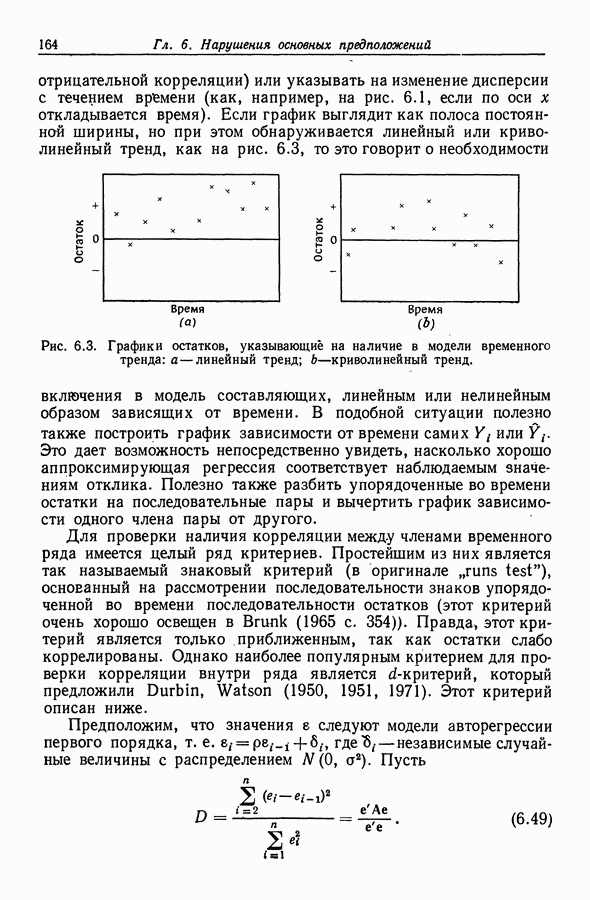
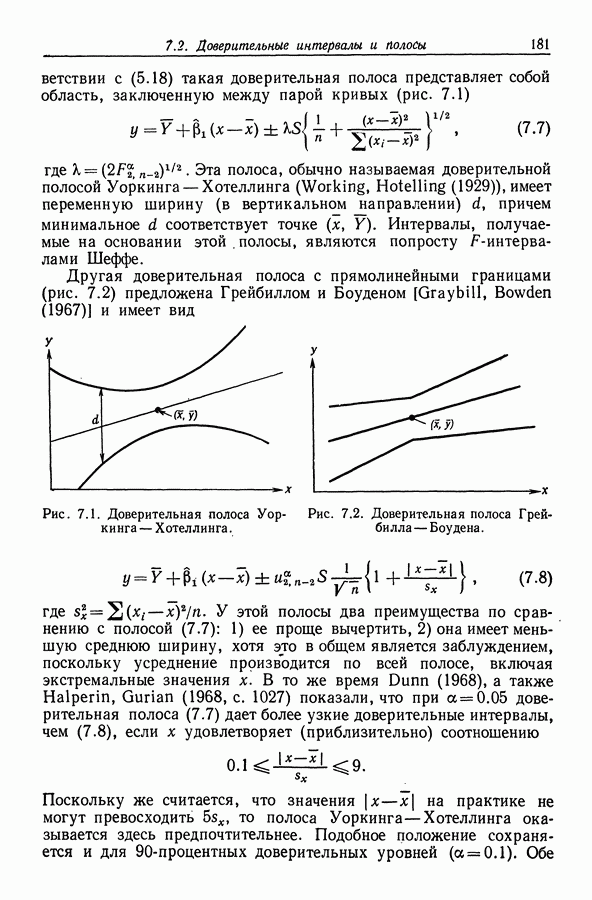
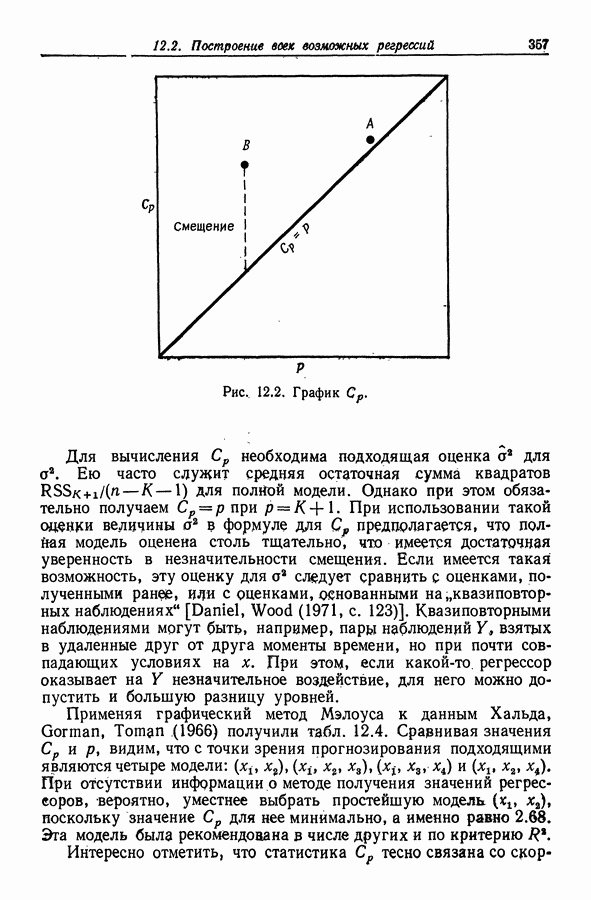
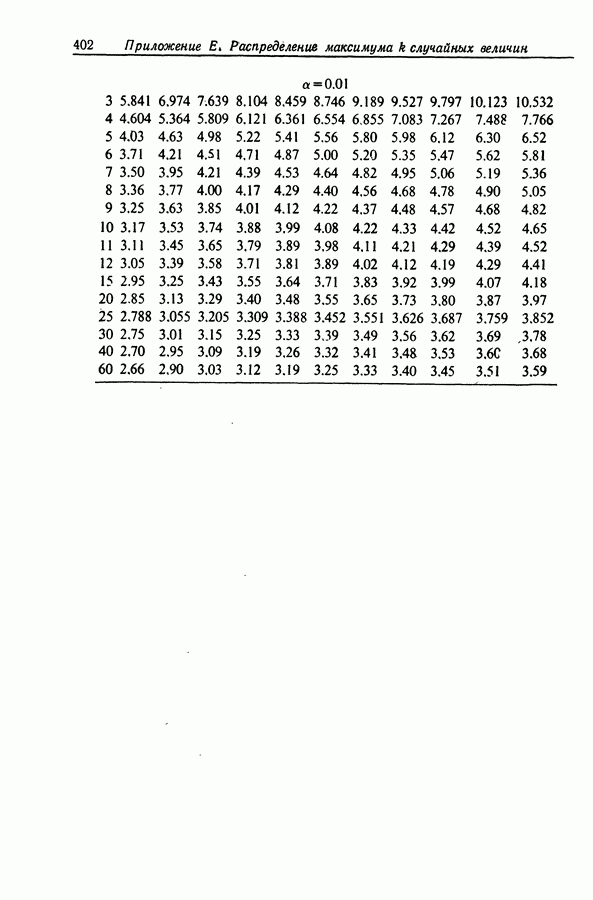
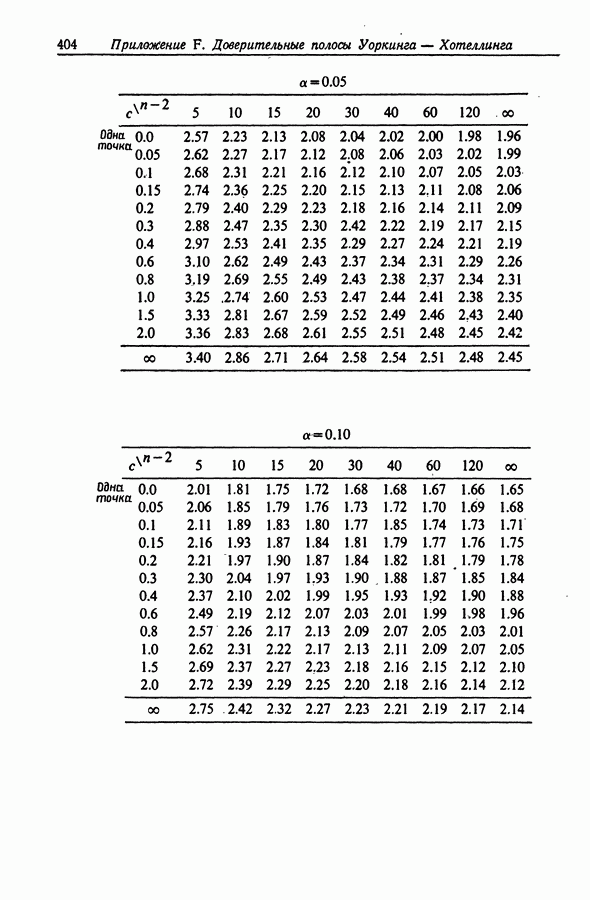
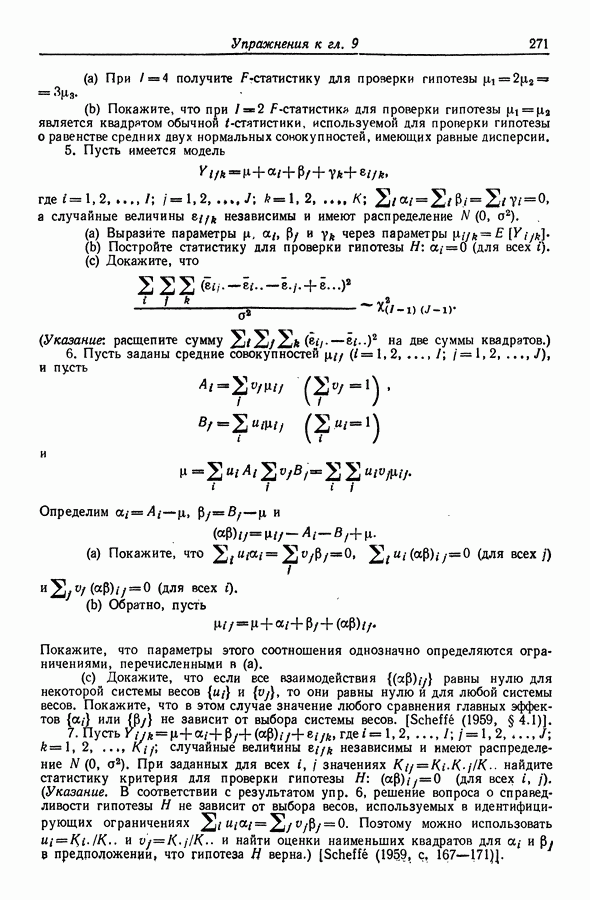11.4. Сравнение методов
Система линейных уравнений  называется плохо обусловленной, если небольшие ошибки или изменения элементов матрицы В и вектора с очень сильно изменяют точное решение х этой системы. Разность
называется плохо обусловленной, если небольшие ошибки или изменения элементов матрицы В и вектора с очень сильно изменяют точное решение х этой системы. Разность  между решением уравнения
между решением уравнения  и решением уравнения
и решением уравнения

можно представить в виде

так что ее величина существенно зависит от входящей сюда обратной матрицы. Если матрица В близка к вырожденной, т. е. небольшие изменения элементов этой матрицы могут привести к ее вырождению, то разность  может оказаться очень большой.
может оказаться очень большой.
При составлении нормальных уравнений метода наименьших квадратов матрицы  и вектор
и вектор  содержат ошибки округления, поскольку они получаются путем выполнения определенных операций над
содержат ошибки округления, поскольку они получаются путем выполнения определенных операций над  Но даже если бы матрицу В можно было вычислить совершенно точно, при ее запоминании в вычислительной машине эта точность может быть утеряна. Дело в том, что все числа должны быть представлены в ЭВМ в двоичной системе, и такое десятичное число, как, скажем, 0.1, образует бесконечную двоичную дробь точно так же, как обыкновенная дробь 1/7 является бесконечной десятичной дробью. Это означает, что если матрица X плохо обусловлена (т. е. "небольшие" изменения ее элементов могут приводить к "большим" изменениям матрицы
Но даже если бы матрицу В можно было вычислить совершенно точно, при ее запоминании в вычислительной машине эта точность может быть утеряна. Дело в том, что все числа должны быть представлены в ЭВМ в двоичной системе, и такое десятичное число, как, скажем, 0.1, образует бесконечную двоичную дробь точно так же, как обыкновенная дробь 1/7 является бесконечной десятичной дробью. Это означает, что если матрица X плохо обусловлена (т. е. "небольшие" изменения ее элементов могут приводить к "большим" изменениям матрицы  и вектора
и вектора  то любые ошибки при формировании матрицы
то любые ошибки при формировании матрицы  могут серьезно повлиять на устойчивость и точность решения. В действительности описанное положение усугубляется еще и тем, что само, решение системы нормальных уравнений нельзя получить в точном виде. В процессе решения происходит накопление ошибок округления, и они в конце концов могут нарушить равновесие и сделать задачу неустойчивой, если матрица
могут серьезно повлиять на устойчивость и точность решения. В действительности описанное положение усугубляется еще и тем, что само, решение системы нормальных уравнений нельзя получить в точном виде. В процессе решения происходит накопление ошибок округления, и они в конце концов могут нарушить равновесие и сделать задачу неустойчивой, если матрица  близка к вырожденной. Проблема плохой обусловленности оказывается особенно серьезной в полиномиальной регрессии (см. разд. 8.1.1),
близка к вырожденной. Проблема плохой обусловленности оказывается особенно серьезной в полиномиальной регрессии (см. разд. 8.1.1),
Степень плохой обусловленности матрицы X измеряется числом обусловленности  которое мы определяем как отношение наибольшего сингулярного значения матрицы X к ее наименьшему ненулевому сингулярному значению (используются и другие определения). Сингулярные значения матрицы X — это положительные квадратные корни из собственных значений матрицы
которое мы определяем как отношение наибольшего сингулярного значения матрицы X к ее наименьшему ненулевому сингулярному значению (используются и другие определения). Сингулярные значения матрицы X — это положительные квадратные корни из собственных значений матрицы  Отметим следующие факты, относящиеся к числам
Отметим следующие факты, относящиеся к числам 

(2) Поскольку  имеем
имеем  .
.
Так как  то из свойства (1) вытекает, что матрица
то из свойства (1) вытекает, что матрица  обусловлена еще хуже, чем матрица X, поэтому, за исключением тех случаев, когда
обусловлена еще хуже, чем матрица X, поэтому, за исключением тех случаев, когда  имеет умеренное значение и матрица
имеет умеренное значение и матрица  может быть построена точно, лучше вообще не строить матрицу
может быть построена точно, лучше вообще не строить матрицу  Учитывая свойство (2) и тот факт, что число
Учитывая свойство (2) и тот факт, что число  до начала вычислений не известно, безопаснее работать с самой матрицей X и получать матрицу
до начала вычислений не известно, безопаснее работать с самой матрицей X и получать матрицу  непосредственно, используя методы ортогонального разложения из разд. 11.2.4. Однако все же и это не столь просто, поскольку влияние
непосредственно, используя методы ортогонального разложения из разд. 11.2.4. Однако все же и это не столь просто, поскольку влияние  полностью исключить невозможно [Golub (1969, с. 385), Wilkinson (1974)]. Из рассмотренных трех методов метод Хаусхольдера является в настоящее время (
полностью исключить невозможно [Golub (1969, с. 385), Wilkinson (1974)]. Из рассмотренных трех методов метод Хаусхольдера является в настоящее время ( по-видимому, наиболее Популярным среди специалистов в области численных методов. Он работает, несколько более быстро, чем
по-видимому, наиболее Популярным среди специалистов в области численных методов. Он работает, несколько более быстро, чем  приблизительно вдвое быстрее, чем метод Гивенса, и обладает примерно такой же точностью, как и каждый из этих двух методов. Однако модификация метода Гивенса, в которой отсутствует извлечение квадратных корней, успешно конкурирует с методом Хаусхольдера, поскольку она требует примерно таких, же вычислительных затрат, легко приспосабливается к взвешенному методу наименьших квадратов и обладает всеми преимуществами, описанными в разд. 11.2.4с. Ее легко приспособить также к случаю неполного ранга (разд. 11.5.4). Анализ ошибок для всех этих методов см. в работах Wilkinson (1967, 1974), Golub (1969, с. 382—385) и Gentleman (1973).
приблизительно вдвое быстрее, чем метод Гивенса, и обладает примерно такой же точностью, как и каждый из этих двух методов. Однако модификация метода Гивенса, в которой отсутствует извлечение квадратных корней, успешно конкурирует с методом Хаусхольдера, поскольку она требует примерно таких, же вычислительных затрат, легко приспосабливается к взвешенному методу наименьших квадратов и обладает всеми преимуществами, описанными в разд. 11.2.4с. Ее легко приспособить также к случаю неполного ранга (разд. 11.5.4). Анализ ошибок для всех этих методов см. в работах Wilkinson (1967, 1974), Golub (1969, с. 382—385) и Gentleman (1973).
В § 11.5 приведен ряд модификаций, допускающих вырожденность матрицы  Например, используя метод выбора главных элементов, т. е. допуская перестановку столбцов матрицы X, при которой на каждом шаге максимизируется следующий диагональный элемент матрицы
Например, используя метод выбора главных элементов, т. е. допуская перестановку столбцов матрицы X, при которой на каждом шаге максимизируется следующий диагональный элемент матрицы  можно все указанные в § 11.2 методы (за исключением метода Гивенса) обобщить таким образом, чтобы они допускали вырожденность матрицы
можно все указанные в § 11.2 методы (за исключением метода Гивенса) обобщить таким образом, чтобы они допускали вырожденность матрицы  В то же время при введении идентифицирующих ограничений можно использовать и метод Гивенса, не производя выбора главных элементов (разд. 11.5.4). Приведенное в разд. 11.5.4 разложение по сингулярным значениям, которое, по-видимому, является не менее точным, чем другие методы, оказывается особенно полезным, когда
В то же время при введении идентифицирующих ограничений можно использовать и метод Гивенса, не производя выбора главных элементов (разд. 11.5.4). Приведенное в разд. 11.5.4 разложение по сингулярным значениям, которое, по-видимому, является не менее точным, чем другие методы, оказывается особенно полезным, когда
ранг матрицы X неизвестен или когда матрица имеет полный ранг, но плохо обусловлена, причем непредсказуемым образом, как, например, в гребневой регрессии [Chambers (1971)]. Однако оно требует в два—четыре раза больших затрат, чем алгоритм Хаусхольдера, и не обладает присущей ему приспособляемостью.
Метод Хаусхольдера легко обобщить для использования его в задаче вычисления  -статистики для проверки общей линейной гипотезы (§ 11.10). К тому же его можно без труда видоизменить таким образом, чтобы допустить возможность добавления строки к матрице
-статистики для проверки общей линейной гипотезы (§ 11.10). К тому же его можно без труда видоизменить таким образом, чтобы допустить возможность добавления строки к матрице  (§ 11.8) или добавления столбца к матрице X (§ 11.9). Удалять строки и столбцы матрицы X лучше всего, используя преобразования Гивенса. Метод
(§ 11.8) или добавления столбца к матрице X (§ 11.9). Удалять строки и столбцы матрицы X лучше всего, используя преобразования Гивенса. Метод  также позволяет простым способом добавлять столбцы к матрице X, однако добавлять строки при этом труднее. Что касается метода Гивенса, то этим методом хорошо добавлять как раз строки, а не столбцы. Ясно, что подходящей процедурой является комбинация методов Хаусхольдера и Гивенса.
также позволяет простым способом добавлять столбцы к матрице X, однако добавлять строки при этом труднее. Что касается метода Гивенса, то этим методом хорошо добавлять как раз строки, а не столбцы. Ясно, что подходящей процедурой является комбинация методов Хаусхольдера и Гивенса.
На практике не так уже редко бывает, что один из регрессоров весьма сильно коррелирован с линейной комбинацией других регрессоров, так что столбцы матрицы X оказываются близкими к линейно зависимым. Это означает, что матрица  близка к вырожденной, наименьшее ее собственное значение мало, а
близка к вырожденной, наименьшее ее собственное значение мало, а  велико. Так, для тестовых данных Longley (1967)
велико. Так, для тестовых данных Longley (1967)  а для полиномиальных моделей Wampler (1970) соответствующее значение имеет порядок
а для полиномиальных моделей Wampler (1970) соответствующее значение имеет порядок  : На самом деле полиномиальные модели регрессии заведомо плохо обусловлены, если степень полинома больше 5 или 6, особенно если значения х являются равноотстоящими (разд. 8.1.1). Поэтому следует исходить из того что всякая разумная программа должна либо приводить к правильно округленному решению
: На самом деле полиномиальные модели регрессии заведомо плохо обусловлены, если степень полинома больше 5 или 6, особенно если значения х являются равноотстоящими (разд. 8.1.1). Поэтому следует исходить из того что всякая разумная программа должна либо приводить к правильно округленному решению  либо указывать на то, что матрица
либо указывать на то, что матрица  слишком плохо обусловлена и не позволяет достичь этого без увеличения точности вычислений (или может быть даже вырождена). При выборе главных элементов, когда на каждом шаге производится максимизация
слишком плохо обусловлена и не позволяет достичь этого без увеличения точности вычислений (или может быть даже вырождена). При выборе главных элементов, когда на каждом шаге производится максимизация  неполнота ранга матрицы X, искаженной ошибками округления, проявляется в том, что на некотором шаге значение
неполнота ранга матрицы X, искаженной ошибками округления, проявляется в том, что на некотором шаге значение  оказывается меньшим некоторого допустимого предела. Более высокую точность при вычислении
оказывается меньшим некоторого допустимого предела. Более высокую точность при вычислении  можно получить, используя итерационное уточнение решения (§ 11.6). Правда, этот метод не, пригоден, когда модель обусловлена слишком плохо. Если после одной итерации заметного улучшения
можно получить, используя итерационное уточнение решения (§ 11.6). Правда, этот метод не, пригоден, когда модель обусловлена слишком плохо. Если после одной итерации заметного улучшения  не наблюдается, это означает, что модель обусловлена в высшей
не наблюдается, это означает, что модель обусловлена в высшей  пени плохо. В таком случае, если производить вычисления с более высокой точностью невозможно, следует попробовать применить более точный метод разложения по сингулярным значениям (разд. 11.5.5) или обращаться с моделью так, как если бы она
пени плохо. В таком случае, если производить вычисления с более высокой точностью невозможно, следует попробовать применить более точный метод разложения по сингулярным значениям (разд. 11.5.5) или обращаться с моделью так, как если бы она
была вырождена. Указанным требованиям удовлетворяет программа [Bjorck, Golub (1967)], использующая преобразования Хаусхольдера. В ней предусмотрен специальный выход "отказ", соответствующий тем ситуациям, когда в результате ошибок округления ранг матрицы X оказывается неполным или когда процедура итерационного уточнения не дает существенного улучшения.
Чтобы по возможности избежать трудностей с вычислениями, рекомендуется перед расчетом регрессий производить, как в разд. 11.7.1, вычитание средних из  Такое "центрирование" данных может приводить к уменьшению числа обусловленности матрицы X [Golub, Styan (1974)]. Некоторые авторы рекомендуют также нормировать столбцы матриц
Такое "центрирование" данных может приводить к уменьшению числа обусловленности матрицы X [Golub, Styan (1974)]. Некоторые авторы рекомендуют также нормировать столбцы матриц  как в разд. 11.7.2, особенно при использовании метода разложения по сингулярным значениям.
как в разд. 11.7.2, особенно при использовании метода разложения по сингулярным значениям.
В заключение этого сравнения алгоритмов, реализующих метод наименьших квадратов, следует упомянуть еще об одном алгоритме [Bauer (1965)]. В этом алгоритме, использующем разложение матрицы X, подобное разложению (11.23) из разд. 11.2.4, применяется схема исключения Гаусса, но только для исключения используется не отдельная строка, а линейная комбинация строк с надлежащим образом выбранными весами. Прекрасные программы на языке АЛГОЛ для этого алгоритма и для большинства других методов, описанных в § 11.2, приводят Wilkinson, Reinsch (1971). Численное сравнение программ, использующих алгоритмы из § 11.2, дает Wampler (1970). Относительно общей библиографии по вопросу применения ЭВМ для анализа данных можно рекомендовать работу Muller (1970).
11.5. Случай неполного ранга
Если матрица X имеет ранг  то матрица
то матрица  вырождена (положительно полуопределена) и нормальные уравнения
вырождена (положительно полуопределена) и нормальные уравнения  уже не именэт единственного решения. Ниже приводится пять численных методов обработки данных в такой ситуации.
уже не именэт единственного решения. Ниже приводится пять численных методов обработки данных в такой ситуации.