ее можно факторизовать для получения разностного уравнения относительно х. Однако порядок разностного уравнения, полученного таким образом, может быть высоким. Если порядок разностного уравнения требуется уменьшить, то появится ошибка аппроксимации. Следовательно, уравнение для процесса у будет давать по крайней мере не худшее предсказание, чем уравнение для  как правило, предсказание, полученное по модели для процесса у, оказывается лучше, чем предсказание, полученное по модели процесса х, из-за упомянутых выше ошибок аппроксимации.
как правило, предсказание, полученное по модели для процесса у, оказывается лучше, чем предсказание, полученное по модели процесса х, из-за упомянутых выше ошибок аппроксимации.
Такого рода анализ, как отмечалось выше, слишком упрощен и был бы корректен, если бы мы знали, что месячные данные точно представимы в виде линейного разностного уравнения с  На практике, однако, мы редко располагаем такими данными. Построенная модель является только приближением заданного процесса. Более того, сама модель, построена ли она для у или налагает ограничения на информацию, используемую для оценивания в ней неизвестных коэффициентов. Например, если мы строим для заданного процесса
На практике, однако, мы редко располагаем такими данными. Построенная модель является только приближением заданного процесса. Более того, сама модель, построена ли она для у или налагает ограничения на информацию, используемую для оценивания в ней неизвестных коэффициентов. Например, если мы строим для заданного процесса  модель
модель  то оценивание коэффициентов будет связано только с использованием свойств нулевого и первого порядка:
то оценивание коэффициентов будет связано только с использованием свойств нулевого и первого порядка:

Такая модель не будет содержать информации вида

которая имеется в исходных данных. Теперь, если модель для агрегированного процесса  подобрана с непосредственным использованием данных, то модель для
подобрана с непосредственным использованием данных, то модель для  будет содержать оценки автоковариаций процесса
будет содержать оценки автоковариаций процесса  которые будут вычислены с помощью ковариаций
которые будут вычислены с помощью ковариаций

а раз так, возможно, что агрегированная модель для х даст более хорошее предсказание, чем исходная модель для  из-за содержащейся в ней дополнительной информации. Из вышесказанного можно заключить, что должны быть построены различные модели с различными уровнями дискретизации так, чтобы из множества различных моделей можно было выбрать наиболее подходящую модель для данной конкретной задачи. Об оценке параметров по агрегированным данным можно прочитать в работах Ингла, Лю Тачунга (1972) и Ли и др. (1978).
из-за содержащейся в ней дополнительной информации. Из вышесказанного можно заключить, что должны быть построены различные модели с различными уровнями дискретизации так, чтобы из множества различных моделей можно было выбрать наиболее подходящую модель для данной конкретной задачи. Об оценке параметров по агрегированным данным можно прочитать в работах Ингла, Лю Тачунга (1972) и Ли и др. (1978).
3е. Заключение
Основной целью этой главы было проиллюстрировать поведение различных типов разностных уравнений, содержащих различные типы членов, таких как  тренд, изменяющиеся во времени коэффициенты. Были также предложены различные классы моделей, которые следует рассматривать при построении моделей эмпирических рядов с такими характерными свойствами, как рост и систематические колебания.
тренд, изменяющиеся во времени коэффициенты. Были также предложены различные классы моделей, которые следует рассматривать при построении моделей эмпирических рядов с такими характерными свойствами, как рост и систематические колебания.
Комментарии
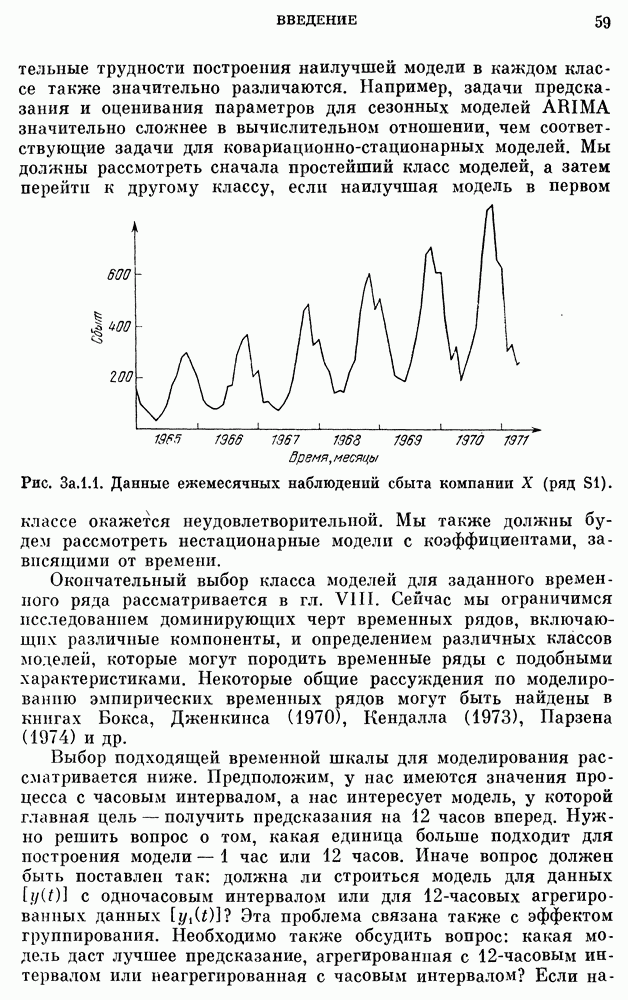
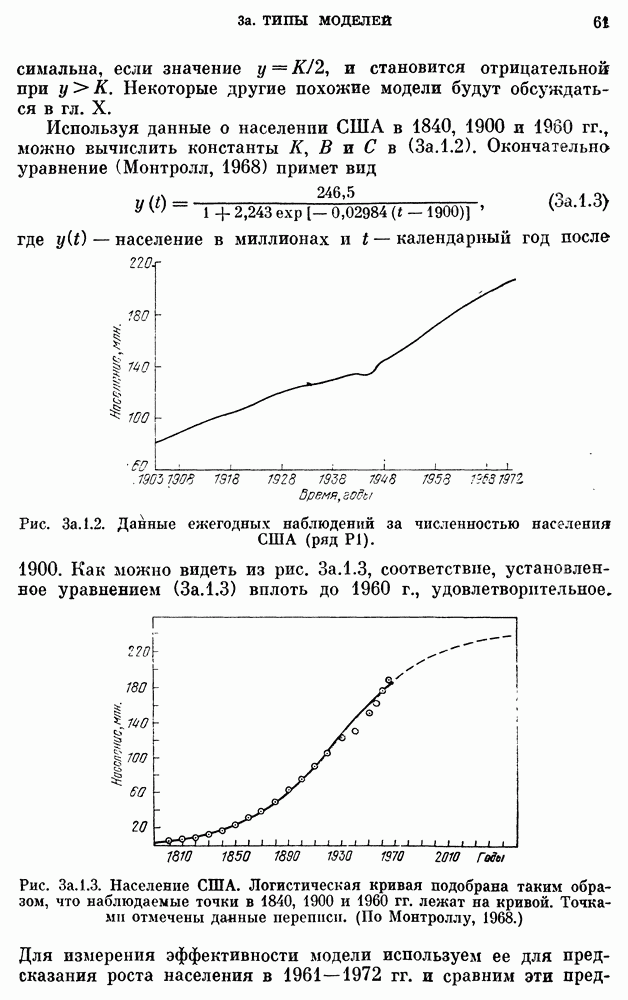
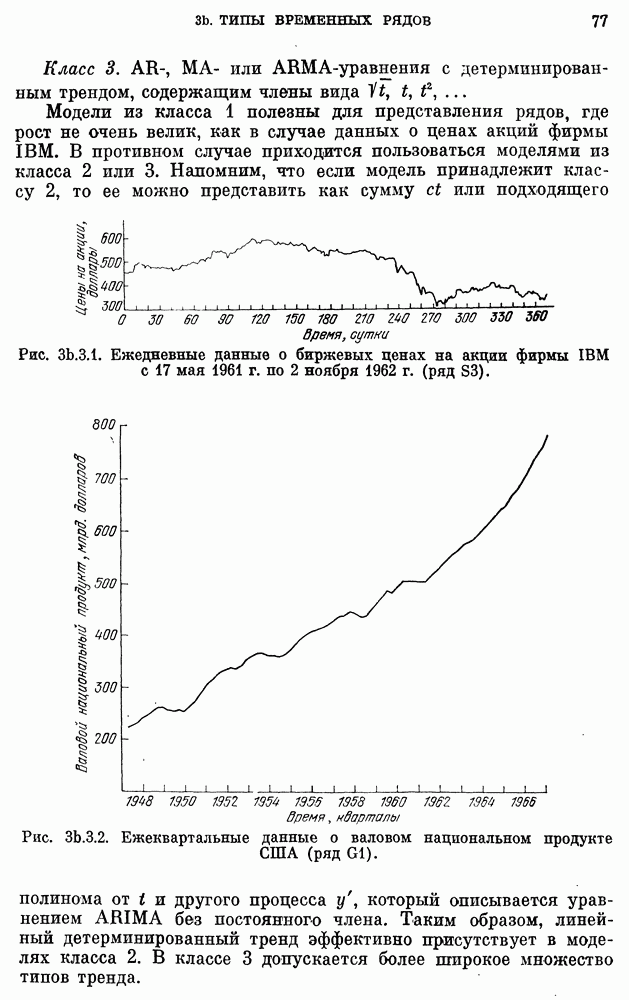
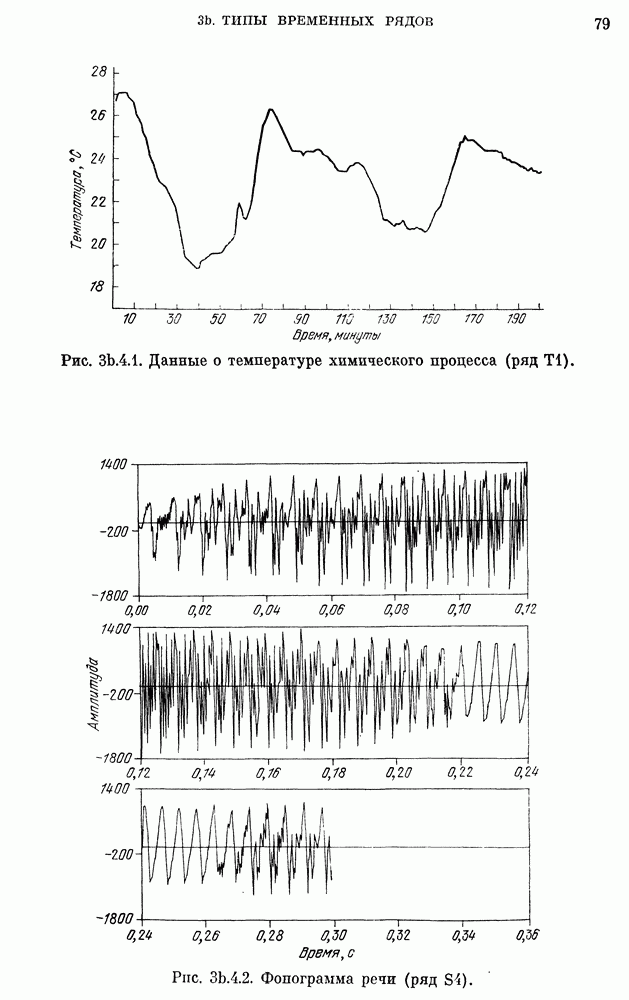
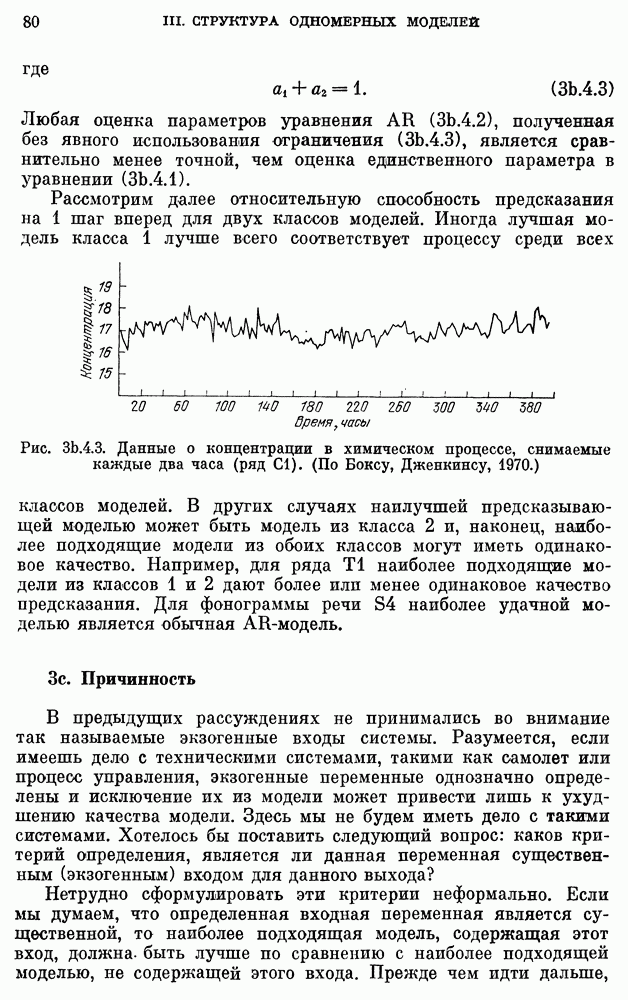
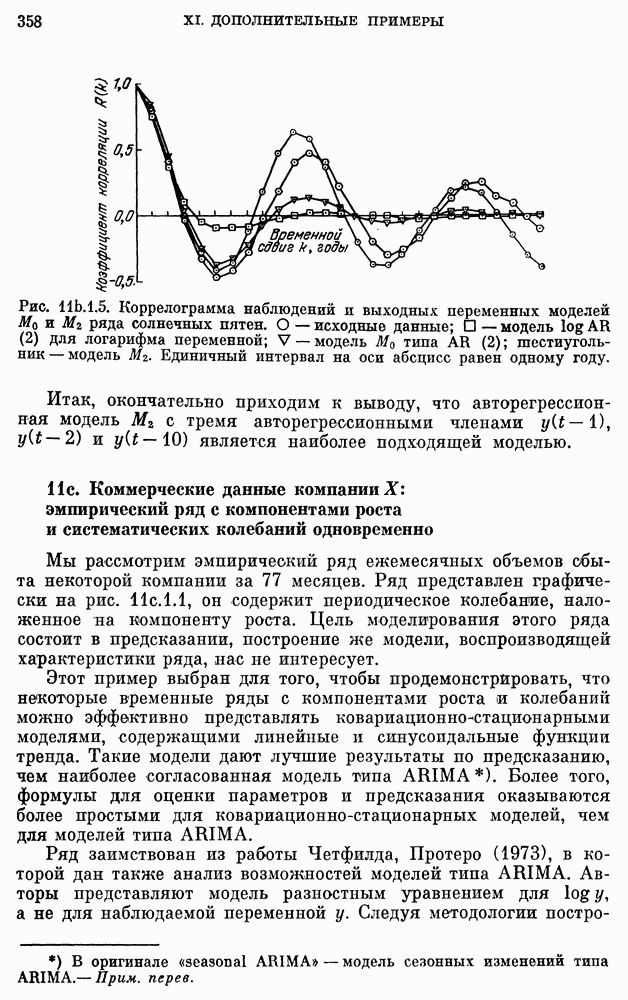
Данные о сбыте компании X на рис. 3a. 1.1 заимствованы у Четфилда и Протеро (1973). Ежегодные данные о численности населения США взяты из Статистического сборника (1974). Данные о валовом национальном продукте на рис. 3Ь.З.2 и о РТДП на рис. 3а.2.1 взяты из книги Нельсона (1973). Данные о стоимости акций фирмы IBM на рис. 3b.З.1, о концентрации химического процесса на рис. 3а.2.3 и о температуре на рис. 3b.4.1 взяты у Бокса, Дженкинса (1970). Данные о годовом числе солнечных пятен на рис. 3b.1.1 приведены по Валдмейеру (1961), данные о рыси на рис. 3а — по изданию ЮНЕСКО (1971).
Задачи
(см. скан)





















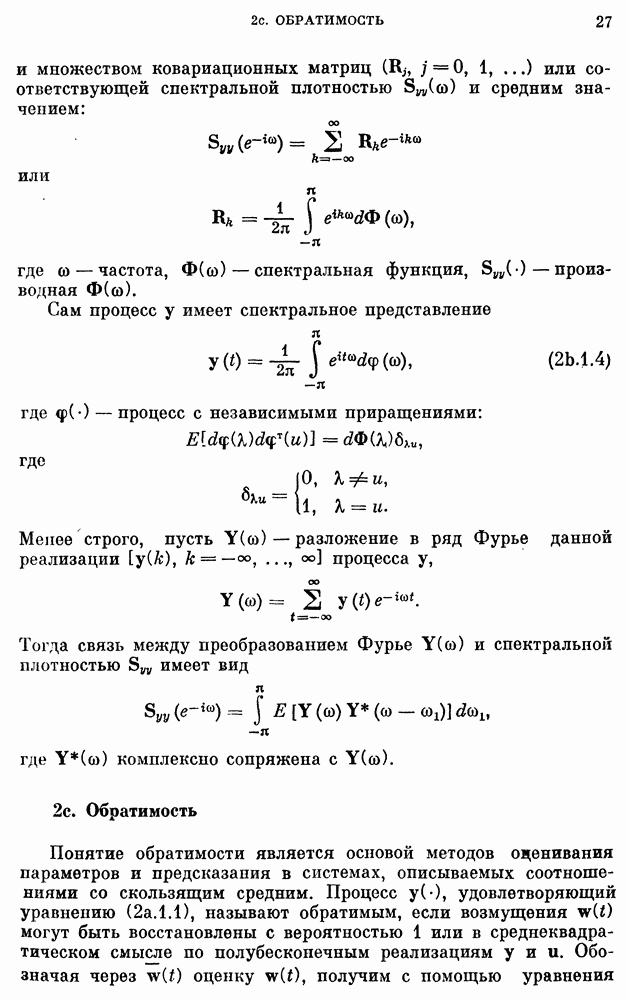





























































































































































































































































































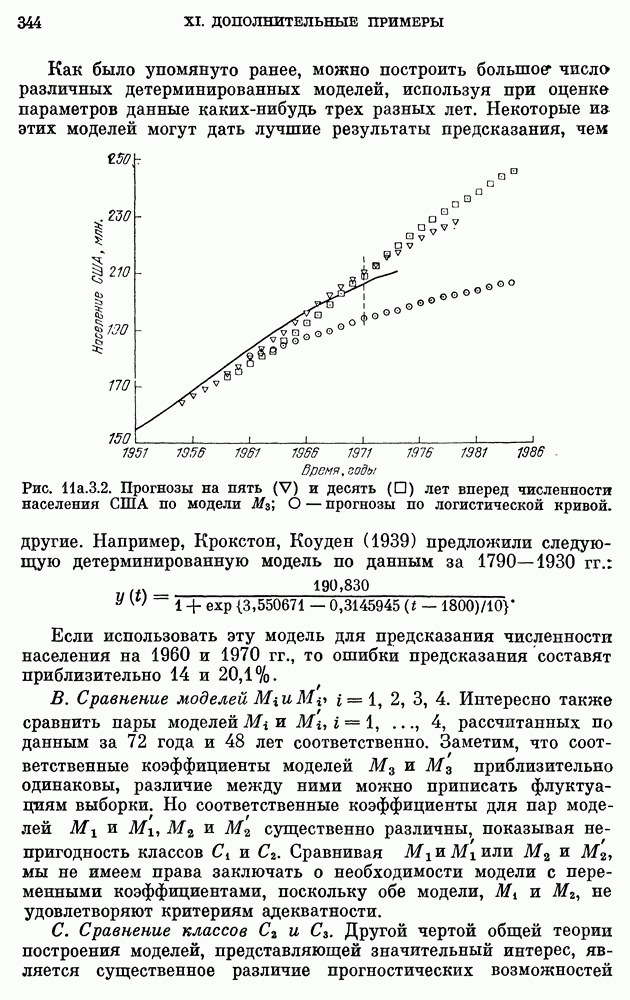

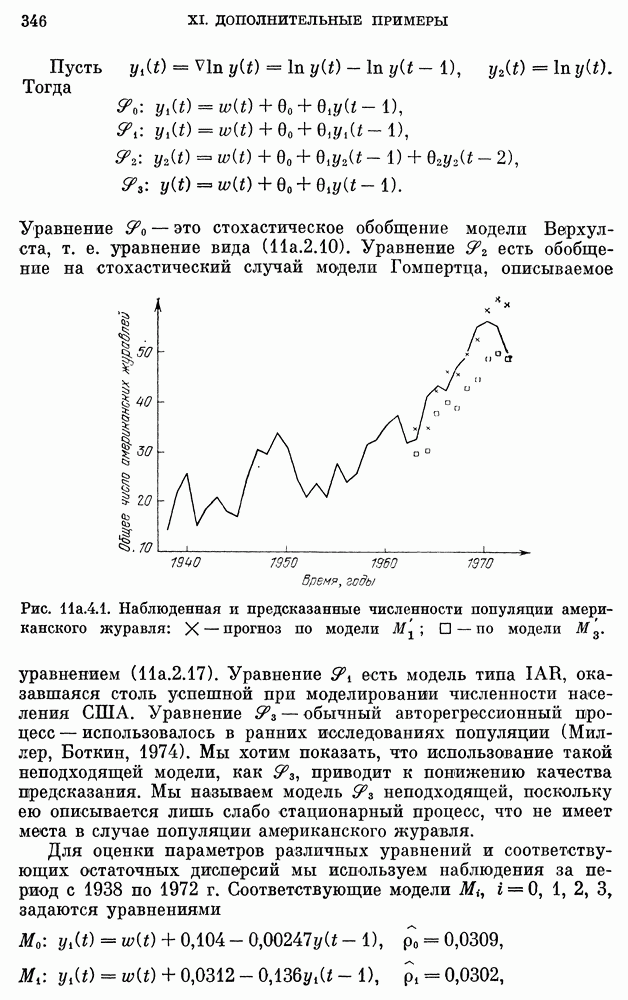

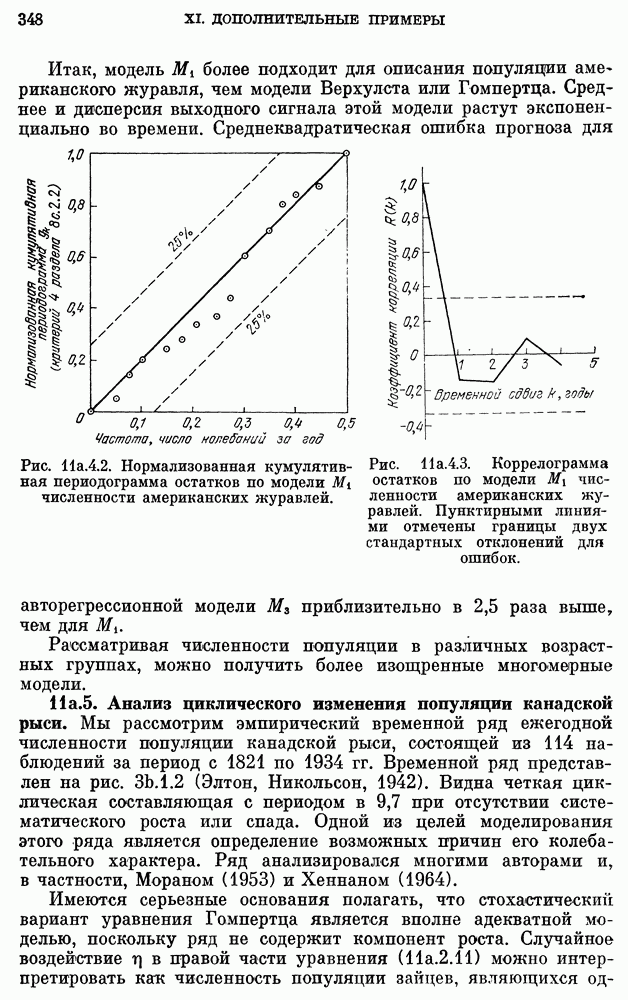
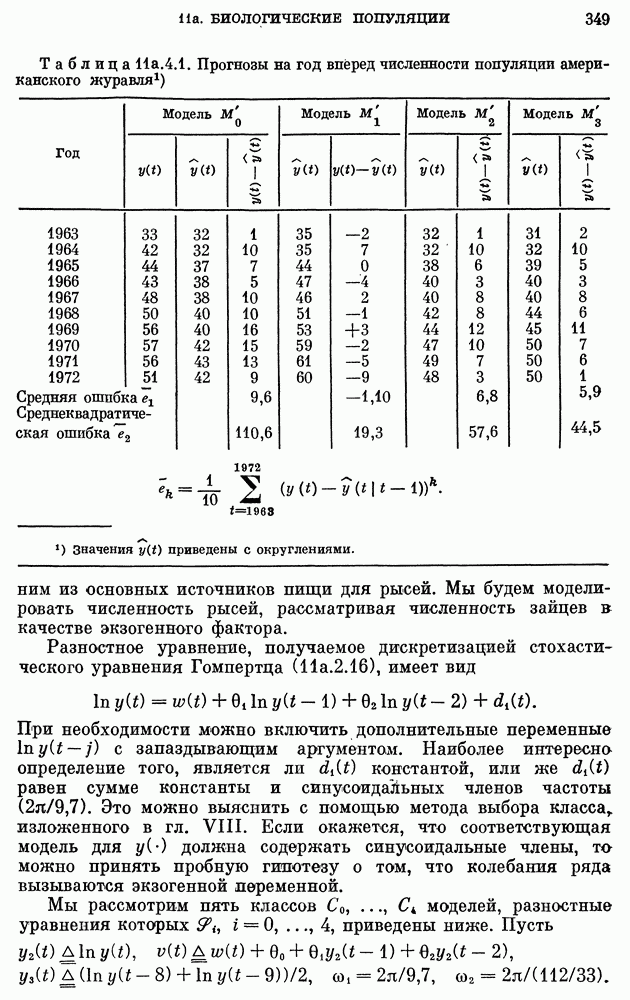




 или же построить модель с агрегированными данными. Модель с агрегированными данными будет иметь интервал дискретизации
или же построить модель с агрегированными данными. Модель с агрегированными данными будет иметь интервал дискретизации  где
где  может изменяться от 2 до 12. Непосредственным решением будет построение месячной модели (модель с
может изменяться от 2 до 12. Непосредственным решением будет построение месячной модели (модель с  поскольку модели с другими уровнями дискретизации могут быть получены из нее. Например, пусть имеются данные
поскольку модели с другими уровнями дискретизации могут быть получены из нее. Например, пусть имеются данные  где
где  соответствует одному месяцу, и пусть модель, построенная с
соответствует одному месяцу, и пусть модель, построенная с  имеет спектральную плотность
имеет спектральную плотность  Рассмотрим агрегированный процесс с
Рассмотрим агрегированный процесс с 

 имеет вид
имеет вид

