8b.2. Проверка гипотез.
Обсуждение теории проверки гипотез можно найти в книгах Рао (1965), Лемана (1964) и др., а ее применение ко временным рядам — у Андерсона (1976), Бокса, Дженкинса (1970), Уиттла (1951) и в других книгах и статьях. Интересная критика классической теории проверки гипотез дана, в частности, Праттом и др. (1965) и Бирнбаумом (1969).
8b.2.1. Вывод решающего правила.
Классическая теория проверки гипотез применима для сравнения только двух классовюделей, скажем,  Пусть даны два класса:
Пусть даны два класса:

Разностное уравнение в классе  содержит меньше членов, чем в классе
содержит меньше членов, чем в классе  Следовательно, класс
Следовательно, класс  можно назвать более простым.
можно назвать более простым.
Требуется найти решающее правило  отображающее заданное мпожество наблюдений
отображающее заданное мпожество наблюдений  в один из двух классов
в один из двух классов  . Более подробно, используя множество наблюдений нужно найти статистику, например
. Более подробно, используя множество наблюдений нужно найти статистику, например  являющуюся функцией и порог
являющуюся функцией и порог  такие, что
такие, что

обладает приемлемыми свойствами. В стохастическом случае всегда существует опасность принять неверное решение, т. е. отнести заданный эмпирически процесс к неправильному классу. Имеются два типа ошибок, I и II рода, а именно, отвергнуть правильный класс  и отвергнуть правильный класс
и отвергнуть правильный класс 

Заметим, что две вероятности ошибки являются функциями не только правила  но также и вектора параметров
но также и вектора параметров  или
или  характеризующего процесс.
характеризующего процесс.
Решающее правило, приводящее к наименьшему числу ошибок, т. е. правило  обеспечивающее малость
обеспечивающее малость  для каждого
для каждого  и малость
и малость  для каждого
для каждого  было бы идеальным. Однако эта задача неудачно поставлена, поскольку уменьшение
было бы идеальным. Однако эта задача неудачно поставлена, поскольку уменьшение  не приводит к уменьшению
не приводит к уменьшению  для каждого
для каждого  Например, при
Например, при  для всех
для всех  но
но  для всех
для всех  Таким образом, надо принимать компромиссное решение.
Таким образом, надо принимать компромиссное решение.
В теории Неймана — Пирсона ограничиваются только теми решающими правилами, у которых вероятность ошибки I рода не превосходитпределенного, заранее заданного значения  Рассмотрим поэтому все решающие правила
Рассмотрим поэтому все решающие правила  удовлетворяющие условию
удовлетворяющие условию

Среди этого класса решающих правил выберем некоторое правило  удовлетворяющее условию:
удовлетворяющее условию:

при условии, что оно существует. Если такое правило существует, назовем его равномерно наиболее мощным решающим правилом. Однако такое равномерно наиболее мощное правило существует редко, поскольку трудно представить решающую функцию  удовлетворяющую
удовлетворяющую  для каждого
для каждого 
Поэтому рассмотрим несколько меньший класс решающих правил — класс правил, подчиняющихся соотношениям

где  называется уровнем значимости и выражается обычно в процентах.
называется уровнем значимости и выражается обычно в процентах.
Как ни странно, обычно существует решающее правило  асимптотически удовлетворяющее условию
асимптотически удовлетворяющее условию  Не надо беспокоиться относительно выбора решающей функции
Не надо беспокоиться относительно выбора решающей функции  когда существует более одного
когда существует более одного  удовлетворяющего условию
удовлетворяющего условию  поскольку шансы такого события очень малы.
поскольку шансы такого события очень малы.
Перейдем теперь к определению решающего правила  удовлетворяющего условию
удовлетворяющего условию  Интуитивно ясно, что таким правилом является критерий отношения правдоподобия. Пусть
Интуитивно ясно, что таким правилом является критерий отношения правдоподобия. Пусть  плотности вероятности множества наблюдений описываемых моделью
плотности вероятности множества наблюдений описываемых моделью  Рассмотрим отношение правдоподобия
Рассмотрим отношение правдоподобия 

Разница между выражениями для правдоподобия  и приведенными в п. 8b.1 состоит в том, что первое представление не позволяет учесть относительные размеры множеств
и приведенными в п. 8b.1 состоит в том, что первое представление не позволяет учесть относительные размеры множеств  Критерий отношения правдоподобия задается в виде
Критерий отношения правдоподобия задается в виде

где  некоторый порог. Упростим сначала функцию
некоторый порог. Упростим сначала функцию  Предполагая нормальность наблюдений обозначим через
Предполагая нормальность наблюдений обозначим через  остаточную дисперсию наилучшей модели в классе
остаточную дисперсию наилучшей модели в классе  для заданных наблюдений
для заданных наблюдений  и через
и через  соответствующую остаточную дисперсию наилучшей модели класса
соответствующую остаточную дисперсию наилучшей модели класса  также построенной по данным Поскольку разностное уравнение для модели из
также построенной по данным Поскольку разностное уравнение для модели из  имеет больше коэффициентов, чем из
имеет больше коэффициентов, чем из  то обычно
то обычно  Справедливость следующего результата была показана в гл. VI:
Справедливость следующего результата была показана в гл. VI:

Следовательно,

Таким образом, решающее правило в выражении  включает только статистику
включает только статистику  Это выражение можно переписать в несколько иной форме
Это выражение можно переписать в несколько иной форме  так, чтобы распределение вероятностей при условии
так, чтобы распределение вероятностей при условии  имело стандартный вид. Решающее правило
имело стандартный вид. Решающее правило  переписано в виде решающего правила 2.
переписано в виде решающего правила 2.
Решающее правило 2 (критерий отношения остаточных дисперсий).

где  число наблюдений в
число наблюдений в  число ненулевых коэффициентов в уравнении
число ненулевых коэффициентов в уравнении  из
из  число добавочных коэффициентов в уравнении из
число добавочных коэффициентов в уравнении из  не содержащихся в уравнении из
не содержащихся в уравнении из 
Предположим, что распределение вероятностей статистики  для случая, когда
для случая, когда  удовлетворяет
удовлетворяет  является F-pacпределением с
является F-pacпределением с  и
и  степенями свободы. Справедливость этого предположения можно проверить для некоторых специальных случаев, таких как классы непреобразованных моделей AR (Уиттл, 1952) или непреобразованных моделей AR с синусоидальными членами. Кроме того, справедливость этого предположения интуитивно очевидна при
степенями свободы. Справедливость этого предположения можно проверить для некоторых специальных случаев, таких как классы непреобразованных моделей AR (Уиттл, 1952) или непреобразованных моделей AR с синусоидальными членами. Кроме того, справедливость этого предположения интуитивно очевидна при  Важным моментом этого предположения является то, что распределение вероятностей не
Важным моментом этого предположения является то, что распределение вероятностей не
зависит ни от 0, ни от  пока
пока  Поскольку для F-распределения имеется таблица, то можно найти порог
Поскольку для F-распределения имеется таблица, то можно найти порог  Для получения конкретных значений вероятности ошибки I рода
Для получения конкретных значений вероятности ошибки I рода 
Однако до сих пор отсутствует способ определения вероятности ошибки II рода. Это один из основных недостатков данной теории. Нужно использовать произвольное значение вероятностп ошибки 80, например 0,05, и считать, что соответствующая вероятность ошибки II рода невелика. Однако не имеется никакой идеи относительно компромисса между выбором  и выбором, скажем,
и выбором, скажем,  Таким образом, хотя решающее правило из
Таким образом, хотя решающее правило из  похоже на правило из § 8а, основанное на методе правдоподобия, правило из § 8а предпочтительнее, потому что оно не содержит произвольных параметров.
похоже на правило из § 8а, основанное на методе правдоподобия, правило из § 8а предпочтительнее, потому что оно не содержит произвольных параметров.
Одним из преимуществ теории этого пункта является возможность получения приближенного выражения для вероятности ошибки I рода, определяемой методом правдоподобия из § 8а для задачи с двумя классами, обладающими специальной структурой, описанной в этом пункте.
Дробь  характеризует относительное уменьшение остаточной дисперсии, вызванное добавочными членами в разностных уравнениях класса
характеризует относительное уменьшение остаточной дисперсии, вызванное добавочными членами в разностных уравнениях класса  которые отсутствуют в классе
которые отсутствуют в классе  Для иллюстрации важности этого отношения рассмотрим следующий специальный случай.
Для иллюстрации важности этого отношения рассмотрим следующий специальный случай.
Пример 8b.1. Пусть два класса  и
и  таковы:
таковы:

По данному множеству наблюдений  требуется найти соответствующий ему класс
требуется найти соответствующий ему класс  или
или  Другими словами, нужно выяснить, является ли член
Другими словами, нужно выяснить, является ли член  необходимым для моделирования у.
необходимым для моделирования у.
В настоящей задаче

Можно интерпретировать отношение  как частный
как частный
быть велика. Из практики известно, что значение  обычно удовлетворительно. Соответствующее значение
обычно удовлетворительно. Соответствующее значение  дается выражением
дается выражением

Обычно, когда значение  наблюдается «на хвосте» распределения, класс
наблюдается «на хвосте» распределения, класс  отклоняется. Если
отклоняется. Если  находится рядом с модой, то
находится рядом с модой, то  принимается. Если
принимается. Если  попадает в промежуточную область, вероятность, отвечающая «хвосту» распределения вправо от этого значения, вычисляется по таблицам
попадает в промежуточную область, вероятность, отвечающая «хвосту» распределения вправо от этого значения, вычисляется по таблицам  -распределения. Тогда критерий позволяет принять класс
-распределения. Тогда критерий позволяет принять класс  с уровнем значимости 80, если вычисленная вероятность меньше, чем
с уровнем значимости 80, если вычисленная вероятность меньше, чем  т. е. если
т. е. если  Порог
Порог  дан ниже для
дан ниже для 
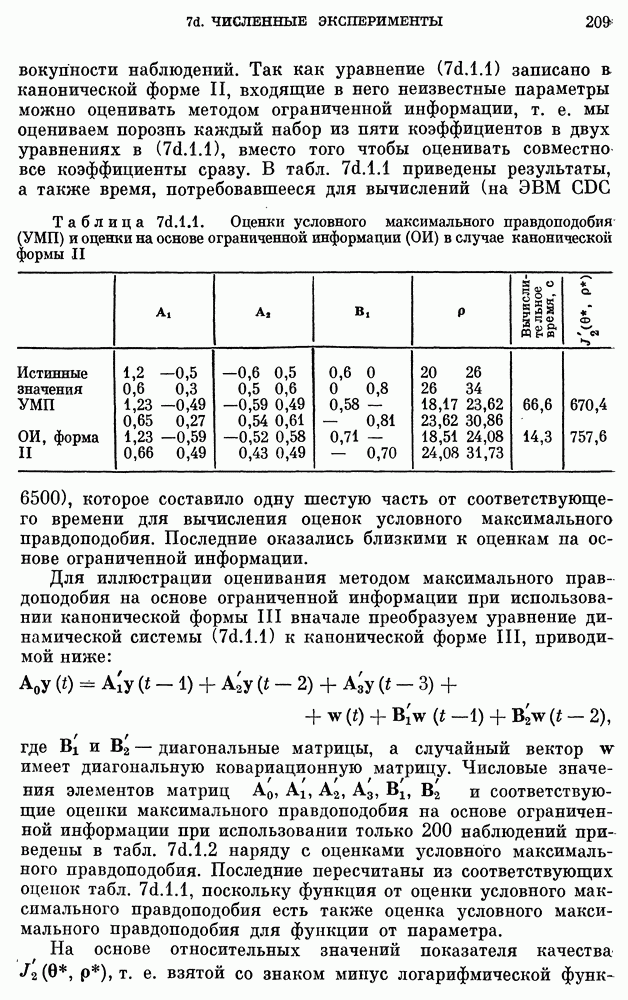
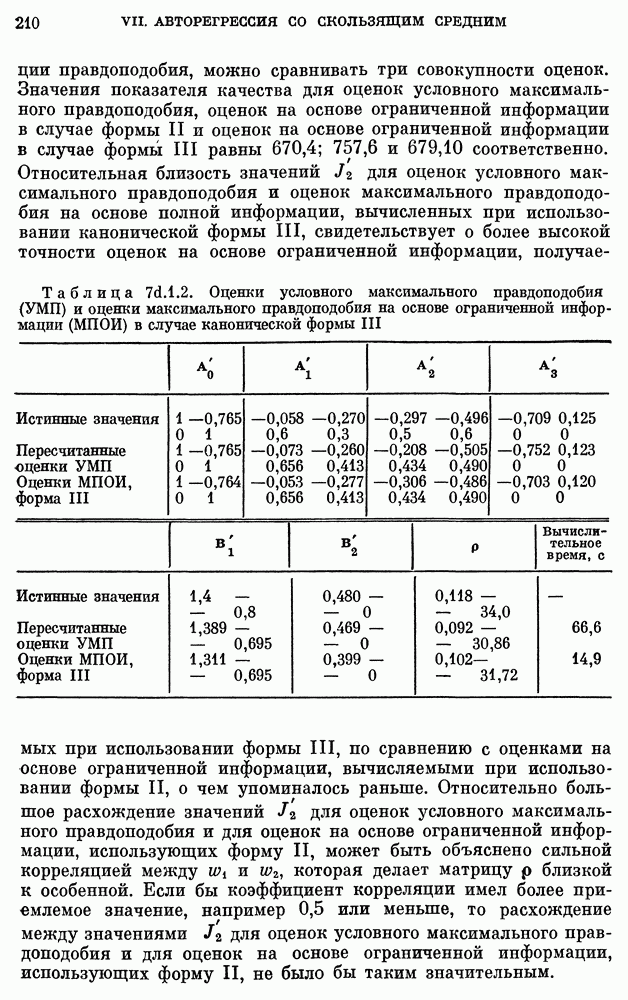
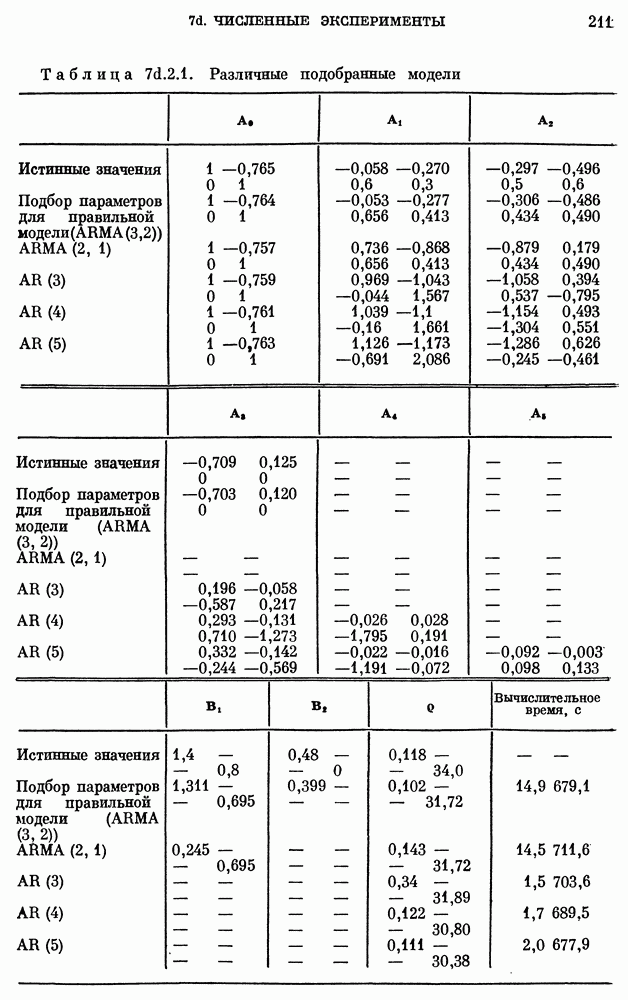
(см. скан)
Из таблицы видно, что решающее правило  для задачи с двумя классами при использовании метода максимального правдоподобия соответствует вероятности 0,05 ошибки I рода. Чтобы увидеть взаимосвязь между принятием гипотезы и размером выборки, рассмотрим пример
для задачи с двумя классами при использовании метода максимального правдоподобия соответствует вероятности 0,05 ошибки I рода. Чтобы увидеть взаимосвязь между принятием гипотезы и размером выборки, рассмотрим пример 
Пример 8b.1 {продолжение). Пусть

Не задавая конкретного размера выборки  значимость
значимость  точно определить нельзя.
точно определить нельзя.
(1) Если указанные выше значения  были получены при
были получены при  то из
то из  получим
получим

В этом случае значение  много больше величины порога 3,94, соответствующего
много больше величины порога 3,94, соответствующего  -процентной вероятности ошибки I рода. Следовательно, для
-процентной вероятности ошибки I рода. Следовательно, для  принимается значение
принимается значение 
(2) Если те же самые значения  были получены для
были получены для  то
то

Это значение значительно меньше, чем порог, и, следовательно, на уровне значимости 5% для данного процесса можно принять класс 
С другой стороны, если нужно пользоваться вероятностью ошибки I рода, равной 0,005, придется принимать  в обоих случаях.
в обоих случаях.
Пример ясно показывает тесную связь между выбираемым классом моделей, имеющимся множеством данных и желаемой точностью.
Если зафиксировать  вероятность ошибки I рода, то использовать сложные модели (т. е. модели, имеющие большое число параметров) приходится, только если
вероятность ошибки I рода, то использовать сложные модели (т. е. модели, имеющие большое число параметров) приходится, только если  относительно велико. Сложность модели, определяемой решающим правилом, является функцией числа используемых наблюдений.
относительно велико. Сложность модели, определяемой решающим правилом, является функцией числа используемых наблюдений.
Рациональный выбор  совершенно неясен. В литературе по статистике часто можно найти утверждения такого типа: «наш критерий использовал
совершенно неясен. В литературе по статистике часто можно найти утверждения такого типа: «наш критерий использовал  -процентный уровень значимости
-процентный уровень значимости  и, следовательно, он лучше других критериев с
и, следовательно, он лучше других критериев с  -процентным уровнем значимости
-процентным уровнем значимости  Такое заявление справедливо только в том случае, когда ошибка I рода гораздо более опасна, чем ошибка II рода, и, следовательно, мы больше выгадываем, работая с возможно более малыми
Такое заявление справедливо только в том случае, когда ошибка I рода гораздо более опасна, чем ошибка II рода, и, следовательно, мы больше выгадываем, работая с возможно более малыми  даже хотя мы и знаем, что уменьшение 8 влечет увеличение вероятности ошибки II рода (Пратт и др., 1965). Рассмотрим, например, следующую гипотезу
даже хотя мы и знаем, что уменьшение 8 влечет увеличение вероятности ошибки II рода (Пратт и др., 1965). Рассмотрим, например, следующую гипотезу  «Виски исцеляет укус змеи», и пусть
«Виски исцеляет укус змеи», и пусть  противоположная гипотеза. Пуританин скорее всего скажет, что принять гипотезу С о, когда она неверна, гораздо опаснее, чем отвергнуть ее в противоположном случае. В первом случае не только возможны смертельные исходы от укусов змей, но еще и увеличится число пьяных на улицах, потребляющих алкоголь под предлогом лечебных свойств. Во втором случае придется искать другие средства для лечения от укуса змей. В этом примере отказ от гипотезы
противоположная гипотеза. Пуританин скорее всего скажет, что принять гипотезу С о, когда она неверна, гораздо опаснее, чем отвергнуть ее в противоположном случае. В первом случае не только возможны смертельные исходы от укусов змей, но еще и увеличится число пьяных на улицах, потребляющих алкоголь под предлогом лечебных свойств. Во втором случае придется искать другие средства для лечения от укуса змей. В этом примере отказ от гипотезы  на уровне
на уровне  можно рассматривать как предпочтительный по сравнению с ее отклонением на уровне
можно рассматривать как предпочтительный по сравнению с ее отклонением на уровне 
Однако такая логика совершенно неприемлема в задачах построения моделей. Нужно считать важными ошибки обоих типов. Следовательно, нельзя сказать, что критерий с  лучше, чем
лучше, чем  так как в первом случае больше вероятность ошибки II рода. Это указывает на важность метода максимального правдоподобия, который не включает использование субъективных параметров типа 8.
так как в первом случае больше вероятность ошибки II рода. Это указывает на важность метода максимального правдоподобия, который не включает использование субъективных параметров типа 8.





















































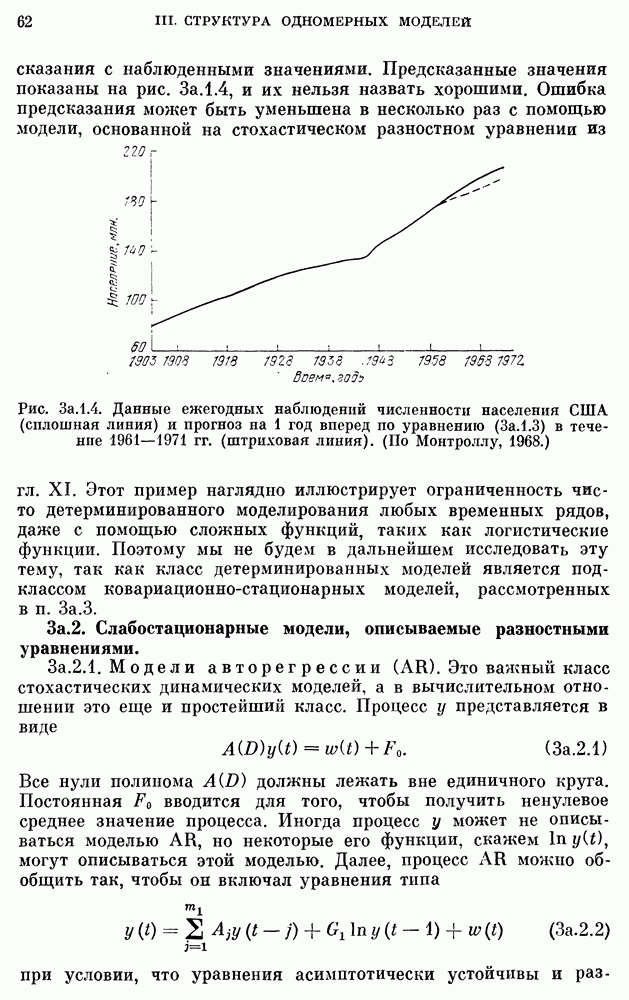


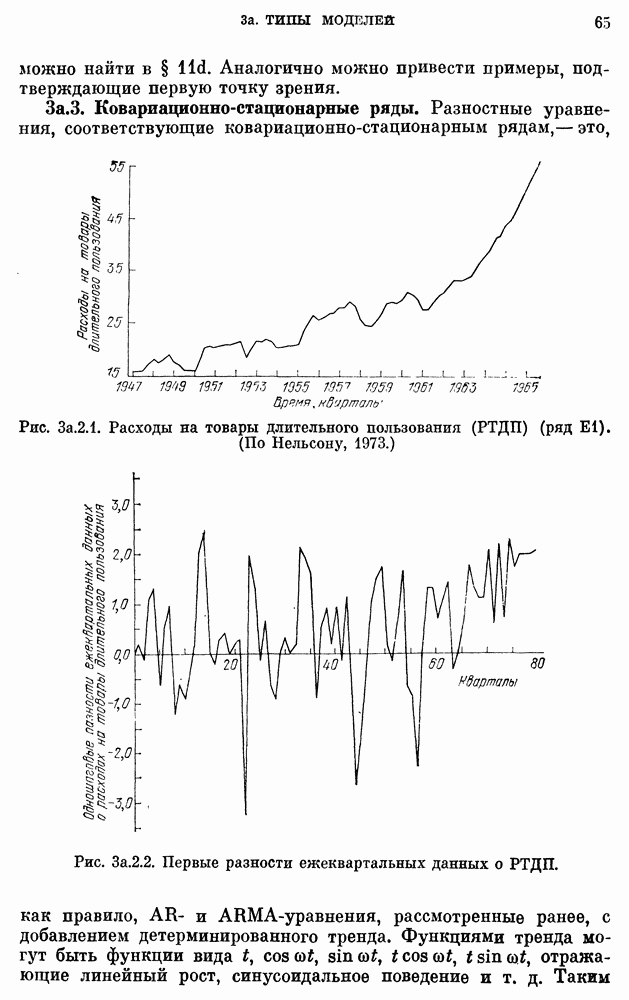








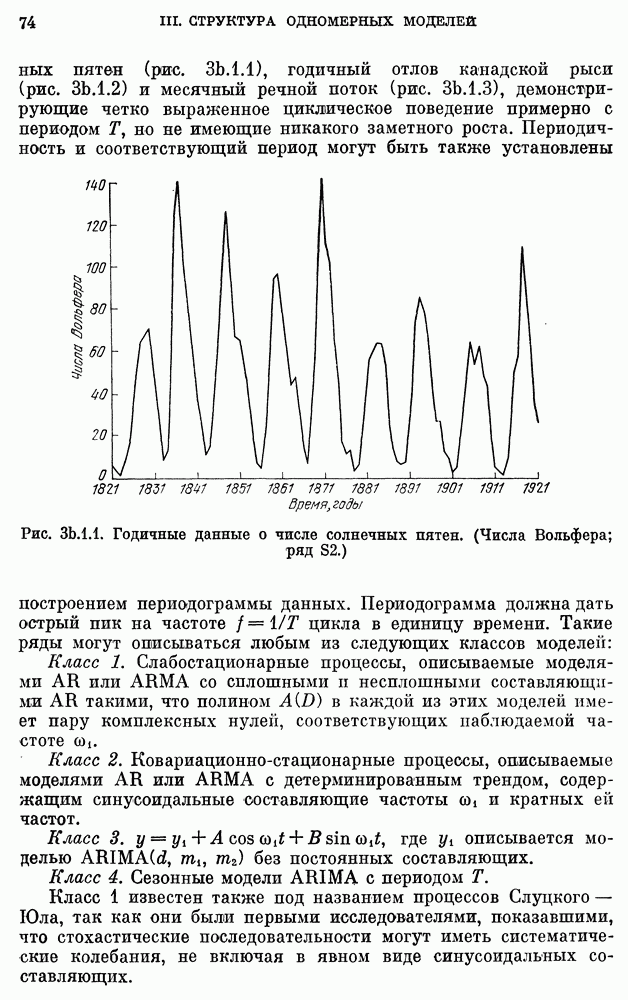
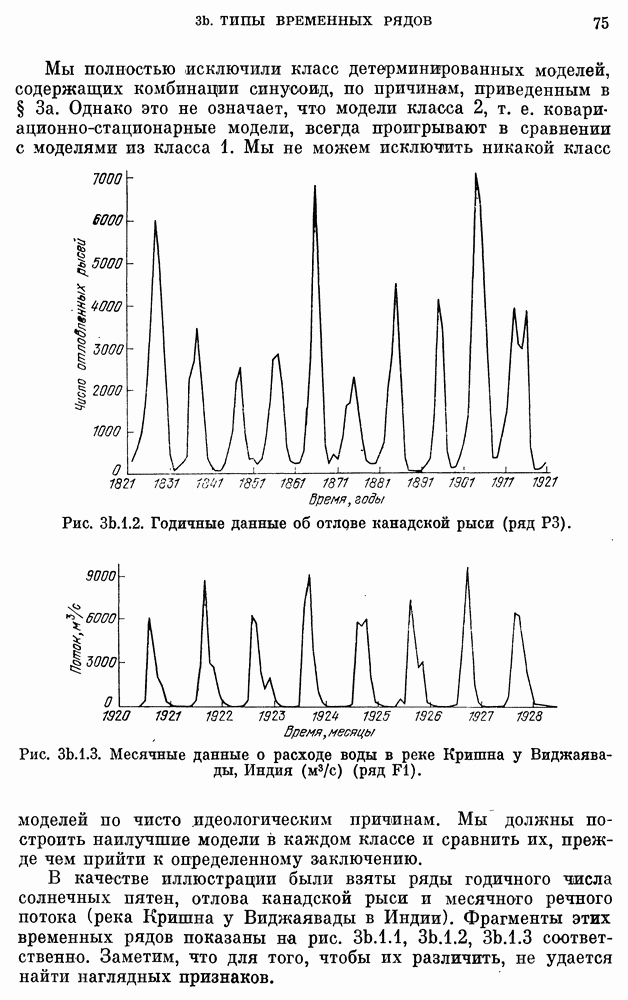







































































































































































































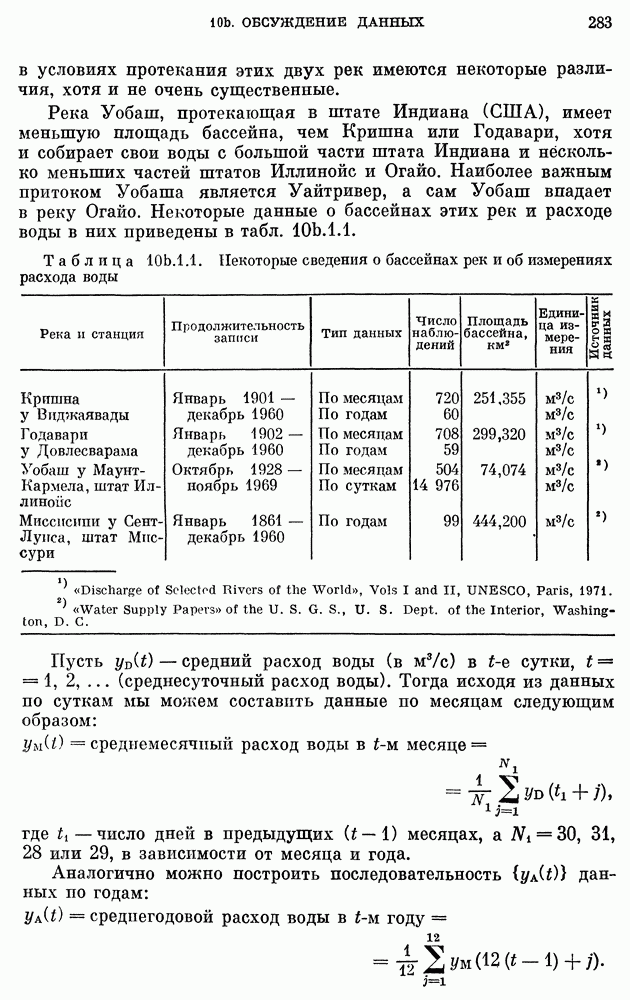



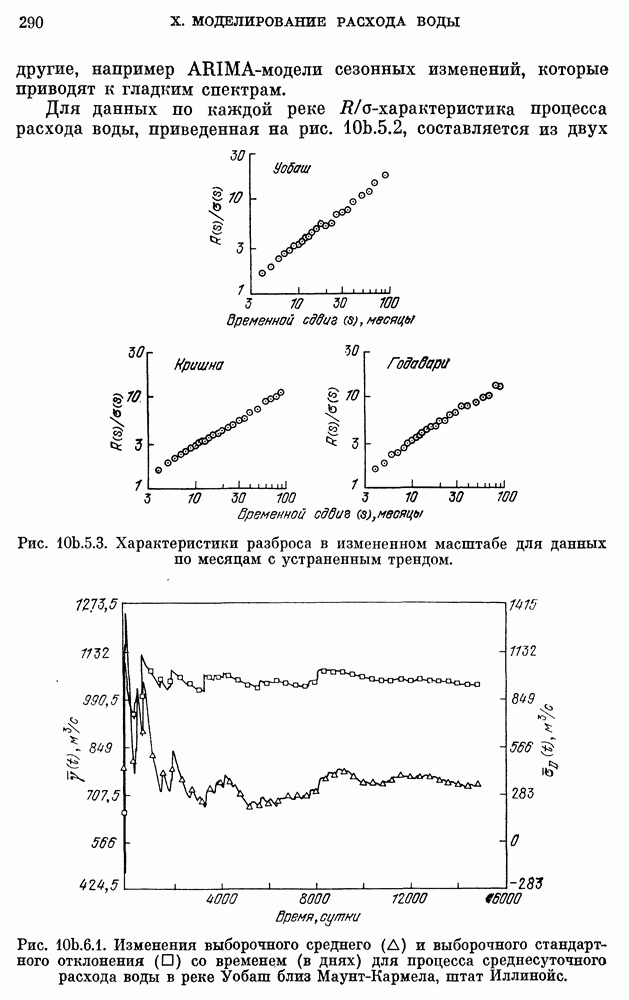
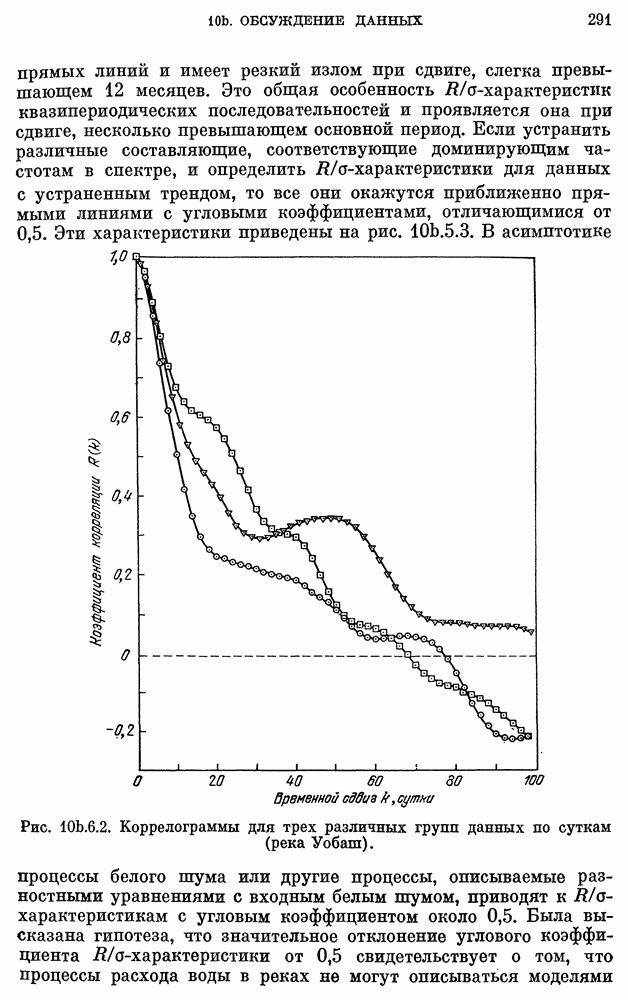


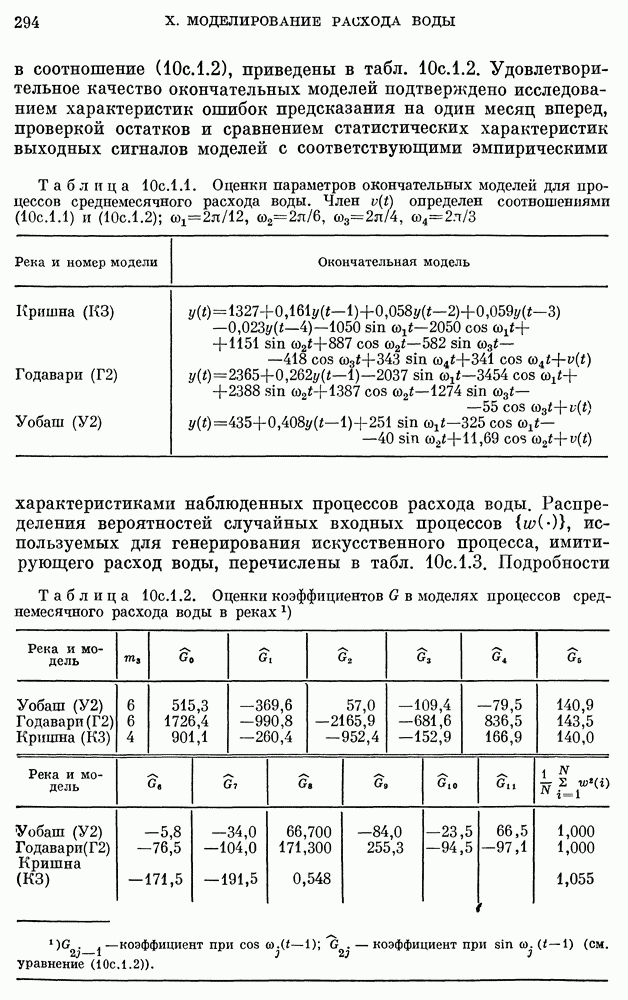






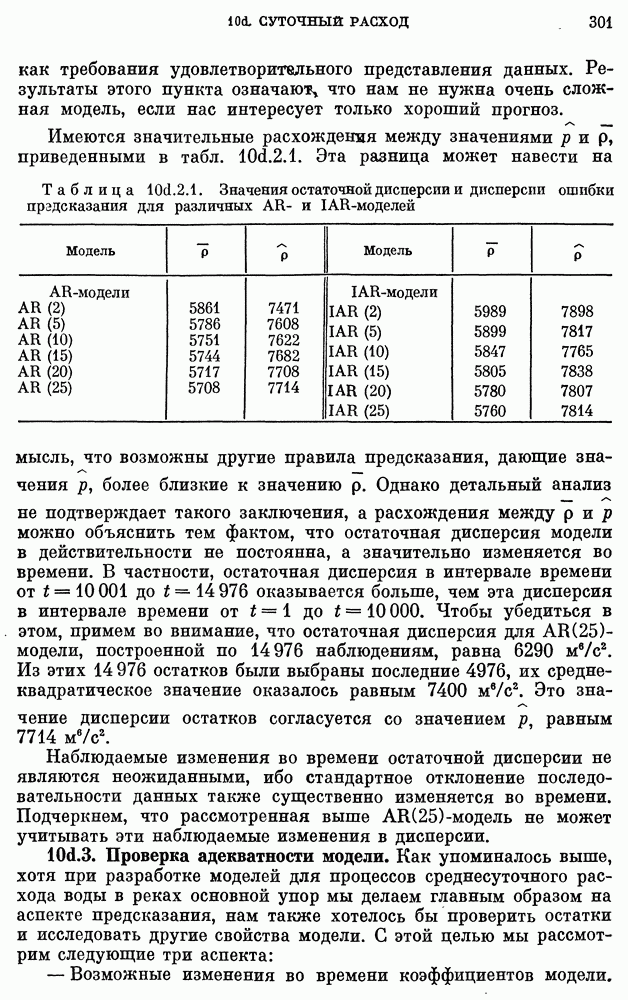














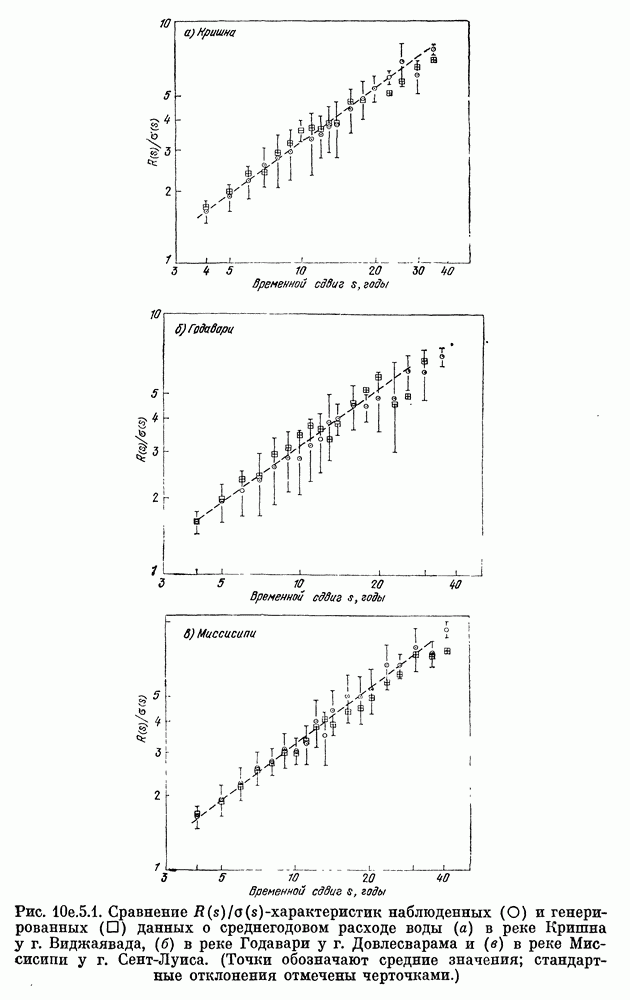



















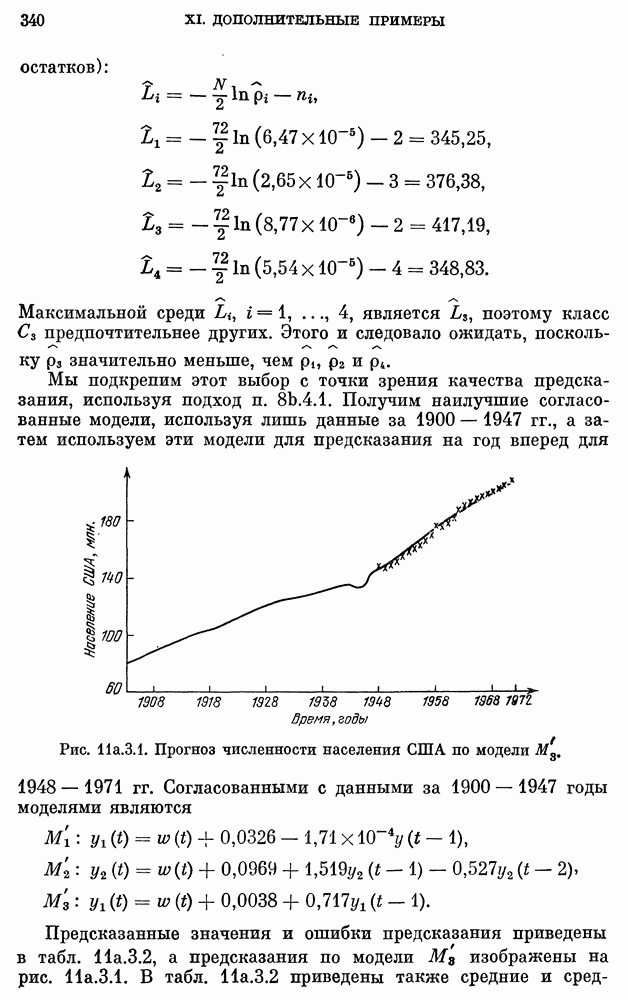
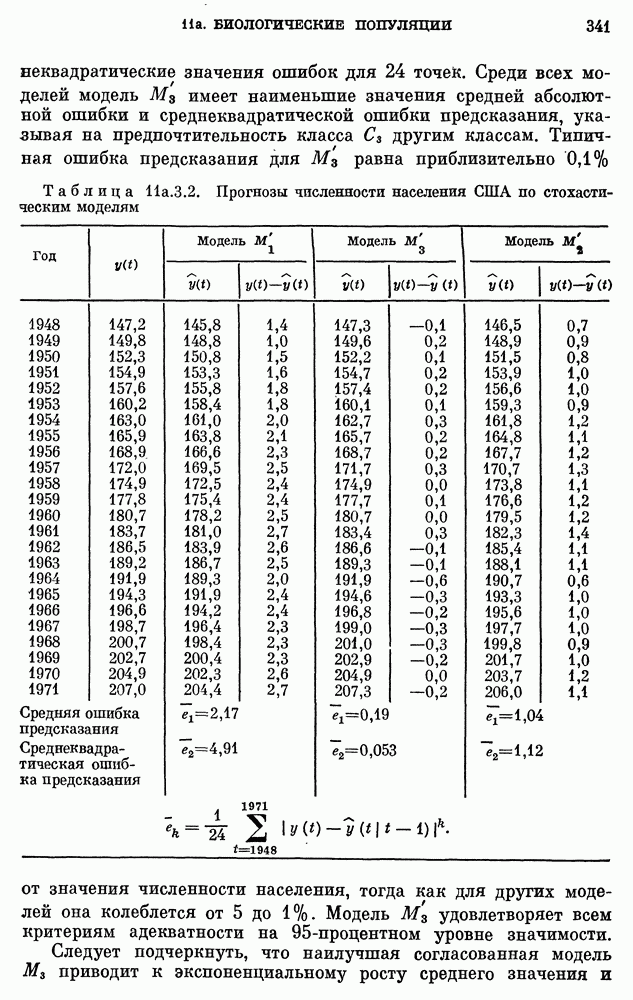







 после исключения влияния промежуточных переменных
после исключения влияния промежуточных переменных  Предположим, что строятся две отдельные модели для
Предположим, что строятся две отдельные модели для  через
через 

 равен отношению
равен отношению  Иначе смысл
Иначе смысл  можно объяснить в терминах дисперсионного анализа. Дисперсию
можно объяснить в терминах дисперсионного анализа. Дисперсию  можно представить следующим образом:
можно представить следующим образом:


 также является последовательностью независимых одинаково распределенных величин, а
также является последовательностью независимых одинаково распределенных величин, а  при
при  и всех
и всех  взаимно независимые случайные величины, или линейно независимые функции времени, или и то и другое, то высказанное выше предположение относительно распределения вероятностей
взаимно независимые случайные величины, или линейно независимые функции времени, или и то и другое, то высказанное выше предположение относительно распределения вероятностей  справедливо. Если отношение
справедливо. Если отношение  значимо на определенном уровне, например
значимо на определенном уровне, например  член
член  можно считать существенным для моделирования
можно считать существенным для моделирования 
 вероятности ошибки I рода. Чтобы понять решающее правило в выражении
вероятности ошибки I рода. Чтобы понять решающее правило в выражении  нужно понять природу
нужно понять природу  -распределения. Пусть
-распределения. Пусть  имеет распределение
имеет распределение  тогда
тогда

 находится в точке
находится в точке  если
если  велико. Выбор уровня значимости
велико. Выбор уровня значимости  произволен. Если принять
произволен. Если принять  слишком малым, то вероятность ошибки II рода можег
слишком малым, то вероятность ошибки II рода можег