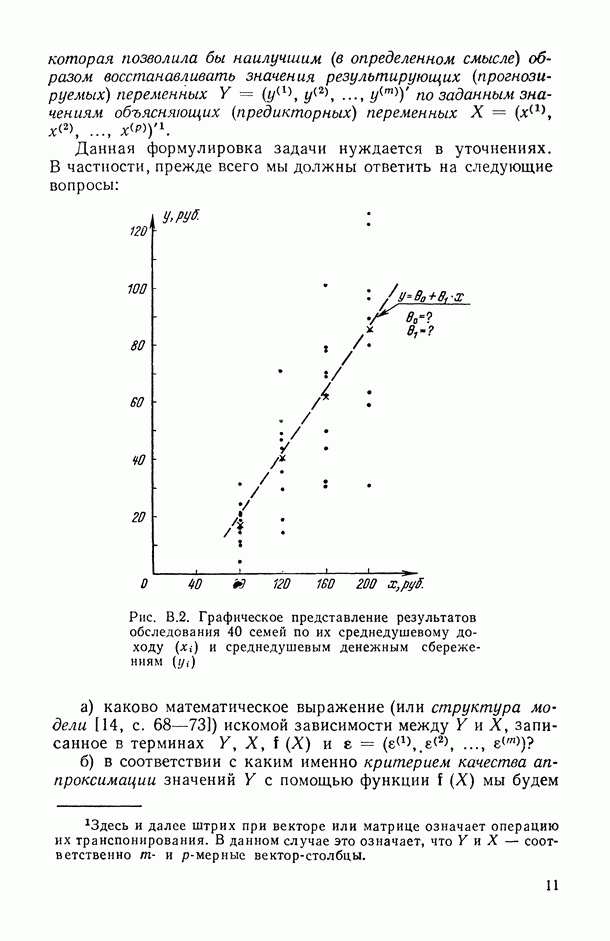
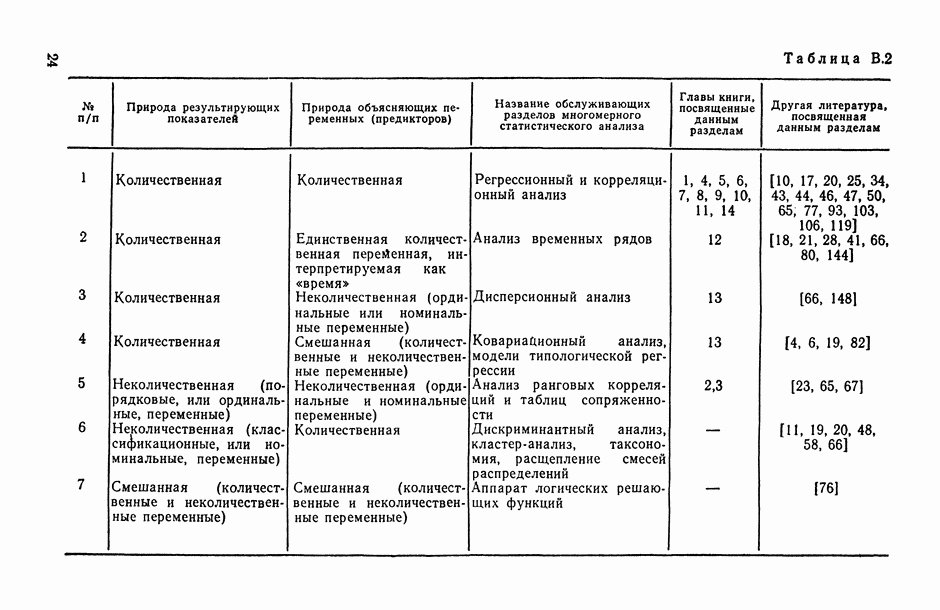
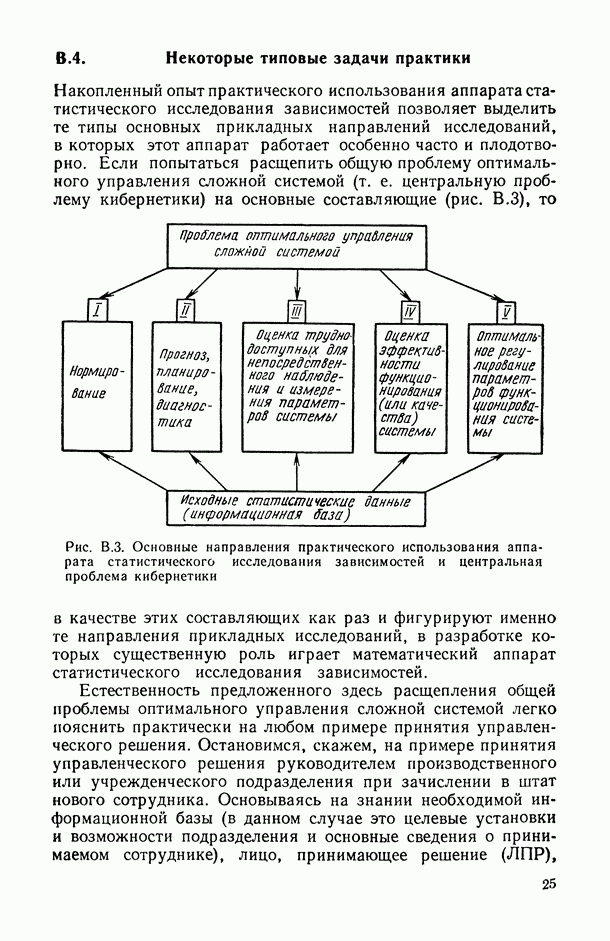
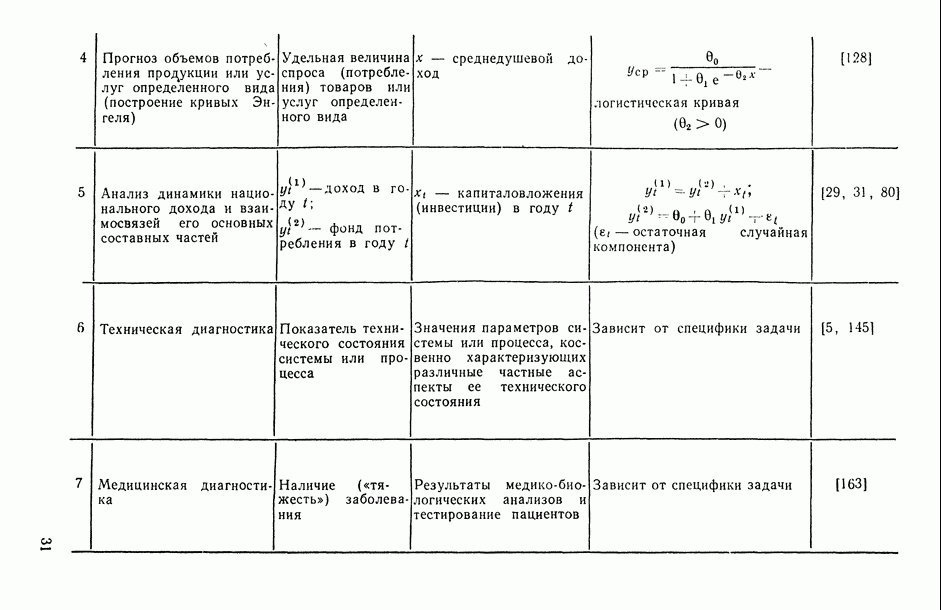
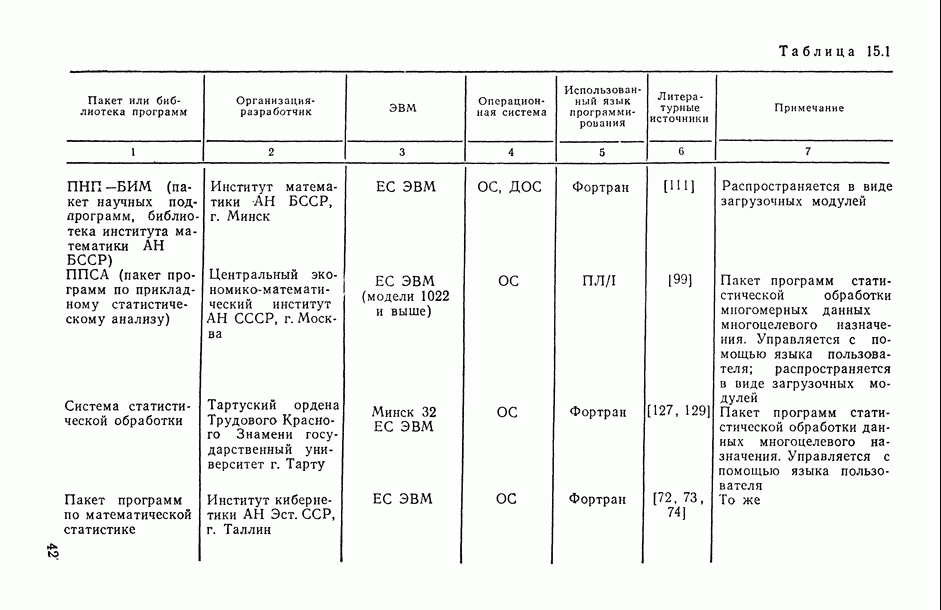
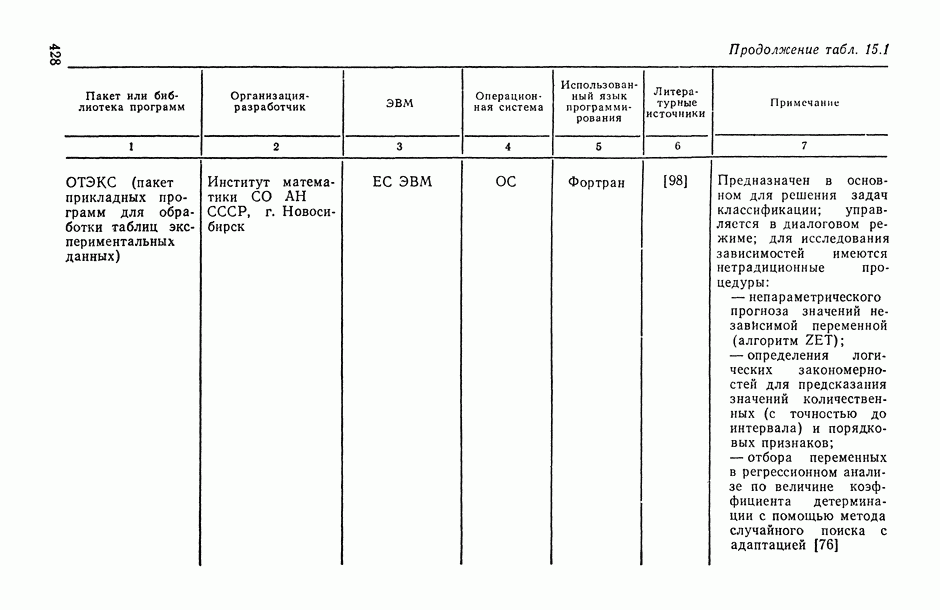
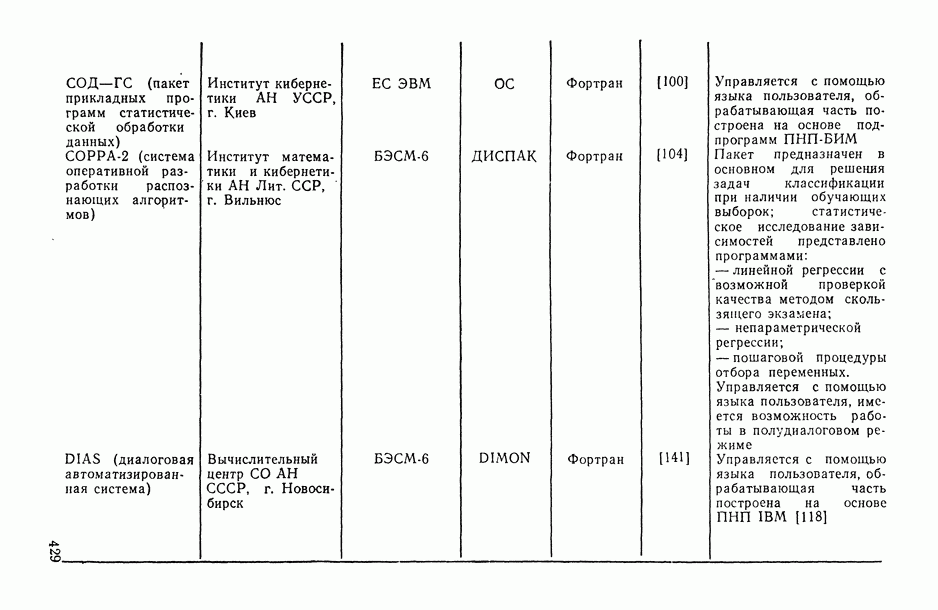
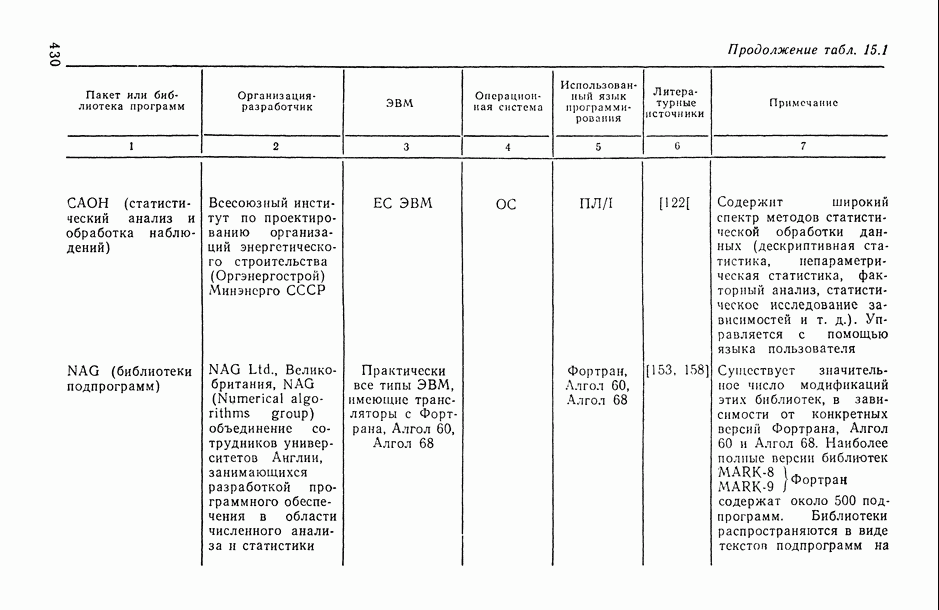
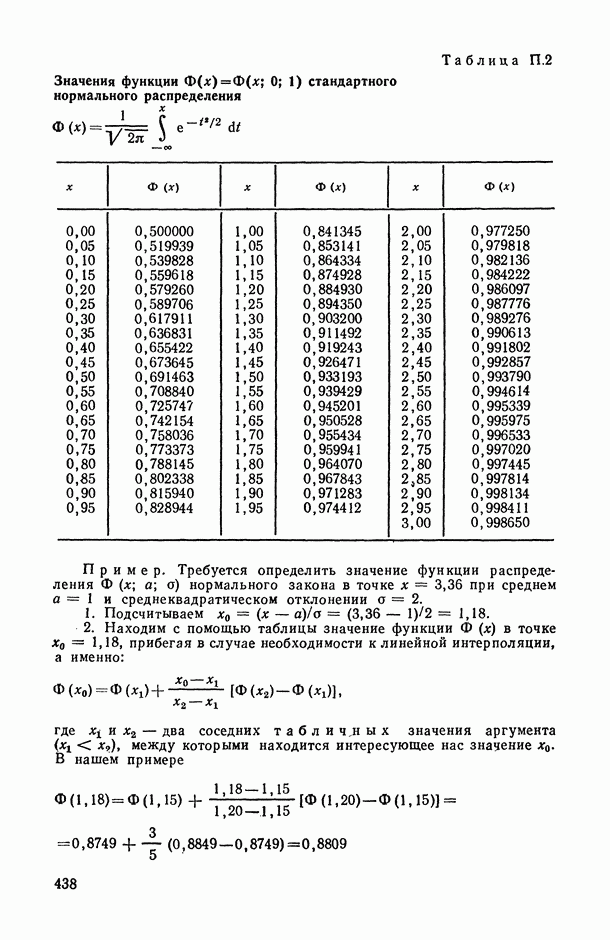
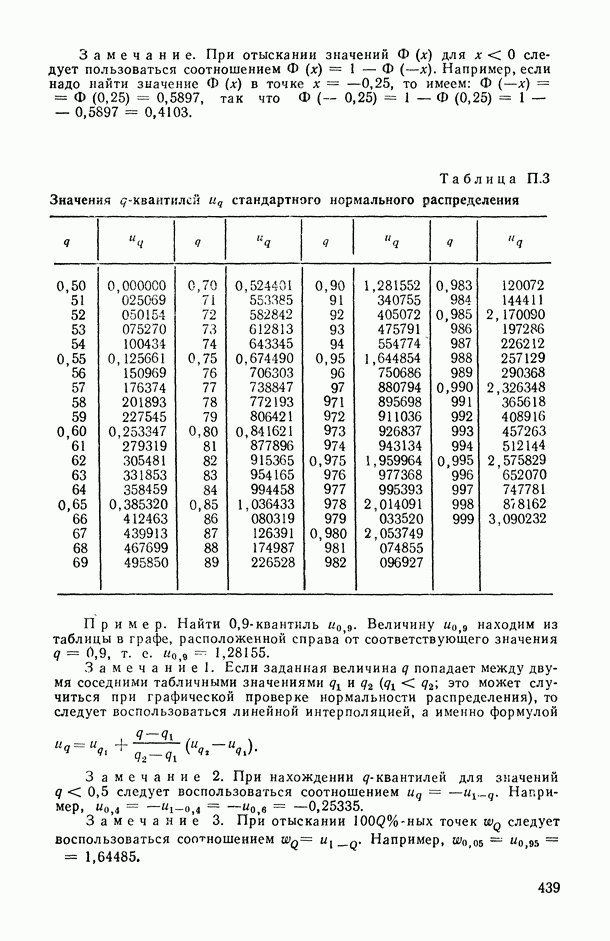
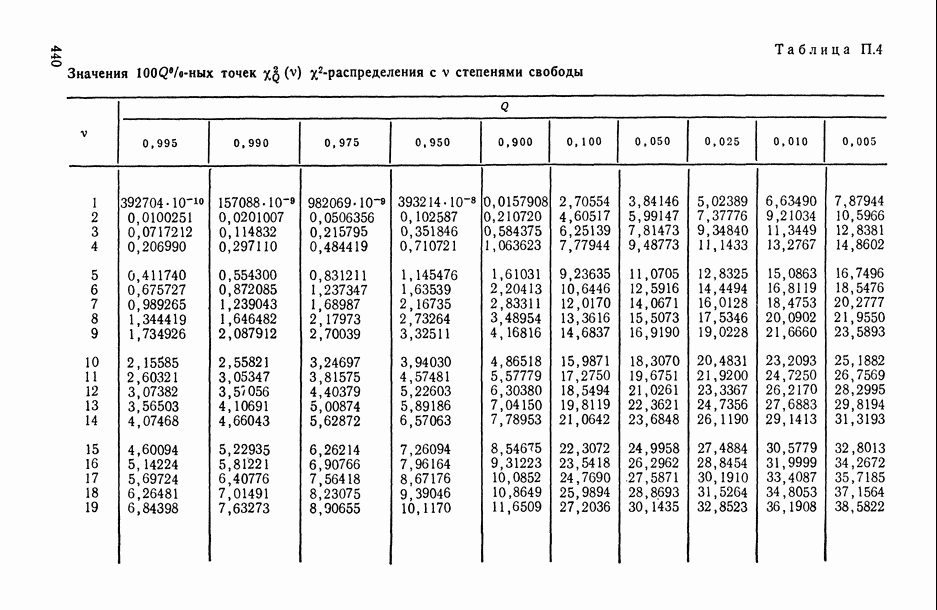
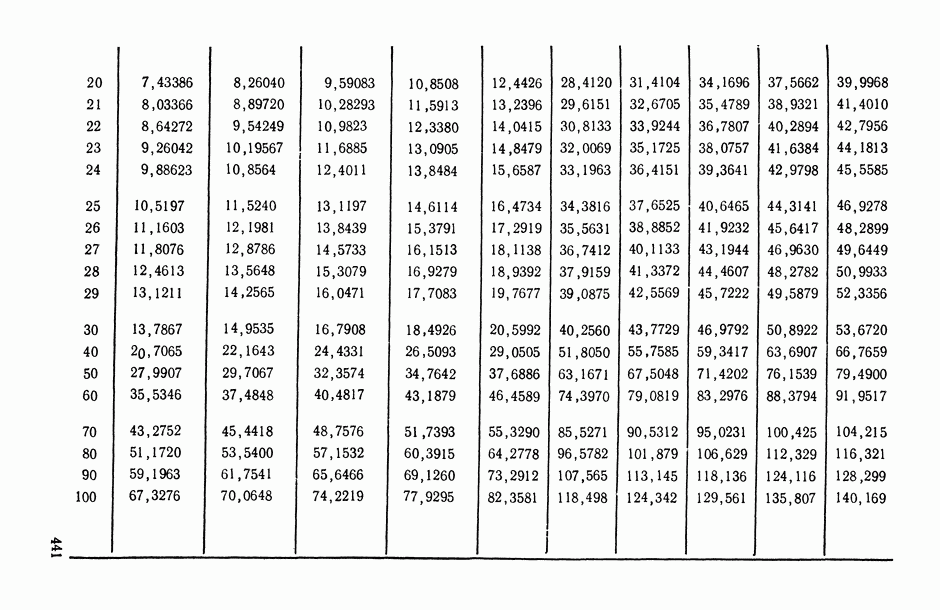
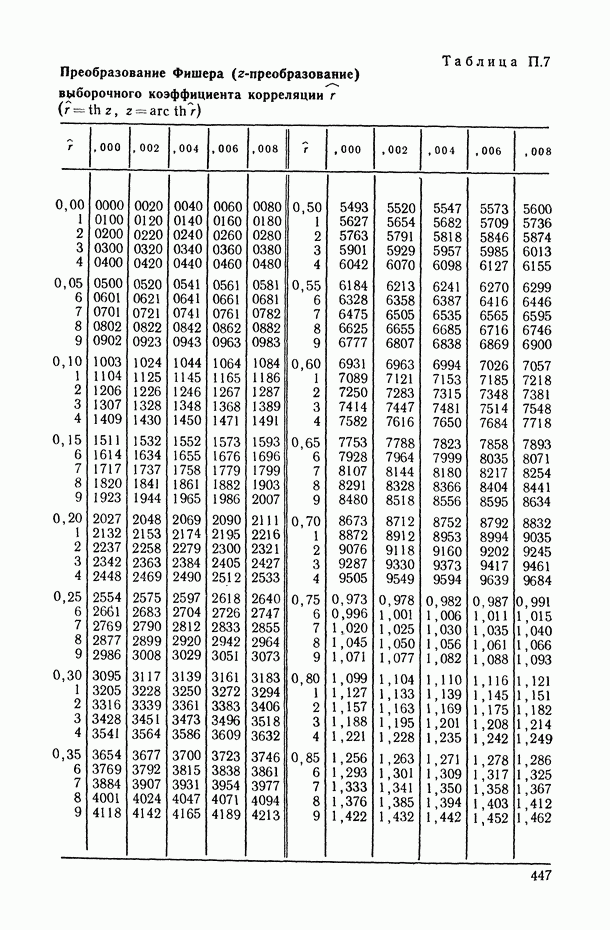
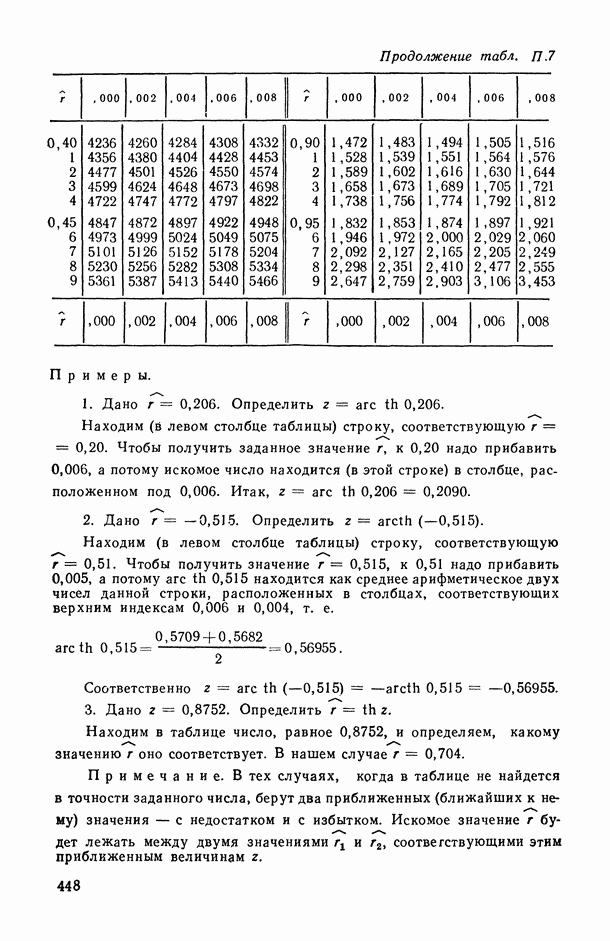
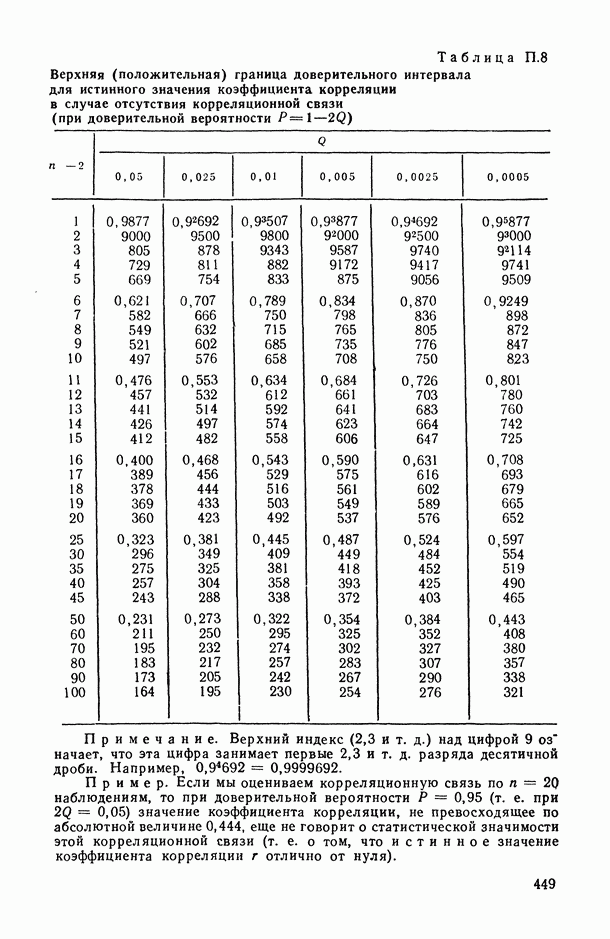
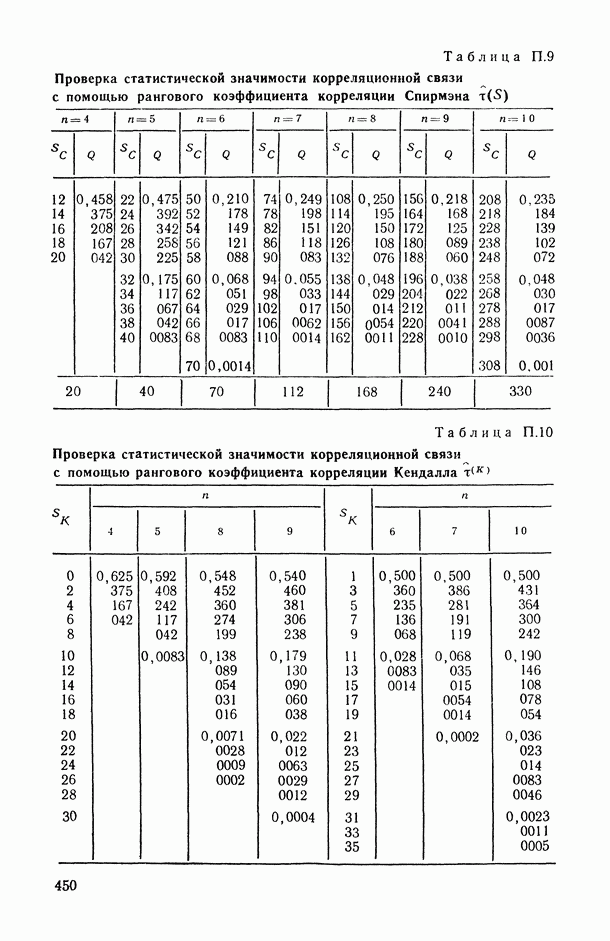
Распознанный текст, спецсимволы и формулы могут содержать ошибки, поэтому с корректным вариантом рекомендуем ознакомиться на отсканированных изображениях учебника выше
Также, советуем воспользоваться поиском по сайту, мы уверены, что вы сможете найти больше информации по нужной Вам тематике

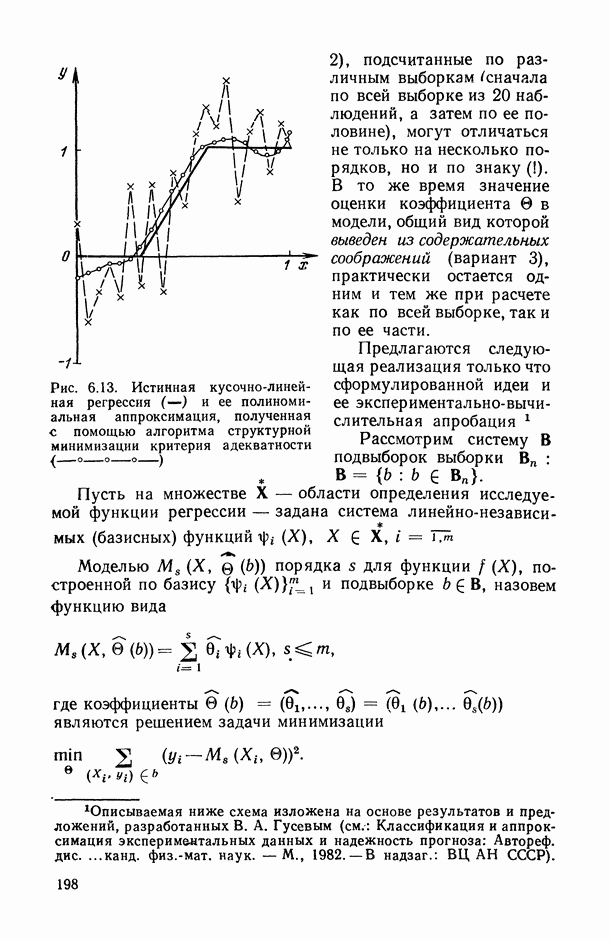
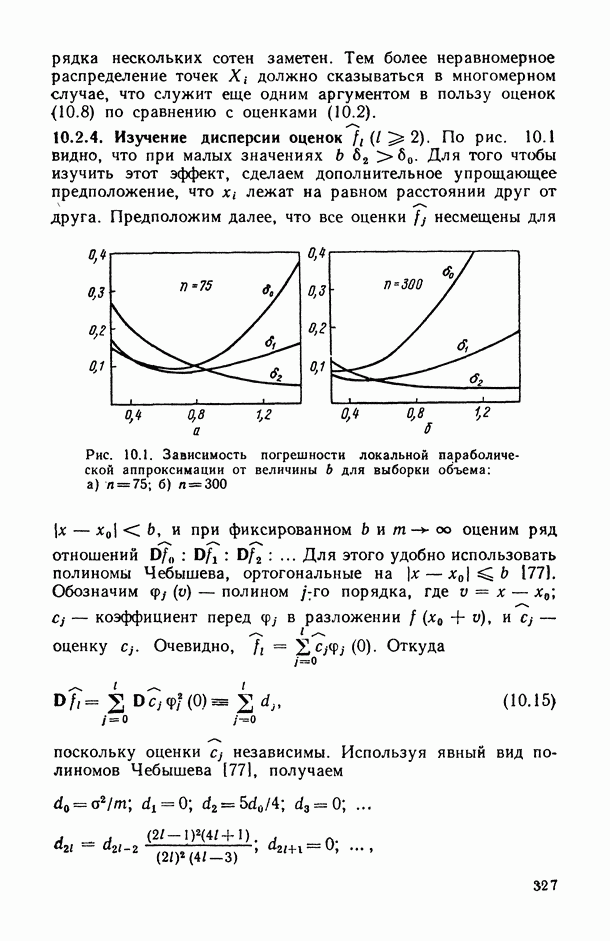
Рис. 6.13. Истинная кусочно-линейная регрессия  и ее полиномиальная аппроксимация, полученная с помощью алгоритма структурной минимизации критерия адекватности
и ее полиномиальная аппроксимация, полученная с помощью алгоритма структурной минимизации критерия адекватности
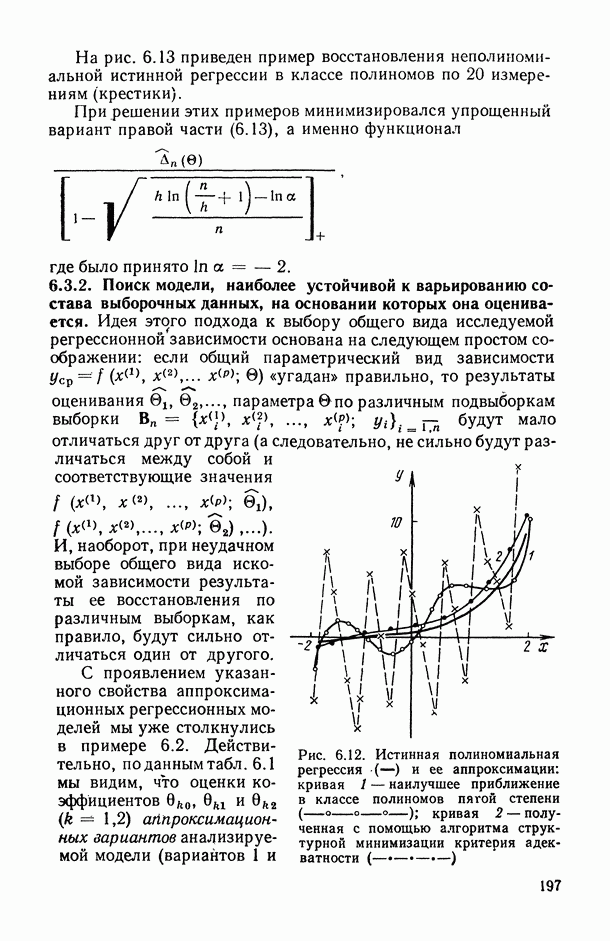
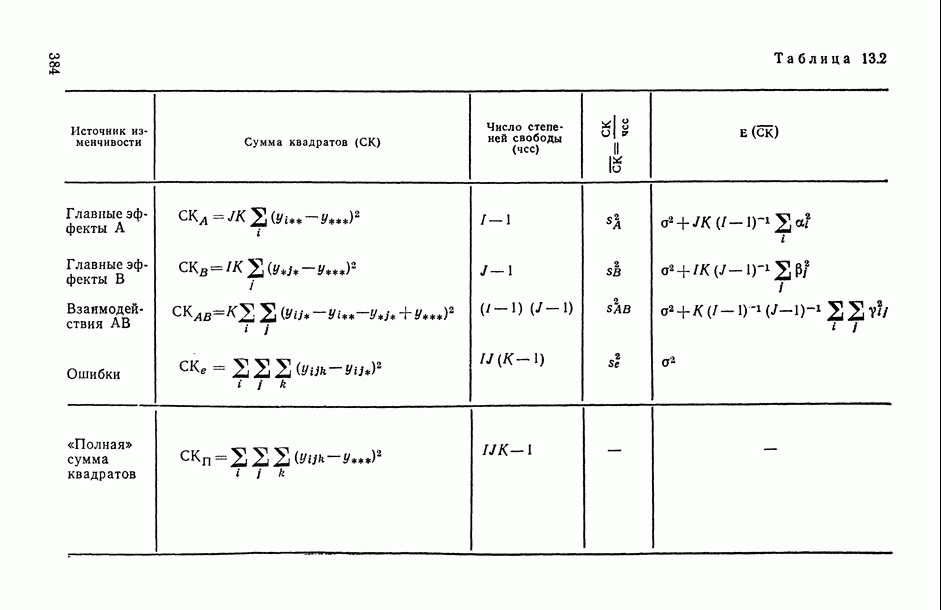
Действительно, поданным табл. 6.1 мы видим, что оценки коэффициентов  апроксимационных вариантов анализируемой модели (вариантов 1 и 2), подсчитанные по различным выборкам сначала по всей выборке из 20 наблюдений, а затем по ее половине), могут отличаться не только на несколько порядков, но и по знаку
апроксимационных вариантов анализируемой модели (вариантов 1 и 2), подсчитанные по различным выборкам сначала по всей выборке из 20 наблюдений, а затем по ее половине), могут отличаться не только на несколько порядков, но и по знаку  . В то же время значение оценки коэффициента
. В то же время значение оценки коэффициента  в модели, общий вид которой выведен из содержательных соображений (вариант 3), практически остается одним и тем же при расчете как по всей выборке, так и по ее части.
в модели, общий вид которой выведен из содержательных соображений (вариант 3), практически остается одним и тем же при расчете как по всей выборке, так и по ее части.
Предлагаются следующая реализация только что сформулированной идеи и ее экспериментально-вычислительная апробация. Рассмотрим систему В подвыборок выборки 

Пусть на множестве X — области определения исследуемой функции регрессии — задана система линейно-независимых (базисных) функций 
Моделью  порядка s для функции
порядка s для функции  , построенной по базису
, построенной по базису  и подвыборке
и подвыборке  , назовем функцию вида
, назовем функцию вида

где коэффициенты  являются решением задачи минимизации
являются решением задачи минимизации

Пусть  — заданное число, а X — некоторое подмножество из X. Назовем множества
— заданное число, а X — некоторое подмножество из X. Назовем множества  - эквивалентными
- эквивалентными  если они удовлетворяют условию
если они удовлетворяют условию

Таким образом,  -эквивалентность множеств
-эквивалентность множеств  т. е. подмножеств] множества
т. е. подмножеств] множества  означает следующее: значение модели
означает следующее: значение модели  функции
функции  , определенной по подвыборке
, определенной по подвыборке  отличается от значения модели
отличается от значения модели  определенной по подвыборке
определенной по подвыборке  , в любой точке X множества X по модулю на величину, небольшую, чем
, в любой точке X множества X по модулю на величину, небольшую, чем  . Можно рассматривать
. Можно рассматривать  - эквивалентность всей выборки
- эквивалентность всей выборки  и ее подвыборок, т. е. сравнивать модель
и ее подвыборок, т. е. сравнивать модель  с моделями
с моделями  построенными по отдельным частям выборки
построенными по отдельным частям выборки 
Рассмотрим такие подвыборки b из  которые содержат ровно а точек, и обозначим их совокупность через
которые содержат ровно а точек, и обозначим их совокупность через  а их число через
а их число через  . Далее, определим число
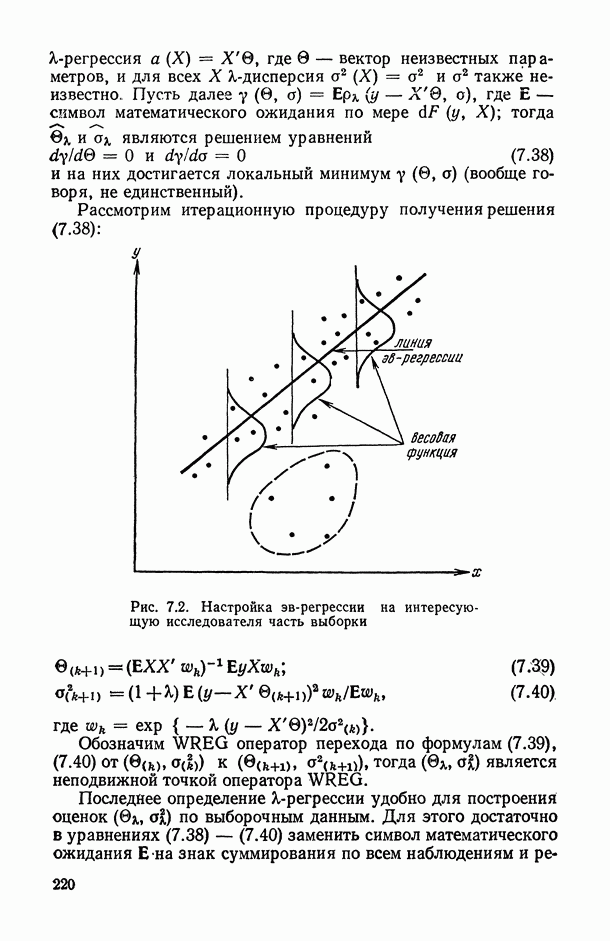
. Далее, определим число  подвыборок
подвыборок  для которых выполнено условие
для которых выполнено условие

Устойчивость модели  порядка s на множестве X для заданного
порядка s на множестве X для заданного  будем измерять величиной
будем измерять величиной

Пусть задана последовательность 
Величину  назовем средней устойчивостью модели на множестве X для последовательности
назовем средней устойчивостью модели на множестве X для последовательности  . Рассмотрим величину
. Рассмотрим величину

максимальную по модулю разности моделей на множестве X. Таким образом, можно рассматривать распределение значений величины бтах на системе подвыборок В. В частности, можно оценить математическое ожидание  величины
величины  и квантиль
и квантиль  порядка Р распределения
порядка Р распределения  .
.
Для оценки качества модели можно использовать следующие характеристики:








































































































































































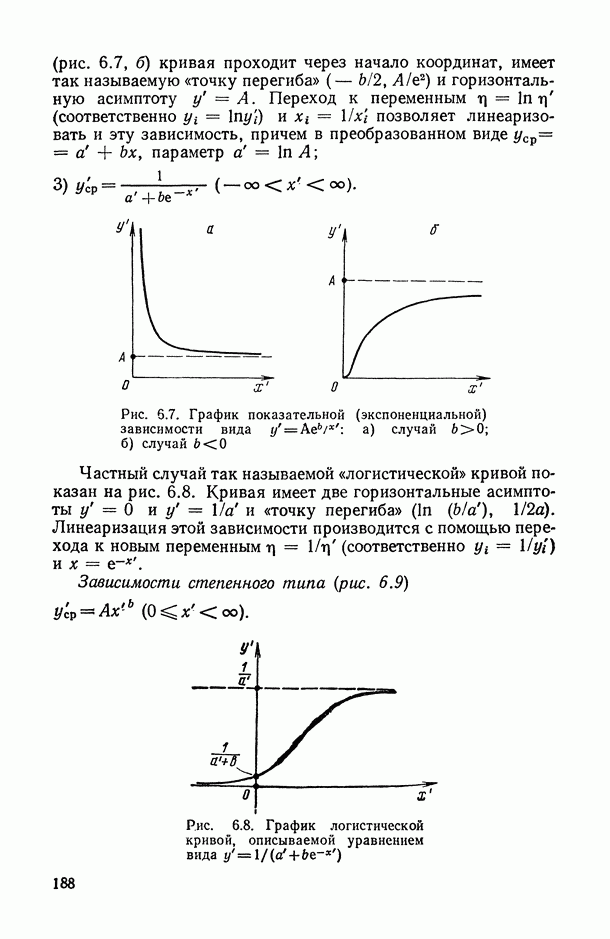
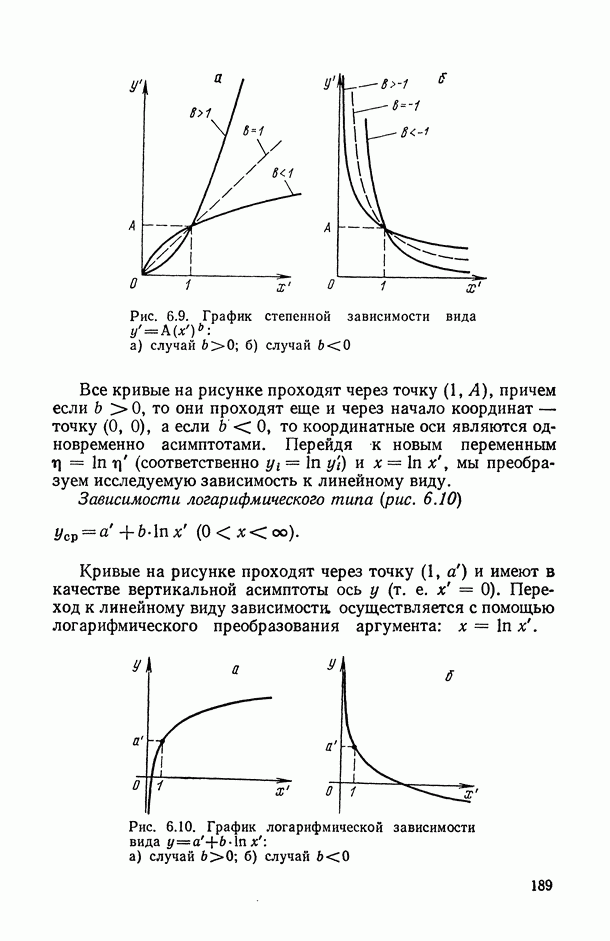


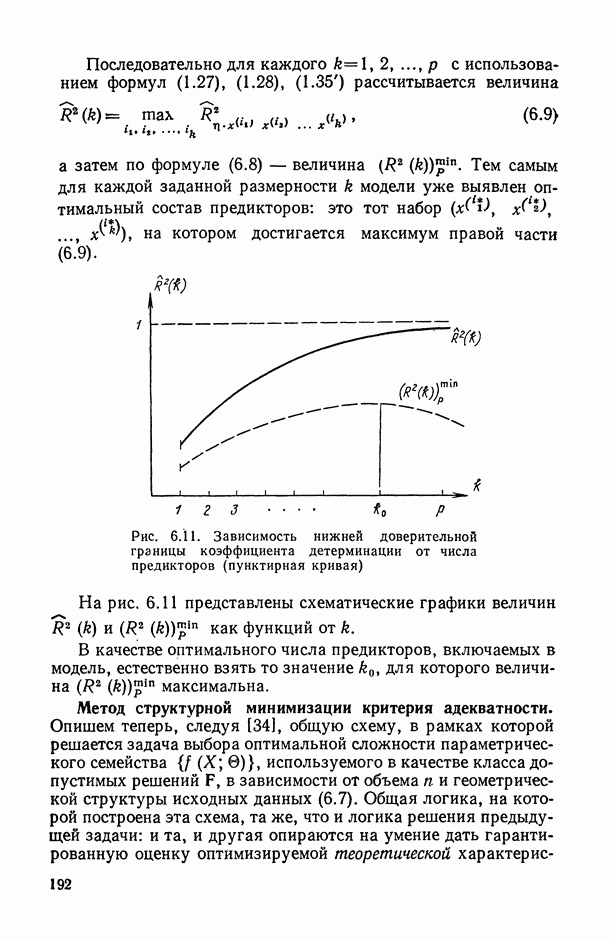


































































































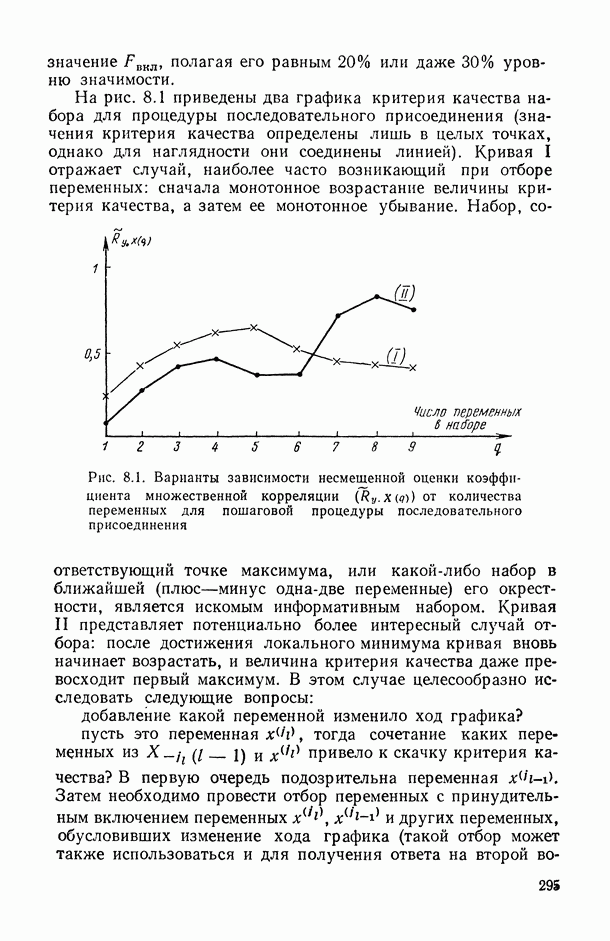



































































































































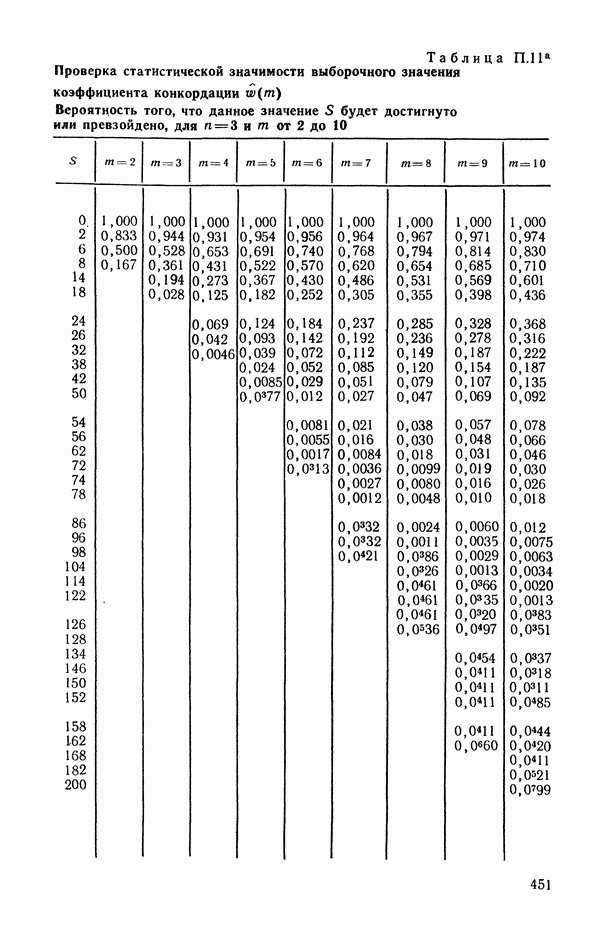
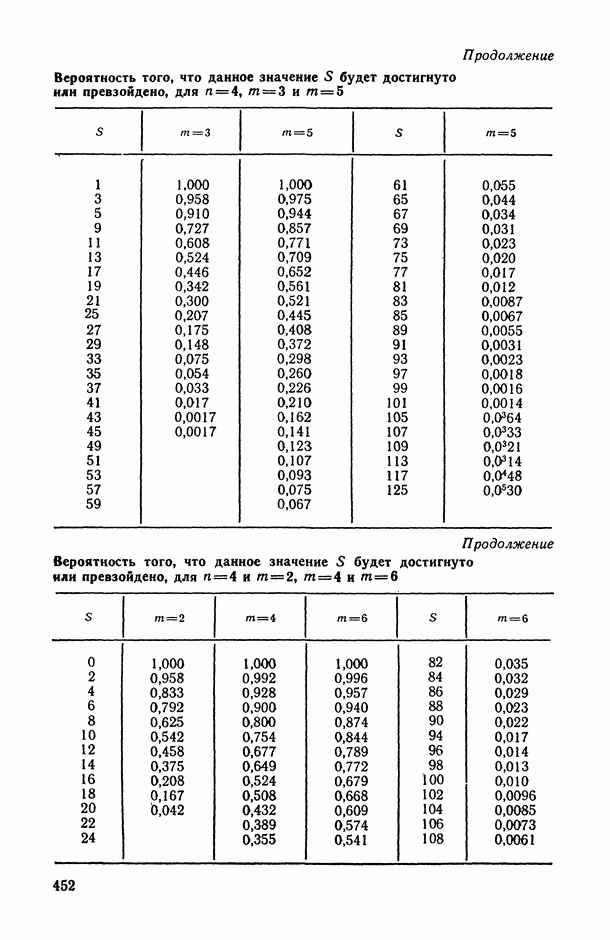
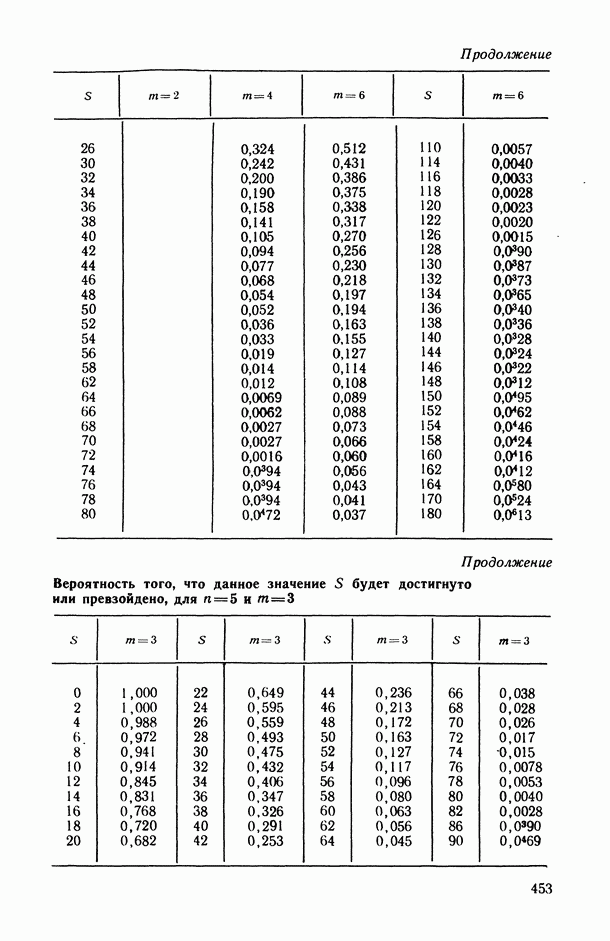


















 «угадан» правильно, то результаты оценивания
«угадан» правильно, то результаты оценивания  параметра
параметра  различным подвыборкам выборки
различным подвыборкам выборки  будут мало отличаться друг от друга (а следовательно, не сильно будут различаться между собой и соответствующие значения
будут мало отличаться друг от друга (а следовательно, не сильно будут различаться между собой и соответствующие значения


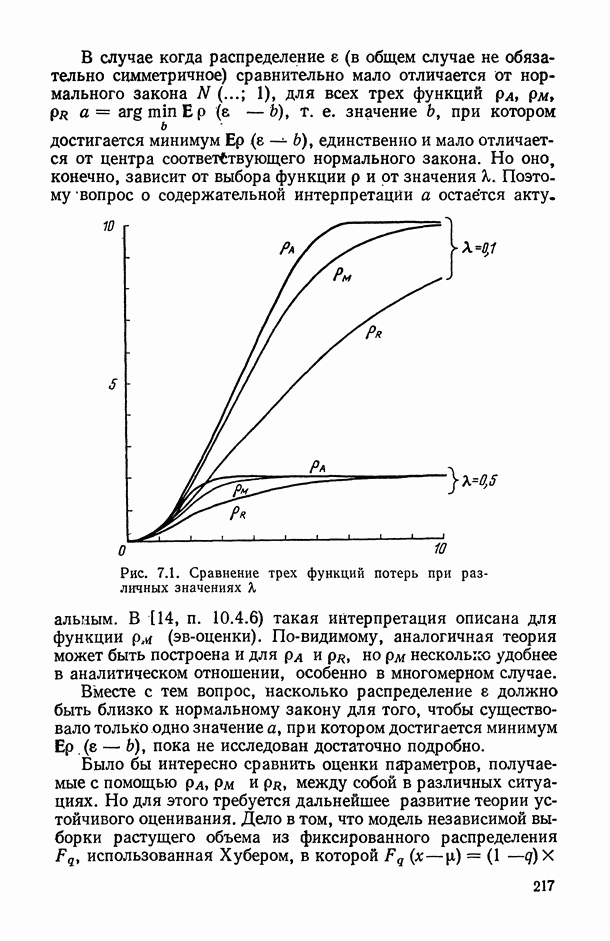
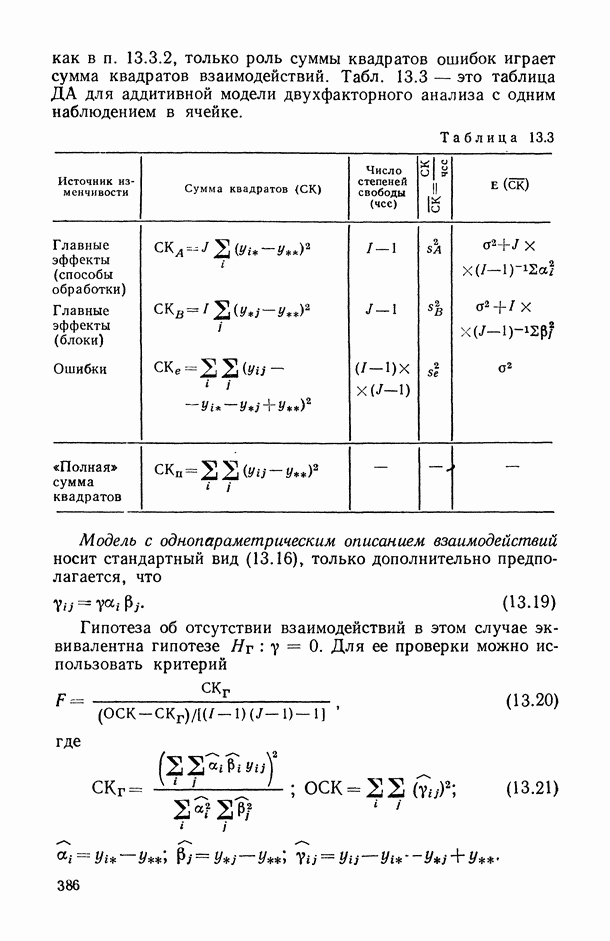
 и ее аппроксимации: кривая 1 — наилучшее приближение в классе полиномов пягой степени (
и ее аппроксимации: кривая 1 — наилучшее приближение в классе полиномов пягой степени ( ); кривая 2 — полученная с помощью алгоритма структурной минимизации критерия адекватности
); кривая 2 — полученная с помощью алгоритма структурной минимизации критерия адекватности 
 — характеристику устойчивости для заданного
— характеристику устойчивости для заданного  — характеристику средней устойчивости для последовательности
— характеристику средней устойчивости для последовательности 
 — математическое ожидание величины
— математическое ожидание величины 
 — квантиль порядка Р распределения величины
— квантиль порядка Р распределения величины 
 достигают максимального, а характеристики Ебах и
достигают максимального, а характеристики Ебах и  — минимального значений. Практическая реализация данного подхода, опирающегося на анализ величин
— минимального значений. Практическая реализация данного подхода, опирающегося на анализ величин  требует привлечения ЭВМ и расчета необходимых статистических характеристик этих величин с помощью метода Монте-Карло [14, § 6.3].
требует привлечения ЭВМ и расчета необходимых статистических характеристик этих величин с помощью метода Монте-Карло [14, § 6.3].

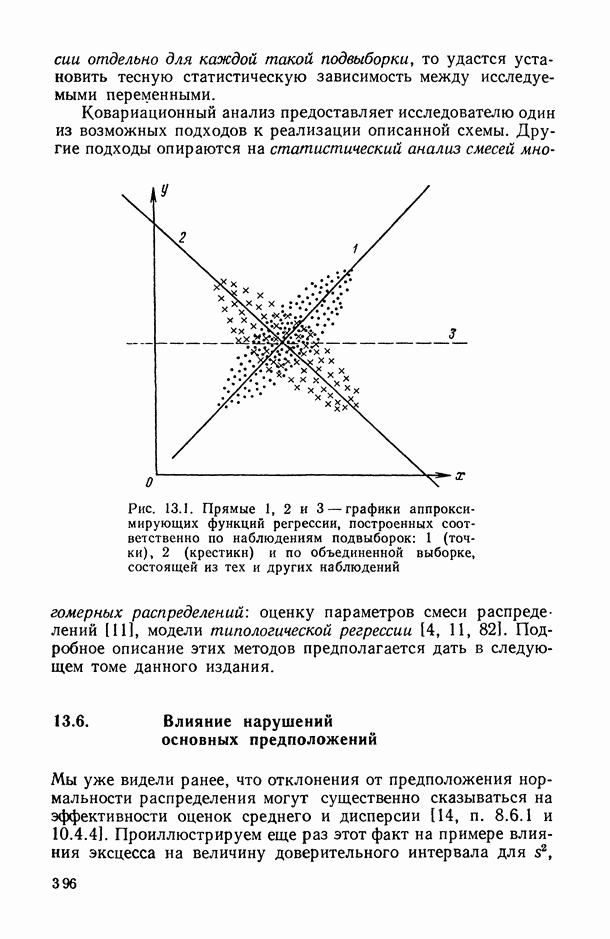
 — непересекающиеся подвыборки объемов
— непересекающиеся подвыборки объемов  случайно и независимо извлеченные (без возвращения) из исходной выборки
случайно и независимо извлеченные (без возвращения) из исходной выборки  . В частности, в условиях справедливости гипотезы
. В частности, в условиях справедливости гипотезы  случайная величина (6.15) должна подчиняться приблизительно
случайная величина (6.15) должна подчиняться приблизительно  -распределению с числом степеней свободы числителя и знаменателя
-распределению с числом степеней свободы числителя и знаменателя  соответственно.
соответственно.
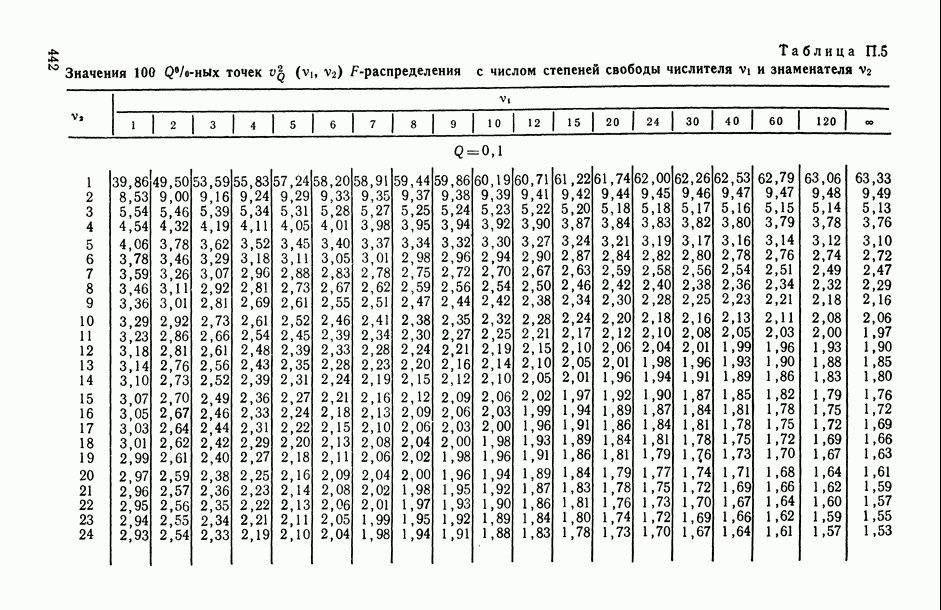
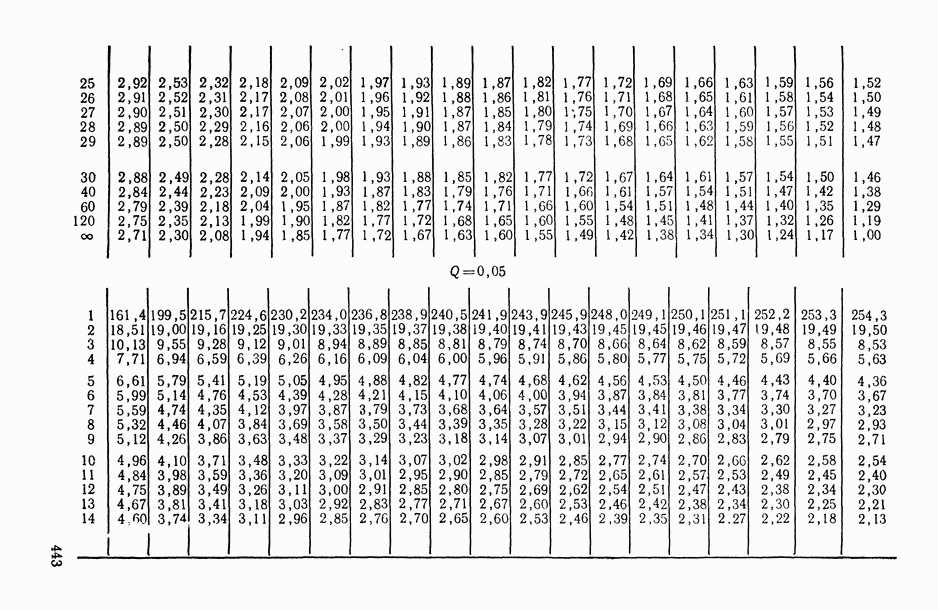
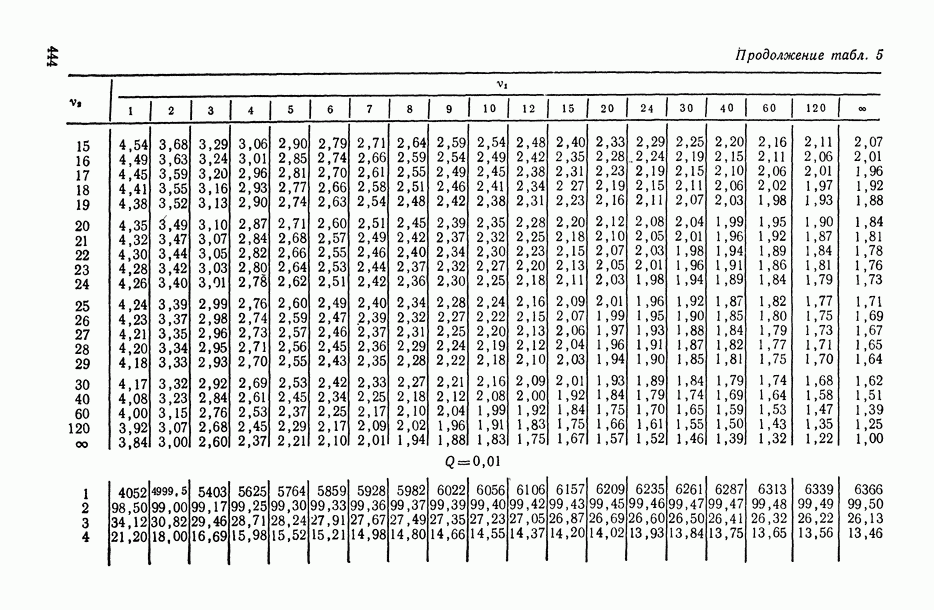
 -распределения (см. табл. П.5). А при достаточно больших объемах
-распределения (см. табл. П.5). А при достаточно больших объемах  исходных выборок
исходных выборок  можно непосредственно проверять факт
можно непосредственно проверять факт  -распределенности случайных
-распределенности случайных
 из
из  подсчитать для различных пар
подсчитать для различных пар  величины (6.15) и применить к ним критерий согласия.
величины (6.15) и применить к ним критерий согласия.
