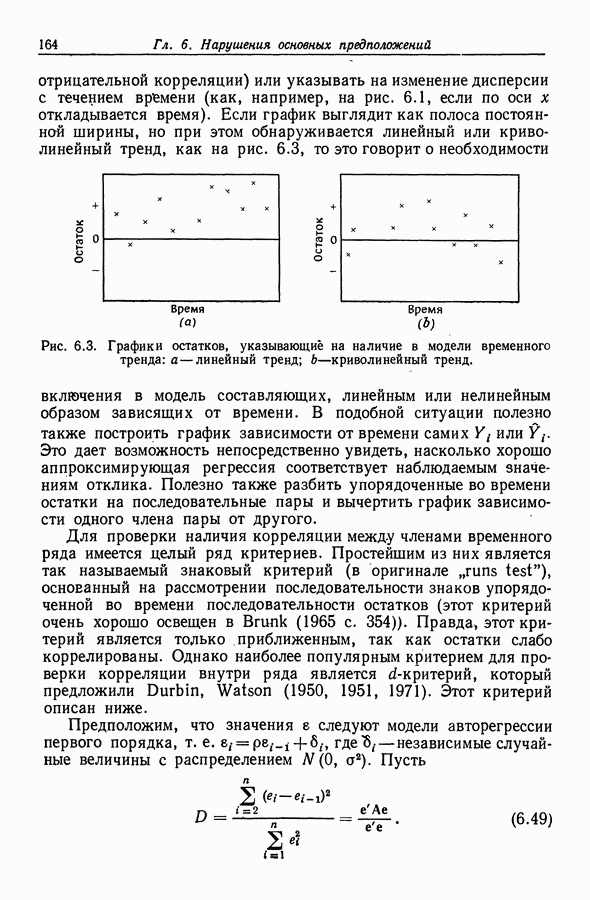
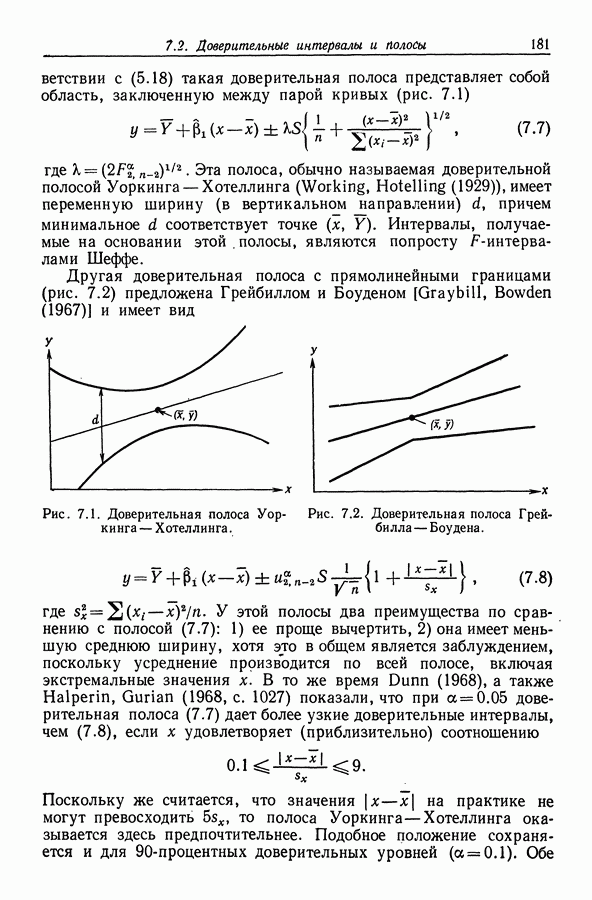
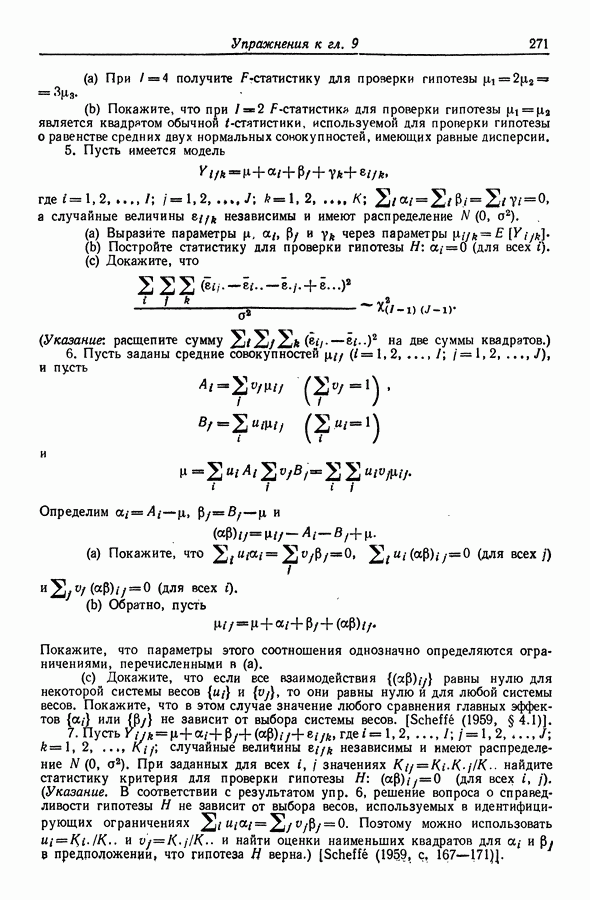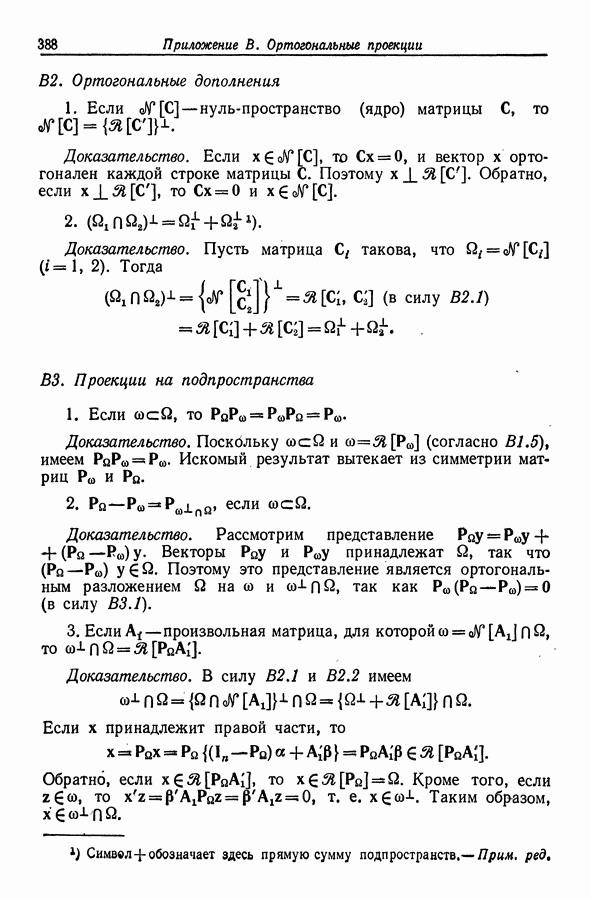12.3.2. t-упорядоченный поиск
Критерий Для проверки гипотезы  в полной модели с К регрессорами основан на статистике
в полной модели с К регрессорами основан на статистике

или, что равносильно, на статистике

где  (остаточная сумма квадратов при подборе модели со всеми К регрессорами, кроме
(остаточная сумма квадратов при подборе модели со всеми К регрессорами, кроме  Как явствует из предыдущего метода, рассмотренного в разд. 12.3.1, регрессоры с малыми значениями
Как явствует из предыдущего метода, рассмотренного в разд. 12.3.1, регрессоры с малыми значениями  будут, как правило, исключаться раньше, так что в "наилучшие" для каждого
будут, как правило, исключаться раньше, так что в "наилучшие" для каждого  наборы регрессоров (лучшие в смысле минимума RSS или минимума будут включаться регрессоры с большими значениями
наборы регрессоров (лучшие в смысле минимума RSS или минимума будут включаться регрессоры с большими значениями  или, что равносильно, с большими значениями В связи с этим предположим, что регрессоры упорядочены в соответствии со значениями
или, что равносильно, с большими значениями В связи с этим предположим, что регрессоры упорядочены в соответствии со значениями  в порядке убывания этих значений. Тогда, осуществляя ввод в модель регрессоров поочередно и в заданном порядке, мы можем надеяться получить при каждом
в порядке убывания этих значений. Тогда, осуществляя ввод в модель регрессоров поочередно и в заданном порядке, мы можем надеяться получить при каждом  К наилучшее или одно из близких к наилучшему подмножество из
К наилучшее или одно из близких к наилучшему подмножество из  элементов. Такой так называемый t-упорядоченный поиск предложили Daniel, Wood (1971). Мы проиллюстрируем его на двух примерах.
элементов. Такой так называемый t-упорядоченный поиск предложили Daniel, Wood (1971). Мы проиллюстрируем его на двух примерах.
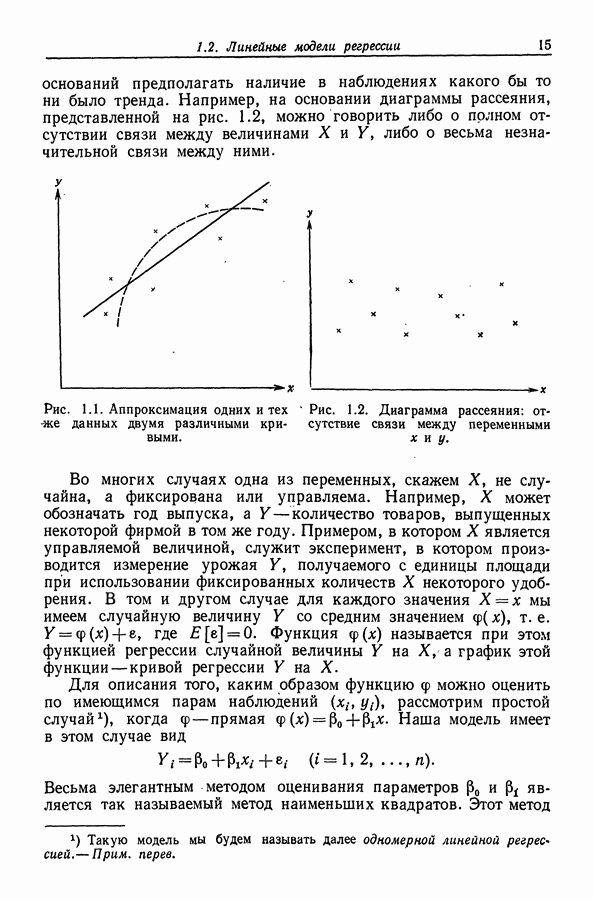
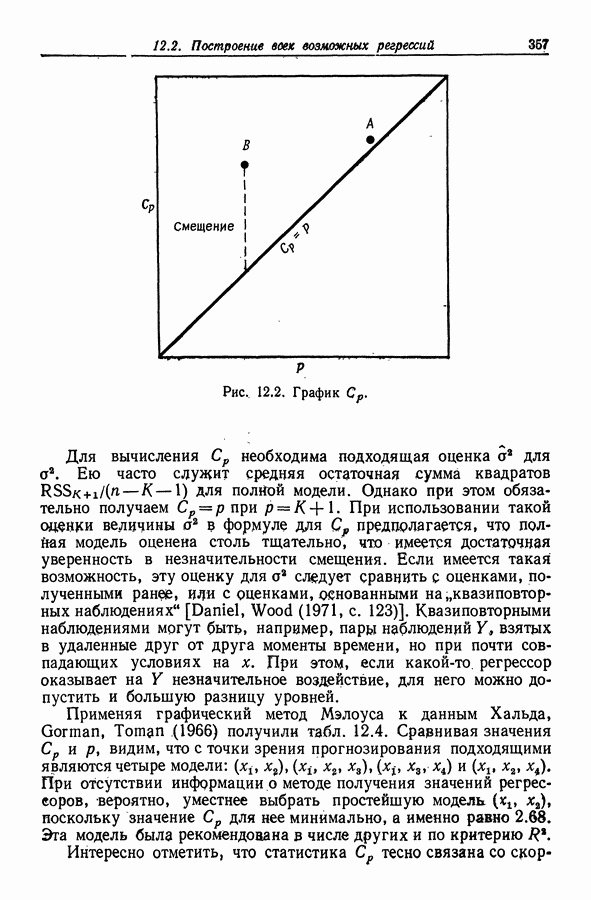
Пример 12.1  данные Хальда (Hald)). Значения для данных Хальда приведены в табл. 12.6. Обращаясь к табл. 12.4, мы находим, что
данные Хальда (Hald)). Значения для данных Хальда приведены в табл. 12.6. Обращаясь к табл. 12.4, мы находим, что  - упорядоченная процедура приводит здесь к наилучшим подмножествам с двумя и тремя элементами
- упорядоченная процедура приводит здесь к наилучшим подмножествам с двумя и тремя элементами  и (1,2,4) соответственно.
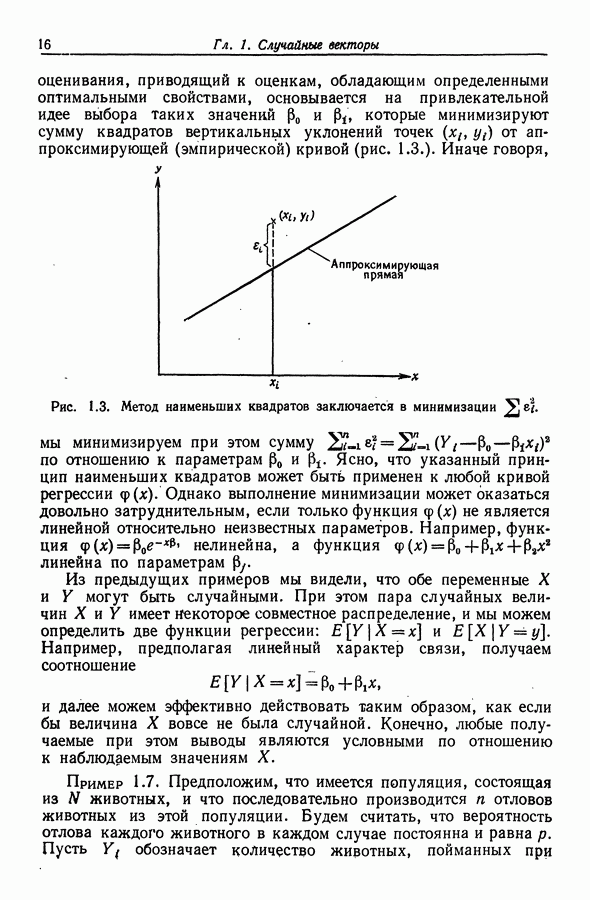
и (1,2,4) соответственно.
Таблица 12.6 (см. скан) Результаты применения  -направленного поиска к данным Хальда
-направленного поиска к данным Хальда
В самом деле, набору (1,2) соответствует минимальное среди всех значение  а набору
а набору  -следующее за ним по величине значение. Из табл. 12.6 можно заключить, что регрессоры
-следующее за ним по величине значение. Из табл. 12.6 можно заключить, что регрессоры  образуют "базовую" совокупность, включаемую во все "наилучшие" модели, и что поэтому можно ограничиться поиском только тех подмножеств, которые содержат
образуют "базовую" совокупность, включаемую во все "наилучшие" модели, и что поэтому можно ограничиться поиском только тех подмножеств, которые содержат  т.е. (1,2,3) и (1,2,4). (В этом примере
т.е. (1,2,3) и (1,2,4). (В этом примере  оценивается величиной
оценивается величиной  так что мы имеем тождество
так что мы имеем тождество 
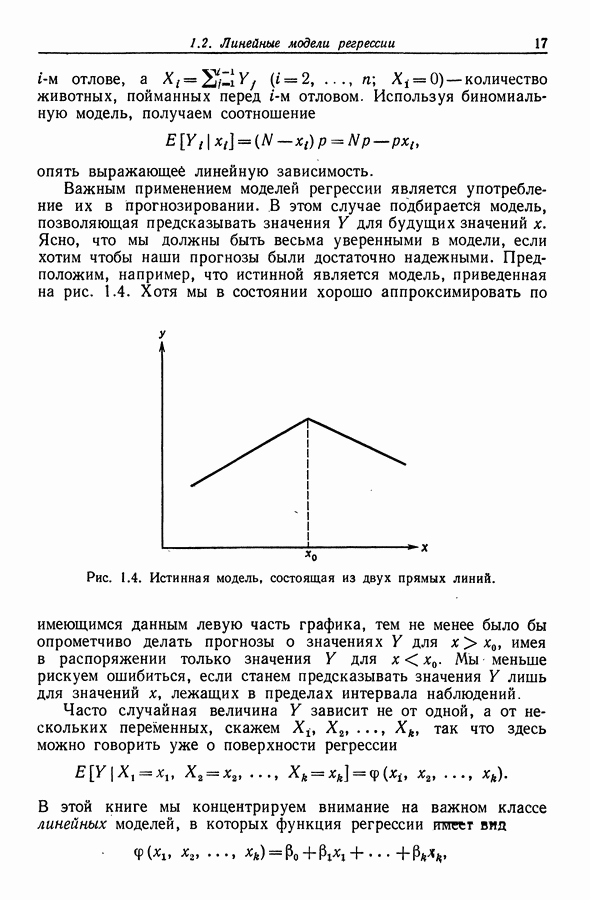
Пример  данные из Gorman, Toman (1966)). Реализация
данные из Gorman, Toman (1966)). Реализация  -упорядоченного поиска указана в табл. 12.7.
-упорядоченного поиска указана в табл. 12.7.
Таблица 12.7 (см. скан) Результаты применения  -направленного поиска к данным из Gorman, Toman (1966)
-направленного поиска к данным из Gorman, Toman (1966)
Этот метод приводит здесь к действительно наилучшим набррам по одной, двум, трем, четырем и пяти переменным. Модели (1,2,6,4) соответствует наименьшее значение  а моделям (1,2,6) и
а моделям (1,2,6) и  -близкие к нему значения. График зависимости
-близкие к нему значения. График зависимости  от
от  для всех
для всех  моделей показывает, что малые значения имеют наборы [Gorman, Toman (1966, с. 39)]
моделей показывает, что малые значения имеют наборы [Gorman, Toman (1966, с. 39)]  . С помощью
. С помощью  -упорядоченного поиска находятся три из них. В данном случае "базовая" совокупность состоит из регрессоров
-упорядоченного поиска находятся три из них. В данном случае "базовая" совокупность состоит из регрессоров  Она на один элемент беднее совокупности, соответствующей точке перемены направления изменения значений
Она на один элемент беднее совокупности, соответствующей точке перемены направления изменения значений  в последнем столбце табл. 12.7 (это значение
в последнем столбце табл. 12.7 (это значение  отмечено звездочкой).
отмечено звездочкой).
Хотя приведенные примеры являются скорее искусственными, поскольку применять  -упорядоченный поиск стоит только при больших значениях
-упорядоченный поиск стоит только при больших значениях  скажем
скажем  тем не мнее они достаточно хорошо показывают, что обычно получается при использовании этого метода. Если среди всех моделей выделяется какая-то одна и конкурирующие модели не очень близки к ней, то точка перемены (отмеченная звездочками в табл. 12.6 и 12.7) правильно указывает на те переменные, которые надо включить в "базовую" совокупность. В менее ярко выраженных случаях, как в примере 12.2, в базовую совокупность часто необходимо включать на одну, реже — на две переменные меньше. Daniel, Wood (1971) предлагают для подстраховки при составлении программы машинного поиска предусматривать выбор "базовой"
тем не мнее они достаточно хорошо показывают, что обычно получается при использовании этого метода. Если среди всех моделей выделяется какая-то одна и конкурирующие модели не очень близки к ней, то точка перемены (отмеченная звездочками в табл. 12.6 и 12.7) правильно указывает на те переменные, которые надо включить в "базовую" совокупность. В менее ярко выраженных случаях, как в примере 12.2, в базовую совокупность часто необходимо включать на одну, реже — на две переменные меньше. Daniel, Wood (1971) предлагают для подстраховки при составлении программы машинного поиска предусматривать выбор "базовой"
совокупности, содержащей на два элемента меньше, чем этого требует помеченное звездочкой значение  Некоторые соображения в отношении того, когда такая мера предосторожности необходима, дает соотношение значений
Некоторые соображения в отношении того, когда такая мера предосторожности необходима, дает соотношение значений  Если наименьшее из значений
Если наименьшее из значений  задаваемых при перечислении значений
задаваемых при перечислении значений  оказывается меньшим или равным
оказывается меньшим или равным  то мы вполне можем довериться указанию звездочки и включить в базовый набор переменные, расположенные в этой строке. Если же помеченным звездочкой значением является, скажем,
то мы вполне можем довериться указанию звездочки и включить в базовый набор переменные, расположенные в этой строке. Если же помеченным звездочкой значением является, скажем,  то, поскольку уменьшение значения
то, поскольку уменьшение значения  на 1 может привести к уменьшению значения
на 1 может привести к уменьшению значения  на
на  качестве базового набора следует брать переменные, расположенные в строке, помещающейся в таблице на две строки выше.
качестве базового набора следует брать переменные, расположенные в строке, помещающейся в таблице на две строки выше.
После того как мы определили базовый набор из  переменных, нам нужно исследовать уже только
переменных, нам нужно исследовать уже только  моделей, содержащих этот набор. Такая редукция может приводить к значительной экономии памяти и машинного времени. Однако если К очень велико, то и значение
моделей, содержащих этот набор. Такая редукция может приводить к значительной экономии памяти и машинного времени. Однако если К очень велико, то и значение  может оказаться слишком большим для полного перебора. В этом случае можно использовать теорию дробных факторных планов типа
может оказаться слишком большим для полного перебора. В этом случае можно использовать теорию дробных факторных планов типа  и найти остальные существенные переменные, рассматривая некоторые подмножества, содержащие базовый набор переменных. Подробности этого метода приводят Gorman, Toman (1966), а также Daniel, Wood (1971). Дальнейшее исследование требует, однако, решения вопроса о выборе подходящего подмножества.
и найти остальные существенные переменные, рассматривая некоторые подмножества, содержащие базовый набор переменных. Подробности этого метода приводят Gorman, Toman (1966), а также Daniel, Wood (1971). Дальнейшее исследование требует, однако, решения вопроса о выборе подходящего подмножества.