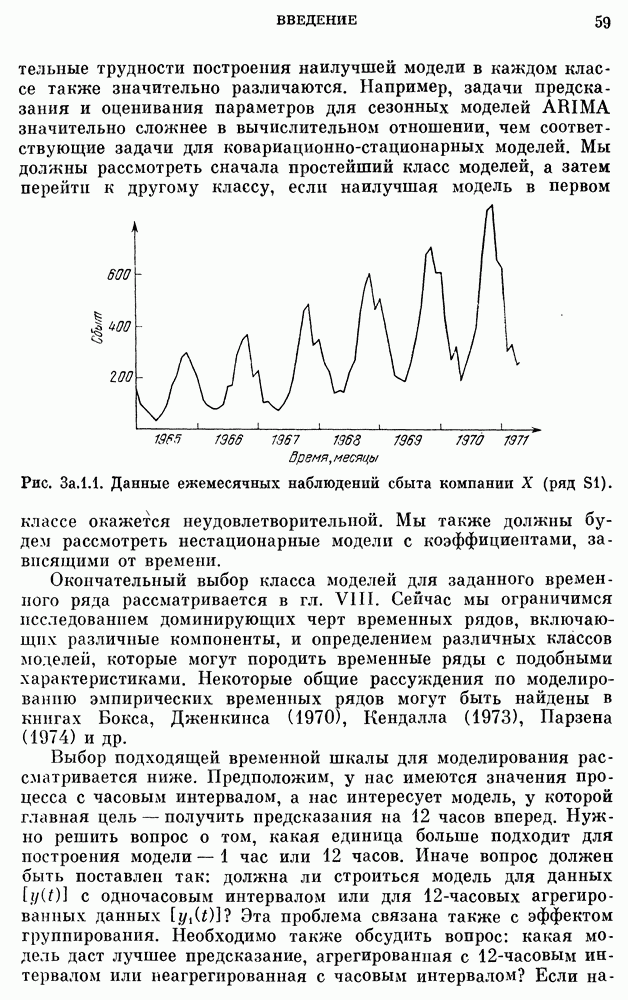
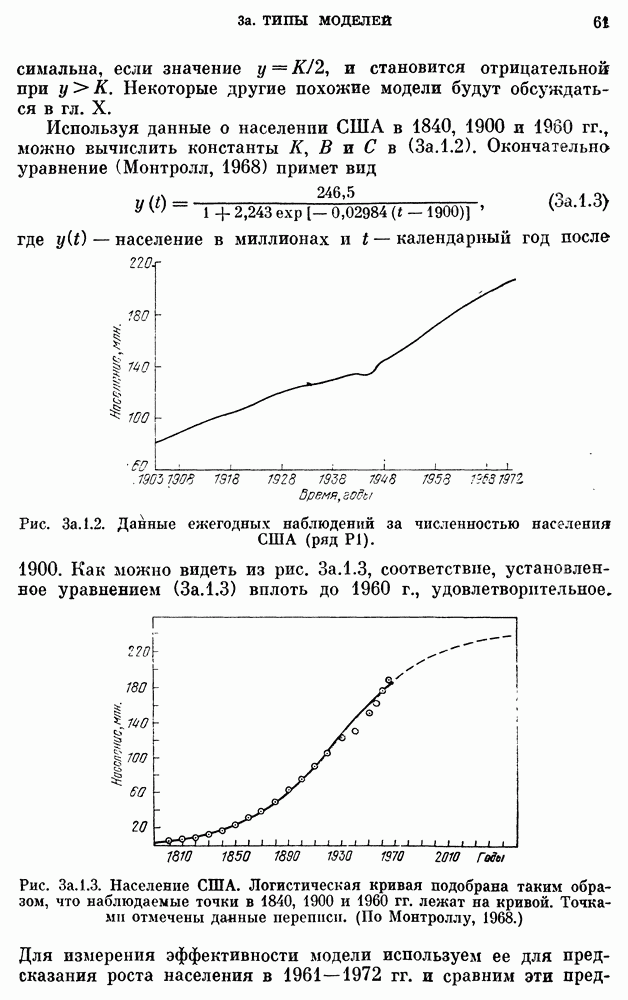
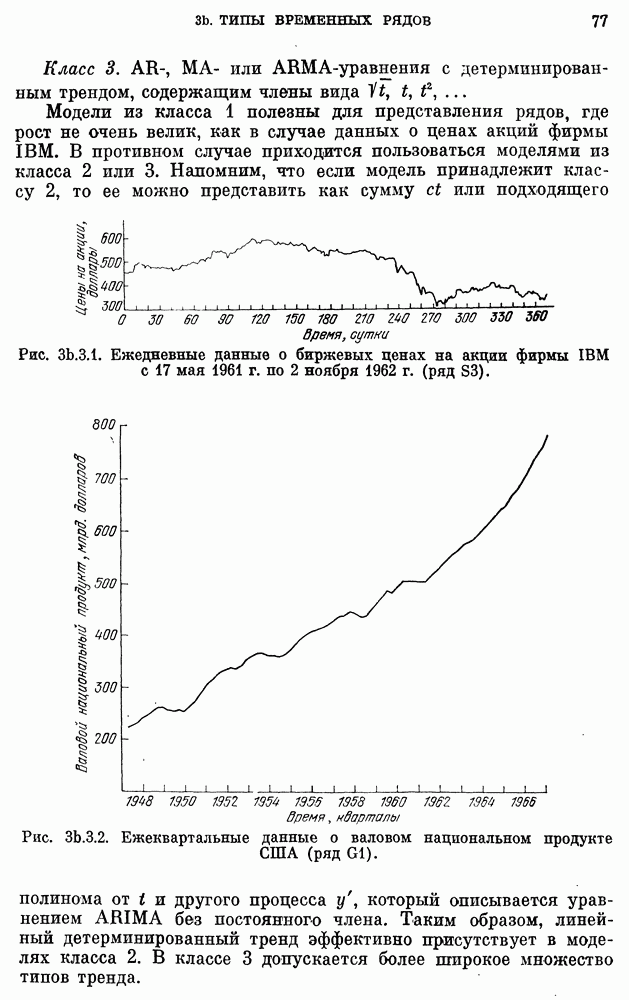
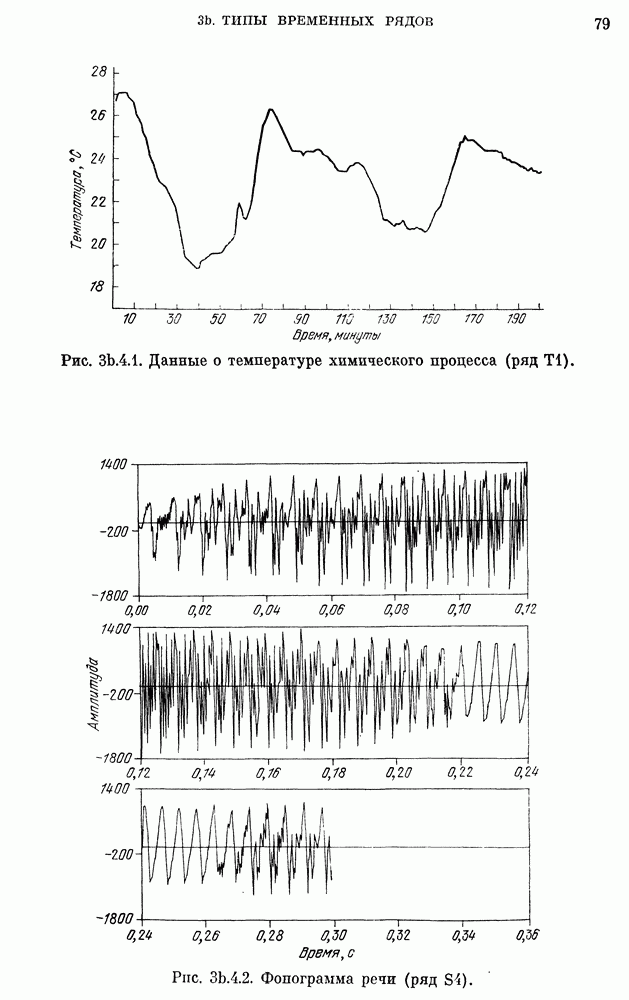
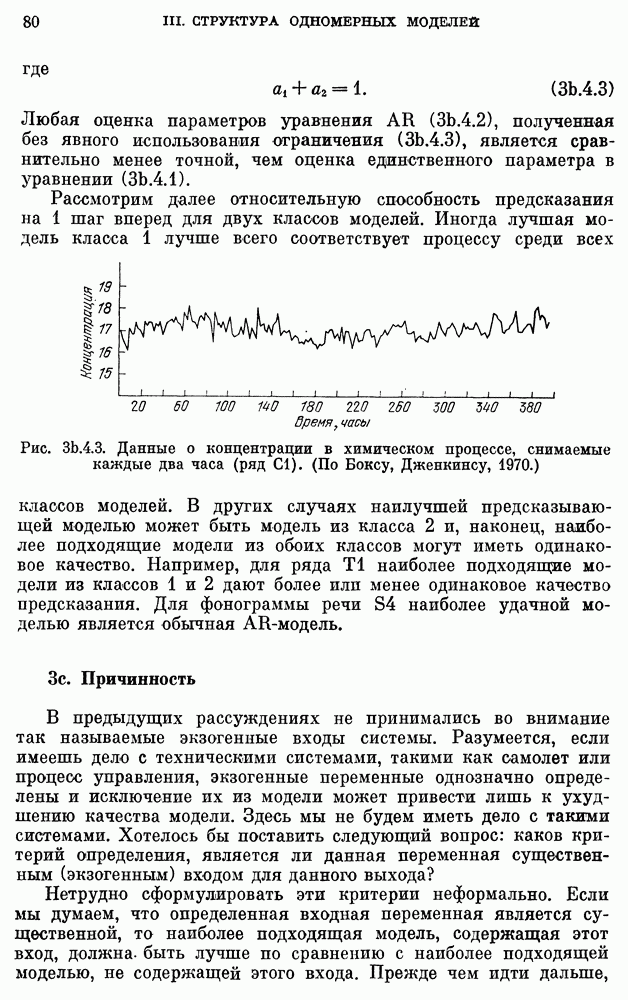
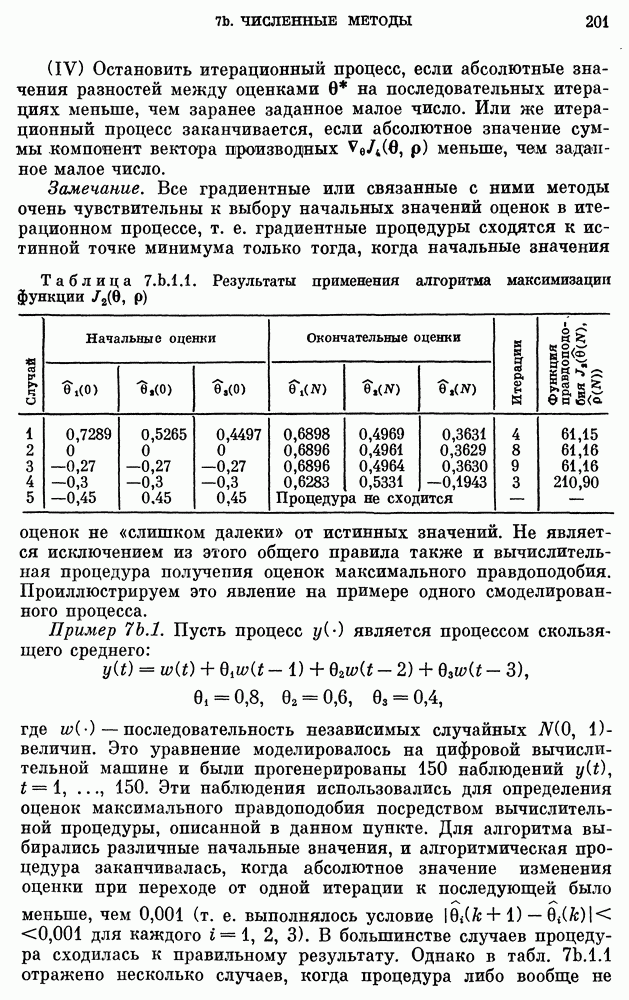
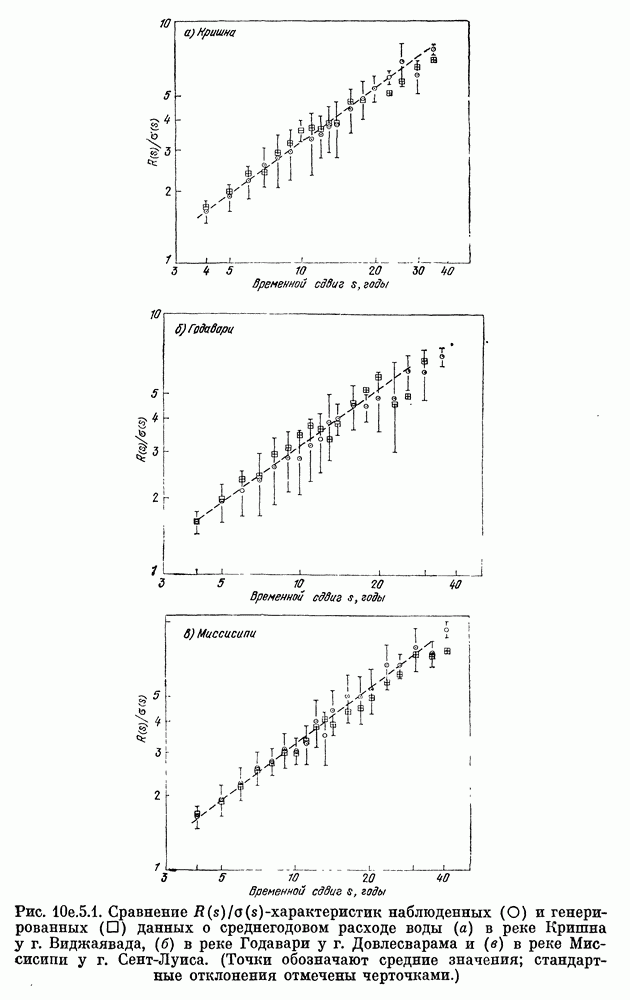
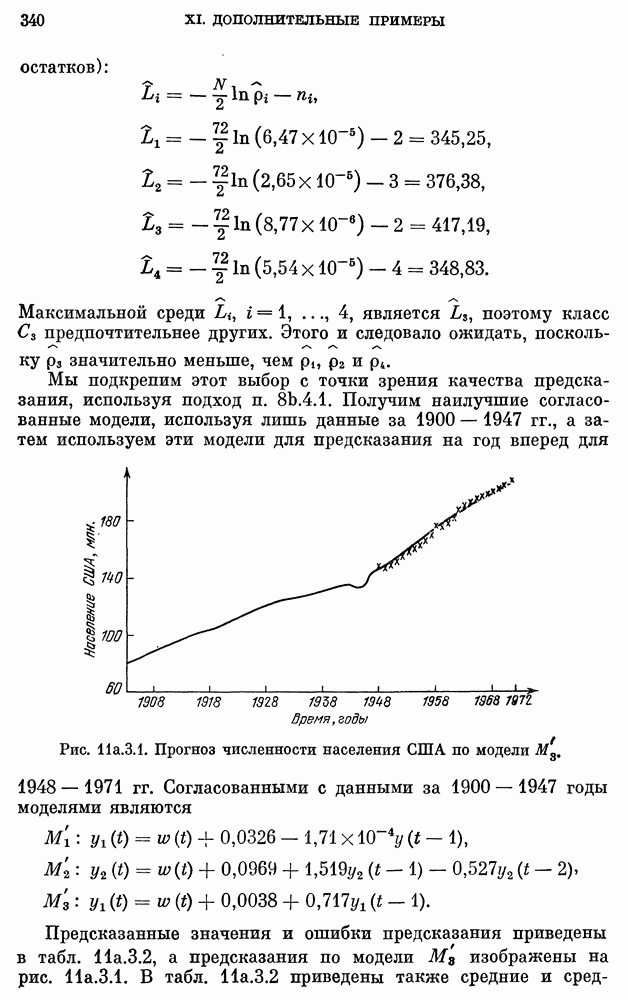
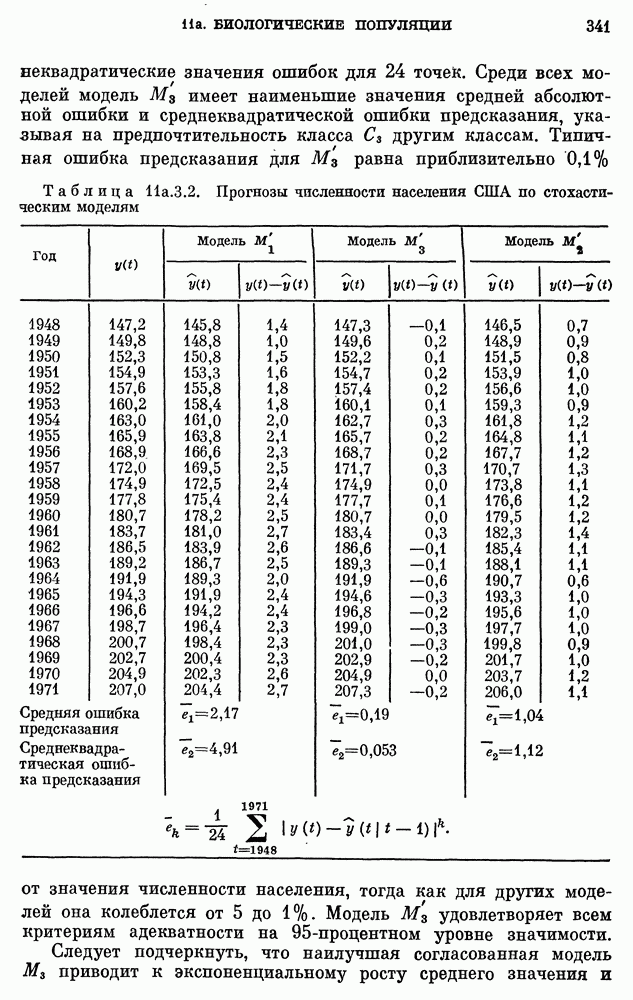
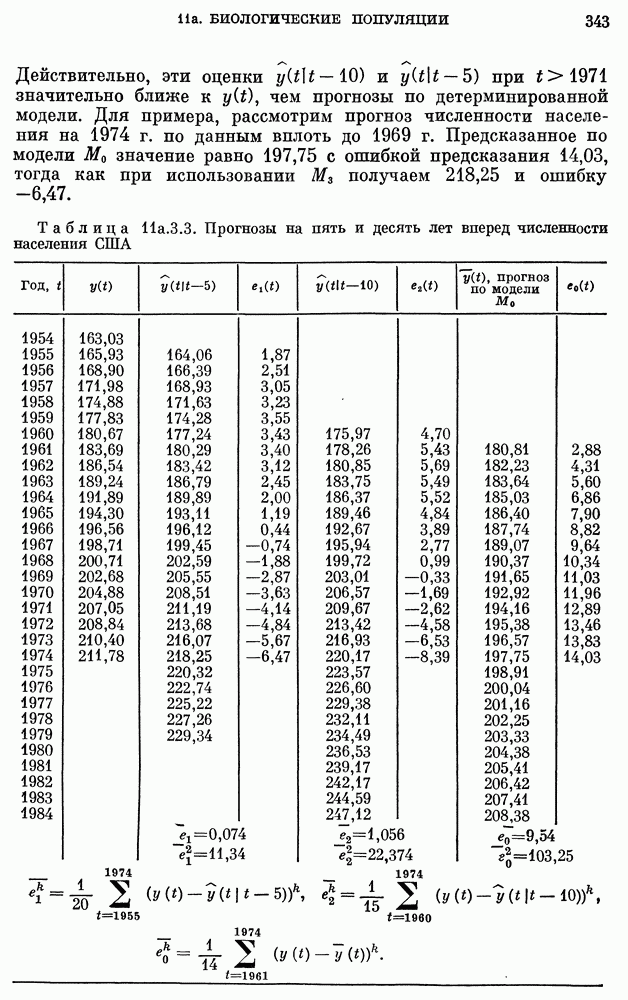
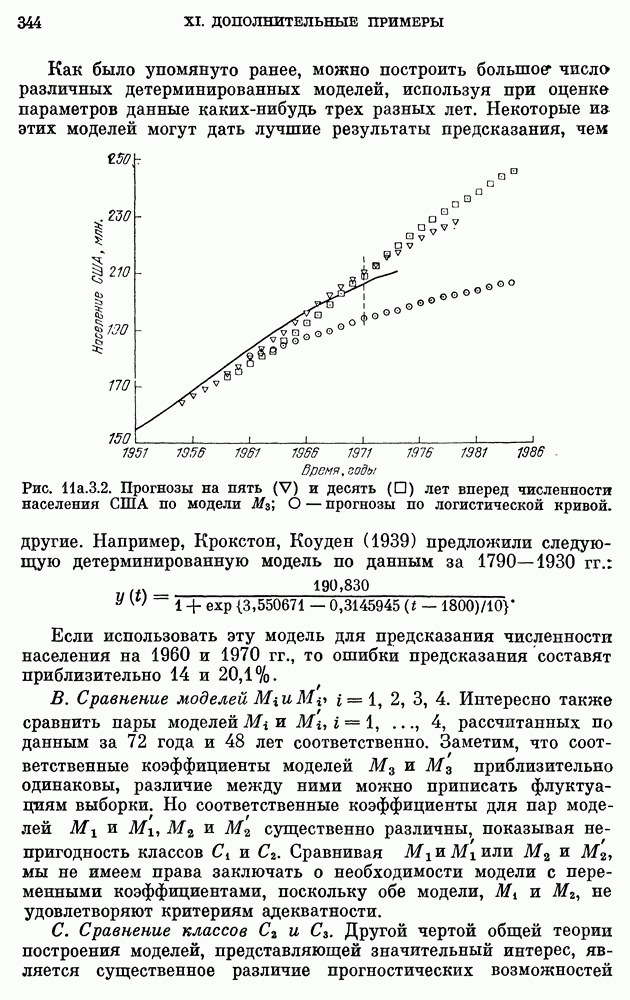
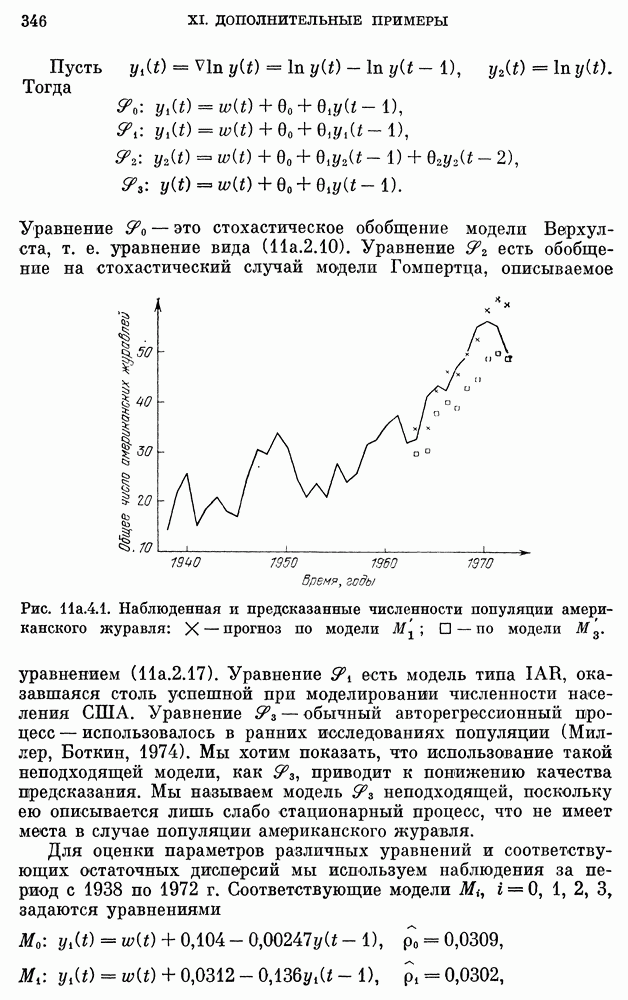
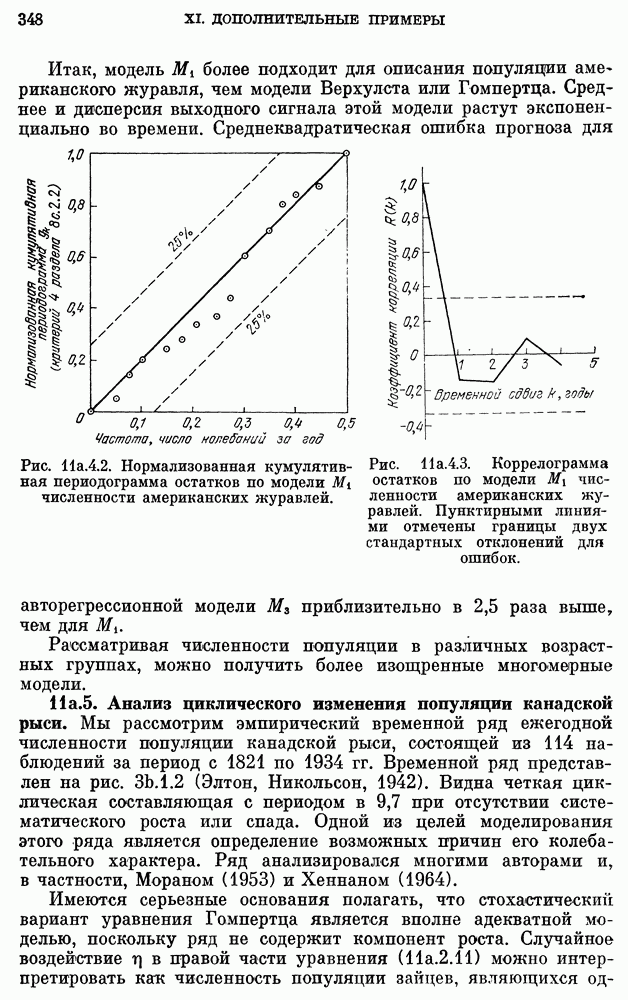
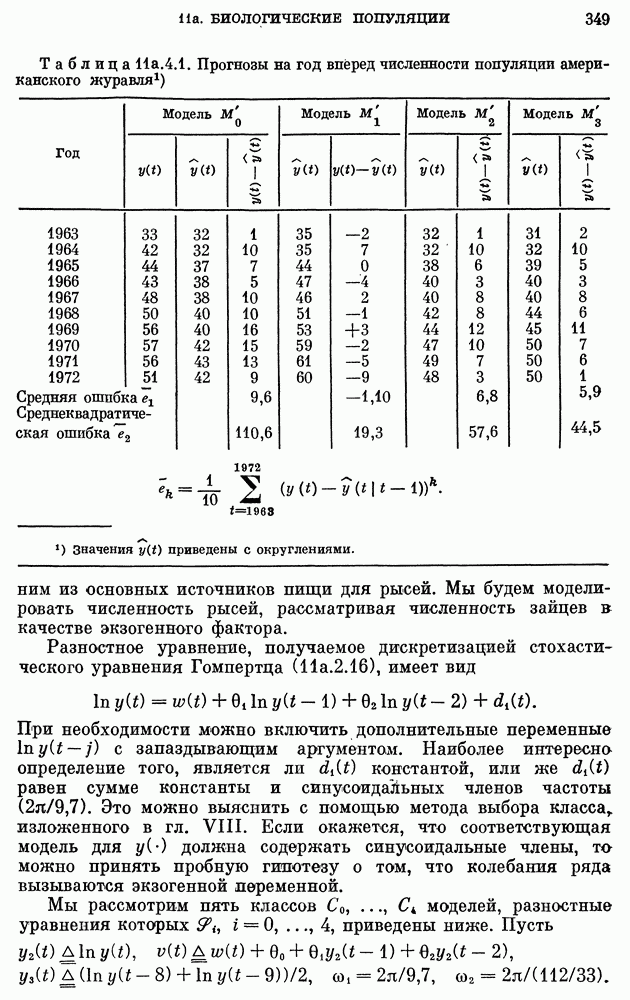
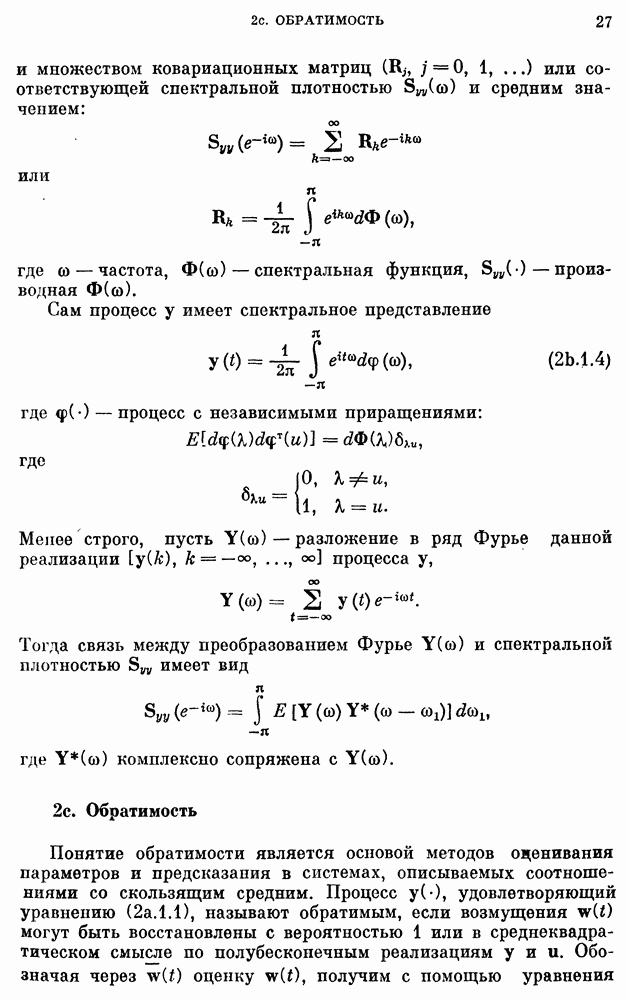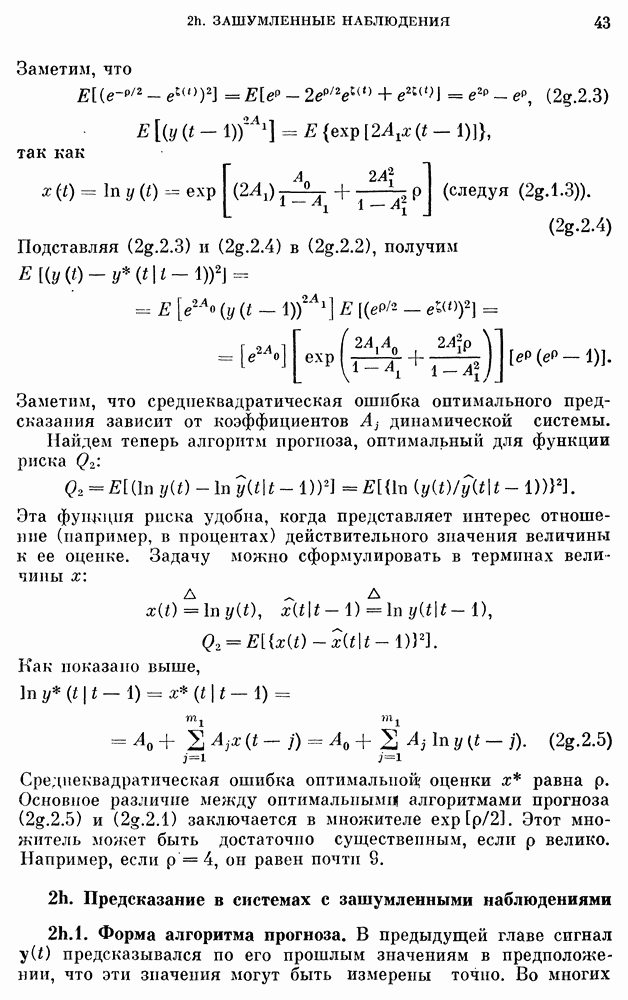8b.4. Методы, основанные на сравнении наиболее подходящих моделей.
В этом пункте определяются наиболее подходящие модели в каждом из  классов по имеющимся данным и производится непосредственное сравнение
классов по имеющимся данным и производится непосредственное сравнение  лучших моделей, в отличие от методов, использованных выше, где непосредственно сравнивались классы, а не модели. Даже несмотря на использование таких величин, как оценки параметров методом условного максимального правдоподобия в каждом классе, рассуждения не основывались на сравнении отдельных моделей в явном виде.
лучших моделей, в отличие от методов, использованных выше, где непосредственно сравнивались классы, а не модели. Даже несмотря на использование таких величин, как оценки параметров методом условного максимального правдоподобия в каждом классе, рассуждения не основывались на сравнении отдельных моделей в явном виде.
8b.4.1. Метод предсказания.
Этот сравнительно простой метод сравнения ряда классов обычно используется в
задачах распознавания образов (Дыода, Харт, 1973). Он основывается на сравнении относительной предсказывающей способности  наилучших моделей. В отличие от метода п. 8b.3, здесь не требуется, чтобы оценки параметров вычислялись в реальном масштабе времени. Следовательно, решающее правило находится значительно проще, чем в п. 8b.3. Пусть
наилучших моделей. В отличие от метода п. 8b.3, здесь не требуется, чтобы оценки параметров вычислялись в реальном масштабе времени. Следовательно, решающее правило находится значительно проще, чем в п. 8b.3. Пусть  четно. Множество данных делится, например, на две равные части; первая часть
четно. Множество данных делится, например, на две равные части; первая часть  используется для получения наилучшей модели процесса в каждом классе. Пусть такой моделью в классе
используется для получения наилучшей модели процесса в каждом классе. Пусть такой моделью в классе  по методу условного максимального правдоподобия является
по методу условного максимального правдоподобия является  Тогда для этой модели получим среднеквадратический одношаговый алгоритм прогноза
Тогда для этой модели получим среднеквадратический одношаговый алгоритм прогноза  Коэффициенты этого алгоритма постоянны и получены из вектора
Коэффициенты этого алгоритма постоянны и получены из вектора  Этот алгоритм прогноза используется для получения наилучших одношаговых алгоритмов прогноза процесса
Этот алгоритм прогноза используется для получения наилучших одношаговых алгоритмов прогноза процесса  по данным наблюдения до момента
по данным наблюдения до момента  Таким образом, при
Таким образом, при  является функцией только наблюдений
является функцией только наблюдений  следовательно, является корректным алгоритмом прогноза
следовательно, является корректным алгоритмом прогноза  в то время как
в то время как  не является таковым для
не является таковым для  поскольку он явно зависит от
поскольку он явно зависит от  используемого для получения оценки
используемого для получения оценки  Показатель предсказывающей способности
Показатель предсказывающей способности  аналогичный описанному ранее, можно теперь вычислить в виде
аналогичный описанному ранее, можно теперь вычислить в виде

Решающее правило 4. Классу  отдается предпочтение в том случае, если
отдается предпочтение в том случае, если  представляет собой единственный элемент множества
представляет собой единственный элемент множества  Если таких элементов несколько, то нужно выбрать один из них с помощью вспомогательного критерия. Данное решающее правило можно обосновать, показав, что следующее выражение асимптотически справедливо, если
Если таких элементов несколько, то нужно выбрать один из них с помощью вспомогательного критерия. Данное решающее правило можно обосновать, показав, что следующее выражение асимптотически справедливо, если  является правильным классом:
является правильным классом:

Приведем схему доказательства. Пусть  Имеются два отдельных случая. Сравним класс
Имеются два отдельных случая. Сравним класс  с классом
с классом  в котором уравнение 9 не содержит по крайней мере одного члена из уравнения В этом случае можно легко получить результат (8b.4.2) по крайней мере асимптотически. Сравним далее
в котором уравнение 9 не содержит по крайней мере одного члена из уравнения В этом случае можно легко получить результат (8b.4.2) по крайней мере асимптотически. Сравним далее  с классом
с классом  в котором уравнение содержит все члены уравнения
в котором уравнение содержит все члены уравнения  Тогда может быть доказан тот же результат
Тогда может быть доказан тот же результат  как показано в приложении 8.1.
как показано в приложении 8.1.
Приведенный здесь алгоритм проще в вычислительном отношении, чем метод рекурсивного предсказания п. 8b.3, но при малых  он также и менее мощный, чем метод из п. 8b.3. Докажем это утверждение. Во-первых, при вычислении среднеквадратической ошибки предсказания в
он также и менее мощный, чем метод из п. 8b.3. Докажем это утверждение. Во-первых, при вычислении среднеквадратической ошибки предсказания в  операция предсказания производится
операция предсказания производится  раз, в то время как в данном методе эта операция используется всего
раз, в то время как в данном методе эта операция используется всего  раз. Соответственно, оценки среднеквадратической ошибки предсказания в этом пункте менее точные, чем ошибки п. 8b.3. Во-вторых, в формулах предсказания п. 8b.3 используются более точные оценки параметров, чем в этом пункте. Например, в п. 8b.3 прогноз
раз. Соответственно, оценки среднеквадратической ошибки предсказания в этом пункте менее точные, чем ошибки п. 8b.3. Во-вторых, в формулах предсказания п. 8b.3 используются более точные оценки параметров, чем в этом пункте. Например, в п. 8b.3 прогноз  основан на оценках параметров, вычисленных по
основан на оценках параметров, вычисленных по  наблюдению. Однако прогноз
наблюдению. Однако прогноз  в данном пункте получен только по оценкам параметров, вычисленным по
в данном пункте получен только по оценкам параметров, вычисленным по  наблюдениям, независимо от значения? t.
наблюдениям, независимо от значения? t.
8b.4.2. Байесов подход. Обозначим наилучшие модели в каждом из  классов через
классов через  Вычислим для каждой из этих моделей апостериорную вероятность того, что она является правильной при данных наблюдениях, и предпочтем ту модель, которая имеет наибольшую апостериорную вероятность. Искомым классом будет класс, связанный с этой моделью.
Вычислим для каждой из этих моделей апостериорную вероятность того, что она является правильной при данных наблюдениях, и предпочтем ту модель, которая имеет наибольшую апостериорную вероятность. Искомым классом будет класс, связанный с этой моделью.
Для вычисления апостериорных вероятностей необходимо знание априорных вероятностей  моделей, которые выбираются следующим образом: если
моделей, которые выбираются следующим образом: если  модель содержит
модель содержит  коэффициентов, то
коэффициентов, то

где k — нормирующий множитель. Интуитивным подтверждением этого выбора является принцип экономности, т. е. при выборе модели нужно отдавать предпочтение модели с наименьшим возможным количеством членов. Дополнительным преимуществом такого выбора является то, что окончательный выбор класса этим методом идентичен выбору по методу правдоподобия для больших  при нормальном шуме.
при нормальном шуме.
Упомянутое выше априорное распределение принадлежит к числу объединенных. Но сторонники субъективного байесова подхода (Сэвидж, 1962) считают, что априорное распределение должно содержать всю имеющуюся описательную информацию о классе. В данном случае априорное распределение основано частично на соображениях описательного характера, а частично просто задается.
Вычислим теперь апостериорные вероятности. Пусть 

Плотность вероятности известна по определению,  где является оценкой условного максимального правдоподобия (или байесовой оценкой) неизвестного вектора параметров
где является оценкой условного максимального правдоподобия (или байесовой оценкой) неизвестного вектора параметров  классе, характеризующего данное множество наблюдений
классе, характеризующего данное множество наблюдений

Таким образом, класс, имеющий более высокую апостериорную вероятность, совпадает с классом, найденным по методу правдоподобия в п. 8b.1.1.
Здесь был  лишь один из аспектов байесовой теории. Другие точки зрения на использование теории Байеса в анализе временных рядов можно найти у Бокса, Тяо (1973) и Зеллнера (1971).
лишь один из аспектов байесовой теории. Другие точки зрения на использование теории Байеса в анализе временных рядов можно найти у Бокса, Тяо (1973) и Зеллнера (1971).