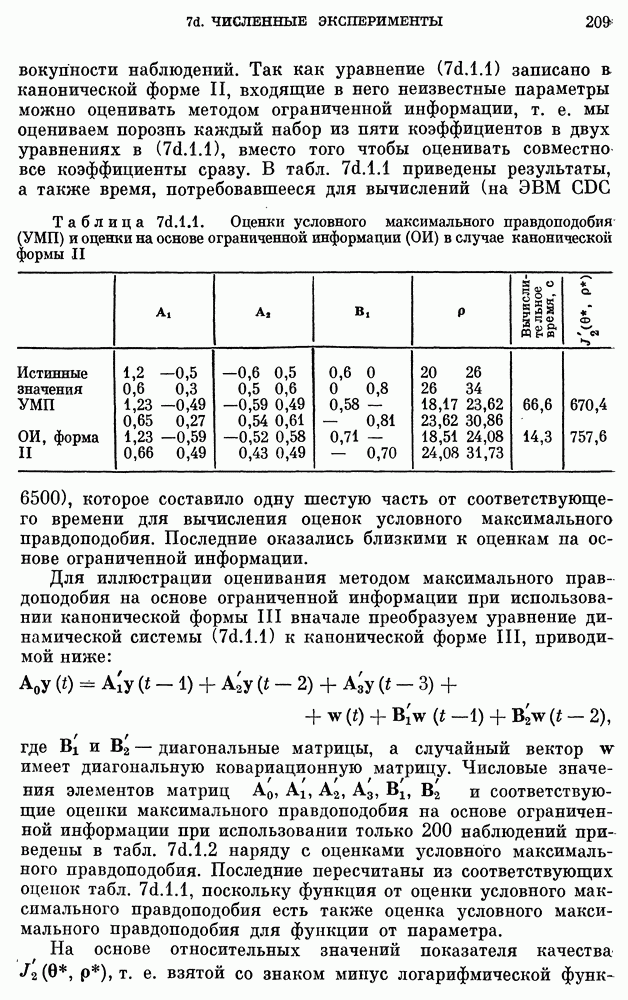
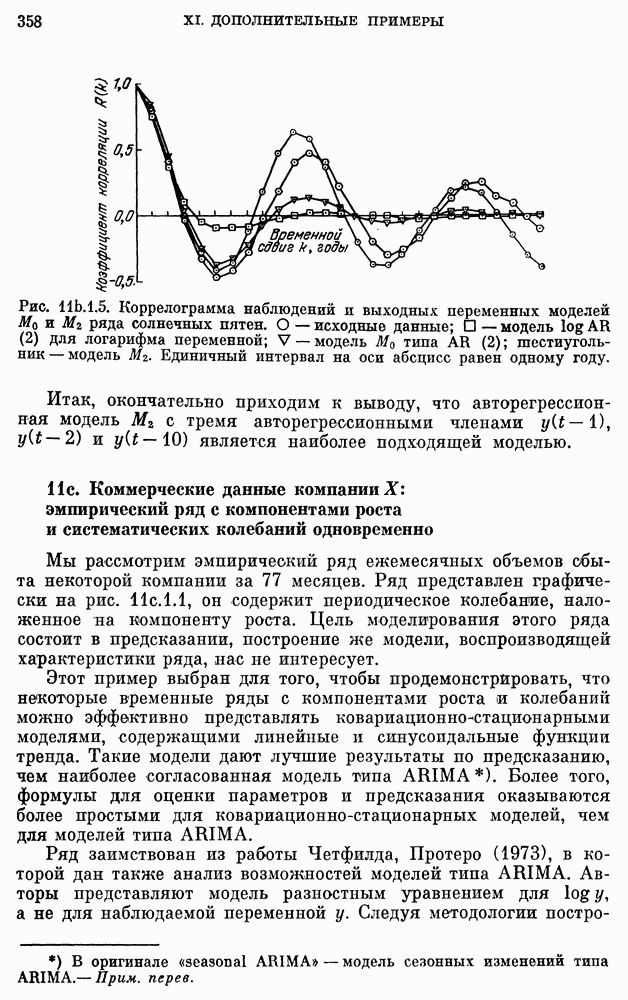
11a.3. Моделирование рядов ежегодной численности населения
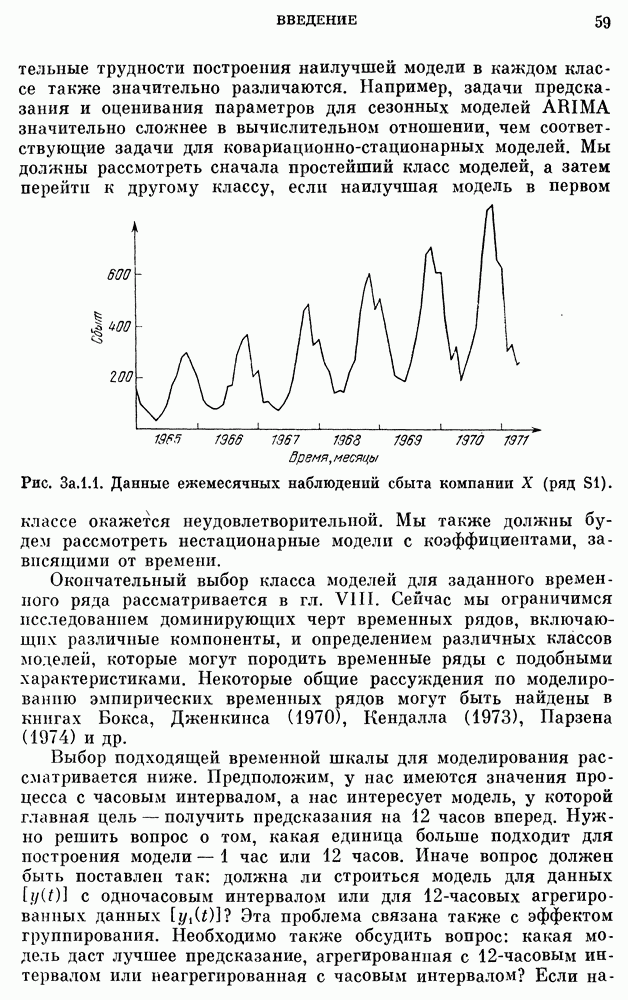
США. Мы рассмотрим ряды ежегодной численности населения США, заимствованные из Statistical Abstracts of the United States (1974).
11a.3.1. Детерминированные модели.
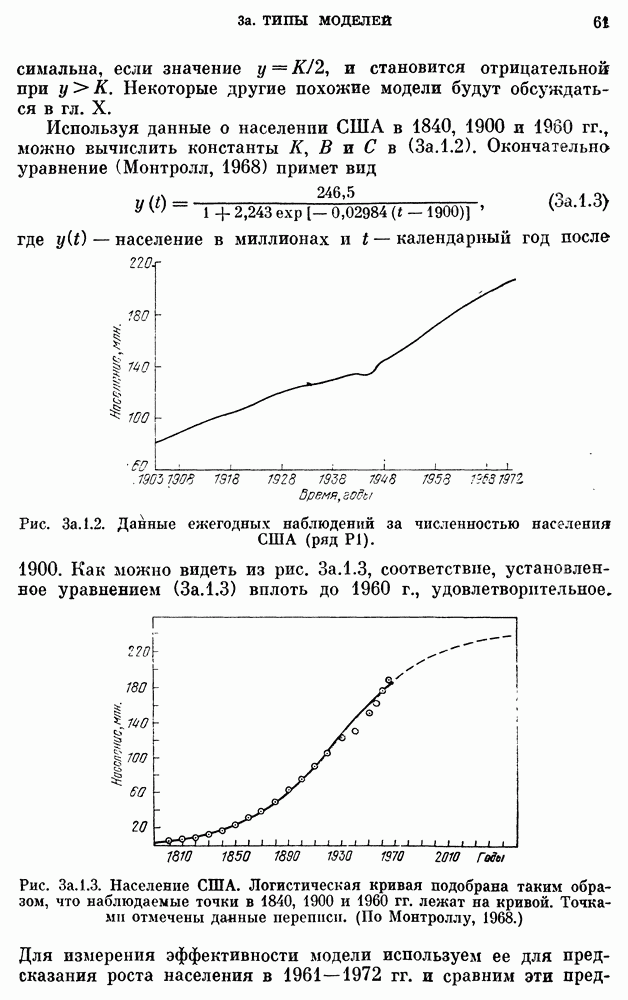
Поскольку мы имеем дело с популяцией, численность которой монотонно возрастает со временем, из двух детерминированных моделей модель Верхулста (11а.2.3) является наиболее подходящей. Три неизвестных параметра модели (11а.2.3), а именно  и
и  можно оценить по значениям численности населения в 1840, 1950 и 1960 гг. Соответствующие оценки и отвечающая им модель задаются соотношениями
можно оценить по значениям численности населения в 1840, 1950 и 1960 гг. Соответствующие оценки и отвечающая им модель задаются соотношениями

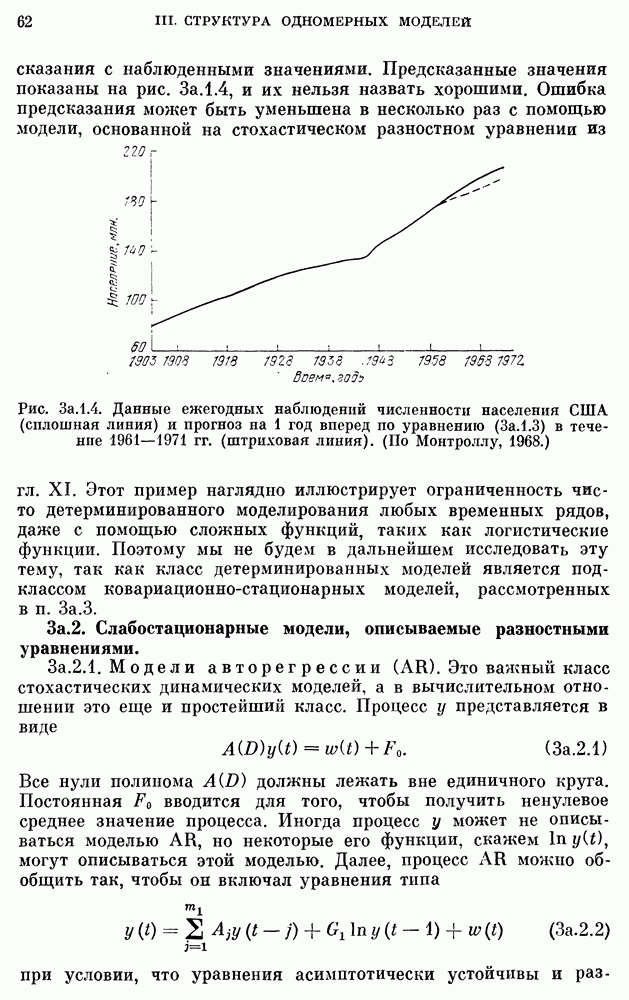
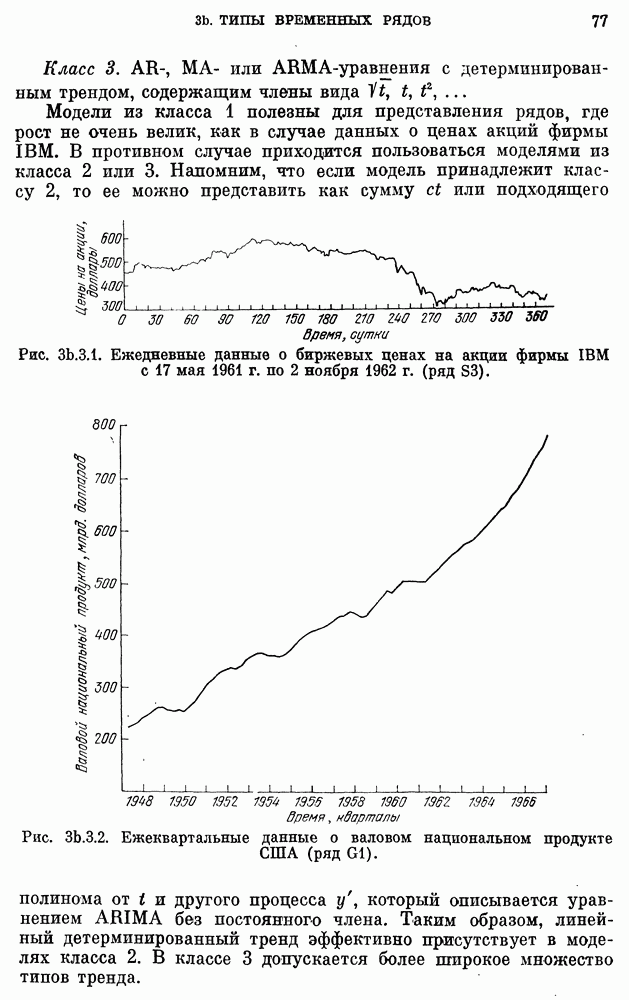
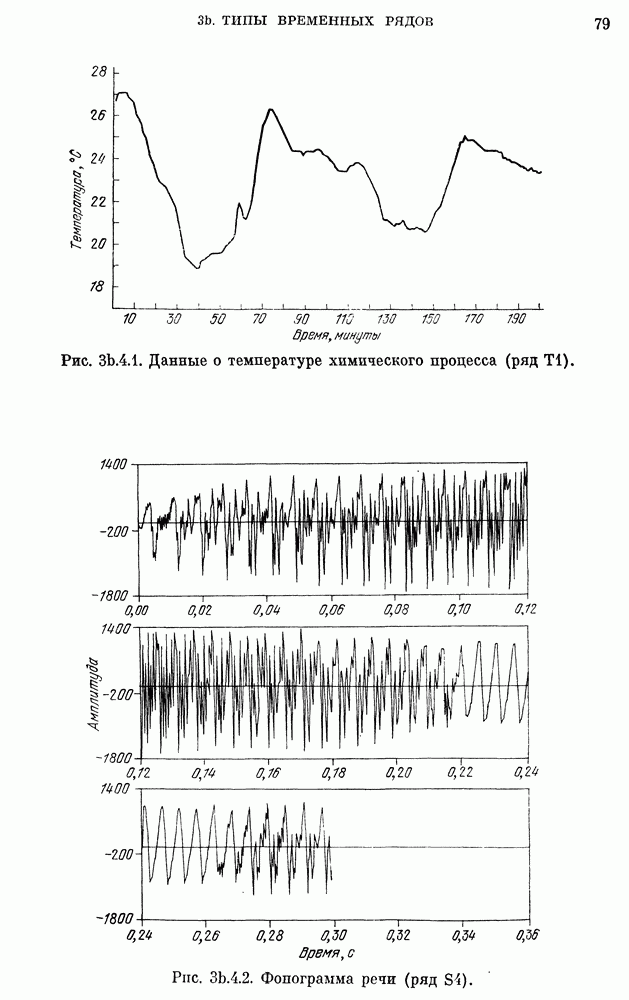
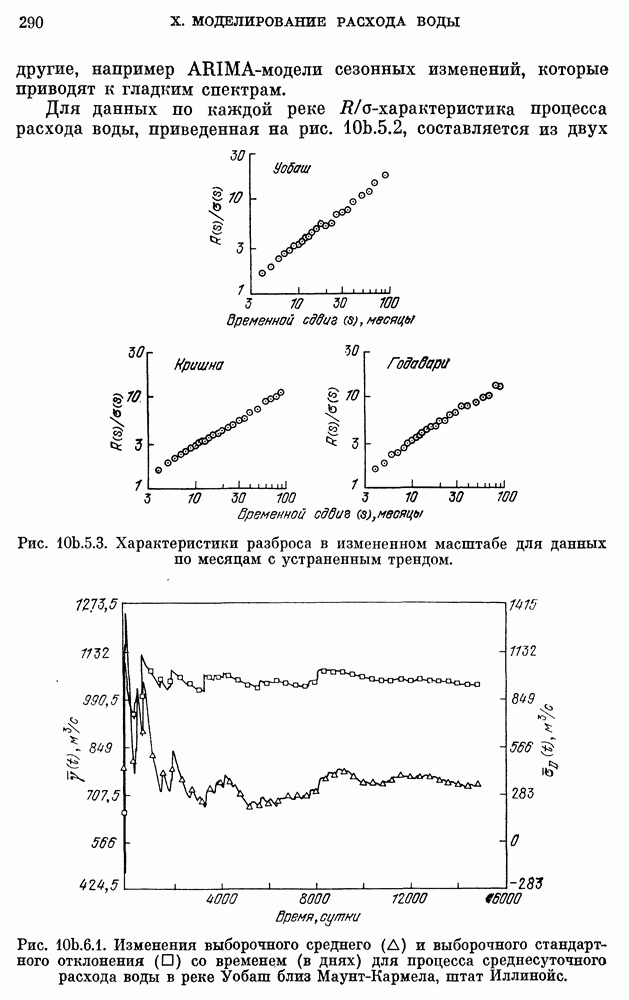
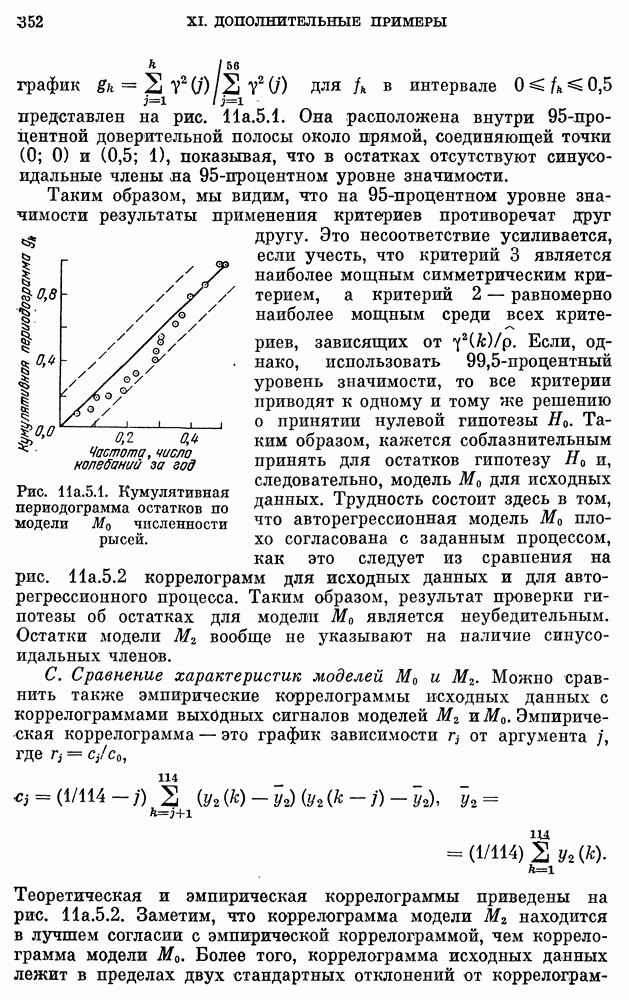
где  измеряется в годах, а численность населения задана в миллионах. График численности населения для подобранной модели накладывается на кривую фактической численности, приведенную на рис.
измеряется в годах, а численность населения задана в миллионах. График численности населения для подобранной модели накладывается на кривую фактической численности, приведенную на рис.  Соответствие очень хорошее для 1790 - 1930 гг., но несколько худшее (хотя и удовлетворительное) для 1930 - 1960 гг. Мы могли бы улучшить соответствие для другого интервала лет, если бы для оценки параметров
Соответствие очень хорошее для 1790 - 1930 гг., но несколько худшее (хотя и удовлетворительное) для 1930 - 1960 гг. Мы могли бы улучшить соответствие для другого интервала лет, если бы для оценки параметров  использовали три других года. Но в рамках детерминированного подхода нет никакого систематического и приемлемого способа сравнения разных моделей. Можно было бы использовать критерий типа наименьших квадратов, но он представляется довольно произвольным. Одно из преимуществ стохастического варианта уравнения
использовали три других года. Но в рамках детерминированного подхода нет никакого систематического и приемлемого способа сравнения разных моделей. Можно было бы использовать критерий типа наименьших квадратов, но он представляется довольно произвольным. Одно из преимуществ стохастического варианта уравнения  состоит в том, что появляется систематический способ оценки его параметров.
состоит в том, что появляется систематический способ оценки его параметров.
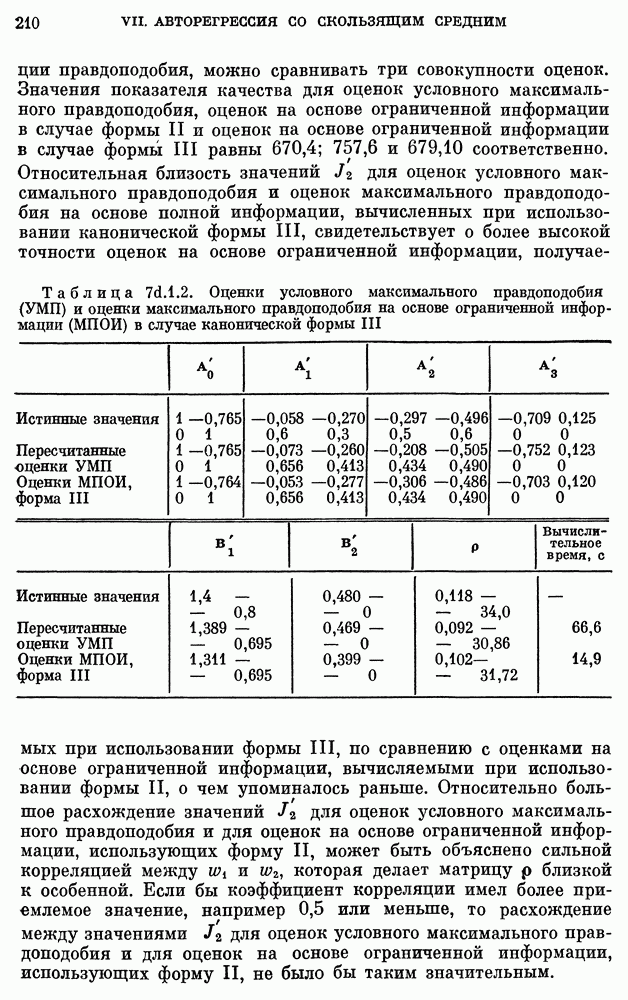
Предположим, что для предсказания на один год численности населения в 1960- 1971 гг. мы используем детерминированную модель (11а.3.1). Результаты представлены в табл.  Предсказанное значение обозначено через у. Среднее значение
Предсказанное значение обозначено через у. Среднее значение
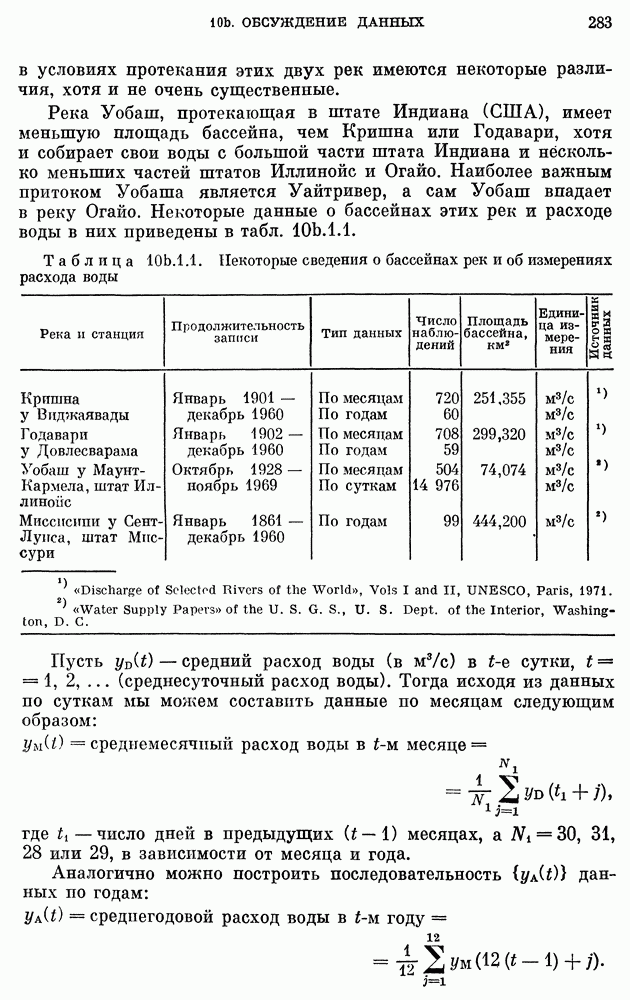
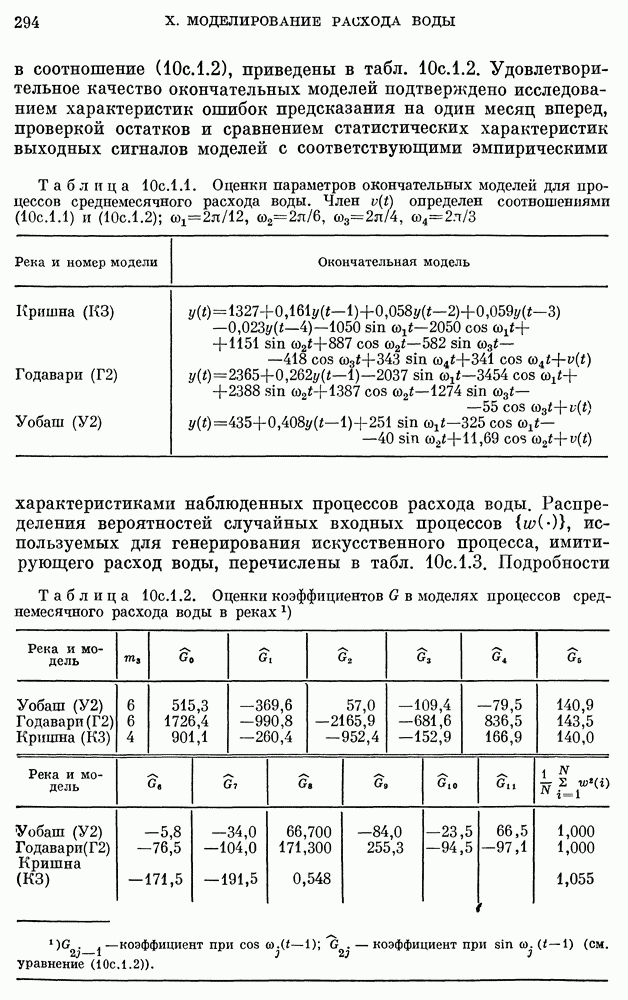
Таблица 11а.3.1. (см. скан) Прогнозы на год вперед численности населения США по детерминированной модели 
ошибки предсказания равно 7,796, а среднеквадратическое значение ошибки предсказания равно 73,162. Наблюденные и предсказанные с помощью модели  значения приведены на рис. 3а.1.4. Заметим, что для рис. 3а.1.4 относительная ошибка предсказания
значения приведены на рис. 3а.1.4. Заметим, что для рис. 3а.1.4 относительная ошибка предсказания  возрастает с ростом
возрастает с ростом  и для 1971 г. равна приблизительно 6%. Таким образом, мы имеем один из самых: типичных примеров детерминированной модели, которая очень хорошо согласована с исходными данными, но имеет плохие характеристики предсказания.
и для 1971 г. равна приблизительно 6%. Таким образом, мы имеем один из самых: типичных примеров детерминированной модели, которая очень хорошо согласована с исходными данными, но имеет плохие характеристики предсказания.
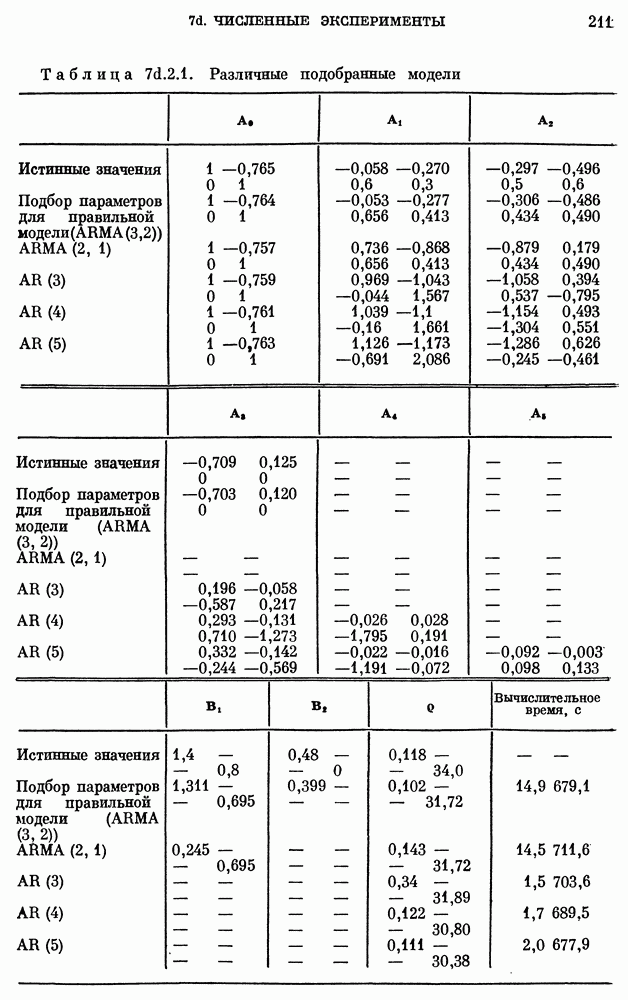
11а.3.2. Стохастические модели.
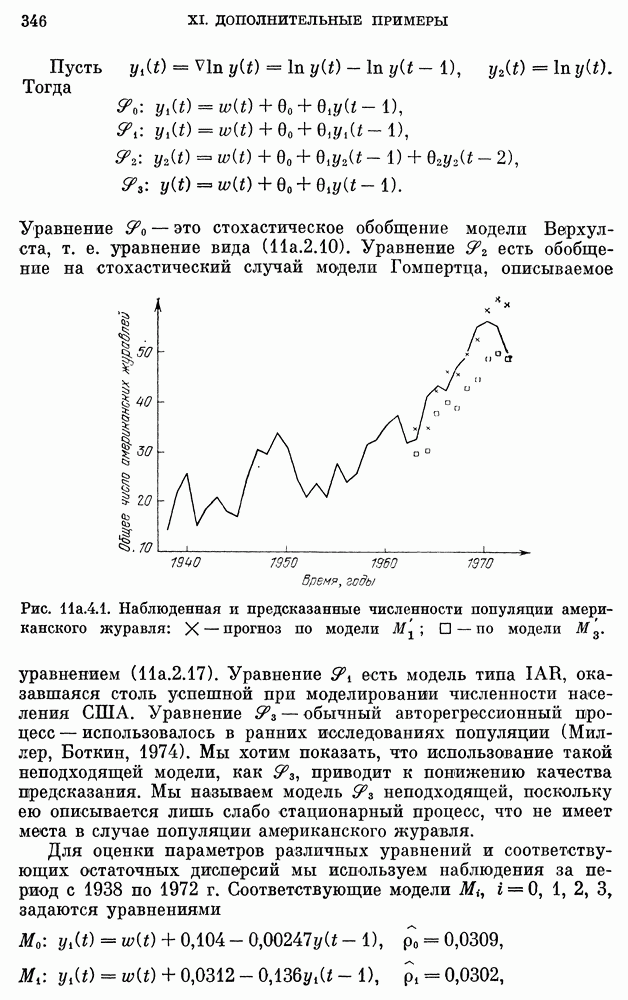
Рассмотрим следующие четыре класса стохастических моделей  , описываемых уравнениями
, описываемых уравнениями  Пусть
Пусть  Тогда
Тогда

Уравнение  есть стохастический вариант модели Верхулста
есть стохастический вариант модели Верхулста  Уравнения
Уравнения  и выводятся из стохастических вариантов моделей Гомпертца. Они совпадают с
и выводятся из стохастических вариантов моделей Гомпертца. Они совпадают с  соответственно. Уравнение
соответственно. Уравнение  совпадает с уравнением
совпадает с уравнением  при
при  Можно порождать дополнительные классы, отвечающие другим уравнениям
Можно порождать дополнительные классы, отвечающие другим уравнениям  получаемым при различных значениях
получаемым при различных значениях  Но необходимости использовать дополнительные классы не возникает, поскольку было найдено, что модель класса
Но необходимости использовать дополнительные классы не возникает, поскольку было найдено, что модель класса  вполне удовлетворительна.
вполне удовлетворительна.
Для получения наилучшим образом согласованных моделей в каждом из перечисленных классов (модели приводятся ниже вместе с дисперсиями остатков) используем данные за  Наилучшим образом согласованную модель в классе С обозначим через
Наилучшим образом согласованную модель в классе С обозначим через 

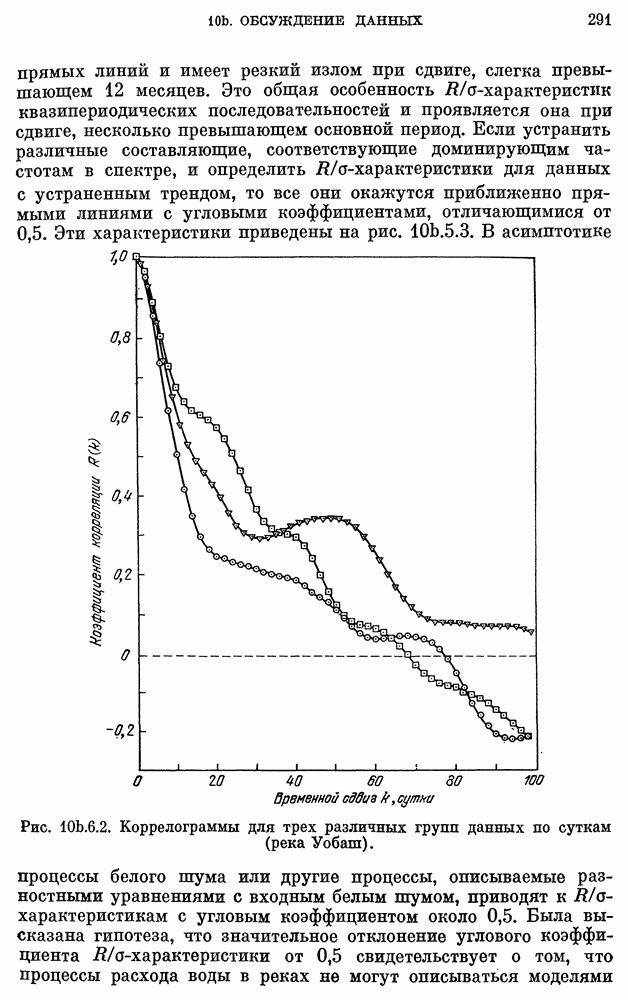
Классы сравниваются с помощью изложенного в  метода правдоподобия. Поскольку все модели включают логарифмические преобразования, будем сравнивать их, используя следующие статистики
метода правдоподобия. Поскольку все модели включают логарифмические преобразования, будем сравнивать их, используя следующие статистики  число параметров,
число параметров,  дисперсия
дисперсия
остатков):

Максимальной среди  является
является  поэтому класс
поэтому класс  предпочтительнее других. Этого и следовало ожидать, поскольку
предпочтительнее других. Этого и следовало ожидать, поскольку  значительно меньше, чем
значительно меньше, чем 
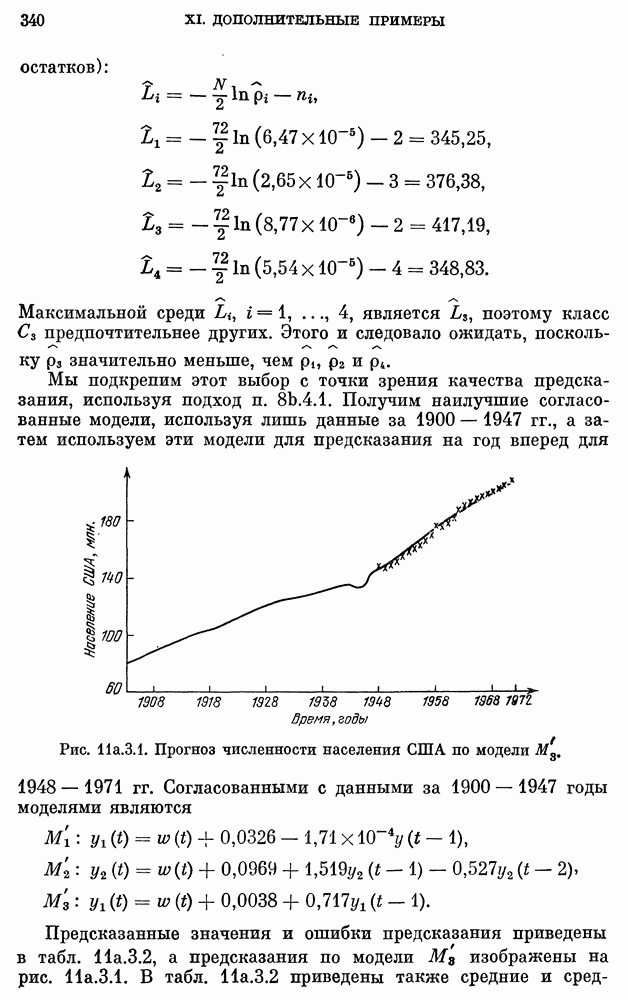
Мы подкрепим этот выбор с точки зрения качества предсказания, используя подход п. 8b.4.1. Получим наилучшие согласованные модели, используя лишь данные за 1900 - 1947 гг., а затем используем эти модели для предсказания на год вперед для 1948 -1971 гг.

Рис. 11а.3.1. Прогноз численности населения США по модели  .
.
Согласованными с данными за 1900 —1947 годы моделями являются

Предсказанные значения и ошибки предсказания приведены в табл. 11а.3.2, а предсказания по модели  изображены на рис. 11а.3.1. В табл. 11а.3.2 приведены также средние и
изображены на рис. 11а.3.1. В табл. 11а.3.2 приведены также средние и
среднеквадратические значения ошибок для 24 точек. Среди всех моделей модель  имеет наименьшие значения средней абсолютной ошибки и среднеквадратической ошибки предсказания, указывая на предпочтительность класса
имеет наименьшие значения средней абсолютной ошибки и среднеквадратической ошибки предсказания, указывая на предпочтительность класса  другим классам. Типичная ошибка предсказания для
другим классам. Типичная ошибка предсказания для  равна приблизительно 0,1% от значения численности населения, тогда как для других моделей она колеблется от 5 до 1%.
равна приблизительно 0,1% от значения численности населения, тогда как для других моделей она колеблется от 5 до 1%.
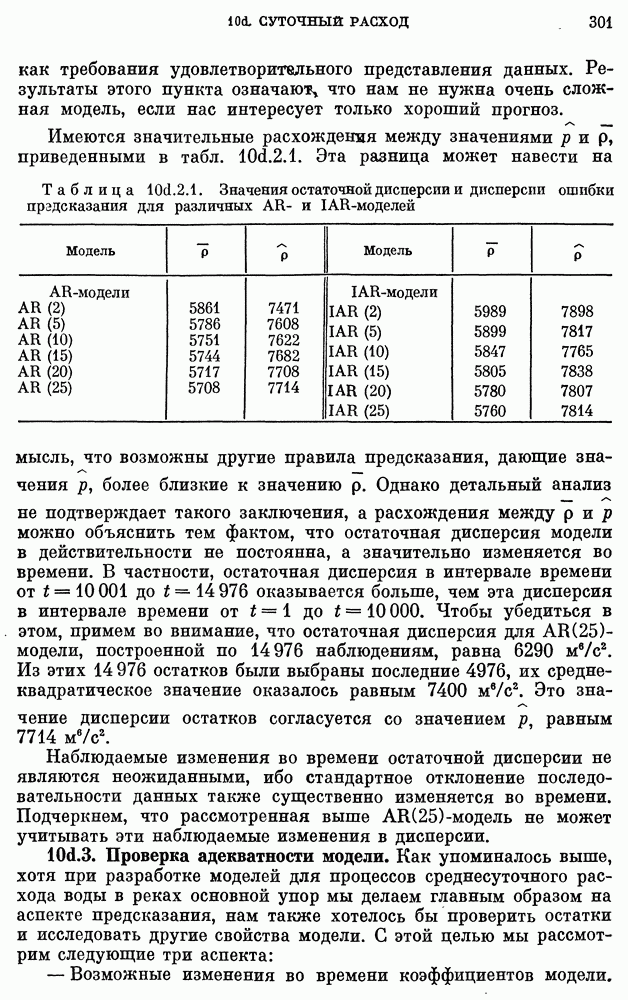
Таблица 11а.3.2. (см. скан) Прогнозы численности населения США по стохастическим моделям
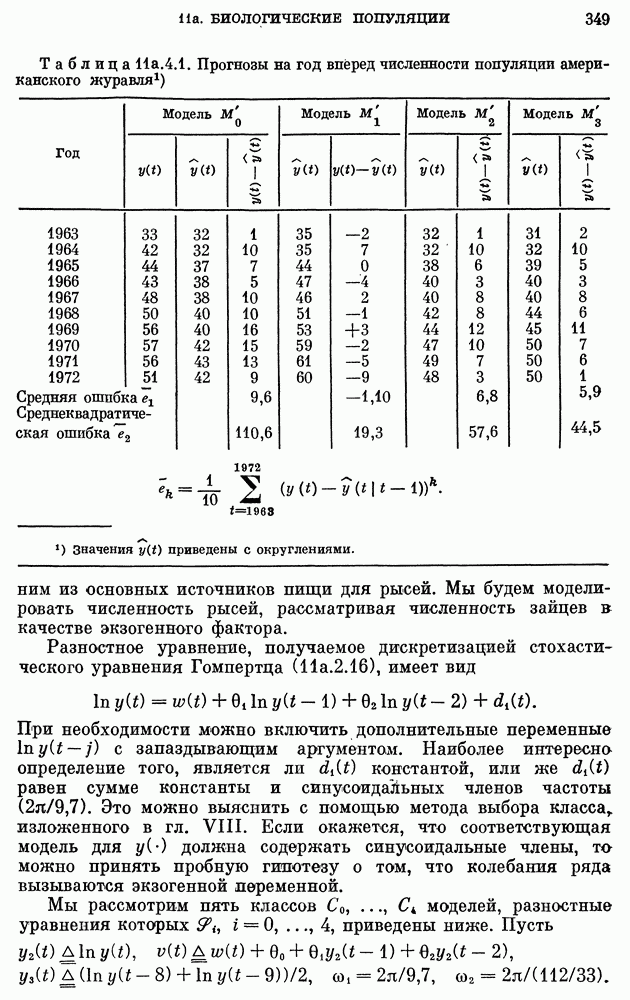
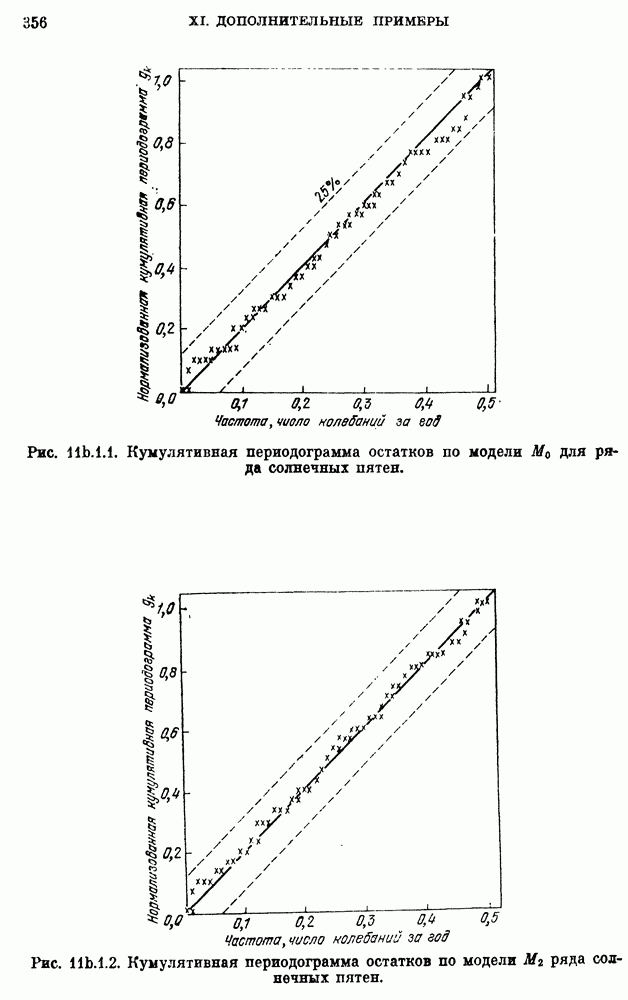
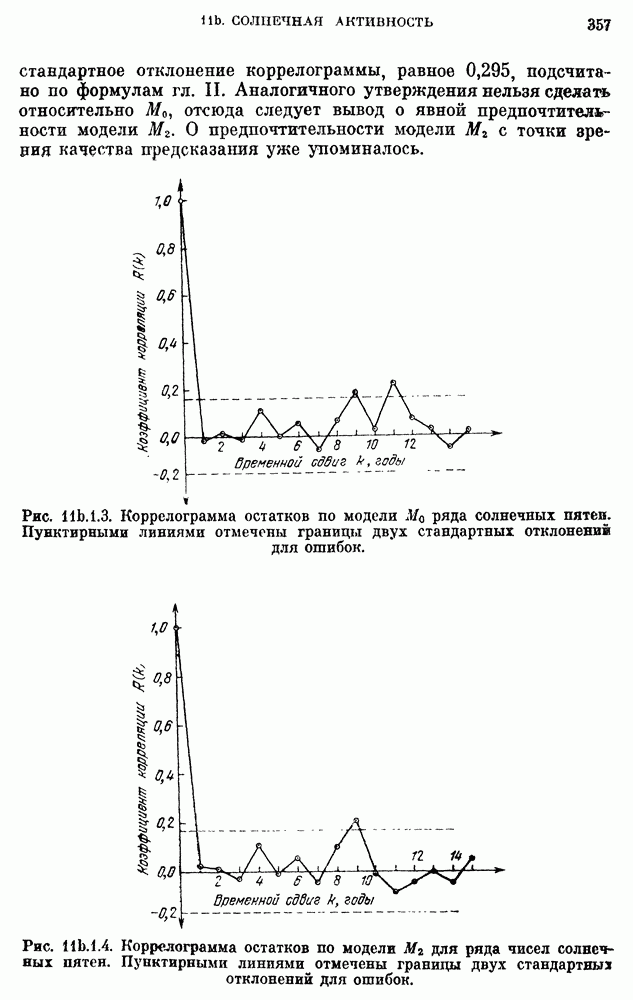
Модель  удовлетворяет всем критериям адекватности на 95-процентном уровне значимости.
удовлетворяет всем критериям адекватности на 95-процентном уровне значимости.
Следует подчеркнуть, что наилучшая согласованная модель  приводит к экспоненциальному росту среднего значения и
приводит к экспоненциальному росту среднего значения и
Как было упомянуто ранее, можно построить болыпоег число различных детерминированных моделей, используя при оценке параметров данные каких-нибудь трех разных лет. Некоторые  этих моделей могут дать лучшие результаты предсказания, чем другие.
этих моделей могут дать лучшие результаты предсказания, чем другие.

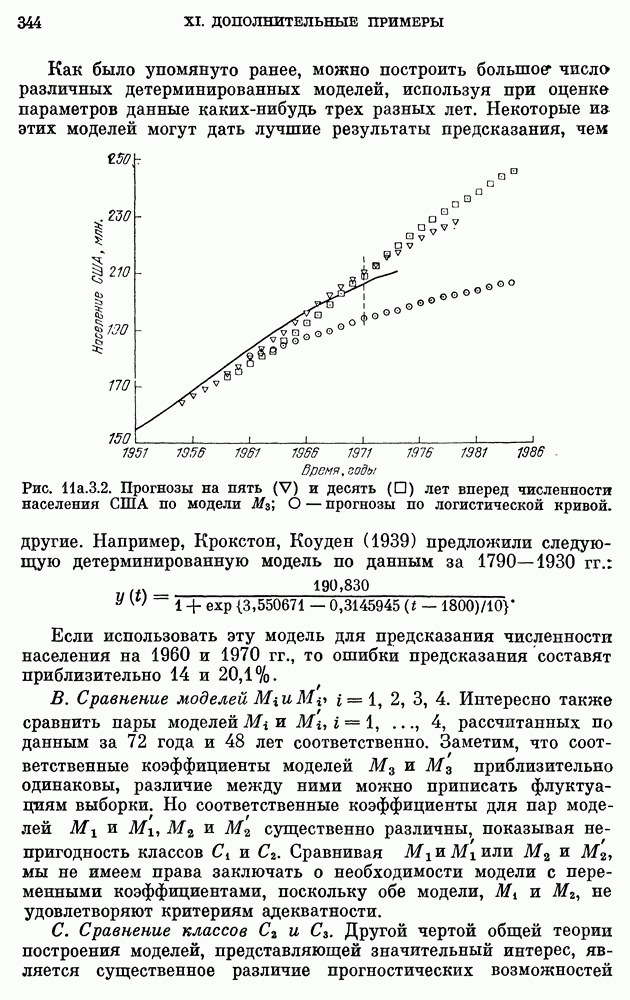
Рис. 11а.3.2. Прогнозы на пять (V) и десять  лет вперед численности населения США по модели
лет вперед численности населения США по модели  — прогнозы по логистической кривой.
— прогнозы по логистической кривой.
Например, Крокстон, Коуден (1939) предложили следующую детерминированную модель по данным за 

Если использовать эту модель для предсказания численности населения на  то ошибки предсказания составят приблизительно 14 и 20,1%.
то ошибки предсказания составят приблизительно 14 и 20,1%.
B. Сравнение моделей  . Интересно также сравнить пары моделей
. Интересно также сравнить пары моделей  рассчитанных по данным за 72 года и 48 лет соответственно. Заметим, что соответственные коэффициенты моделей
рассчитанных по данным за 72 года и 48 лет соответственно. Заметим, что соответственные коэффициенты моделей  приблизительно одинаковы, различие между ними можно приписать флуктуациям выборки. Но соответственные коэффициенты для пар моделей
приблизительно одинаковы, различие между ними можно приписать флуктуациям выборки. Но соответственные коэффициенты для пар моделей  существенно различны, показывая непригодность классов
существенно различны, показывая непригодность классов  Сравнивая
Сравнивая  или
или  мы не имеем права заключать о необходимости модели с переменными коэффициентами, поскольку обе модели,
мы не имеем права заключать о необходимости модели с переменными коэффициентами, поскольку обе модели,  не удовлетворяют критериям адекватности.
не удовлетворяют критериям адекватности.
C. Сравнение классов  Другой чертой общей теории построения моделей, представляющей значительный интерес, является существенное различие прогностических возможностей
Другой чертой общей теории построения моделей, представляющей значительный интерес, является существенное различие прогностических возможностей
наилучшим образом согласованных моделей классов  Обе модели оказываются авторегрессионными уравнениями второго порядка относительно переменной
Обе модели оказываются авторегрессионными уравнениями второго порядка относительно переменной  с добавленным постоянным членом. Но остаточные дисперсии и прогностические возможности для этих моделей существенно различны. Конечно, следует ожидать расхождения характеристик двух моделей, поскольку модель IAR с постоянным членом приводит к асимптотическому возрастанию средних и дисперсий, тогда как обычная модель
с добавленным постоянным членом. Но остаточные дисперсии и прогностические возможности для этих моделей существенно различны. Конечно, следует ожидать расхождения характеристик двух моделей, поскольку модель IAR с постоянным членом приводит к асимптотическому возрастанию средних и дисперсий, тогда как обычная модель  к их устойчивому поведению. Это ясно показывает, насколько опасно использовать обычную модель AR для процесса, описываемого моделью IAR с постоянным членом.
к их устойчивому поведению. Это ясно показывает, насколько опасно использовать обычную модель AR для процесса, описываемого моделью IAR с постоянным членом.
D. Сравнение модели  с детерминированной моделью
с детерминированной моделью  Напомним, что модель
Напомним, что модель  есть стохастический аналог детерминированной модели
есть стохастический аналог детерминированной модели  Поэтому можно сравнивать коэффициенты моделей. Из уравнения
Поэтому можно сравнивать коэффициенты моделей. Из уравнения  получаем оценки
получаем оценки 

так что

Обратим внимание на расхождение между оценками коэффициента  в моделях
в моделях  а также на большую разницу в ошибках предсказания для детерминированной модели
а также на большую разницу в ошибках предсказания для детерминированной модели  из
из  и ее стохастического варианта
и ее стохастического варианта  выявляемую при сравнении данных табл. 11а.3.1 и 11а.3.2. Преимущество стохастической модели можно объяснить двумя причинами. (I) Стохастическая модель
выявляемую при сравнении данных табл. 11а.3.1 и 11а.3.2. Преимущество стохастической модели можно объяснить двумя причинами. (I) Стохастическая модель  использует фактические наблюдения по всем годам, предшествующим предсказываемому. Этого нельзя сказать о модели
использует фактические наблюдения по всем годам, предшествующим предсказываемому. Этого нельзя сказать о модели  которая использует для предсказания меньше информации, чем
которая использует для предсказания меньше информации, чем  Параметры стохастической модели
Параметры стохастической модели  оцениваются более систематическим способом, чем параметры модели
оцениваются более систематическим способом, чем параметры модели  оценки параметров
оценки параметров  довольно произвольны, так как три ее коэффициента оцениваются по значениям численности населения для трех произвольных годов.
довольно произвольны, так как три ее коэффициента оцениваются по значениям численности населения для трех произвольных годов.













































































































































































































































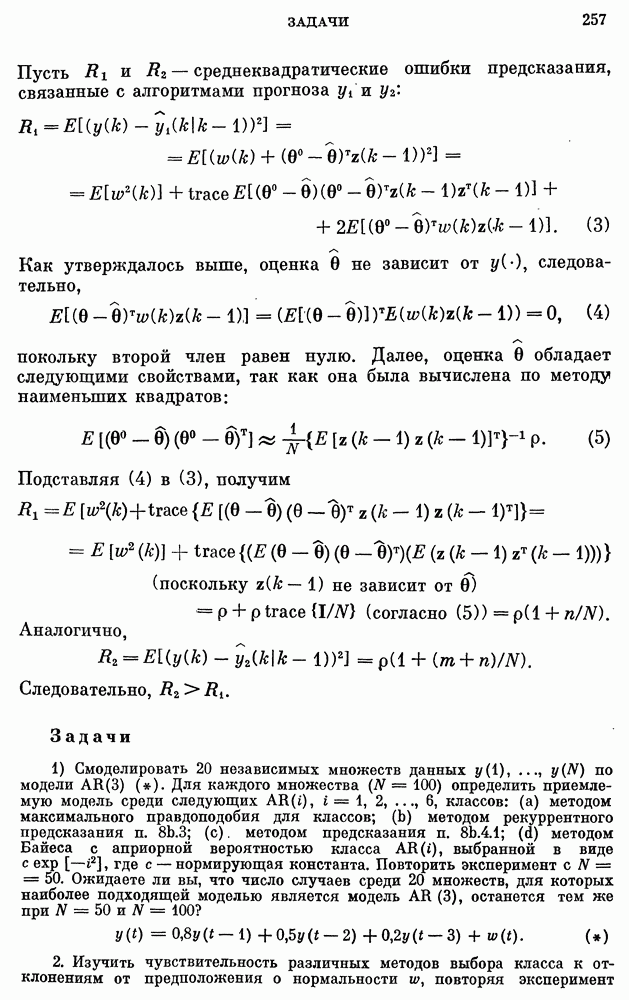












































































 к бесконечности, не подкрепляются статистическими данными. Это заключение было обосновано как методами правдоподобия, так и методами, базирующимися на исследовании качества предсказания. Рассмотрим некоторые другие аспекты.
к бесконечности, не подкрепляются статистическими данными. Это заключение было обосновано как методами правдоподобия, так и методами, базирующимися на исследовании качества предсказания. Рассмотрим некоторые другие аспекты.
 гораздо более предпочтительна, чем детерминированная модель. Пусть
гораздо более предпочтительна, чем детерминированная модель. Пусть  обозначает оптимальный прогноз процесса
обозначает оптимальный прогноз процесса  по наблюдениям
по наблюдениям  для модели
для модели  при использовании критерия
при использовании критерия 

 . Для вычисления
. Для вычисления  к) при различных к поступим следующим образом. (I) Вычислим все прогнозы
к) при различных к поступим следующим образом. (I) Вычислим все прогнозы  на один шаг вперед для соответствующих
на один шаг вперед для соответствующих 
 для различных используя прогнозы, найденные на шаге (I):
для различных используя прогнозы, найденные на шаге (I):

 для различных
для различных  В общем случае
В общем случае

 прогнозы
прогнозы  на пять лет вперед и прогнозы
на пять лет вперед и прогнозы  на десять лет вперед для модели
на десять лет вперед для модели  при различных
при различных  Графики значений прогнозов изображены на рис. 11а.3.2. Заметим, что детерминированная модель систематически и намного недооценивает численность населения, тогда как прогнозы
Графики значений прогнозов изображены на рис. 11а.3.2. Заметим, что детерминированная модель систематически и намного недооценивает численность населения, тогда как прогнозы  располагаются по другую сторону от кривой фактически наблюденной численности. Можно было бы критически относиться к прогнозам
располагаются по другую сторону от кривой фактически наблюденной численности. Можно было бы критически относиться к прогнозам  при
при  поскольку они были вычислены с помощью модели
поскольку они были вычислены с помощью модели  выбранной по данным вплоть до 1971 г. Однако это замечание не относится к прогнозам
выбранной по данным вплоть до 1971 г. Однако это замечание не относится к прогнозам  при
при 
 при
при  значительно ближе к
значительно ближе к  чем прогнозы по детерминированной модели. Для примера, рассмотрим прогноз численности населения на 1974 г. по данным вплоть до 1969 г. Предсказанное по модели
чем прогнозы по детерминированной модели. Для примера, рассмотрим прогноз численности населения на 1974 г. по данным вплоть до 1969 г. Предсказанное по модели  значение равно 197,75 с ошибкой предсказания 14,03, тогда как при использовании
значение равно 197,75 с ошибкой предсказания 14,03, тогда как при использовании  получаем 218,25 и ошибку
получаем 218,25 и ошибку  .
.