Пред.
След.
Макеты страниц
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике ДЛЯ СТУДЕНТОВ И ШКОЛЬНИКОВ ЕСТЬ
ZADANIA.TO
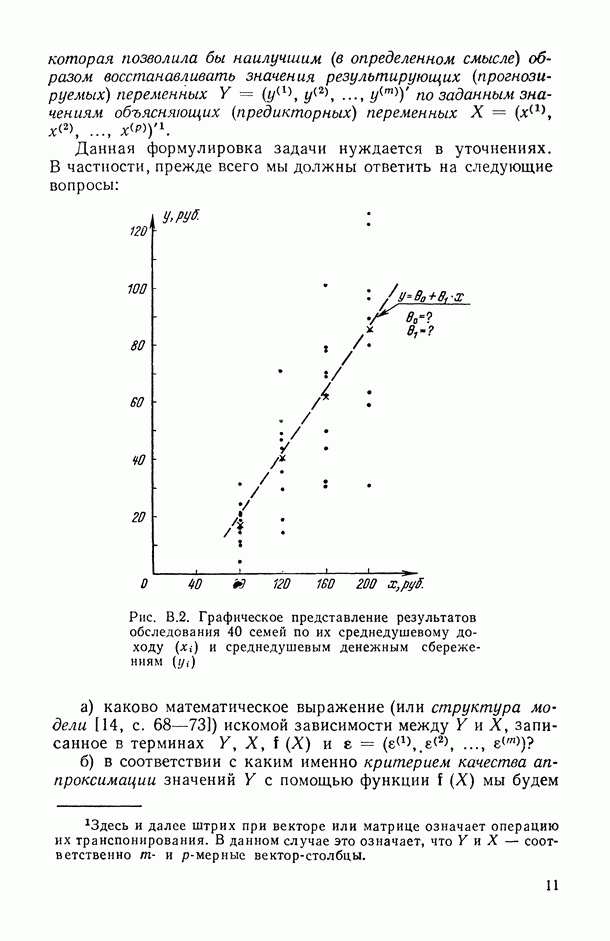
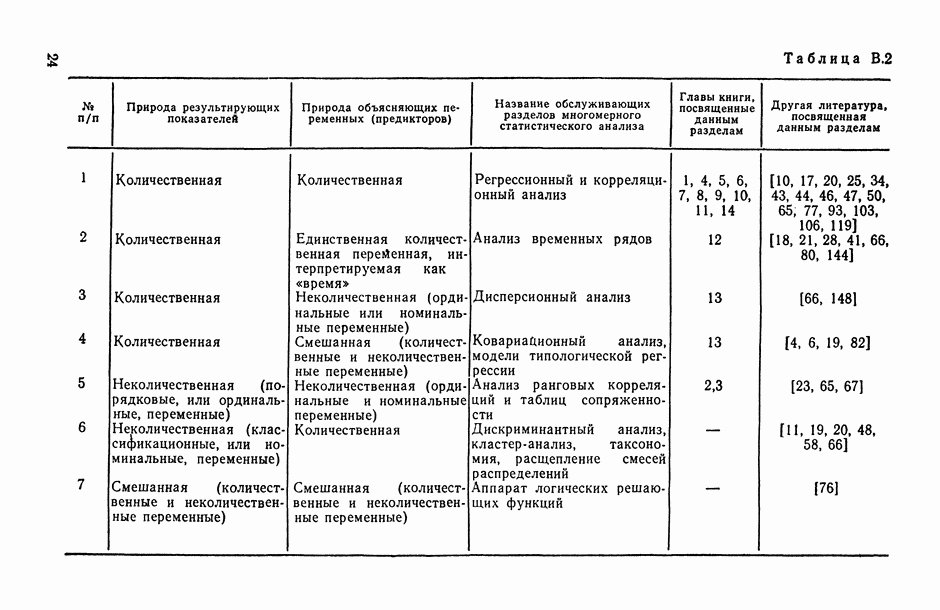
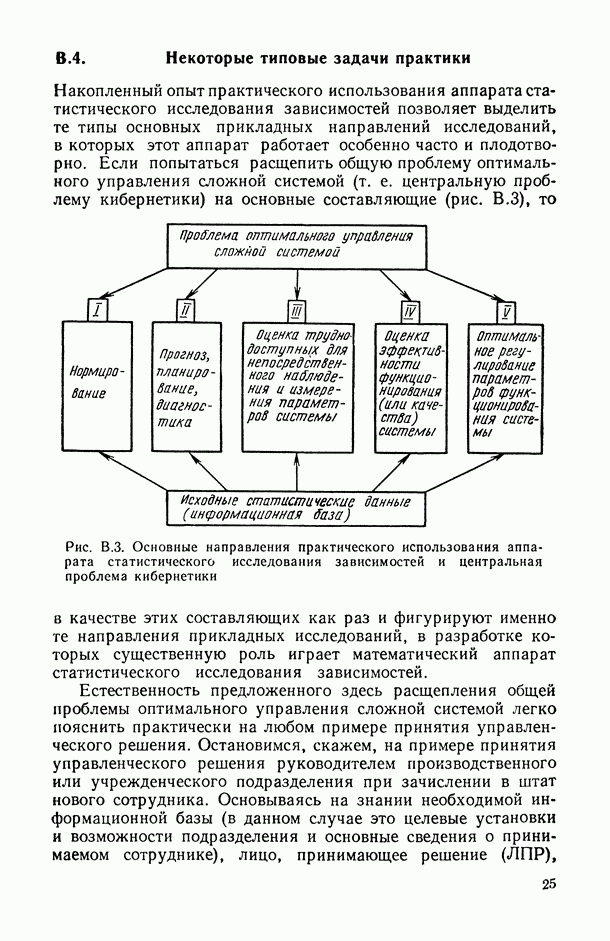
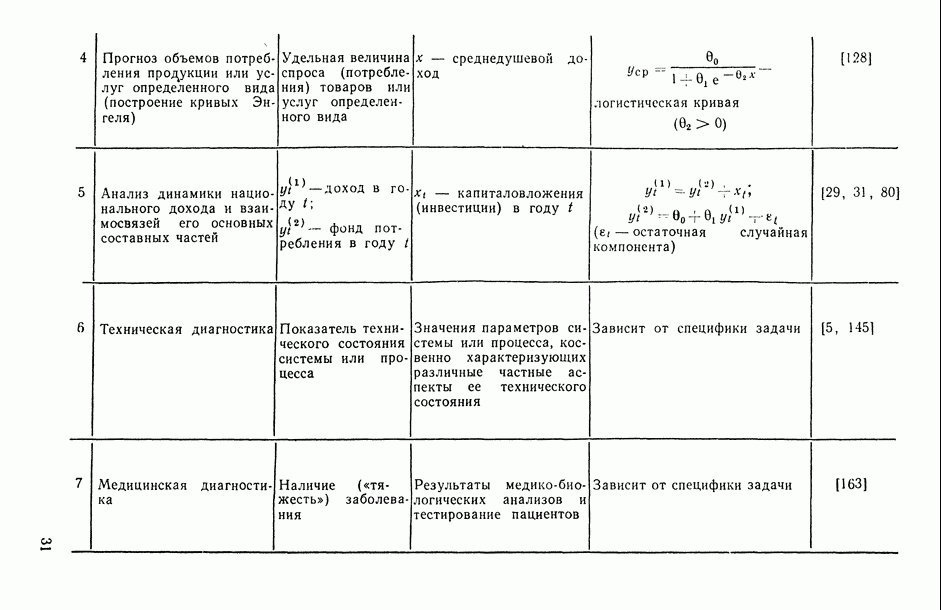
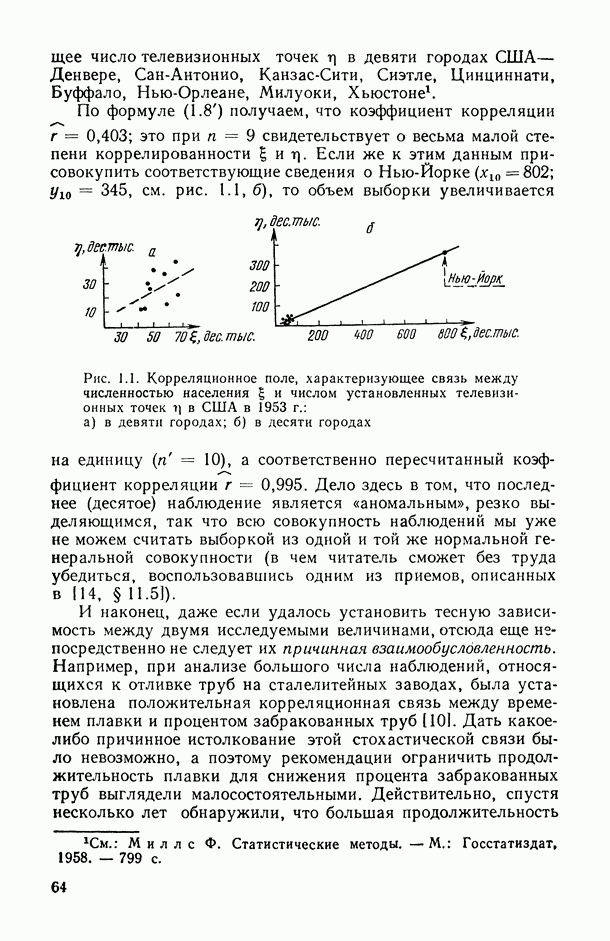
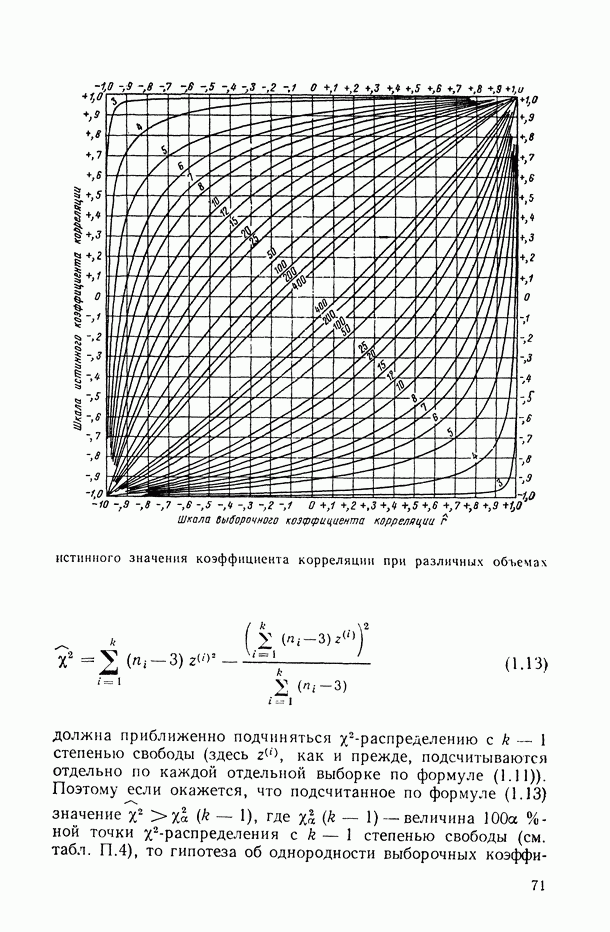
Раздел I. АНАЛИЗ СТРУКТУРЫ И ТЕСНОТЫ СТАТИСТИЧЕСКОЙ СВЯЗИ МЕЖДУ ИССЛЕДУЕМЫМИ ПЕРЕМЕННЫМИ (корреляционный анализ)Имеется ли вообще какая-либо связь между исследуемыми переменными, какова структура этих связей и как измерить их тесноту? — эти вопросы исследователь ставит перед собой уже на ранней стадии статистического исследования зависимостей (см. описание этапа 3 в § В.6). В частности, исследователь должен уметь: а) выбрать (с учетом специфики и природы анализируемых переменных) подходящий измеритель статистической связи (индекс или коэффициент корреляции, корреляционное отношение, какую-либо информационную характеристику связи, ранговый коэффициент корреляции и т. п.); б) оценить (с помощью точечной и интервальной оценок) его числовое значение по имеющимся выборочным данным; в) проверить гипотезу о том, что полученное числовое значение анализируемого измерителя связи действительно свидетельствует о наличии статистической связи (или, как говорят, проверить исследуемую корреляционную характеристику на статистически значимое ее отличие от нуля); г) проанализировать структуру связей между компонентами исследуемого многомерного признака, снабдив проведенный анализ специальным плоским геометрическим представлением исследуемой структуры, в котором компоненты (переменные) изображаются точками, а связи между ними — соединяющими их отрезками (см. рис. 4.1 и 4.2). Описанию методов и моделей, цривлекаемых для решения всех тих вопросов, и посвящен данный раздел. Глава 1. АНАЛИЗ ТЕСНОТЫ СВЯЗИ МЕЖДУ КОЛИЧЕСТВЕННЫМИ ПЕРЕМЕННЫМИ1.1. Анализ парных связей1.1.1. Понятие индекса корреляции.Прежде чем приступать к исследованию конкретного вида связей между рассматриваемыми переменными, т. е. к оценке неизвестных параметров В в соотношениях типа
следует выяснить, существует ли вообще эта связь, и, в случае положительного ответа, попытаться установить степень тесноты этой связи. Во введении (§ В.5) описаны различные типы зависимостей, которые могут наблюдаться между исследуемыми переменными. Умение правильно классифицировать каждую конкретную многомерную систему наблюдений играет решающую роль при выборе соответствующих математико-статистических методов поиска изучаемой зависимости и при ее неформальной, физически содержательной интерпретации. Однако в данном пункте в целях унификации подхода к решению исследуемой в этой главе задачи мы временно прибегнем к некоторому формальному обобщению рассмотренных ранее схем В, С и D. В частности, будет предложен подход, при котором во всех вышеупомянутых схемах зависимостей исследуемая независимая переменная интерпретируется как случайная переменная (параметр) от которой зависит закон условного распределения зависимой переменной Итак, при каждом фиксированном значении Очевидно, в схеме В (наблюдения производятся в фиксированных точках В схеме Если
где В схемах С и Если рассмотреть случай единственного результирующего показателя
Рассмотрим, например, частный случай схемы С, когда вектор исследуемых показателей
— Тогда можно показать (см., например, [20, с. 45]), что условное распределение вектора результирующих показателей
и ковариационной матрицей
Из (1.3) и (1.4), в частности, следует: а) функция б) ковариационная матрица условного распределения вектора результирующих показателей в) если рассматривается парная регрессионная зависимость, т. е. зависимость единственного результирующего показателя
и с дисперсией
(здесь и Будем рассматривать в дальнейшем (если специально не оговорено противное) случай единственного результирующего показателя, т. е. случай Итак, величина Воспользовавшись соотношением (2в.3.6) из [117, с. 94], получим следующее полезное соотношение, связывающее три вышеупомянутые меры случайного разброса:
Это означает, что полная вариация исследуемой зависимой переменной складывается из контролируемой нами вариации функции регрессии и из не поддающейся нашему контролю вариации остаточной случайной компоненты. Очевидно, связь между Можно, в частности, задаться вопросом: какая доля степени изменчивости интересующего нас зависимого признака (т. е. какая доля дисперсии с) обусловливается изменчивостью описывающей его функции независимой переменной
Из (1.5) и (1.6) непосредственно следует, что При этом минимальное значение индекса корреляции В то же время максимальное значение индекса корреляции Таким образом, введенный с помощью (1.6) индекс корреляции Наилучшие методы построения статистической оценки
|
 |
Оглавление
|

































































































































































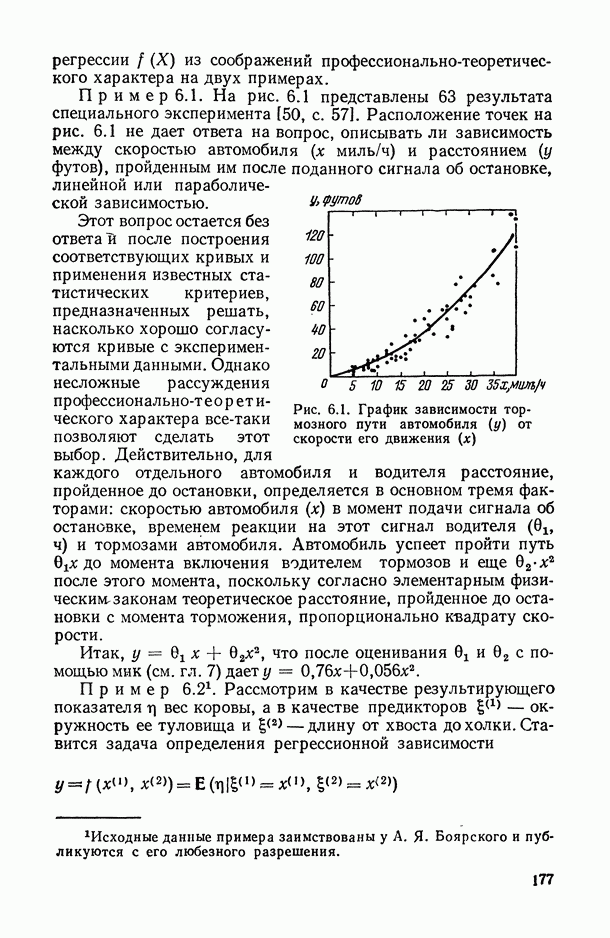




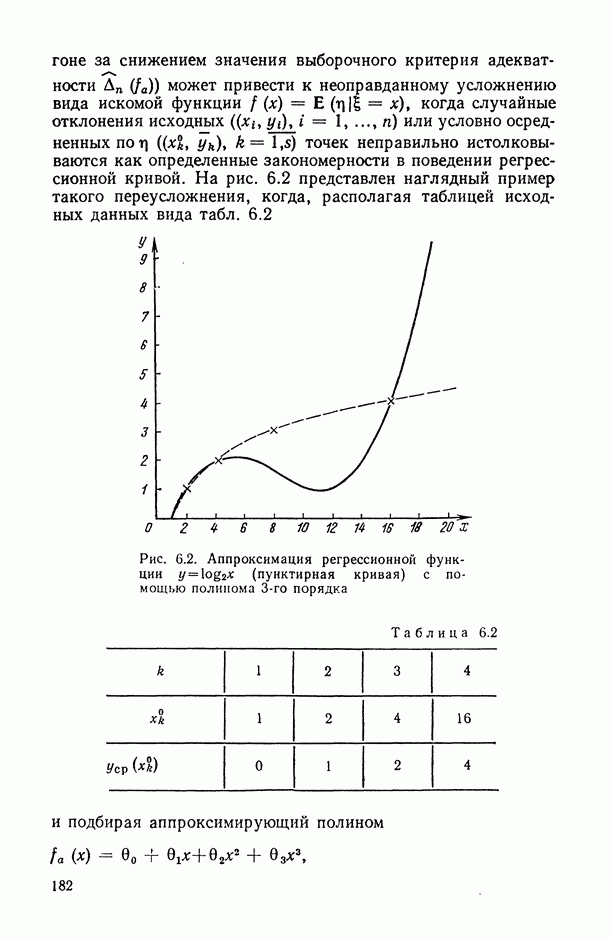



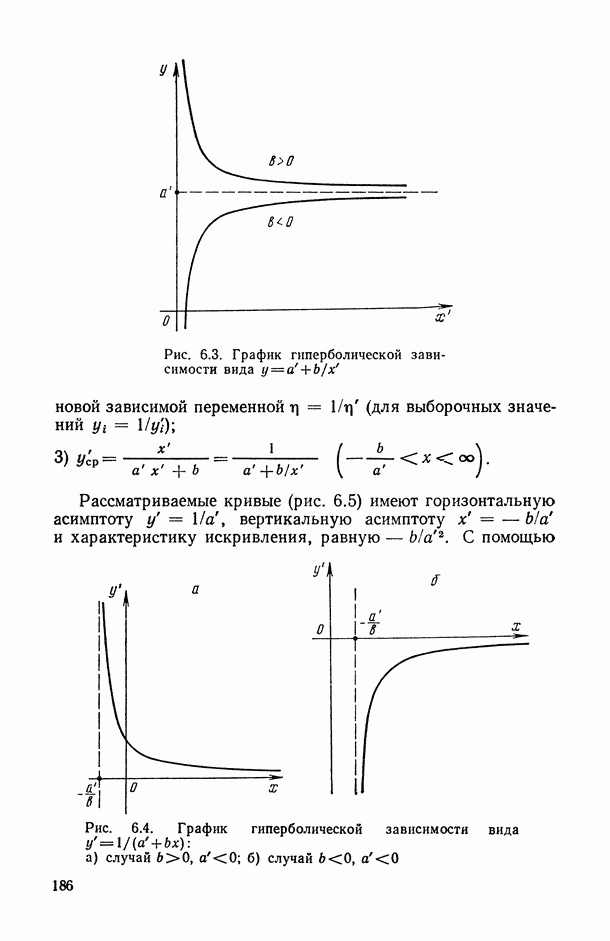
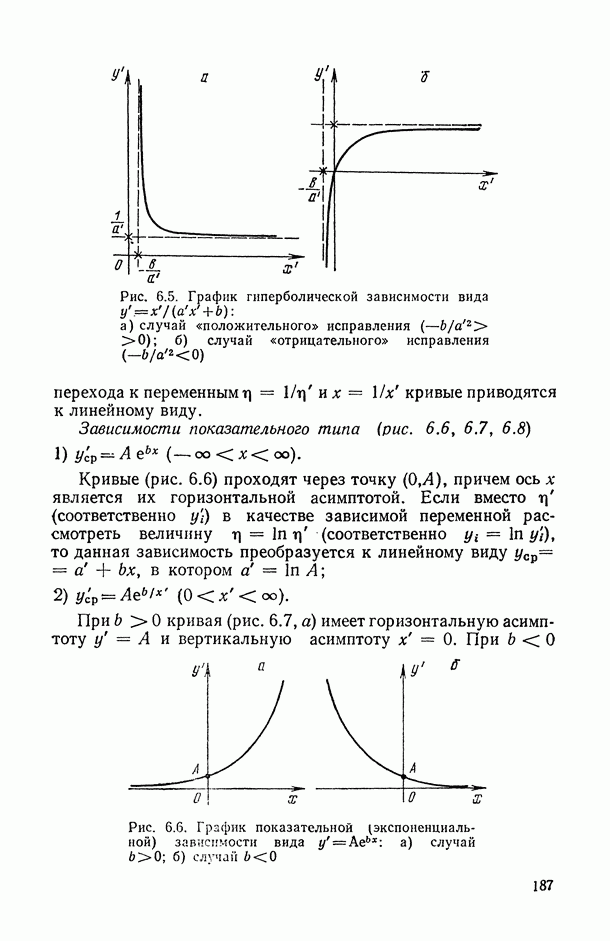
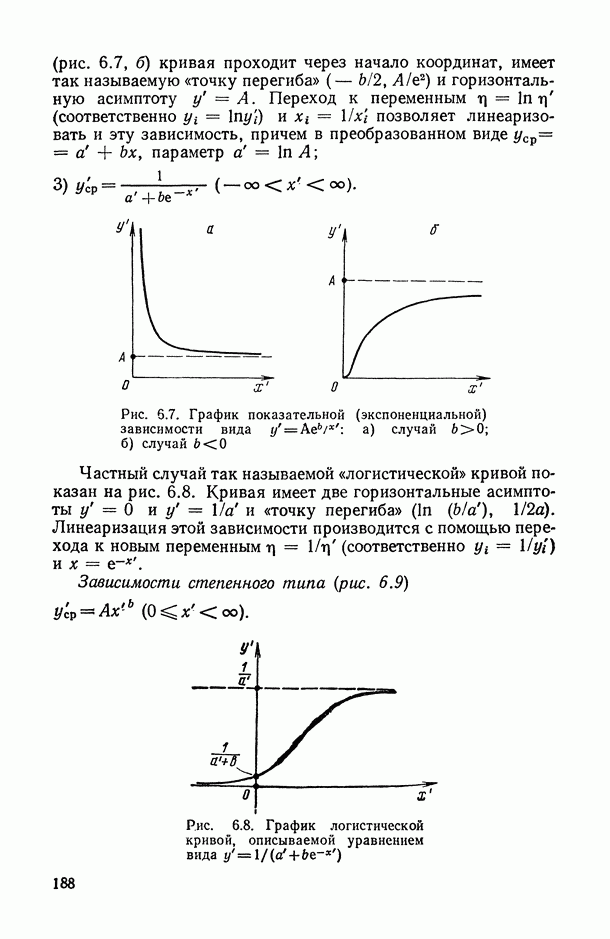
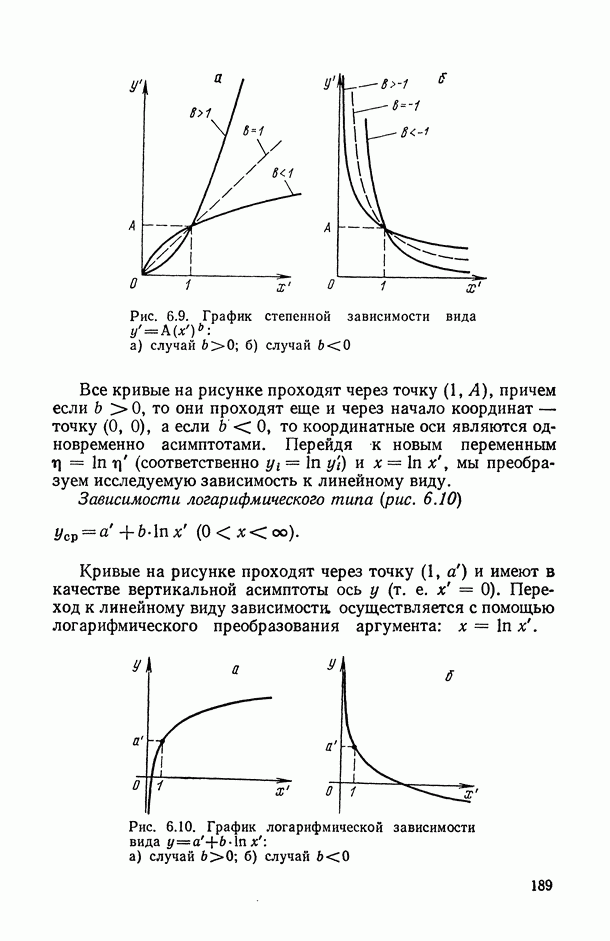







































































































































































































































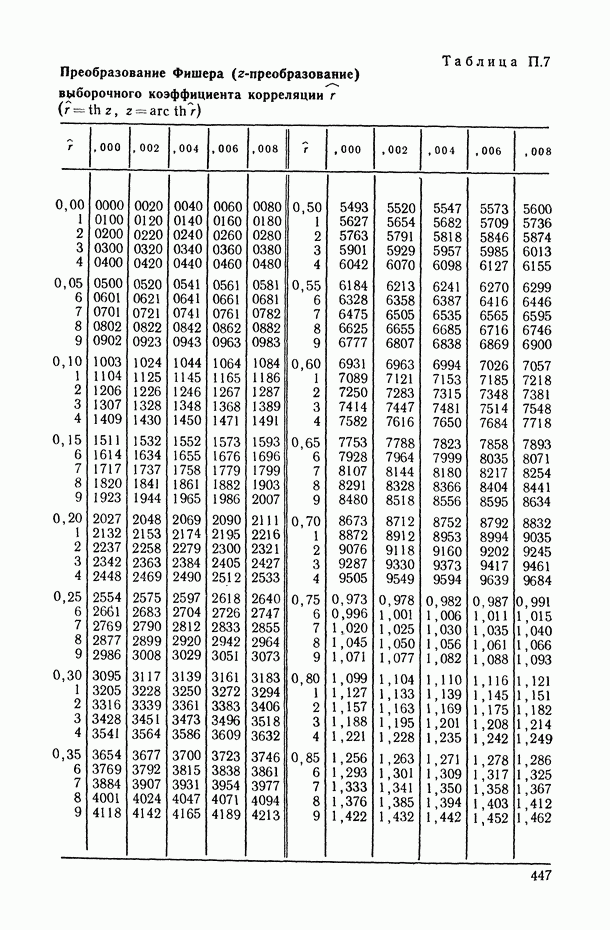
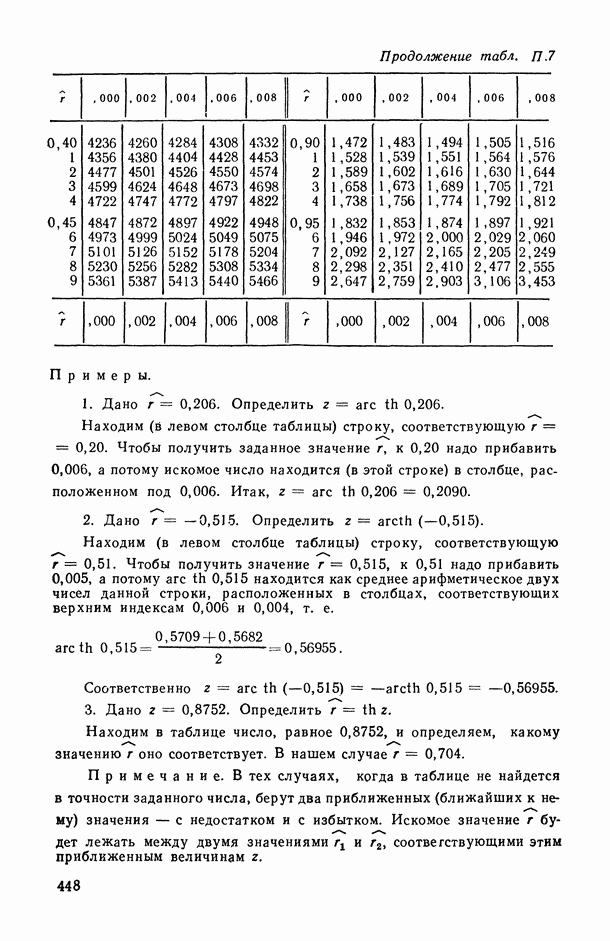
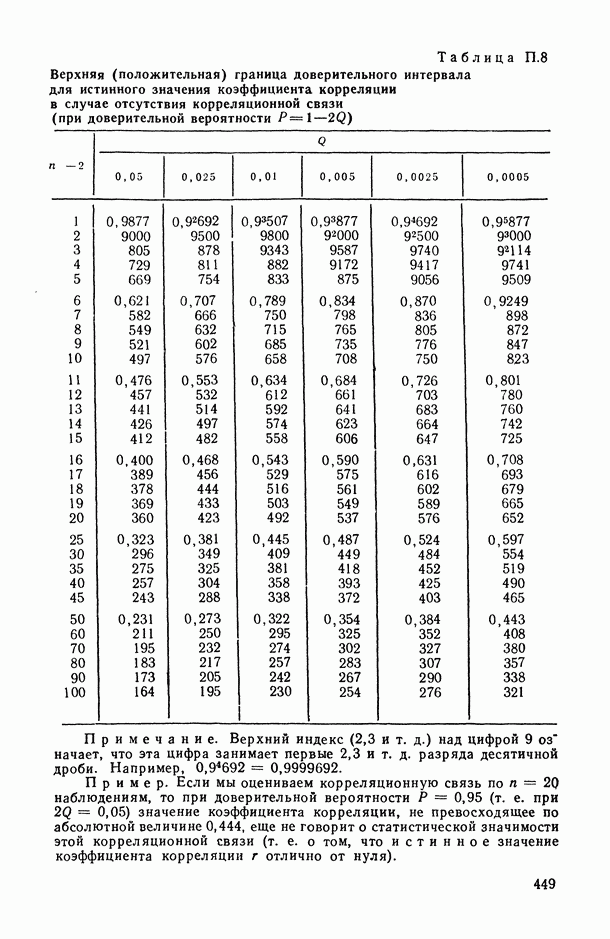
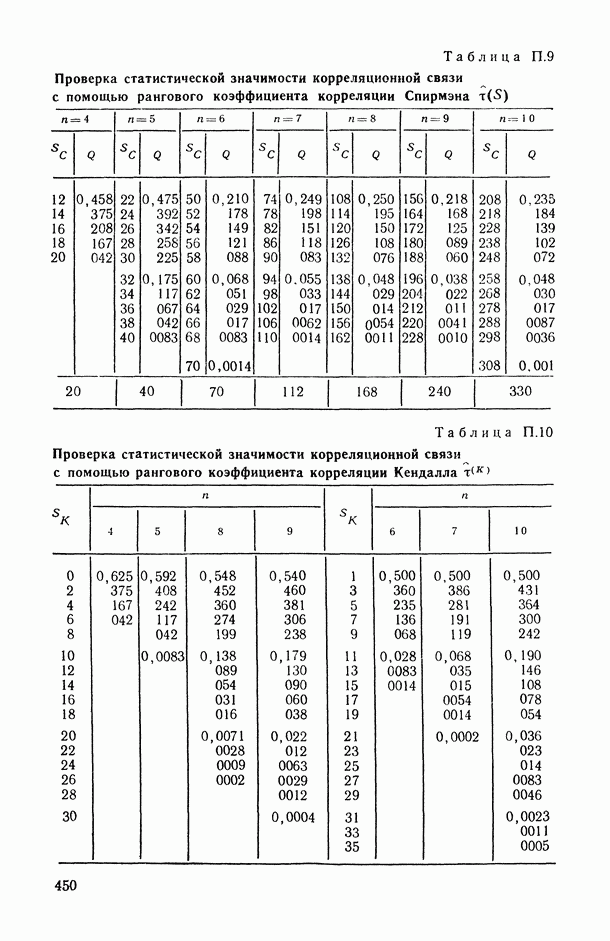



















 .
.
 распределение зависимой переменной
распределение зависимой переменной  задается плотностью
задается плотностью  зависящей от X. Соответственно будут зависеть от X и математическое ожидание
зависящей от X. Соответственно будут зависеть от X и математическое ожидание  , и дисперсия
, и дисперсия  . Природа же исследуемой многомерной схемы, т. е. тип искомой зависимости, будет определяться спецификой частного закона распределения наблюдаемой независимой переменной
. Природа же исследуемой многомерной схемы, т. е. тип искомой зависимости, будет определяться спецификой частного закона распределения наблюдаемой независимой переменной
 без случайных ошибок в регистрации независимой переменной) случайную величину
без случайных ошибок в регистрации независимой переменной) случайную величину  следует рассматривать как дискретную с областью мыслимых значений
следует рассматривать как дискретную с областью мыслимых значений  (не исключается возможность повторения одинаковых значений
(не исключается возможность повторения одинаковых значений  в этом ряду) и с частным законом распределения
в этом ряду) и с частным законом распределения  , задаваемым вероятностями
, задаваемым вероятностями 
 плотность
плотность  частного распределения определяется, помимо набора наблюдаемых абсцисс
частного распределения определяется, помимо набора наблюдаемых абсцисс  законами распределения ошибок измерения
законами распределения ошибок измерения  .
.
 — число различных уровней
— число различных уровней  структурной компоненты X, при которых снимались экспериментальные данные
структурной компоненты X, при которых снимались экспериментальные данные  — плотность распределения ошибки
— плотность распределения ошибки  то
то

 — число наблюдений, произведенных «на уровне»
— число наблюдений, произведенных «на уровне» 
 объясняющие наблюдаемые переменные соответственно
объясняющие наблюдаемые переменные соответственно  по своей природе случайны, следовательно, им также соответствует некоторая плотность частного распределения
по своей природе случайны, следовательно, им также соответствует некоторая плотность частного распределения  .
.
 и мысленно спроектировать все точки исследуемой многомерной системы на ось его возможных значений О у, то получим выборку из одномерного закона с плотностью
и мысленно спроектировать все точки исследуемой многомерной системы на ось его возможных значений О у, то получим выборку из одномерного закона с плотностью  характеризующего вероятностную природу безусловной случайной величины
характеризующего вероятностную природу безусловной случайной величины  При такой интерпретации очевидно, что плотность частного (безусловного) распределения
При такой интерпретации очевидно, что плотность частного (безусловного) распределения  получается как смесь соответствующих условных плотностей
получается как смесь соответствующих условных плотностей  , а именно:
, а именно:  (в схеме
(в схеме  в дальнейшем при усреднении по
в дальнейшем при усреднении по  мы не будем специально оговаривать случай схемы В, подразумевая переход от интегрирования по X к суммированию по
мы не будем специально оговаривать случай схемы В, подразумевая переход от интегрирования по X к суммированию по  Соответственно в нашем дальнейшем изложении будут участвовать характеристики
Соответственно в нашем дальнейшем изложении будут участвовать характеристики


 -мерная нормальная случайная величина [14, с. 173], и пусть
-мерная нормальная случайная величина [14, с. 173], и пусть  — соответственно векторы средних значений объясняющих переменных
— соответственно векторы средних значений объясняющих переменных  и результирующих показателей
и результирующих показателей  — ковариационные матрицы [14, с. 138] соответственно векторов
— ковариационные матрицы [14, с. 138] соответственно векторов 
 при условии, что значения объясняющих переменных зафиксированы на уровне
при условии, что значения объясняющих переменных зафиксированы на уровне  (т. е. при условии
(т. е. при условии  также нормально с условным средним значением
также нормально с условным средним значением


 регрессии
регрессии  по
по  при совместном нормальном законе распределения исследуемых показателей линейна по X;
при совместном нормальном законе распределения исследуемых показателей линейна по X;
 не зависит от X;
не зависит от X;
 от единственной объясняющей переменной
от единственной объясняющей переменной  в схеме С, причем распределение случайной величины
в схеме С, причем распределение случайной величины  подчиняется двумерному нормальному закону, то условное распределение случайной величины
подчиняется двумерному нормальному закону, то условное распределение случайной величины  тоже нормально с условным средним значением (функцией регрессии)
тоже нормально с условным средним значением (функцией регрессии)


 — средние значения соответственно объясняющей переменной
— средние значения соответственно объясняющей переменной  и результирующего показателя
и результирующего показателя  и — их дисперсии, а
и — их дисперсии, а  — коэффициент корреляции между ними, см., например, [14, гл. 5]).
— коэффициент корреляции между ними, см., например, [14, гл. 5]).

 характеризует полную вариацию (дисперсию) исследуемого результирующего показателя
характеризует полную вариацию (дисперсию) исследуемого результирующего показателя  в то время как
в то время как  определяет дисперсию функции регрессии
определяет дисперсию функции регрессии  — усредненную (по различным значениям
— усредненную (по различным значениям  ) величину условной дисперсии
) величину условной дисперсии  , т. е. среднюю величину дисперсии неконтролируемой остаточной случайной компоненты
, т. е. среднюю величину дисперсии неконтролируемой остаточной случайной компоненты  (см. соотношения (В. 14), (В.16), (В.21)).
(см. соотношения (В. 14), (В.16), (В.21)).

 в соотношениях (В. 14), (В. 16), (В.21) и т. п. будет тем теснее, тем определеннее, чем менее «размазанными» окажутся участвующие в них остаточные неконтролируемые случайные компоненты
в соотношениях (В. 14), (В. 16), (В.21) и т. п. будет тем теснее, тем определеннее, чем менее «размазанными» окажутся участвующие в них остаточные неконтролируемые случайные компоненты  и
и 
 (т. е. ее дисперсией
(т. е. ее дисперсией  ) Так мы приходим к понятию наиболее общей характеристики степени тесноты связи между
) Так мы приходим к понятию наиболее общей характеристики степени тесноты связи между  — индекса корреляции
— индекса корреляции  , где
, где


 соответствует полному отсутствию варьирования
соответствует полному отсутствию варьирования  с изменением
с изменением  а это означает полное отсутствие какого-либо влияния
а это означает полное отсутствие какого-либо влияния  , т. е., как говорят, отсутствие корреляционной связи между результирующим показателем
, т. е., как говорят, отсутствие корреляционной связи между результирующим показателем  и объясняющими переменными
и объясняющими переменными
 соответствует полному отсутствию варьирования остаточной случайной компоненты
соответствует полному отсутствию варьирования остаточной случайной компоненты  . А поскольку среднее значение остаточной случайной компоненты равно нулю, то она практически исчезает из разложений (В. 14), (В. 16), (В.21). Это означает наличие чисто функциональной связи между
. А поскольку среднее значение остаточной случайной компоненты равно нулю, то она практически исчезает из разложений (В. 14), (В. 16), (В.21). Это означает наличие чисто функциональной связи между  и, следовательно, возможность детерминированного восстановления значений
и, следовательно, возможность детерминированного восстановления значений  по соответствующим значениям объясняющих переменных
по соответствующим значениям объясняющих переменных
 между результирующим показателем
между результирующим показателем  и объясняющими переменными
и объясняющими переменными  формально определен для любой двумерной системы наблюдений. Квадрат его величины
формально определен для любой двумерной системы наблюдений. Квадрат его величины  показывает, какая доля дисперсии исследуемого результирующего показателя
показывает, какая доля дисперсии исследуемого результирующего показателя  определяется (детерминируется) изменчивостью (дисперсией) соответствующей функции регрессии
определяется (детерминируется) изменчивостью (дисперсией) соответствующей функции регрессии  от аргумента
от аргумента  , поэтому часто называется коэффициентом детерминации. Соответственно оставшаяся доля дисперсии
, поэтому часто называется коэффициентом детерминации. Соответственно оставшаяся доля дисперсии  объясняется воздействием неконтролируемой случайной остаточной компоненты («помехи»), а следовательно, определяет ту верхнюю границу точности, с которой мы сможем восстанавливать (предсказывать) значения
объясняется воздействием неконтролируемой случайной остаточной компоненты («помехи»), а следовательно, определяет ту верхнюю границу точности, с которой мы сможем восстанавливать (предсказывать) значения  по заданным значениям объясняющих переменных
по заданным значениям объясняющих переменных  .
.
 для неизвестного теоретического значения индекса корреляции
для неизвестного теоретического значения индекса корреляции  так же как и различные варианты его интерпретации, зависят от ряда исходных предпосылок каждой конкретной двумерной схемы (общий вид функции
так же как и различные варианты его интерпретации, зависят от ряда исходных предпосылок каждой конкретной двумерной схемы (общий вид функции  , вид распределения многомерной случайной величины
, вид распределения многомерной случайной величины  и т. п.). Описание их поэтому дается ниже отдельно для каждого из некоторых специальных частных случаев.
и т. п.). Описание их поэтому дается ниже отдельно для каждого из некоторых специальных частных случаев.