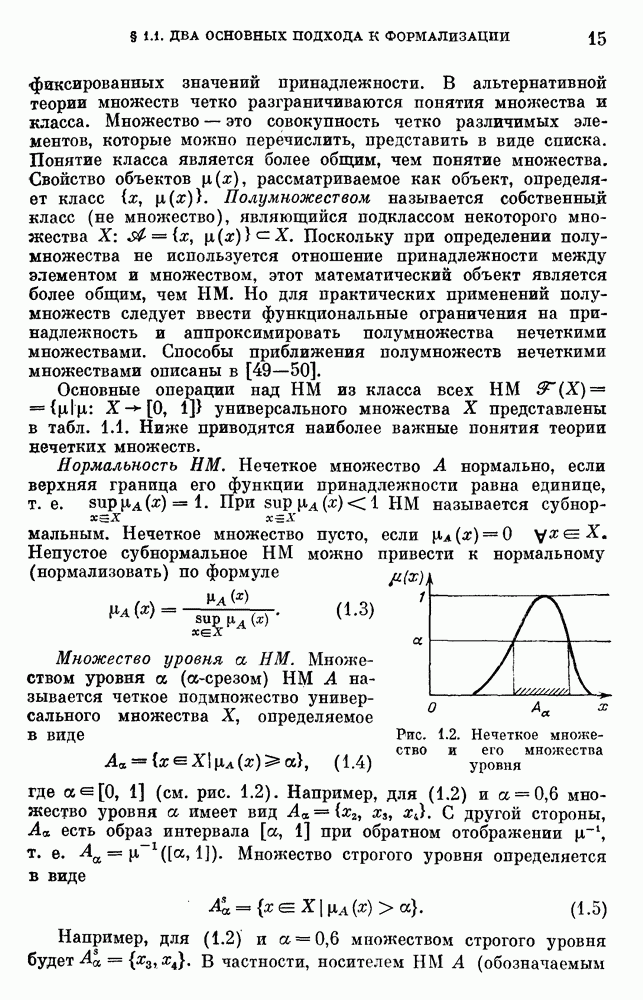
 описывает точность информации А, тогда по определению
описывает точность информации А, тогда по определению



 менялась таким образом, чтобы
менялась таким образом, чтобы  возрастала. Предположим, что
возрастала. Предположим, что  удовлетворяет
удовлетворяет  -правилу. Пусть
-правилу. Пусть  является убывающей, тогда
является убывающей, тогда

 При этих условиях существует I:
При этих условиях существует I:

 нечеткой меры
нечеткой меры  которые увеличивают
которые увеличивают  и уменьшением тех значений
и уменьшением тех значений  меры
меры  которые не увеличивают
которые не увеличивают  Можно показать, что на величину
Можно показать, что на величину  влияют только такие
влияют только такие  что
что  . Следовательно, алгоритм обучения следующий:
. Следовательно, алгоритм обучения следующий:

 регулирует скорость обучения, т. е. скорость сходимости
регулирует скорость обучения, т. е. скорость сходимости  Чем меньше а, тем сильнее изменяется
Чем меньше а, тем сильнее изменяется  . В приведенном алгоритме нет необходимости увеличивать
. В приведенном алгоритме нет необходимости увеличивать  больше, чем на
больше, чем на  так как большее увеличение
так как большее увеличение  не влияет на
не влияет на  Приведем некоторые свойства модели обучения.
Приведем некоторые свойства модели обучения.
 больше старого
больше старого  и новое
и новое  меньше старого
меньше старого  следовательно, новая мера
следовательно, новая мера  не меньше старой меры
не меньше старой меры  и новая мера:
и новая мера:

 сходится к
сходится к  сходится
сходится  для
для 
 для всех у, то
для всех у, то 
 Следовательно,
Следовательно,  сходится к с для всех
сходится к с для всех 
 не зависит от начального значения тогда, когда на вход повторно поступает одна и та же информация.
не зависит от начального значения тогда, когда на вход повторно поступает одна и та же информация.
 подчиняется Я-правилу и имеет вид:
подчиняется Я-правилу и имеет вид:

 рис. 8.5 показано изменение априорной нечеткой плотности
рис. 8.5 показано изменение априорной нечеткой плотности  при повторном появлении на входе одной и той же информации.
при повторном появлении на входе одной и той же информации.


 в случае рис. 8.5, б на входе
в случае рис. 8.5, б на входе  . На рисунке числа указывают номер итерации.
. На рисунке числа указывают номер итерации.
 — оценивает число точек, проанализированных на предыдущих шагах;
— оценивает число точек, проанализированных на предыдущих шагах;
 оценивает среднее значение функции по результатам предыдущих шагов;
оценивает среднее значение функции по результатам предыдущих шагов;
 — оценивает число точек, значение функции в которых принадлежит десятке лучших в своей области;
— оценивает число точек, значение функции в которых принадлежит десятке лучших в своей области;
 оценивает максимум по прошлым попыткам;
оценивает максимум по прошлым попыткам;
 — оценивает градиент функции.
— оценивает градиент функции.
 показывает степень важности подмножеств критериев и
показывает степень важности подмножеств критериев и  оценивает предположение о нахождении экстремума в блоке
оценивает предположение о нахождении экстремума в блоке  в соответствии с критерием
в соответствии с критерием  Например,
Например,  может зависеть от числа ранее проанализированных точек в блоке
может зависеть от числа ранее проанализированных точек в блоке  Пусть входная информация А определяется формулой
Пусть входная информация А определяется формулой

 максимум анализируемой функции, найденный к рассматриваемому моменту в блоке
максимум анализируемой функции, найденный к рассматриваемому моменту в блоке  . Очевидно, что А сходится к максимизирующему множеству функции. На каждой итерации осуществляется следующее: проверяется заданное число новых точек, число этих точек выбирается пропорционально
. Очевидно, что А сходится к максимизирующему множеству функции. На каждой итерации осуществляется следующее: проверяется заданное число новых точек, число этих точек выбирается пропорционально  в каждой точке
в каждой точке  вычисляется и нормализуется мера
вычисляется и нормализуется мера  нормализуется
нормализуется  по
по  вычисляется
вычисляется  а затем
а затем  посредством правил подкрепления корректируется
посредством правил подкрепления корректируется  Затем выполняется новая итерация и так до тех пор, пока не сойдется
Затем выполняется новая итерация и так до тех пор, пока не сойдется 
 — априорная плотность вероятности на
— априорная плотность вероятности на  — условная плотность вероятности по отношению к
— условная плотность вероятности по отношению к  Условная плотность вероятности нечеткого события А вычисляется по формуле:
Условная плотность вероятности нечеткого события А вычисляется по формуле:

 на X:
на X:

 то
то  что фактически означает отсутствие обучения. Нечеткая же модель способна различать постоянную информацию и отсутствие информации. Кроме того, в нечеткой модели имеется возможность изменять скорость сходимости посредством параметра а.
что фактически означает отсутствие обучения. Нечеткая же модель способна различать постоянную информацию и отсутствие информации. Кроме того, в нечеткой модели имеется возможность изменять скорость сходимости посредством параметра а.