Разрешая выражение (1.26) относительно мы приходим (с учетом постоянства по X величины в данном случае) к ранее введенному определению множественного коэффициента корреляции (1.24).
Отнесем ко второму типу линейных нормальных моделей тот частный случай «схемы В» (т. е. зависимости случайного результирующего показателя  от неслучайных объясняющих переменных X, см. § В.5), в котором функция регрессии
от неслучайных объясняющих переменных X, см. § В.5), в котором функция регрессии  линейна по X, а остаточная случайная компонента
линейна по X, а остаточная случайная компонента  подчиняется нормальному закону с постоянной (не зависящей от X) дисперсией В этом случае линейность регрессии, гомоскедастичность (постоянство условной дисперсии
подчиняется нормальному закону с постоянной (не зависящей от X) дисперсией В этом случае линейность регрессии, гомоскедастичность (постоянство условной дисперсии  )
)  и формула (1.26) следуют непосредственно из определения модели и из (1.24).
и формула (1.26) следуют непосредственно из определения модели и из (1.24).
Можно показать (см. например, [65, гл.  ), что при статистической обработке выборок, извлеченных из линейнонормальных генеральных совокупностей, множественный коэффициент корреляции R. и его выборочное значение
), что при статистической обработке выборок, извлеченных из линейнонормальных генеральных совокупностей, множественный коэффициент корреляции R. и его выборочное значение  обладают рядом дополнительных свойств (приведенные ниже формулы и свойства теоретического множественного коэффициента корреляции
обладают рядом дополнительных свойств (приведенные ниже формулы и свойства теоретического множественного коэффициента корреляции  автоматически переносятся на выборочный
автоматически переносятся на выборочный  заменой участвующих в них теоретических характеристик соответствующими выборочными значениями).
заменой участвующих в них теоретических характеристик соответствующими выборочными значениями).
1. Вычисление  матрице парных коэффициентов корреляции. Обозначая, как и прежде,
матрице парных коэффициентов корреляции. Обозначая, как и прежде,  -корреляционную матрицу
-корреляционную матрицу  через R, а алгебраическое дополнение элемента
через R, а алгебраическое дополнение элемента  в ее определителе через
в ее определителе через  имеем
имеем

2. Вычисление  по частным коэффициентам корреляции
по частным коэффициентам корреляции

3. Множественный коэффициент корреляции мажорирует любой парный или частный коэффициент корреляции, характеризующий статистическую связь результирующего показателя, т. е.

где  — любое подмножество множества индексов
— любое подмножество множества индексов  не содержащее индекса
не содержащее индекса  (соотношение (1.29) следует из (1.28)). Напоминаем, что
(соотношение (1.29) следует из (1.28)). Напоминаем, что 
4. Присоединение каждой новой предсказывающей переменной  может уменьшить величины R (независимо от порядка присоединения), т. е.
может уменьшить величины R (независимо от порядка присоединения), т. е.

5. Множественный коэффициент корреляции  быть определен как максимальное значение обычного парного коэффициента корреляции между
быть определен как максимальное значение обычного парного коэффициента корреляции между  и линейной комбинацией
и линейной комбинацией  (максимум — по всевозможным линейным комбинациям) либо как обычный парный коэффициент корреляции между
(максимум — по всевозможным линейным комбинациям) либо как обычный парный коэффициент корреляции между  и условным математическим ожиданием
и условным математическим ожиданием 
6. Статистические свойства выборочного множественного коэффициента корреляции  -распределение, моменты, доверительные интервалы) состоят в следующем.
-распределение, моменты, доверительные интервалы) состоят в следующем.
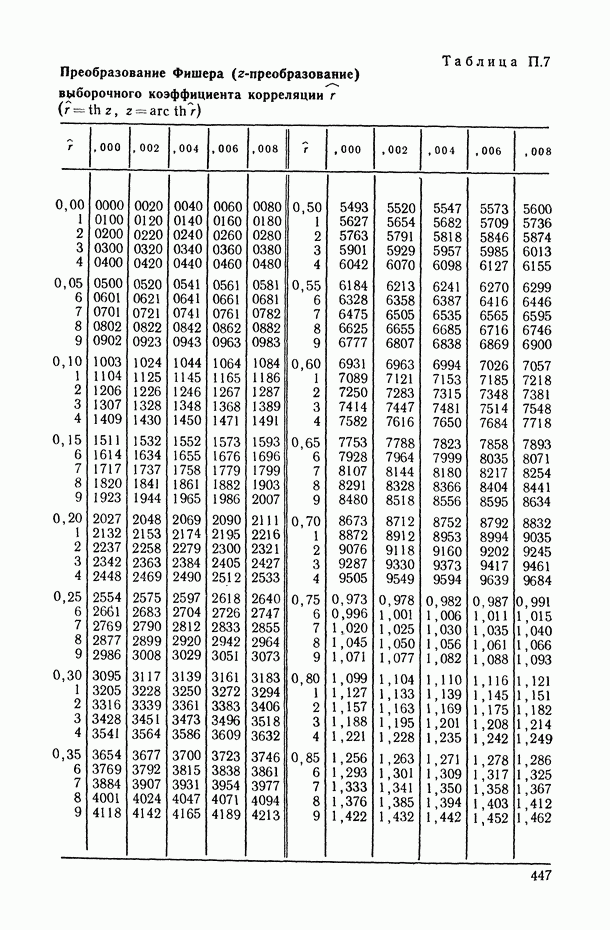
Для проверки гипотезы  т. е. для выяснения вопроса, можно ли считать выборочное значение множественного коэффициента корреляции
т. е. для выяснения вопроса, можно ли считать выборочное значение множественного коэффициента корреляции  статистически значимо отличающимся от нуля, пользуются фактом
статистически значимо отличающимся от нуля, пользуются фактом  -распределенности случайной величины
-распределенности случайной величины

справедливым в рамках обоих рассмотренных выше типов линейно-нормальных моделей при условии, что истинное значение множественного коэффициента корреляции  равно нулю.
равно нулю.
Если окажется, что  , то гипотеза об отсутствии множественной корреляционной связи между
, то гипотеза об отсутствии множественной корреляционной связи между  отвергается при уровне значимости критерия, равном а (здесь, как и ранее,
отвергается при уровне значимости критерия, равном а (здесь, как и ранее,  —
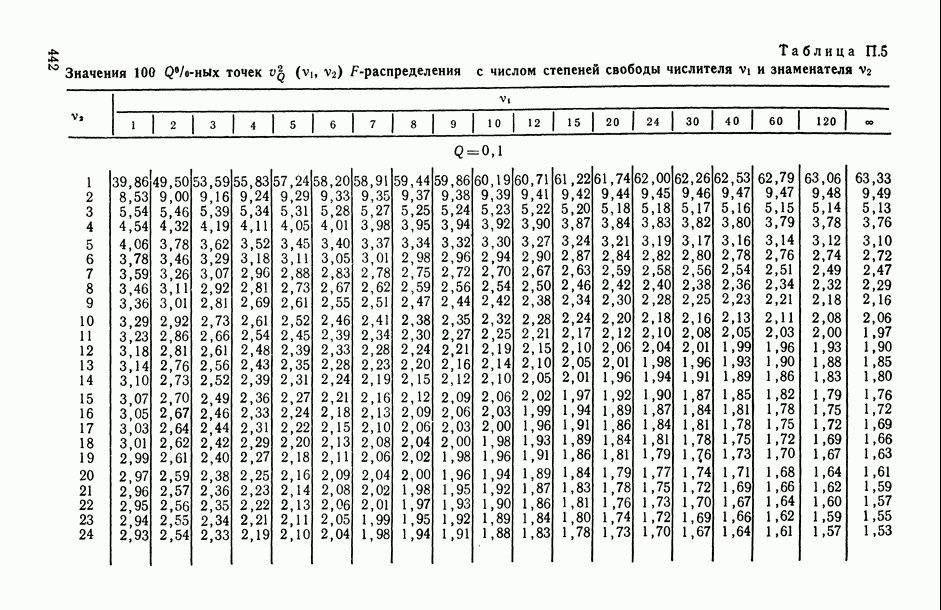
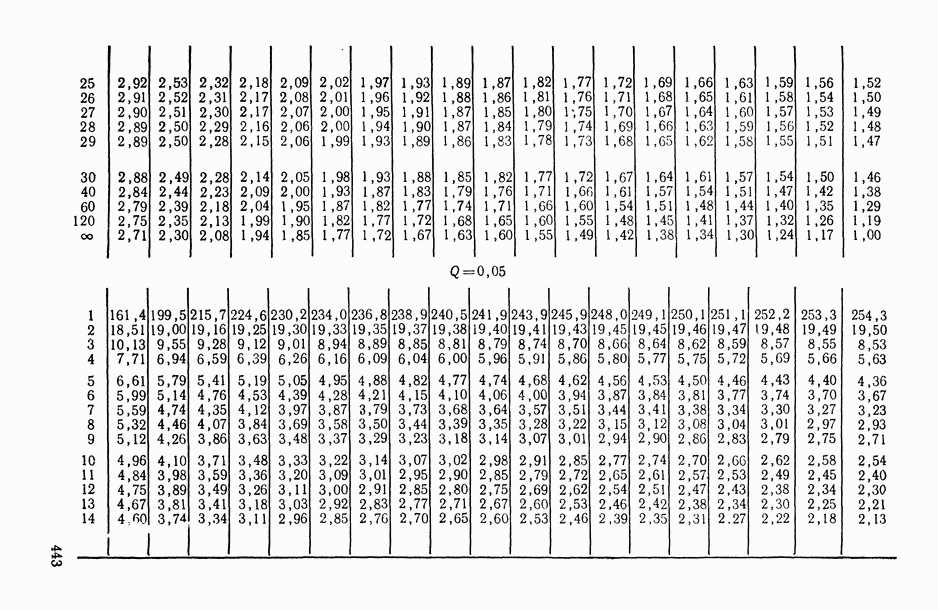
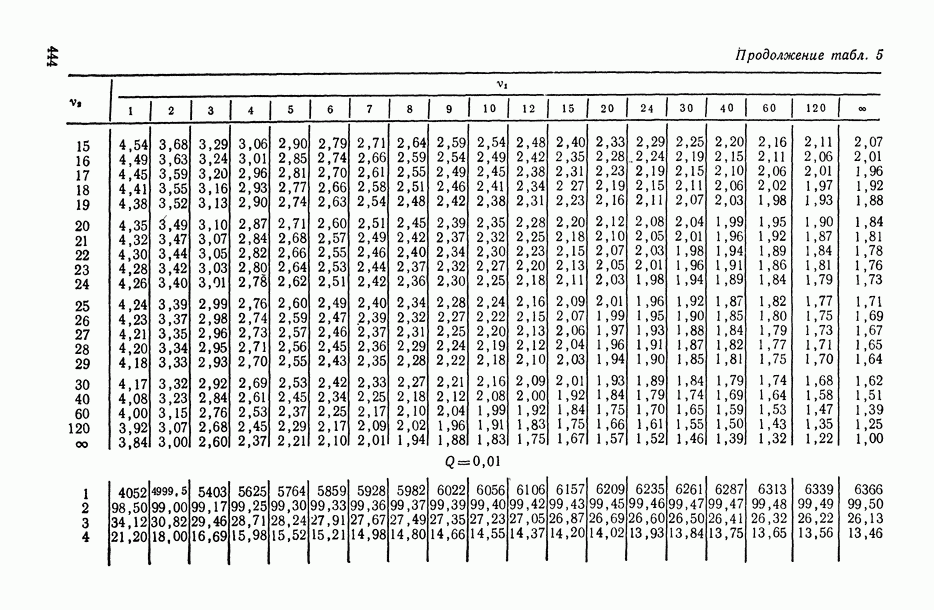
—  -ная точка F-распределения с числом степеней свободы числителя
-ная точка F-распределения с числом степеней свободы числителя  и знаменателя
и знаменателя  находится из табл. П.5).
находится из табл. П.5).
Можно показать (см. [65, гл. 27]), что в условиях второго типа линейно-нормальных моделей (объясняющие переменные X неслучайны) описанный критерий является равномерно наиболее мощным. Это вытекает из того, что при  величина
величина  подчинена нецентральному
подчинена нецентральному  ;
;  - распределению с параметром нецентральносьти, равным
- распределению с параметром нецентральносьти, равным 
Последним обстоятельством можно воспользоваться и при приближенном построении доверительных интервалов для неизвестного истинного значения В точности повторяя рассуждения п. 1.1.5, относящиеся к построению доверительных интервалов для неизвестной величины квадрата корреляционного отношения  (см. формулы (1.17)-(1.20)), мы придем к следующей рекомендации по построению интервальной оценки для справедливой, правда, лишь при
(см. формулы (1.17)-(1.20)), мы придем к следующей рекомендации по построению интервальной оценки для справедливой, правда, лишь при  : с доверительной вероятностью, приблизительно равной
: с доверительной вероятностью, приблизительно равной  (величина а задана), выполняется неравенство
(величина а задана), выполняется неравенство
 (1.31)
(1.31)
в котором  — 100%-ная точка центрального F-распределения с числом степеней свободы числителя
— 100%-ная точка центрального F-распределения с числом степеней свободы числителя

и знаменателя  (в (1.32) символ
(в (1.32) символ  обозначает ближайшее целое число к а).
обозначает ближайшее целое число к а).
Однако в условиях первого типа линейно-нормальных моделей (наблюдения  ) извлечены из
) извлечены из  -мерной нормальной генеральной совокупности; соответственно объясняющие переменные
-мерной нормальной генеральной совокупности; соответственно объясняющие переменные  случайные величины) распределение величины
случайные величины) распределение величины  при
при  и конечных объемах выборки
и конечных объемах выборки  существенно отличается от того распределения
существенно отличается от того распределения  которое мы имели при неслучайных объясняющих переменных (можно, правда, показать, что при
которое мы имели при неслучайных объясняющих переменных (можно, правда, показать, что при  распределение случайной величины
распределение случайной величины  сходится в линейно-нормальных моделях и первого и второго типа к нецентральному
сходится в линейно-нормальных моделях и первого и второго типа к нецентральному  -распределению с числом степеней свободы, равным
-распределению с числом степеней свободы, равным  , и с параметром нецентральности равным
, и с параметром нецентральности равным 
В [233] показано, что несмещенной оценкой коэффициента служит статистика

где  , а
, а  — гипергеометрическая функция (см., например, [1, с. 370]).
— гипергеометрическая функция (см., например, [1, с. 370]).
Простая аппроксимация правой части (1.35) дает:

Из последней формулы видно, что «подправленная» оценка всегда меньше смещенной оценки  .
.
Отметим, что при малых истинных значениях  и при «не слишком малых» величинах отношения
и при «не слишком малых» величинах отношения  подправленные оценки, подсчитанные по формулам (1.35) и (1.35), могут принимать отрицательные значения. Можно устранить абсурдность отрицательных значений оценки, используя в качестве «еще раз подправленной» оценки величину
подправленные оценки, подсчитанные по формулам (1.35) и (1.35), могут принимать отрицательные значения. Можно устранить абсурдность отрицательных значений оценки, используя в качестве «еще раз подправленной» оценки величину

(правда, уже не будет несмещенной оценкой).





























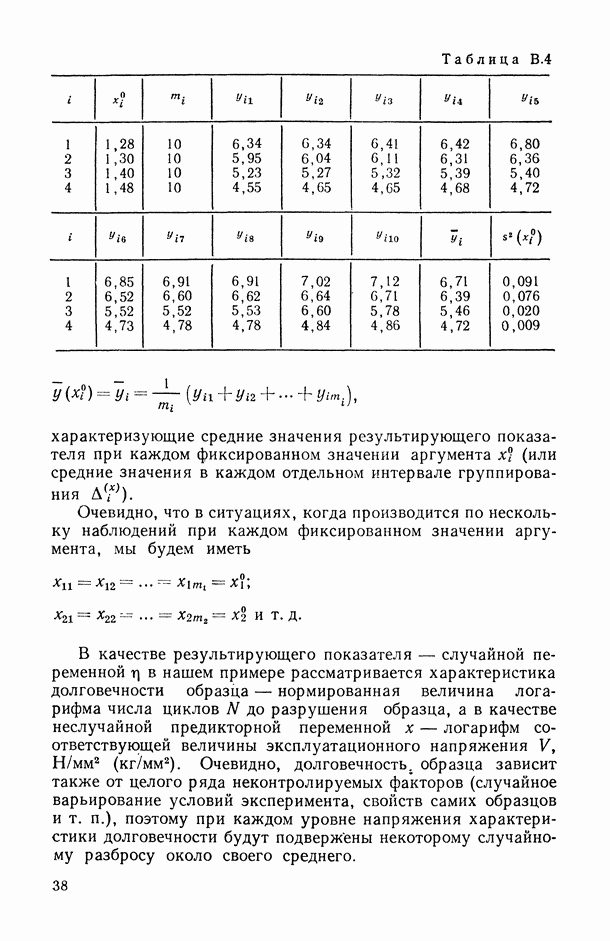











































































































































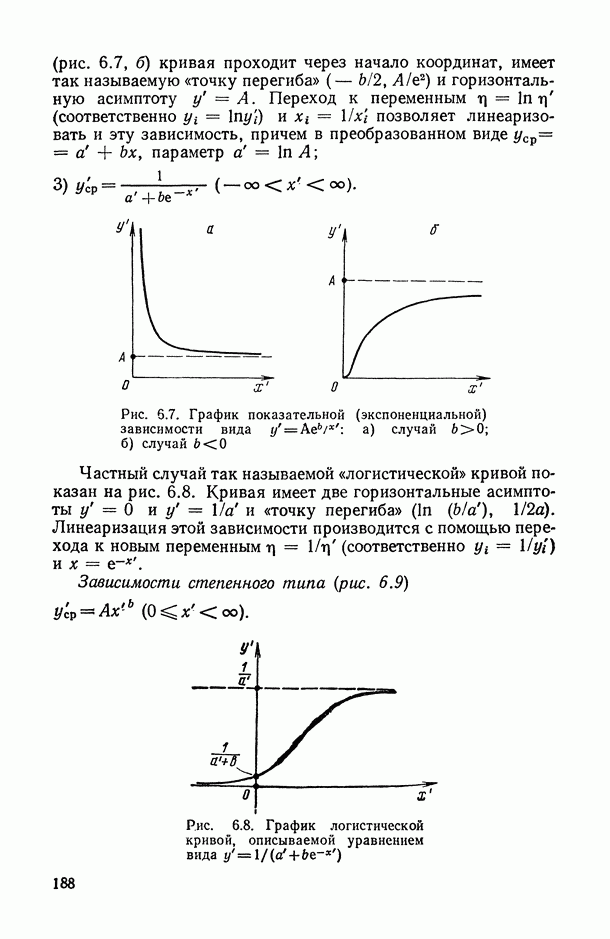
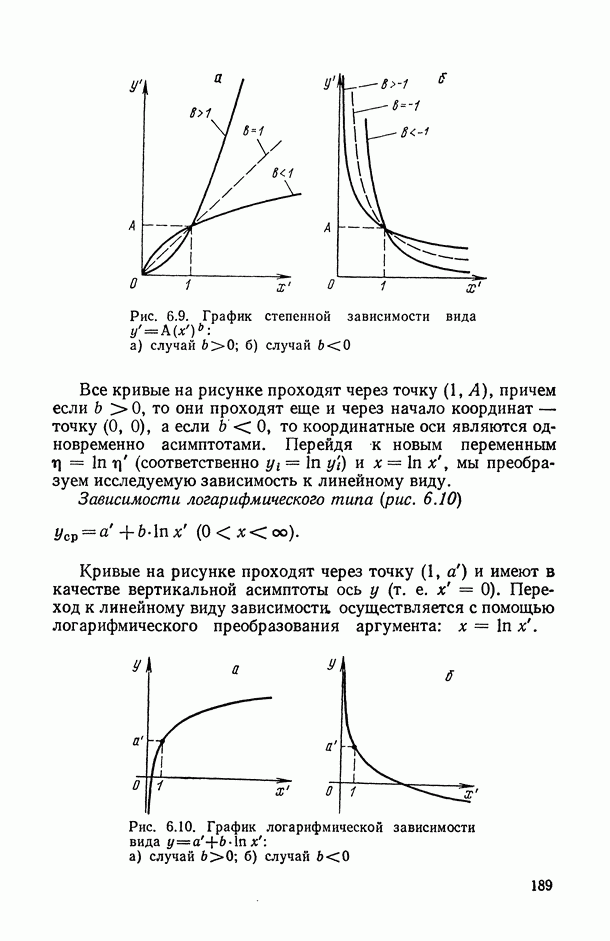


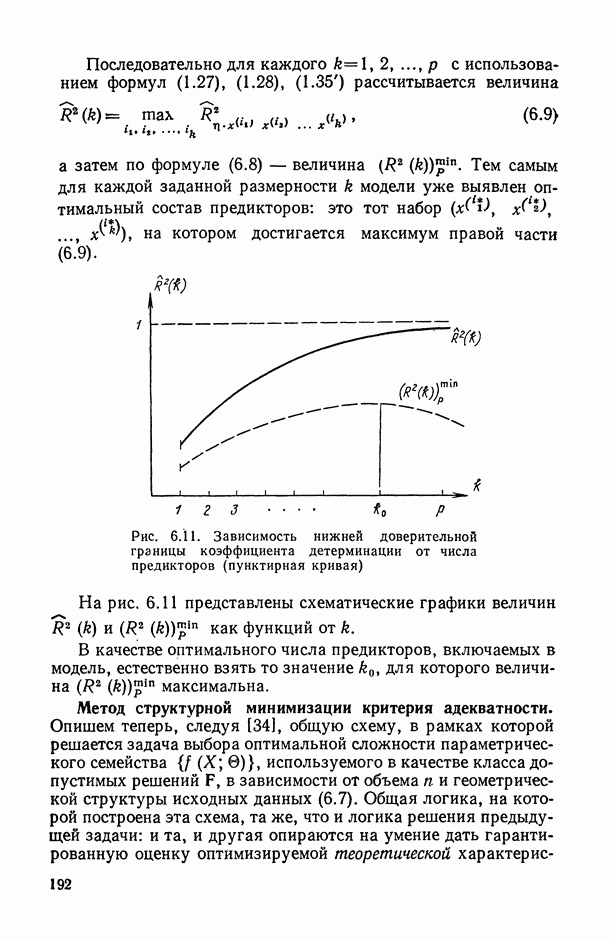




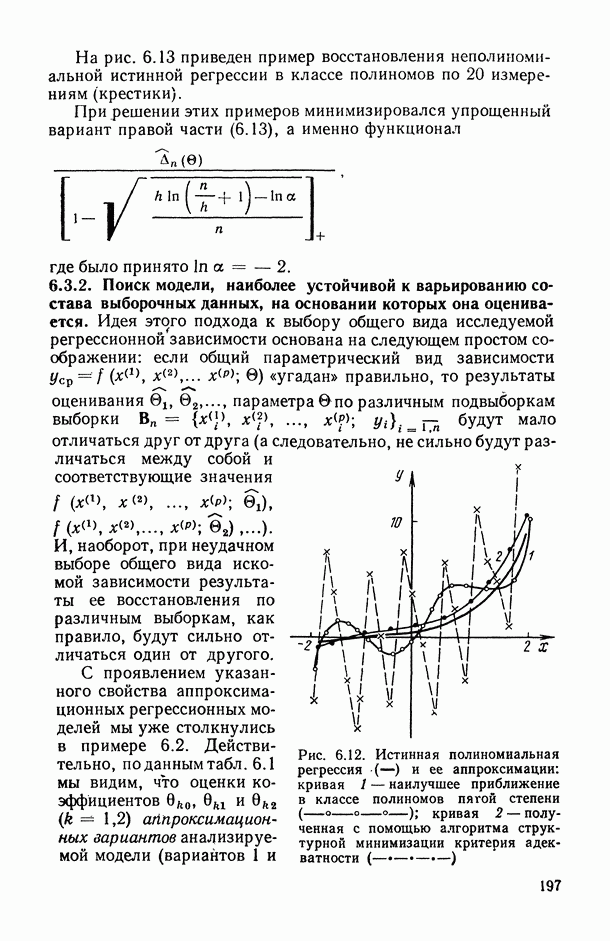
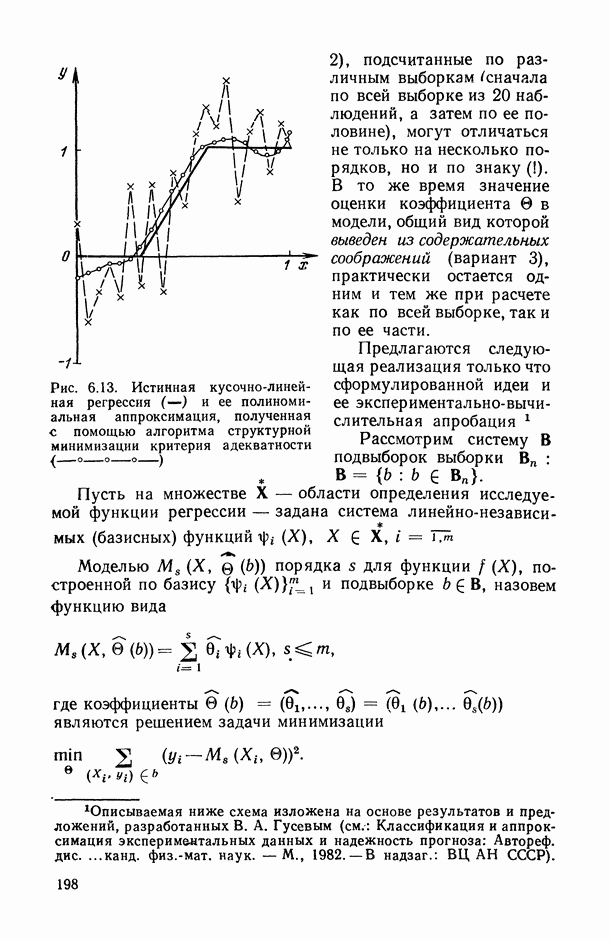


















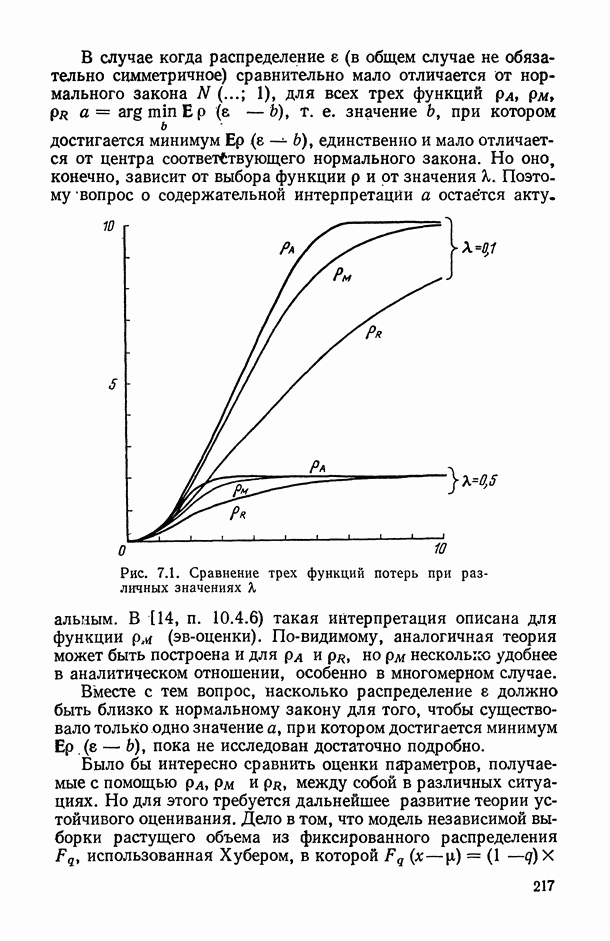


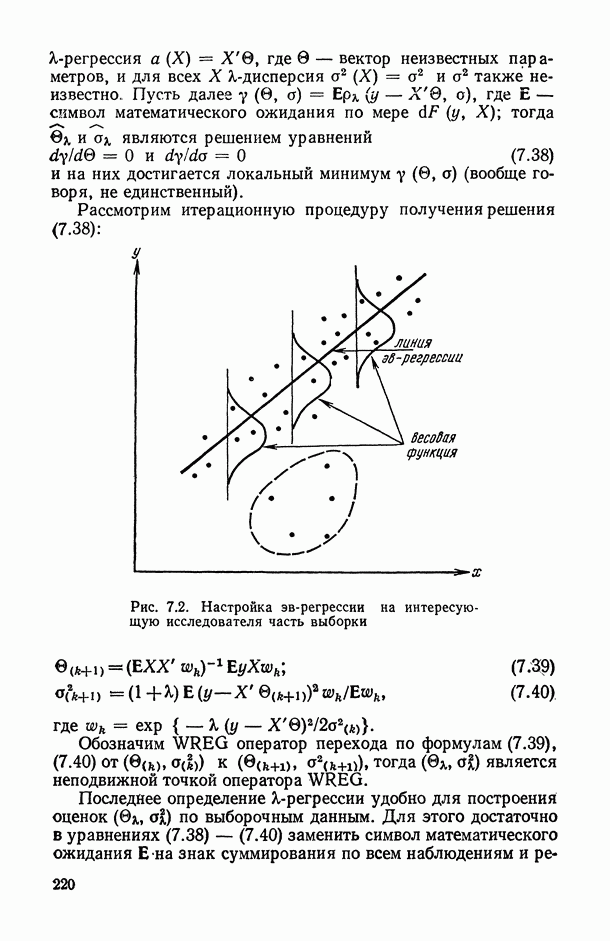










































































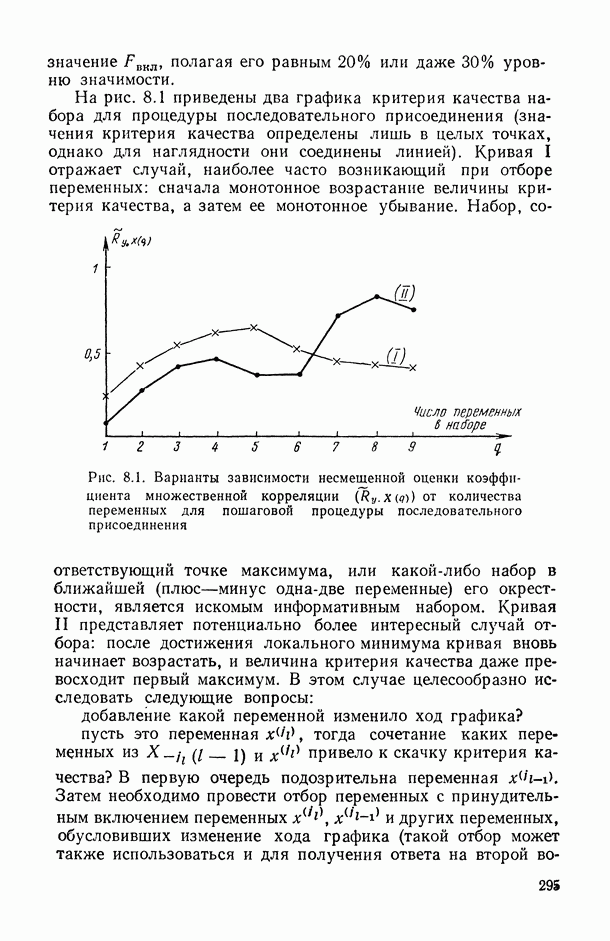



































































































































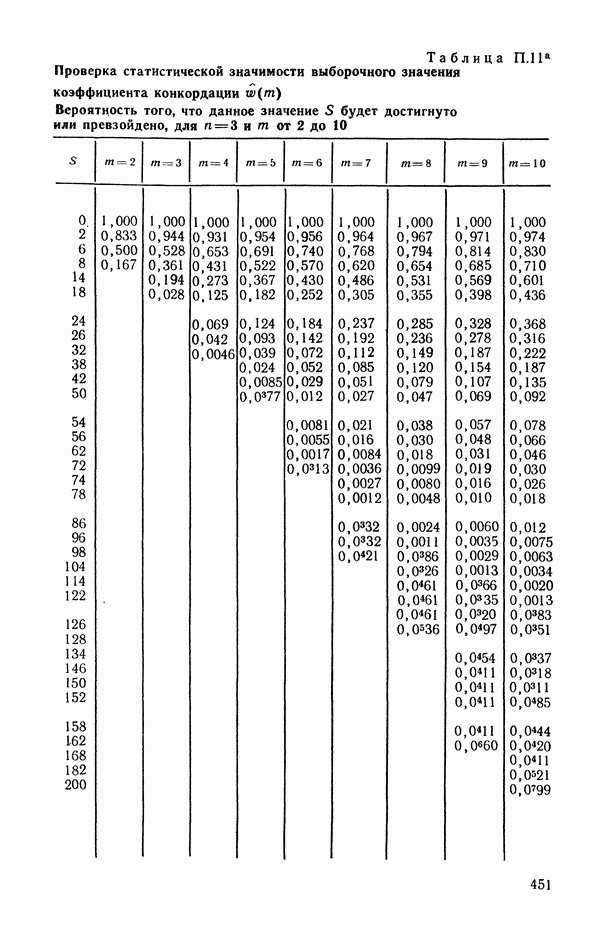
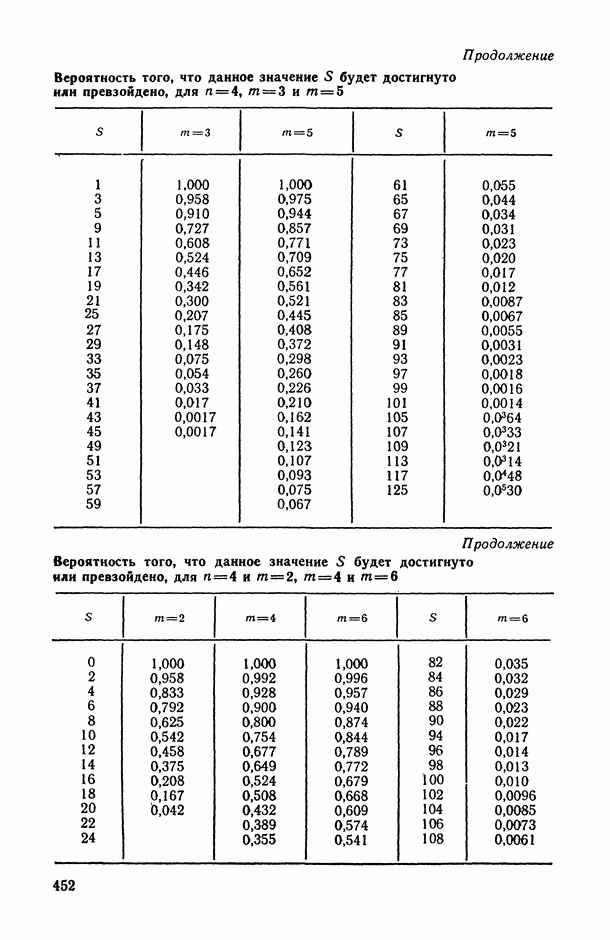
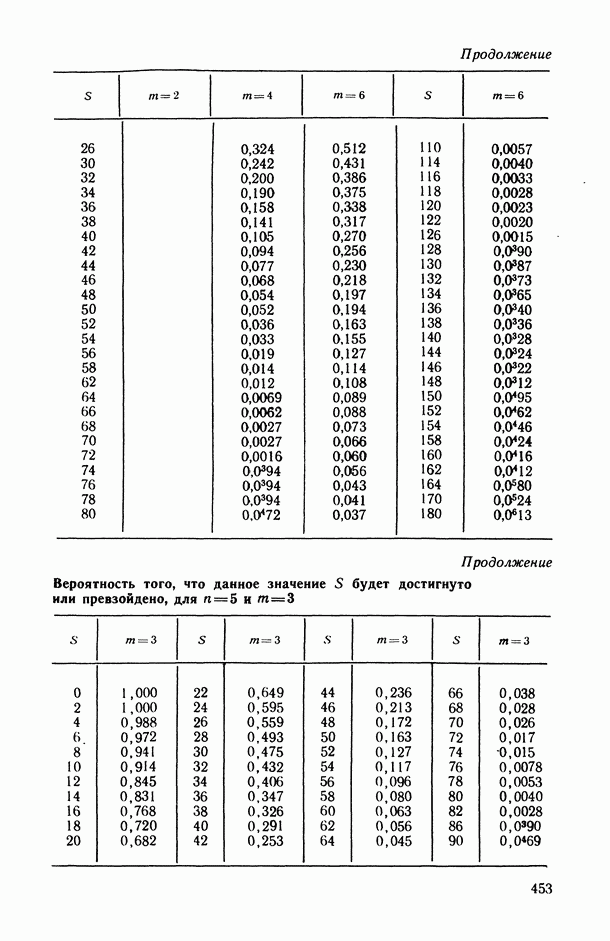


















 могут интерпретироваться как выборка объема
могут интерпретироваться как выборка объема  из
из  -мерной нормальной генеральной совокупности с вектором средних значений
-мерной нормальной генеральной совокупности с вектором средних значений


 сразу следует:
сразу следует:
 регрессии
регрессии  по
по  линейна по аргументам, а именно:
линейна по аргументам, а именно:

 — ковариации анализируемых переменных (мы полагаем, для единообразия записи,
— ковариации анализируемых переменных (мы полагаем, для единообразия записи,  — элементы матрицы
— элементы матрицы 
 результирующего показателя
результирующего показателя  не зависит от того, на каких уровнях X фиксируются значения объясняющих переменных
не зависит от того, на каких уровнях X фиксируются значения объясняющих переменных  , в частности
, в частности





 По формулам (1.33), (1.33) мы видим, что при вычислении выборочных значений
По формулам (1.33), (1.33) мы видим, что при вычислении выборочных значений  в соответствии с рекомендациями (1.27), (1.28), относящимися к условиям линейно-нормальных моделей, получаются смещенные (а при ограниченных объемах выборок
в соответствии с рекомендациями (1.27), (1.28), относящимися к условиям линейно-нормальных моделей, получаются смещенные (а при ограниченных объемах выборок  и большом числе
и большом числе  предсказывающих переменных — существенно смещенные) оценки для неизвестного истинного значения
предсказывающих переменных — существенно смещенные) оценки для неизвестного истинного значения  . Поэтому желательно попытаться перейти к некоторой другой оценке неизвестного теоретического значения
. Поэтому желательно попытаться перейти к некоторой другой оценке неизвестного теоретического значения  путем такой коррекции оценки
путем такой коррекции оценки  которая позволила бы устранить это смещение.
которая позволила бы устранить это смещение.
