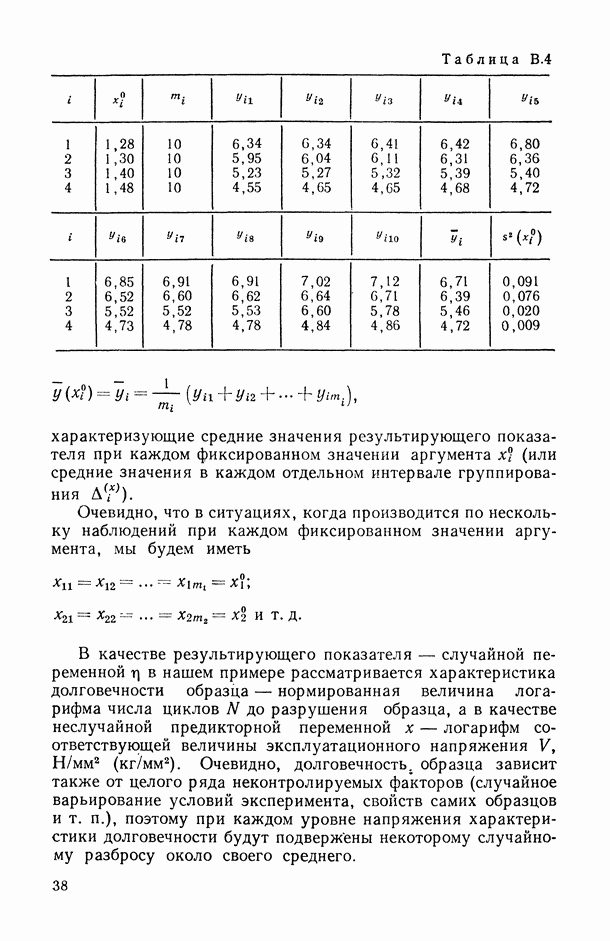
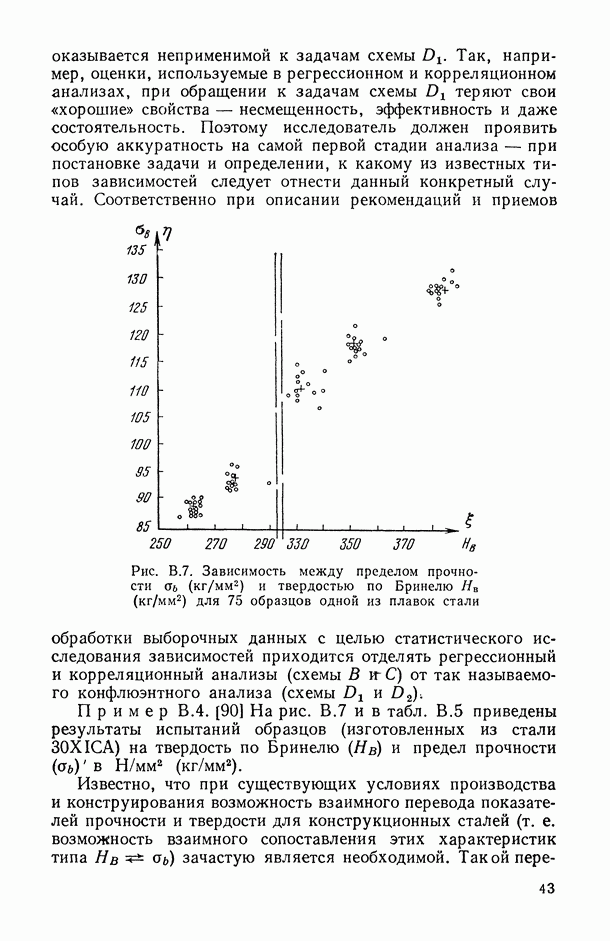
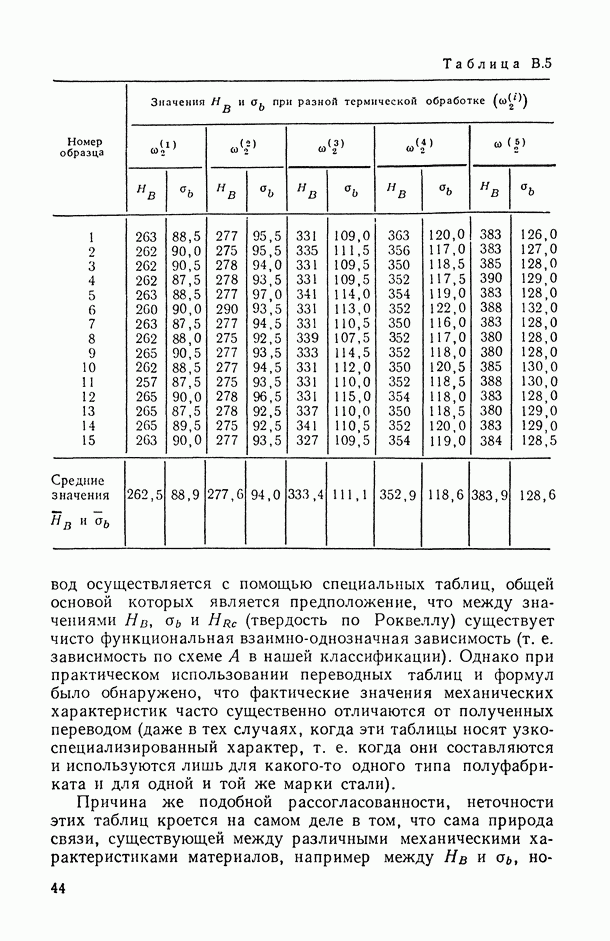
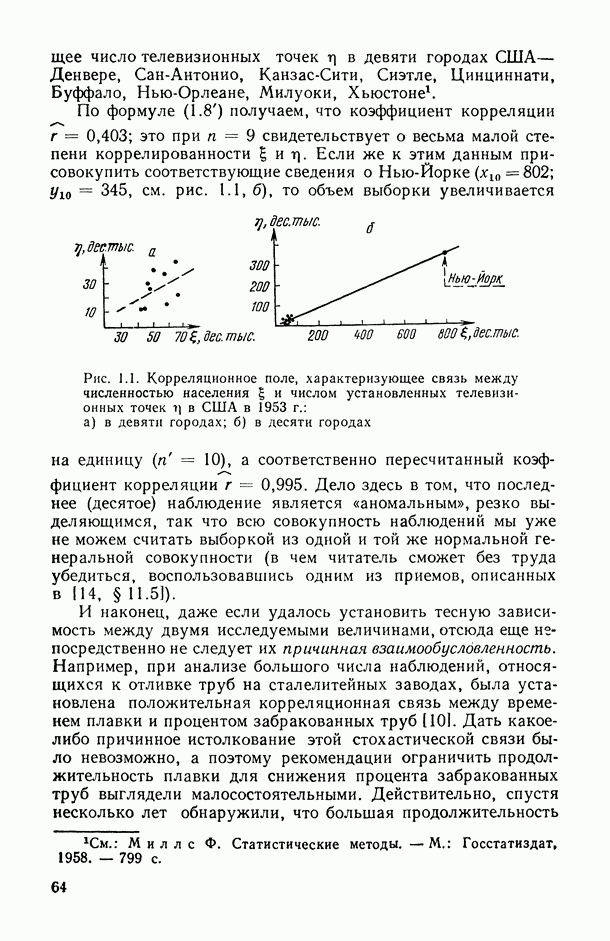
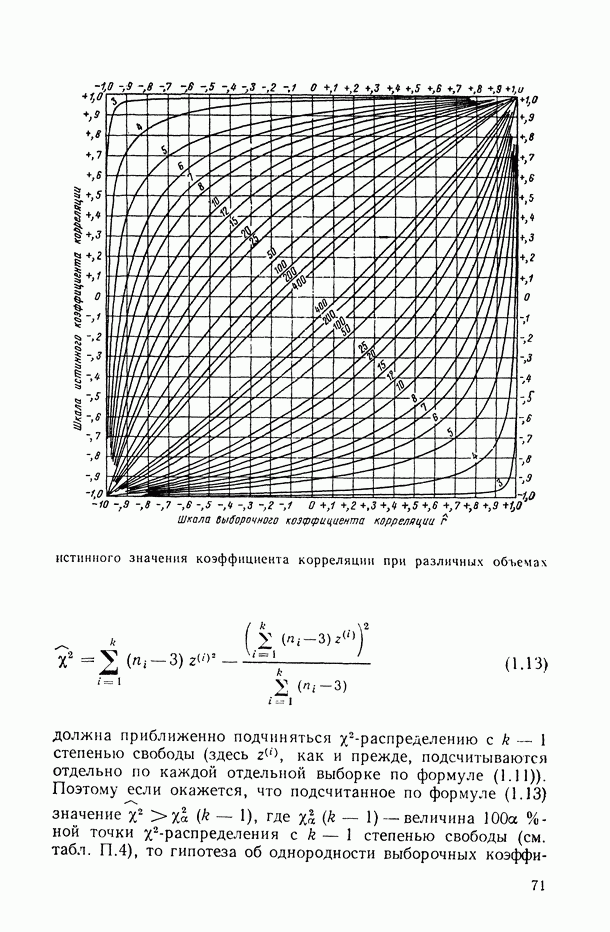
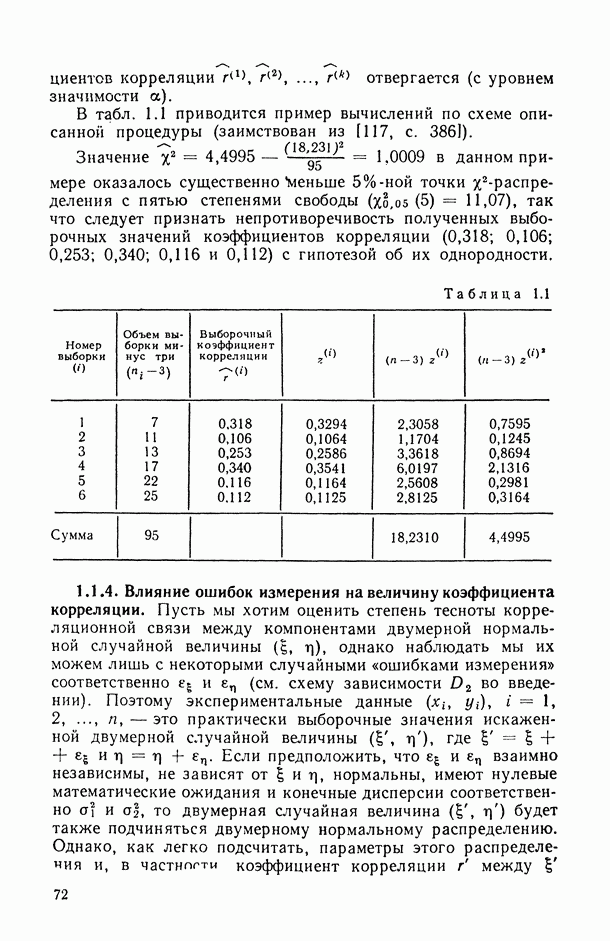
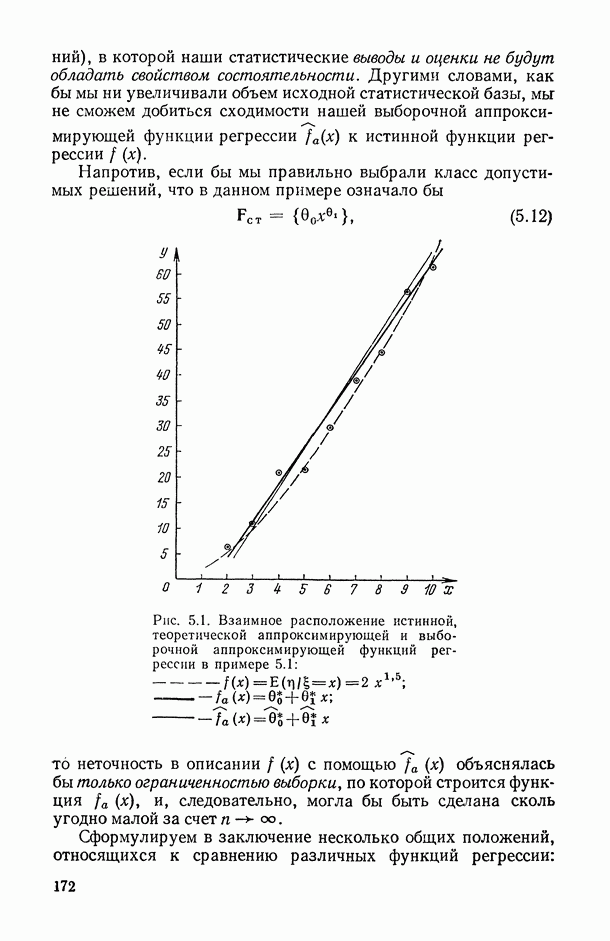
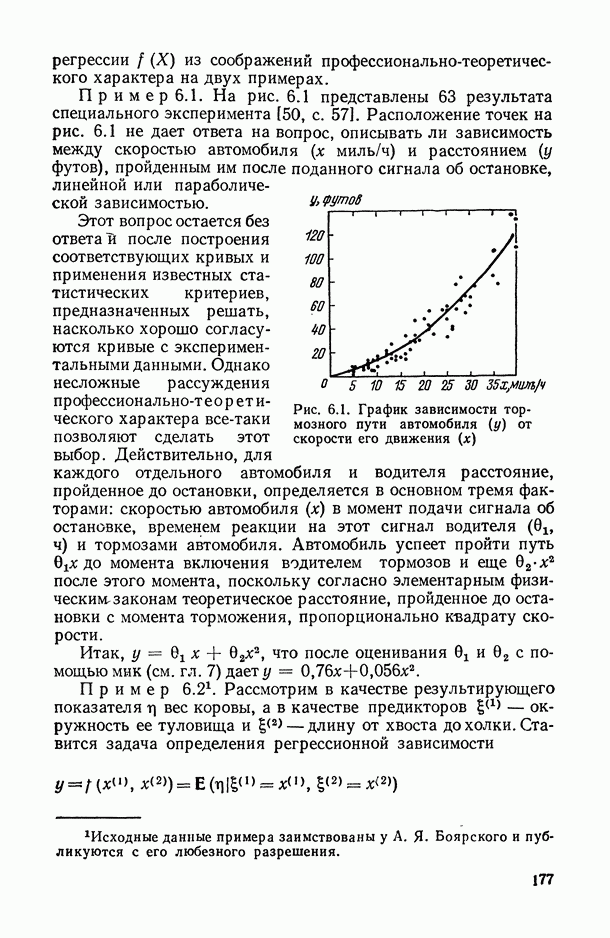
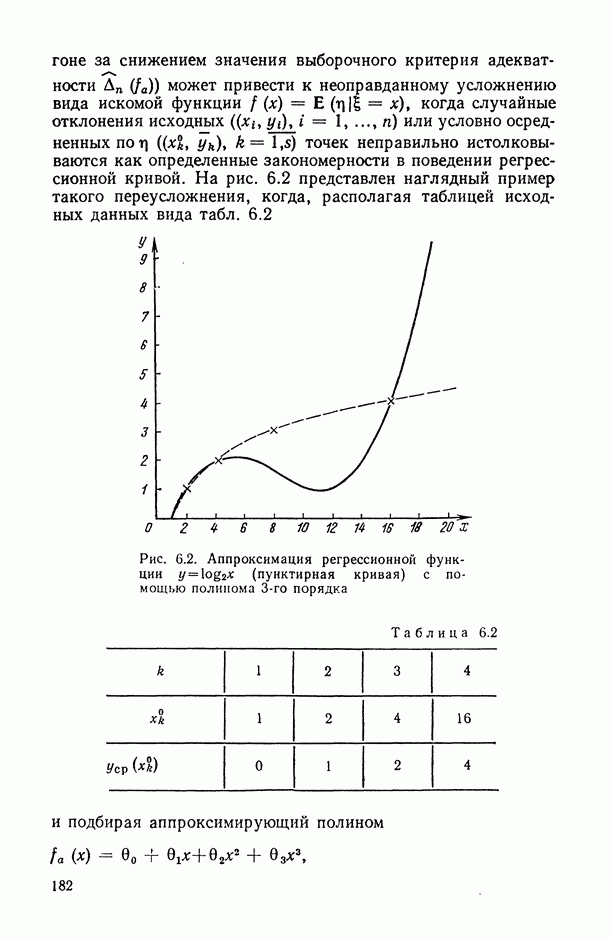
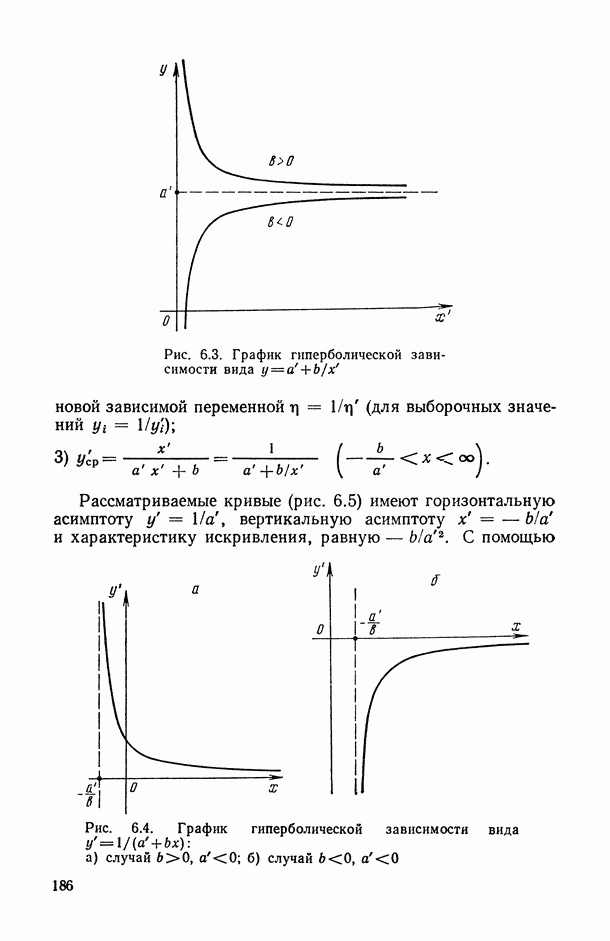
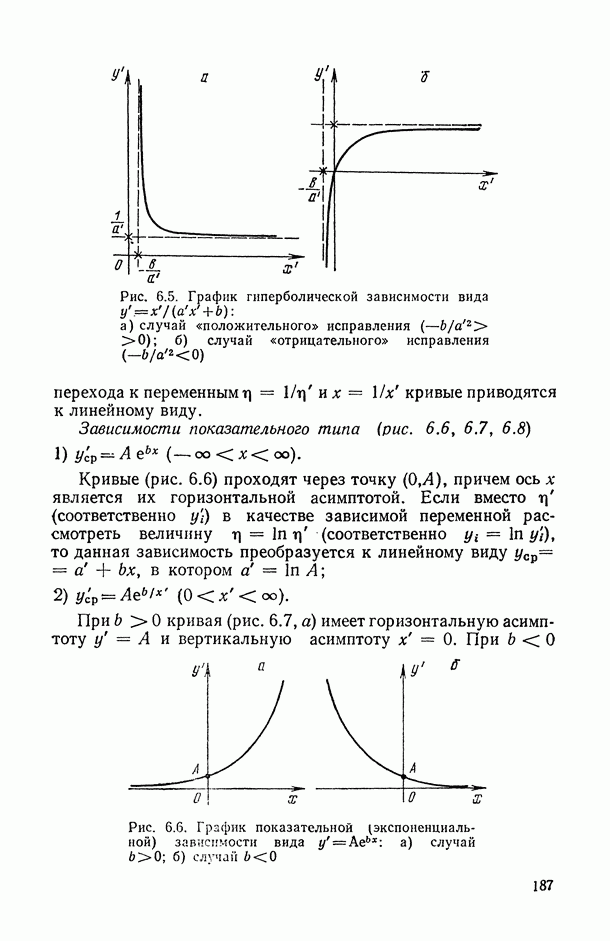
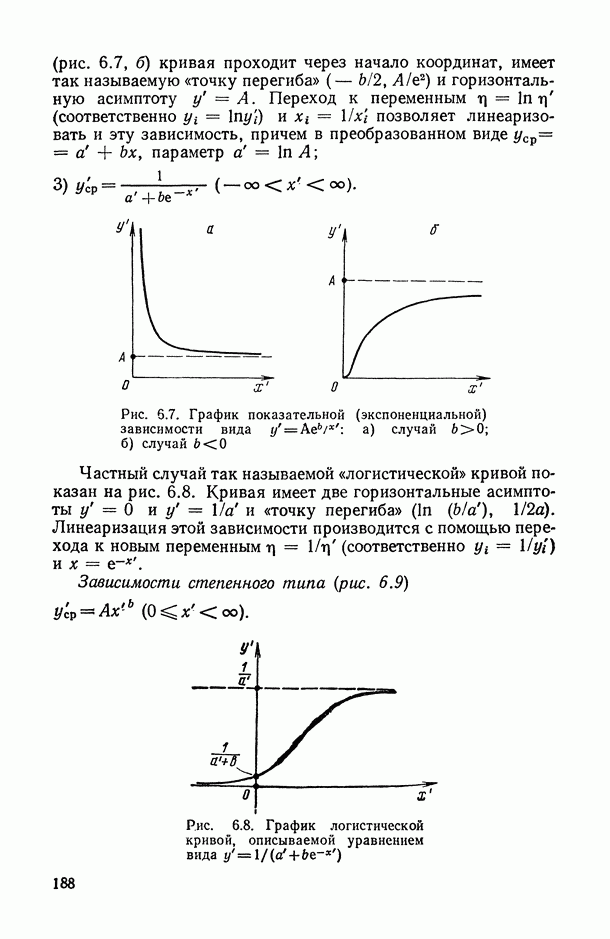
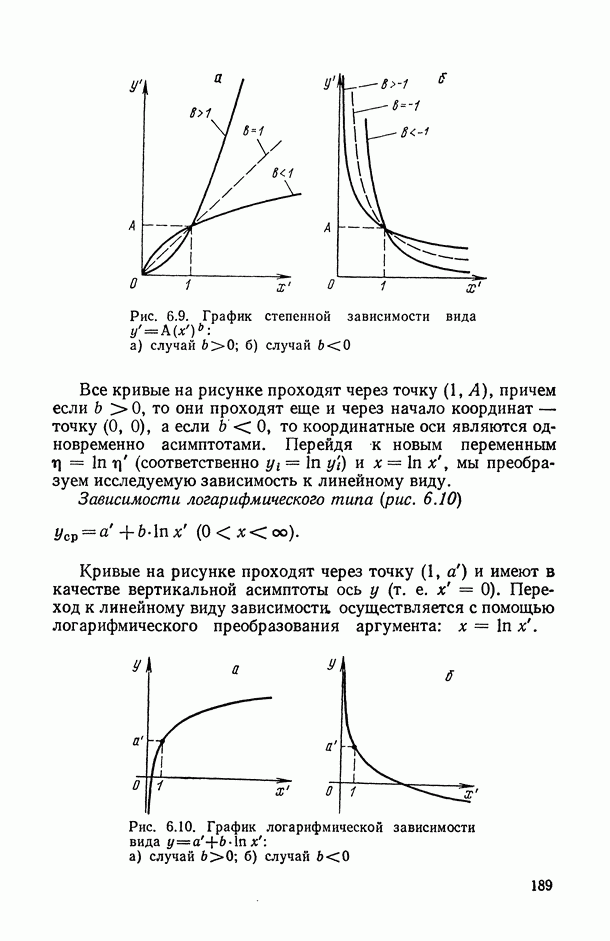
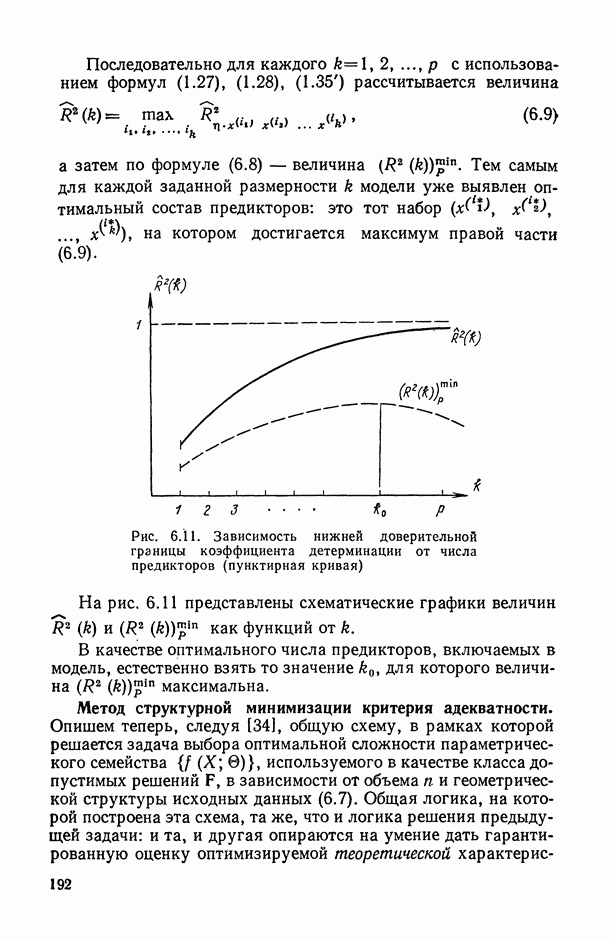
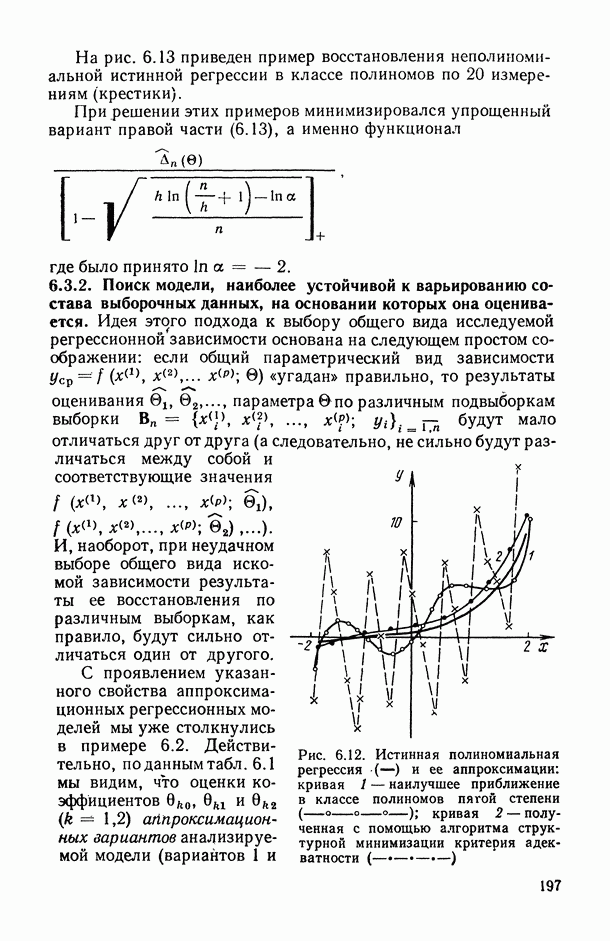
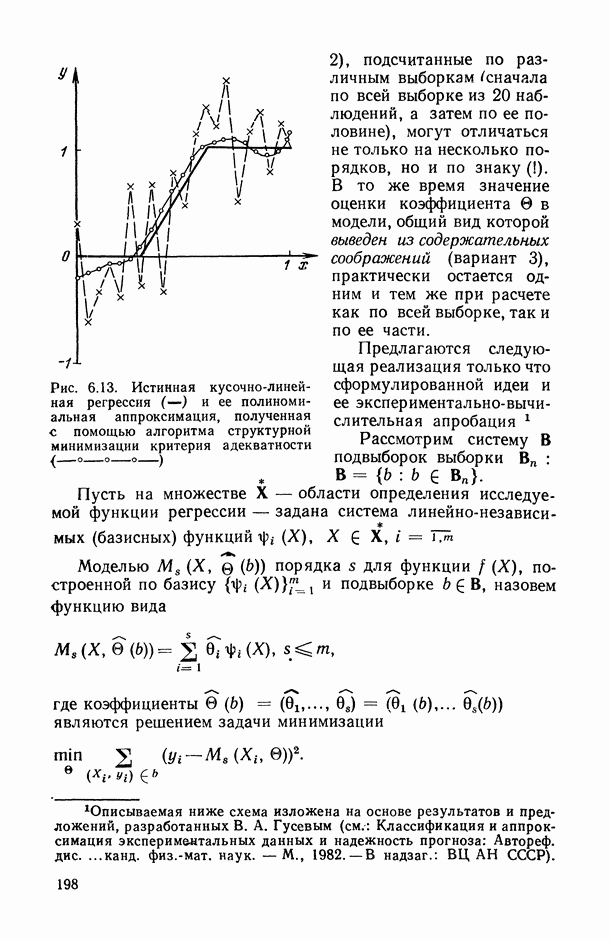
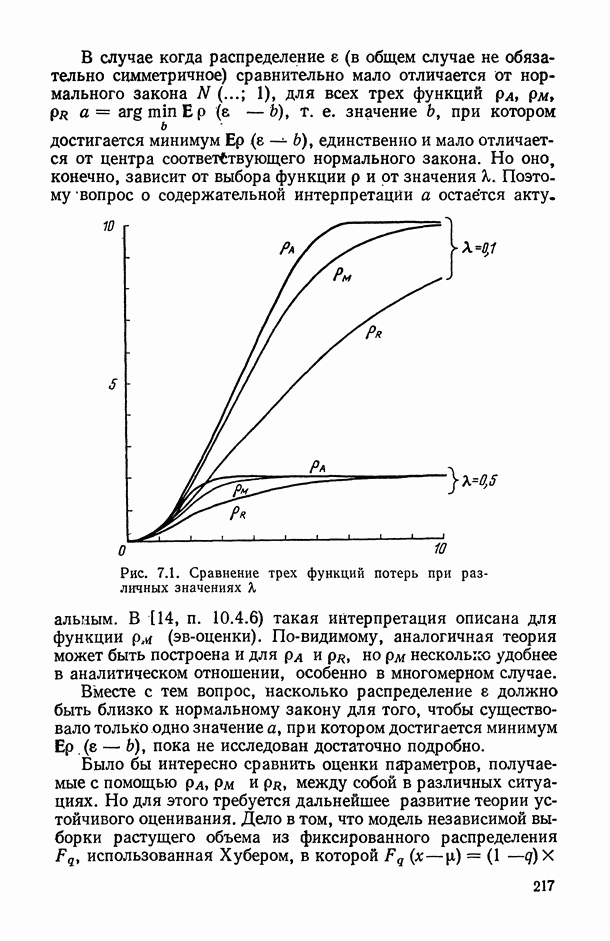
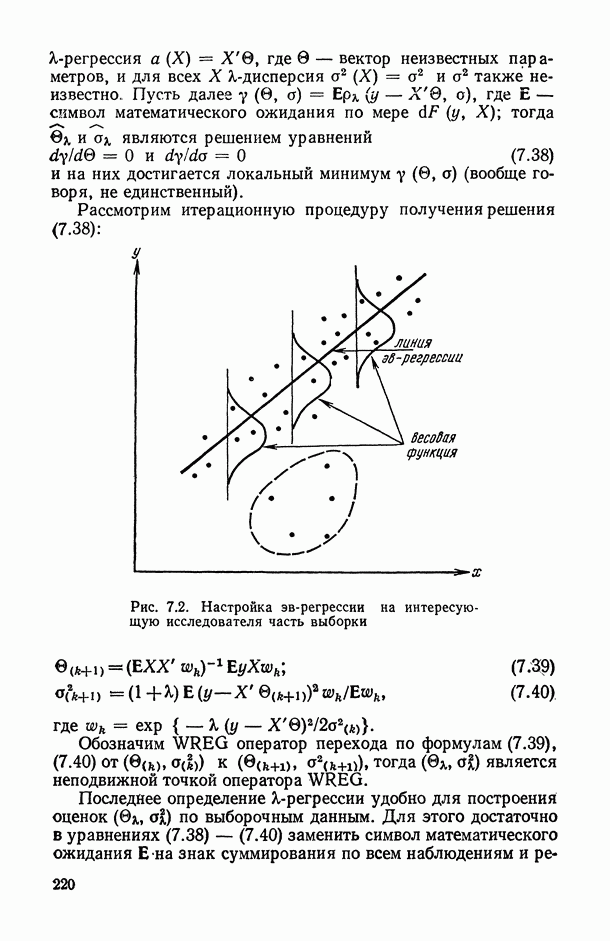
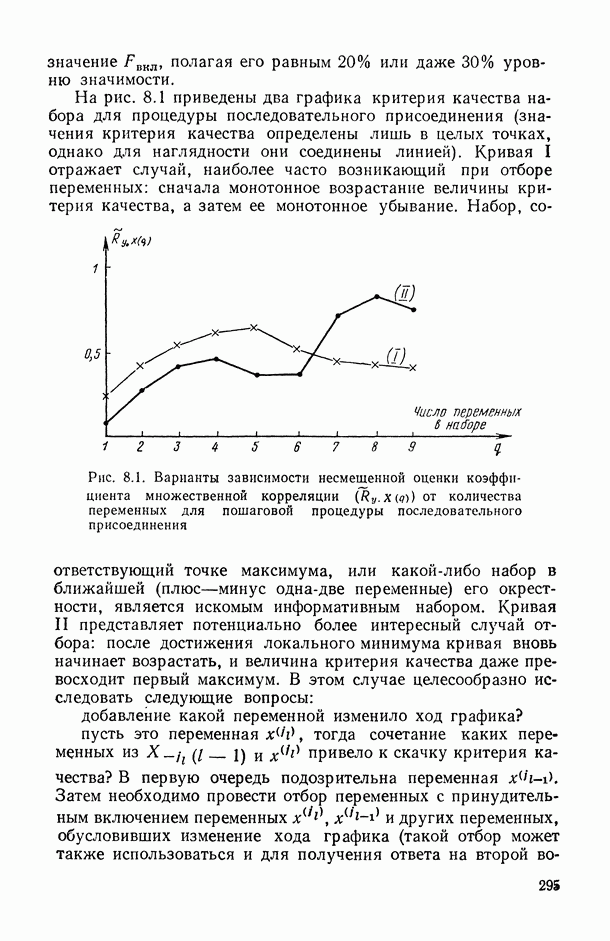
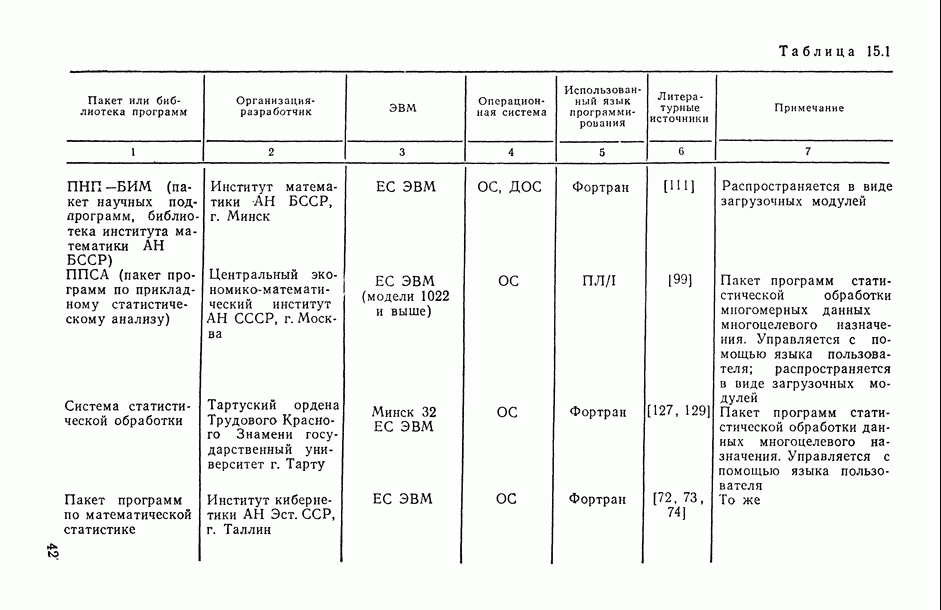
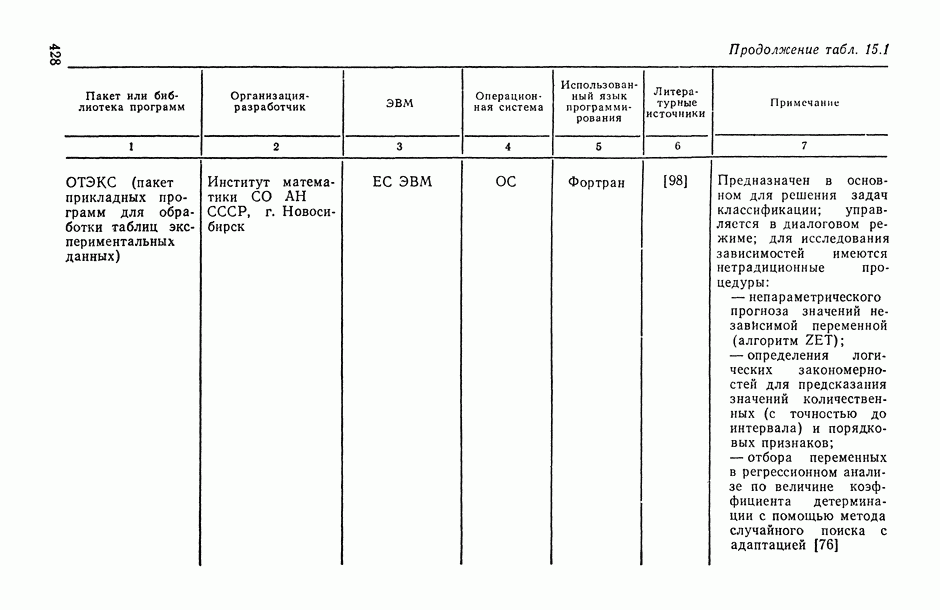
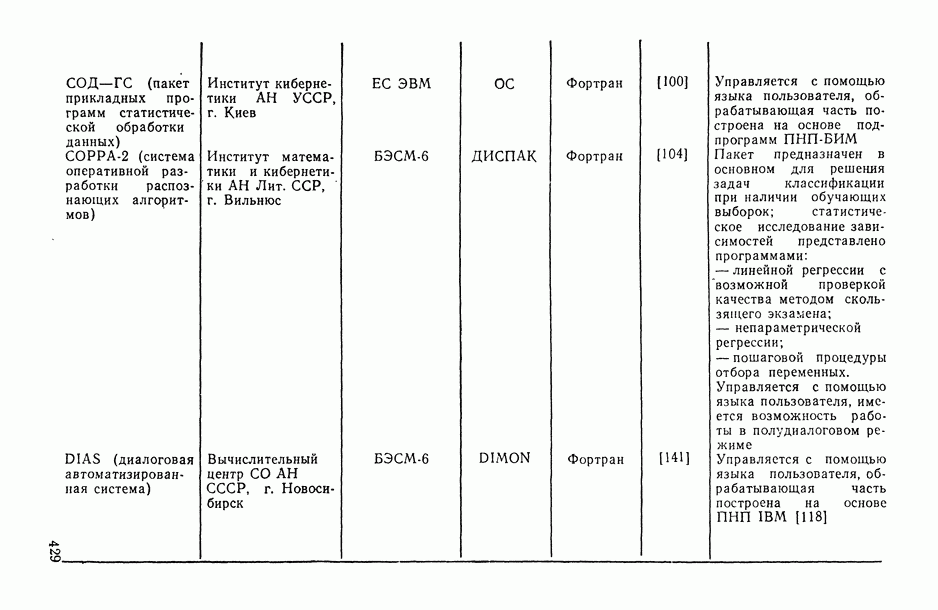
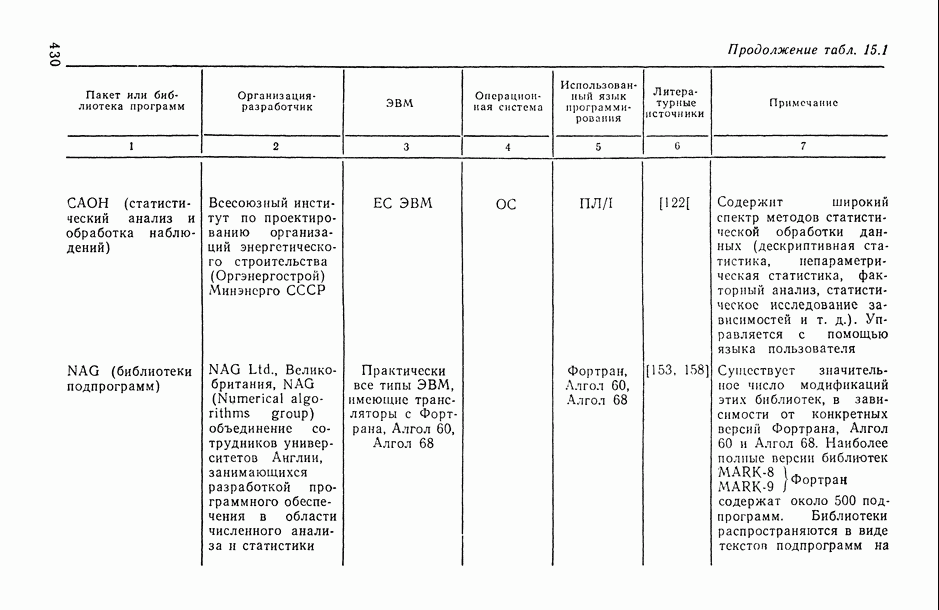
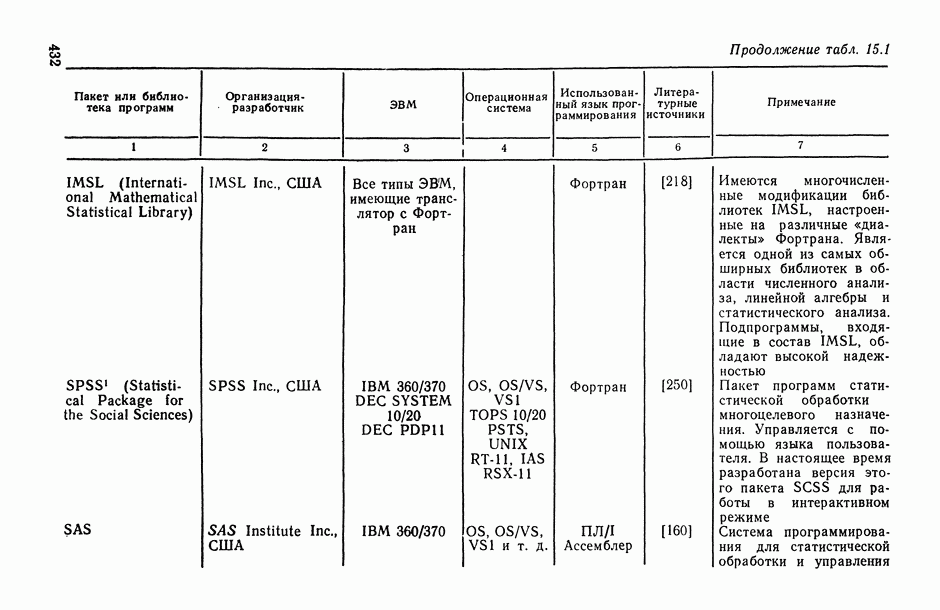
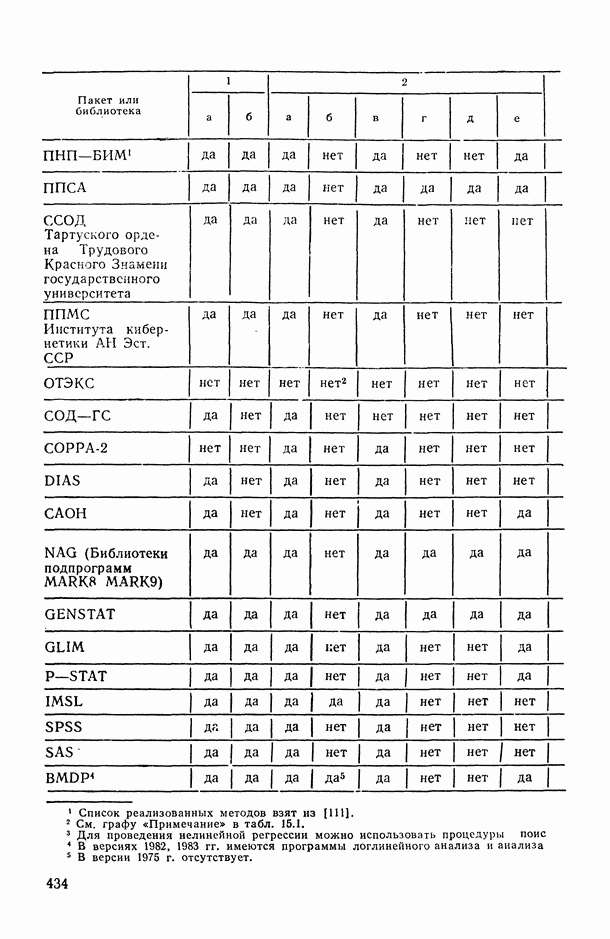
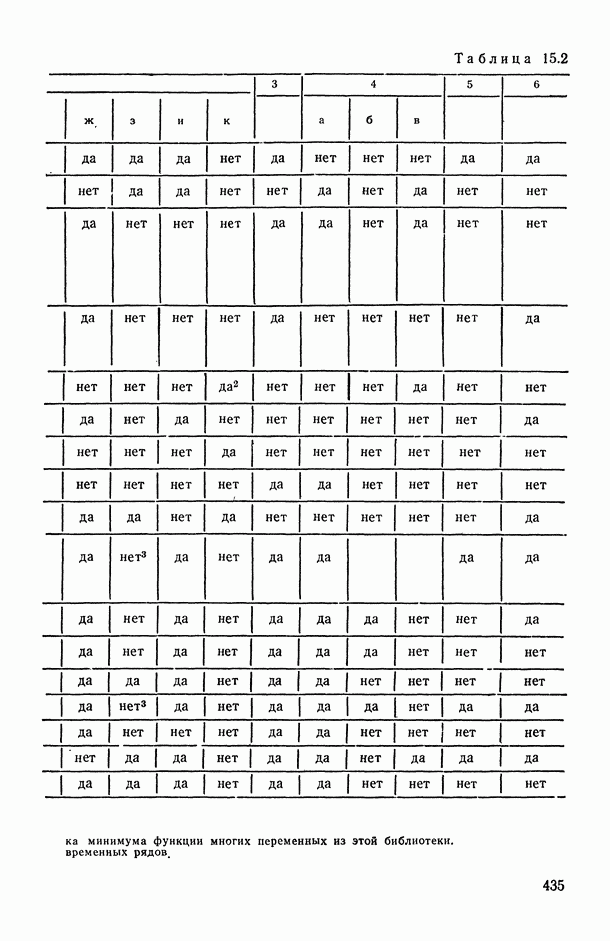
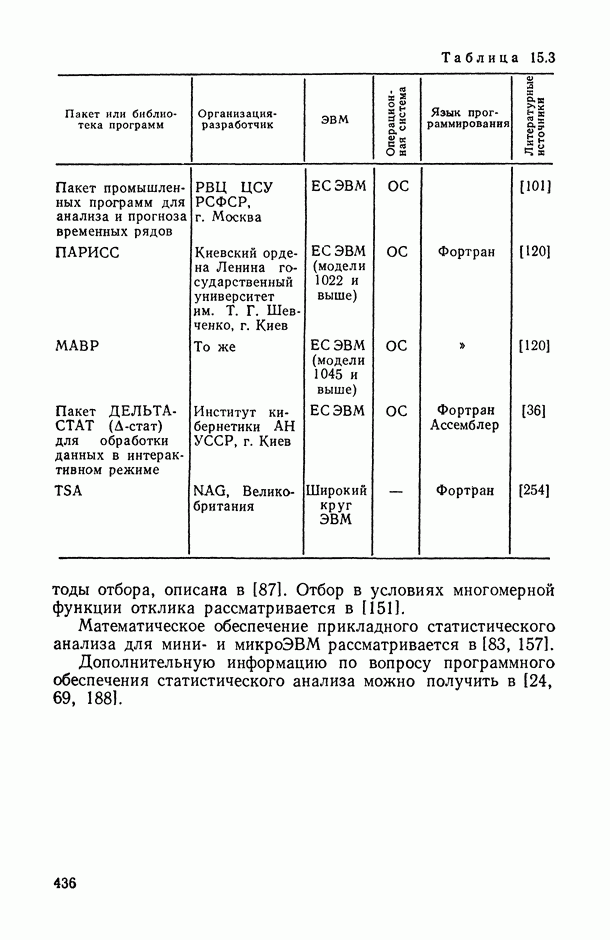
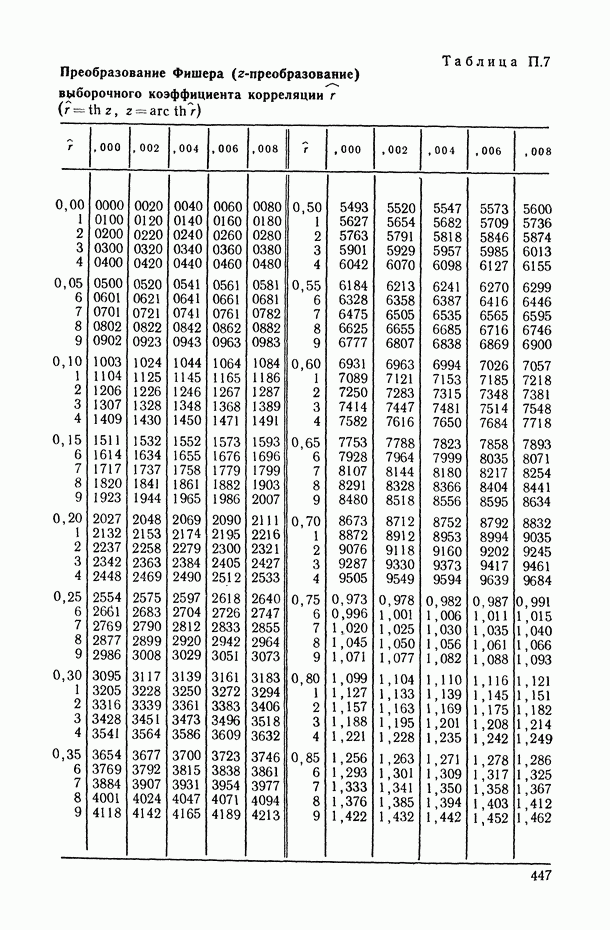
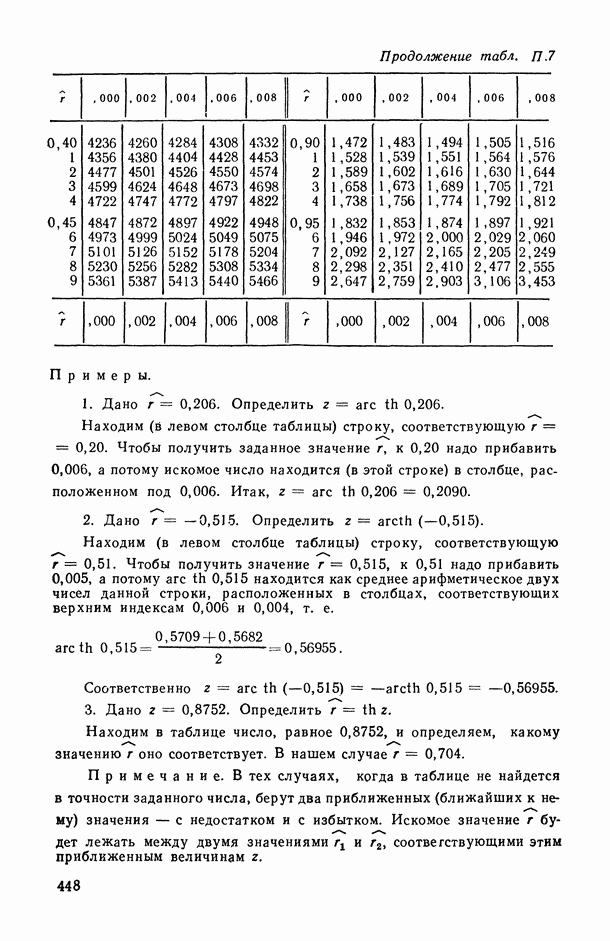
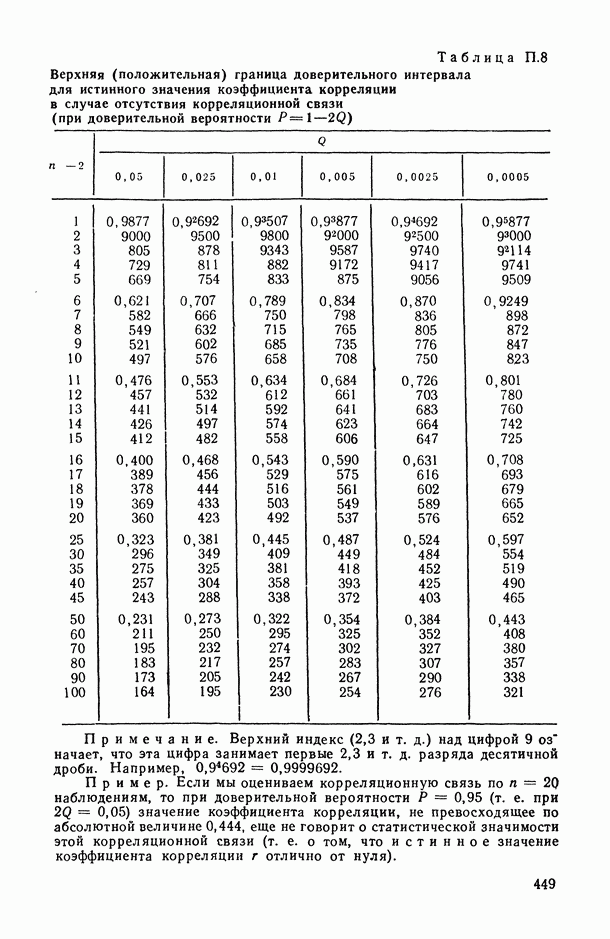
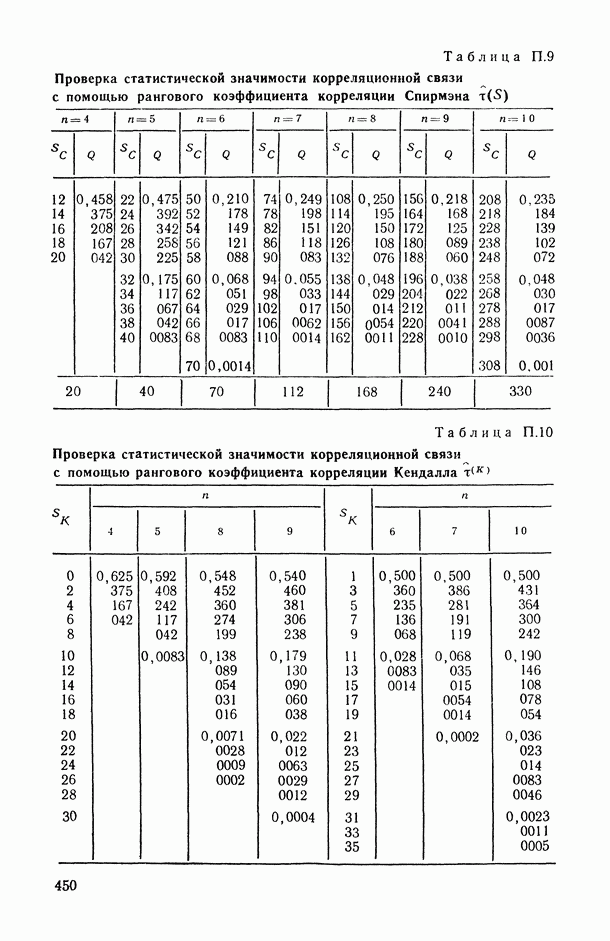
1.3. Анализ множественных связей
1.3.1. Степень тесноты множественной статистической связи и среднеквадратическая ошибка прогноза (аппроксимации) одной переменной по совокупности других.
Интуитивно и из смысла рассмотренных выше характеристик степени тесноты статистической связи ясно, что чем теснее эта связь, тем больше информации содержит одна переменная относительно другой, тем точнее можно восстановить (спрогнозировать, аппроксимировать) неизвестное значение одной переменной по заданной величине другой.
При решении практических задач чаще других рассматривается схема, в которой поведение какого-то одного (результирующего) признака  стараются «объяснить» поведением совокупности других (предикторных) переменных
стараются «объяснить» поведением совокупности других (предикторных) переменных  Если зафиксировать «значение»
Если зафиксировать «значение»  , то из всех возможных способов определения прогнозного (аппроксимирующего) значения
, то из всех возможных способов определения прогнозного (аппроксимирующего) значения  для неизвестного значения
для неизвестного значения  наилучшим (в смысле минимума среднего квадрата ошибки прогноза), как оказалось, является условное среднее значение анализируемого результирующего показателя
наилучшим (в смысле минимума среднего квадрата ошибки прогноза), как оказалось, является условное среднее значение анализируемого результирующего показателя  , т. е. величина
, т. е. величина  , где усреднение производится при условии, что объясняющие переменные зафиксированы на уровне
, где усреднение производится при условии, что объясняющие переменные зафиксированы на уровне  . Действительно, легко видеть, что для любой другой функции
. Действительно, легко видеть, что для любой другой функции  будем иметь:
будем иметь:

А поскольку  то всегда
то всегда

В этих выкладках использовался способ вычисления математического ожидания в два этапа: на первом фиксируются значения X и усреднение производится по значениям  (при фиксированном X), т. е. берется условное математическое ожидание при условии, наложенном на на втором этапе результат усредняется по всевозможным значениям X (нижний индекс у знака математического ожидания показывает, по каким именно значениям производится усреднение).
(при фиксированном X), т. е. берется условное математическое ожидание при условии, наложенном на на втором этапе результат усредняется по всевозможным значениям X (нижний индекс у знака математического ожидания показывает, по каким именно значениям производится усреднение).
Таким образом, мы снова (как и в п. В.5 и 1.1.1) пришли к функции регрессии  на этот раз как к функции от
на этот раз как к функции от  переменных
переменных  наиболее точно (в смысле среднеквадратической ошибки) воспроизводящей условное значение исследуемого результирующего показателя
наиболее точно (в смысле среднеквадратической ошибки) воспроизводящей условное значение исследуемого результирующего показателя  по заданной величине X объясняющих переменных
по заданной величине X объясняющих переменных 
Вернемся теперь к соотношению (1.5), связывающему между собой общую вариацию результирующего показателя  ), вариацию функции регрессии
), вариацию функции регрессии  ) и усредненную (по различным возможным значениям X объясняющих переменных) величину условной дисперсии «регрессионных остатков»
) и усредненную (по различным возможным значениям X объясняющих переменных) величину условной дисперсии «регрессионных остатков»  . Оно остается справедливым и в случае многомерной предикторной переменной
. Оно остается справедливым и в случае многомерной предикторной переменной  (или
(или  ).
).
Следовательно, так же как и в случае парной зависимости, вариация (случайный разброс) результирующего показателя  складывается из контролируемой нами (по значению предикторной переменной
складывается из контролируемой нами (по значению предикторной переменной  вариации функции регрессии
вариации функции регрессии  и из не поддающегося нашему контролю случайного разброса значений
и из не поддающегося нашему контролю случайного разброса значений  (при фиксированном X) относительно функции регрессии
(при фиксированном X) относительно функции регрессии  . Именно этот неконтролируемый разброс (характеризуемый величиной
. Именно этот неконтролируемый разброс (характеризуемый величиной  ) и определяет одновременно и среднеквадратическую ошибку прогноза (или аппроксимации) величины результирующего показателя
) и определяет одновременно и среднеквадратическую ошибку прогноза (или аппроксимации) величины результирующего показателя  по значениям предикторных переменных X, и степень тесноты связи, существующей между величиной
по значениям предикторных переменных X, и степень тесноты связи, существующей между величиной  с одной стороны, и значениями X — с другой: чем меньше значение
с одной стороны, и значениями X — с другой: чем меньше значение  тем точнее прогноз и тем теснее связь между
тем точнее прогноз и тем теснее связь между  .
.
Эти соображения приводят нас к следующему способу измерения множественной статистической связи.