Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике
11.7. Центрирование и шкалирование данных
11.7.1. Центрирование данных
Поскольку элементы первого столбца матрицы X обычно выбираются равными единице, нормальные уравнения при  имеют вид
имеют вид

 Деля первое уравнение на
Деля первое уравнение на  и вычитая соответствующие кратные первого уравнения из остальных уравнений, мы можем обратить последние три элемента первого столбца матрицы
и вычитая соответствующие кратные первого уравнения из остальных уравнений, мы можем обратить последние три элемента первого столбца матрицы  в нуль. Таким образом, получаем систему
в нуль. Таким образом, получаем систему

где  Кроме того, мы пользовались формулами
Кроме того, мы пользовались формулами

Поэтому, полагая  имеем
имеем

a b является решением уравнения

Фактически это означает, что мы можем найти вектор  вычитая из всех данных соответствующие средние и работая уже с "центрированными" данными
вычитая из всех данных соответствующие средние и работая уже с "центрированными" данными  Ктакому подходу интуитивно подводит аппроксимирующая модель
Ктакому подходу интуитивно подводит аппроксимирующая модель

подстановка в которую выражения для  приводит ее к виду
приводит ее к виду

Отметим, что через центрированные данные можно выразить также остатки, остаточную сумму квадратов и квадрат множественного коэффициента корреляции  Именно,
Именно,

а из соотношения (4.30) § 4.2 имеем

или (в силу (11.44))

Хотя мы рассмотрели только случай  тем не менее ясно, что соответствующая теория сохраняет силу и в общем случае.
тем не менее ясно, что соответствующая теория сохраняет силу и в общем случае.
Предположим, что мы хотим проверить гипотезу  Тогда соответствующая
Тогда соответствующая  -статистика (см. (4.13) в разд. 4.1.3) равна
-статистика (см. (4.13) в разд. 4.1.3) равна

где  Чтобы найти
Чтобы найти  заметим прежде всего, что
заметим прежде всего, что

для всех  Тогда
Тогда

и поэтому

Это означает, что  является
является  диагональным элементом указанной обратной матрицы, что было доказано непосредственно в примере 4.3 из разд. 4.1.3; там
диагональным элементом указанной обратной матрицы, что было доказано непосредственно в примере 4.3 из разд. 4.1.3; там  Изменяя, если необходимо, индексацию, мы можем предполагать,
Изменяя, если необходимо, индексацию, мы можем предполагать,  Пусть
Пусть

Тогда, согласно 

 Сравнивая это с выражением (11.45), а именно с
Сравнивая это с выражением (11.45), а именно с

видим, что  равняется остаточной сумме квадратов, которую мы получили бы, рассматривая регрессию на
равняется остаточной сумме квадратов, которую мы получили бы, рассматривая регрессию на  . В частности, из (11.46), имеем
. В частности, из (11.46), имеем

где  квадрат множественного коэффициента корреляции, соответствующего регрессии
квадрат множественного коэффициента корреляции, соответствующего регрессии  на остальных регрессорах. Таким обрдзом, вообще
на остальных регрессорах. Таким обрдзом, вообще

где  квадрат множественного коэффициента корреляции, соответствующего регрессии
квадрат множественного коэффициента корреляции, соответствующего регрессии  на остальных регрессорах,
на остальных регрессорах, 
Интересно отметить, что редукция первого столбца матрицы  к виду (1, 0, 0, 0,) в (11.40) представляет собой попросту первый шаг процедуры последовательного исключения Гаусса. Поскольку же процедура исключения (в форме сокращенной процедуры Дулитла) достаточно широко использовалась при расчетах на настольных калькуляторах, то не удивительно, что вычитание средних стало стандартным приемом в статистической практике. В ранних программах для ЭВМ была заметна тенденция вычислять матрицу
к виду (1, 0, 0, 0,) в (11.40) представляет собой попросту первый шаг процедуры последовательного исключения Гаусса. Поскольку же процедура исключения (в форме сокращенной процедуры Дулитла) достаточно широко использовалась при расчетах на настольных калькуляторах, то не удивительно, что вычитание средних стало стандартным приемом в статистической практике. В ранних программах для ЭВМ была заметна тенденция вычислять матрицу  по формуле (11.42), которую вообще считают более удобной для расчетов на настольных калькуляторах, нежели формулу (11.41) [Longley (1967)]. В то же время в работе Ling (1974, с. 866) можно найти некоторые интересные результаты по этому поводу. Другие методы вычисления указанных величин приводят Youngs, Grammer (1971, с. 664—665) и Ling (1974) (см. упр. 13 в конце главы). Однако из современных исследований по численному анализу следует, видимо, заключить, что работать надо непосредственно с матрицей X, используя методы ортогонального разложения разд. 11.2.4, и что стоит, быть может, вовсе избегать вычисления матрицы
по формуле (11.42), которую вообще считают более удобной для расчетов на настольных калькуляторах, нежели формулу (11.41) [Longley (1967)]. В то же время в работе Ling (1974, с. 866) можно найти некоторые интересные результаты по этому поводу. Другие методы вычисления указанных величин приводят Youngs, Grammer (1971, с. 664—665) и Ling (1974) (см. упр. 13 в конце главы). Однако из современных исследований по численному анализу следует, видимо, заключить, что работать надо непосредственно с матрицей X, используя методы ортогонального разложения разд. 11.2.4, и что стоит, быть может, вовсе избегать вычисления матрицы 
11.7.2. Шкалирование
Некоторые авторы предлагают шкалировать вектор  и столбцы матрицы X таким образом, чтобы они имели единичные нормы, т. е. работать с вектором
и столбцы матрицы X таким образом, чтобы они имели единичные нормы, т. е. работать с вектором

и матрицей  где
где

Хотя для проведения такого шкалирования и нет особых теоретических оснований, мы все же подробно изучим его влияние, поскольку оно служит основой некоторых хорошо известных процедур для пошаговой регрессии 
Заметим, что

представляет собой выборочную корреляцию регрессоров  а
а

есть выборочная корреляция между  Поэтому уравнения
Поэтому уравнения  принимают вид
принимают вид

где

Здесь  называется корреляционной матрицей. Если применить методы разд. 11.2.4 вместо матрицы (
называется корреляционной матрицей. Если применить методы разд. 11.2.4 вместо матрицы ( к матрице
к матрице  то с их помощью получим решение
то с их помощью получим решение

Отметим, что  можно найти также из получающейся в результате верхней треугольной матрицы (см. (11.9), разд. 11.2.2) и что остаточная сумма квадратов для этой модели равна
можно найти также из получающейся в результате верхней треугольной матрицы (см. (11.9), разд. 11.2.2) и что остаточная сумма квадратов для этой модели равна

Элементы вектора  находятся по формуле
находятся по формуле  а диагональные элементы
а диагональные элементы  матрицы
матрицы  формуле
формуле

Выражение для  -статистики для проверки гипотезы
-статистики для проверки гипотезы  имеет вид (ср. с (11.47))
имеет вид (ср. с (11.47))

поскольку, согласно (11.50) и (11.48), 
Основные аргументы в пользу применения шкалирования, видимо, таковы. Во-первых, матрица  может оказаться обусловленной лучше, чем матрица
может оказаться обусловленной лучше, чем матрица  поскольку все диагональные элементы матрицы
поскольку все диагональные элементы матрицы  равны [Golub (1969, с. 371, 385),
равны [Golub (1969, с. 371, 385),




























































































































































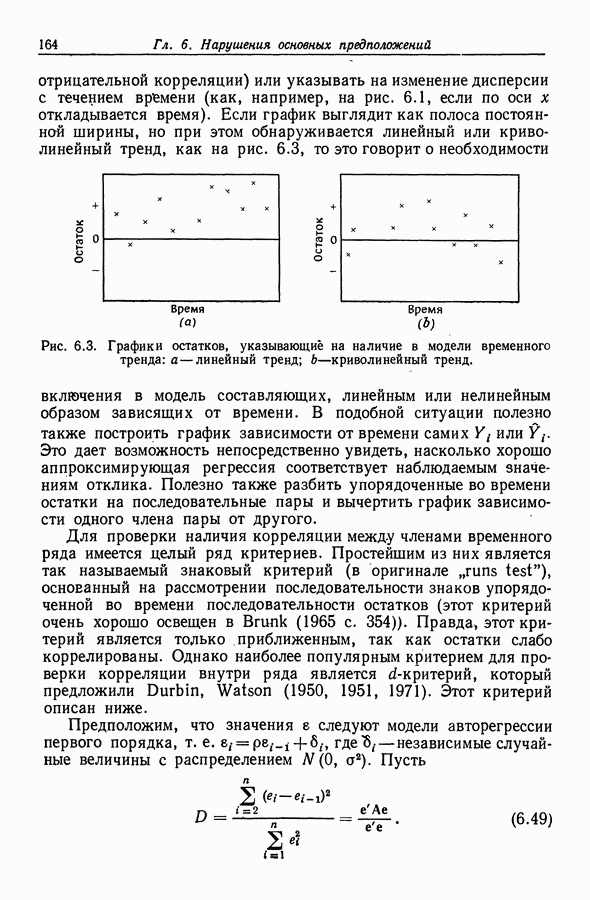
















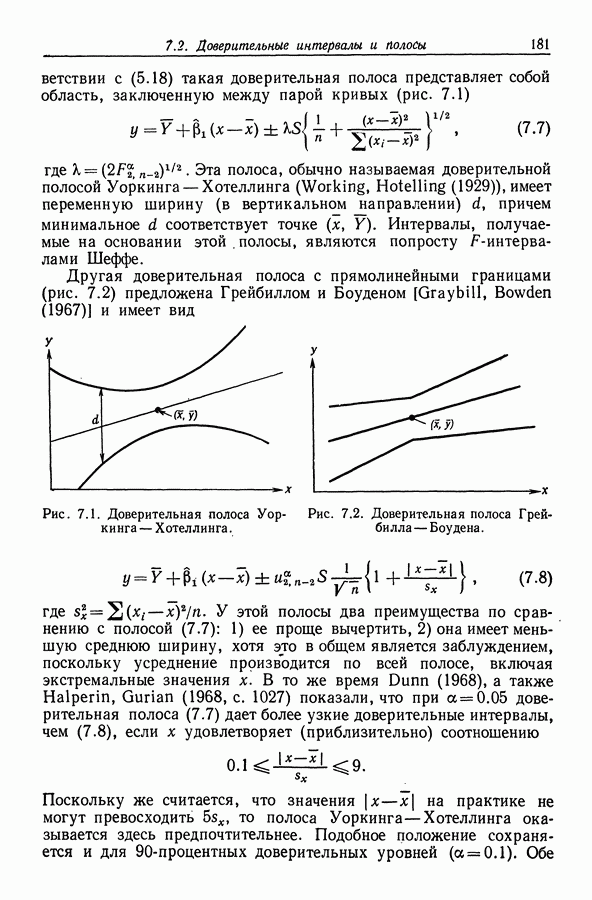



































































































































































































































































 Во-вторых, значения всех коэффициентов корреляции лежат между —
Во-вторых, значения всех коэффициентов корреляции лежат между —  а когда числа расположены в таком интервале, вредное влияние ошибок округления сводится к минимуму. Однако преимущества здесь можно добиться только в том случае, если значения
а когда числа расположены в таком интервале, вредное влияние ошибок округления сводится к минимуму. Однако преимущества здесь можно добиться только в том случае, если значения  подсчитаны точно.
подсчитаны точно.
