Пред.
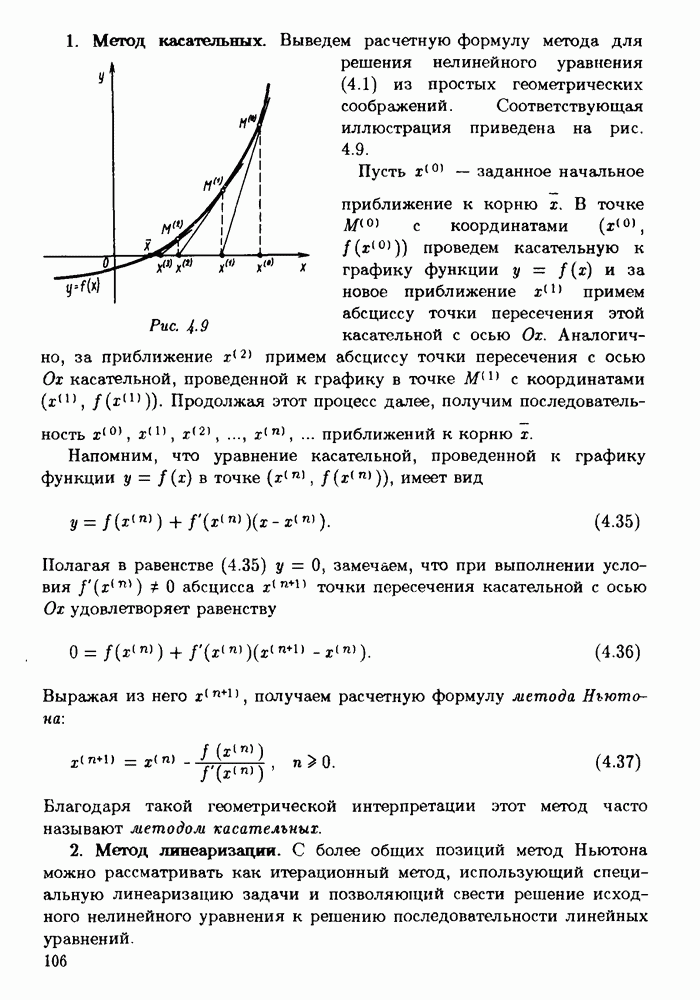
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
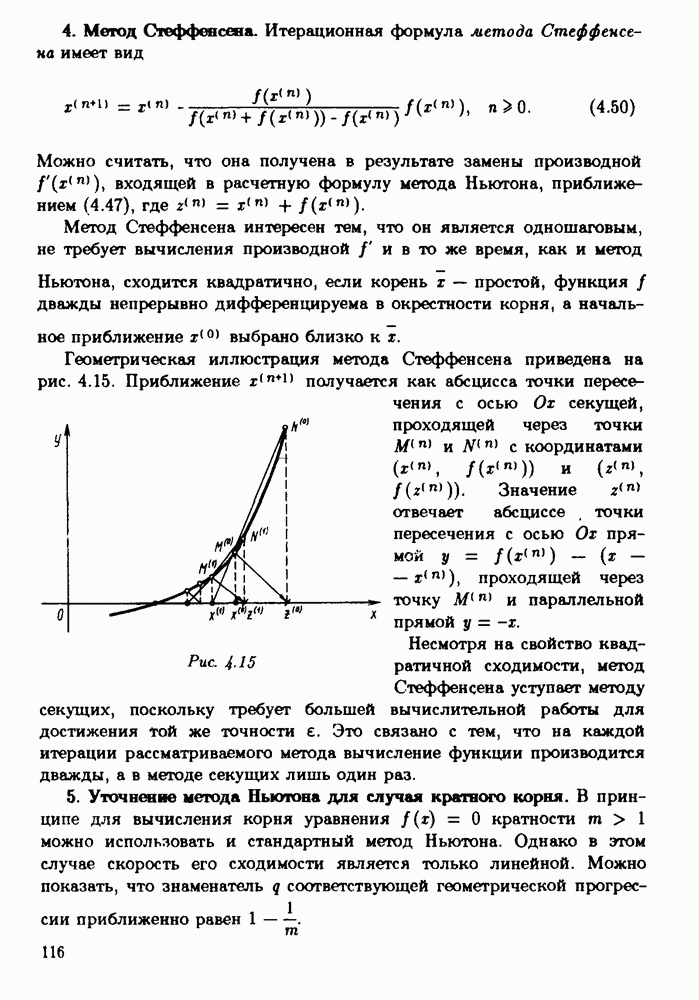
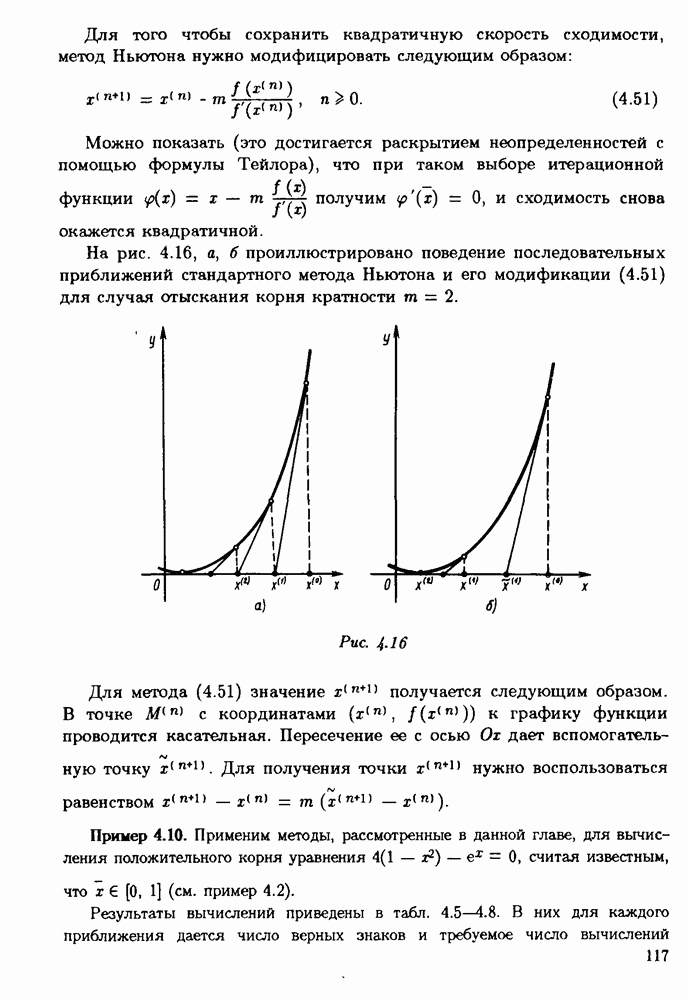
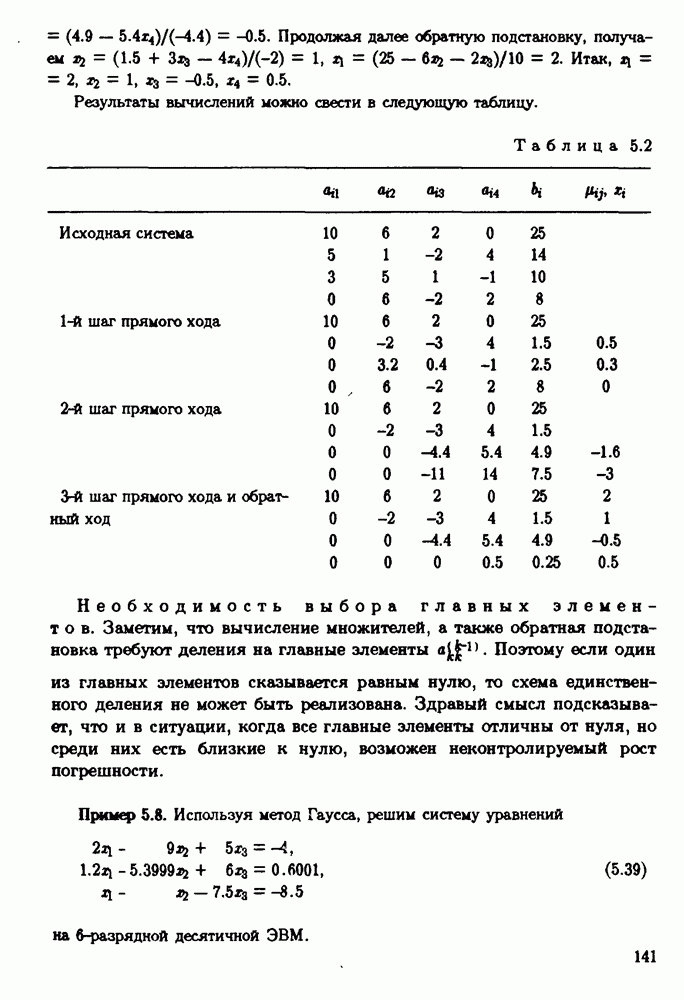
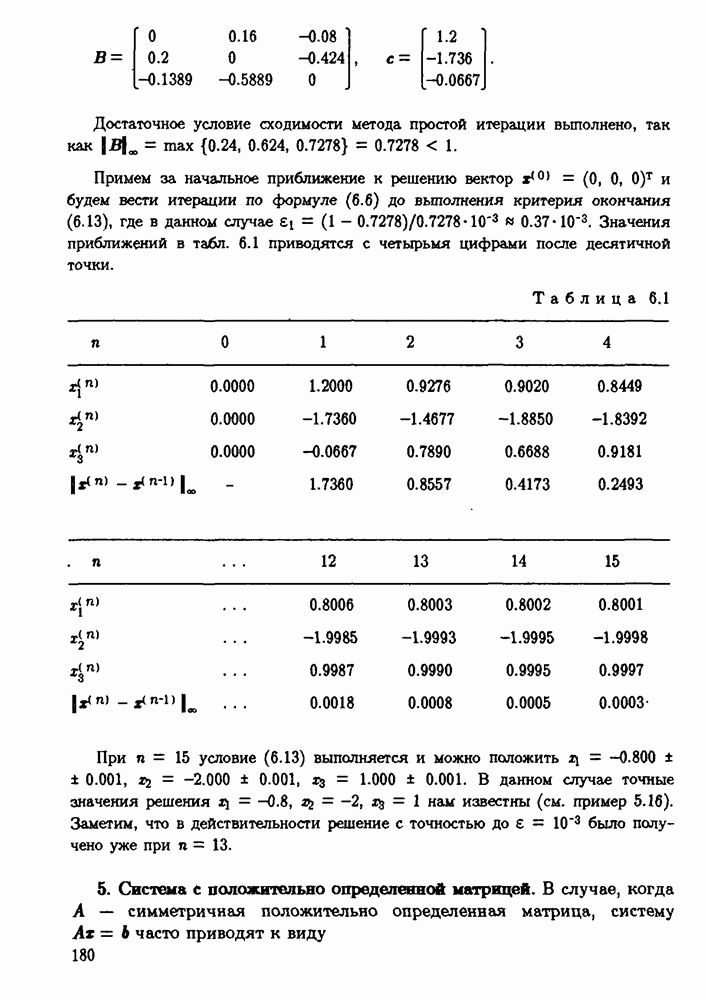
ZADANIA.TO
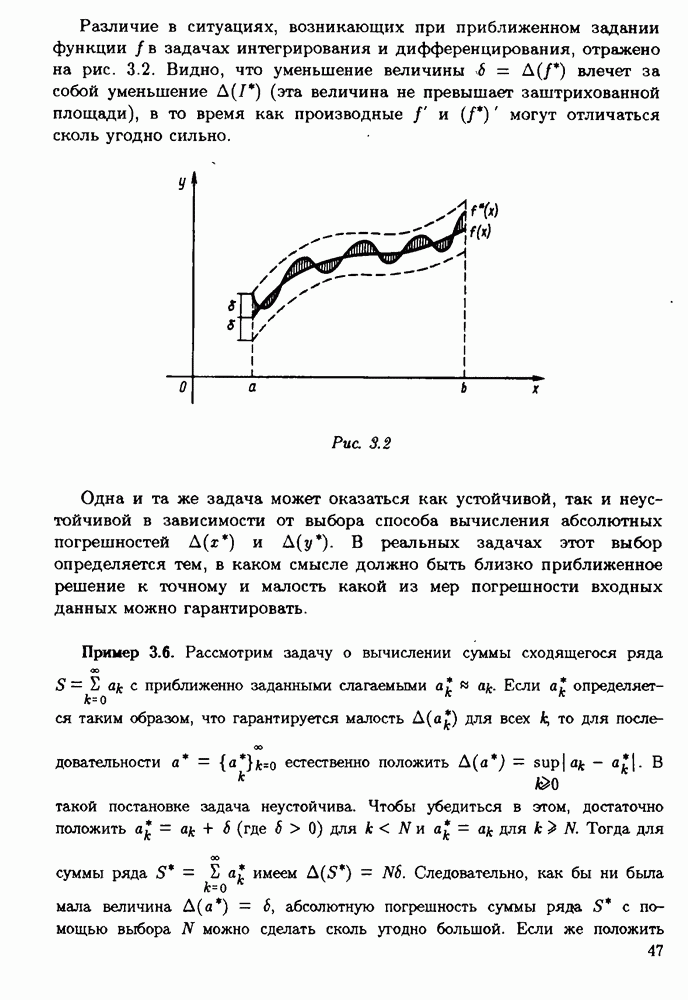
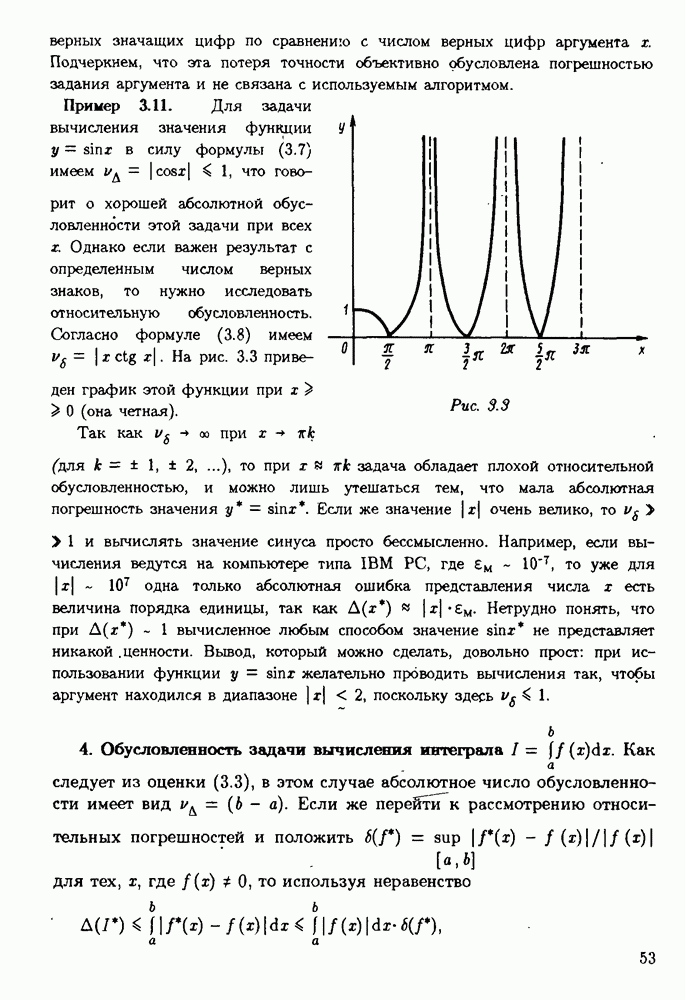
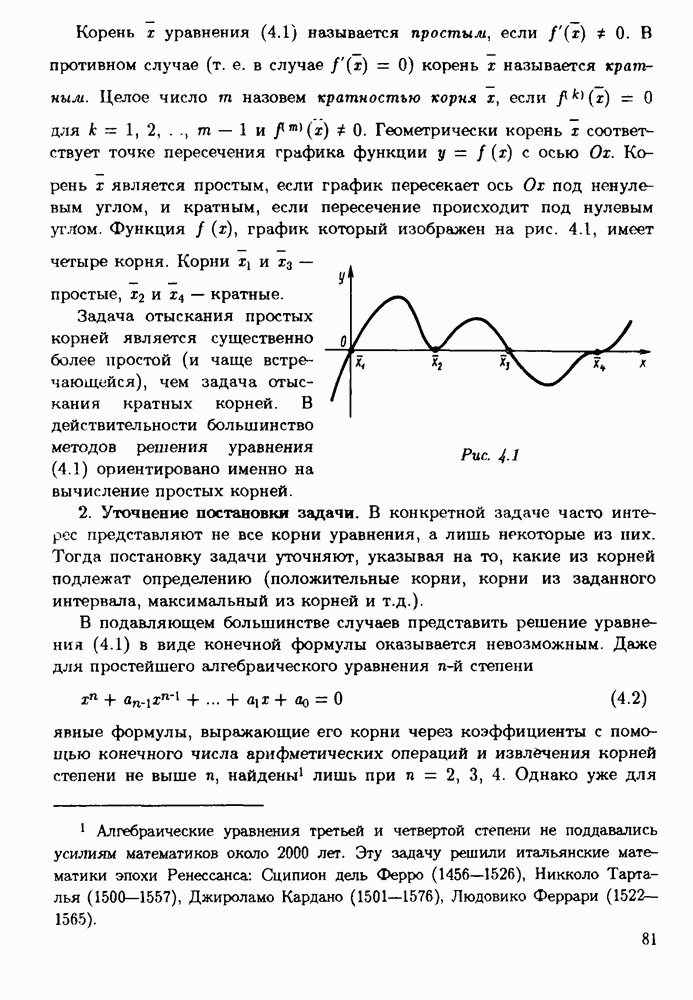
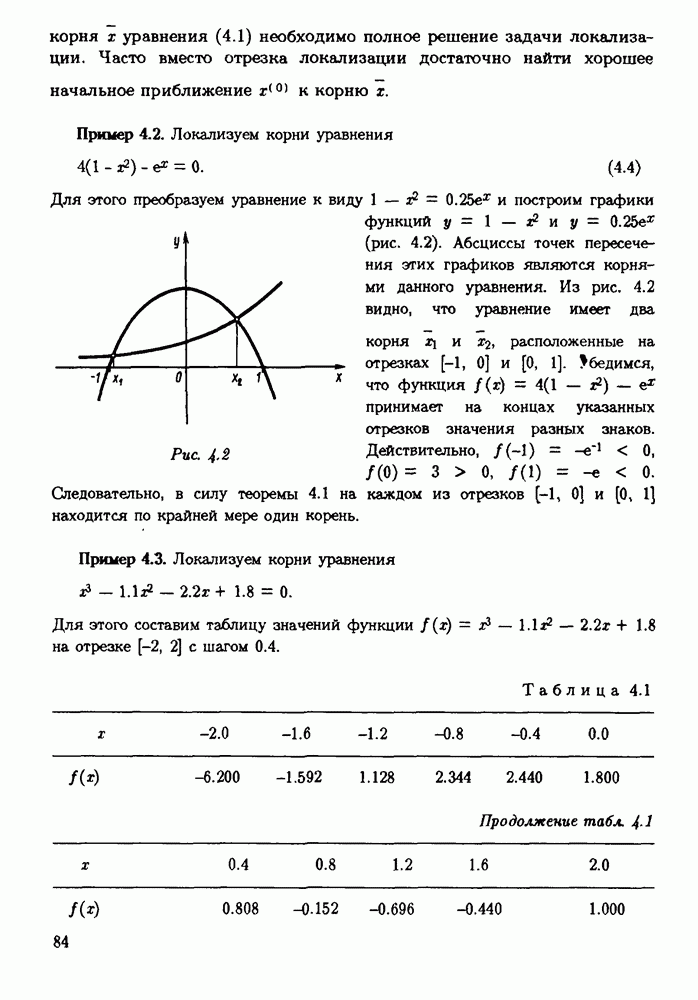
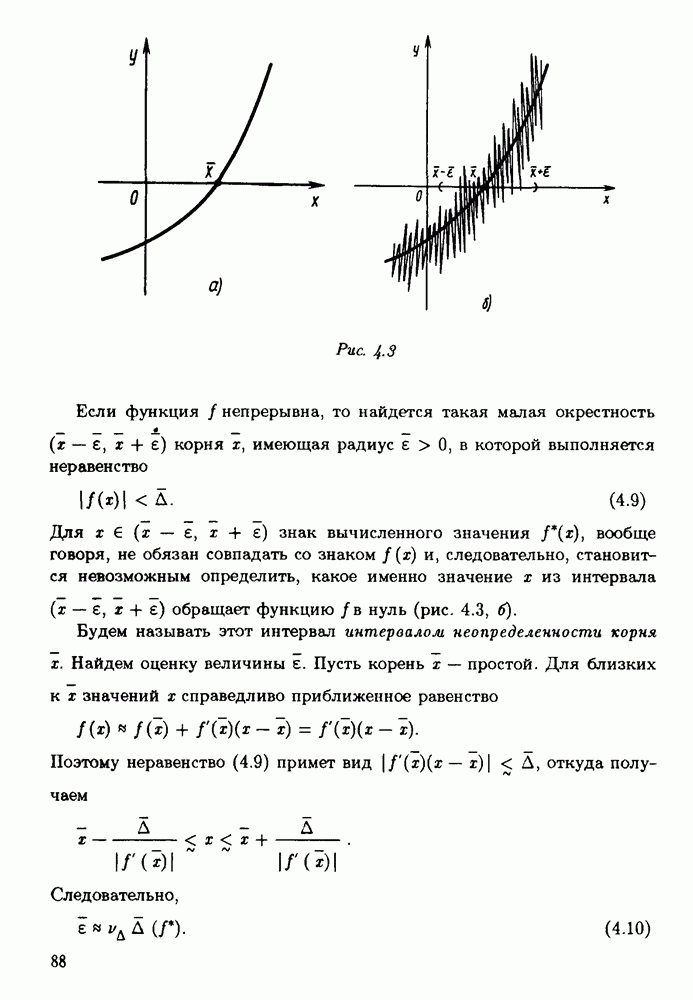
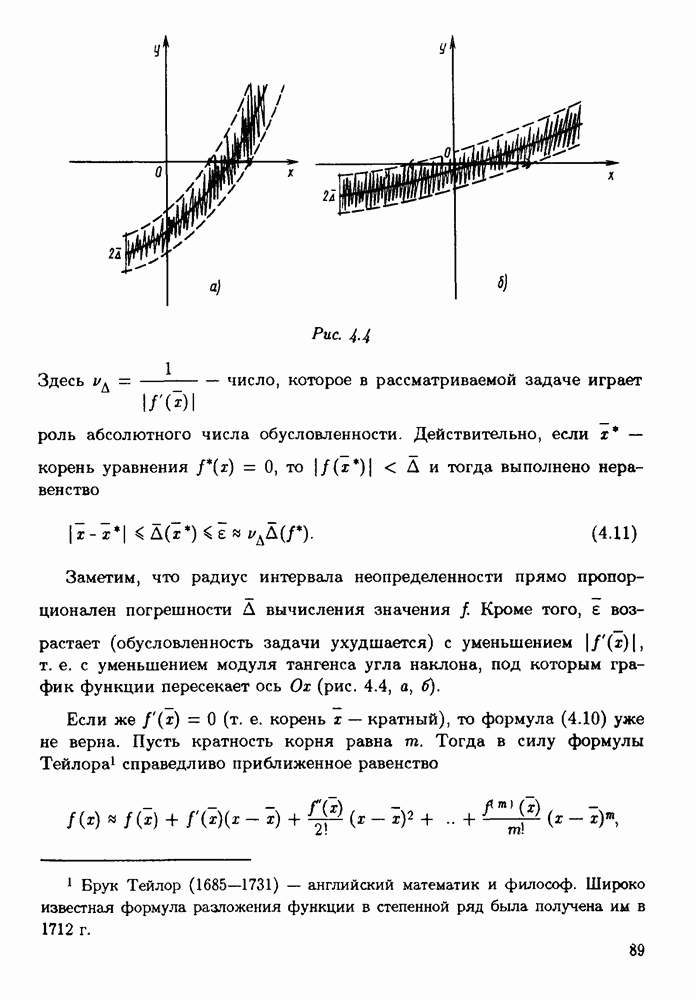
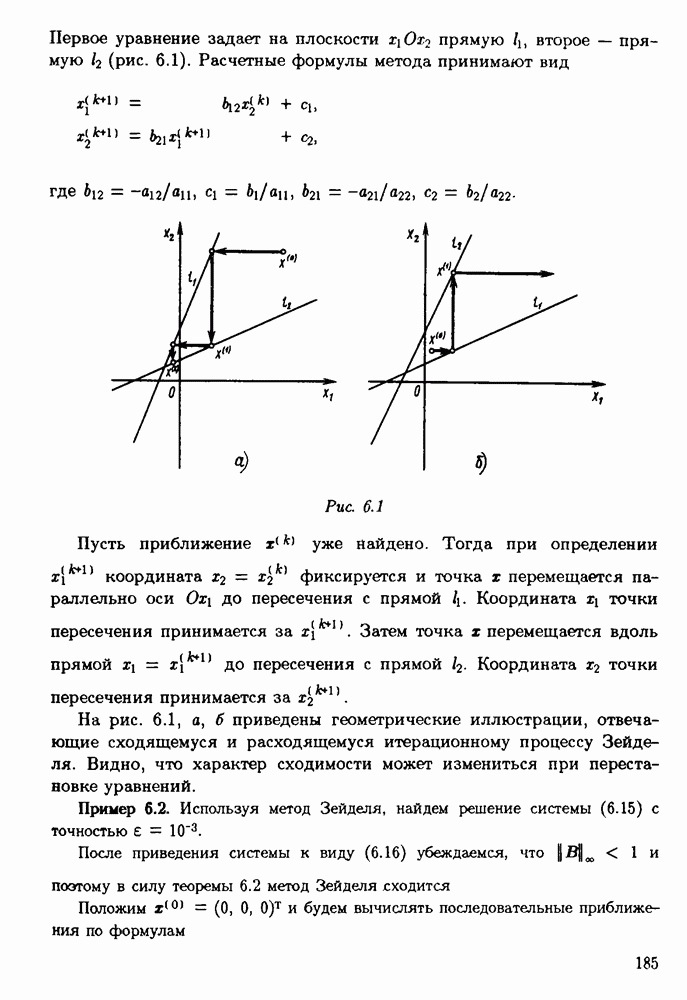
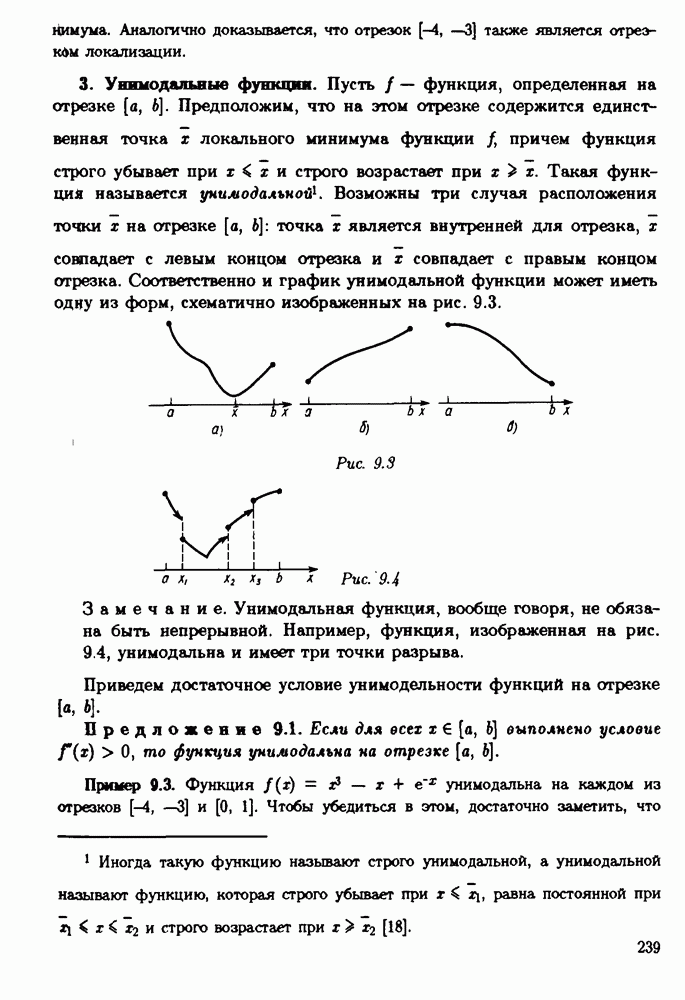
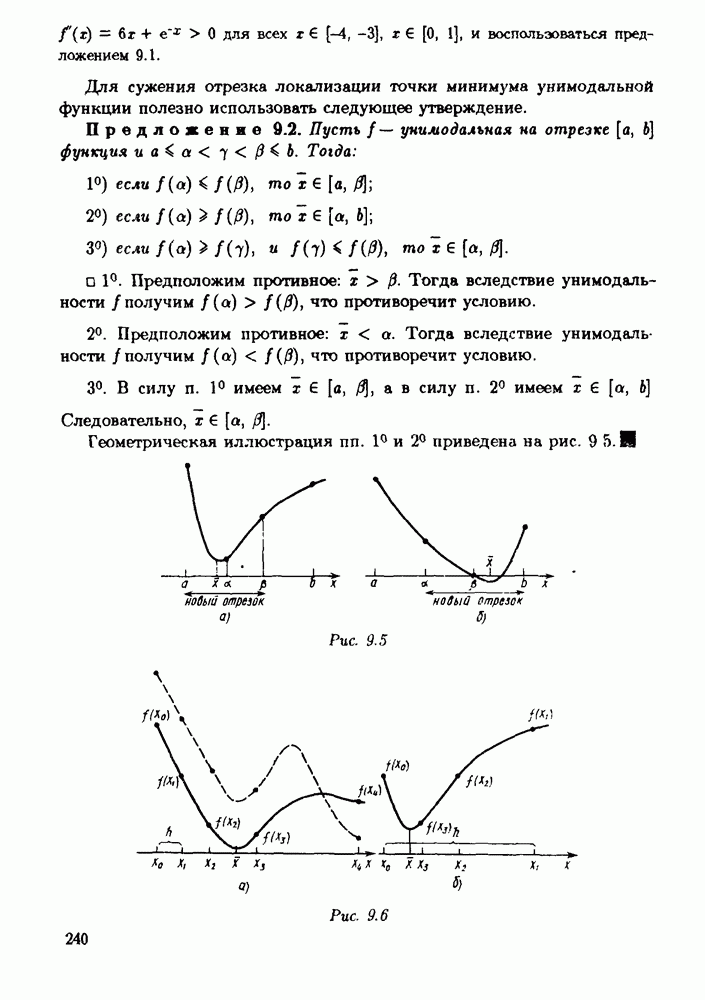
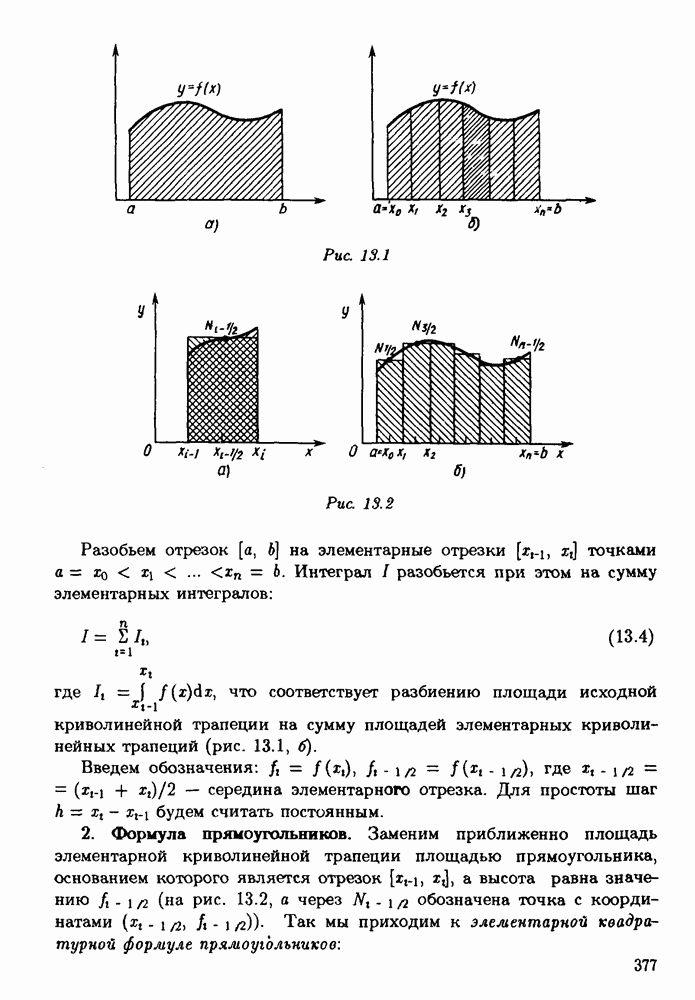
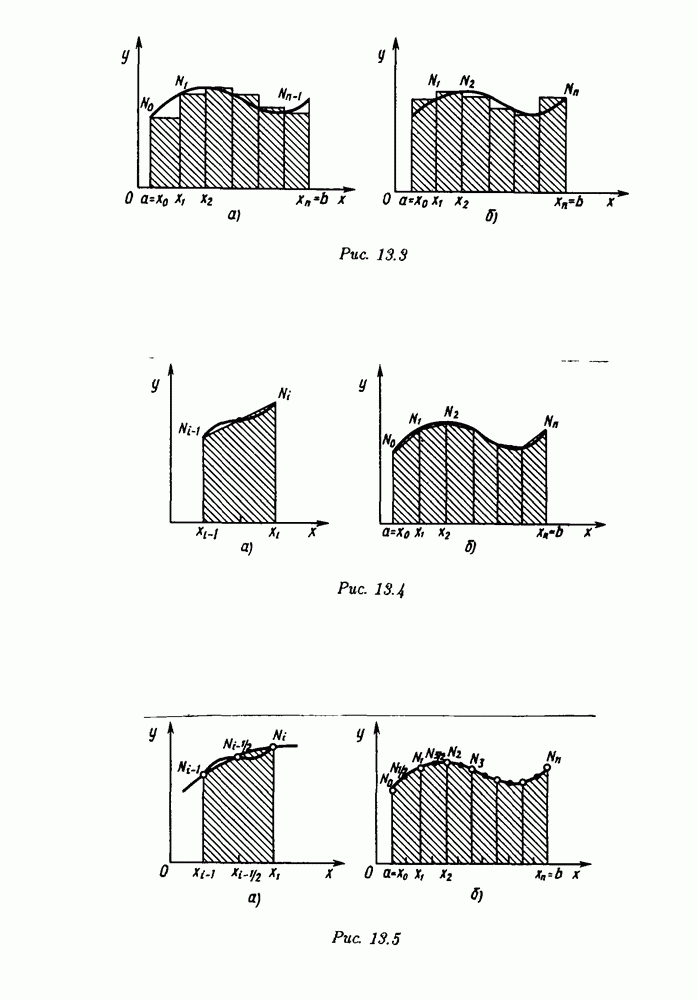
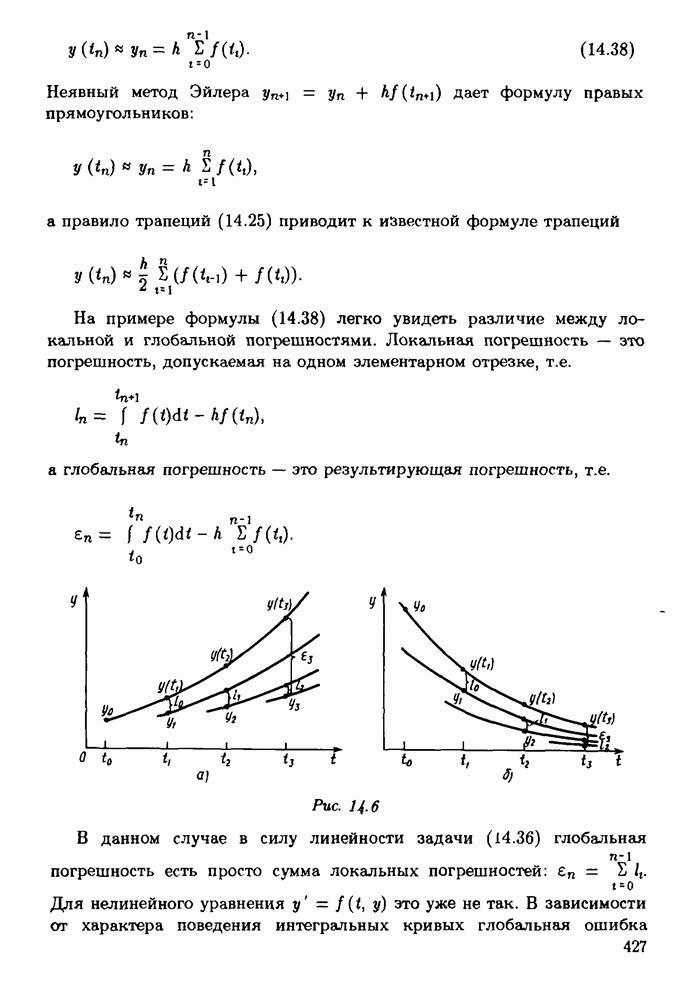
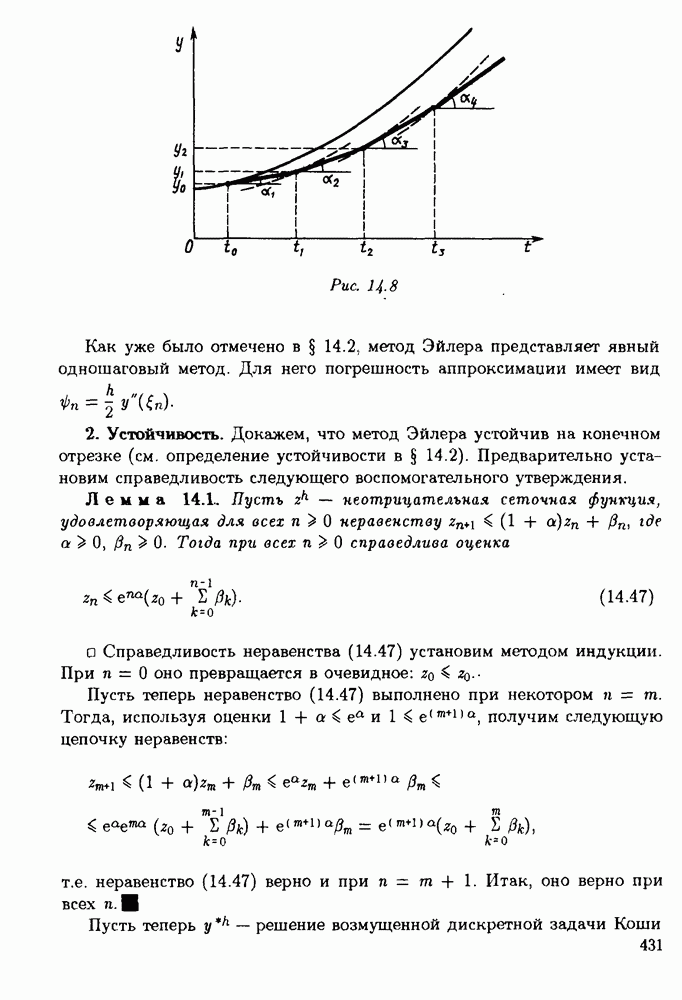
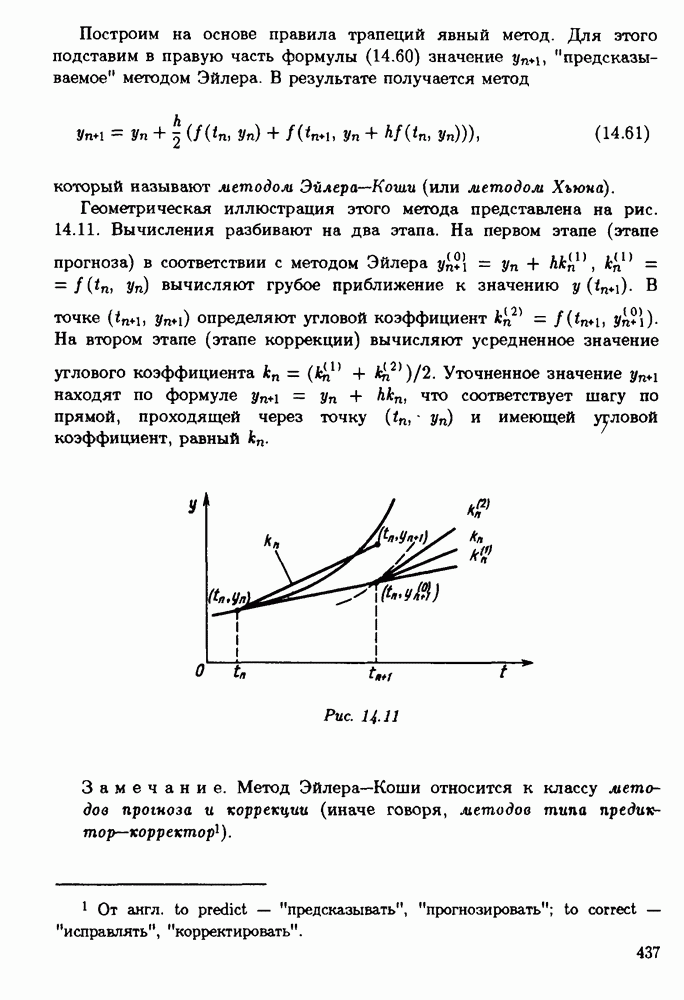
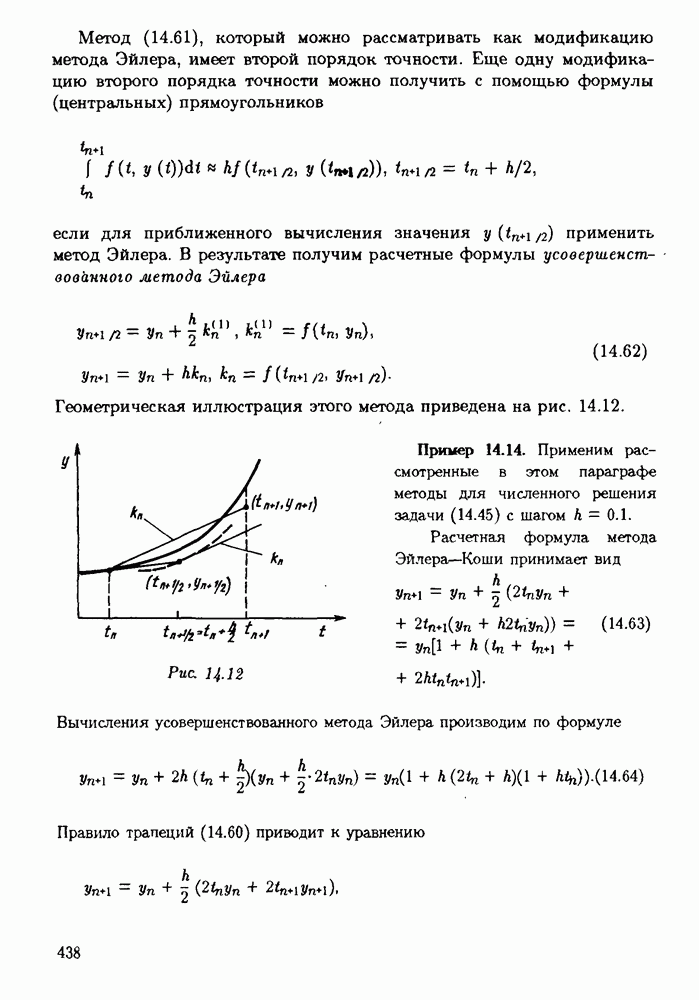
§ 3.6. Различные подходы к анализу ошибок1. Прямой анализ ошибок.Общий эффект влияния ошибок обычно учитывают следующим образом. Изучают воздействие ошибок входных данных, метода и округлений на получаемый результат у к пытаются оценить некоторую меру близости у к истинному решению у. Такой метод исследования называяют прямым анализом ошибок В большинстве случаев в данной книге мы будем следовать этому традиционному пути. Во многих (но далеко не во всех) случаях оценки погрешности удается получить; однако довольно часто они оказываются сильно завышенными и приводят к неоправданному пессимизму в оценке качества приближенного решения. Реальная величина погрешности у - у часто значительно меньше, чем ее оценка, рассчитанная на самый неблагоприятный случай и выведенная с помощью прямого анализа. Особенно трудным является прямой анализ вычислительной погрешности. 2. Обратный анализ ошибок.В последнее время получил широкое распространение другой подход к оценке влияния ошибок. Оказывается, что довольно часто приближенное решение у можно трактовать как точное решение той же задачи, но отвечающее возмущенным исходным данным х. Оценка величины такого эквивалентного возмущения и является целью обратного анализа ошибок. В прикладных задачах входные данные, как правило, содержат погрешности. Обратный анализ показывает, что ошибки, внесенные в решение в процессе его вычисления, оказываются равносильными некоторым дополнительным ошибкам, внесенным во входные данные. Сопоставление величины эквивалентного возмущения и уровня ошибок входных данных позволяет судить о качестве найденного решения. На рис. 3.5 представлена графическая иллюстрация обратного анализа ошибок. Здесь данное х таково, что решением задачи, соответствующим х, является у — результат приближенного решения задачи с входным данным х. На рисунке заштрихована область неопределенности входного данного; в пределах этой области входные данные для решающего задачу неразличимы. В представленном случае х оказалось внутри этой области, поэтому результат у следует признать вполне приемлемым.
Рис. 3.5 Каждый из указанных двух подходов к оценке погрешности имеет свои достоинства и полезным является разумное их сочетание. Пример 3.32. Пусть на
При вводе в ЭВМ последние два коэффициента будут округлены до шести значащих цифр и уравнение примет вид
Допустим, что некоторый алгоритм, примененный к этому уравнению, дал значение приближенного решения ошибок, чтобы оценить качество полученного приближения нужно было бы задаться вопросом: насколько отличается
которые после округления коэффициентов совпадают с уравнением (3.22) и становятся неотличимы от исходного уравнения. Найденное решение следует признать превосходным с точки зрения "философии" обратного анализа ошибок, так как оно является точным решением задачи, лежащей в пределах области неопределенности задачи (3.22). Рассчитывать на то, что после записи уравнения в виде (3.22) удастся получить лучший ответ, просто бессмысленно. Конечно, это немного обидно, особенно если учесть, что исходное уравнение в действительности есть развернутая запись уравнения Представляется, что значение обратного анализа ошибок недостаточно осознанно, в особенности среди непрофессиональных вычислителей. Этот подход показывает на возможность иного взгляда на оценку качества приближенного решения, а, значит, и на качество многих вычислительных алгоритмов. Сложившийся стереотип заставляет искать приближенное решение у математической задачи, мало отличающееся от ее истинного решения у. Однако для большинства практических задач в силу неопределенности в постановке и входных данных в действительности существует и область неопределенности решения (см. рис. 3.5). Поскольку эта область неизвестна, оценить степень близости вычисленного решения у к ней очень трудно. Гораздо проще, быть может, получить ответ на аналогичный вопрос для входного данного х, соответствующего решению у. Поэтому можно сформулировать цель вычислений и так: "найти точное решение задачи, которая мало отличается от поставленной задачи" или же так: "найти решение задачи с входным данным х, находящимся в пределах области неопределенности заданного входного данного Пример 3-33. Пусть для задачи Коши
где Условие Подчеркнем, что в основе методов решения некорректных и плохо обусловленных задач также лежит существенное переосмысление постановок вычислительных задач. 3. Статистический анализ ошибок.Даже для простых алгоритмов строгий анализ влияния ошибок округления очень сложен. При большом числе выполняемых операций гарантированные оценки погрешности, рассчитанные на самый неблагоприятный случай, как правило, бывают сильно завышенными. Можно надеяться на то, что появляющиеся в реальном вычислительном процессе ошибки округления случайны и их взаимное влияние приводит к определенной компенсации результирующей ошибки. Статистический анализ ошибок, исходящий из предположения об их случайности, направлен на исследование не максимально возможных, а наиболее вероятных ошибок. Для сравнения покажем отличие в результатах на примере задачи вычисления суммы 4. Некоторые нестрогие способы анализа.Распространенным методом оценки влияния вычислительной погрешности является расчет с обычной и удвоенной точностью. Если результаты двух вычислений получаются существенно различными, это является свидетельством плохой обусловленности алгоритма. В то же время есть надежда на то, что совпадающие в ответах цифры верны. Примерно такие же суждения о чувствительности решения к ошибкам округления можно сделать, если провести вычисления на двух различных вычислительных машинах или использовать различные компиляторы. Разумеется, такое исследование имеет смысл провести на одном-двух типичных примерах до начала массовых однотипных расчетов. Влияние ошибок во входных данных на результат вычислений можно увидеть, если решить задачу несколько раз, изменяя случайным образом входные данные в пределах ошибки их задания. Проделав такой эксперимент несколько раз, можно грубо оценить погрешность решения, вызванную погрешностями входных данных.
|
 |
Оглавление
|




































































































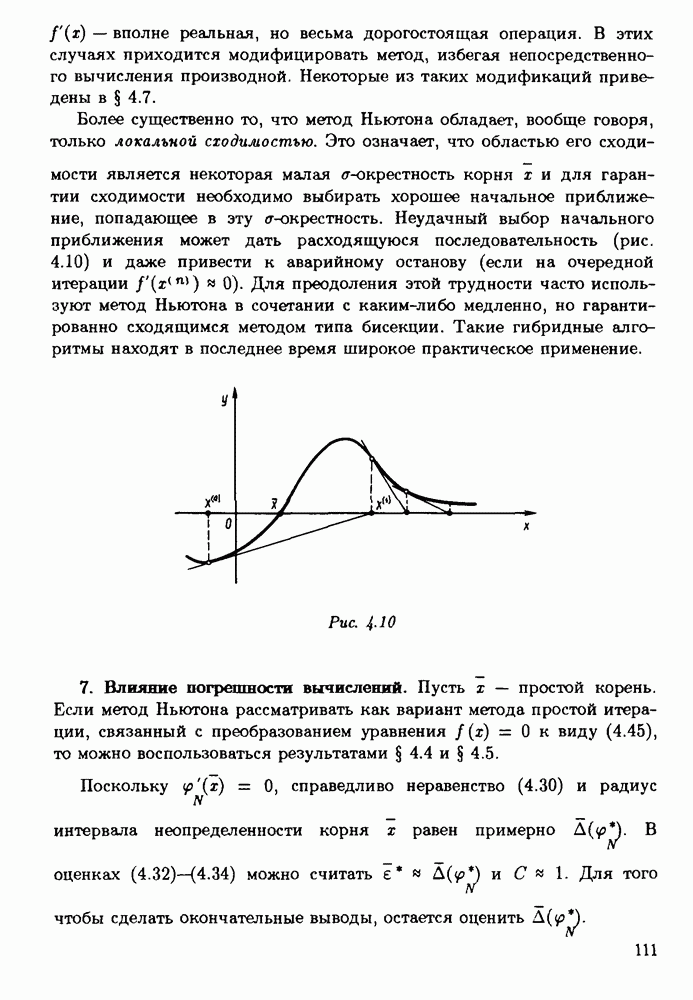

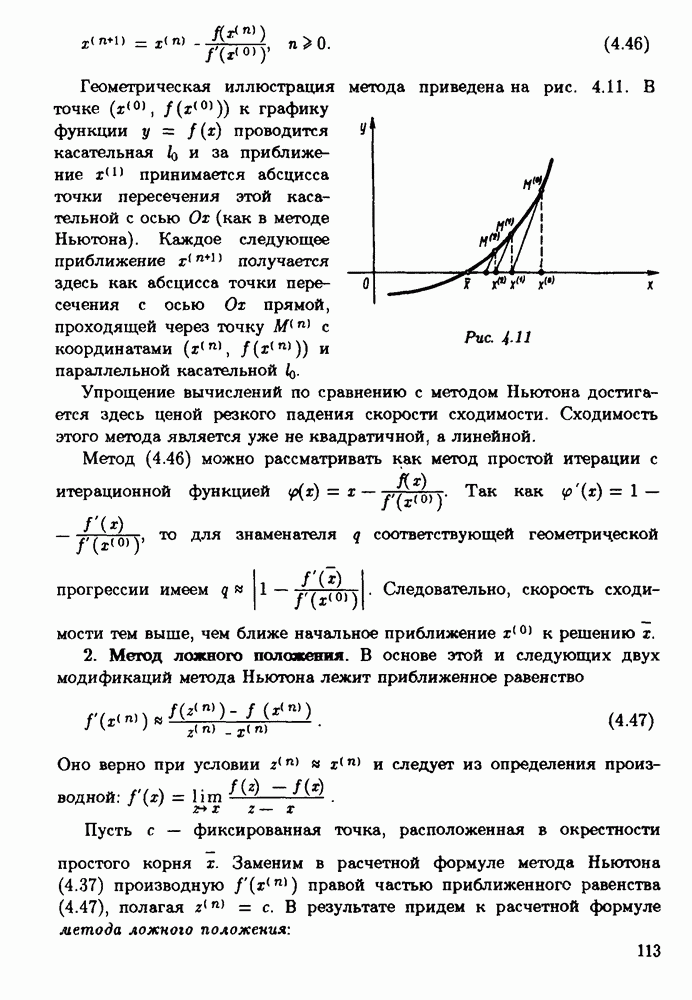
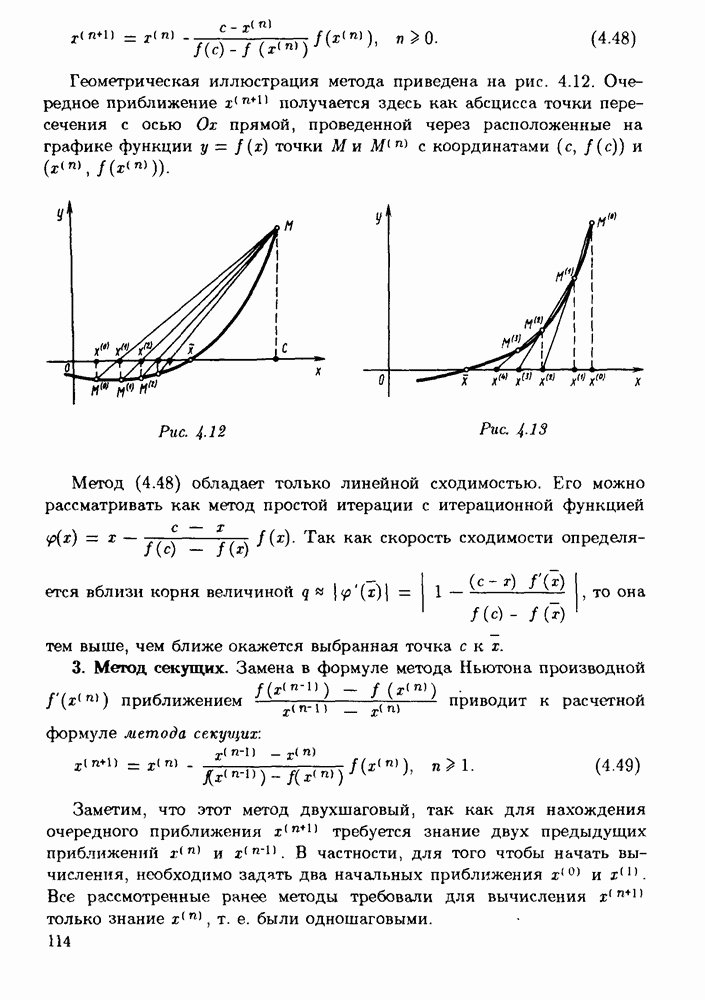















































































































































































































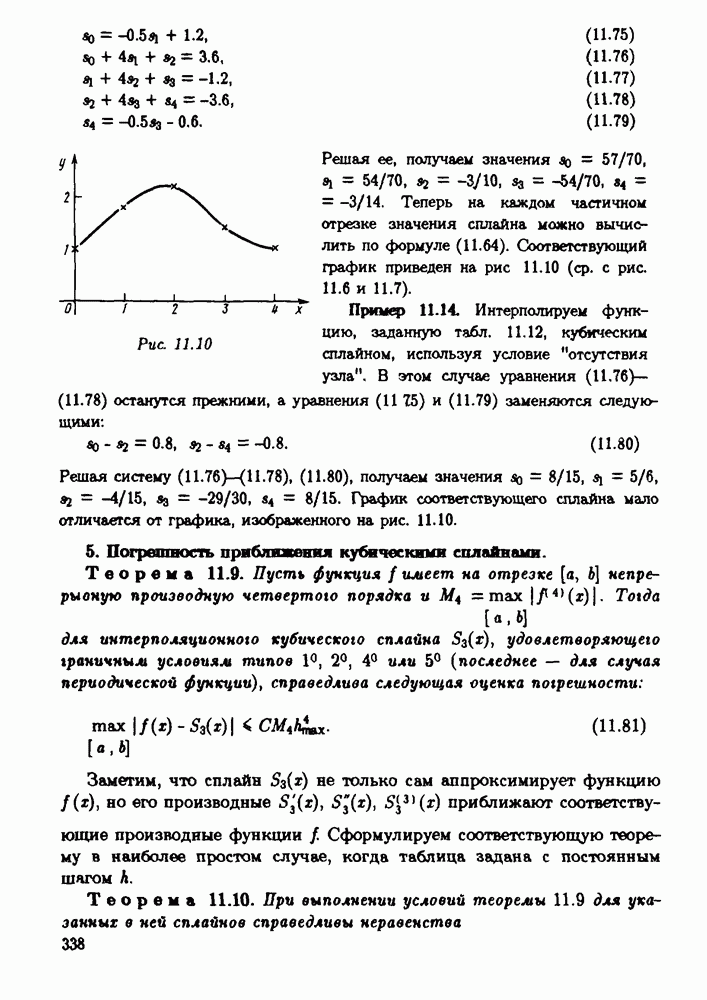

















































































































































































 -разрядной десятичной ЭВМ вычисляется корень уравнения
-разрядной десятичной ЭВМ вычисляется корень уравнения


 Следуя логике прямого анализа
Следуя логике прямого анализа
 от истинного решения х уравнения
от истинного решения х уравнения  Мы поступим иначе. Подставляя
Мы поступим иначе. Подставляя  в левую часть уравнения (3.22), получим значение
в левую часть уравнения (3.22), получим значение  Заметим теперь, что
Заметим теперь, что  является точным решением уравнений
является точным решением уравнений

 и истинным значением корня является
и истинным значением корня является 


 найдено приближенное решение
найдено приближенное решение  Как оценить его качество?
Как оценить его качество?
 очевидно, выполнено. Подставляя
очевидно, выполнено. Подставляя  в левую часть уравнения, убеждаемся, что
в левую часть уравнения, убеждаемся, что  удовлетворяет уравнению (3.23) с коэффициентом
удовлетворяет уравнению (3.23) с коэффициентом  и 2.586 вместо а. Обратим внимание на то, что "истинное" значение
и 2.586 вместо а. Обратим внимание на то, что "истинное" значение  коэффициента а нам в действительности неизвестно и
коэффициента а нам в действительности неизвестно и  лишь некоторое его приближение. Числовой параметр 2.6 в лучшем случае получен округлением "истинного" значения, и, следовательно, а может отличаться от
лишь некоторое его приближение. Числовой параметр 2.6 в лучшем случае получен округлением "истинного" значения, и, следовательно, а может отличаться от  и на 0.05. Так как
и на 0.05. Так как  то в силу естественной неопределенности в постановке задачи функция
то в силу естественной неопределенности в постановке задачи функция  с позиции обратного анализа ошибок может считаться таким же равноправным решением поставленной задачи, как и найденное сколь угодно точно решение задачи (3.23). Во всяком случае теперь для того, чтобы отказаться от найденного приближенного решения, нужны довольно веские аргументы.
с позиции обратного анализа ошибок может считаться таким же равноправным решением поставленной задачи, как и найденное сколь угодно точно решение задачи (3.23). Во всяком случае теперь для того, чтобы отказаться от найденного приближенного решения, нужны довольно веские аргументы.
 большого числа положительных слагаемых. Гарантированная оценка погрешности дает значение относительной погрешности
большого числа положительных слагаемых. Гарантированная оценка погрешности дает значение относительной погрешности  растущее пропорционально
растущее пропорционально  . В то же время статистический анализ показывает, что если ошибки округления являются случайными с нулевым средним значением, то
. В то же время статистический анализ показывает, что если ошибки округления являются случайными с нулевым средним значением, то  растет пропорционально
растет пропорционально  т.е. гораздо медленнее. К сожалению, на тех ЭВМ, где округление производится усечением, последнее предположение не выполнено, так как ошибки округления смещены в одну сторону и поэтому имеют ненулевое среднее значение. Здесь
т.е. гораздо медленнее. К сожалению, на тех ЭВМ, где округление производится усечением, последнее предположение не выполнено, так как ошибки округления смещены в одну сторону и поэтому имеют ненулевое среднее значение. Здесь  растет опять пропорционально
растет опять пропорционально 