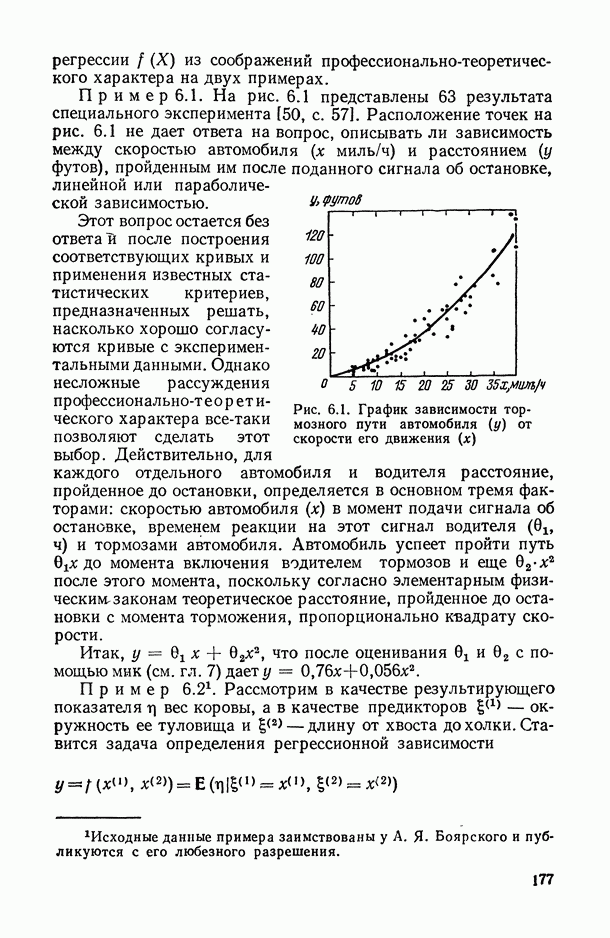
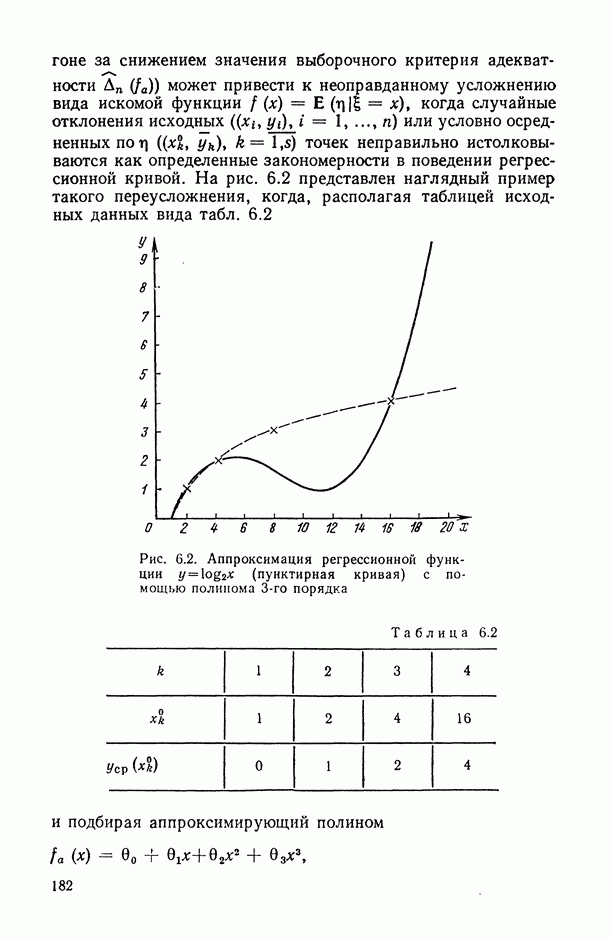
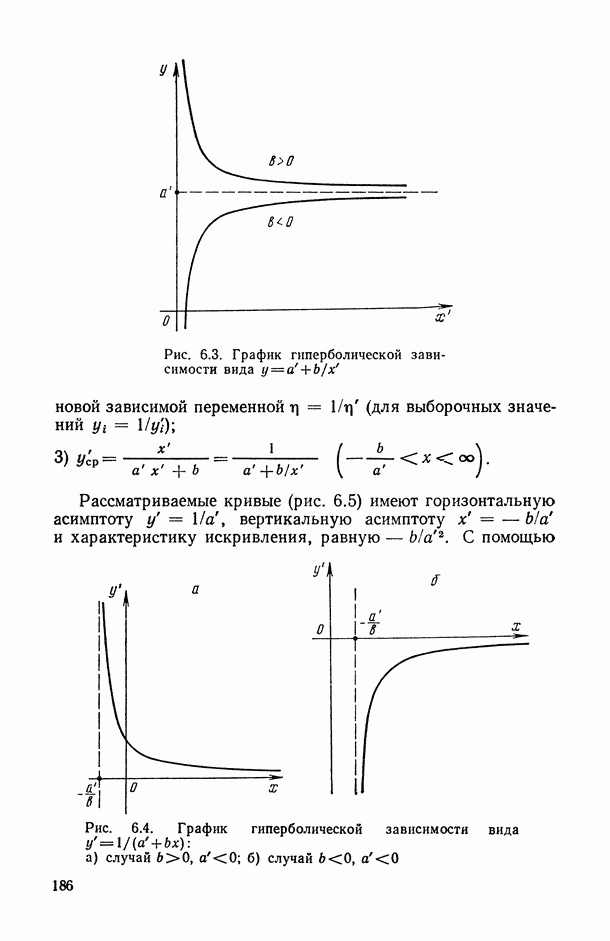
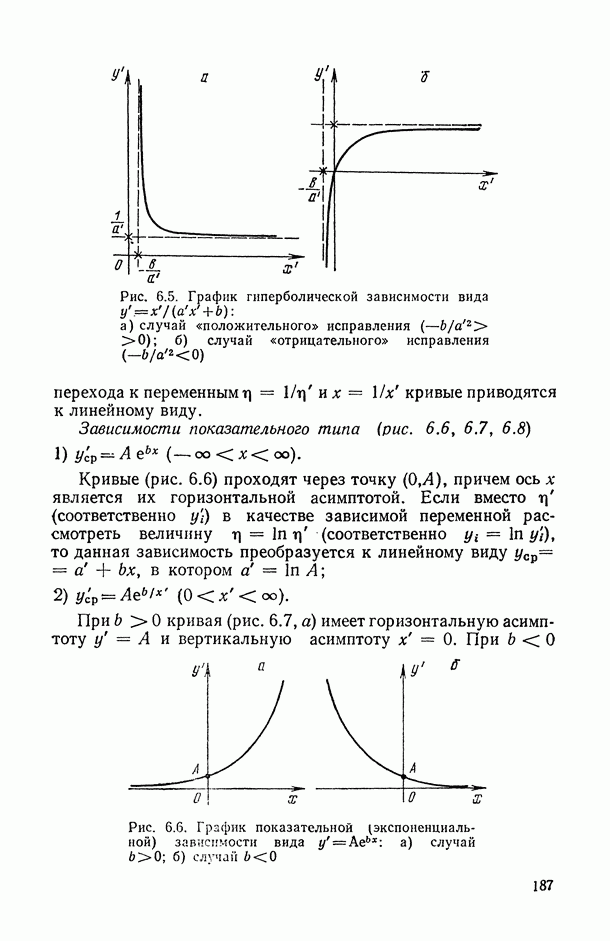
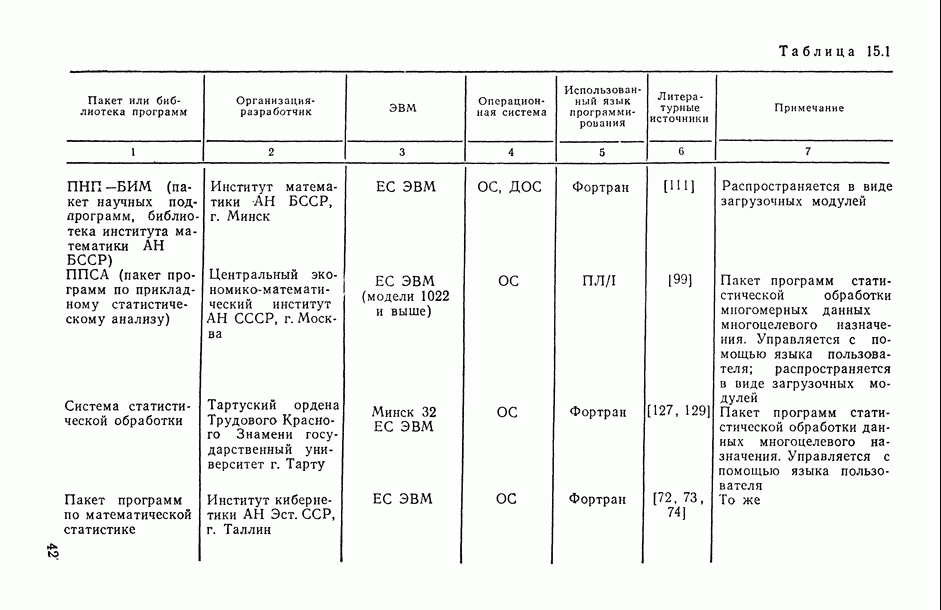
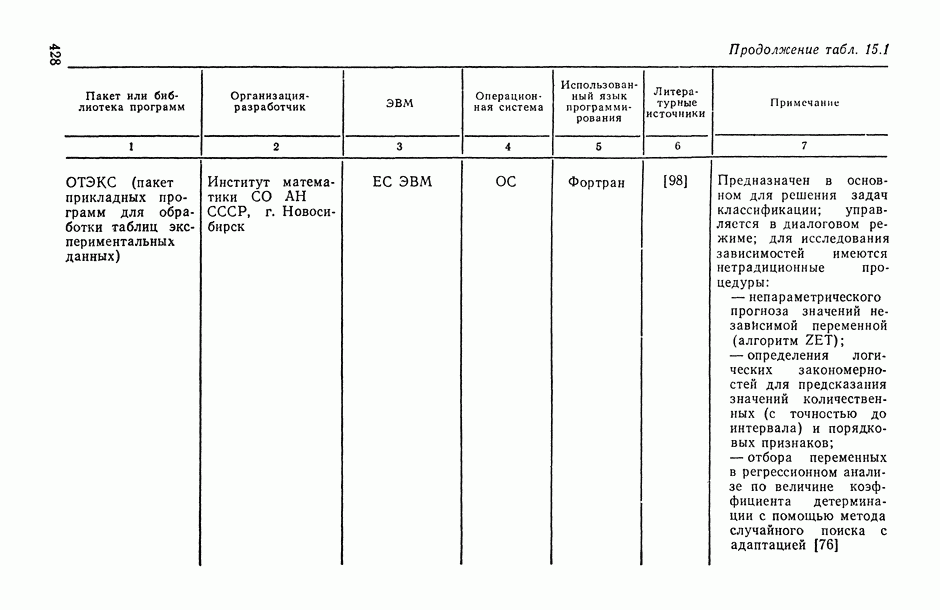
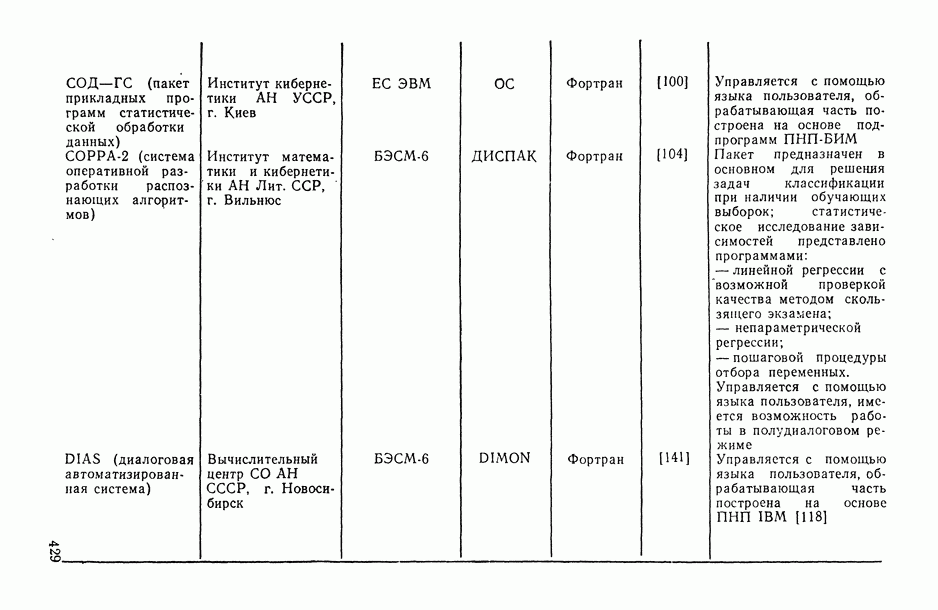
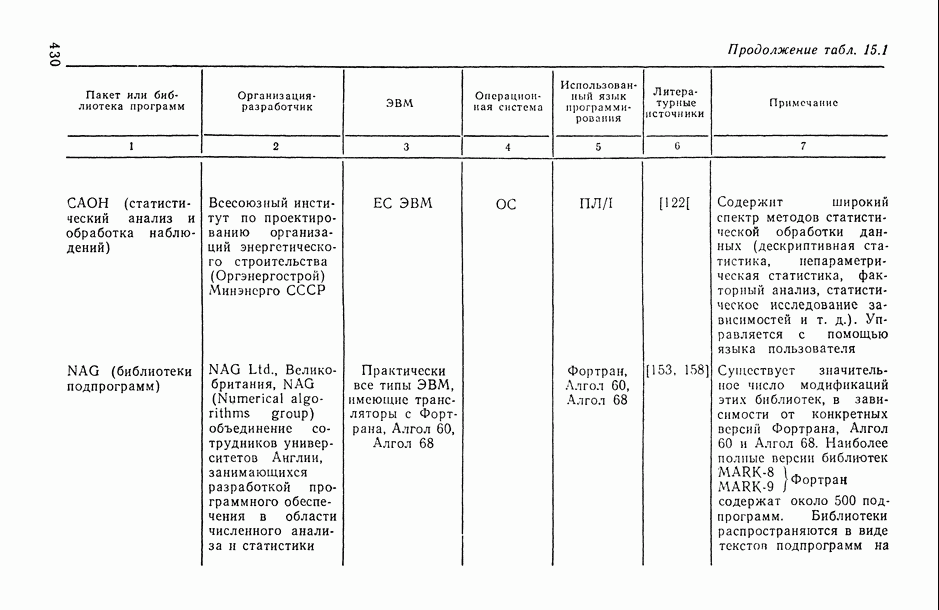
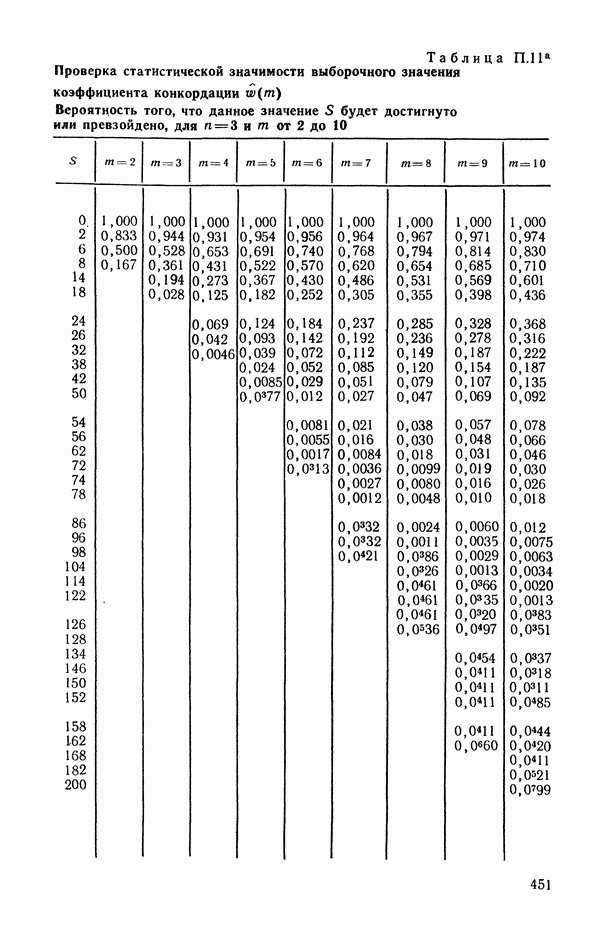
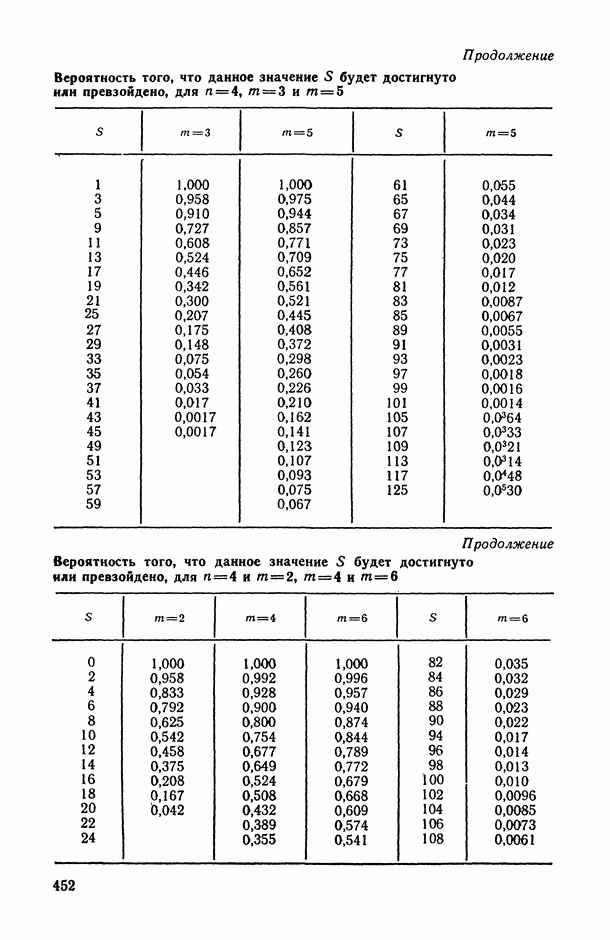
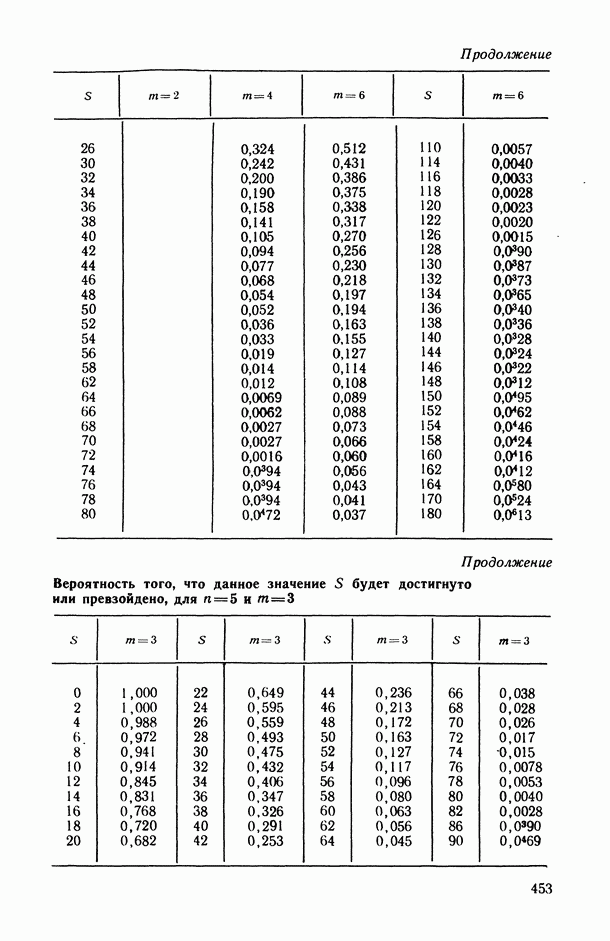
ВЫВОДЫ
1. Аппарат статистического исследования зависимостей — составная часть многомерного статистического анализа — нацелен на решение основной проблемы естествознания: как на основании частных результатов статистического наблюдения за анализируемыми событиями или показателями выявить и описать существующие между ними стохастические взаимосвязи.
2. Анализируемые переменные величины по своей роли в исследовании подразделяются на результирующие (прогнозируемые) Y и объясняющие (предсказывающие, или предикторные) X. Среди компонент векторов Y и X могут быть и количественные, и порядковые (ординальные), и классификационные (номинальные).
3. Центральным математическим объектом в процессе статистического исследования зависимостей является функция f(X), называемая функцией регрессии Y по X и описывающая, как правило, изменение условного среднего значения  результирующего показателя Y (вычисленного при фиксированных на уровне X значениях объясняющих переменных) в зависимости от изменения значений объясняющих переменных X.
результирующего показателя Y (вычисленного при фиксированных на уровне X значениях объясняющих переменных) в зависимости от изменения значений объясняющих переменных X.
4. Конечные прикладные цели статистического исследования зависимостей могут быть в основном трех типов: 1) установление самого факта наличия (или отсутствия) статистически значимой связи между Y и X, исследование структуры этих связей; 2) прогноз (восстановление) неизвестных значений индивидуальных или средних значений результирующего показателя по заданным значениям соответствующих объясняющих (предикторных) переменных; 3) выявление причинных связей между объясняющими переменными X и результирующими показателями  частичное управление значениями Y путем регулирования величин объясняющих переменных X.
частичное управление значениями Y путем регулирования величин объясняющих переменных X.
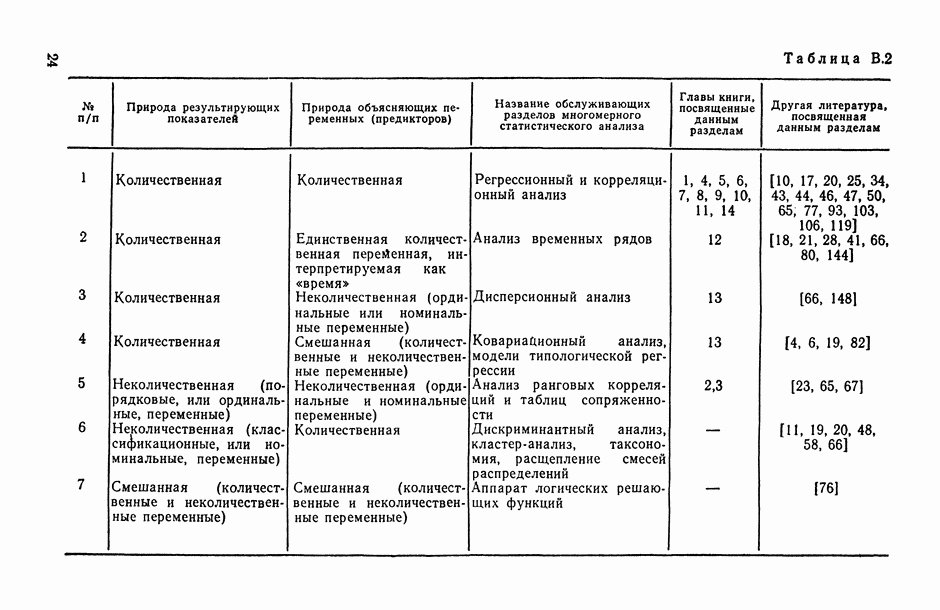
5. Разделы многомерного статистического анализа, составляющие математический аппарат статистического исследования зависимостей, формировались и развивались с учетом специфики анализируемых моделей, обусловленной в первую очередь природой исследуемых переменных. Так, изучение зависимостей между количественными переменными обслуживается регрессионным и корреляционным анализами и анализом временных рядов (гл. 1 —12, 14), изучение зависимостей количественного результирующего показателя от неколичественных или разнотипных объясняющих переменных — дисперсионным и ковариационным анализами, моделями типологической регрессии (гл. 13); для исследования зависимостей в условиях активного эксперимента служит теория оптимального планирования экспериментов [2, 3, 136]; наконец, для исследования системы зависимостей, в которых одни и те же переменные в разных уравнениях этой системы могут одновременно выполнять и роль результирующих, и роль объясняющих, служит теория систем одновременных эконометрических уравнений (гл. 14).
Аппарат исследования зависимостей неколичественных или разнотипных результирующих показателей от количественных или разнотипных объясняющих переменных в книге не рассматривается.
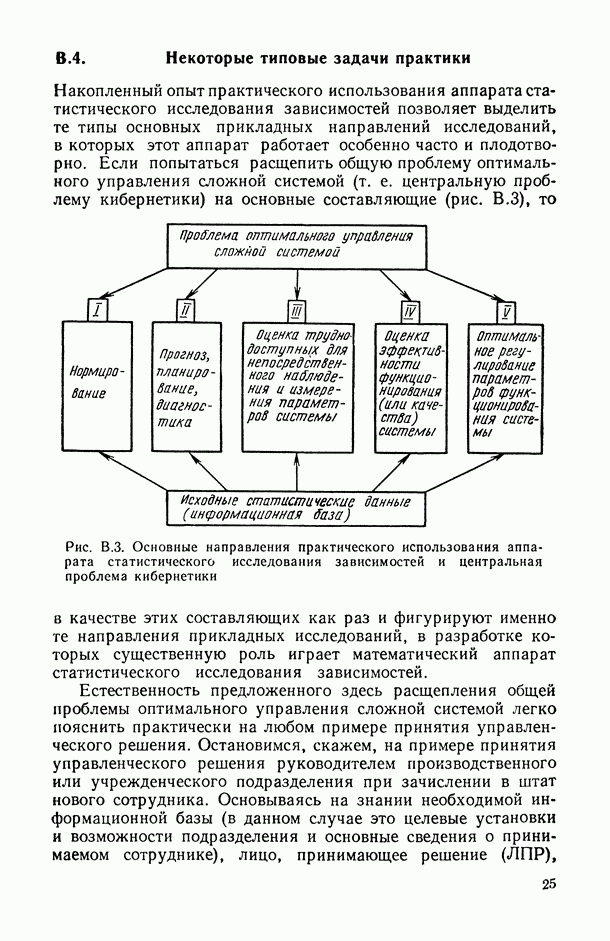
6. К основным типовым задачам практики, в которых использование аппарата статистического исследования зависимостей оказывается наиболее уместным и эффективным, следует отнести задачи: 1) нормирования; 2) прогноза, планирования и диагностики; 3) оценки труднодоступных (для непосредственного наблюдения и измерения) характеристик исследуемой системы; 4) оценки эффективности функционирования (или качества) анализируемой системы; 5) регулирования параметров функционирования анализируемой системы. Все эти задачи являются основными составными частями центральной проблемы кибернетики — проблемы «управления, связи и переработки информации» (см.: Математическая энциклопедия. Т. 2 — М.: Советская энциклопедия, 1979, с. 850).
7. По своей природе исследуемые зависимости могут быть разделены на: 1) детерминированные (тип А), когда исследуется функциональная зависимость между неслучайными переменными; 2) регрессионные (тип В), когда исследуется зависимость случайного результирующего показателя от неслучайных объясняющих переменных — параметров системы; 3) корреляционные (тип С), когда исследуется зависимость между случайными переменными, причем объясняющие переменные могут быть измерены без искажений; 4) конфлюэнтные (типы  ), когда исследуется функциональная зависимость между случайными или неслучайными переменными в ситуации, когда те и другие могут быть измерены только с некоторой случайной ошибкой.
), когда исследуется функциональная зависимость между случайными или неслучайными переменными в ситуации, когда те и другие могут быть измерены только с некоторой случайной ошибкой.
8. Весь процесс статистического исследования зависимостей может быть разбит на семь последовательно реализуемых основных этапов, хронологический характер связей которых дополняется связями итерационного взаимодействия (см. рис. В.8): этап I (постановочный); этап 2 (информационный); этап 3 (корреляционный анализ); этап 4 (определение класса допустимых решений); этап 5 (анализ мультиколлинеарности предсказывающих переменных и отбор наиболее информативных из них); этап 6 (вычисление оценок неизвестных параметров, входящих в исследуемое уравнение статистической связи); этап 7 (анализ точности полученных уравнений связи).