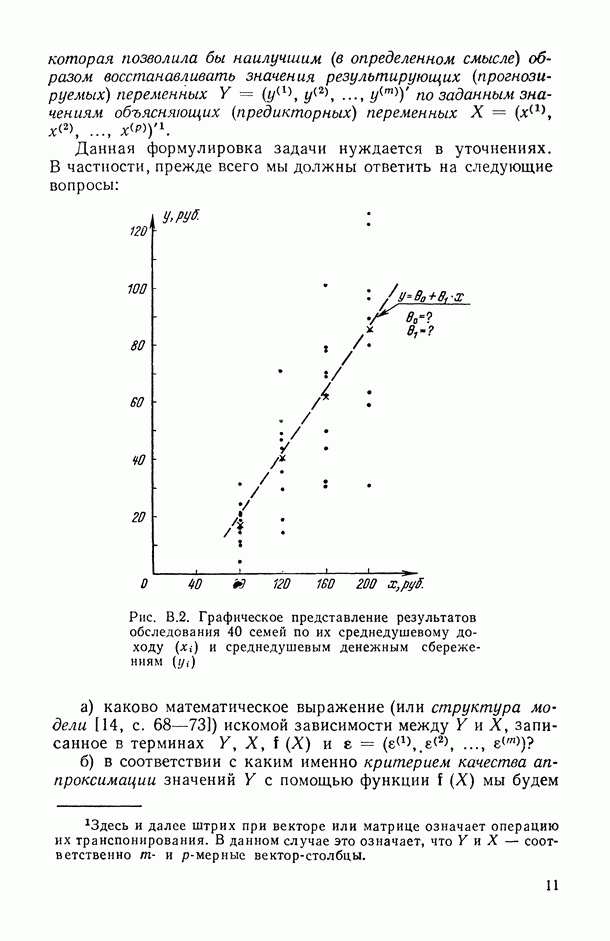
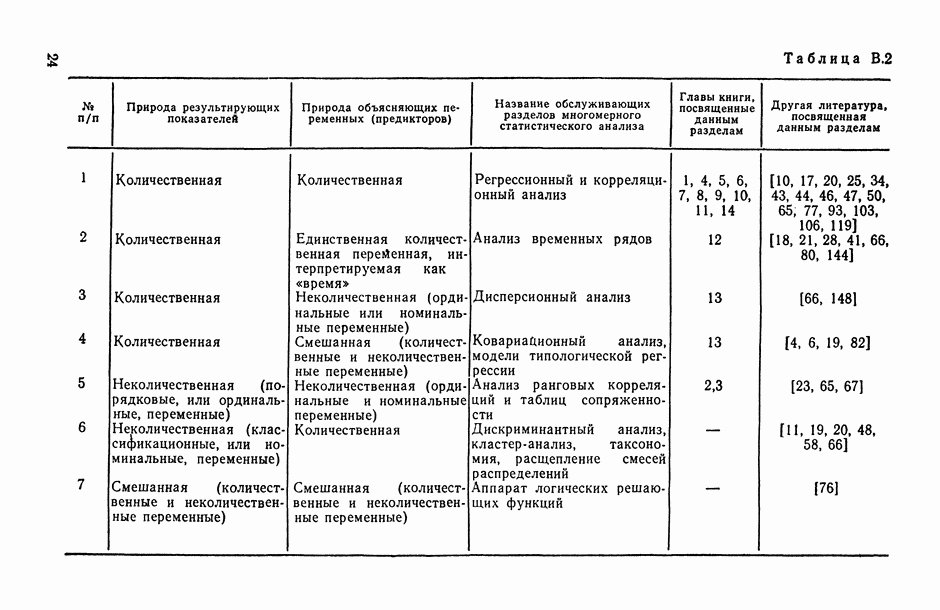
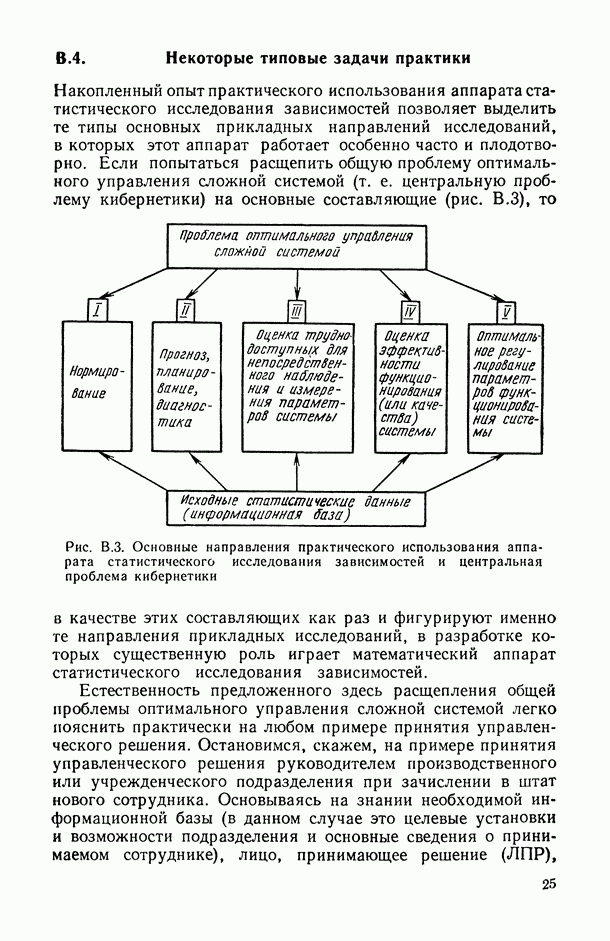
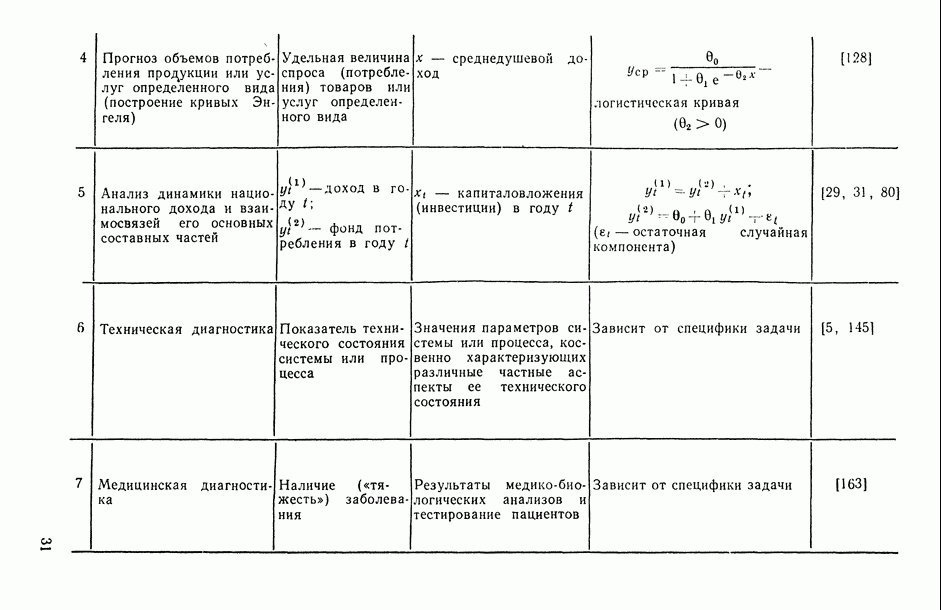
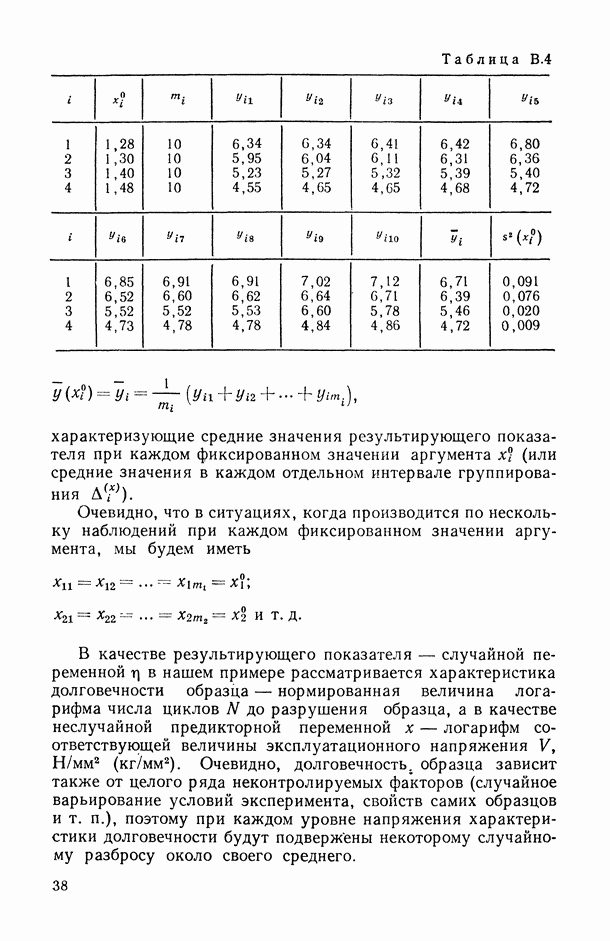
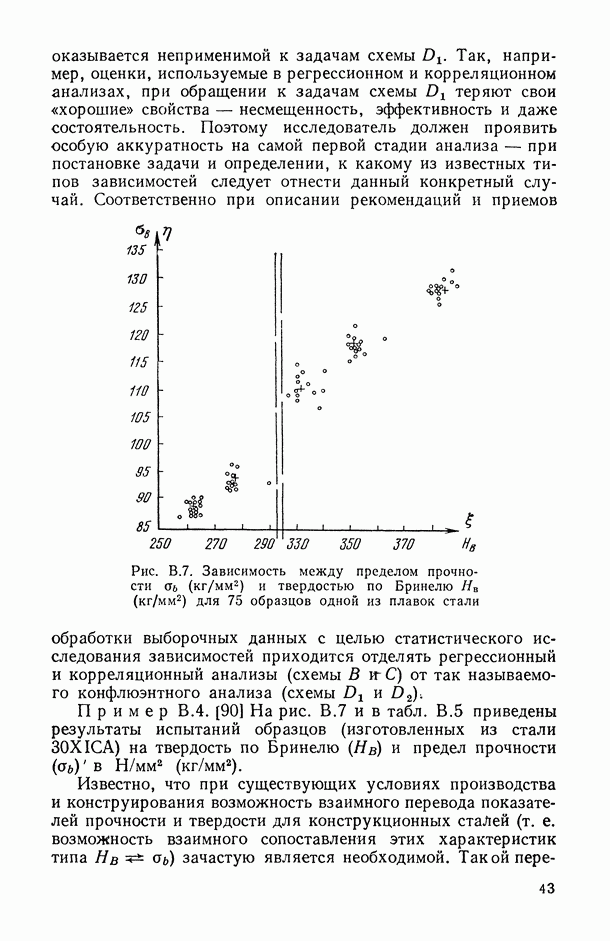
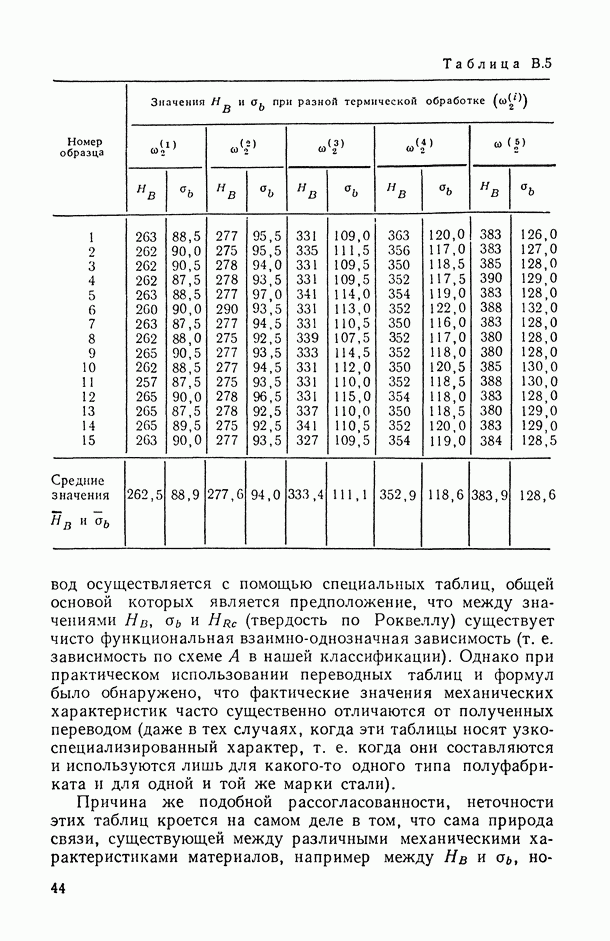
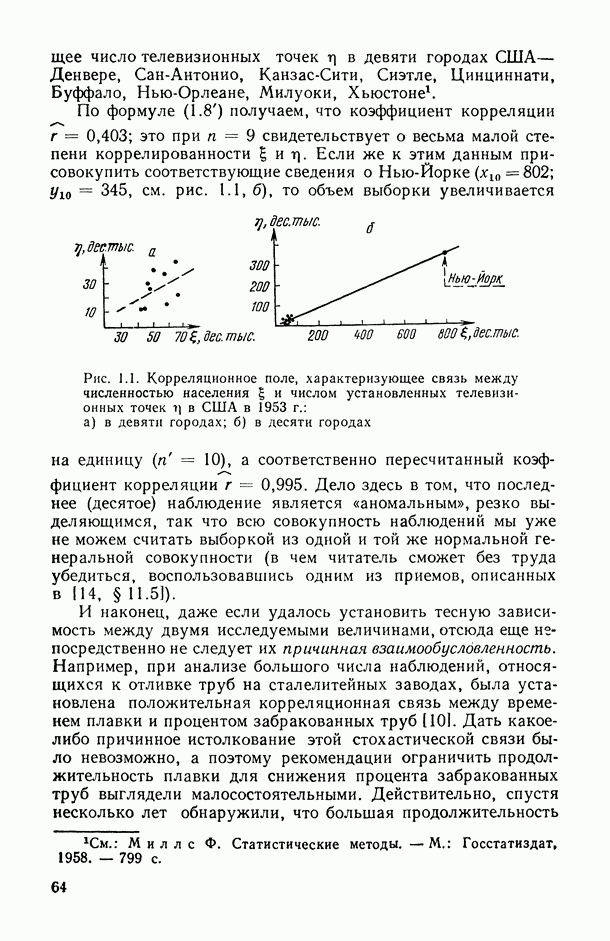
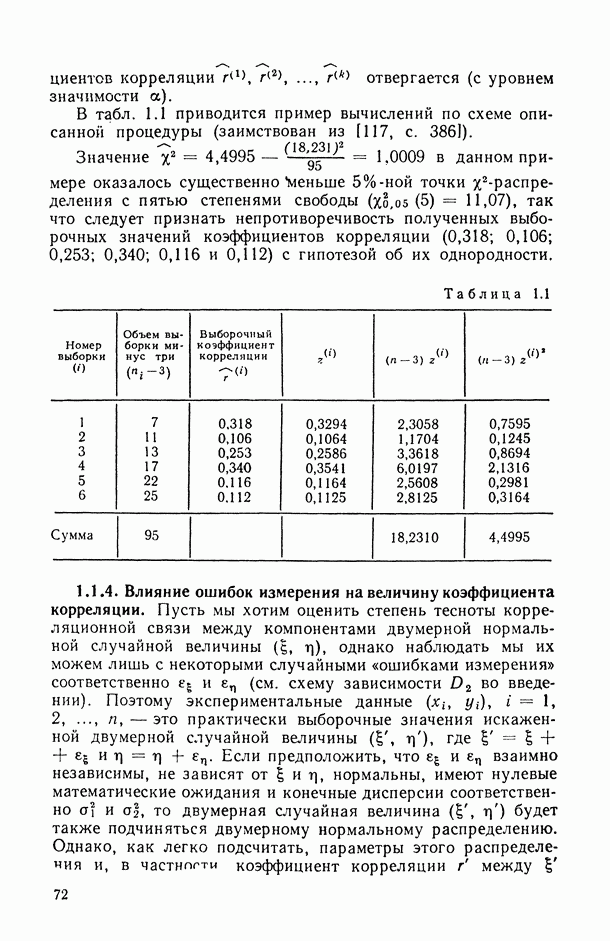
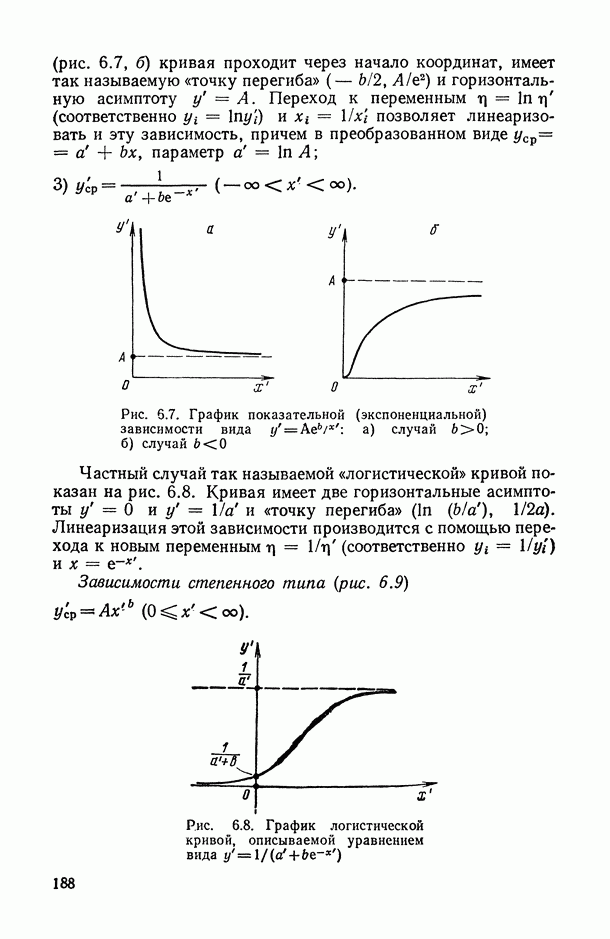
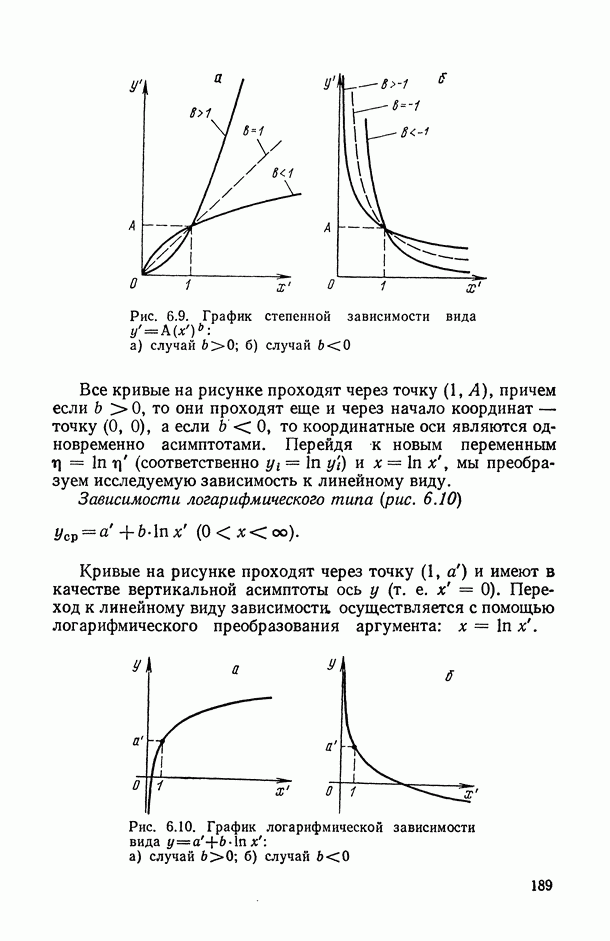
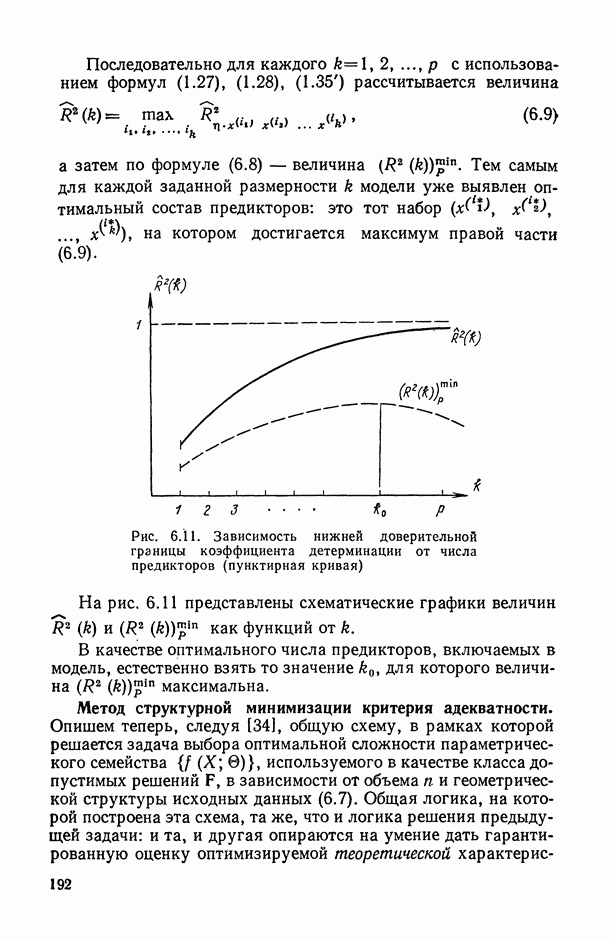
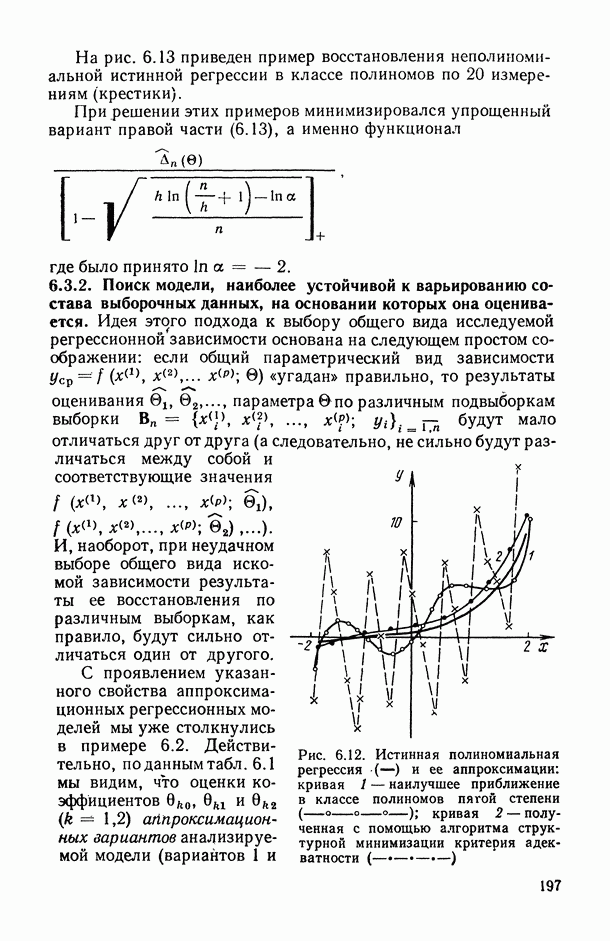
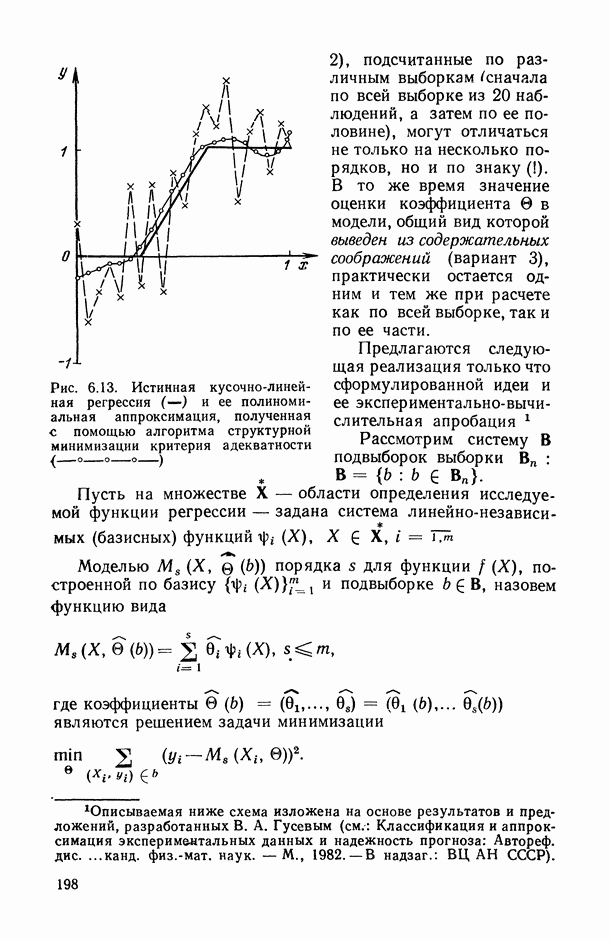
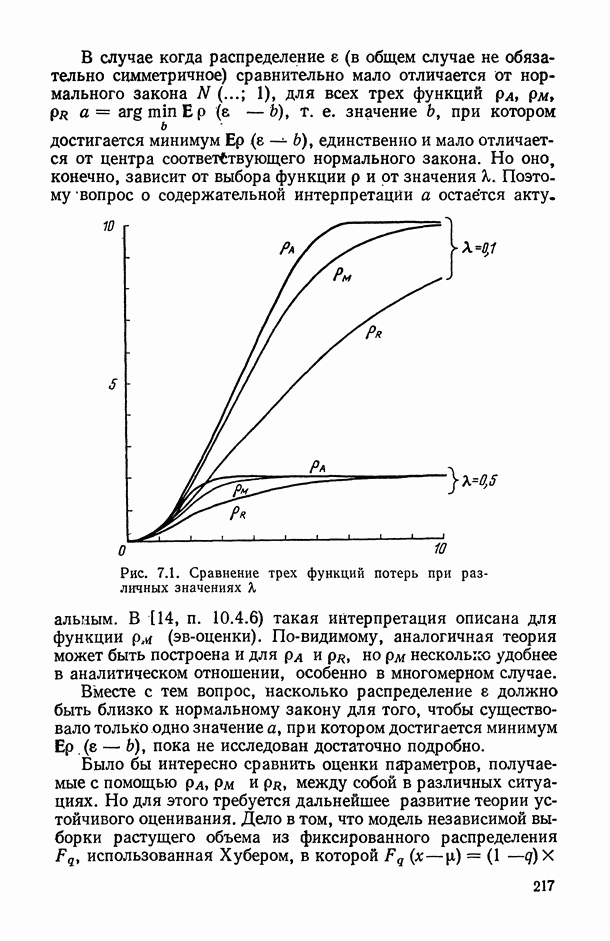
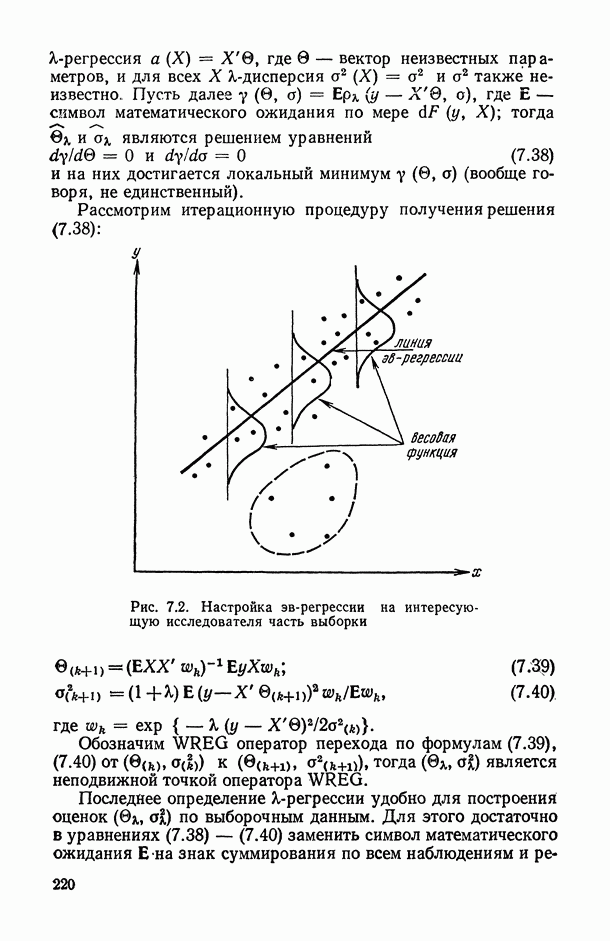
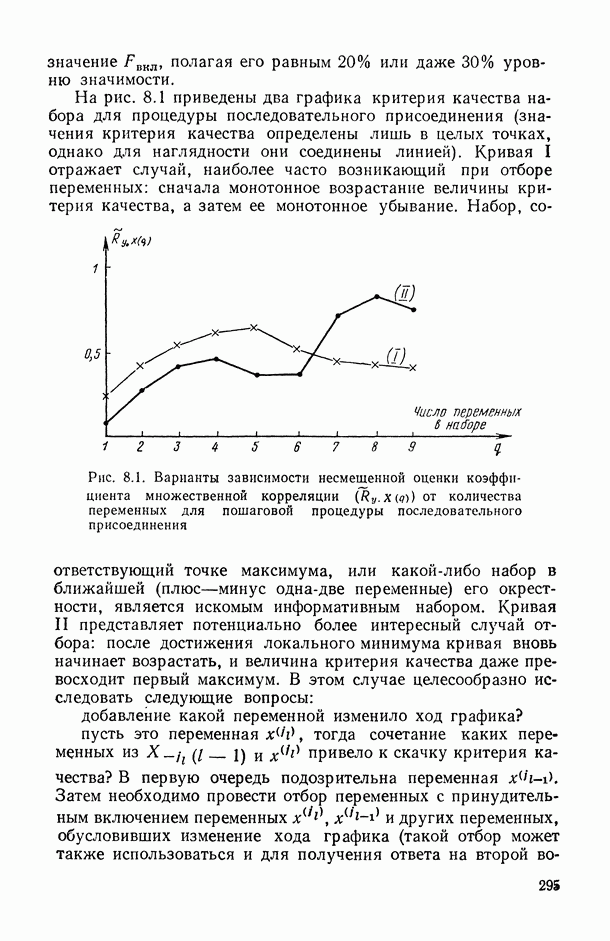
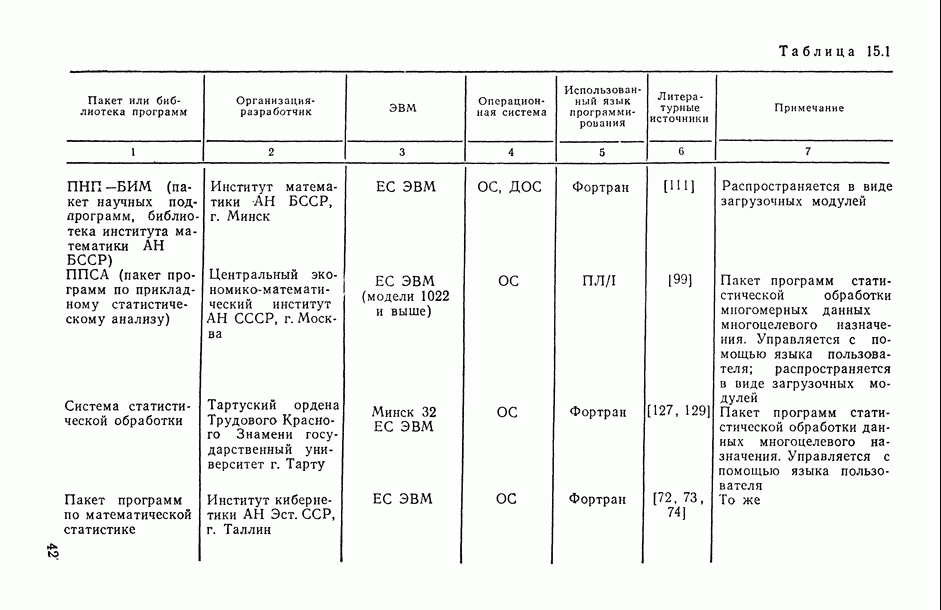
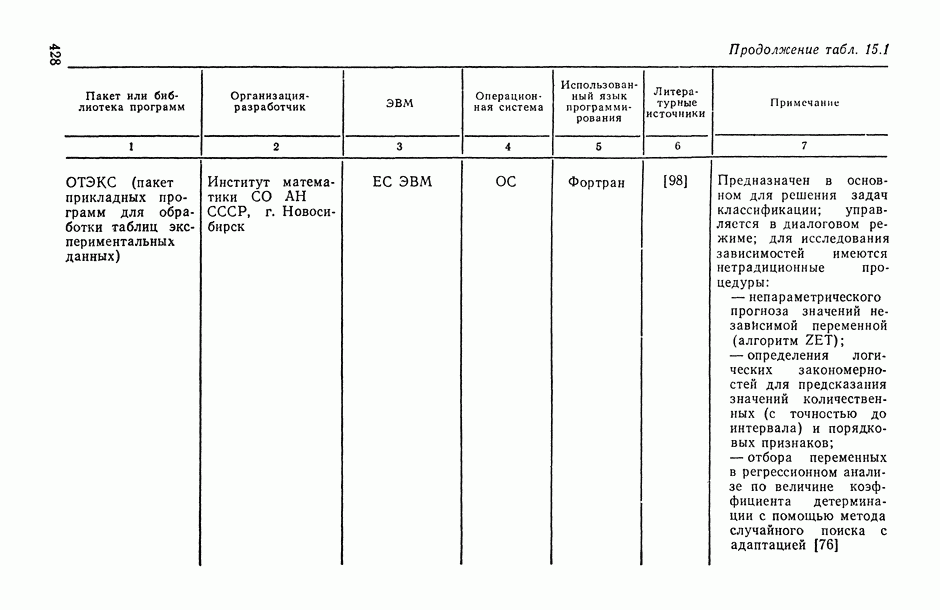
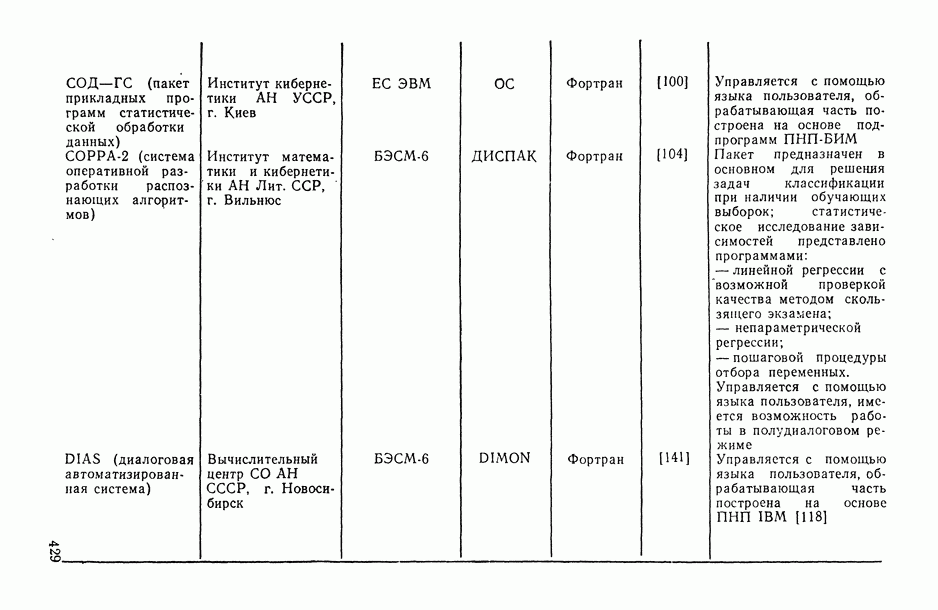
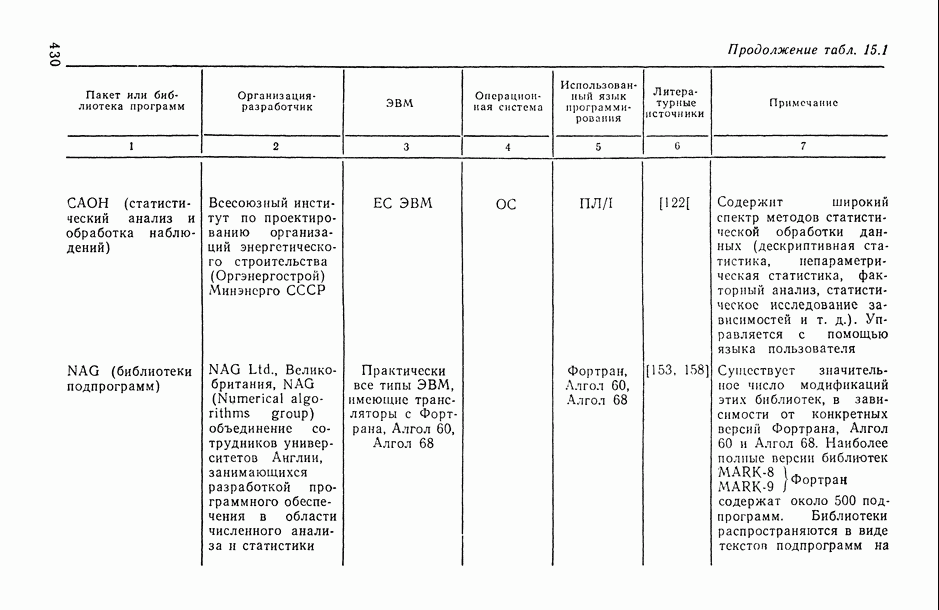
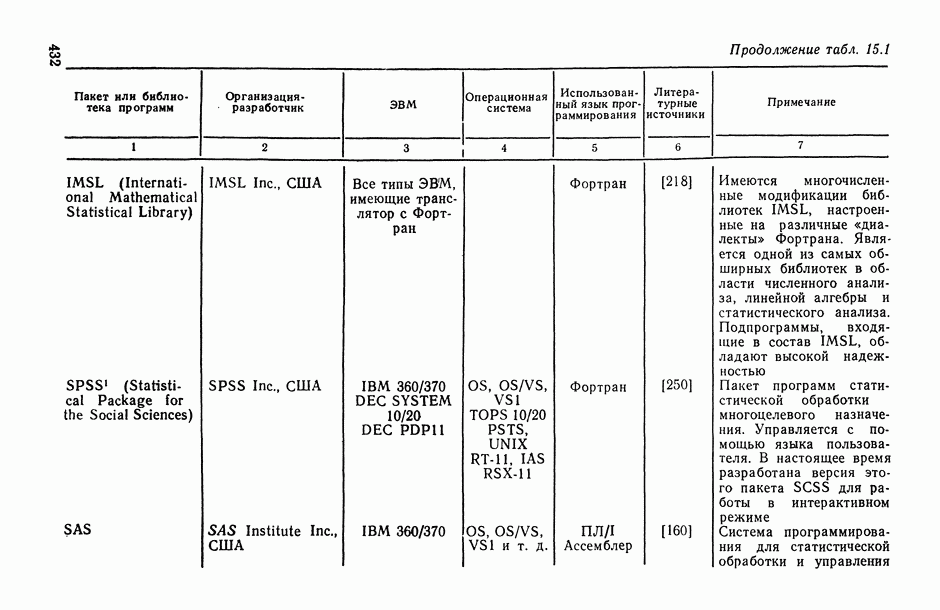
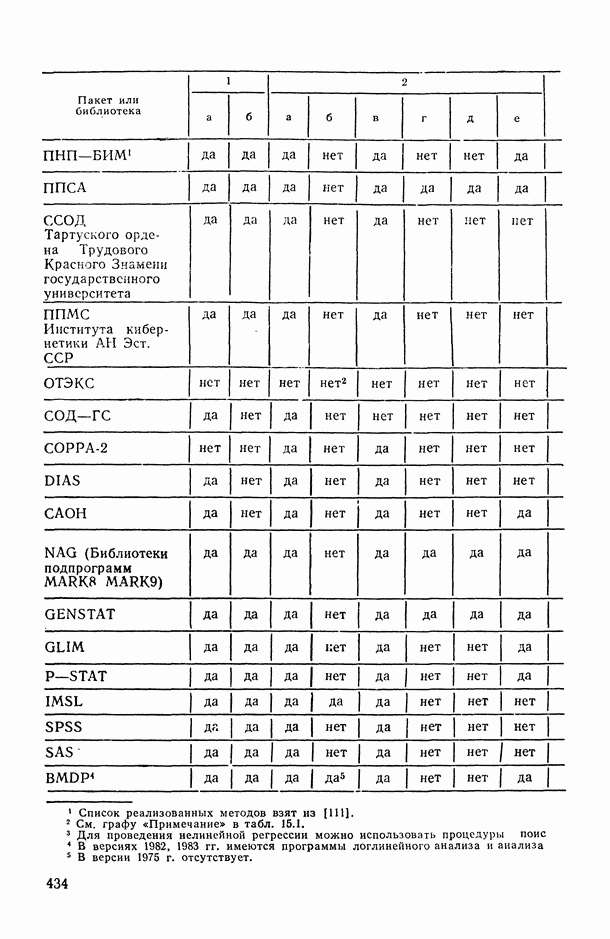
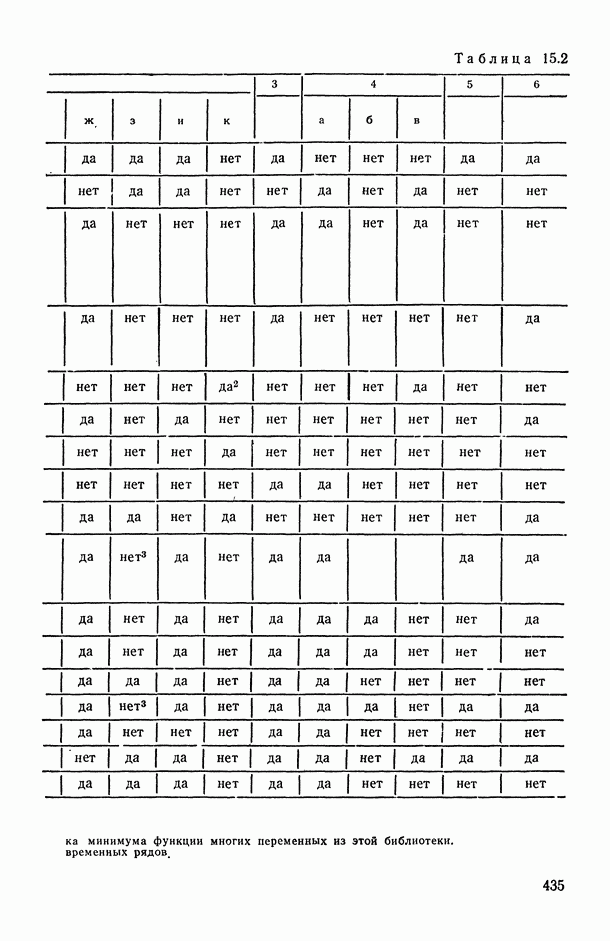
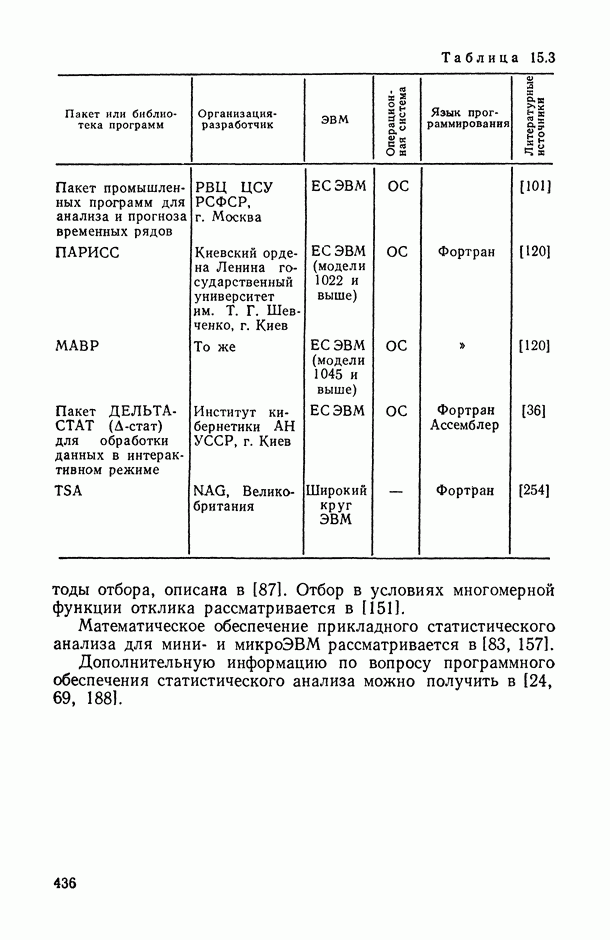
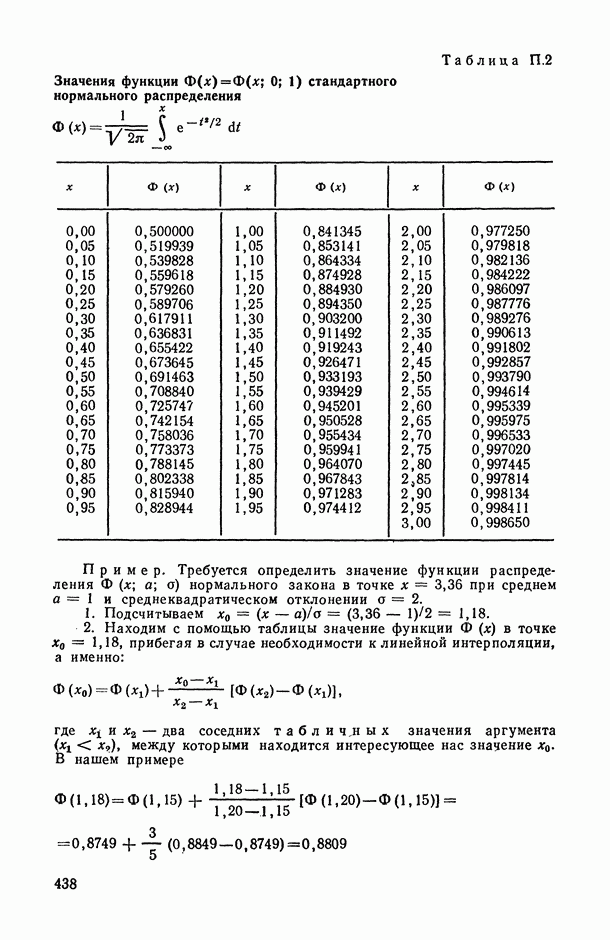
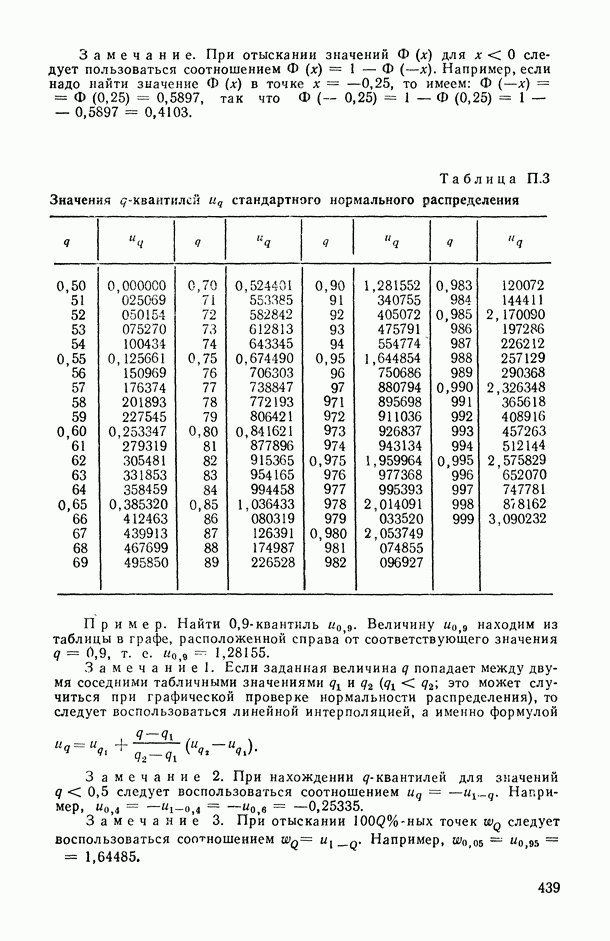
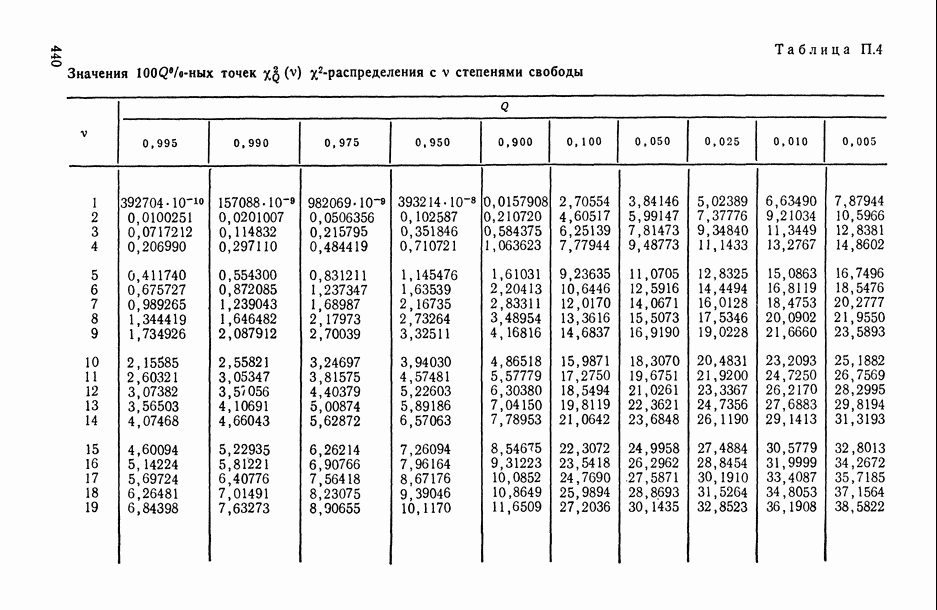
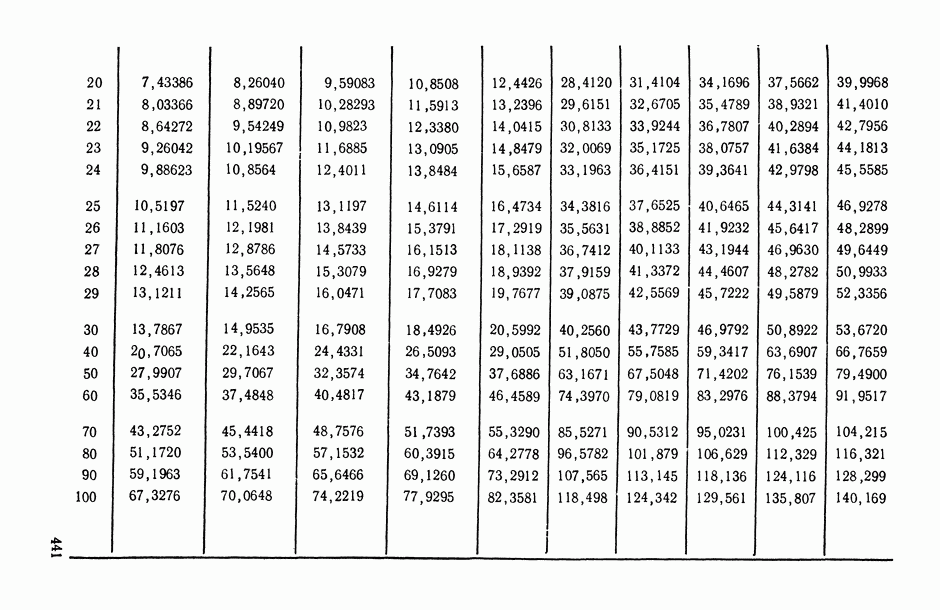
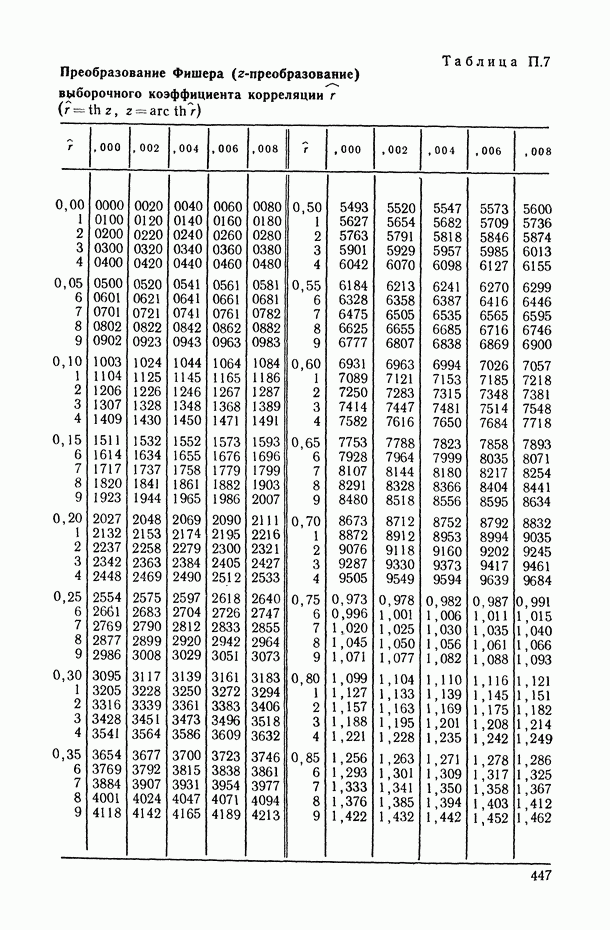
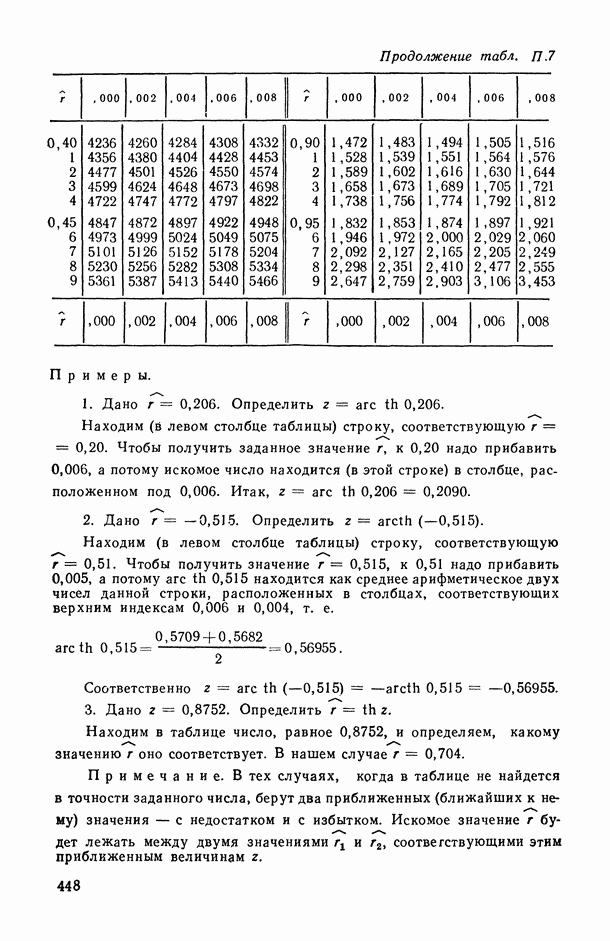
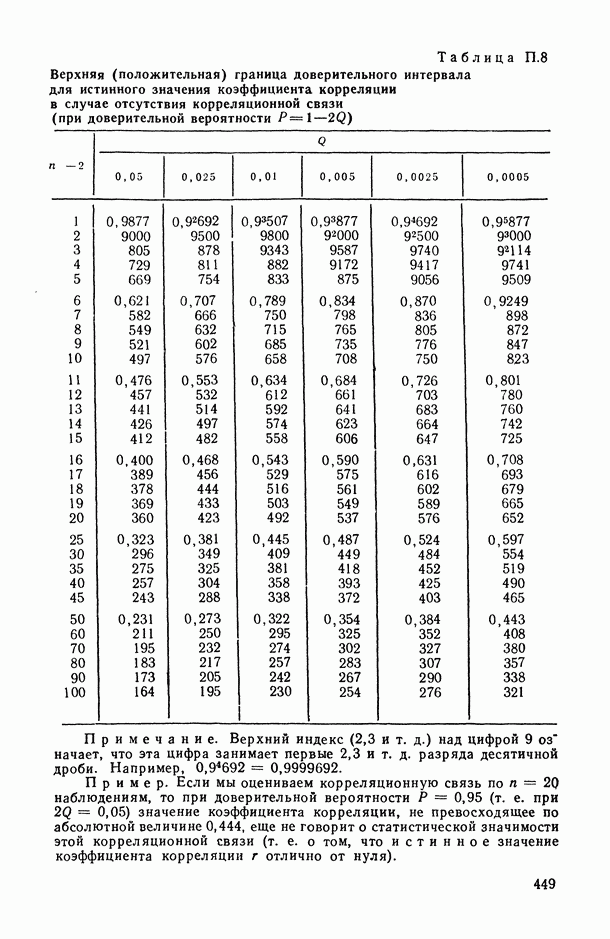
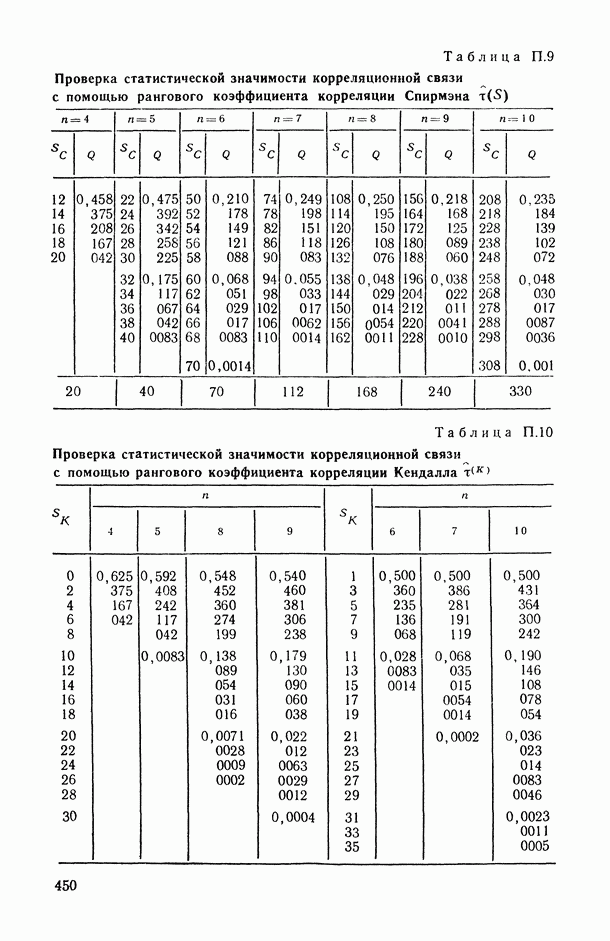
8.2. Регрессия на главные компоненты
Поскольку мультиколлинеарность связана с высокой степенью корреляции между исходными переменными, можно попытаться обойти эту трудность, используя в качестве новых переменных некоторые линейные комбинации исходных переменных, выбранные так, чтобы корреляции между ними были малы или вообще отсутствовали. Тогда матрица корреляций между оценками параметров относительно новых переменных будет близка к диагональной, что существенно упростит интерпретацию.
Когда переменных немного или имеются некоторые априорные теоретические данные, выбор таких комбинаций может быть осуществлен из содержательных соображений; в более общей ситуации один из возможных подходов основывается на использовании так называемых главных компонент (см. [14, п. 10.5.21), что приводит к регрессии на главные компоненты [195, 201, 219].
Пусть  — нормированные собственные векторы матрицы R, расположенные в порядке убывания соответствующих им собственных чисел
— нормированные собственные векторы матрицы R, расположенные в порядке убывания соответствующих им собственных чисел  . Тогда
. Тогда  главная компонента [14, п. 10.5.2] определяется как линейная комбинация исходных переменных, коэффициенты которой равны компонентам
главная компонента [14, п. 10.5.2] определяется как линейная комбинация исходных переменных, коэффициенты которой равны компонентам  собственного вектора, т. е.
собственного вектора, т. е. 
Поскольку главные компоненты некоррелированы, значения оценок  параметров
параметров  регрессии при
регрессии при  компоненте не зависят от того, какие еще компоненты включены в уравнение регрессии, и равны:
компоненте не зависят от того, какие еще компоненты включены в уравнение регрессии, и равны:
 (8.9)
(8.9)
где  — значение
— значение  главной компоненты для
главной компоненты для  наблюдения. Матрица ковариаций оценок
наблюдения. Матрица ковариаций оценок  диагональна, и непосредственно из (11.11) следует, что дисперсия
диагональна, и непосредственно из (11.11) следует, что дисперсия  коэффициента
коэффициента  равна:
равна:

т. е. ошибка коэффициента регрессии минимальна для первой главной компоненты и растет с увеличением номера главной компоненты.
Квадрат коэффициента корреляции между  главной компонентой и у
главной компонентой и у

Отсутствие корреляции между главными компонентами позволяет легко организовать пошаговую процедуру отбора (см. п.8.7.3) информативных для предсказания у главных компонент, результат которой в этом случае будет эквивалентен полному перебору.
Рассмотрим следующие критерии отбора, использующие главные компоненты.
1. t-статистика для проверки значимости коэффициента регрессии при j-й главной компоненте:

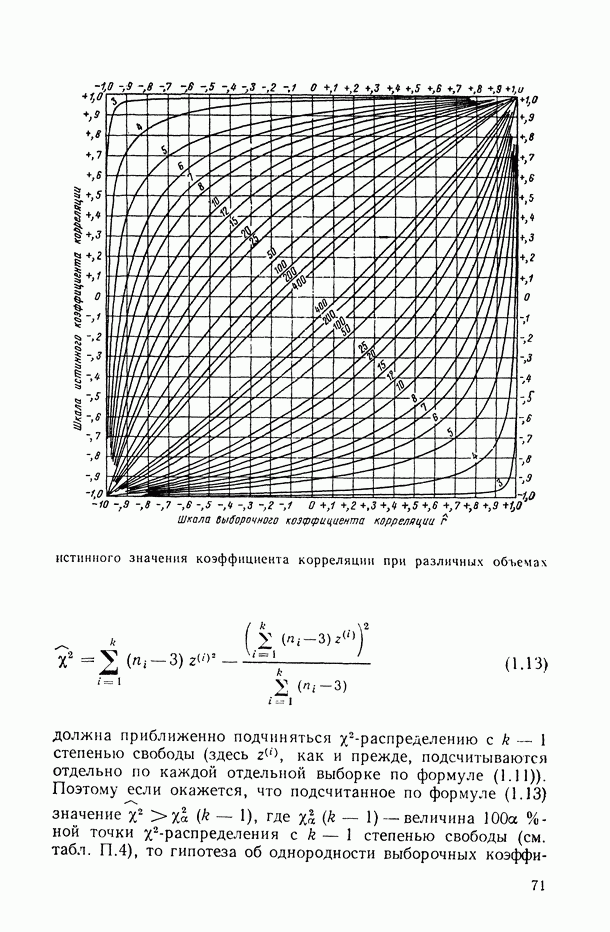
В случае истинности нулевой гипотезы  эта величина имеет
эта величина имеет  -распределение. Будем использовать схему пошагового удаления переменных. Задаваясь некоторым пороговым значением
-распределение. Будем использовать схему пошагового удаления переменных. Задаваясь некоторым пороговым значением  исключаем из уравнения регрессии
исключаем из уравнения регрессии  главную компоненту, если
главную компоненту, если

В силу независимости оценок параметров  никакого пересчета остальных крэффициентов при удалении той или иной главной компоненты проводить не надо. Обычно в качестве
никакого пересчета остальных крэффициентов при удалении той или иной главной компоненты проводить не надо. Обычно в качестве  выбирают значения
выбирают значения  для
для  -распределения с соответствующим числом степеней свободы. Другой способ выбора критического значения дан в п. 8.5.2 (см. (8.58)).
-распределения с соответствующим числом степеней свободы. Другой способ выбора критического значения дан в п. 8.5.2 (см. (8.58)).
Число степеней свободы зависит от того, какая оценка дисперсии ошибки используется. Можно использовать мнк-оценку дисперсии или, что эквивалентно, оценку дисперсии, получаемую при включении в уравнение регрессии всех  главных компонент. Тогда число степеней свободы
главных компонент. Тогда число степеней свободы  —
—  а оценка дисперсии
а оценка дисперсии  имеет вид:
имеет вид:

где  — оценка коэффициента множественной корреляции между у и всеми
— оценка коэффициента множественной корреляции между у и всеми  главными компонентами.
главными компонентами.
С другсй стороны, пусть после удаления очередной главной компоненты  осталось k главных компонент. Тогда, продолжая процедуру отбора, можно использовать оценку дисперсии
осталось k главных компонент. Тогда, продолжая процедуру отбора, можно использовать оценку дисперсии  соответствующую уравнению с оставшимися k главными компонентами:
соответствующую уравнению с оставшимися k главными компонентами:

где  — коэффициент множественной корреляции между у и оставшимися k главными компонентами. Поскольку главные компоненты некоррелированы, то имеем
— коэффициент множественной корреляции между у и оставшимися k главными компонентами. Поскольку главные компоненты некоррелированы, то имеем  где
где  если главная компонента включена в набор главных компонент, входящих в уравнение регрессии, и
если главная компонента включена в набор главных компонент, входящих в уравнение регрессии, и  — в противном случае.
— в противном случае.
При такой оценке дисперсии число степеней свободы 
2. F-статистика для добавочной информации. Используем пошаговую процедуру простого присоединения главных компонент. Пусть в наборе уже имеется k главных компонент. Тогда из всех оставшихся главных компонент находим компоненту с максимальным значением F-статистики

и включаем ее в уравнение регрессии, если выполняется условие  В качестве критического значения
В качестве критического значения  берут значения процентных точек, например
берут значения процентных точек, например  Для
Для  -распределения с одной и
-распределения с одной и  —
—  степенями свободы. Если компонент, для которых выполняется условие
степенями свободы. Если компонент, для которых выполняется условие  нет, то процесс отбора главных компонент считается оконченным. Можно показать, что использование
нет, то процесс отбора главных компонент считается оконченным. Можно показать, что использование  -критерия приводит к тому же набору компонент, что и использование
-критерия приводит к тому же набору компонент, что и использование  -критерия с меняющейся оценкой дисперсии (8.15).
-критерия с меняющейся оценкой дисперсии (8.15).
3. Величина собственного числа для i-й главной компоненты. Именно эта величина предлагается для отбора главных компонент в некоторых работах [163, 43, 219]. Если сильно взаимно коррелируют, то, начиная с некоторого номера  , значения собственных чисел
, значения собственных чисел  близки к нулю, а соответствующие коэффициенты регрессии могут стать большими по абсолютной величине. Дисперсии оценок коэффициентов регрессии, соответствующих этим главным компонентам, также будут велики. Отсюда следует целесообразность удаления главных компонент с малыми собственными числами, т. е. полагаем
близки к нулю, а соответствующие коэффициенты регрессии могут стать большими по абсолютной величине. Дисперсии оценок коэффициентов регрессии, соответствующих этим главным компонентам, также будут велики. Отсюда следует целесообразность удаления главных компонент с малыми собственными числами, т. е. полагаем

или, учитывая, что главные компоненты упорядочены по убыванию собственных чисел,

где  — первый номер, для которого выполняется неравенство
— первый номер, для которого выполняется неравенство  .
.
Критическое значение  обычно выбирается в виде
обычно выбирается в виде

где  — след корреляционной матрицы; е — малая величина, например
— след корреляционной матрицы; е — малая величина, например 
Другой метод выбора числа компонент основан на общепринятой методологии использования главных компонент. Задаемся некоторой величиной доли следа а, близкой к 1, и включаем в уравнение регрессии компоненты до тех пор, пока

Как только это неравенство перестает выполняться, включение компонент прекращается, и коэффициенты регрессии оставшихся главных компонент объявляются статистически незначимыми.
Подход к отбору главных компонент на основе величины собственных чисел эквивалентен регуляризации при вычислении псевдообратной матрицы на ЭВМ [171. Он может быть использован и при наличии точной линейной зависимости между переменными, которая, однако, «замаскирована» ошибками округления при представлении данных в ЭВМ.
Однако процедуры отбора главных компонент, основанные на  -статистиках, правильнее нацелены на решение сущности задачи, хотя при их использовании могут быть отброшены и некоторые главные компоненты, соответствующие большим значениям (если они слабо коррелированы с переменной у). Правда, как правило, компоненты с малыми значениями собственных чисел оказываются одновременно и слабо коррелированными с у и также отбрасываются, так что отбор существенных главных компонент по этим критериям автоматически приводит и к регуляризации задачи. Зная включенные в уравнение компоненты и соответствующие им коэффициенты регрессии, легко найти коэффициенты регрессии относительно исходных переменных
-статистиках, правильнее нацелены на решение сущности задачи, хотя при их использовании могут быть отброшены и некоторые главные компоненты, соответствующие большим значениям (если они слабо коррелированы с переменной у). Правда, как правило, компоненты с малыми значениями собственных чисел оказываются одновременно и слабо коррелированными с у и также отбрасываются, так что отбор существенных главных компонент по этим критериям автоматически приводит и к регуляризации задачи. Зная включенные в уравнение компоненты и соответствующие им коэффициенты регрессии, легко найти коэффициенты регрессии относительно исходных переменных 

где  если главная компонента включена в информативный набор, и
если главная компонента включена в информативный набор, и  — в противном случае.
— в противном случае.
Вообще говоря, полученные таким образом оценки для коэффициентов  будут смещенными. Формулы для дисперсий и смещений этих коэффициентов приведены в п. 8.5.
будут смещенными. Формулы для дисперсий и смещений этих коэффициентов приведены в п. 8.5.