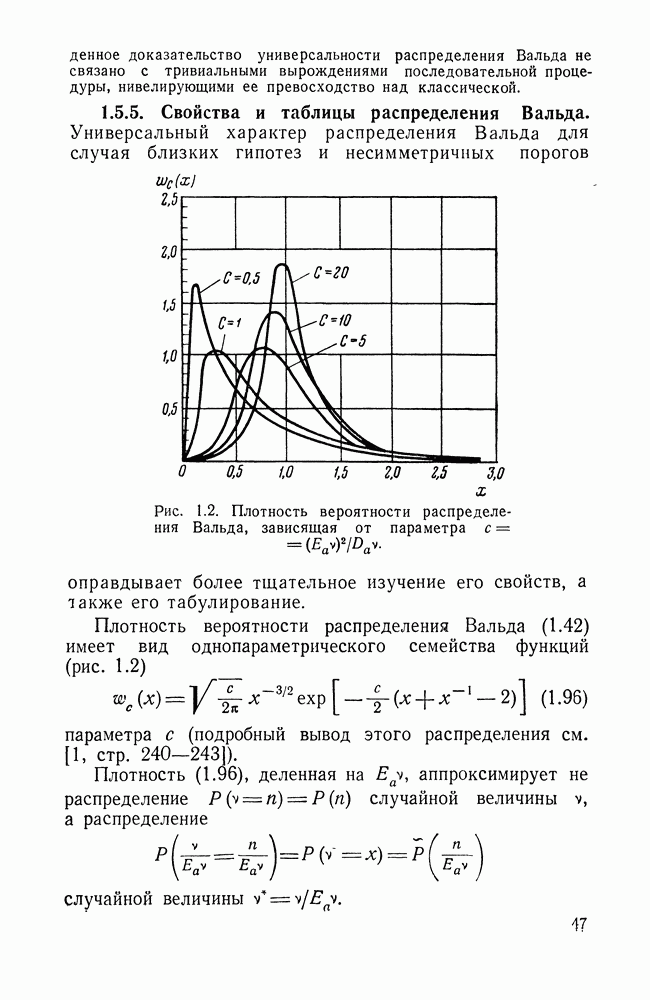
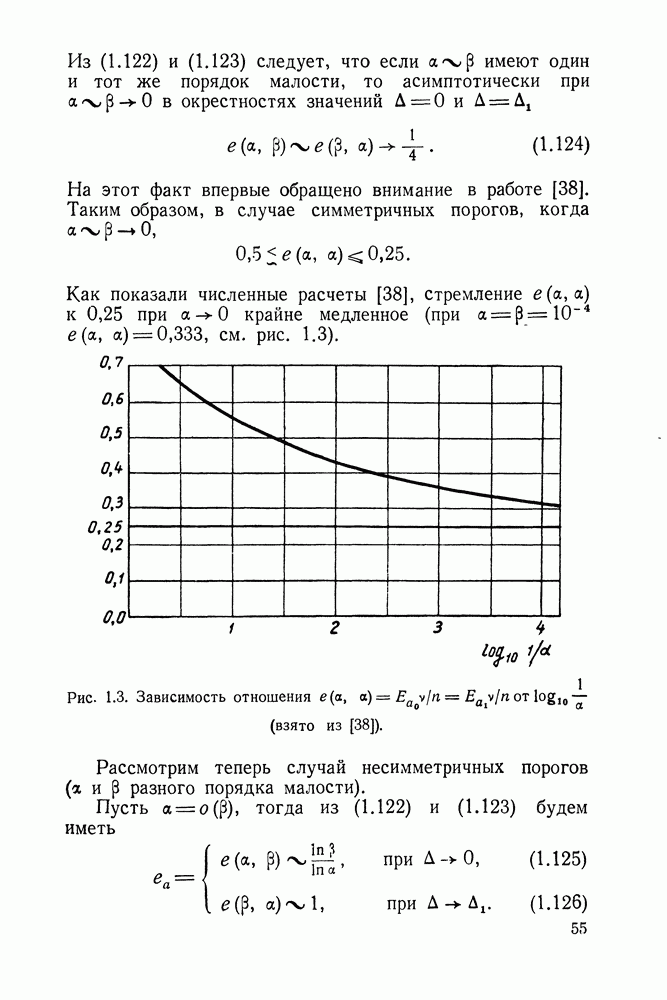
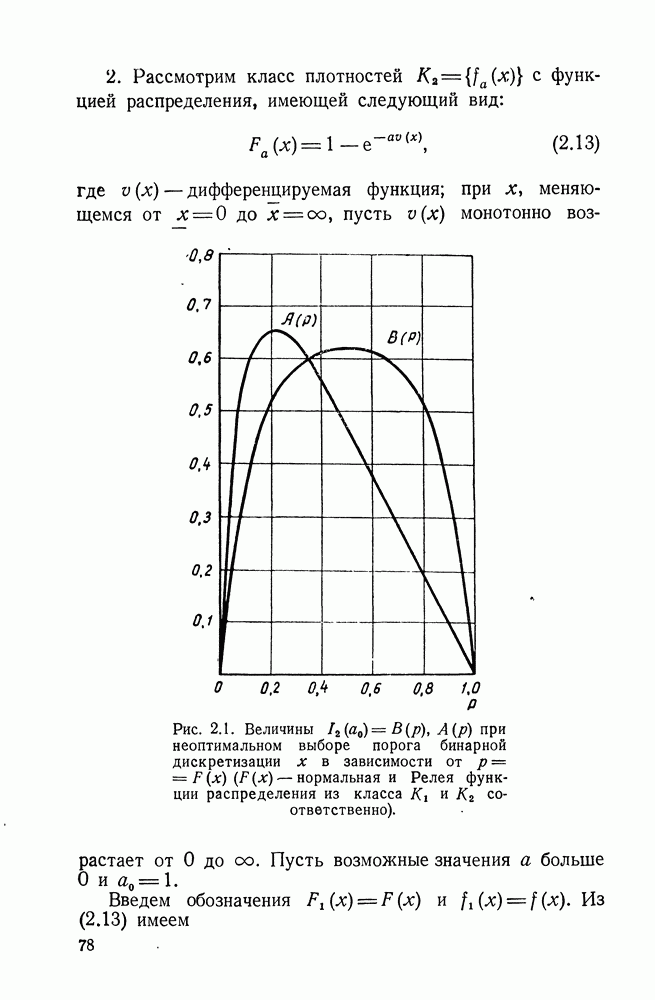
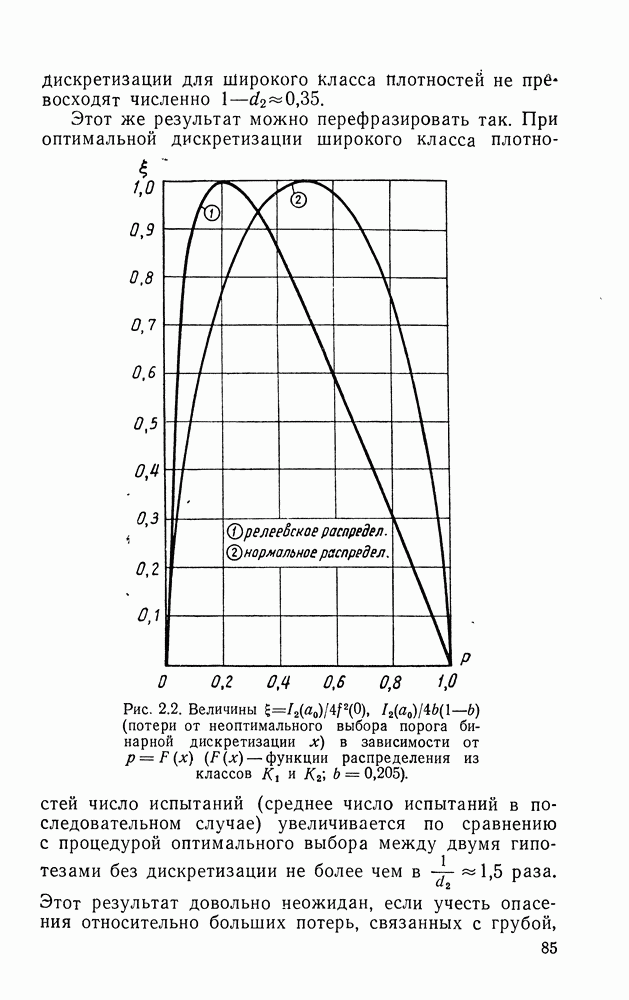
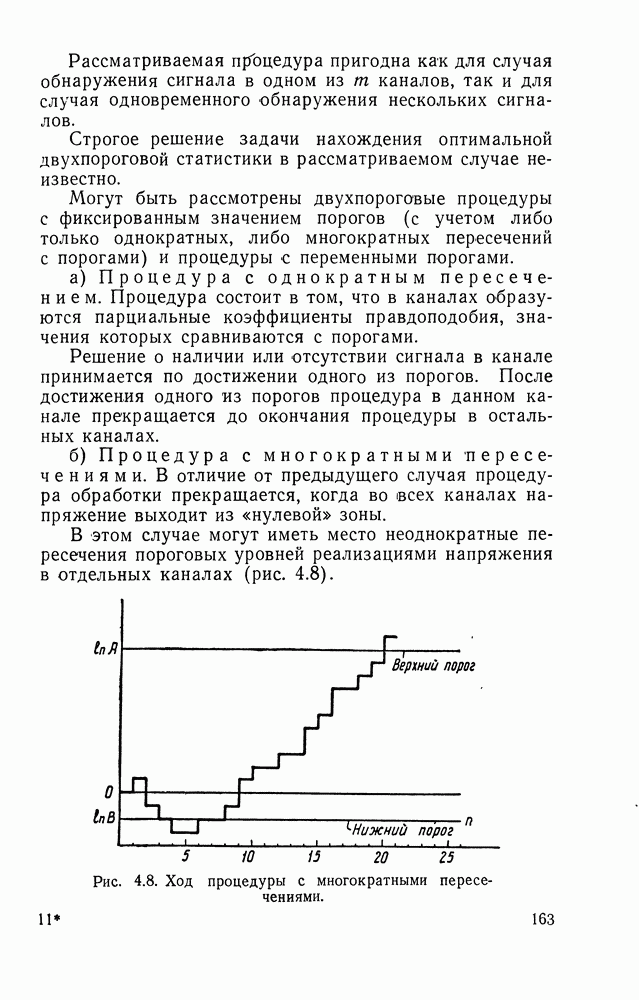
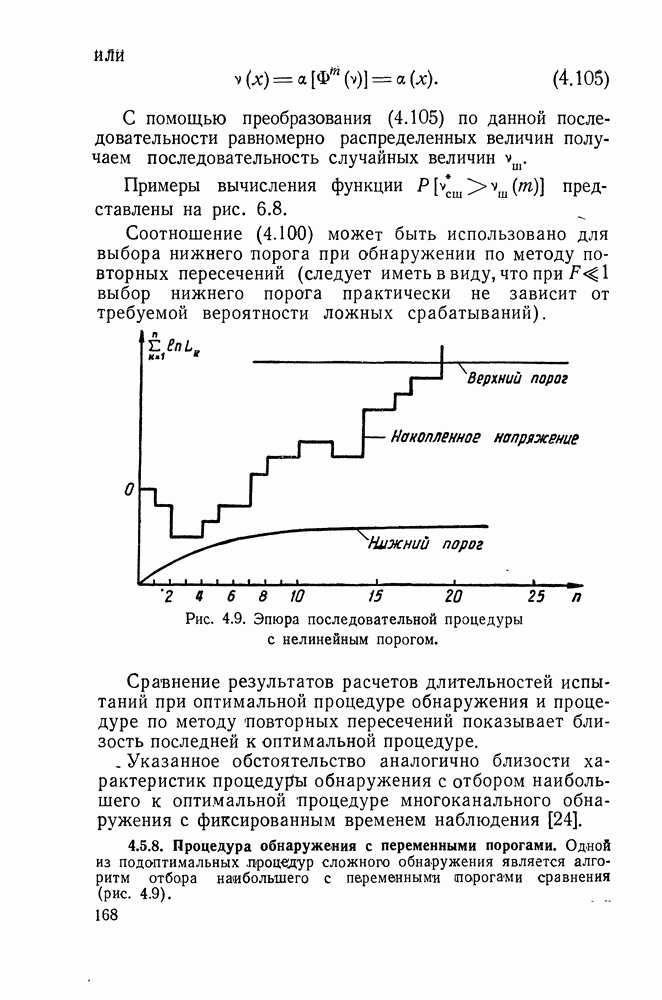
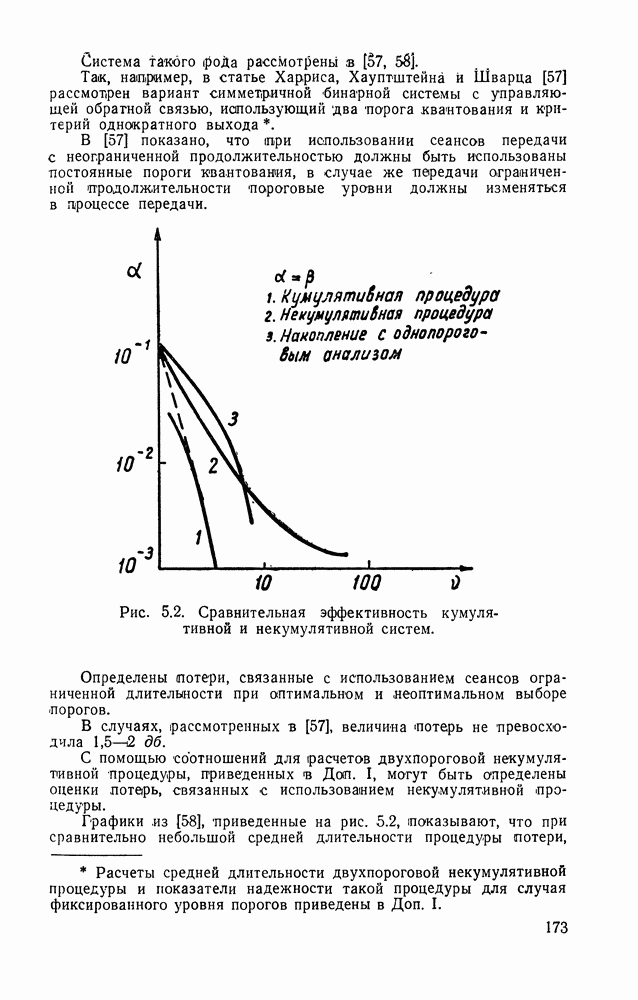
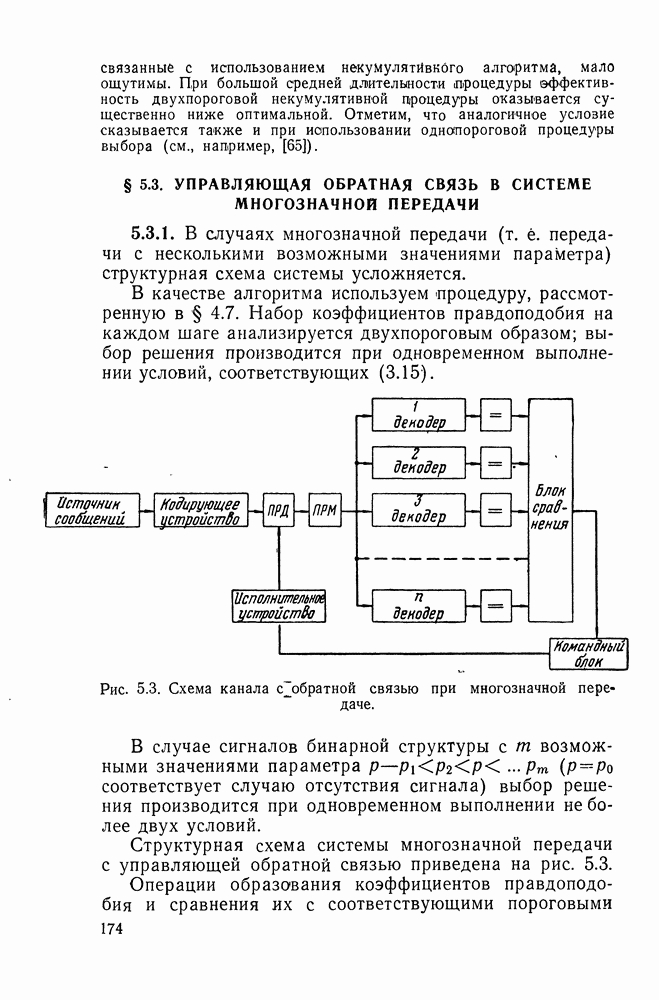
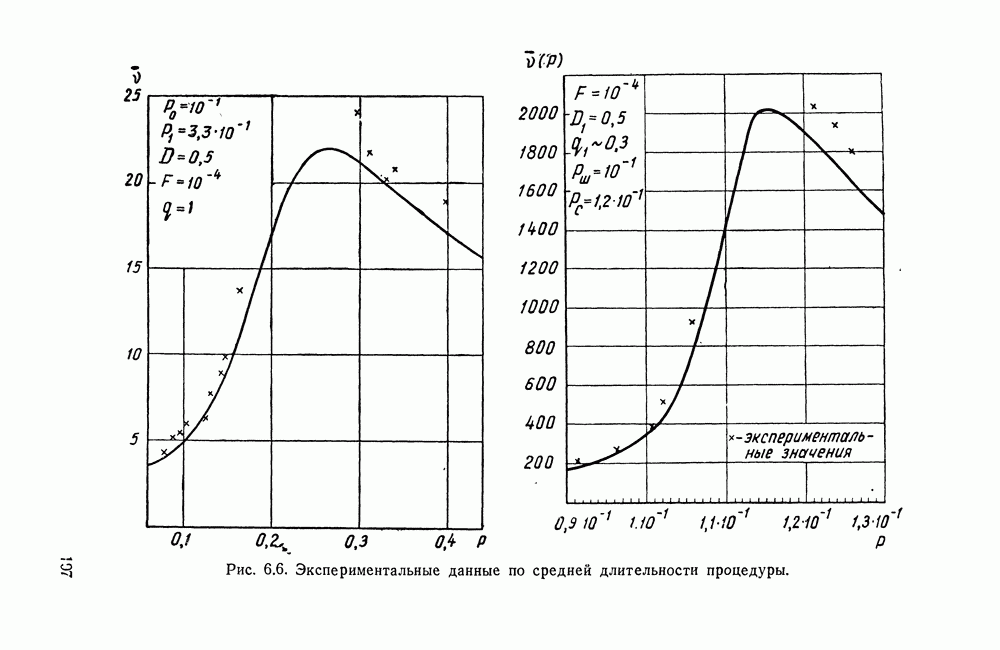
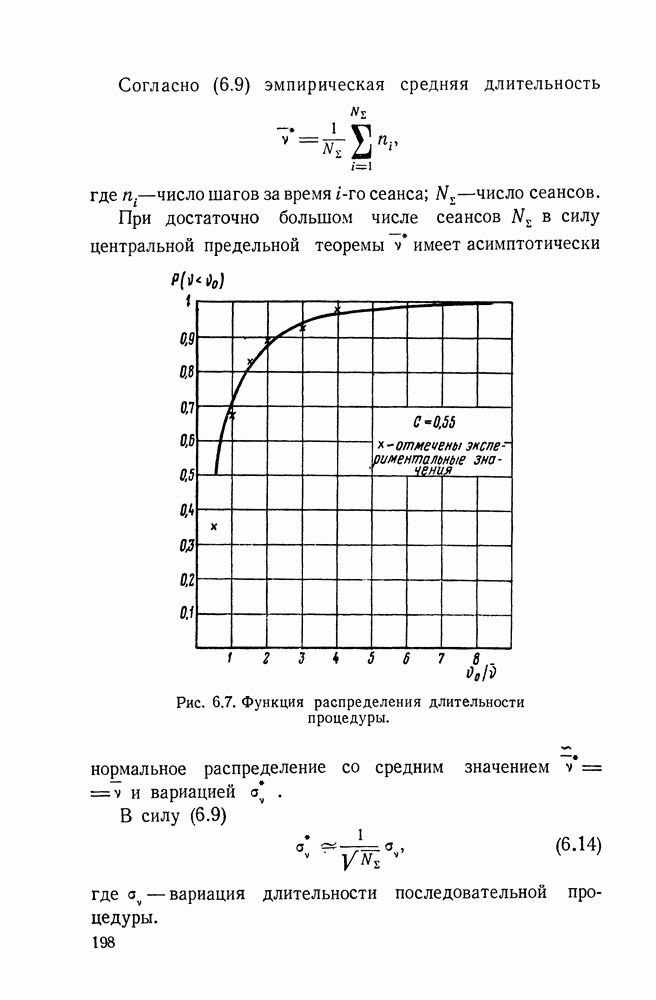
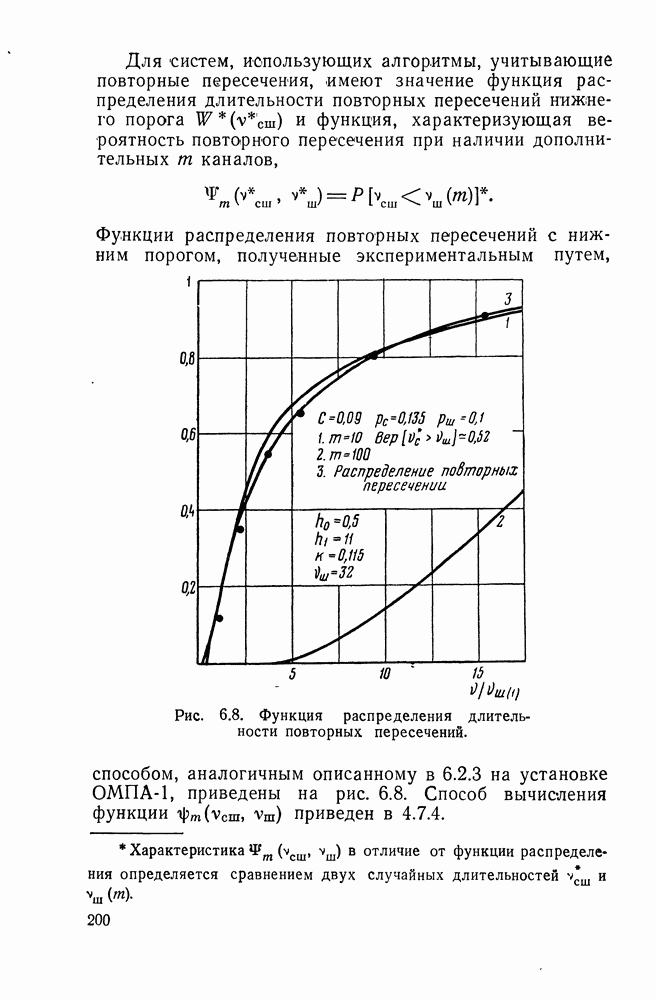
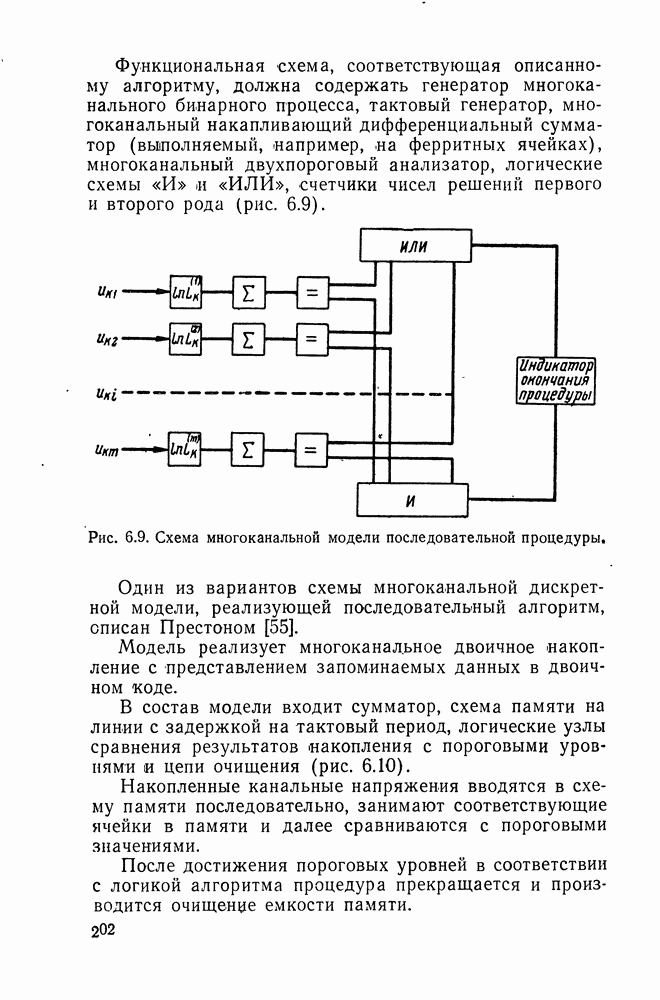
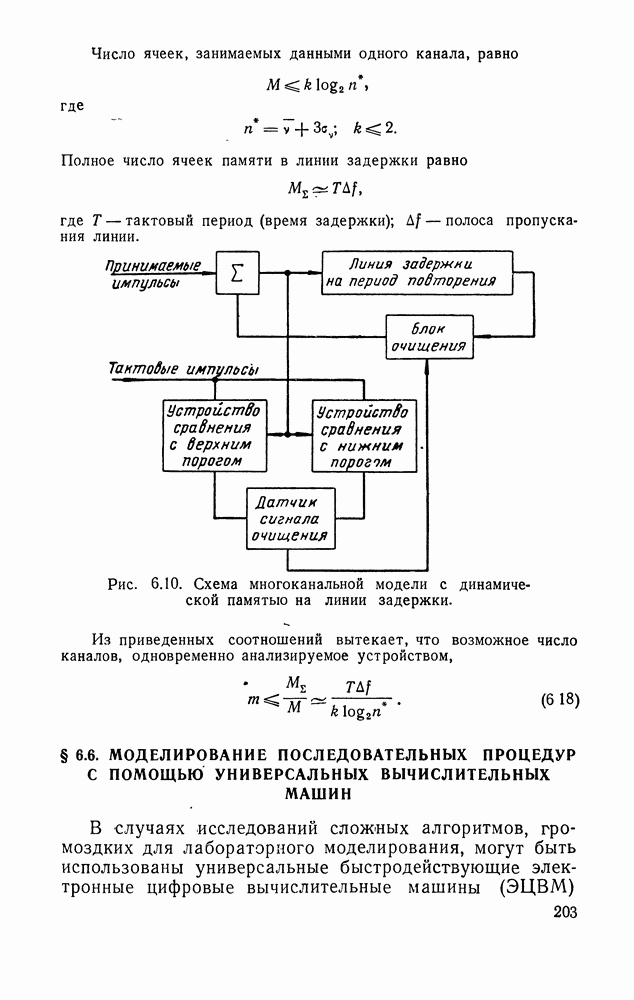
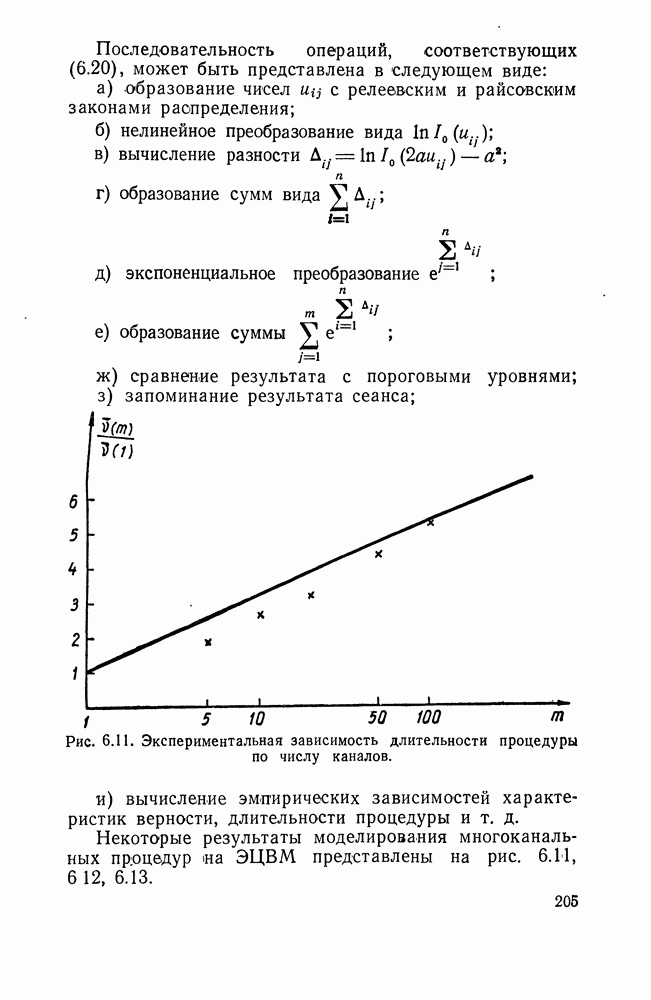
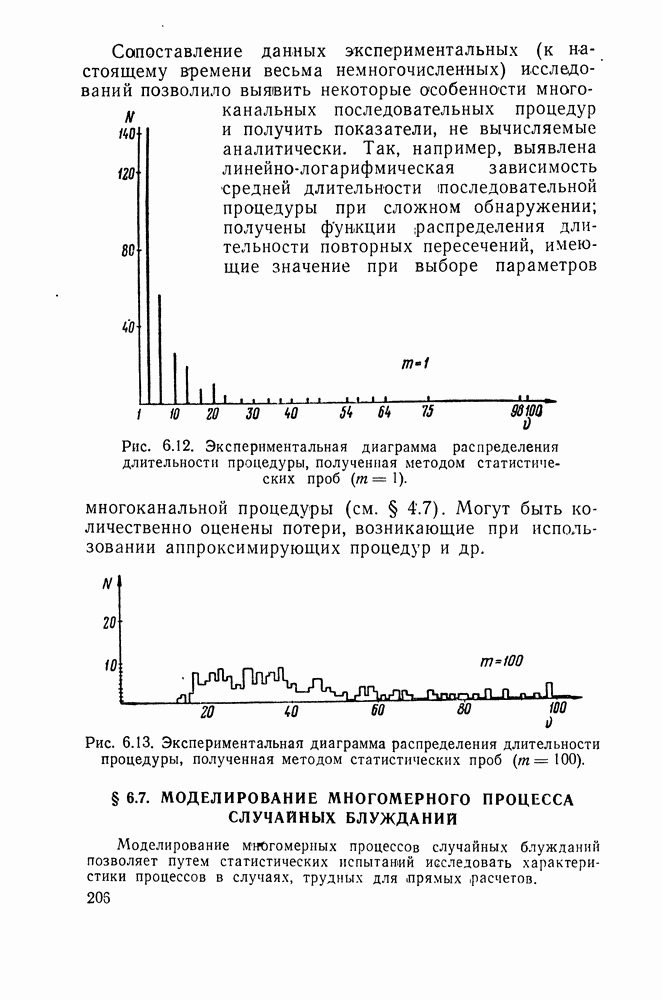
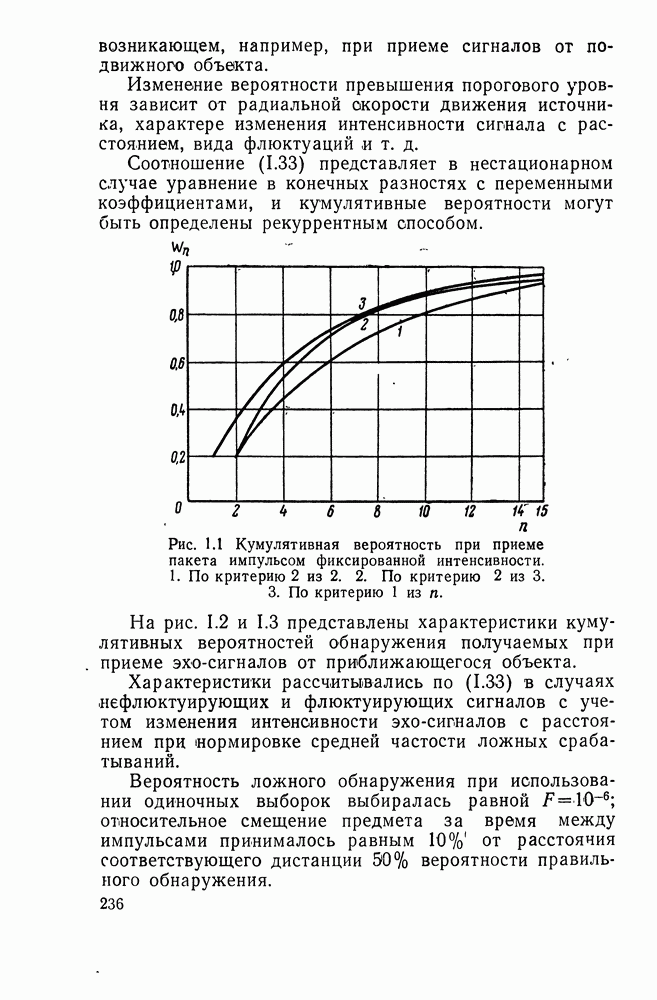
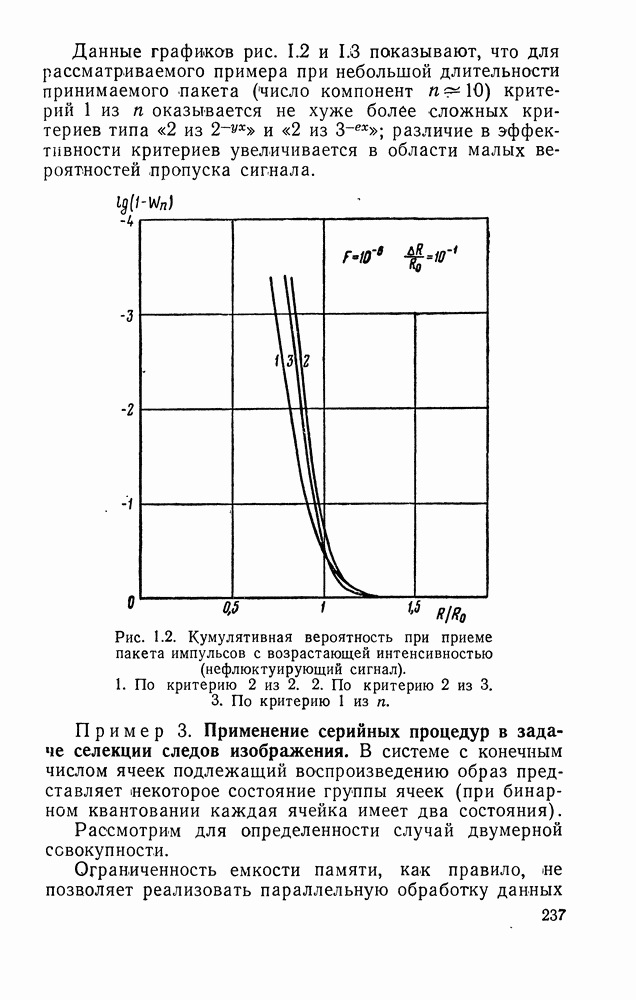
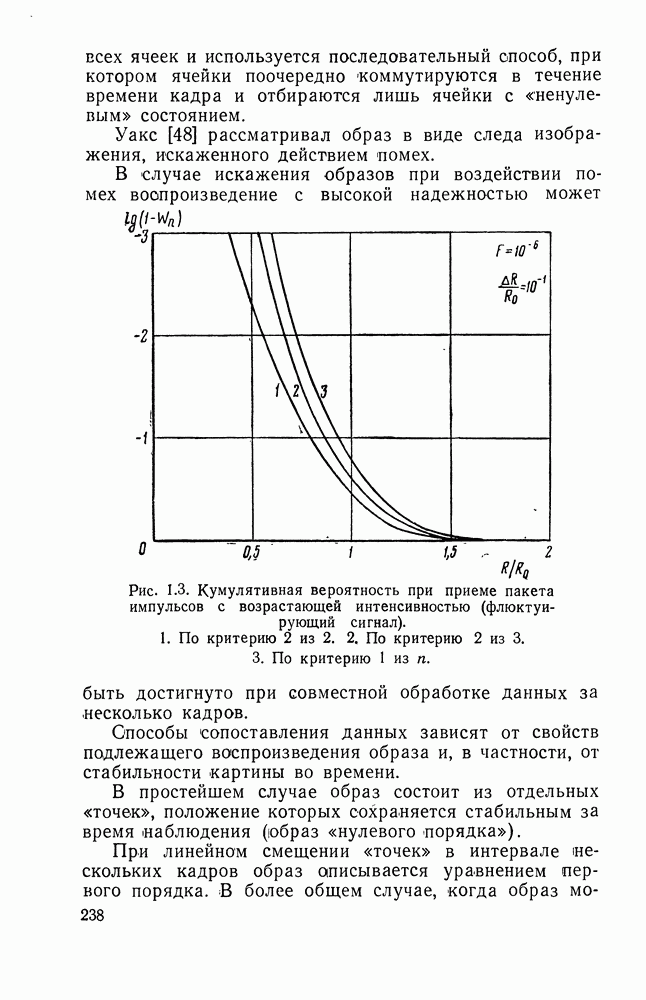
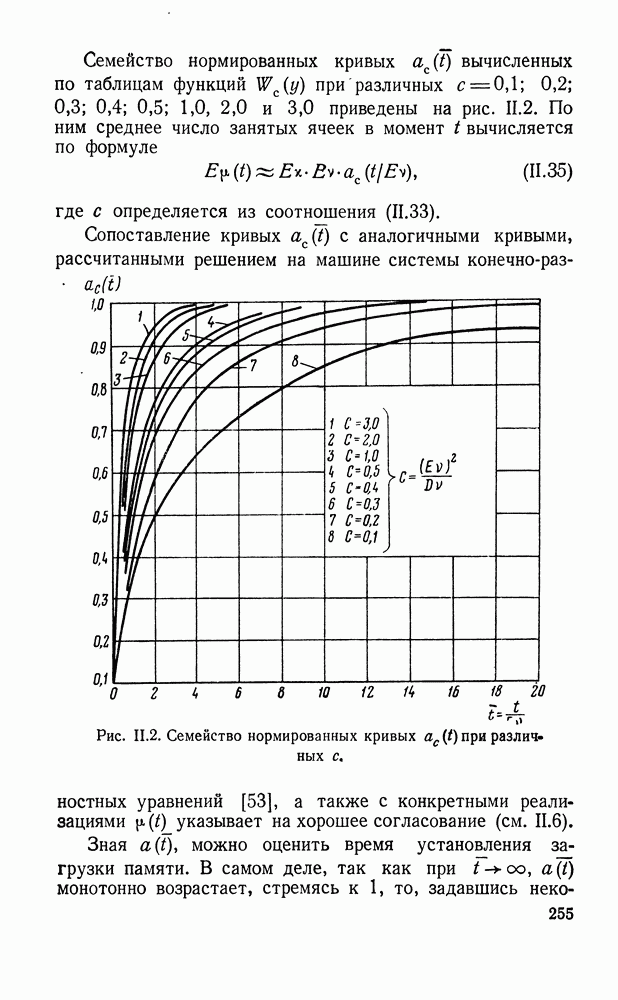
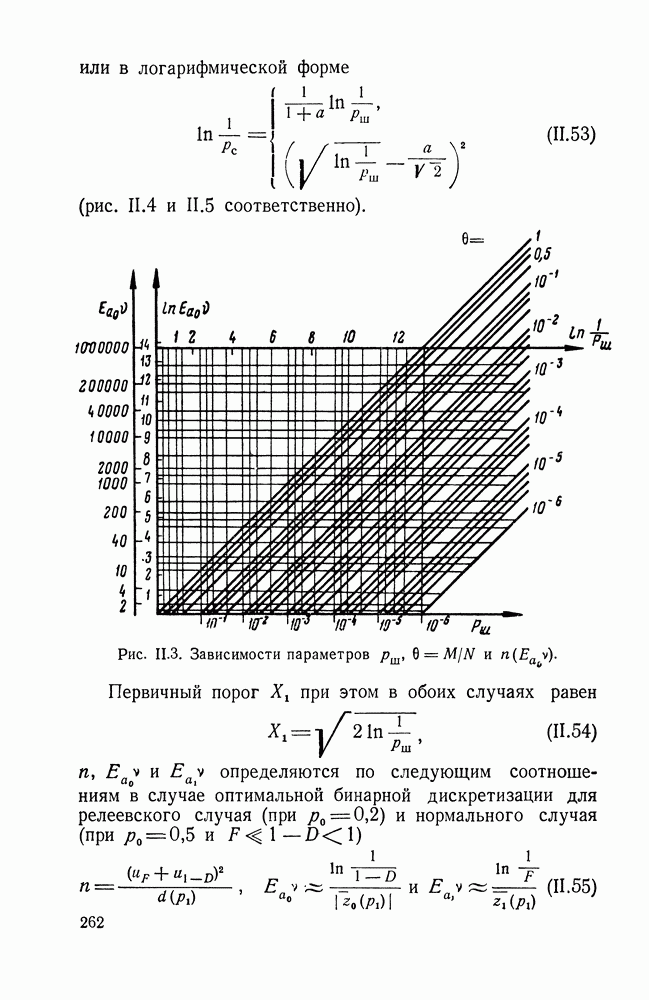
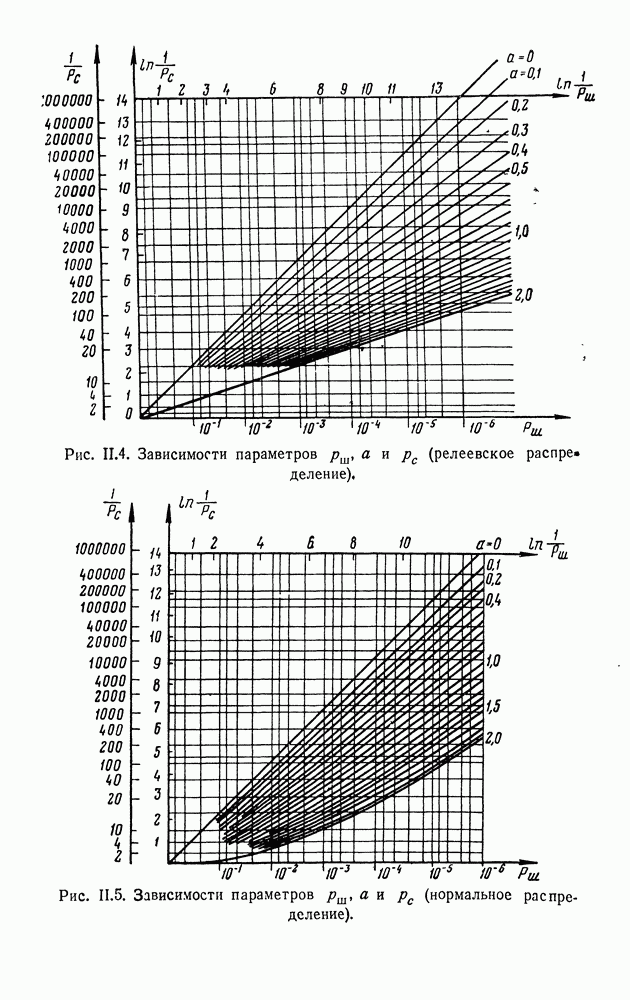
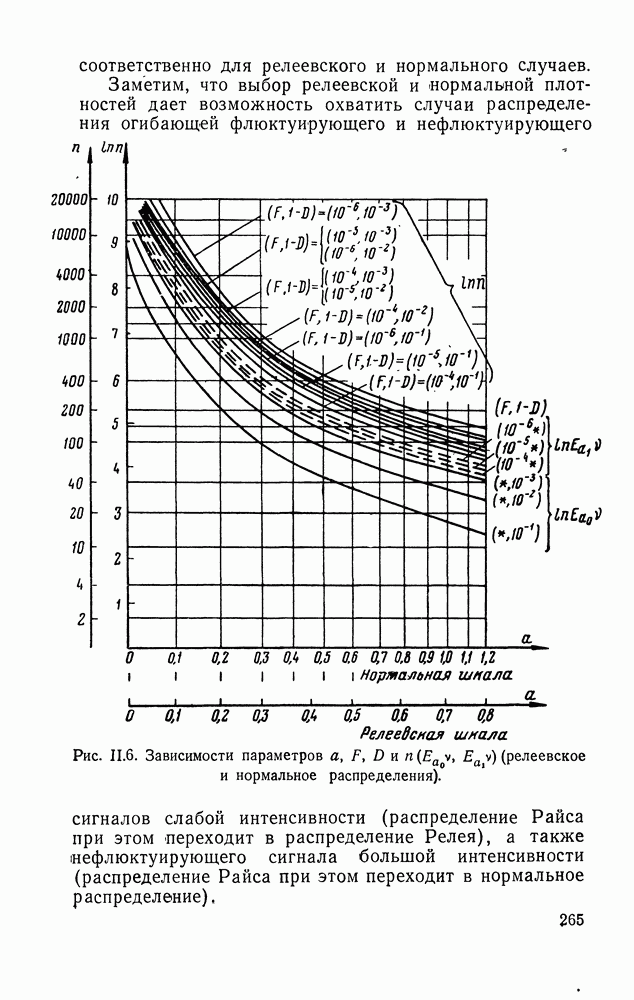
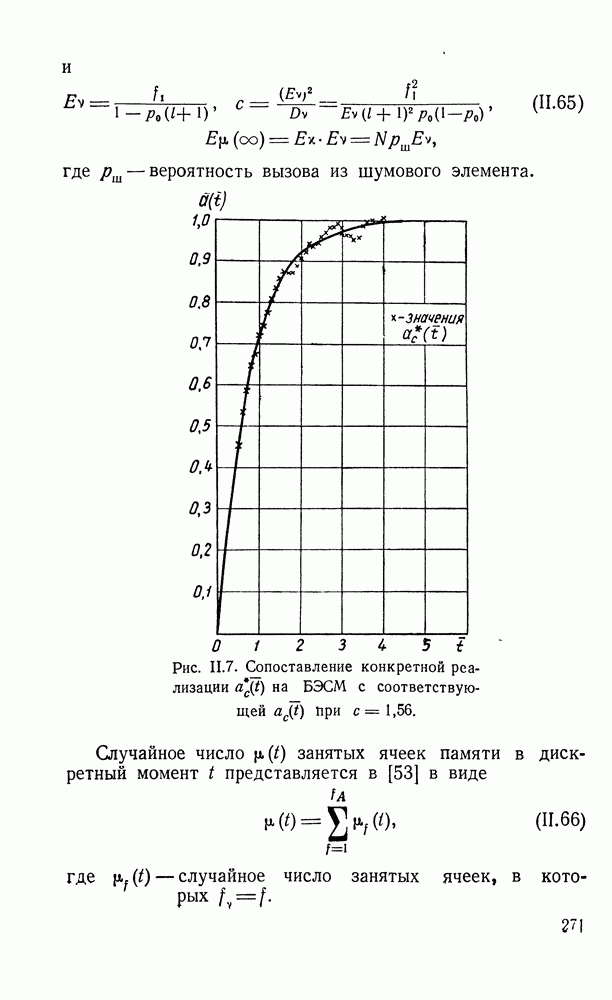
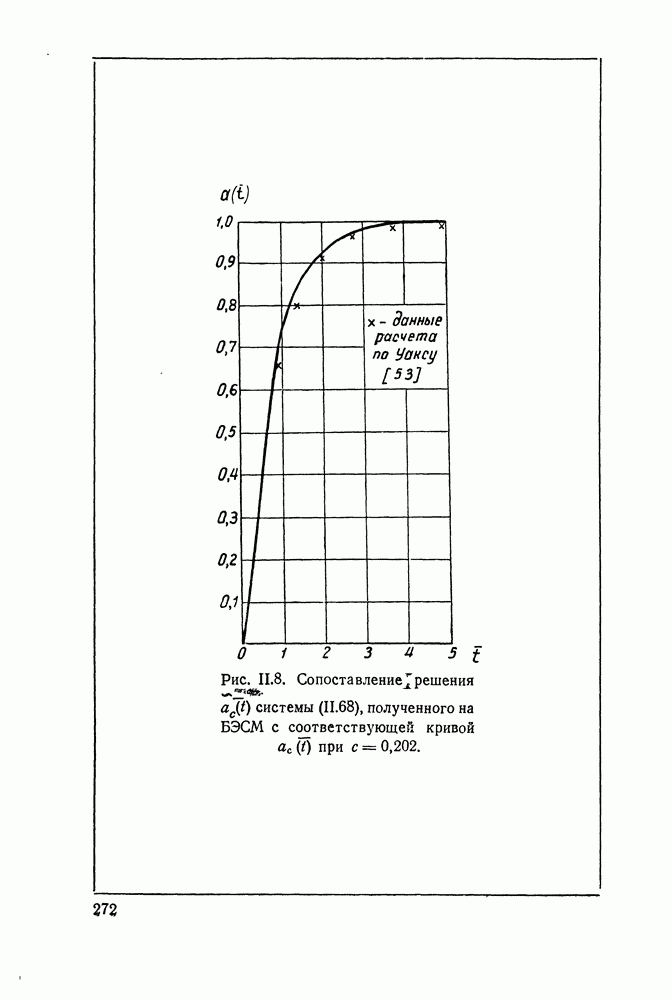
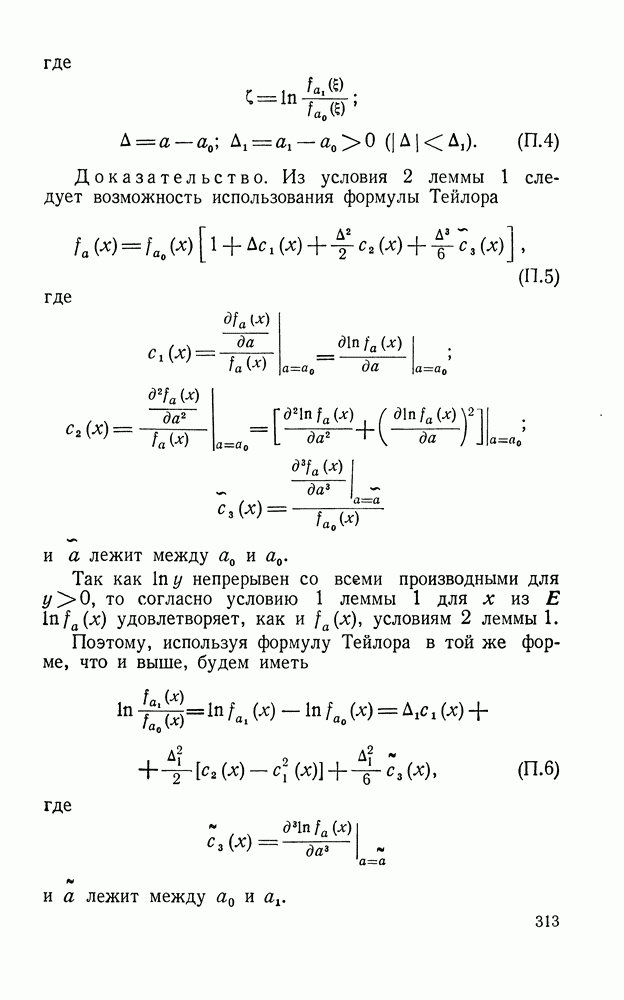
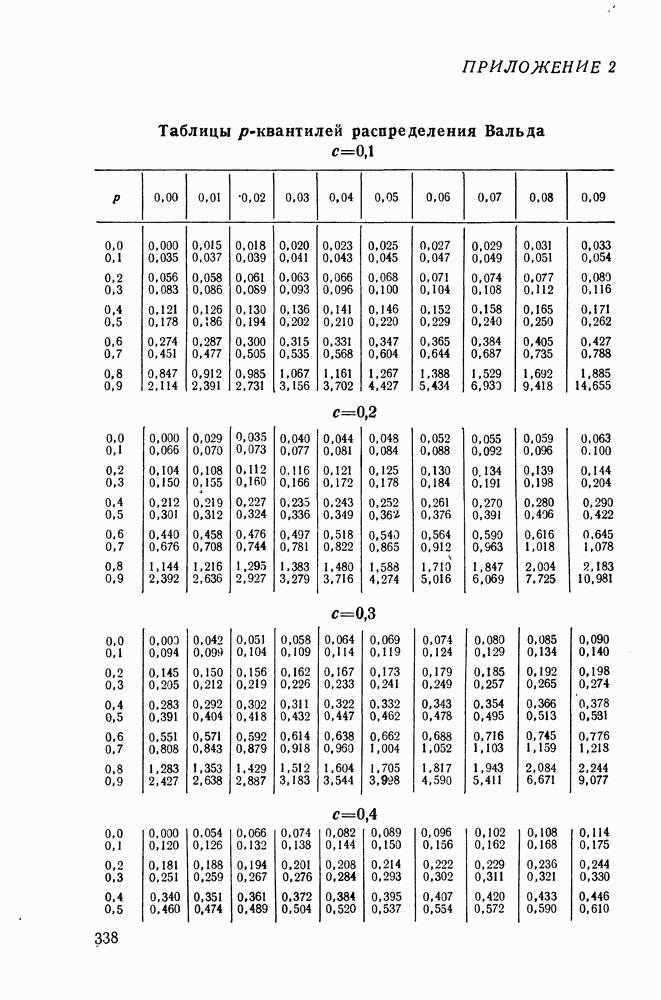
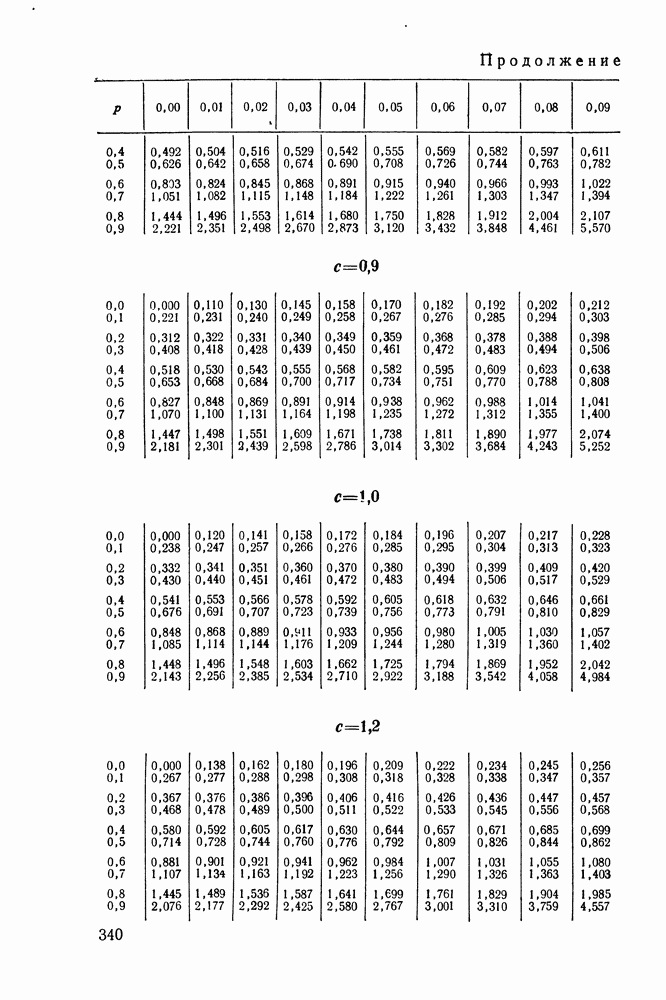
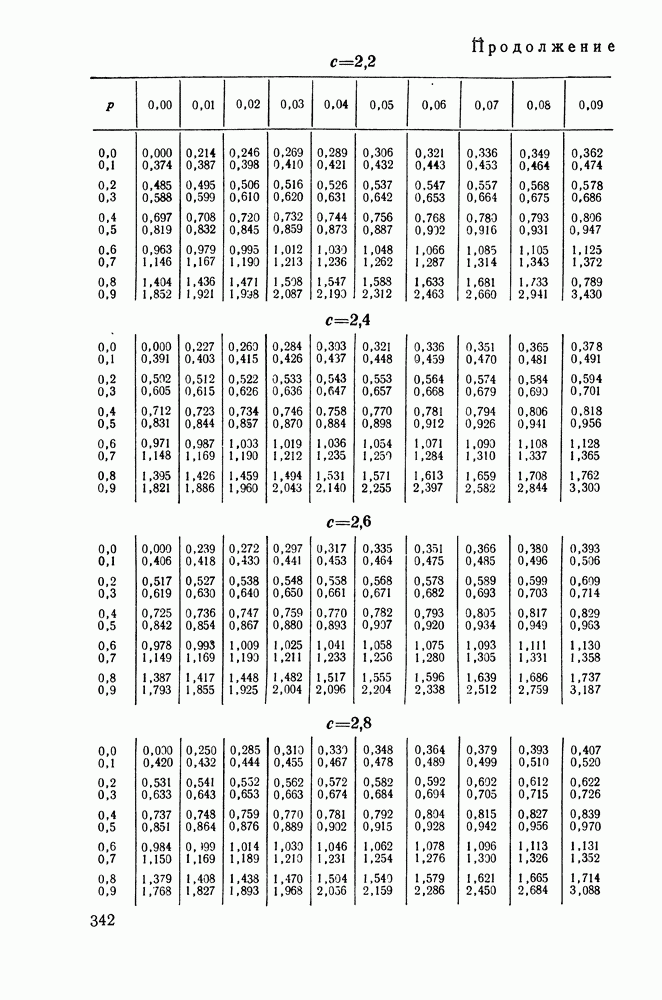
ДОПОЛНЕНИЕ II. СТАТИСТИЧЕСКОЕ РАЗЛИЧЕНИЕ ИНФОРМАЦИОННЫХ ПОТОКОВ КИБЕРНЕТИЧЕСКИМИ УСТРОЙСТВАМИ
§ II.1. ВВОДНЫЕ ЗАМЕЧАНИЯ
По мере усложнения и автоматизации приемных систем связи, поисковых систем (см. Доп. III), систем переработки .и систематизации информации при наличии помех и развития других сложных кибернетических систем задача обнаружения сигналов на фоне шумов оказывается одной из частных задач внутри общей задачи оптимизации таких кибернетических систем.
Под последними понимаются автоматические устройства, направленно работающие длительное время без вмешательства человека по заданной им программе (с различной степенью гибкости вплоть до самонастройки и обучаемости).
Такого рода устройства  настоящее время не мыслятся без включения в них быстродействующих вычислительных машин с большим объемом памяти. В этом дополнении рассматриваются статистические задачи, связанные с работой кибернетических устройств (к. у.).
настоящее время не мыслятся без включения в них быстродействующих вычислительных машин с большим объемом памяти. В этом дополнении рассматриваются статистические задачи, связанные с работой кибернетических устройств (к. у.).
При этом учитывается объем памяти к. у., содержащей  ячеек. Информационный поток, подлежащий статистическому анализу к. у., мыслится как совокупность
ячеек. Информационный поток, подлежащий статистическому анализу к. у., мыслится как совокупность  одновременно действующих источников информации (элементов фазового пространства, каналов и так далее, точное определение информационного потока, см. 11.2). Выбор оптимальных статистических критериев различения информационных потоков «шумового» и «сигнального» характера оказывается существенным для экономии объема памяти к. у. В частности, при прочих равных обстоятельствах выигрыш в числе
одновременно действующих источников информации (элементов фазового пространства, каналов и так далее, точное определение информационного потока, см. 11.2). Выбор оптимальных статистических критериев различения информационных потоков «шумового» и «сигнального» характера оказывается существенным для экономии объема памяти к. у. В частности, при прочих равных обстоятельствах выигрыш в числе
испытаний к. у. с последовательным статистическим анализом по сравнению с классическим соответствует такому же выигрышу в объеме памяти (см. II.4).
Новые кибернетические задачи возникают здесь в первую очередь  связи с тем обстоятельством, что обработку информации, которая поступает по
связи с тем обстоятельством, что обработку информации, которая поступает по  каналам, естественно производить с помощью кибернетического устройства, имеющего по возможности минимальное число
каналам, естественно производить с помощью кибернетического устройства, имеющего по возможности минимальное число  ячеек памяти. Если
ячеек памяти. Если  невелико и можно иметь
невелико и можно иметь  то рассматриваемые задачи сводятся к известным задачам математической статистики.
то рассматриваемые задачи сводятся к известным задачам математической статистики.
В самом деле, тогда можно каждую ячейку памяти закрепить за одним каналом и производить оптимальную статистическую обработку (типа рассмотренных в гл. 1) данных, поступающих по каждому из каналов.
Если  велико и невозможно или экономически не выгодно создание к. у. с
велико и невозможно или экономически не выгодно создание к. у. с  ячейками памяти, то решение поставленных задач нельзя свести к известным оптимальным решениям математической статистики.
ячейками памяти, то решение поставленных задач нельзя свести к известным оптимальным решениям математической статистики.
Как следствие «нехватки» памяти при  возникает необходимость в периодических во времени просмотрах каналов с отбором и анализом лишь «подозрительной» части из них.
возникает необходимость в периодических во времени просмотрах каналов с отбором и анализом лишь «подозрительной» части из них.
Это обстоятельство создает нерегулярность поступления данных на вход к. у. Ниже будет показано, что процесс поступления входных данных можно схематизировать потоком в смысле теории массового обслуживания (см. II.3).