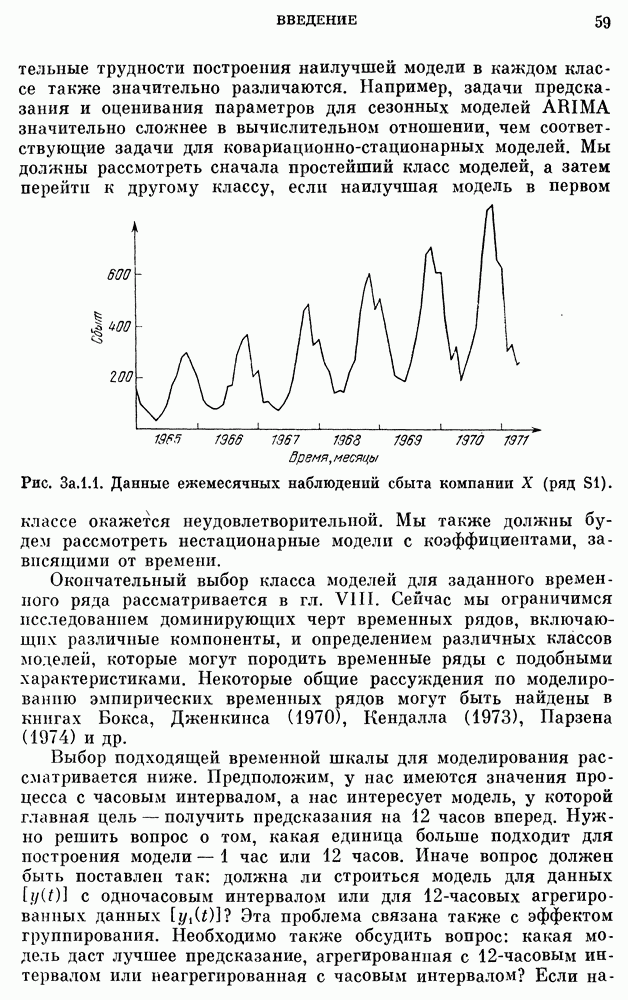
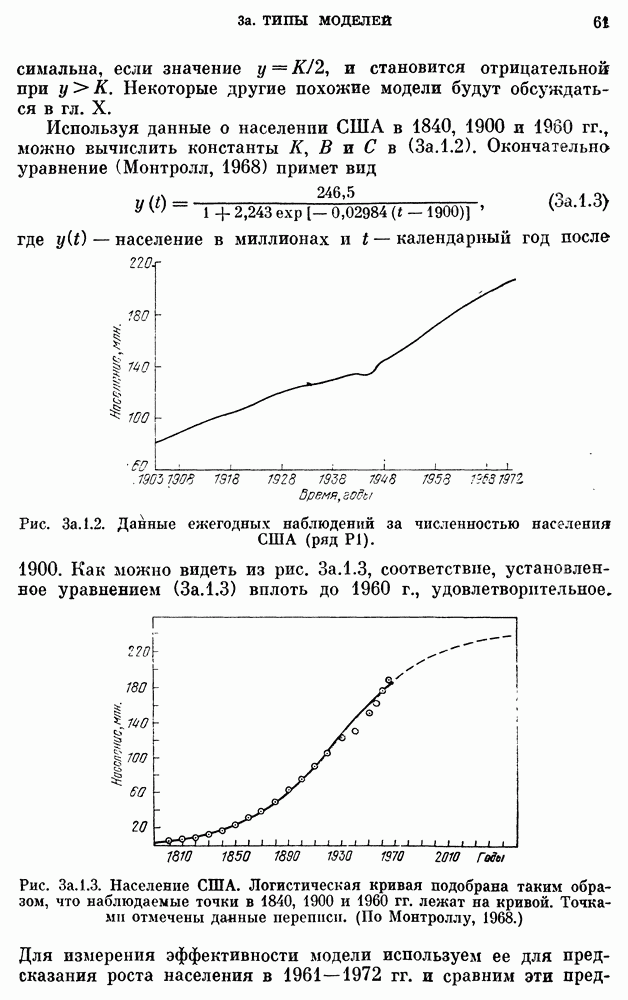
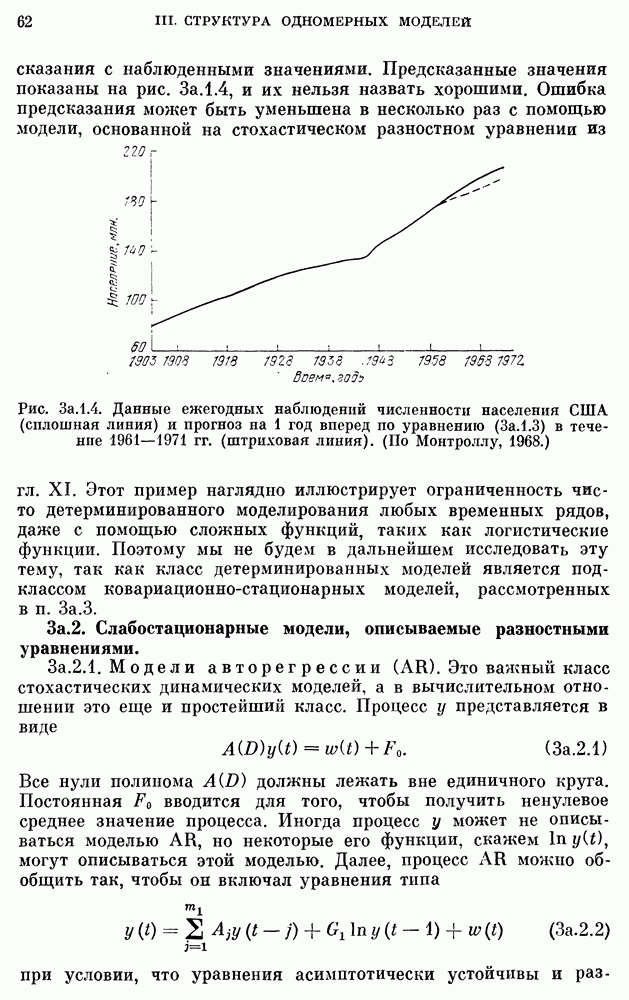
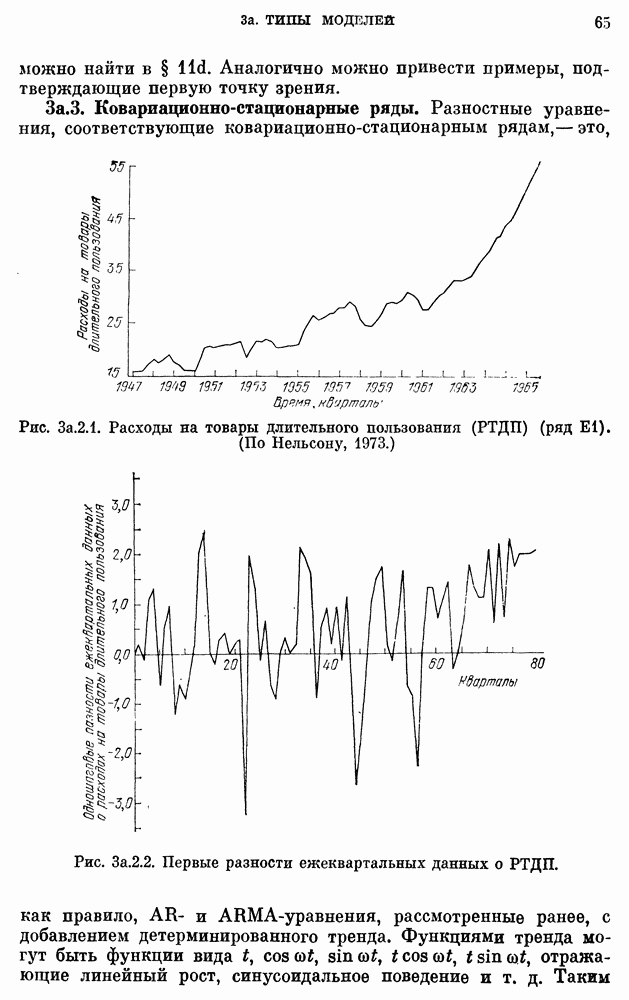
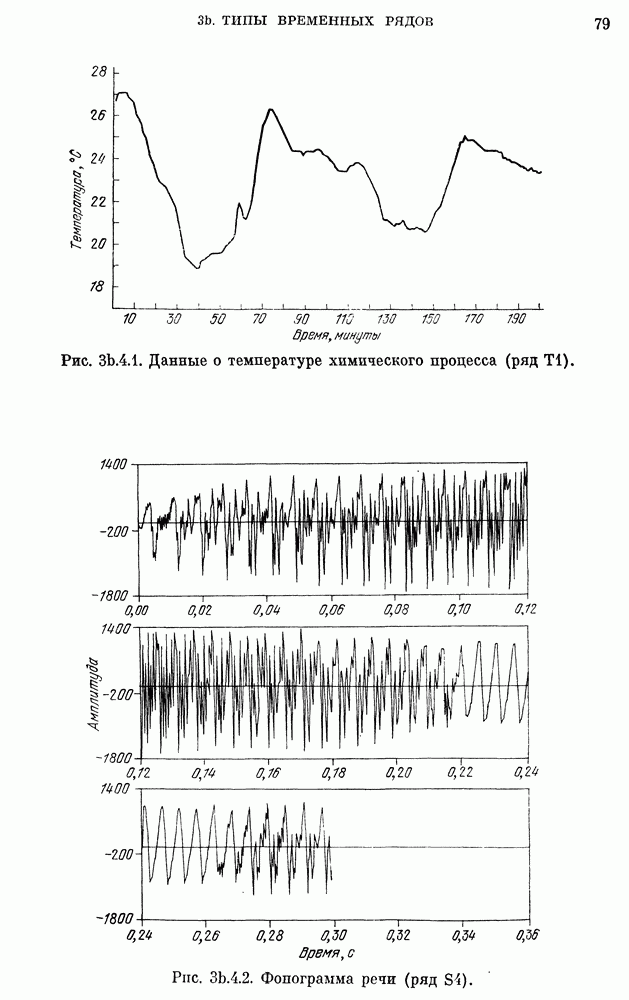
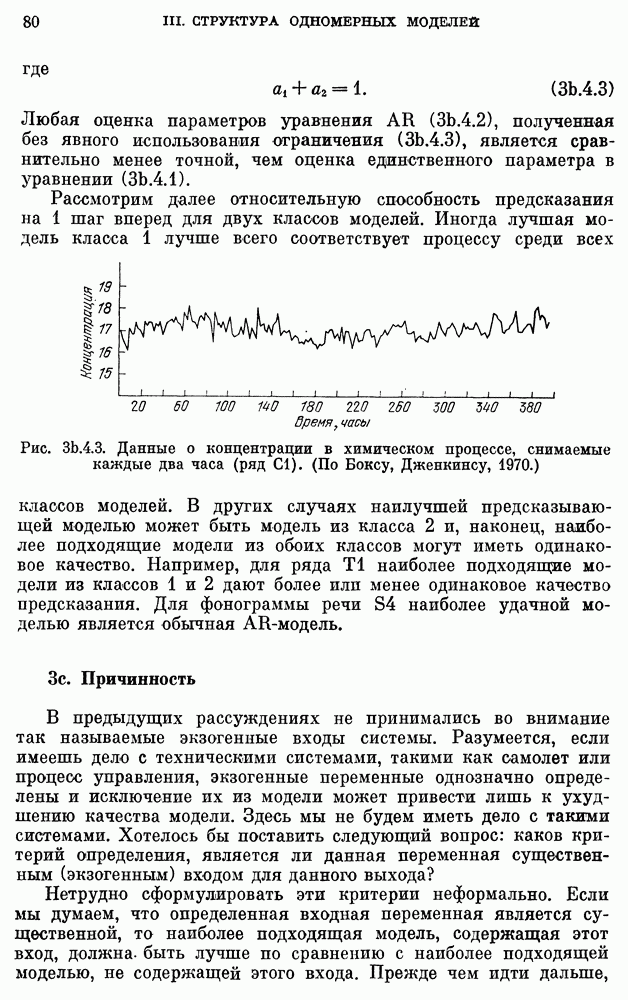
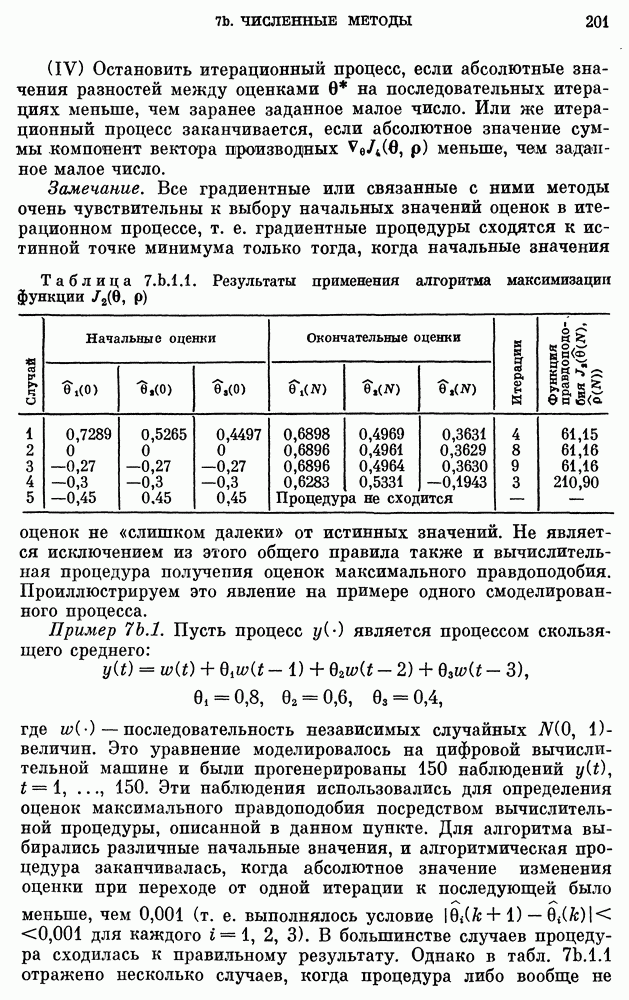
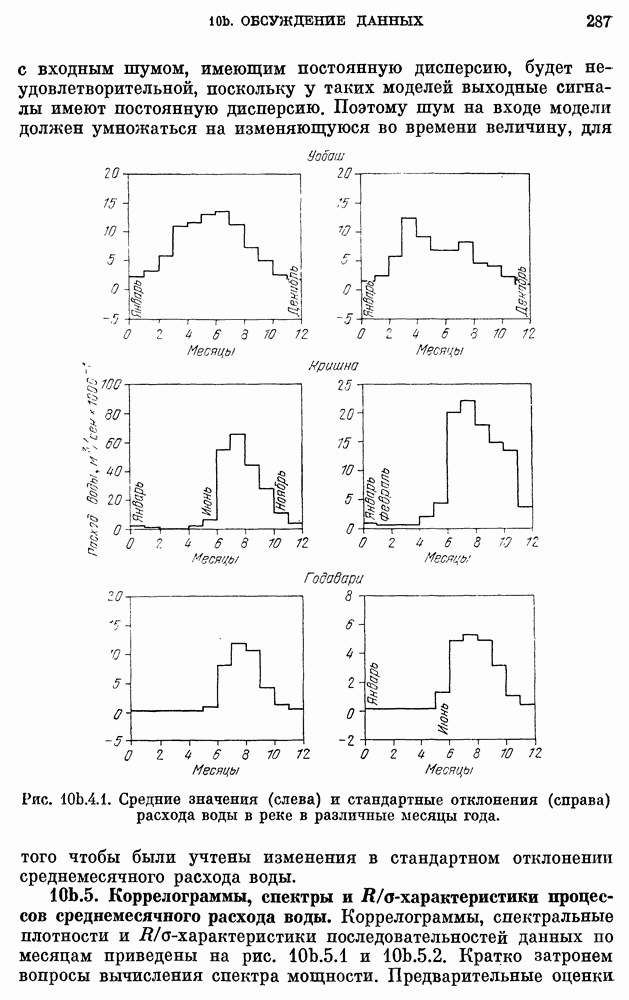
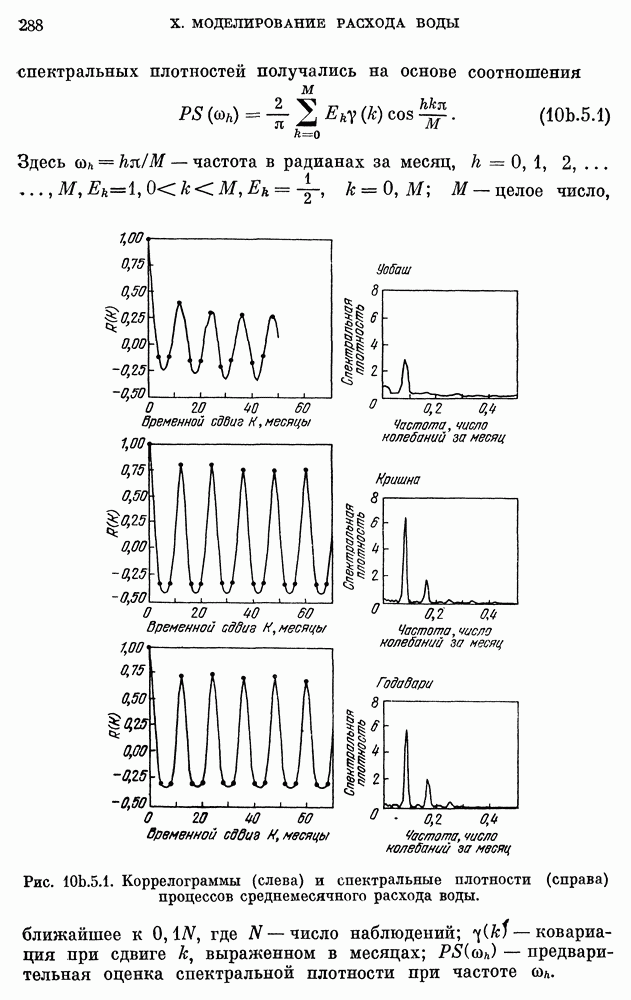
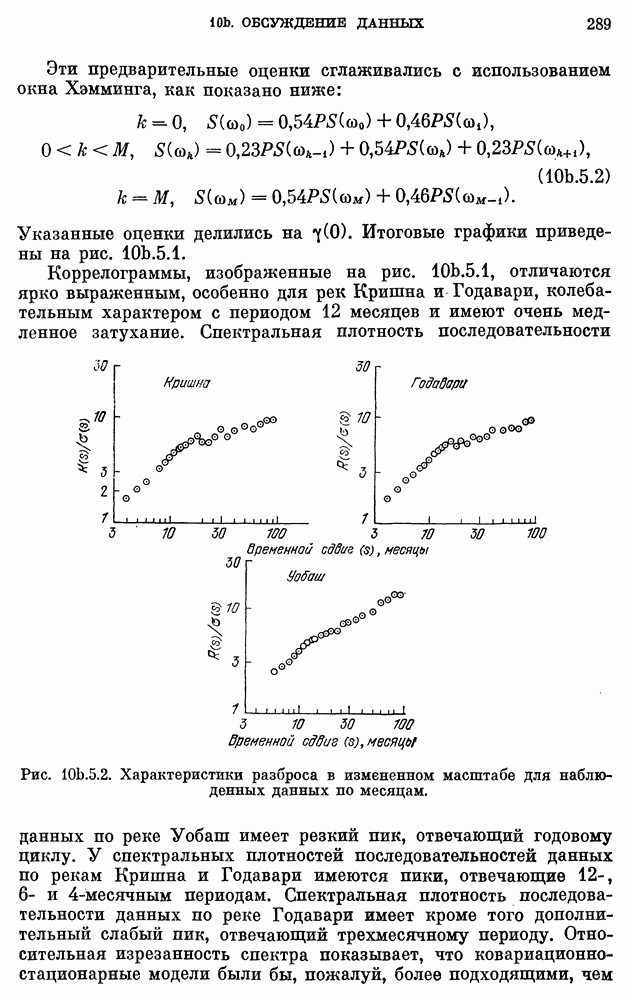
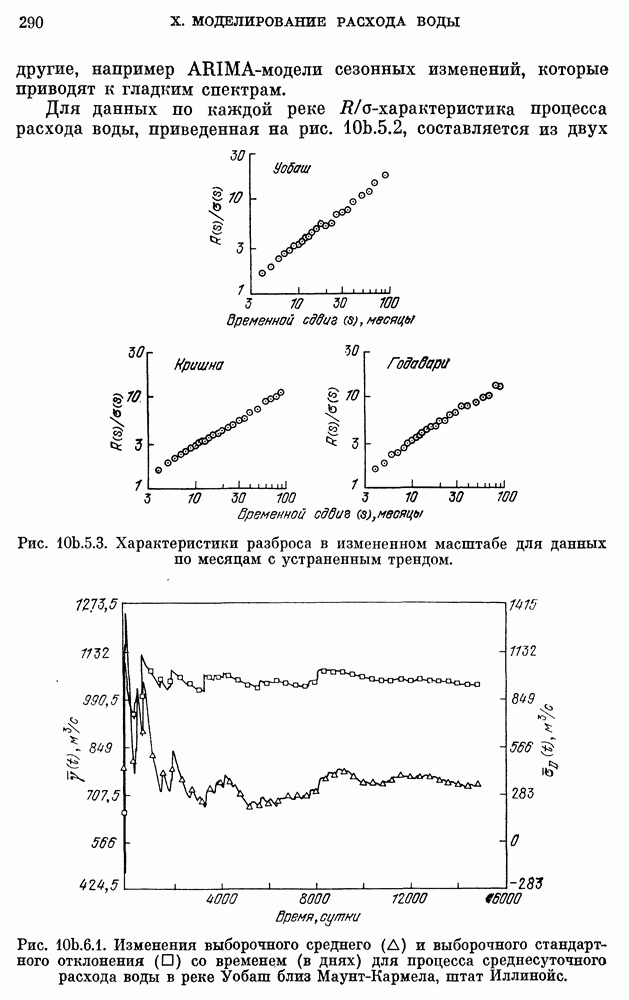
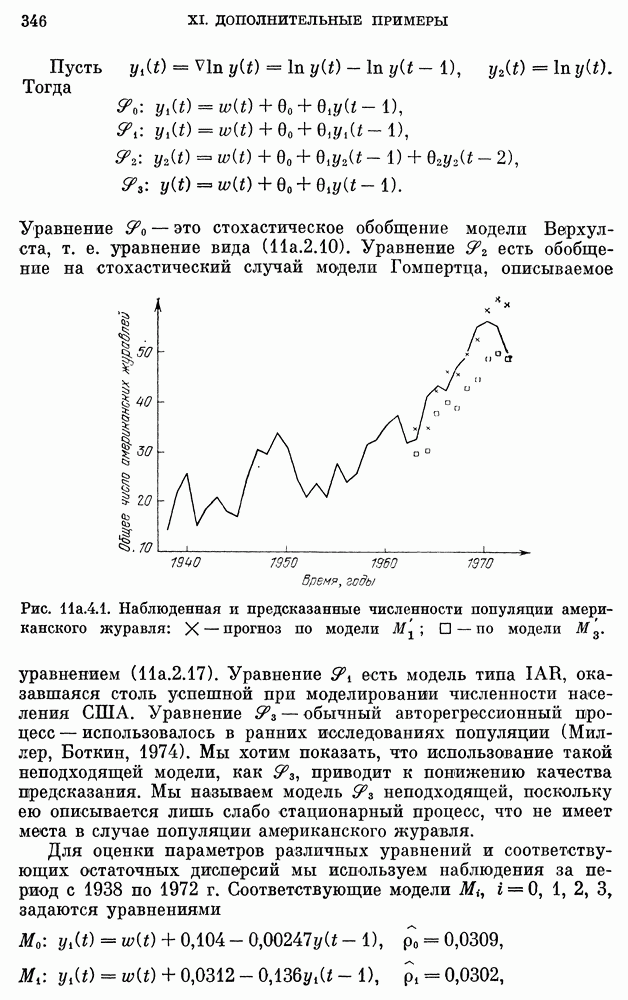
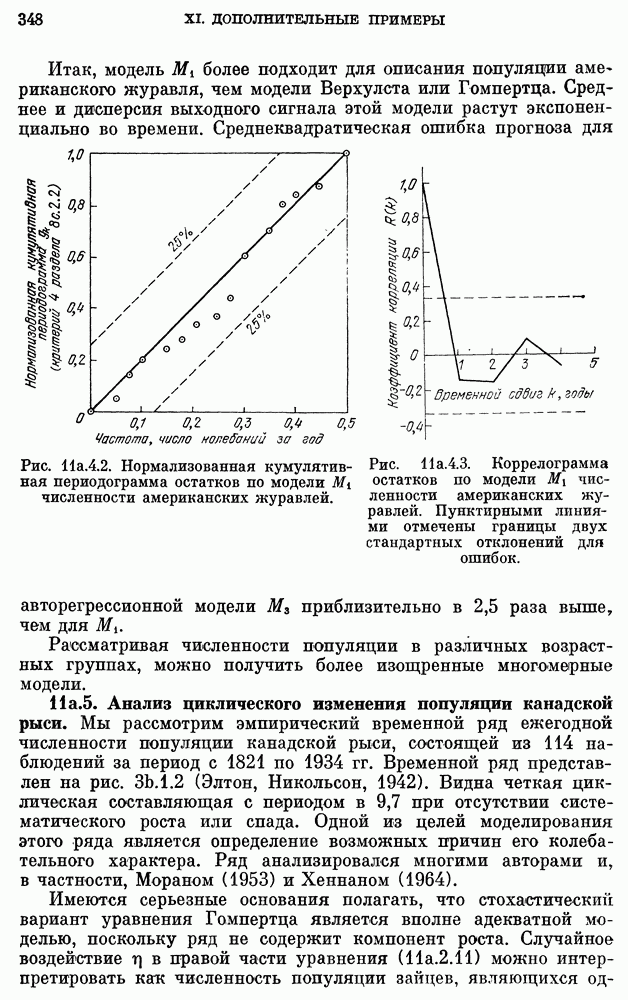
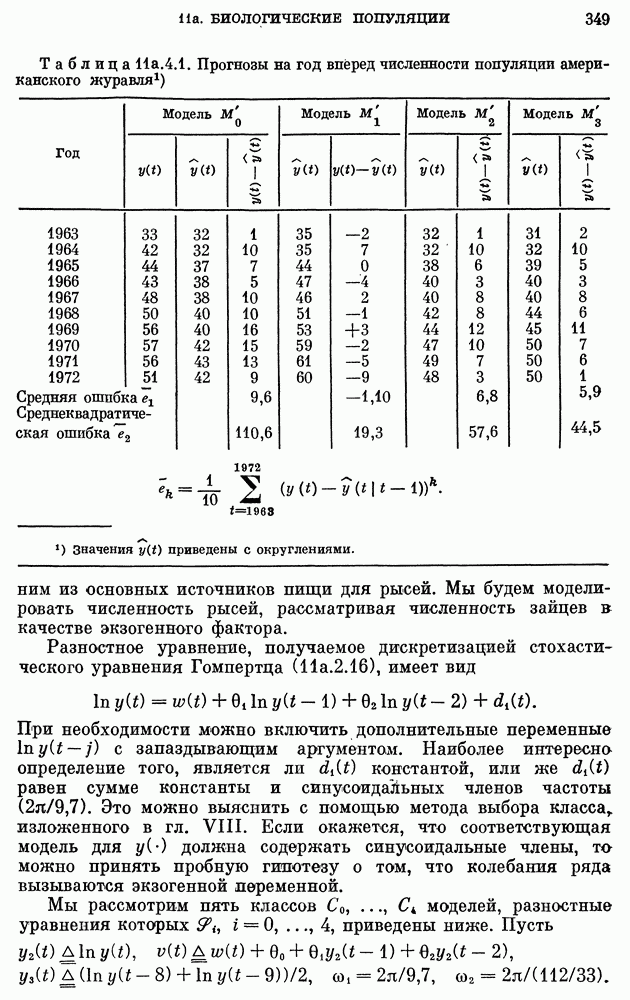
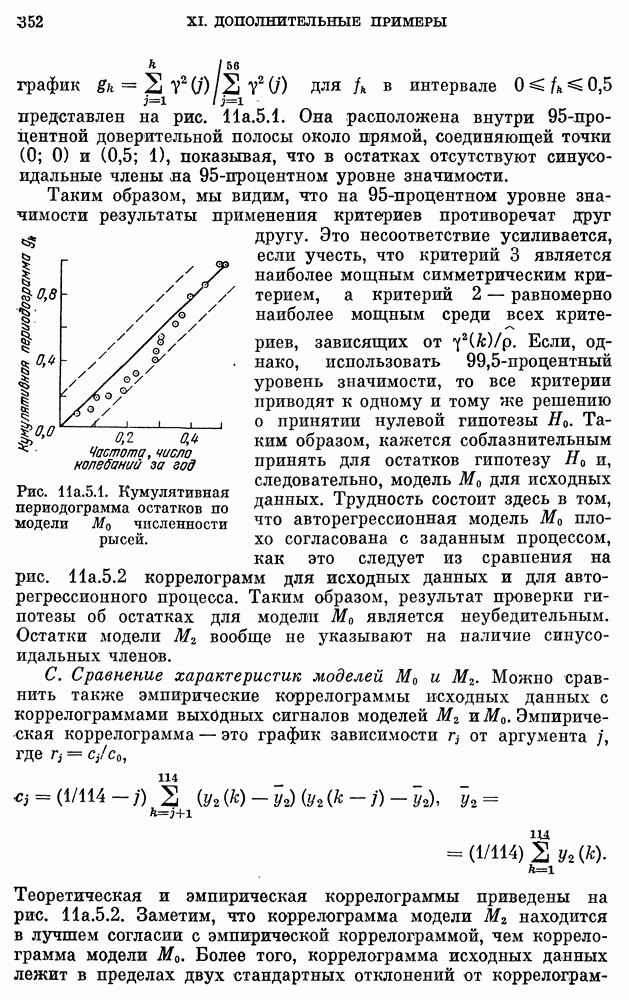
10е. Модели для данных по годам о расходе воды
Построение и проверка адекватности AR- и ARMA-моделей для данных о расходе воды, идущих с годовым интервалом — относительно нетрудная задача. Тем не менее не так давно утверждалось, что только модели с дробными шумами могут описывать, наблюденные последовательности среднегодового расхода воды в
реках благодаря их способности воспроизводить временную характеристику разброса в измененном масштабе.
Однако способность модели передавать одно частное свойство процесса вовсе не означаем что модель может представлять другие характеристики данных, такие как коррелограмма и спектральная плотность. Далее, способность модели с дробным шумом сохранять информацию о коэффициенте Херста  не означает ее превосходства над наилучшими AR- и ARMA-моделями с точки зрения прямой проверки, например проверки гипотез.
не означает ее превосходства над наилучшими AR- и ARMA-моделями с точки зрения прямой проверки, например проверки гипотез.
Имея в виду эти соображения, сравним наилучшие модель авторегрессии и модель с дробным шумом для процессов среднегодового расхода воды со следующих точек зрения: а) способности воспроизводить корреляцию и временную характеристику разброса в измененном масштабе,  классической проверки гипотез и байесовых критериев,
классической проверки гипотез и байесовых критериев,  свойств ошибок прогноза на один шаг вперед и
свойств ошибок прогноза на один шаг вперед и  физической интерпретации. Результаты обсуждаются в
физической интерпретации. Результаты обсуждаются в  Будут рассмотрены только процессы расхода воды, нормированные следующим образом:
Будут рассмотрены только процессы расхода воды, нормированные следующим образом:

10е.1. Различные типы моделей.
Среди моделей в виде конечных разностных уравнений для моделирования процессов среднегодового расхода воды достаточно ограничиться классом авторегрессионных. Нет надобности в рассмотрении IAR-модели и других, так как выборочные корреляционные функции довольно быстро затухают с ростом сдвига. Члены скользящего среднего также не улучшают качества подобранной модели. Поэтому для данных о расходе воды по годам разрабатываются AR-модели.
Их порядок для каждой реки можно определить способом, рассмотренным в гл. VIII. Мы опускаем детали и приводим только окончательные модели. Будем обозначать их через  чтобы отличить от соответствующих моделей с дробным шумом, для которых употребляется обозначение
чтобы отличить от соответствующих моделей с дробным шумом, для которых употребляется обозначение  Через
Через  обозначается нормированный процесс среднегодового расхода воды.
обозначается нормированный процесс среднегодового расхода воды.
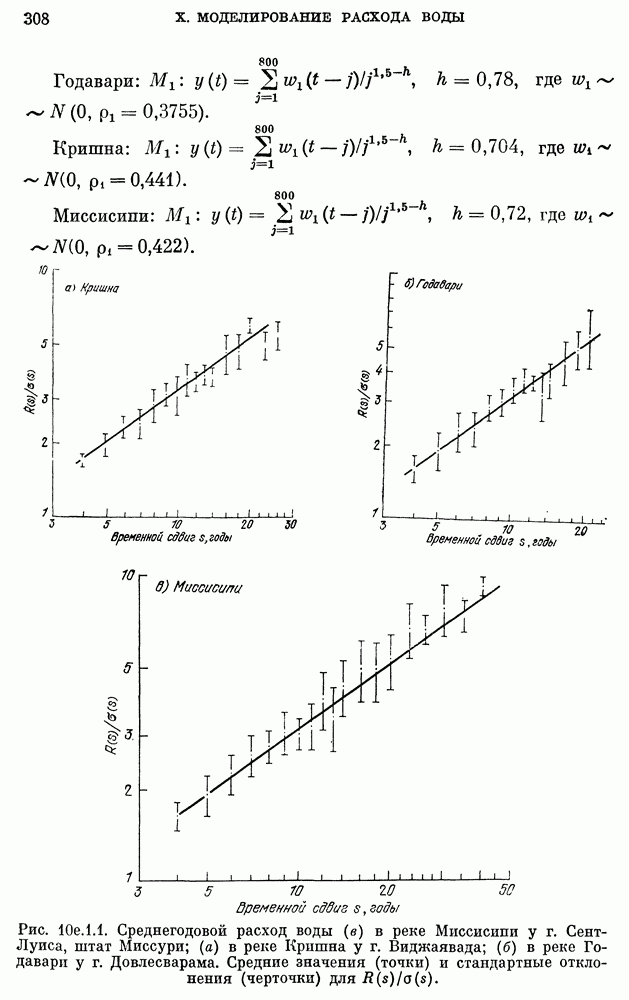
Годавари: 

Кришна: 

Миссисипи: 

Член  в модели
в модели  для реки Годавари и член
для реки Годавари и член 
Важно отметить, что модель с дробным шумом  сравнивается только с наилучшей моделью
сравнивается только с наилучшей моделью  в классе ARMA, а не с произвольной моделью. Произвольно выбранную ARMA-модель нельзя использовать для сравнения с моделью с дробным шумом, поскольку результаты такого сравнения могут вводить в сильное заблуждение. Например, для данных о расходе воды в реке Годавари была подобрана ARMA(1, 1)-модель с использованием описанных ранее методов. Полученная модель имеет вид
в классе ARMA, а не с произвольной моделью. Произвольно выбранную ARMA-модель нельзя использовать для сравнения с моделью с дробным шумом, поскольку результаты такого сравнения могут вводить в сильное заблуждение. Например, для данных о расходе воды в реке Годавари была подобрана ARMA(1, 1)-модель с использованием описанных ранее методов. Полученная модель имеет вид

Примечательной чертой вышеуказанной модели являются очень большие значения двух ее коэффициентов и, как следствие, неустойчивость модели. Причина такого явления заключается в том, что выборочный коэффициент корреляции  при сдвиге 1 для данных по реке Годавари очень мал и почти незначим, а отношение
при сдвиге 1 для данных по реке Годавари очень мал и почти незначим, а отношение  соответственно очень велико (оно равно 125,5). Следовательно, для того, чтобы получить правильные результаты, нужно использовать для сравнения соответствующий представитель из класса ARMA. Хотя исследования по моделированию показали, что
соответственно очень велико (оно равно 125,5). Следовательно, для того, чтобы получить правильные результаты, нужно использовать для сравнения соответствующий представитель из класса ARMA. Хотя исследования по моделированию показали, что  -модель может воспроизводить как коэффициент корреляции при сдвиге 1, так и
-модель может воспроизводить как коэффициент корреляции при сдвиге 1, так и  -характеристики некоторых моделей с дробным шумом, тем не менее из представленного примера явствует, что
-характеристики некоторых моделей с дробным шумом, тем не менее из представленного примера явствует, что  -модель, как таковая, является очень плохой моделью для наблюденного процесса.
-модель, как таковая, является очень плохой моделью для наблюденного процесса.
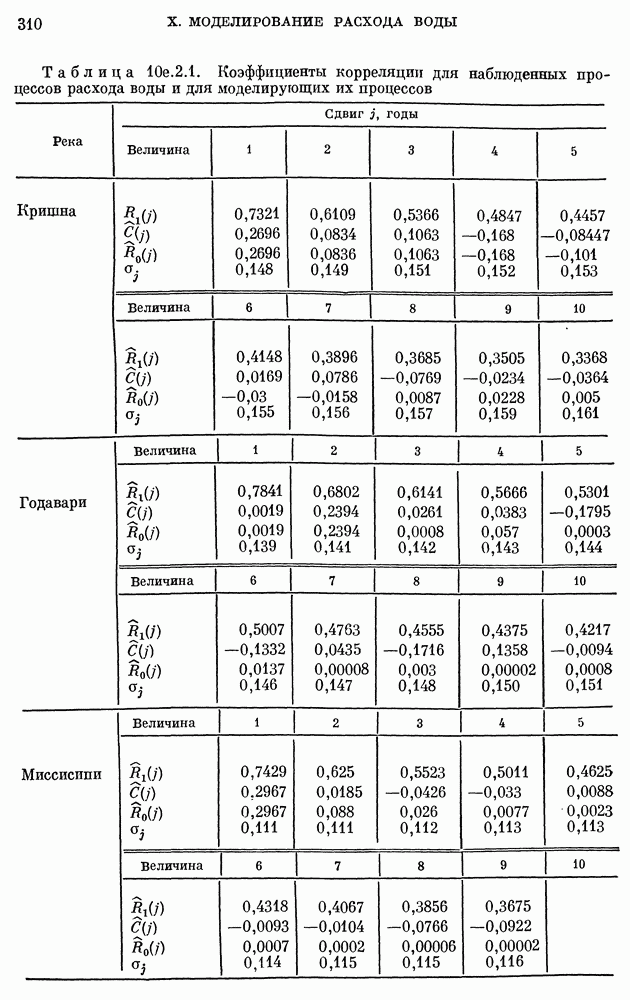
10е.2. Сравнение моделей М0 и М1 основанное на коэффициентах корреляции.
Теоретические коэффициенты корреляции  процесса на выходе модели
процесса на выходе модели  процесса на выходе модели можно сравнить с соответствующими выборочными коэффициентами корреляции
процесса на выходе модели можно сравнить с соответствующими выборочными коэффициентами корреляции  . В табл. 10е.2.1 приведены значения коэффициентов корреляции
. В табл. 10е.2.1 приведены значения коэффициентов корреляции  при десяти значениях сдвига 7 для данных, взятых с годовым интервалом, для рек Кришна, Годавари и Миссисипи. Эти результаты показывают, что для каждой реки выборочные коэффициенты корреляции
при десяти значениях сдвига 7 для данных, взятых с годовым интервалом, для рек Кришна, Годавари и Миссисипи. Эти результаты показывают, что для каждой реки выборочные коэффициенты корреляции  оказываются ближе к коэффициентам корреляции
оказываются ближе к коэффициентам корреляции  модели
модели  чем к коэффициентам
чем к коэффициентам  модели
модели 
Даже если наблюденные данные действительно происходят от процесса, описываемого моделью  выборочный коэффициент корреляции
выборочный коэффициент корреляции  не будет тождественно равен соответствующему теоретическому значению
не будет тождественно равен соответствующему теоретическому значению  для всех 7, поскольку
для всех 7, поскольку  вычислялся по конечной выборке. Для того чтобы выяснить, можно ли разницу между
вычислялся по конечной выборке. Для того чтобы выяснить, можно ли разницу между  объяснить случайными колебаниями выборки, можно поступить следующим образом. Рассмотрим оценку
объяснить случайными колебаниями выборки, можно поступить следующим образом. Рассмотрим оценку
 которая вычисляется по выборке
которая вычисляется по выборке  полученной путем моделирования уравнения модели
полученной путем моделирования уравнения модели  на цифровой вычислительной машине. Пусть
на цифровой вычислительной машине. Пусть  стандартное отклонение этой оценки, представляющееся выражением
стандартное отклонение этой оценки, представляющееся выражением

Из табл. 10е.2.1 видно, что  Поэтому мы заключаем, что разность между
Поэтому мы заключаем, что разность между  незначима для
незначима для  и объясняется лишь случайными колебаниями выборки. Следовательно, имеющиеся данные для всех рек можно рассматривать, как прогенерированные моделью
и объясняется лишь случайными колебаниями выборки. Следовательно, имеющиеся данные для всех рек можно рассматривать, как прогенерированные моделью 
С другой стороны, теоретические коэффициенты корреляции  выходного процесса модели
выходного процесса модели  сильно отличаются от соответствующих выборочных коэффициентов корреляции
сильно отличаются от соответствующих выборочных коэффициентов корреляции  для всех исследованных рек, что порождает сомнения в обоснованности модели
для всех исследованных рек, что порождает сомнения в обоснованности модели  для представления имеющихся данных.
для представления имеющихся данных.
10е.3. Сравнение моделей методами классической теории проверки гипотез.
Классическая теория проверки гипотез обсуждалась в гл. VIII. Будем считать модель  нулевой гипотезой,
нулевой гипотезой,  альтернативной. Всякое решающее правило для выбора между этими двумя моделями приводит к ошибкам двух родов. Истинной моделью может быть
альтернативной. Всякое решающее правило для выбора между этими двумя моделями приводит к ошибкам двух родов. Истинной моделью может быть  которая ошибочно классифицируется как
которая ошибочно классифицируется как  (ошибка I рода). Если, наоборот, истинная
(ошибка I рода). Если, наоборот, истинная  классифицируется как
классифицируется как  то имеет место ошибка II рода. Нашей целью является отыскание решающего правила, минимизирующего вероятность ошибки II рода при заданной вероятности ошибки I рода. Таким правилом является описываемый ниже критерий отношения правдоподобия, основанный на всей совокупности имеющихся наблюдений
то имеет место ошибка II рода. Нашей целью является отыскание решающего правила, минимизирующего вероятность ошибки II рода при заданной вероятности ошибки I рода. Таким правилом является описываемый ниже критерий отношения правдоподобия, основанный на всей совокупности имеющихся наблюдений  :
:

Порог обсуждаемый позднее, должен выбираться, исходя из предписанного значения вероятности ошибки I рода.
Пусть  По определению модели
По определению модели  имеем
имеем

Аналогично,

где  -матрица, элементами которой являются ковариации
-матрица, элементами которой являются ковариации  в случае модели
в случае модели  а — соответствующая
а — соответствующая  -матрица в случае модели
-матрица в случае модели 

Ковариации  для моделей
для моделей  и
и  можно вычислить по формулам гл. II. Численные значения
можно вычислить по формулам гл. II. Численные значения  при
при  можно найти в табл. 10е.2.1 для рек Кришна, Годавари и Миссисипи.
можно найти в табл. 10е.2.1 для рек Кришна, Годавари и Миссисипи.
Подстановкой в правило  выражений
выражений  для
для  левую часть
левую часть  можно упростить, после чего решающее правило принимает вид
можно упростить, после чего решающее правило принимает вид

где 
Порог с следует выбирать так, чтобы вероятность ошибки I рода равнялась предписанному значению, например 0,05. Для выбора значения с необходимо знать распределение вероятностей статистики  при условии, что наблюдения
при условии, что наблюдения  происходят от модели
происходят от модели  Мы не располагаем выражением в замкнутой форме для этого распределения вероятностей, но его можно приближенно определить с помощью моделирования следующим образом. Уравнение модели моделируется на цифровой вычислительной машине для получения значений
Мы не располагаем выражением в замкнутой форме для этого распределения вероятностей, но его можно приближенно определить с помощью моделирования следующим образом. Уравнение модели моделируется на цифровой вычислительной машине для получения значений  Затем последние
Затем последние  из этих значений
из этих значений  используются для вычисления статистики х, значение которой обозначается
используются для вычисления статистики х, значение которой обозначается  Аналогично можно осуществить
Аналогично можно осуществить  статистически независимых вычислительных экспериментов, которые дадут
статистически независимых вычислительных экспериментов, которые дадут  значений статистики х, скажем
значений статистики х, скажем  Гистограмма этих
Гистограмма этих  значений дает хорошее приближение к плотности вероятности статистики х при гипотезе
значений дает хорошее приближение к плотности вероятности статистики х при гипотезе  Эту плотность обозначим
Эту плотность обозначим 
Вероятность  ошибки I рода при заданном пороге с равна
ошибки I рода при заданном пороге с равна

Отсюда можно выбрать порог с так, чтобы  равнялась предписанному значению этой вероятности, которое было выбрано равным 0,05.
равнялась предписанному значению этой вероятности, которое было выбрано равным 0,05.
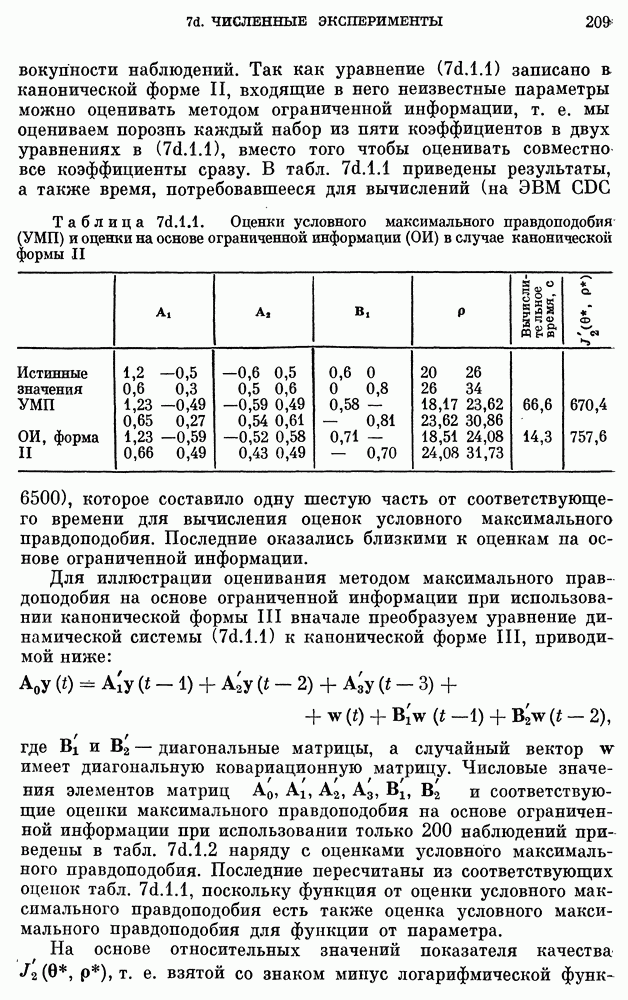
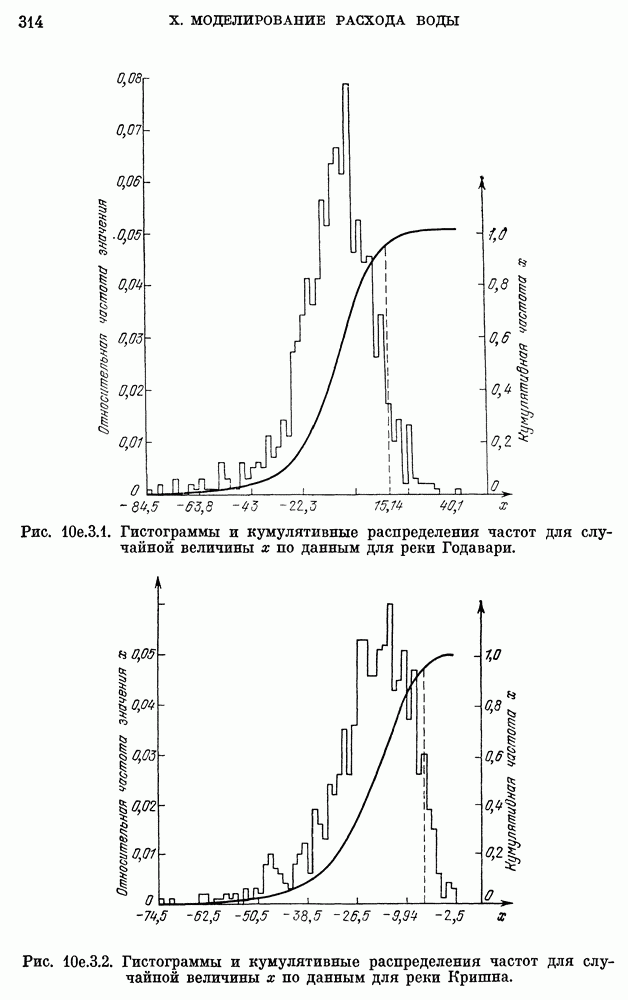
Результаты, полученные с помощью вышеописанной процедуры, мы приведем только в случае рек Кришна и Годавари, для которых имелось по 59 наблюдений. Поскольку вычисление плотности вероятности  при
при  очень сложно и требует много времени, то
очень сложно и требует много времени, то  было выбрано равным 19. Соответствующие гистограммы и кумулятивные распределения частот для статистики х приведены на рис. 10е.3.1 и 10е.3.2 для данных по рекам Годавари и Кришна соответственно. По этим кривым в соответствии с вероятностями правильного решения 0,95 были получены значения порога с. Эти значения приведены в табл. 10е.3.1: для реки Годавари
было выбрано равным 19. Соответствующие гистограммы и кумулятивные распределения частот для статистики х приведены на рис. 10е.3.1 и 10е.3.2 для данных по рекам Годавари и Кришна соответственно. По этим кривым в соответствии с вероятностями правильного решения 0,95 были получены значения порога с. Эти значения приведены в табл. 10е.3.1: для реки Годавари  ; для реки Кришна
; для реки Кришна  . Данные по каждой реке можно разбить на три группы по 19 элементов в каждой группе, а именно,
. Данные по каждой реке можно разбить на три группы по 19 элементов в каждой группе, а именно,  Значения статистики х вычислялись раздельно для каждой группы и приводятся в табл. 10е.3.1.
Значения статистики х вычислялись раздельно для каждой группы и приводятся в табл. 10е.3.1.
Таблица 10е.3.1. (см. скан) Результаты сравнения моделей методами классической теории проверки гипотез
Результаты для реки Годавари, приведенные в табл. 10е.3.1, показывают, что значение х много меньше, чем с для всех трех групп, что свидетельствует о подавляющем превосходстве модели  над моделью
над моделью  Результаты для реки Кришна показывают, что значение х в двух группах меньше, чем с, но значение х для оставшейся группы превышает с. Среднее по этим трем значениям х равно —26,31. Это число также значительно меньше
Результаты для реки Кришна показывают, что значение х в двух группах меньше, чем с, но значение х для оставшейся группы превышает с. Среднее по этим трем значениям х равно —26,31. Это число также значительно меньше  , что вновь показывает превосходство модели
, что вновь показывает превосходство модели  над
над 
Важно отметить, что это заключение не изменится, если учесть небольшую ошибку в определении с, обусловленную небольшим отличием эмпирически найденной гистограммы от фактической плотности вероятности случайной величины х.
10е.4. Сравнительные качества прогнозов, даваемых моделями из классов M0 и M1
В этом пункте мы воспользуемся формулами прогноза на один шаг вперед для рассматриваемых двух

(кликните для просмотра скана)
моделей, чтобы получить прогноз среднегодового расхода воды на год вперед и вычислить соответствующую среднеквадратическую ошибку прогноза. Модель, для которой получается меньшее из двух наблюденных значений среднеквадратической ошибки прогноза, будет более приемлемой, чем другая модель, особенно если разность между двумя наблюденными значениями этой ошибки существенна.
Далее, для каждой модели мы можем проверить, является ли наблюденное значение среднеквадратической ошибки оптимального прогноза расхода воды на один шаг вперед, вычисляемого по формулам прогноза, близким к соответствующему теоретическому значению среднеквадратической ошибки прогноза, даваемого моделью  в случае
в случае  в случае
в случае  Если наблюденное и теоретическое значения средних квадратических ошибок сильно отличаются друг от друга, то соответствующую модель следует учесть неудовлетворительной.
Если наблюденное и теоретическое значения средних квадратических ошибок сильно отличаются друг от друга, то соответствующую модель следует учесть неудовлетворительной.
10е.4.1. Прогноз в случае модели с дробным шумом.
Применим методы линейного прогноза, обсужденные в гл. II. Оптимальный в смысле средней квадратической ошибки линейный прогноз  определяется формулой
определяется формулой

Здесь  есть
есть  -матрица, у которой
-матрица, у которой  элемент равен
элемент равен

— ковариация значений процесса у на выходе модели  при сдвиге к и
при сдвиге к и

Для выбора целого числа  вычисляем показатель качества при различных значениях
вычисляем показатель качества при различных значениях  скажем
скажем  Показатель
Показатель  определен соотношением
определен соотношением  Выбирается то значение
Выбирается то значение  при котором
при котором  минимально. Допустим, что
минимально. Допустим, что  равно 20. Затем правило прогноза, определенное в
равно 20. Затем правило прогноза, определенное в  используется для предсказаний на один шаг вперед значений
используется для предсказаний на один шаг вперед значений  Соответствующая наблюденная средиеквадратическая ошибка прогноза обозначается через
Соответствующая наблюденная средиеквадратическая ошибка прогноза обозначается через 

Поскольку оценка  вычислялась по
вычислялась по  наблюдениям, ее стандартное отклонение равно
наблюдениям, ее стандартное отклонение равно 
10е.4.2. Прогноз в случае AR-модели M0.
Пусть  теоретическое значение среднеквадратической ошибки прогноза на один шаг вперед. Обозначим через
теоретическое значение среднеквадратической ошибки прогноза на один шаг вперед. Обозначим через  прогноз с наименьшей среднеквадратической ошибкой, полученный на AR-модели для величины
прогноз с наименьшей среднеквадратической ошибкой, полученный на AR-модели для величины  по измерениям
по измерениям 

Выборочнуюсреднеквадратическуюошибку  прогноза
прогноза  можно найти, используя ту же, что и раньше, совокупность наблюдений
можно найти, используя ту же, что и раньше, совокупность наблюдений 

10е.4.3. Результаты сравнения ошибок прогноза.
А. Река Годавари. Модель с дробным шумом  Выборочные среднеквадратические ошибки
Выборочные среднеквадратические ошибки  определенные формулой
определенные формулой  вычислялись для оптимальных прогнозов вида
вычислялись для оптимальных прогнозов вида  Эти ошибки приведены в табл. 10е.4.1 для различных значений
Эти ошибки приведены в табл. 10е.4.1 для различных значений 
Таблица 10е.4.1. (см. скан) Изменение среднеквадратической ошибки прогноза в зависимости от сдвига 
Исходя из табл.  выбираем
выбираем  равным 2, так как соответствующий показатель
равным 2, так как соответствующий показатель  имеет наименьшее значение, равное 1,069. Теоретическое значение средней квадратической ошибки, обозначаемое
имеет наименьшее значение, равное 1,069. Теоретическое значение средней квадратической ошибки, обозначаемое  равно 0,3755. Таким образом, расхождение между теоретическим достижимым значением
равно 0,3755. Таким образом, расхождение между теоретическим достижимым значением  среднеквадратической ошибки прогноза и значением
среднеквадратической ошибки прогноза и значением  достигаемым на модели, очень велико, что указывает на плохое качество прогноза
достигаемым на модели, очень велико, что указывает на плохое качество прогноза  и неадекватность модели
и неадекватность модели  Более того, выборочные средние квадратические ошибки прогноза
Более того, выборочные средние квадратические ошибки прогноза  приведенные в табл.
приведенные в табл.  всегда превышают единицу, которая является значением выборочной дисперсии предсказываемого сигнала. Это обстоятельство само по себе свидетельствует о плохом качестве прогноза посредством модели
всегда превышают единицу, которая является значением выборочной дисперсии предсказываемого сигнала. Это обстоятельство само по себе свидетельствует о плохом качестве прогноза посредством модели 
2. АR-модель. Теоретическое значение среднеквадратической ошибки прогноза, обозначаемое  равно 0,9053. Выборочпая среднеквадратическая ошибка
равно 0,9053. Выборочпая среднеквадратическая ошибка  вычисляемая исходя из
вычисляемая исходя из
соотношений (10е.4.3) и (10е.4.4), равна 0,724. Стандартное отклонение оценки  задается величиной
задается величиной  которая оказывается равной 0,2045. Таким образом, выборочная среднеквадратическая ошибка
которая оказывается равной 0,2045. Таким образом, выборочная среднеквадратическая ошибка  находится в пределах одного стандартного отклонения от теоретического предельного значения
находится в пределах одного стандартного отклонения от теоретического предельного значения  Кроме того, выборочная среднеквадратическая ошибка прогноза
Кроме того, выборочная среднеквадратическая ошибка прогноза  при использовании AR-модели значительно меньше, чем соответствующая величина
при использовании AR-модели значительно меньше, чем соответствующая величина  получаемая на модели с дробным шумом
получаемая на модели с дробным шумом  Таким образом, модель
Таким образом, модель  явно превосходит модель
явно превосходит модель 
Река Кришна. 1. Модель с дробным шумом  Значения выборочной среднеквадратической ошибки приведены в табл.
Значения выборочной среднеквадратической ошибки приведены в табл.  для различных значений
для различных значений  Согласно цифрам, приведенным в табл.
Согласно цифрам, приведенным в табл.  оптимальное значение
оптимальное значение  оказывается равным 10, соответствующая среднеквадратическая ошибка равна 0,64, тогда как теоретически достижимая среднеквадратическая ошибка — 0,441. Имеется значительное расхождение между наблюденной среднеквадратической ошибкой и теоретически достижимой среднеквадратической ошибкой, причем последняя также и в этом случае оказывается существенно меньше, чем первая.
оказывается равным 10, соответствующая среднеквадратическая ошибка равна 0,64, тогда как теоретически достижимая среднеквадратическая ошибка — 0,441. Имеется значительное расхождение между наблюденной среднеквадратической ошибкой и теоретически достижимой среднеквадратической ошибкой, причем последняя также и в этом случае оказывается существенно меньше, чем первая.
2. AR-моделъ  Теоретически достижимая среднеквадратическая ошибка
Теоретически достижимая среднеквадратическая ошибка  равна 0,8278. Наблюденная среднеквадратическая ошибка
равна 0,8278. Наблюденная среднеквадратическая ошибка  прогноза вида
прогноза вида  для модели
для модели  равна 0,611. Стандартное отклонение оценки
равна 0,611. Стандартное отклонение оценки  задается величиной
задается величиной  и равно 0,188. Таким образом, наблюдаемая среднеквадратическая ошибка находится в пределах двух стандартных отклонений от теоретически достижимого минимума. Кроме тогог наблюденная среднеквадратическая ошибка модели
и равно 0,188. Таким образом, наблюдаемая среднеквадратическая ошибка находится в пределах двух стандартных отклонений от теоретически достижимого минимума. Кроме тогог наблюденная среднеквадратическая ошибка модели  меньше, чем соответствующая ошибка модели
меньше, чем соответствующая ошибка модели  Следовательно, также и при описании процесса расхода воды в реке Кришна качества прогноза у модели
Следовательно, также и при описании процесса расхода воды в реке Кришна качества прогноза у модели  превосходит качество прогноза у модели
превосходит качество прогноза у модели 
Река Миссисипи. 1. Модель с дробным шумом  Значения
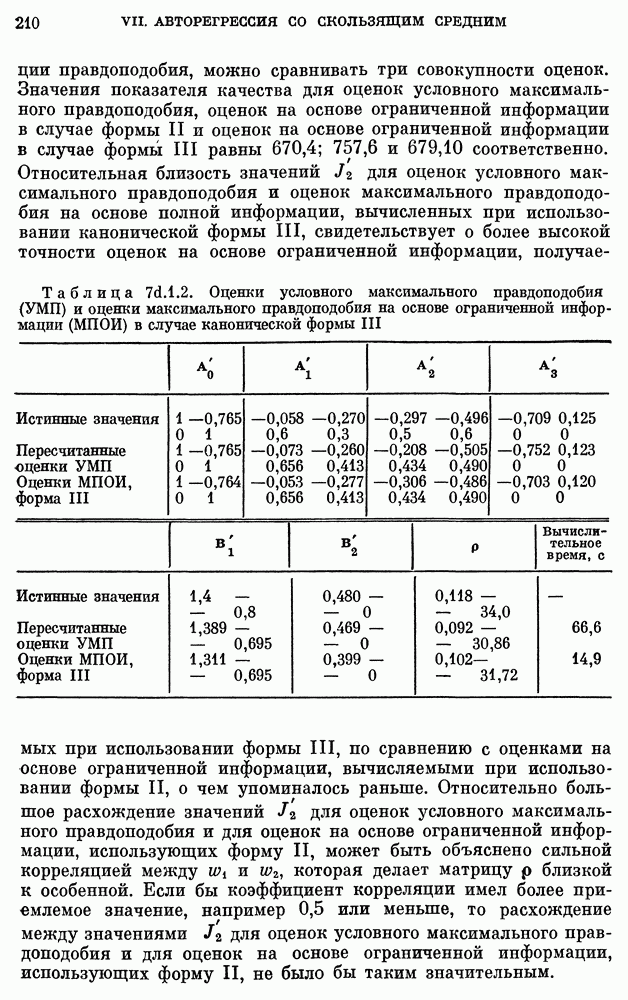
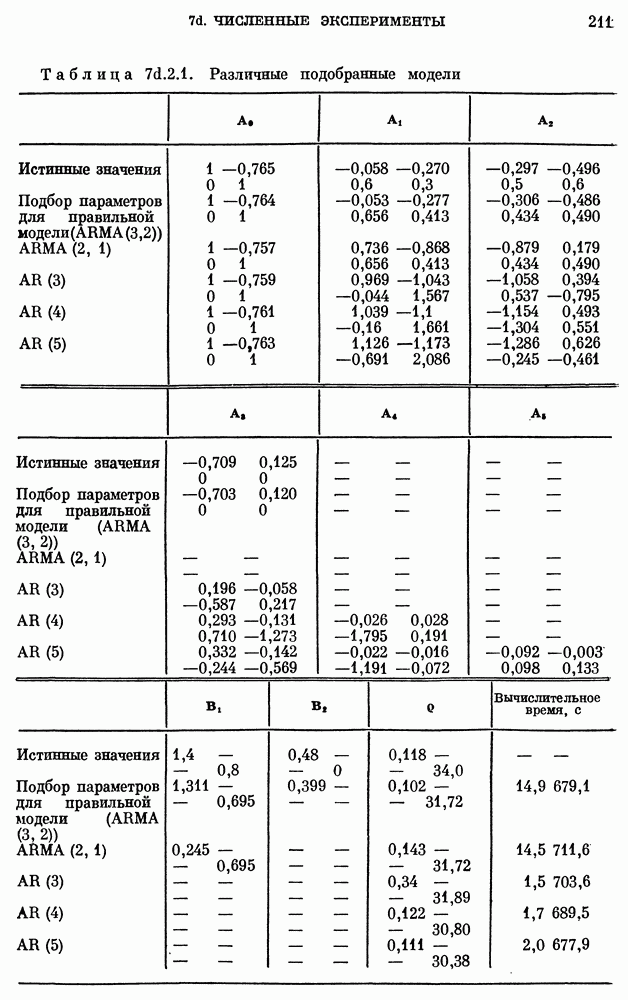
Значения  выборочной среднеквадратической ошибки приведены в табл. 10е.4.1 для различных значений
выборочной среднеквадратической ошибки приведены в табл. 10е.4.1 для различных значений  Согласно приведенным там результатам оптимальное значение
Согласно приведенным там результатам оптимальное значение  равно примерно 10, соответствующая среднеквадратическая ошибка равна 1,055, превышая тем самым единицу, т. е. дисперсию процесса. Прогноз практически бесполезен. Как и выше, имеется значительное расхождение между наблюденной среднеквадратической ошибкой и теоретически достижимой среднеквадратической ошибкой, равной 0,422.
равно примерно 10, соответствующая среднеквадратическая ошибка равна 1,055, превышая тем самым единицу, т. е. дисперсию процесса. Прогноз практически бесполезен. Как и выше, имеется значительное расхождение между наблюденной среднеквадратической ошибкой и теоретически достижимой среднеквадратической ошибкой, равной 0,422.
2. AR-модель  Теоретически достижимая среднеквадратическая ошибка равна 0,97. Наблюденная среднеквадратическая ошибка
Теоретически достижимая среднеквадратическая ошибка равна 0,97. Наблюденная среднеквадратическая ошибка  равна 0,92. Стандартное отклонение оценки
равна 0,92. Стандартное отклонение оценки  дается величиной
дается величиной  равной 0,1545. Таким образом, наблюденная
равной 0,1545. Таким образом, наблюденная
среднеквадратическая ошибка находится в пределах одного стандартного отклонения от теоретически достижимого минимума. Кроме того, наблюденная минимальная среднеквадратическая ошибка для модели  меньше соответствующей ошибки для модели
меньше соответствующей ошибки для модели  Следовательно, также и в случае реки Миссисипи качество прогноза по модели
Следовательно, также и в случае реки Миссисипи качество прогноза по модели  выше, чем по модели
выше, чем по модели 
Следует отметить, что величины  в соотношении
в соотношении  для
для  строго говоря, не являются предсказаниями, поскольку коэффициенты в выражениях для этих величин вычисляются на основе всей совокупности наблюдений
строго говоря, не являются предсказаниями, поскольку коэффициенты в выражениях для этих величин вычисляются на основе всей совокупности наблюдений  Величины
Величины  сами по себе могут описываться как оценки для
сами по себе могут описываться как оценки для  вместо того чтобы обозначать среднеквадратические ошибки прогноза. Но убедительность рассуждений, приводящих к заключению о превосходстве модели
вместо того чтобы обозначать среднеквадратические ошибки прогноза. Но убедительность рассуждений, приводящих к заключению о превосходстве модели  над
над  остается непоколебленной этим соображением, так как оно касается в равной степени прогнозов
остается непоколебленной этим соображением, так как оно касается в равной степени прогнозов 
Из-за малого количества имеющихся наблюдений мы не использовали разбиение выборки на части, служащие для оценивания параметров и для проверки прогноза.
10е.5. Сравнение, основанное на R/a-характеристиках.
Сравним модели  в отношении их способности воспроизводить
в отношении их способности воспроизводить  -характеристики наблюденных временных рядов расхода воды в реке. По определению и построению модели с дробным шумом она воспроизводит наблюденную характеристику
-характеристики наблюденных временных рядов расхода воды в реке. По определению и построению модели с дробным шумом она воспроизводит наблюденную характеристику  как функцию от
как функцию от  Поэтому остается обсудить только модель
Поэтому остается обсудить только модель  Мы повторим определение разброса
Мы повторим определение разброса  в измененном масштабе.
в измененном масштабе.
При использовании нормированного наблюденного процесса расхода воды  строится последовательность
строится последовательность 

где  целые числа. Значение разброса в измененном масштабе последовательности
целые числа. Значение разброса в измененном масштабе последовательности 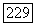 в момент времени
в момент времени 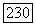 при сдвиге
при сдвиге 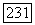 дается величиной
дается величиной 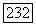

Обозначим через 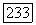 выборочную дисперсию последовательности
выборочную дисперсию последовательности 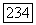 определяемую на интервале
определяемую на интервале 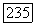

Пусть 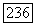 Мы намереваемся оценить отношения
Мы намереваемся оценить отношения 
В случае модели  явное выражение для
явное выражение для  как функции от
как функции от  получить невозможно. Следовательно, приходится реализовывать модель
получить невозможно. Следовательно, приходится реализовывать модель 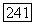 на вычислительной машине и оценивать характеристику
на вычислительной машине и оценивать характеристику 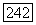 функцию от
функцию от 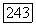 исходя из генерируемых данных способом, обсужденным в гл. II. Число полученных с помощью модели
исходя из генерируемых данных способом, обсужденным в гл. II. Число полученных с помощью модели  точек, используемых затем для построения
точек, используемых затем для построения 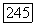 -характеристики, равно 90.
-характеристики, равно 90.
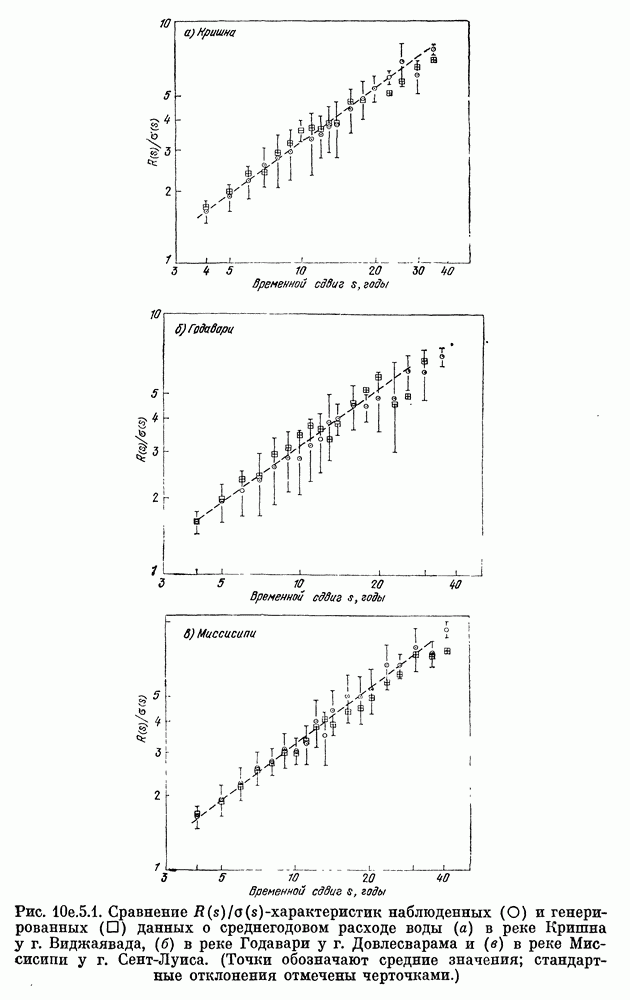
На рис. 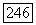 изображены характеристики
изображены характеристики 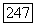 оцененные по выходным данным цифровой вычислительной машины в случае модели
оцененные по выходным данным цифровой вычислительной машины в случае модели 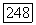 для рек Кришна, Годавари и Миссисипи, а также верхняя и нижняя границы
для рек Кришна, Годавари и Миссисипи, а также верхняя и нижняя границы 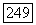 где
где 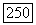 выборочное стандартное отклонение оценки
выборочное стандартное отклонение оценки 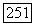 вычисляемое по наблюдениям способом, указанным в гл. II.
вычисляемое по наблюдениям способом, указанным в гл. II.
В случае рек Кришна и Годавари 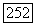 -оценка, строящаяся по данным о расходе воды, лежит в пределах одного стандартного отклонения от
-оценка, строящаяся по данным о расходе воды, лежит в пределах одного стандартного отклонения от 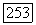 -оценки, вычисляемой по выборочным данным модели
-оценки, вычисляемой по выборочным данным модели 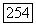 для всех сдвигов, не превышающих 30, где 30 — грубо говоря, половина объема выборки 59: Аналогично, для реки Миссисипи
для всех сдвигов, не превышающих 30, где 30 — грубо говоря, половина объема выборки 59: Аналогично, для реки Миссисипи  -оценка, вычисляемая по данным о расходе воды в реках, находится в пределах одного стандартного отклонения от
-оценка, вычисляемая по данным о расходе воды в реках, находится в пределах одного стандартного отклонения от 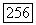 -оценки, вычисляемой по модели, для
-оценки, вычисляемой по модели, для 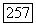 Следовательно, модель согласуется с данными постольку, поскольку дело касается
Следовательно, модель согласуется с данными постольку, поскольку дело касается 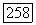 -характеристик. Таким образом,
-характеристик. Таким образом, 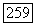 -характеристика сама по себе не в состоянии указать лучшую модель из пары
-характеристика сама по себе не в состоянии указать лучшую модель из пары 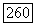
На вычислительных машинах были проведены исследования AR-моделей (Квимпо, 1967) и ARMA-моделей (ОКоннелл, 1975). Результаты этих исследований показывают, что угловой коэффициент 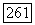 графика
графика 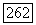 -модели всегда превышает 0,5. Результаты, представленные выше, показывают, что угловой коэффициент
-модели всегда превышает 0,5. Результаты, представленные выше, показывают, что угловой коэффициент 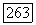 графика
графика 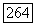 построенного по результатам реализации модели на вычислительной машине, воспроизводит угловой коэффициент графика
построенного по результатам реализации модели на вычислительной машине, воспроизводит угловой коэффициент графика 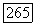 построенного по данным о расходе водьг в реках. Значения
построенного по данным о расходе водьг в реках. Значения 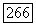 вычисленные при использовании смоделированных данных, лежат в пределах одного стандартного отклонения от значений
вычисленные при использовании смоделированных данных, лежат в пределах одного стандартного отклонения от значений 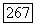 вычисленных с использованием наблюденных данных о расходе воды. Далее, оцененные стандартные отклонения для значений
вычисленных с использованием наблюденных данных о расходе воды. Далее, оцененные стандартные отклонения для значений 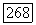 вычисленных по наблюденным данным о потоках, сравнимы с оцененными стандартными отклонениями для значений
вычисленных по наблюденным данным о потоках, сравнимы с оцененными стандартными отклонениями для значений 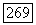 вычисленных по смоделированным данным.
вычисленных по смоделированным данным.
В литературе часто утверждается «на теоретической базе» (Мандельброт, Уоллис, 1969а), будто AR-модели не могут воспроизводить наблюденные 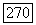 -характеристики последовательностей расхода воды в реках. Рассуждения ведутся следующим образом. Рассмотрим случайную величину разброса
-характеристики последовательностей расхода воды в реках. Рассуждения ведутся следующим образом. Рассмотрим случайную величину разброса 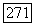 определенную в
определенную в 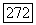 строящуюся по случайной последовательности
строящуюся по случайной последовательности

(кликните для просмотра скана)
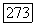 Если последовательность
Если последовательность 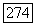 описывается AR-моделью, то
описывается AR-моделью, то

Поскольку угловой коэффициент эмпирического графика  полученного по имеющимся данным, заметно превышает 0,5, утверждается, что AR-модели непригодны. Это рассуждение заслуживает дальнейшего анализа.
полученного по имеющимся данным, заметно превышает 0,5, утверждается, что AR-модели непригодны. Это рассуждение заслуживает дальнейшего анализа.
Соотношение 10е.5.1 верно лишь при больших  Нет ни теоретических, ни эмпирических оснований полагать, что оно справедливо для малых значений
Нет ни теоретических, ни эмпирических оснований полагать, что оно справедливо для малых значений  например равных 100 или даже нескольким сотням. В настоящее время неизвестно, как велико должно быть
например равных 100 или даже нескольким сотням. В настоящее время неизвестно, как велико должно быть  чтобы
чтобы  стало справедливым.
стало справедливым.
Уместно упомянуть, что существуют некоторые несоответствия при толковании наблюдаемых  -характеристик также и в случае модели с дробным шумом. Рассмотрим не содержащую тренда последовательность среднемесячного расхода воды реки, т. е. последовательность, из которой устранены синусоидальные составляющие. Если последовательность среднегодового расхода описывается моделью с дробным шумом, то последовательность среднемесячного расхода с устраненным трендом также должна описываться этой же самой моделью с дробным шумом (т. е. оценка
-характеристик также и в случае модели с дробным шумом. Рассмотрим не содержащую тренда последовательность среднемесячного расхода воды реки, т. е. последовательность, из которой устранены синусоидальные составляющие. Если последовательность среднегодового расхода описывается моделью с дробным шумом, то последовательность среднемесячного расхода с устраненным трендом также должна описываться этой же самой моделью с дробным шумом (т. е. оценка  должна быть той же самой или почти той же самой в обеих моделях). Однако это не имеет места на практике. Например, для данных по реке Годавари значения
должна быть той же самой или почти той же самой в обеих моделях). Однако это не имеет места на практике. Например, для данных по реке Годавари значения  равны 0,88 и 0,78 для данных по месяцам с устраненным трендом и для данных по годам соответственно. То же самое справедливо и в отношении данных по другим рекам.
равны 0,88 и 0,78 для данных по месяцам с устраненным трендом и для данных по годам соответственно. То же самое справедливо и в отношении данных по другим рекам.
На это можно возразить, что рассматриваются две разные оценки одной и той же величины 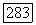 а от двух произвольных оценок одной и той же величины нельзя ожидать совпадения. Это рассуждение было бы разумным, если бы можно было показать, что наблюдаемая разность между этими двумя оценками «типична», т. е. она сравнима с математическим ожиданием абсолютного значения разности этих двух оценок. Однако таких данных мы не находим в литературе.
а от двух произвольных оценок одной и той же величины нельзя ожидать совпадения. Это рассуждение было бы разумным, если бы можно было показать, что наблюдаемая разность между этими двумя оценками «типична», т. е. она сравнима с математическим ожиданием абсолютного значения разности этих двух оценок. Однако таких данных мы не находим в литературе.
10е.6. Сравнение моделей на основе байесова подхода.
Сравниваемые модели  имеют вид
имеют вид

Здесь 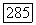 последовательности гауссовых одинаково распределенных случайных величин с нулевым математическим
последовательности гауссовых одинаково распределенных случайных величин с нулевым математическим
ожиданием и дисперсиями 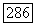 соответственно. Параметры
соответственно. Параметры 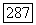 вычислялись с использованием ранее обсужденных методов;
вычислялись с использованием ранее обсужденных методов;  большое целое число, которое здесь было выбрано равным 800.
большое целое число, которое здесь было выбрано равным 800.
Эмпирические данные, используемые для проверки адекватности модели, представлены последовательностью 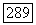 Как указывалось ранее, наблюдения нормированы. Пусть
Как указывалось ранее, наблюдения нормированы. Пусть

Байесова теория решений обсуждалась в гл. VIII. Ключевым моментом в байесовом подходе являются апостериорные вероятности 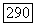 Здесь
Здесь  условная вероятность того, что правильна модель
условная вероятность того, что правильна модель 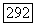 при заданной совокупности наблюдений
при заданной совокупности наблюдений 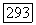 определяется аналогично.
определяется аналогично.
Любое решение сопряжено с ошибками, и соответствующие потери при различных обстоятельствах могут быть заданы следующей матрицей.

Здесь 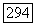 потери, которые мы несем при выборе модели
потери, которые мы несем при выборе модели 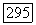 для представления имеющихся данных, в то время как правильной моделью является
для представления имеющихся данных, в то время как правильной моделью является 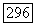 Обычно
Обычно

Ясно, что следует выбирать то решающее правило, которое приводит к наименьшему значению средних потерь. Средние потери при двух возможных решениях задаются величинами 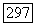 и где
и где 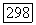 средние потери, когда на основе наблюдений
средние потери, когда на основе наблюдений 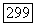 объявляется правильной модель
объявляется правильной модель 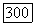

средние потери, когда на основе наблюдений объявляется правильной модель

Следовательно, оптимальное решающее правило, т. е. решающее правило, приводящее к минимальным средним потерям, будет
 выходной последовательности модели
выходной последовательности модели  которые можно вычислять указанным ранее способом. Аналогично, пусть
которые можно вычислять указанным ранее способом. Аналогично, пусть  ковариационная матрица вектора С
ковариационная матрица вектора С  описываемого моделью
описываемого моделью

 ковариации выходной последовательности модели
ковариации выходной последовательности модели  которые могут вычисляться указанным ранее способом. Для
которые могут вычисляться указанным ранее способом. Для  имеем следующее выражение:
имеем следующее выражение:

Подставляя выражения  для апостериорных вероятностей в правило
для апостериорных вероятностей в правило  получаем искомое решающее правило.
получаем искомое решающее правило.
Результаты. Численные значения апостериорных вероятностей моделей для данных по рекам Кришна, Годавари и Миссисипи приведены в табл. 10е.6.1, а некоторые дополнительные числовые данные — в табл. 10е.6.2.
Таблица 10е.6.1. (см. скан) Результаты сравнения моделей на основе байесова подхода
Из результатов, представленных в табл. 10е.6.1, видно, что показания в пользу модели  просто подавляющи в случае всех трех рек.
просто подавляющи в случае всех трех рек.
Таблица 10е.6.2. (см. скан) Значения некоторых статистик, используемых при байесовом сравнении моделей
В проведенном анализе обе априорных вероятности  принимались равными 0,5, поскольку заранее не отдавалось предпочтения ни одной из моделей. Но даже если
принимались равными 0,5, поскольку заранее не отдавалось предпочтения ни одной из моделей. Но даже если
предварительно отдать сильное предпочтение модели  все равно показания будут резко в пользу модели
все равно показания будут резко в пользу модели  Например, если для реки Кришна взять
Например, если для реки Кришна взять  то
то

Такое большое отношение заслуживает некоторых комментариев. Из  получаем
получаем

Для реки Кришна имеем  тогда как значение
тогда как значение  равно лишь 58,99. Даже если эти два числа рассматривать как имеющие один и тот же порядок, все равно образование экспоненты в формуле
равно лишь 58,99. Даже если эти два числа рассматривать как имеющие один и тот же порядок, все равно образование экспоненты в формуле  приводит к очень малому отношению вероятностей, определяемому этой формулой.
приводит к очень малому отношению вероятностей, определяемому этой формулой.
Из относительной малости величины  по сравнению с
по сравнению с  можно вывести только одно заключение, а именно: маловероятно, чтобы наблюдения
можно вывести только одно заключение, а именно: маловероятно, чтобы наблюдения  происходили от модели, у которой ковариационная матрица
происходили от модели, у которой ковариационная матрица  выходного вектора есть матрица
выходного вектора есть матрица  определенная формулой
определенная формулой
Интересно также рассмотреть относительные значения определителей матриц В случае реки Кришна при имеем

По определению сумма всех собственных значений матрицы совпадает с суммой всех собственных значений матрицы и равна 59. Равенство в означает, что одно или несколько собственных значений матрицы очень малы и, следовательно, почти особенная в сравнении с Эта черта в свою очередь показывает непригодность модели поскольку ковариационная матрица выходного сигнала для любой разумной модели должна быть неособенной, а ее определитель должен существенно отличаться от нуля.
10е.7. Обсуждение.
В предыдущих разделах мы рассмотрели вопросы сравнения моделей с нескольких точек зрения. Использование байесова подхода для сравнения моделей приводит как с вычислительной, так и с концептуальной точек зрения к простейшему критерию. Хотя выбор априорных вероятностей того,
что первая или вторая модель правильны, здесь произволен, это может по существу не сказываться на конечном выводе, как было показано на примере. Критерий отношения правдоподобия свободен от этого недостатка, но требует сложных вычислений для определения порога. Оба этих критерия основаны на сравнении распределений вероятностей имеющихся наблюдений для двух моделей. Значение использования этих двух критериев для выбора модели самоочевидно, когда мы считаем, что одним из основных назначений модели является генерирование синтетических данных, которые имели бы вероятностные характеристики, близкие к вероятностным характеристикам наблюдаемых данных о расходе воды в реке. Поскольку одно из важных применений модели — предсказание, то сравнение моделей в отношении их качества прогноза также является очень естественным. Сравнение -характеристик и корреляционных свойств наблюдаемых данных с соответствующими характеристиками, получаемыми для выходных сигналов моделей важно постольку, поскольку данные, генерируемые моделью, должны сохранять эти свойства.
Используя эти критерии при обработке данных о среднегодовом расходе воды в реках Кришна, Годавари и Миссисипи, мы убеждаемся в том, что в каждом случае авторегрессионная модель превосходит модель с дробным шумом с точек зрения байесова критерия, классического критерия проверки гипотез, качества прогноза на один шаг вперед и воспроизведения корреляционных характеристик. Что касается -характеристик, то для обеих моделей они близки к соответствующим характеристикам данных о фактическом расходе воды. Таким образом, можно утверждать, что AR-модель лучше, чем модель с дробным шумом, для всех этих рек.
Критическим моментом в случае AR-модели является вопрос, пригодна ли модель с постоянными коэффициентами для трактовки данных, охватывающих свыше 100 лет. Этот вопрос довольно подробно обсуждается в п. 3а.4.3.
Интересно рассмотреть физический смысл случайных входных сигналов в моделях Случайная входная последовательность в модели может быть естественным образом объяснена выпадениями осадков, имеющими место в интервале ибо известно, что временной ряд, образованный данными о годовых количествах осадков, можно адекватно описать последовательность независимых случайных величин.
В то же время затруднительно дать физическую интерпретацию случайной входной последовательности в модели Интерпретация случайной входной величины в модели как количества осадков не выдерживает критики, поскольку описывающий расход воды выходной процесс в этой модели зависит от входных значений в отдаленном прошлом. Трудно представить себе, чтобы количество осадков в настоящем году существенно
влияло на расход воды в реке спустя 10 или 20 лет. И Шайдеггер (1970), и Клемс (1974) подвергли модель с дробным шумом резкой критике на том основании, что не существует никакого физического механизма, который мог бы обусловить такую долгую память для процессов расхода воды в реках. Поэтому модели с дробным шумом имеют очень шаткую физическую основу.
Далее встречаются утверждения, что предпочтение должно отдаваться моделям с дробным шумом, так как они лучше, чем другие модели отражают долгосрочные характеристики процессов расхода воды, а также по той причине, что они объясняют явление устойчивости, другими словами инерции, этих процессов. Однако в литературе отсутствует точное определение явления «инерции» последовательности расхода воды в реке. Как указывали Монин (1969) и др. выражения «долгий срок», «короткий срок» и т. д. теряют смысл, если только не определены точно постоянные времени процесса. Если постоянные времени ограничены одним или несколькими годами (меньше, чем 20 лет), как это имело место в данном разделе, то модель из семейства ARMA оказывается адекватной реальному процессу. Аналогично, если предполагается, что явление «устойчивости» может быть представлено -характеристикой, то даже исследованная AR-модель оказывается адекватно отражающей это явление.
Наконец, встречаются утверждения, что имеющихся данных недостаточно, чтобы проводить различия между моделями типа ARMA и моделями с дробным шумом. В действительности же имеющихся данных недостает только в том случае, если в качестве основы для решения в пользу того или иного класса используются -характеристики. Однако, если для сравнения различных стохастических моделей используются стандартные методы, например, такие как несколько критериев, обсужденных в предыдущих пунктах, то результаты могут быть вполне определенными.






















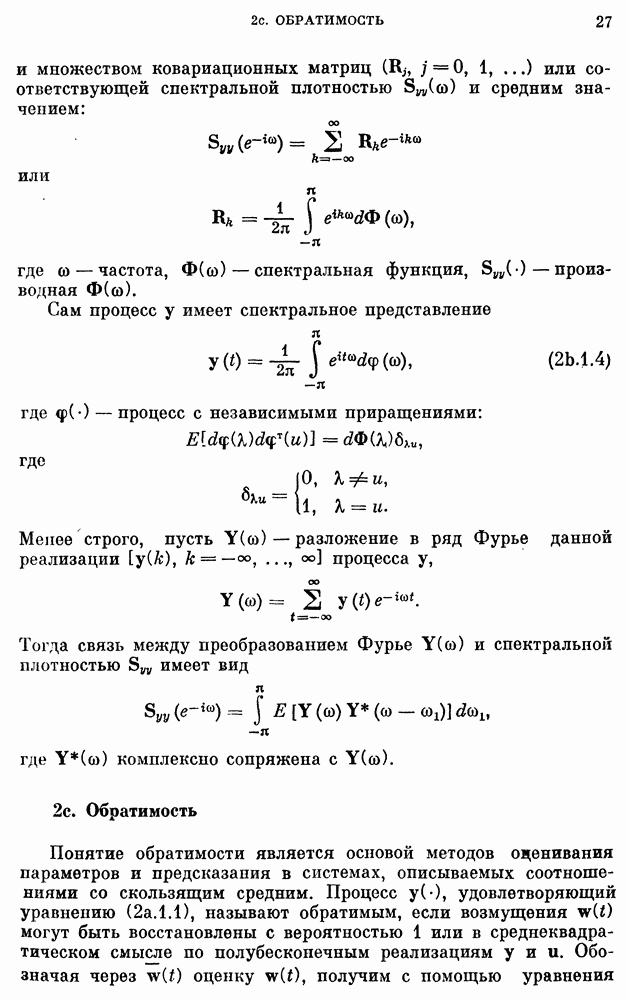















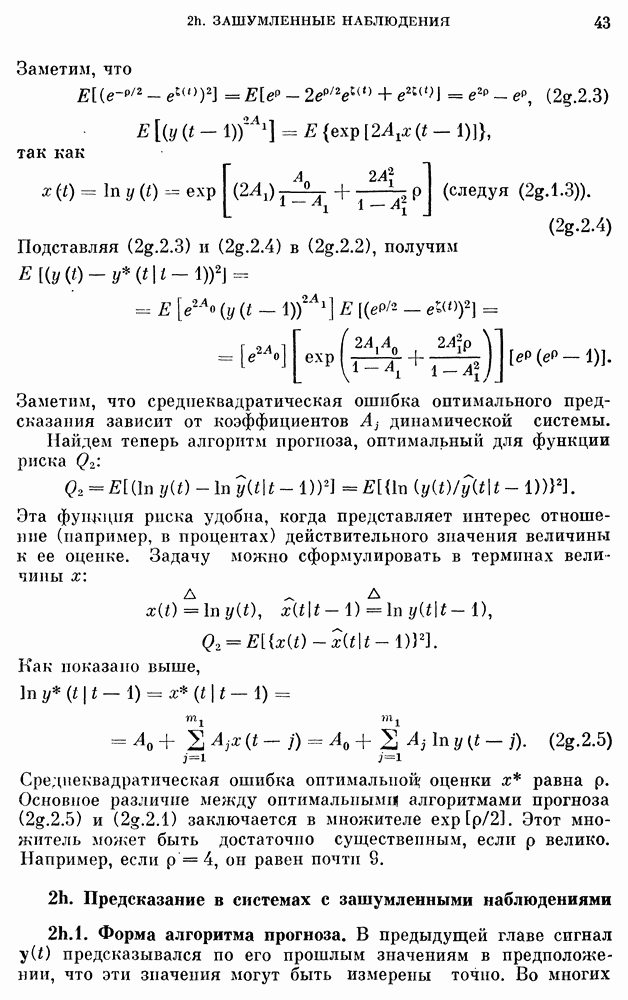




































































































































































































































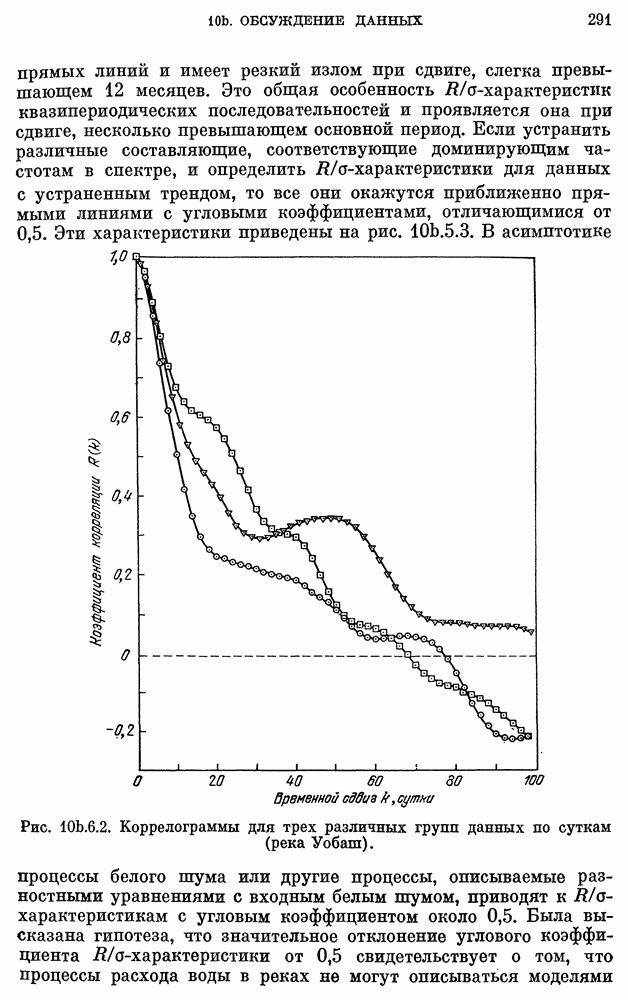


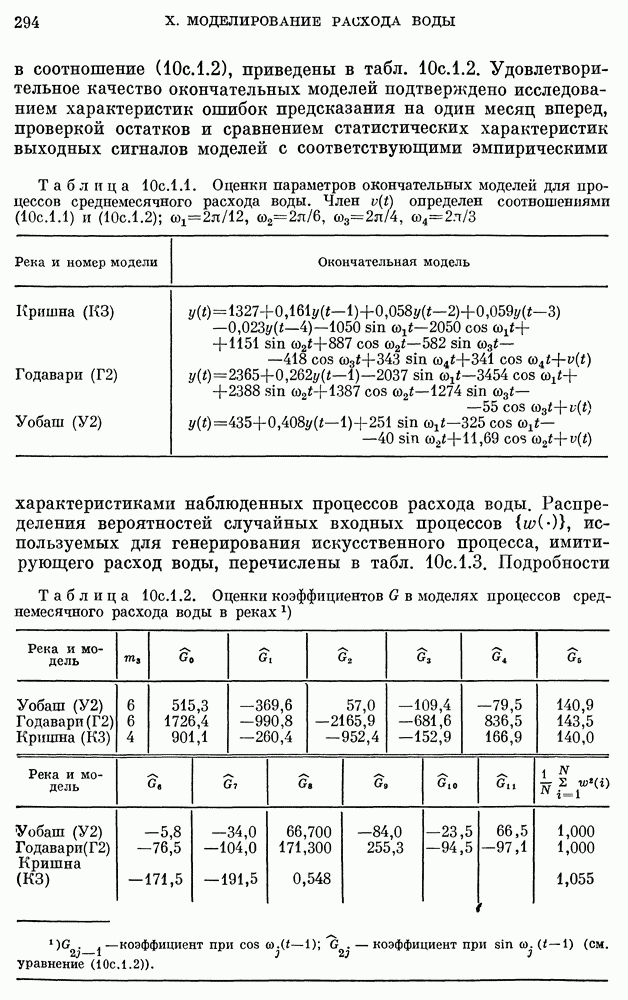






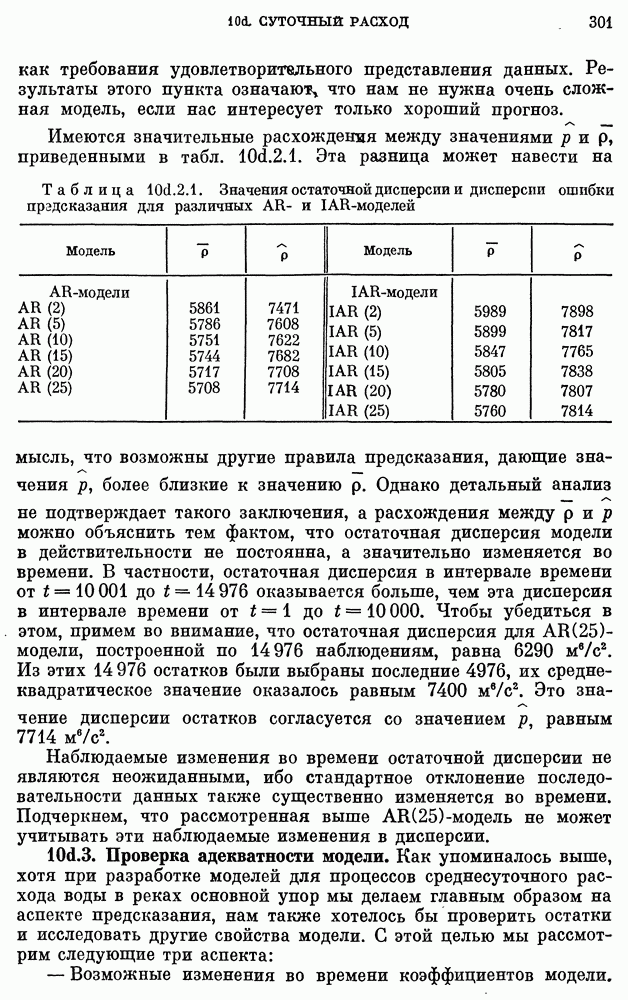

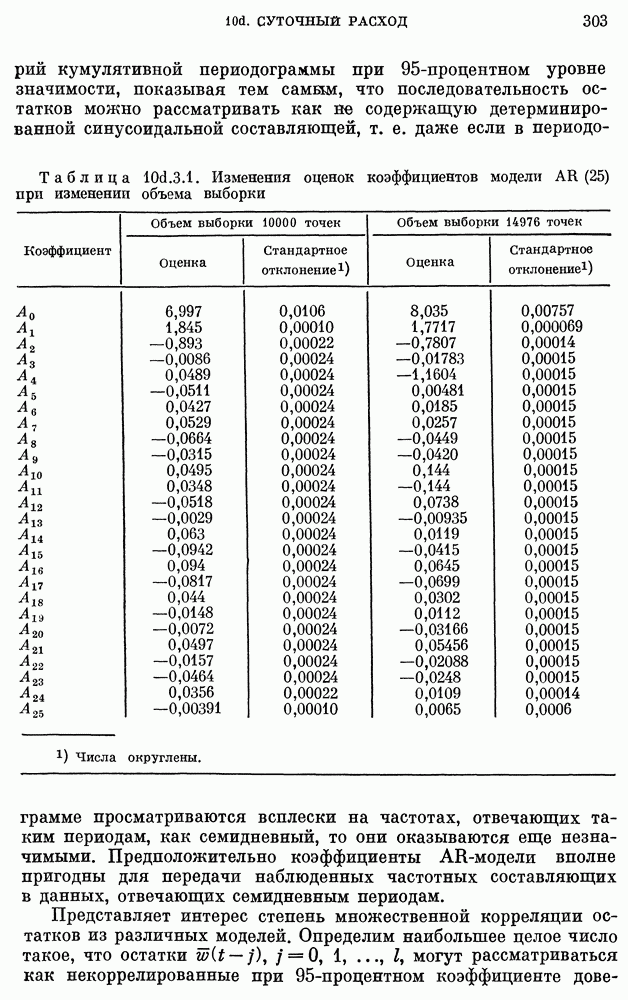





































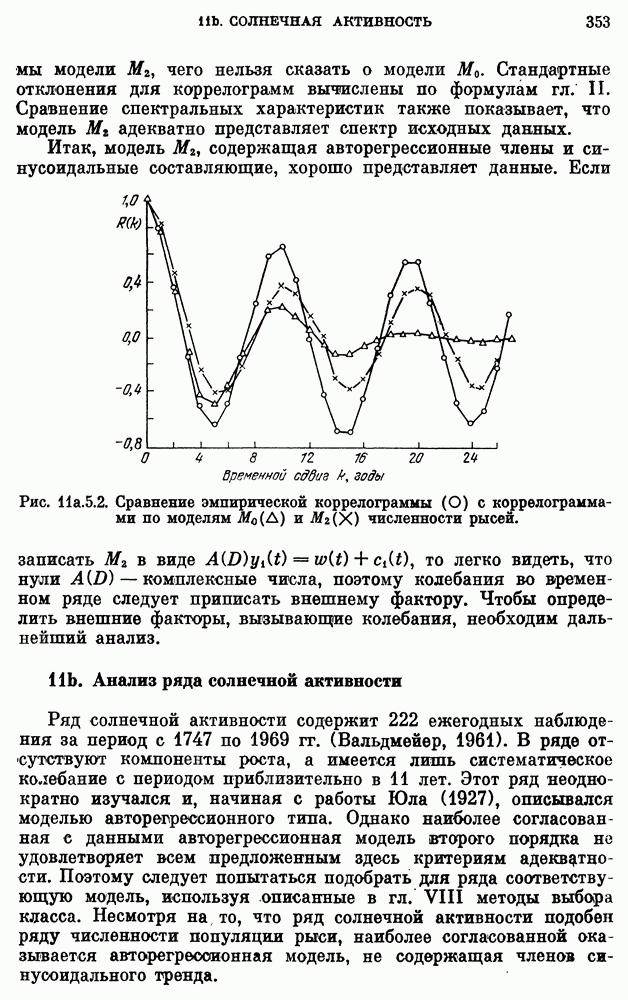


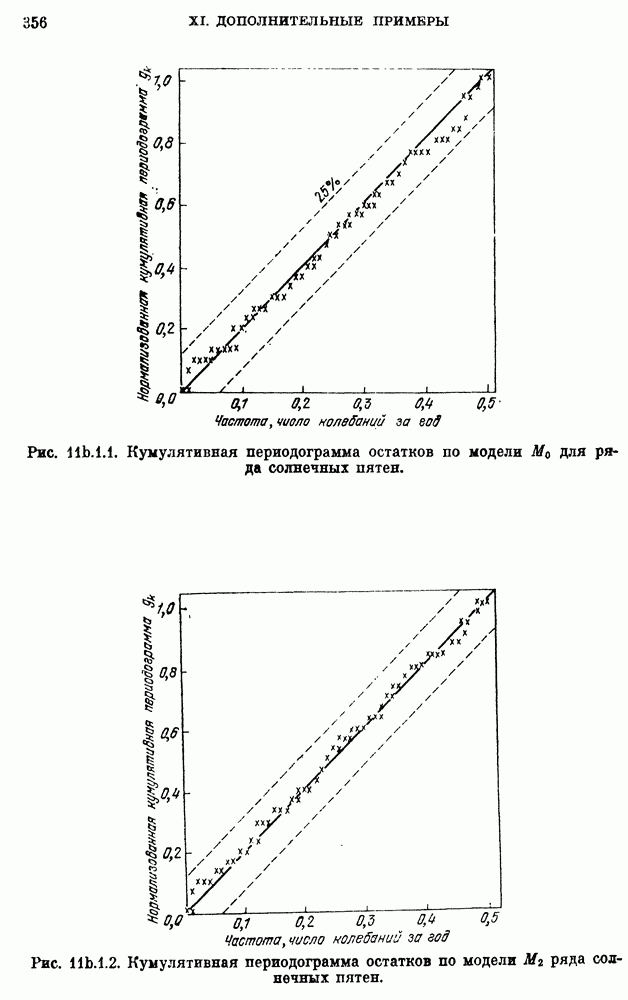
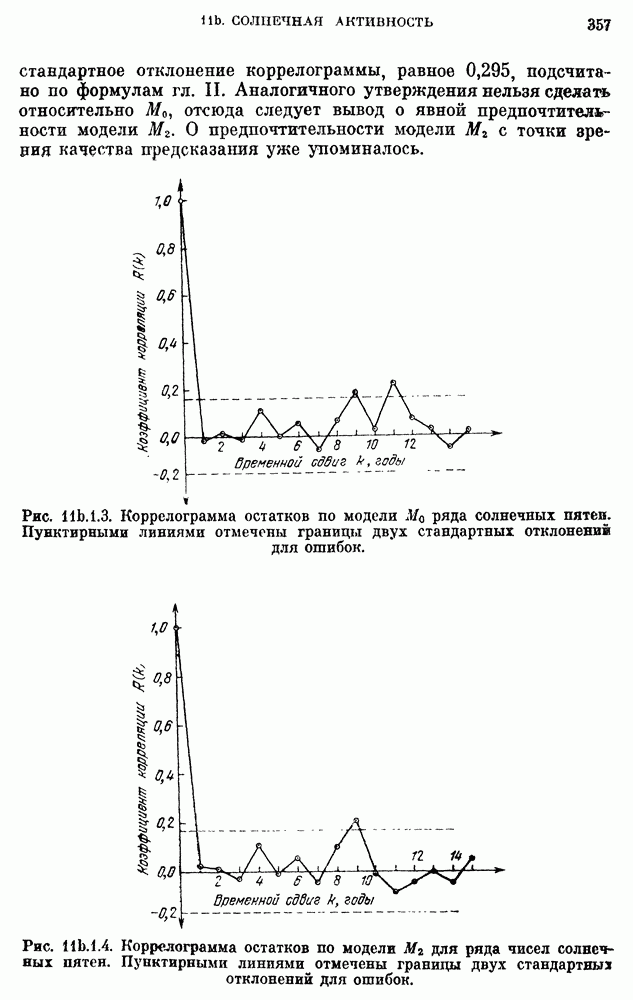
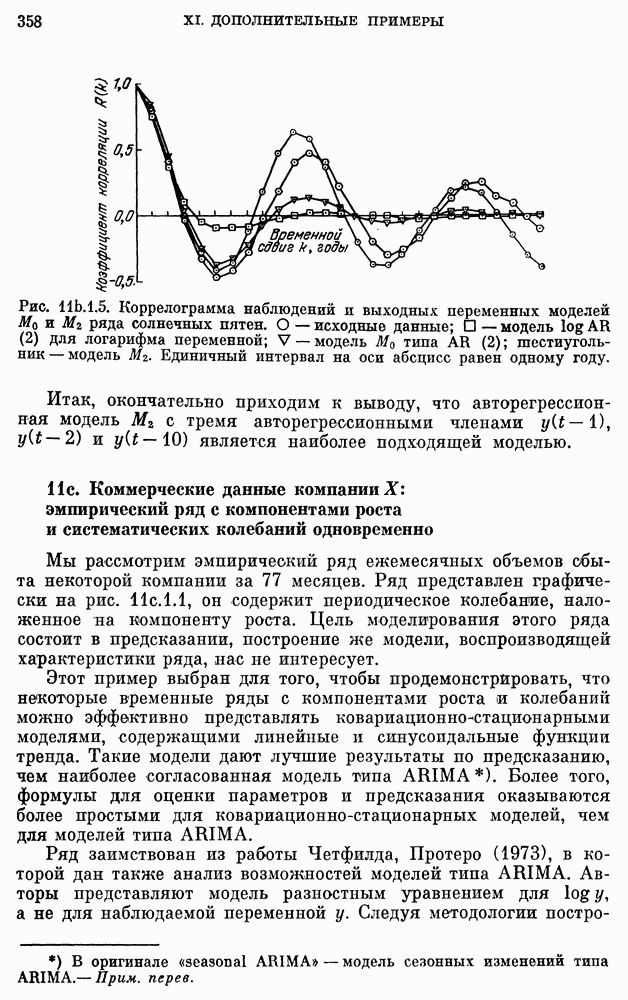
 для реки Кришнач исключены, поскольку оценки коэффициентов при этих членах оказались незначимыми согласно критерию 5 из п. 8с.2.3. Однако предположение о нормальности не может быть обосновано из-за малого количества наблюдений.
для реки Кришнач исключены, поскольку оценки коэффициентов при этих членах оказались незначимыми согласно критерию 5 из п. 8с.2.3. Однако предположение о нормальности не может быть обосновано из-за малого количества наблюдений.

 большое целое число, а
большое целое число, а  последовательность независимых случайных величин с нулевым математическим ожиданием, имеющих нормальное распределение
последовательность независимых случайных величин с нулевым математическим ожиданием, имеющих нормальное распределение 
 наилучшей модели с дробным шумом для каждой реки. Хорошей оценкой параметра
наилучшей модели с дробным шумом для каждой реки. Хорошей оценкой параметра 







