Пред.
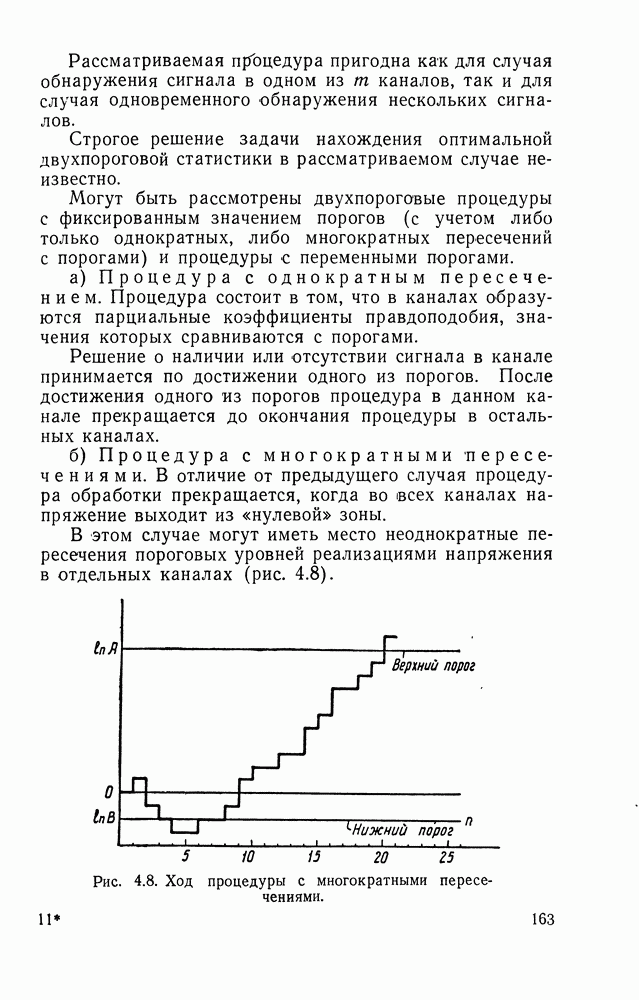
След.
Макеты страниц
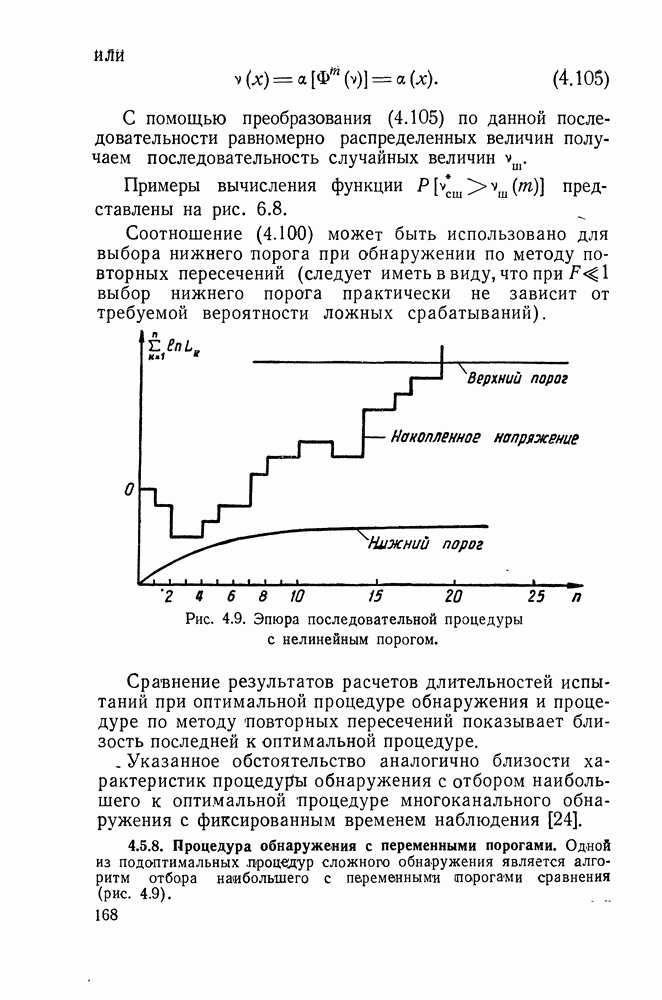
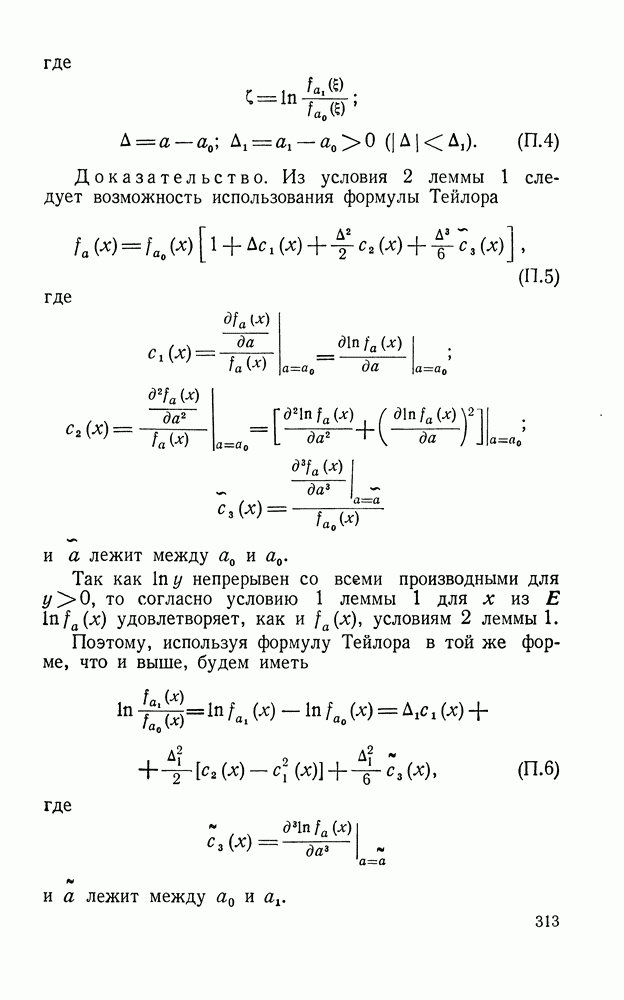
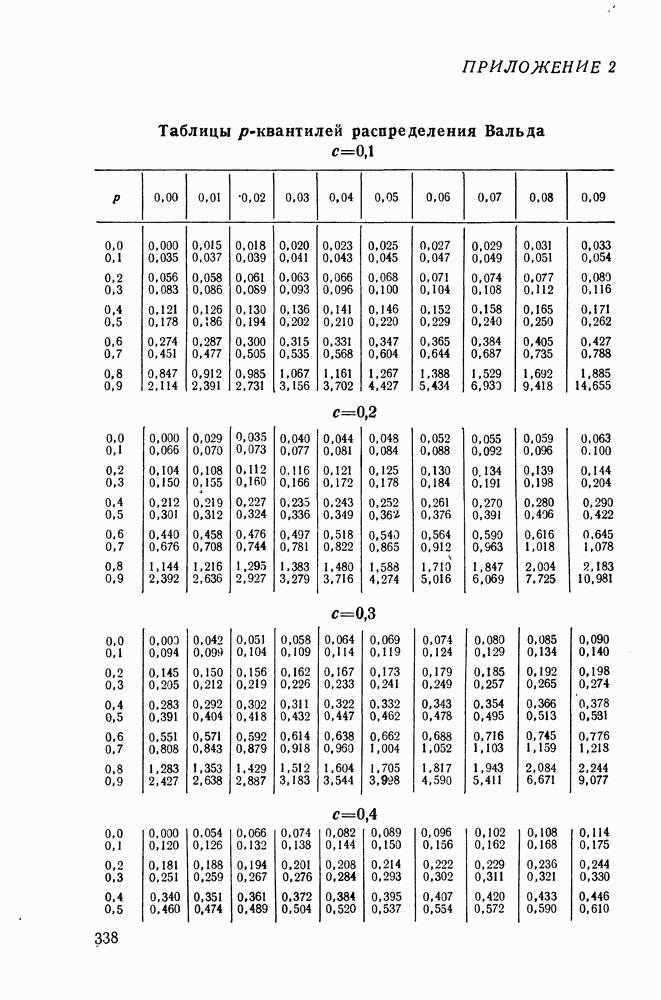
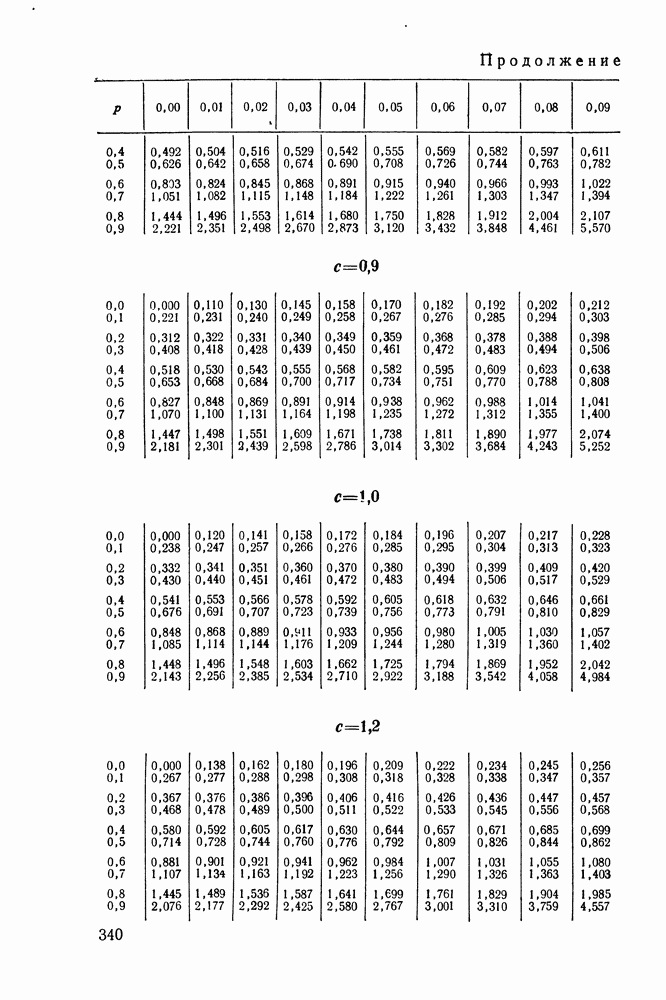
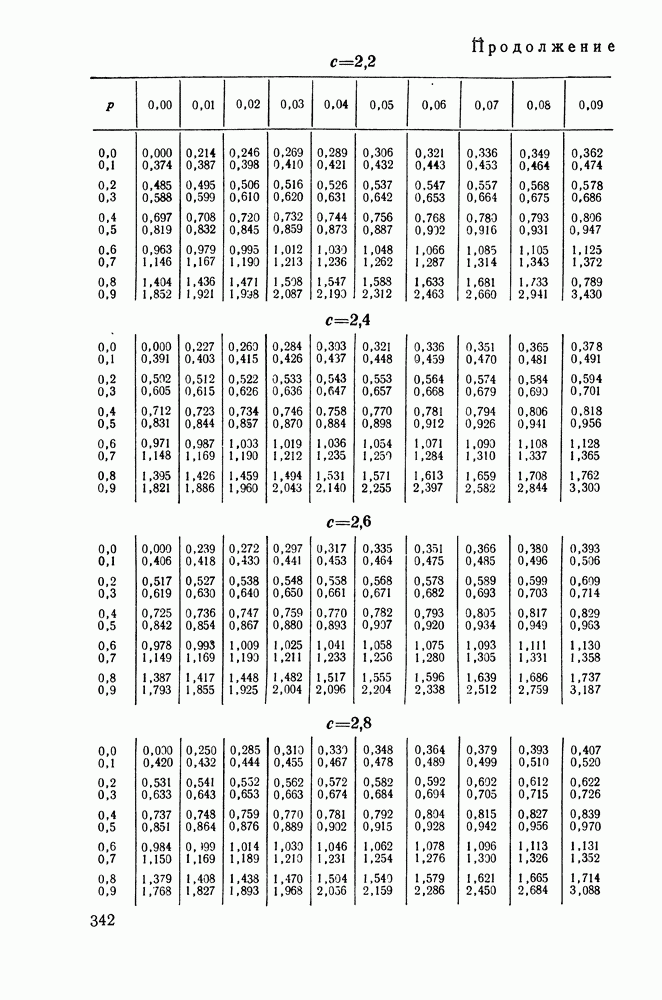
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
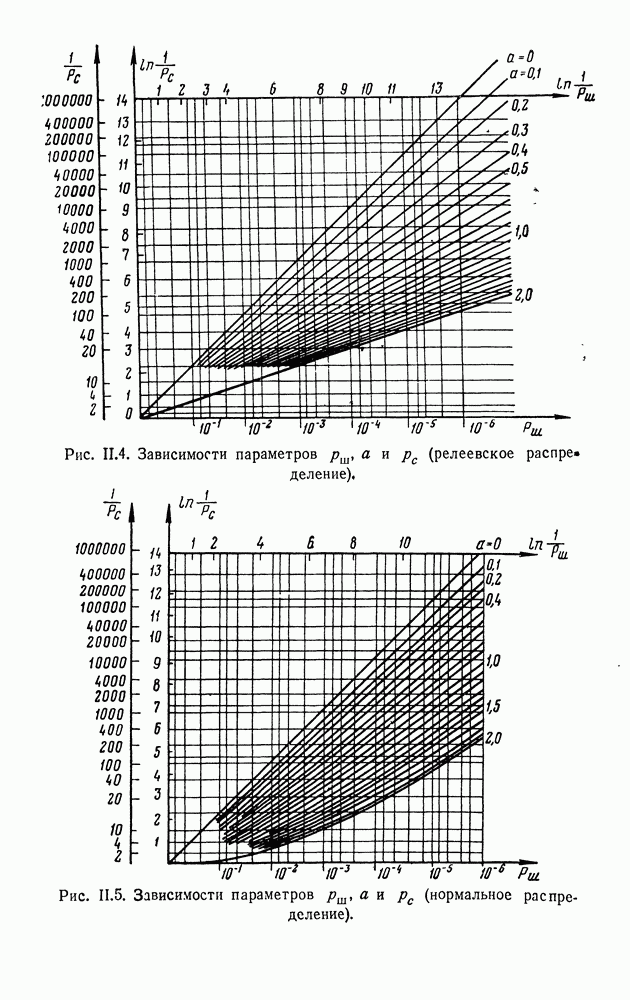
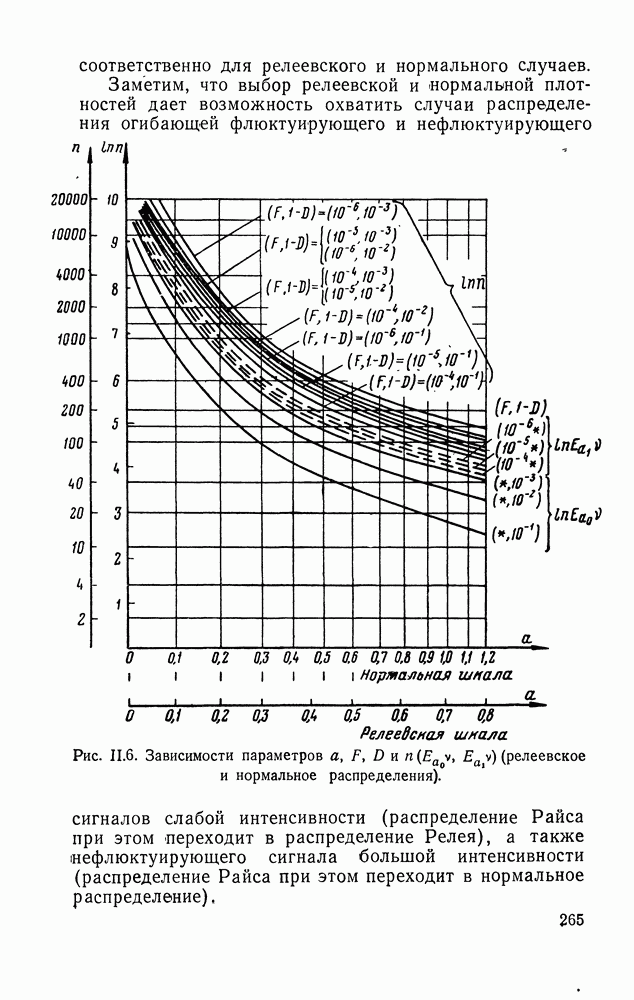
§ II.2 ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ И ПОСТАНОВКА ЗАДАЧИИнформационным потоком [75]
будем называть Образом будем называть некоторую совокупность компонент
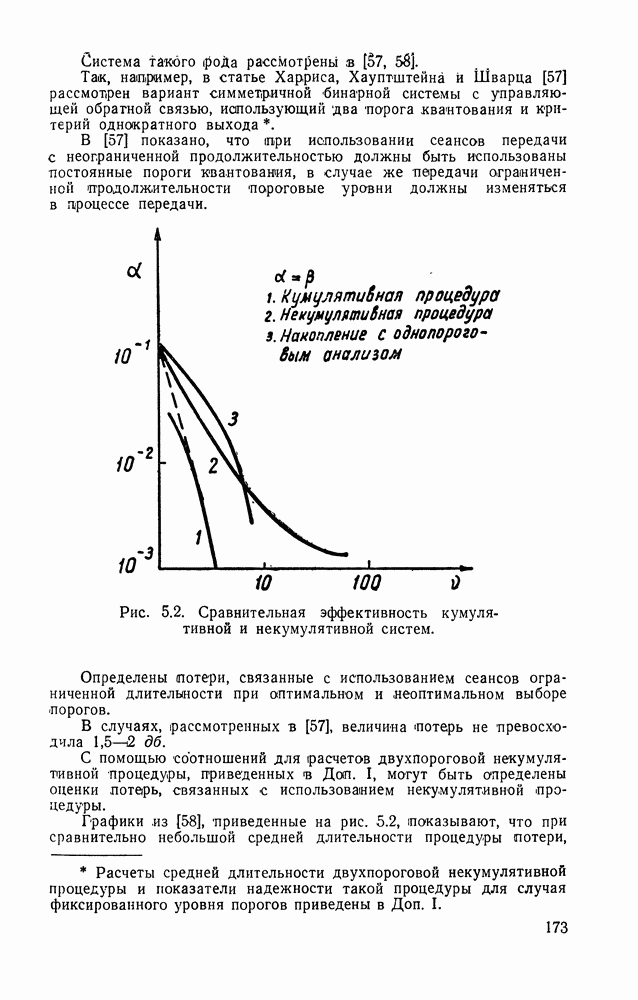
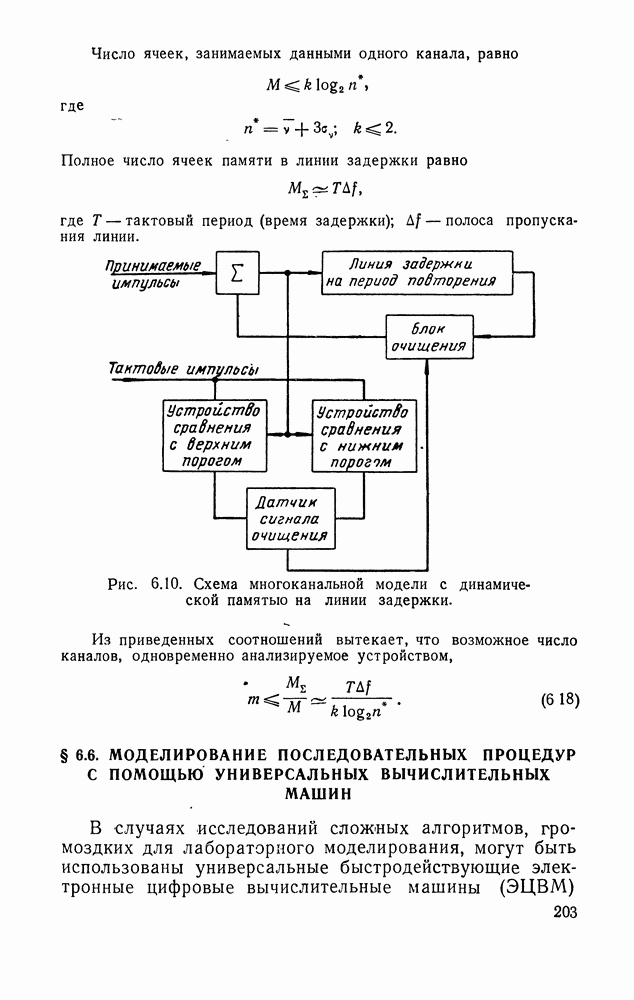
с индексами, могущими, вообще говоря, со временем изменяться. Если со временем Задача статистического различения информационных потоков в общем виде при бесконечном объеме памяти к. у. Такая общая постановка, как правило, недостаточна для эффективного решения. Для приложений характерно специальное задание потоков Кроме того, для приложений весьма существен учет ограниченности объема памяти к. у. классификации образов различного порядка (Доп. I). Задачи такого рода применительно к обнаружению следов при наличии шумов рассматривались в (53]. Перейдем к подробному описанию функций к. у. Функции к. у. выглядят следующим образом (рис. II.1): а) Преобразование многомерного информационного потока с одновременно существующими компонентами в одномерный во времени векторный процесс с последовательными во времени компонентами, что достигается периодическим просмотром элементов фазового пространства.
Рис. II.1. Функциональная схема кибернетического устройства статистического различения информационных потоков. б) Фиксация «подозрительного» элемента, требующего последующего дополнительного анализа (узел фиксации к. у.). в) Накопление во времени данных за несколько просмотров от фиксированных элементов в соответствующих ячейках памяти (память к. у.). г) Анализ результатов накопления и окончательное решение о шумовом или сигнальном характере элемента (узел анализа к. у.). В силу динамического изменения во времени образов .k. у. значительно быстрее должно осуществлять периодический просмотр элементов фазового пространства. Далее узел фиксации по какому-либо простому правилу должен выделять «подозрительные» элементы фазового пространства. Эта операция преобразует информационный поток в поток вызовов теории массового обслуживания [см. § II.3]. После этого устанавливается временная жесткая связь между элементами фазового пространства и ячейками памяти к. у., в которых происходит накопление данных за несколько просмотров вплоть до окончательного решения в узле анализа о шумовом или сигнальном характере элементов фазового пространства. После вынесения решения ячейка очищается и может воспринимать новые данные. Все это создает динамический режим загрузки памяти к. у., определяемый вероятностными закономерностями. Можно поставить задачу отыскания оптимальных процедур, которые должно осуществлять к. у. для различения образов, при ограниченном времени наблюдения с заданными вероятностями ошибок и заданной весьма близкой к нулю вероятностью переполнения памяти к. у. (переполнение памяти приводит к срыву работы). Однако точная математическая постановка такой задачи еще не сформулирована. Поэтому ниже решение общей задачи будет оптимизировано лишь в узле анализа, где будут использованы оптимальные статистические процедуры выбора между двумя гипотезами. Ясно, что оптимальность для «части» может и не быть оптимальностью для «целого». Однако мы будем использовать эти процедуры, не имея ничего лучшего взамен. Впрочем, в Доп. I отмечалась практическая предпочтительность (в том числе и с точки зрения загрузки памяти) серийных процедур по сравнению с оптимальными процедурами, основанными на накоплении данных. В ряде практических ситуаций проигрыш в вероятностях ошибок, связанный с использованием серийных процедур компенсируемый большим числом наблюдений, чем это требуется при оптимальных процедурах, является менее существенным, чем выигрыш в объеме памяти. Все эти соображения лишь подчеркивают актуальность установления оптимальных принципов в этой важной области. Приступим к более конкретной постановке задачи. Пусть в зависимости от отношения сигнал/шум а напряжение выбора «подозрительных» элементов в одном просмотре можно принять следующий критерий. Назначим первичный порог Если значение
и
Пусть доли сигнальных и шумовых элементов в фазовом пространстве в момент
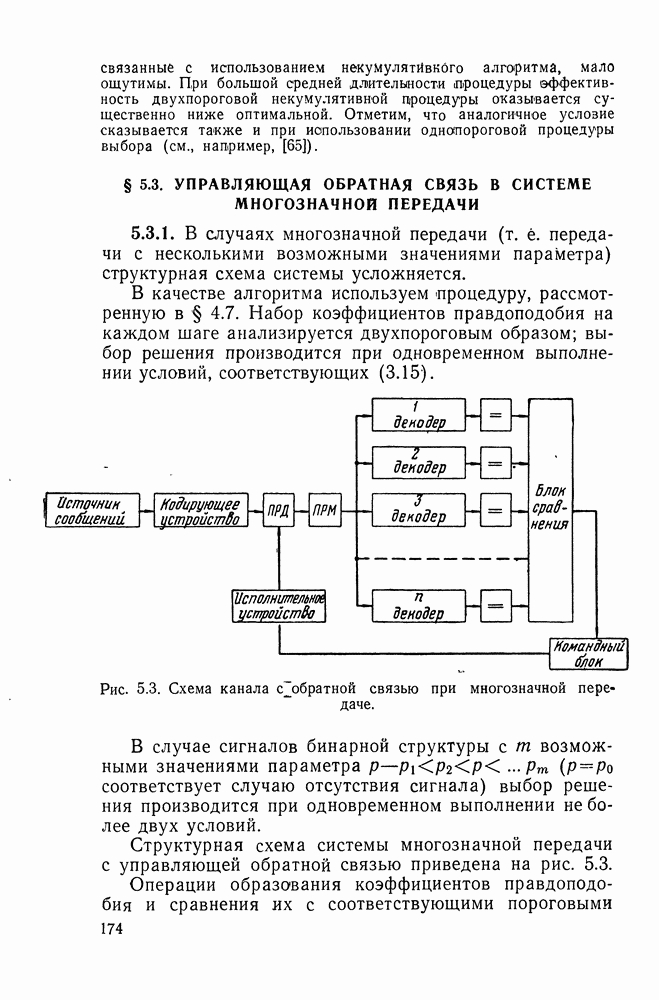
равное композиции двух биномиальных распределений, где
Пусть далее в ячейках памяти к. у. осуществляется узлом анализа оптимальный выбор между двумя гипотезами Но —
в последовательном случае. Будем считать за единицу времени время, идущее на один просмотр фазового пространства. При этом случайное число
и вероятность переполнения памяти оказывается равной
Важной характеристикой качества работы к. у. является общая величина х задержки в выдаче правильного решения о сигнальном характере элемента фазового пространства. Эта величина является случайной. В самом деле, при выбранном критерии фиксации вероятность фиксации сигнального элемента при —
Поэтому общая задержка и, слагающаяся из
равное композиции распределений (11.10) и Если в узле анализа решение выносится на основании классической процедуры, то распределение Итак, заданные параметры 1) распределение числа занятых ячеек памяти 2) распределение задержки выдачи правильного решения о сигнальном характере элемента фазового пространства (11.11). Задача состоит в их вычислении. И то, и другое распределение существенно зависит от распределения
|
 |
Оглавление
|



















































































































































































































































































































 -мерный процесс с компонентами У.
-мерный процесс с компонентами У.  определенными, вообще говоря, на абстрактных множествах
определенными, вообще говоря, на абстрактных множествах  Процесс
Процесс  как это принято, определяется совокупностью.
как это принято, определяется совокупностью.  согласованных между собой
согласованных между собой  -мерных распределений
-мерных распределений  реализаций
реализаций  во времени
во времени 

 индексы компонент образа не меняются, то образ называется неподвижным. В противном случае он называется подвижным. В частном случае, если подвижный образ состоит из одной компоненты, то он называется следом [53]. Ясно, что распределения вероятностей компонент образа определяются как частные распределения распределений вероятностей информационного потока
индексы компонент образа не меняются, то образ называется неподвижным. В противном случае он называется подвижным. В частном случае, если подвижный образ состоит из одной компоненты, то он называется следом [53]. Ясно, что распределения вероятностей компонент образа определяются как частные распределения распределений вероятностей информационного потока
 может быть поставлена как многоальтернативная задача выбора между
может быть поставлена как многоальтернативная задача выбора между  гипотезами
гипотезами  В самом деле, пусть априори известна возможность существования
В самом деле, пусть априори известна возможность существования  на данном интервале времени
на данном интервале времени  одного из
одного из  информационных потоков
информационных потоков  определяемых соответственно распределениями
определяемых соответственно распределениями  Тогда задачу статистического различения информационных потоков (по имеющейся реализации потока
Тогда задачу статистического различения информационных потоков (по имеющейся реализации потока  на интервале
на интервале  можно рассматривать, как задачу выбора между
можно рассматривать, как задачу выбора между  гипотезами
гипотезами  заданными вероятностями ошибок
заданными вероятностями ошибок  Здесь
Здесь  означает вероятность принять гипотезу
означает вероятность принять гипотезу  когда на самом деле верна гипотеза
когда на самом деле верна гипотеза 
 при котором нулевая гипотеза
при котором нулевая гипотеза  связана с шумовым потоком
связана с шумовым потоком  а остальные гипотезы
а остальные гипотезы  с потоками
с потоками  определяемыми теми или иными распределениями образов на фоне шумового потока.
определяемыми теми или иными распределениями образов на фоне шумового потока.
 Далее в общем определении подвижного образа необходимо внесение большей определенности, например
Далее в общем определении подвижного образа необходимо внесение большей определенности, например

 в элементе фазового пространства определяется плотностью
в элементе фазового пространства определяется плотностью  В качестве простейшего критерия
В качестве простейшего критерия
 и будем фиксировать в узле фиксации элементы фазового пространства с напряжениями превосходящими
и будем фиксировать в узле фиксации элементы фазового пространства с напряжениями превосходящими 
 при наличии шума в элементе и
при наличии шума в элементе и  при наличии сигнала и шума, то вероятности фиксации шумовых и сигнальных элементов соответственно равны
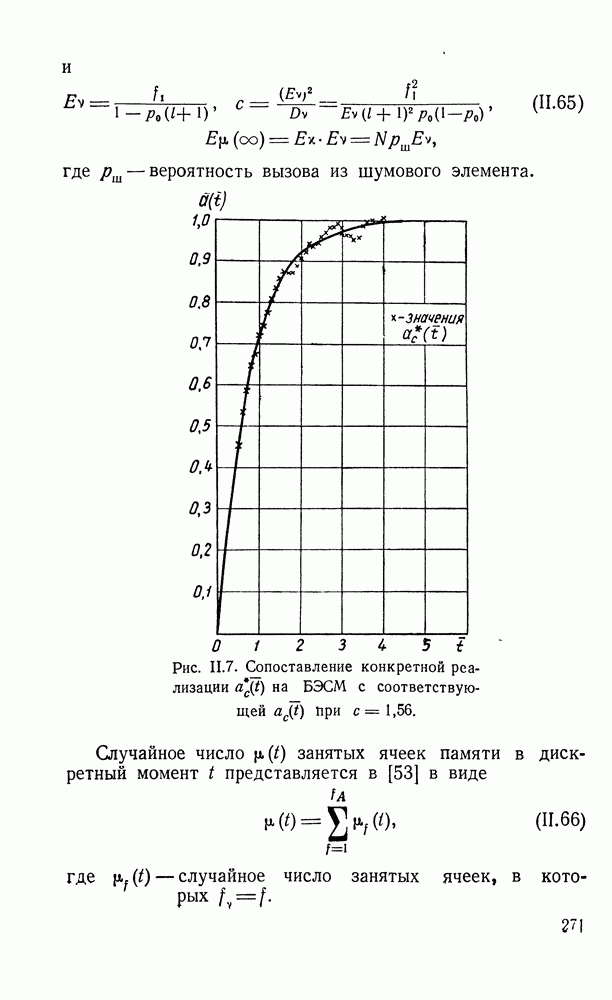
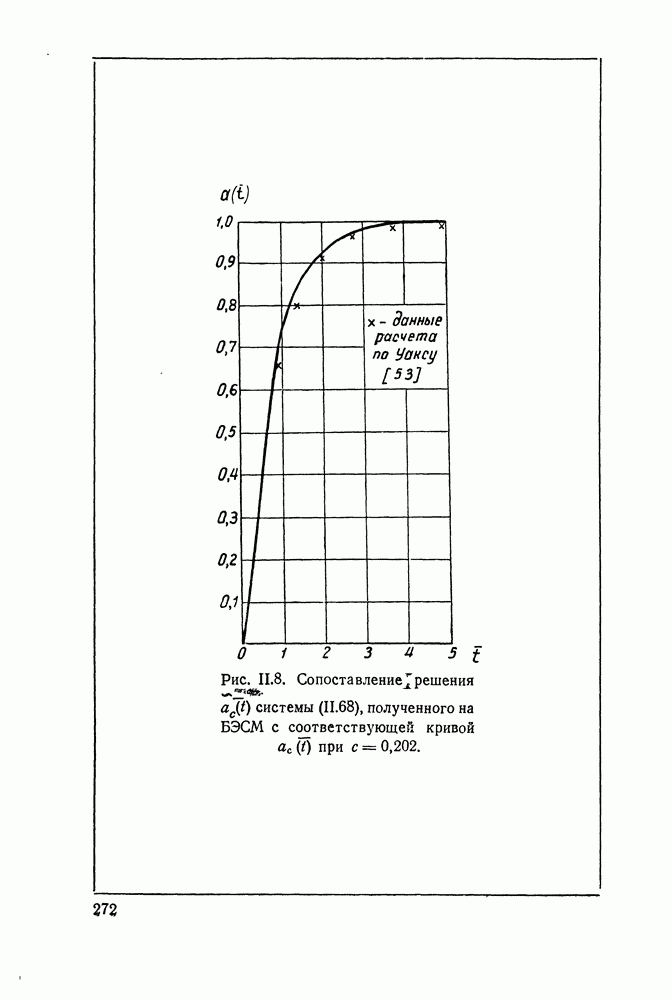
при наличии сигнала и шума, то вероятности фиксации шумовых и сигнальных элементов соответственно равны


 равны соответственно
равны соответственно  и Тогда случайное число
и Тогда случайное число  фиксированных при просмотре в момент
фиксированных при просмотре в момент  элементов фазового пространства имеет, как легко показать, распределение
элементов фазового пространства имеет, как легко показать, распределение


 с заданными вероятностями ошибок первого и второго рода соответственно
с заданными вероятностями ошибок первого и второго рода соответственно  Это приводит к задержке данных в памяти к. у., соответствующей фиксированному числу наблюдений
Это приводит к задержке данных в памяти к. у., соответствующей фиксированному числу наблюдений  в случае классической процедуры или случайному числу наблюдений
в случае классической процедуры или случайному числу наблюдений  с распределением
с распределением

 занятых ячеек памяти имеет некоторое распределение
занятых ячеек памяти имеет некоторое распределение


 просмотре имеет геометрическое распределение
просмотре имеет геометрическое распределение

 и величины задержки данных в памяти машины
и величины задержки данных в памяти машины  до вынесения окончательного решения
до вынесения окончательного решения  имеет распределение
имеет распределение


 в (11.11) вырождается в соответствующую
в (11.11) вырождается в соответствующую  -функцию.
-функцию.
 при известной плотности
при известной плотности  определяют два распределения, характеризующих качество работы к. у.:
определяют два распределения, характеризующих качество работы к. у.:
 «а основе которого вычисляется вероятность переполнения памяти
«а основе которого вычисляется вероятность переполнения памяти  и
и
 (вырождающегося в
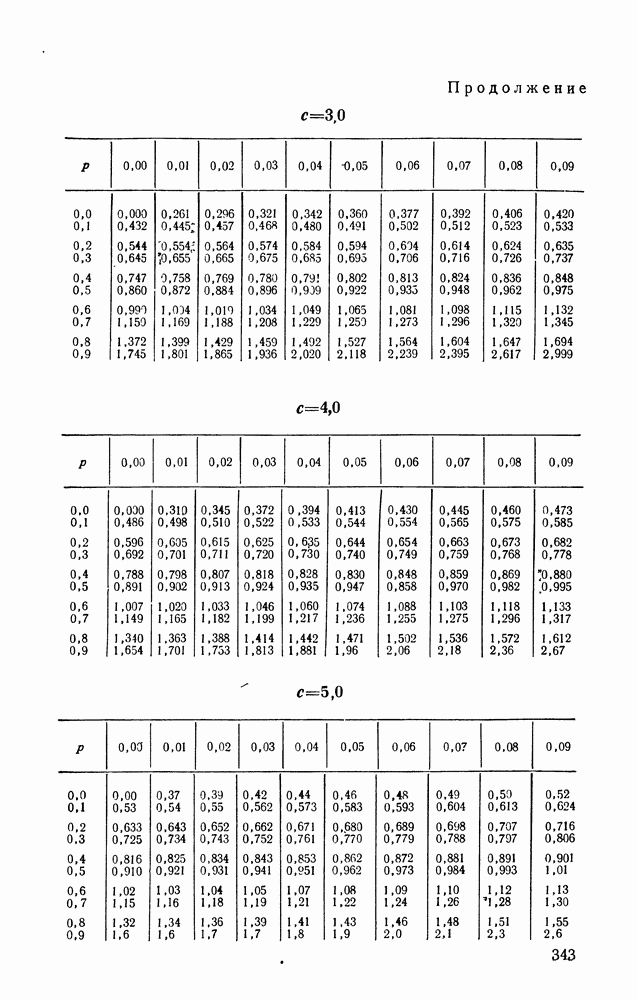
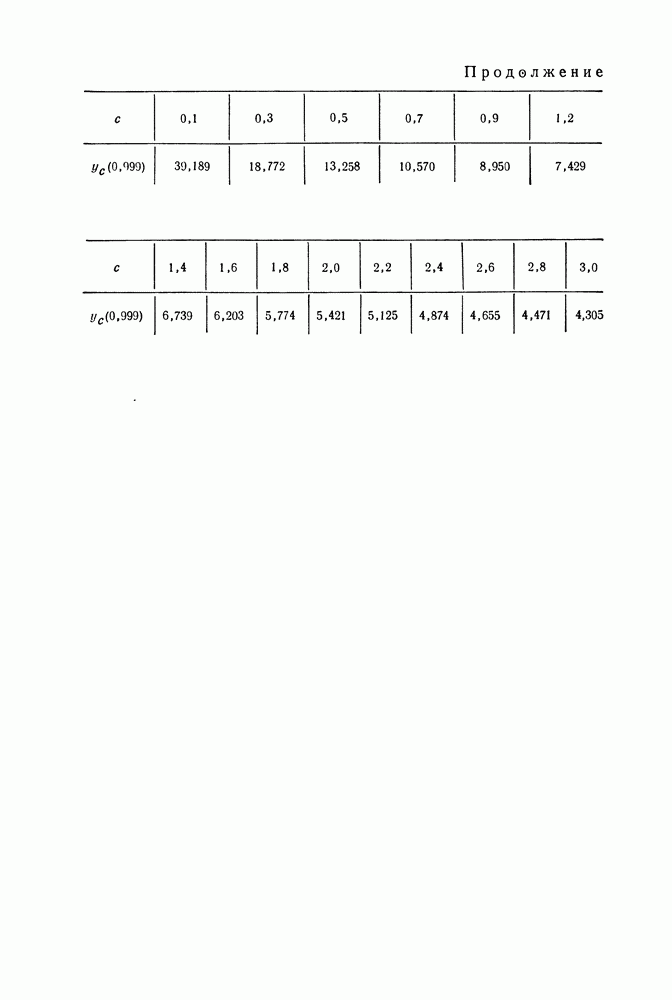
(вырождающегося в  -распределение в случае классического анализа данных), подробно изученного в гл. 1 для случая последовательного анализа. Подсчет второго распределения (11.11) очевиден. Подсчет первого распределения
-распределение в случае классического анализа данных), подробно изученного в гл. 1 для случая последовательного анализа. Подсчет второго распределения (11.11) очевиден. Подсчет первого распределения  сопряжен с рядом аналитических трудностей, преодолению которых посвящен следующий параграф.
сопряжен с рядом аналитических трудностей, преодолению которых посвящен следующий параграф.