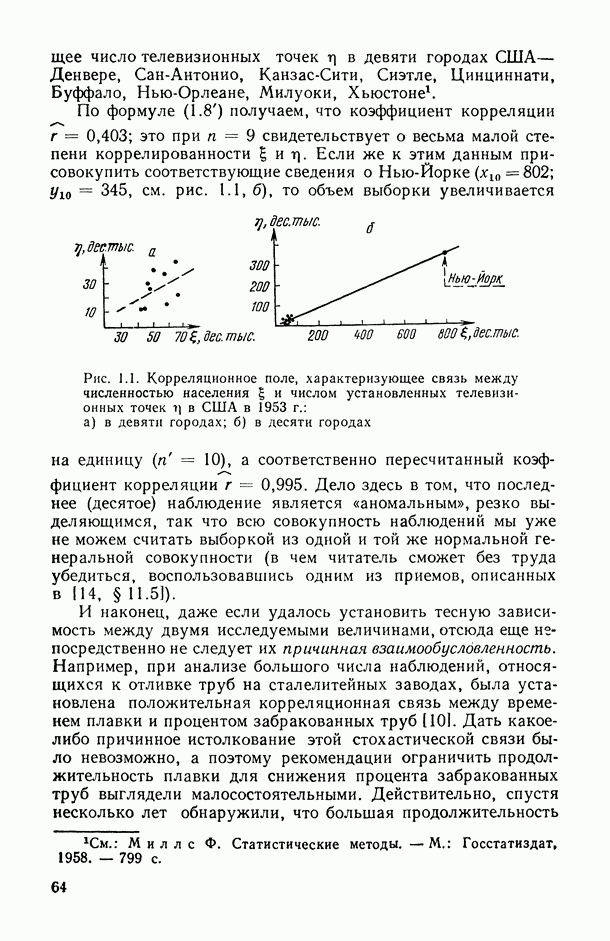
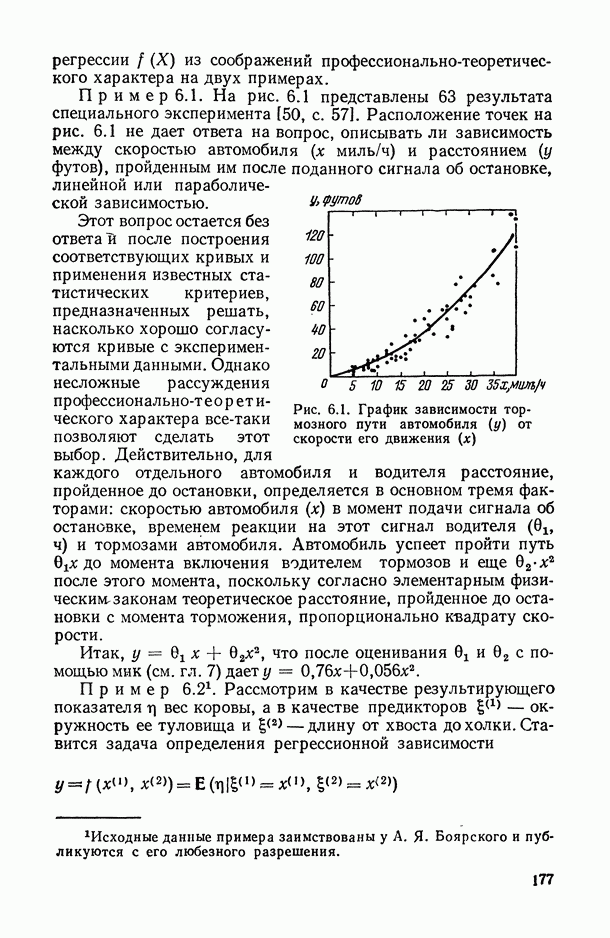
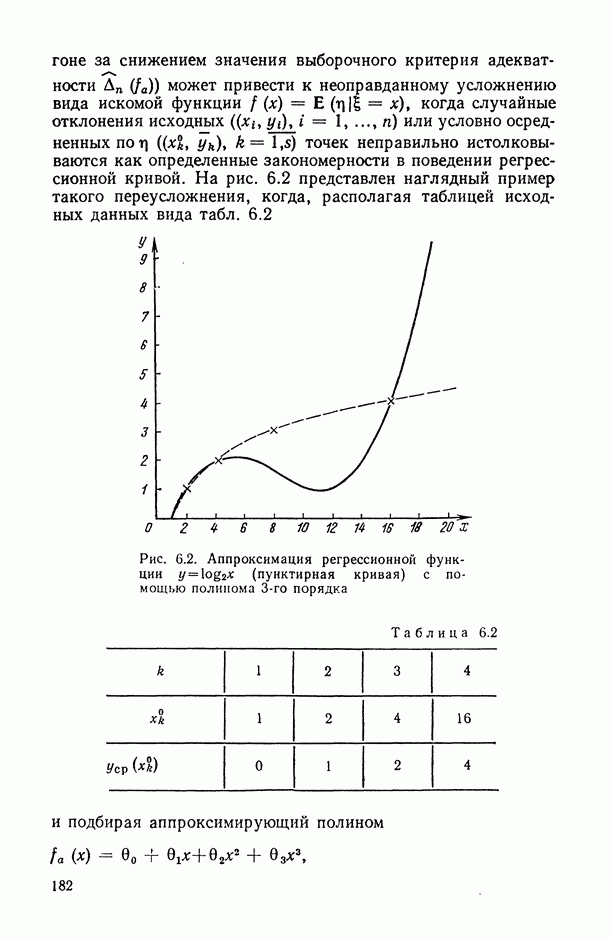
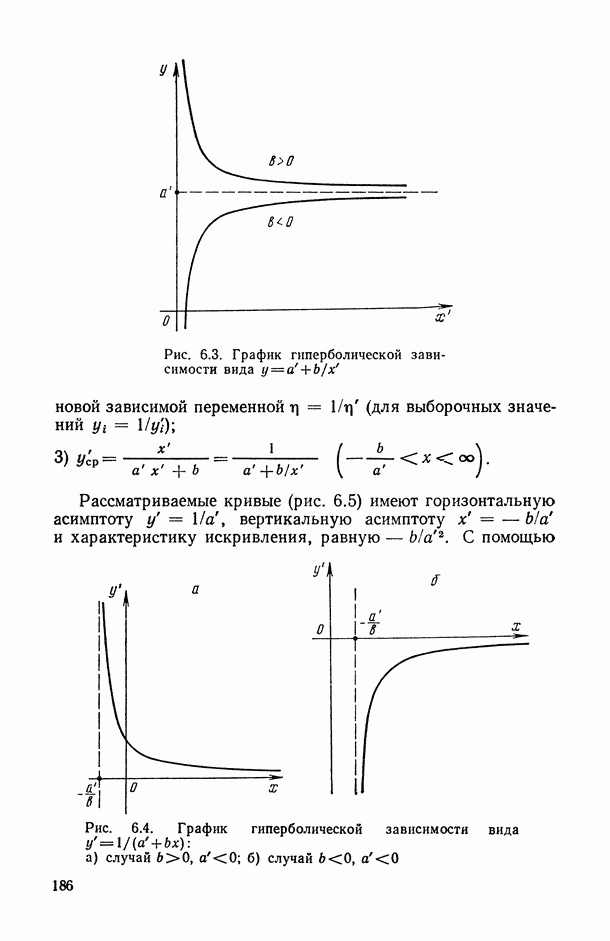
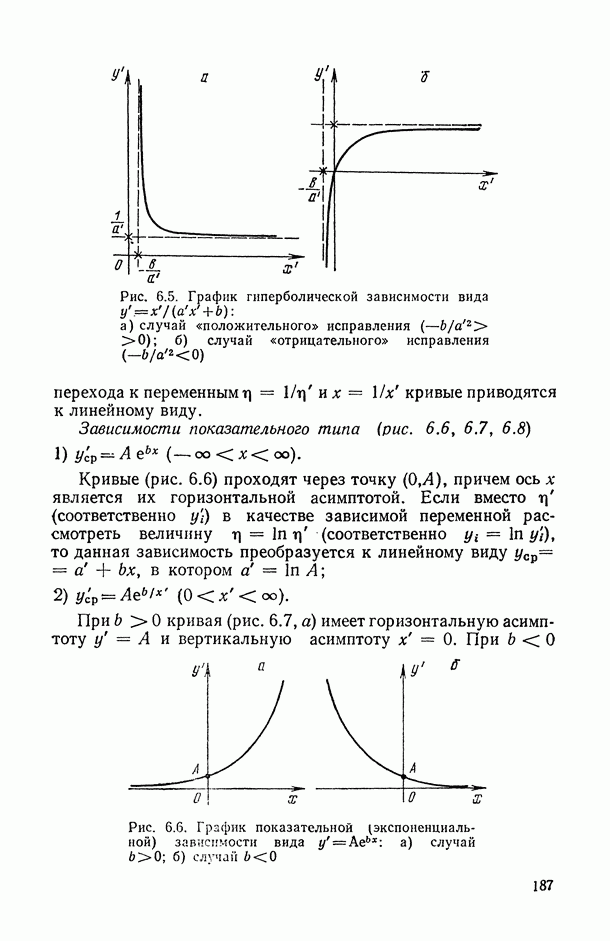
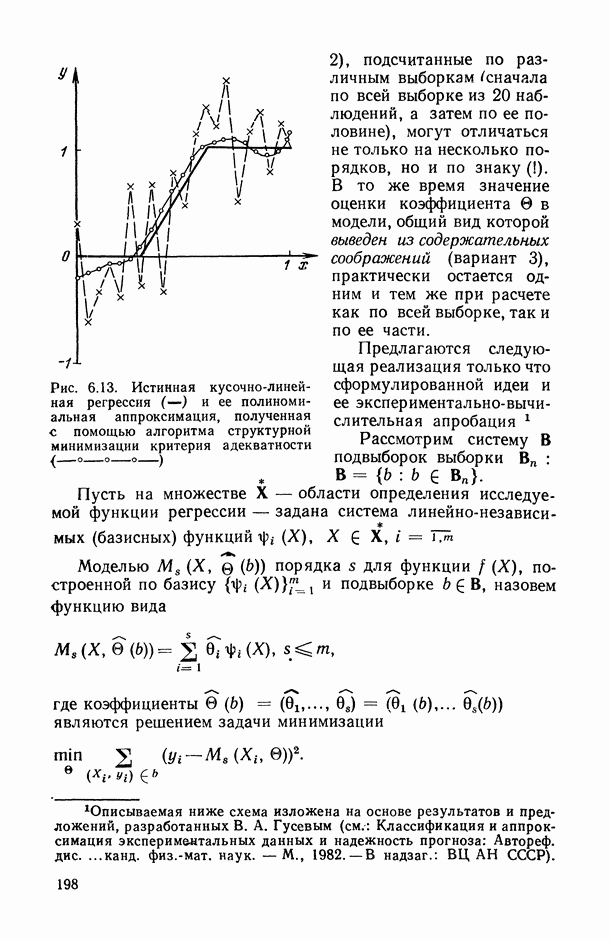
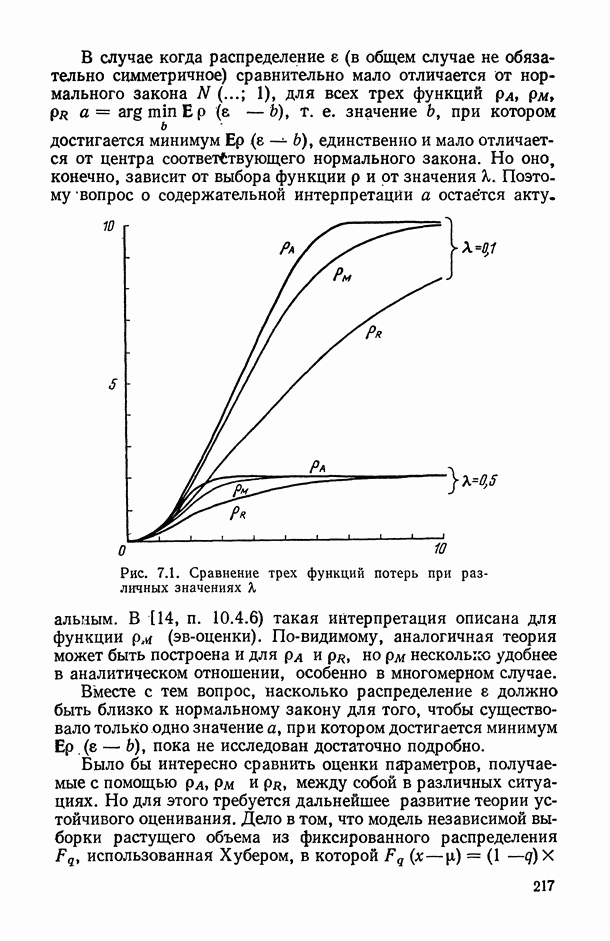
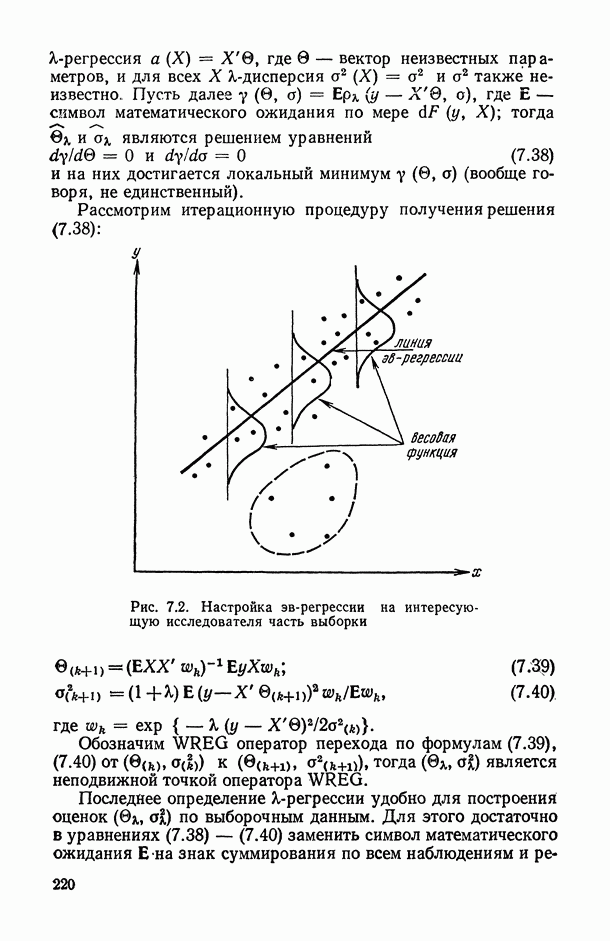
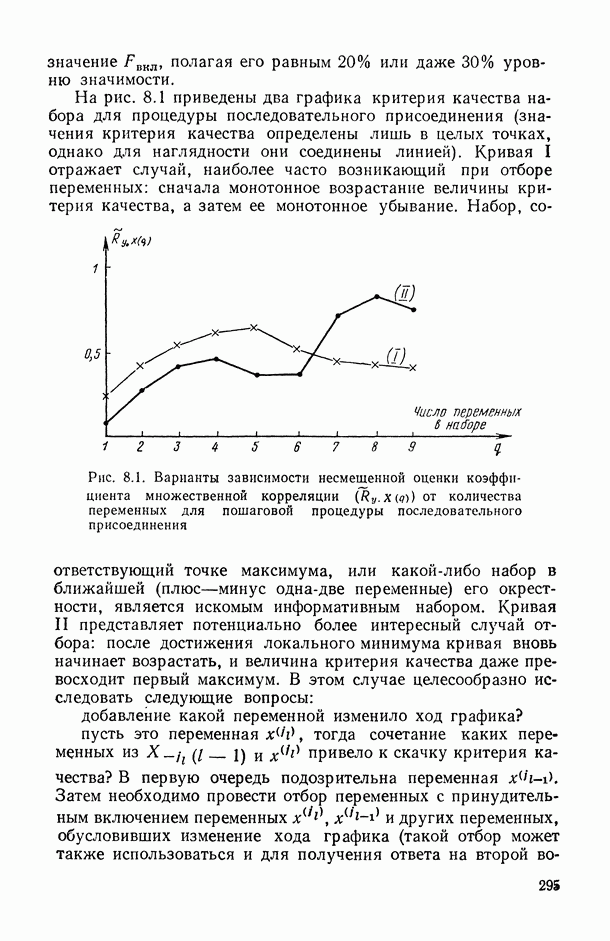
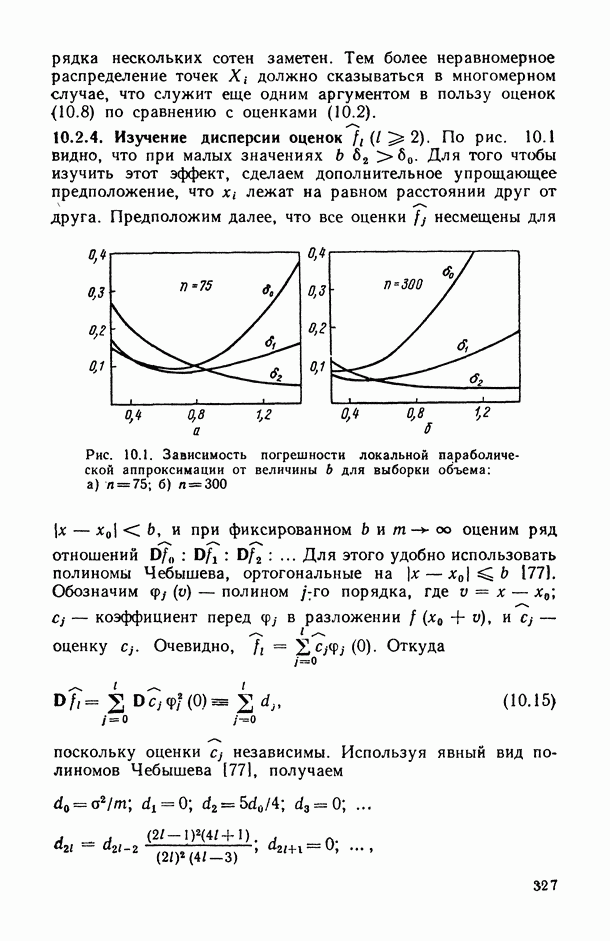
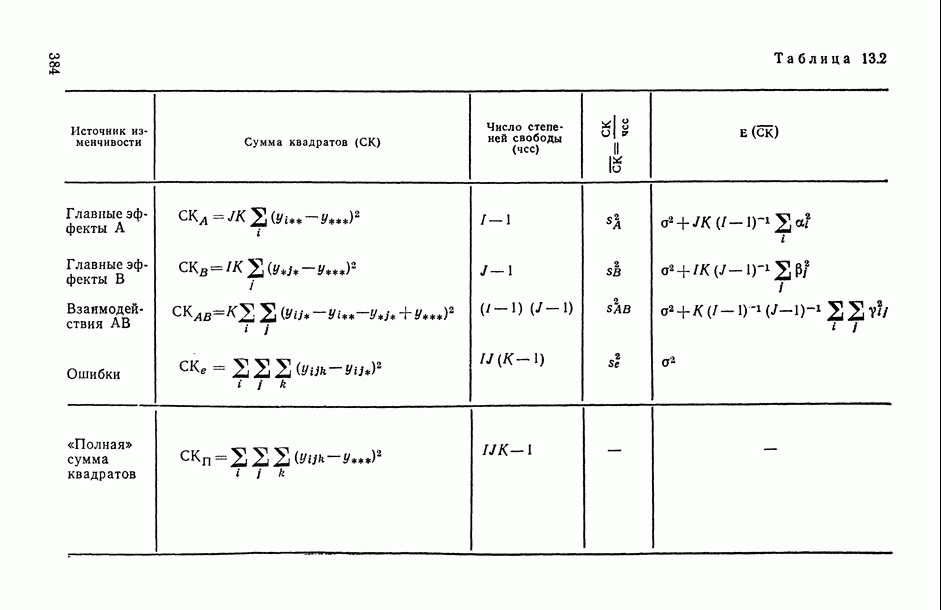
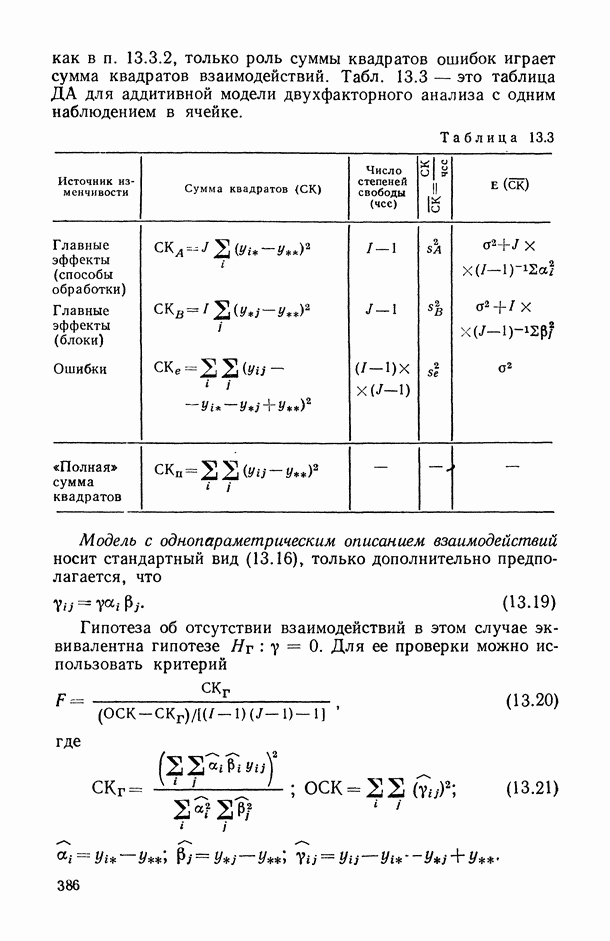
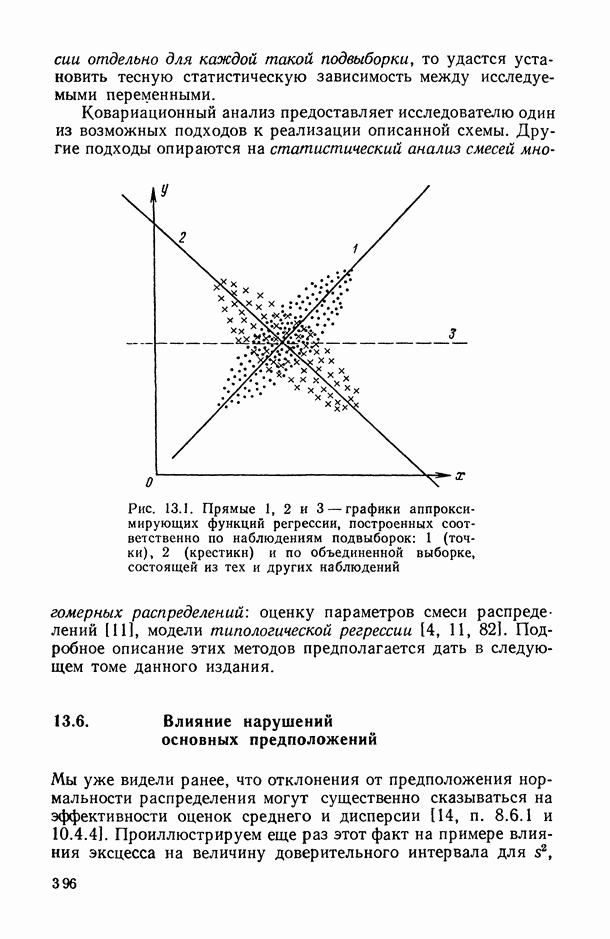
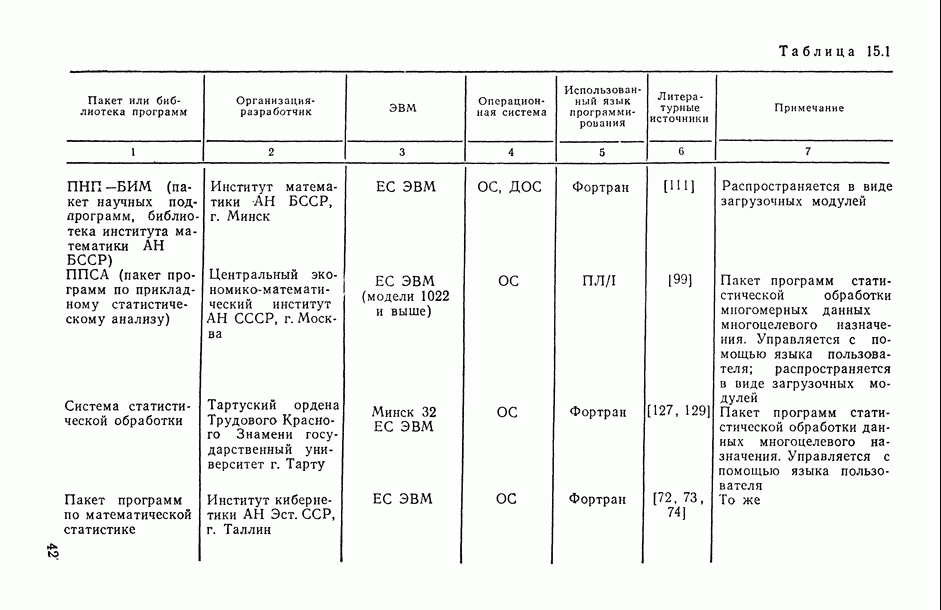
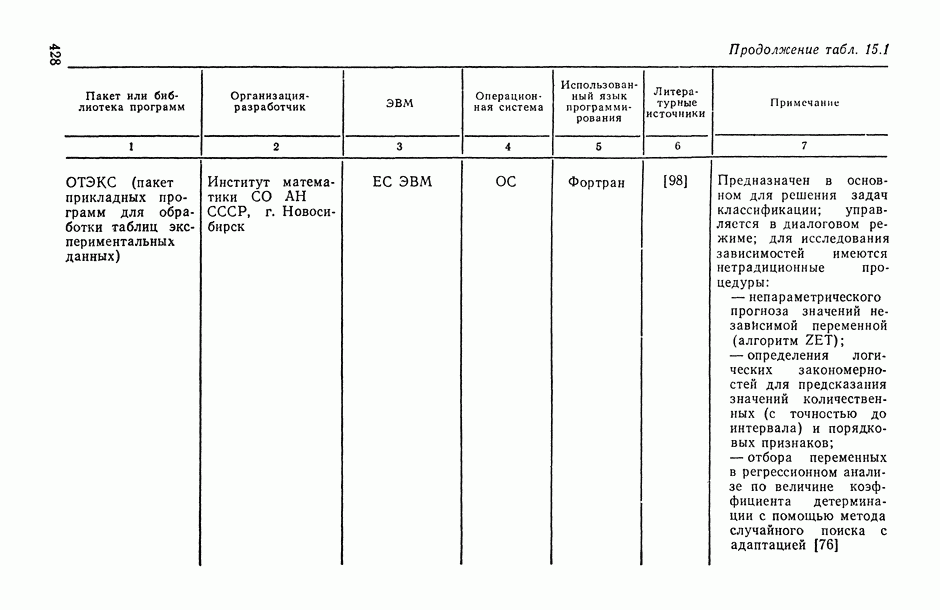
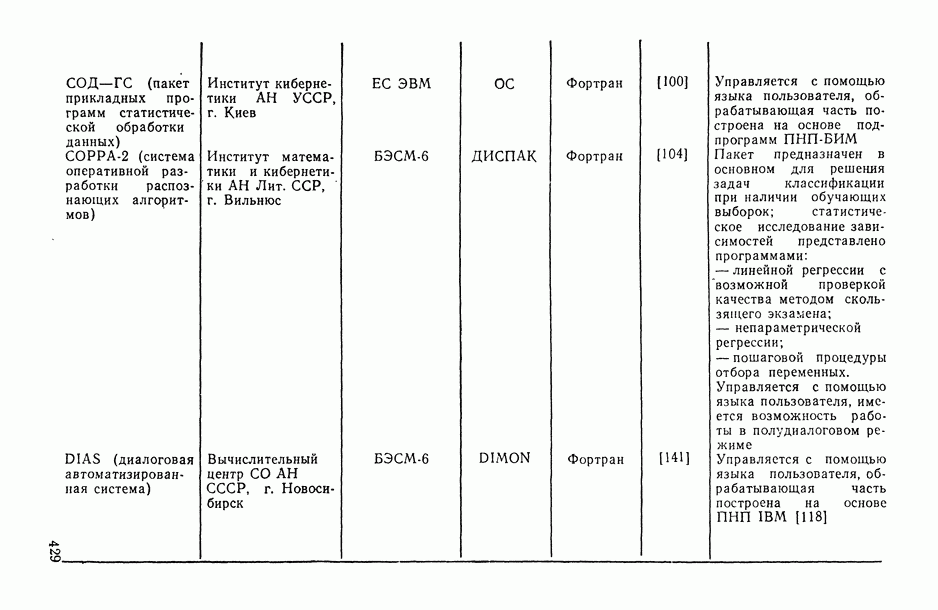
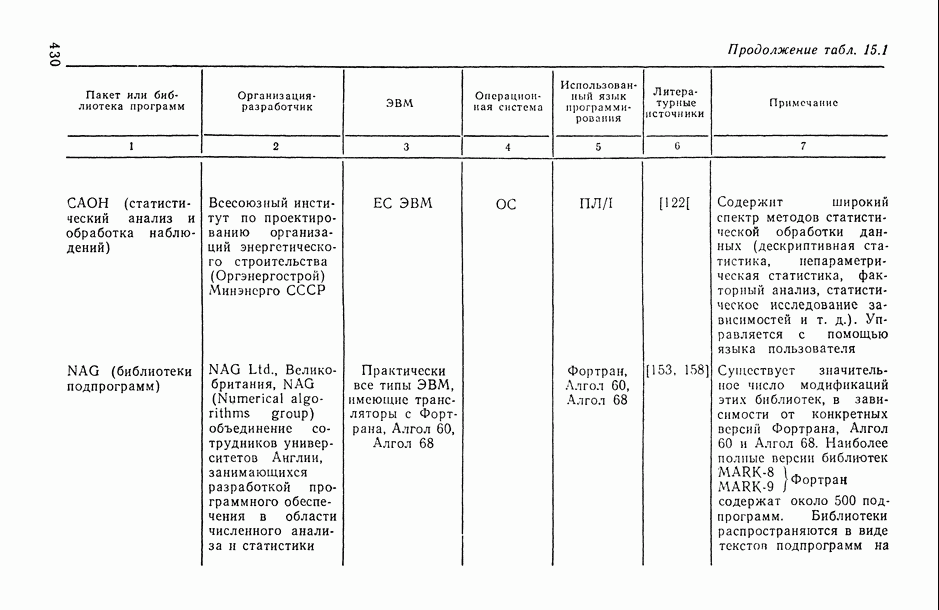
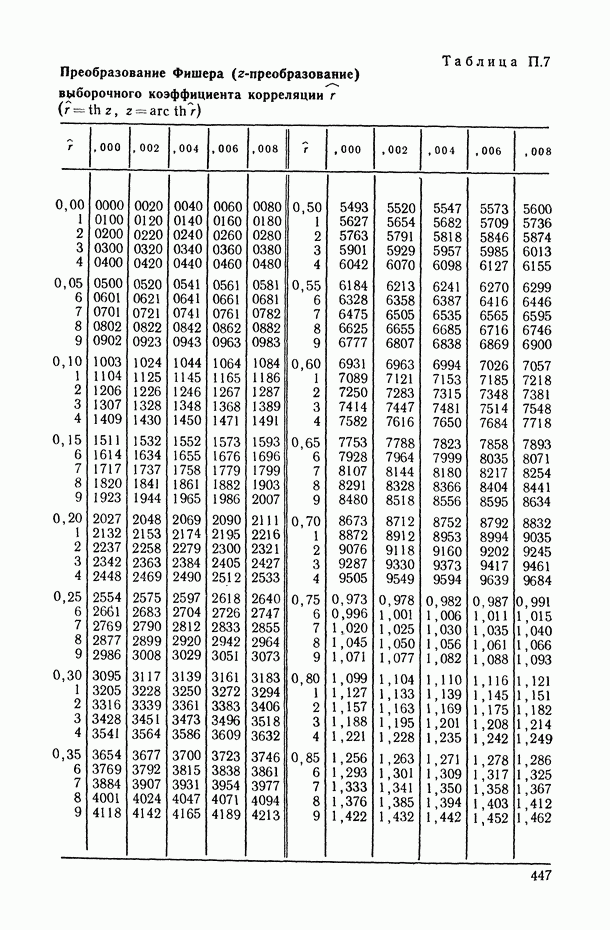
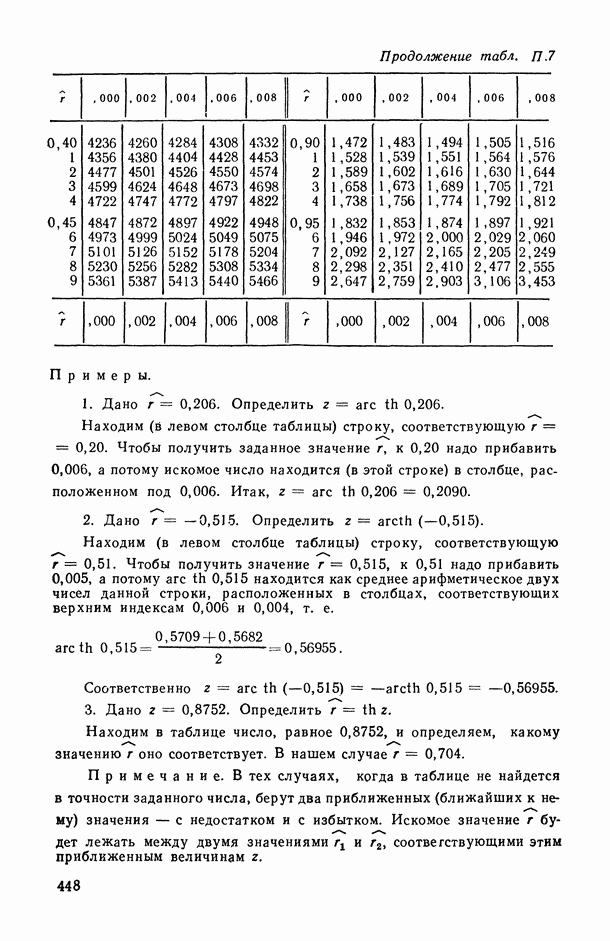
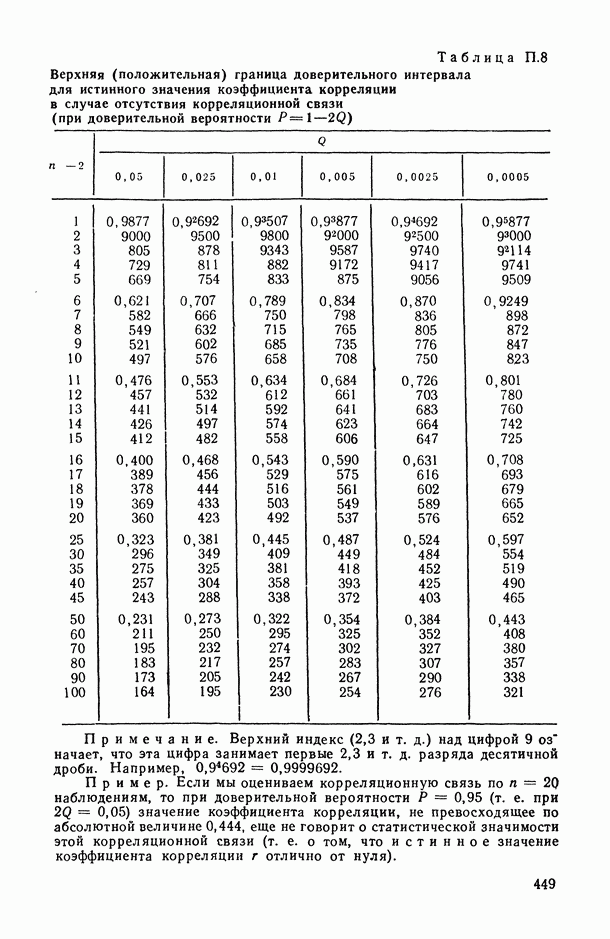
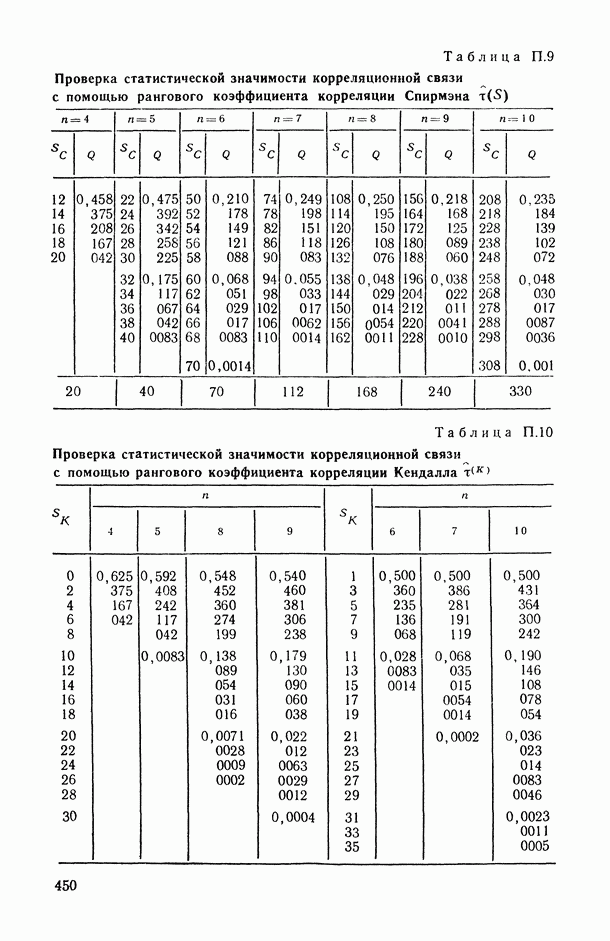
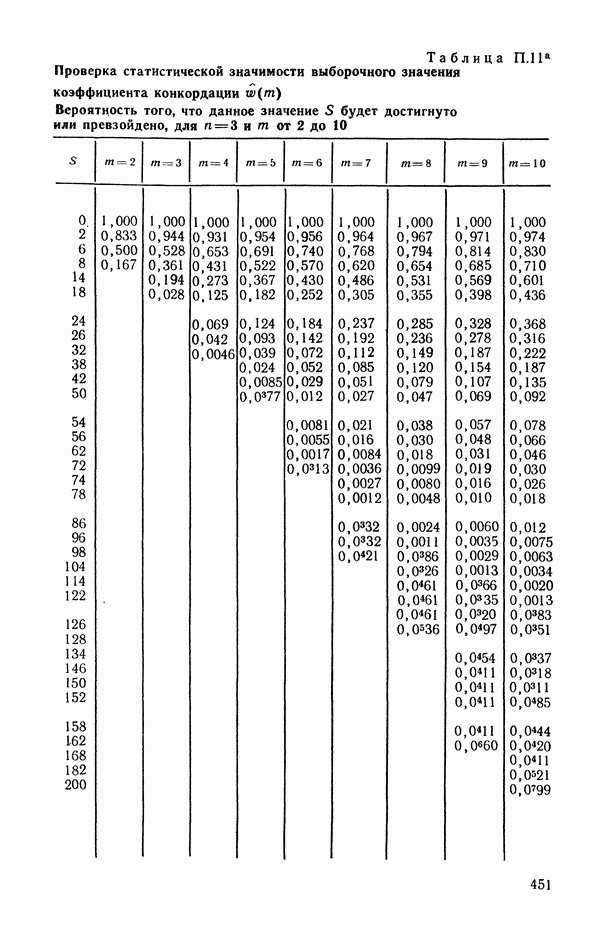
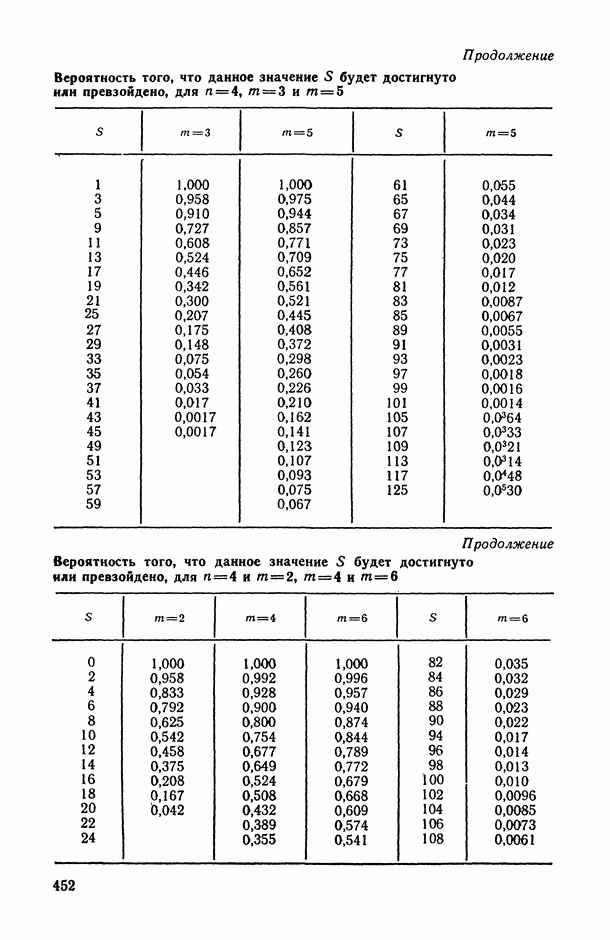
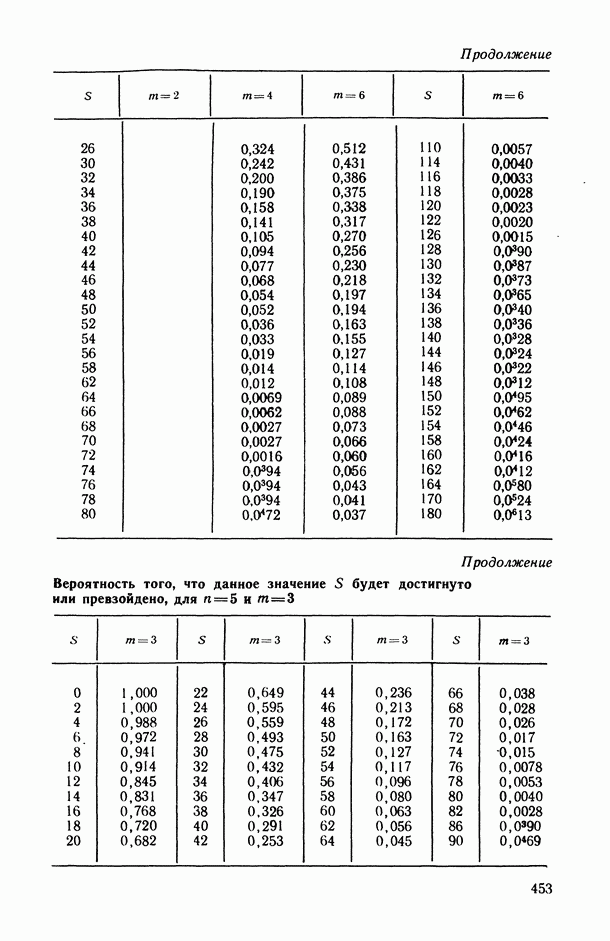
2.1.4. Вероятностные пространства ранжировок, генерируемые порядковыми переменными [14, гл. 4, 5].
Вытекающая из определения порядковой случайной величины специфика заключается в первую очередь в том, что ее «возможные значения» определены в пространстве ранжировок, причем длина этих ранжировок  определяется числом статистически обследованных объектов (т. е. объемом выборки!). В то же время множество возможных значений количественной случайной переменной, а следовательно, и ее закон распределения вероятностей никак не зависят от объема обрабатываемой статистической выборки [14, гл. 51. Для приведения «к общему знаменателю» этих двух схем можно воспользоваться одним из двух подходов
определяется числом статистически обследованных объектов (т. е. объемом выборки!). В то же время множество возможных значений количественной случайной переменной, а следовательно, и ее закон распределения вероятностей никак не зависят от объема обрабатываемой статистической выборки [14, гл. 51. Для приведения «к общему знаменателю» этих двух схем можно воспользоваться одним из двух подходов
а) формализованным описанием (с помощью той или иной математической модели) самого механизма генерирования ранжировок, основанным на допущении, что решение о предпочтении объекта  объекту
объекту  принимается на базе сравнения восстанавливаемых каким-либо способом со случайной ошибкой значений латентных (т. е. не поддающихся непосредственному измерению) числовых характеристик
принимается на базе сравнения восстанавливаемых каким-либо способом со случайной ошибкой значений латентных (т. е. не поддающихся непосредственному измерению) числовых характеристик  «ценности» или «предпочтительности» этих объектов (см., например, о моделях Терстоуна—Мостеллера, Льюса и др. в кн.: Статистические методы анализа экспертных оценок. - М.: Наука, 1977); в этом случае параметр
«ценности» или «предпочтительности» этих объектов (см., например, о моделях Терстоуна—Мостеллера, Льюса и др. в кн.: Статистические методы анализа экспертных оценок. - М.: Наука, 1977); в этом случае параметр  (число сравниваемых объектов) сохраняет за собой роль объема выборки, а закон распределения вероятностей ранжировок рассматривается как распределение в выборочном пространстве, генерируемое вероятностным пространством случайной величины
(число сравниваемых объектов) сохраняет за собой роль объема выборки, а закон распределения вероятностей ранжировок рассматривается как распределение в выборочном пространстве, генерируемое вероятностным пространством случайной величины 
б) определением в качестве i-гo случайного эксперимента [14, п. 4.1.11 результата «наблюдения»  ранжировки по
ранжировки по  свойству
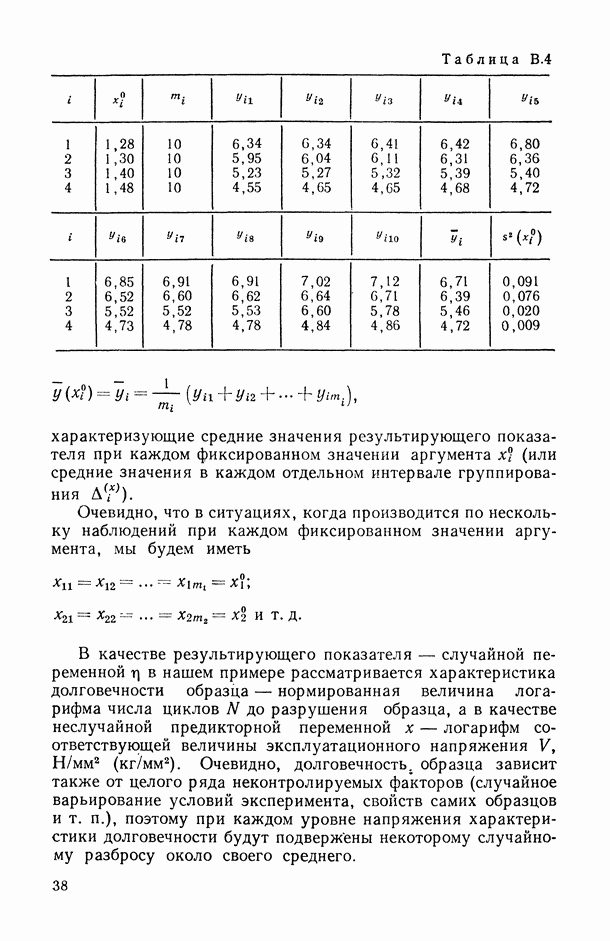
свойству  ; тогда число сравниваемых объектов
; тогда число сравниваемых объектов  будет играть роль размерности нашего наблюдения, а объем выборки будет определяться числом рассматриваемых свойств (т. е.
будет играть роль размерности нашего наблюдения, а объем выборки будет определяться числом рассматриваемых свойств (т. е.  ).
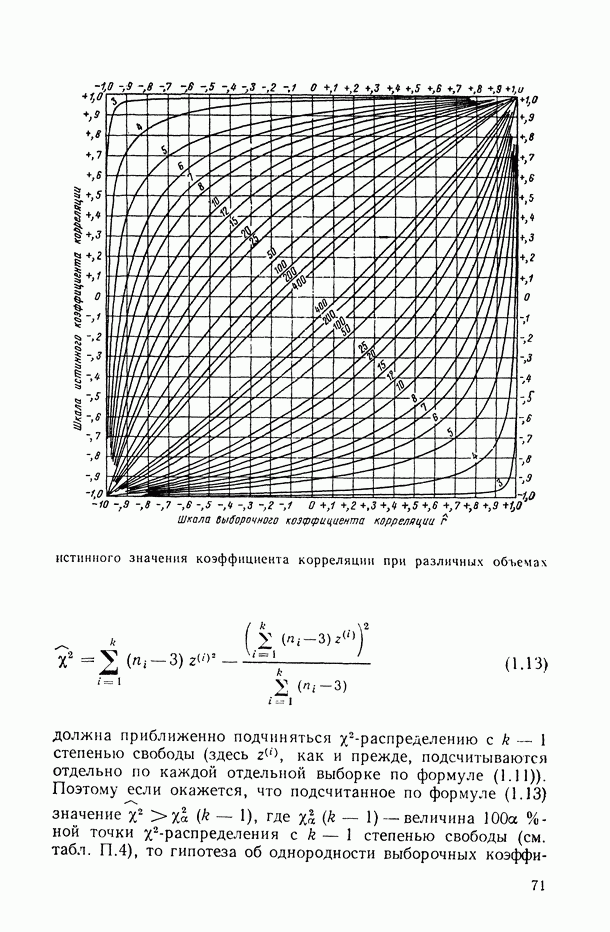
).
Остановимся на последнем подходе к построению и интерпретации вероятностных пространств ранжировок. В этом случае мы приходим к следующей модели вероятностного пространства ранжировок длины  , генерируемого порядковой переменной
, генерируемого порядковой переменной 
Пространство элементарных исходов  стоит из
стоит из  всевозможных перестановок и не зависит от номера переменной к. Распределение вероятностей задается последовательностью
всевозможных перестановок и не зависит от номера переменной к. Распределение вероятностей задается последовательностью  элементы которой, вообще говоря, зависят от номера «генерирующей» переменной к.
элементы которой, вообще говоря, зависят от номера «генерирующей» переменной к.
Поскольку множество элементарных исходов  дискретно (и конечно!), любое его подмножество измеримо и, следовательно, может быть интерпретировано как случайное событие.
дискретно (и конечно!), любое его подмножество измеримо и, следовательно, может быть интерпретировано как случайное событие.
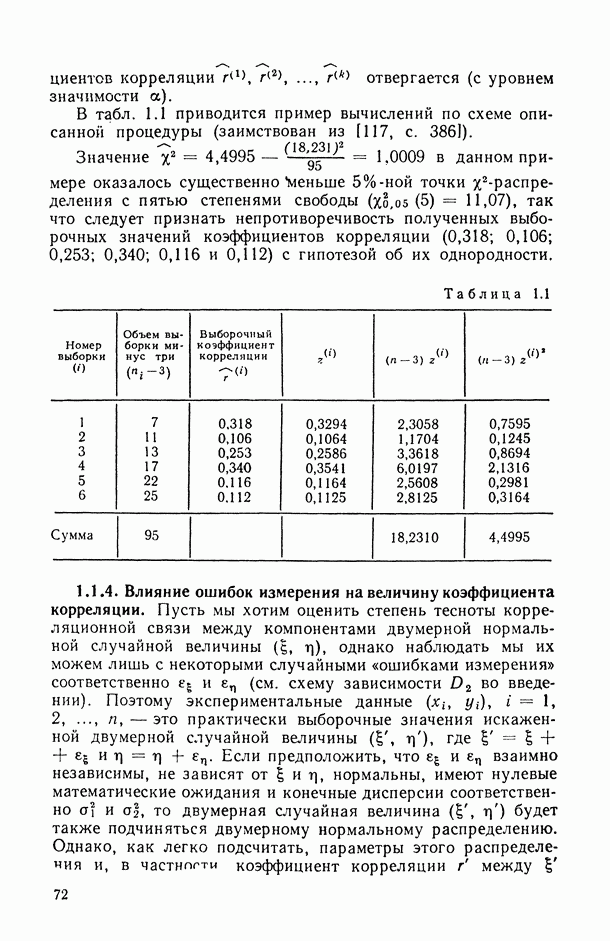
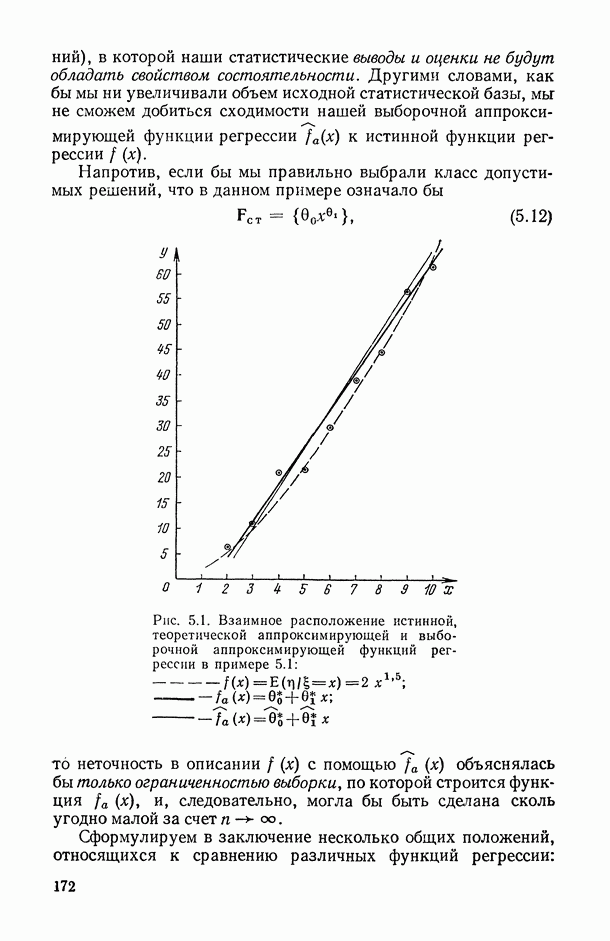
Далее (см. § 2.2-2.3) будут предложены рекомендации по вычислению выборочных характеристик парной и множественной ранговой статистической связи. Однако исследование их важных статистических свойств (и в частности, конструирование на их основе статистических критериев и доверительных интервалов для неизвестных теоретических значений анализируемых характеристик) возможно лишь при некоторых дополнительных допущениях (гипотезах) относительно характера последовательностей и статистических связей между 
Наиболее исследованным является случай, когда постулируется справедливость следующей гипотезы  случайные переменные
случайные переменные  статистически независимы (см. [14, § 5.5]);
статистически независимы (см. [14, § 5.5]);

Содержательно допущения гипотезы  означают, что ранжирования заданного множества объектов по различным свойствам
означают, что ранжирования заданного множества объектов по различным свойствам  никак друг с другом не связаны (допущение
никак друг с другом не связаны (допущение  ) и что ни одно из этих свойств не определяет никаких предпочтений в задаче сравнения «качества» анализируемых объектов, так как в результате случайного эксперимента с одинаковой вероятностью может появиться любое из
) и что ни одно из этих свойств не определяет никаких предпочтений в задаче сравнения «качества» анализируемых объектов, так как в результате случайного эксперимента с одинаковой вероятностью может появиться любое из  возможных упорядочений (допущение
возможных упорядочений (допущение  ).
).
К сожалению, статистический анализ, проведенный в рамках допущений (2.1), дает возможность лишь принять или отклонить гипотезу  . А поскольку на практике выборочные ранговые корреляционные характеристики оказываются, как правило, весьма высокими по абсолютной величине (что свидетельствует о том, что мы находимся вне условий нулевой гипотезы), то их распределение в реальной ситуации оказывается неизвестным и на их основе не удается делать дальнейшие выводы (аналогичные, например, тем, которые следуют из п. 1.1.3, 1.1.5, 1.2.3, 1.3.3 относительно парных, частных и множественных корреляционных связей между количественными переменными).
. А поскольку на практике выборочные ранговые корреляционные характеристики оказываются, как правило, весьма высокими по абсолютной величине (что свидетельствует о том, что мы находимся вне условий нулевой гипотезы), то их распределение в реальной ситуации оказывается неизвестным и на их основе не удается делать дальнейшие выводы (аналогичные, например, тем, которые следуют из п. 1.1.3, 1.1.5, 1.2.3, 1.3.3 относительно парных, частных и множественных корреляционных связей между количественными переменными).
Более интересными в прикладном плане нам представляются условия, постулируемые в рамках гипотезы 

Под свойством монотонности понимается выполнение следующего условия: если введенное некоторым образом «расстояние»  между любым упорядочением
между любым упорядочением  , и некоторым «истинным» упорядочением
, и некоторым «истинным» упорядочением  не превосходит
не превосходит  , то
, то  другими словами, чем «ближе» ранжировка к истинной, тем с большей вероятностью мы ее получим в результате случайного эксперимента над переменной
другими словами, чем «ближе» ранжировка к истинной, тем с большей вероятностью мы ее получим в результате случайного эксперимента над переменной  р), и, следовательно, истинная ранжировка
р), и, следовательно, истинная ранжировка  является наиболее вероятным исходом случайного эксперимента.
является наиболее вероятным исходом случайного эксперимента.
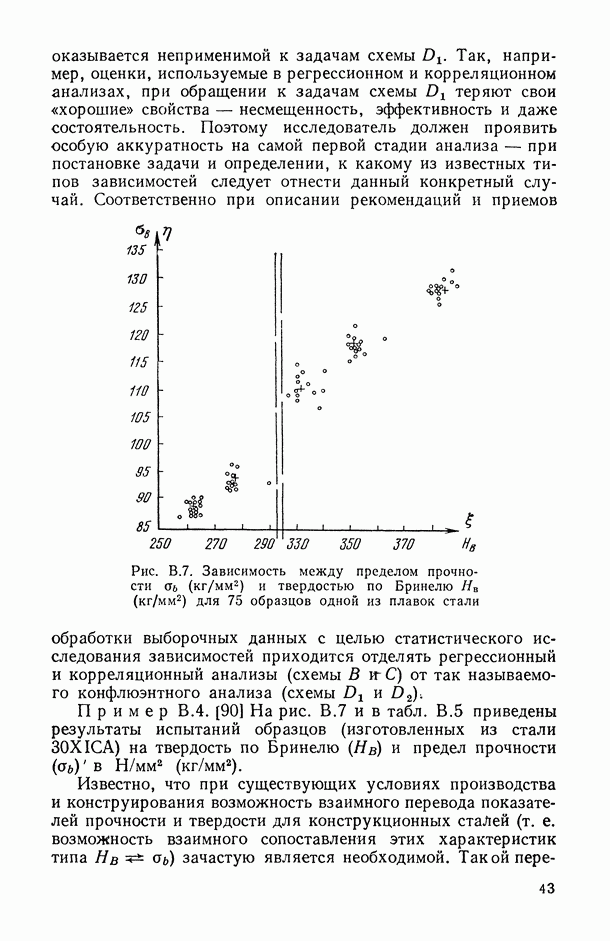
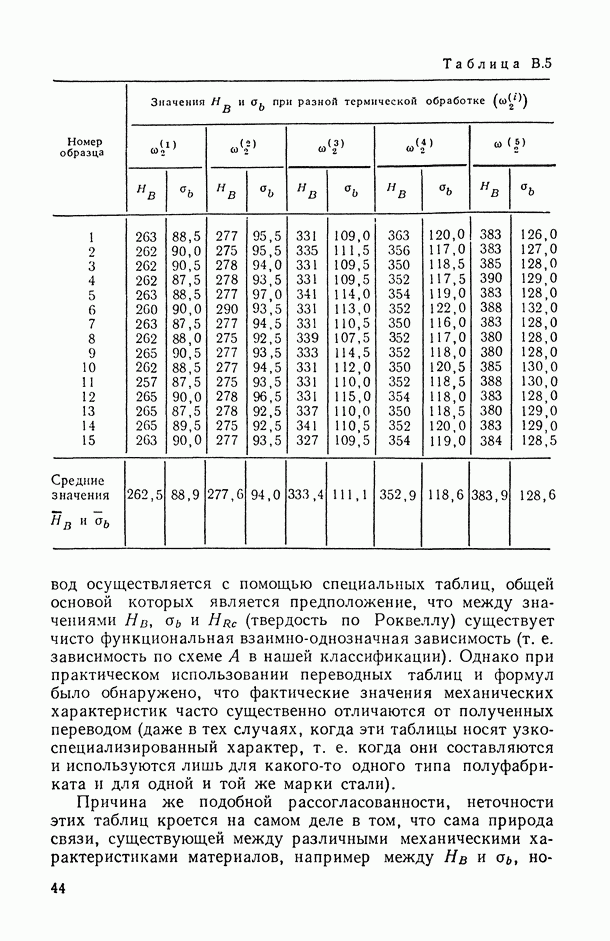
Некоторые результаты, связанные со статистическим анализом ранжировок в рамках условий (2.2), можно найти в [105, 131].