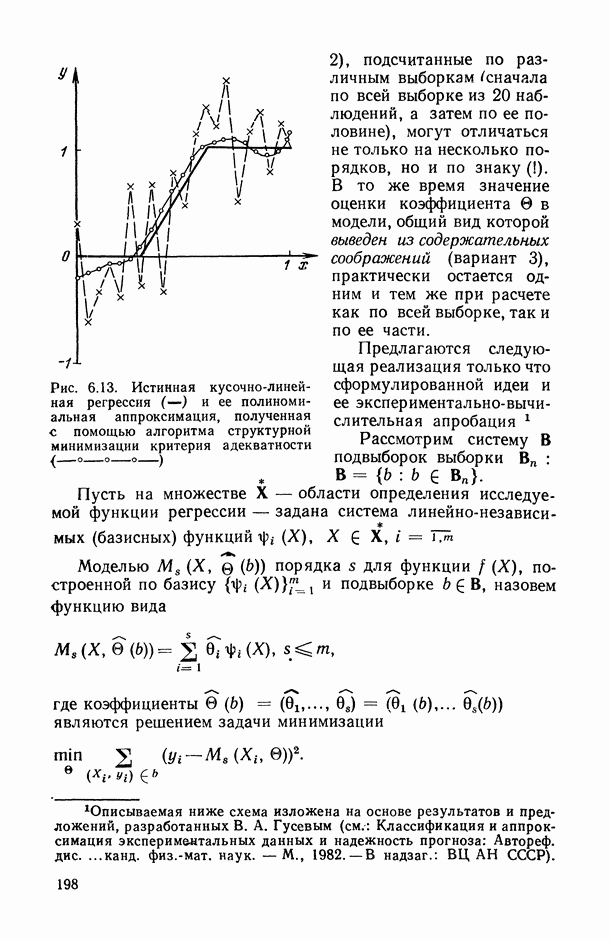
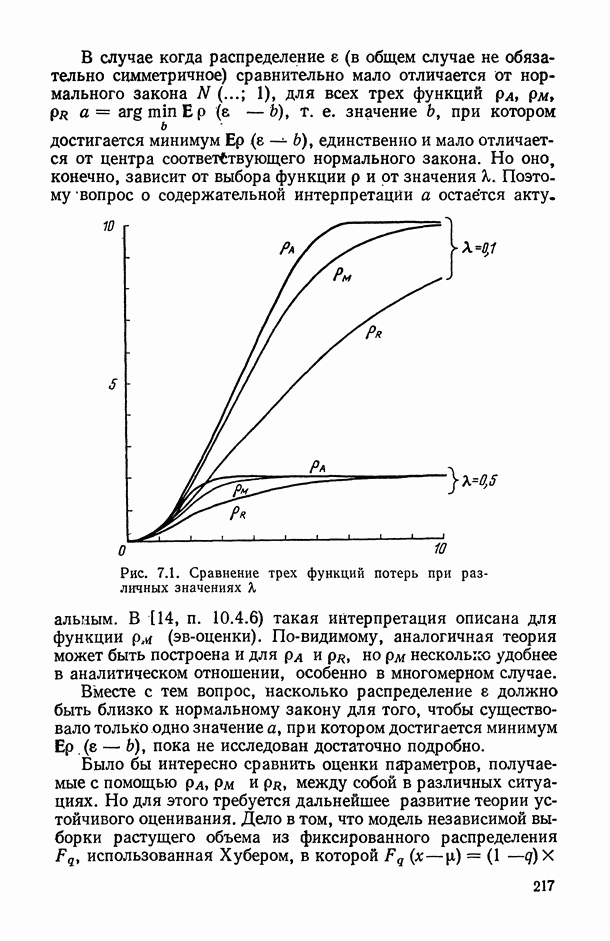
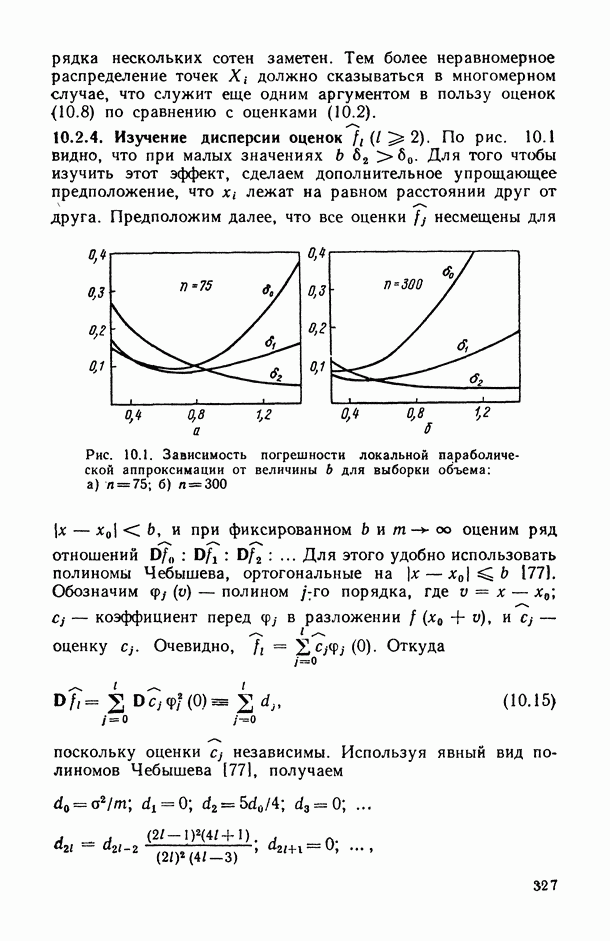
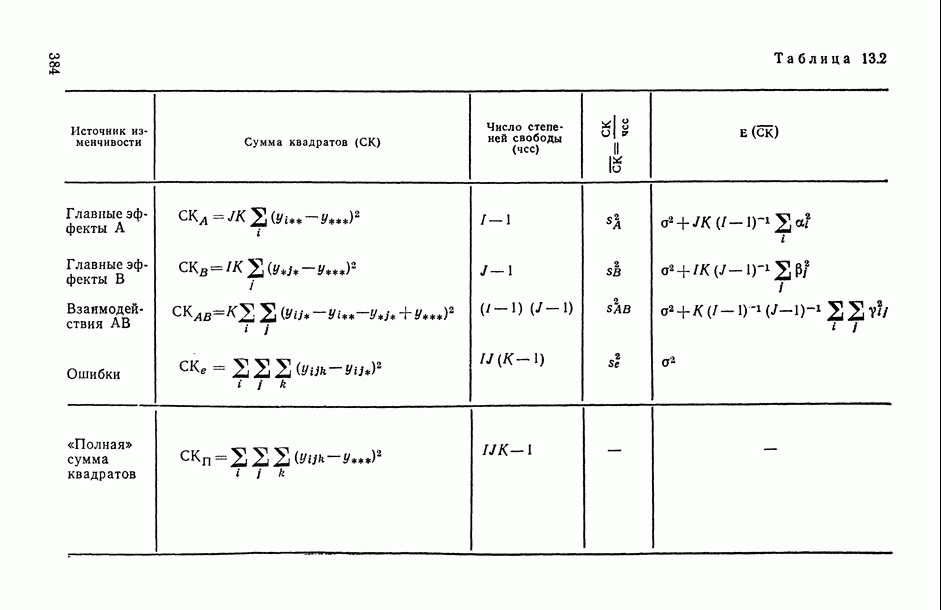
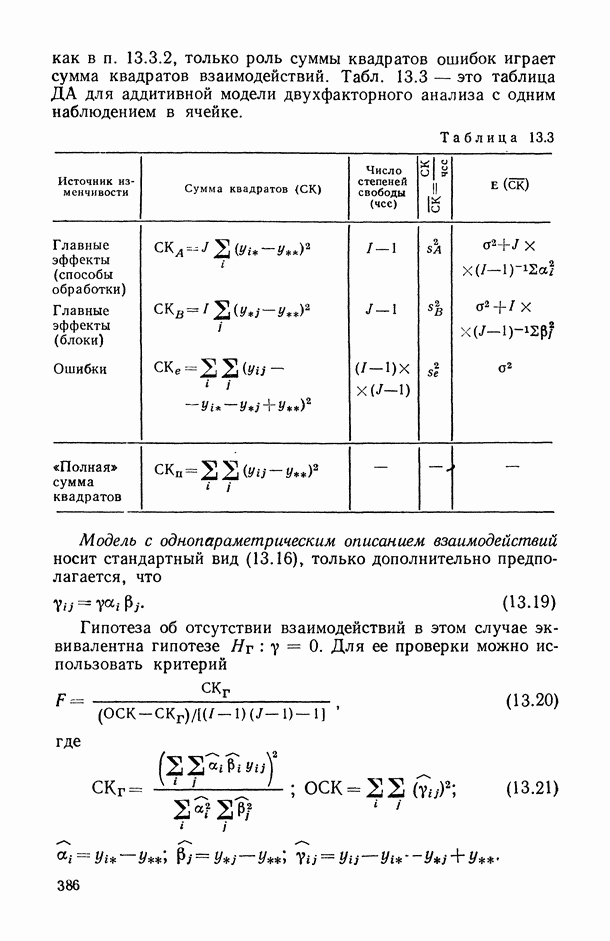
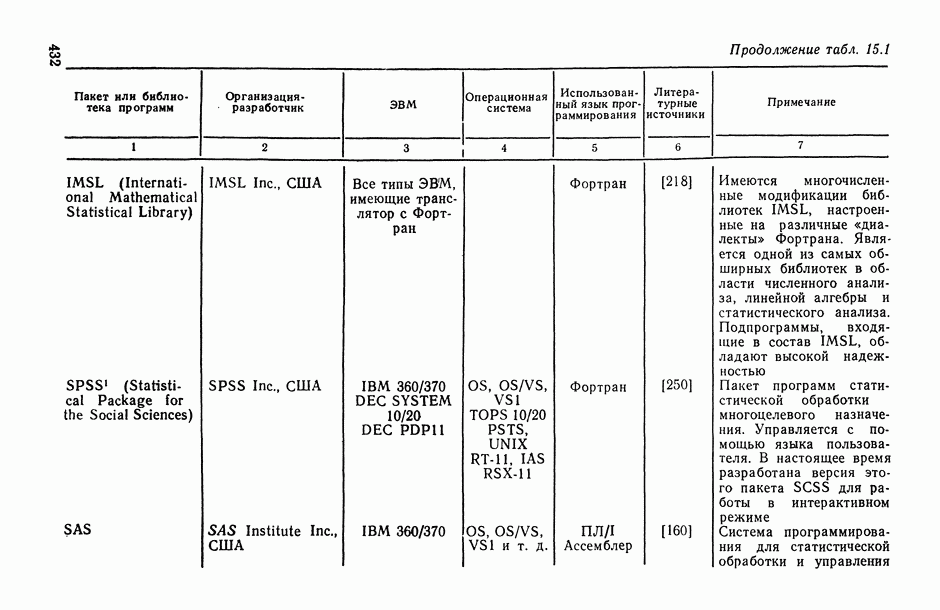
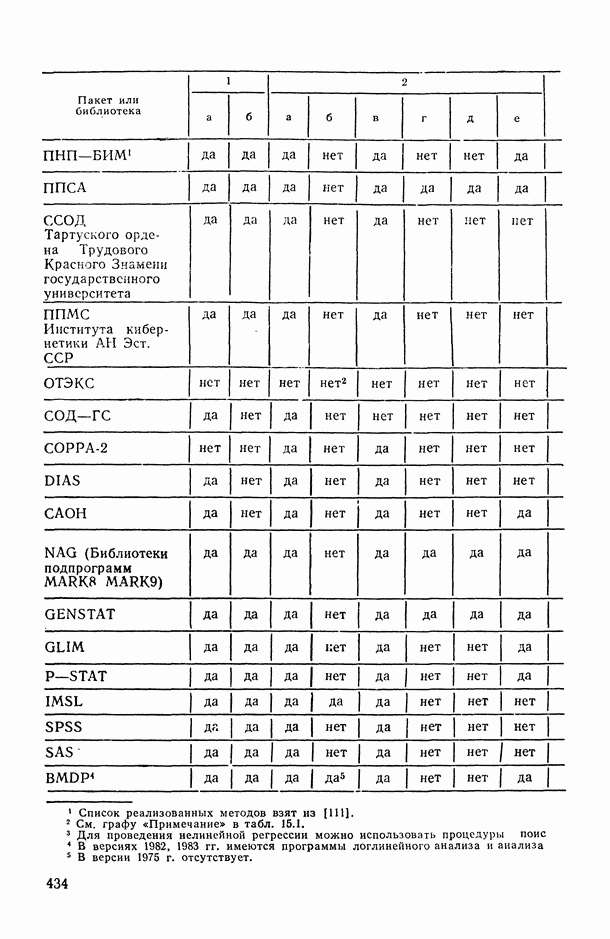
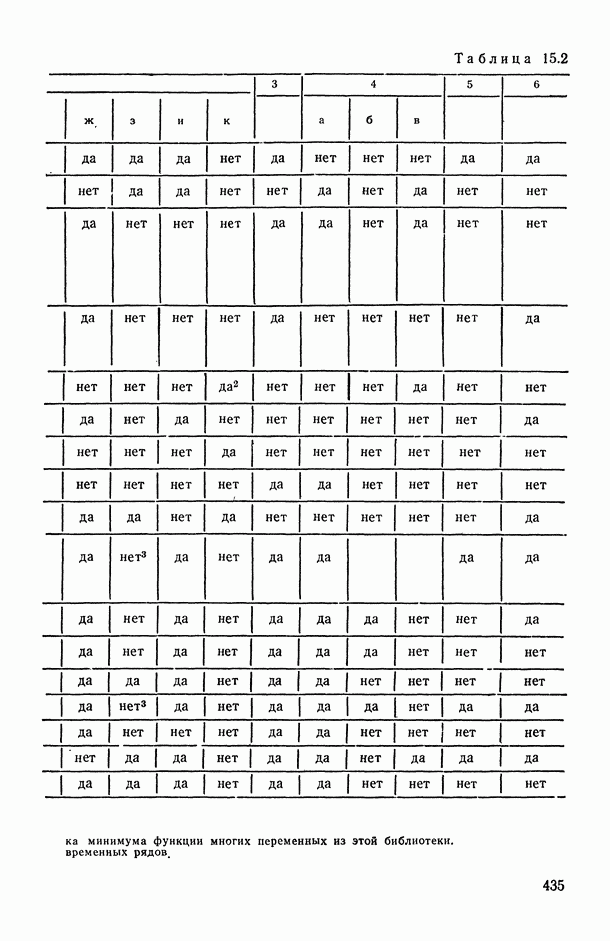
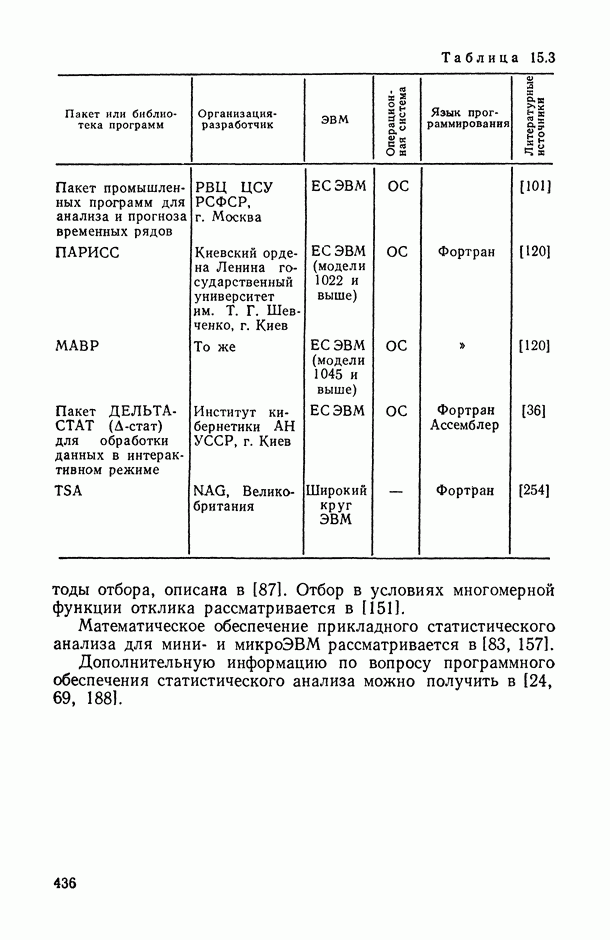
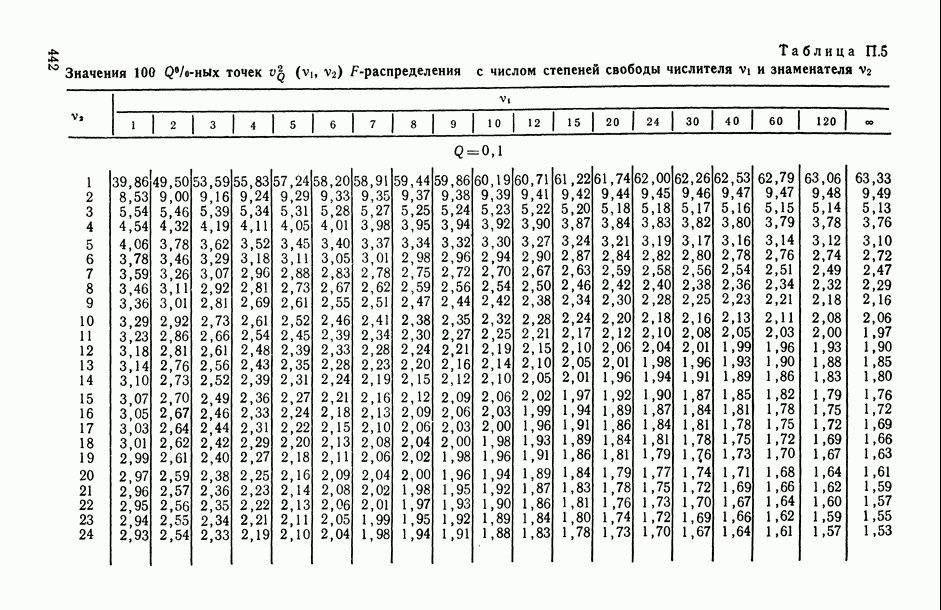
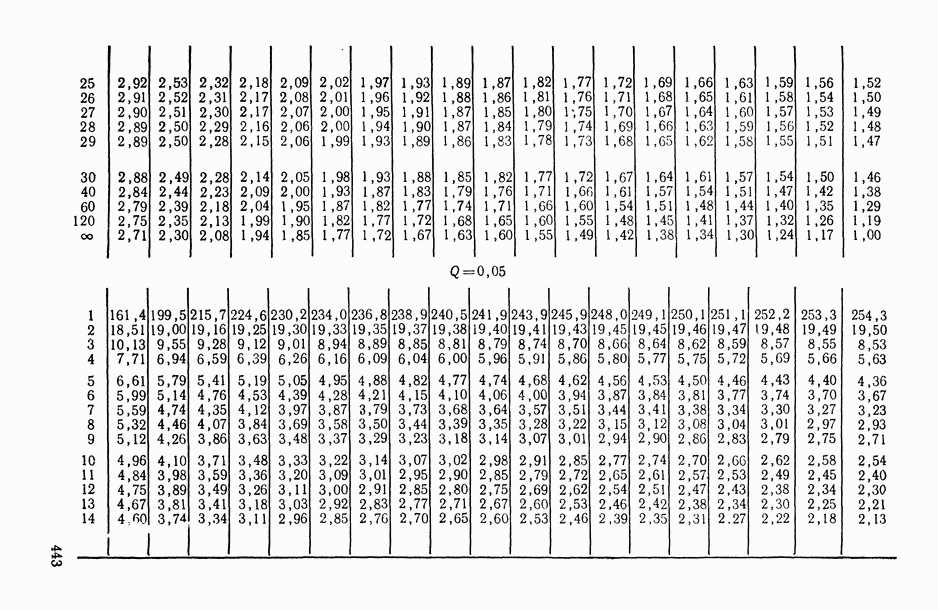
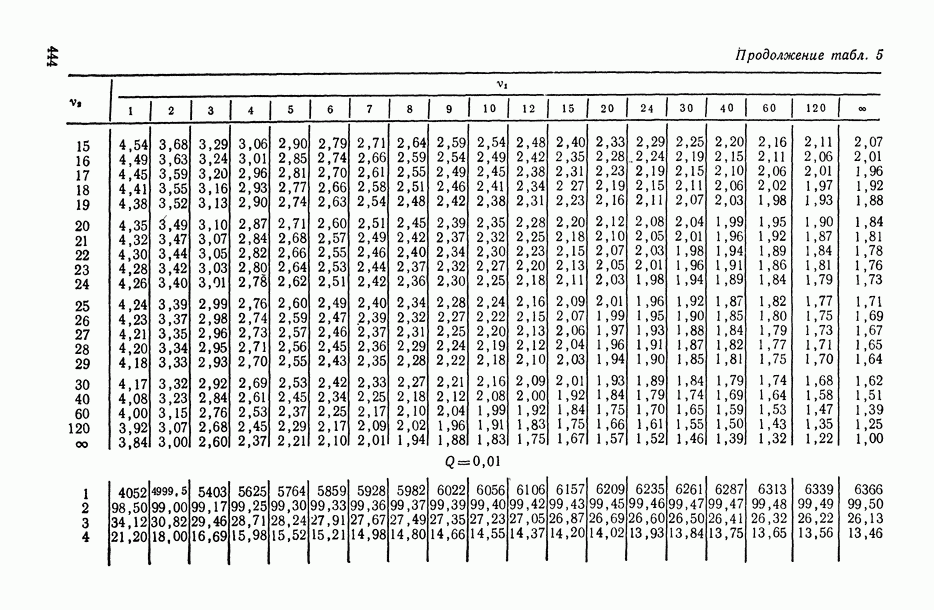
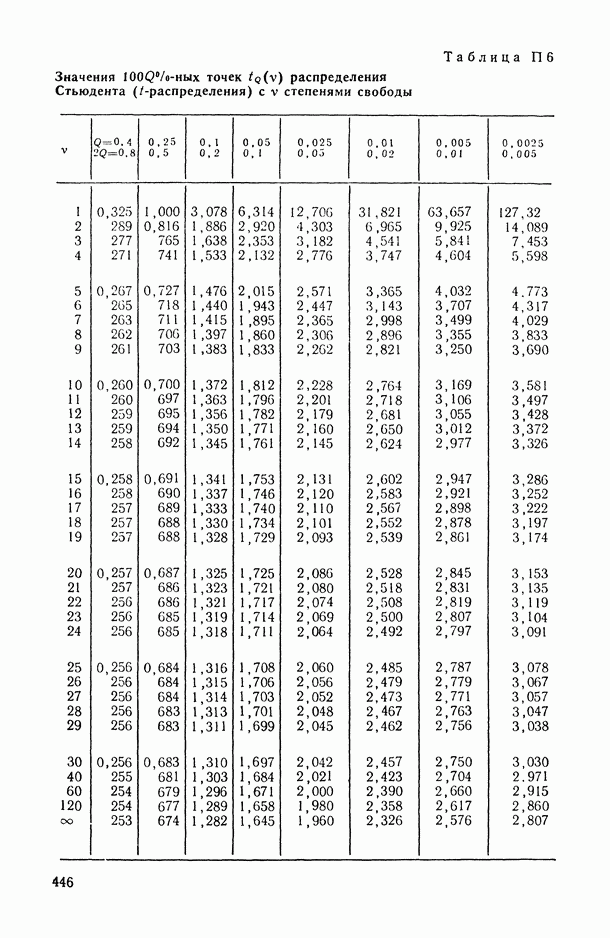
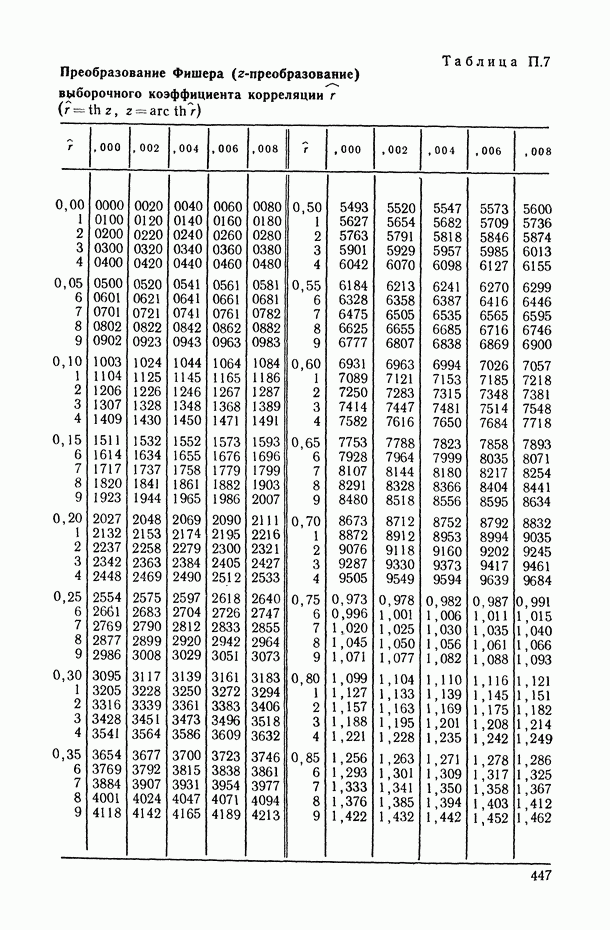
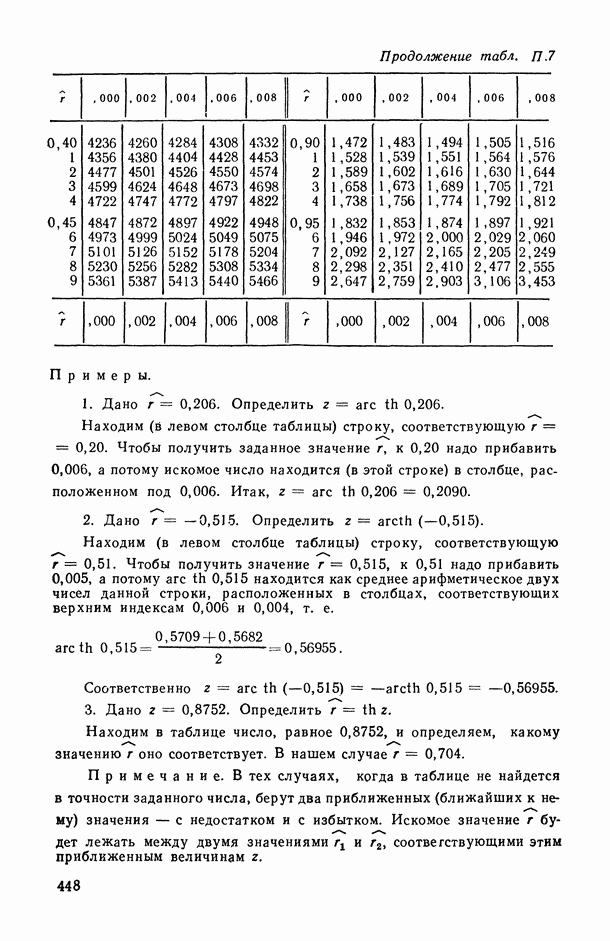
11.3. Исследование точности регрессионной модели в реалистической ситуации
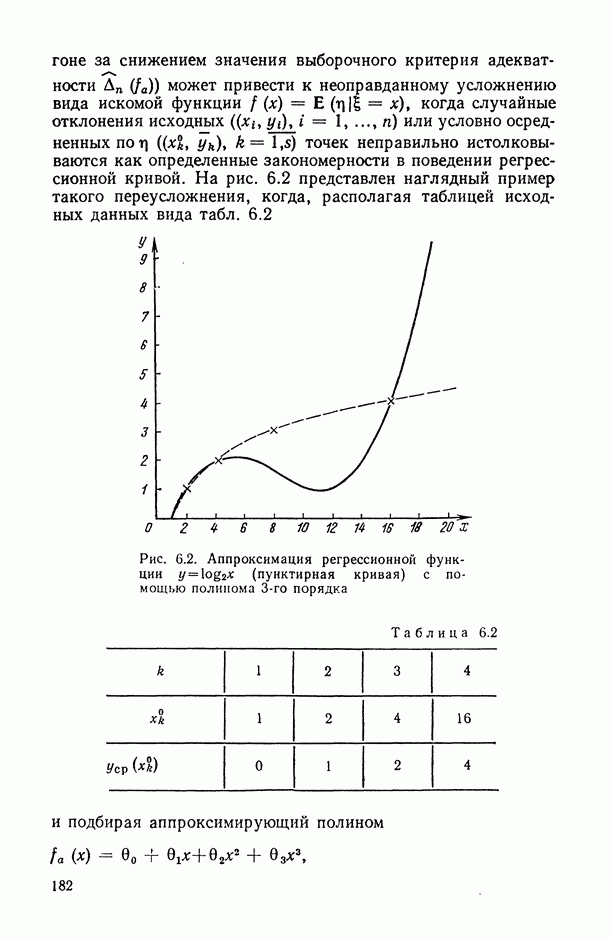
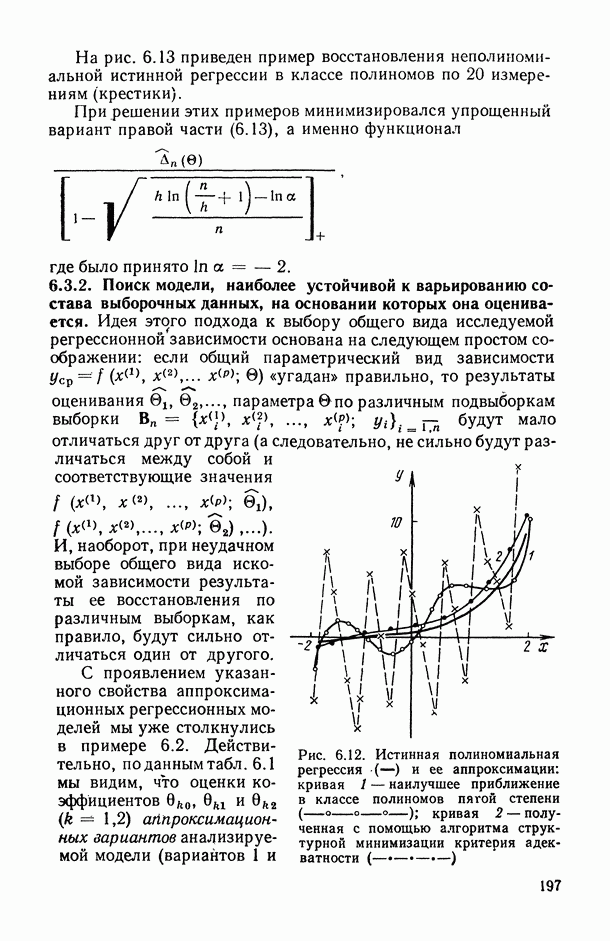
Неточный выбор общего вида функции регрессии, приводящий к нарушению базового допущения (11.21), на которое существенно опираются все выводы по оцениванию точности регрессионной модели, может заключаться как в неполном или избыточном представлении набора объясняющих переменных  так и в искажении самой структуры модели. Наиболее неприятные последствия влечет второй тип ошибки. В этом можно убедиться при рассмотрении примера 6.2, а также примера, представленного в табл. 6.2 и на рис. 6 2. Действительно, анализируя данные табл. 6.1 (в которой представлены результаты расчетов по примеру 6.2), мы видим, в частности, что при использовании формально-аппроксимационных вариантов регрессионной модели (т. е. в ситуации
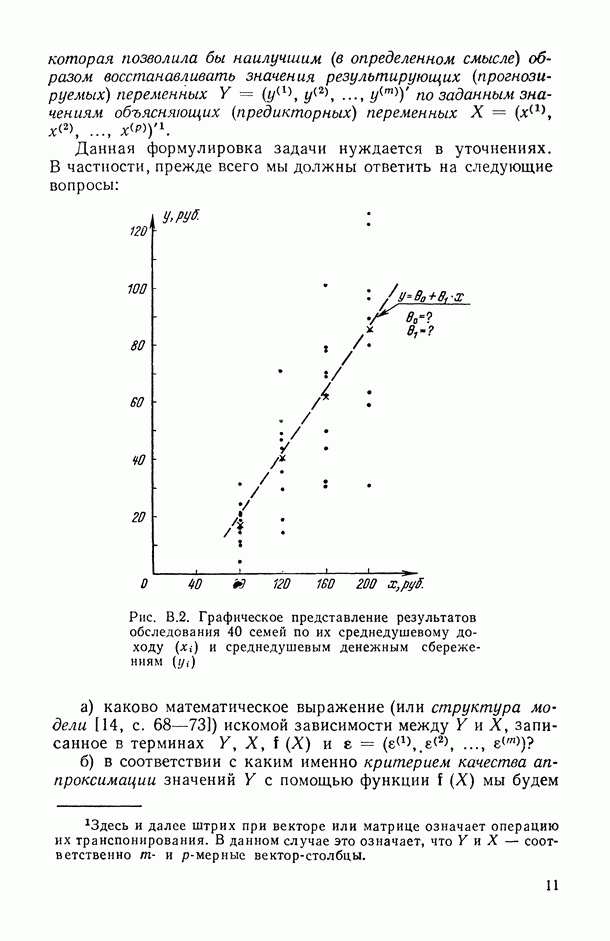
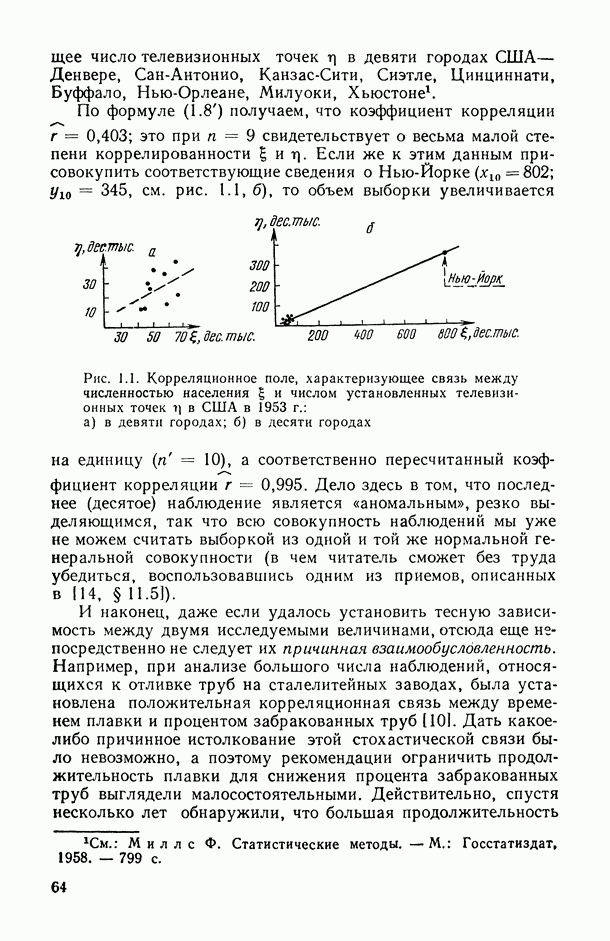
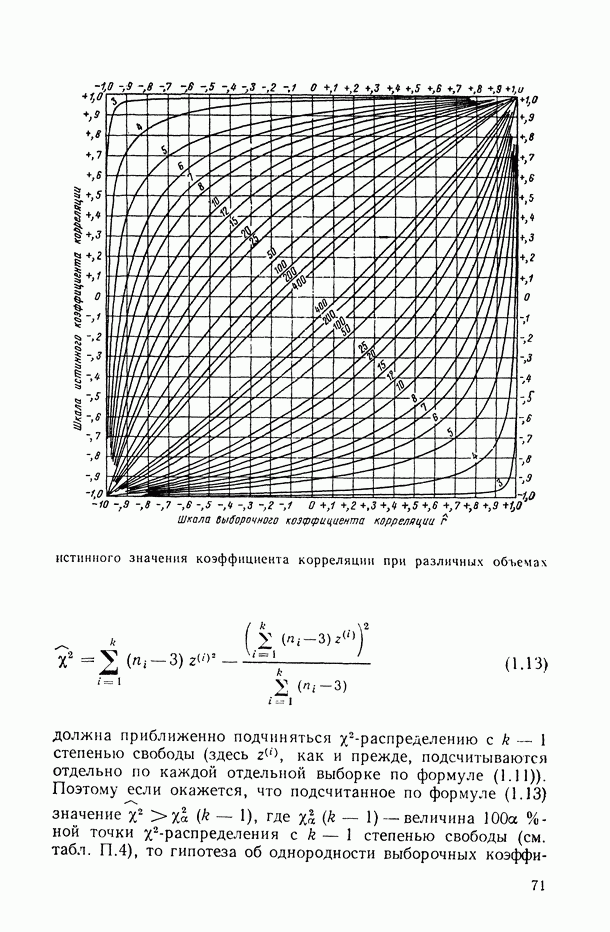
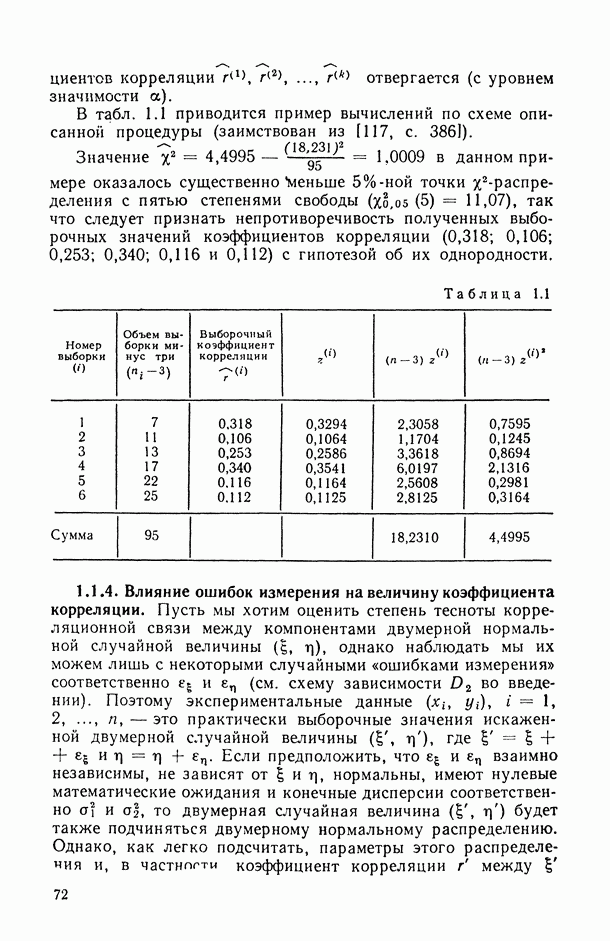
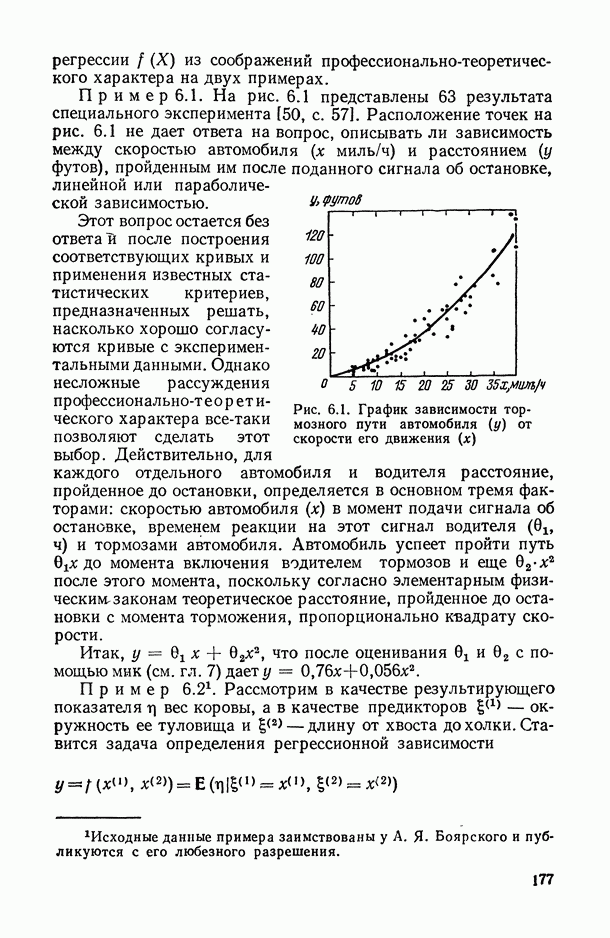
так и в искажении самой структуры модели. Наиболее неприятные последствия влечет второй тип ошибки. В этом можно убедиться при рассмотрении примера 6.2, а также примера, представленного в табл. 6.2 и на рис. 6 2. Действительно, анализируя данные табл. 6.1 (в которой представлены результаты расчетов по примеру 6.2), мы видим, в частности, что при использовании формально-аппроксимационных вариантов регрессионной модели (т. е. в ситуации  оценки среднеквадратической ошибки остатков (а), полученные по формуле (11.27) по данным той же самой выборки, по которой вычислены и оценки в неизвестных параметров модели, дают более чем в 3 раза заниженные (по сравнению с действительными) значения (см. графы 4 и 6). Более того, из примера, представленного на рис. 6.2 (и в табл. 6.2), следует, что значение выборочного критерия адекватности
оценки среднеквадратической ошибки остатков (а), полученные по формуле (11.27) по данным той же самой выборки, по которой вычислены и оценки в неизвестных параметров модели, дают более чем в 3 раза заниженные (по сравнению с действительными) значения (см. графы 4 и 6). Более того, из примера, представленного на рис. 6.2 (и в табл. 6.2), следует, что значение выборочного критерия адекватности  (пропорционального величине
(пропорционального величине  ) вообще может быть нулевым (!), в то время как ошибки восстановления неизвестных значений функции регрессии
) вообще может быть нулевым (!), в то время как ошибки восстановления неизвестных значений функции регрессии  или результирующего показателя
или результирующего показателя  по заданной величине предиктора
по заданной величине предиктора  могут быть практически сколь угодно велики (ср. поведение
могут быть практически сколь угодно велики (ср. поведение  при
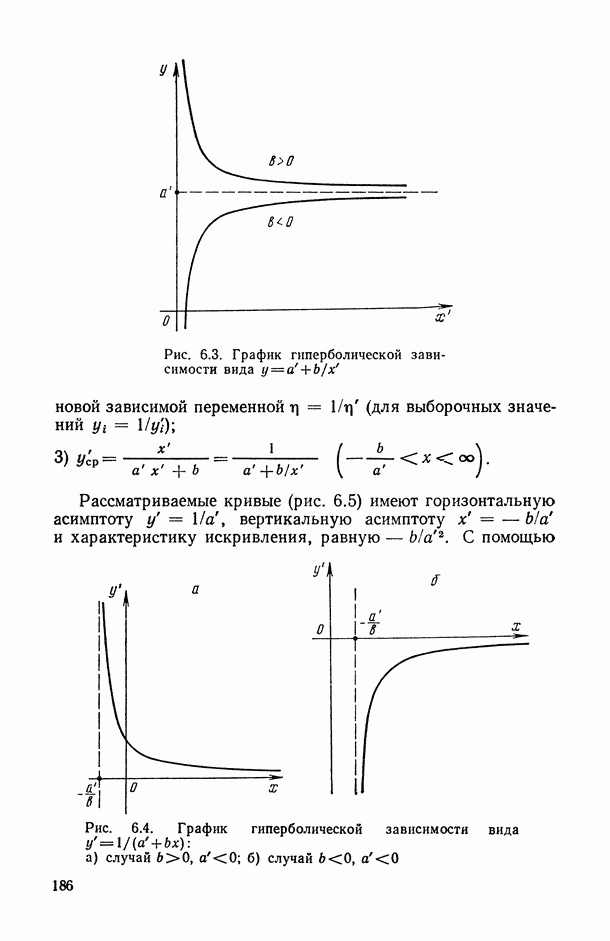
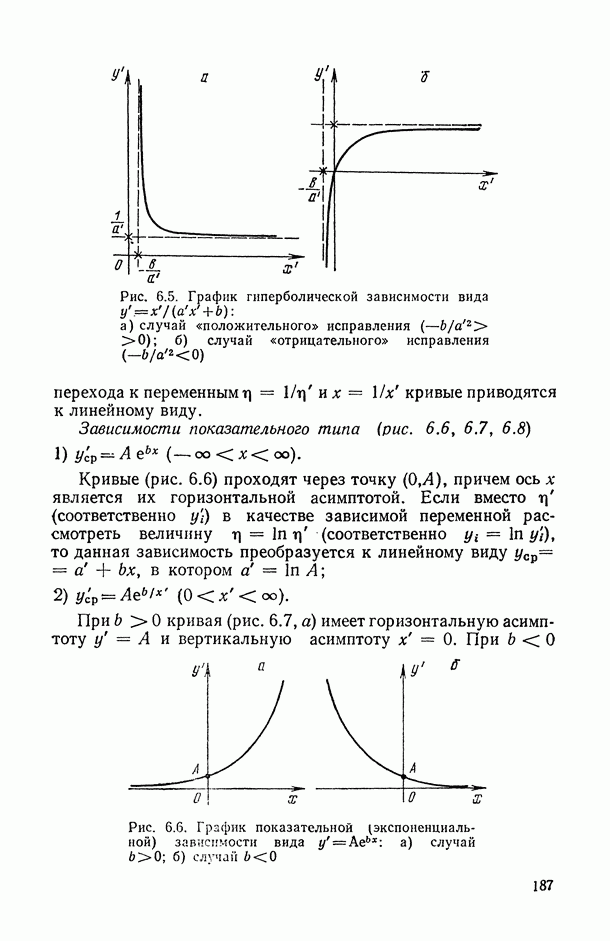
при  [7; 14] и при
[7; 14] и при  ).
).
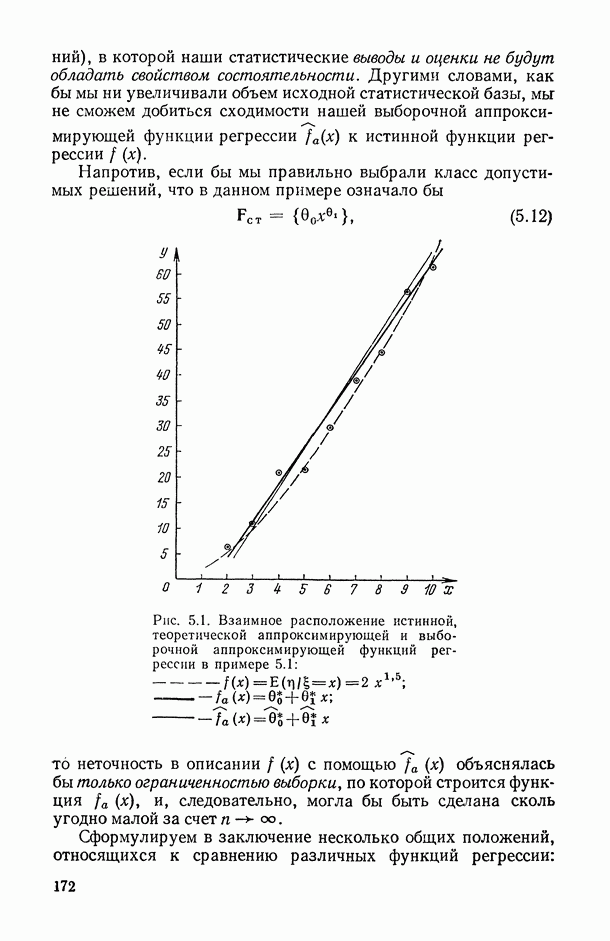
Подмеченные в рассмотренных примерах особенности аппроксимационных вариантов регрессионных моделей (так мы будем называть варианты, в которых истинная функция регрессии  приводят к следующим основным положениям исследования точности статистических выводов в регрессионном анализе в данной ситуации:
приводят к следующим основным положениям исследования точности статистических выводов в регрессионном анализе в данной ситуации:
1) при анализе точности аппроксимационных вариантов регрессионных моделей не следует претендовать на построение сколько-нибудь точных доверительных интервалов ни для неизвестных значений параметров 0 (они, как правило, не имеют в данной ситуации самостоятельной содержательной интерпретации), ни для функции регрессии  или результирующего показателя
или результирующего показателя  (поскольку, пользуясь аппроксимацией
(поскольку, пользуясь аппроксимацией  , отличающейся по структуре от истинной функции регрессии
, отличающейся по структуре от истинной функции регрессии  , мы не можем иметь достоверной априорной информации о вероятностной природе остатков
, мы не можем иметь достоверной априорной информации о вероятностной природе остатков 
2) имеющуюся выборку наблюдений  целесообразно разбить (одним или несколькими различными способами) на две непересекающиеся подвыборки объемов
целесообразно разбить (одним или несколькими различными способами) на две непересекающиеся подвыборки объемов  обучающую
обучающую  на основании наблюдений которой строятся мнк-оценки
на основании наблюдений которой строятся мнк-оценки  неизвестных параметров аппроксимационной функции регрессии
неизвестных параметров аппроксимационной функции регрессии  , и экзаменующую (или контрольную) Вкзу по наблюдениям которой оцениваются основные характеристики точности анализируемой модели (в первую очередь регрессионные остатки
, и экзаменующую (или контрольную) Вкзу по наблюдениям которой оцениваются основные характеристики точности анализируемой модели (в первую очередь регрессионные остатки  );
);
3) основной  по существу, единственной) характеристикой точности аппроксимационного варианта регрессионной модели является оценка о среднеквадратической ошибки аппроксимации а, вычисляемая по формуле
по существу, единственной) характеристикой точности аппроксимационного варианта регрессионной модели является оценка о среднеквадратической ошибки аппроксимации а, вычисляемая по формуле

где подразумевается, что имеющаяся выборка наблюдений  разбита k различными способами на две непересекающиеся подвыборки — обучающую
разбита k различными способами на две непересекающиеся подвыборки — обучающую  и экзаменующую (или контрольную) Вэкз соответственно объемов
и экзаменующую (или контрольную) Вэкз соответственно объемов  а мнк-оценки
а мнк-оценки  неизвестных параметров
неизвестных параметров  построены только по
построены только по  данным, входящим в состав обучающей выборки
данным, входящим в состав обучающей выборки  Знание о позволяет оценить максимально возможную погрешность аппроксимации неизвестной функции регрессии
Знание о позволяет оценить максимально возможную погрешность аппроксимации неизвестной функции регрессии  (в пределах обследованного диапазона значений X) приблизительно величиной порядка
(в пределах обследованного диапазона значений X) приблизительно величиной порядка  , а результирующего показателя
, а результирующего показателя  величиной порядка
величиной порядка  ;
;

































































































































































































































































































































































































































 или результирующего показателя
или результирующего показателя  по значению предиктора X, лежащему вне статистически обследованной области значений объясняющих переменных (см. также гл. 6 и 8).
по значению предиктора X, лежащему вне статистически обследованной области значений объясняющих переменных (см. также гл. 6 и 8).
 разбиений исходной выборки
разбиений исходной выборки  на обучающую
на обучающую  и экзаменующую
и экзаменующую  следующим образом:
следующим образом:

 для всех
для всех  вариант обучающей выборки содержит все наблюдения исходной выборки
вариант обучающей выборки содержит все наблюдения исходной выборки  кроме одного —
кроме одного —  соответственно
соответственно  вариант экзаменующей выборки содержит единственное наблюдение —
вариант экзаменующей выборки содержит единственное наблюдение —  Применение к такой последовательности обучающих и экзаменующих выборок формулы (11.27) дает:
Применение к такой последовательности обучающих и экзаменующих выборок формулы (11.27) дает:

 -кратное вычисление оценок
-кратное вычисление оценок  -кратное вычисление выборочных функций регрессии
-кратное вычисление выборочных функций регрессии  и т. д. Однако непосредственный анализ основных формул метода наименьших квадратов в случае линейного вида аппроксимирующих функций
и т. д. Однако непосредственный анализ основных формул метода наименьших квадратов в случае линейного вида аппроксимирующих функций  (см. формулы (11.3), (11.9)-(11.12)) позволяет установить полезные соотношения между интересующими нас характеристиками, подсчитанными по всей выборке
(см. формулы (11.3), (11.9)-(11.12)) позволяет установить полезные соотношения между интересующими нас характеристиками, подсчитанными по всей выборке  и теми же характеристиками, подсчитанными по выборке, в которой нет наблюдения
и теми же характеристиками, подсчитанными по выборке, в которой нет наблюдения  :
:

 (11.29)
(11.29)
 и т. д. по соответствующим характеристикам, подсчитанным по наблюдениям всей выборки
и т. д. по соответствующим характеристикам, подсчитанным по наблюдениям всей выборки  .
.
