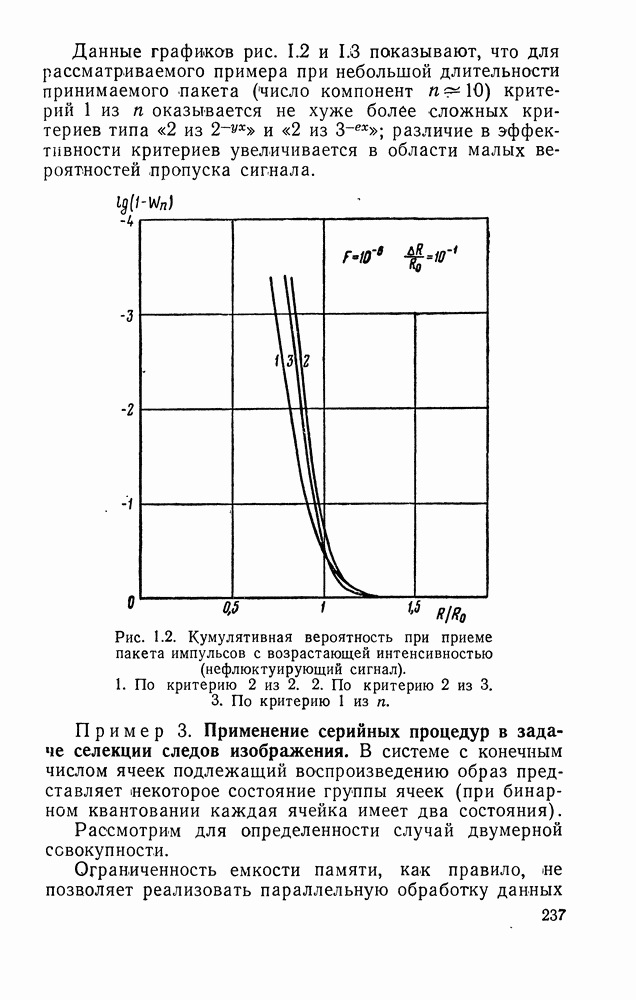
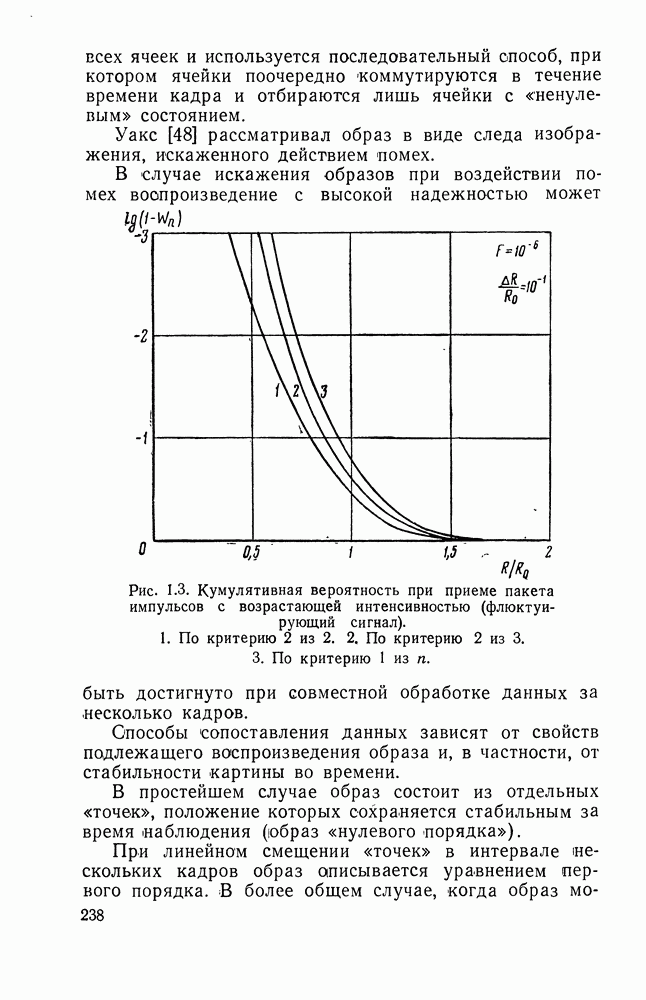
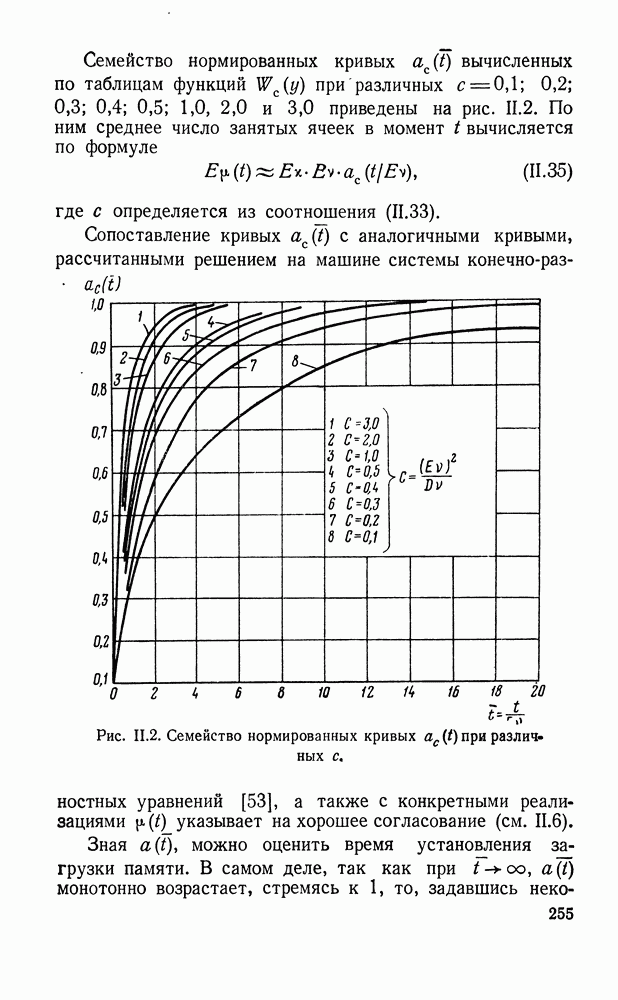
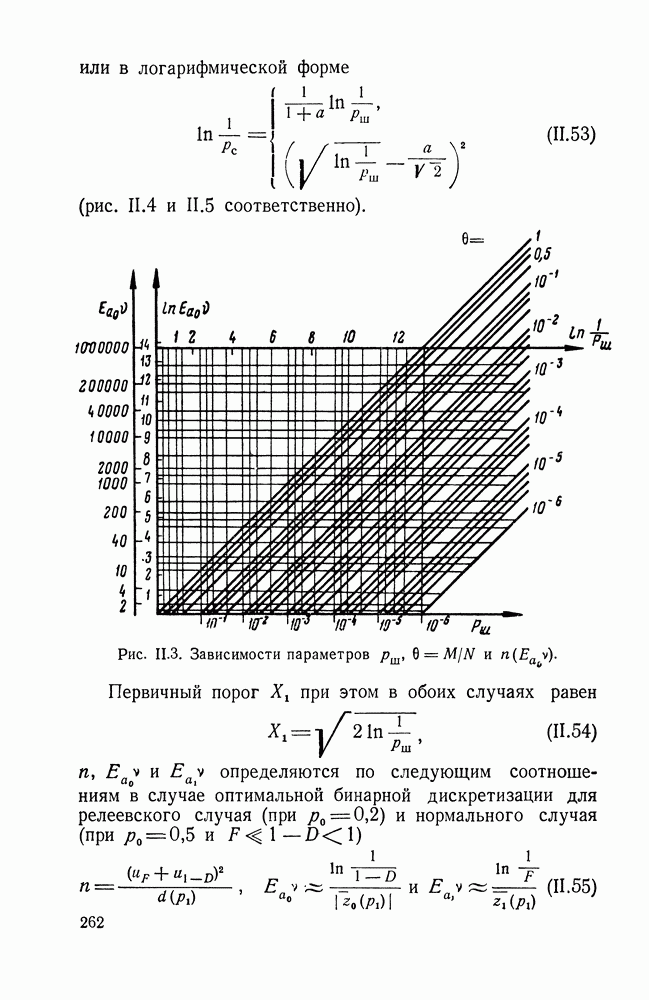
Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
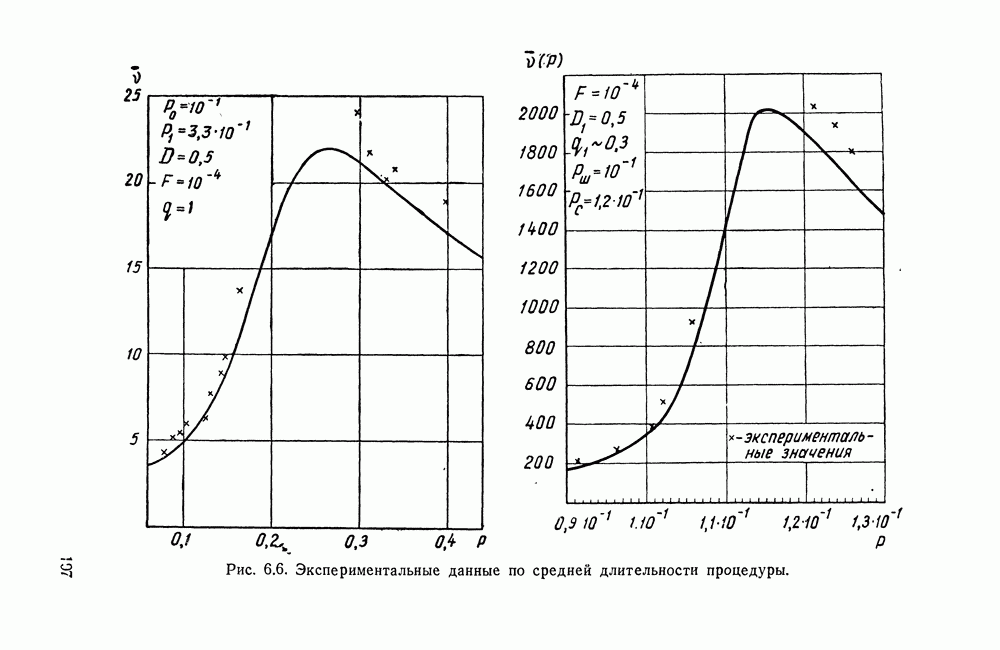
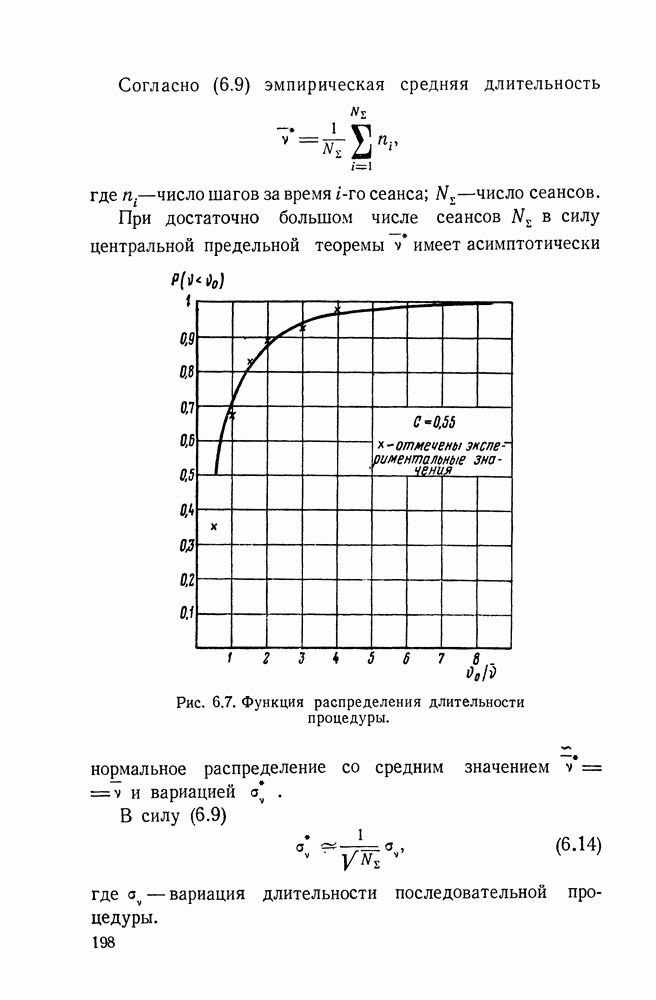
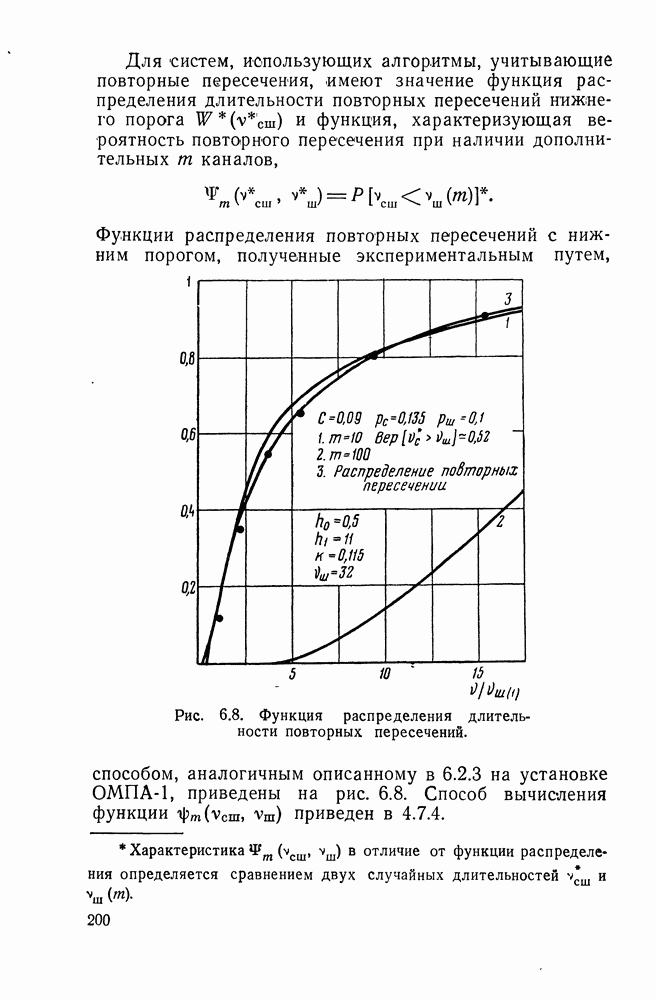
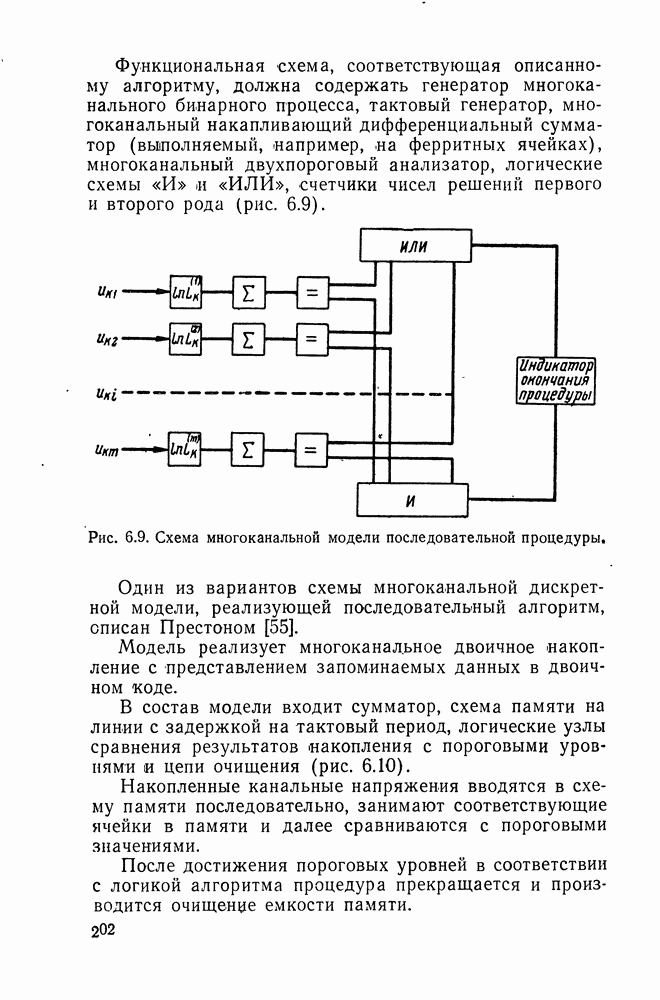
§ IV.4. ПОСЛЕДОВАТЕЛЬНОЕ ДЕКОДИРОВАНИЕ И ТЕХНИЧЕСКИЕ ВОЗМОЖНОСТИ ЕГО РЕАЛИЗАЦИИДо сих пор в оптимальную схему надежного различения большого числа сигналов, наряду с оптимальным кодированием включалась процедура оптимального декодирования, основанная на Прежде всего покажем возможность такой замены. В § 5.2, 5.3 была указана возможность применения последовательного анализа в системах посимвольного приема по каналу с шумами при использовании надежной обратной связи. Передача в рассматриваемом случае входных кодовых комбинаций в целом не исключает такой возможности. В самом деле, пусть в рассматриваемом случае имеется надежный (без шумов) канал обратной связи. Пусть по-прежнему на входе и (выходе имеется Такой сигнал явится одновременно сигналом для передачи новой входной кодовой комбинации и т. д. Использование последовательного декодирования вместо классического приведет лишь к изменению той части предельной теоремы, где говорится об одном из
с двумя порогами
и
вид которых определяется существенно разными по порядку малости вероятностями ошибок первого и второго рода
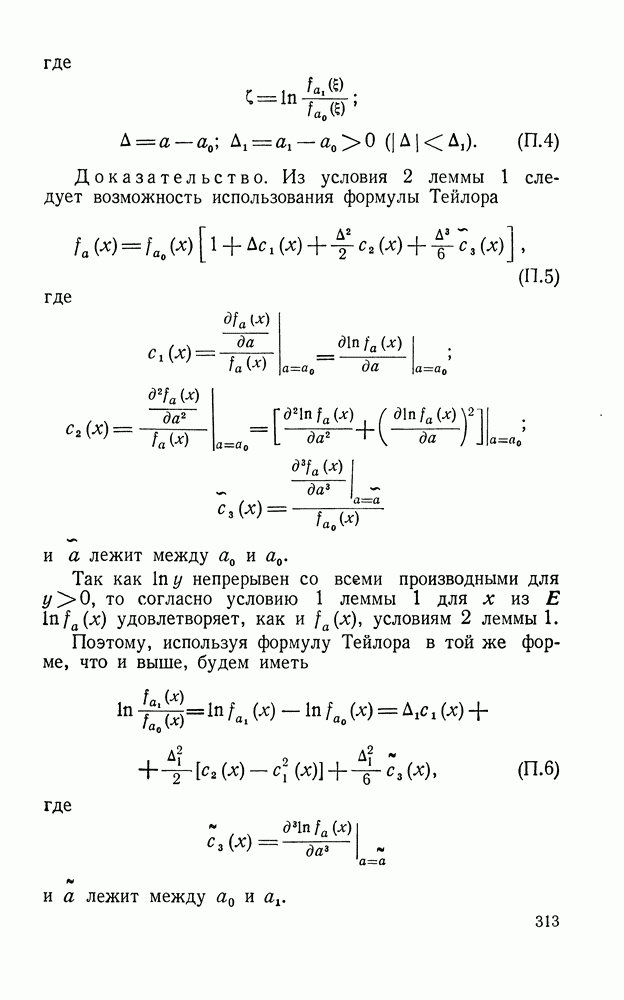
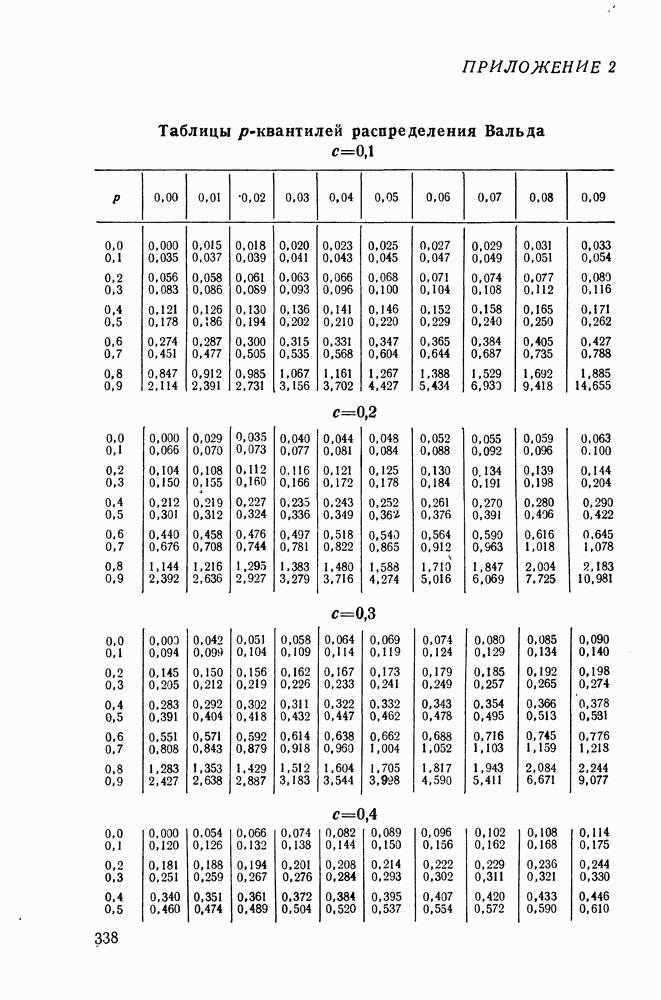
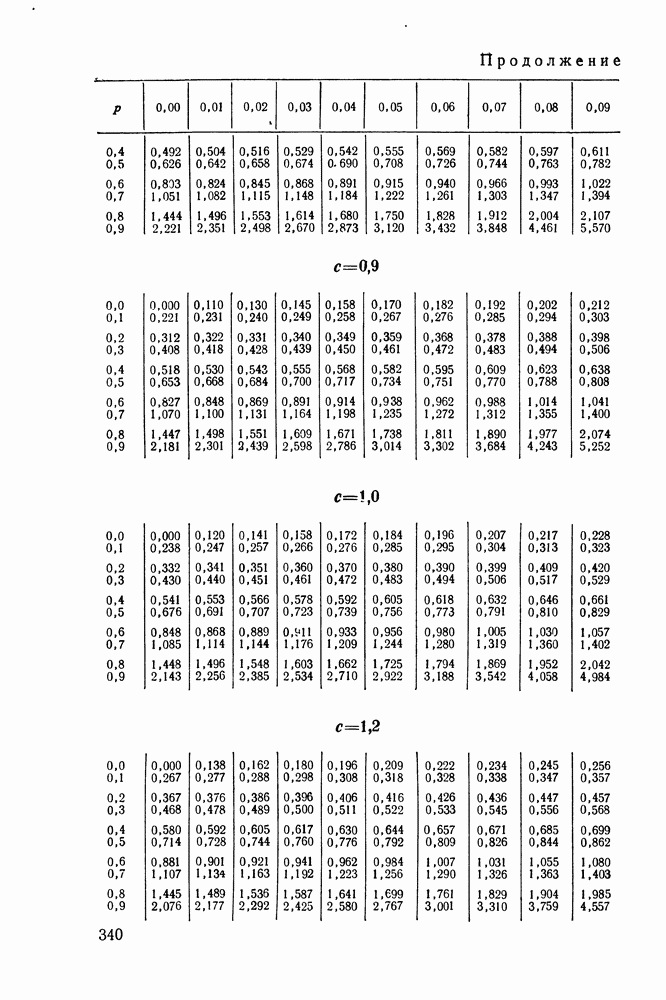
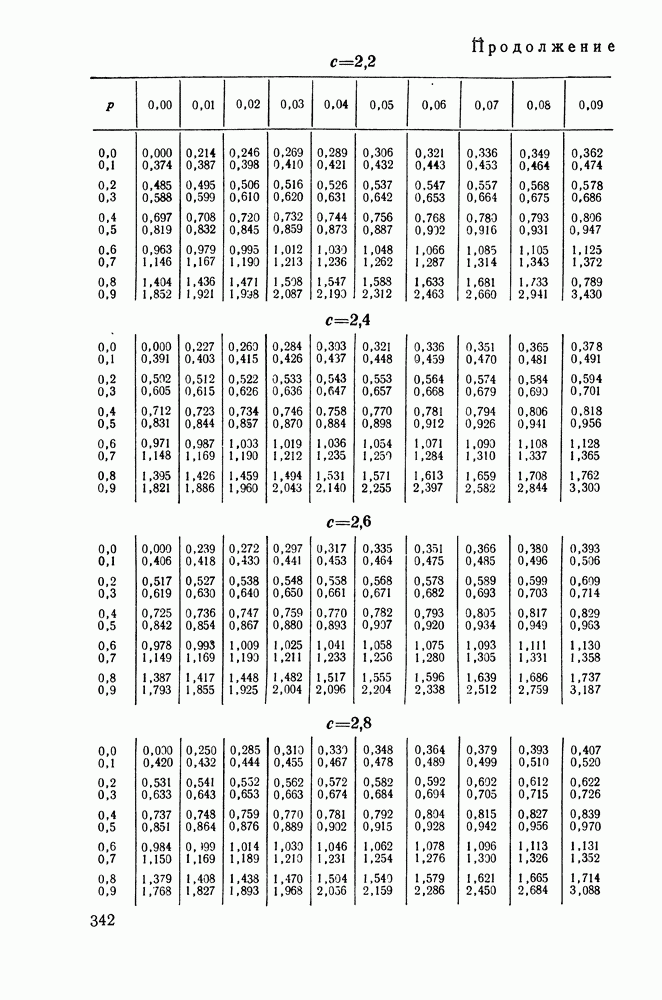
(см. приложение 1, п. 4). Из соотношений
Усечением в случаях малого Приступим теперь к оценке эффективности последовательного декодирования в целом. Для этого заметим, что, вообще говоря, имеются два способа осуществления декодирования, состоящего из 1. Можно производить одним устройством выборов между двумя гипотезами один за другим во времени; 2. Можно одновременно осуществлять Следует сразу же подчеркнуть, что существенный выигрыш в среднем времени декодирования при использовании последовательного декодирования по сравнению с классическим декодированием имеет место лишь при первом способе его осуществления (считаем время, идущее на осуществление одного выбора между гипотезами, пропорциональным необходимой для этого длине выходной кодовой комбинации). В самом деле, при первом способе осуществления декодирования, идущее на него время равно сумме При втором способе осуществление декодирования близко по структуре к многоканальному приему сигнала в одном из В самом деле, не говоря уже о затяжке одной из них, когда верна гипотеза Ясно, что последовательное декодирование не может привести к увеличению значения фундаментальной константы канала С. Остановимся теперь на вопросе о принципиальных технических возможностях осуществления рассмотренных схем кодирования и декодирования. Так как В связи с этим может представить интерес возможность избежать устройства с большим объемом памяти на входе канала [94]. Эта возможность состоит в сложном, но детерминированном взаимооднозначном преобразовании Преобразования такого типа находят широкое применение для регулярного получения случайных чисел, используемых при расчетах по методу Монте-Карло. В самом деле, для этого достаточно, чтобы все Для осуществления этого имеется много средств, на которых мы здесь останавливаться не будем. Получившиеся таким образом посимвольным преобразованием Однако на выходе необходимо иметь синхронный с входом экземпляр преобразования кодовую таблицу А отрезков Можно показать [94], что наличие регулярно (не случайно) построенной
|
 |
Оглавление
|

































































































































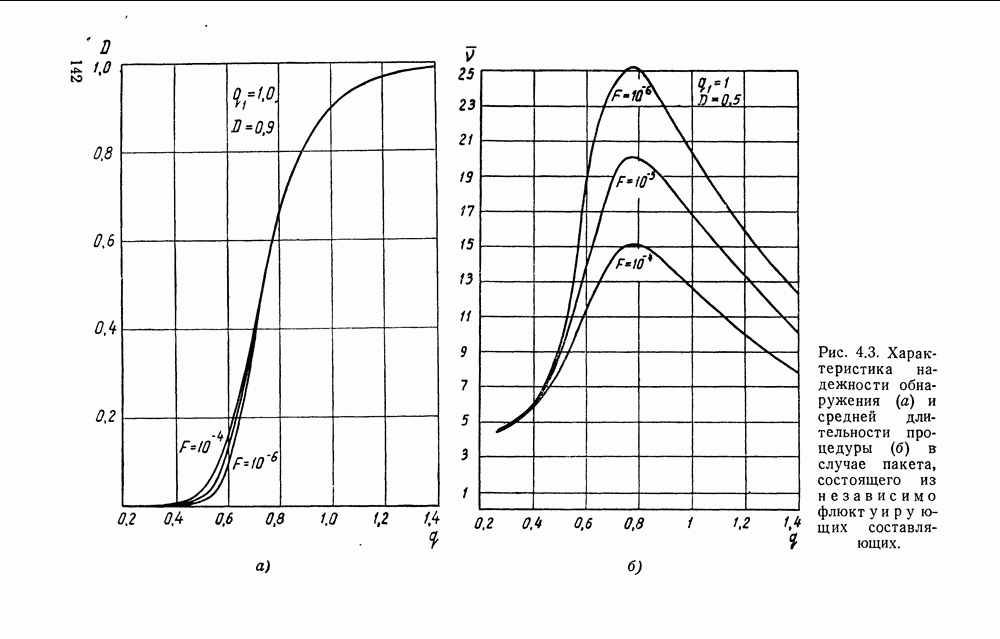


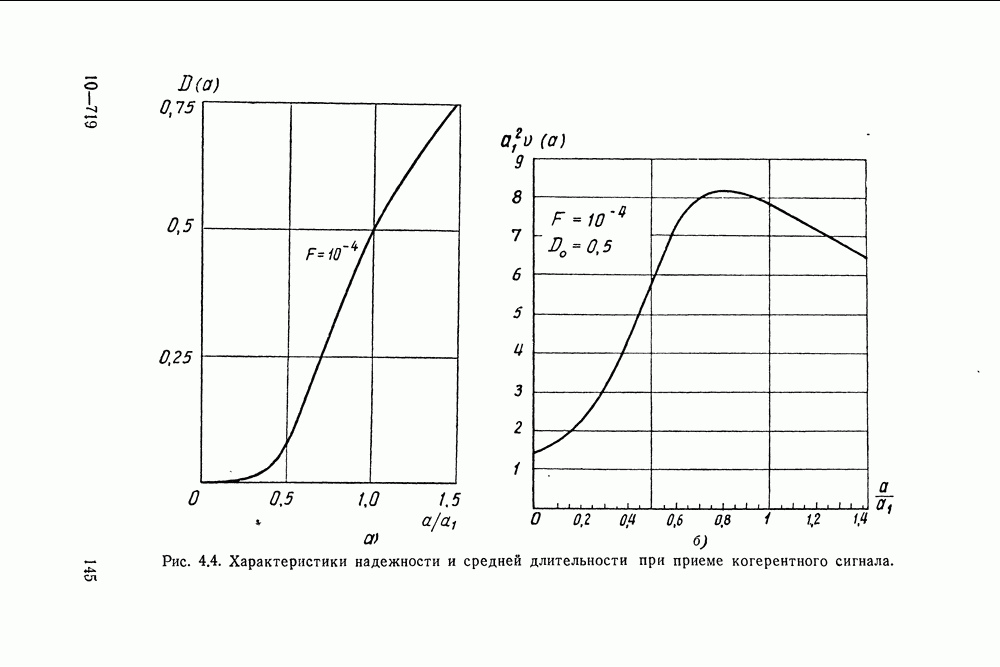


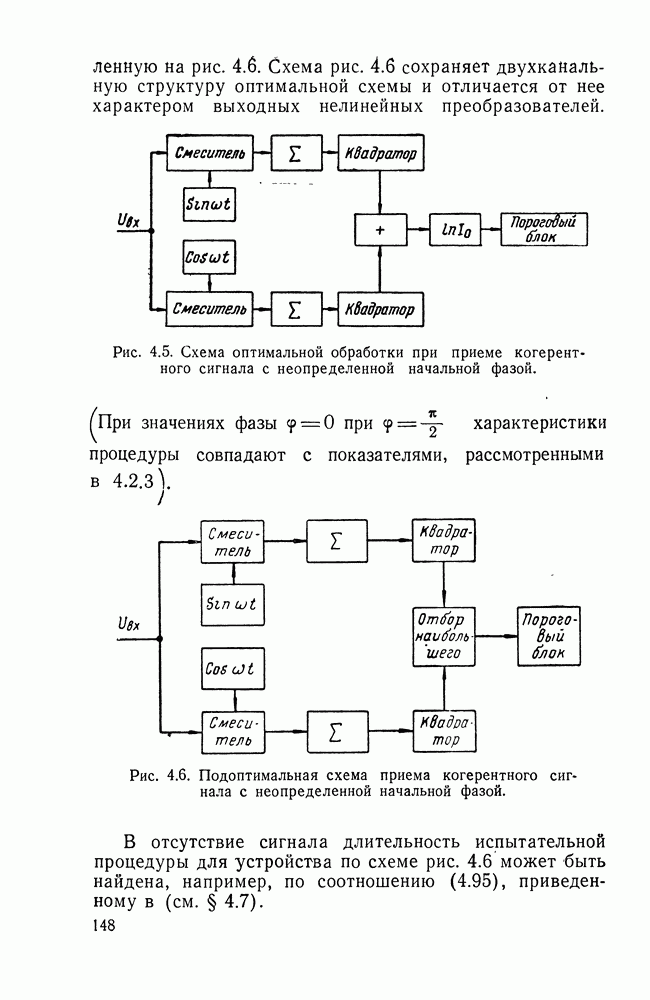












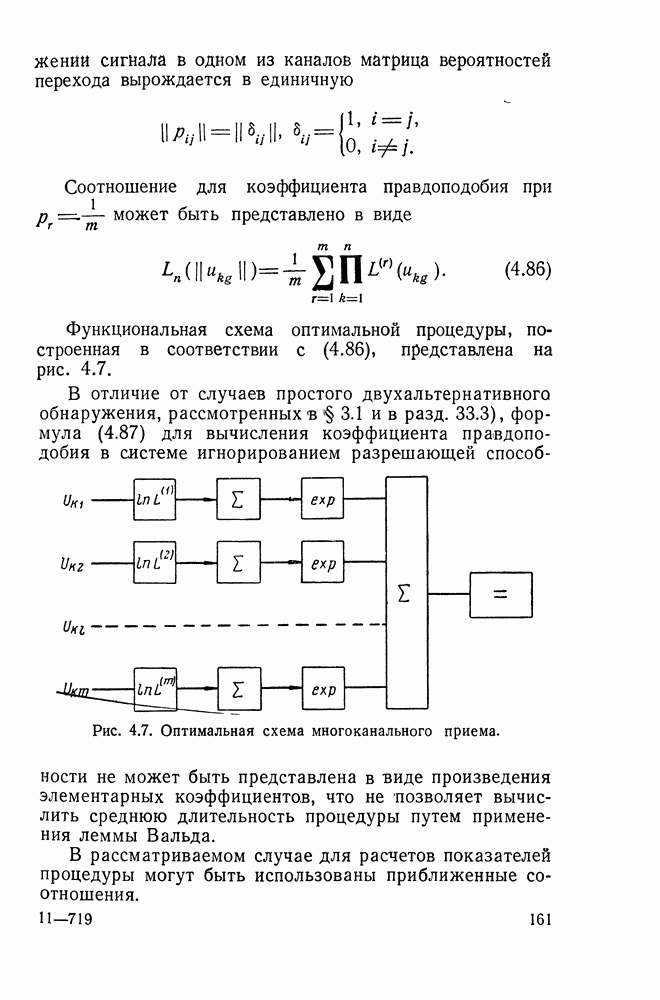

































































































































































 классических выборах между двумя гипотезами
классических выборах между двумя гипотезами  -классическое декодирование). Возможна ли замена в этой схеме классического декодирования последовательным декодированием, основанным на
-классическое декодирование). Возможна ли замена в этой схеме классического декодирования последовательным декодированием, основанным на  последовательных выборах между двумя гипотезами, и если возможна, то к какому положительному эффекту она приводит?
последовательных выборах между двумя гипотезами, и если возможна, то к какому положительному эффекту она приводит?
 кодовая таблица, но вместо классического декодирования основанного на фиксированной длине
кодовая таблица, но вместо классического декодирования основанного на фиксированной длине  выходной кодовой комбинации
выходной кодовой комбинации  будем проводить последовательное декодирование х, усеченное длиной
будем проводить последовательное декодирование х, усеченное длиной  По каналу обратной связи будем передавать с выхода на вход сигнал об окончании декодирования принятой выходной кодовой комбинации х. Оно осуществляется, как правило, по некоторой начальной части х, содержащей
По каналу обратной связи будем передавать с выхода на вход сигнал об окончании декодирования принятой выходной кодовой комбинации х. Оно осуществляется, как правило, по некоторой начальной части х, содержащей  первых символов
первых символов  случайная величина).
случайная величина).
 классических выборов между гипотезами
классических выборов между гипотезами  . В новом варианте последовательный выбор между
. В новом варианте последовательный выбор между  в оптимальном случае должен основываться на последовательном анализе накопленных сумм [см.
в оптимальном случае должен основываться на последовательном анализе накопленных сумм [см.  ]
]




 и (1.122),
и (1.122),  получим отношение среднего
получим отношение среднего  длины части выходной кодовой комбинации до вынесения решения к соответствующей фиксированной ее длине
длины части выходной кодовой комбинации до вынесения решения к соответствующей фиксированной ее длине  в классическом случае
в классическом случае

 можно пренебречь. Соотношения
можно пренебречь. Соотношения  и
и  показывают, что использование последовательного анализа в одном из
показывают, что использование последовательного анализа в одном из  выборов между двумя гипотезами приводит к тем большему эффекту, чем
выборов между двумя гипотезами приводит к тем большему эффекту, чем  ближе к С при гипотезе
ближе к С при гипотезе  и чем
и чем  меньше С при гипотезе
меньше С при гипотезе 
 элементарных процедур выбора между двумя гипотезами:
элементарных процедур выбора между двумя гипотезами:

 таких выборов
таких выборов  устройствами. (Технически это, по-видимому, неоправдано особенно при больших
устройствами. (Технически это, по-видимому, неоправдано особенно при больших 
 времен, идущих на элементарные выборы между двумя гипотезами. Все они, за исключением одного, происходят когда верна гипотеза
времен, идущих на элементарные выборы между двумя гипотезами. Все они, за исключением одного, происходят когда верна гипотеза  Поэтому отношение среднего времени для осуществления последовательного декодирования ко времени для осуществления классического декодирования будет совпадать при больших
Поэтому отношение среднего времени для осуществления последовательного декодирования ко времени для осуществления классического декодирования будет совпадать при больших  с соответствующим отношением для элементарных выборов, когда верна гипотеза
с соответствующим отношением для элементарных выборов, когда верна гипотеза  т. е. равно
т. е. равно  (см. IV.23). Как уже отмечалось, особый эффект имеет место при
(см. IV.23). Как уже отмечалось, особый эффект имеет место при  близком к С.
близком к С.
 каналов [см. § 4.5.)]. В рассматриваемом случае больших
каналов [см. § 4.5.)]. В рассматриваемом случае больших  выигрыш от последовательного декодирования нивелируется из-за необходимости ждать для вынесения окончательного решения окончания всех
выигрыш от последовательного декодирования нивелируется из-за необходимости ждать для вынесения окончательного решения окончания всех  элементарных последовательных процедур.
элементарных последовательных процедур.
 с ростом
с ростом  увеличивается вероятность затяжки до классического усечения, хотя бы одной из
увеличивается вероятность затяжки до классического усечения, хотя бы одной из  последовательных процедур, когда верна гипотеза
последовательных процедур, когда верна гипотеза 
 кодовая таблица, сопоставляющая сигналам входные кодовые комбинации, должна храниться на входе и выходе, то необходимо иметь
кодовая таблица, сопоставляющая сигналам входные кодовые комбинации, должна храниться на входе и выходе, то необходимо иметь  ячеек памяти. В работе [92] дан способ сокращения объема памяти до числа ячеек, растущих медленнее, чем
ячеек памяти. В работе [92] дан способ сокращения объема памяти до числа ячеек, растущих медленнее, чем  И все же недостаток объема памяти является основным тормозом в осуществлении рассмотренных схем (существующее быстродействие достаточно).
И все же недостаток объема памяти является основным тормозом в осуществлении рассмотренных схем (существующее быстродействие достаточно).
 в каждый момент дискретного времени символов
в каждый момент дискретного времени символов  сигнала (подвергнутого дискретизации в случае его непрерывности) во входные символы
сигнала (подвергнутого дискретизации в случае его непрерывности) во входные символы  Какова бы ни была структура сигнала, можно построить такое преобразование
Какова бы ни была структура сигнала, можно построить такое преобразование  которое переведет их в полиноминально распределенные символы
которое переведет их в полиноминально распределенные символы  с оптимальными абсолютными вероятностями
с оптимальными абсолютными вероятностями  для канала, заданного матрицей
для канала, заданного матрицей 
 последовательностей
последовательностей  были псевдослучайными с одними и теми же абсолютными вероятностями
были псевдослучайными с одними и теми же абсолютными вероятностями
 символы
символы  используются для образования оптимальных входных кодовых комбинаций по мере поступления символов
используются для образования оптимальных входных кодовых комбинаций по мере поступления символов  сигнала без
сигнала без  кодовой таблицы на входе.
кодовой таблицы на входе.

 сигнала Длины
сигнала Длины  Это дает возможность восстановить необходимую для декодирования
Это дает возможность восстановить необходимую для декодирования  -кодовую таблицу А входных кодовых комбинаций, получающуюся из А преобразованием ее столбцов с помощью
-кодовую таблицу А входных кодовых комбинаций, получающуюся из А преобразованием ее столбцов с помощью  Таким образом, в рассматриваемой схеме необходим большой объем памяти лишь на выходе. Такие несимметричные ситуации могут иметь место в ряде практических случаев.
Таким образом, в рассматриваемой схеме необходим большой объем памяти лишь на выходе. Такие несимметричные ситуации могут иметь место в ряде практических случаев.
 -кодовой таблицы не избавляет от необходимости иметь большой объем памяти как на входе, так и на выходе канала.
-кодовой таблицы не избавляет от необходимости иметь большой объем памяти как на входе, так и на выходе канала.